Release 8.0
A58238-01
Library |
Product |
Contents |
Index |
| Oracle8 Parallel Server Concepts & Administration Release 8.0 A58238-01 |
|
![]()
![]()
This chapter gives a high-level view of how the Oracle Parallel Server (OPS) provides high performance parallel processing. Key issues include:
See Also: Chapter 7, "Overview of Locking Mechanisms", for an understanding of lock hierarchy in Oracle.
Oracle Parallel Server can be enabled or disabled:
| Oracle + Option |
Parallel Server Disabled |
Parallel Server Enabled | |
|---|---|---|---|
| Single Node | Multiple Nodes | ||
|
OPS not installed |
Yes: default |
No |
No |
|
OPS installed |
Yes: default |
Yes: Single Shared |
Yes: Multiple Shared |
When parallel server is disabled, only one Oracle instance can mount or open the database. This mode is necessary to create and completely recover a database. It is useful to implement Oracle Parallel Server but leave it disabled if standard Oracle functionality can meet your current needs, but you want your system to be parallel-server ready.
When parallel server is enabled, one or more instances of a parallel server mount the same database. All instances mount the database and read from and write to the same datafiles. Single shared mode describes an Oracle Parallel Server configuration in which only one instance is running. Global operations exist, but are not needed at the moment. The instance operates as though it is in a cluster (with Integrated DLM overhead, and so on), although there is no contention for resources. Multiple shared mode describes an Oracle Parallel Server configuration with multiple instances running.
Figure 4-1 illustrates a typical configuration in which Oracle Parallel Server is enabled with three instances on separate nodes accessing the database.

Note: Each instance can access the redo log files of the other instances.
See Also: "Enabling Parallel Server and Starting Instances" on page 18-12
Inter-node synchronization is an issue that does not need to be addressed in standard Oracle. But with Oracle Parallel Server you must have a broad understanding of the dimensions in which synchronization must occur. Some of these include:
In Oracle Parallel Server exclusive mode, all synchronization is done within the instance. In shared mode, synchronization is accomplished with the help of the Integrated Distributed Lock Manager component.
Block access between instances is done on a per-block level. When certain blocks are locked by an instance, other instances are not permitted to access them. Every time Oracle tries to read a block from the database it needs to get an instance lock. Ownership of the lock is thus assigned to the instance.
Since Oracle Parallel Server runs in an environment having multiple memories, there can be multiple copies of the same data block in the multiple memories. Internode synchronization using the Integrated DLM is used to ensure that all copies of the block are valid: these block-level locks are the buffer cache locks.
Block level locking occurs only when parallel server is enabled. It is transparent to the user and to the application. (Row level locking also operates, whether parallel server is enabled or disabled.)
See Also: Chapter 9, "Parallel Cache Management Instance Locks"
Oracle Parallel Server provides row level locking in addition to block level locking in the buffer cache. In fact, row level locks are stored within the block.
Consider the following example. Instance 1 reads file 2, block 10 in order to update row 1. Instance 2 also reads file 2, block 10, in order to update row 2. Here, instance 1 obtains an instance lock on block 10, then locks and updates row 1. (The row lock is implicit because of the UPDATE statement.)
Instance 2 will then force instance 1 to write the updated block to disk, and instance 1 will give up ownership of the lock on block 10 so that instance 2 can have ownership of it. Instance 2 will then lock row 2 and perform its own UPDATE.
Free lists and free list groups are used to optimize space management in Oracle Parallel Server.
The problem of allocating space for inserts illustrates space management issues. When a table uses more space, how can you make sure that no one else uses the same space? How can you make sure that two nodes are not inserting into the same space on the same disk, in the same file?
Consider the following example. Instance 1 reads file 2, block 10 in order to insert a row. Instance 2 reads file 3, block 20, in order to insert another row. Each instance proceeds to insert rows as needed. If one particular block were responsible for assigning enough space for all these inserts, that block would constantly ping between the instances. Instance 1 would lose ownership of the block when instance 2 needs to make an insert, and so forth. The situation would involve a great deal of contention, and performance would suffer.
By contrast, free list groups make good space management possible. If two instances are inserting into the same object (such as a table), but each instance has its own set of free lists for that object, then contention for a single block would be avoided. Each instance would insert into a different block belonging to the object.
In standard Oracle, the system change number (SCN) is maintained and incremented in the SGA by an exclusive mode instance. In Oracle Parallel Server shared mode, the SCN must be maintained globally. Its implementation may vary from platform to platform. The SCN may be handled by the Integrated DLM, by the Lamport SCN scheme, or by using a hardware clock or dedicated SCN server.
A parallel server takes advantage of systems of linked processors sharing resources without sacrificing any transaction processing features of Oracle. The following sections discuss in more detail certain features that optimize performance on the Oracle Parallel Server.
Within a single instance, Oracle uses a buffer cache in memory to reduce the amount of disk I/O necessary for database operations. Since each node in the parallel server has its own memory that is not shared with other nodes, Oracle Parallel Server must coordinate the buffer caches of different nodes while minimizing additional disk I/O that could reduce performance. The Oracle parallel cache management technology maintains the high-performance features of Oracle while coordinating multiple buffer caches.
See Also: Oracle8 Concepts for further information about each of these high-performance features.
Fast commits, group commits, and deferred writes operate on a per-instance basis in Oracle and work the same whether in exclusive or shared mode.
Oracle only reads data blocks from disk if they are not already in the buffer cache of the instance that needs the data. Because data block writes are deferred, they often contain modifications from multiple transactions.
Optimally, Oracle writes modified data blocks to disk only when necessary:
Oracle may also perform unnecessary writes to disk caused by forced reads or forced writes.
See Also: "How to Detect False Pinging" on page 15-16
The Oracle row locking feature allows multiple transactions on separate nodes to lock and update different rows of the same data block, without any of the transactions waiting for the others to commit. If a row has been modified but not yet committed, the original row values are available to all instances for read access (this is called multiversion read consistency).
A parallel server supports all of the backup features of Oracle in exclusive mode, including both online and offline backups of either an entire database or individual tablespaces.
If you operate Oracle in ARCHIVELOG mode, online redo log files are archived before they can be overwritten. In a parallel server, each instance can automatically archive its own redo log files or one or more instances can archive the redo log files manually for all instances.
In ARCHIVELOG mode, you can make both online and offline backups. If you operate Oracle in NOARCHIVELOG mode, you can only make offline backups. Operating production databases in ARCHIVELOG mode is strongly recommended.
A parallel server allows users on multiple instances to generate unique sequence numbers with minimal cooperation or contention among instances.
The sequence number generator allows multiple instances to access and increment a sequence without contention among instances for sequence numbers and without waiting for any transactions to commit. Each instance can have its own sequence cache for faster access to sequence numbers. Integrated DLM locks coordinate sequences across instances in a parallel server.
The System Change Number (SCN) is a logical time stamp Oracle uses to order events within a single instance, and across all instances. For example, Oracle assigns an SCN to each transaction. Conceptually, there is a global serial point that generates SCNs. In practice, however, SCNs can be read and generated in parallel. One of the SCN generation schemes is called the Lamport SCN generation scheme.
The Lamport SCN generation scheme is fast and scalable because it can generate SCNs in parallel on all instances. In this scheme, all messages across instances, including lock messages, piggyback SCNs. These piggybacked SCNs propagate causalities within Oracle. As long as causalities are respected in this way, multiple instances can generate SCNs in parallel, with no need for extra communication among these instances.
On most platforms, Oracle uses the Lamport SCN generation scheme when the MAX_COMMIT_PROPAGATION_DELAY is larger than a platform-specific threshold (typically 7 seconds). You can examine the alert log after an instance is started to see whether the Lamport SCN generation scheme has been picked.
See Also: Your Oracle system-specific documentation.
Standard Oracle can use multiple use free lists as a way to reduce contention on blocks. A free list is a list of data blocks, located in extents, that contain free space. These data blocks are used when inserts or updates are made to a database object such as a table or a cluster. No contention among instances occurs when different instances' transactions insert data into the same table. This is achieved by locating free space for the new rows using free space lists that are associated with one or more instances. The free list may be from a common pool of blocks, or multiple free lists may be partitioned so that specific extents in files are allocated to objects.
With a single free list, when multiple inserts are taking place, single threading occurs as these processes try to allocate space from the free list. The advantage of using multiple free lists is that it allows processes to search a specific pool of blocks when space is needed, thus reducing contention among users for free space.
See Also: Chapter 11, "Space Management and Free List Groups"
Oracle Parallel Server can use free list groups to eliminate contention between instances for access to a single block containing free lists.
Even if multiple free lists reside in a single block, on Oracle Parallel Server the block containing the free lists would have forced reads/writes between all the instances all the time. To avoid this problem, free lists can be grouped, with one group assigned to each instance. Each instance then has its own block containing free lists. Since each instance uses its own free lists, there is no contention between instances to access the same block containing free lists.
Disk affinity determines on which instances or processes to perform a parallelized DML or query operation. Affinity is especially important for parallel DML when running in Oracle Parallel Server configurations. Affinity information which persists across statements can improve the buffer cache hit ratio and reduce forced reads/writes on blocks between instances.
The granularity of parallelism for most PDML operations is by partition. For parallel query, granularity is by rowid. Parallel DML operations need a partition-to-instance mapping to implement affinity. The segment header of the partition is used to determine the affinity of the partition for MPPs. Better performance is achieved by having nodes mainly access local devices, with a better buffer cache hit ratio for every node.
For other Oracle Parallel Server configurations, a deterministic mapping of partitions to instances is used. Partition-to-instance affinity information is used to determine slave allocation and work assignment for all OPS/MPP configurations.
See Also: Parallel Data Manipulation Language (parallel DML) and degree of parallelism are discussed at length in Oracle8 Concepts. For a discussion of PDML tuning and optimizer hints, please see Oracle8 Tuning.
Application failover enables the application to automatically reconnect to the database if the connection is broken. Any active transaction will be rolled back, but the new database connection will otherwise be identical to the original one. This is true regardless of whether the connection was lost because the instance died or for some other reason.
With application failover, a client sees no loss of connection as long as there is one instance left serving the application. The DBA controls which applications run on particular instances, and creates a failover order for each application.
See Also: "Client-side Application Failover" on page 22-2
Cache coherency is the technique of keeping multiple copies of an object consistent. This section describes:
With the Oracle Parallel Server option, separate Oracle instances run simultaneously on one or more nodes using a technology called parallel cache management.
Parallel cache management uses Integrated Distributed Lock Manager locks to coordinate access to resources required by the instances of a parallel server. Rollback segments, dictionary entries, and data blocks are some examples of database resources. The most often required database resources are data blocks.
Cache coherency is provided by the Parallel Cache Manager for the buffer caches of instances located on separate nodes. The set of global constant (GC_*) initialization parameters associated with PCM buffer cache locks are not used with the dictionary cache, library cache, and so on.
The Parallel Cache Manager ensures that a master copy data block in an SGA has identical copies in other SGAs that require a copy of the master. Thus, the most recent copy of the block in all SGAs contains all changes made to that block by all instances in the system, regardless of whether any of the transactions on those instances have committed.
If a data block is modified in one buffer cache, then all existing copies in other buffer caches are no longer current. New copies can be obtained after the modification operation completes.
Parallel cache management enforces cache coherency while minimizing I/O and use of the Integrated DLM. I/O and lock operations for cache coherency are only done when the current version of a data block is in one instance's buffer cache and another instance requests that block for update.
Multiple transactions running on a single instance of a parallel server can share access to a set of data blocks without additional instance lock operations, as long as the blocks are not needed by transactions running on other instances.
In shared mode, the Integrated Distributed Lock Manager maintains the status of instance locks. In exclusive mode, all locks are local and the IDLM is not used to coordinate database resources.
Instances use instance locks simply to indicate the ownership of a master copy of a resource. When an instance becomes the owner of a master copy of a database resource, it also inherently becomes the owner of the instance lock covering the resource, with fixed locking. (Releasable locks are, of course, released.) A master copy indicates that it is an updatable copy of the resource. The instance only disowns the instance lock when another instance requests the resource for update. Once another instance owns the master copy of the resource, it becomes the owner of the instance lock.
Attention: Transactions and parallel cache management are autonomous mechanisms in Oracle. PCM locks function independently of any form of transaction lock.
Consider the following example and the illustrations in Figure 4-2. (This example assumes that one PCM lock covers one block--although many blocks could be covered.)
See Also: "How Buffer State and Lock Mode Change" on page 9-11
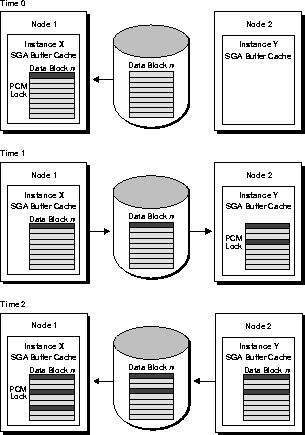
PCM locks and row locks operate independently of each other. An instance can disown a PCM lock without affecting row locks held in the set of blocks covered by the PCM lock. A row lock is acquired during a transaction. A database resource, such as a data block, acquires a PCM lock when it is read for update by an instance. During a transaction, a PCM lock can therefore be disowned and owned many times if the blocks are needed in other instances.
In contrast, transactions do not release row locks until changes to the rows are either committed or rolled back. Oracle uses internal mechanisms for concurrency control to isolate transactions, so that modifications to data made by one transaction are not visible to other transactions until the transaction modifying the data commits. The row lock concurrency control mechanisms are independent of parallel cache management: concurrency control does not require PCM locks, and PCM lock operations do not depend on individual transactions committing or rolling back.
An instance can acquire the instance lock that covers a set of data blocks in either shared or exclusive mode, depending on the type of access required.
If one instance needs to update a data block and a second instance already holds the instance lock that covers the block, the first instance uses the IDLM lock to request that the second instance disown the instance lock, writing the block(s) to disk if necessary.
Multiple instances can own an instance lock as long as they only need to read, not modify, the blocks covered by that instance lock. Thus, all instances can be sure that their memory-resident copy of the block is a current copy, or that they can read the current copy from disk without any instance lock operations to request the block from another instance. This means that instances do not have to disown instance locks for the portion of a database accessed for read-only use, which may be a substantial portion of the time in many applications.
This mode is used so that locks need not be continually obtained and released-locks are just converted from one mode to another.
See Also: Chapter 15, "Allocating PCM Instance Locks", for a detailed description of allocating PCM locks for datafiles.
Oracle Parallel Server ensures that all of the standard Oracle caches are synchronized across the instances. Changing a block on one node, and its ramifications for the other nodes, is a familiar example of synchronization. Synchronization has broader implications, however.
Understanding the way that caches are synchronized across instances can help you to understand the ongoing overhead which affects the performance of your system. Consider a five-node parallel server in which someone drops a table on one node. Each of the five dictionary caches has a copy of the definition of that particular table, thus the node that drops the table from its own dictionary cache must also flush the other four dictionary caches. It does this automatically through the Integrated DLM. Users on the other nodes will be notified of the change in lock status.
There are big advantages to having each node cache the library and table information. Occasionally, a command like DROP TABLE will force other caches to be flushed, but the brief effect this may have on performance does not diminish the advantage of having multiple caches.