Release 8.0
A58246-01
Library |
Product |
Contents |
Index |
| Oracle8 Tuning Release 8.0 A58246-01 |
|
![]()
![]()
This chapter describes the various types of application that use Oracle databases and the suggested approaches and features available when designing each type. Topics in this chapter include
You can build thousands of types of applications on top of an Oracle Server. This section categorizes the most popular types of application and describes the design considerations for each. Each section lists topics that are crucial for performance for that type of system.
See Also: Oracle8 Concepts, Oracle8 Application Developer's Guide, and Oracle8 Administrator's Guide for more information on these topics and how to implement them in your system.
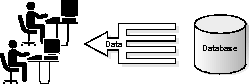
Online transaction processing (OLTP) applications are high-throughput, insert/update-intensive systems. These systems are characterized by constantly growing large volumes of data that several hundred users access concurrently. Typical OLTP applications are airline reservation systems, large order-entry applications, and banking applications. The key goals of an OLTP system are availability (sometimes 7 day/24 hour availability); speed (throughput); concurrency; and recoverability.
Figure 5-1 illustrates the interaction between an OLTP application and an Oracle Server.

When you design an OLTP system, you must ensure that the large number of concurrent users does not interfere with the system's performance. You must also avoid excessive use of indexes and clusters, because these structures slow down insert and update activity.
The following issues are crucial in tuning an OLTP system:
See Also: Oracle8 Concepts and Oracle8 Administrator's Guide for a description of each of these topics. Read about these topics before designing your system and decide which features can benefit your particular situation.
Data warehousing applications distill large amounts of information into understandable reports. Typically, decision support applications perform queries on the large amount of data gathered from OLTP applications. Decision makers in an organization use these applications to determine what strategies the organization should take, based on the available information. Figure 5-2 illustrates the interaction between a decision support application and an Oracle Server.

An example of a decision support system is a marketing tool that determines the buying patterns of consumers based on information gathered from demographic studies. The demographic data is assembled and entered into the system, and the marketing staff queries this data to determine which items sell best in which locations. This report helps to decide which items to purchase and market in the various locations.
The key goals of a data warehousing system are response time, accuracy, and availability. When you design a decision support system, you must ensure that queries on large amounts of data can be performed within a reasonable time frame. Decision makers often need reports on a daily basis, so you may need to guarantee that the report can complete overnight.
The key to performance in a decision support system is properly tuned queries and proper use of indexes, clusters, and hashing. The following issues are crucial in tuning a decision support system:
One way to improve the response time in data warehousing systems is to use parallel execution, which enables multiple processes to work together simultaneously to process a single SQL statement. By dividing the work necessary to process a statement among multiple server processes, the Oracle Server can process the statement more quickly than if only a single server process processed it.
Figure 5-3 illustrates the parallel execution feature of the Oracle Server.
Parallel execution can dramatically improve performance for data-intensive operations associated with decision support applications or very large database environments. Symmetric multiprocessing (SMP), clustered, or massively parallel systems gain the largest performance benefits from parallel execution, because the operation can be effectively split among many CPUs on a single system.
Parallel execution helps system performance scale when adding hardware resources. If your system's CPUs and disk controllers are already heavily loaded, you need to alleviate the system's load before using parallel execution to improve performance.
Many applications rely on several configurations and Oracle options. You must decide what type of activity your application performs and determine which features are best suited for it. One typical multipurpose configuration is a combination of OLTP and data warehousing systems. Often data gathered by an OLTP application "feeds" a data warehousing system.
Figure 5-4 illustrates multiple configurations and applications accessing an Oracle Server.
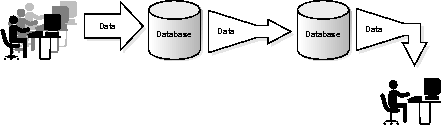
One example of a combination OLTP/data warehousing system is a marketing tool that determines the buying patterns of consumers based on information gathered from retail stores. The retail stores gather a large amount of data from daily purchases, and the marketing staff queries this data to determine which items sell best in which locations. This report is then used to determine inventory levels for particular items in each store.
In this example, both systems could use the same database, but the conflicting goals of OLTP and data warehousing cause performance problems for both parts of the system. To solve this problem, an OLTP database stores the data gathered by the retail stores, then an image of that data is copied into a second database, which is queried by the data warehousing application. This configuration slightly compromises the goal of accuracy for the data warehousing application (the data is copied only once per day), but the trade-off is significantly better performance from both systems.
For hybrid systems you must determine which goals are most important. You may need to compromise on meeting lower-priority goals to achieve acceptable performance across the whole system.
You can configure your system depending on the hardware and software available to you. The basic configurations are:
Depending on your application and your operating system, each of these or a combination of these configurations will best suit your needs.
Distributed applications involve spreading data over multiple databases on multiple machines. Several smaller server machines can be cheaper and more flexible than one large, centrally located server. This configuration takes advantage of small, powerful server machines and cheaper connectivity options. Distributed systems allow you to have data physically located at several sites, and each site can transparently access all of the data.
Figure 5-5 illustrates the distributed database configuration of the Oracle Server.
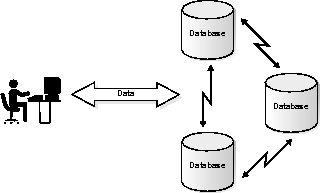
An example of a distributed database system is a mail order application with order entry clerks in several locations across the country. Each clerk has access to a copy of the central inventory database, but the clerks perform local operations on an order-entry system. The local orders are forwarded each day to the central shipping department. While the inventory and shipping departments are centrally located, the clerks are spread across the country for the convenience of the customers.
The key goals of a distributed database system are availability, accuracy, concurrency, and recoverability. When you design a distributed database system, the location of the data is the most important factor. You must ensure that local clients have quick access to the data they use most frequently, and that remote operations do not occur often. Replication is one means of dealing with the issue of data location. The following issues are crucial to the design of distributed database systems:
The Oracle Parallel Server is available on clustered or massively parallel systems. A parallel server allows multiple machines to have separate instances all accessing the same database. This configuration greatly enhances data throughput. Figure 5-6 illustrates the Parallel Server option of the Oracle Server.
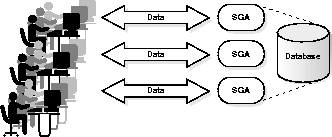
When you configure a system with the Parallel Server option, your key concern is data contention among the various nodes. Each node that requires updatable data must first obtain a lock on that data to ensure data consistency. If multiple nodes all want to access the same data, that data must first be written to disk, and then the next node can obtain the lock. This type of contention can significantly slow a parallel server; on such systems data must be effectively partitioned among the various nodes for optimal performance. (Note that read-only data can be efficiently shared across the parallel server without the problem of lock contention.)
See Also: Oracle8 Parallel Server Concepts & Administration
Client/server architecture distributes the work of a system between the client (application) machine and the server (in this case an Oracle Server). Typically, client machines are workstations that execute a graphical user interface (GUI) application connected to a larger server machine that houses the Oracle Server.
See Also: "Solving CPU Problems by Changing System Architecture" on page 13-10 for information about multi-tier systems.