Release 2 (9.2)
Part Number A96653-01
 Home |
 Book List |
 Contents |
 Index |
 Master Index |
 Feedback |
| Oracle9i Data Guard Concepts and Administration Release 2 (9.2) Part Number A96653-01 |
|
A standby database environment includes a primary database with from one to nine associated standby databases and potentially cascaded standby databases. This chapter describes the following main factors affecting the Data Guard configuration:
Although a standby database can be synchronized with one and only one primary database, a single primary database can directly support up to nine standby databases. These standby databases are separate and independent, and can reside on multiple systems or on a single system. Also, cascading standby databases can be set up to send incoming redo information to other locations in the same manner as the primary database, with up to one level of redirection.
Typically, you create a standby database for one or more of the following reasons:
There are a number of factors to consider when weighing whether to implement a physical standby database, a logical standby database, or both in a Data Guard configuration:
Standby databases can be located at the same location as the primary database to provide protection against hardware failures, or located at a remote location from the primary database to protect against electrical power loss, physical structure loss, or other catastrophic outages.
Both physical and logical standby databases protect against data corruption through failover capabilities. Both types of standby databases support the maximum availability and maximum performance modes of data protection. Physical standby databases go a step further by supporting standby redo logs and the maximum protection mode. (See Section 5.7 for complete information about the data protection modes.)
In addition, you can delay the application of redo logs already received at one or more standby databases. The ability to stagger the application of changes to standby databases enables not only the protection of production data from data center disasters, but also provides a window of protection from user errors or corruptions.
Online backup operations can be run against physical standby databases to off-load work from the primary database. These backup copies can be applied to the primary database, if needed.
Consider the following points for logical and physical standby databases:
A physical standby database can be deployed against any Oracle production database to protect against data loss or corruption. All datatypes, tables, and DML operations are supported by a physical standby database. In this release of Oracle9i, some datatypes and DML operations cannot be maintained in a logical standby database. Before setting up a logical standby database for disaster recovery, you must make sure the logical standby database can maintain all of the datatypes and tables in your primary database.
| See Also:
Section 4.1 for information about datatypes and database structures not supported by logical standby databases |
Both physical and logical standby databases provide switchover capabilities in which the standby database can take over processing for the primary database, and the original primary database can be transitioned into the standby role. A switchover operation can be performed without the need to re-create the new standby database from the new primary database. The primary database is then available for maintenance operations.
One crucial aspect of any Data Guard environment is archiving the redo logs from the primary database to the standby database. You configure the primary database to archive automatically to the standby database using log transport services.
When a primary database archives to a standby database, log transport services automatically transmit the online redo logs through Oracle Net to a directory on the standby system. As redo logs are generated on the primary database, log transport services automatically transmit them and log apply services apply them to each standby database. This allows standby databases to remain synchronized with the primary database.
The mechanism for applying redo logs to a standby database is independent of the mechanism for automatic archiving of redo logs to the standby database. Thus, log transport services on the primary database can continue to archive to the standby database even if the log apply services on the standby database have been stopped, but only if the standby instance is mounted for physical standby databases or open for logical standby databases.
For example, you can take a physical standby database out of managed recovery mode and temporarily place it in read-only mode. While the physical standby database is in read-only mode, archived redo logs continue to accumulate on the standby system.
Even if you configure the primary database to archive automatically to the standby destination, you can still copy the completed archived redo logs manually if necessary.
For example, assume that a problem with the Oracle Net configuration prevents the copying of archived redo logs to the standby location. The primary database continues to archive locally, so you can copy the logs manually using operating system commands, then register the archived redo logs at the standby location. Log apply services automatically apply the archived redo logs to the standby database.
Log transport services provide the following functions:
The log apply services component of the Data Guard environment is responsible for maintaining a physical standby database in either a managed recovery mode or in open read-only mode, and for applying SQL statements to a logical standby database. It coordinates activities with the log transport services.
Log apply services provide the following functions:
One crucial aspect of the Data Guard environment is the number and configuration of the databases involved. Of particular importance are whether:
You can locate a standby database:
The location of systems involved in the Data Guard environment has obvious implications for a disaster recovery strategy. For example, if the primary system in a data center is destroyed, then you cannot perform failover to a standby database unless it resides on a different system, which may or may not be in the same data center. In a worst case scenario, if the data center is completely destroyed, then you cannot perform a failover to a standby database unless the standby database is located on a different system in a remote location.
| See Also:
Section 10.1.5 for a disaster recovery scenario |
The directory structure of the various standby databases is important because it determines the path names for the standby datafiles and redo logs. If you have a standby database on the same system as the primary database, you must use a different directory structure; otherwise, the standby database attempts to overwrite the primary database files.
For physical standby databases, use the same path names for the standby files if possible. This option eliminates the need to set filename conversion parameters. Nevertheless, if you need to use a system with a different directory structure or place the standby and primary databases on the same system, you can do so with a minimum of extra administration.
The three basic configuration options are illustrated in Figure 2-1. These include:
Standby1)Standby2)--this is the recommended methodStandby3)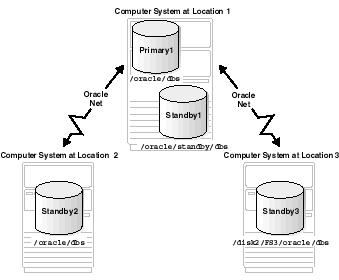
Text description of the illustration sbr81097.gif
Table 2-1 describes possible configurations of primary and standby databases and the consequences of each.
| Standby System | Directory Structure | Consequences |
|---|---|---|
|
Same as primary system |
Different than primary system (required) |
|
|
Separate system |
Same as primary system |
|
|
Separate system |
Different than primary system |
|
As database activity is recorded in the online redo logs on the primary database, the same information is transmitted to local and remote standby databases. You can set up standby databases in any of the following types of configurations:
A physical standby database is an identical copy of the primary database. The physical standby database's on-disk database structures are identical to the primary database on a block-for-block basis. The logs are applied to physical standby databases by log apply services.
A logical standby database is an Oracle database that contains the same user data as the primary database. However, the contents of the logical standby database may differ from the primary database by having only a subset of the tables or by including additional metadata, such as additional indexes or materialized views. The redo data in the logs is converted to SQL statements that are then applied to the database. The SQL apply mode allows for differences in the primary and standby databases.
This type of standby database allows archival of redo logs to another system in the configuration. An archive log repository is created by using a standby control file, starting the instance, and mounting the database. This database contains no datafiles and cannot be used for primary database recovery. This alternative is useful as a way of holding redo logs for a short period of time, perhaps a day, after which the logs can then be deleted. This avoids most of the storage and processing expense of another fully configured standby database.
It is possible to set up a cross-instance archival database environment. Within a Real Application Clusters environment, each instance directs its archived redo logs to a single instance of the cluster. This instance, known as the recovery instance, is typically the instance where managed recovery is performed. The recovery instance typically has a tape drive available for RMAN backup and restore support. Typically, this type of usage requires a physical standby database.
Because there can be several databases on one computer system, you can implement any combination of primary and standby databases in a variety of configurations. Only mission-critical databases require a standby database for disaster recovery. However, standby databases can also be used to off-load the primary database. This section provides some examples of Data Guard configurations from actual customer situations.
Figure 2-2 shows two large mission-critical databases configured on locations that are geographically separated to achieve a Data Guard disaster recovery environment. The primary database at location 1 has its standby database at location 2, and the primary database at location 2 has its standby database at location 1 to make efficient use of each system with no idle hardware. If either primary database becomes incapacitated, the physical standby database on the other location can be failed over to the primary role so processing can continue. In addition, the use of Real Application Clusters provides the ability to scale each location with additional nodes in the future.
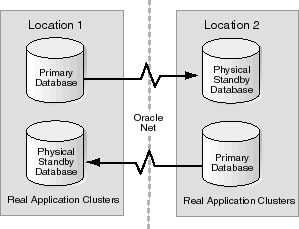
Text description of the illustration bidirectional.gif
Figure 2-3 shows a Data Guard configuration that implements a primary database instance that transmits redo logs to physical and logical standby databases that are both remote from the primary database instance. In this configuration, a physical standby database is configured for disaster recovery and backup operations, and a logical standby database is configured primarily for reporting but it can also be used for disaster recovery. For straight backup and reporting operations, you could locate the standby database at the same location as the primary database. However, for disaster recovery, the standby databases must be located on remote systems.
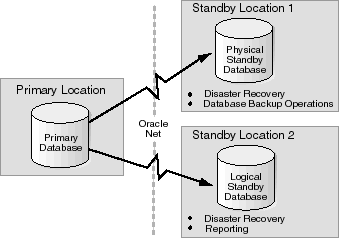
Text description of the illustration offloadwork.gif
Figure 2-4 shows a configuration in which Data Guard and Real Application Clusters provide complementary Oracle features that together help you to implement high availability, disaster protection, and scalability. In the example, the organization has chosen to use one shared standby database system, hosting several standby databases for disaster recovery. This approach amortizes the hardware costs of standby systems, because several primary databases are served by one standby system.
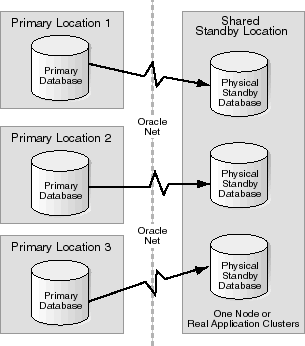
|
 Copyright © 1999, 2002 Oracle Corporation. All Rights Reserved. |
|

