Release 2 (9.2)
Part Number A96590-01
 Home |
 Book List |
 Contents |
 Index |
 Master Index |
 Feedback |
| Oracle9i Application Developer's Guide - Fundamentals Release 2 (9.2) Part Number A96590-01 |
|
This chapter covers the following topics:
| See Also:
For the syntax of the |
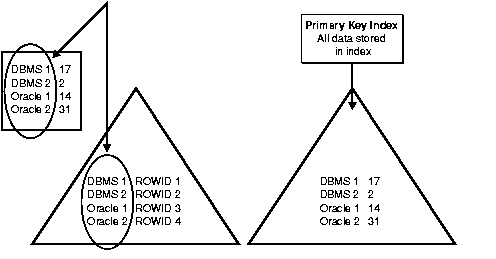
An index-organized table--in contrast to an ordinary table--has its own way of structuring, storing, and indexing data. A comparison with an ordinary table may help to explain its uniqueness.
A row in an ordinary table has a stable physical location. Once this location is established, the row never completely moves. Even if it is partially moved with the addition of new data, there is always a row piece at the original physical address--identified by the original physical rowid--from which the system can find the rest of the row. As long as the row exists, its physical rowid does not change. An index in an ordinary table stores both the column data and the rowid.
A row in an index-organized table does not have a stable physical location. It keeps data in sorted order, in the leaves of a B*-tree index built on the table's primary key. These rows can move around to preserve the sorted order. For example, an insertion can cause an existing row to move to a different slot, or even to a different block.
The leaves of the B*-tree index hold the primary key and the actual row data. Changes to the table data--for example, adding new rows, or updating or deleting existing rows--result only in updating the index.
| See Also:
For more information on B*-tree indexes, see Oracle9i Database Concepts |
Because they store rows in a format optimized for access by the primary key, index-organized tables offer the following advantages over ordinary tables:
Once a search has located the key values, the remaining data is present at that location. The index-organized table eliminates the I/O operation of following a rowid back to table data.
When your database must be available 100% of the time, index-organized tables provide the following advantages:
The key columns are not duplicated in both the table and the index, and no additional storage is needed for rowids. When the key columns take up a large part of the row, the storage savings can be as much as 50%.
You can move your existing data into an index-organized table and do all the operations you would perform in an ordinary table. Some of the features of index-organized tables are:
All of the alter options available on ordinary tables are available for index-organized tables. This includes ADD, MODIFY, and DROP COLUMNS and CONSTRAINTS. However, the primary key constraint for an index-organized table cannot be dropped, deferred, or disabled.
Because of the inherent movability of rows in a B*-tree index, a secondary index on an index-organized table cannot be based on a physical rowid, which is inherently fixed. Instead, a secondary index for an index-organized table is based on the logical rowid. An index-organized table row has no permanent physical address and can move across data blocks when new rows are inserted. However, even if the physical location of a row changes, its logical rowid remains valid.
A logical rowid includes the table's primary key and a physical guess which identifies the database block address at which the row is likely to be found. The physical guess makes rowid-based access to non-volatile index-organized tables comparable to similar access of ordinary tables.
Logical rowids are similar to physical rowids in the following ways:
ROWID from an index-organized table, and access the rows using ROWID as a column name in a WHERE clause.The database server uses a single datatype, called universal rowid, to support both logical and physical rowids.
To switch to index-organized tables, applications that use rowids might have to change to universal rowids, but these changes are made easier by the UROWID datatype, which lets applications access logical and physical rowids in a unified manner.
Secondary indexes on index-organized tables differ from indexes on ordinary tables in two ways:
ALTER TABLE MOVE does not make the secondary index unusable.Both unique and non-unique secondary indexes, as well as function-based secondary indexes, are supported. Bitmap indexes on non-partitioned index-organized tables are supported, provided the index-organized table is created with a mapping table. For more information about mapping tables, see the information about index-organized tables in Oracle9i Database Concepts
You can create internal and external LOB columns in index-organized tables to store large unstructured data such as audio, video, and images. The SQL DDL, DML, and piece-wise operations on LOBs in index-organized tables exhibit the same behavior as in ordinary tables. The main differences are:
LOB's data and index segments are created in the tablespace in which the primary key index segment of the index-organized table is created.LOBs in index-organized tables with overflow segments are the same as those in ordinary tables. All LOBs in index-organized tables created without an overflow segment are stored out-of-line (that is, the default storage attribute is DISABLE STORAGE IN ROW). Specifying an ENABLE STORAGE IN ROW for such LOBs causes an error.LOB columns are supported in range-partitioned index-organized tables.
Other LOB features--such as BFILEs, temporary LOBs, and varying character width LOBs--are also supported in index-organized tables. You use them as you would in ordinary tables.
Queries on index-organized tables involving primary key index scan can be executed in parallel.
Most of the object features are supported on index-organized tables, including Object Type, VARRAYs, Nested Table, and REF Columns.
This utility supports both ordinary and direct path load of index-organized tables and their associated indexes (including partitioning support). However, direct path parallel load to an index-organized table is not supported. An alternate method of achieving the same result is to perform parallel load to an ordinary table using SQL*Loader, then use the parallel CREATE TABLE AS SELECT option to build the index-organized table.
This utility supports export (both ordinary and direct path) and import of non-partitioned and partitioned index-organized tables.
You can replicate both non-partitioned and partitioned index-organized tables.
The Oracle Enterprise Manager supports generating SQL statements for CREATE and ALTER operations on an index-organized table.
Key compression allows elimination of repeated occurrences of key column prefixes in index-organized tables and indexes. The salient characteristics of the scheme are:
There are several occasions when you may prefer to use index-organized tables over ordinary tables.
Oracle Advanced Queuing provides message queuing as an integrated part of the database server, and uses index-organized tables to hold metadata information for multiple consumer queues.
For tables, where the majority of columns form the primary key, there is a significant amount of redundant data stored. You can avoid this redundant storage by using an index-organized table. Also, by using an index-organized table, you increase the efficiency of the primary key-based access to non-key columns.
The ability to partition index-organized tables on a range of column values makes them suitable for VLDB applications.
One major advantage of an index-organized table comes from the logical nature of its secondary indexes. After an ALTER TABLE MOVE and SPLIT operation, global indexes on index-organized tables remain usable because the index rows contain logical rowids. You can avoid a complete index rebuild, which can be very expensive. Also, the ALTER TABLE MOVE operation can be done on-line, making index-organized tables ideal for applications requiring 24x7 availability.
Similarly, after an ALTER TABLE MOVE operation, local indexes on index-organized tables are still usable.
These partition maintenance operations do make the local and global indexes on index-organized table slower as the guess component of the logical rowid becomes invalid. However, the indexes are still usable through the primary key-component of the logical rowid. Note that the invalid physical guesses in these indexes can be fixed online with the help of ALTER INDEX ... UPDATE BLOCK REFERENCES operation.
Time-series applications use a set of time-stamped rows belonging to a single item, such as a stock price. The ability to cluster rows based on the primary key makes index-organized tables attractive for such applications. By defining an index-organized table with primary key (stock symbol, time stamp), the Oracle8 Time Series option can store and manipulate time-series data efficiently. You can achieve more storage savings by compressing repeated occurrences of the item identifier (for example, the stock symbol) in a time series by using an index-organized table with key compression.
For a nested table column, Oracle internally creates a storage table to hold all the nested table rows.
You can store the nested table as an index-organized table:
CREATE TYPE Project_t AS OBJECT(Pno NUMBER, Pname VARCHAR2(80)); CREATE TYPE Project_set AS TABLE OF Project_t; CREATE TABLE Employees (Eno NUMBER, Projects PROJECT_SET) NESTED TABLE Projects_ntab STORE AS Emp_project_tab ((PRIMARY KEY(Nested_table_id, Pno)) ORGANIZATION INDEX) RETURN AS LOCATOR;
The rows belonging to a single nested table instance are identified by a NESTED_TABLE_ID column. If an ordinary table is used to store nested table columns, the nested table rows typically get de-clustered. But when you use an index-organized table, the nested table rows can be clustered based on the NESTED_TABLE_ID column.
The Extensible Indexing Framework lets you add a new access method to the database. Typically, domain-specific indexing schemes need some storage mechanism to hold their index data. Index-organized tables are ideal candidates for such domain index storage. The interMedia Spatial and Text features use index-organized tables for storing their index data.
This example illustrates some of the basic tasks in creating and using index-organized tables. In this example, a text search engine keeps a record of all the web pages that use specific words or phrases, so that it can return a list of hypertext links in response to a search query.
This example illustrates the following tasks:
The CREATE TABLE AS SELECT command lets you move existing data from an ordinary table into an index-organized table. In the following example, an index-organized table, called docindex, is created from an ordinary table called doctable.
CREATE TABLE Docindex ( Token, Doc_id, Token_frequency, CONSTRAINT Pk_docindex PRIMARY KEY (Token, Doc_id) ) ORGANIZATION INDEX TABLESPACE Ind_tbs PARALLEL (DEGREE 2) AS SELECT * from Doc_tab;
Note that the PARALLEL clause allows the table creation to be performed in parallel.
To create an index-organized table, you use the ORGANIZATION INDEX clause. In the following example, an inverted index--typically used by Web text-search engines--uses an index-organized table.
CREATE TABLE Docindex ( Token CHAR(20), Doc_id NUMBER, Token_frequency NUMBER, CONSTRAINT Pk_docindex PRIMARY KEY (Token, Doc_id) ) ORGANIZATION INDEX TABLESPACE Ind_tbs;
The following example shows how you declare the UROWID datatype.
DECLARE Rid UROWID; BEGIN INSERT INTO Docindex VALUES ('Or80', 2, 30) RETURNING Rowid INTO RID; UPDATE Docindex SET Token='Or81' WHERE ROWID = Rid; END;
You can create secondary indexes on index-organized tables to provide multiple access paths. The following example shows the creation of an index on (doc_id, token).
CREATE INDEX Doc_id_index on Docindex(Doc_id, Token);
This secondary index allows Oracle to efficiently process queries involving predicates on doc_id, as the following example illustrates.
SELECT Token FROM Docindex WHERE Doc_id = 1;
Applications manipulate the index-organized tables just like an ordinary table, using standard SQL statements for SELECT, INSERT, UPDATE, or DELETE operations. For example, you can manipulate the docindex table as follows:
INSERT INTO Docindex VALUES ('Oracle8.1', 3, 17); SELECT * FROM Docindex; UPDATE Docindex SET Token = 'Oracle8' WHERE Token = 'Oracle8.1'; DELETE FROM Docindex WHERE Doc_id = 1;
Also, you can use SELECT FOR UPDATE statements to lock rows of an index-organized table. All of these operations result in manipulating the primary key B*-tree index. Both query and DML operations involving index-organized tables are optimized by using this cost-based approach.
Storing all non-key columns in the primary key B*-tree index structure may not always be desirable because, for example:
or because
To overcome these problems, you can associate an overflow data segment with an index-organized table. In the following example, an additional column, token_offsets, is required for the docindex table. This example shows how you can create an index-organized table and use the OVERFLOW option to create an overflow data segment.
CREATE TABLE Docindex2 ( Token CHAR(20), Doc_id NUMBER, Token_frequency NUMBER, Token_offsets VARCHAR(512), CONSTRAINT Pk_docindex2 PRIMARY KEY (Token, Doc_id) ) ORGANIZATION INDEX TABLESPACE Ind_tbs PCTTHRESHOLD 20 OVERFLOW TABLESPACE Ovf_tbs INITRANS 4;
For the overflow data segment, you can specify physical storage attributes such as TABLESPACE, INITRANS, and so on.
For an index-organized table with an overflow segment, the index row contains a <key, row head> pair, where the row head contains the first few non-key columns and a rowid that points to an overflow row-piece containing the remaining column values. Although this approach incurs the storage cost of one rowid for each row, it nevertheless avoids key column duplication.
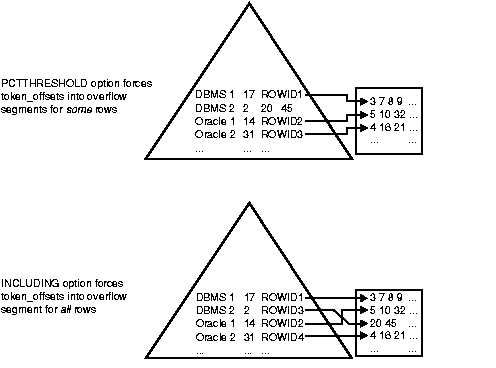
To determine the last non-key column to include in the index row head piece, you use the PCTTHRESHOLD option specified as a percentage of the leaf block size. The remaining non-key columns are stored in the overflow data segment as one or more row-pieces. Specifically, the last non-key column to be included is chosen so that the index row size (key +row head) does not exceed the specified threshold (which, in the following example, is 20% of the index leaf block). By default, PCTTHRESHOLD is set at 50 when omitted.
The PCTTHRESHOLD option determines the last non-key column to be included in the index for each row. It does not, however, allow you to specify that the same set of columns be included in the index for all rows in the table. For this purpose, the INCLUDING option is provided.
The CREATE TABLE statement in the following example includes all the columns up to the token_frequency column in the index leaf block and forces the token_offsets column to the overflow segment.
CREATE TABLE Docindex3 ( Token CHAR(20), Doc_id NUMBER, Token_frequency NUMBER, Token_offsets VARCHAR(512), CONSTRAINT Pk_docindex3 PRIMARY KEY (Token, Doc_id) ) ORGANIZATION INDEX TABLESPACE Ind_tbs INCLUDING Token_frequency OVERFLOW TABLESPACE Ovf_tbs;
Such vertical partitioning of a row between the index and data segments allows for higher clustering of rows in the index. This results in better query performance for the columns stored in the index. For example, if the token_offsets column is infrequently accessed, then pushing this column out of the index results in better clustering of index rows in the primary key B*-tree structure (Figure 6-3). This in turn results in overall improved query performance. However, there is one additional block access for columns stored in the overflow data segment, and this can slow performance.
The INCLUDING option ensures that all columns after the specified including column are stored in the overflow segment. If the including column specified is such that corresponding index row size exceeds the specified threshold, then the last non-key column to be included is determined according to the PCTTHRESHOLD option.
You can use the ALTER TABLE command to modify physical and storage attributes for both the index and overflow data segments as well as alter PCTTHRESHOLD and INCLUDING column values. The following example sets the INITRANS of index segment to 4, PCTTHRESHOLD to 20, and the INITRANS of the overflow data segment to 6. The altered values are used for subsequent operations on the table.
ALTER TABLE Docindex INITRANS 4 PCTTHRESHOLD 20 OVERFLOW INITRANS 6;
For index-organized tables created without an overflow data segment, you can add an overflow data segment using ALTER TABLE ADD OVERFLOW option. The following example shows how to add an overflow segment to the docindex table.
ALTER TABLE Docindex ADD OVERFLOW;
Index-organized tables are analyzed by the ANALYZE command, just like ordinary tables. The following example analyzes the docindex table:
ANALYZE TABLE Docindex COMPUTE STATISTICS;
The ANALYZE command analyzes both the primary key index segment and the overflow data segment, and computes logical as well as physical statistics for the table. You can determine how many rows have one or more chained overflow row-pieces using the ANALYZE LIST CHAINED ROWS option. With the logical rowid feature, a separate CHAINED_ROWS table is not needed.
Data can be loaded into both non-partitioned and partitioned index-organized tables using the ordinary or direct path with the SQL*Loader. The data can also be exported or imported using the Export/Import utility. Index-organized tables can also be replicated in a distributed database just like ordinary tables.
You can partition index-organized tables by range of column values or by a hash value derived from a set of columns. The set of partitioning columns must be a subset of the primary key columns. Only a single partition needs to be searched for to verify the uniqueness of the primary key during DML operations. This preserves the partition independence property.
The following are key aspects of partitioned index-organized tables:
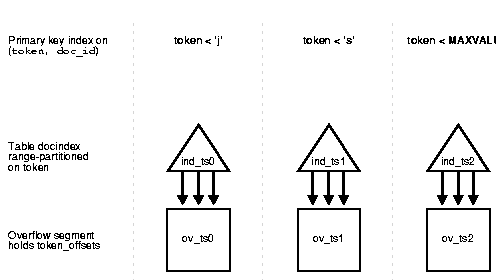
ORGANIZATION INDEX clause to create an index-organized table as part of table-level attributes. This property is implicitly inherited by all partitions.OVERFLOW option as part of table-level attribute to create an index-organized table with overflow data segment.OVERFLOW option results in the creation of overflow data segments, which are themselves equi-partitioned with the primary key index segments. That is, each partition has an index segment and an overflow data segment.ROW MOVEMENT ENABLE clause of the CREATE TABLE statement. Rows might move from one partition to another due to changes in the columns used to derive the hash value.PCTTHRESHOLD and INCLUDING column can only be specified at the table level.OVERFLOW keyword apply to primary index segments. All the attributes specified after the OVERFLOW keyword apply to overflow data segments.The following example continues the example of the docindex table. It illustrates a range partition on token values.
CREATE TABLE Docindex4 (Token CHAR(20), Doc_id NUMBER, Token_frequency NUMBER, Token_offsets VARCHAR(512), CONSTRAINT Pk_docindex4 PRIMARY KEY (Token, Doc_id) ) ORGANIZATION INDEX INITRANS 4 INCLUDING Token_frequency OVERFLOW INITRANS 6 PARTITION BY RANGE(token) ( PARTITION P1 VALUES LESS THAN ('j') TABLESPACE Ind_ts0 OVERFLOW TABLESPACE Ov_ts0, PARTITION P2 VALUES LESS THAN ('s') TABLESPACE Ind_ts1 OVERFLOW TABLESPACE Ov_ts1, PARTITION P3 VALUES LESS THAN (MAXVALUE) TABLESPACE Ind_ts2 OVERFLOW TABLESPACE Ov_ts2);
This creates the table shown in Figure 6-4. The INCLUDING clause stores the token_offsets column in the overflow data segment for each partition.
Partitioned indexes on index-organized tables are supported. Local prefixed, local non-prefixed, and global prefixed partitioned indexes are supported on index-organized tables. The only difference is that these indexes store logical rowids instead of physical rowids.
All of the ALTER TABLE operations are available for partitioned index-organized tables. These operations are slightly different with index-organized tables than with ordinary tables:
ALTER TABLE MOVE partition operations, all indexes--local, global, and non-partitioned--remain USABLE because the indexes contain logical rowids. However, the guess stored in the logical rowid becomes invalid.SPLIT partition operations, all non-partitioned indexes or global index partitions remain usable.ALTER TABLE EXCHANGE partition, the target table must be a compatible index-organized table.ALTER TABLE ADD OVERFLOW command to add an overflow segment and specify table-level default and partition-level physical and storage attributes. This operation results in adding an overflow data segment to each partition.ALTER INDEX operations are very similar to those on ordinary tables. The only difference is that operations that reconstruct the entire index--namely, ALTER INDEX REBUILD and SPLIT_PARTITION--result in reconstructing the guess stored as part of the logical rowid. New ALTER INDEX UPDATE BLOCK REFERENCES syntax fixes the invalid physical guesses without reconstructing the indexes.
Query and DML operations on partitioned index-organized tables work the same as on ordinary partitioned tables.
You enable key compression by using the COMPRESS clause when specifying physical attributes for the index segment. You can specify the prefix length (as number of columns) to identify how the key can be broken into a prefix and a suffix. Prefix length can be between 1 and the number of primary key columns minus 1.
CREATE TABLE Docindex5 ( Token CHAR(20), Doc_id NUMBER, Token_frequency NUMBER, Token_offsets VARCHAR(512), CONSTRAINT pk_docindex5 PRIMARY KEY (Token, Doc_id) ) ORGANIZATION INDEX TABLESPACE Ind_tbs COMPRESS 1 INCLUDING Token_frequency OVERFLOW TABLESPACE Ovf_tbs;
Common prefixes of length 1 (that is, token column) are compressed in the primary key (token, doc_id) occurrences. For the list of primary key values (`DBMS', 1), (`DBMS', 2), (`Oracle', 1), (`Oracle', 2), the repeated occurrences of `DBMS' and `Oracle' are compressed away.
If a prefix length is not specified, by default it is set to the number of primary key columns minus 1. You can specify the compress option when creating an index-organized table or when moving an index-organized table using ALTER TABLE MOVE. For example, you can disable compression as follows:
ALTER TABLE Docindex5 MOVE NOCOMPRESS;
Similarly, the indexes for ordinary tables and index-organized tables can be compressed using the COMPRESS option.
You can also compress the keys for partitioned index-organized tables, by specifying the compression clause as part of the table-level defaults. Compression can be enabled or disabled for each partition. The prefix length cannot be changed at the partition level.
CREATE TABLE Docindex6 ( Token CHAR(20), Doc_id NUMBER, Token_frequency NUMBER, Token_offsets VARCHAR(512), CONSTRAINT Pk_docindex6 PRIMARY KEY (Token, Doc_id) ) ORGANIZATION INDEX INITRANS 4 COMPRESS 1 INCLUDING Token_frequency OVERFLOW INITRANS 6 PARTITION BY RANGE(Token) ( PARTITION P1 VALUES LESS THAN ('j') TABLESPACE Ind_ts0 OVERFLOW TABLESPACE Ov_ts0, PARTITION P2 VALUES LESS THAN ('s') TABLESPACE Ind_ts1 NOCOMPRESS OVERFLOW TABLESPACE Ov_ts1, PARTITION P3 VALUES LESS THAN (MAXVALUE) TABLESPACE Ind_ts2 OVERFLOW TABLESPACE Ov_ts2 );
All partitions inherit the table-level default for prefix length. Partitions P1 and P3 are created with key-compression enabled. For partition P2, the compression is disabled by the partition level NOCOMPRESS option.
For ALTER TABLE MOVE and SPLIT operations, the COMRPESS option can be altered. The following example rebuilds the partition with key compression enabled.
ALTER TABLE Docindex6 MOVE PARTITION P2 COMPRESS;
An SQL command, ALTER TABLE MOVE, lets you rebuild the table. This should be used when the B*-tree structure containing an index-organized table gets fragmented due to a large number of inserts, updates, or deletes. The MOVE option rebuilds the primary key B*-tree index.
By default, the overflow data segment is not rebuilt, except when:
By default, LOB columns related to index and data segments are not rebuilt, except when the LOB columns are explicitly specified as part of the MOVE statement. The following example rebuilds the B*-tree index containing the table data after setting INITRANS to 6 for index blocks.
ALTER TABLE docindex MOVE INITRANS 6;
The following example rebuilds both the primary key index and overflow data segment.
ALTER TABLE docindex MOVE TABLESPACE Ovf_tbs OVERFLOW TABLESPACE ov_ts0;
By default, during the move, the table is not available for other operations. However, you can move an index-organized table using the ONLINE option. The following example allows the table to be available for DML and query operations during the actual move operation. This feature makes the index-organized table suitable for applications requiring 24x7 availability.
|
Caution: You may need to set your |
ALTER TABLE Docindex MOVE ONLINE;
ONLINE move is supported only for index-organized tables that do not have an overflow segment.
|
 Copyright © 1996, 2002 Oracle Corporation. All Rights Reserved. |
|

