




|
|
This topic includes the following sections:
Except under unusual conditions where a data record is a complete and indivisible entity, you need to be able to break records into fields to be able to use or change the information the record contains. In an ATMI environment, records can be divided into fields through either of the following:
One common way of subdividing records is with a structure that divides a contiguous area of storage into fields. The fields are given names for identification; the kind of data carried in each field is shown by a data type declaration.
For example, if a data item in a C language program is to contain information about an employee's identification number, name, address, and gender, it could be set up with a structure such as the following:
struct S {
long empid;
char name[20];
char addr[40];
char gender;
};
Here the data type of the field named empid is declared to be a long integer, name and addr are declared to be character arrays of 20 and 40 characters respectively, and gender is declared to be a single character, presumably with a range of m or f.
If, in your C program, the variable p points to a structure of type struct S, the references p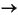
empid, pname, paddr and pgender can be used to address the fields.
The COBOL COPY file for the same data structure would be as follows (the application would supply the 01 line):
05 EMPID PIC S9(9) USAGE IS COMP-5.
05 NAME PIC X(20).
05 ADDR PIC X(40).
05 GENDER PIC X(01).
05 FILLER PIC X(03).
If, in your COBOL program, the 01 line is named MYREC, the references EMPID IN MYREC, NAME IN MYREC, ADDR IN MYREC, and GENDER IN MYREC can be used to access the fields.
Although this method of representing data is widely used and is often appropriate, it has two major potential disadvantages:
Fielded buffers provide an alternative method for subdividing a record into fields.
A fielded buffer is a data structure that provides associative access to the fields of a record; that is, the name of a field is associated with an identifier that includes the storage location as well as the data type of the field.
The main advantage of the fielded buffer is data independence. Fields can be added to the buffer, deleted from it, or changed in length without forcing programs that reference the fields to be recompiled. To achieve this data independence, fields are:
Fielded buffers can be used throughout the ATMI environment as the standard method of representing data sent between cooperating processes.
Fielded buffers are created, updated, accessed, input, and output via Field Manipulation Language (FML). FML provides:
FML is implemented as a library of functions and macros that can be called from C programs. It provides a separate set of functions for:
The last set of functions listed above constitutes the FML VIEWS software. VIEWS is a set of functions that exchange data between FML fielded buffers and structures in C or COBOL language application programs. When a program receives a fielded buffer from another process, the program has the choice of:
If you need to perform lengthy manipulations on buffer data, the performance of your program can be improved by transferring fielded buffer data to structures or records, and operating on the data using normal C or COBOL statements. Then you can put the data back into a fielded buffer (again using VIEWS functions), and send the buffer off to another process.
Before you can use VIEWS, you must set up your program such that it can recognize the format of incoming fielded buffer data. You can do this setup task by using a set of view descriptions kept in a cache on your system.
A view description is created and stored in a source viewfile. The view description maps fields in fielded buffers to members in C structures or COBOL records. The source view descriptions are compiled, and can then be used to map data transferred between fielded buffers and C structures or COBOL records in a program.
By keeping view descriptions cached in a central file, you can increase the data independence of your programs; you only need to change the view description(s) and recompile them to effect changes in data format throughout an application that uses VIEWS.
This topic includes the following sections:
A fielded buffer is a data structure that provides associative access to the fields of a record.
Each field in an FML fielded buffer is labeled with an integer that combines information about the data type of the accompanying field with a unique identifying number. The label is called the field identifier, or fldid. For variable-length items, the fldid is followed by a length indicator.
A buffer can be represented as a sequence of fldid/data pairs, with fldid/length/data triples for variable-length items, as shown in the following diagram.

In the header file that is included (with #include) whenever FML functions are used (fml.h or fml32.h), field identifiers are defined (with typedef) as FLDID (or FLDID32 for FML32), field value lengths as FLDLEN (FLDLEN32 for FML32), and field occurrence numbers as FLDOCC (FLDOCC32 for FML32).
The supported field types are short, long, float, double, char, string, carray (character array), mbstring (multibyte character array—available in Tuxedo release 8.1 or later), ptr (pointer to a buffer), fml32 (an embedded FML32 buffer), and view32 (an embedded VIEW32 buffer). The mbstring, ptr, fml32, and view32 types are supported only for the FML32 interface. These types are included as #define statements in fml.h (or fml32.h), as shown in the following listing.
#define FLD_SHORT 0 /* short int */
#define FLD_LONG 1 /* long int */
#define FLD_CHAR 2 /* character */
#define FLD_FLOAT 3 /* single-precision float */
#define FLD_DOUBLE 4 /* double-precision float */
#define FLD_STRING 5 /* string - null terminated */
#define FLD_CARRAY 6 /* character array */
#define FLD_PTR 9 /* pointer to a buffer */
#define FLD_FML32 10 /* embedded FML32 buffer */
#define FLD_VIEW32 11 /* embedded VIEW32 buffer */
#define FLD_MBSTRING 12 /* multibyte character array */
FLD_STRING, FLD_CARRAY, and FLD_MBSTRING are all arrays, but differ in the following way:
Functions that add or change a field have a FLDLEN argument that must be filled in when you are dealing with FLD_CARRAY or FLD_MBSTRING fields. The size of a string or carray is limited to 65,535 characters in FML, and 2 billion bytes for FML32.
It is not a good idea to store unsigned data types in fielded buffers. You should either convert all unsigned short data to long or cast the data into the proper unsigned data type whenever you retrieve data from fielded buffers (using the FML conversion functions).
Most FML functions do not perform type checking; they expect that the value you update or retrieve from a fielded buffer matches its native type. For example, if a buffer field is defined to be a FLD_LONG, you should always pass the address of a long value. The FML conversion functions convert data from a user specified type to the native field type (and from the field type to a user specified type) in addition to placing the data in (or retrieving the data from) the fielded buffer.
The FLD_PTR field type makes it possible to embed pointers to application data in an FML32 buffer. Applications can add, change, access, and delete pointers to data buffers. The buffer pointed to by a FLD_PTR field must be allocated using the tpalloc(3c) call. The FLD_PTR field type is supported only in FML32.
The FLD_FML32 field type makes it possible to store an entire record as a single field in an FML32 buffer. Similarly, the FLD_VIEW32 field type allows an entire C structure to be stored as a single field in an FML32 buffer. The FLD_FML32 and FLD_VIEW32 field types are supported only in FML32.
In addition to the data types supported by most FML functions, VIEWS indirectly supports type int in source view descriptions. When the view description is compiled, the view compiler automatically converts any int types to either short or long types, depending on your machine. For more information, see VIEWS Features.
VIEWS also supports the dec_t packed decimal type in source view descriptions. This data type is useful for transferring VIEW structures to COBOL programs. In a C program using the dec_t type, the field must be initialized and accessed using the functions described in decimal(3c) in the BEA Tuxedo ATMI C Function Reference. Within the COBOL program, the field can be accessed directly using a packed decimal (COMP-3) definition. Because FML does not support a dec_t field, this field is automatically converted to the data type of the corresponding FML field in the fielded buffer (for example, a string field) when converting from a VIEW to FML.
In the BEA Tuxedo system, fields are usually referred to by their field identifier (fldid), an integer. (Refer to Defining Field Names and Identifiers for a detailed description of field identifiers.) This allows you to reference fields in a program without using the field name, which may change.
Identifiers are assigned (mapped) to field names through one of the following:
A typical application might use one, or both of the above methods to map field identifiers to field names.
In order for FML to access the data in fielded records, there must be some way for FML to access the field name/identifier mappings. FML gets this information in one of two ways:
Field name/identifier mapping is not available in COBOL.
Field name/identifier mappings can be made available to FML programs at run time through field table files. It is the responsibility of the programmer to set two environment variables that tell FML where the field name/identifier mapping table files are located.
The environment variable FLDTBLDIR contains a list of directories where field tables can be found. The environment variable FIELDTBLS contains a list of the files in the table directories that are to be used. For FML32, the environment variable names are FLDTBLDIR32 and FIELDTBLS32.
Within application programs, the FML function Fldid() provides for a run-time translation of a field name to its field identifier. Fname() translates a field identifier to its field name (see Fldid(3fml) and Fname(3fml)). (The function names for FML32 are Fldid32 and Fname32.) The first invocation of either function causes space in memory to be dynamically allocated for the field tables and the tables to be loaded into the address space of the process. The space can be recovered when the tables are no longer needed. (Refer to Loading Field Tables for more information.)
This method should be used when field name/identifier mappings are likely to change throughout the life of the application. This topic is covered in more detail in Defining and Using Fields.
Use mkfldhdr() (or mkfldhdr32()) to make header files out of field table files. These header files are included (with #include) in C programs, and provide another way to map field names to field identifiers: at compile time. For more information on mkfldhdr, mkfldhdr32(1), refer to BEA Tuxedo Command Reference.
Using field header files, the C preprocessor converts all field name references to field identifiers at compile time; thus, you do not need to use the Fldid() or Fname() functions as you would with the field table files described in the previous section.
If you always know the field names needed by your program, you can save some data space by including your field table header files (with #include). The space saving allows your program to get to the task at hand more quickly.
Because this method resolves mappings at compile time, however, it should not be used if the field name/identifier mappings in the application are likely to change. For more information, see Defining and Using Fields.
When a fielded buffer has many fields, access is expedited in FML by the use of an internal index. The user is normally unaware of the existence of this index.
Fielded buffer indexes do, however, take up space in memory and on disk. When you store a fielded buffer on disk, or transmit a fielded buffer between processes or between computers, you can save disk space and/or transmittal time by first discarding the index.
The Funindex() function enables you to discard the index. When the fielded buffer is read from disk (or received from a sending process), the index can be explicitly reconstructed with the Findex() function.
Note that these space savings do not apply to memory. The Funindex() function does not recover in-core memory used by the index of a fielded buffer.
For more information, refer to Funindex, Funindex32(3fml) or Findex, Findex32(3fml) in BEA Tuxedo ATMI FML Function Reference.
Any field in a fielded buffer can occur more than once. Many FML functions take an argument that specifies which occurrence of a field is to be retrieved or modified. If a field occurs more than once, the first occurrence is numbered 0, and additional occurrences are numbered sequentially. The set of all occurrences makes up a logical sequence, but no overhead is associated with the occurrence number (that is, it is not stored in the fielded buffer).
If another occurrence of a field is added, it is added at the end of the set and is referred to as the next highest occurrence. When an occurrence other than the highest is deleted, all higher occurrences of the field are shifted down by one (for example, occurrence 6 becomes occurrence 5, 5 becomes 4, and so on).
The next action taken by an application program is frequently determined by the value of one or more fields in a fielded buffer received (by the application) from another source, such as a user's terminal or a database record. FML provides several functions that create boolean expressions on fielded buffers or VIEWs and determine whether a given buffer or VIEW meets the criteria specified by the expression.
Once you create a Boolean expression, it is compiled into an evaluation tree. The evaluation tree is then used to determine whether a fielded buffer or VIEW matches the specified Boolean conditions.
For instance, a program may read a data record into a fielded buffer (Buffer A), and apply a Boolean expression to the buffer. If Buffer A meets the conditions specified by the Boolean expression, then an FML function is used to update another buffer, Buffer B, with data from Buffer A.
The VIEWS facility is particularly useful when a program does a lot of processing on the data in a fielded buffer, either after the program has received the buffer or before the program sends the buffer to another program.
Under such conditions, you may improve processing efficiency by using VIEWS functions to transfer fielded buffer data from the buffer to a C structure before you manipulate it. Processing efficiency is improved because C functions require less processing time than FML functions for manipulating fields in a buffer. When you finish processing the data in the C structure, you can transfer that data back to the fielded buffer before sending it to another program.
The VIEWS facility has the following features:
source view descriptions that specify C structure-to-fielded buffer mappings or COBOL record-to-fielded buffer mappings, and make possible the transfer of data between structures and buffers.viewc or viewc32 view compiler is used to generate object view descriptions (stored in binary files) that are interpreted by your application programs at run time. The compiler also generates header files that can be used in C programs to define the structures used in view descriptions, and optionally generates COPY files that can be used in COBOL programs to define the records used in the view descriptions. For more information about these view compilers, see viewc, viewc32(1) in BEA Tuxedo Command Reference.FUPDATE, FJOIN, FOJOIN, or FCONCAT. These modes are similar to the ones supported by the following FML functions: Fupdate, Fupdate32(3fml), Fjoin, Fjoin32(3fml), Fojoin, Fojoin32(3fml), and Fconcat, Fconcat32(3fml).FLD_PTR, FLD_FML32, and FLD_VIEW32. In addition, integer and packed decimal are supported.Ftypcvt() automatically. For more information, refer to Ftypcvt, Ftypcvt32(3fml) in BEA Tuxedo ATMI FML Function Reference.
A source viewfile is an ordinary text file that contains one or more source view descriptions. Source viewfiles are used as input to a view compiler—viewc or viewc32—which compiles the source view descriptions and stores them in object viewfiles. For more information on the view compiler, refer to viewc, viewc32(1) in BEA Tuxedo Command Reference.
The view compiler also creates C header files for object viewfiles. These header files can be included in application programs to define the structures used in object view descriptions.
The view compiler optionally creates COBOL COPY files for object viewfiles. These COPY files can be included in COPY programs to define the record formats used in object view descriptions.
NULL values are used to indicate empty members in a structure, and can be specified by the user for each structure member in a viewfile. If the user does not specify a NULL value for a member, default NULL values are used.
Note that a structure member containing the NULL value for that member is not transferred during a structure-to-fielded buffer transfer.
It is also possible to inhibit the transfer of data between a C or COBOL structure member and a field in a fielded buffer, even though a mapping exists between them. This is specified in the source viewfile.
The FML VIEWS functions are Fvstof(), Fvftos(), Fvnull(), Fvopt(), Fvselinit(), and Fvsinit(). For COBOL, the VIEWS facility provides two procedures: FVSTOF and FVFTOS. Upon calling any view function, the named object viewfile, if found, is loaded into the viewfile cache automatically. Each file specified in the environment variable VIEWFILES is searched in order (see Setting Up Your Environment for FML and VIEWS). The first object viewfile with the specified name is loaded. Subsequent object viewfiles with the same name, if any, are ignored. For more information on the FML VIEWS functions, refer to BEA Tuxedo ATMI FML Function Reference.
Note that arrays of structures, pointers, unions, and typedefs are not supported in VIEWS.
Because VIEWS is concerned with moving fields between fielded buffers and C structures or COBOL records, it must deal with the possibility of multiple occurrence fields in the buffer.
To store multiple occurrences of a field in a structure, a member is declared as an array in C or with the OCCURS clause in COBOL; each occurrence of a field occupies one element of the array. The size of the array reflects the maximum number of field occurrences in the buffer.
When transferring data from fielded buffers to C structures or COBOL records, if the number of elements in the receiving array is greater than the number of occurrences in the fielded buffer, the extra elements are assigned the (default or user-specified) NULL value. If the number of occurrences in the buffer is greater than the number of elements in the array, the extra occurrences in the buffer are ignored.
When data is transferred from C structures or COBOL records to fielded buffers, array members with the value equal to the (default or user-specified) NULL values are ignored.
When an FML function detects an error, one of the following values is returned:
All FML function call returns should be checked against the appropriate value above to detect errors.
In all error cases, the external integer Ferror is set to the error number as defined in fml.h. Ferror32 is set to the error number for FML32 as defined in fml32.h.
The F_error() (or F_error32()) function is provided to produce a message on the standard error output. It takes one parameter, a string. It prints the argument string, appended with a colon and a blank, and then prints an error message, followed by a newline character. The error message displayed is the one defined for the error number currently in Ferror, which is set when errors occur.
To be of most use, the argument string to the F_error() (or F_error32()) function should include the name of the program that incurred the error. Refer to F_error, F_error32(3fml) in BEA Tuxedo ATMI FML Function Reference.
Fstrerror, Fstrerror32(3fml) can be used to retrieve the text of an error message from a message catalog; it returns a pointer that can be used as an argument to userlog(3c), or to F_error() or F_error32().
For a description of the error codes produced by an FML function, see the entry for that function in BEA Tuxedo ATMI FML Function Reference.


|