| Oracle® Database管理者ガイド 11gリリース2 (11.2) B56301-08 |
|


 前 |
 次 |
|
注意: この章では、DBMS_SCHEDULERパッケージを使用してスケジューラ・オブジェクトを処理する方法について説明します。同じ作業をOracle Enterprise Managerを使用して実行できます。
DBMS_SCHEDULERの詳細は『Oracle Database PL/SQLパッケージ・プロシージャおよびタイプ・リファレンス』 |
Oracle Schedulerは、一連のスケジューラ・オブジェクトを作成および管理することにより操作します。各スケジューラ・オブジェクトは、[schema.]nameの形式の完全なデータベース・スキーマ・オブジェクトです。スケジューラ・オブジェクトは、データベース・オブジェクトの命名規則に正確に従い、他のデータベース・オブジェクトとSQLネームスペースを共有します。
SQLの命名規則に従ってDBMS_SCHEDULERパッケージのスケジューラ・オブジェクトに名前を付けます。デフォルトでは、二重引用符で囲まれていないかぎり、スケジューラ・オブジェクトの名前は大文字になります。たとえば、ジョブを作成する際に、job_name => 'my_job'はjob_name => 'My_Job'およびjob_name => 'MY_JOB'と同じですが、job_name => '"my_job"'とは異なります。スケジューラ・オブジェクト名のカンマ区切リストがDBMS_SCHEDULERパッケージ内で使用される場合も、これらの命名規則に従います。
ジョブとは、スケジュールとプログラムの組合せに、プログラムに必要な追加の引数が指定されたものです。この項では、ジョブの基本的なタスクについて説明します。この項の内容は、次のとおりです。
表29-1に、ジョブの一般的なタスクとそれに対応するプロシージャおよび権限を示します。
表29-1 ジョブのタスクとそのプロシージャ
| タスク | プロシージャ | 必要な権限 |
|---|---|---|
|
ジョブの作成 |
|
|
|
ジョブの変更 |
|
|
|
ジョブの実行 |
|
|
|
ジョブのコピー |
|
|
|
ジョブの削除 |
|
|
|
ジョブの停止 |
|
|
|
ジョブの使用禁止 |
|
|
|
ジョブの使用可能化 |
|
|
権限の詳細は、「スケジューラ権限」を参照してください。
この項の内容は次のとおりです。
1つ以上のジョブを作成するには、DBMS_SCHEDULER.CREATE_JOBまたはDBMS_SCHEDULER.CREATE_JOBSプロシージャ、あるいはEnterprise Managerを使用します。単一のジョブを作成するには、CREATE_JOBプロシージャを使用します。このプロシージャを使用して、異なるオブジェクトに基づく様々なタイプの複数のジョブを作成するとオーバーロードになります。単一トランザクションに複数のジョブを作成する場合は、CREATE_JOBSプロシージャを使用してください。
自分のスキーマにジョブを作成するにはCREATE JOB権限が、SYS以外のすべてのスキーマにジョブを作成するにはCREATE ANY JOB権限が必要です。
作成される各ジョブに対して、ジョブ・タイプ、処理およびスケジュールを指定します。必要応じて、資格証明の名前、宛先や宛先グループ名、ジョブ・クラスおよび他の属性も指定できます。ジョブを有効にするとすぐに、スケジュールされた次の日付と時刻に、スケジューラによってジョブが自動的に実行されます。デフォルトでは、作成時にジョブは無効になっており、DBMS_SCHEDULER.ENABLEで有効にして実行する必要があります。CREATE_JOBプロシージャのenabled引数をTRUEに設定することもできます。その場合、ジョブを作成するとすぐに、スケジュールに従ってジョブを自動的に実行する準備が整います。
一部のジョブ属性はCREATE_JOBでは設定できないため、かわりにDBMS_SCHEDULER.SET_ATTRIBUTEで設定する必要があります。たとえば、ジョブにlogging_level属性を設定するには、CREATE_JOBをコールした後、SET_ATTRIBUTEをコールする必要があります。
schema.job_nameを指定すると、別のスキーマ内にジョブを作成できます。したがって、ジョブの作成者がジョブの所有者であるとはかぎりません。ジョブの所有者は、ジョブが作成されるスキーマを所有しているユーザーです。実行時のジョブのNLS環境は、そのジョブが作成された時点に存在していた環境です。
例29-1に、update_salesというデータベース・ジョブを作成する方法を示します。このジョブは、売上集計表を更新する、OPSスキーマ内のパッケージ・プロシージャをコールします。
例29-1 ジョブの作成
BEGIN DBMS_SCHEDULER.CREATE_JOB ( job_name => 'update_sales', job_type => 'STORED_PROCEDURE', job_action => 'OPS.SALES_PKG.UPDATE_SALES_SUMMARY', start_date => '28-APR-08 07.00.00 PM Australia/Sydney', repeat_interval => 'FREQ=DAILY;INTERVAL=2', /* every other day */ end_date => '20-NOV-08 07.00.00 PM Australia/Sydney', auto_drop => FALSE, job_class => 'batch_update_jobs', comments => 'My new job'); END; /
destination_name属性は指定されていないため、ジョブは作成元の(ローカル)データベースで実行されます。ジョブは、ジョブを作成したユーザーとして実行されます。
repeat_interval引数では、このジョブが終了日時に達するまで1日おきに実行されるように指定しています。繰返しジョブの実行回数を制限するもう1つの方法として、max_runs属性を正の数に設定する方法があります。
ジョブの作成時、デフォルトではジョブは使用禁止になっています。ジョブは、スケジューラによって自動的に実行される前に、DBMS_SCHEDULER.ENABLEで使用可能にする必要があります。
ジョブは、デフォルトでは完了後に自動的に削除されるように設定されています。auto_drop属性をFALSEに設定すると、ジョブは保持されます。繰返しジョブは、ジョブ終了日をすぎるか、最大実行回数(max_runs)または最大失敗回数(max_failures)に達するまでは自動削除されないことに注意してください。
作成したジョブは、*_SCHEDULER_JOBSビューを使用して問い合せることができます。
CREATE_JOBプロシージャはオーバーロードになるため、複数の異なる使用方法があります。インラインのジョブの処理とジョブ・スケジュールの指定とも呼ばれ、例29-1に示すようなジョブの処理とジョブの繰返し間隔の指定に加えて、ジョブの処理を指定するプログラム・オブジェクト(プログラム)、繰返し間隔を指定するスケジュール・オブジェクト(スケジュール)、またはプログラムとスケジュールの両方を指し示すジョブを作成することもできます。次の各項で、これについて説明します。
ジョブの処理をインラインで記述するかわりに、名前付きプログラムを指し示してジョブを作成することもできます。名前付きプログラムを使用してジョブを作成するには、ジョブの作成時にCREATE_JOBプロシージャでprogram_nameの値を指定し、job_type、job_actionおよびnumber_of_argumentsの値は指定しません。
既存のプログラムを使用してジョブを作成するには、ジョブの所有者がプログラムの所有者であるか、プログラムに対するEXECUTE権限を持っている必要があります。次のPL/SQLブロックは、my_new_job1という標準ジョブを作成する名前付きプログラムが指定されたCREATE_JOBプロシージャの例です。
BEGIN DBMS_SCHEDULER.CREATE_JOB ( job_name => 'my_new_job1', program_name => 'my_saved_program', repeat_interval => 'FREQ=DAILY;BYHOUR=12', comments => 'Daily at noon'); END; /
次のPL/SQLブロックでは、軽量ジョブが作成されます。軽量ジョブは1つのプログラムを参照する必要があり、プログラム・タイプは'PLSQL_BLOCK'または'STORED_PROCEDURE'であることが必要です。さらに、プログラムはジョブの作成時に使用可能になっている必要があります。
BEGIN DBMS_SCHEDULER.CREATE_JOB ( job_name => 'my_lightweight_job1', program_name => 'polling_prog_n2', repeat_interval => 'FREQ=SECONDLY;INTERVAL=10', end_date => '30-APR-09 04.00.00 AM Australia/Sydney', job_style => 'LIGHTWEIGHT', comments => 'Job that polls device n2 every 10 seconds'); END; /
ジョブのスケジュールをインラインで記述するかわりに、名前付きスケジュールを指し示してジョブを作成することもできます。名前付きスケジュールを使用してジョブを作成するには、ジョブの作成時にCREATE_JOBプロシージャでschedule_nameの値を指定し、start_date、repeat_intervalおよびend_dateの値は指定しません。
すべてのスケジュールはPUBLICに対するアクセス権限付きで作成されるため、任意の名前付きスケジュールを使用してジョブを作成できます。次のCREATE_JOBプロシージャには名前付きスケジュールがあり、my_new_job2という標準ジョブを作成します。
BEGIN DBMS_SCHEDULER.CREATE_JOB ( job_name => 'my_new_job2', job_type => 'PLSQL_BLOCK', job_action => 'BEGIN SALES_PKG.UPDATE_SALES_SUMMARY; END;', schedule_name => 'my_saved_schedule'); END; /
ジョブは、名前付きプログラムと名前付きスケジュールの両方を指し示して作成することもできます。たとえば、次のCREATE_JOBプロシージャは、既存のプログラムmy_saved_program1および既存のスケジュールmy_saved_schedule1に基づいて、標準ジョブをmy_new_job3という名前で作成します。
BEGIN DBMS_SCHEDULER.CREATE_JOB ( job_name => 'my_new_job3', program_name => 'my_saved_program1', schedule_name => 'my_saved_schedule1'); END; /
ローカル外部ジョブ、リモート外部ジョブおよびリモート・データベース・ジョブの場合、ジョブを実行するための資格証明を指定する必要があります。そのためには、資格証明オブジェクトを作成して、それをcredential_nameジョブ属性に割り当てます。
リモート外部ジョブおよびリモート・データベース・ジョブの場合は、宛先オブジェクトを作成してdestination_nameジョブ属性に割り当てることにより、ジョブの宛先を指定します。NULLのdestination_name属性が指定されたジョブは、ジョブが作成されたホストで実行されます。
この項の内容は次のとおりです。
表29-2に、資格証明および宛先のタスクとそのプロシージャおよび権限を示します。
表29-2 資格証明および宛先のタスクとそのプロシージャ
| タスク | プロシージャ | 必要な権限 |
|---|---|---|
|
資格証明の作成 |
|
|
|
資格証明の削除 |
|
|
|
外部宛先の作成 |
(なし) |
「宛先の作成」を参照 |
|
外部宛先の削除 |
|
|
|
データベース宛先の作成 |
|
|
|
データベース宛先の削除 |
|
|
|
宛先グループの作成 |
|
|
|
宛先グループの削除 |
|
|
|
宛先グループへのメンバーの追加 |
|
|
|
宛先グループからのメンバーの削除 |
|
|
資格証明は、専用のデータベース・オブジェクトに格納されているユーザー名とパスワードのペアです。ジョブに資格証明を割り当てることによって、ジョブを実行する前にOracle Databaseまたはオペレーティング・システムで認証できるようにします。
資格証明を作成する手順は、次のとおりです。
DBMS_SCHEDULER.CREATE_CREDENTIALプロシージャをコールします。
自分のスキーマに資格証明を作成するにはCREATE JOB権限が、SYS以外のスキーマに資格証明を作成するにはCREATE ANY JOB権限が必要です。資格証明を使用できるのは、資格証明のEXECUTE権限がジョブの所有者に付与されているジョブ、またはジョブの所有者が資格証明の所有者を兼ねているジョブのみです。資格証明は他のスキーマ・オブジェクトのようにスキーマに属しているため、資格証明に対する権限はGRANT SQL文を使用して付与します。
例29-2 資格証明の作成
BEGIN
DBMS_SCHEDULER.CREATE_CREDENTIAL('DW_CREDENTIAL', 'dwuser', 'dW001515');
END;
/
GRANT EXECUTE ON DW_CREDENTIAL TO salesuser;
データベース内の資格証明のリストを表示するには、*_SCHEDULER_CREDENTIALSビューを問い合せます。資格証明パスワードは不明瞭な状態で格納されるため、*_SCHEDULER_CREDENTIALSビューには表示されません。
宛先とは、ジョブを実行する場所を定義したスケジューラ・オブジェクトです。ジョブが実行される場所を指定するには、ジョブのdestination_name属性に単一の宛先または宛先グループを指定します。destination_name属性をNULLのままにすると、ジョブはローカル・ホスト(ジョブが作成されたホスト)で実行されます。
リモート外部ジョブが実行される場所を指定するには、外部宛先を使用します。リモート・データベース・ジョブが実行される場所を指定するには、データベース宛先を使用します。
別のユーザーが作成した宛先を使用するのにオブジェクト権限は必要ありません。
外部宛先を作成する手順は、次のとおりです。
リモート・スケジューラ・エージェントをデータベースに登録します。
手順は、「リモート・ホストでのスケジューラ・エージェントのインストールと構成」を参照してください。
|
注意: 外部宛先を作成するためのDBMS_SCHEDULERパッケージ・プロシージャはありません。外部宛先は、リモート・エージェントを登録することによって暗黙的に作成します。
リモート・ジョブのターゲットとなるホストで他のデータベース・インスタンスを実行している場合は、ローカル・スケジューラ・エージェントも登録できます。この場合、ローカル・ホストを参照する外部宛先が作成されます。 |
外部宛先の名前は自動的にエージェント名に設定されます。外部宛先が作成されたかどうかを確認するには、DBA_SCHEDULER_EXTERNAL_DESTSビューまたはALL_SCHEDULER_EXTERNAL_DESTSビューを問い合せます。
データベース宛先を作成する手順は、次のとおりです。
DBMS_SCHEDULER.CREATE_DATABASE_DESTINATIONプロシージャをコールします。
プロシージャの引数として外部宛先の名前を指定する必要があります。これにより、データベース宛先が指し示すリモート・ホストが指定されます。また、ネット・サービス名を指定したり、接続先のデータベース・インスタンスを識別する接続記述子を入力します。ネット・サービス名を指定した場合、その名前はローカルのtnsnames.oraファイルで解決される必要があります。データベース・インスタンスを指定しなかった場合、リモート・スケジューラ・エージェントは、エージェント構成ファイルに指定されているデフォルトのデータベースに接続されます。
データベース宛先を作成するには、CREATE JOBシステム権限が必要です。自身のスキーマ以外のスキーマにデータベース接続先を作成するには、CREATE ANY JOB権限が必要です。
例29-3 データベース宛先の作成
次の例では、DBHOST1_ORCLDWという名前のデータベース宛先を作成しています。この例では、次のことを想定しています。
リモート・ホストdbhost1.example.comにスケジューラ・エージェントをインストールし、そのエージェントをローカル・データベースに登録していること。
エージェント構成ファイル内のエージェント名の設定を変更していないこと。つまり、エージェント名および外部宛先の名前がデフォルトのDBHOST1に設定されていること。
ローカル・ホスト上のNet Configuration Assistantを使用して、リモート・ホストdbhost1.example.comに存在するorcldwという名前のOracle Databaseインスタンスに対してtnsnames.ora内に接続記述子を作成していること。また、ORCLDWのネット・サービス名(別名)をこの接続記述子に割り当てていること。
BEGIN DBMS_SCHEDULER.CREATE_DATABASE_DESTINATION ( destination_name => 'DBHOST1_ORCLDW', agent => 'DBHOST1', tns_name => 'ORCLDW', comments => 'Instance named orcldw on host dbhost1.example.com'); END; /
データベース宛先が作成されたかどうかを確認するには、*_SCHEDULER_DB_DESTSビューを問い合せます。
複数の宛先で実行するジョブを作成するには、宛先グループを作成して、そのグループをジョブのdestination_name属性に割り当てる必要があります。グループの作成時にグループ・メンバー(宛先)を指定することも、後でグループ・メンバーを追加することもできます。
宛先グループを作成する手順は、次のとおりです。
DBMS_SCHEDULER.CREATE_GROUPプロシージャをコールします。
リモート外部ジョブの場合、EXTERNAL_DESTタイプのグループを指定し、すべてのグループ・メンバーを外部宛先にする必要があります。リモート・データベース・ジョブの場合、DB_DESTタイプのグループを指定し、すべてのメンバーをデータベース宛先にする必要があります。
宛先グループのメンバーは、次の形式で指定する必要があります。
[[schema.]credential@][schema.]destination
説明:
credentialは、既存の資格証明の名前です。
destinationは、既存のデータベース宛先または外部宛先の名前です。
接続先メンバーの資格証明部分はオプションです。省略すると、この接続先メンバーを使用するジョブはデフォルトの資格証明を使用します。
同じタイプの別のグループを宛先グループのメンバーとして含めることができます。グループの作成時に別のグループを含めた場合、その中に含まれるメンバーはスケジューラによって自動的に展開されます。
ジョブを実行する多数の宛先の1つとしてローカル・ホストを使用する場合、どちらのタイプの宛先グループのグループ・メンバーとしてもLOCALキーワードを指定できます。外部宛先グループの場合にかぎり、LOCALの前に資格証明の接頭辞を付けることができます。
グループの所有者は、そのグループを作成したユーザーです。自分のスキーマにグループを作成するにはCREATE JOBシステム権限が必要になり、別のスキーマにグループを作成するにはCREATE ANY JOBシステム権限が必要になります。SELECTをグループに付与することによって、グループのオブジェクト権限を他のユーザーに付与できます。
例29-4 データベース宛先グループの作成
次の例では、データベース宛先グループを作成しています。一部のメンバーには資格証明がないため、この宛先グループを使用するジョブではデフォルトの資格証明を使用する必要があります。
BEGIN
DBMS_SCHEDULER.CREATE_GROUP(
GROUP_NAME => 'all_dbs',
GROUP_TYPE => 'DB_DEST',
MEMBER => 'oltp_admin@orcl, orcldw1, LOCAL',
COMMENTS => 'All databases managed by me');
END;
/
次のコードでは、グループに別のメンバーを追加しています。
BEGIN
DBMS_SCHEDULER.ADD_GROUP_MEMBER(
GROUP_NAME => 'all_dbs',
MEMBER => 'dw_admin@orcldw2');
END;
/
次の例では、ジョブのdestination_nameオブジェクトにデータベース宛先オブジェクトを指定することで、リモート・データベース・ジョブを作成しています。リモート・データベースでジョブを認証できるように、資格証明も指定する必要があります。この例では、例29-2で作成した資格証明および例29-3で作成したデータベース宛先を使用しています。
BEGIN DBMS_SCHEDULER.CREATE_JOB ( job_name => 'SALES_SUMMARY1', job_type => 'STORED_PROCEDURE', job_action => 'SALES.SALES_REPORT1', start_date => '15-JUL-09 11.00.00 PM Europe/Warsaw', repeat_interval => 'FREQ=DAILY', credential_name => 'DW_CREDENTIAL', destination_name => 'DBHOST1_ORCLDW'); END; /
複数の宛先で実行し、1箇所で管理するジョブを作成できます。このようにする代表的な理由としては、管理対象のすべてのデータベースでデータベース・メンテナンス・ジョブを実行することがあげられます。各データベースでジョブを作成するのではなく、ジョブを1つ作成し、そのジョブに対して複数の宛先を指定します。ジョブを作成したデータベース(local database)から、すべての場所のジョブのすべてのインスタンスの状態と結果を監視できます。
複数の宛先のジョブを作成する手順は、次のとおりです。
DBMS_SCHEDULER.CREATE_JOBプロシージャをコールして、ジョブのdestination_name属性にデータベース宛先グループまたは外部宛先グループの名前を設定します。
一部の宛先グループ・メンバーに資格証明の接頭辞(スキーマ)が付いていない場合、ジョブにデフォルトの資格証明を割り当てます。
ジョブを実行する宛先の1つとしてローカル・ホストまたはローカル・データベースを使用するには、LOCALキーワードを宛先グループのメンバーの1つにする必要があります。
宛先グループのリストを取得するには、次の問合せを発行します。
SELECT owner, group_name, group_type, number_of_members FROM all_scheduler_groups WHERE group_type = 'DB_DEST' or group_type = 'EXTERNAL_DEST'; OWNER GROUP_NAME GROUP_TYPE NUMBER_OF_MEMBERS --------------- --------------- ------------- ----------------- DBA1 ALL_DBS DB_DEST 4 DBA1 ALL_HOSTS EXTERNAL_DEST 4
次の例では、例29-4で作成したデータベース宛先グループを使用して、複数の宛先のデータベース・ジョブを作成しています。このジョブはシステム管理ジョブであるため、システム管理者権限を含む資格証明が使用されます。
BEGIN
DBMS_SCHEDULER.CREATE_CREDENTIAL('DBA_CREDENTIAL', 'dba1', 'sYs040533');
DBMS_SCHEDULER.CREATE_JOB (
job_name => 'MAINT_SET1',
job_type => 'STORED_PROCEDURE',
job_action => 'MAINT_PROC1',
start_date => '15-JUL-09 11.00.00 PM Europe/Warsaw',
repeat_interval => 'FREQ=DAILY',
credential_name => 'DBA_CREDENTIAL',
destination_name => 'ALL_DBS');
END;
/
ジョブの作成後、次の場合にジョブ引数の設定が必要な場合があります。
インラインのジョブ処理が、引数を必要とするストアド・プロシージャまたはその他の実行可能ファイルの場合
ジョブが名前付きプログラム・オブジェクトを参照していて、そのデフォルト・プログラム引数の1つ以上を上書きする場合
ジョブが名前付きプログラム・オブジェクトを参照していて、そのプログラム引数の1つ以上にデフォルト値が割り当てられていない場合
ジョブ引数を設定するには、SET_JOB_ARGUMENT_VALUEまたはSET_JOB_ANYDATA_VALUEプロシージャ、あるいはEnterprise Managerを使用します。SET_JOB_ANYDATA_VALUEは、VARCHAR2文字列として表現できない複雑なデータ型に使用されます。
引数を必要とする場合があるジョブの例の1つに、開始日と終了日が必要なレポート作成プログラムを開始するジョブがあります。次のコード例では、レポート作成プログラムの2番目の引数である終了日のジョブ引数が設定されます。
BEGIN DBMS_SCHEDULER.SET_JOB_ARGUMENT_VALUE ( job_name => 'ops_reports', argument_position => 2, argument_value => '12-DEC-03'); END; /
値がすでに設定されている引数についてこのプロシージャを使用すると、その引数は上書きされます。引数値を設定するには、引数名または引数の位置を使用します。引数名を使用するには、ジョブが名前付きプログラム・オブジェクトを参照し、そのプログラム・オブジェクト内で引数に名前が割り当てられている必要があります。プログラムがインラインで記述されている場合にサポートされるのは、位置による設定のみです。引数は、タイプがPLSQL_BLOCKのジョブに対してはサポートされません。
設定されている値を削除するには、RESET_JOB_ARGUMENTプロシージャを使用します。このプロシージャは、通常の引数およびANYDATA引数の両方に使用できます。
SET_JOB_ARGUMENT_VALUEでは、SQLタイプの引数のみがサポートされます。したがって、SQLタイプではない引数の値(ブール値など)は、プログラムまたはジョブ引数としてサポートされません。
ジョブの作成後に、SET_ATTRIBUTEまたはSET_JOB_ATTRIBUTESプロシージャを使用して、追加のジョブ属性を設定したり、属性値を変更できます。また、Enterprise Managerを使用してジョブ属性を設定することもできます。ジョブ属性の多くはCREATE_JOBのコールを使用して設定できますが、destinationやcredential_nameなどの一部の属性は、ジョブの作成後にSET_ATTRIBUTEまたはSET_JOB_ATTRIBUTESを使用することによってのみ設定できます。
デタッチ済ジョブでは、detached属性がTRUEに設定されているプログラム・オブジェクト(プログラム)を指し示す必要があります。
例29-5 コールド・バックアップを実行するデタッチ済ジョブの作成
LinuxとUNIXに関する次の例では、データベースのコールド・バックアップを実行する夜間ジョブを作成しています。これには、3つのステップが含まれています。
ステップ1: RMAN起動スクリプトの作成
コールド・バックアップを実行するRMANスクリプトを呼び出すシェル・スクリプトを作成します。このシェル・スクリプトは$ORACLE_HOME/scripts/coldbackup.shに置かれます。これは、Oracle Databaseをインストールしたユーザー(通常はユーザーoracle)が実行できる必要があります。
#!/bin/sh export ORACLE_HOME=/u01/app/oracle/product/11.2.0/db_1 export ORACLE_SID=orcl export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:$ORACLE_HOME/lib $ORACLE_HOME/bin/rman TARGET / @$ORACLE_HOME/scripts/coldbackup.rman trace /u01/app/oracle/backup/coldbackup.out & exit 0
ステップ2: RMANスクリプトの作成
コールド・バックアップを実行してからジョブを終了する、RMANスクリプトを作成します。このスクリプトは$ORACLE_HOME/scripts/coldbackup.rmanに置かれます。
run {
# Shut down database for backups and put into MOUNT mode
shutdown immediate
startup mount
# Perform full database backup
backup full format "/u01/app/oracle/backup/%d_FULL_%U" (database) ;
# Open database after backup
alter database open;
# Call notification routine to indicate job completed successfully
sql " BEGIN DBMS_SCHEDULER.END_DETACHED_JOB_RUN(''sys.backup_job'', 0,
null); END; ";
}
ステップ3: ジョブの作成とデタッチ済プログラムの使用
次のPL/SQLブロックを発行します。
BEGIN
DBMS_SCHEDULER.CREATE_PROGRAM(
program_name => 'sys.backup_program',
program_type => 'executable',
program_action => '?/scripts/coldbackup.sh',
enabled => TRUE);
DBMS_SCHEDULER.SET_ATTRIBUTE('sys.backup_program', 'detached', TRUE);
DBMS_SCHEDULER.CREATE_JOB(
job_name => 'sys.backup_job',
program_name => 'sys.backup_program',
repeat_interval => 'FREQ=DAILY;BYHOUR=1;BYMINUTE=0');
DBMS_SCHEDULER.ENABLE('sys.backup_job');
END;
/
多数のジョブを作成する必要がある場合は、CREATE_JOBSプロシージャを使用すると、トランザクションのオーバーヘッドを減らしてパフォーマンスを改善できる可能性があります。例29-6に、このプロシージャを使用して単一トランザクションで複数のジョブを作成する方法を示します。
例29-6 単一トランザクションでの複数ジョブの作成
DECLARE
newjob sys.job_definition;
newjobarr sys.job_definition_array;
BEGIN
-- Create an array of JOB_DEFINITION object types
newjobarr := sys.job_definition_array();
-- Allocate sufficient space in the array
newjobarr.extend(5);
-- Add definitions for 5 jobs
FOR i IN 1..5 LOOP
-- Create a JOB_DEFINITION object type
newjob := sys.job_definition(job_name => 'TESTJOB' || to_char(i),
job_style => 'REGULAR',
program_name => 'PROG1',
repeat_interval => 'FREQ=HOURLY',
start_date => systimestamp + interval '600' second,
max_runs => 2,
auto_drop => FALSE,
enabled => TRUE
);
-- Add it to the array
newjobarr(i) := newjob;
END LOOP;
-- Call CREATE_JOBS to create jobs in one transaction
DBMS_SCHEDULER.CREATE_JOBS(newjobarr, 'TRANSACTIONAL');
END;
/
PL/SQL procedure successfully completed.
SELECT JOB_NAME FROM USER_SCHEDULER_JOBS;
JOB_NAME
------------------------------
TESTJOB1
TESTJOB2
TESTJOB3
TESTJOB4
TESTJOB5
5 rows selected.
この項では、次の例を通して、外部ジョブに関するいくつかの実践的手法を示します。
例29-7 DOSコマンドを実行するローカル外部ジョブの作成
次の例に、Windows上でDOS組込みコマンド(この例ではmkdir)を実行するローカル外部ジョブの作成方法を示します。このジョブでは、/cオプションを指定してcmd.exeが実行されます。
BEGIN
DBMS_SCHEDULER.CREATE_JOB(
job_name => 'MKDIR_JOB',
job_type => 'EXECUTABLE',
number_of_arguments => 3,
job_action => '\windows\system32\cmd.exe',
auto_drop => FALSE,
credential_name => 'TESTCRED');
DBMS_SCHEDULER.SET_JOB_ARGUMENT_VALUE('mkdir_job',1,'/c');
DBMS_SCHEDULER.SET_JOB_ARGUMENT_VALUE('mkdir_job',2,'mkdir');
DBMS_SCHEDULER.SET_JOB_ARGUMENT_VALUE('mkdir_job',3,'\temp\extjob_test_dir');
DBMS_SCHEDULER.ENABLE('MKDIR_JOB');
END;
/
例29-8 ローカル外部ジョブの作成とstdoutの取得
LinuxおよびUNIX用のこの例では、ローカル外部ジョブを作成および実行してから、GET_FILEプロシージャを使用してジョブのstdout出力を取得する方法を示します。ローカル外部ジョブの場合、ORACLE_HOME/scheduler/logにあるログ・ファイルにstdout出力が保存されます。このパスをGET_FILEに指定する必要はなく、ログ・ビューでジョブの外部ログIDを問い合せて、最後に「_stdout」を追加したファイル名のみを指定します。
-- User scott must have CREATE JOB and CREATE EXTERNAL JOB privileges grant create job, create external job to scott ; connect scott/password set serveroutput on -- Create a credential for the job to use exec dbms_scheduler.create_credential('my_cred','host_username','host_passwd') -- Create a job that lists a directory. After running, the job is dropped. begin DBMS_SCHEDULER.CREATE_JOB( job_name => 'lsdir', job_type => 'EXECUTABLE', job_action => '/bin/ls', number_of_arguments => 1, enabled => false, auto_drop => true, credential_name => 'my_cred'); DBMS_SCHEDULER.SET_JOB_ARGUMENT_VALUE('lsdir',1,'/tmp'); DBMS_SCHEDULER.ENABLE('lsdir'); end; / -- Wait a bit for the job to run, and then check the job results. select job_name, status, error#, actual_start_date, additional_info from user_scheduler_job_run_details where job_name='LSDIR'; -- Now use the external log id from the additional_info column to -- formulate the log file name and retrieve the output declare my_blob blob; log_id varchar2(50); begin select regexp_substr(additional_info,'job[_0-9]*') into log_id from user_scheduler_job_run_details where job_name='LSDIR'; dbms_lob.createtemporary(my_blob, false); dbms_scheduler.get_file( source_file => log_id ||'_stdout', credential_name => 'my_cred', file_contents => my_blob, source_host => null); dbms_output.put_line(my_blob); end; /
|
注意: リモート外部ジョブの場合、メソッドは同じですが次の違いがあります。
|
|
関連項目:
|
ジョブを変更するには、その属性を変更します。そのためには、SET_ATTRIBUTE、SET_ATTRIBUTE_NULLまたはSET_JOB_ATTRIBUTESパッケージ・プロシージャ、あるいはEnterprise Managerを使用します。ジョブ属性の詳細は、『Oracle Database PL/SQLパッケージおよびタイプ・リファレンス』のCREATE_JOBプロシージャに関する項を参照してください。
すべてのジョブは変更可能で、ジョブ名以外のすべてのジョブ属性を変更できます。変更する際に実行中のジョブ・インスタンスがある場合、そのインスタンスはこのコールによる影響を受けません。このプロシージャによる変更は、今後実行されるジョブに対してのみ反映されます。
通常、データベースによって自動的に作成されたジョブは変更しないでください。データベースによって作成されたジョブには、ジョブのビューでTRUEに設定された列SYSTEMがあります。ジョブの属性は、*_SCHEDULER_JOBSビューで使用可能です。
実行中のジョブのジョブ属性も変更できます。ただし、その変更は、スケジュールされている次回のジョブ実行時まで反映されません。
SET_ATTRIBUTE、SET_ATTRIBUTE_NULLおよびSET_JOB_ATTRIBUTESプロシージャの詳細は、『Oracle Database PL/SQLパッケージおよびタイプ・リファレンス』を参照してください。
次の例では、ジョブupdate_salesのrepeat_intervalを毎週水曜日の1回に変更しています。
BEGIN DBMS_SCHEDULER.SET_ATTRIBUTE ( name => 'update_sales', attribute => 'repeat_interval', value => 'freq=weekly; byday=wed'); END; /
ジョブを実行するには、次の3つの方法があります。
ジョブ・スケジュールに従って実行する方法: この場合、ジョブが有効であれば、スケジューラ・ジョブ・コーディネータによって自動的にジョブが取り出され、ジョブ・スレーブの制御下で実行されます。ジョブは、ジョブ所有者のユーザーとして、または資格証明のあるローカル外部ジョブの場合は、資格証明で指定したユーザーとして実行されます。ジョブが成功したかどうかを確認するには、ジョブ・ビュー(*_SCHEDULER_JOBS)またはジョブ・ログ(*_SCHEDULER_JOB_LOGおよび*_SCHEDULER_JOB_RUN_DETAILS)で問い合せる必要があります。ジョブ・スレーブおよびスケジューラ・アーキテクチャの詳細は、「ジョブの実行方法」を参照してください。
イベントの発生時に実行する方法: イベント・キューで特定のイベントが受信されるか、File Watcherでファイル到着イベントが呼び出されると、使用可能になっているイベントベースのジョブが開始されます ( 「イベントを使用したジョブの開始」 を参照)。(「イベントを使用したジョブの開始」を参照してください。)または、資格証明を使用するローカル外部ジョブの場合は、資格証明内に指定されているユーザーとして実行されます。ジョブが成功したかどうかを確認するには、ジョブ・ビューまたはジョブ・ログを問い合せる必要があります。
DBMS_SCHEDULER.RUN_JOBを呼び出して実行する方法: RUN_JOBプロシージャを使用して、ジョブをテストしたり、指定したスケジュール以外で実行できます。ジョブは非同期に実行できますが、これは前の2つのジョブ実行方法、つまり同期して実行する方法に類似しており、この方法ではRUN_JOBを呼び出したセッションにユーザーがログインするとジョブが実行されます。RUN_JOBのuse_current_session引数によって、ジョブが同期または非同期のどちらで実行されるかが決まります。
RUN_JOBでは、ジョブ名のカンマ区切りのリストを使用できます。
次の例では、2つのジョブを非同期で実行しています。
BEGIN
DBMS_SCHEDULER.RUN_JOB(
JOB_NAME => 'DSS.ETLJOB1, DSS.ETLJOB2',
USE_CURRENT_SESSION => FALSE);
END;
/
|
注意: スケジュールに従ってジョブを実行する場合は、RUN_JOBをコールする必要はありません。ジョブが使用可能であれば、スケジューラによって自動的に実行されます。 |
STOP_JOBプロシージャまたはEnterprise Managerを使用して、1つ以上の実行中のジョブを停止できます。STOP_JOBでは、ジョブ、ジョブ・クラスおよびジョブ宛先IDのカンマ区切リストを使用できます。ジョブ宛先IDは、スケジューラによって割り当てられる番号で、ジョブ、資格証明および宛先の一意の組合せを表します。これは、複数宛先のジョブの特定の子ジョブを識別して、その子のみを停止するのに便利な方法です。子ジョブのジョブ宛先IDは*_SCHEDULER_JOB_DESTSのビューから取得します。
ジョブ・クラスが指定されている場合、そのジョブ・クラス内の実行中のジョブはすべて停止されます。たとえば、次の文では、ジョブjob1、ジョブ・クラスdw_jobs内のすべてのジョブ、および複数の宛先のジョブに含まれる2つの子ジョブが停止されます。
BEGIN
DBMS_SCHEDULER.STOP_JOB('job1, sys.dw_jobs, 984, 1223');
END;
/
指定したジョブのインスタンスはすべて停止されます。ジョブの停止後、1回かぎりのジョブの状態はSTOPPEDに設定され、繰返しジョブの状態は、(次回のジョブ実行がスケジュールされているため)SCHEDULEDに設定されます。また、ジョブ・ログには、OPERATIONがSTOPPEDに設定され、ADDITIONAL_INFOがREASON="Stop job called by user: username"に設定されたエントリが作成されます。
デフォルトでは、スケジューラは割込みメカニズムを使用してジョブを正常に停止しようとします。この方法では、制御がスレーブ・プロセスに戻され、スレーブ・プロセスはジョブ実行の統計を収集できます。forceオプションがTRUEに設定されている場合、ジョブは即時に停止するため、そのジョブ実行について特定の実行時間の統計が使用できない場合があります。
チェーンを実行中のジョブを停止すると、実行中のすべてのステップが(各ステップでforceオプションをTRUEに設定してSTOP_JOBをコールすることによって)自動的に停止されます。
STOP_JOBのcommit_semantics引数を使用すると、複数のジョブが指定されている場合の結果および1つ以上のジョブを停止しようとしたときに発生するエラーを制御できます。この引数をABSORB_ERRORSに設定すると、エラーが発生した後もプロシージャを続行して、残りのジョブの停止試行を実行できる場合があります。エラーが発生したことがプロシージャによって示された場合は、エラーの内容を判断するために、ビューSCHEDULER_BATCH_ERRORSを問い合せることができます。コミット・セマンティクスの詳細は、「ジョブの削除」を参照してください。
STOP_JOBプロシージャの詳細は、『Oracle Database PL/SQLパッケージおよびタイプ・リファレンス』を参照してください。
|
注意: ジョブが停止したときにロールバックされるのは、現行トランザクションのみです。これは、データの一貫性を損なう原因となる場合があります。 |
スケジューラを使用している場合、外部ジョブの実装者は、forceがFALSEに設定されたSTOP_JOBがコールされた場合に、その外部ジョブを正常にクリーン・アップするメカニズムを利用できます。次の説明は、すべてのプラットフォーム上で資格証明を使用せずに作成されたローカル外部ジョブと、UNIXおよびLinuxプラットフォーム上のリモート外部ジョブにのみ該当します。
UNIXおよびLinuxでは、スケジューラによって起動されたプロセスにSIGTERMシグナルが送信されます。外部ジョブの実装者は、割込みハンドラにSIGTERMをトラップし、ジョブの実装内容をすべてクリーン・アップして終了する必要があります。Windowsでは、forceがFALSEに設定されたSTOP_JOBは、Windows XP、Windows 2003およびそれ以降のオペレーティング・システムでのみサポートされます。これらのプラットフォームでは、スケジューラによって起動されるプロセスがコンソール・プロセスです。このプロセスを停止するために、スケジューラはCTRL_BREAKをプロセスに送信します。CTRL_BREAKは、SetConsoleCtrlHandler()ルーチンにハンドラを登録することによって処理できます。
チェーンを指し示すジョブが停止すると、実行中のチェーンのステップがすべて停止します。
個々のチェーン・ステップの停止の詳細は、「個々のチェーン・ステップの停止」を参照してください。
1つ以上のジョブを削除するには、DROP_JOBプロシージャまたはEnterprise Managerを使用します。DROP_JOBでは、ジョブおよびジョブ・クラスのカンマ区切りリストを使用できます。ジョブ・クラスを指定すると、そのジョブ・クラスのすべてのジョブは削除されますが、ジョブ・クラス自体は削除されません。(ジョブ・クラスを削除するには、DROP_JOB_CLASSを使用します。ジョブ・クラスの削除方法の詳細は、「ジョブ・クラスの削除」を参照してください。)DROP_JOBでジョブ宛先IDを使用して複数宛先ジョブの子ジョブを削除することはできません。
次の文では、ジョブjob1とjob3、およびジョブ・クラスjobclass1とjobclass2内のすべてのジョブが削除されます。
BEGIN
DBMS_SCHEDULER.DROP_JOB ('job1, job3, sys.jobclass1, sys.jobclass2');
END;
/
プロシージャ・コール時にジョブが実行中の場合、ジョブの削除試行は失敗します。このデフォルトの動作は、forceまたはdeferオプションを設定することによって変更できます。
forceオプションをTRUEに設定すると、最初に、実行中のジョブの停止試行がスケジューラの割込みメカニズム(forceオプションをFALSEに設定してSTOP_JOBをコール)によって行われます。ジョブが正常に停止されると、次にそのジョブが削除されます。または、STOP_JOBをコールして最初にジョブを停止してから、DROP_JOBをコールすることもできます。STOP_JOBが失敗した場合は、forceオプションを設定してSTOP_JOBをコールできます(この場合、MANAGE SCHEDULER権限が必要です)。その後、そのジョブを削除できます。デフォルトでは、STOP_JOBおよびDROP_JOBプロシージャの両方で、forceはFALSEに設定されています。
deferオプションをTRUEに設定すると、実行中のジョブは完了してから削除されます。forceとdeferオプションは相互に排他的で、両方を設定するとエラーになります。
複数のジョブを削除するように指定する場合は、commit_semantics引数を使用して、いずれかのジョブでエラーが発生した場合の結果を決定します。この引数には、次の値を指定できます。
STOP_ON_FIRST_ERROR(デフォルト): 最初のエラーでコールが戻り、エラー発生前に正常終了した削除操作がディスクにコミットされます。
TRANSACTIONAL: 最初のエラーでコールが戻り、エラー発生前の削除操作がロールバックされます。forceがFALSEに設定されている必要があります。
ABSORB_ERRORS: エラーへの対応が取り組まれ、残りのジョブの削除が試行されて、正常終了したすべての削除操作がコミットされます。
commit_semanticsを設定できるのは、job_nameリストにジョブ・クラスが含まれていない場合のみです。ジョブ・クラスを指定している場合は、デフォルトのコミット・セマンティクス(STOP_ON_FIRST_ERROR)が適用されます。
次の例では、deferオプションとTRANSACTIONALコミット・セマンティクスを使用して、ジョブmyjob1およびmyjob2を削除しています。
BEGIN
DBMS_SCHEDULER.DROP_JOB(
job_name => 'myjob1, myjob2',
defer => TRUE,
commit_semantics => 'TRANSACTIONAL');
END;
/
次の例では、ABSORB_ERRORSコミット・セマンティクスを示しています。プロシージャのコール時にmyjob1が実行されており、myjob2は実行されていないことを想定しています。
BEGIN
DBMS_SCHEDULER.DROP_JOB(
job_name => 'myjob1, myjob2',
commit_semantics => 'ABSORB_ERRORS');
END;
/
Error report:
ORA-27362: batch API call completed with errors
SCHEDULER_BATCH_ERRORSビューを問い合せて、エラーの内容を判断できます。
SELECT object_name, error_code, error_message FROM scheduler_batch_errors; OBJECT_NAME ERROR CODE ERROR_MESSAGE -------------- ---------- --------------------------------------------------- STEVE.MYJOB1 27478 "ORA-27478: job "STEVE.MYJOB1" is running
USER_SCHEDULER_JOBSを確認すると、myjob2は正常に削除され、myjob1は残っていることがわかります。
DROP_JOBプロシージャの詳細は、『Oracle Database PL/SQLパッケージおよびタイプ・リファレンス』を参照してください。
1つ以上のジョブを無効(使用禁止)にするには、DISABLEプロシージャまたはEnterprise Managerを使用します。ジョブは他の理由で使用禁止になる場合もあります。たとえば、ジョブが属しているジョブ・クラスが削除されると、ジョブは使用禁止になります。また、ジョブが指し示しているプログラムまたはスケジュールのいずれかが削除された場合も使用禁止になります。ジョブが指し示しているプログラムまたはスケジュールが使用禁止の場合は、そのジョブ自体は使用禁止にならないため、スケジューラがジョブを実行しようとしたときに、エラーとなることに注意してください。
ジョブを使用禁止にするとは、ジョブのメタデータが存在してもジョブを実行できず、ジョブ・コーディネータがこれらのジョブを処理対象として取得しないことを意味します。ジョブが使用禁止になると、ジョブ表内のそのstateはdisabledに変更されます。
forceオプションをFALSEに設定してジョブを使用禁止にすると、ジョブが現在実行中の場合はエラーが返されます。forceがTRUEに設定されているときは、ジョブは使用禁止になりますが、現在実行中のインスタンスは完了できます。
commit_semanticsがSTOP_ON_FIRST_ERRORに設定されている場合は、最初のエラーでコールが戻り、エラー発生前に正常終了した使用禁止操作がディスクにコミットされます。commit_semanticsがTRANSACTIONALに、forceがFALSEに設定されている場合は、最初のエラーでコールが戻り、エラー発生前の使用禁止操作がロールバックされます。commit_semanticsがABSORB_ERRORSに設定されている場合は、エラーへの対応が取り組まれ、残りのジョブの使用禁止が試行されて、正常に終了したすべての使用禁止操作がコミットされます。エラーが発生したことがプロシージャによって示された場合は、エラーの内容を判断するために、ビューSCHEDULER_BATCH_ERRORSを問い合せることができます。
デフォルトでは、commit_semanticsはSTOP_ON_FIRST_ERRORに設定されています。
DISABLEプロシージャ・コールにジョブ名またはジョブ・クラス名のカンマ区切りのリストを指定することで、1回のコールで複数のジョブを使用禁止にすることもできます。たとえば、次の文では、ジョブとジョブ・クラスを組み合せて指定しています。
BEGIN
DBMS_SCHEDULER.DISABLE('job1, job2, job3, sys.jobclass1, sys.jobclass2');
END;
/
DISABLEプロシージャの詳細は、『Oracle Database PL/SQLパッケージおよびタイプ・リファレンス』を参照してください。
1つ以上のジョブを有効(使用可能)にするには、ENABLEプロシージャまたはEnterprise Managerを使用します。このプロシージャを使用すると、ジョブは、ジョブ・コーディネータによって取り出され、処理されるようになります。ジョブは、デフォルトで使用禁止で作成されるため、実行するには使用可能にする必要があります。ジョブを使用可能にすると、妥当性チェックが実行されます。チェックに失敗すると、ジョブは使用可能になりません。
使用禁止のジョブを使用可能にすると、ジョブはスケジュールに従って実行を即時開始します。また、使用禁止のジョブを使用可能にすると、ジョブのRUN_COUNT、FAILURE_COUNTおよびRETRY_COUNT属性が再設定されます。
commit_semanticsがSTOP_ON_FIRST_ERRORに設定されている場合は、最初のエラーでコールが戻り、エラー発生前に正常終了した使用可能にする操作がディスクにコミットされます。commit_semanticsがTRANSACTIONALに設定されている場合は、最初のエラーでコールが戻り、エラー発生前の使用可能にする操作がロールバックされます。commit_semanticsがABSORB_ERRORSに設定されている場合は、エラーへの対応が取り組まれ、残りのジョブを使用可能にする操作が試行されて、正常に終了した使用可能にする操作がすべてコミットされます。エラーが発生したことがプロシージャによって示された場合は、エラーの内容を判断するために、ビューSCHEDULER_BATCH_ERRORSを問い合せることができます。
デフォルトでは、commit_semanticsはSTOP_ON_FIRST_ERRORに設定されています。
ENABLEプロシージャ・コールにジョブ名またはジョブ・クラス名のカンマ区切りのリストを指定することで、1回のコールで複数のジョブを使用可能にすることもできます。たとえば、次の文では、ジョブとジョブ・クラスを組み合せて指定しています。
BEGIN
DBMS_SCHEDULER.ENABLE ('job1, job2, job3,
sys.jobclass1, sys.jobclass2, sys.jobclass3');
END;
/
ENABLEプロシージャの詳細は、『Oracle Database PL/SQLパッケージおよびタイプ・リファレンス』を参照してください。
ジョブをコピーするには、COPY_JOBプロシージャまたはEnterprise Managerを使用します。このコールによって、旧ジョブのすべての属性(ジョブ名以外)が新規ジョブにコピーされます。新規ジョブは使用禁止の状態で作成されます。
COPY_JOBプロシージャの詳細は、『Oracle Database PL/SQLパッケージおよびタイプ・リファレンス』を参照してください。
資格証明が割り当てられている外部ジョブでは、stdoutとstderrがログ・ファイルに書き込まれます。ローカル外部ジョブでは、ディレクトリORACLE_HOME/scheduler/log内のログ・ファイルに書き込まれます。リモート外部ジョブでは、ディレクトリAGENT_HOME/data/log内のログ・ファイルに書き込まれます。これらのファイルの内容は、DBMS_SCHEDULER.GET_FILEで取得できます。ファイル名は、ジョブ・ログIDとそれに続く文字列_stdoutまたは_stderrで構成されています。ジョブのジョブ・ログIDを取得するには、*_SCHEDULER_JOB_RUN_DETAILSビューのADDITIONAL_INFO列を問い合せて、次のような名前/値ペアを解析します。
EXTERNAL_LOG_ID="job_71035_3158"
たとえば、ファイル名はjob_71035_3158_stdoutのようになります。例29-8「ローカル外部ジョブの作成とstdoutの取得」には、stdoutの出力の取得方法が示されています。この例はローカル外部ジョブに関するものですが、メソッドはリモート外部ジョブの場合も同じです。
また、ローカル外部ジョブまたはリモート外部ジョブによってstderrに出力が書き込まれる際は、最初の200バイトが*_SCHEDULER_JOB_RUN_DETAILSビューのADDITIONAL_INFO列に記録されます。この情報は、次のような名前/値ペアの形式で記録されます。
STANDARD_ERROR="text"
|
注意: ADDITIONAL_INFO列には、複数の名前と値のペアを指定できます。順不同のため、STANDARD_ERRORの名前と値のペアを検索するには、フィールドを解析する必要があります。 |
|
関連項目: DBMS_SCHEDULER.GET_FILEの詳細は、『Oracle Database PL/SQLパッケージ・プロシージャおよびタイプ・リファレンス』 |
プログラムは、特定のタスクに関するメタデータの集まりです。必要に応じて、プログラムを使用してジョブの定義を支援できます。この項では、基本的なプログラム・タスクについて説明します。この項の内容は、次のとおりです。
表29-3に、プログラムの一般的なタスクとそれに対応するプロシージャおよび権限を示します。
表29-3 プログラムのタスクとそのプロシージャ
| タスク | プロシージャ | 必要な権限 |
|---|---|---|
|
プログラムの作成 |
|
|
|
プログラムの変更 |
|
|
|
プログラムの削除 |
|
|
|
プログラムの使用禁止 |
|
|
|
プログラムの使用可能化 |
|
|
権限の詳細は、「スケジューラ権限」を参照してください。
プログラムを作成するには、CREATE_PROGRAMプロシージャまたはEnterprise Managerを使用します。デフォルトでは、プログラムは作成者のスキーマに作成されます。別のユーザーのスキーマにプログラムを作成するには、スキーマ名でプログラム名を修飾する必要があります。他のユーザーがこのプログラムを使用するには、プログラムに対するEXECUTE権限が必要です。このため、プログラムを作成したら、EXECUTE権限を付与する必要があります。my_program1というプログラムの作成例を次に示します。
BEGIN DBMS_SCHEDULER.CREATE_PROGRAM ( program_name => 'my_program1', program_action => '/usr/local/bin/date', program_type => 'EXECUTABLE', comments => 'My comments here'); END; /
プログラムは、デフォルトで使用禁止状態で作成されるため、そのプログラムを指し示すジョブを使用可能にするには、プログラムを使用可能にする必要があります。
「プログラム引数の定義」に説明されているDEFINE_XXX_ARGUMENTプロシージャを使用してプログラムのすべての引数を指定する前に、引数が必要なプログラムを使用可能にしないでください。
プログラムを作成した後、プログラムの引数を定義できます。引数は、コーリング順序内の位置によって定義され、オプションで引数名とデフォルト値を指定できます。プログラム引数のデフォルト値が定義されていない場合は、そのプログラムを参照するジョブで引数の値を指定する必要があります。(ジョブで、デフォルト値を上書きすることもできます。)すべての引数値を指定しないと、ジョブを有効にできません。
プログラム引数値を設定するには、DEFINE_PROGRAM_ARGUMENTまたはDEFINE_ANYDATA_ARGUMENTプロシージャを使用します。DEFINE_ANYDATA_ARGUMENTは、ANYDATAオブジェクト内にカプセル化する必要がある複雑な型に使用されます。引数を必要とする場合があるプログラムの例の1つに、開始日と終了日が必要なレポート作成プログラムを開始するジョブがあります。次のコード例では、レポート作成プログラムの2番目の引数である終了日の引数が設定されます。この例では、SET_JOB_ANYDATA_VALUEやSET_JOB_ARGUMENT_VALUEなどの他のパッケージ・プロシージャから(位置ではなく)名前で引数を参照できるように、引数に名前が割り当てられています。
BEGIN DBMS_SCHEDULER.DEFINE_PROGRAM_ARGUMENT ( program_name => 'operations_reporting', argument_position => 2, argument_name => 'end_date', argument_type => 'VARCHAR2', default_value => '12-DEC-03'); END; /
argument_type引数の有効な値はSQLデータ型のみであるため、ブールはサポートされていません。外部実行可能ファイルの場合、CHARやVARCHAR2などの文字列型のみを使用できます。
プログラム引数は、名前または位置で削除できます。次に例を示します。
BEGIN DBMS_SCHEDULER.DROP_PROGRAM_ARGUMENT ( program_name => 'operations_reporting', argument_position => 2); DBMS_SCHEDULER.DROP_PROGRAM_ARGUMENT ( program_name => 'operations_reporting', argument_name => 'end_date'); END; /
一部の特殊なケースでは、プログラムのロジックがスケジューラの環境によって異なる場合があります。この目的のために、スケジューラには、プログラムに引数として渡すことができる事前定義のメタデータ引数がいくつかあります。たとえば、スケジュールがウィンドウ名である一部のジョブについては、ジョブの開始時にウィンドウがオープンしている時間の長さを認識していると便利です。これは、ウィンドウ終了時間をプログラムに対するメタデータ引数として定義すると可能です。
特定ジョブのメタデータに対するアクセス権限がプログラムに必要な場合は、プログラムの実行時にスケジューラによって値が指定されるように、DEFINE_METADATA_ARGUMENTプロシージャを使用して特別なメタデータ引数を定義できます。
プログラムを変更するには、その属性を変更します。プログラムを変更するには、Enterprise ManagerまたはDBMS_SCHEDULER.SET_ATTRIBUTEおよびDBMS_SCHEDULER.SET_ATTRIBUTE_NULLパッケージ・プロシージャを使用します。プログラム属性の詳細は、『Oracle Database PL/SQLパッケージおよびタイプ・リファレンス』のDBMS_SCHEDULER.CREATE_PROGRAMプロシージャに関する項を参照してください。
変更したプログラムが、現在実行中のジョブで使用されている場合、そのジョブは変更操作前に定義されたプログラムで引き続き実行されます。
次の例では、プログラムmy_program1で実行される実行可能ファイルを変更しています。
BEGIN DBMS_SCHEDULER.SET_ATTRIBUTE ( name => 'my_program1', attribute => 'program_action', value => '/usr/local/bin/salesreports1'); END; /
1つ以上のプログラムを削除するには、DROP_PROGRAMプロシージャまたはEnterprise Managerを使用します。
削除されたプログラムを指し示している実行中のジョブはDROP_PROGRAMコールの影響を受けず、実行を継続できます。プログラムを削除すると、プログラムに関連する引数もすべて削除されます。プログラム名のカンマ区切りのリストを指定することで、1回のコールで複数のプログラムを削除できます。たとえば、次の文では3つのプログラムが削除されます。
BEGIN
DBMS_SCHEDULER.DROP_PROGRAM('program1, program2, program3');
END;
/
DROP_PROGRAMプロシージャの詳細は、『Oracle Database PL/SQLパッケージおよびタイプ・リファレンス』を参照してください。
1つ以上のプログラムを無効(使用禁止)にするには、DISABLEプロシージャまたはEnterprise Managerを使用します。プログラムが使用禁止になると、ステータスがdisabledに変更されます。使用禁止プログラムとは、メタデータが存在しても、このプログラムを指定したジョブを実行できないことを意味します。
使用禁止のプログラムを指し示している実行中のジョブはDISABLEコールの影響を受けず、実行を継続できます。プログラムが使用禁止になった場合でも、そのプログラムに関係する引数は影響を受けません。
プログラムは他の理由で使用禁止になる場合もあります。たとえば、プログラム引数が削除された場合やnumber_of_argumentsの変更ですべての引数を定義できなくなった場合などです。
DISABLEプロシージャの詳細は、『Oracle Database PL/SQLパッケージおよびタイプ・リファレンス』を参照してください。
1つ以上のプログラムを有効(使用可能)にするには、ENABLEプロシージャまたはEnterprise Managerを使用します。プログラムが使用可能になると、使用可能フラグがTRUEに設定されます。プログラムは、デフォルトで使用禁止で作成されるため、そのプログラムを指し示すジョブを使用可能にするには、プログラムを使用可能にする必要があります。プログラムが使用可能になる前に、処理が有効であること、およびすべての引数が定義されていることを確認するために妥当性チェックが実行されます。
ENABLEプロシージャ・コールにプログラム名のカンマ区切りのリストを指定することで、1回のコールで複数のプログラムを使用可能にできます。たとえば、次の文では3つのプログラムが使用可能になります。
BEGIN
DBMS_SCHEDULER.ENABLE('program1, program2, program3');
END;
/
ENABLEプロシージャの詳細は、『Oracle Database PL/SQLパッケージおよびタイプ・リファレンス』を参照してください。
必要に応じて、スケジュール・オブジェクト(スケジュール)を使用してジョブの実行時期を定義できます。スケジュールは、データベースにオブジェクトとして作成および保存することによってユーザー間で共有できます。
この項では、スケジュールの基本的なタスクについて説明します。この項の内容は、次のとおりです。
|
関連項目:
|
表29-4に、スケジュールの一般的なタスクとその処理に使用するプロシージャを示します。
表29-4 スケジュールのタスクとそのプロシージャ
| タスク | プロシージャ | 必要な権限 |
|---|---|---|
|
スケジュールの作成 |
|
|
|
スケジュールの変更 |
|
|
|
スケジュールの削除 |
|
|
権限の詳細は、「スケジューラ権限」を参照してください。
スケジュールを作成するには、CREATE_SCHEDULEプロシージャまたはEnterprise Managerを使用します。スケジュールは、そのスケジュールを作成するユーザーのスキーマ内に作成され、最初に作成した時点で使用可能です。また、別のユーザーのスキーマ内に作成できます。スケジュールが作成されると、他のユーザーもそのスケジュールを使用できます。スケジュールは、PUBLICへのアクセス権を伴って作成されます。このため、スケジュールへのアクセス権限を明示的に付与する必要はありません。次に、スケジュールの作成例を示します。
BEGIN DBMS_SCHEDULER.CREATE_SCHEDULE ( schedule_name => 'my_stats_schedule', start_date => SYSTIMESTAMP, end_date => SYSTIMESTAMP + INTERVAL '30' day, repeat_interval => 'FREQ=HOURLY; INTERVAL=4', comments => 'Every 4 hours'); END; /
|
関連項目:
|
スケジュールを変更するには、SET_ATTRIBUTEおよびSET_ATTRIBUTE_NULLパッケージ・プロシージャまたはEnterprise Managerを使用します。スケジュールを変更すると、スケジュールの定義が変更されます。スケジュール名以外のすべての属性を変更できます。スケジュールの属性は、*_SCHEDULER_SCHEDULESビューで使用可能です。
スケジュールを変更しても、このスケジュールを使用している実行中のジョブとオープン中のウィンドウに影響を与えることはありません。変更が有効になるのは、次回のジョブ実行時またはウィンドウ・オープン時からです。
SET_ATTRIBUTEプロシージャの詳細は、『Oracle Database PL/SQLパッケージおよびタイプ・リファレンス』を参照してください。
スケジュールを削除するには、DROP_SCHEDULEプロシージャまたはEnterprise Managerを使用します。このプロシージャ・コールによって、スケジュール・オブジェクトがデータベースから削除されます。
DROP_SCHEDULEプロシージャの詳細は、『Oracle Database PL/SQLパッケージおよびタイプ・リファレンス』を参照してください。
ジョブの繰返し時期および間隔を制御するには、ジョブ自体またはジョブが参照する名前付きスケジュールのrepeat_interval属性を設定します。repeat_intervalは、DBMS_SCHEDULERパッケージまたはEnterprise Managerで設定できます。
repeat_intervalの評価結果は、一連のタイムスタンプです。各タイムスタンプの時点で、スケジューラがジョブを実行します。ジョブまたはスケジュールの開始日も、タイムスタンプの結果セットの決定に役立つことに注意してください。(repeat_intervalの評価の詳細は、『Oracle Database PL/SQLパッケージ・プロシージャおよびタイプ・リファレンス』を参照してください。)repeat_intervalに値を指定しないと、指定した開始日に1回のみジョブが実行されます。
ジョブが開始されるとすぐに、repeat_intervalが評価されて、次にスケジュールされるジョブの実行時刻が決定されます。ジョブがまだ実行されている間に、次にスケジュールされる実行時刻になる場合があります。ただし、ジョブの新しいインスタンスは、現在のジョブが完了するまで開始されません。
繰返し間隔を指定する方法は、次の2通りあります。
ジョブの繰返し間隔を設定する主要な方法は、スケジューラのカレンダ指定式を使用してrepeat_interval属性を設定する方法です。repeat_intervalのカレンダ指定構文およびCREATE_SCHEDULEプロシージャの詳細は、『Oracle Database PL/SQLパッケージ・プロシージャおよびタイプ・リファレンス』を参照してください。
次に、簡単な繰返し間隔の例を示します。わかりやすくするために、開始日は評価結果に影響を与えないと仮定します。
毎週金曜日に実行(3つの例はすべて同等です。)
FREQ=DAILY; BYDAY=FRI; FREQ=WEEKLY; BYDAY=FRI; FREQ=YEARLY; BYDAY=FRI;
隔週金曜日に実行。
FREQ=WEEKLY; INTERVAL=2; BYDAY=FRI;
毎月末に実行。
FREQ=MONTHLY; BYMONTHDAY=-1;
毎月末の翌日に実行。
FREQ=MONTHLY; BYMONTHDAY=-2;
3月10日に実行(両方の例は同等です。)
FREQ=YEARLY; BYMONTH=MAR; BYMONTHDAY=10; FREQ=YEARLY; BYDATE=0310;
10日おきに実行。
FREQ=DAILY; INTERVAL=10;
毎日午後4時、5時および6時に実行。
FREQ=DAILY; BYHOUR=16,17,18;
隔月15日に実行。
FREQ=MONTHLY; INTERVAL=2; BYMONTHDAY=15;
毎月29日に実行。
FREQ=MONTHLY; BYMONTHDAY=29;
毎月第2水曜日に実行。
FREQ=MONTHLY; BYDAY=2WED;
毎年最終金曜日に実行。
FREQ=YEARLY; BYDAY=-1FRI;
50時間おきに実行。
FREQ=HOURLY; INTERVAL=50;
隔月末に実行。
FREQ=MONTHLY; INTERVAL=2; BYMONTHDAY=-1;
毎月初めの3日間1時間おきに実行。
FREQ=HOURLY; BYMONTHDAY=1,2,3;
以降は、多少複雑な繰返し間隔の例です。
毎月最後の稼働日に実行(稼働日は月曜日から金曜日と仮定)。
FREQ=MONTHLY; BYDAY=MON,TUE,WED,THU,FRI; BYSETPOS=-1
会社の祝日を除く、毎月の最後の稼働日に実行(この例では、Company_Holidaysという既存の名前付きスケジュールを参照しています。)
FREQ=MONTHLY; BYDAY=MON,TUE,WED,THU,FRI; EXCLUDE=Company_Holidays; BYSETPOS=-1
毎週金曜日および会社の休業日の正午に実行。
FREQ=YEARLY;BYDAY=FRI;BYHOUR=12;INCLUDE=Company_Holidays
7月4日、メモリアル・デーおよびレイバー・デーの3つの祝日に実行(この例では、それぞれの祝日に対応する1日を定義したJUL4、MEMおよびLABの既存の3つの名前付きスケジュールを参照しています。)
JUL4,MEM,LAB
カレンダ指定式評価の例
繰返し間隔を"FREQ=MINUTELY;INTERVAL=2;BYHOUR=17; BYMINUTE=2,4,5,50,51,7;"に、開始日を28-FEB-2004 23:00:00に設定すると、次のスケジュールが生成されます。
SUN 29-FEB-2004 17:02:00 SUN 29-FEB-2004 17:04:00 SUN 29-FEB-2004 17:50:00 MON 01-MAR-2004 17:02:00 MON 01-MAR-2004 17:04:00 MON 01-MAR-2004 17:50:00 ...
繰返し間隔を"FREQ=MONTHLY;BYMONTHDAY=15, -1"に、開始日を29-DEC-2003 9:00:00に設定すると、次のスケジュールが生成されます。
WED 31-DEC-2003 09:00:00 THU 15-JAN-2004 09:00:00 SAT 31-JAN-2004 09:00:00 SUN 15-FEB-2004 09:00:00 SUN 29-FEB-2004 09:00:00 MON 15-MAR-2004 09:00:00 WED 31-MAR-2004 09:00:00 ...
繰返し間隔を"FREQ=MONTHLY;"に、開始日を29-DEC-2003 9:00:00に設定すると、次のスケジュールが生成されます。(BYMONTHDAY句がないため、開始日から日付が取得されることに注意してください。)
MON 29-DEC-2003 09:00:00 THU 29-JAN-2004 09:00:00 SUN 29-FEB-2004 09:00:00 MON 29-MAR-2004 09:00:00 ...
カレンダ指定式の使用例
カレンダ指定構文を使用した次の例について考えてみます。
BEGIN DBMS_SCHEDULER.CREATE_JOB ( job_name => 'scott.my_job1', start_date => '15-JUL-04 01.00.00 AM Europe/Warsaw', repeat_interval => 'FREQ=MINUTELY; INTERVAL=30;', end_date => '15-SEP-04 01.00.00 AM Europe/Warsaw', comments => 'My comments here'); END; /
これにより、my_job1がscottに作成されます。7月15日に始めて実行されて、9月15日まで実行されます。このジョブの開始日は7月15日、終了日は9月15日で、30分おきに実行されます。
カレンダ指定構文より複雑な機能が必要な場合は、PL/SQL式を使用できます。ただし、PL/SQL式はウィンドウまたは名前付きスケジュールでは使用できません。PL/SQL式は、日付またはタイムスタンプに評価される必要があります。これ以外に制限はないため、適切なプログラミングによって、あらゆる繰返し間隔を作成できます。例として、次の文を考えてみます。
BEGIN DBMS_SCHEDULER.CREATE_JOB ( job_name => 'scott.my_job2', start_date => '15-JUL-04 01.00.00 AM Europe/Warsaw', repeat_interval => 'SYSTIMESTAMP + INTERVAL '30' MINUTE', end_date => '15-SEP-04 01.00.00 AM Europe/Warsaw', comments => 'My comments here'); END; /
これにより、my_job1がscottに作成されます。7月15日に始めて実行されて、9月15日まで30分ごとに実行されます。repeat_intervalが、30分後の日付を返すSYSTIMESTAMP + INTERVAL '30' MINUTEに設定されているため、30分ごとにジョブが実行されます。
カレンダ指定式とPL/SQL繰返し間隔の動作には、次のような重要な相違があります。
開始日
カレンダ指定構文を使用する場合、開始日は参照専用の日になります。そのため、スケジュールはこの日に有効になります。開始日にジョブが開始されるという意味ではありません。
PL/SQL式を使用した場合、開始日はジョブが最初に実行を開始した実際の時間を表します。
次回の実行時期
カレンダ指定構文を使用した場合、次回のジョブ実行時期は固定されています。
PL/SQL式を使用する場合、次にジョブが実行される時期は、ジョブの現在の実行の実際の開始時刻によって異なります。違いを示す例として、ジョブが午後2時に開始して、2時間ごとに繰り返すスケジュールになっている場合、カレンダ指定構文で繰返し間隔が指定されていると、ジョブは4時、6時などに繰り返し実行されます。PL/SQLを使用して、ジョブが2時10分に開始された場合、ジョブは4時10分に繰り返されますが、実際には次のジョブが4時11分に開始した場合は、後続の実行が6時11分になります。
これら2つの点を例で示すために、15-July-2003 1:45:00という開始日付が設定されていて、2時間ごとに繰り返す必要がある場合を考えます。"FREQ=HOURLY; INTERVAL=2; BYMINUTE=0;"というカレンダ指定構文では、次のスケジュールが生成されます。
TUE 15-JUL-2003 03:00:00 TUE 15-JUL-2003 05:00:00 TUE 15-JUL-2003 07:00:00 TUE 15-JUL-2003 09:00:00 TUE 15-JUL-2003 11:00:00 ...
カレンダ式では、2時間おきの毎正時に繰返しを実行します。
一方、PL/SQL式"SYSTIMESTAMP + interval '2' hour"では、実行時間は次のようになります。
TUE 15-JUL-2003 01:45:00 TUE 15-JUL-2003 03:45:05 TUE 15-JUL-2003 05:45:09 TUE 15-JUL-2003 07:45:14 TUE 15-JUL-2003 09:45:20 ...
ジョブの繰返しでは、次回のジョブ実行時間のスケジュールは、タイム・ゾーン列のあるタイムスタンプに格納されます。カレンダ指定構文を使用する場合、タイム・ゾーンはstart_dateから取り出されます。start_dateが指定されていない場合の動作の詳細は、『Oracle Database PL/SQLパッケージおよびタイプ・リファレンス』を参照してください。
PL/SQL式に基づいた繰返し間隔の場合、タイム・ゾーンはPL/SQL式が返すタイムスタンプの一部になっています。いずれの場合も、リージョン名を使用することが重要です。たとえば、"+2:00"のように絶対タイム・ゾーン・オフセットを指定するのではなく、"Europe/Istanbul"のように指定します。タイム・ゾーンがリージョン名で指定されている場合のみ、スケジューラはそのリージョンに適用される夏時間調整に従います。
この項の内容は次のとおりです。
イベントは、なんらかの処理または発生が検出されたことを、アプリケーションまたはシステム・プロセスが別のアプリケーションまたはシステム・プロセスに示すために送信するメッセージです。イベントは、1つのアプリケーションまたはプロセスによって呼び出され(送信)、1つ以上のアプリケーションまたはプロセスによって使用されます(受信)。
スケジューラでは、次の2種類のイベントが使用されます。
アプリケーションによって呼び出されるイベント
アプリケーションは、スケジューラが使用するイベントを呼び出すことができます。スケジューラは、ジョブを開始することでこのイベントを処理します。たとえば、在庫が一定のしきい値を下回ったことを感知した在庫追跡システムでは、在庫の補充ジョブを開始するイベントを呼び出すことができます。
「アプリケーションによって呼び出されたイベントによるジョブの開始」を参照してください。
File Watcherによって呼び出されるファイル到着イベント
File Watcher(Oracle Database 11g リリース2で導入されたスケジューラ・オブジェクト)を作成して、システムへのファイルの到着を監視できます。その後、File Watcherでファイルの存在が検出されたときに開始するジョブを構成できます。たとえば、チェーン店用のデータ・ウェアハウスでは、店舗内の店頭システムからアップロードされた日次売上レポートからデータがロードされます。データ・ウェアハウスのロード・ジョブは、新しい日次レポートが到着するたびに開始されます。
「ファイルがシステムに到着したことによるジョブの開始」を参照してください。
|
関連項目:
|
アプリケーションで、ジョブを開始するようにスケジューラに通知するイベントを呼び出すことができます。この方法で開始されるジョブは、イベントベースのジョブと呼ばれます。日付、時間、繰り返し発生する情報を定義するかわりに、イベントを参照する名前付きスケジュールを作成できます。このようなスケジュール(イベント・スケジュール)が割り当てられたジョブは、イベントが呼び出されると実行されます。
ジョブの開始をスケジューラに通知するイベントを呼び出すために、アプリケーションは、このジョブの設定時に指定したOracle Streamsアドバンスト・キューイングのキューにメッセージをエンキューします。ジョブが開始されると、ジョブはオプションでイベントのメッセージ内容を取得できます。
イベントベースのジョブを作成するには、次の2つの追加属性を設定する必要があります。
queue_spec
キュー仕様。アプリケーションがジョブ開始イベントを呼び出すためのメッセージをエンキューするキューの名前が含まれます。または、セキュアなキューの場合はキュー名の後にカンマとエージェント名が記述されます。
event_condition
メッセージでジョブを開始するためにTRUEと評価される必要のあるメッセージ・プロパティに基づく条件式。この式では、Oracle Streams Advanced Queuingルールの構文を使用する必要があります。したがって、メッセージ・ペイロードがオブジェクト・タイプで、式のオブジェクト属性の前にtab.user_dataを付加した場合は、ユーザー・データ・プロパティを式に含めることができます。
ルールの詳細は、『Oracle Database PL/SQLパッケージ・プロシージャおよびタイプ・リファレンス』のDBMS_AQADM.ADD_SUBSCRIBERプロシージャに関する項を参照してください。
次の例では、event_conditionが、午前0時から午前9時の間に発生する在庫不足イベントのみを選択するように設定されます。メッセージ・ペイロードはevent_typeとevent_timestampの2つの属性を持つオブジェクトであるとします。
event_condition = 'tab.user_data.event_type = ''LOW_INVENTORY'' and extract hour from tab.user_data.event_timestamp < 9'
queue_specおよびevent_conditionは、インラインのジョブ属性として指定するか、またはこれらの属性を指定したイベント・スケジュールを作成し、ジョブからこのスケジュールを指し示すことができます。
|
注意: スケジューラは、event_conditionに一致するイベントが発生するたびにイベントベースのジョブを実行します。ただし、デフォルトでは、ジョブがすでに実行されている間に発生したイベントは無視され、イベントは消費されますが別のジョブの実行がトリガーされることはありません。Oracle Database 11g リリース1以降では、ジョブ属性PARALLEL_INSTANCESをTRUEに設定することで、このデフォルト動作を変更できます。この場合、ジョブのインスタンスがイベントのすべてのインスタンスに対して起動され、すべてのジョブ・インスタンスが軽量ジョブになります。詳細は、 |
表29-5に、アプリケーションによって呼び出される(スケジューラによって使用される)イベントに関する一般的な管理タスクとそれに対応するプロシージャを示します。
表29-5 アプリケーションによって呼び出されるイベントに対するイベント・タスクとそのプロシージャ
| タスク | プロシージャ | 必要な権限 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
関連項目: キューの作成およびメッセージのエンキュー方法は、『Oracle Streamsアドバンスト・キューイング・ユーザーズ・ガイド』を参照してください。 |
イベントベースのジョブを作成するには、CREATE_JOBプロシージャまたはEnterprise Managerを使用します。ジョブには、ジョブ属性としてイベント情報をインラインで組み込むか、またはイベント・スケジュールを指し示してイベント情報を指定できます。
時間スケジュールに基づくジョブと同様に、イベントベースのジョブは、ジョブ終了日をすぎるか、max_runsまたは最大失敗回数(max_failures)に達するまでは自動削除されません。
イベント情報をジョブ属性として指定するには、CREATE_JOBの代替構文を使用して、queue_specおよびevent_condition属性を組み込みます。
次の例では、項目の在庫レベルが低しきい値レベルを下回ったことがアプリケーションからスケジューラに伝達されるときに開始されるジョブを作成しています。
BEGIN DBMS_SCHEDULER.CREATE_JOB ( job_name => 'process_lowinv_j1', program_name => 'process_lowinv_p1', event_condition => 'tab.user_data.event_type = ''LOW_INVENTORY''', queue_spec => 'inv_events_q, inv_agent1', enabled => TRUE, comments => 'Start an inventory replenishment job'); END; /
CREATE_JOBプロシージャの詳細は、『Oracle Database PL/SQLパッケージおよびタイプ・リファレンス』を参照してください。
イベント情報をイベント・スケジュールで指定するには、ジョブのschedule_name属性にイベント・スケジュールの名前を設定する必要があります。次に例を示します。
BEGIN DBMS_SCHEDULER.CREATE_JOB ( job_name => 'process_lowinv_j1', program_name => 'process_lowinv_p1', schedule_name => 'inventory_events_schedule', enabled => TRUE, comments => 'Start an inventory replenishment job'); END; /
詳細は、「イベント・スケジュールの作成」を参照してください。
イベントベースのジョブを変更するには、SET_ATTRIBUTEプロシージャを使用します。イベントをインラインで指定するジョブの場合、SET_ATTRIBUTEを使用してqueue_spec属性とevent_condition属性を別々に設定することはできません。かわりに、event_specと呼ばれる属性を設定し、イベント条件とキュー仕様を3番目と4番目の引数としてSET_ATTRIBUTEに渡す必要があります。
次に、event_spec属性の使用例を示します。
BEGIN
DBMS_SCHEDULER.SET_ATTRIBUTE ('my_job', 'event_spec',
'tab.user_data.event_type = ''LOW_INVENTORY''', 'inv_events_q, inv_agent1');
END;
/
SET_ATTRIBUTEプロシージャの詳細は、『Oracle Database PL/SQLパッケージおよびタイプ・リファレンス』を参照してください。
イベントに基づいたスケジュールを作成できます。作成したスケジュールは、複数のジョブに再利用できます。そのためには、CREATE_EVENT_SCHEDULEプロシージャまたはEnterprise Managerを使用します。次に、イベント・スケジュールの作成例を示します。
BEGIN DBMS_SCHEDULER.CREATE_EVENT_SCHEDULE ( schedule_name => 'inventory_events_schedule', start_date => SYSTIMESTAMP, event_condition => 'tab.user_data.event_type = ''LOW_INVENTORY''', queue_spec => 'inv_events_q, inv_agent1'); END; /
イベント・スケジュールを削除するには、DROP_SCHEDULEプロシージャを使用します。CREATE_EVENT_SCHEDULEの詳細は、『Oracle Database PL/SQLパッケージおよびタイプ・リファレンス』を参照してください。
イベント・スケジュールのイベント情報を変更する方法は、ジョブのイベント情報を変更する方法と同じです。詳細は、「イベントベースのジョブの変更」を参照してください。
次の例は、イベント・スケジュールのイベント情報を変更するためのSET_ATTRIBUTEプロシージャおよびevent_spec属性の使用方法を示しています。
BEGIN
DBMS_SCHEDULER.SET_ATTRIBUTE ('inventory_events_schedule', 'event_spec',
'tab.user_data.event_type = ''LOW_INVENTORY''', 'inv_events_q, inv_agent1');
END;
/
SET_ATTRIBUTEプロシージャの詳細は、『Oracle Database PL/SQLパッケージおよびタイプ・リファレンス』を参照してください。
メタデータの引数を介して、スケジューラは、イベントベースのジョブに対して、ジョブを開始したイベントのメッセージ内容を渡すことができます。次のルールが適用されます。
ジョブは、タイプSTORED_PROCEDUREの名前付きプログラムを使用する必要があります。
名前付きプログラムの引数の1つがメタデータ引数であり、そのmetadata_attributeがEVENT_MESSAGEに設定されている必要があります。
プログラムを実装するストアド・プロシージャには、名前付きプログラムのメタデータ引数に対応する位置に引数が必要です。引数の型は、アプリケーションがジョブ開始イベントをエンキューするキューのデータ型であることが必要です。
EVENT_MESSAGEメタデータ引数があるジョブをRUN_JOBプロシージャを使用して手動で実行した場合、その引数に渡される値はNULLです。
次の例は、イベント・メッセージの内容を受け取ることができるイベントベースのジョブを作成する方法を示しています。
create or replace procedure my_stored_proc (event_msg IN event_queue_type)
as
begin
-- retrieve and process message body
end;
/
begin
dbms_scheduler.create_program (
program_name => 'my_prog',
program_action=> 'my_stored_proc',
program_type => 'STORED_PROCEDURE',
number_of_arguments => 1,
enabled => FALSE) ;
dbms_scheduler.define_metadata_argument (
program_name => 'my_prog',
argument_position => 1 ,
metadata_attribute => 'EVENT_MESSAGE') ;
dbms_scheduler.enable ('my_prog');
exception
when others then raise ;
end ;
/
begin
dbms_scheduler.create_job (
job_name => 'my_evt_job' ,
program_name => 'my_prog',
schedule_name => 'my_evt_sch',
enabled => true,
auto_Drop => false) ;
exception
when others then raise ;
end ;
/
ファイルがローカル・システムまたはリモート・システムに到着したときにジョブを開始するようにスケジューラを構成できます。ジョブはイベントベースのジョブであり、ファイル到着イベントはFile Watcher(Oracle Database 11g リリース2で導入されたスケジューラ・オブジェクト)によって呼び出されます。
この項の内容は次のとおりです。
File Watcherは、ファイルがシステムに到着したことによってスケジューラでジョブが開始される場合の対象ファイルの場所、名前などのプロパティを定義したスケジューラ・オブジェクトです。ファイル・ウォッチャを作成し、次に、そのファイル・ウォッチャを参照する任意の数のイベントベースのジョブまたはイベント・スケジュールを作成します。File Watcherでは、指定されたファイルの到着、新たに到着したファイルを検出すると、到着イベントを呼び出します。
新たに到着したファイルとは、変更されているため、最新の実行またはFile Watcherジョブがターゲット・ファイル・ディレクトリの監視を開始した時間よりタイムスタンプが遅いファイルです。
File Watcherがファイルが新たに到着したものか否かを判断する方法は、UNIXコマンドls -lrtまたはWindows DOSコマンドdir /odを繰り返し実行してディレクトリ内の新しいファイルを監視するのと同じです。この両方のコマンドでは必ず、最近に変更されたファイルが最後にリストされます。つまり最も古いものが最初で最も新しいものが最後になります。
|
注意: 動作は次のとおりです。UNIX Windows |
CREATE_FILE_WATCHERプロシージャのsteady_state_durationパラメータ(『Oracle Database PL/SQLパッケージおよびタイプ・リファレンス』を参照)は、File Watcherがファイルを検出したと判断するまでに、ファイルが未変更のままであることが必要な最小時間間隔を指定します。これは1時間を超えることはできません。パラメータがNULLの場合、内部値が使用されます。
ファイルの到着イベントによって開始されたジョブでは、新しく到着したファイルを示すイベント・メッセージを取得できます。このメッセージには、ファイルの検索、オープンおよび処理に必要な情報が含まれます。
File Watcherでは、ローカル・システム(Oracle Databaseを実行しているホスト・コンピュータ)またはリモート・システムでファイルを監視できます。リモート・システムではスケジューラ・エージェントが実行され、そのエージェントがデータベースに登録されている必要があります。
File Watcherでは、10分間隔でファイルの到着がチェックされます。この間隔は調整可能です。詳細は、「ファイルの到着を検出する間隔の変更」を参照してください。
スキーマにFile Watcherを作成するには、CREATE JOBシステム権限が必要です。自分のスキーマと異なるスキーマ(許可されないSYSスキーマ以外)にFile Watcherを作成するには、CREATE ANY JOBシステム権限が必要です。別のスキーマ内のジョブでFile Watcherを参照できるように、File Watcherに対するEXECUTEオブジェクト権限を付与できます。また、別のユーザーがFile Watcherを変更できるように、File Watcherに対するALTERオブジェクト権限を付与できます。
File Watcherを使用するには、データベースのJava仮想マシン(JVM)コンポーネントをインストールする必要があります。
リモート・システムからファイル到着イベントを受け取るには、そのシステムにスケジューラ・エージェントをインストールし、そのエージェントをデータベースに登録する必要があります。リモート・システムでファイル到着イベントを生成するのに、Oracle Databaseインスタンスが実行されている必要はありません。
リモート・システムでのファイル到着イベントの呼出しを有効にする手順は、次のとおりです。
リモート外部ジョブを実行するようにローカル・データベースを設定します。
詳細は、「リモート・ジョブを実行するためのデータベースの設定」を参照してください。
最初のリモート・システムでスケジューラ・エージェントをインストール、構成、登録および起動します。
手順は、「リモート・ホストでのスケジューラ・エージェントのインストールと構成」を参照してください。
これにより、ローカル・データベースで管理されている外部宛先のリストにリモート・ホストが追加されます。
追加の各リモート・システムに対して前述の手順を繰り返します。
File Watcherを作成し、指定したファイルが到着したときに開始されるイベントベースのジョブを作成するには、次のタスクを実行します。
File Watcherでは、ホスト・オペレーティング・システムでファイルへのアクセスを認証するために使用されるスケジューラ資格証明オブジェクト(資格証明)が必要になります。資格証明を作成するために必要な権限の詳細は、「資格証明」を参照してください。
次の手順を実行します。
監視対象ファイルにアクセスする必要があるオペレーティング・システム・ユーザーの資格証明を作成します。
BEGIN
DBMS_SCHEDULER.CREATE_CREDENTIAL('WATCH_CREDENTIAL', 'salesapps', 'sa324w1');
END;
/
File Watcherによって開始されるイベントベースのジョブを所有するスキーマに、資格証明に対するEXECUTEオブジェクト権限を付与します。
GRANT EXECUTE ON WATCH_CREDENTIAL to DSSUSER;
次の手順を実行します。
『Oracle Database PL/SQLパッケージおよびタイプ・リファレンス』のDBMS_SCHEDULER.CREATE_FILE_WATCHERプロシージャに関する項の説明に従って属性を割り当て、File Watcherを作成します。ファイル名にワイルドカード・パラメータを指定できます。DIRECTORY_PATH属性の「?」接頭辞は、Oracleホーム・ディレクトリへのパスを示します。NULLのdestinationはローカル・ホストを示します。リモート・ホストのファイルを監視するには、ビューALL_SCHEDULER_EXTERNAL_DESTSから取得できる有効な外部宛先名を指定します。
BEGIN
DBMS_SCHEDULER.CREATE_FILE_WATCHER(
FILE_WATCHER_NAME => 'EOD_FILE_WATCHER',
DIRECTORY_PATH => '?/eod_reports',
FILE_NAME => 'eod*.txt',
CREDENTIAL_NAME => 'WATCH_CREDENTIAL',
DESTINATION => NULL,
ENABLED => FALSE);
END;
/
File Watcherを参照するイベントベースのジョブを所有するスキーマに、File Watcherに対するEXECUTEを付与します。
GRANT EXECUTE ON EOD_FILE_WATCHER to DSSUSER;
アプリケーションでファイル到着イベント・メッセージの内容(ファイル名、ファイル・サイズなど)を取得できるように、スケジューラ・プログラム・オブジェクトを作成し、イベント・メッセージを参照するメタデータ引数を指定します。
次の手順を実行します。
プログラムを作成します。
BEGIN
DBMS_SCHEDULER.CREATE_PROGRAM(
PROGRAM_NAME => 'DSSUSER.EOD_PROGRAM',
PROGRAM_TYPE => 'STORED_PROCEDURE',
PROGRAM_ACTION => 'EOD_PROCESSOR',
NUMBER_OF_ARGUMENTS => 1,
ENABLED => FALSE);
END;
/
event_message属性を使用してメタデータ引数を定義します。
BEGIN
DBMS_SCHEDULER.DEFINE_METADATA_ARGUMENT(
PROGRAM_NAME => 'DSSUSER.EOD_PROGRAM',
METADATA_ATTRIBUTE => 'event_message',
ARGUMENT_POSITION => 1);
END;
/
プログラムで呼び出すストアド・プロシージャを作成します。
ファイル到着イベントを処理するストアド・プロシージャには、SYS.SCHEDULER_FILEWATCHER_RESULTタイプの引数(イベント・メッセージのデータ型)を指定する必要があります。この引数の位置は、定義済のメタデータ引数の位置と一致させる必要があります。これにより、プロシージャでこの抽象データ型の属性にアクセスして、到着したファイルに関する情報を把握できるようになります。
|
関連項目:
|
「イベントベースのジョブの作成」の説明に従ってイベントベースのジョブを作成します。ただし、queue_spec属性にキューの仕様を指定するかわりに、File Watcherの名前を指定してください。通常は、event_conditionジョブ属性をnullのままにしますが、必要に応じて条件を指定できます。
ジョブに対してqueue_spec属性を設定するかわりに、イベント・スケジュールを作成し、そのイベント・スケジュールのqueue_spec属性でFile Watcherを参照し、ジョブのschedule_name属性でそのイベント・スケジュールを参照できます。
次の手順を実行して、イベントベースのジョブを準備します。
ジョブを作成します。
BEGIN
DBMS_SCHEDULER.CREATE_JOB(
JOB_NAME => 'DSSUSER.EOD_JOB',
PROGRAM_NAME => 'DSSUSER.EOD_PROGRAM',
EVENT_CONDITION => NULL,
QUEUE_SPEC => 'EOD_FILE_WATCHER',
AUTO_DROP => FALSE,
ENABLED => FALSE);
END;
/
ジョブによって前のイベントがすでに処理されていても、ファイル到着イベントの各インスタンスに対してジョブを実行する場合は、parallel_instances属性をTRUEに設定します。この設定を使用すると、ジョブは軽量ジョブとして実行され、ジョブの複数のインスタンスを迅速に開始できるようになります。イベントベースのジョブで別のイベントがすでに処理されている間に発生するFile Watcherイベントを破棄するには、parallel_instances属性をFALSE(デフォルト)のままにします。
BEGIN
DBMS_SCHEDULER.SET_ATTRIBUTE('DSSUSER.EOD_JOB','PARALLEL_INSTANCES',TRUE);
END;
/
この属性の詳細は、『Oracle Database PL/SQLパッケージおよびタイプ・リファレンス』のSET_ATTRIBUTEに関する項を参照してください。
File Watcher、プログラムおよびジョブを有効にします。
BEGIN
DBMS_SCHEDULER.ENABLE('DSSUSER.EOD_PROGRAM,DSSUSER.EOD_JOB,EOD_FILE_WATCHER');
END;
/
この例では、イベントベースのジョブによって、各地からの日次売上レポートがローカル・ホストに到着するのを監視しています。各レポート・ファイルが到着すると、ストアド・プロシージャによりファイルに関する情報が取得され、eod_reportsという表に格納されます。その後、定期レポート集計ジョブにより、この表を問い合せて、すべての未処理ファイルを処理し、新たに処理したファイルを処理済としてマークできます。
ここでは、次のコードを実行するデータベース・ユーザーにSYS.SCHEDULER_FILEWATCHER_RESULTデータ型に対するEXECUTEが付与されていることを想定しています。
begin
dbms_scheduler.create_credential(
credential_name => 'watch_credential',
username => 'pos1',
password => 'jk4545st');
end;
/
create table eod_reports (when timestamp, file_name varchar2(100),
file_size number, processed char(1));
create or replace procedure q_eod_report
(payload IN sys.scheduler_filewatcher_result) as
begin
insert into eod_reports values
(payload.file_timestamp,
payload.directory_path || '/' || payload.actual_file_name,
payload.file_size,
'N');
end;
/
begin
dbms_scheduler.create_program(
program_name => 'eod_prog',
program_type => 'stored_procedure',
program_action => 'q_eod_report',
number_of_arguments => 1,
enabled => false);
dbms_scheduler.define_metadata_argument(
program_name => 'eod_prog',
metadata_attribute => 'event_message',
argument_position => 1);
dbms_scheduler.enable('eod_prog');
end;
/
begin
dbms_scheduler.create_file_watcher(
file_watcher_name => 'eod_reports_watcher',
directory_path => '?/eod_reports',
file_name => 'eod*.txt',
credential_name => 'watch_credential',
destination => null,
enabled => false);
end;
/
begin
dbms_scheduler.create_job(
job_name => 'eod_job',
program_name => 'eod_prog',
event_condition => 'tab.user_data.file_size > 10',
queue_spec => 'eod_reports_watcher',
auto_drop => false,
enabled => false);
dbms_scheduler.set_attribute('eod_job','parallel_instances',true);
end;
/
exec dbms_scheduler.enable('eod_reports_watcher,eod_job');
DBMS_SCHEDULER PL/SQLパッケージには、File Watcherの属性を有効化、無効化、削除および設定するためのプロシージャが用意されています。
この項の内容は、次のとおりです。
|
関連項目: DBMS_SCHEDULER PL/SQLパッケージの詳細は、『Oracle Database PL/SQLパッケージおよびタイプ・リファレンス』 |
File Watcherが無効になっている場合、「タスク5: すべてのオブジェクトの有効化」に示すように、DBMS_SCHEDULER.ENABLEを使用して有効にできます。
File Watcherを有効にできるのは、そのすべての属性が有効な値に設定され、File Watcherの所有者に指定の資格証明に対するEXECUTE権限が付与されている場合のみです。
File Watcherの属性を変更するには、DBMS_SCHEDULER.SET_ATTRIBUTEおよびDBMS_SCHEDULER.SET_ATTRIBUTE_NULLパッケージ・プロシージャを使用します。File Watcherの属性の詳細は、CREATE_FILE_WATCHERプロシージャの説明を参照してください。
File Watcherを無効にするにはDBMS_SCHEDULER.DISABLEを使用し、File Watcherを削除するにはDBMS_SCHEDULER.DROP_FILE_WATCHERを使用します。File Watcherに依存するジョブが存在する場合、File Watcherを無効にしたり、削除することはできません。このような場合に無効化または削除操作を強制するには、FORCE属性をTRUEに設定します。File Watcherの無効化または削除を強制すると、File Watcherに依存するジョブは無効になります。
File Watcherでは、デフォルトでは10分間隔でファイルの到着がチェックされます。この間隔は変更可能です。
ファイルの到着を検出する間隔を変更する手順は、次のとおりです。
SYSユーザーとしてデータベースに接続します。
事前定義のスケジュールSYS.FILE_WATCHER_SCHEDULEのREPEAT_INTERVAL属性を変更します。有効なカレンダ指定構文を使用してください。
次の例では、ファイルの到着を検出する頻度を2分間隔に変更しています。
BEGIN
DBMS_SCHEDULER.SET_ATTRIBUTE('FILE_WATCHER_SCHEDULE', 'REPEAT_INTERVAL',
'FREQ=MINUTELY;INTERVAL=2');
END;
/
*_SCHEDULER_FILE_WATCHERSビューを問い合せることによって、File Watcherに関する情報を表示できます。
SELECT file_watcher_name, destination, directory_path, file_name, credential_name FROM dba_scheduler_file_watchers; FILE_WATCHER_NAME DESTINATION DIRECTORY_PATH FILE_NAME CREDENTIAL_NAME -------------------- -------------------- -------------------- ---------- ---------------- MYFW dsshost.example.com /tmp abc MYFW_CRED EOD_FILE_WATCHER ?/eod_reports eod*.txt WATCH_CREDENTIAL
|
関連項目: *_SCHEDULER_FILE_WATCHERSビューの詳細は、『Oracle Databaseリファレンス』 |
ジョブ・チェーン(「チェーン」)は、結合した1つの目的のために互いにリンクされた一連の名前付きタスクです。チェーンは、前の1つ以上のジョブの結果に応じて異なるジョブが開始される依存性ベースのスケジューリングを実装できる手段です。
チェーンを作成して使用するには、次のタスクを実行します。
| タスク | 参照先 |
|---|---|
| 1. チェーン・オブジェクトを作成します。 | チェーンの作成 |
| 2. チェーン内のステップを定義します。 | チェーン・ステップの定義 |
| 3. ルールを追加します。 | チェーンへのルールの追加 |
| 4. チェーンを使用可能にします。 | チェーンの有効化 |
| 5. チェーンを指し示すジョブ(チェーン・ジョブ)を作成します。 | チェーン用のジョブの作成 |
この項で説明する他の内容は、次のとおりです。
表29-6に、チェーンに関する一般的なタスクとそれに対応するプロシージャを示します。
表29-6 チェーンのタスクとそのプロシージャ
| タスク | プロシージャ | 必要な権限 |
|---|---|---|
|
チェーンの作成 |
|
所有者の場合、 |
|
チェーンの削除 |
|
チェーンの所有権、あるいはチェーンに対する |
|
チェーンの変更 |
|
チェーンの所有権、あるいはチェーンに対する |
|
実行中チェーンの変更 |
|
ジョブの所有権、あるいはジョブに対する |
|
チェーンの実行 |
|
|
|
チェーンへのルールの追加 |
|
チェーンの所有権、あるいはチェーンに対する |
|
チェーン内のルールの変更 |
|
チェーンの所有権、あるいはチェーンに対する |
|
チェーンからのルールの削除 |
|
チェーンの所有権、あるいはチェーンに対する |
|
チェーンの有効化 |
|
チェーンの所有権、あるいはチェーンに対する |
|
チェーンの無効化 |
|
チェーンの所有権、あるいはチェーンに対する |
|
ステップの作成 |
|
チェーンの所有権、あるいはチェーンに対する |
|
ステップの削除 |
|
チェーンの所有権、あるいはチェーンに対する |
|
ステップの変更(ステップへの追加の属性値の割当てを含む) |
|
チェーンの所有権、あるいはチェーンに対する |
チェーンを作成するには、CREATE_CHAINプロシージャを使用します。最初に、必要な権限があることを確認してください。詳細は、「チェーンの各権限の設定」を参照してください。
CREATE_CHAINを使用してチェーン・オブジェクトを作成した後、チェーン・ステップおよびチェーン・ルールを別々に定義します。
次に、チェーンの作成例を示します。
BEGIN DBMS_SCHEDULER.CREATE_CHAIN ( chain_name => 'my_chain1', rule_set_name => NULL, evaluation_interval => NULL, comments => 'My first chain'); END; /
rule_set_nameおよびevaluation_interval引数は通常NULLのままです。evaluation_intervalでは、チェーン・ルールが評価される繰返し間隔を定義できます。rule_set_nameは、Oracle Streams内で定義されたルール・セットです。
|
関連項目:
|
チェーン・オブジェクトの作成後、1つ以上のチェーン・ステップを定義します。各ステップは、次のいずれかを指し示します。
スケジューラ・プログラム・オブジェクト(プログラム)
別のチェーン(ネストしたチェーン)
イベント・スケジュール、インライン・イベントまたはFile Watcher
プログラムまたはネストしたチェーンを指し示すステップを定義するには、DEFINE_CHAIN_STEPプロシージャを使用します。次に、my_chain1に2つのステップを追加する例を示します。
BEGIN DBMS_SCHEDULER.DEFINE_CHAIN_STEP ( chain_name => 'my_chain1', step_name => 'my_step1', program_name => 'my_program1'); DBMS_SCHEDULER.DEFINE_CHAIN_STEP ( chain_name => 'my_chain1', step_name => 'my_step2', program_name => 'my_chain2'); END; /
ステップを定義する際に、名前付きプログラムまたはチェーンが存在している必要はありません。ただし、チェーンの実行時には存在して有効になっている必要があり、そうでないとエラーが発生します。
イベントの発生を待機するステップを定義するには、DEFINE_CHAIN_EVENT_STEPプロシージャを使用します。プロシージャの引数を使用して、イベント・スケジュールを指し示すか、インラインのキュー仕様およびイベント条件を組み込むか、またはFile Watcherの名前を指定できます。この例では、名前付きイベント・スケジュール内に指定されているイベントを待機する、3番目のチェーン・ステップが作成されます。
BEGIN DBMS_SCHEDULER.DEFINE_CHAIN_EVENT_STEP ( chain_name => 'my_chain1', step_name => 'my_step3', event_schedule_name => 'my_event_schedule'); END; /
イベント・ステップでは、ステップが開始されるまでそのイベントを待機することはありません。
ローカルの外部実行可能ファイルを実行するステップ
ローカルの外部実行可能ファイルを実行するステップを定義した後、次の例に示すように、ALTER_CHAINプロシージャを使用して、ステップに資格証明を割り当てる必要があります。
BEGIN
DBMS_SCHEDULER.ALTER_CHAIN('chain1','step1','credential_name','MY_CREDENTIAL');
END;
/
リモートの宛先で実行するステップ
リモート・ホストまたはリモート・データベース上のデータベース・プログラム・ユニットで外部実行可能ファイルを実行するステップを定義した後、次の例に示すように、ALTER_CHAINプロシージャを使用して、ステップに資格証明と宛先の両方を割り当てる必要があります。
BEGIN
DBMS_SCHEDULER.ALTER_CHAIN('chain1','step2','credential_name','DW_CREDENTIAL');
DBMS_SCHEDULER.ALTER_CHAIN('chain1','step2','destination_name','DBHOST1_ORCLDW');
END;
/
ステップを再開可能にする方法
データベース・リカバリ後、デフォルトでは、実行中だったステップがSTOPPEDとしてマークされ、チェーンが続行されます。ALTER_CHAINを使用してチェーン・ステップのrestart_on_recovery属性をTRUEに設定すると、これらのステップをデータベース・リカバリ後に自動的に再開するように指定できます。
DEFINE_CHAIN_STEP、DEFINE_CHAIN_EVENT_STEPおよびALTER_CHAINプロシージャの詳細は、『Oracle Database PL/SQLパッケージおよびタイプ・リファレンス』を参照してください。
チェーンにルールを追加するには、DEFINE_CHAIN_RULEプロシージャを使用します。このプロシージャは、チェーンに追加する各ルールに対して1回ずつコールします。
チェーン・ルールでは、ステップの実行時期、およびステップ間の依存関係が定義されます。各ルールには条件と処理があります。ルールが評価されるときに、ルールの条件がTRUEに評価されると、その処理が実行されます。条件では、スケジューラ・チェーン条件の構文、またはSQLのWHERE句で有効な構文を使用できます。この構文には、ステップの完了ステータスなど、チェーン・ステップの属性への参照を組み込むことができます。標準な処理は、指定したステップを実行すること、またはステップのリストを実行することです。
チェーン・ルールはすべてまとまって機能し、チェーン全体の処理を定義します。チェーン・ジョブの開始時および各ステップの終了時に、次に実行される処理を判断するためにすべてのルールが評価されます。複数のルールにTRUE条件がある場合は、複数の処理を発生させることができます。チェーンのevaluation_interval属性を設定して、ルールを一定間隔で評価させることもできます。
条件は通常、1つ以上の先行するステップの結果に基づきます。たとえば、先行する2つのステップが成功した場合はあるステップを実行し、2つのステップのいずれかが失敗した場合には別のステップを実行する場合があります。
スケジューラのチェーン条件構文には、次の2つの書式があります。
stepname [NOT] {SUCCEEDED|FAILED|STOPPED|COMPLETED} stepname ERROR_CODE {comparision_operator|[NOT] IN} {integer|list_of_integers}
条件をブール演算子AND、ORおよびNOT()と組み合せて条件式を作成できます。式にカッコを使用すると、評価順序を指定できます。
ステップに割り当てたプログラム内でRAISE_APPLICATION_ERROR PL/SQL文を使用して、ERROR_CODEを設定できます。この方法でプログラムにより設定されるエラー・コードは負の数値ですが、チェーン・ルール内でERROR_CODEをテストするときには正の数値をテストします。たとえば、プログラムに次の文が含まれている場合を考えます。
RAISE_APPLICATION_ERROR(-20100, errmsg);
チェーン・ルールの条件を次のように指定する必要があります。
stepname ERROR_CODE=20100
ステップ属性
次のリストに、SQL WHERE句の構文を使用する際に条件に含めることのできるステップ属性を示します。
completedstatestart_dateend_dateerror_codedurationcompleted属性はブール値で、state属性がSUCCEEDED、FAILEDまたはSTOPPEDのときにはTRUEです。
表29-7に、state属性に使用される値を示します。これらの値は、*_SCHEDULER_RUNNING_CHAINSビューのSTATE列で参照可能です。
表29-7 チェーン・ステップのstate属性の値
| state属性の値 | 意味 |
|---|---|
|
|
ステップのチェーンは実行中ですが、ステップはまだ開始されていません。 |
|
|
ルールによって |
|
|
ステップは実行中です。イベント・ステップの場合、ステップは開始されており、イベントを待機中です。 |
|
|
ステップの |
|
|
ステップは正常に完了しています。ステップの |
|
|
ステップはエラーで完了しました。 |
|
|
ステップは |
|
|
ステップはネストしたチェーンであり、停止されています。 |
SQL WHERE句の構文のルールと例は、『Oracle Database PL/SQLパッケージおよびタイプ・リファレンス』のDEFINE_CHAIN_RULEプロシージャに関する項を参照してください。
スケジューラ・チェーン条件の構文を使用した条件の例
次の例では、スケジューラ・チェーン条件の構文を使用しています。
次の条件を含んだルールによって開始されたステップは、form_validation_stepというステップが完了(SUCCEEDED、FAILEDまたはSTOPPED)すると開始されます。
form_validation_step COMPLETED
次の条件も同様ですが、条件が満たされるにはステップが成功する必要があることを示しています。
form_validation_step SUCCEEDED
次の条件では、エラーがあるかどうかをテストしています。ステップform_validation_stepが失敗して20001以外のエラー・コードが戻された場合は、TRUEになります。
form_validation_step FAILED AND form_validation_step ERROR_CODE != 20001
他の例は、『Oracle Database PL/SQLパッケージおよびタイプ・リファレンス』のDEFINE_CHAIN_RULEプロシージャに関する項を参照してください。
SQL WHERE構文を使用した条件の例
':step1.state=''SUCCEEDED'''
チェーンの開始
チェーン・ジョブの開始時にチェーンを開始できるように、少なくとも1つのルールに、常にTRUEに評価される条件が必要です。このための最も簡単な方法は、スケジュール・チェーン条件の構文を使用している場合は条件を'TRUE'に設定すること、またはSQL構文を使用している場合は条件を'1=1'に設定することです。
チェーンの終了
少なくとも1つのチェーン・ルールに、'END'のactionが含まれている必要があります。チェーン・ジョブは、END処理が含まれているルールの1つがTRUEに評価されるまでは完了しません。通常は、異なるEND処理が設定された別々のルールがあり、エラー・コードを伴う場合と伴わない場合があります。
チェーンに実行するステップがなくなるか、またはイベントの発生の待機中ではなく、END処理が含まれているルールでTRUEに評価されるルールがない(またはEND処理が設定されているルールがない)場合、チェーン・ジョブの状態はCHAIN_STALLEDになります。詳細は、「停止状態チェーンの処理」を参照してください。
ルールの定義例
次の例では、ステップstep1でチェーンを開始するルールおよびstep1の完了時にステップstep2を開始するルールを定義しています。rule_nameおよびcommentsはオプションですが、デフォルトでNULLになります。rule_nameを使用する場合は、DEFINE_CHAIN_RULEに対する別の呼出しで、そのルールを後で再定義できます。新しい定義で、以前の定義が上書きされます。
BEGIN DBMS_SCHEDULER.DEFINE_CHAIN_RULE ( chain_name => 'my_chain1', condition => 'TRUE', action => 'START step1', rule_name => 'my_rule1', comments => 'start the chain'); DBMS_SCHEDULER.DEFINE_CHAIN_RULE ( chain_name => 'my_chain1', condition => 'step1 completed', action => 'START step2', rule_name => 'my_rule2'); END; /
|
関連項目:
|
スケジューラでは、チェーン・ジョブの開始時と各チェーン・ステップの終了時に、すべてのチェーン・ルールが評価されます。1時間に1回など、一定の時間間隔でもルールが評価されるようにチェーンを構成できます。この機能は、時間に基づいて、またはチェーン外部での発生に基づいてチェーン・ステップを開始するのに役立ちます。次に、いくつかの例を示します。
チェーン・ステップがリソース集中型であるため、オフピーク時に実行する必要があるとします。ステップの条件として、別のステップの完了と午後6時から午前0時までの時間の両方を設定できます。スケジューラでは、この条件がTRUEになる時期を判別するために、ルールをその都度評価する必要があります。
ステップが、チェーン外部にある他のプロセスから表にデータが到着するまで待機する必要があるとします。このステップの条件として、別のステップの完了と行を含む特定の表の両方を設定できます。スケジューラでは、この条件がTRUEになる時期を判別するために、ルールをその都度評価する必要があります。この条件はSQL WHERE句構文を使用し、次のようになります。
':step1.state=''SUCCEEDED'' AND select count(*) from oe.sync_table > 0'
チェーンの評価間隔を設定するには、チェーンの作成時にevaluation_interval属性を設定します。この属性のデータ型はINTERVAL DAY TO SECONDです。
BEGIN DBMS_SCHEDULER.CREATE_CHAIN ( chain_name => 'my_chain1', rule_set_name => NULL, evaluation_interval => INTERVAL '30' MINUTE, comments => 'Chain with 30 minute evaluation interval'); END; /
チェーンを有効(使用可能)にするには、ENABLEプロシージャを使用します。ジョブでチェーンを実行するには、チェーンを使用可能にする必要があります。すでに使用可能なチェーンを使用可能にしてもエラーは戻りません。
次の例では、チェーンmy_chain1が使用可能になります。
BEGIN
DBMS_SCHEDULER.ENABLE ('my_chain1');
END;
/
ENABLEプロシージャの詳細は、『Oracle Database PL/SQLパッケージおよびタイプ・リファレンス』を参照してください。
|
注意: チェーンは、次の場合にスケジューラによって自動的に使用禁止にされます。
|
チェーンを実行するには、RUN_CHAINプロシージャを使用するか、タイプ'CHAIN'のジョブ(チェーン・ジョブ)を作成してスケジュールする必要があります。ジョブの処理では、次の例に示すように、チェーン名を参照する必要があります。
BEGIN DBMS_SCHEDULER.CREATE_JOB ( job_name => 'chain_job_1', job_type => 'CHAIN', job_action => 'my_chain1', repeat_interval => 'freq=daily;byhour=13;byminute=0;bysecond=0', enabled => TRUE); END; /
実行中のチェーン・ジョブの各ステップには、スケジューラによって、チェーン・ジョブと同じジョブ名と所有者を設定したステップ・ジョブが作成されます。各ステップ・ジョブにはさらに、そのジョブを一意に識別するためのサブ名があります。ジョブのサブ名は、ビュー*_SCHEDULER_RUNNING_JOBS、*_SCHEDULER_JOB_LOGおよび*_SCHEDULER_JOB_RUN_DETAILSに列として組み込まれます。また、次の場合を除いて、ジョブのサブ名は通常はステップ名と同じです。
ネストされたチェーンの場合、現在のステップ名がすでにジョブのサブ名として使用されている場合があります。この場合、スケジューラは、'_N'をステップ名の最後に追加しますが、ここで、Nはジョブのサブ名を一意にするための整数を表します。
ステップ・ジョブの作成時にエラーが発生した場合、スケジューラは、ジョブ・サブ名を'step_name_0'に設定して、ジョブ・ログ・ビュー(*_SCHEDULER_JOB_LOGおよび*_SCHEDULER_JOB_RUN_DETAILS)にFAILEDエントリを記録します。
|
関連項目:
|
DROP_CHAINプロシージャを使用して、ステップとルールを含めたチェーンを削除します。次に、チェーンmy_chain1を削除する例を示します。
BEGIN DBMS_SCHEDULER.DROP_CHAIN ( chain_name => 'my_chain1', force => TRUE); END; /
DROP_CHAINプロシージャの詳細は、『Oracle Database PL/SQLパッケージおよびタイプ・リファレンス』を参照してください。
次の2つのプロシージャを使用して、チェーンを即時に実行できます。
RUN_JOB
RUN_CHAIN
すでにチェーン用のチェーン・ジョブを作成している場合は、RUN_JOBプロシージャを使用してそのジョブを実行(したがってチェーンを実行)できますが、RUN_JOBのuse_current_session引数をFALSEに設定する必要があります。
RUN_CHAINプロシージャを使用すると、チェーンに対するチェーン・ジョブをあらかじめ作成することなく、チェーンを実行できます。また、RUN_CHAINを使用してチェーンの一部のみを実行することもできます。
RUN_CHAINは、指定したチェーンを実行する一時ジョブを作成します。ジョブ名を指定すると、その名前のジョブが作成されますが、それ以外の場合はデフォルトのジョブ名が割り当てられます。
開始ステップ・リストを指定すると、チェーンの実行開始時にそれらのステップのみが開始されます (通常開始されるステップは、それらがリスト内にない場合は実行されません)。開始ステップのリストが提供されない場合は、チェーンが通常どおり開始されます。つまり、初期評価が行われ、実行を開始するステップが判断されます。次に、チェーンmy_chain1を即時に実行する例を示します。
BEGIN DBMS_SCHEDULER.RUN_CHAIN ( chain_name => 'my_chain1', job_name => 'partial_chain_job', start_steps => 'my_step2, my_step4'); END; /
チェーンからルールを削除するには、DROP_CHAIN_RULEプロシージャを使用します。次に、my_rule1を削除する例を示します。
BEGIN DBMS_SCHEDULER.DROP_CHAIN_RULE ( chain_name => 'my_chain1', rule_name => 'my_rule1', force => TRUE); END; /
DROP_CHAIN_RULEプロシージャの詳細は、『Oracle Database PL/SQLパッケージおよびタイプ・リファレンス』を参照してください。
チェーンを無効(使用禁止)にするには、DISABLEプロシージャを使用します。次に、my_chain1を使用禁止にする例を示します。
BEGIN
DBMS_SCHEDULER.DISABLE ('my_chain1');
END;
/
DISABLEプロシージャの詳細は、『Oracle Database PL/SQLパッケージおよびタイプ・リファレンス』を参照してください。
|
注意: チェーンは、次の場合にスケジューラによって自動的に使用禁止にされます。
|
チェーンからステップを削除するには、DROP_CHAIN_STEPプロシージャを使用します。次に、my_chain2からmy_step2を削除する例を示します。
BEGIN DBMS_SCHEDULER.DROP_CHAIN_STEP ( chain_name => 'my_chain2', step_name => 'my_step2', force => TRUE); END; /
DROP_CHAIN_STEPプロシージャの詳細は、『Oracle Database PL/SQLパッケージおよびタイプ・リファレンス』を参照してください。
実行中のチェーンを停止するには、DBMS_SCHEDULER.STOP_JOBをコールして、チェーン・ジョブ(チェーンを開始したジョブ)の名前を渡します。チェーン・ジョブを停止すると、実行中のチェーンの全ステップが停止され、チェーンが終了します。
STOP_JOBプロシージャの詳細は、『Oracle Database PL/SQLパッケージおよびタイプ・リファレンス』を参照してください。
個々のチェーン・ステップを停止するには2つの方法があります。
ルールの条件を満たしたときに1つ以上のステップを停止するチェーン・ルールの作成。
STOP_JOBプロシージャのコール
停止するステップごとに、スキーマ名、チェーン・ジョブ名およびステップ・ジョブ・サブ名を指定する必要があります。
BEGIN
DBMS_SCHEDULER.STOP_JOB('oe.chainrunjob.stepa');
END;
/
この例では、chainrunjobはチェーン・ジョブ名で、stepaはステップ・ジョブ・サブ名です。通常、ステップ・ジョブ・サブ名はステップ名と同じですが、異なる場合もあります。ステップ・ジョブ・サブ名は、*_SCHEDULER_RUNNING_CHAINSビューのSTEP_JOB_SUBNAME列から取得できます。
チェーン・ステップを停止すると、stateがSTOPPEDに設定され、チェーン・ルールが評価されて次に実行するステップが判別されます。
STOP_JOBプロシージャの詳細は、『Oracle Database PL/SQLパッケージおよびタイプ・リファレンス』を参照してください。
チェーン全体、またはチェーンの個別ブランチを一時停止できます。そのためには、DBMS_SCHEDULER.ALTER_CHAINまたはALTER_RUNNING_CHAINを使用して、1つ以上のステップのPAUSE属性をTRUEに設定します。チェーン・ステップを一時停止すると、チェーンの実行をそのステップの実行後に一時停止できます。
ステップを一時停止すると、そのステップの実行後にstate属性がPAUSEDに変わりますが、completed属性はFALSEのままです。そのため、一時停止したステップの完了に依存しているステップは実行されません。一時停止したステップのPAUSE属性をFALSEにリセットすると、state属性が完了状態(SUCCEEDED、FAILEDまたはSTOPPED)に設定され、一時停止したステップの完了を待機しているステップを実行できるようになります。
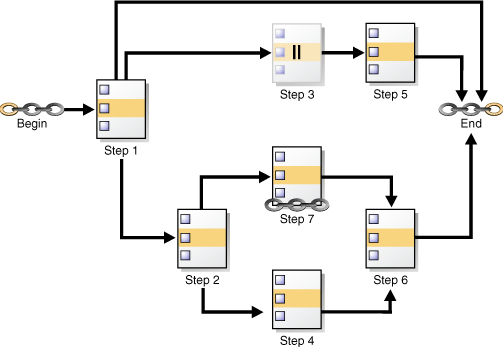
図29-1では、ステップ3が一時停止されています。ステップ3の一時停止が解除されるまで、ステップ5は実行されません。ステップ2のみを一時停止した場合、ステップ4、6および7は実行されません。ただし、ステップ1、3および5は実行できます。いずれの場合も、チェーンのブランチを1つのみ一時停止することになります。
チェーン全体を一時停止するには、チェーンのステップをすべて一時停止します。チェーンの一時停止を解除するには、チェーン・ステップの1つ、多数またはすべての一時停止を解除します。図29-1のチェーンでは、ステップ1を一時停止すると、ステップ1の実行後にチェーン全体も一時停止します。
|
関連項目: |
チェーンの1つ以上のステップをスキップできます。そのためには、DBMS_SCHEDULER.ALTER_CHAINまたはALTER_RUNNING_CHAINを使用して、1つ以上のステップのSKIP属性をTRUEに設定します。ステップのSKIP属性がTRUEの場合、そのステップを実行するためのチェーン条件を満たすと、そのステップは実行されるかわりに、即時に成功した場合と同様に処理されます。SKIPをTRUEに設定しても、実行中のステップ、遅延後に実行するようにスケジュールされているステップまたは実行済のステップには影響しません。
ステップのスキップが特に役立つのは、チェーンのテスト時です。たとえば、図29-1に示したチェーンをテストする際に、ステップ7をスキップすると、このステップはネストしたチェーンであるため、テスト時間を大幅に短縮できます。
チェーンの一部のみを実行するには2つの方法があります。
ALTER_CHAINプロシージャを使用して、1つ以上のステップに対してPAUSE属性をTRUEに設定してから、RUN_JOBでチェーン・ジョブを起動するか、RUN_CHAINでチェーンを起動します。一時停止しているステップに依存するステップは実行されません。(ただし、一時停止しているステップは実行されます。)
この方法のデメリットは、チェーンを将来実行する場合に備えて、影響を受けるステップのPAUSE属性の設定をFALSEに戻す必要があることです。
RUN_CHAINプロシージャを使用して、実行しないステップをスキップし、チェーンの特定ステップのみを開始します。
この方法の方が簡単であり、ステップの開始前に初期状態を設定することもできます。
この2つの方法の両方を使用して、チェーンの開始時と終了時の両方でステップをスキップすることが必要な場合もあります。
詳細は、『Oracle Database PL/SQLパッケージおよびタイプ・リファレンス』のRUN_CHAINプロシージャに関する項を参照してください。
次の2つのビューを使用して、実行中のチェーンのステータスを表示できます。
*_SCHEDULER_RUNNING_JOBS*_SCHEDULER_RUNNING_CHAINS*_SCHEDULER_RUNNING_JOBSビューには、チェーン・ジョブに関する1行と実行中の各ステップに関する1行が含まれています。*_SCHEDULER_RUNNING_CHAINSビューには、各チェーン・ステップ(ネストしたチェーンを含む)に関する1行と、各ステップの実行ステータス(NOT_STARTED、RUNNING、STOPPED、SUCCEEDEDなど)が含まれています。
これらのビューの詳細は、『Oracle Databaseリファレンス』を参照してください。
ステップの完了時には、常にチェーン・ルールが評価され、次に実行するステップが判別されます。いずれのルールでも別のステップが開始されず、チェーンが終了せず、チェーンのevaluation_intervalがNULLの場合は、チェーンがstalled状態になります。チェーンが停止状態になっている場合、実行中のステップはありません。また、(指定の時間間隔だけ待機した後に)実行するようにスケジュールされているステップや、イベントを待機中のイベント・ステップもありません。この場合、チェーンを実行しているジョブの状態はCHAIN_STALLEDに設定されます。(ただし、ジョブは*_SCHEDULER_RUNNING_JOBSビューにリストされたままです)。
停止状態のチェーンの問題を解決するには、ビューALL_SCHEDULER_RUNNING_CHAINS(チェーン(ネストしたチェーンを含む)内のすべてのステップの状態が示されます)とビューALL_SCHEDULER_CHAIN_RULES(すべてのチェーン・ルールが含まれます)が使用されます。
ALTER_RUNNING_CHAINプロシージャを使用していずれかのステップのstateを変更すると、チェーンの実行を継続できます。たとえば、ステップ11がステップ9の正常終了まで待機してから開始するようになっており、状態の変更がこれに関係する場合、ステップ9のstateを'SUCCEEDED'に設定することもできます。
あるいは、1つ以上のルールが正しくない場合は、DEFINE_CHAIN_RULEプロシージャを使用して、(同じルール名を使用して)それらのルールを置換するか、または新規ルールを作成できます。新規および更新したルールは、実行中のチェーンと次回以降のすべてのチェーン実行に適用されます。ルールの追加または更新後は、停止状態のチェーン・ジョブでEVALUATE_RUNNING_CHAINを実行し、必要な処理をトリガーする必要があります。
3つのスケジューラ・ジョブ(ジョブ・クラス、ウィンドウおよびウィンドウ・グループ)を使用して、Oracle Schedulerジョブに優先度を付けます。これらのオブジェクトでは、ジョブをデータベース・リソース・マネージャのコンシューマ・グループに関連付けることによって、ジョブに優先度を付けます。これにより、これらのジョブに割り当てられるリソースの量が制御されます。また、ジョブ・クラスでは、グループ内のすべてのジョブに同一のリソース・レベルが割り当てられている場合に、ジョブのグループ間に相対的な優先度を設定できます。
この項の内容は次のとおりです。
ジョブ・クラスでは、ジョブをグループ化して優先度を付けることができます。また、メンバー・ジョブに一連の属性値を簡単に割り当てることができます。ジョブ・クラスは、データベース・リソース・マネージャに関連するジョブ・クラス属性を通して各メンバー・ジョブの優先度に影響します。詳細は、「リソース・マネージャを使用したジョブ間のリソース割当て」を参照してください。
データベースとともに作成されるデフォルトのジョブ・クラスがあります。ジョブ・クラスを指定せずにジョブを作成すると、ジョブはこのデフォルトのジョブ・クラス(DEFAULT_JOB_CLASS)に割り当てられます。デフォルトのジョブ・クラスでは、EXECUTE権限がPUBLICに付与されているため、ジョブの作成権限を持つすべてのデータベース・ユーザーは、デフォルトのジョブ・クラスにジョブを作成できます。
この項では、ジョブ・クラスの基本的なタスクについて説明します。この項の内容は、次のとおりです。
表29-8に、ジョブ・クラスの一般的なタスクとそれに対応するプロシージャおよび権限を示します。
表29-8 ジョブ・クラスのタスクとそのプロシージャ
| タスク | プロシージャ | 必要な権限 |
|---|---|---|
|
ジョブ・クラスの作成 |
|
|
|
ジョブ・クラスの変更 |
|
|
|
ジョブ・クラスの削除 |
|
|
権限の詳細は、「スケジューラ権限」を参照してください。
ジョブ・クラスを作成するには、CREATE_JOB_CLASSプロシージャまたはEnterprise Managerを使用します。ジョブ・クラスは、常にSYSスキーマに作成されます。
次の文では、すべての財務ジョブ用のジョブ・クラスが作成されます。
BEGIN DBMS_SCHEDULER.CREATE_JOB_CLASS ( job_class_name => 'finance_jobs', resource_consumer_group => 'finance_group'); END; /
このジョブ・クラス内のすべてのジョブは、finance_groupリソース・コンシューマ・グループに割り当てられます。
ジョブ・クラスを問い合せるには、*_SCHEDULER_JOB_CLASSESビューを使用します。
ジョブ・クラスを変更するには、SET_ATTRIBUTEプロシージャまたはEnterprise Managerを使用します。また、ジョブ・クラス名以外のすべての属性を変更できます。ジョブ・クラスの属性は、*_SCHEDULER_JOB_CLASSESビューで使用可能です。
ジョブ・クラスを変更した場合、そのクラスに属する実行中のジョブには影響しません。この変更は、今後実行されるジョブに対してのみ有効です。
1つ以上のジョブ・クラスを削除するには、DROP_JOB_CLASSプロシージャまたはEnterprise Managerを使用します。ジョブ・クラスの削除とは、そのジョブ・クラスのすべてのメタデータをデータベースから削除することです。
DROP_JOB_CLASSプロシージャ・コールにジョブ・クラス名のカンマ区切りのリストを指定することで、1回のコールで複数のジョブ・クラスを削除できます。たとえば、次の文では3つのジョブ・クラスが削除されます。
BEGIN
DBMS_SCHEDULER.DROP_JOB_CLASS('jobclass1, jobclass2, jobclass3');
END;
/
SET_ATTRIBUTEプロシージャを使用して、同じジョブ・クラス内でジョブの相対的な優先度を変更できます。ジョブの優先度は、1を最も高い優先度として1から5の範囲で設定する必要があります。たとえば、次の文では、my_job1のジョブ優先度の設定が1に変更されます。
BEGIN DBMS_SCHEDULER.SET_ATTRIBUTE ( name => 'my_emp_job1', attribute => 'job_priority', value => 1); END; /
属性が変更されたことを確認するには、次の文を発行します。
SELECT JOB_NAME, JOB_PRIORITY FROM DBA_SCHEDULER_JOBS; JOB_NAME JOB_PRIORITY ------------------------------ ------------ MY_EMP_JOB 3 MY_EMP_JOB1 1 MY_NEW_JOB1 3 MY_NEW_JOB2 3 MY_NEW_JOB3 3
システムにおけるジョブの全体的な優先度は、最初に、そのジョブのジョブ・クラスが割り当てられているリソース・コンシューマ・グループと現行のリソース・プランの組合せによって決定され、次に、ジョブ・クラス内の相対的な優先度によって決定されます。
|
関連項目:
|
ウィンドウを使用すると、異なる時間帯で別々のリソース・プランを自動的にアクティブにできます。ジョブを実行すると、そのジョブに割り当てられているリソースが、リソース・プランの変更時に変わることがわかります。ジョブは、そのschedule_name属性でウィンドウを指定できます。スケジューラは、このウィンドウがオープンしているジョブを開始します。ウィンドウには、ワークロード・サイクル中の様々な時間にオープンできるように、スケジュールが関連付けられます。
ウィンドウの主な属性は次のとおりです。
スケジュール
ウィンドウが有効である時期を制御します。
継続時間
ウィンドウがオープンしている長さを制御します。
リソース・プラン
ウィンドウのオープン時にアクティブ化されるリソース・プランの名前を設定します。
特定の時間に有効にできるウィンドウは1つのみです。ウィンドウはSYSスキーマに属します。
すべてのウィンドウ・アクティビティは、*_SCHEDULER_WINDOW_LOGビュー(ウィンドウ・ログと呼ばれます)に記録されます。ウィンドウ・ログの記録例は、「ウィンドウ・ログ」を参照してください。
この項では、ウィンドウの基本的なタスクについて説明します。この項の内容は、次のとおりです。
表29-9に、ウィンドウの一般的なタスクとその処理に使用するプロシージャを示します。
表29-9 ウィンドウのタスクとそのプロシージャ
| タスク | プロシージャ | 必要な権限 |
|---|---|---|
|
ウィンドウの作成 |
|
|
|
ウィンドウのオープン |
|
|
|
ウィンドウのクローズ |
|
|
|
ウィンドウの変更 |
|
|
|
ウィンドウの削除 |
|
|
|
ウィンドウの使用禁止 |
|
|
|
ウィンドウの使用可能化 |
|
|
権限の詳細は、「スケジューラ権限」を参照してください。
ウィンドウを作成するには、Enterprise ManagerまたはDBMS_SCHEDULER.CREATE_WINDOWパッケージ・プロシージャを使用します。パッケージ・プロシージャを使用する場合は、resource_planパラメータをNULLのままにできることです。この場合は、ウィンドウのオープン時に現行のプランが有効のままになります。
ウィンドウを作成するには、MANAGE SCHEDULER権限が必要です。
ウィンドウにスケジュールを指定する場合、スケジューラではそのスケジュールにウィンドウがすでに定義されているかどうかはチェックされません。したがって、複数のウィンドウが重複する場合があります。また、繰返し間隔としてPL/SQL式が設定されている名前付きスケジュールの使用は、ウィンドウに対してはサポートされていません。
ウィンドウ属性の詳細は、『Oracle Database PL/SQLパッケージおよびタイプ・リファレンス』のCREATE_WINDOWプロシージャに関する項を参照してください。
次の例では、営業時間中にmixed_workload_planリソース・プランを有効にするdaytimeというウィンドウを作成しています。
BEGIN
DBMS_SCHEDULER.CREATE_WINDOW (
window_name => 'daytime',
resource_plan => 'mixed_workload_plan',
start_date => '28-APR-09 08.00.00 AM',
repeat_interval => 'freq=daily; byday=mon,tue,wed,thu,fri',
duration => interval '9' hour,
window_priority => 'low',
comments => 'OLTP transactions have priority');
END;
/
ウィンドウが正しく作成されたことを検証するには、DBA_SCHEDULER_WINDOWSビューを問い合せます。次に、文の発行例を示します。
SELECT WINDOW_NAME, RESOURCE_PLAN, DURATION, REPEAT_INTERVAL FROM DBA_SCHEDULER_WINDOWS; WINDOW_NAME RESOURCE_PLAN DURATION REPEAT_INTERVAL ----------- ------------------- ------------- --------------- DAYTIME MIXED_WORKLOAD_PLAN +000 09:00:00 freq=daily; byday=mon,tue,wed,thu,fri
ウィンドウを変更するには、その属性を変更します。そのためには、SET_ATTRIBUTEおよびSET_ATTRIBUTE_NULLプロシージャまたはEnterprise Managerを使用します。変更するときは、WINDOW_NAME以外のすべてのウィンドウ属性を変更できます。ウィンドウ属性の詳細は、『Oracle Database PL/SQLパッケージおよびタイプ・リファレンス』のCREATE_WINDOWプロシージャに関する項を参照してください。
ウィンドウを変更した場合、アクティブ・ウィンドウには影響しません。この変更は、次回ウィンドウをオープンするときからのみ有効になります。
すべてのウィンドウを変更できます。使用禁止のウィンドウを変更した場合は、変更した後も使用禁止のままです。使用可能なウィンドウは自動的に使用禁止になり、変更後、使用可能化プロセスで実行される妥当性チェックが成功した場合は再び使用可能になります。
SET_ATTRIBUTEおよびSET_ATTRIBUTE_NULLプロシージャの詳細は、『Oracle Database PL/SQLパッケージおよびタイプ・リファレンス』を参照してください。
ウィンドウがオープンすると、スケジューラは、ウィンドウの作成時に関連付けられたリソース・プランに切り替えます。ウィンドウのオープン時に実行中のジョブがある場合、そのジョブに割り当てられているリソースはリソース・プランの切替えによって変更される場合があります。
ウィンドウをオープンする方法は、次の2通りあります。
ウィンドウのスケジュールに基づいたオープン
OPEN_WINDOWプロシージャを使用した手動オープン
このプロシージャは、スケジュールとは関係なくウィンドウをオープンします。ウィンドウがオープンし、関連付けられたリソース・プランが即時に有効になります。手動でオープンできるのは、使用可能なウィンドウのみです。
OPEN_WINDOWプロシージャで、duration属性を使用して、ウィンドウがオープンしている時間の長さを指定できます。継続時間の型はINTERVAL DAY TO SECONDです。継続時間の指定がない場合、ウィンドウはそのウィンドウに保存されている通常の継続時間の間オープン状態です。
手動によるウィンドウのオープンは、通常のスケジュール・ウィンドウの実行には影響しません。
手動でオープンしたウィンドウをクローズする場合で、クローズするときに他のウィンドウもある場合、どのウィンドウをオープンするかを決定するために、オーバーラップ・ウィンドウのルールが適用されます。
すでにオープンしているウィンドウがある場合でも、OPEN_WINDOWコールまたはEnterprise ManagerでforceオプションをTRUEに設定すると、ウィンドウを強制的にオープンできます。
forceオプションがTRUEに設定されているときは、その時点でオープンしているウィンドウの優先度の方が高い場合でも、スケジューラはウィンドウを自動的にクローズします。この手動でオープンしたウィンドウの継続時間中は、Schedulerにより他のスケジュール・ウィンドウはオープンされません(より優先順位の高いウィンドウもオープンされません)。すでにオープンしているウィンドウをオープンできます。この場合、ウィンドウは、OPEN_WINDOWコマンドが発行された時点から、コールで指定された継続時間の間オープンしたままになります。
これを示す例を考えます。window1は、4時間の期間という設定で作成されました。もう2時間オープンしています。この時点でOPEN_WINDOW呼出しを使用してwindow1を再びオープンし、期間を指定しないと、window1には4時間という期間が設定されるため、もう4時間オープンすることになります。30分という期間を指定すると、ウィンドウは30分でクローズします。
ウィンドウがオープンすると、ウィンドウ・ログにエントリが作成されます。
現在のリソース・プランが、ALTER SYSTEM文FORCEオプションあるいはDBMS_RESOURCE_MANAGER.SWITCH_PLANパッケージ・プロシージャのallow_scheduler_plan_switches引数FALSEを使用して、手動で切り替えられたものである場合、ウィンドウでリソース・プランの切替えに失敗する可能性があります。この場合、リソース・プランの切替え失敗がウィンドウ・ログに書き込まれます。
OPEN_WINDOWおよびDBMS_RESOURCE_MANAGER.SWITCH_PLANプロシージャの詳細は、『Oracle Database PL/SQLパッケージおよびタイプ・リファレンス』を参照してください。
ウィンドウをクローズする方法は、次の2通りあります。
スケジュールに基づいたクローズ
ウィンドウは作成時に定義されたスケジュールに基づいてクローズします。
CLOSE_WINDOWプロシージャを使用した手動クローズ
CLOSE_WINDOWプロシージャは、オープン中のウィンドウを期間終了前にクローズします。
ウィンドウはクローズすると無効になります。ウィンドウがクローズすると、スケジューラは、リソース・プランをそのウィンドウ期間外で有効だったリソース・プランに切り替えるか、またはウィンドウの重複がある場合は別のウィンドウに切り替えます。存在しないウィンドウ、またはオープンしていないウィンドウをクローズしようとすると、エラーが発生します。
実行中のジョブは、そのジョブが実行されているウィンドウがクローズした場合でも、stop_on_window_close属性がジョブの作成時にTRUEに設定されていないかぎりクローズしません。ただし、リソース・プランが変更される場合があるため、ジョブに割り当てられているリソースは変更される可能性があります。
実行中のジョブにスケジュールとしてウィンドウ・グループが設定されていると、そのジョブは、同じウィンドウ・グループのメンバーである別のウィンドウが元のウィンドウのクローズ時にアクティブになった場合、停止しません。これは、stop_on_window_close属性がTRUEに設定された状態でジョブが作成されている場合でも同じです。
ウィンドウがクローズ状態になると、ウィンドウ・ログDBA_SCHEDULER_WINDOW_LOGにエントリが追加されます。
CLOSE_WINDOWプロシージャの詳細は、『Oracle Database PL/SQLパッケージおよびタイプ・リファレンス』を参照してください。
1つ以上のウィンドウを削除するには、DROP_WINDOWプロシージャまたはEnterprise Managerを使用します。ウィンドウが削除されると、そのウィンドウに関するすべてのメタデータが*_SCHEDULER_WINDOWSビューから削除されます。また、ウィンドウに対するすべての参照がウィンドウ・グループから削除されます。
DROP_WINDOWプロシージャにウィンドウ名またはウィンドウ・グループ名のカンマ区切りのリストを指定すると、1回のコールで複数のウィンドウを削除できます。たとえば、次の文ではウィンドウとウィンドウ・グループの両方が削除されます。
BEGIN
DBMS_SCHEDULER.DROP_WINDOW ('window1, window2, window3,
windowgroup1, windowgroup2');
END;
/
ウィンドウ・グループ名を指定した場合、ウィンドウ・グループ内のウィンドウは削除されますが、ウィンドウ・グループは削除されません。ウィンドウ・グループを削除するには、DROP_WINDOW_GROUPプロシージャを使用する必要があります。
DROP_WINDOWプロシージャの詳細は、『Oracle Database PL/SQLパッケージ・プロシージャおよびタイプ・リファレンス』を参照してください。
1つ以上のウィンドウを無効(使用禁止)にするには、DISABLEプロシージャまたはEnterprise Managerを使用します。そのため、ウィンドウはオープンしません。ただし、ウィンドウのメタデータは依然存在するため、再び使用可能に設定できます。DISABLEプロシージャは複数のスケジューラ・オブジェクトに対して使用されるため、ウィンドウを使用禁止にするときは、先頭にSYSを付ける必要があります。
ウィンドウは他の理由で使用禁止になる場合もあります。たとえば、ウィンドウはそのスケジュールの終了時に使用禁止になります。また、存在しないスケジュールをウィンドウが指し示している場合も使用禁止になります。
スケジュールとしてウィンドウが設定されているジョブがある場合、そのウィンドウは、プロシージャ・コールでforceをTRUEに設定しないかぎり、使用禁止にできません。デフォルトでは、forceはFALSEに設定されます。ウィンドウが使用禁止の場合、このウィンドウがスケジュールとして設定されているジョブを使用禁止にすることはできません。
DISABLEプロシージャ・コールにウィンドウ名またはウィンドウ・グループ名のカンマ区切りのリストを指定することで、1回のコールで複数のウィンドウを使用禁止にすることもできます。たとえば、次の文ではウィンドウとウィンドウ・グループの両方が使用禁止になります。
BEGIN
DBMS_SCHEDULER.DISABLE ('sys.window1, sys.window2,
sys.window3, sys.windowgroup1, sys.windowgroup2');
END;
/
DISABLEプロシージャの詳細は、『Oracle Database PL/SQLパッケージおよびタイプ・リファレンス』を参照してください。
1つ以上のウィンドウを有効(使用可能)にするには、ENABLEプロシージャまたはEnterprise Managerを使用します。使用可能なウィンドウとは、オープン可能なウィンドウのことです。ウィンドウは、デフォルトでenabledで作成されます。ENABLEプロシージャを使用してウィンドウを使用可能にすると、妥当性チェックが実行され、このチェックが成功した場合のみウィンドウは使用可能になります。ウィンドウが使用可能になると、ウィンドウ・ログ表にログが記録されます。ENABLEプロシージャは複数のスケジューラ・オブジェクトに対して使用されるため、ウィンドウを使用可能にするときは、先頭にSYSを付ける必要があります。
ウィンドウ名のカンマ区切りのリストを指定することで、1回のコールで複数のウィンドウを使用可能にできます。たとえば、次の文では3つのウィンドウが使用可能になります。
BEGIN
DBMS_SCHEDULER.ENABLE ('sys.window1, sys.window2, sys.window3');
END;
/
ENABLEプロシージャの詳細は、『Oracle Database PL/SQLパッケージおよびタイプ・リファレンス』を参照してください。
ウィンドウ・グループを使用すると、1日あるいは1週間などの間に複数期間実行するジョブを簡単にスケジュールできます。ウィンドウ・グループを作成してウィンドウをグループに加え、ウィンドウ・グループ名をジョブのschedule_name属性に設定すると、ジョブがウィンドウ・グループ内のすべてのウィンドウの指定期間に実行されます。
ウィンドウ・グループはSYSスキーマにあります。この項では、基本的なウィンドウ・グループ・タスクについて説明します。この項の内容は、次のとおりです。
表29-10に、ウィンドウ・グループの一般的なタスクとその処理に使用するプロシージャを示します。
表29-10 ウィンドウ・グループのタスクとそのプロシージャ
| タスク | プロシージャ | 必要な権限 |
|---|---|---|
|
ウィンドウ・グループの作成 |
|
|
|
ウィンドウ・グループの削除 |
|
|
|
ウィンドウ・グループへのメンバーの追加 |
|
|
|
ウィンドウ・グループからのメンバーの削除 |
|
|
|
ウィンドウ・グループの有効化 |
|
|
|
ウィンドウ・グループの無効化 |
|
|
権限の詳細は、「スケジューラ権限」を参照してください。
ウィンドウ・グループを作成するには、DBMS_SCHEDULER.CREATE_GROUPプロシージャを使用して、グループ・タイプとしてWINDOWを指定します。グループのメンバー・ウィンドウは、グループの作成時に指定するか、または後でADD_GROUP_MEMBERプロシージャを使用して追加できます。ウィンドウ・グループは、他のウィンドウ・グループのメンバーになれません。ただし、メンバーを設定しないウィンドウ・グループは作成できます。
ウィンドウ・グループを作成し、存在しないメンバー・ウィンドウを指定すると、エラーが生成され、ウィンドウ・グループは作成されません。ウィンドウがすでにウィンドウ・グループのメンバーである場合、再度追加されることはありません。
ウィンドウ・グループはSYSスキーマで作成します。ウィンドウ・グループは、ウィンドウと同様に、PUBLICへのアクセス権を伴って作成されるため、ウィンドウ・グループへのアクセス権限は必要ありません。
次の文では、downtimeというウィンドウ・グループが作成され、2つのウィンドウ(weeknightsとweekends)が追加されます。
BEGIN DBMS_SCHEDULER.CREATE_GROUP ( group_name => 'downtime', group_type => 'WINDOW', member => 'weeknights, weekends'); END; /
ウィンドウ・グループの内容を確認するには、MANAGE SCHEDULER権限を持つユーザーとして次の問合せを発行します。
SELECT group_name, enabled, number_of_members FROM dba_scheduler_groups WHERE group_type = 'WINDOW'; GROUP_NAME ENABLED NUMBER_OF_MEMBERS -------------- -------- ----------------- DOWNTIME TRUE 2 SELECT group_name, member_name FROM dba_scheduler_group_members; GROUP_NAME MEMBER_NAME --------------- -------------------- DOWNTIME "SYS"."WEEKENDS" DOWNTIME "SYS"."WEEKNIGHTS"
1つ以上のウィンドウ・グループを削除するには、DROP_GROUPプロシージャを使用します。このプロシージャをコールすると、ウィンドウ・グループは削除されますが、ウィンドウ・グループのメンバーであるウィンドウは削除されません。ウィンドウ・グループ自体は削除せずに、ウィンドウ・グループのメンバーであるウィンドウをすべて削除するには、DROP_WINDOWプロシージャを使用し、そのコールにウィンドウ・グループ名を指定します。
DROP_GROUPプロシージャ・コールにウィンドウ・グループ名のカンマ区切りのリストを指定することで、1回のコールで複数のウィンドウ・グループを削除できます。各ウィンドウ・グループ名の前にSYSスキーマの接頭辞を付ける必要があります。たとえば、次の文では3つのウィンドウ・グループが削除されます。
BEGIN
DBMS_SCHEDULER.DROP_GROUP('sys.windowgroup1, sys.windowgroup2, sys.windowgroup3');
END;
/
ウィンドウ・グループにウィンドウを追加するには、ADD_GROUP_MEMBERプロシージャを使用します。
ウィンドウのカンマ区切りのリストを指定すると、1回のコールで複数のメンバーをウィンドウ・グループに追加できます。たとえば、次の文ではウィンドウ・グループwindow_group1に2つのウィンドウが追加されます。
BEGIN
DBMS_SCHEDULER.ADD_GROUP_MEMBER ('sys.windowgroup1','window2, window3');
END;
/
すでにオープンしているウィンドウがウィンドウ・グループに追加された場合、スケジューラは、ウィンドウ・グループ内の次のウィンドウがオープンするまで、このウィンドウ・グループを指し示すジョブを開始しません。
ウィンドウ・グループから1つ以上のウィンドウを削除するには、REMOVE_GROUP_MEMBERプロシージャを使用します。stop_on_window_closeフラグが設定されているジョブが停止するのは、ウィンドウがクローズするときのみです。オープン中のウィンドウをウィンドウ・グループから削除しても、この処理への影響はありません。
ウィンドウのカンマ区切りのリストを指定すると、1回のコールで複数のメンバーをウィンドウ・グループから削除できます。たとえば、次の文では2つのウィンドウが削除されます。
BEGIN
DBMS_SCHEDULER.REMOVE_GROUP_MEMBER('sys.window_group1', 'window2, window3');
END;
/
1つ以上のウィンドウ・グループを有効(使用可能)にするには、ENABLEプロシージャを使用します。デフォルトでは、ウィンドウ・グループはENABLEDで作成されます。次に例を示します。
BEGIN
DBMS_SCHEDULER.ENABLE('sys.windowgroup1, sys.windowgroup2, sys.windowgroup3');
END;
/
ウィンドウ・グループを無効(使用禁止)にするには、DISABLEプロシージャを使用します。ウィンドウ・グループがスケジュールとして使用禁止になっているジョブは、メンバー・ウィンドウがオープンしても実行されません。ウィンドウ・グループを使用禁止にしても、そのメンバー・ウィンドウは使用禁止になりません。
また、ウィンドウ・グループ名のカンマ区切りのリストを指定することで、1回のコールで複数のウィンドウ・グループを使用禁止にすることもできます。たとえば、次の文では3つのウィンドウ・グループが使用禁止になります。
BEGIN
DBMS_SCHEDULER.DISABLE('sys.windowgroup1, sys.windowgroup2, sys.windowgroup3');
END;
/
データベース・リソース・マネージャ(リソース・マネージャ)は、データベース・セッション間のリソースの割当て方法を制御します。スケジューラ・ジョブのような非同期セッションだけでなく、ユーザー・セッションのような同期セッションも制御します。データベースのすべての「作業単位」をリソース・コンシューマ・グループにグループ化し、リソース・プランを使用して、様々なコンシューマ・グループ間のリソースの割当て方法を指定します。リソース・マネージャが割り当てる主なシステム・リソースはCPUです。
スケジューラ・ジョブの場合、最初に各ジョブをジョブ・クラスに割り当てて、次にジョブ・クラスをコンシューマ・グループに関連付けることによって、リソースが割り当てられます。その後、リソースは、コンシューマ・グループ内のスケジューラ・ジョブと他のセッションとの間で分配されます。また、ジョブ・クラス内のジョブに相対的な優先度を割り当てて、それに従ってそれらのジョブにリソースが分配されるようにすることもできます。
現行のリソース・プランはいつでも手動で変更できます。かわりに、スケジューラ・ウィンドウを作成することで現行のリソース・プランを変更することもできます。ウィンドウには、リソース・プラン属性があります。ウィンドウがオープンすると、現行のプランがウィンドウのリソース・プランに切り替えられます。
スケジューラは、完了に必要なリソースを確保できないまま同時に多数のジョブを実行するかわりに、少なくとも一部のジョブを完了できるように、同時に実行するジョブの数を制限しようとします。
スケジューラとリソース・マネージャは緊密に統合されています。ジョブ・コーディネータは、リソース・マネージャからデータベース・リソースの可用性を取得します。その情報に基づいて、コーディネータは、開始するジョブの数を決定します。実行するために十分なリソースがあるジョブ・クラスのジョブのみを起動します。コンシューマ・グループに割り当てられた最大リソースに到達したとリソース・マネージャが判断するまで、そのコンシューマ・グループにマップされた特定のジョブ・クラスのジョブをコーディネータが起動し続けます。そのため、実行準備が完了したジョブがジョブ表にあっても、ジョブを実行するリソースがないため、ジョブ・コーディネータに取り出されない場合があります。そのため、スケジュールされた正確な時刻にジョブが実行される保証はありません。コーディネータは、どのコンシューマ・グループにまだ使用可能なリソースがあるかに基づいて、ジョブ表からジョブを取り出します。
リソース・マネージャでは、実行中の各ジョブに割り当てられているリソースを指定のリソース・プランに基づいて継続的に管理します。リソース・マネージャが管理できるのはデータベースのプロセスのみであることに注意してください。リソースのアクティブな管理は、外部ジョブには適用されません。
|
注意: リソース・マネージャがアクティブになるのは、CPU使用率が100%に近づいた場合のみです。 |
次の例は、リソースがジョブに割り当てられる方法を示しています。アクティブなリソース・プランの名前が「Night Plan」で、コンシューマ・グループDWにマップするJC1、コンシューマ・グループOLTPにマップするJC2およびデフォルト・コンシューマ・グループにマップするJC3の3つのジョブ・クラスがあるとします。図29-2は、このシナリオを簡単な図で表したものです。
このリソース・プランでは、ジョブ・クラスJC1に属するジョブが明らかに優先されます。コンシューマ・グループDWはリソースを60%取得するため、ジョブ・クラスJC1に属するジョブはリソースを60%取得します。コンシューマ・グループOLTPはリソースを30%取得するため、ジョブ・クラスJC2内のジョブはリソースを30%取得します。コンシューマ・グループOtherでは、他のすべてのコンシューマ・グループがリソースを10%取得することが指定されます。そのため、ジョブ・クラスJC3に属するすべてのジョブが、10%のリソースを共有し、リソースを最大10%取得できます。
あるコンシューマ・グループで未使用のリソースは、他のコンシューマ・グループで使用できます。したがって、ジョブ・クラスJC1のジョブが割当ての60%を完全に使用していない場合、その未使用部分はクラスJC2とJC3のジョブが使用できます。リソース・マネージャは、CPU使用が100%に達するまで、リソース使用の制限を開始しません。詳細は、第27章のOracle Database Resource Managerを使用したリソースの管理を参照してください。
スケジューラ・ジョブは、次のいくつかの方法で監視できます。
ジョブ・ログの表示
ジョブ・ログには、*_SCHEDULER_JOB_LOGおよび*_SCHEDULER_JOB_RUN_DETAILSデータ・ディクショナリ・ビューが含まれます。
* = {DBA|ALL|USER}
「ジョブ・ログの表示」を参照してください。
追加のデータ・ディクショナリ・ビューの問合せ
DBA_SCHEDULER_RUNNING_JOBSやDBA_SCHEDULER_RUNNING_CHAINSなどのビューを問い合せて、実行中のジョブとチェーンのステータスおよび詳細を表示します。
スケジューラからジョブ状態イベントを受け取るアプリケーションの作成
「スケジューラによって呼び出されるイベントによるジョブ状態の監視」を参照してください。
状態変化に応じて電子メール通知を送信するジョブの構成
「電子メール通知によるジョブ状態の監視」を参照してください。
ジョブの実行、状態変化および失敗について、ジョブ・ログ内の情報を表示できます。ジョブ・ログには、ローカル・ジョブとリモート・ジョブの両方の結果が示されます。ジョブ・ログは、次の2つのデータ・ディクショナリ・ビューとして実装されます。
*_SCHEDULER_JOB_LOG
*_SCHEDULER_JOB_RUN_DETAILS
スケジューラは、有効なロギング・レベルに応じて、ジョブの実行時、作成時、削除時、有効化時などにジョブ・ログ・エントリを作成できます。繰返しスケジュールが設定されたジョブの場合、スケジューラではジョブ・ログ(ジョブ・インスタンスごとに1つ)に複数のエントリが作成されます。各ログ・エントリは、ジョブの完了ステータスなど、特定の実行に関する情報を提供します。
次の例では、max_runs属性の値が4に設定されている繰返しジョブのジョブ・ログ・エントリを示しています。
SELECT job_name, job_class, operation, status FROM USER_SCHEDULER_JOB_LOG; JOB_NAME JOB_CLASS OPERATION STATUS ---------------- -------------------- --------------- ---------- JOB1 CLASS1 RUN SUCCEEDED JOB1 CLASS1 RUN SUCCEEDED JOB1 CLASS1 RUN SUCCEEDED JOB1 CLASS1 RUN SUCCEEDED JOB1 CLASS1 COMPLETED
ジョブまたはジョブ・クラスのlogging_level属性を設定することによって、ジョブ・ログに情報を書き込む頻度を制御できます。表29-11に、logging_levelに指定可能な値を示します。
表29-11 ジョブのロギング・レベル
| ロギング・レベル | 説明 |
|---|---|
|
|
ロギングは実行されません。 |
|
|
ジョブが失敗した場合にのみログ・エントリが作成されます。 |
|
|
ジョブが実行されるたびにログ・エントリが作成されます。 |
|
|
ジョブが実行されるたびに、および作成、有効化、無効化、更新( |
ジョブの実行に関するログ・エントリは、ジョブの実行が正常に完了するか、失敗するかまたは停止するまで作成されません。
次の例は、完全なジョブ・ライフサイクルのジョブ・ログ・エントリを示しています。この場合、ジョブ・クラスのロギング・レベルはLOGGING_FULLで、ジョブは非繰返しジョブです。最初に正常に実行された後、もう一度実行されるようにジョブが有効化されています。次に、停止され、削除されています。
SELECT to_char(log_date, 'DD-MON-YY HH24:MI:SS') TIMESTAMP, job_name, job_class, operation, status FROM USER_SCHEDULER_JOB_LOG WHERE job_name = 'JOB2' ORDER BY log_date; TIMESTAMP JOB_NAME JOB_CLASS OPERATION STATUS -------------------- --------- ---------- ---------- --------- 18-DEC-07 23:10:56 JOB2 CLASS1 CREATE 18-DEC-07 23:12:01 JOB2 CLASS1 UPDATE 18-DEC-07 23:12:31 JOB2 CLASS1 ENABLE 18-DEC-07 23:12:41 JOB2 CLASS1 RUN SUCCEEDED 18-DEC-07 23:13:12 JOB2 CLASS1 ENABLE 18-DEC-07 23:13:18 JOB2 RUN STOPPED 18-DEC-07 23:19:36 JOB2 CLASS1 DROP
RUN、RETRY_RUNまたはRECOVERY_RUN操作に関する*_SCHEDULER_JOB_LOG内の行ごとに、*_SCHEDULER_JOB_RUN_DETAILSビューには対応する行があります。2つの異なるビューの行は、それぞれのLOG_ID列で関係付けられています。実行詳細ビューを参照して、ジョブが失敗した理由や停止された理由を判断できます。
SELECT to_char(log_date, 'DD-MON-YY HH24:MI:SS') TIMESTAMP, job_name, status, SUBSTR(additional_info, 1, 40) ADDITIONAL_INFO FROM user_scheduler_job_run_details ORDER BY log_date; TIMESTAMP JOB_NAME STATUS ADDITIONAL_INFO -------------------- ---------- --------- ---------------------------------------- 18-DEC-07 23:12:41 JOB2 SUCCEEDED 18-DEC-07 23:12:18 JOB2 STOPPED REASON="Stop job called by user:'SYSTEM' 19-DEC-07 14:12:20 REMOTE_16 FAILED ORA-29273: HTTP request failed ORA-06512
実行詳細ビューには、実際のジョブ開始時刻と継続時間も含まれています。
表29-11に示されている値を指定できるlogging_level属性が、ジョブとジョブ・クラスの両方にあります。ジョブ・クラスのデフォルト・ロギング・レベルはLOGGING_RUNSで、個々のジョブのデフォルト・レベルはLOGGING_OFFです。ジョブ・クラスのロギング・レベルが、クラス内のジョブのロギング・レベルよりも高い場合は、ジョブ・クラスのロギング・レベルが優先されます。そのため、デフォルトでは、すべてのジョブの実行がジョブ・ログに記録されます。
非常に短くて頻度の高いジョブの場合は、個々の実行をすべて記録すると負荷が非常に高くなるため、ロギングをオフに設定して、ジョブが失敗した場合にのみロギングが行われるように設定する場合もあります。ただし、特定のクラスのジョブで発生したすべての事象の完全な監査証跡を取得する必要がある場合には、そのクラスの完全なロギングを有効にします。
すべてのジョブの監査証跡が確実に作成されるようにするには、個々のジョブ作成者がロギングをオフにできないようにする必要があります。これをサポートするために、スケジューラではクラス別のレベルがジョブの情報を記録する最低レベルとなっています。ジョブ作成者は、個々のジョブに対するロギング・レベルを上げることはできますが、下げることはできません。したがって、個々のジョブのロギング・レベルをすべてLOGGING_OFFに設定すると、クラス内のすべてのジョブがクラスでの指定に従って記録されます。
この機能は、デバッグの目的で提供されています。たとえば、クラス別のレベルでジョブ実行を記録するように設定されているときに、ジョブ・レベルでロギングがオフにされた場合でも、スケジューラはジョブの実行を記録します。ただし、ジョブ作成者が完全ロギングをオンにしているときに、クラス別のレベルでは実行のみを記録するように設定されている場合は、ジョブの上位のロギング・レベルが優先され、この個別ジョブのすべての操作がログに記録されます。このように、エンド・ユーザーは、完全ロギングをオンにして自分のジョブをテストできます。
個々のジョブのロギング・レベルを設定するには、そのジョブについてSET_ATTRIBUTEプロシージャを使用する必要があります。たとえば、mytestjobというジョブの完全ロギングをオンにするには、次の文を発行します。
BEGIN DBMS_SCHEDULER.SET_ATTRIBUTE ( 'mytestjob', 'logging_level', DBMS_SCHEDULER.LOGGING_FULL); END; /
ジョブ・クラスのロギング・レベルを設定できるのは、MANAGE SCHEDULER権限を付与されているユーザーのみです。
複数の宛先のジョブの場合、親ジョブの全体的な状態は子ジョブの結果に依存します。たとえば、すべての子ジョブが成功した場合、親ジョブの状態はSUCCEEDEDに設定されます。すべてが失敗した場合、親ジョブの状態はFAILEDに設定されます。一部が失敗し、一部が成功した場合、親ジョブの状態はSOME FAILEDに設定されます。
一部の宛先で子ジョブの開始が遅延するような状況では、親ジョブの状態がファイナライズされるまでに大幅な遅延が生じる可能性があります。複数の宛先のジョブが繰返しジョブの場合は、スケジュールされている次回の実行に進むジョブもあれば、前回の実行がまだ終了しないジョブが生じることもあります。この場合、親ジョブの状態はINCOMPLETEに設定されます。ただし、最終的には、遅延しているジョブも他の兄弟ジョブに追いつき、親ジョブの最終的な状態を決定できるようになります。
表29-12に、複数の宛先のジョブを対象としたジョブ監視ビューの内容を示します。
表29-12 複数の宛先のジョブを対象としたスケジューラ・データ・ディクショナリ・ビューの内容
| ビュー名 | 目次 |
|---|---|
|
|
親ジョブの1つのエントリ |
|
|
親ジョブの1つのエントリ(親ジョブが開始された場合)および実行中の子ジョブごとに1つのエントリ |
|
|
親ジョブの1つのエントリ(親ジョブが開始された場合)(operation = ' |
|
|
子ジョブごとに1つのエントリ(子ジョブが完了した場合)および親ジョブの1つのエントリ(最後の子ジョブが完了し、親が完了した場合) |
|
|
親ジョブの宛先ごとに1つのエントリ |
*_SCHEDULER_JOB_DESTSビューでは、各子ジョブに割り当てられている一意のジョブ宛先ID(job_dest_id)を調べることができます。このIDは、ジョブ、資格証明および宛先の一意の組合せを表します。このIDは、STOP_JOBプロシージャで使用できます。また、*_SCHEDULER_JOB_DESTSビューで各子ジョブのジョブ状態を監視できます。
この項の内容は次のとおりです。
ジョブの状態が変化したときに、スケジューラがイベントを呼び出すようにジョブを構成できます。スケジューラは、ジョブの開始時、ジョブの完了時、ジョブがその割当ての実行時間を超えたときなどにイベントを呼び出します。イベントのコンシューマは、そのイベントに対応して処理を実行するアプリケーションです。たとえば、システムの負荷が高いために、スケジュールされた開始時間から30分を経過してもジョブが開始されない場合、スケジューラは、ハンドラのアプリケーションによって低優先度のジョブを停止させてシステム・リソースを解放するイベントを呼び出すことができます。スケジューラでは、ローカル(標準)・ジョブ、リモート・データベース・ジョブ、ローカル外部ジョブおよびリモート外部ジョブに対してジョブ状態イベントを呼び出すことができます。
表29-13に、スケジューラによって呼び出されるジョブ状態イベントのタイプを示します。
表29-13 スケジューラによって呼び出されるジョブ状態イベントのタイプ
| イベント・タイプ | 説明 |
|---|---|
|
|
イベントではなく、すべてのイベントを簡単に有効にするための定数です。 |
|
|
ジョブ属性 |
|
|
チェーンを実行するジョブが |
|
|
|
|
|
Schedulerまたは |
|
|
エラーが発生したか、異常終了したため、ジョブが失敗しました。 |
|
|
ジョブは、 |
|
|
ジョブの実行が、失敗、成功または停止しました。 |
|
|
ジョブのスケジュール制限に達しました。ジョブ開始の遅延時間がジョブ属性 |
|
|
ジョブが開始されました。 |
|
|
|
|
|
ジョブが正常に完了しました。 |
ジョブ状態イベントの呼出しを有効にするには、raise_eventsジョブ属性を設定します。デフォルトでは、ジョブはジョブ状態イベントを呼び出しません。
スケジューラは、Oracle Streamsアドバンスト・キューイングを使用してイベントを呼び出します。ジョブの状態の変更に関するイベントが発生すると、スケジューラは、メッセージをデフォルトのイベント・キューにエンキューします。アプリケーションは、このキューをサブスクライブし、イベント・メッセージをデキューして、適切な処理を行います。
ジョブに対するジョブの状態変化イベントを有効(使用可能)にすると、スケジューラは、メッセージをスケジューラ・イベント・キューSYS.SCHEDULER$_EVENT_QUEUEにエンキューすることによってこれらのイベントを呼び出します。このキューはセキュアなキューであるため、アプリケーションによっては、特定のユーザーがキューの操作を実行できるようにキューを構成する必要があります。セキュアなキューの詳細は、『Oracle Streams概要および管理』を参照してください。
スケジューラのイベント・キューが無制限に大きくなるのを防ぐために、デフォルトでは、スケジューラが呼び出したイベントは24時間で失効します。(失効したイベントはキューから削除されます。)SET_SCHEDULER_ATTRIBUTEプロシージャを使用して、event_expiry_timeスケジューラ属性を設定することで、この有効期間を変更できます。詳細は、『Oracle Database PL/SQLパッケージおよびタイプ・リファレンス』を参照してください。
ジョブに対してジョブ状態イベントの呼出しを有効にするには、SET_ATTRIBUTEプロシージャを使用して、raise_eventsジョブ属性のビット・フラグをオンにします。各ビット・フラグは、イベントの呼出しの対象となる様々なジョブ状態を表します。たとえば、最下位ビットをオンにすることで、job startedイベントを呼び出すことができます。複数の状態変化イベント・タイプを1回のコールで使用可能にするには、必要なビット・フラグの値を加算し、その結果を引数としてSET_ATTRIBUTEに提供します。
次の例では、ジョブdw_reportsに対して複数の状態変更イベントを有効にしています。次のイベント・タイプが有効になっていますが、両方ともなんらかのエラーを示しています。
JOB_FAILED
JOB_SCH_LIM_REACHED
BEGIN
DBMS_SCHEDULER.SET_ATTRIBUTE('dw_reports', 'raise_events',
DBMS_SCHEDULER.JOB_FAILED + DBMS_SCHEDULER.JOB_SCH_LIM_REACHED);
END;
/
|
注意: raise_eventsジョブ属性を指定してJOB_OVER_MAX_DURイベントを使用可能にする必要はありません。このイベントは常に使用可能になっています。 |
|
関連項目: ジョブ状態ビット・フラグの名前と値は、 |
ジョブ状態イベントを使用するには、アプリケーションがスケジューラ・イベント・キューSYS.SCHEDULER$_EVENT_QUEUEをサブスクライブする必要があります。このキューはセキュアなキューであり、所有者はSYSです。あるユーザーについてこのキューのサブスクリプションを作成するには、次の処理を実行します。
SYSユーザーまたはMANAGE ANY QUEUE権限のあるユーザーでデータベースにログインします。
新規または既存のエージェントを使用してキューをサブスクライブします。
パッケージ・プロシージャDBMS_AQADM.ENABLE_DB_ACCESSを次のように実行します。
DBMS_AQADM.ENABLE_DB_ACCESS(agent_name, db_username);
agent_nameは、イベント・キューのサブスクライブに使用したエージェントを表し、db_usernameは、サブスクリプションを作成する対象のユーザーです。
ユーザーにデキュー権限を付与する必要はありません。スケジューラ・イベント・キューに関するデキュー権限は、PUBLICに付与されます。
または、次の例に示すように、ユーザーがADD_EVENT_QUEUE_SUBSCRIBERプロシージャを使用してスケジューラ・イベント・キューをサブスクライブすることもできます。
DBMS_SCHEDULER.ADD_EVENT_QUEUE_SUBSCRIBER(subscriber_name);
この例のsubscriber_nameは、スケジューラ・イベント・キューのサブスクライブに使用されるOracle Streamsアドバンスト・キューイング(AQ)・エージェントの名前です。(NULLの場合は、呼出しユーザーのユーザー名でエージェントが作成されます。)このコールによって、スケジューラ・イベント・キューのサブスクリプションが作成され、指定エージェントを使用してデキューする許可がユーザーに付与されます。サブスクリプションはルールベースです。ルールによって、ユーザーが許可されるのは、所有するジョブが呼び出したイベントの参照のみで、その他のメッセージはすべて除外されます。サブスクリプションが使用可能になると、ユーザーは一定の間隔でメッセージをポーリングするか、またはメッセージが通知されるようにAQに登録できます。
詳細は、『Oracle Streamsアドバンスト・キューイング・ユーザーズ・ガイド』を参照してください。
スケジューラ・イベント・キュー
スケジューラ・イベント・キューSYS.SCHEDULER$_EVENT_QUEUEのタイプはscheduler$_event_infoです。このタイプの詳細は、『Oracle Database PL/SQLパッケージおよびタイプ・リファレンス』を参照してください。
この項の内容は次のとおりです。
ジョブの状態が変化したときに電子メール通知を送信するようにジョブを構成できます。表29-13に、電子メールを送信できるジョブ状態イベントを示します。電子メール通知は、指定したジョブ状態イベントのリストに含まれる任意のイベントをトリガーとして、複数の受信者に送信できます。また、フィルタ条件を指定して、その条件に一致するジョブ状態イベントのみで通知を生成することもできます。メッセージの件名と本文の両方に、ジョブ所有者、ジョブ名、イベント・タイプ、エラー・コード、エラー・メッセージなどの変数を含めることができます。これらの変数の値は、電子メール通知が送信される前に、スケジューラによって自動的に設定されます。
単一のジョブに対して複数のジョブ状態電子メール通知を構成できます。これらの通知は、ジョブ状態イベント・リスト、受信者およびフィルタ条件によって区別できます。
たとえば、ジョブがエラー・コード600または700で失敗した場合は常に主任DBAとシニアDBAの1人に電子メールを送信するようにジョブを構成できます。また、同じジョブに対して、ジョブがスケジュールどおり開始されなかった場合は主任DBAのみに通知を送信するように構成することもできます。
電子メール通知を送信するようにジョブを構成するには、スケジューラ属性email_serverに、電子メールの送信に使用するSMTPサーバーのアドレスを設定する必要があります。また、必要に応じて、送信者未指定のジョブに対しては、スケジューラ属性email_senderに、デフォルトの送信者電子メール・アドレスを設定できます。
スケジューラでは、SMTPサーバーとの通信におけるSSLプロトコルおよびTLSプロトコルがサポートされています。また、認証を必要とするSMTPサーバーもサポートされています。
ジョブに対する電子メール通知を追加するには、DBMS_SCHEDULER.ADD_JOB_EMAIL_NOTIFICATIONパッケージ・プロシージャを使用します。
BEGIN DBMS_SCHEDULER.ADD_JOB_EMAIL_NOTIFICATION ( job_name => 'EOD_JOB', recipients => 'jsmith@example.com, rjones@example.com', sender => 'do_not_reply@example.com', subject => 'Scheduler Job Notification-%job_owner%.%job_name%-%event_type%', body => '%event_type% occurred at %event_timestamp%. %error_message%', events => 'JOB_FAILED, JOB_BROKEN, JOB_DISABLED, JOB_SCH_LIM_REACHED'); END; /
subjectおよびbody引数では、%文字で囲まれた変数が使用されています。複数の受信者および複数のイベントを指定した場合、指定したイベントのいずれかが呼び出されると各受信者に通知されます。これを確認するには、USER_SCHEDULER_NOTIFICATIONSビューを問い合せます。
SELECT JOB_NAME, RECIPIENT, EVENT FROM USER_SCHEDULER_NOTIFICATIONS; JOB_NAME RECIPIENT EVENT ----------- -------------------- ------------------- EOD_JOB jsmith@example.com JOB_FAILED EOD_JOB jsmith@example.com JOB_BROKEN EOD_JOB jsmith@example.com JOB_SCH_LIM_REACHED EOD_JOB jsmith@example.com JOB_DISABLED EOD_JOB rjones@example.com JOB_FAILED EOD_JOB rjones@example.com JOB_BROKEN EOD_JOB rjones@example.com JOB_SCH_LIM_REACHED EOD_JOB rjones@example.com JOB_DISABLED
ジョブに対して異なる通知を構成するたびに、ADD_JOB_EMAIL_NOTIFICATIONをコールします。job_nameとrecipientsの指定は必須です。他のすべての引数には、デフォルト値があります。デフォルトのsenderは、前の項で説明したように、スケジューラ属性によって定義されます。subject、bodyおよびevents引数のデフォルト値は、『Oracle Database PL/SQLパッケージおよびタイプ・リファレンス』のADD_JOB_EMAIL_NOTIFICATIONプロシージャに関する項を参照してください。
次の例では、同じジョブに対して、異なるイベントに関する追加の電子メール通知を構成しています。この例では、sender、subjectおよびbody引数のデフォルト値をそのまま使用しています。
BEGIN DBMS_SCHEDULER.ADD_JOB_EMAIL_NOTIFICATION ( job_name => 'EOD_JOB', recipients => 'jsmith@example.com', events => 'JOB_OVER_MAX_DUR'); END; /
この例では、events引数も省略して、イベントのデフォルト値をそのまま使用しています。
次の例は最初の例と類似していますが、この場合、フィルタ条件を使用して、エラー番号が600または700でジョブが失敗した場合にのみ電子メール通知を送信するように指定しています。
BEGIN DBMS_SCHEDULER.ADD_JOB_EMAIL_NOTIFICATION ( job_name => 'EOD_JOB', recipients => 'jsmith@example.com, rjones@example.com', sender => 'do_not_reply@example.com', subject => 'Job Notification-%job_owner%.%job_name%-%event_type%', body => '%event_type% at %event_timestamp%. %error_message%', events => 'JOB_FAILED', filter_condition => ':event.error_code=600 or :event.error_code=700'); END; /
|
関連項目: |
ジョブに対する電子メール通知を削除するには、DBMS_SCHEDULER.REMOVE_JOB_EMAIL_NOTIFICATIONパッケージ・プロシージャを使用します。
BEGIN DBMS_SCHEDULER.REMOVE_JOB_EMAIL_NOTIFICATION ( job_name => 'EOD_JOB', recipients => 'jsmith@example.com, rjones@example.com', events => 'JOB_DISABLED, JOB_SCH_LIM_REACHED'); END; /
複数の受信者および複数のイベントを指定した場合、指定した各イベントの通知が各受信者に対して削除されます。前の項で説明したものと同じ問合せを実行した場合、結果は次のようになります。
SELECT JOB_NAME, RECIPIENT, EVENT FROM USER_SCHEDULER_NOTIFICATIONS; JOB_NAME RECIPIENT EVENT ----------- -------------------- ------------------- EOD_JOB jsmith@example.com JOB_FAILED EOD_JOB jsmith@example.com JOB_BROKEN EOD_JOB rjones@example.com JOB_FAILED EOD_JOB rjones@example.com JOB_BROKEN
REMOVE_JOB_EMAIL_NOTIFICATION引数を指定する場合、次のルールが別途適用されます。
events引数をNULLのままにすると、指定した受信者に対して、すべてのイベントの通知が削除されます。
recipients引数をNULLのままにすると、すべての受信者に対して、指定したイベントの通知が削除されます。
recipientsとeventsの両方をNULLのままにすると、該当ジョブのすべての通知が削除されます。
今まで通知を作成したことのない受信者とイベントを指定した場合、エラーは生成されません。
|
関連項目: |
前の項で説明したように、*_SCHEDULER_NOTIFICATIONSビューを問い合せることによって、現在の電子メール通知に関する情報を表示できます。
|
関連項目: これらのビューの詳細は、『Oracle Databaseリファレンス』を参照してください。 |