| Oracle® Databaseユーティリティ 11gリリース2 (11.2) B56303-08 |
|


 前 |
 次 |
この章では、SQL*Loader制御ファイルについて説明します。この章の内容は、次のとおりです。
SQL*Loader制御ファイルは、DDL命令を含むテキスト・ファイルです。DDLを使用して、SQL*Loaderセッションの次の項目を制御します。
SQL*Loaderによってロードされるデータの位置
SQL*Loaderによるデータ書式設定の方法
データのロード時のSQL*Loaderの設定(メモリー管理、拒否レコード、ロード処理の中断など)
SQL*Loaderによるロード中のデータの処理方法
SQL*LoaderのDDL構文図については、付録Aを参照してください。
SQL*Loader制御ファイルを作成するには、viやxemacsなどのテキスト・エディタを使用します。
通常、制御ファイルには、次の3つの項目が次の順序で含まれます。
セッション全体の情報
表およびフィールド・リストの情報
入力データ(オプションの項目)
例9-1に、サンプル制御ファイルを示します。
例9-1 サンプル制御ファイル
1 -- This is a sample control file 2 LOAD DATA 3 INFILE 'sample.dat' 4 BADFILE 'sample.bad' 5 DISCARDFILE 'sample.dsc' 6 APPEND 7 INTO TABLE emp 8 WHEN (57) = '.' 9 TRAILING NULLCOLS 10 (hiredate SYSDATE, deptno POSITION(1:2) INTEGER EXTERNAL(2) NULLIF deptno=BLANKS, job POSITION(7:14) CHAR TERMINATED BY WHITESPACE NULLIF job=BLANKS "UPPER(:job)", mgr POSITION(28:31) INTEGER EXTERNAL TERMINATED BY WHITESPACE, NULLIF mgr=BLANKS, ename POSITION(34:41) CHAR TERMINATED BY WHITESPACE "UPPER(:ename)", empno POSITION(45) INTEGER EXTERNAL TERMINATED BY WHITESPACE, sal POSITION(51) CHAR TERMINATED BY WHITESPACE "TO_NUMBER(:sal,'$99,999.99')", comm INTEGER EXTERNAL ENCLOSED BY '(' AND '%' ":comm * 100" )
このサンプル制御ファイルの左側の数字は、実際の制御ファイルでは表示されません。これらの数字は、次の説明の番号に対応しています。
制御ファイルにコメントを入力します。詳細は、「制御ファイルのコメント」を参照してください。
LOAD DATA文によって、SQL*Loaderで新しくデータ・ロードが開始されます。構文の詳細は、付録Aを参照してください。
INFILE句には、ロードするデータが入っているデータ・ファイルの名前を指定します。詳細は、「データ・ファイルの指定」を参照してください。
BADFILE句には、拒否レコードが書き込まれるファイルの名前を指定します。詳細は、「不良ファイルの指定」を参照してください。
DISCARDFILE句には、廃棄レコードが書き込まれるファイルの名前を指定します。詳細は、「廃棄ファイルの指定」を参照してください。
APPEND句は、空ではない表にデータをロードする場合に使用できるオプションの1つです。詳細は、「空でない表へのデータのロード」を参照してください。
空の表にデータをロードするには、INSERT句を使用します。詳細は、「空の表へのデータのロード」を参照してください。
INTO TABLE句を使用して、表、フィールドおよびデータ型を識別できます。この句で、データ・ファイル中のレコードとデータベース中の表の関係を定義します。詳細は、「表名の指定」を参照してください。
WHEN句には、1つ以上のフィールド条件を指定します。SQL*Loaderで、この条件に基づいてデータをロードするかどうかを判断します。詳細は、「条件に基づいたレコードのロード」を参照してください。
TRAILING NULLCOLS句を使用すると、相対位置に指定した列がレコード中に存在しない場合、その列の値はNULLとして処理されます。詳細は、「データが欠落しているショート・レコードの処理」を参照してください。
制御ファイルの残りの部分には、ロード中の表の列形式の詳細を参照できるフィールド・リストが含まれます。制御ファイルのこの部分の詳細は、第10章を参照してください。
コメントはファイル中のコマンド部分のどこにでも記述できますが、データの部分には記述できません。コメントの前にハイフンを2つ続けて記述します。次に例を示します。
--This is a comment
二重ハイフンの右側のすべてのテキストは行末まで無視されます。
SQL*Loader制御ファイルでは、OPTIONS句を使用してコマンドライン・パラメータを指定できます。OPTIONS句は、制御ファイルを、通常使用するオプションの組合せで起動する場合に使用します。OPTIONS句は、LOAD DATA文の前に置きます。
OPTIONS句では、次のコマンドライン・パラメータを指定できます。これらのパラメータの詳細は、第8章を参照してください。
BINDSIZE = n
COLUMNARRAYROWS = n
DATE_CACHE = n
DIRECT = {TRUE | FALSE}
ERRORS = n
EXTERNAL_TABLE = {NOT_USED | GENERATE_ONLY | EXECUTE}
FILE
LOAD = n
MULTITHREADING = {TRUE | FALSE}
PARALLEL = {TRUE | FALSE}
READSIZE = n
RESUMABLE = {TRUE | FALSE}
RESUMABLE_NAME = 'text string'
RESUMABLE_TIMEOUT = n
ROWS = n
SILENT = {HEADER | FEEDBACK | ERRORS | DISCARDS | PARTITIONS | ALL}
SKIP = n
SKIP_INDEX_MAINTENANCE = {TRUE | FALSE}
SKIP_UNUSABLE_INDEXES = {TRUE | FALSE}
STREAMSIZE = n
次に、SQL*Loader制御ファイルで使用できるOPTIONS句の使用例を示します。
OPTIONS (BINDSIZE=100000, SILENT=(ERRORS, FEEDBACK) )
|
注意: コマンドラインで指定したパラメータ値は、制御ファイルのOPTIONS句で指定したパラメータ値を上書きします。 |
通常、オブジェクト名(表名や列名など)の指定に関して、SQL*LoaderはSQL標準規則に準拠しています。この項では、次の項目について説明します。
SQLおよびSQL*Loaderの予約語は、二重引用符で囲みます。SQL*Loaderの予約語はCONSTANTのみです。
二重引用符は、オブジェクト名にSQLが認識可能な文字($、#、_)以外の特殊文字が含まれている場合、またはオブジェクト名に大/小文字の区別が必要な場合に使用する必要があります。
|
参照: 『Oracle Database SQL言語リファレンス』 |
次の項では、ご使用のオペレーティング・システムによって異なる仕様について説明します。
完全パス名を指定すると、問題が発生する場合があります。これは、特殊文字の使用が原因でオペレーティング・システム依存の非互換が発生するためです。多くの場合、パス名を一重引用符で囲んで指定すると、このエラーは回避できます。
DDL構文では、(ご使用のオペレーティング・システムでエスケープ文字の使用が許可されている場合)二重引用符の前にエスケープ文字のバックスラッシュ「\」を付けて、二重引用符で区切られた文字列の中で二重引用符を使用できます。一重引用符で区切られた文字列中で一重引用符を使用する場合も、その前にバックスラッシュを付けます。
たとえば、homedir\data"norm\mydataという文字列には、二重引用符が含まれています。二重引用符の直前にバックスラッシュを付けることによって、二重引用符を文字列として使用できます。
INFILE 'homedir\data\"norm\mydata'
また、バックスラッシュを2回続けて書くことによって、バックスラッシュ自体を文字列中に表示できます。
次に例を示します。
"so'\"far" or 'so\'"far' is parsed as so'"far "'so\\far'" or '\'so\\far\'' is parsed as 'so\far' "so\\\\far" or 'so\\\\far' is parsed as so\\far
|
注意: 先頭位置の二重引用符はエスケープできません。そのため、先頭に引用符の付く文字列は作成しないでください。 |
SQL*Loader制御ファイルには、オペレーティング・システム間で移植不能な、2種類の文字列があります(filename文字列およびfile processing option文字列)。別のオペレーティング・システム用に変換した場合、これらの文字列を修正する必要があります。SQL*Loader制御ファイルのこれ以外の文字列はすべて、異なるオペレーティング・システム間で移植可能です。
オペレーティング・システムで、パス名のディレクトリを区切る文字としてバックスラッシュが使用されている場合、およびオペレーティング・システムで実行しているOracle Databaseのリリースで、ファイル名およびその他の移植不能文字列に対してバックスラッシュをエスケープ文字として使用可能な場合は、パス名のディレクトリ間の区切りにバックスラッシュを2つ続けて指定して、パス名全体を一重引用符で囲みます。
現在オペレーティング・システム上で実行中のOracle Databaseのリリースでは、移植不能文字列に対してエスケープ文字を使用できない場合があります。エスケープ文字が禁止されている場合、バックスラッシュは、エスケープ文字ではなく通常の文字として処理されます(ただし、移植不能文字列以外の文字列では使用可能)。この場合、次のようなパス名を指定できます。
INFILE 'topdir\mydir\myfile'
バックスラッシュを2つ続ける必要はありません。
バックスラッシュはエスケープ文字として認識されないため、一重引用符で囲まれた文字列の中に、一重引用符で囲まれた別の文字列を埋め込むことはできません。これは、二重引用符についても同様です。二重引用符で囲まれた文字列は、二重引用符で区切られた他の文字列の中に埋め込むことはできません。
Oracle Database 10gでは、SQL*Loader制御ファイルでXMLTYPE句を使用できます。形式は、XMLTYPE(フィールド名)です。正しいSQL文を構築するために、この句を使用してXMLType表を識別します。例9-2では、スキーマベースのXMLType表にデータをロードするために、SQL*Loaderの制御ファイルでXMLTYPE句を使用する方法を示します。
例9-2 SQL*Loader制御ファイルでのXMLType表の識別
XMLスキーマ定義は次のとおりです。XMLスキーマxdb_user.xsdがOracle XML DBに登録され、表xdb_tab5が作成されます。
begin dbms_xmlschema.registerSchema('xdb_user.xsd',
'<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema"
xmlns:xdb="http://xmlns.oracle.com/xdb">
<xs:element name = "Employee"
xdb:defaultTable="EMP31B_TAB">
<xs:complexType>
<xs:sequence>
<xs:element name = "EmployeeId" type = "xs:positiveInteger"/>
<xs:element name = "Name" type = "xs:string"/>
<xs:element name = "Salary" type = "xs:positiveInteger"/>
<xs:element name = "DeptId" type = "xs:positiveInteger"
xdb:SQLName="DEPTID"/>
</xs:sequence>
</xs:complexType>
</xs:element>
</xs:schema>',
TRUE, TRUE, FALSE); end;
/
表を定義する方法は、次のとおりです。
CREATE TABLE xdb_tab5 OF XMLTYPE XMLSCHEMA "xdb_user.xsd" ELEMENT "Employee";
データを表xdb_tab5にロードするために使用する制御ファイルは、次のようになります。登録されたXMLスキーマxdb_user.xsdを使用して、XMLTypeデータがロードされます。XMLTYPE句を使用して、この表をXMLType表として識別します。ダイレクト・パスまたは従来型モードのいずれかを使用して、表にデータをロードできます。
LOAD DATA INFILE * INTO TABLE xdb_tab5 TRUNCATE xmltype(xmldata) ( xmldata char(4000) ) BEGINDATA <Employee> <EmployeeId>111</EmployeeId> <Name>Ravi</Name> <Salary>100000</Sal ary> <DeptId>12</DeptId></Employee> <Employee> <EmployeeId>112</EmployeeId> <Name>John</Name> <Salary>150000</Sal ary> <DeptId>12</DeptId></Employee> <Employee> <EmployeeId>113</EmployeeId> <Name>Michael</Name> <Salary>75000</S alary> <DeptId>12</DeptId></Employee> <Employee> <EmployeeId>114</EmployeeId> <Name>Mark</Name> <Salary>125000</Sal ary> <DeptId>16</DeptId></Employee> <Employee> <EmployeeId>115</EmployeeId> <Name>Aaron</Name> <Salary>600000</Sa lary> <DeptId>16</DeptId></Employee>
|
参照: SQL*Loaderを使用したXMLデータのロードの詳細は、『Oracle XML DB開発者ガイド』を参照してください。 |
ロードするデータを含むデータ・ファイルを指定するには、INFILEキーワードにファイル名を続け、必要な場合はファイル処理オプション文字列を続けます。指定するファイルが複数ある場合は、INFILEキーワードを複数使用できます。
|
注意: コマンドラインからデータ・ファイルを指定する場合は、「コマンドライン・パラメータ」で説明しているDATAパラメータを使用します。コマンドラインでファイル名を指定すると、制御ファイルの最初のINFILE句が上書きされます。 |
ファイル名が指定されない場合は、制御ファイル名の拡張子(ファイルのタイプ)を.datにしたファイル名がデフォルトで採用されます。
ロードするデータを制御ファイル内にも記述した場合は、ファイル名にアスタリスク(*)を指定してください。この指定の詳細は、「BEGINDATAによる制御ファイルのデータの識別」を参照してください。
|
注意: ここで説明する内容は、プライマリ・データ・ファイルのみに適用されます。LOBFILEまたはSDFには適用されません。LOBFILEの詳細は、「LOBFILEからのLOBデータのロード」を参照してください。 SDFの詳細は、「セカンダリ・データ・ファイル(SDF)」を参照してください。 |
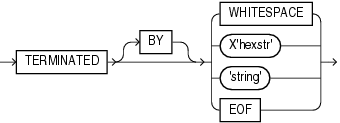
INFILEの構文は次のとおりです。
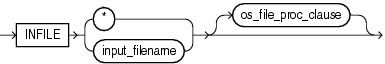
表9-1では、INFILEキーワードのパラメータについて説明します。
表9-1 INFILEキーワードのパラメータ
| パラメータ | 説明 |
|---|---|
|
|
データ・ファイル指定が続くことを示します。 |
|
|
データが入っているファイルの名前。 ファイル名に空白やその他の句読点文字が含まれている場合は、一重引用符で囲む必要があります。詳細は、「ファイル名およびオブジェクト名の指定」を参照してください。 |
|
|
データが制御ファイル中にある場合は、ファイル名のかわりにアスタリスク(*)を指定します。制御ファイルおよびデータ・ファイルにデータがある場合は、読み込むデータをまずアスタリスクで指定する必要があります。 |
|
|
ファイル処理オプション文字列。データ・ファイルの形式を指定します。また、この指定によってデータ・ファイルの読取りを最適化できます。この文字列の構文は、ご使用のオペレーティング・システムに依存します。詳細は、「データ・ファイル形式およびバッファリングの指定」を参照してください。 |
次に、INFILE構文を指定する様々な方法を示します。
制御ファイルにデータがある場合
INFILE *
デフォルトの拡張子.datを持つファイルsampleにデータがある場合
INFILE sample
フルパスに指定されたファイルdatafile.datにデータがある場合
INFILE 'c:/topdir/subdir/datafile.dat'
|
注意: ファイル名に空白やその他の句読点文字が含まれている場合は、ファイル名を一重引用符で囲む必要があります。 |
1回のSQL*Loaderの実行で複数のデータ・ファイルのデータをロードする場合は、各データ・ファイルに対してINFILE句を指定します。このとき、レコードのレイアウトは同じである必要がありますが、データ・ファイルに同じファイル処理オプションは必要ありません。たとえば、最初と2番目のファイルが異なるファイル処理オプション文字列で指定されていても、3番目のファイルが制御ファイル中のデータで構成されていても実行することができます。
各データ・ファイルに、個別の不良ファイルおよび廃棄ファイルを指定することもできます。このような場合、個別の不良ファイルおよび廃棄ファイルは、各データ・ファイル名の直後に宣言する必要があります。次に、4つのデータ・ファイルを個別の不良ファイルおよび廃棄ファイルとともに指定している制御ファイルの例を示します。
INFILE mydat1.dat BADFILE mydat1.bad DISCARDFILE mydat1.dis INFILE mydat2.dat INFILE mydat3.dat DISCARDFILE mydat3.dis INFILE mydat4.dat DISCARDMAX 10 0
mydat1.datでは、不良ファイルと廃棄ファイルの両方が明示的に指定されています。したがって、必要に応じて両方のファイルが作成されます。
mydat2.datでは、不良ファイルも廃棄ファイルも指定されていません。そのため、不良ファイルのみが必要に応じて作成されます。不良ファイルが作成された場合、デフォルトのファイル名および拡張子mydat2.badが使用されます。一方、廃棄ファイルについては、行が廃棄されても廃棄ファイルは作成されません。
mydat3.datでは、必要に応じてデフォルトの不良ファイルが作成されます。また、必要に応じて、指定された名前の廃棄ファイル(mydat3.dis)も作成されます。
mydat4.datでは、必要に応じてデフォルトの不良ファイルが作成されます。DISCARDMAXオプションが指定されているため、SQL*Loaderによって廃棄ファイルが使用されることを前提として、廃棄ファイルがデフォルト名(mydat4.dsc)で作成されます。
データが制御ファイルにある場合、ファイル名ではなくアスタリスクがINFILE句の後に続きます。実際のデータは、ロード構成の指定後、制御ファイルに書き込まれます。
最初のデータ・レコードの前に、BEGINDATA文を指定します。構文は次のとおりです。
BEGINDATA data
BEGINDATA文を使用する場合は、次のことに注意してください。
制御ファイルにデータが含まれているにもかかわらず、BEGINDATA文を省略すると、SQL*Loaderでデータが制御情報として解釈されるため、エラー・メッセージが発行されます。データが個別ファイルにある場合は、BEGINDATA文は使用できません。
BEGINDATAを含む行がデータの先頭行として解釈されてしまうため、BEGINDATA文と同じ行には、空白またはその他の文字を入力しないでください。
コメントもデータとして解釈されてしまうため、BEGINDATAの後に続けて記述しないでください。
SQL*Loaderの設定時、制御ファイルの形式およびバッファリングの指定に対して、オペレーティング・システムに依存したファイル処理オプション文字列(os_file_proc_clause)を制御ファイルに指定できます。
たとえば、ご使用のオペレーティング・システムに、次のようなオプション文字列の構文があるとします。
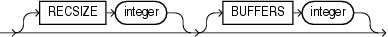
この構文では、RECSIZEは固定長レコードのサイズ、BUFFERSは非同期I/Oを行うためのバッファ数です。
mydata.datというファイルを80バイトのレコードを含むファイルとして宣言し、SQL*LoaderのI/O処理で使用されるバッファ数を8とする場合は、次の制御ファイルのエントリを使用します。
INFILE 'mydata.dat' "RECSIZE 80 BUFFERS 8"
|
注意: この例では、ファイル名に一重引用符を使用し、その他の指定には二重引用符を使用しています。 |
|
参照: Windowsシステムでのos_file_proc_clauseの使用方法については、『Oracle Databaseプラットフォーム・ガイド for Microsoft Windows』を参照してください。 |
SQL*Loaderを実行すると、不良ファイルまたは拒否ファイルと呼ばれるファイルが生成されることがあります。これらのファイルには、書式エラーまたはOracleエラーが発生したためにロードを拒否されたレコードが格納されます。不良ファイルが作成されるように指定した場合は、次の規則に従って作成されます。
レコードが1つ以上拒否された場合、不良ファイルが作成され、拒否レコードがログに記録されます。
レコードが1つも拒否されない場合、不良ファイルは作成されません。
不良ファイルが作成される場合、同じ名前の既存のファイルは上書きされます。そのため、残しておきたいファイルが上書きされないようにする必要があります。
|
注意: 一部のシステムでは、同じ名前のファイルがすでに存在する場合でも、新しいバージョンのファイルが作成される場合があります。 |
不良ファイルの名前を指定する場合は、BADFILE句の後にファイル名を続けます。不良ファイルの名前を指定しなかった場合は、デフォルトで、データ・ファイル名に拡張子(またはファイル・タイプ).badを付けたものがファイル名になります。コマンドラインから不良ファイルを指定する場合は、「コマンドライン・パラメータ」で説明しているBADパラメータを使用します。
コマンドラインから指定した不良ファイル名は、制御ファイル中の最初に記述されるINFILE句に対して指定されたものとみなされます。この場合、前述の句の中で不良ファイル名が指定されていても、コマンドラインから指定した不良ファイル名が優先されます。
生成される不良ファイルのファイル形式やレコード形式は、データ・ファイルと同じです。したがって、データを修正した後そのまま再ロードすることができます。ストリーム・レコード形式のデータ・ファイルに関しては、データ・ファイルにあるレコード終了記号が不良ファイル内でも使用されます。
不良ファイルの構文は次のとおりです。

BADFILE句の後に、不良ファイルのファイル名を指定します。
filenameパラメータには、使用するプラットフォームに有効なファイル名を指定します。ファイル名に空白やその他の句読点文字が含まれている場合は、一重引用符で囲む必要があります。
ファイル名sampleおよびデフォルトのファイル拡張子(またはファイル・タイプ) .badで不良ファイルを指定するには、制御ファイルで次のように入力します。
BADFILE sample
ファイル名bad0001およびファイル拡張子(またはファイル・タイプ).rejで不良ファイルを指定するには、次のいずれかの行を入力します。
BADFILE bad0001.rej BADFILE '/REJECT_DIR/bad0001.rej'
LOBFILEおよびSDFのデータは、拒否された行がある場合、不良ファイルには書き込まれません。LOBのロード中にエラーが発生した場合、その行は拒否されません。この場合、LOB列は、空のまま(NULLではなく長さが0(ゼロ)バイト)になります。ただし、LOBFILEを使用してXML列をロードし、このLOBデータのロード中にエラーが発生した場合、XML列はNULLになります。
レコードは、次の理由で拒否されます。
レコードの挿入時に、指定されたデータ型と実際のデータが適合しないなどのOracleエラーが発生する場合。
レコードが不適切にフォーマットされて、SQL*Loaderがフィールドの境界を検索できない場合。
レコードが制約に違反するか、または一意の索引を非一意にしようとする場合。
デリミタの指定が不適切であっても、WHEN句の指定条件に基づいてデータを評価できる場合は、条件判断が行われ、データが挿入または拒否されます。
前述のリストの2番目の理由でロードが拒否された場合、従来型パス・ロードでもダイレクト・パス・ロードでも表に行は書込みできません。
前述のリストの1番目または3番目の理由でいずれかの表に違反がある場合、従来型パス・ロードでは、表に行は書込みできません。行はその表に対して拒否され、拒否ファイルに書き込まれます。
従来型パス・ロードでは、データ・ファイルのレコードが複数の表にロードされているときに1つ以上の表から拒否されると、そのレコードはいずれの表にもロードされません。
ログ・ファイルには、拒否レコードそれぞれについてのOracleエラー情報が記録されます。拒否レコードの例の詳細は、事例4を参照してください。(事例の使用方法については、「SQL*Loaderの事例」を参照してください。)
ロード条件を満たさないレコードがある場合、SQL*Loaderを実行すると、廃棄ファイルが生成されることがあります。このファイルに出力されたレコードは廃棄レコードと呼ばれます。廃棄レコードは、制御ファイル中のWHEN句の指定を満たすことができなかったものです。これらのレコードは、拒否レコードとは異なります。廃棄レコードに必ず不良データがあるとはかぎりません。また、廃棄レコードに対して、挿入は行われません。
廃棄ファイルは次の規則に従って生成されます。
廃棄ファイル名を指定し、1つ以上のレコードが制御ファイルに指定したすべてのWHEN句の条件に満たない場合に生成されます。(廃棄ファイルが生成されると、同じ名前の既存のファイルは上書きされることに注意してください。)
廃棄レコードがない場合、廃棄ファイルは生成されません。
制御ファイル内から廃棄ファイルを作成するには、DISCARDFILE filename、DISCARDS、DISCARDMAXのいずれかを指定します。
コマンドラインから廃棄ファイルを作成するには、DISCARDまたはDISCARDMAXのいずれかを指定します。
このように、名前を指定して廃棄ファイルを直接指定することも、また、廃棄数の最大値を指定することで間接的に廃棄ファイルの生成を指示することもできます。
生成される廃棄ファイルのファイル形式やレコード形式は、データ・ファイルと同じです。ストリーム・レコード形式のデータ・ファイルに関しては、データ・ファイルにあるレコード終了記号が廃棄ファイル内でも使用されます。
廃棄ファイルの名前を指定する場合は、DISCARDFILE句の後にファイル名を続けます。

DISCARDFILE句の後には、廃棄ファイルのファイル名を指定します。
filenameパラメータには、使用するプラットフォームに有効なファイル名を指定します。ファイル名に空白やその他の句読点文字が含まれている場合は、一重引用符で囲む必要があります。
デフォルトのファイル名は、データ・ファイル名にデフォルトのファイル拡張子(またはファイル・タイプ).dscを付けたものが採用されます。廃棄ファイル名をコマンドラインから指定した場合は、制御ファイル中で指定されたファイル名よりも、コマンドラインからの指定ファイル名が優先されます。生成される廃棄ファイルと同じ名前のファイルがすでに存在する場合は、既存ファイルが上書きされるか、新しいバージョンのファイルが生成されます。どちらの処理が行われるかは、使用するオペレーティング・システムによって異なります。
コマンドラインから廃棄ファイルを指定する方法の詳細は、「DISCARD(ファイル名)」を参照してください。
コマンドラインで指定したファイル名で、制御ファイルに指定した廃棄ファイルが上書きされます。
次に、制御ファイル内から廃棄ファイルの名前を指定する様々な方法を示します。
ファイル名circularおよびデフォルトのファイル拡張子(またはファイル・タイプ).dscで廃棄ファイルを指定するには、次のとおり入力します。
DISCARDFILE circular
ファイル名notapplおよびファイル拡張子(またはファイル・タイプ).mayで廃棄ファイルを指定するには、次のとおり入力します。
DISCARDFILE notappl.may
廃棄ファイルforget.meにフルパスを指定するには、次のとおり入力します。
DISCARDFILE '/discard_dir/forget.me'
レコードに対してINTO TABLE句が指定されていない場合、そのレコードは廃棄されます。レコードの廃棄は、SQL*Loader制御ファイル中に記述されたすべてのINTO TABLE句がWHEN句を持っていて、レコードがそれらのどの条件にも該当しない場合、またはすべてのフィールドがNULLである場合に発生します。
INTO TABLE句がWHEN句なしで指定されている場合、レコードは廃棄されません。すべてのレコードに関して、指定の表への挿入が試みられます。このとき、レコードが拒否されることはありますが、廃棄されることはありません。
「事例7: 書式化されたレポートからのデータの抽出」に廃棄ファイルの使用例があります。(事例の使用方法については、「SQL*Loaderの事例」を参照してください。)
DISCARDSまたはDISCARDMAXキーワードにintegerを指定して、各データ・ファイルに対して廃棄されるレコード数を制限できます。
廃棄の上限に達すると、データ・ファイルの処理が中止され、引き続き、次のデータ・ファイル(存在する場合)の処理が実行されます。
データ・ファイルごとに異なる数の上限を設定できます。ただし、1回のみ廃棄数を指定した場合は、指定した廃棄上限値はすべてのファイルに適用されます。
廃棄数の上限値が指定されていて、廃棄ファイル名の指定がない場合、SQL*Loaderによってデフォルトのファイル名とファイル拡張子(またはファイル・タイプ)で廃棄ファイルが作成されます。
SQL*Loaderでは、(キャラクタ・セットまたはコード・ページと呼ばれる)異なる文字コード体系がサポートされます。SQL*Loaderでは、Oracleグローバリゼーション・サポート・テクノロジの機能を使用して、様々な文字コード体系(シングルバイトおよびマルチバイト)を扱うことができます。
|
参照: Oracle Databaseグローバリゼーション・サポート・ガイド |
次の項では、サポートしている文字コード体系について簡単に説明します。
マルチバイト・キャラクタ・セットは、アジア系言語をサポートするために使用されます。データをマルチバイト形式でロードしたり、データベース・オブジェクト名(フィールド、表など)をマルチバイト文字で指定することもできます。制御ファイルでは、コメントおよびオブジェクト名にもマルチバイト文字を使用できます。
SQL*Loaderでは、Unicodeキャラクタ・セットのデータのロードがサポートされています。
Unicodeは、エンコーディングされたユニバーサル・キャラクタ・セットであり、単一のキャラクタ・セットでほとんどの言語による情報の格納をサポートします。Unicodeでは、プラットフォーム、プログラムまたは言語に関係なく、すべての文字に一意のコード値が指定されます。Unicodeには、2つの異なるエンコーディング(UTF-16およびUTF-8)が存在します。
|
注意: このマニュアルでは、UTF-16およびUTF16の両方の用語が使用されています。UTF-16という用語は、一般的にUnicodeのUTF-16エンコーディングを意味します。UTF16(ハイフンなし)という用語は、キャラクタ・セットの固有の名前で、UTF-16エンコーディングの使用時にCHARACTERSETパラメータに指定する必要のある用語です。UTF-8およびUTF8の場合も同様です。 |
UnicodeのUTF-16エンコーディングは、固定幅マルチバイト・エンコーディングで、文字コード0x0000から0x007fは、シングルバイトASCIIコードの0x00から0x7fと同じ意味です。
UnicodeのUTF-8エンコーディングは、可変幅マルチバイト・エンコーディングで、文字コード0x00から0x7fがASCIIと同じ意味です。UTF-8の文字は1バイト、2バイトまたは3バイトの長さになります。
|
参照:
|
Oracle Databaseでは、SQLのCHARデータ型(CHAR、VARCHAR2、CLOBおよびLONG)に格納されたデータ、表名などの識別子、SQL文およびPL/SQLソース・コードに対して、データベース・キャラクタ・セットが使用されます。シングルバイト・キャラクタ・セットおよびASCII文字またはEBCDIC文字のいずれかを含む可変幅キャラクタ・セットのみがデータベース・キャラクタ・セットとしてサポートされます。マルチバイト固定幅キャラクタ・セット(たとえば、AL16UTF16)は、データベース・キャラクタ・セットとしてサポートされません。
SQLのNCHARデータ型(NCHAR、NVARCHAR2およびNCLOB)に格納されたデータ用のデータベースでは、代替キャラクタ・セットを使用できます。代替キャラクタ・セットは、データベース各国語キャラクタ・セットと呼ばれます。Unicodeキャラクタ・セットのみが、データベース各国語キャラクタ・セットとしてサポートされます。
デフォルトでは、データ・ファイルには、NLS_LANGパラメータで定義されているキャラクタ・セットが使用されます。NLS_LANGでサポートされているデータ・ファイル・キャラクタ・セットは、データベース・キャラクタ・セットとしてサポートされているものと同じです。SQL*Loaderでは、データ・ファイル内のOracleでサポートされているすべてのキャラクタ・セットがサポートされます(データベース・キャラクタ・セットとしてサポートされていないものもサポートされます)。
たとえば、SQL*Loaderでは、データ・ファイル内のマルチバイト固定幅キャラクタ・セット(AL16UTF16、JA16EUCFIXEDなど)がサポートされます。また、SQL*Loaderでは、リトル・エンディアン・バイト順序によるUTF-16エンコーディングもサポートされます。ただし、Oracle Databaseでは、ビッグ・エンディアン・バイト順序によるUTF-16エンコーディング(AL16UTF16)のみが、データベース・キャラクタ・セットとしてではなく、データベースの各国語キャラクタ・セットとしてのみサポートされます。
データ・ファイルのキャラクタ・セットは、NLS_LANGパラメータ、またはSQL*LoaderのCHARACTERSETパラメータを使用して設定できます。
CHARACTERSETパラメータが指定されていない場合、すべてのデータ・ファイルに対するデフォルトのキャラクタ・セットは、NLS_LANGパラメータで定義されたセッション・キャラクタ・セットです。入力データ・ファイルで使用されるキャラクタ・セットは、CHARACTERSETパラメータで指定できます。
SQL*Loaderでは、データ・ファイル・キャラクタ・セット、データベース・キャラクタ・セットおよびデータベース各国語キャラクタ・セットが異なる場合、データ・ファイルのデータをデータベース・キャラクタ・セットまたはデータベース各国語キャラクタ・セットに自動的に変換できます。
データのキャラクタ・セット変換が必要な場合、ターゲットのキャラクタ・セットは、ソースのデータ・ファイル・キャラクタ・セットのスーパーセットである必要があります。そうでない場合、ターゲット・キャラクタ・セットに同じ文字がない文字は、置換文字(通常、疑問符(?)などのデフォルトの文字)に変換されます。これによって、データが失われます。
データベース・キャラクタ・タイプCHARおよびVARCHAR2のサイズは、バイト単位(バイト長セマンティクス)または文字単位(文字長セマンティクス)で指定できます。バイト単位で指定され、データ・キャラクタ・セットの変換が必要な場合、変換される文字のソース・キャラクタ・セットより多くのバイトがターゲット・キャラクタ・セットで使用されると、変換後の値はソースの値より大きくなることがあります。これによって、ターゲットの大きい値がデータベースの列のサイズを超える場合、次のエラー・メッセージがレポートされます。
ORA-01401: inserted value too large for column
データベースの列サイズを文字単位で指定するか、または制御ファイルの文字サイズを使用してデータを記述することによっても、この問題を回避できます。また、最大列サイズがバイト単位で、変換後の値を保持できる大きさであることを確認する方法もあります。
|
参照:
|
SQL*Loaderの従来型パスまたはOracle Call Interface(OCI)を使用して、VARRAYまたは主キー・ベースREFに、データベース・キャラクタ・セットとは異なるキャラクタ・セットのデータをロードする場合は、次のような問題が発生する可能性があります。
データベースの列に対してフィールドが大きすぎるという理由で、実際には大きすぎない場合でも、行が拒否される可能性があります。
大きすぎるフィールドのみが拒否されるロード処理で、1行もロードされないまま異常終了する可能性があります。
主キー・ベースREF列をSQL*Plusで選択した場合、それらの列が空白として返されるにもかかわらず、行が正しくロードされたようにレポートされる可能性があります。
これらの問題を回避するには、データをロードする前にNLS_LANG環境変数を使用して、クライアントのキャラクタ・セットをデータベース・キャラクタ・セットに設定します。
CHARACTERSETパラメータを指定して、SQL*Loaderに入力データ・ファイルのキャラクタ・セットを示します。CHARACTERSETパラメータが指定されていない場合、すべてのデータ・ファイルに対するデフォルトのキャラクタ・セットは、NLS_LANGパラメータで定義されたセッション・キャラクタ・セットです。文字データ(SQL*Loaderデータ型のCHAR、VARCHAR、VARCHARC、数値型EXTERNALおよび日時データ型と期間データ型のフィールド)のみが、データ・ファイルのキャラクタ・セットに影響されます。
CHARACTERSETの構文は次のとおりです。
CHARACTERSET char_set_name
char_set_name変数で、キャラクタ・セット名を指定します。通常、指定された名前はOracleがサポートしているキャラクタ・セットの名前である必要があります。
UnicodeのUTF-16エンコーディングの場合は、名前はAL16UTF16でなくUTF16を使用します。AL16UTF16(UTF-16エンコードされたデータに対してサポートされるOracleキャラクタ・セット名)は、ビッグ・エンディアンのバイト順序のUTF-16データにのみ使用されます。ただし、データ・ファイルを作成したシステムのバイト順序を使用してデータを設定することが許可されているため、データ・ファイル内のデータはビッグ・エンディアンまたはリトル・エンディアンのいずれかにできます。このため、異なるキャラクタ・セット名(UTF16)が使用されます。また、キャラクタ・セット名AL16UTF16もサポートされています。ただし、リトル・エンディアンのバイト順序のデータ・ファイルにAL16UTF16を指定すると、SQL*Loaderによって警告メッセージが発行され、データ・ファイルはビッグ・エンディアンとして処理されます。
CHARACTERSETパラメータは、LOBFILEおよびSDFのみでなくプライマリ・データ・ファイルに対しても指定できます。すべてのプライマリ・データ・ファイルは同じキャラクタ・セットとみなされます。INFILEパラメータの前に指定されるCHARACTERSETパラメータは、プライマリ・データ・ファイルのリスト全体に適用されます。CHARACTERSETパラメータがプライマリ・データ・ファイルに対して指定される場合、指定された値は、LOBFILEおよびSDFのデフォルトとしても使用されます。LOBFILEまたはSDF仕様でCHARACTERSETパラメータを指定すると、デフォルト設定は上書きされます。
CHARACTERSETパラメータで設定されたキャラクタ・セットは、制御ファイルのデータ(INFILEで指定されている)には適用されません。NLS_LANGパラメータで指定されているセッション・キャラクタ・セット以外のキャラクタ・セットでデータをロードするには、そのデータを別のデータ・ファイルに置く必要があります。
|
参照:
|
SQL*Loader制御ファイル自体のキャラクタ・セットは、NLS_LANGパラメータで指定されているセッション・キャラクタ・セットであることが前提です。制御ファイル・キャラクタ・セットがデータ・ファイル・キャラクタ・セットと異なる場合は、次のことに注意してください。SQL*Loader制御ファイルで文字列として指定されたデリミタおよび比較句の値は、比較が行われる前に、制御ファイル・キャラクタ・セットからデータ・ファイル・キャラクタ・セットに変換されます。正しく指定するには、文字列値ではなく16進文字列を指定してください。
16進文字列がUnicodeのUTF-16エンコーディングのデータ・ファイルで使用される場合、ビッグ・エンディアンのシステムとリトル・エンディアンのシステムでバイト順序が異なります。たとえば、ビッグ・エンディアンのシステムでは、UTF-16の「,」(カンマ)はX'002c'です。リトル・エンディアンのシステムではX'2c00'です。SQL*Loaderでは、常に、ビッグ・エンディアン形式で16進文字列を指定する必要があります。必要に応じて、比較が行われる前に、SQL*Loaderによってバイトが交換されます。これによって、ビッグ・エンディアンおよびリトル・エンディアンの両システム上の制御ファイルで同じ構文を使用することができます。
UnicodeのUTF-16エンコーディングのストリーム形式のデータ・ファイルで使用されるレコード終了記号のデフォルトは、UTF-16では「\n」(ビッグ・エンディアンのシステムでは0x000Aで、リトル・エンディアンのシステムでは0x0A00)です。INFILE行上の"STR 'char_str'"指定または"STR x'hex_str'"指定を使用して、これらのデフォルト設定を上書きできます。たとえば、次のいずれかの行を使用して、'\n'のかわりに'ab'をレコード終了記号として使用できます。
INFILE myfile.dat "STR 'ab'" INFILE myfile.dat "STR x'00410042'"
BEGINDATA文の後に指定するデータも、NLS_LANGパラメータで指定されたセッション・キャラクタ・セットであることが前提です。
SQL*Loaderのデータ型(CHAR、VARCHAR、VARCHARC、DATEおよび数値型EXTERNAL)に関して、SQL*Loaderでは、バイト単位(バイト長セマンティクス)または文字単位(文字長セマンティクス)のいずれかで指定される文字フィールドの長さがサポートされます。たとえば、制御ファイルでのCHAR(10)指定は、10バイトまたは10文字を意味します。データ・ファイルでシングルバイト・キャラクタ・セットが使用されている場合、これらは同じです。ただし、データ・ファイルでマルチバイト・キャラクタ・セットが使用されている場合、異なることもあります。
キャラクタ・セット変換中に文字列の拡張によって発生する挿入エラーを回避するには、データ・ファイルおよびターゲット・データベースの列の両方で文字長セマンティクスを使用します。
バイト長セマンティクスは、UTF16キャラクタ・セット(デフォルトで文字長セマンティクスを使用します)を使用するデータ・ファイル以外のすべてのデータ・ファイルのデフォルトです。デフォルトに上書きするには、次の構文で示すとおり、CHARまたはCHARACTERを指定します。
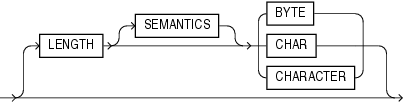
LENGTHパラメータは、SQL*Loader制御ファイルのCHARACTERSETパラメータの後に置かれます。LENGTHパラメータは、プライマリ・データ・ファイルに関する構文の指定のみではなく、LOBFILEデータ・ファイルおよびセカンダリ・データ・ファイル(SDF)にも適用されます。INFILEパラメータの前のLENGTH指定は、プライマリ・データ・ファイルのリスト全体に適用されます。プライマリ・データ・ファイルに対するLENGTH指定は、LOBFILEおよびSDFに対するデフォルトとして使用されます。LOBFILEおよびSDF仕様でLENGTHを指定することによって、デフォルトを上書きできます。CHARACTERSETパラメータとは異なり、LENGTHパラメータは、制御ファイル内に含まれるデータ(INFILE *構文)に適用されます。
LENGTHパラメータに対しては、CHARのかわりにCHARACTERを指定できます。
文字長セマンティクスがSQL*Loaderのデータ・ファイルに対して使用されている場合は、次のSQL*Loaderデータ型で文字長セマンティクスが使用されます。
CHAR
VARCHAR
VARCHARC
DATE
数値型EXTERNAL(INTEGER、FLOAT、DECIMALおよびZONED)
VARCHARデータ型では、長さサブフィールドはバイナリのSMALLINT長さサブフィールドです。ただし、その値は文字単位の文字列の長さを示します。
次のデータ型では、データ・ファイルで文字長セマンティクスが使用されていてもバイト長セマンティクスを使用します。これは、データがバイナリであるか、またはZONEDおよびDECIMALの場合は、特別にバイナリにエンコーディングされた形式であるためです。
INTEGER
SMALLINT
FLOAT
DOUBLE
BYTEINT
ZONED
DECIMAL
RAW
VARRAW
VARRAWC
GRAPHIC
GRAPHIC EXTERNAL
VARGRAPHIC
POSITIONパラメータの開始引数および終了引数は、文字長セマンティクスがデータ・ファイルで使用されていても、バイト単位で解釈されます。これは、異なるデータ型のデータが混在するデータ・ファイル(一部では文字長セマンティクスを使用し、一部ではバイト長セマンティクスを使用する)を処理する場合に必要です。SMALLINT長さフィールドおよび文字データを含むVARCHARデータ型で位置を処理する場合にも必要です。SMALLINT長さフィールドは、システムによって一定のバイト数(通常、2バイト)を必要とします。ただし、その値は、文字列の長さを文字単位で示します。
データ・ファイルの文字長セマンティクスは、データベースの列で文字長セマンティクスが使用されているかどうかに関係なく使用できます。したがって、データ・ファイルおよびデータベースの列で、同じまたは異なる長さのセマンティクスを使用できます。
通常、シフト・センシティブ文字データのロードは、ASCIIデータまたはEBCDICデータのロードに比べて非常に遅くなります。シフト・センシティブ文字データを最速でロードするには、デリミタのない固定位置フィールドを使用します。パフォーマンスを向上させるには、次の点に注意してください。
フィールド・データに、同数のシフトアウト/シフトイン・バイトが含まれる必要があります。
フィールドは、シングルバイト・モードで開始および終了する必要があります。
最初のバイトをシフトアウト、最後のバイトをシフトインにできます。
最初と最後の文字は、マルチバイトにできません。
空白が保存され、マルチバイトの空白を確認する必要がある場合、より遅いパスが使用されます。これは、シングルバイトの空白の削除が実行された後、シフトイン・バイトがフィールドの最後のバイトとなる場合に、発生する可能性があります。
ロードは様々な理由で中断されます。主な理由は領域エラーで、SQL*Loaderで使用されるデータ行および索引エントリ用の領域の不足によって発生します。エラーの最大数を超えた場合、サーバーからSQL*Loaderに予期しないエラーが返された場合、レコードがデータ・ファイルに対して長すぎた場合、または[Ctrl]キーを押しながら[C]キーを押した場合にも、ロードが中断されます。
ロードが中断された場合のSQL*Loaderの動作は、ロードのモードが従来型パス・ロードかダイレクト・パス・ロードか、およびロードが中断された理由によって異なります。また、中断されたロードを継続する場合、SKIPパラメータを使用するかどうか、およびこのパラメータに指定する値は、状況によって異なります。次の項に例を示します。
従来型パス・ロードでは、バインド配列のすべてのデータがすべての表にロードされた後で、データがコミットされます。ロードが中断された場合は、直前のコミット操作の時点までに処理された行のみがロードされます。データの部分コミットは行われません。
ダイレクト・パス・ロードでは、中断されたロードの動作は、ロードが中断された理由によって異なります。
領域エラーが原因でロードが中断されたときのSQL*Loaderの動作は、データを複数のサブパーティションにロード中だったかどうかで異なります。
データを複数のサブパーティションにロードしているとき(パーティション表、コンポジット・パーティション表、またはコンポジット・パーティション表の1つのパーティションにロードしているとき)に領域エラーが発生した場合
複数のサブパーティションへのロード中に領域エラーが発生した場合、ロードは中断され、ROWSが指定されていなければデータは保存されません(この場合、コミット済のデータはすべて保存されます)。このような動作は、行が順不同にロードされる可能性を考慮したためです。順不同になるのは、それぞれの行が順序を考慮せずにパーティションに割り当てられ、そのパーティションが別々にロードされることが原因です。パーティションに割り当てられているすべての行がロードされる前にロードが中断されると、レコード番号nの行はロードされていても、レコード番号n-1の行がロードされていない可能性があります。したがって、単純にSKIP=Nを使用するだけではロードを続行できません。
非パーティション表、パーティション表の1つのパーティション、またはコンポジット・パーティション表の1つのサブパーティションにデータをロードしているときに、領域エラーが発生した場合
制御ファイルに記述されているINTO TABLE文が1つの場合、SQL*Loaderは、エラーが発生する前にロードされていた行と同じ数の行をコミットします。
制御ファイルにINTO TABLE文が複数ある場合、SQL*Loaderは、データ・ファイルから他の表に読取り済のデータをロードし、そのデータをコミットします。
いずれの場合も、この動作は、ROWSパラメータが指定されていたかどうかに関係なく実行されます。ロードを継続する場合は、SKIPパラメータを使用して、ロード済の行をスキップできます。INTO TABLE文が複数あった場合は、それぞれの表に異なる数の行がロードされている可能性があります。したがって、ロードを継続するには、表ごとに異なるSKIPパラメータの値を指定することが必要な場合があります。SKIPパラメータの値がすべての表で同じ場合にのみ、SQL*Loaderによってその値が報告されます。
エラーが最大数を超えると、SQL*Loaderによって、すべての表へのレコードのロードが停止され、その時点までに終了している処理がコミットされます。ロードを継続する場合、SKIPパラメータに指定する値は表によって異なります。SKIPパラメータの値がすべての表で同じ場合にのみ、SQL*Loaderによってその値が報告されます。
致命的エラーが発生した場合は、ロードが停止されます。ロードの開始時にROWSが指定されていないかぎり、データは保存されません。指定されている場合、コミット済のすべてのデータが保存されます。SKIPパラメータの値がすべての表で同じ場合にのみ、SQL*Loaderによってその値が報告されます。
SQL*Loaderによるデータの保存中に[Ctrl]キーを押しながら[C]キーを押すと、データの保存は継続され、保存の完了後にロードが停止されます。データを保存中でない場合は、コミットされていない処理をコミットせずにロードが停止されます。つまり、SKIPパラメータの値は、すべての表で同じになります。
ロードが中断されると、すでにロードされたデータはそのまま表に残り、その表は有効な状態のままとなります。従来型パスを使用した場合、すべての索引は有効な状態のままとなります。
ダイレクト・パス・ロード方法を使用した場合は、表の索引はすべて使用禁止状態のままになります。このような索引は、継続処理をする前、またはロードが再開されすべて終了した後に、再構築または再作成できます。
これ以外の索引は、他にエラーが発生していないかぎり有効です。索引が使用禁止状態のままになるその他の理由については、「使用禁止状態(Index Unusable)のままの索引」を参照してください。
SQL*Loaderのログ・ファイルには、表や索引の状態、および入力データ・ファイルから読み込まれた論理レコード数の情報が記録されます。これらの情報は、中断されたロードを再開する場合に利用できます。
ダイレクト・パス・ロードまたは従来型パス・ロードを、終了前にSQL*Loaderで中断する必要がある場合は、すでにコミットされているか、またはセーブポイントが付けられている行が存在しています。中断されたロードを継続するには、SKIPパラメータを使用して、前回のロードによってすでに処理されている論理レコードの数を指定します。ロードの中断時に、次のようなメッセージ形式でログ・ファイルにSKIPの値が書き込まれます。
Specify SKIP=1001 when continuing the load.
SKIPパラメータの値を指定するこのメッセージの前には、ロードが中断された理由を示すメッセージが書き込まれています。
複数表へのロードの場合は、SKIPパラメータの値がすべての表で同じ場合にのみ、値が表示されます。
Oracle9iでは、64KBを超えるユーザー定義のレコード・サイズがサポートされています(「READSIZE(読取りバッファ・サイズ)」を参照)。これによって、論理レコードを複数の物理レコードに細分化する必要がなくなります。ただし、細分化する必要が完全になくなるわけではありません。複数の物理レコードを結合して1つの論理レコードに戻すには、対象とするデータによって、次の句のうちの1つを指定します。
CONCATENATE
CONTINUEIF
常に一定の数の物理レコードを結合して1つの論理レコードを構成する場合、CONCATENATEを使用します。次の例では、integerによって結合する物理レコードの数を指定します。
CONCATENATE integer
CONCATENATEに指定された整数値によって、SQL*Loaderで列配列の各行に割り当てられる物理レコード構造の数が決まります。ダイレクト・パス・ロードでは、COLUMNARRAYROWSのデフォルト値が大きいため、CONCATENATEにも大きい値を指定すると、メモリーの過剰割当てが発生する可能性があります。この場合は、COLUMNARRAYROWSパラメータの値を小さくして列配列の行の数を減らすことによって、パフォーマンスを向上できます。
CONTINUEIFは、結合する物理レコードの数が異なる場合に使用します。CONTINUEIF句を使用する場合は、後に条件を指定します。この条件は、各物理レコードが読み込まれるたびに評価されます。たとえば、2つのレコードがあって、その最初のレコードの80バイト目にシャープ記号(#)がある場合、2つのレコードは結合されます。この場合、指定の位置に他の文字があると、2番目のレコードは最初のレコードに結合されません。
次に、CONTINUEIFの完全な構文を示します。この構文で、さらに柔軟な処理を実行できます。

表9-2では、CONTINUEIF句のパラメータについて説明します。
表9-2 CONTINUEIF句のパラメータ
| パラメータ | 説明 |
|---|---|
|
|
現在のレコードについて条件が真のとき、次の物理レコードを読み込んで現在のレコードに連結します。この処理は、条件が偽になるまで繰り返されます。条件が偽になると、現在の物理レコードが現在の論理レコードを構成する最後の物理レコードになります。 |
|
|
次のレコードで条件が真になると、現在の物理レコードを現在の論理レコードに連結します。この処理は、条件が偽になるまで繰り返されます。 |
|
|
サポートされているのは等号演算子(=)と不等号演算子(!= または<>)です。 等号演算子を指定すると、フィールドと比較文字列が完全に一致したときに、条件が真となります。不等号演算子を指定した場合は、どの文字が異なっていても、条件は真となります。 |
|
|
レコードの最後の文字(空白以外)に対して、
|
|
|
物理レコード中の列の開始番号と終了番号です。 列番号は1から始まります。ハイフンまたはコロンを使用することもできます(
|
|
|
startとendで定義された継続フィールドと比較する文字列です。比較演算の内容は、operatorで指定された演算子によって異なります。文字列は一重引用符または二重引用符で囲みます。文字列は1文字ずつ比較され、必要があれば、空白埋め文字が右側に追加されます。 |
|
|
16進形式で指定された文字列で、使用方法は |
|
|
論理レコードには' |
CONTINUEIF句の中で指定する位置は、各物理レコード中の位置を示します。物理レコード中の位置が参照されるのは、この場合のみです。これ以外の場合、参照先は論理レコードとなります。
CONTINUEIF THISおよびCONTINUEIF LASTでは、PRESERVEパラメータを指定しない場合、論理レコードの作成時にすべての物理レコードから継続フィールドが削除されます。継続フィールドが読み込まれるまでは、データは同じ論理レコードに連結します。たとえば、CONTINUEIF THIS(3:5)='***'を指定すると、3から5までの位置がすべてのレコードから削除されます。つまり、レコードの3から5までの位置にある継続文字が削除されます。また、3から5までの位置にある文字は、継続文字が3から5までの位置にない場合でもレコードから削除されます。
CONTINUEIF THISおよびCONTINUEIF LASTでは、PRESERVEパラメータを使用した場合、論理レコードの作成時にすべての物理レコードに継続フィールドが保持されます。
CONTINUEIF LASTは、CONTINUEIF THISおよびCONTINUEIF NEXTとは異なります。CONTINUEIF LASTでは、継続フィールドの位置がレコードごとに異なり、PRESERVEが指定されていない場合でも、継続フィールドは削除されません。
例9-3から例9-6に、PRESERVEパラメータの有無にかかわらず、CONTINUEIF THISおよびCONTINUEIF NEXTの使用例を示します。
例9-3 PRESERVEパラメータを使用しないCONTINUEIF THIS
ここで、物理レコードは次のような14バイトのレコードとします。また、ピリオドは空白を表します。
%%aaaaaaaa....
%%bbbbbbbb....
..cccccccc....
%%dddddddddd..
%%eeeeeeeeee..
..ffffffffff..
次の例では、CONTINUEIF THIS句にPRESERVEパラメータは使用されていません。
CONTINUEIF THIS (1:2) = '%%'
したがって、論理レコードは次のように作成されます。
aaaaaaaa....bbbbbbbb....cccccccc....
dddddddddd..eeeeeeeeee..ffffffffff..
列1および列2(たとえば、物理レコード1の%%)は、論理レコード作成時に物理レコードから削除されることに注意してください。
例9-4 PRESERVEパラメータを使用するCONTINUEIF THIS
例9-3の物理レコードと同じ物理レコードがあるとします。
次の例では、CONTINUEIF THIS句にPRESERVEパラメータが使用されています。
CONTINUEIF THIS PRESERVE (1:2) = '%%'
したがって、論理レコードは次のように作成されます。
%%aaaaaaaa....%%bbbbbbbb......cccccccc....
%%dddddddddd..%%eeeeeeeeee....ffffffffff..
列1および列2は、論理レコード作成時に物理レコードから削除されないことに注意してください。
例9-5 PRESERVEパラメータを使用しないCONTINUEIF NEXT
ここで、物理レコードは次のような14バイトのレコードとします。また、ピリオドは空白を表します。
..aaaaaaaa....
%%bbbbbbbb....
%%cccccccc....
..dddddddddd..
%%eeeeeeeeee..
%%ffffffffff..
次の例では、CONTINUEIF NEXT句にPRESERVEパラメータは使用されていません。
CONTINUEIF NEXT (1:2) = '%%'
したがって、論理レコードは次のように作成されます(例9-3と同じ結果)。
aaaaaaaa....bbbbbbbb....cccccccc....
dddddddddd..eeeeeeeeee..ffffffffff..
例9-6 PRESERVEパラメータを使用するCONTINUEIF NEXT
例9-5の物理レコードと同じ物理レコードがあるとします。
次の例では、CONTINUEIF NEXT句にPRESERVEパラメータが使用されています。
CONTINUEIF NEXT PRESERVE (1:2) = '%%'
したがって、論理レコードは次のように作成されます。
..aaaaaaaa....%%bbbbbbbb....%%cccccccc....
..dddddddddd..%%eeeeeeeeee..%%ffffffffff..
この項では、次の内容について説明します。
ロードする表の指定方法
表にロードするレコードの指定方法
レコードに対するデフォルトのデータ・デリミタ
データが欠落しているショート・レコードの処理方法
LOAD DATA文のINTO TABLE句を使用して、表、フィールドおよびデータ型を識別できます。この句で、データ・ファイル中のレコードとデータベース中の表の関係を定義します。フィールドやデータ型の指定については後述します。
INTO TABLE句が持つ様々な機能の1つに、データのロード先となる表を指定する機能があります。複数の表にロードするには、それぞれの表に対してINTO TABLE句を指定する必要があります。
INTO TABLE句を記述する場合、キーワードINTO TABLEの次に、データを受け取るOracleの表名を指定します。
構文は次のようになります。
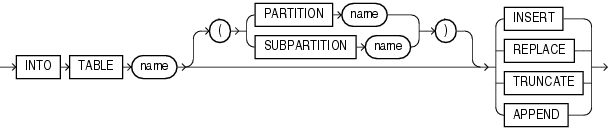
表名には、すでに存在する表を指定してください。表名がSQLやSQL*Loaderの予約済キーワードと同じ場合、表名に特殊文字が含まれる場合、または表名の中の大/小文字を区別する必要がある場合は、表名を二重引用符で囲みます。
INTO TABLE scott."CONSTANT" INTO TABLE scott."Constant" INTO TABLE scott."-CONSTANT"
ユーザーが表をロードするには、INSERT権限が必要です。表がユーザーのスキーマにない場合、ユーザーはシノニムを使用して表を参照するか、またはスキーマ名を表名の一部として含める必要があります(たとえば、scott.empはscottスキーマの表empを参照します)。
表のロード時に、INTO TABLE句を使用して、表固有のロード方法(INSERT、APPEND、REPLACEまたはTRUNCATE)を指定できます。指定したロード方法は、その表のみに適用されます。表固有のロード方法は、グローバルな表のロード方法よりも優先されます。INTO TABLE句の前にロード方法が特に指定されていない場合、グローバルな表のロード方法は、デフォルトでINSERTとなります。次の項では、これらのオプションを使用して空および空でない表へデータをロードする方法について説明します。
ロード先の表が空の場合は、INSERTオプションを使用します。
これは、SQL*Loaderのデフォルトの方法です。ロードする前に表を空にする必要があります。表に行が存在する場合はエラーが返され、SQL*Loaderは終了します。「事例1: 可変長データのロード」に例があります。(事例の使用方法については、「SQL*Loaderの事例」を参照してください。)
ロード先の表にすでにデータが存在する場合は、次の3つのオプションがあります。
APPEND
REPLACE
TRUNCATE
表にデータがすでに存在する場合、SQL*Loaderで新しい行が表に追加されます。データが存在しない場合には、単に新しい行がロードされます。APPENDオプションを使用するには、SELECT権限が必要です。「事例3: 自由区分形式ファイルのロード」に例があります。(事例の使用方法については、「SQL*Loaderの事例」を参照してください。)
REPLACEオプションを使用すると、SQLのDELETE FROM TABLE文が実行されます。表の既存の行はすべて削除され、新しくデータがロードされます。この場合、その表がロード実行者のスキーマ内に存在するか、ロード実行者がその表に対してDELETE権限を持っている必要があります。「事例4: 結合された物理レコードのロード」に例があります。(事例の使用方法については、「SQL*Loaderの事例」を参照してください。)
行削除によって、その表に定義された削除トリガーが起動します。DELETE CASCADEが表に指定されている場合、カスケード化された削除が同様に実行されます。削除のカスケード化の詳細は、『Oracle Database概要』のデータ整合性に関する説明を参照してください。
REPLACEは、個々の行ではなく表を置換する方法です。既存レコードにNULL列があっても、SQL*Loaderはそのレコードを更新しません。既存の行を更新するには、次の手順を実行してください。
データを作業表にロードします。
相関副問合せを指定した、SQLのUPDATE文を使用します。
作業表を削除します。
TRUNCATEオプションを使用すると、SQLのTRUNCATE TABLE table_name REUSE STORAGE文が実行され、表のエクステントが再利用されます。TRUNCATEオプションにより、表またはクラスタからすべての行が短時間で効率的に削除されるため、最大限の処理パフォーマンスを実現できます。TRUNCATE文を実行する前に、表の参照整合性制約を使用禁止にします。参照整合性制約が使用禁止でない場合、SQL*Loaderによってエラーが返されます。
整合性制約が使用禁止になると、その表に対してはDELETE CASCADEは定義されません。DELETE CASCADE機能が必要な場合は、ロードを開始する前に、表の内容を手動で削除する必要があります。
この場合、表がロード実行者のスキーマにあるか、ロード実行者がDROP ANY TABLE権限を所有している必要があります。
|
参照: この項で説明されているSQL文の詳細は、『Oracle Database SQL言語リファレンス』を参照してください。 |
パラレル・ロードでは、個々の表に対してOPTIONSパラメータを指定できます(このパラメータは、パラレル・ロードの場合のみ有効です)。
OPTIONSパラメータの構文は次のとおりです。

WHEN句を使用して論理レコード中の条件をテストし、その論理レコードをロードするか廃棄するかを選択できます。
WHEN句を表名の後に記述し、その後にフィールド条件を1つ以上指定します。field_conditionの構文は、次のとおりです。
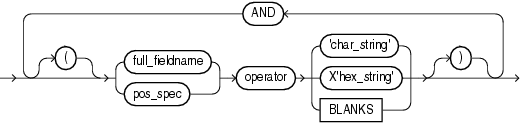
たとえば、次のように指定すると、第5列の値がqであるレコードがすべてロードされます。
WHEN (5) = 'q'
WHEN句では各条件の前にANDを使用して、複数の条件を設定できます。小カッコの指定は任意ですが、ANDによって複数の条件を設定している場合は、あいまいさを避けるために必ず使用してください。次に例を示します。
WHEN (deptno = '10') AND (job = 'SALES')
|
参照:
|
データ・ファイル中のデータ・フィールドがすべて同じ文字で終了している場合、FIELDS句を使用してデフォルトのデリミタを指定することができます。fields_spec、termination_specおよびenclosure_spec句の構文は、次のとおりです。
|
注意: 囲み文字列には、1つ以上の文字が含まれます。 |
特定の列に対してデリミタを上書きする場合は、その列名の後に適用するデリミタを指定します。「事例3: 自由区分形式ファイルのロード」に例があります。(事例の使用方法については、「SQL*Loaderの事例」を参照してください。)
制御ファイルの定義で指定したフィールドの数が、実際にレコード中に存在するフィールドより多い場合、残りの(指定された余分の)列にNULL値を設定するか、またはエラーを出力するかがSQL*Loaderによって判断されます。
制御ファイルの定義でフィールドの開始位置として論理レコードの終了位置よりも後の位置が明示的に指定されている場合、SQL*Loaderによって、このフィールドにNULL値が設定されます。フィールドが(次に示す例の中のdnameおよびlocのように)相対位置に定義されていて、そのフィールドが現れる前にレコードのデータが終わった場合は、SQL*LoaderによってこのフィールドにNULL値が設定されるか、またはエラーが出力されます。SQL*Loaderによる処理は、TRAILING NULLCOLS句(次の構文図を参照)を指定しているかどうかによって決まります。
TRAILING NULLCOLS句を使用すると、相対位置で指定した列がレコード中に存在しない場合、SQL*Loaderによりその列の値はNULLとして処理されます。
たとえば、次のようなデータについて考えます。
10 Accounting
このデータが次の制御ファイルで読み込まれ、そのレコードはdnameの後で終了するとします。
INTO TABLE dept
TRAILING NULLCOLS
( deptno CHAR TERMINATED BY " ",
dname CHAR TERMINATED BY WHITESPACE,
loc CHAR TERMINATED BY WHITESPACE
)
この場合、その後のlocフィールドにはNULL値が設定されています。この例でTRAILING NULLCOLS句を指定しなかった場合は、データ欠落のためエラーとなります。
この項では、索引エントリの作成方法を制御する次のSQL*Loaderオプションについて説明します。
SORTED INDEXES
SINGLEROW
SORTED INDEXES句はダイレクト・パス・ロードに適用できます。このオプションを指定すると、入力データはロード前に指定の索引でソートされていることがSQL*Loaderで認識されるため、ロード時にはSQL*Loaderのパフォーマンスが最適化されます。
SINGLEROWオプションは、APPENDオプションを使用してかぎられたメモリーでダイレクト・パス・ロードを実行する場合、または少数のレコードを大規模な表にロードする場合に使用します。このオプションを使用すると、各索引エントリが、一度に1レコードずつ直接索引に挿入されます。
表に行を追加(APPEND)する場合、デフォルトではSINGLEROWは使用されません。この場合、索引エントリは個別の一時記憶域に置かれ、ロード終了時に元の索引とマージされます。この方法では、パフォーマンスが向上して最適な索引が作成されますが、記憶域も余分に必要となります。マージ処理が実行されている間は、元の索引、新しい索引、および新しいエントリのための領域が同時に記憶域を占有します。
SINGLEROWオプションの場合、新しい索引エントリや新しい索引のための記憶域は必要ありません。結果としてできる索引は、新しくソートされたものほど最適化されていない可能性がありますが、作成するための記憶域は少なくて済みます。ただし、各索引が挿入されるたびにUNDO情報が追加で作成されるため、時間がかかります。このオプションは、次の場合に使用してください。
使用可能な記憶域がかぎられている場合。
ロードされる行数が表のサイズに比べて小さい場合(比率が1:20以下かどうかが目安になります)。
複数のINTO TABLE句を指定すると、次の処理が可能になります。
ここでは、まず、複数のINTO TABLE句で同じ表を参照するという最も一般的な使用方法を示します。この項では、複数のINTO TABLE句の様々な指定方法を説明します。また、POSITIONパラメータの指定方法についても説明します。
|
注意: INTO TABLE句を複数指定した場合、次のINTO TABLE句の処理に移ったときのフィールド・スキャンは、前回フィールド・スキャンを停止した位置から続行されます。この項の残りの部分では、このような動作を利用する重要な方法について詳しく説明します。また、固定フィールド位置やPOSITIONパラメータを使用した別の手順についても説明します。 |
データ記憶域および転送メディアには、物理レコードが固定長のものがあります。データ・レコードが比較的短い場合、メディアを効率的に使用するために複数の論理レコードをまとめて1つの物理レコードに記録できます。
ここでは、入力ファイルの1件の物理レコードを2件の論理レコードとみなし、INTO TABLE句を2回指定してemp表にデータをロードする方法について説明します。たとえば、次のようなデータの例を考えます。
1119 Smith 1120 Yvonne 1121 Albert 1130 Thomas
次の制御ファイルを使用して論理レコードを抽出します。
INTO TABLE emp
(empno POSITION(1:4) INTEGER EXTERNAL,
ename POSITION(6:15) CHAR)
INTO TABLE emp
(empno POSITION(17:20) INTEGER EXTERNAL,
ename POSITION(21:30) CHAR)
同じレコードを、別の指定方法でロードできます。次の制御ファイルでは、絶対的位置を指定するかわりに相対的な位置を指定しています。ここでは、各フィールドが空白(" ")1文字、またはいくつかの空白やタブ(WHITESPACE)で区切られていることを示しています。
INTO TABLE emp
(empno INTEGER EXTERNAL TERMINATED BY " ",
ename CHAR TERMINATED BY WHITESPACE)
INTO TABLE emp
(empno INTEGER EXTERNAL TERMINATED BY " ",
ename CHAR) TERMINATED BY WHITESPACE)
この例では、2番目のempnoフィールドは、別のINTO TABLE句に指定されていますが、1番目のenameの直後に指定されていることに注意してください。新しいINTO TABLE句に対して、レコードの先頭からのフィールド・スキャンが実行されるわけではありません。かわりに、前回スキャンが停止した位置から続行されます。
レコードのスキャンを特定の位置から強制的に開始するには、POSITIONパラメータを使用します。詳細は、「異なる入力レコード形式の区別」および「複数表へのデータのロード」を参照してください。
通常、データ・ファイルには様々な形式のレコードが含まれています。ここでは、次のようなデータについて考えます。この例では、emp表およびdept表のレコードが、データ中に混在しています。
1 50 Manufacturing — DEPT record 2 1119 Smith 50 — EMP record 2 1120 Snyder 50 1 60 Shipping 2 1121 Stevens 60
これら2つの形式は、レコードIDフィールドで区別されます。部門レコードの最初の列は1、従業員レコードの最初の列は2になります。このデータをロードするため、次の制御ファイルではフィールドの正確な位置を指定しています。
INTO TABLE dept
WHEN recid = 1
(recid FILLER POSITION(1:1) INTEGER EXTERNAL,
deptno POSITION(3:4) INTEGER EXTERNAL,
dname POSITION(8:21) CHAR)
INTO TABLE emp
WHEN recid <> 1
(recid FILLER POSITION(1:1) INTEGER EXTERNAL,
empno POSITION(3:6) INTEGER EXTERNAL,
ename POSITION(8:17) CHAR,
deptno POSITION(19:20) INTEGER EXTERNAL)
前述の例のレコードは、デリミタ付きのデータとしてもロードできます。ただし、その場合はPOSITIONパラメータを使用する必要があります。次の制御ファイルを使用します。
INTO TABLE dept
WHEN recid = 1
(recid FILLER INTEGER EXTERNAL TERMINATED BY WHITESPACE,
deptno INTEGER EXTERNAL TERMINATED BY WHITESPACE,
dname CHAR TERMINATED BY WHITESPACE)
INTO TABLE emp
WHEN recid <> 1
(recid FILLER POSITION(1) INTEGER EXTERNAL TERMINATED BY ' ',
empno INTEGER EXTERNAL TERMINATED BY ' '
ename CHAR TERMINATED BY WHITESPACE,
deptno INTEGER EXTERNAL TERMINATED BY ' ')
2番目のINTO TABLE句のPOSITIONパラメータは、このデータを正しくロードするために必要です。このように指定すると、2つ目の書式に一致するデータを確認するときのフィールド・スキャンは、列1から開始されます。この指定がない場合、SQL*Loaderでは、recidフィールドがdnameフィールドの後にあるものとしてスキャンされます。
通常、データ・ファイルには、同じ行オブジェクト型から継承された行オブジェクトで構成される単一のレコードが含まれています。たとえば、次のような単純なオブジェクト型およびオブジェクト表の定義について考えてみます。ここでは、NOT FINALのベース・オブジェクト型が、ベース型から行オブジェクトを継承する2つのオブジェクト・サブタイプとともに定義されています。
CREATE TYPE person_t AS OBJECT (name VARCHAR2(30), age NUMBER(3)) not final; CREATE TYPE employee_t UNDER person_t (empid NUMBER(5), deptno NUMBER(4), dept VARCHAR2(30)) not final; CREATE TYPE student_t UNDER person_t (stdid NUMBER(5), major VARCHAR2(20)) not final; CREATE TABLE persons OF person_t;
次の入力データ・ファイルには、これらの行オブジェクト・サブタイプが混在しています。型IDフィールドは、3つのサブタイプで区別されます。person_tオブジェクトでは、最初の列にPがあり、employee_tオブジェクトではE、student_tオブジェクトではSがあります。
P,James,31, P,Thomas,22, E,Pat,38,93645,1122,Engineering, P,Bill,19, P,Scott,55, S,Judy,45,27316,English, S,Karen,34,80356,History, E,Karen,61,90056,1323,Manufacturing, S,Pat,29,98625,Spanish, S,Cody,22,99743,Math, P,Ted,43, E,Judy,44,87616,1544,Accounting, E,Bob,50,63421,1314,Shipping, S,Bob,32,67420,Psychology, E,Cody,33,25143,1002,Human Resources,
次の制御ファイルでは、POSITIONパラメータに基づく相対的な位置指定によって、このデータをロードします。固有のオブジェクト型名を持つTREAT AS句の使用方法に注意してください。これによって、オブジェクト表のすべての入力行オブジェクトが名前付きオブジェクト型の定義に準拠することが、SQL*Loaderで認識されます。
INTO TABLE persons REPLACE WHEN typid = 'P' TREAT AS person_t FIELDS TERMINATED BY "," (typid FILLER POSITION(1) CHAR, name CHAR, age CHAR) INTO TABLE persons REPLACE WHEN typid = 'E' TREAT AS employee_t FIELDS TERMINATED BY "," (typid FILLER POSITION(1) CHAR, name CHAR, age CHAR, empid CHAR, deptno CHAR, dept CHAR) INTO TABLE persons REPLACE WHEN typid = 'S' TREAT AS student_t FIELDS TERMINATED BY "," (typid FILLER POSITION(1) CHAR, name CHAR, age CHAR, stdid CHAR, major CHAR)
複数のINTO TABLE句でPOSITIONパラメータを指定すると、1件のレコードのデータを正規化された複数の表にロードできます。例については、「事例5: 複数表へのデータのロード」を参照してください。(事例の使用方法については、「SQL*Loaderの事例」を参照してください。)
複数のINTO TABLE句を指定すると、1件の入力レコードから複数の論理レコードを抽出できます。また、同一ファイル中の異なる形式のレコードを区別できます。
デリミタ付きデータの場合、期待する結果を得るには、POSITIONパラメータを正しく指定する必要があります。
複数のINTO TABLE句でPOSITIONパラメータを指定しない場合、1件の(デリミタ付きデータ)入力レコードの異なる部分が処理されます。これによって、1件のレコードから複数の表へのデータ・ロードが可能になります。複数のINTO TABLE句でPOSITIONパラメータを指定すると、同一のレコードを異なる方法で処理できます。つまり、1つの入力ファイルで複数の形式を識別できます。
SQL*Loaderでは、データのデータベースへの転送時にSQL配列インタフェース・オプションが使用されます。まず、一度に複数の行が読み込まれてバインド配列に格納されます。SQL*LoaderからOracle DatabaseにINSERTコマンドが送られると、配列全体が一度に挿入されます。バインド配列内の行が挿入された後、COMMIT文が発行されます。
バインド配列サイズを決定する必要があるのは、SQL*Loaderの従来型パス・オプションを使用する場合のみです。ダイレクト・パス・ロードでは、Oracle SQLインタフェースではなくダイレクト・パスAPIが使用されるため、バインド配列サイズを決定する必要はありません。
|
参照: ダイレクト・パス・ロードの概要は、『Oracle Call Interfaceプログラマーズ・ガイド』を参照してください。 |
バインド配列には、1行以上が入る領域を確保してください。行の最大長が、BINDSIZEパラメータで指定されたバインド配列のサイズを超えると、SQL*Loaderからエラーが出力されます。通常、バインド配列内に入る範囲の行が格納されます。この場合の読取り行数の上限は、ROWSパラメータで指定された行数となります。(従来型パス・ロードでのROWSの最大値は65534です。)
バインド配列全体が連続するメモリーを占有する必要はありませんが、バインド配列内の各フィールドを格納するバッファには連続するメモリーが必要です。オペレーティング・システムで、フィールド格納用として連続する十分なメモリーを確保できないと、SQL*Loaderからエラーが出力されます。
バインド配列を大きくすると、Oracle Databaseへのコール数を最小に、またパフォーマンスを最大にできます。一般に、バインド配列サイズを大きくする場合、100行まではサイズの増加に比例してパフォーマンスが大幅に向上します。ただし、100行を超えるバインド配列サイズを設定しても、パフォーマンスはそれほど向上しません。したがって、一般に配列サイズ(バイト単位)は100行が目安となります。
一般に、サイズが適切であれば、SQL*Loaderで効果的に処理できます。通常は、この項で説明するような細かい計算をする必要はありません。この項は、パフォーマンスを最大にする場合、またはメモリー使用量を確認する場合に参照してください。
バインド配列サイズを指定する場合に、コマンドライン・パラメータBINDSIZEまたは制御ファイル中のOPTIONS句を使用すると、バインド配列の上限値が設定されます。バインド配列は、この上限値を超えることはありません。
初期化の段階で、SQL*Loaderでは単一行のロードに必要なサイズがバイト単位で決定されます。このサイズが指定された最大値を超える場合は、エラーが返され、ロードが終了します。
次にSQL*Loaderでは、このサイズとロードする行数が乗算されます。このとき、ロードする行数は、コマンドライン・パラメータROWSで指定されていても、制御ファイル中のOPTIONS句で指定されていてもかまいません。
このサイズがバインド配列の最大値を超えないかぎり、ロードは継続されます。SQL*Loaderでは、バインド配列の最大サイズの限界まで行数は拡張されません。行数とバインド配列の最大サイズの両方が指定された場合、SQL*Loaderでは、これらの値の小さい方がバインド配列に適用されます。
バインド配列の最大サイズが小さく、指定の行数を格納できない場合は、その最大サイズに収まる分の行数が採用されます。
バインド配列サイズは、配列内の行数に各行の最大長を掛け合せた値となります。行の最大長は、次のように、フィールドの最大長の合計にオーバーヘッドを加えた値となります。
bind array size =
(number of rows) * ( SUM(fixed field lengths)
+ SUM(maximum varying field lengths)
+ ( (number of varying length fields)
* (size of length indicator) )
)
ほとんどのフィールドのサイズは、固定長です。このような固定長フィールドの場合、ロードされる各行のサイズは同じです。固定長フィールドについては、「SQL*Loaderのデータ型」で説明するとおり、フィールド・サイズがフィールドの最大長(バイト)となります。そのため、オーバーヘッドは発生しません。
行によってサイズが変化するフィールドには、次のようなものがあります。
CHAR
DATE
INTERVAL DAY TO SECOND
INTERVAL DAY TO YEAR
LONG VARRAW
数値型EXTERNAL
TIME
TIMESTAMP
TIME WITH TIME ZONE
TIMESTAMP WITH TIME ZONE
VARCHAR
VARCHARC
VARGRAPHIC
VARRAW
VARRAWC
これらのデータ型の最大長の詳細は、「SQL*Loaderのデータ型」を参照してください。ここでの最大長とは、入力データ・レコードの中でフィールドが占有できる長さを、バイト数で表したものです。この最大長は、バインド配列の中で各フィールドが占有する格納領域のサイズも表しています。バインド配列には、サイズが変化するこれらのフィールドについてのオーバーヘッドも含まれます。
文字データ型(CHAR、DATEおよび数値型EXTERNAL)がデリミタ付きで指定された場合は、これらのフィールドに対して指定されたフィールド長が最大長となります。逆に、デリミタなしでこれらのデータ型が指定された場合は、レコードのサイズは固定ですが、挿入時にフィールド中の空白文字が切り捨てられるため、フィールド長は変化します。したがって、これらのデータ型は、たとえ固定長フィールドであっても内部的には可変長フィールドとして扱われます。
長さインジケータは、バインド配列内のそれぞれのフィールドに格納されています。バインド配列におけるフィールドの領域として、そのフィールドの可能最大長のデータを格納できるだけのサイズが確保されています。一方、実際のフィールド長は、行ごとに長さインジケータで示されます。
|
注意: 従来型パス・ロードでは、バインド配列のサイズの割当て時にLOBFILEは含まれません。 |
ほとんどのシステムでは、長さインジケータのサイズは2バイトです。まれに3バイトのシステムもあります。長さインジケータのサイズを調べるには、次の制御ファイルを作成して実行します。
OPTIONS (ROWS=1) LOAD DATA INFILE * APPEND INTO TABLE DEPT (deptno POSITION(1:1) CHAR(1)) BEGINDATA a
この制御ファイルは、1行のバインド配列を使用して、1バイトのCHARをロードします。この例では、実際にデータはロードされません。これは、aを数値型の列(deptno)にロードすると、変換エラーが発生するためです。このときのログ・ファイルに示されたバインド配列サイズから、(文字フィールドの長さである)1を引いた値が、フィールド長のインジケータのサイズとなります。
|
注意: これと同様の方法で、計算しないでバインド配列サイズを求めることもできます。制御ファイルにデータを記述せず、ROWS=1と指定して実行すると、1行のデータに必要なメモリーのサイズがわかります。このサイズとバインド配列に格納する行数を掛け合せれば、バインド配列サイズを判断できます。 |
表9-3から表9-6の表に、各データ型のメモリー要件を示します。「L」は制御ファイルで指定したデータ長です。「P」は精度です。「S」はフィールド長インジケータのサイズです。これらの値の詳細は、「SQL*Loaderのデータ型」を参照してください。
表9-3 固定長フィールド
| データ型 | バイト単位のサイズ(オペレーティング・システムによって異なる) |
|---|---|
|
|
C言語の |
|
|
|
|
|
C言語の |
|
|
C言語の |
|
|
C言語の |
|
|
C言語の |
|
|
|
|
|
|
|
|
2つの数値で構成されます。最初に長さを指定し、次に(オプションで) |
|
|
このデータ型は、 |
表9-4 非グラフィック・フィールド
| データ型 | デフォルト・サイズ | 指定するサイズ |
|---|---|---|
|
(パック) |
なし |
(N+1)/2切上げ |
|
|
なし |
P |
|
|
なし |
L |
|
|
1 |
L + S |
|
日時データ型および期間データ型(デリミタなし) |
なし |
L + S |
|
数値型 |
なし |
L + S |
VARCHAR型、VARGRAPHIC型フィールド、およびデリミタ付きのCHAR型、DATE型、数値型EXTERNAL型フィールドの場合、そのデータ型に割り当てられているデフォルト・サイズに特に注意してください。このデフォルト・サイズによっては、メモリーを大量に使用することがあります。特に、デフォルト・サイズにバインド配列の行数を掛け合せると、使用するメモリーは非常に大きくなります。これらのフィールドに対しては、最大長としてできるだけ小さな値を指定してください。次の例について考えてみます。
CHAR(10) TERMINATED BY ","
バイト長セマンティクスを使用する場合、次の例では、バインド配列で(10+2)×64=768バイトのメモリーを使用します(ここでは、長さインジケータを2バイトで一度に64行ロードするとして計算しています)。
同じ例で文字長セマンティクスを使用する場合、バインド配列では((10 * s) + 2) * 64バイトのメモリーを使用します(ここでは、「s」はデータ・ファイル・キャラクタ・セットにおける1文字のバイト単位での最大サイズです)。
ここで、次の例について考えてみます。
CHAR TERMINATED BY ","
バイト長セマンティクスまたは文字長セマンティクスを使用しているかどうかにかかわらず、この例では、(255+2)×64=16,448バイトが必要になります。これは、デリミタ付きフィールドのデフォルト最大長が255バイトであるためです。この指定によって、バインド配列に入る行数が大きく違ってきます。
制御ファイルに複数のINTO TABLE句が指定されている場合のバインド配列サイズの計算は、複数のINTO TABLE句が指定されていない場合と同様に行います。いい換えると、制御ファイルに指定されているフィールド全体を1つの長いデータ構造体、つまりバインド配列の中の1行のデータ構造体であると考えます。
データ・レコード中の同じフィールドを複数のINTO TABLE句が参照する場合は、そのフィールドが参照されると、常に、バインド配列に追加の領域が必要となります。このようなフィールドについては、特にバッファの割当てを最小限に抑える必要があります。
|
注意: CONSTANT、EXPRESSION、RECNUM、SYSDATEおよび SEQUENCEの各関数を指定すると、SQL*Loaderによってデータが生成されます。このようにして生成されたデータは、バインド配列の領域を必要としません。 |