| Oracle® Databaseデータ・ウェアハウス・ガイド 11gリリース2 (11.2) B56309-04 |
|


 前 |
 次 |
この章では、データ・ウェアハウスの基本的な側面であるSQLによる集計処理について説明します。内容は次のとおりです。
集計は、データ・ウェアハウスの基本的な処理です。ウェアハウスにおける集計パフォーマンスを向上させるため、Oracle Databaseでは次の機能が用意されています。
GROUP BY句を拡張するCUBEおよびROLLUP
3つのGROUPING関数
GROUPING SETS式
ピボット操作
SQLに対するCUBE、ROLLUPおよびGROUPING SETS拡張により、問合せとレポートがより簡単で高速になります。CUBE、ROLLUPおよびグルーピング・セットでは、行を様々にグルーピングした文のUNION ALLと同じ単一の結果セットが生成されます。ROLLUPでは、SUM、COUNT、MAX、MINおよびAVGなどの集計を、最も詳細なものから総計まで、レベルを上げながら集計が作成されます。CUBEはROLLUPと同様の拡張で、一文で集計可能なすべての組合せについて計算を行うことができます。CUBE、ROLLUPおよびGROUPING SETS拡張を使用すると、GROUP BY句で必要なグルーピングを指定できます。これにより、CUBE操作を実行せずに複数のディメンション間で効率的に分析できます。CUBEの計算は、大きな処理負荷が生じますが、キューブをグルーピング・セットに置き換えると、パフォーマンスを大幅に改善できます。
パフォーマンスを向上させるために、CUBE、ROLLUPおよびGROUPING SETSをパラレル化できます。つまり、複数のプロセスで、すべての文を同時に実行できます。これらの機能によって集計計算がより効率的になるため、データベースのパフォーマンスおよびスケーラビリティが向上します。
3つのGROUPING関数を使用すると、各行が属するグループを識別し、小計行をソートして結果にフィルタを適用できます。
意思決定支援システムの重要な概念の1つは、多次元分析です。必要なディメンションをすべて組み合せて企業を調査します。ここでは、質問の指定に使用される任意のカテゴリという意味でディメンションという用語を使用します。最も一般的には、時間、地理、製品、部門、流通チャネルなどのディメンションが指定されますが、企業活動が多方面にわたるのと同様に、可能なディメンションの数にも制限はありません。特定のディメンション値の集合に対応付けられたイベントまたはエンティティは、通常、ファクトと呼ばれます。ファクトには、売上件数または国内通貨での売上金額、利益、顧客数、生産量など、追跡する価値があるすべてのものが含まれます。
多次元的な問合せの例を次に示します。
1999年および2000年について、すべての製品の総売上を、州から国、地域単位へと地理ディメンションの集計レベルを上げながら表示します。
1999年と2000年における南アメリカの地域別経費を示す事業のクロス集計分析を作成します。可能な小計をすべて組み込みます。
自動車製品に関する2000年の販売収入に従って、アジアでの販売代理店の上位10社をリストし、そのコミッションのランキングを作成します。
これらの問合せには、すべて複数のディメンションが伴います。多次元の質問の多くには、集計データの他、時間、地理または予算別のデータセットの比較が必要です。
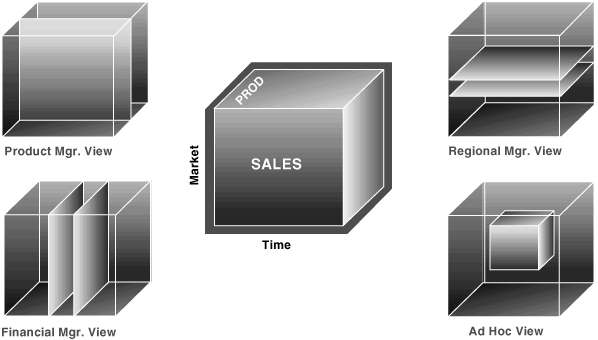
アナリストは一般に、多数のディメンションを持つデータを視覚的に表現する際、データ・キューブ(n個のディメンションの共通部分にファクトが格納される領域)を使用します。図21-1に、あるデータ・キューブと、このデータ・キューブが様々なグループによって異なる方法で利用される様子を示します。キューブには、製品、市場、売上および時間のディメンションで編成された売上データが格納されています。これが単方向ディメンションであることに注意してください。実際のデータは通常の表に物理的に格納されます。キューブ・データは、詳細データと集計データの両方で構成されます。
キューブからデータのスライスを取り出すことができます。これらは、表21-1に示すようなクロス集計レポートに対応します。地域マネージャは、異なる市場に適用されるキューブ・スライスを比較することで、データを解析します。これとは対照的に、製品マネージャは、異なる製品に適用するスライスを比較します。非定型作業を行うユーザーは、サブセット・キューブ内で、様々にデータを絞り込んで処理できます。
多次元の質問への回答には、多くの場合、数百万行にもなる膨大な量のデータへのアクセスおよび問合せが伴います。巨大な組織によって生成される大量のディテール・データは、最低レベルでは解析できないため、情報の集計ビューが不可欠です。合計やカウントなど、多数のディメンションにまたがる集計は、多次元分析にとってきわめて重要です。したがって、分析作業には、便利で効率的なデータ集計が必要となります。
多次元での処理のみでなく、すべてのタイプの処理が、拡張された集計機能の効果を得ることができます。トランザクション処理システムや、財務システム、製造システムでは、大量のシステム・リソースを必要とする膨大な数の成果レポートが生成されます。これらのレポート作成時の効率が向上することで、システムの負荷が削減されます。実際、データを詳細レベルから高度なレベルまで集計する場合には、どのようなコンピュータ処理でも集計パフォーマンスの最適化によるメリットが得られます。
これらの拡張された集計機能の提供によって、次に示すような多くの効果が得られます。
大量の作業にも少量のSQLコードしか必要としない単純化されたプログラム
より高速で高効率の問合せ処理
集計作業がサーバー側に移行されることによる、クライアント処理の負荷およびネットワーク通信量の削減
類似した問合せで既存の作業を効率化できることによる、集計のキャッシング機会の増加
GROUP BY拡張の使用例を示すために、この章ではサンプル・スキーマのshのデータを使用します。この章の例はすべて、この会社のデータを例として使用します。この架空の会社は世界中で販売を行っており、売上を金額情報と数量情報の両面から追跡しています。多数のデータ行があるため、問合せは、この例のように通常はWHERE句で厳密に制限され、結果は少数の行に限定されます。
例21-1 単純なクロス集計レポート(小計付き)
表21-1は、クロス集計レポートの例です。このレポートは、2000年9月のインターネット販売および直接販売における、米国(US)とフランス(France)のcountry_idおよびchannel_desc別の総売上を示しています。
表21-1 単純なクロス集計レポート(小計付き)
| チャネル | 国 | ||
|---|---|---|---|
|
France |
US |
合計 |
|
|
インターネット |
9,597 |
124,224 |
133,821 |
|
直接販売 |
61,202 |
638,201 |
699,403 |
|
合計 |
70,799 |
762,425 |
833,224 |
値の数が9個のみのこのような単純なレポートでも、4つの小計および1つの総計が生成されています。このレポートに必要な値の半数は、SUM(amount_sold)を要求してGROUP BY(channel_desc, country_id)を行うような問合せのみでは計算されません。上位レベルの集計を取得するには、さらに問合せが必要になります。小計の計算について改善されたデータベース・コマンドによって、問合せ、レポートおよび分析的な操作で大きな効果を得ることができます。
SELECT channels.channel_desc, countries.country_iso_code,
TO_CHAR(SUM(amount_sold), '9,999,999,999') SALES$
FROM sales, customers, times, channels, countries
WHERE sales.time_id=times.time_id AND sales.cust_id=customers.cust_id AND
sales.channel_id= channels.channel_id AND channels.channel_desc IN
('Direct Sales', 'Internet') AND times.calendar_month_desc='2000-09'
AND customers.country_id=countries.country_id
AND countries.country_iso_code IN ('US','FR')
GROUP BY CUBE(channels.channel_desc, countries.country_iso_code);
CHANNEL_DESC CO SALES$
-------------------- -- --------------
833,224
FR 70,799
US 762,425
Internet 133,821
Internet FR 9,597
Internet US 124,224
Direct Sales 699,403
Direct Sales FR 61,202
Direct Sales US 638,201
ROLLUPを使用すると、SELECT文により、指定したディメンション・グループの小計を複数のレベルで計算できます。総計も計算できます。ROLLUPは、GROUP BY句の単純な拡張であるため、その構文は非常に簡単です。ROLLUPによる拡張は非常に効率的で、問合せにかかるオーバーヘッドは最小限に抑えられます。
ROLLUPのアクションは簡単です。これは、最も詳細なレベルから総計まで、ROLLUP句で指定されたグループ・リストに従ってロールアップする小計を作成します。ROLLUPは、その引数として、グルーピング列の順序付けリストを取ります。最初に、GROUP BY句で指定された標準の集計値を計算します。次に、グルーピング列のリストを右から左に移動しながら、順番に高いレベルの小計を作成します。最後に、総計を作成します。
ROLLUPは、n+1のレベルで小計を作成します。ここで、nはグルーピング列の数です。たとえば、time、regionおよびdepartment(n=3)のグルーピング列でROLLUPを指定した問合せの場合、結果セットには4つの集計レベルの行が含まれます。
ROLLUPを使用するときにデータの圧縮が必要となることがあります。これは、古いパーティションに対する更新が少ない場合に特に役立ちます。
時間や地理などの階層的なディメンションに従って小計する場合に非常に有効です。たとえば、問合せでROLLUP(y, m, day)またはROLLUP(country, state, city)のように指定できます。
サマリー表を使用しているデータ・ウェアハウス管理者の場合は、ROLLUPを使用することでサマリー表のメンテナンスが簡単になり、時間を短縮できます。
ROLLUPは、SELECT文のGROUP BY句で使用します。形式は次のとおりです。
SELECT … GROUP BY ROLLUP(grouping_column_reference_list)
例21-2 ROLLUP
この例では、shサンプル・スキーマ・データを使用します。このデータは、図21-1で使用されているものと同じです。ROLLUPは、3つのディメンションにまたがっています。
SELECT channels.channel_desc, calendar_month_desc,
countries.country_iso_code,
TO_CHAR(SUM(amount_sold), '9,999,999,999') SALES$
FROM sales, customers, times, channels, countries
WHERE sales.time_id=times.time_id
AND sales.cust_id=customers.cust_id
AND customers.country_id = countries.country_id
AND sales.channel_id = channels.channel_id
AND channels.channel_desc IN ('Direct Sales', 'Internet')
AND times.calendar_month_desc IN ('2000-09', '2000-10')
AND countries.country_iso_code IN ('GB', 'US')
GROUP BY
ROLLUP(channels.channel_desc, calendar_month_desc, countries.country_iso_code);
CHANNEL_DESC CALENDAR CO SALES$
-------------------- -------- -- --------------
Internet 2000-09 GB 16,569
Internet 2000-09 US 124,224
Internet 2000-09 140,793
Internet 2000-10 GB 14,539
Internet 2000-10 US 137,054
Internet 2000-10 151,593
Internet 292,387
Direct Sales 2000-09 GB 85,223
Direct Sales 2000-09 US 638,201
Direct Sales 2000-09 723,424
Direct Sales 2000-10 GB 91,925
Direct Sales 2000-10 US 682,297
Direct Sales 2000-10 774,222
Direct Sales 1,497,646
1,790,032
丸めのため、結果が常に加算されるとは限らないことに注意してください。
この問合せでは、次の行集合が戻されます。
ROLLUPを使用しないでGROUP BYによって生成される通常の集計行。
channel_descとcalendar_monthの組合せごとに、country_idをまたがって集計される第1レベルの小計。
channel_desc値ごとに、calendar_month_descとcountry_idをまたがって集計される第2レベルの小計。
総計行。
一部の小計のみを含めるためのロールアップもできます。このような部分的ロールアップで使用する構文は次のとおりです。
GROUP BY expr1, ROLLUP(expr2, expr3);
この場合、GROUP BY句は3つ(2+1)の集計レベルで小計を作成します。つまり、(expr1, expr2, expr3)のレベル、(expr1, expr2)のレベル、および(expr1)のレベルです。
例21-3 部分的ROLLUP
SELECT channel_desc, calendar_month_desc, countries.country_iso_code,
TO_CHAR(SUM(amount_sold), '9,999,999,999') SALES$
FROM sales, customers, times, channels, countries
WHERE sales.time_id=times.time_id AND sales.cust_id=customers.cust_id
AND customers.country_id = countries.country_id
AND sales.channel_id= channels.channel_id
AND channels.channel_desc IN ('Direct Sales', 'Internet')
AND times.calendar_month_desc IN ('2000-09', '2000-10')
AND countries.country_iso_code IN ('GB', 'US')
GROUP BY channel_desc, ROLLUP(calendar_month_desc, countries.country_iso_code);
CHANNEL_DESC CALENDAR CO SALES$
-------------------- -------- -- --------------
Internet 2000-09 GB 16,569
Internet 2000-09 US 124,224
Internet 2000-09 140,793
Internet 2000-10 GB 14,539
Internet 2000-10 US 137,054
Internet 2000-10 151,593
Internet 292,387
Direct Sales 2000-09 GB 85,223
Direct Sales 2000-09 US 638,201
Direct Sales 2000-09 723,424
Direct Sales 2000-10 GB 91,925
Direct Sales 2000-10 US 682,297
Direct Sales 2000-10 774,222
Direct Sales 1,497,646
この問合せでは、次の行集合が戻されます。
ROLLUPを使用しないでGROUP BYによって生成される通常の集計行。
channel_descとcalendar_month_descの組合せごとに、country_idをまたがって集計される第1レベルの小計。
channel_desc値ごとに、calendar_month_descとcountry_idをまたがって集計される第2レベルの小計。
総計行は生成されません。
CUBEは、指定されたグルーピング列の集合を取り、それらが取り得るすべての組合せに対して小計を作成します。多次元分析の観点では、CUBEは、指定されたディメンションを持つデータ・キューブに対して計算されるすべての小計を生成します。CUBE(time, region, department)を指定した場合、結果セットには、同等のROLLUP文および追加組合せ内にある値がすべて含まれます。たとえば、図21-1では、すべての地域にわたる部門の合計(279,000および319,000)はROLLUP(time, region, department)句では計算されませんが、CUBE(time, region, department)句では計算されます。CUBEに対して指定された列がn個ある場合、戻される小計の組合せは2からn個になります。例21-4に、3つのディメンションを持つキューブの例を示します。
|
関連項目: 構文および制限の詳細は、『Oracle Database SQL言語リファレンス』を参照してください。 |
クロス集計レポートを必要とする状況では、CUBEの使用を考慮してください。クロス集計レポートに必要なデータは、CUBEを使用して単一のSELECTで作成できます。ROLLUPと同様に、CUBEもサマリー表の作成に有効です。CUBE問合せがパラレルに実行されるよりサマリー表を利用した方が高速です。
CUBEは、通常、1つのディメンションの異なるレベルを表す列を使用する問合せより、複数のディメンションの列を使用する問合せに最も適しています。たとえば、一般的に要求されるクロス集計作成では、month、stateおよびproductのすべての組合せに対する小計が必要です。これらは、3つの独立したディメンションであり、取り得るすべての組合せに対する小計を処理した分析が一般的です。反対に、year、monthおよびdayが取り得るすべての組合せを示すクロス集計作成では、timeディメンションに階層があるため、必要な値はいくつかに限られています。年間を通して合計された、毎月の日別利益のような小計は、ほとんどの分析では必要ありません。「年間の毎月16日の総売上はいくらか」といった質問を必要とするユーザーは、比較的少数です。ロールアップ計算を効率的に処理する例は、「ROLLUPおよびCUBEでの階層処理」を参照してください。
CUBEは、SELECT文のGROUP BY句で使用します。形式は次のとおりです。
SELECT … GROUP BY CUBE (grouping_column_reference_list)
例21-4 CUBE
SELECT channel_desc, calendar_month_desc, countries.country_iso_code,
TO_CHAR(SUM(amount_sold), '9,999,999,999') SALES$
FROM sales, customers, times, channels, countries
WHERE sales.time_id=times.time_id AND sales.cust_id=customers.cust_id AND
sales.channel_id= channels.channel_id
AND customers.country_id = countries.country_id
AND channels.channel_desc IN
('Direct Sales', 'Internet') AND times.calendar_month_desc IN
('2000-09', '2000-10') AND countries.country_iso_code IN ('GB', 'US')
GROUP BY CUBE(channel_desc, calendar_month_desc, countries.country_iso_code);
CHANNEL_DESC CALENDAR CO SALES$
-------------------- -------- -- --------------
1,790,032
GB 208,257
US 1,581,775
2000-09 864,217
2000-09 GB 101,792
2000-09 US 762,425
2000-10 925,815
2000-10 GB 106,465
2000-10 US 819,351
Internet 292,387
Internet GB 31,109
Internet US 261,278
Internet 2000-09 140,793
Internet 2000-09 GB 16,569
Internet 2000-09 US 124,224
Internet 2000-10 151,593
Internet 2000-10 GB 14,539
Internet 2000-10 US 137,054
Direct Sales 1,497,646
Direct Sales GB 177,148
Direct Sales US 1,320,497
Direct Sales 2000-09 723,424
Direct Sales 2000-09 GB 85,223
Direct Sales 2000-09 US 638,201
Direct Sales 2000-10 774,222
Direct Sales 2000-10 GB 91,925
Direct Sales 2000-10 US 682,297
この問合せは、3つのディメンションにまたがるCUBE集計を示しています。
部分的CUBEは、特定のディメンションに制限してCUBE演算子の外側の列に進むという点で、部分的ROLLUPに似ています。この場合、取り得るすべての組合せに対する小計は、CUBEリスト内(カッコ内)のディメンションに制限され、GROUP BYリスト内の前の項目と組み合されます。
部分的CUBEの構文は、次のとおりです。
GROUP BY expr1, CUBE(expr2, expr3)
この構文例では2×2、つまり次の4つの小計が計算されます。詳細は次のとおりです。
(expr1, expr2, expr3)
(expr1, expr2)
(expr1, expr3)
(expr1)
例21-5 部分的CUBE
salesデータベースを使用して、次の文を発行できます。
SELECT channel_desc, calendar_month_desc, countries.country_iso_code,
TO_CHAR(SUM(amount_sold), '9,999,999,999') SALES$
FROM sales, customers, times, channels, countries
WHERE sales.time_id = times.time_id
AND sales.cust_id = customers.cust_id
AND customers.country_id=countries.country_id
AND sales.channel_id = channels.channel_id
AND channels.channel_desc IN ('Direct Sales', 'Internet')
AND times.calendar_month_desc IN ('2000-09', '2000-10')
AND countries.country_iso_code IN ('GB', 'US')
GROUP BY channel_desc, CUBE(calendar_month_desc, countries.country_iso_code);
CHANNEL_DESC CALENDAR CO SALES$
-------------------- -------- -- --------------
Internet 292,387
Internet GB 31,109
Internet US 261,278
Internet 2000-09 140,793
Internet 2000-09 GB 16,569
Internet 2000-09 US 124,224
Internet 2000-10 151,593
Internet 2000-10 GB 14,539
Internet 2000-10 US 137,054
Direct Sales 1,497,646
Direct Sales GB 177,148
Direct Sales US 1,320,497
Direct Sales 2000-09 723,424
Direct Sales 2000-09 GB 85,223
Direct Sales 2000-09 US 638,201
Direct Sales 2000-10 774,222
Direct Sales 2000-10 GB 91,925
Direct Sales 2000-10 US 682,297
ROLLUPの場合と同様に、UNION ALL文と組み合された複数のSELECT文によって、CUBEを使用する場合と同じ情報が収集できます。ただし、この場合は多数のSELECT文が必要となります。nディメンションのキューブの場合、2からn個のSELECT文が必要です。3ディメンションの場合も、UNION ALLでリンクされたSELECT文を発行することになります。SELECT文が多すぎるため、処理の効率が悪くなり、SQL文が極端に長くなります。
可能なすべての組合せを計算する際にディメンションを1つのみ追加すると、どのような影響があるかを考えてみます。SELECT文の数は、2倍の16になります。CUBE句で使用される列が増加するほど、UNION ALLを使用する方法と比較した場合の効果も大きくなります。
ROLLUPおよびCUBEの使用については、2つの課題があります。第1の課題は、どの結果セット行が小計であるかをプログラム上でどのように判断するか、および指定された小計の正確な集計レベルをどのように探し出すかということです。合計に対する割合などを計算する場合に小計がよく必要となるため、どの行が求める小計であるかを判断する簡単な方法が必要です。第2の課題は、格納されるNULL値と、ROLLUPまたはCUBEによって作成される「NULL」値の両方が参照結果に含まれる場合、どう処理するかということです。この2つをどのように区別するかが問題になります。ここでは、このような場合について例をあげて説明します。
|
関連項目: 構文および制限の詳細は、『Oracle Database SQL言語リファレンス』を参照してください。 |
GROUPINGは、このような問題を処理します。単一の列を引数として使用し、ROLLUPまたはCUBE操作によってNULLが作成された場合に、GROUPINGは1を戻します。つまり、NULLが小計の行であることを示す場合、GROUPINGは1を戻します。格納されたNULLなど、その他のタイプの値では0(ゼロ)を戻します。
GROUPINGは、SELECT文のリスト部分で使用します。形式は次のとおりです。
SELECT … [GROUPING(dimension_column)…] …
GROUP BY … {CUBE | ROLLUP| GROUPING SETS} (dimension_column)
例21-6 GROUPINGによる列のマスク
次の例では、GROUPINGを使用して、例21-3に示した結果セットに対する一連のマスク列を作成します。マスク列は、プログラムで簡単に分析できます。
SELECT channel_desc, calendar_month_desc, country_iso_code,
TO_CHAR(SUM(amount_sold), '9,999,999,999') SALES$, GROUPING(channel_desc) AS Ch,
GROUPING(calendar_month_desc) AS Mo, GROUPING(country_iso_code) AS Co
FROM sales, customers, times, channels, countries
WHERE sales.time_id=times.time_id
AND sales.cust_id=customers.cust_id
AND customers.country_id = countries.country_id
AND sales.channel_id= channels.channel_id
AND channels.channel_desc IN ('Direct Sales', 'Internet')
AND times.calendar_month_desc IN ('2000-09', '2000-10')
AND countries.country_iso_code IN ('GB', 'US')
GROUP BY ROLLUP(channel_desc, calendar_month_desc, countries.country_iso_code);
CHANNEL_DESC CALENDAR CO SALES$ CH MO CO
-------------------- -------- -- -------------- ---------- ---------- ----------
Internet 2000-09 GB 16,569 0 0 0
Internet 2000-09 US 124,224 0 0 0
Internet 2000-09 140,793 0 0 1
Internet 2000-10 GB 14,539 0 0 0
Internet 2000-10 US 137,054 0 0 0
Internet 2000-10 151,593 0 0 1
Internet 292,387 0 1 1
Direct Sales 2000-09 GB 85,223 0 0 0
Direct Sales 2000-09 US 638,201 0 0 0
Direct Sales 2000-09 723,424 0 0 1
Direct Sales 2000-10 GB 91,925 0 0 0
Direct Sales 2000-10 US 682,297 0 0 0
Direct Sales 2000-10 774,222 0 0 1
Direct Sales 1,497,646 0 1 1
1,790,032 1 1 1
プログラムは、T、RおよびD列に対するマスク「0 0 0」によって、ディテール行を簡単に識別できます。第1レベルの小計行は「0 0 1」のマスクを持ち、第2レベルの小計行はマスク「0 1 1」、全体の総計行はマスク「1 1 1」を持ちます。
例21-7に示すようにGROUPINGおよびDECODE関数を使用して、結果セットを読みやすくできます。
例21-7 可読性を高めるためのGROUPING
SELECT DECODE(GROUPING(channel_desc), 1, 'Multi-channel sum', channel_desc) AS
Channel, DECODE (GROUPING (country_iso_code), 1, 'Multi-country sum',
country_iso_code) AS Country, TO_CHAR(SUM(amount_sold), '9,999,999,999') SALES$
FROM sales, customers, times, channels, countries
WHERE sales.time_id=times.time_id
AND sales.cust_id=customers.cust_id
AND customers.country_id = countries.country_id
AND sales.channel_id= channels.channel_id
AND channels.channel_desc IN ('Direct Sales', 'Internet')
AND times.calendar_month_desc= '2000-09'
AND country_iso_code IN ('GB', 'US')
GROUP BY CUBE(channel_desc, country_iso_code);
CHANNEL COUNTRY SALES$
-------------------- ----------------- --------------
Multi-channel sum Multi-country sum 864,217
Multi-channel sum GB 101,792
Multi-channel sum US 762,425
Internet Multi-country sum 140,793
Internet GB 16,569
Internet US 124,224
Direct Sales Multi-country sum 723,424
Direct Sales GB 85,223
Direct Sales US 638,201
前述の文を理解するために、channel_desc列を処理する最初の列指定に注目してください。前述の文の最初の行を考えてみます。
SELECT DECODE(GROUPING(channel_desc), 1, 'All Channels', channel_desc)AS Channel
ここで、channel_descの値は、GROUPING関数を含むDECODE関数で決定されます。行の値がROLLUPまたはCUBEによって作成された集計である場合、GROUPING関数は1を戻し、それ以外の場合は0(ゼロ)を戻します。次に、DECODE関数は、GROUPING関数の結果を処理します。1が戻された場合は、テキスト「All Channels」が戻されます。0(ゼロ)が戻された場合、データベースからchannel_descの値が戻されます。データベースから戻される値は、「Internet」のような実際の値または格納されたNULLです。country_idを表示する2番目の列指定も同様に処理されます。
GROUPING関数は、2種類のNULLの識別に役立つのみでなく、小計行のソートまたは結果のフィルタも可能です。例21-8では、CUBEによって作成された小計のサブセットを取り出し、基本レベルの集計は取り出しません。HAVING句で、GROUPING関数を使用する列を制約します。
例21-8 HAVINGと組み合せたGROUPING
SELECT channel_desc, calendar_month_desc, country_iso_code, TO_CHAR(
SUM(amount_sold), '9,999,999,999') SALES$, GROUPING(channel_desc) CH, GROUPING
(calendar_month_desc) MO, GROUPING(country_iso_code) CO
FROM sales, customers, times, channels, countries
WHERE sales.time_id=times.time_id AND sales.cust_id=customers.cust_id
AND customers.country_id = countries.country_id
AND sales.channel_id= channels.channel_id
AND channels.channel_desc IN ('Direct Sales', 'Internet')
AND times.calendar_month_desc IN ('2000-09', '2000-10')
AND country_iso_code IN ('GB', 'US')
GROUP BY CUBE(channel_desc, calendar_month_desc, country_iso_code)
HAVING (GROUPING(channel_desc)=1 AND GROUPING(calendar_month_desc)= 1
AND GROUPING(country_iso_code)=1) OR (GROUPING(channel_desc)=1
AND GROUPING (calendar_month_desc)= 1) OR (GROUPING(country_iso_code)=1
AND GROUPING(calendar_month_desc)= 1);
CHANNEL_DESC C CO SALES$ CH MO CO
-------------------- - -- -------------- ---------- ---------- ----------
US 1,581,775 1 1 0
GB 208,257 1 1 0
Direct Sales 1,497,646 0 1 1
Internet 292,387 0 1 1
1,790,032 1 1 1
例21-8でグループが正確に指定されていることを確認するために、例21-8の結果セットと例21-3の結果セットを比較します。前者には、timeおよびdepartmentについて集計された年間合計、地域合計および総計のみが含まれています。
特定の行のGROUP BYレベルを調べるには、問合せでGROUP BY列ごとにGROUPING関数情報を戻す必要があります。そのためにGROUPING関数を使用する場合は、各GROUP BY列にGROUPING関数を使用するもう1つの列が必要です。たとえば、4列のGROUP BY句は4つのGROUPING関数を使用して分析する必要があります。これは、SQLで記述するには不便であり、問合せに必要な列の数が増加します。問合せの結果セットを表に格納する場合は、マテリアライズド・ビューの場合と同様に余分な列により記憶領域が使用されます。
このような問題に対処するために、GROUPING_ID関数を使用できます。GROUPING_IDは、正確なGROUP BYレベルを判断できるように、単一の数値を戻します。GROUPING_IDは、行ごとに、該当するGROUPING関数を使用した場合に生成される1と0のセットを取り、それを連結してビット・ベクトルを形成します。このビット・ベクトルは2進数として扱われ、GROUPING_ID関数はこの数値の10進値を戻します。たとえば、式CUBE(a, b)でグルーピングする場合、可能な値は表21-2のようになります。
GROUPING_IDでは、グルーピング・セット指定により作成されたグルーピングが明確に区別されるため、マテリアライズド・ビューのリフレッシュおよびリライトに非常に有効です。
GROUP BYの拡張は強力で柔軟性があり、重複するグルーピングを含む複雑な結果セットの出力も可能です。GROUP_ID関数を使用すると、重複するグルーピングを区別できます。特定レベルで計算される複数の行集合がある場合、GROUP_IDは最初の集合の行すべてに値0を割り当てます。特定のグルーピングに関する重複行の他の集合にはすべて、1から始まる上位の値が割り当てられます。たとえば、重複するグルーピングを生成する次の問合せを考えてみます。
例21-9 GROUP_ID
SELECT country_iso_code, SUBSTR(cust_state_province,1,12), SUM(amount_sold),
GROUPING_ID(country_iso_code, cust_state_province) GROUPING_ID, GROUP_ID()
FROM sales, customers, times, countries
WHERE sales.time_id=times.time_id AND sales.cust_id=customers.cust_id
AND customers.country_id=countries.country_id AND times.time_id= '30-OCT-00'
AND country_iso_code IN ('FR', 'ES')
GROUP BY GROUPING SETS (country_iso_code,
ROLLUP(country_iso_code, cust_state_province));
CO SUBSTR(CUST_ SUM(AMOUNT_SOLD) GROUPING_ID GROUP_ID()
-- ------------ ---------------- ----------- ----------
ES Alicante 135.32 0 0
ES Valencia 4133.56 0 0
ES Barcelona 24.22 0 0
FR Centre 74.3 0 0
FR Aquitaine 231.97 0 0
FR Rhtne-Alpes 1624.69 0 0
FR Ile-de-Franc 1860.59 0 0
FR Languedoc-Ro 4287.4 0 0
12372.05 3 0
ES 4293.1 1 0
FR 8078.95 1 0
ES 4293.1 1 1
FR 8078.95 1 1
この問合せでは、(country_id, cust_state_province)、(country_id)、(country_id)および()というグルーピングが生成されます。グルーピング(country_id)が2度繰り返されていることに注意してください。GROUPING SETSの構文については、「GROUPING SETS式」を参照してください。
この関数を使用すると、結果にフィルタを適用して重複するグルーピングを排除できます。たとえば、問合せにHAVING句の条件GROUP_ID()=0を追加し、前述の例から重複するグルーピング(region)を排除できます。
GROUP BY句の中でGROUPING SETS式を使用して、作成するグループの集合を選択的に指定できます。これにより、CUBE全体を計算せずに、複数のディメンションにまたがる正確な指定ができます。次に例を示します。
SELECT channel_desc, calendar_month_desc, country_iso_code,
TO_CHAR(SUM(amount_sold), '9,999,999,999') SALES$
FROM sales, customers, times, channels, countries
WHERE sales.time_id=times.time_id AND sales.cust_id=customers.cust_id AND
sales.channel_id= channels.channel_id AND channels.channel_desc IN
('Direct Sales', 'Internet') AND times.calendar_month_desc IN
('2000-09', '2000-10') AND country_iso_code IN ('GB', 'US')
GROUP BY GROUPING SETS((channel_desc, calendar_month_desc, country_iso_code),
(channel_desc, country_iso_code), (calendar_month_desc, country_iso_code));
この文は複合列を使用していることに注意してください。詳細は、「複合列」を参照してください。この文では、次の3つのグルーピングにまたがる集計が計算されます。
(channel_desc, calendar_month_desc, country_iso_code)
(channel_desc, country_iso_code)
(calendar_month_desc, country_iso_code)
前述の文を次の代替文と比較します。次の文は、CUBE操作とGROUPING_ID関数を使用して必要な行を戻します。
SELECT channel_desc, calendar_month_desc, country_iso_code,
TO_CHAR(SUM(amount_sold), '9,999,999,999') SALES$,
GROUPING_ID(channel_desc, calendar_month_desc, country_iso_code) gid
FROM sales, customers, times, channels, countries
WHERE sales.time_id=times.time_id AND sales.cust_id=customers.cust_id AND
sales.channel_id= channels.channel_id AND channels.channel_desc IN
('Direct Sales', 'Internet') AND times.calendar_month_desc IN
('2000-09', '2000-10') AND country_iso_code IN ('GB', 'US')
GROUP BY CUBE(channel_desc, calendar_month_desc, country_iso_code)
HAVING GROUPING_ID(channel_desc, calendar_month_desc, country_iso_code)=0
OR GROUPING_ID(channel_desc, calendar_month_desc, country_iso_code)=2
OR GROUPING_ID(channel_desc, calendar_month_desc, country_iso_code)=4;
この文では、8(2×2×2)のグルーピングがすべて計算されますが、必要としているのは上の3グループのみです。
もう1つの方法は次の文ですが、複数の組合せがあるため長くなります。この文では、実表を3回スキャンする必要があり、非効率的です。CUBEとROLLUPは、きわめて限定的な意味を持つグルーピング・セットとみなすことができます。たとえば、次の文を考えてみます。
CUBE(a, b, c)
この文は、次の文と同等です。
GROUPING SETS ((a, b, c), (a, b), (a, c), (b, c), (a), (b), (c), ()) ROLLUP(a, b, c)
さらに、この文は、次の文と同等です。
GROUPING SETS ((a, b, c), (a, b), ())
GROUPING SETSの構文では、同じ問合せで複数のグルーピングを定義できます。GROUP BYでは、指定したグルーピングがすべて計算され、UNION ALLと組み合されます。たとえば、次の文を考えてみます。
GROUP BY GROUPING sets (channel_desc, calendar_month_desc, country_id )
この文は、次の文と同等です。
GROUP BY channel_desc UNION ALL GROUP BY calendar_month_desc UNION ALL GROUP BY country_id
表21-3に、グルーピング・セット指定および同等のGROUP BY指定を示します。一部の例では複合列が使用されているため注意してください。
表21-3 GROUPING SETS文および同等のGROUP BY文
| GROUPING SETS文 | 同等のGROUP BY文 |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
問合せブロックにまたがって検索して実行計画を生成するオプティマイザがなければ、UNIONに基づく問合せでは実表salesを複数回スキャンする必要があります。通常、ファクト表は大型のため、これはきわめて非効率的です。GROUPING SETS文を使用すると、必要なすべてのグルーピングを同じ問合せブロック内で使用できます。
複合列は、グルーピングの計算中に1単位として処理される列のコレクションです。次の文のように、列をカッコで囲んで指定します。
ROLLUP (year, (quarter, month), day)
この文では、データは年から四半期にまたがってはロールアップされませんが、かわりに、UNION ALLの次のグルーピングと同等化されます。
(year, quarter, month, day),
(year, quarter, month),
(year)
()
(quarter, month)は複合列を形成し、1単位として処理されます。通常、複合列は、ROLLUP、CUBE、GROUPING SETSおよび連結されたグルーピングに有効です。たとえば、CUBEまたはROLLUPでは、複合列は特定レベルにまたがる集計がスキップされることを意味します。つまり、次の文になります。
GROUP BY ROLLUP(a, (b, c))
これは、次と同等です。
GROUP BY a, b, c UNION ALL GROUP BY a UNION ALL GROUP BY ()
(b, c)は1単位として処理され、(b, c)にまたがるロールアップは適用されません。たとえば、zの場合、(b, c)およびGROUP BY式はGROUP BY ROLLUP(a, z)に減少します。これを次の通常のロールアップと比較します。
GROUP BY ROLLUP(a, b, c)
これは、次のようになります。
GROUP BY a, b, c UNION ALL GROUP BY a, b UNION ALL GROUP BY a UNION ALL GROUP BY ().
同様に、次の文は4つのGROUP BYと同等です。
GROUP BY CUBE((a, b), c) GROUP BY a, b, c UNION ALL GROUP BY a, b UNION ALL GROUP BY c UNION ALL GROUP By ()
GROUPING SETSでは、複合列はGROUP BYの特定レベルを示すために使用されます。複合列の他の例については、表21-3を参照してください。
例21-10 複合列
CUBEとROLLUPで必要な集計レベルは、完全には制御できません。たとえば、次の文を考えてみます。
SELECT channel_desc, calendar_month_desc, country_iso_code,
TO_CHAR(SUM(amount_sold), '9,999,999,999') SALES$
FROM sales, customers, times, channels, countries
WHERE sales.time_id=times.time_id AND sales.cust_id=customers.cust_id
AND customers.country_id = countries.country_id
AND sales.channel_id= channels.channel_id
AND channels.channel_desc IN ('Direct Sales', 'Internet')
AND times.calendar_month_desc IN ('2000-09', '2000-10')
AND country_iso_code IN ('GB', 'US')
GROUP BY ROLLUP(channel_desc, calendar_month_desc, country_iso_code);
この文では、Oracleにより次のグルーピングが計算されます。
(channel_desc, calendar_month_desc, country_iso_code)
(channel_desc, calendar_month_desc)
(channel_desc)
()
これらのうち、1、3および4番目のグルーピングのみが必要な場合に、計算をこれらのグルーピングに制限するには、複合列を使用する必要があります。複合列を使用すると、月と国をロールアップ中に1単位として処理することで計算を制限できます。カッコ内の列は、CUBEおよびROLLUPの計算中に1単位として処理されます。つまり、次のようになります。
SELECT channel_desc, calendar_month_desc, country_iso_code,
TO_CHAR(SUM(amount_sold), '9,999,999,999') SALES$
FROM sales, customers, times, channels, countries
WHERE sales.time_id=times.time_id AND sales.cust_id=customers.cust_id AND
sales.channel_id= channels.channel_id AND channels.channel_desc IN
('Direct Sales', 'Internet') AND times.calendar_month_desc IN
('2000-09', '2000-10') AND country_iso_code IN ('GB', 'US')
GROUP BY ROLLUP(channel_desc, (calendar_month_desc, country_iso_code));
CHANNEL_DESC CALENDAR CO SALES$
-------------------- -------- -- --------------
Internet 2000-09 GB 228,241
Internet 2000-09 US 228,241
Internet 2000-10 GB 239,236
Internet 2000-10 US 239,236
Internet 934,955
Direct Sales 2000-09 GB 1,217,808
Direct Sales 2000-09 US 1,217,808
Direct Sales 2000-10 GB 1,225,584
Direct Sales 2000-10 US 1,225,584
Direct Sales 4,886,784
5,821,739
連結グルーピングにより、一貫した方法でグルーピングの有効な組合せを生成できます。連結グルーピングで指定したグルーピングにより、各グルーピング・セットからのグルーピングのクロス積が得られます。クロス積操作により、ごく少数の連結グルーピングで多数の最終グループを生成できます。複数のグルーピング・セット、キューブおよびロールアップをカンマで区切って指定するのみで、連結グルーピングを指定できます。連結グルーピング・セットの例を次に示します。
GROUP BY GROUPING SETS(a, b), GROUPING SETS(c, d)
このSQLは、次のグルーピングを定義します。
(a, c), (a, d), (b, c), (b, d)
グルーピング・セットの連結は、次の理由できわめて有効です。
問合せの開発が簡単
すべてのグルーピングを手動で列挙する必要がありません。
アプリケーションで使用
分析用アプリケーションで生成されるSQLでは、グルーピング・セットの連結を伴うことがよくあります。この場合、それぞれのグルーピング・セットがディメンションに必要なグルーピングを定義します。
例21-11 連結グルーピング
GROUP BY句に複数のグルーピングを指定することもできます。たとえば、各製品の売上値をtimeディメンション(year、monthおよびday)のすべてのレベルとgeographyディメンション(region)のすべてのレベルにまたがってロールアップして集計する場合は、次の文を発行できます。
SELECT channel_desc, calendar_year, calendar_quarter_desc, country_iso_code,
cust_state_province, TO_CHAR(SUM(amount_sold), '9,999,999,999') SALES$
FROM sales, customers, times, channels, countries
WHERE sales.time_id = times.time_id AND sales.cust_id = customers.cust_id
AND sales.channel_id = channels.channel_id AND countries.country_id =
customers.country_id AND channels.channel_desc IN
('Direct Sales', 'Internet') AND times.calendar_month_desc IN ('2000-09',
'2000-10') AND countries.country_iso_code IN ('GB', 'FR')
GROUP BY channel_desc, GROUPING SETS (ROLLUP(calendar_year,
calendar_quarter_desc),
ROLLUP(country_iso_code, cust_state_province));
その結果、次のようなグルーピングとなります。
(channel_desc, calendar_year, calendar_quarter_desc)
(channel_desc, calendar_year)
(channel_desc)
(channel_desc, country_iso_code, cust_state_province)
(channel_desc, country_iso_code)
(channel_desc)
これは、次のクロス積です。
channel_desc
ROLLUP(calendar_year, calendar_quarter_desc)。これは、((calendar_year, calendar_quarter_desc), (calendar_year), ())と同等です。
ROLLUP(country_iso_code, cust_state_province)。これは、((country_iso_code, cust_state_province), (country_iso_code), ())と同等です。
出力には(channel_desc)グループが2つ含まれていることに注意してください。余分な(channel_desc)グループを排除するには、問合せでGROUP_ID関数を使用します。
連結結合のもう1つの例を例21-12に示します。この例は、2つのグルーピング・セットのクロス積を示しています。
例21-12 連結グルーピング(2つのグルーピング・セットのクロス積)
SELECT country_iso_code, cust_state_province, calendar_year,
calendar_quarter_desc, TO_CHAR(SUM(amount_sold), '9,999,999,999') SALES$
FROM sales, customers, times, channels, countries
WHERE sales.time_id=times.time_id AND sales.cust_id=customers.cust_id AND
countries.country_id=customers.country_id AND
sales.channel_id= channels.channel_id AND channels.channel_desc IN
('Direct Sales', 'Internet') AND times.calendar_month_desc IN
('2000-09', '2000-10') AND country_iso_code IN ('GB', 'FR')
GROUP BY GROUPING SETS (country_iso_code, cust_state_province),
GROUPING SETS (calendar_year, calendar_quarter_desc);
この文では、次のようなグルーピングが計算されます。
(country_iso_code, year)、(country_iso_code, calendar_quarter_desc)、(cust_state_province, year)および(cust_state_province, calendar_quarter_desc)
連結グルーピングの最も重要な用途の1つは、階層的データ・キューブに必要な集計を生成することです。階層的キューブは、データが各ディメンションのロールアップ階層に沿って集計され、これらの集計がディメンション間で組み合されるデータセットです。ビジネス・インテリジェンス問合せに必要な典型的な集計の集合が含まれます。連結グルーピングを使用すると、n個のROLLUPを使用するのみで階層キューブに必要な集計をすべて生成し、不要な集計の生成を回避できます。nはディメンション数です。
shサンプル・スキーマ・データセットのディメンションが3つのみで、それぞれにマルチレベルの階層があるとします。
time: year、quarter、month、day(weekは別の階層内)
product: category、subcategory、prod_name
geography: region、subregion、country、state、city
このデータは、階層レベルごとに1列を使用して表され、ディメンションの列は合計12列および売上高を保持する列となります。
ビジネス・インテリジェンスのニーズに合せ、ディメンションの様々な組合せについて特定の集計を計算して格納できます。例21-13では、「day」を除くすべてのレベルの集計を作成しますが、これでは作成する行数が多すぎます。特に、各ディメンション内でROLLUPを使用して有効な集計を生成する必要があります。各ディメンションでROLLUPベースの集計を生成した後に、それを他のディメンションと組み合せます。これにより、階層的キューブが生成されます。これは12のディメンション列すべてを使用するCUBEとまったく同じではないため注意してください。2から12乗(4,096)の集計グループが作成されますが、そのうちで必要としているのはごく少数です。連結グルーピング・セットを使用すると、必要な集計のみを簡単に生成できます。例21-13に、GROUP BY句が必要とされる例を示します。
例21-13 連結グルーピングと階層的キューブ
SELECT calendar_year, calendar_quarter_desc, calendar_month_desc,
country_region, country_subregion, countries.country_iso_code,
cust_state_province, cust_city, prod_category_desc, prod_subcategory_desc,
prod_name, TO_CHAR(SUM (amount_sold), '9,999,999,999') SALES$
FROM sales, customers, times, channels, countries, products
WHERE sales.time_id=times.time_id AND sales.cust_id=customers.cust_id AND
sales.channel_id= channels.channel_id AND sales.prod_id=products.prod_id AND
customers.country_id=countries.country_id AND channels.channel_desc IN
('Direct Sales', 'Internet') AND times.calendar_month_desc IN
('2000-09', '2000-10') AND prod_name IN ('Envoy Ambassador',
'Mouse Pad') AND countries.country_iso_code IN ('GB', 'US')
GROUP BY ROLLUP(calendar_year, calendar_quarter_desc, calendar_month_desc),
ROLLUP(country_region, country_subregion, countries.country_iso_code,
cust_state_province, cust_city),
ROLLUP(prod_category_desc, prod_subcategory_desc, prod_name);
GROUP BY指定のロールアップにより、ディメンションごとに4つずつ、次のグループが生成されます。
表21-4 階層的CUBEの例
| 時間別ROLLUP | 製品別ROLLUP | 地理別ROLLUP |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
前述のSQLで指定されている連結グルーピングでは、表に示したROLLUP集計を使用してクロス積が実行されます。クロス積により、階層的データ・キューブに必要な96(4×4×6)の集計グループが作成されます。96個のグルーピング・セット式を必要とするような内容を、3つのROLLUP式を使用して置き換えることには、重要なメリットがあります。つまり、簡潔なSQLはエラーの可能性が大幅に減少すること、メンテナンスがはるかに容易であること、そして問合せを大幅に最適化できることです。より多数のディメンションとレベルを持つキューブによる連結グルーピングの使用方法を指定すると、さらに大きなメリットが得られます。
階層的キューブの詳細は、「SQLでの階層的キューブの処理」を参照してください。
この項の内容は、次のとおりです。
ROLLUPおよびCUBEは、システムにあるどの階層メタデータからも独立して動作します。計算は、主にそれらを使用するSELECT文で指定された列を基にして実行されます。この方法では、階層メタデータを使用できるかどうかにかかわらず、CUBEおよびROLLUPが使用可能になります。階層ディメンションでレベルを処理するには、ROLLUPを使用し、別の列を使用して明示的にレベルを示すことが最も簡単な方法です。次に、簡単な例を示します。この例では、月は四半期にロールアップされ、四半期は年にロールアップされます。
例21-14 ROLLUPおよびCUBEでの階層処理
SELECT calendar_year, calendar_quarter_number,
calendar_month_number, SUM(amount_sold)
FROM sales, times, products, customers, countries
WHERE sales.time_id=times.time_id
AND sales.prod_id=products.prod_id
AND customers.country_id = countries.country_id
AND sales.cust_id=customers.cust_id
AND prod_name IN ('Envoy Ambassador', 'Mouse Pad')
AND country_iso_code = 'GB' AND calendar_year=1999
GROUP BY ROLLUP(calendar_year, calendar_quarter_number, calendar_month_number);
CALENDAR_YEAR CALENDAR_QUARTER_NUMBER CALENDAR_MONTH_NUMBER SUM(AMOUNT_SOLD)
------------- ----------------------- --------------------- ----------------
1999 1 1 5521.34
1999 1 2 22232.95
1999 1 3 10672.63
1999 1 38426.92
1999 2 4 23658.05
1999 2 5 5766.31
1999 2 6 23939.32
1999 2 53363.68
1999 3 7 12132.18
1999 3 8 13128.96
1999 3 9 19571.96
1999 3 44833.1
1999 4 10 15752.18
1999 4 11 7011.21
1999 4 12 14257.5
1999 4 37020.89
1999 173644.59
173644.59
CUBE、ROLLUPおよびGROUPING SETSは、GROUP BY句の列容量を制限しません。GROUP BY句で処理できる列は、拡張機能使用の有無にかかわらず255列以内です。ただし、CUBEでは組合せの数が膨大になるため、CUBEによる拡張で多数の列を指定することは望ましくありません。CUBEに対する20列のリストで、結果セットに2から20の組合せが作成されたとします。膨大なCUBEリストは、システム・リソースを極限まで使用するため、そのような問合せでは、パフォーマンスおよびシステムにかかる負荷を慎重にテストする必要があります。
SELECT文のHAVING句は、GROUP BYの使用による影響を受けません。HAVING句で指定する条件は、結果セットの小計行および小計以外の行の両方に適用されます。問合せでHAVING句から小計行または小計以外の行を排除する必要がある場合もあります。これは、HAVING句とともにGROUPINGまたはGROUPING_ID関数を使用することによって可能になります。この例については、例21-8および関連するSQLを参照してください。
多くの場合、問合せでは行を特定の方法で順序付けする必要があり、これはORDER BY句で行われます。ORDER BY句はGROUP BYの計算が完了した後に適用されるため、SELECT文のORDER BY句はGROUP BYの使用による影響を受けません。
ORDER BY指定では、結果セットの集計行と非集計行が区別されないため注意してください。たとえば、売上高を降順でリストし、各グループの最後に小計を置く必要があるとします。売上高を降順で順序付けするのみでは、小計(最大値)が各グループの最初に置かれるため不十分です。したがって、ORDER BY句の列には、集計列と非集計列を区別する列を含める必要があります。この要件は、ORDER BYをGROUP BYへの集計拡張とともに使用する問合せでは、通常、1つ以上のGROUPING関数を使用する必要があることを意味します。
この章の例では、SUM関数で使用するROLLUPおよびCUBEを示しています。これは最も一般的な集計タイプですが、これらの拡張は、GROUP BY句で使用できるその他のすべての関数(COUNT、AVG、MIN、MAX、STDDEVおよびVARIANCE)で使用することもできます。COUNTは、クロス集計分析で必要になる場合が多く、2番目に使用頻度の高い関数と考えられます。
WITH句(旧称はsubquery_factoring_clause)を使用すると、同じ問合せブロックが複雑な問合せに複数回発生する場合に、SELECT文中で再使用できます。WITHは、SQL-99標準の一部です。これは、問合せに同じ問合せブロックの参照が複数あり、結合と集計が存在する場合に特に便利です。WITH句を使用すると、Oracleでは問合せブロックの結果が取り出され、それがユーザーの一時表領域に格納されます。Oracle Databaseでは、WITH句の再帰的使用はサポートされないため注意してください。ただし、BOM(部品表)で使用する問合せや、親子階層から親子孫階層に拡張する問合せなどで使用されるWITH句の再帰的使用はサポートしています。詳細は、『Oracle Database SQL言語リファレンス』を参照してください。
次の問合せは、WITH句を使用してパフォーマンスを改善し、SQLをより単純に記述できる一例です。この問合せでは、各チャネルの売上合計が計算され、channel_summaryという名前で保持されます。次に、各チャネルの総売上がチェックされ、総売上の3分の1を超えているチャネルの売上があるかどうかが調べられます。WITH句を使用すると、channel_summaryデータは1回のみ計算され、大きいsales表の余分なスキャンを回避できます。
例21-15 WITH句
WITH channel_summary AS (SELECT channels.channel_desc, SUM(amount_sold) AS channel_total FROM sales, channels WHERE sales.channel_id = channels.channel_id GROUP BY channels.channel_desc) SELECT channel_desc, channel_total FROM channel_summary WHERE channel_total > (SELECT SUM(channel_total) * 1/3 FROM channel_summary); CHANNEL_DESC CHANNEL_TOTAL -------------------- ------------- Direct Sales 57875260.6
この例は、第22章「分析計算およびレポート用SQL関数」で説明する集計レポート関数を使用しても、効率的に実行できます。
Oracle Databaseでは、簡単で効率的なSQL問合せで階層的キューブを指定できます。このような階層的キューブは、多くの分析用SQL製品で論理キューブと呼ばれているものと同じです。データを階層的キューブ形式で指定するには、GROUP BY句に対する拡張機能の1つである連結グルーピング・セットを使用して、階層的データ・キューブに必要な集計を生成できます。連結ロールアップ(各ディメンションの階層に沿ってロールアップしてから、複数のディメンションにまたがってそのデータを連結すること)を使用すると、階層的キューブに必要な集計をすべて生成できます。
例21-16 連結ROLLUP
2次元の例(例21-13と同様)の階層的キューブの作成に必要なGROUP BY句は、次のとおりです。次の簡単な構文で連結ロールアップが実行されます。
GROUP BY ROLLUP(year, quarter, month), ROLLUP(Division, brand, item)
この連結ロールアップでは、表21-4「階層的CUBEの例」にリストされているROLLUP集計を使用してクロス積を実行します。クロス積により、階層的データ・キューブに必要な16(4×4)の集計グループが作成されます。
分析アプリケーションではデータをキューブとして扱いますが、必要なのはキューブの特定のスライスおよび領域のみです。連結ロールアップ(階層的キューブ)により、リレーショナル・データをキューブとして扱えます。複雑な分析用問合せを処理する基本的な手法は、キューブの中の必要なスライスを正確に指定する外側の問合せ内に、階層的キューブ問合せを入れるというものです。Oracle Databaseでは、スライス問合せの中にネストされている階層キューブの処理を最適化します。強力なアルゴリズムを多数適用することにより、今までにないような速度と規模でこのような問合せを処理できます。これにより、SQLの分析ツールや分析アプリケーションで一貫した問合せスタイルを使用して、非常に複雑な問合せでも処理できます。
例21-17 階層的キューブの問合せ
次の分析問合せを考えてみます。この問合せは、スライス問合せの中にネストされている階層的キューブ問合せで構成されています。
SELECT month, division, sum_sales FROM
(SELECT year, quarter, month, division, brand, item, SUM(sales) sum_sales,
GROUPING_ID(grouping-columns) gid
FROM sales, products, time
WHERE join-condition
GROUP BY ROLLUP(year, quarter, month),
ROLLUP(division, brand, item))
WHERE division = 25 AND month = 200201 AND gid = gid-for-Division-Month;
内側に指定されている階層的キューブは、ディメンションが2つと各ディメンションにレベルが4つ含まれる単純なキューブを定義しています。これにより、16のグループ(4つの時間レベル×4つの製品レベル)が生成されます。問合せ内のGROUPING_ID関数は、引数内のgrouping-columnsの集計レベルに基づいて、各行が属するグループを識別します。
外側の問合せは、この問合せに必要な制約を適用し、Divisionを値25に、Monthを値200201(この場合は2002年1月を表す)に限定します。概念的には、この問合せはキューブからデータの小さいかたまりをスライスし(切り取り)ます。GID列に対する外側の問合せの制約(問合せでgid-for-division-monthにより示されている)は、データがdivisionとmonthとの組合せとしてグループ化されていることを示すキーの値です。GID制約により、monthとdivisionというGROUP BY句のレベルで集計された行のみが選択されます。
Oracle Databaseでは、外側の問合せの条件に基づき、問合せ処理から不要な集計グループが排除されます。前述の外側の問合せの条件により、結果セットはdivisionおよびmonthを集計する1つのグループに限定されます。year、month、brandおよびitemを含むその他のグループは、ここではすべて不要です。グループ・プルーニング最適化ではこれを認識し、この問合せを次のように変換します。
SELECT month, division, sum_sales FROM (SELECT null, null, month, division, null, null, SUM(sales) sum_sales, GROUPING_ID(grouping-columns) gid FROM sales, products, time WHERE join-condition GROUP BY month, division) WHERE division = 25 AND month = 200201 AND gid = gid-for-Division-Month;
太字の部分が変更された箇所を示します。これで、内側の問合せには、monthとdivisionを含む単純なGROUP BY句が含まれます。year列、quarter列、brand列およびitem列は、単純化されたGROUP BY句に合うようにNULLに変換されています。これで、問合せではグループを1つのみ要求するので、16個のグループのうち15個が処理から除外され、処理量が大幅に削減されます。より多くのディメンションとレベルを持つキューブでは、グループ・プルーニングによる節約はさらに大きくなる可能性があります。グループ・プルーニング変換処理は、GROUP BY句のすべての拡張機能(ROLLUP、CUBEおよびGROUPING SETS)に適用されます。
オプティマイザにより前述の問合せは単純なGROUP BYに変換されましたが、グループが事前計算されてマテリアライズド・ビューに格納されていると、応答時間をさらに高速化できます。OLAP問合せではキューブの任意のスライスを求めることがあるため、多数のグループを事前に計算してマテリアライズド・ビューに格納しておくことが必要になります。これは次の項で説明します。
分析用SQLでは、複数ユーザーに対する応答時間が速いことが要求されます。そのため、キューブの大部分を事前に計算してマテリアライズド・ビューに保持する必要があります。
データ・ウェアハウス設計者は、マテリアライズド・ビューのデータ量を正確に選択できます。データ・ウェアハウスでは、階層的キューブ全体を完全にマテリアライズド・ビューにして保持できます。その場合は記憶領域の量が最も多くなりますが、キューブ内のすべての問合せにすばやく応答できます。または、部分的にマテリアライズド・ビューにしたものをデータ・ウェアハウスに格納することもできます。この場合、記憶領域は節約されますが、高速に応答できるのは問合せ全体の一部のみに限定されます。問合せが、データセットで考えられるすべてのレベルの集計グループを対象としている場合は、階層キューブ全体をマテリアライズするのが最適の方法となることもあります。
これは、各ディメンションの集計階層が他の各ディメンションと組み合せて事前に計算されることを意味します。したがって、階層キューブ全体を事前に計算するには、小さい集計グループの集合より多くのディスク領域が必要であり、作成やリフレッシュの回数も増えます。処理時間およびディスク領域と問合せパフォーマンスとのトレードオフについて、作成を決定する前に考慮する必要があります。また、ディスク領域要件を少なくするためにデータ圧縮の使用も検討します。
|
関連項目:
|
この項では、完全な階層的キューブおよび部分的な階層的キューブのマテリアライズド・ビューを示します。例の多くは、機能を示すもので、実際に実行されるものではありません。
ローリング・ウィンドウを使用することが多いデータ・ウェアハウスでは、複数のマテリアライズド・ビューに対し、必要な時間のレベルごとに1つずつの階層的キューブを格納してください。これにより、完全な階層的キューブは、sales_hierarchical_mon_cube_mv、sales_hierarchical_qtr_cube_mv、sales_hierarchical_yr_cube_mvおよびsales_hierarchical_all_cube_mvという4つのマテリアライズド・ビューに格納されることになります。
次の文では、3つのコンポジット・パーティション化されたマテリアライズド・ビューと1つのリスト・パーティション化されたマテリアライズド・ビューのセットに、完全な階層的キューブを作成します。
例21-18 完全な階層的キューブのマテリアライズド・ビュー
CREATE MATERIALIZED VIEW sales_hierarchical_mon_cube_mv
PARTITION BY RANGE (mon)
SUBPARTITION BY LIST (gid)
REFRESH FAST ON DEMAND
ENABLE QUERY REWRITE AS
SELECT calendar_year yr, calendar_quarter_desc qtr, calendar_month_desc mon,
country_id, cust_state_province, cust_city,
prod_category, prod_subcategory, prod_name,
GROUPING_ID(calendar_year, calendar_quarter_desc, calendar_month_desc,
country_id, cust_state_province, cust_city,
prod_category, prod_subcategory, prod_name) gid,
SUM(amount_sold) s_sales, COUNT(amount_sold) c_sales,
COUNT(*) c_star
FROM sales s, products p, customers c, times t
WHERE s.cust_id = c.cust_id AND s.prod_id = p.prod_id AND s.time_id = t.time_id
GROUP BY calendar_year, calendar_quarter_desc, calendar_month_desc,
ROLLUP(country_id, cust_state_province, cust_city),
ROLLUP(prod_category, prod_subcategory, prod_name),
...;
CREATE MATERIALIZED VIEW sales_hierarchical_qtr_cube_mv
REFRESH FAST ON DEMAND
ENABLE QUERY REWRITE AS
SELECT calendar_year yr, calendar_quarter_desc qtr,
country_id, cust_state_province, cust_city,
prod_category, prod_subcategory, prod_name,
GROUPING_ID(calendar_year, calendar_quarter_desc,
country_id, cust_state_province, cust_city,
prod_category, prod_subcategory, prod_name) gid,
SUM(amount_sold) s_sales, COUNT(amount_sold) c_sales,
COUNT(*) c_star
FROM sales s, products p, customers c, times t
WHERE s.cust_id = c.cust_id AND s.prod_id = p.prod_id
AND s.time_id = t.time_id
GROUP BY calendar_year, calendar_quarter_desc,
ROLLUP(country_id, cust_state_province, cust_city),
ROLLUP(prod_category, prod_subcategory, prod_name),
PARTITION BY RANGE (qtr)
SUBPARTITION BY LIST (gid)
...;
CREATE MATERIALIZED VIEW sales_hierarchical_yr_cube_mv
PARTITION BY RANGE (year)
SUBPARTITION BY LIST (gid)
REFRESH FAST ON DEMAND
ENABLE QUERY REWRITE AS
SELECT calendar_year yr, country_id, cust_state_province, cust_city,
prod_category, prod_subcategory, prod_name,
GROUPING_ID(calendar_year, country_id, cust_state_province, cust_city,
prod_category, prod_subcategory, prod_name) gid,
SUM(amount_sold) s_sales, COUNT(amount_sold) c_sales, COUNT(*) c_star
FROM sales s, products p, customers c, times t
WHERE s.cust_id = c.cust_id AND s.prod_id = p.prod_id AND s.time_id = t.time_id
GROUP BY calendar_year,
ROLLUP(country_id, cust_state_province, cust_city),
ROLLUP(prod_category, prod_subcategory, prod_name),
...;
CREATE MATERIALIZED VIEW sales_hierarchical_all_cube_mv
REFRESH FAST ON DEMAND
ENABLE QUERY REWRITE AS
SELECT country_id, cust_state_province, cust_city,
prod_category, prod_subcategory, prod_name,
GROUPING_ID(country_id, cust_state_province, cust_city,
prod_category, prod_subcategory, prod_name) gid,
SUM(amount_sold) s_sales, COUNT(amount_sold) c_sales, COUNT(*) c_star
FROM sales s, products p, customers c, times t
WHERE s.cust_id = c.cust_id AND s.prod_id = p.prod_id AND s.time_id = t.time_id
GROUP BY ROLLUP(country_id, cust_state_province, cust_city),
ROLLUP(prod_category, prod_subcategory, prod_name),
PARTITION BY LIST (gid)
...;
これにより、sales表に対するパーティション・メンテナンス操作の際に、sales_hierarchical_mon_cube_mv、sales_hierarchical_qtr_cube_mvおよびsales_hierarchical_yr_cube_mvの各マテリアライズド・ビューでPCTリフレッシュを使用できるようになります。実表に大幅な変更があり、ログ・ベースの高速リフレッシュがPCTリフレッシュよりも遅くなると予想される場合にも、PCTリフレッシュを使用できます。FORCEメソッド(method => '?')を指定して、DBMS_MVIEWパッケージのリフレッシュ・サブプログラムを実行すると、Oracle Databaseはリフレッシュに最適な方法を選択します。PCTリフレッシュの詳細は、「パーティション・チェンジ・トラッキング(PCT)リフレッシュ」を参照してください。
sales_hierarchical_qtr_cube_mvにはtimes表の列は含まれないため、このマテリアライズド・ビューではPCTリフレッシュは有効になりません。ただし、FORCEメソッド(method => '?')を指定すれば、DBMS_MVIEWパッケージのリフレッシュ・サブプログラムをコールできます。Oracle Databaseは、リフレッシュに最適な方法を選択します。
部分的なキューブ(つまり、完全なキューブからのグルーピングのサブセット)が必要な場合は、キューブを「連合キューブ」として格納することをお薦めします。連合キューブは、必要な各グルーピングを別個のマテリアライズド・ビューに格納します。
CREATE MATERIALIZED VIEW sales_mon_city_prod_mv
PARTITION BY RANGE (mon)
...
BUILD DEFERRED
REFRESH FAST ON DEMAND
USING TRUSTED CONSTRAINTS
ENABLE QUERY REWRITE AS
SELECT calendar_month_desc mon, cust_city, prod_name, SUM(amount_sold) s_sales,
COUNT(amount_sold) c_sales, COUNT(*) c_star
FROM sales s, products p, customers c, times t
WHERE s.cust_id = c.cust_id AND s.prod_id = p.prod_id
AND s.time_id = t.time_id
GROUP BY calendar_month_desc, cust_city, prod_name;
CREATE MATERIALIZED VIEW sales_qtr_city_prod_mv
PARTITION BY RANGE (qtr)
...
BUILD DEFERRED
REFRESH FAST ON DEMAND
USING TRUSTED CONSTRAINTS
ENABLE QUERY REWRITE AS
SELECT calendar_quarter_desc qtr, cust_city, prod_name,SUM(amount_sold) s_sales,
COUNT(amount_sold) c_sales, COUNT(*) c_star
FROM sales s, products p, customers c, times t
WHERE s.cust_id = c.cust_id AND s.prod_id =p.prod_id AND s.time_id = t.time_id
GROUP BY calendar_quarter_desc, cust_city, prod_name;
CREATE MATERIALIZED VIEW sales_yr_city_prod_mv
PARTITION BY RANGE (yr)
...
BUILD DEFERRED
REFRESH FAST ON DEMAND
USING TRUSTED CONSTRAINTS
ENABLE QUERY REWRITE AS
SELECT calendar_year yr, cust_city, prod_name, SUM(amount_sold) s_sales,
COUNT(amount_sold) c_sales, COUNT(*) c_star
FROM sales s, products p, customers c, times t
WHERE s.cust_id = c.cust_id AND s.prod_id =p.prod_id AND s.time_id = t.time_id
GROUP BY calendar_year, cust_city, prod_name;
CREATE MATERIALIZED VIEW sales_mon_city_scat_mv
PARTITION BY RANGE (mon)
...
BUILD DEFERRED
REFRESH FAST ON DEMAND
USING TRUSTED CONSTRAINTS
ENABLE QUERY REWRITE AS
SELECT calendar_month_desc mon, cust_city, prod_subcategory,
SUM(amount_sold) s_sales, COUNT(amount_sold) c_sales, COUNT(*) c_star
FROM sales s, products p, customers c, times t
WHERE s.cust_id = c.cust_id AND s.prod_id =p.prod_id AND s.time_id =t.time_id
GROUP BY calendar_month_desc, cust_city, prod_subcategory;
CREATE MATERIALIZED VIEW sales_qtr_city_cat_mv
PARTITION BY RANGE (qtr)
...
BUILD DEFERRED
REFRESH FAST ON DEMAND
USING TRUSTED CONSTRAINTS
ENABLE QUERY REWRITE AS
SELECT calendar_quarter_desc qtr, cust_city, prod_category cat,
SUM(amount_sold) s_sales, COUNT(amount_sold) c_sales, COUNT(*) c_star
FROM sales s, products p, customers c, times t
WHERE s.cust_id = c.cust_id AND s.prod_id =p.prod_id AND s.time_id =t.time_id
GROUP BY calendar_quarter_desc, cust_city, prod_category;
CREATE MATERIALIZED VIEW sales_yr_city_all_mv
PARTITION BY RANGE (yr)
...
BUILD DEFERRED
REFRESH FAST ON DEMAND
USING TRUSTED CONSTRAINTS
ENABLE QUERY REWRITE AS
SELECT calendar_year yr, cust_city, SUM(amount_sold) s_sales,
COUNT(amount_sold) c_sales, COUNT(*) c_star
FROM sales s, products p, customers c, times t
WHERE s.cust_id = c.cust_id AND s.prod_id = p.prod_id AND s.time_id = t.time_id
GROUP BY calendar_year, cust_city;
これらのマテリアライズド・ビューは、BUILD DEFERREDとして作成でき、次にDBMS_MVIEW.REFRESH_DEPENDENT(number_of_failures, 'SALES', 'C' ...)を実行すると、ディテール表salesで定義されている各マテリアライズド・ビューの完全リフレッシュが、最も効率的な順序でスケジューリングされます。詳細は、「リフレッシュのスケジューリング」を参照してください。
各マテリアライズド・ビューは、SELECT構文のリストで時間レベル(月、四半期、年)にパーティション化されるので、PCTは各マテリアライズド・ビューのsales表で使用できます。これによって、FASTおよびCOMPLETEリフレッシュ方法に加え、PCTリフレッシュ方法も適用できます。