12 Understanding a High-Availability System
This chapter provides an overview of the Oracle Communications Billing and Revenue Management (BRM) high-availability architecture. In addition, it explains how the BRM components in a high-availability system handle failover.
For information about setting up a high-availability system, see "Configuring a High-Availability System".
For information about the standard BRM system architecture, see "BRM System Architecture" in BRM Concepts.
About High-Availability BRM Systems
A high-availability system is designed to continue functioning when one or more of its components fail. To do this, it contains backup components to which it automatically switches (fails over) when an active component stops working. The failover should appear seamless to users and should not interrupt service.
In a BRM system, high availability is required primarily for real-time processing of prepaid and postpaid services and for operations performed by customer service representatives (CSRs). Batch processes, such as invoicing and billing, typically do not require high availability because they do not involve real-time interaction with users. You can handle failure in batch processing by restarting the component or by accepting slower performance rather than by switching to a backup component. Therefore, this chapter covers high-availability systems for real-time processing only.
About the Architecture of a High-Availability BRM System
A high-availability BRM system contains one or more backup components for each of the following components:
-
Connection Manager (CM)
-
In-Memory Database Cache Data Manager (IMDB Cache DM)
-
Oracle IMDB Cache (the data store)
-
Oracle Clusterware (includes a built-in backup mechanism)
-
Oracle Real Application Clusters (Oracle RAC) instance
The primary and backup components should not run on the same physical host or use the same power supply.
Each instance—primary and backup—of a component should be connected to all instances of the component's server-side peer (the component that it calls). For example, each CM should be connected to each IMDB Cache DM. This ensures that if one instance of a component fails, another one is available to process data.
Note:
In addition to backups, the level of availability of the components in a BRM system depends on the sizing that you use (that is, the number of computers in the system). The more computers that you spread your components across, the fewer components that are affected if one of the computers fails.Figure 12-1 shows the architecture of the basic set of components required to create a high-availability BRM system. Dashed lines represent backup connections.
Figure 12-1 Basic High-Availability BRM System
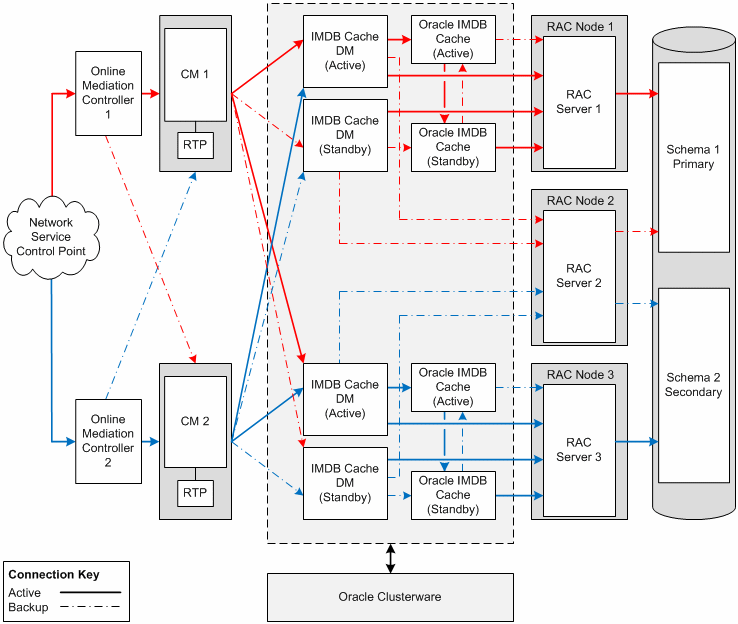
Description of ''Figure 12-1 Basic High-Availability BRM System''
Each component in a high-availability system starts the failover process in the following situations:
-
A network connection to the underlying host server is lost.
-
A response to a request is not received within the timeout period specified for the component that sent the request. The delay can be due to hardware, software, or network problems.
The following sections explain how each component in a high-availability BRM system handles failover:
For information about setting up components in a high-availability system, see "Configuring a High-Availability System".
About Connection Managers in a High-Availability System
In a high-availability system, the CMs detect failures in the pipelines and in the IMDB Cache DMs to which they connect. This section describes how CMs handle such failures:
For information about configuring CMs for a high-availability system, see "Configuring Connection Managers for High Availability".
How CMs Handle Real-Time Pipeline Failure
When a CM receives a request for rating that requires discounts to be applied or zoning to be considered by Pipeline Manager, the CM forwards the request to the instance of Pipeline Manager running real-time discounting and zoning pipelines. If the Pipeline Manager instance fails and does not send a response to the CM, the request times out, and the CM sends an error message to the calling application.
Note:
If a request has no discounting or zoning requirements, the CM sends the request to the IMDB Cache DM.How CMs Handle IMDB Cache DM Failure
In a high-availability system, the failure of an IMDB Cache DM is detected by a CM. CMs handle the following types of IMDB Cache DM failure:
For an overview of the IMDB Cache DM, see BRM Concepts.
For information about IMDB Cache DMs in a high-availability system, see "About IMDB Cache DMs and Data Stores in a High-Availability System".
Initial Connection Failure
In a high-availability system, each CM connects to an active and a standby IMDB Cache DM. If the active DM does not respond when the CM tries to establish a connection to it, the CM performs the following actions:
-
Checks the dm_pointer entries in the CM pin.conf file for the host name and port number of the standby IMDB Cache DM and connects to the standby DM.
-
Logs a failover message in the CM log file.
-
Initiates the IMDB Cache DM failover process by sending a login request to the standby DM with the PCM_OPFLG_RETRY flag.
The standby IMDB Cache DM accepts the login request and starts the failover process only if its associated Oracle IMDB Cache (data store) is active.
Otherwise, it rejects the login request with the PIN_ERR_NOT_ACTIVE error and forces the CM to retry the formerly active DM. (The PIN_ERR_NOT_ACTIVE error is recorded as PIN_ERR_NOT_PRIMARY in the CM log file.)
-
If the standby IMDB Cache DM rejects the CM's login request, the CM tries to connect to the formerly active IMDB Cache DM at intervals specified in the pcm_bad_connection_retry_delay_time_in_secs entry in the CM pin.conf and IMDB Cache DM pin.conf files.
Session Failure
If a CM loses its connection to the active IMDB Cache DM during a session or if a request from the CM to the active DM times out, the CM performs the following actions:
-
Closes the connection to the active IMDB Cache DM.
-
Logs a failure message in the CM log file.
-
Checks the dm_pointer entries in its pin.conf file for the name and port number of the standby IMDB Cache DM.
-
Initiates the IMDB Cache DM failover process by sending a login request to the standby DM with the PCM_OPFLG_RETRY flag.
-
If the failed entry opcode is not in an explicit transaction, the CM retries the opcode with the PCM_OPFLG_RETRY flag.
Explicit transaction means that Oracle Communications Service Broker (OCSB) Online Mediation Controller (OCMC) sent a transaction open request to the CM before retrying the failed entry opcode.
-
If the failed entry opcode is in an explicit transaction, the CM returns the PIN_ERRCLASS_SYSTEM_RETRYABLE error to OCMC.
OCMC ends the transaction and then retries the same transaction.
The standby DM accepts the request and starts the failover process only if the Oracle IMDB Cache (data store) that it connects to is active.
Otherwise, it rejects the request with the PIN_ERR_NOT_ACTIVE error and forces the CM to resend its request to the formerly active DM. (The PIN_ERR_NOT_ACTIVE error is recorded as PIN_ERR_NOT_PRIMARY in the CM log file.)
-
-
If the standby DM rejects the request, the CM tries to reconnect to the formerly active DM and resume the interrupted session.
About IMDB Cache DMs and Data Stores in a High-Availability System
The basic BRM high-availability architecture has one pair of active and standby IMDB Cache DM instances and one pair of active and standby Oracle IMDB Cache instances for each BRM database schema. Larger high-availability systems can have several IMDB Cache DMs and Oracle IMDB Cache pairs for each schema.
Note:
An Oracle IMDB Cache instance is also called a data store.Figure 12-2 shows a typical relationship between the IMDB Cache DMs and data stores in a high-availability system. The dashed line represents a backup connection.
Figure 12-2 Typical Relationship between IMDB Cache DMs and Data Stores in a High-Availability System
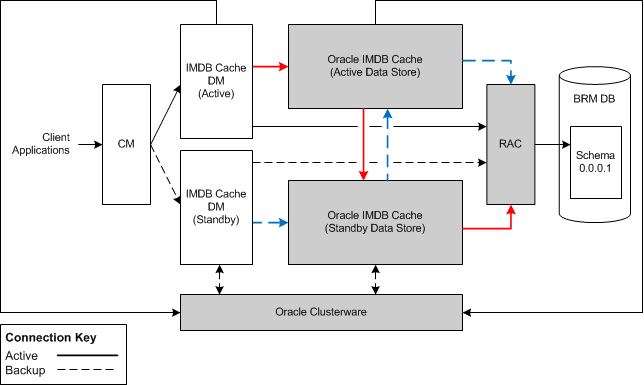
Description of ''Figure 12-2 Typical Relationship between IMDB Cache DMs and Data Stores in a High-Availability System''
As the preceding figure illustrates, the active IMDB Cache DM is connected to the active data store and the standby IMDB Cache DM is connected to the standby data store. Both IMDB Cache DM instances are also directly connected to the Oracle RAC-enabled BRM database. The replication agent associated with the active data store propagates the updates to the standby data store. Updates in the standby data store are propagated to the BRM database.
When an IMDB Cache DM starts, it connects to its associated data store and checks the state of that data store. If the data store is active, the IMDB Cache DM sets its own processing state to active. If the data store is on standby, the IMDB Cache DM sets its processing state to standby.
The active IMDB Cache DM processes all requests, and only the data in the active data store is updated. The standby data store receives the updates from the active data store and propagates them to the BRM database.
The standby IMDB Cache DM processes requests only when the state of its data store changes to active.
In a high-availability system, the data store ensures data availability and integrity.
This section covers the following topics:
For information on IMDB Cache DMs and data stores, see "Using Oracle IMDB Cache Manager".
For information on configuring IMDB Cache DMs for a high-availability system, see "Configuring IMDB Cache Manager for High Availability".
How IMDB Cache DMs Fail Over
An IMDB Cache DM failure can occur in the following situations:
-
The node on which the active IMDB Cache DM and its data store reside fails. See "About Active Node Failure".
-
The IMDB Cache DM associated with the active data store fails. See "About Active IMDB Cache DM Failure".
About Active Node Failure
In a high-availability system, an IMDB Cache DM instance and its associated data store reside on the same physical server (node).
When an active node fails, the failover process is as follows:
-
Oracle Clusterware detects the active data store failure and does the following:
-
Changes the state of the standby data store to active.
-
Changes the state of the formerly active data store to standby.
-
-
The CM sends requests to the standby IMDB Cache DM instance.
-
The standby IMDB Cache DM checks the state of its associated data store.
-
If the data store is active, the standby DM changes its own processing state to active and processes the request.
-
If the data store is on standby or if the standby DM's connection to the data store fails, the standby DM rejects the CM request with the PIN_ERR_NOT_ACTIVE error. (The error is recorded as PIN_ERR_NOT_PRIMARY in the CM log file.)
-
About Active IMDB Cache DM Failure
IMDB Cache DM failover is managed by Oracle Clusterware. When Oracle Clusterware detects an IMDB Cache DM failure, the failover process is as follows:
-
Oracle Clusterware tries to restart the formerly active DM.
-
While Oracle Clusterware is trying to restart the DM, the CM continues trying to connect to the DM at intervals for the duration of the specified retry time period (see "pcm_bad_connection_retry_delay_time_in_secs ").
If the CM cannot connect within the specified time period, it redirects requests to the standby IMDB Cache DM.
-
If Oracle Clusterware can restart the formerly active DM, the DM checks the state of its associated data store.
-
If the data store is active, the DM sets its processing state to active and starts processing CM requests.
-
If the data store is on standby, the IMDB Cache DM sets its processing state to standby.
-
-
If Oracle Clusterware cannot restart the formerly active DM, you must manually activate the standby DM. See "Manually Activating a Standby IMDB Cache DM".
Manually Activating a Standby IMDB Cache DM
When an active IMDB Cache DM fails, its associated data store is not notified of the failure, so the data store's status remains active. This prevents the standby data store from becoming active.
Because its associated data store is still on standby, the standby DM rejects all CM requests with the PIN_ERR_NOT_ACTIVE error to indicate that it is in standby mode and not accepting requests. (The PIN_ERR_NOT_ACTIVE error is recorded as PIN_ERR_NOT_PRIMARY in the CM log file.)
Therefore, if an internal IMDB Cache DM error prevents Oracle Clusterware from restarting a DM, you must manually change the standby data store's state to active. This enables the standby DM to switch its state to active and process the requests redirected to it by the CM.
Important:
All CM requests will fail until either the active or standby IMDB Cache DM establishes a connection with an active data store.How IMDB Cache DMs Handle Data Store Failure
When the active IMDB Cache DM receives a request from the CM, it passes the request to its associated data store only if that data store's state is active.
The data store is considered to have failed in the following situations:
-
When the initial IMDB Cache DM connection to the data store fails. See "Initial Connection Failure".
-
When the connection to the data store is lost during a transaction or a request has timed out. See "Transaction Failure".
Initial Connection Failure
When the active IMDB Cache DM's attempt to connect to its data store fails, the following actions occur:
-
The DM logs a connection failure message in the IMDB Cache DM log file.
-
The DM retries the connection to the data store.
-
If the retry connection fails, the DM rejects the CM request and logs a PIN_ERR_STORAGE error.
-
Oracle Clusterware detects the active data store failure and does the following:
-
Changes the state of the standby data store to active.
-
Changes the state of the formerly active data store to standby.
-
-
The CM sends the request to the standby IMDB Cache DM.
-
The standby DM checks the state of its associated data store.
-
If the data store is active, the standby DM sets its processing state to active and processes the request.
-
If the data store is on standby or if the connection to the data store fails, the standby DM rejects the CM request with the PIN_ERR_NOT_ACTIVE error. (The error is recorded as PIN_ERR_NOT_PRIMARY in the CM log file.)
-
If the standby DM's connection to its data store fails, the CM tries to reconnect to the active IMDB Cache DM.
-
Transaction Failure
If the active IMDB Cache DM loses its connection with its data store during a transaction or if a request from the active DM to its data store times out, the following actions occur:
-
The DM logs a connection failure message in the IMDB Cache DM log file.
-
The DM retries the connection to its data store.
-
If the connection fails, the DM sets its processing state to standby and rejects the CM request with the PIN_ERR_NOT_ACTIVE error.
-
The CM sends the request to the original standby IMDB Cache DM.
-
Oracle Clusterware detects the active data store failure and does the following:
-
Changes the state of the original standby data store to active.
-
Changes the state of the formerly active data store to standby.
-
-
The original standby DM checks the state of its associated data store.
-
If the data store is active, the original standby DM sets its processing state to active and processes the request.
-
If the data store is on standby or if the connection to the data store fails, the original standby DM rejects the CM request with the PIN_ERR_NOT_ACTIVE error. (The error is recorded as PIN_ERR_NOT_PRIMARY in the CM log file.)
-
How IMDB Cache DMs Handle Oracle RAC Failure
In a high-availability system, each IMDB Cache DM maintains connections to a primary Oracle RAC node and to a backup Oracle RAC node through connect descriptors in the tnsnames.ora file referenced by the DM. The database service associated with the connect descriptor specifies which Oracle RAC node is primary and which is the backup for that DM. See "Setting Up Oracle RAC for Failover in a High-Availability System".
In Figure 12-3, solid lines represent primary connections and dashed lines represent backup connections.
Figure 12-3 IMDB Cache DM Connections to Oracle RAC Nodes
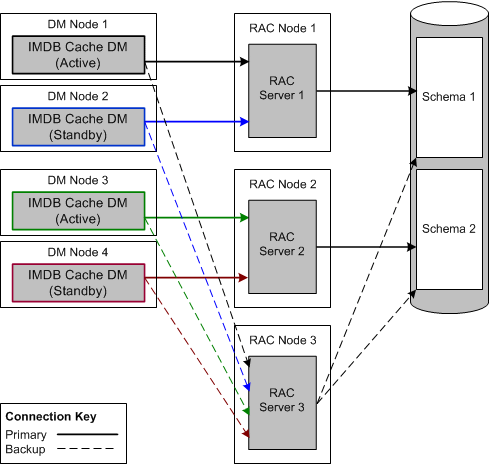
Description of ''Figure 12-3 IMDB Cache DM Connections to Oracle RAC Nodes''
In normal processing, each IMDB Cache DM sends requests to its primary Oracle RAC instance. If that Oracle RAC instance becomes unavailable, the IMDB Cache DM connects to its backup Oracle RAC instance. This section describes how IMDB Cache DMs handle Oracle RAC failure.
In a high-availability system, IMDB Cache DMs handle the following types of Oracle RAC failure:
Initial Connection Failure
Connection failures can be due to hardware, software, network, or listener problems or to a lack of response from the Oracle RAC instance. If an IMDB Cache DM's initial attempt to connect to its primary Oracle RAC instance fails, the IMDB Cache DM connects to its backup Oracle RAC instance
Session Failure
When an Oracle RAC instance fails while processing a request, the IMDB Cache DM detects the failure and connects to its backup Oracle RAC instance. Any transaction that is active when the failure occurs is rolled back. Information about the failover is logged in the IMDB Cache DM pinlog file.
If an IMDB Cache DM loses the connection to its primary Oracle RAC instance in the middle of a session, it performs the following actions:
-
Tries to reestablish the connection to its primary Oracle RAC instance.
-
Performs one of the following actions:
-
If the reconnection attempt is successful, continues processing the request.
-
If the reconnection attempt is unsuccessful, clears any incomplete connection to the primary Oracle RAC instance and tries to connect to its backup Oracle RAC instance.
In the following situations, the IMDB Cache DM returns a PIN_ERRCLASS_SYSTEM_RETRYABLE error and PIN_ERR_STORAGE error code to the CM so the client can retry the transaction:
— The failover occurs in the middle of a transaction.
— The failover occurs outside a transaction, and the IMDB Cache DM cannot finish the operation.
If the failover happens outside a transaction and the IMDB Cache DM can finish the operation, the failover is transparent to the CM.
-
About the BRM Database in a High-Availability System
This section describes the database components of a high-availability system:
For an overview of multischema systems, see the discussion about the multischema architecture in BRM Concepts.
For information about configuring the BRM database in a high-availability system, see "Configuring the BRM Database for High Availability".
About Oracle Real Application Clusters and Oracle Clusterware
For a high-availability system, you must use Oracle RAC, which consists of multiple Oracle RAC instances. Each Oracle RAC instance has the following characteristics:
-
Runs on its own cluster node and server
-
Is typically associated with only one schema
-
Concurrently processes data for a single database with all the other Oracle RAC instances in the cluster
Oracle RAC requires a highly available, high-speed storage system. A storage area network (SAN) running on clustered hardware is recommended. The cluster nodes are connected through a high-performance grid.
Oracle Clusterware is used to manage Oracle RAC servers. It also facilitates state management of Oracle IMDB Cache instances (data stores) and manages the failover of IMDB Cache DM instances by restarting the IMDB Cache DM process when it detects a failure.
For information about installing and configuring Oracle RAC instances and Oracle Clusterware, see the Oracle RAC and Oracle Clusterware documentation.
About Multischema High-Availability Systems
Multischema high-availability systems are built on an Oracle RAC system with one primary Oracle RAC instance for every schema in your system plus at least one backup Oracle RAC instance. The backup Oracle RAC instance can take over for any primary Oracle RAC instance that fails.
Each IMDB Cache DM is connected to a primary Oracle RAC instance and to the backup Oracle RAC instance. Because a primary Oracle RAC instance never handles the load of more than one server, all primary Oracle RAC servers can be sized to run at 80% capacity during peak processing times. This reduces your system's overall spare idle capacity.
Note:
You can increase the number of backup Oracle RAC instances to meet business requirements.Figure 12-4 shows the configuration for a multischema high-availability system with two schemas. Solid lines represent primary connections and dashed lines represent backup connections.
Figure 12-4 Multischema High-Availability System Configuration with Two Database Schemas
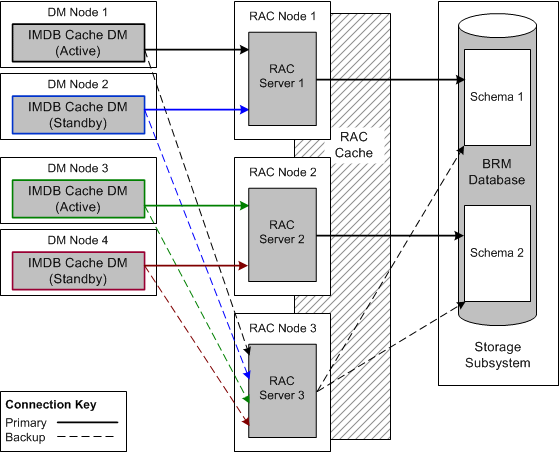
Description of ''Figure 12-4 Multischema High-Availability System Configuration with Two Database Schemas''