| Oracle® Communications Data Model Reference 11g Release 2 (11.2) Part Number E15886-05 |
|
|
PDF · Mobi · ePub |
| Oracle® Communications Data Model Reference 11g Release 2 (11.2) Part Number E15886-05 |
|
|
PDF · Mobi · ePub |
This chapter provides reference information about the data mining models provided with Oracle Communications Data Model.
This chapter includes the following sections:
Oracle Communications Data Model mining models include data mining packages, source tables (MV) and target tables. The source tables are extracted from Oracle Communications Data Model main schema and are used to train the models. The target tables contain the mining result data, for example, mined rules. Data mining packages pull in the source data, feed it into the data mining packages, and populate the target tables with the results. The data in the target tables can be presented in reports.
Note:
Oracle Communications Data Model does not support modified or new data models. Consequently, do not change the data models that are defined and delivered with Oracle Communications Data Model, but, instead, to create a data model copy a delivered data model.As shown in Table 10-1, the Oracle Communications Data Model mining models use the specified algorithms for the specific problem.
Table 10-1 Oracle Communications Data Model Algorithm Types Used by Model
| Model | Algorithms Used by Data Mining Model |
|---|---|
|
Decision Tree (DT), Support Vector Machine (SVM) |
|
|
k-Means (KM) |
|
|
Support Vector Machine (SVM) |
|
|
Support Vector Machine (SVM) |
|
|
Support Vector Machine (SVM) |
|
|
Generalized Linear Models (GLM) |
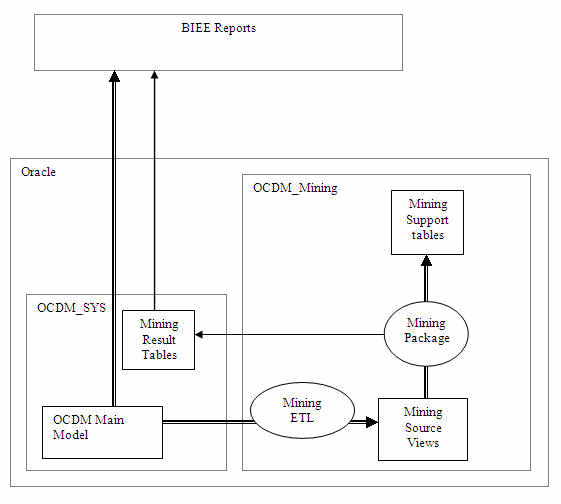
The Oracle Communications Data Model mining consists of two schemas: ocdm_mining and ocdm_sys. Figure 10-1 shows how these schemas function in Oracle Communications Data Model mining.
The ocdm_mining schema includes the following:
Mining Model Package (pkg_ocdm_mining): Given source data in the views, the mining package generates Mined Rules, Predicted Results, and additional information.
Mining Model Source Views: Materialized views transform the data from ocdm_sys schema and present them to Oracle Mining algorithms as multiple materialized views. All tables are implemented as MVs, not physical tables.
Mining Model Support Tables: The mining model support tables are primarily intermediate tables used during the mining model creation or testing process. Most of the mining model support tables have names that start with "DM$".
Note:
Do not delete the mining model support tables; theDM$ tables can be very difficult to reconstruct if they are deleted.The ocdm_sys schema includes the following:
OCDM Main Model, which are all the base, reference, lookup, derived and aggregate tables.
Mining Result Tables: Mining Result Tables save the output from Mining models. This output is normally produced from mining apply process. The tables are created in ocdm_sys schema.
Figure 10-1 Oracle Communications Data Model Mining Schemas
Over time, the customer information and the customer behavior may change. Therefore, you may want to refresh the trained mining models based on the latest customer and usage data. The mining model refresh process is generally divided into three tasks:
Data Preparation: Load and transform the data into a format that the mining algorithms can understand. Also a customer needs to prepare two sets of data corresponding to next two tasks:
Training Data
Scoring data
Training: Based on part of customer data, user can run certain algorithms and then a mining model is generated.
Scoring (applying): The trained model can be applied onto other customer data. This applies the model to do the prediction or other missions the model is designed to perform.
For more information about the Oracle Mining training and Scoring (applying) process, see Oracle Data Mining Concepts.
To refresh all six mining models based on latest customer data, call the procedure named pkg_ocdm_mining.refresh_model. This procedure performs the following tasks for each model:
Refreshes the mining source materialized views based on latest data from OCDM_SY.
Trains each mode again using the new training data.
Applies each model onto the new apply data set.
This procedure has been integrated into Oracle Communications Data Model Intra-ETL workflow.
The errors that occur during mining model refresh are saved into the table named: DWC_INTRA_ETL_ACTIVITY as is other standard Oracle Communications Data Model Intra-ETL package errors and information.
Table 10-2 shows the dwd_cust_mnng result table.
Table 10-2 dwd_cust_mnng Data Mining Result Table
| Name | Type | Description |
|---|---|---|
|
|
VARCHAR2(50), |
Month code when the month was trained and applied. In current version it was set as Null. |
|
|
VARCHAR2(50), |
Customer key to uniquely identify the customer. |
|
|
VARCHAR2(1), |
Boolean value whether customer will churn in next three months according to SVM model. |
|
|
NUMBER(16,12), |
The probability value of how likely customer will churn in next 3 months. This is the probability that the SVM prediction is correct. |
|
|
VARCHAR2(1), |
Boolean value whether customer will churn in next three months according to DT model. |
|
|
|
The ID of the node in the decision tree where the customer is assigned. |
|
|
|
The k-Means algorithm divides the set of all customers into segments. This value identifies the segment that the customer belongs to. |
|
|
|
The band code of customer lifetime value, predicted by LTV Generalized Linear Models Regression. For more information, see Oracle Data Mining Concepts. |
|
|
|
The real value of Customer Lifetime value, predicted by LTV (GLMR) Mode. |
|
|
|
The band code of Customer Survival period (Life Expectancy), predicted by Life_Exp (GLMR) Model. |
|
|
|
The value of Customer Survival period (Life Expectancy), predicted by Life_Exp (GLMR) Mode. |
|
|
|
The customer sentiment category detected by Customer sentiment model (SVM + Text). This is an SVM model on transformed TEXTs (transformed into a words matrix). |
|
|
|
The manual score applied by end user. The end user generates this model. For example, an employee from the operator might generate this model. Usually this is the call center agent. For example, when the message is recorded, there could be a manual tag associated with the message indicating that the customer is happy or upset. |
|
|
|
The probability of which customer is in possible model (Happy). This is the probability that customer is happy with their service. For example, a value of 60% means there is 60% chance that customer is happy with the service and a 40% chance that customer is not happy. |
Table 10-3 shows the dwd_cust_prod_affltn result table.
Table 10-3 dwd_cust_prod_affltn Data Mining Result Table
| Name | Type | Description |
|---|---|---|
|
|
|
Month code when the month was trained and applied. In current version it was set as Null. |
|
|
|
Customer key to uniquely identify the customer. |
|
|
|
The product code which was predicted against. This is target product for promotion. |
|
|
|
The likelihood, predicted by the SVM model, that the customer will purchase the product. |
|
|
|
Boolean value to indicate whether customer may purchase the product. This indicates that a value 1 is BUY and a value of 0 is "NOT to BUY". |
Table 10-4 shows the dwd_chrn_svm_factor result table.
Table 10-4 dwd_chrn_svm_factor Data Mining Result Table
| Name | Type | Description |
|---|---|---|
|
|
|
Name of the factor. |
|
|
|
Subname of the factor if there is any. For example, if the ATTRIBUTE_NAME has the value, "Payment_Method", then the ATTRIBUTE_SUBNAME could be and of the following:
Each ATTRIBUTE_SUBNAME has a different weight, coefficient, in the model. |
|
|
|
Value of the factor, if there is any. For example, for payment method, value of "cash" and "direct debit" might have different influence and ranking. |
|
|
|
Importance of the factor. The factors are ranked according to this value. |
The churn prediction model identifies the characteristics of a customer likely to churn. When you apply the model you get a prediction of how likely a particular customer is to churn. This is based on customer information such as customer demographic information, service quality, last tariff plan, calling usage, and other factors. Using the patterns learned, the model can also perform the calculation over current customer base (called 'Apply') to predict who are the customers mostly like to churn in next few months. With this knowledge, operators can initiate certain retention programs to reduce the customer churn rate. However, the churn prediction produces a likely to churn value. Further processing may be required to determine if it is desirable to retain a customer that is likely to churn. For example, you may only want to initiate retention programs for high value customers.
There are several levels to define churn, namely Customer, Account, and subscription. For some operators with only limited business line, customer and account churn at same time, while subscription is at a lower level. Customer can stop using some products (termination of subscription) while continue to use the other products. In later case, operator still have the customer and may promote other products in the future. However, if customer completely stopped using any products from the operator, it is very difficult for operator to bring customer back.
In Oracle Communications Data Model, the churn was defined at Customer Level, which is, a customer is recognized as a churner only when he stop using any product from the operator.
If customers churn at a given month, we may receive the data only 3 months after the actual Churn. So time window should be adjusted.
Table 10-5 shows the attributes identified from the Foundation Data Warehouse as input source variables for the DT model.
Table 10-5 DMV_CUST_CHRN_SRC_ALL
| Attribute | Description |
|---|---|
|
|
Primary Key for customer |
|
|
Target column of churn model |
|
|
Number of future contract count in last 3 months |
|
|
Subscription count in last 3 months |
|
|
Suspension count in last 3 months |
|
|
Contract count in last 3 months |
|
|
Complaint count in last 3 months |
|
|
Complaint call count to call center in last 3 months |
|
|
Complaint call count to call center in the life time in last 3 months |
|
|
Contract left days in last 3 months |
|
|
Account left value in last 3 months |
|
|
Remaining contract sum in last 3 months |
|
|
Debt total in last 3 months |
|
|
Loyalty program balance in last 3 months |
|
|
Total payment revenue in last 3 months |
|
|
Monthly revenue (arpu) in last 3 months |
|
|
Contract arpu amount in last 3 months |
|
|
Party type code, individual or organizational in last 3 months |
|
|
Business legal status |
|
|
Marital status for individual user |
|
|
Household size |
|
|
Job Code |
|
|
Nationality code |
|
|
Education level |
|
|
Gender |
|
|
Driver license indicator |
|
|
Job contract type, it is permanent employee or contracted. |
|
|
Barring reason code if in barring status |
|
|
Post code |
|
|
CITY |
|
|
STATE |
|
|
Country |
|
|
Name prefix such as, Dr, Ms, and so on. |
|
|
Name of workplace |
|
|
Place of birth |
|
|
Job position |
|
|
The customer's legal title to home (rents, owns, and so on) |
|
|
ETHNIC BACKGROUND |
|
|
Previous employer tax number |
|
|
Number of children |
|
|
Number of dependents |
|
|
Tenure of dwelling in month |
|
|
Dwelling size |
|
ETHNCTY |
Ethnicity |
|
|
Classifies the individual for minority reporting purposes. |
|
|
Dwelling type |
|
|
Dwelling Status |
|
|
Source of income |
|
|
Customer type code |
|
|
Customer segment code |
|
|
Address loc key |
|
|
Customer score key |
|
|
Primary status code |
|
|
Primary status reason code |
|
|
Job code in SOC classification |
|
|
Organization type |
|
|
Language code |
|
|
For how long contact address is in effective, in days |
|
|
Bankrupt status start date in days |
|
|
Bankrupt status |
|
|
For how long billing address is in effective, in days |
|
|
For how long payment account is in effective, in days |
|
|
Mail allowed indicator |
|
|
Whether the customer is responsible for payment |
|
|
For how long customer lives in current location, in days |
|
|
End of job contract date |
|
|
Start of job date |
|
|
Economical active indicator |
|
|
Age on net band code |
|
|
Age on net number |
|
|
Credit category |
|
|
Age band |
|
|
Debt aging band |
|
|
Payment method type |
|
|
Arpu band code |
|
|
Sales channel key |
|
|
Sales channel representative key |
|
|
Organization business unit key |
|
|
Customer revenue band code |
|
|
Number of future contract count in last 3 months |
|
|
Subscription count in last 3 months |
|
|
Suspension count |
|
|
Contract count |
|
|
Complaint count in the life time |
|
|
Complaint count |
|
|
Complaint call count to call center |
|
|
Complaint call count to call center in the life time |
|
|
Life Span in days |
|
|
Contract left days |
|
|
Account left value |
|
|
Remaining contract sum |
|
|
Debt total |
|
|
Loyalty program balance |
|
|
Total payment revenue |
|
|
Total Revenue as of current month |
|
|
Monthly revenue (arpu) |
|
|
Life time revenue |
|
|
Contract arpu amount |
|
|
Estimated acquisition cost (optional attribute) |
|
|
Whether the customer uses the Broadband product |
|
|
Whether the customer uses PayTV product |
|
|
Whether the customer uses IDD product |
|
|
Whether the customer uses fixed line telephone product |
|
|
Whether the customer uses wireless telephone product |
|
|
Whether the customer is a new customer |
|
|
Number of digit 4 in the customer phone number |
|
|
Number of digit 13 in the customer phone number |
|
|
Number of digit 6 in the customer phone number |
|
|
Number of digit 9 in the customer phone number |
|
|
Score of customer number for customer specific rating program |
|
|
From which operator customer ported in from |
|
|
How many times customer ported in |
|
|
How many times customer ported out |
All the data from dmv_cust_chrn_src_all contains non-null value in the CHRN_IND column. This table is then divided into two tables: dmv_cust_chrn_src_prd and dmv_cust_chrn_src_tst. The table dmv_cust_chrn_src_prd has about 60% of the customers and dmv_cust_chrn_src_tst has the rest of the customers. The churn prediction model was trained on table dmv_cust_chrn_src_prd and then tested on dmv_cust_chrn_src_tst for its accuracy.
During the training process, a temporary prediction model OCDM_CHURN_DT_NEW is built and compared with the existing prediction model OCDM_CHURN_DT. If the new temporary model OCDM_CHURN_DT_NEW outperforms the existing model in accuracy, it replaces the existing model, otherwise, it is dropped.
The table dmv_cuts_chrn_src_all is derived from the tables:
ocdm_sys.DWR_CUST
ocdm_sys.DWD_ACCT_STTSTC
ocdm_sys.DWR_BSNS_MO
ocdm_sys.DWR_HH
ocdm_sys.DWR_JB
The mined results are saved into the target table with the following columns:
dwd_cust_mnng.PRDCT_CHURN_SVM_IND
dwd_cust_mnng.PRDCT_CHURN_SVM_PROB
dwd_cust_mnng.PRDCT_CHURN_DT_IND
dwd_cust_mnng.PRDCT_CHURN_DT_ND_NBR
For more information on these four columns, refer to the Mining target data dictionary.
The two mining algorithms are used separately and the two mining models for churn prediction problem:
Decision Trees Classification
SVM Classification
For more information on mining algorithms, see Oracle Data Mining Concepts and Oracle Data Mining Application Developer's Guide.
The business problem is to group customers into generally homogeneous groups (Segments) based on customer demographic value, usage pattern and list of telecom products they subscribe to (customer subscriber history).Business Analysts can look into each segment to further understand the customer group discovered by the model and name each segments.
The discovered clustering rules draw a profile of the customers along with their product subscription. Thus, the clustering rules generated for each profile group will show the most important similar characteristics in each group. For example, an operator may have a group having significantly more short message (SMS) usage than any other groups. Alternatively, there may be a group with extremely higher profit than any other group (covering high end customers).
Customer profiling model use source view DMV_CUST_PROFILE_SRC, which is a subset of table dmv_cust_chrn_apply_all. It contains those information:
The mined results are saved into target table with the following columns:
dwd_cust_mnng.clstr_sgmnt_code
The business problem is to identify which factor may have with more influence on customer churn problem or Customer Revenue. The marketing department should leverage those information to better understand customer behavior. The major factors, namely, Geography Demography, Customer Segment/Group, VAS usage should be included. The attributes are mostly categorical for business user to understand customer profile.
This model is derived from the Churn Prediction model through the SVM algorithm, but due to it's usefulness, we still present this result as a separated model.
Table 10-6 shows the columns where the customer churn factor model saves results in the table dwd_chrn_svm_factor.
Table 10-6 Customer Churn Factor Output Columns in dwd_chrn_svm_factor Table
| Attribute | Datatype | Description |
|---|---|---|
|
|
|
Name of the factor. |
|
|
|
Subname of the factor if there is any. Each ATTRIBUTE_SUBNAME has a different weight, coefficient, in the model. |
|
|
|
Value of the factor, if there is any. For example, for payment method, value of "cash" and "direct debit" might have different influence and ranking. |
|
|
|
Importance of the factor. The factors are ranked according to this value. |
The business problem is to identify the patterns of which products are typically purchased together or one after another over the lifetime of a customer. This helps in providing recommendations about which products should be presented to customers according to their potential acceptance score. A typical scenario is call center can call certain customers with some specific purpose to cross-sell some products. Operators need the list of customers to save promotion cost and improve efficiency.
The trained model generates recommendations about promotion target products. This is done based on what products the customer has subscribed to taking into account other factors such as customers credit history and the risk involved in offering the particular product to the customer.
Table dmv_prod_mix_src is the input into mining algorithm for model training. This table is derived from the following tables:
ocdm_mining.dmv_cust_chrn_src_all
ocdm_sys.dwd_vas_sbrp_qck_summ
For a given product to do promotion, the model generates list of customer most likely to buy. The prediction was done by SVM algorithm. The result is saved into table dwd_cust_prod_affltn in the following columns.
Table 10-7 Cross-Sell Opportunity Output Columns in dwd_cust_prod_affltn Table
| Attribute | Datatype | Description |
|---|---|---|
|
|
|
Month code when the month was trained and applied. In current version it was set as Null. |
|
|
|
Customer key to uniquely identify the customer. |
|
|
|
The product code which was predicted against. This is target product for promotion. |
|
|
|
The probability output from SVM algorithm, serve as likelihood customer may purchase the product. |
|
|
|
Boolean value to indicate whether the customer may purchase the product. This indicates that a value 1 is BUY and a value of 0 is "NOT to BUY" |
The business problem is to measure customer sentiment regarding the service quality according to any text message received from the customer. Those text messages may be emails from customer, or written down by call center agents during call center calls, and so on.
This model leverages Text mining capability provided by Oracle database. For more information, see Oracle Data Mining Concepts.
The source table into mining algorithm is: dm_cust_cmmnt, which has columns of:
Table 10-8 Data Mining Source Columns in dm_cust_cmmnt Table
| Attribute | Datatype | Description |
|---|---|---|
|
|
|
Customer Key |
|
|
|
Manual scores or manually adjusted after reading |
|
|
|
Sentiment scored by Mining Model |
|
|
|
The probability of customer belonging to happy group |
|
|
|
The probability of customer belonging to un-happy group |
|
|
|
The text messages all together from the customer. |
The procedure pkg_ocdm_mining.create_sentiment_svm_model(month_code) refreshes data in the table dm_cust_cmmnt and then refreshes the sentiment mining model. This procedure also populates the sentiment mining result table DWD_CUST_MNNG.
For more information, see "Oracle Communications Data Model Mining Result Tables".
The mined results are saved into target table with the following columns:
dwd_cust_mnng.SNTMNT_CTGRY_CD
dwd_cust_mnng.MANUAL_SNTMNT_CTGRY
dwd_cust_mnng.SNTMNT_PROB
We want to tell how long customer will likely to continue to use the service (Survival), rather than leaving. And also we want to know how much value customer is likely to bring into the operator along their lifetime. This is a regression model. The source data are those customers on net at least 5 years ago; the model target is the age of customer. For those customers churned in less than 5 years, we know the exact age, but for those still on net, the age will be total lifetime.
The difference of this model to the Model 1 (Churn Prediction) is that this is a regression model rather than classification. The target Lifetime is a continuous real value.
The dmv_cust_ltv_prdct_src is the source table for LTV prediction model. This table is subset of the churn model source table dmv_cust_chrm_src_all. The customer joined in less than three years are filtered out from the training data set to provide a valid input into the model.
Life Time Span and Life Time Value (LTV) are the two target measures to predict. The results are saved into table dwd_cust_mining:
dwd_cust_mnng.LTV_BAND_CD
dwd_cust_mnng.LTV_VALUE
dwd_cust_mnng.LT_SRVVL_CD
dwd_cust_mnng.LT_SRVVL_VAL
The LTV_value and LT_SRVVL_VAL are the predicted real value from the model, and then binned into ten categories and form the other two columns: LTV_BAND_CD and LT_SRVVL_CD.
|
Copyright © 2010, 2011, Oracle and/or its affiliates. All rights reserved. Legal Notices |
|