Working with Data
Data Overview
Demand Signal Repository is able to receive data not only for a manufacturer’s own items, but for competitor items. This allows manufacturers to perform comparative sales analysis of its own items versus competitor items. As well, sales personnel are able to view inventory and delivery information.
Product descriptions and retailer item hierarchy associations for competitor items are typically received from the retailer. A retailer may send item hierarchy data for their own items and competitor items together in the same file. The retailer may be able to provide a vendor number to identify the particular supplier of competitor items; if not, the manufacturer must rely upon another source to identify the supplier – either a 3rd party or their own internal knowledge of the GTIN values.
Competitor item data has the same general format and organization as the manufacturer’s own item data, but is treated differently for aggregation and reporting purposes. Mapping of competitor items to the manufacturer’s item hierarchy is a service provided by 3rd parties such as Nielsen or IRI – otherwise, manufacturer personnel must classify the competitor items themselves using their own knowledge. Competitor items are added to the manufacturer’s item hierarchy by the same mechanism used to load and maintain hierarchies for a manufacturer’s own items.
At aggregate level within either the retailer or manufacturer hierarchies, Demand Signal Repository maintains the manufacturer’s aggregate value and the aggregate value for each of the competitor organizations. You can also view the total value for all suppliers.
As the manufacturer does not generally have the competitor’s internal item identification, the GTIN will be used for both the global and local ID by default.
Sharing Data with Manufacturer Applications
Demand Signal Repository shares demand data with manufacturer applications at both the lowest level of detail, and at an aggregate level. A web service for each group of facts in the data model will allow an application to select and retrieve data according to the dimensions of time, manufacturer item hierarchy, retailer org hierarchy (selected levels) and location.
Hierarchy Loading
All hierarchy and calendar data (except for the Gregorian calendar) must be loaded into Demand Signal Repository from external sources:
-
Organization Hierarchies: Organization hierarchies consist of organizations, business units, and a fixed taxonomy (district, area, region, etc.) that relates them. The inbound interface tables follow the same structure – one each dedicated to the organizations with their attributes, the business units with their attributes, and a table containing the parent/child relationships in the hierarchy.
-
Item Hierarchies: Item hierarchies are organization-specific. SKU-level attributes are loaded into one interface table; parent-child relationships go into another. Demand Signal Repository adds, deletes and moves in the same manner as the organization hierarchy.
Item and organization hierarchies may be updated by loading a new complete hierarchy that reflects the changes since the last hierarchy was loaded. Updates are handled as follows:
-
New nodes: New nodes must be added to the existing hierarchy in the places indicated by the new hierarchy.
-
Removed nodes: If a node in the existing hierarchy no longer is included in the new hierarchy, the affected node in the existing hierarchy, Demand Signal Repository takes no action in order to maintain the consistency of historical data. A user may explicitly set the ending effectivity date to indicate that the node is no longer valid.
-
Moved nodes: If a node moves from one position in the hierarchy to another, a successor node is created in the new location, and the existing node’s ending effectivity date is set. Any descendants of the moved node move along with its parent, without creating successor nodes.
Other changes to nodes in the updated hierarchy (such as a revised description) simply overwrite the corresponding attributes in the node in the existing hierarchy, without creating a successor node.
Caution: Changes to a hierarchy are made as of the source system date in the incoming file. If the source system date is in the past, and fact data has been loaded in the interim, aggregate quantities may not match those generated in the retailer’s source system for the same data. It is a best practice to load any new hierarchy data prior to any fact data load.
Note: Both SKU- and item-level attributes are loaded via SKU-level interface table rows. If different SKUs that belong to the same item specify different values for item-level parameters, the values specified by the last SKU loaded will overwrite the previous values, so that all SKUs for that item will inherit the item-level attributes from the last SKU.
Alternate Organization Hierarchies
Demand Signal Repository captures, analyzes, and displays facts based on a customer’s view of their organizational structure. However, some manufacturers (and their supply chain partners) may also have their own view of how the customer’s organization is structured for purposes of account management, promotion planning, collecting and aggregating consumption data, and so on. This view is oftentimes different from how the customer views its organization structure.
You can view a customer’s organization using an alternate organization hierarchy while keeping the original customer organization hierarchy intact. Facts can be inquired upon using the original customer organization hierarchy, or one or more alternate organization hierarchies. This allows users to view customer data at aggregate levels that represent the various ways in which the manufacturer conducts business with the customer. Users can also analyze fact data at a level that is equivalent to other systems in use by the Manufacturer. For example, to analyze and report on DSR retail demand data by planning account (that is, a level in an alternate organization hierarchy), which would be equivalent to the planning account used in Oracle Demantra Predictive Trade Planning or Oracle Siebel Consumer Goods.
The Alternate Organization Hierarchy feature allows other views of the customer’s organization to co-exist within DSR along with the original customer organization hierarchy.
Here’s an example of an alternate organization hierarchy. The customer, ValueChoice, has five levels within its buying organization, including business units (which are distribution center or store locations). The Business Unit must be the last level in the alternate organization hierarchy in order for the associated facts, such as sales or inventory facts, to be aggregated to higher levels in the alternate organization hierarchy.
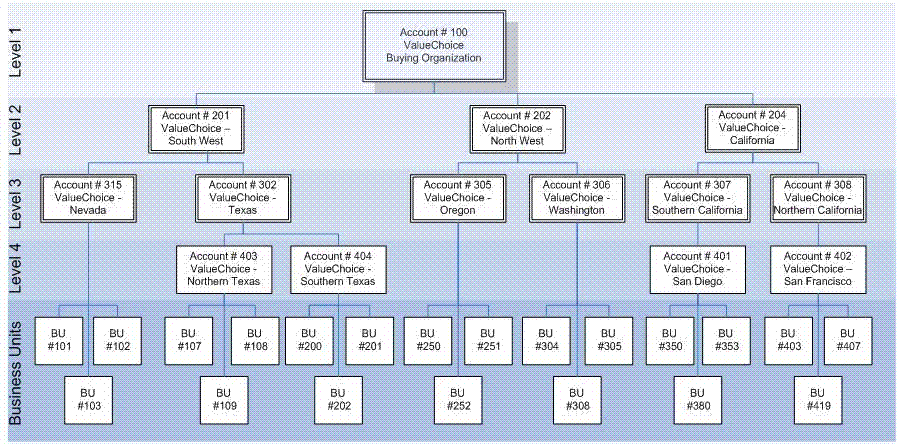
A hierarchy level can contain accounts that have different levels of granularity. For example, at Level 2 in the hierarchy, we see accounts which represent a large geographical area (such as South West and North West) as well as an account that encompasses just one state (California). This occurs because some geographical areas, such as California, may have more stores, than several other states combined. Consequently, California requires the same level of account management as larger territories.
In addition, the hierarchy may be “ragged”, meaning it does not contain the same number of levels across all branches of the hierarchy. For example, account # 315, ValueChoice – Nevada, does not have a level 4 account. Neither does Washington or Oregon. In this case, the business unit is associated directly to the level 3 account.
In this example, the account numbers that have been assigned directly correlate to their respective levels, in the real world the account numbers would vary across hierarchy levels, meaning Account # 3456 may be a level 1 account, while Account # 10, may be a level 3 account.
This example illustrates a hierarchy that has 4 levels plus business unit. DSR supports having an Alternate Organization Hierarchy of up to 10 levels (plus business unit).
The Alternate Organization Hierarchy provides a flexible organization structure, which can vary depending on the source of the data, or the type of analysis performed. Example uses for the Alternate Organization Hierarchy include:
-
Representing the organization hierarchy as defined by the Syndicated Data Provider: Manufacturers who subscribe to a syndicated data provider service for account information can load this information into the alternate organization hierarchy and leave the original customer organization hierarchy untouched, so that account team’s can still talk to customers in terms of the customer’s view of their organization.
-
Representing the Customer Buying Organization or Account Planning Hierarchy: The manufacturer’s own view of the customer’s organization may be based on how the customer’s buying organization is. When performing activities, such as promotion planning and execution, a promotion may apply to a level within the retailer’s organization, which represents the area for which a buyer is responsible. For example, a retail department or buying region. One or more of these views of the customer organization can be loaded to the alternate organization hierarchy so sales can be analyzed by planning account.
Interface Tables
The following OWB interface tables are used with Alternate Organization Hierarchies:
-
DDR_I_AOH_ATTR: Interface table for loading Alternate Organization Hierarchy code and descriptions. The target table is DDR_R_ORG_HCHY.
-
DDR_I_AOH_ACCT_ATTR: Interface table for loading AOH account attributes and their associated parent relationship. Target tables are DDR_R_ORG_BSNS_ENT and DDR_R_AOH_LVL_DTL.
-
DDR_I_BU_AOH_ASSOC: Interface table for loading AOH / BU associations. Target table is DDR_R_BU_AOH_ASSOC.
Error Tables
For each of the interface tables listed on the previous slide, there is a corresponding error table. The error table contains all the columns found in the interface table, plus an error message column which contains the associated error message (or messages) and a load ID which assigns a unique number each time data is loaded and errors are encountered.
-
DDR_E_AOH_ATTR: Holds error records for DDR_I_AOH_ATTR interface table.
-
DDR_E_AOH_ACCT_ATTR: Holds error records for DDR_I_AOH_ACCT_ATTR interface table.
-
DDR_E_BU_AOH_ASSOC: Holds error records for DDR_I_BU_AOH_ASSOC interface table.
DDR_R_ORG_HCHY Target Table
The Organization Hierarchy (DDR_R_ORG_HCHY) table stores the Alternate Organization Hierarchy Code and associated description. This table existed in previous releases of DSR, but was not in use until now. Listed here are some of the key columns:Organization Hierarchy ID is the unique index to the table. It is a number assigned by the system. Each Hierarchy Code (HRCHY_CD) is assigned a unique Organization Hierarchy ID.
The effective From and Through date are currently informational only. When loading the table, the source system date is used as the effective from date. Effective through date is left blank.
The Source System Date is the date in which the data was created on the source system. The Source System Identifier is used to identify where the data came from.
DDR_R_ORG_BSNS_ENT Target Table
The Organization Business Entity (DDR_R_ORG_BSNS_ENT) table stores AOH Account Attributes and the associated parent relationship. Listed here are some of the key columns:
-
Organization Business Entity ID is the unique index to the table. It is a number assigned by the system. Each Business Entity Code (BSNS_ENT_CD) is assigned a unique Organization Business Entity ID.
-
The effective from and through date are informational only. When loading the table, the source system date is used as the effective from date. Effective through date is left blank.
-
Attributes are captured for each business entity such as name, description, and address. In addition, there are 20 user-defined fields (10 character and 10 numeric) which can be used to capture additional information. These user-defined attributes can be made visible in Answers by modifying DSR’s OBIEE repository.
DDR_R_AOH_LVL_DTL Target Table
The AOH Level Detail (DDR_R_AOH_LVL_DTL) table stores a flattened version of the AOH parent/child relationships. This table is populated at the same as when the Business Entity (from the previous slide) are loaded. Listed here are some of the key columns:
-
Business Entity ID (BSNS_ENT_ID) is the unique index to the table. There is a direct association between this table and the Organization Business Entity (DDR_R_ORG_BSNS_ENT) table. A record exists in this table for each child record in Organization Business Entity (DDR_R_ORG_BSNS_ENT) table.
-
Parent Business Entity Codes (and associated Ids) 1 through 9 contain a flattened version of the child’s lineage up to the topmost level. DSR supports an Alternate Organization Hierarchy of 10 levels (not including business unit) without having to modify the existing AOH tables.
DDR_R_BU_AOH_ASSOC
The BU AOH Association (DDR_R_BU_AOH_ASSOC) table stores the relationship between AOH Account and Business Unit.
The combination of Org Hierarchy ID (ORG_HCHY_ID) and Business Unit ID (BSNS_UNIT_ID) make up the unique index to the table. A business unit can only be associated to one AOH account within each Alternate Organization Hierarchy (also known as Organization Hierarchy ID).
Alternate Organization Hierarchies Materialized Views
Materialized views were created to provide quicker access when querying over the alternate organization hierarchy table in OBIEE. The AOH materialized views are used to aggregate facts with accounts at distinct levels. So each materialized view contains only the accounts at that level and their complete lineage. These materialized views are refreshed as part of the REFERENCE_MV_COMPLETE_REFRESH process flow:
-
DDR_R_AOH_LVL_1_ATTR_MV: Contains a “flattened version” of the AOH (level 1 accounts only).
-
DDR_R_AOH_LVL_2_ATTR_MV: Contains a “flattened version” of the AOH (level 2 accounts and their lineage).
-
DDR_R_AOH_LVL_3_ATTR_MV: Contains a “flattened version” of the AOH (level 3 accounts and their lineage).
-
DDR_R_AOH_LVL_4_ATTR_MV: Contains a “flattened version” of the AOH (level 4 accounts and their lineage).
Alternate Organization Hierarchies Process Flows
The following OWB process flows have been created to support Alternate Organization Hierarchies:
-
AOH_ATTR: Loads the AOH Codes which uniquely identifies each Alternate Organization Hierarchy in use.
-
AOH_ACCT_LVL: Loads account information, including how the accounts are related to each other through the use of parent account.
-
BU_ACCT_ASSOC: Loads the relationship between Business Units and Alternate Organization Hierarchy Accounts. This allows facts associated with a Business Unit to be viewed using the Alternate Organization Hierarchy.
-
SYND_GEO: Loads data which is used to translate the syndicated provider’s geography key to dimension values (market area, region, AOH Account, and so on) that are meaningful to DSR.
-
SYND_CNSMPTN_INF_STG_TO_TGT: Loads external aggregated consumption (for example, sales) measures received from syndicated data providers.
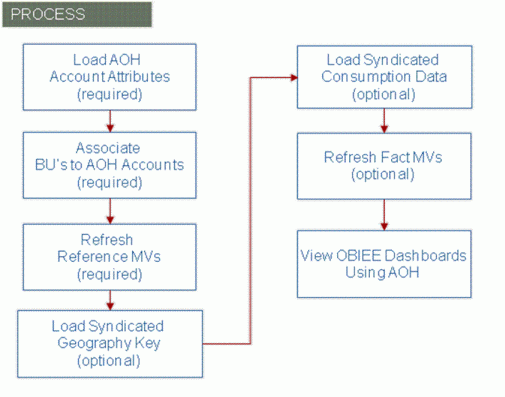
To view DSR facts using an Alternate Organization Hierarchy, you need to complete the following steps:
-
Load the Alternate Organization Hierarchy Account Attributes. This defines the valid accounts (or nodes) within the hierarchy and how they related to each other.
-
Load information which associates the customer’s business units (meaning stores or distribution centers) to an account within the Alternate Organization Hierarchy.
-
Refresh the reference data materialized views which summarizes data to improve performance when running queries.
After completing these steps, you can use the Alternate Organization Hierarchy and display facts associated with the Business Units. This includes Sales, Sales Forecast, Inventory, Order and Shipment facts. If you also need to associate Syndicated Consumption Data to an account within the Alternate Organization Hierarchy, you will also need to perform the following tasks:
-
Load the Syndicated Geography Key information. This information provides a cross-reference from the Geography Key provided by the syndicated data provider to the appropriate Alternate Organization Hierarchy Account (or other dimension within DSR).
-
Load the Syndicated Consumption Data.
-
3. Refresh the Fact Materialized Views which summarizes data to improve performance when running queries.
You can now view dashboards or create queries in OBIEE that use the Alternate Organization Hierarchy.
Step 1 Load Account Attributes
Maps and Process Flows have been created to load Alternate Organization Hierarchy information. The first step is to load Alternate Organization Hierarchy Account information. The Alternate Organization Hierarchy Account Attributes Process Flow loads account information, such as account name, address, and contact information, including how the accounts are related to each other through the use of parent account.
When you execute the AOH Account Level process flow, the system reads data from the source table, performs the necessary validations and populates the target tables listed below. Prior to loading Alternate Organization Account information, you must load:
-
Organization Hierarchy (DDR_R_ORG_HCHY) with at least one Alternate Organization Hierarchy code
-
Country codes (DDR_R_CNTRY)
-
State codes (DDR_R_STATE).
| Process Flow Name: | AOH_ACCT_LVL |
| Source Table(s): | DDR_I_AOH_ACCT_ATTR |
| Target Table(s): | DDR_R_ORG_BSNS_ENT DDR_R_AOH_LVL_DTL |
| Dependent Table(s): | DDR_R_ORG_HCHY DDR_R_STATE DDR_R_CNTRY |
| Required Fields: | AOH Code Account Code Account Name Parent Account Ultimate Parent Account |
| Key Validations: | AOH Code be a valid value in the Organization Hierarchy (DDR_R_ORG_HCHY) table Country Code and City Codes (if populated) must be valid. Address information is optional, so these fields are not required. Parent Account must be valid account within the same Ultimate Parent Account. So, if the account record that’s being validated belongs to Ultimate Parent Account 100, the parent of that account must also have an Ultimate Parent Account of 100. Ultimate Parent Account must be a level 1 account, meaning it cannot be a child of another account. |
Step 2: Associate Business Units to Alternate Organization Hierarchy Accounts
The second step is to connect the existing Business Units to the Alternate Organization Hierarchy. The Business Unit Account Association Attributes Process Flow loads data which associates Business Units to an Alternate Organization Hierarchy Account. This allows facts associated with a Business Unit to be viewed using the Alternate Organization Hierarchy.
When you execute the BU Account Association process flow, the system reads data from the source table, performs the necessary validations and populates the target table listed here.
Prior to loading the Business Unit / Account Association information, you will need to have loaded the Alternate Organization Hierarchy Account tables (DDR_R_ORG_BSNS_ENT and DDR_R_AOH_LVL_DTL) as well as the Customer’s Organization Business Unit table (DDR_R_ORG_BSNS_UNIT).
| Process Flow Name: | BU_ACCT_ASSOC |
| Source Table(s): | DDR_I_BU_AOH_ASSOC |
| Target Table(s): | DDR_R_BU_AOH_ASSOC |
| Dependent Table(s): | DDR_R_ORG_BSNS_ENT DDR_R_ORG_BSNS_UNIT DDR_R_AOH_LVL_DTL |
| Required Fields: | Org Code Business Unit Code AOH Code Business Unit Parent Account Code |
| Key Validations: | Org Code / Business Unit Code must be a valid combination. Meaning the store must reside under the specified organization AOH Code / Parent Account Code must be a valid combination. The Account being associated to the Business Unit cannot have any child accounts. Meaning the account must be at lowest level. This can be at level 2, 3, 4 or lower, so long as there are no additional children parented to that account |
Note: Partial and Simulation modes are supported for this process flow.
Step 3: Refresh Reference Materialized Views
Once all Alternate Organization Hierarchy reference data is loaded, you will need to refresh reference materialized views. Materialized views are database objects that are used to aggregate data. A view might be created by joining several tables and aggregating measures by summarization, averaging, etc. With materialized views, the performance-intensive operations (for example joining or grouping) are done when the view is refreshed. The materialized view process flows are located under the “Other Process Flows” module. They are broken down into two groups:
-
The MV_COM (Materialized View Complete) folder contains process flows which populate the materialized views from scratch.
-
The MV_FAST (Materialized View Fast) folder contains process flows which will update existing views and apply changes made since the materialized view was last updated.
When using the Alternate Organization Hierarchy feature you must perform a complete refresh. Fast refreshes are not supported. You can either refresh the reference data at this time, or you can postpone the refresh of the reference materialized views until all facts are loaded and then refresh both the reference and fact materialized views at the same time.
Note: If you have syndicated data that you want to associate to an account in the Alternate Organization, and if that syndicated data provider uses a geography key, you will need to load the Syndicated Geography Key cross-reference information. The Syndicated Geography Key Process Flow loads data which is used to translate the syndicated provider’s geography key to the appropriate dimension values (market area, region, AOH Account, etc.) that are meaningful to DSR.
When you execute the Syndicated Geography Key process flow, the system reads data from the source table, performs the necessary validations and populates the target table listed here.
| Process Flow Name: | SYND_GEO |
| Source Table(s): | DDR_I_SYND_GEO_KEY |
| Target Table(s): | DDR_R_SYND_GEO_KEY |
| Dependencies: | customer organization hierarchy market Area geography region and/or sub-region channel source AOH account |
Step 4: Load Syndicated Geography Key
Before running the syndicated geography key process flow, you must load any dimension data to which the syndicated geography is related. This includes:
-
Customer Organization Hierarchy
-
Market Areas
-
Geography regions and/or sub-regions
-
Channel Types
-
Source codes.
-
AOH Account Information
| Required Fields: | Source Geography Key Geography Name |
| Key Validations: | Source must be valid Organization Hierarchy and AOH Account are mutually exclusive Org Hierarchy Level must be valid ORGANIZATION, CHAIN, AREA, REGION, DISTRICT, BU AOH Code / Account code combination must be valid Channel Type, Market Area, Geography Region, Geography Sub-region (if populated) must be valid Org Hierarchy Level / Code, Market Area, Geography Region, Sub-region cannot all be null Market Area, Geography Region, Geography Sub-region are mutually exclusive |
Note: Partial and Simulation modes are supported. Changes to geography key definition may require manual clean up or re-loading of consumption data. Syndicated Geography Key deleted when Process Action = ‘D’
Step 5: Load Syndicated Consumption Data
The Syndicated Consumption Data Process Flow loads external aggregated consumption (for example, sales) measures received from syndicated data providers. By default, the measures do not have any aggregation rule and can only be viewed at the level they were loaded.
Before running the syndicated consumption process flow, you must load any dimension data to which the syndicated consumption data is related. This includes:
-
Manufacturer item hierarchy
-
Customer organization hierarchy
-
Market area
-
Geographic region or sub-region
-
Manufacturer business week
-
Channel Type, Measure Set, and Source code (in look up master)
-
AOH Account information
| Process Flow Name: | SYND_CNSMPTN_INF_STG_TO_TGT |
| Source Table(s): | DDR_I_SYND_CNSMPTN_DATA |
| Target Table(s): | DDR_B_SYND_CNSMPTN_DATA |
| Dependencies: | Manufacturer item hierarchy Customer organization hierarchy Market Area Geographic region or sub-region Manufacturer Business Week Channel Type Measure Set Source AOH Account |
| Required Fields: | Record ID Source Code Measure Set Week End Date |
| Key Validations: | Source Code and Measure Set must be valid Syndicated product and geography keys must be valid (if populated) Either Syndicated Product Key or Item Hierarchy Level / Item Hierarchy Codes must be populated Either Syndicated Geography Key or one of the following combinations must be populated:
|
| Additional Information: | All (or None), Partial, and Simulation modes are supported. All consumption data is assumed to be at week level. No currency conversion. No allocation to lower dimensional levels. Default aggregation rule is none. |
Step 6: Refresh Fact Materialized Views
Once all fact data is loaded, you will need to refresh reference materialized views. This step must be completed for the data to appear on the distributor dashboard. You can choose to perform either a complete refresh of the fact data or a fast refresh. If you postponed refreshing the reference data materialized views, you must refresh both reference and fact materialized views at this time.
To refresh fact materialized views, use one of the following process flows:
-
FACT_MV_COMPLETE_REFRESH
-
FACT_MV_FAST_REFRESH
Note: There is no interface table to load, running the process flows are simply a matter of starting the process flow.
Step 7: View Dashboard
The last step is to view the Alternate Organization Hierarchy and associated facts in OBIEE dashboards and reports. DSR has provided a sample out of the box dashboard which utilizes the Alternate Organization Hierarchy. Existing dashboards and reports can be easily modified to use the alternate organization hierarchy instead of the Customer Organization Hierarchy.
The Sales Performance by Account dashboard page can be found on the miscellaneous reports dashboard.
By drilling down on the level two account, you can see sales and forecast facts broken down by level three account. You can continue to drill down through the levels until you reach the individual business units (stores or distribution centers).
Time and Organization Allocations
Point of Sale and sales forecast fact data is imported to Oracle Demand Signal Repository at an aggregate level. This data is allocated within DSR to the appropriate business unit and day level. With time allocation, weekly Point of Sale and Sales Forecast data is allocated as a percentage to each day of the week. Similarly, organization allocation assigns, at any level of the retail organization, percentages to each associated business unit.
Allocation percentages are loaded into DSR using the existing method for loading interface tables. These percentages are visible from the BI Answers catalog, so that end users can view the percentages that were used when allocating sales facts to the business unit or day level. For more information on loading allocations, see Data Loading Interface Tables.
Time Allocation
Time allocation assigns percentages to each day of the week to allocate weekly Point of Sale and Sales Forecast data to a specific day. The following table is an example of time allocation data:
| BSNS_UNIT_CD | WK_NBR | PRCNT_ALLOC | STATUS_IND |
| Goodway #001 | 1 | 20 | A |
| Goodway #001 | 2 | 20 | A |
| Goodway #001 | 3 | 15 | A |
| Goodway #001 | 4 | 10 | A |
| Goodway #001 | 5 | 10 | A |
| Goodway #001 | 6 | 10 | A |
| Goodway #001 | 7 | 15 | A |
| Goodway #001 | 1 | 15 | |
| Goodway #001 | 2 | 15 | |
| Goodway #001 | 3 | 15 | |
| Goodway #001 | 4 | 15 | |
| Goodway #001 | 5 | 15 | |
| Goodway #001 | 6 | 15 | |
| Goodway #001 | 7 | 10 |
The WK_NBR column represents a day of the week relative to the Point of Sale or Sales Forecast data’s transaction date. For example, If weekly point of sales data has a transaction of November 23rd (a Sunday), based on the rules specified above, the system will allocate 20% of sales to Sunday, November 23, 20% of sales to Saturday, November 22nd, 15% of sales to Friday, November 21st, and so on.
DSR expects that weekly point of sales and sales forecast from a single business unit will always have a transaction date which refers to the same day of the week (for example, always a Sunday’s date, or always a Friday’s date, etc.) Weekly data should normally follow the retailer’s business week, so that the transaction date would always reference the week ending date.
Note: Only records with a status indicator of A (Active) are used to allocate point of sale or sales forecast data.
Organization Allocation
Organization allocation assigns percentages to specified business units, in order to allocate Point of Sale and Sales Forecast data at any level of the retail organization hierarchy. The following table is an example of organization allocation data:
| ORG_CD | BSNS_UNIT_CD | PRCNT_ALLOC | LOC_IDNT_CD | ORG_LVL_CD |
| GW | Goodway #001 | 100 | CA | DISTRICT |
| GW | Goodway #002 | 100 | OR | DISTRICT |
| GW | Goodway #003 | 40 | TX | DISTRICT |
| GW | Goodway #004 | 60 | TX | DISTRICT |
| GW | Goodway #005 | 100 | AR | DISTRICT |
| BM | BigMart #001 | 40 | Pacific | REGION |
| BM | BigMart #002 | 60 | Pacific | REGION |
| BM | BigMart #003 | 25 | Plains | REGION |
| BM | BigMart #004 | 35 | Plains | REGION |
| BM | BigMart #005 | 40 | Plains | REGION |
Notice that the allocation is always from a level in the organization hierarchy directly to the lowest level of the organization hierarchy (Business Unit). If data is received at the region level, the allocation is direct to the business unit, and not to the district (the next level down in the hierarchy).
Data Loading Interface Tables
The data loading capabilities of Demand Signal Repository are divided into multiple layers:
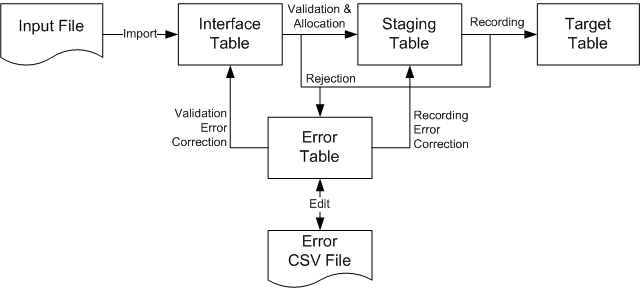
Interface table - If the retailer provides data in a file, the manufacturer imports it into a set of interface tables that correspond to the retailer data sources received. Demand Signal Repository provides a standard interface table layout, and a sample set of input files that match the interface tables field-for-field. A manufacturer has the option creating its own interface table structure that differs from the standard structure that Demand Signal Repository provides.
Staging table – Demand Signal Repository performs validations and allocation on the data in the interface table, and (except in the case of simulation mode) writes values that pass the tests to staging tables that map one-to-one with the target tables in the Demand Signal Repository database.
Error table – Values in the interface tables that do not pass validation are moved to the error table, accompanied by error messages that identify the cause of the problem. From here, the data can be exported to a CSV file format, where it can be edited to correct any errors, and resubmitted for processing. Corrected values are typically moved back to the interface tables for re-validation, except in the case of errors that were originally encountered in the process of moving from staging to target – these are moved directly to the staging tables for further processing.
Target table – If the mode used to run the data loader is “partial”, or the mode was “all or none” and none of the records had errors, data is moved from the staging tables to the target tables in the database, where it becomes visible to Demand Signal Repository users. In the case of “simulation” mode, the records are never moved to the target tables.
Loading Fact Data
Each related group of fact data types that corresponds to the entities in the data model has its own inbound interface table.
Data that accompanies each fact table data load includes:
-
Global Item ID - A universally unique identifier for the product item, which is used to link each retailer’s report of sales results to the corresponding manufacturer’s item. Most often, this number will be a 14-digit Global Trade Item Number (GTIN) assigned by the GS1 standards organization. GTINs are a superset of the former UPC and EAN item codes used in the retail industry.
-
Global Item ID Type – An indicator of the identification scheme used to assign the global item number. By default, the value is “GTIN” if unspecified. The combination of the Global Item Number and the Global Item Number Type forms the key for product item IDs in the system. The manufacturer must take care that UPCs, EAN codes and GTINs that it receives from different retailers have been formatted consistently (UPCs and EAN codes masked with leading zeros, no separator characters such as “-“, presence/absence of check digit). Otherwise, the same item sold at multiple retailers will be identified as different items.
-
Retail Item Number – The input file may provide a second identifier for the item, which is the retailer’s proprietary item number. This number is primarily used for validation, but it can also be used in place of the global item number for retail data sources that lack a global number reference. In cases where only the retail item number is supplied, Demand Signal Repository must already have an item record with an assigned global item number, so the data can be mapped to a unique item on the manufacturer side.
Note: Retailers may sometimes have many-to-one mappings of their item codes (SKUs) to GTINs (due to recycling of SKU codes), as well as one-to-many mappings (because the retailer considers a manufacturer’s successor item to be equivalent). If a retail item number is supplied alone in the many-to-one case, it should be accepted; in the one-to-many case, it should be rejected unless the record also includes a global item number that disambiguates the item assignment.
-
Retail Company (Organization) ID – The global identifier for the legal entity that supplied the data. This is typically a standard 12-digit Global Location Number (GLN) assigned by the GS1 standards organization. However, in environments that have not adopted GLNs, this could also be a 9-digit Dun and Bradstreet company identifier (DUNS number), or a 13-digit DUNS number plus a four-digit local location qualifier (DUNS+4 number). This identifier must be at least 20 characters long, in order to accommodate other proprietary company identification schemes. If a proprietary scheme is used, it is the customer’s responsibility to ensure the uniqueness of company IDs.
-
Retail Location (Business Unit) ID – The global identifier for the location (typically a retail store or distribution center) for which the data is being reported. In the case of data values that apply to the entire retail enterprise, this value could also be the same as the Retail Company ID.
The Retail Location ID is typically a standard 12-digit Global Location Number (GLN) assigned by the GS1 standards organization. However, in environments that have not adopted GLNs, this could also be a 13-digit DUNS number plus a four-digit local location qualifier (DUNS+4 number). This identifier must be at least 20 characters wide, in order to accommodate other proprietary location identification schemes. If a proprietary scheme is used, it is the customer’s responsibility to ensure the uniqueness of retail location IDs.
-
Retail Location ID Type - An indicator of the identification scheme used to assign the Retail Company ID. By default, the value is “GLN” if unspecified. Other permitted values are “DUNS”, “DUNS_PLUS_4” and “PRIVATE.” The combination of the Retail Location ID and the Retail Location ID Type forms the key for location IDs in the system.
-
Quantities and Amounts – Any quantity or amount provided for each fact is a decimal value with unlimited precision, which may have a positive or negative sign.
-
Unit of Measure – The unit of measure to be tied to a quantity is specified using a standard ISO code. The default unit of measure (if unspecified) is “each” (EA).
-
Date – For daily data, the date is the day for which the value is being reported. If weekly data is being processed, the date is the ending date for the week.
-
Source Date/Time – The date or date/time that the data was created. This is an optional field, which can be used to cross-reference the data with the source system.
-
Source System – The source file name or system that provided the data. This is an optional filed, which can be used to cross-reference the data with the source system.
Validation
Demand Signal Repository uses two validation methods to reject point of sale data that reports sales for items at stores other than their authorized stores:
-
Strict Validation – When strict validation is set, the data loading process will reject any records that contain a global item numbers / business unit (store) combination that has not previously been configured as an authorized item/store. The rejected item and store records will be set aside so they can be reviewed and reloaded after the authorizations are set up for them.
-
Item Discovery – When item discovery is set, the data loading process will create a new authorized item/store record in the system the first time that it encounters a global item number at a business unit (store) where it has never previously been reported. A log will record the new item/store combinations that were created as a result of the data load.
Authorized item/store combinations have effective dates. By default, if an authorized item/store combination is created through item discovery, its effective date will be the date that it is created. During the data loading process, Demand Signal Repository provides the following functional validations:
-
Data Formatting Errors – Problems with the column count, column order, delimiters or other details of the file format prevents processing.
-
Ambiguous Item – The retailer provided data solely in terms of its local item number, and there is more than one GTIN that maps to that local item.
-
Unrecognized Item – Either one or both of the global item number or retail item numbers do not match any item in the system.
-
Duplicate Item – A single file contains two or more records with the same Global Item Number or Retail Item Number for the same data type, date and location. In this case, both records should be rejected.
Note: This validation is optional, and switched off by default, due to potential performance concerns.
-
Unrecognized Location – The retail location ID does not match any location ID currently in the system.
-
ID Type Mismatch – An Item ID Type, Retail Company ID Type or Retail Location ID type is provided that does not match the type currently listed for an item in Demand Signal Repository, and item discovery is not set.
-
Invalid Selling Location – Strict validation is set and an item was reported as being sold at a location that is not in its authorized list.
-
No Allocation Profile Found – Data was loaded at an aggregate level, but no allocation profile was defined for the organization and/or week.
Replenishment Rules
Some retailers provide information to suppliers (for example, Consumer Goods manufacturers) about the rules used to replenish inventory at store locations. Suppliers use these rules to determine whether out-of-stocks or overstocks are being caused by an inappropriate inventory management policy, or to anticipate future order volumes.
These replenishment rules can be loaded into DSR to provide visibility into the criteria used by the store or distribution center when reordering products. Replenishment rules enable DSR to determine if out-of-stocks or overstocks are being caused by an inappropriate inventory management policy, or to anticipate future order volumes. As well, replenishment rules are used in the Exception Management workbench to calculate over and under stock conditions.

Replenishment Measures
The following Replenishment Rule measures are supported in DSR:
-
Reorder quantity
-
Reorder interval
-
Reorder threshold
-
Replenishment method
-
Lead time days
-
Target days of supply
-
Target on hand quantity
-
Maximum days supply
-
Maximum stock on hand quantity
-
Minimum days supply
-
Minimum stock on hand quantity
Loading Replenishment Rules
DSR stores replenishment rules in the DDR_R_RTL_SKU_BU_INV_RL table. Data is loaded into this table using the existing data loading interfaces. For more information, see Data Loading Interface Tables.
Materialized Views
Materialized views are database objects that are used to aggregate data. For example, a materialized view might be created by joining several tables and then aggregating measures by summarization, averaging, and so on. Materialized views improve system performance, since performance-intensive operations (for example, joining or grouping) are performed when the view is refreshed. Queries can access materialized views to retrieve pre-aggregated measures and provide a faster response time.
The Materialized Views process flows are located in OWB's Other Process Flows module. They are organized in two different groups:
-
MV_COM (Materialized Views Complete): This folder contains process flows that populate the materialized views from scratch.
-
MV_FAST (Materialized Views Fast): This folder contains process flows that update existing views and apply changes made since the last update.
Each of the above folders contains three process flows:
-
FACT_MV_COMPLETE_REFRESH/FACT_MV_FAST_REFRESH: refreshes the fact data materialized views.
-
REFERENCE_MV_COMPLETE_REFRESH/REFERENCE_MV_FAST_REFRESH: refreshes the reference data materialized views.
-
MV_COMPLETE_REFRESH/MV_FAST_REFRESH: refreshes both fact and reference data materialized views.
User-Defined Fields
User-defined fields provide flexibility in capturing and displaying additional attributes within Oracle Demand Signal Repository. A set of 20 user-defined fields (ten alphanumeric and 10 numeric) have been added to each of the DSR entities below:
-
Manufacturer Item Hierarchy (all levels)
-
Retailer Item Hierarchy (all levels)
-
Organization Hierarchy (all levels)
-
Item Cluster Definition
-
Retailer Cluster Definition
-
Customer Promotion Plans
The column names and data type for the User-Defined Fields are shown in the table below:
| Column Name | Data Type | Column | Data Type |
| Attribute1 | VarChar2 (240) | Attribute11 | Number |
| Attribute2 | VarChar2 (240) | Attribute12 | Number |
| Attribute3 | VarChar2 (240) | Attribute13 | Number |
| Attribute4 | VarChar2 (240) | Attribute14 | Number |
| Attribute5 | VarChar2 (240) | Attribute15 | Number |
| Attribute6 | VarChar2 (240) | Attribute16 | Number |
| Attribute7 | VarChar2 (240) | Attribute17 | Number |
| Attribute8 | VarChar2 (240) | Attribute18 | Number |
| Attribute9 | VarChar2 (240) | Attribute19 | Number |
| Attribute10 | VarChar2 (240) | Attribute20 | Number |
By default, the first three fields are visible within DSR. Administrators can add or remove the visibility for each field. These user-defined fields do not require customization, since these fields use existing interface tables and Oracle Warehouse Builder process flows.
Viewing User-Defined Fields as Attributes
To view user-defined fields as attributes:
-
Login to OBIEE.
-
Choose DSR Reports.
-
Choose the Reference Folder.
-
Create query or report with the dimension level and related attributes.
-
Display the report.
Forecast Types and Purpose Codes
Retailers provide different types of forecasts to Manufacturers, including base demand without promotional volumes, promotional demand only, or total demand (including both base and promotion data). Administrators may want to configure DSR to display attributes in the forecast sales source file that describe the forecast data provided by the Retailer.
The provided forecast can be to represent demand for:
-
Projected Orders
-
Projected Receipts
-
Projected Store Sales
-
Projected Shipments
A new Reference folder, named Forecast, contains the new dimensions Forecast Type, Purpose Code. All forecast measures can be displayed and analyzed using the Forecast Type and Forecast Purpose attributes. Reports and analysis can now be done on the components of a forecast in order to analyze the source of the demand. Forecasts can be viewed by specific type and purpose, or by the Forecast’s components: Base, Promoted and Total.
Forecast Type and Purpose codes Process Flow
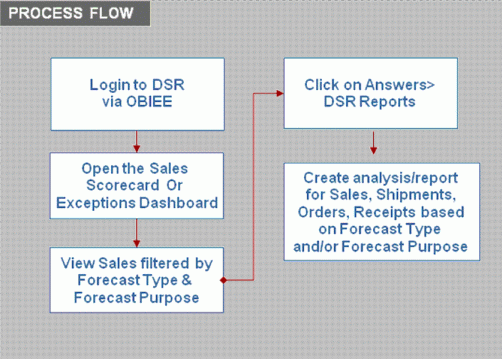
The process to view Manufacturer Promotion data is:
-
Login to OBIEE.
-
Open the Sales Scorecard Or Exceptions Dashboard.
-
View Sales filtered by Forecast Type & Forecast Purpose.
-
Click on Answers>DSR Reports.
Oracle Warehouse Builder (OWB) contains MAPs and Process Flows to load data from the interface tables into DSR. MAPs move the data from the interface tables into the target or error tables. The Process Flows run the MAPs that load forecast data, including the forecast type and forecast purpose codes.
Forecast Type and Purpose Code Setup Flow
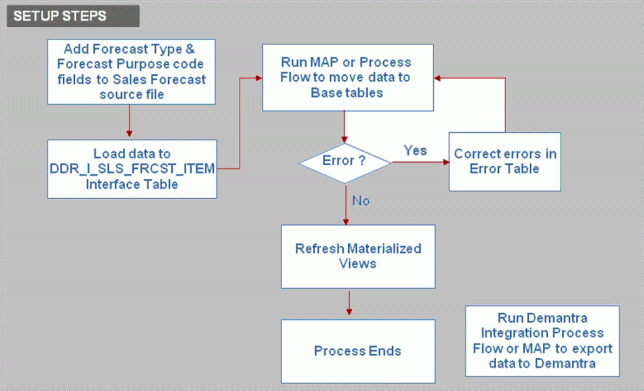
The process to load Forecast Type and Purpose Codes is:
-
Create the source files, or modify existing files, to include the Forecast Type and Forecast Purpose code fields.
-
Load data to the DDR_I_SLS_FRCST_ITEM Interface table.
-
Run MAP or process flow to move data to target tables.
-
Correct any errors.
-
Rerun the MAP or process flow.
-
-
Refresh the Materialized views.
-
Run the Demantra Integration Process Flow or MAP to export data to Demantra.
Note: This step can be run anytime after the Material Views are refreshed.
Forecast Type Process Flows
DSR uses the following process flows to setup forecast types and purpose codes:
-
FORECAST_EF_TO_INF_STG: EXCEL file to interface staging table.
-
FORECAST_ERR_TO_INF_STG: Error table to interface staging table.
-
FORECAST_INF_STG_TO_TGT: Interface staging table to target.
-
DDR_B_SLS_FRCST_ITEM_IS_MAP: Moves data from the interface table to the staging table, we do most of the validations in the Interface to staging maps.
-
DDR_B_SLS_FRCST_ITEM_SF_MAP: Moves the data from the staging table to the Final or Base table.
Forecast Type Tables
The tables pertaining to forecast data information are:
-
DDR_I_SLS_FRCST_ITEM: Interface staging table.
-
DDR_S_SLS_FRCST_ITEM: Staging table
-
DDR_B_SLS_FRCST_ITEM: Base table
-
DDR_E_SLS_FRCST_ITEM: Error table
Dependencies and Interactions
Point-of-Sale data can be exported from DSR to Demantra. The existing Demantra export process has been modified to consider forecast type and forecast purpose codes. Only data with Forecast Type of ‘TOTAL’ is exported. The following are the details for the data that is exported:
-
Retailer POS Forecast data with a Forecast Type = ‘TOTAL’ and Forecast Purpose = ‘SALES
Implementation Considerations
The Maps & Process Flows validate the Forecast Type & Purpose Code against the Lookup Master, DDR_R_LKUP_MST. For validation purposes, Frcst_Typ, Frcst_Purpose values have been preseeded in LKUP_TYP_CD and LKUP_CD columns in DDR_R_LKUP_MST. The preseeded values for LKUP_CD are in the chart below:
| Type | Purpose |
| Base | Sales |
| Promo | Orders |
| Total | Shipment |
Manufacturer Promotions
DSR is able to capture, display, and analyze manufacturer promotions. This gives Manufacturers insight into the reasons for the success or failure of a promotion by providing:
-
Promotion compliance (the number or percentage of stores reporting promotional sales).
-
Promoted volume (lift) in sales due to promotion activity.
-
Items sold on promotion.
-
Non-compliant stores (items in a Manufacturer promotion not promoted by the customer).
-
Items sold on promotion other than the Manufacturer offered promotion.
DSR loads manufacturer promotion information using out of the box generic interface tables and Oracle Warehouse Builder process flows. You can associate sales to a manufacturer promotion which provides the capability to report promoted versus non-compliant sales.
Manufacturer Promotions Process Flow
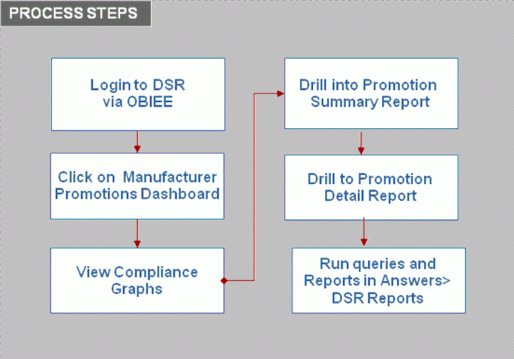
The User process to access Manufacturer Promotions is:
-
Login to DSR via OBIEE..
-
Click on the Manufacturer Promotions Dashboard.
-
View Compliance graphs.
-
Navigate to the Summary reports.
-
Navigate to the Detail report.
-
Run queries and reports in Answers>DSR Reports.
Manufacturer Promotions Setup Flow
The process to load Manufacturer Promotion data is:
-
Ceate the Mfr Promotion reference file and detail file in the required format.
-
Create a record, SLS_TYP, in existing table DDR_R_LKUP_TYP.
-
Add values for the lookup names in table DDR_R_LKUP_MST table (such as Manufacturer Promoted, Manufacturer Non Compliant, Other Promoted, or Regular).
-
Load the files to the relevant interface tables. Note that the Manufacturer must load the data into the interface tables.
-
Run the MAP or the Process Flow to load the data to the Mfr Promotion reference table and check for errors.
-
PRMTN_CD, RTL_ORG_CD and MFG_SKU_ITEM_NBR are checked for duplication and to ensure they are valid.
-
PRMTN_FROM_DT and PRMTN_TO_DT are checked for validity.
-
PRMTN_SHIP_FROM_DT and PRMTN_SHIP_TO_DT are checked for validity.
-
-
Run the Process Flow to associate the promotions to Customer sales.
-
Run the Process Flow to refresh the Materialized Views.
The values for lookup type, SLS_TYP, are contained in table DDR_R_LKUP_MST. These sales types are used in associating the Manufacturer Promotion data to the Customer’s sales data.
| LKUP_CD | LKUP_NAME | LKUP_DESC |
| 1 | Manufacturer Promoted | POS Sales that were identified by the customer as promotional sales and have been associated to a manufacturer promotion. |
| 2 | Manufacturer Non Compliant | POS Sales that were identified by the customer as regular (non-promotional) sales but according to the manufacturer promotion plan criteria should have been promoted. |
| 3 | Other Promoted | POS Sales that were identified by the customer as promotional sales but there is no associated manufacturer promotion. |
| 4 | Regular | POS Sales that were identified by the customer as regular (non-promotional) sales and there is no associated manufacturer promotion. |
Process Flows can be used to load the data in stages to facilitate troubleshooting. These Process Flows allow the Administrator to load the data in stages:
-
Load to the Interface table.
-
Run the Process Flow to move data to the target table.
-
Check error table and correct errors, if any.
-
Run the Process Flow to move corrected data to the interface table.
-
Run the Process Flow to move data to the target table.
-
MFG_PRMTN_ERR_TO_INF moves corrected data from the error table to the interface table.
-
MFG_PRMTN is then used to move corrected data from the interface table to the reference table.
-
This chart contains the Manufacturer Promotion data available in the DSR tables after the setup and load process:
| DDR_R_MFG_PRMTN Table | DDR_R_MFG_PRMTN_DTL Table |
| Promotion Code | Promotion Start/End Date Ship From/To Date |
| Promotion Name | Promoted Price |
| Promotion Description | Expected Base Sales Quantity Expected Incremental Sales Quantity Expected Total Sales Quantity |
| Promotion Type | Expected Base Sales Amount Expected Incremental Sales Amount Expected Total Sales Amount |
| Promotion Status | Expected ACV % Number of Stores Running Promotion |
| Promotion Dimension Attributes 1 - 20 | Promotion Detail Attributes 1 - 20 |
Manufacturer Promotions are associated to Retailer sales by running the OWB process flow PRM_ASSC>MFG_PRMTN_ASSC. In the INPUT Parameters screen, the PRMTN_ASSC_DAYS parameter determines the number of days prior to the current date to be considered; the default is 14 days.
An item’s sales record and promotion flag value are used in determining whether an item should be associated with a loaded Manufacturer’s Promotion:
| PRMTN_FLAG | PRMTN_ID | SLS_TYP | Description |
| Y | ID | 1 | POS Sales that were identified by the customer as promotional sales and have been associated to a manufacturer promotion. |
| N | ID | 2 | POS Sales that were identified by the customer as regular (non-promotional) sales but according to the manufacturer promotion plan criteria should have been promoted. |
| Y | NULL | 3 | POS Sales that were identified by the customer as promotional sales but there is no associated manufacturer promotion. |
| N | NULL | 4 | POS Sales that were identified by the customer as regular (non-promotional) sales and there is no associated manufacturer promotion. |
Mapping Criteria
For POS records within a specified date range, a POS record within the Promotion timeframe that matches a SKU and Retailer in the Manufacturer’s Promotion Plan will cause the POS record to be mapped to the Promotion. For overlapping promotions, the SKU is mapped to the promotion with the earliest Effective End Date.
Refreshing the Materialized Views
After loading the data and associating the sales to promotions, use one of the following Process Flows to refresh the Materialized Views:
-
ALL_MV_COMPLETE: performs a complete refresh of all Materialized Views.
-
FACT_MV_COMPLETE: performs a complete refresh of fact Materialized Views.
-
REFERENCE_MV_COMPLETE: performs a complete refresh of reference Materialized Views.
-
ALL_MV_FAST: performs a net change refresh of all Materialized Views.
-
FACT_MV_FAST: performs a net change refresh of fact Materialized Views.
-
REFERENCE_MV_FAST: performs a net change refresh of Reference Materialized Views.
Note: The Process Flows used to refresh Materialized Views are in Oracle Warehouse Builder under DSR_OTHER_PROCESS_FLOWS.
Enabling Third Party Distributors
Manufacturers use Demand Signal Repository to gain visibility into products as they move downstream in the supply chain to the consumer. In previous releases, Demand Signal Repository captured and analyzed data coming direct from retail customers. With this feature, Demand Signal Repository has extended its capabilities to capture data coming from third party distributors.
The business benefits to having third party distributor functionality include:
-
Increased visibility into downstream data, regardless of whether the manufacturer ships directly to the customer, or indirectly to the customer using a third party distributor.
-
The ability to follow inventory from the third party distributor to retail customers.
Third Party Distributors Process Flow
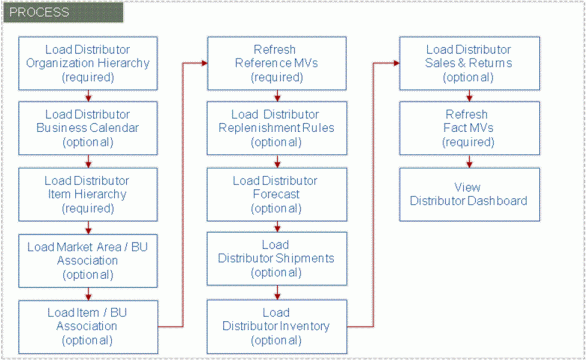
To use Third Party Distributors, you need to complete the following steps:
-
Load the distributor’s organization hierarchy which defines the distributor’s distribution centers.
-
Load the distributor’s business calendar, if you’ll be creating reports which use this calendar.
-
Load the distributor’s item hierarchy which defines the items in the terms that the distributor recognizes.
-
To assign market areas to distribution centers (for market area analysis), you will need to load the Business Unit / Market Area associations.
-
If the discovery mode is turned off and sales or forecast data is being loaded, load the Item/BU associations.
-
Refresh the reference data materialized views.
-
Load the distributor’s replenishment rules which contain information on how inventory is replenished.
-
Next, Load distributor shipment forecasts, if available.
-
Optionally, you may load distributor shipment facts. Note that while this step is optional, the most common facts manufacturer’s receive from distributors is shipment facts, so it highly likely that you will be loading these facts.
-
Load distributor inventory information.
-
If you receive sales and return information from the distributor, in which case you can load that information into DSR.
-
Once all fact data is loaded, refresh the fact materialized views which summarizes data to improve performance when running queries.
At this point you are ready to view the Distributor dashboard.
Step 1: Load Distributor Organization Hierarchy
The first step is to load the Distributor Organization Hierarchy. Distributors are loaded similar to retailers except that the Organization Type must be “DST” (for distributor). The organization type is used as a filter in the Distributor Dashboard to distinguish distributors from other organization types.
The ORG_HCHY process flow loads the distributor organization, its related organization hierarchy, and the individual business units (also known as distribution centers). For more information, see "Loading Organizations and Hierarchies".
Step 2: Load Distributor Business Calendar
The next step is to load the Distributor Business Calendar. All existing out-of-the-box DSR reports and dashboards use the manufacturer’s business calendar, if you are creating queries which need to use the distributor’s business calendar, you will need to load the distributor’s business calendar as well.
The calendar is loaded by executing the PL/SQL procedure DDR_POP_CALENDAR_PKG; Populate_BSNS_Calender. This procedure creates a specified number of years based on the passed parameters. The populate business calendar procedure performs inserts only. If you need to regenerate a particular business year (because it was created incorrectly in the first place), you will need to truncate the distributor’s business calendar before re-executing this procedure. Additional years can be created without having to delete existing years. For more information, see "Loading Organizations and Hierarchies".
Step 3: Load Distributor Item Hierarchy
Use the CST_ITM_HCHY process flow to load the Distributor Item Hierarchy. The distributor item hierarchy is loaded in the same manner as retailer item hierarchy.
Step 4: Load Market Area / BU Association
Use the MARKET_AREA_BSNS_UNIT process flow to load the Market Area / Business Unit Association. This is an optional step and is only required if you wish to perform analysis on the distributor’s distribution centers by market area. For more information, see "Loading Organizations and Hierarchies".
Step 5: Load Item / BU Association
Use the MARKET_AREA_BSNS_UNIT process flow to load the Item/ Business Unit Association. The Item Business Unit Association process flow loads data that identifies the SKUs each business unit is authorized to sell. When discovery mode (a system parameter) is set to an “N”, this table is used when loading sales and returns, and sales forecast fact data. This is an optional step and is only required if the discovery mode system parameter is set to an N (No) and you are planning to load distributor POS or forecast data.
For more information, see "Loading Organizations and Hierarchies".
Step 6: Refresh Reference Materialized Views
Once all distributor reference data is loaded, you will need to refresh reference materialized views. Materialized views are database objects that are used to aggregate data. A view might be created by joining several tables and aggregating measures by summarization, averaging, and so on. With materialized views, performance-intensive operations (like joining and grouping) are done when the view is refreshed and not when the user performs the query.
The materialized view process flows are located under the “Other Process Flows” Module). They are broken down into two groups:
-
The MV_COM (Materialized View Complete) folder contains process flows which populate the materialized views from scratch.
-
The MV_FAST (Materialized View Fast) folder contains process flows which will update existing views and apply changes made since the materialized view was last updated.
There are three process flows under each (MV_COM and MV_FAST) folder:
-
The first process flow listed in each folder (FACT_MV_COMPLETE_REFRESH or FACT_MV_FAST_REFRESH) refreshes fact data materialized views.
-
The last process flow listed in each folder (REFERENCE_MV_COMPLETE_REFRESH or REFERENCE_MV_FAST_REFRESH) refreshes reference data materialized views.
-
The process flow listed in the middle of each folder (MV_COMPLETE_REFRESH and MV_FAST_REFRESH) refreshes both reference and fact data materialized views.
You can either refresh the reference data at this time, or you can postpone the refresh of the reference materialized views until all facts are loaded and then refresh both the reference and fact materialized views. Since there is no interface table to load, running the process flows are simply a matter of starting the process flow.
Step 7: Load Distributor Replenishment Rules
Use the SKU_BSNS_INV_RULE process flow to load the distributors’ inventory replenishment rules. This step is optional as not every distributor will provide this information. Capturing the customer’s inventory replenishment rules by BU / SKU combination provides insight into stocking policies and possible out of stock causes. For more information, see "Replenishment Rules".
Step 8: Load Distributor Forecast
Use the FORECAST_INF_STG_TO_TGT process flow to load forecast information, if it is available from the distributor. The Forecast Purpose Code and Forecast Type code columns are used to differentiate the types of forecasts.
The existing forecast process flow was enhanced to capture the additional information.
Step 9: Load Distributor Shipments - Process Flow Description
Use the SHIPMENT_INF_STG_TO_TGT process flow to load distributor shipments. The Shipments process flow loads shipped units and monetary amount for a given ship-from location (org and BU)/ship-to location (org and BU) /SKU/day combination. For example, a shipment records might represent a total of 250 Units of SKU 123 being shipped from AAA Distribution’s west coast distribution center to Bigmart store #100.
When you execute the Shipment process flow, the system reads data from the source table, DSR performs the necessary validations (which we will discuss in a subsequent slide) and populates the target table listed here.
Prior to loading the distribution shipment information, you will need to have loaded business units, both retailer and manufacturer SKUs, and calendar information.
| Process Flow Name: | SHIPMENT_INF_STG_TO_TGT |
| Source Table(s): | DDR_I_RTL_SHIP_ITEM |
| Target Table(s): | DDR_B_RTL_SHIP_ITEM_DAY |
| Dependent Table(s): | DDR_R_ORG_BSNS_UNIT DDR_R_RTL_SKU_ITEM DDR_R_MFG_SKU_ITEM DDR_R_DAY |
| Required Validations: | Mfg Org Code Retailer/Distributor Org Code Business Unit Ship To Org Code Ship To Business Unit Retail SKU Item Number Unit of Measure Transaction Date Global Item ID and Global ID Type are required if Retail SKU Item Number is associated to more than one Global ID / Global ID Type. |
| Key Validations: | Common validations |
Note: When upgrading from a previous release, Ship-To Organization Code and Ship To Business Unit must be populated by:
-
Truncating shipment data and reloading
-
Custom SQL Script
Step 10: Load Distributor Inventory
Use the INVNTORY_INF_STG_TO_TGT process flow to load inventory information, assuming it is available from the distributor. The inventory facts are captured at a lower level than the other facts within DSR. Inventory facts are captured at the store/SKU/Day/Stocking Location level. For example, if a store stocks a SKU in two different places within the store, DSR can capture the quantity at each stocking location. In addition to On-Hand information, the inventory facts also include, Received, In-Transit, On Quality Hold and On Back Order quantities and amounts.
Step 11: Load Distributor Sales and Returns
Use the SLS_RTRN_INF_STG_TO_TGT process flow to capture sales and return information at the store/SKU/day/level.
Step 12: Refresh Fact Materialized Views
Use the FACT_MV_COMPLETE_REFRESH and FACT_MV_FAST_REFRESH process flows to refresh the fact materialized views. This step must be completed for the data to appear on the distributor dashboard. You can choose to perform either a complete refresh of the fact data or a fast refresh. If you postponed refreshing the reference data materialized views, you must refresh both reference and fact materialized views at this time.
There is no interface table to load, running the process flows are simply a matter of starting the process flow.
Step 13: View Distributor Dashboard
The last step is to view the data using the Distributor dashboard. The Distributor dashboard provides visibility into distributor shipment, forecast and inventory facts. The dashboard can be filtered by one or more distributors and/or product categories, in addition to a date range.
The Manufacturer Shipments by Distributor chart provides a breakdown of manufacturer shipment amount by distributor.
The Distributor Shipments by Customer chart displays the top n customers based on outbound shipment amount from the distributor(s) to the customer.
The Manufacturer Shipment Trend chart displays a weekly trend of shipments from the manufacturer to the selected distributors. This lets you know whether manufacturer shipments to the selected distributor(s) are on the rise or decline.
The Forecast Accuracy by Distributor chart displays the average shipment forecast accuracy percent by distributor to see how well each distributor forecast shipments.
The Distributor Inventory by Product Category chart displays the monetary value of the on-hand inventory at selected distributors by product category.
The Customer Shipments by Supplier chart displays shipments to a customer broken down by the ship from organization (supplier).
The Distributor Shipment Throughput by Product Category chart compares inbound shipments to the distributor and outbound shipments from the distributor by product category, allowing you to see whether inventory at the distributor is increasing or decreasing by product category.
The Distributor Shipment Throughput Trend displays inbound shipments to the distributor and outbound shipments from the distributor by week. This lets you know whether inventory is passing through the distributor at an equal rate at which it arrives.
Manufacturer Shipments
Manufacturers use Demand Signal Repository to gain visibility into products as they move downstream in the supply chain to the consumer. In previous releases, Demand Signal Repository captured and analyzed data from retail customers. This feature extends the capture of data to include Manufacturer Shipments.
The business benefits to having Manufacturer Shipments include:
-
Ability to analyze manufacturer shipments within Demand Signal Repository.
-
Ability to compare supply against demand to determine potential causes of poor performance.
Manufacturer Shipments Process Flow
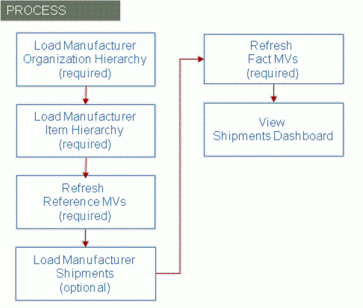
To use Manufacturer Shipments, you need to complete the following steps:
-
Load the manufacturer’s organization hierarchy which defines the manufacturer’s shipping locations.
-
Load the manufacturer’s item hierarchy.
-
Refresh the reference data materialized views.
-
Load manufacturer shipment facts.
-
Refresh the fact materialized views which summarizes data to improve performance when running queries.
-
View the Shipments dashboard.
Step 1: Load Manufacturer Organization Hierarchy
Manufacturers are loaded similar to other organizations like retailers and distributors except that the Organization Type must be “MFG” (for manufacturer). It’s not necessary to capture all the manufacturer’s locations, only the locations from which product is shipped.
The ORG_HCHY process flow loads the manufacturer organization, its related organization hierarchy and the individual business units, or shipping locations.
Step 2: Load Manufacturer Item Hierarchy
Manufacturer item hierarchy is loaded using the MFG_ITEM_HCHY OWB process flow. This is the same method as in previous releases of DSR. No changes were required to support manufacturer shipments.
Step 3: Refresh Reference Materialized Views
Once all reference data is loaded, you will need to refresh reference materialized views. Materialized views are database objects that are used to aggregate data. A view might be created by joining several tables and aggregating measures by summarization, averaging, and so on. With materialized views, performance-intensive operations like joining and grouping are done when the view is refreshed (vs. when the user performs the query).
The materialized view process flows are located under the “Other Process Flows” Module. They are broken down into two groups:
-
The MV_COM (Materialized View Complete) folder contains process flows which populate the materialized views from scratch.
-
The MV_FAST (Materialized View Fast) folder contains process flows which will update existing views and apply changes made since the materialized view was last updated.
There are three process flows under each (MV_COM and MV_FAST) folder:
-
The first process flow listed in each folder (FACT_MV_COMPLETE_REFRESH or FACT_MV_FAST_REFRESH) refreshes fact data materialized views.
-
The last process flow listed in each folder (REFERENCE_MV_COMPLETE_REFRESH or REFERENCE_MV_FAST_REFRESH) refreshes reference data materialized views.
-
The process flow listed in the middle of each folder (MV_COMPLETE_REFRESH and MV_FAST_REFRESH) refreshes both reference and fact data materialized views.
You can either refresh the reference data at this time, or you can postpone the refresh of the reference materialized views until all facts are loaded and then refresh both the reference and fact materialized views. Since there is no interface table to load, running the process flows are simply a matter of starting the process flow.
Step 4: Load Manufacturer Shipments
The next step is to load manufacturer shipments. Manufacturer shipments reside in a new fact table, separate from customer and distributor shipments. The Manufacturer shipments process flow loads shipped units and monetary amount for a given ship-from location (org and BU)/ship-to location (org and BU) /SKU/day combination. For example, a shipment record might represent a total of 250 units of SKU 123 being shipped from the manufacturer’s Houston manufacturing facility to ValueChoice’s Texas distribution center.
When you execute the manufacturer’s shipment process flow, the system reads data from the source table, performs the necessary validations, and populates the target table. Prior to loading the manufacturer shipment information, you will need to have loaded business units (both ship-from and ship-to locations), manufacturer SKUs, and calendar information.
The Shipments process flow loads shipped units and monetary amount for a given ship-from location/ship-to location /SKU/day combination. For example, 250 units of SKU 123 being shipped from the manufacturer’s Houston manufacturing facility to ValueChoice’s Texas distribution center.
| Process Flow Name: | MFG_SHIP_INF_STG_TO_TGT |
| Source Table(s): | DDR_I_MFG_SHIP_ITEM |
| Target Table(s): | DDR_B_MFG_SHIP_ITEM_DAY |
| Dependent Table(s): | DDR_R_ORG_BSNS_UNIT DDR_R_DAY DDR_R_MFG_SKU_ITEM |
Step 5: Refresh Fact Materialized Views
Once all fact data is loaded (including manufacturer shipments), you will need to refresh fact materialized views. This step must be completed for the data to appear on the manufacturer dashboard.
You can choose to perform either a complete refresh of the fact data or a fast refresh. If you postponed refreshing the reference data materialized views, you must refresh both reference and fact materialized views at this time. There is no interface table to load, running the process flows are simply a matter of starting the process flow.
Step 6: View manufacturer Dashboard
The last step is to view the data using the shipments dashboard. The shipments dashboard provides visibility into manufacturer and customer shipments. The dashboard can be filtered by one or more customers and/or product categories, in addition to a date range.
The Manufacturer Shipments chart compares year over year shipment history to see if shipments are increasing/decreasing. You can drill down within the chart from month, to week to day.
The Customer Sales chart displays customer sales quantity by month. It compares year over year sales to see if sales are increasing/decreasing. This chart is used to make a side-by side comparison with manufacturer shipments to see any correlation between increase/decrease in manufacturer shipments vs. customer sales. Similar to the Manufacturer Shipments chart, you can drill down from month to week to day.
The Inbound Shipments vs. Receipts by Product Category chart displays inbound customer shipments compared to receipts by product category. Receipt quantities in excess of shipments sent from a distribution center may indicate phantom inventory (products purchased through unauthorized sources). You can drill down within the chart from product category, to sub-category, to item and then individual SKU.
The Inbound Shipments vs. Receipts by Business Unit chart displays inbound customer shipments compared to receipts by product category. Here you can drill to a separate Inbound Shipments vs. Receipts by Business Unit report which breaks down shipments by product category (for the selected business unit).