|
| |
| Sun Java System Messaging Server 6 2005Q1 Administration Guide | |
Chapter 8
MTA ConceptsThis chapter provides a conceptual description of the MTA. It consists of the following sections:
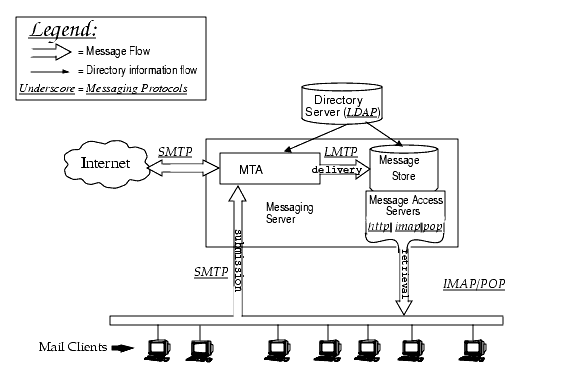
The MTA FunctionalityThe Message Transfer Agent, or MTA is a component of the Messaging Server (Figure 8-1). At its most basic level, the MTA is a message router. It accepts messages from other servers, reads the address, and routes it to the next server on way to its final destination, typically a user’s mailbox.
Over the years, a lot of functionality has been added to the MTA, and with it, size, power, and complexity. These MTA functions overlap, but, in general, can be classified as follows:
- Routing. Accepts a message, expands or transforms it if necessary (for example if it is an alias), and routes it to the next server, channel, program, file, or whatever. The routing function has been expanded to allow administrator specification of the internal and external mechanics of how messages are routed. For example, it is possible to specify things such as SMTP authentication, use of various SMTP commands and protocol, TCP/IP or DNS lookup support, job submission, process control and message queueing and so on.
- Address Rewriting. Envelope addresses are often rewritten as part of the routing process, but envelope or header addresses can also be rewritten to a more desired or appropriate form.
- Filtering. The MTA can filter messages based on address, domain, possible virus or spam content, size, IP address, header content, and so on. Filtered messages can be discarded, rejected, modified, sent to a file, sent to a program, or be sent to the next server on its way to a user mailbox.
- Content Modification. Message headers or content can be modified. Example: making a message readable to a specific client or in a specific character set or checking for spam or viruses.
- Auditing. Tracking who submitted what, where and when.
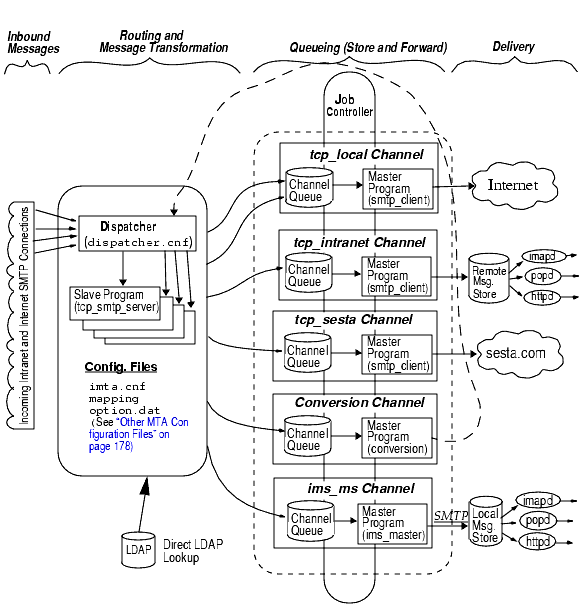
A number of subcomponents and processes support these functions and are shown in Figure 8-2. This chapter describes these subcomponents and processes. In addition, a number of tools allow system administrators to enable and configure these functions. These include MTA options, configutil parameters, mapping tables, keywords, channels, and rewrite rules. These are described in later MTA chapters:
Figure 8-2 MTA Architecture
MTA Architecture and Message Flow OverviewThis section provides a short overview of MTA architecture and message flow (Figure 8-2). Note that the MTA is a highly complex component and that Figure 8-2 is simplified depiction of messages flowing through the system. In fact, this picture is not a perfectly accurate depiction of all messages flowing through the system. For purposes of conceptual discussion, however, it must suffice.
Dispatcher and SMTP Server (Slave Program)
Messages enter the MTA from the internet or intranet via SMTP sessions. When the MTA receives a request for an SMTP connection, the MTA dispatcher (a multithreaded connection dispatching agent), executes a slave program (tcp_smtp_server) to handle the SMTP session. The dispatcher maintains pools of multithreaded processes for each service. As additional sessions are requested, the dispatcher activates an SMTP server program to handle each session. A process in the Dispatcher’s process pool may concurrently handle many connections. Together the dispatcher and slave program perform a number of different functions on each incoming message. Three primary functions are:
- Message blocking - messages from specified IP addresses, mail addresses, ports, channels, header strings and so on, may be blocked (Chapter 17, "Mail Filtering and Access Control".”)
- Address changing. Incoming From: or To: addresses may be rewritten to a different form.
- Channel enqueueing. Addresses are run through the rewrite rules to determine which channel the message should be sent.
For more information see The Dispatcher
Routing and Address Rewriting
SMTP servers enqueue messages, but so can a number of other channels including, the conversion channel and reprocess channel. During this phase of delivery, however, a number of tasks are achieved during this phase of delivery, but the primary tasks are:
Channels
The channel is the fundamental MTA component used for message processing. A channel represents a message connection with another system (for example, another MTA, another channel, or the local message store). As mail comes in, different messages require different routing and processing depending on the message’s source and destination. For example, mail to be delivered to a local message store will be processed differently from mail to be delivered to the internet which will be processed differently from mail to be sent to another MTA within the mail system. Channels provide the mechanism for customizing the processing and routing required for each connection. In a default installation, the majority of messages go to a channels handling internet, intranet, and local messages.
Specialized channels for specific situations can also be created. For example, suppose that a certain internet domain processes mail very slowly causing mail addressed to this domain to clog up the MTA. A special channel could be created to provide special handling for messages addressed to the slow domain, thus relieving the system of this domain bottleneck.
The domain part of the address determines to what channel the message is enqueued. The mechanism for reading the domain and determining the appropriate channel is called the rewrite rules (see Rewrite Rules).
Channels typically consist of a channel queue and a channel processing program called a master program. After the slave program delivers the message to the appropriate channel queue, the master program performs the desired processing and routing. Channels, like rewrite rules, are specified and configured in the imta.cnf file. An example of a channel entry is shown below:
tcp_intranet smtp mx single_sys subdirs 20 noreverse maxjobs 7 SMTP_POOL maytlsserver allowswitchchannel saslswitchchannel tcp_auth
tcp_intranet-daemonThe first word, in this case tcp_intranet is the channel name. The last word is called the channel tag. The words in between are called channel keywords and specify how messages are to be processed. Hundreds of different keywords allow messages to be processed in many ways. A complete description of channel keywords is provided in the Sun Java System Messaging Server Administration Reference and Chapter 12, "Configuring Channel Definitions".”
Message Delivery
After the message is processed, the master program sends the message to the next stop along the message’s delivery path. This may be the intended recipient’s mailbox, another MTA, or even a different channel. Forwarding to another channel is not shown in the picture, but is common occurrence.
Note that the local parts of addresses and received fields are typically 7-bit characters. If the MTA reads 8-bit characters in the in these fields, it replaces each 8-bit character with asterisks.
The DispatcherThe Dispatcher is a multithreaded dispatching agent that permits multiple multithreaded server processes to share responsibility for SMTP connection services. When using the Dispatcher, it is possible to have several multithreaded SMTP server processes running concurrently, all handling connections to the same port. In addition, each server may have one or more active connections.
The Dispatcher acts as a central receiver for the TCP ports listed in its configuration. For each defined service, the Dispatcher may create one or more SMTP server processes to handle the connections after they are established.
In general, when the Dispatcher receives a connection for a defined TCP port, it checks its pool of available worker processes for the service on that port and chooses the best candidate for the new connection. If no suitable candidate is available and the configuration permits it, the Dispatcher may create a new worker process to handle this and subsequent connections. The Dispatcher may also create a new worker process in expectation of future incoming connections. There are several configuration options which may be used to tune the Dispatcher's control of its various services, and in particular, to control the number of worker processes and the number of connections each worker process handles.
See Dispatcher Configuration File for more information.
Creation and Expiration of Server Processes
Automatic housekeeping facilities within the Dispatcher control the creation of new and expiration of old or idle server processes. The basic options that control the Dispatcher's behavior are MIN_PROCS and MAX_PROCS. MIN_PROCS provides a guaranteed level of service by having a number of server processes ready and waiting for incoming connections. MAX_PROCS, on the other hand, sets an upper limit on how many server processes may be concurrently active for the given service.
It is possible that a currently running server process might not be able to accept any connections because it is already handling the maximum number of connections of which it is capable, or because the process has been scheduled for termination. The Dispatcher may create additional processes to assist with future connections.
The MIN_CONNS and MAX_CONNS options provide a mechanism to help you distribute the connections among your server processes. MIN_CONNS specifies the number of connections that flags a server process as “busy enough” while MAX_CONNS specifies the “busiest” that a server process can be.
In general, the Dispatcher creates a new server process when the current number of server processes is less than MIN_PROCS or when all existing server processes are “busy enough” (the number of currently active connections each has is at least MIN_CONNS).
If a server process is killed unexpectedly, for example, by the UNIX system kill command, the Dispatcher still creates new server processes as new connections come in.
For information about configuring the Dispatcher, see Dispatcher Configuration File.
To Start and Stop the Dispatcher
To start the Dispatcher, execute the command:
start-msg dispatcher
This command subsumes and makes obsolete any other start-msg command that was used previously to start up a component of the MTA that the Dispatcher has been configured to manage. Specifically, you should no longer use imsimta start smtp. An attempt to execute any of the obsoleted commands causes the MTA to issue a warning.
To shut down the Dispatcher, execute the command:
stop-msg dispatcher
What happens with the server processes when the Dispatcher is shut down depends upon the underlying TCP/IP package. If you modify your MTA configuration or options that apply to the Dispatcher, you must restart the Dispatcher so that the new configuration or options take effect.
To restart the Dispatcher, execute the command:
imsimta restart dispatcher
Restarting the Dispatcher has the effect of shutting down the currently running Dispatcher, then immediately starting a new one.
Rewrite RulesRewrite rules determine the following:
Each rewrite rule consists of a pattern and a template. The pattern is a string to match against the domain part of an address. The template specifies the actions to take if the domain part matches the pattern. It consists of two things: 1) a set of instructions (that is, a string of control characters) specifying how the address should be rewritten and 2) the name of the channel to which the message shall be sent. After the address is rewritten, the message is enqueued to the destination channel for delivery to the intended recipient.
An example of a rewrite rule is shown below:
siroe.com $U%$D@tcp_siroe-daemon
siroe.com is the domain pattern. Any message with the address containing siroe.com will be rewritten as per the template instructions ($U%$D). $U specifies that the rewritten address use the same user name. % specifies that the rewritten address use the same domain separator. $D specifies that the rewritten address use the same domain name that was matched in the pattern. @tcp_siroe-daemon specifies that the message with its rewritten address be sent to the the channel called tcp_siroe-daemon. See Chapter 11, "Configuring Rewrite Rules"” for more details.
For more information about configuring rewrite rules, see The MTA Configuration File and Chapter 11, "Configuring Rewrite Rules".”
ChannelsThe channel is the fundamental MTA component that processes a message. A channel represents a connection with another computer system or group of systems. The actual hardware connection or software transport or both may vary widely from one channel to the next.
Channels perform the following functions:
Messages are enqueued by channels on the way into the MTA and dequeued on the way out. Typically, a message enters via one channel and leaves by another. A channel might dequeue a message, process the message, or enqueue the message to another MTA channel.
Master and Slave Programs
Generally (but not always), a channel is associated with two programs: master and slave. The slave program accepts messages from another system and adds them to a channel’s message queue. The master program transfers messages from the channel to another system.
For example, an SMTP channel has a master program that transmits messages and a slave program that receives messages. These are, respectively, the SMTP client and server.
The master channel program is typically responsible for outgoing connections where the MTA has initiated the operation. The master channel program:
The slave channel program typically accepts incoming connections where the MTA is responding to an external request. The slave channel program:
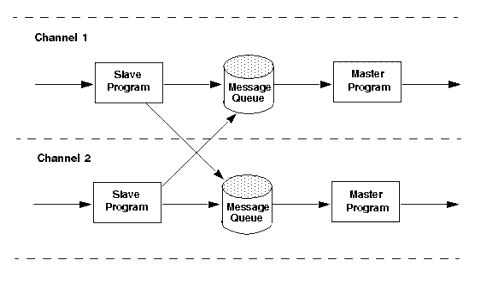
For example, Figure 8-3 shows two channel programs, Channel 1 and Channel 2. The slave program in Channel 1 receives a message from a remote system. It looks at the address, applies rewrite rules as necessary, then based on the rewritten address enqueues the message to the appropriate channel message queue.
The master program dequeues the message from the queue and initiates network transport of the message. Note that the master program can only dequeue messages from its own channel queue.
Figure 8-3 Master and Slave Programs
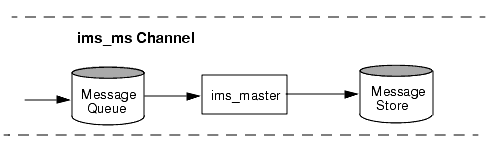
Although a typical channel has both a master and a slave program, it is possible for a channel to contain only a slave program or a master program. For example, the ims-ms channel supplied with Messaging Server contains only a master program because this channel is responsible only for dequeuing messages to the local message store, as shown in Figure 8-4.
Figure 8-4 ims-ms Channel
Channel Message Queues
All channels have an associated message queue. When a message enters the messaging system, a slave program determines to which message queue the message is enqueued. The enqueued messages are stored in message files in the channel queue directories. By default, these directories are stored at the following location: msg_svr_base/data/queue/channel/*.
Channel Definitions
Channel definitions appear in the lower half of the MTA configuration file, imta.cnf, following the rewrite rules (see The MTA Configuration File). The first blank line to appear in the file signifies the end of the rewrite rules section and the start of the channel definitions.
A channel definition contains the name of the channel followed by an optional list of keywords that define the configuration of the channel, and a unique channel tag, which is used in rewrite rules to route messages to the channel. Channel definitions are separated by single blank lines. Comments, but no blank lines, may appear inside a channel definition.
Collectively, the channel definitions are referred to as the channel host table. An individual channel definition is called a channel block. For example, in the example below, the channel host table contains three channel definitions or blocks.
A typical channel entry will look something like this:
tcp_intranet smtp mx single_sys subdirs 20 noreverse maxjobs 7 SMTP_POOL maytlsserver allowswitchchannel saslswitchchannel tcp_auth
tcp_intranet-daemonThe first word, in this case tcp_intranet, is the channel name. The last word, in this case tcp_intranet-daemon, is called the channel tag. The channel tag is the name used by rewrite rules to direct messages. The words in between the channel name and channel tag are called channel keywords and specify how the message is to be processed. Hundreds of different keywords allow messages to processed in many ways. A complete listing of channel keywords is listed and described in the Sun Java System Messaging Server Administration Reference and Chapter 12, "Configuring Channel Definitions".
The channel host table defines the channels Messaging Server can use and the names of the systems associated with each channel.
On UNIX systems, the first channel block in the file always describes the local channel, l. (An exception is a defaults channel, which can appear before the local channel.) The local channel is used to make routing decisions and for sending mail sent by UNIX mail tools.
You can also set global options for channels in the MTA Option file, option.dat, or set options for a specific channel in a channel option file. For more information on the option files, see Option File, and TCP/IP (SMTP) Channel Option Files. For details on configuring channels, see Chapter 12, "Configuring Channel Definitions". For more information about creating MTA channels, see The MTA Configuration File.
The MTA Directory InformationFor each message that it processes, the MTA needs to access directory information about the users, groups, and domains that it supports. This information is stored in an LDAP directory service. The MTA directly accesses the LDAP directory. This is fully described in Chapter 9, "MTA Address Translation and Routing."
The Job ControllerEach time a message is enqueued to a channel, the Job Controller ensures that there is a job running to deliver the message. This might involve starting a new job process, adding a thread, or simply noting that a job is already running. If a job cannot be started because the job limit for the channel or pool has been reached, the Job Controller waits until another job has exited. When the job limit is no longer exceeded, the Job Controller starts another job.
Channel jobs run inside processing pools within the Job Controller. A pool can be thought of a “place” where the channel jobs are run. The pool provides a computing area where a set of jobs can operate without vying for resources with jobs outside of the pool. For more information on pools see Job Controller File and Processing Pools for Channel Execution Jobs.
Job limits for the channel are determined by the maxjobs channel keyword. Job limits for the pool are determined by the JOB_LIMIT option for the pool.
Messaging Server normally attempts to deliver all messages immediately. If a message cannot be delivered on the first attempt, however, the message is delayed for a period of time determined by the appropriate backoff keyword. As soon as the time specified in the backoff keyword has elapsed, the delayed message is available for delivery, and if necessary, a channel job is started to process the message.
The Job Controller’s in-memory data structure of messages currently being processed and awaiting processing typically reflects the full set of message files stored on disk in the MTA queue area. However, if a backlog of message files on disk builds up enough to exceed the Job Controller’s in-memory data structure size limit, then the Job Controller tracks in memory only a subset of the total number of messages files on disk. The Job Controller processes only those messages it is tracking in memory. After a sufficient number of messages have been delivered to free enough in-memory storage, the Job Controller automatically refreshes its in-memory store by scanning the MTA queue area to update its list of messages. The Job Controller then begins processing the additional message files it just retrieved from disk. The Job Controller performs these scans of the MTA queue area automatically.
If your site routinely experiences heavy message backlogs, you might want to tune the Job Controller by using the MAX_MESSAGES option. By increasing the MAX_MESSAGES option value to allow Job Controller to use more memory, you can reduce the number of occasions when message backlogs overflow the Job Controller’s in-memory cache. This reduces the overhead involved when the Job Controller must scan the MTA queue directory. Keep in mind, however, that when the Job Controller does need to rebuild the in-memory cache, the process will take longer because the cache is larger. Note also that because the Job Controller must scan the MTA queue directory every time it is started or restarted, large message backlogs mean that starts or restarts of the Job Controller will incur more overhead than starts or restarts when no such backlog exists.
For information about pools and configuring the Job Controller, see Job Controller File and Configuring Message Processing and Delivery.
To Start and Stop the Job Controller
To start the Job Controller, execute the command:
start-msg job_controller
To shut down the Job Controller, execute the command:
stop-msg job_controller
To restart the Job Controller, execute the command:
imsimta restart job_controller
Restarting the Job Controller has the effect of shutting down the currently running Job Controller, then immediately starting a new one.