|
|
| Sun ONE Directory Server 5.2 Deployment Guide |
Chapter 6 Designing the Replication Process
Replicating your directory contents increases the availability and performance of your directory. In Chapter 4 and Chapter 5, you made decisions about the design of your directory tree and your directory topology. This chapter addresses the physical and geographical location of your data, and specifically, how to use replication to ensure that your data is available when and where you need it.
This chapter discusses uses for replication and offers advice on designing a replication strategy for your directory environment. It contains the following sections:
- Introduction to Replication
- Common Replication Scenarios
- Defining a Replication Strategy
- Using Replication with Other Directory Features
- Replication Monitoring
Introduction to Replication
Replication is the mechanism that automatically copies directory data from one Directory Server to another. Using replication, you can copy any directory tree or subtree (stored in its own database) between servers, except the configuration or monitoring information subtrees.
Replication enables you to provide a highly available directory service, and to geographically distribute your data. In practical terms, replication brings the following benefits:
- Fault tolerance/Failover
By replicating directory trees to multiple servers, you can ensure your directory is available even if some hardware, software, or network problem prevents your directory client applications from accessing a particular Directory Server. Your clients can be referred to another directory for read and write operations. Note that to support write failover you must have more than one master copy of your data in your replication environment.
- Load balancing
By replicating your directory tree across servers, you can reduce the access load on any given machine, thereby improving server response time.
- Higher performance and reduced response times
By replicating directory entries to a location close to your users, you can vastly improve directory response times.
- Local data management
Replication allows you to own and manage data locally while sharing it with other Directory Servers across your enterprise.
Before defining a replication strategy for your directory information, you should understand how replication works. This section describes:
Replication Concepts
When you consider replication, you always start by making the following fundamental decisions:
- What information you want to replicate.
- Which server or servers hold the master copy of that information.
- Which server or servers hold the read-only copy of the information.
- What should happen when a consumer replica receives modification requests from client applications; that is, to which server should it refer the request.
These decisions cannot be made effectively without an understanding of how the Directory Server handles these concepts. For example, when you decide what information you want to replicate, you need to know what is the smallest replication unit that the Directory Server can handle.
To ensure that you fully understand the replication process and the possibilities it provides you for your Directory Server deployment, the following sections explain the replication concepts used by Directory Server. This provides a solid framework for thinking about the global decisions you will need to take.
Replica
A database that participates in replication is defined as a replica. There are several kinds of replicas:
- Master replica or read-write replica: a read-write database that contains a master copy of the directory data. A master replica can process update requests from directory clients.
- Consumer replica: a read-only database that contains a copy of the information held in the master replica. A consumer replica can process search requests from directory clients but refers update requests to master replicas.
- Hub replica: a read-only database just like a consumer replica. The difference is that it is stored on a Directory Server that acts as a supplier of one or more consumer replicas.
You can configure a Directory Server to manage several replicas. Each replica can have a different role in replication. For example, you could have a Directory Server that stores the dc=engineering,dc=example,dc=com suffix in a master replica, and the dc=sales,dc=example,dc=com suffix in a consumer replica.
Unit of Replication
In Directory Server the smallest unit of replication is the database. The replication mechanism requires that one database correspond to one suffix. This means that you cannot replicate a suffix (or namespace) that is distributed over two or more databases using custom distribution logic. The unit of replication concept applies to both consumers and suppliers, which means that you cannot replicate two databases to a consumer holding only one database, and vice versa.
Replica ID
Master replicas require a unique replica identifier (ID) and consumer replicas all have the same replica ID. The replica ID for masters can be any 16 bit integer between 1 and 65534, while consumer replicas all have the replica ID of 65535. The replica ID lies at the heart of the replication mechanism as it identifies to which replica the changes occurred, thus enabling them to be replicated correctly.
Note If a server hosts several replicas, the replicas may have the same replica ID, provided that the replica ID is unique between the masters of a single, replicated naming context or suffix.
Supplier/Consumer
A server that replicates to other servers is called a supplier. A server that is updated by other servers is called a consumer.
In some cases a server can be both a supplier and a consumer. This is true in the following cases:
- When the Directory Server manages a combination of master replicas and consumer replicas.
- When the Directory Server contains a hub replica; that is, it receives updates from a supplier and replicates the changes to consumer(s). For more information, refer to "Cascading Replication".
- In multi-master replication, when a master replica is mastered on two different Directory Servers, each Directory Server acts as a supplier and a consumer of the other Directory Server. For more information, refer to "Multi-Master Replication".
When we refer to a server that only plays the role of consumer; that is, it only contains a consumer replica, we refer to this server as a dedicated consumer.
In Directory Server, replication is always initiated by the supplier, never by the consumer. We refer to this as supplier-initiated replication, as suppliers push the data to consumers.
Earlier versions of the Directory Server allowed consumer-initiated replication where you could configure consumers to pull data from a suppliers. Since the 5.0 release of Directory Server, this has been replaced by a procedure in which the consumer can prompt the supplier to send updates.
For a master replica, the server must:
- Respond to update (add, delete, modrdn, or modify) requests from directory clients.
- Maintain historical information and a change log for the replica.
- Initiate replication to consumers.
The server containing the master replica is always responsible for recording the changes made to the master replicas it manages. It makes sure that any changes are replicated to consumers.
For a hub replica, the server must:
- Respond to read requests.
- Refer update requests to the server that contains the master replica.
- Maintain the historical information for the replica.
- Initiate replication to consumers.
For more information on cascading replication, refer to "Cascading Replication".
For a consumer replica, the server must:
- Respond to read requests.
- Maintain historical information for the replica.
- Refer update requests to the server that contains the master replica.
Anytime a request to add, delete, or change an entry is received by a consumer, the request is referred via the client to the server, or servers, that contain the master replica; that is, the server acting as the supplier in the replication flow. The supplier performs the request, then replicates the change.
It is possible to configure the consumer or hub replicas not to return a referral, but to return an error instead if it is desirable for security and performance reasons to do so. Refer to the Note for more information.
Online Replica Promotion and Demotion
Sun ONE Directory Server 5.2 provides online replica promotion and demotion functionality. Once online promotion or demotion is complete, the servers immediately start or stop accepting updates. To promote a consumer replica to a master replica, you need to promote it first to a hub replica and then to a master replica. The same incremental approach applies to online demotion.
In addition to providing increased flexibility, online replica promotion and demotion affords you increased failover capabilities. Take the example of a two-way, multi-master scenario with two hubs configured for additional load balancing and failover. Should one of the masters go offline, you simply need to promote one of the hubs to maintain optimal read-write availability, and then, when the master replica comes back online, a simple demotion back to hub replica returns you to the original state of affairs.
Note Before demoting a hub to a consumer, which will result in the replica no longer being able to propagate any changes due to the fact that as a consumer it will not have a change log, you must verify that the hub is in sync with the other servers. To ensure that the hub is in sync you can use the replication monitoring tool insync, which is presented in the section entitled "Replication Monitoring".
Change Log
Every server acting as a supplier, that is a master replica or a hub replica, maintains a change log. A change log is a record that describes the modifications that have occurred on a master replica. The server acting as a supplier then replays these modifications to its consumers
When an entry is modified, renamed, added or deleted, a change record describing the LDAP operation that was performed is recorded in the change log.
In earlier versions of Directory Server, the change log was accessible over LDAP. Now, however, it is intended only for internal use by the server, and is stored in its own database which means that it is no longer accessible over LDAP. If you have applications that need to read the change log, you need to use the Retro Change Log Plug-in for backward compatibility. For more information about the Retro Change Log Plug-in refer to the Using the Retro Change Log Plug-In section in the Sun ONE Directory Server Administration Guide.
Replication Identity
When replication occurs between two servers, the server acting as the consumer authenticates the server acting as supplier when it binds to the consumer to send replication updates. This authentication process requires that the entry used by the supplier to bind to the consumer is stored on the consumer server. This entry is called the Replication Manager entry. When, in the context of replication, the Directory Server Console refers to DN or bind DN, it is referring to the bind DN of the Replication Manager Entry.
The Replication Manager entry, or any entry you create to fulfill that role, must meet the following criteria:
- You must have at least one on every server acting as a consumer (whether they be dedicated consumers, hubs, or masters in a multi-master environment).
- This entry must not be part of the replicated data for security reasons and initialization issues.
Note This entry has a special user profile that bypasses all access control rules defined on the consumer server. However, this special user profile is only valid in the context of replication.
When you configure replication between two servers, you must identify the Replication Manager entry on both servers:
- On the server acting as the consumer, you must specify this entry as the one authorized to perform replication updates, when you configure the consumer replicas, hub replicas, or master replicas (in the case of multi-master replication) in your replication topology.
- On the server acting as the supplier, that is all master and hub replicas, when you configure the replication agreement, you must specify the bind DN of this entry in the replication agreement.
Replication Agreement
Directory Servers use replication agreements to define replication. A replication agreement describes replication between one supplier and one consumer. The agreement is configured on the supplier. For replication to work it is important to remember that the replication agreement must be enabled. It identifies:
- The database to replicate.
- The consumer server to which the data is pushed.
- A pointer to a set of attributes to exclude or include from the replicated data if fractional replication is configured.
- The times during which replication can occur.
- The bind DN and credentials the supplier must use to bind to the consumer, called the Replication Manager entry (for more information, refer to "Replication Identity").
- How the connection is secured (SSL, client authentication).
- The group and window sizes to configure the number of changes you can group into one request and the number of requests that can be sent before consumer acknowledgement is required.
- Status information about the replication agreement.
- On Solaris and Linux systems, information on the level of compression used in replication.
Consumer Initialization or Total Update
Consumer initialization, or total update, is the process whereby you physically copy all data from the server acting as the supplier to the server acting as the consumer. Once you have created a replication agreement, the consumer within that agreement needs to be initialized. It is only after consumer initialization is complete, that the supplier can begin replaying, or replicating the future update operations to the consumer(s). Under normal operations, the consumer should not require further initialization; however, if the data on a supplier is restored from backup for any reason, then you may need to re-initialize some of the consumers dependent on that supplier. An example where consumer re-initialization would be necessary is if the restored supplier was the only supplier for the consumer in the topology. It is possible to initialize consumers both online and offline (manually). For further information on the consumer initialization procedures see the Initializing Replicas section in the Sun ONE Directory Server Administration Guide. Directory Server 5.2 also offers an advanced binary copy feature which can be used to clone either master or consumer replicas using the binary backup files from one server to restore the identical directory contents on another server. Certain restrictions on this feature make it practical and time efficient only for replicas with very large database files. For information on the binary backup procedures and an exhaustive list of the feature's strict limitations see "Binary Backup (db2bak)".
In a multi-master replication topology, the default behavior of a read-write replica that has been reinitialized either online or offline from a backup or an ldif file, is to REFUSE client update requests. Note that this is in contrast to previous versions of Directory Server. By default the replica will remain in read-only mode indefinitely and will refer any update operations to other suppliers in the topology. In such a case, the administrator may configure the replica to begin accepting updates again in two ways:
- Manually enable read-write mode by using the Directory Server console or setting the ds5BeginReplicaAcceptUpdates attribute to start. This allows the administrator to use the insync replication monitoring tool to ensure that the replica has completely converged with the other suppliers in the topology. This is the recommended procedure because the administrator can guarantee that the replica is in sync before allowing update operations.
- Configure the replica to automatically revert to read-write mode after a given delay specified by the replica specific ds5referralDelayAfterInit attribute. This procedure presents the risk of allowing update operations on the replica before it is completely synchronized with the other master replicas, which may lead to unexpected errors.
For more information on these procedures refer to the the Initializing Replicas section of the Sun ONE Directory Server Administration Guide. For more information regarding the replication configuration attributes refer to the replication attributes listed in the Core Server Configuration Attributes chapter of the Sun ONE Directory Server Reference Manual.
Incremental Update
Incremental update is the process whereby updates are replicated by the supplier to the consumer following consumer initialization or total update. In contrast to previous releases of Directory Server, Sun ONE Directory Server 5.2 allows a consumer to be incrementally updated by several suppliers at once, provided that the updates themselves originate from different replica IDs. Simultaneous incremental updates from several suppliers (but different replica IDs) improves the performance of the incremental update procedure.
Data Consistency
Consistency refers to how closely the contents of replicated databases match each other at a given point in time. When you set up replication between two servers, part of the configuration is to schedule updates. With Directory Server, it is always the server acting as the supplier that determines when consumers need to be updated, and initiates replication. Replication can take place only after the consumers have been initialized.
Directory Server offers the option of keeping replicas always synchronized, or of scheduling updates for a particular time of day, or day in the week. The obvious advantage of keeping replicas always in sync is that it provides better data consistency. The cost, however, is the network traffic resulting from the frequent update operations. This solution is the best in cases where:
- You have a reliable high-speed connection between servers.
- The client requests serviced by your directory are mainly search, read, and compare operations, with relatively few add and modify operations.
In cases where you can afford to have looser consistency in data, you can choose the frequency of updates that best suits your needs or lowers the effect on network traffic. This solution is the best in cases where:
- You have unreliable or intermittently available network connections (such as a dial-up connection to synchronize replicas).
- The client requests serviced by your directory are mainly add and modify operations.
- You need to reduce the communication costs.
In the case of multi-master replication, the replicas on each master are said to be loosely consistent because at any given time, there can be differences in the data stored on each master. This is true even when you have selected to always keep replicas in sync, because:
- There is a latency in the propagation of replication updates between masters.
- The master that serviced the add or modify operation does not wait for the second master to validate it before returning an "operation successful" message to the client.
Common Replication Scenarios
You need to decide how the updates flow from server to server and how the servers interact when propagating replication updates to build a replication strategy which fits your replication requirements. There are five basic scenarios:
- Single-Master Replication
- Multi-Master Replication
- Cascading Replication
- Fractional Replication
- Mixed Environments
The following sections describe these scenarios and provide strategies for deciding the method that is most appropriate for your environment. You can also combine these basic scenarios to build the replication topology that best suits your needs.
Note Whatever replication scenario you choose to implement, remember to consider schema replication. See "Schema Replication" for further information.
Single-Master Replication
In the most basic replication configuration, a server acting as a supplier copies a master replica directly to one or more consumer servers. In this configuration, all directory modifications are made to the master replica stored on the supplier, and the consumers contain read-only copies of the data.
The supplier maintains a change log that records all the changes made to the master replica. The supplier also stores the replication agreement.
The consumer stores the entry corresponding to the Replication Manager entry, so that the consumer can authenticate the supplier when the supplier binds to send replication updates.
The supplier server must propagate all modifications to the consumer replicas. Figure 6-1 shows this simple configuration.
Figure 6-1 Single-Master Replication
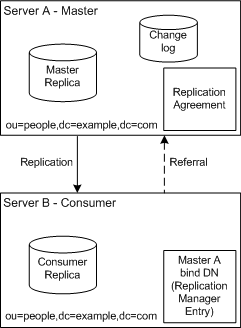
In the example illustrated in Figure 6-1, the ou=people,dc=example,dc=com suffix receives a large number of search and update requests from clients. Therefore, to distribute the load, this suffix, which is mastered on Server A, is replicated to a consumer replica located on Server B.
Server B can process and respond to search requests from clients, but cannot process requests to modify directory entries. Server B processes modification requests received from clients by sending a referral to Server A back to the client.
Although Figure 6-1 shows just one server acting as a consumer, the supplier can replicate to several consumers. The total number of consumers that a single supplier can manage depends on the speed of your network and the total number of entries that are modified on a daily basis.
Multi-Master Replication
In a multi-master replication environment, master replicas of the same information exist on more than one server. This section on multi-master replication is divided into the following parts:
- Multi-Master Replication Basic Concepts
- Multi-Master Replication Capabilities
- Fully-Connected, Four-Way, Multi-Master Topology
- Multi-Master Replication over Wide Area Networks (WAN)
Multi-Master Replication Basic Concepts
In a multi-master configuration where master replicas of the same information exist on more than one server, data can be updated simultaneously in two or more different locations. This means that each server maintains a change log for the master replica involved in the replication topology. The changes that occur on each server are replicated to the other(s). This means that each server plays both roles of supplier and consumer. Multi-master configurations have the following advantages:
- Automatic write failover when one supplier is inaccessible.
- Updates are made on a local supplier in a geographically distributed environment.
When the same data is modified on both servers at approximately the same time, update reconciliation procedures are applied; i.e. the most recent change takes precedence. However, some conflicting changes may break the LDAP model, which will result in the entry being marked as a conflicting entry. To resolve these "conflicting entries," the Administrator(s) will need to decide what to do with these entries and manually update them.
Note If the uniqueness of your attributes is important to your deployment, then we higly recommend that you enable the Attribute Value Uniqueness plug-in in multi-master replication environments, as it allows you to reduce the number of naming conflicts. For more information on the Attribute Value Uniqueness plug-in see the section entitled "Common Replication Scenarios".
Although two separate servers can have master copies of the same data, within the scope of a single replication agreement, there is only ever one supplier and one consumer. So, to create a multi-master environment between two suppliers that share responsibility for the same data, you need to create two replication agreements. Figure 6-1 shows this configuration:
Figure 6-2 Multi-Master Replication Configuration (Two Masters)
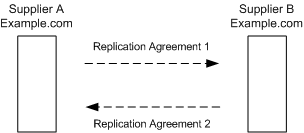
Supplier A and Supplier B each hold a master replica of the same data and there are two replication agreements governing the replication flow of this multi-master configuration.
Directory Server 5.2 supports a maximum of four masters in a multi-master replication topology. The number of consumers and hubs is theoretically unlimited, although the number of consumers to which a single supplier can replicate will depend on the capacity of the supplier server.
Multi-Master Replication Capabilities
Sun ONE Directory Server 5.2 provides a more streamlined, flexible protocol that makes it easier for you to adapt your deployment to your replication and performance requirements. Sun ONE Directory Server 5.2 allows you to:
- Replicate updates based on the replica ID. Replica ID-based updates result in improved performance in that they make it possible for a consumer to be updated by multiple suppliers at the same time (provided that the updates originate from different replica IDs).
- Enable or disable a replication agreement with a given consumer, which provides you with greater replication configuration flexibility for your deployment. You can configure certain topologies in the knowledge that should you, at a later date, wish to modify that topology, you can easily do so.
Fully-Connected, Four-Way, Multi-Master Topology
Figure 6-3 shows a fully-connected, four-way, multi-master topology. Thanks to its four-way master failover configuration, this fully-connected topology provides a highly-available solution that guarantees data integrity. It is the most secure in terms of read-write failover capability, but it is worth noting that this failover capability does not come without overheads in terms of performance. It will depend on your high-availability requirements as to whether or not you will want to deploy the fully-connected, multi-master configuration. Should your high-availability requirements be less stringent, or should you wish to reduce your replication traffic for performance reasons, you may want to opt for a "lighter" deployment in terms of read-write failover.
Figure 6-3 Fully-Connected Four-Way Multi-Master Replication Configuration
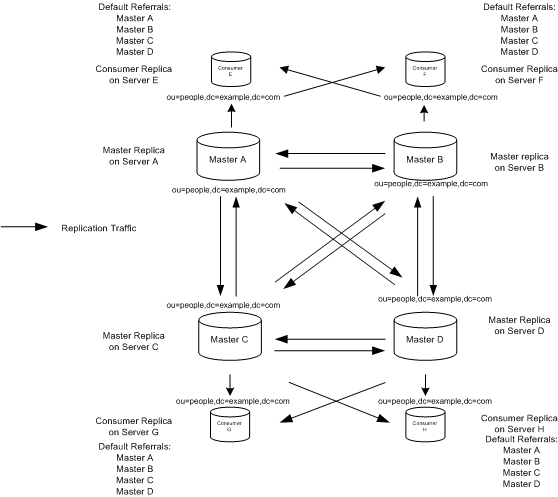
In Figure 6-3 the ou=people,dc=example,dc=com suffix is held on four masters to ensure that it is always available for modification requests. Each master maintains its own change log. When one of the masters processes a modification request from a client, it records the operation in its change log. It then sends the replication update to the other masters, and in turn to the other consumers. This requires that the masters have replication agreements with each other, as well as with the consumers. Each master also stores a Replication Manager entry that it uses to authenticate the other masters when they bind to send replication updates.
In Figure 6-3 each consumer stores two entries, corresponding to the Replication Manager entries, so that they can authenticate the masters when they bind to send replication updates. It is possible for each consumer to have just one Replication Manager entry, enabling all masters to use the same Replication Manager entry for authentication.
The consumers have referrals set up by default for all masters in the topology. When consumers receive modification requests from the clients, referrals to the masters are sent back to the clients by the consumers.
Note In replication environments consumers do not forward modification requests from clients to the servers acting as suppliers. In the event of a consumer receiving a modification request, the consumer will return a list containing the URLs of the possible masters that could satisfy the client's modification request.
Sun ONE Directory Server 5.2 allows you to control these referrals in that you can overwrite the referrals set automatically by the server by adding your own.
Being able to control referrals helps you to optimize your deployment's security and performance, in that it:
- ensures your referrals point to secure ports only,
- allows you to point to a Sun ONE Directory Proxy Server for load balancing reasons,
- allows you to redirect to a local server only in the case of a deployment with servers separated by a WAN, and
- allows you to limit referrals to a subset of masters in 4-way multi-master topologies.
For information regarding the configuration of referrals see the Setting Referrals section of the Sun ONE Directory Server Administration Guide.
To better understand the replication elements you need to configure to deploy this fully-connected, four-way, multi-master replication topology, Figure 6-4 presents a detailed view of the replication agreements, change logs, and Replication Manager entries that you need to set up on master A, and Figure 6-5 provides the same detailed view for consumer E.
Figure 6-4 Replication Configuration for Master A in the Fully-Connected, Four-Way, Multi-Master Replication Topology
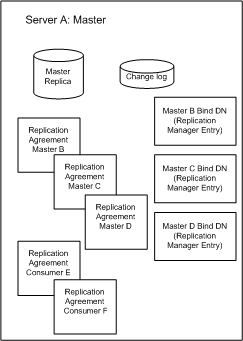
As we can see in Figure 6-4 the master A requires a master replica, a change log and Replication Manager entries or bind DNs for masters B, C, and D (in the case where you do not use the same Replication Manager entry for all four masters). In addition to the change log and Replication Manager entries, master A also requires replication agreements for the three other masters B, C, and D, and consumers E and F.
Figure 6-5 Replication Configuration for Consumer Server E in Fully-Connected, Four-Way, Multi-Master Replication Topology
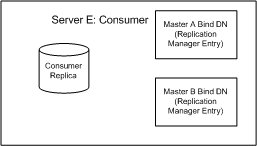
The detailed view of the replication configuration for consumer E presented in Figure 6-5 shows us that consumer E requires a consumer replica and Replication Manager entries to authenticate master A and master B when they bind to send replication updates.
Multi-Master Replication over Wide Area Networks (WAN)
Multi-master replication (MMR) over Wide Area Networks (WAN) is a new feature of Sun ONE Directory Server 5.2 that will allow for MMR configurations across geographical boundaries in international, multiple data-center deployments. Previously master Directory Servers had to be connected via high-speed, low-latency networks with minimum connection speeds of 100Mb/second, for full MMR support which ruled out the possibility of MMR over WAN, but this is no longer the case. Sun ONE Directory Server now supports MMR over WAN, that means that geographical boundaries no longer constitute a stumbling block for multi-master replication. The flexibility this new feature will afford large deployments is immense.
In order to render MMR over WAN a viable deployment possibility, the Sun ONE Directory Server 5.2 replication protocol now provides for fully asynchronous support and window and grouping mechanisms. The following section will examine these mechanisms in more detail.
Note Although the viability of MMR over WAN is a direct result of these protocol improvements, they are equally valid for Local Area Network (LAN) deployments.
Grouping and Window Mechanisms
To optimize the replication flow, Directory Server allows you to group changes rather than having to send them individually. It also allows you to specify a certain number of requests that can be sent to the consumer without the supplier having to wait for an acknowledgement from the consumer before continuing. You use the ds5ReplicaTransportGroupSize attribute to specify the number of changes that can be grouped into a single update request and the ds5ReplicaTransportWindowSize attribute to specify the number of sendUpdate requests that can occur before consumer acknowledgement is required. The default group size is 1 and the default window size is 10, which means that unless otherwise specified, default replication behavior will not group requests, but will allow 10 sendUpdate requests to be sent before consumer acknowledgement is required.
Cascading Replication
In a cascading replication scenario, a server acting as a hub receives updates from a server acting as a supplier, and replays those updates on consumers. The hub is a hybrid: it holds a read-only copy of the data, like a consumer and it maintains a change log like a supplier.
Hubs pass on copies of the master data as they are received from the original master refer update requests from directory clients to the master.
This cascading replication scenario is illustrated in Figure 6-6:
Figure 6-6 Cascading Replication Scenario
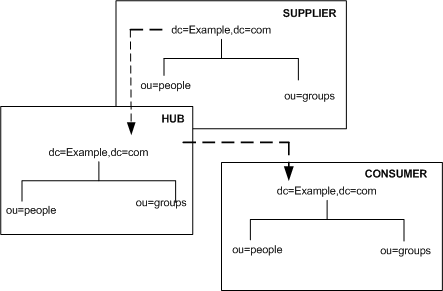
Cascading replication is very useful in the following cases:
- When you need to balance heavy traffic loads: for example, because your masters need to handle all update traffic, it would put them under a very heavy load to support all replication traffic to consumers as well. You can off-load replication traffic to a hub that can service replication updates to a large number of consumers.
- To reduce connection costs by using a local hub in geographically distributed environments.
- To increase performance of your directory service: if you direct all client applications performing read operations to the consumers, and all those performing update operations to the master, you can remove all of the indexes (except system indexes) from your hub. This will dramatically increase the speed of replication between the server acting as the master and the server acting as the hub.
A similar scenario, from a different perspective, is illustrated in Figure 6-7. This illustration shows how the servers are configured in terms of Replication Agreements and change logs as well the default referrals.
Figure 6-7 Server Configuration in Cascading Replication
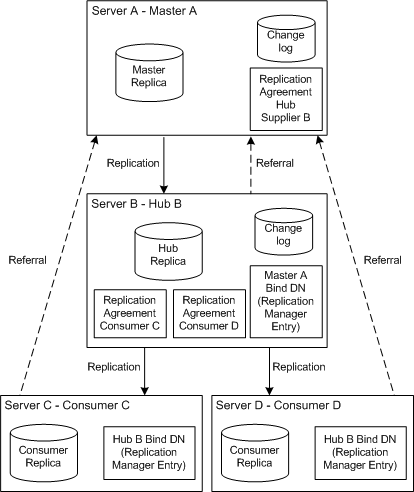
In the example illustrated in Figure 6-7, a server acting as a hub is used to balance the load of replication updates by sharing it between a server acting as a master server and the hub.
The master and the hub both maintain a change log. However, only the master can process directory modification requests from clients. The hub contains a Replication Manager entry for Master A, so that Master A can bind to the hub to send replication updates, and consumers C and D both contain Replication Manager entries for Hub B, which it uses to authenticate when sending its updates to the consumers.
The consumer and the hub can process search requests received from clients, but in the case of modification requests, send the client a referral to the master. Figure 6-7 shows that Consumer C and D have a referral to Master A. These are the automatic referrals that are created when you create the replication agreement between the hub and the consumers. You can, however, as we have already stated, choose to overwrite these referrals should you wish to do so for performance or security reasons. For more information see Note.
Note You can combine multi-master and cascading replication scenarios. For example, in the multi-master scenario illustrated in Figure 6-8, Server C and Server D could be hubs that would replicate to any number of consumers.
Mixed Environments
You can combine any of the scenarios outlined in the previous sections to best fit your needs. For example, you could combine a multi-master configuration with a cascading configuration to produce a topology similar to the scenario illustrated in Figure 6-8:
Figure 6-8 Combined Multi-Master and Cascading Replication
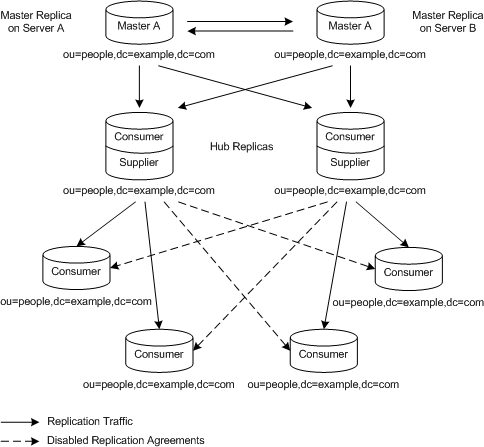
In the example illustrated in Figure 6-8, we have two masters and two hubs replicating data to four consumers. The hubs are used to balance the load of replication updates by sharing it between the masters and the hubs. This kind of configuration can prove to be valuable when you have a heavy load of replication updates to manage.
As in the example illustrated in Figure 6-7, both the hubs and the masters A and B, maintain change logs. It is, however, only the masters that can process directory modification requests from clients. When the hubs or the consumers receive modification requests from clients, they send the client a referral to the masters, in order for the request to be processed. The referrals are not indicated in Figure 6-8, but they exist between each of the four consumers and both masters, as well as between each of the hubs and the masters. These referrals are automatically created when you define your topology.
In the example illustrated in Figure 6-8 the dotted lines represent disabled replication agreements. If these replication agreements are not enabled, then the topology presented contains a single point of failure, if one of the hubs were to go off line. Whether or not you decide to enable the replication agreements to provide full read-write failover, will depend on your high availability requirements, but you need to be aware that by not enabling the agreements you are exposing yourself to a single point of failure risk.
Fractional Replication
In previous releases of Directory Server, the smallest unit of replication was the database and there was no way of replicating only a subset of the information inside a given database. Although the smallest unit of replication remains the database, Sun ONE Directory Server 5.2 offers new fractional replication functionality to cater for replication granularity requirements. This section is divided into two parts:
What is Fractional Replication?
Fractional replication allows you to replicate a subset of the attributes of all entries in a given database from a supplier to a consumer. The following cases are just two examples of the scenarios where fractional replication can prove to be very useful:
- When you need to synchronize between intranet and extranet servers and filter out content for security reasons, fractional replication provides the filtering functionality.
- When you need to reduce replication costs, fractional replication allows you to be selective in what you choose to replicate. If your deployment only requires certain attributes to be available everywhere, then instead of replicating all attributes, you can use the fractional replication functionality to replicate required attributes only. For example you may want e-mail and phone attributes to be replicated but not all the other attributes that exist, particularly if the other attributes are ones that are modified quite frequently and as a result generate heavy traffic loads. Fractional replication allows you to filter in the required attributes and reduce traffic to a minimum. This filtering functionality can prove to be extremely valuable in replication environments where Directory Servers are separated by WANs.
Configuring Fractional Replication
In order to set up fractional replication you can either choose to exclude or include a list of attributes to be replicated, and this can be configured easily from the console. However, should you, at a later stage, wish to change your fractional replication configuration, you can do so as long as you remember to disable the replication agreements before proceeding to make any changes. Once you have made your changes you will need to enable your replication agreement again and re-initialize your consumers so that the new configuration is taken into account.
Generally speaking you replicate all required attributes for each entry as defined in the schema, to avoid schema violations, but should you want to filter out some of the required attributes using the fractional replication functionality, then you need to be sure to disable schema checking. Having schema checking enabled with fractional replication can prevent you from being able to initialize off line, that is from an ldif file, because it would not allow you to load the ldif file if required attributes were filtered out. It is worth noting that turning schema checking off may have the added benefit of improving performance. It is also important to bear in mind that when you have disabled schema checking on a fractional consumer replica, the whole server instance on which that fractional consumer replica resides will not enforce schema. As a result, you should avoid configuring supplier (read-write) replicas for different directory information trees on the same server instance.
Please note also that since schema is pushed by suppliers in fractional replication configurations, the schema on the fractional consumer replica will be a copy of the master replica's schema and, therefore, it will not correspond to the fractional replication configuration being applied.
Defining a Replication Strategy
The replication strategy that you define is determined by the service you want to provide:
- If high availability is your primary concern, you should create a data center with multiple directory servers on a single site. You can use single-master replication to provide read-failover or multi-master replication to provide write-failover. How to configure replication for high availability is described in "Using Replication for High Availability".
- If disaster recovery is your primary concern, you will want to create two distinct data centers, one in each geographical location, separated by WAN. Each data center will host two masters to provide failover and the fact that each data center is doubled, will protect you in the event of a disaster in one of the locations. To maintain write-failover high availability over geographically distributed sites, you can use four-way multi-master replication over a WAN.
- If local availability is your primary concern, you should use replication to geographically distribute data to directory servers in local offices around the world. You can decide to hold a master copy of all information in a single location, such as the company headquarters, or to let local sites manage the parts of the DIT that are relevant for them. The type of replication configuration to set up is described in "Using Replication for Local Availability".
- In all cases, you probably want to balance the load of requests serviced by your directory servers, and avoid network congestion. Strategies for load balancing your directory servers and your network are provided in "Using Replication for Load Balancing".
To determine your replication strategy, start by performing a survey of your network, your users, your applications, and how they use the directory service you can provide. For guidelines on performing this survey, refer to "Replication Survey."
Once you understand your replication strategy, you can start deploying your directory. This is a case where deploying your service in stages will pay large dividends. By placing your directory into production in stages, you can get a better sense of the loads that your enterprise places on your directory. Unless you can base your load analysis on an already operating directory, be prepared to alter your directory as you develop a better understanding of how your directory is used.
The following sections describe in more detail the factors affecting your replication strategy:
- Replication Backward Compatibility
- Replication Survey
- Replication Resource Requirements
- Using Replication for High Availability
- Using Replication for Local Availability
- Using Replication for Load Balancing
- Example Replication Strategy for a Small Site
- Example Replication Strategy for a Large Site
Replication Backward Compatibility
One of the first things you need to establish is which versions of Directory Server you will be using in your replication configuration. In order to be sure that your replication configuration will function correctly we advise you take into account the information in Table 6-1 which presents the possible master and consumer combinations between the different versions of Directory Server and their associated restrictions.
Replication Survey
The type of information you need to gather from your survey to help you define your replication strategy includes:
- Quality of the networks connecting different buildings or remote sites, and the amount of available bandwidth.
- Physical location of users, how many users are at each site, what is their activity.
For example, a site that manages human resource databases or financial information is likely to put a heavier load on your directory than a site containing engineering staff that uses the directory for simple telephone book purposes.
- The number of applications that access the directory, and relative percentage of read/search/compare operations to write operations.
For example, if your messaging server uses the directory, you need to know how many operations it performs for each e-mail message it handles. Other products that rely on the directory are typically products such as authentication applications, or meta-directory applications. For each one you must find out the type and frequency of operations that are performed in the directory.
- The number and size of the entries stored in the directory.
The following sections will try to address these issues and guide you through the important issues you will need to consider when developing your replciation topology.
Replication Resource Requirements
Using replication requires more resources. Consider the following resource requirements when defining your replication strategy:
- Disk usage.
On suppliers, the change log is written to after each update operation. For suppliers containing multiple replicated databases the change log will be used more frequently, and the disk usage will be even higher.
Caution
Consumers must be at least equivalent in terms of machine size to suppliers, to prevent bottlenecks from occurring.
- Server threads.
Each replication agreement creates two additional threads. The replication agreement threads are separate from the operational threads. If there are several replication agreements, the number of threads available to client applications is reduced, possibly affecting the server performance for the client applications.
- File descriptors.
The number of file descriptors available to the server is reduced by the change log (one file descriptor) and each replication agreement (one file descriptor per agreement).
Using Replication for High Availability
Use replication to prevent the loss of a single server from causing your directory to become unavailable. At a minimum you should replicate the local directory tree to at least one backup server.
Some directory architects argue that you should replicate three times per physical location for maximum data reliability. How much you use replication for fault tolerance is up to you, but you should base this decision on the quality of the hardware and networks used by your directory. Unreliable hardware needs more backup servers.
Note You should not use replication as a replacement for a regular data backup policy. For information on backing up your directory data, refer to Backing Up Data section of the Sun ONE Directory Server Administration Guide and "Choosing a Backup Method"
If you need to guarantee write-failover for all your directory clients, you should use a multi-master replication scenario. The grouping and window mechanisms present in the multi-master replication flow allow you to configure your replication agreements in such a way as to optimize your replication performance. However, should read-failover be sufficient, you can use single-master replication.
LDAP client applications can usually be configured to search only one LDAP server. That is, unless you have written a custom client application to rotate through LDAP servers located at different DNS hostnames, you can only configure your LDAP client application to look at a single DNS hostname for a Directory Server. Therefore, you will probably need to use either DNS round robins or network sorts to provide fail-over to your backup Directory Servers. For information on setting up and using DNS round robins or network sorts, see your DNS documentation.
With regard to maintaining write-failover high availability over two geographically distributed sites, you can use four-way multi-master replication over a WAN. You set up two master servers in one location and two master servers in the second location and configure them to be fully-connected over a WAN, to safeguard against the eventuality of one master going off line. As with multi-master replication over a LAN, you can use the grouping and window mechanisms to optimize your replication performance.
Alternatively, you can use the Sun ONE Directory Proxy Server product. For more information on Sun ONE Directory Proxy Server, go to http://www.sun.com/software.
Using Replication for Local Availability
Your need to replicate for local availability is determined by the quality of your network as well as the activities of your site. In addition, you should carefully consider the nature of the data contained in your directory and the consequences to your enterprise in the event that the data becomes temporarily unavailable. The more mission critical this data is, the less tolerant you can be of outages caused by poor network connections.
You should use replication for local availability for the following reasons:
- You need a local master copy of the data.
This is an important strategy for large, multinational enterprises that need to maintain directory information of interest only to the employees in a specific country. Having a local master copy of the data is also important to any enterprise where interoffice politics dictate that data be controlled at a divisional or organizational level.
- You are using unreliable or intermittently available network connections.
Intermittent network connections can occur if you are using unreliable WANs, such as often occurs in international networks.
- Your networks periodically experience extremely heavy loads that may cause the performance of your directory to be severely reduced.
For example, enterprises with aging networks may experience these conditions during normal business hours.
- You want to reduce the network load and work load on the master replica.
Your network may be perfectly reliable and available, but you nevertheless want to reduce the cost on your network.
Using Replication for Load Balancing
Replication can balance the load on your Directory Servers in several ways:
- By spreading your user's search activities across several servers.
- By dedicating servers to read-only activities (writes occur only on the server containing the master replica).
- By dedicating special servers to specific tasks, such as supporting mail server activities.
Figure 6-9 Using Multi-Mastered Replication for Load Balancing
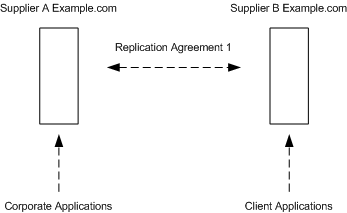
One of the more important reasons to replicate directory data is to balance the work load of your network. When possible, you should move data to servers that can be accessed using a reasonably fast and reliable network connection. The most important considerations are the speed and reliability of the network connection between your server and your directory users.
Directory entries generally average around one KB in size. Therefore, an entire entry lookup adds about one KB to your network load each time. If your directory users perform around ten directory lookups per day, then for every directory user you will see an increased network load of around 10,000 bytes per day. Given a slow, heavily loaded, or unreliable WAN, you may need to replicate your directory tree to a local server.
You must carefully consider whether the benefit of locally available data is worth the cost of the increased network load because of replication. For example, if you are replicating an entire directory tree to a remote site, you are potentially adding a large strain on your network in comparison to the traffic caused by your users' directory lookups. This is especially true if your directory tree changes frequently, yet you have only a few users at the remote site performing a few directory lookups per day.
For example, consider that your directory tree on average includes in excess of 1,000,000 entries and that it is not unusual for about ten percent of those entries to change every day. If your average directory entry is only one KB in size, this means you could be increasing your network load by 100 MB per day. However, if your remote site has only a few employees, say 100, and they are performing an average of ten directory lookups a day, then the network load caused by their directory access is only one MB per day.
Given the difference in loads caused by replication versus that caused by normal directory usage, you may decide that replication for network load-balancing purposes is not desirable. On the other hand, you may find that the benefits of locally available directory data far outweigh any considerations you may have regarding network loads.
A good compromise between making data available to local sites without overloading the network is to use scheduled replication. For more information on data consistency and replication schedules, refer to "Data Consistency".
Example of Network Load Balancing
Suppose your enterprise has offices in two cities. Each office has specific subtrees that they manage, as illustrated in Figure 6-10:
Figure 6-10 New York and Los Angeles Subtree Managed in Respective Geographical Locations
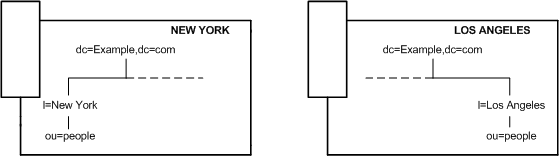
Each office contains a high-speed network, but you are using a dial-up connection to network between the two cities. To balance your network load:
- Select one server in each office to be the master for the locally managed data.
Replicate locally managed data from that server to the corresponding master in the remote office. Having a master copy of the data in each location prevents users from having to perform update and lookup operations over the dial-up connection, which allows for optimized performance.
- Replicate the directory tree on each master (including data supplied from the remote office) to at least one local Directory Server to ensure availability of the directory data.
- Configure cascading replication in each location with an increased number of consumers dedicated to lookups on the local data to provide further load balancing.
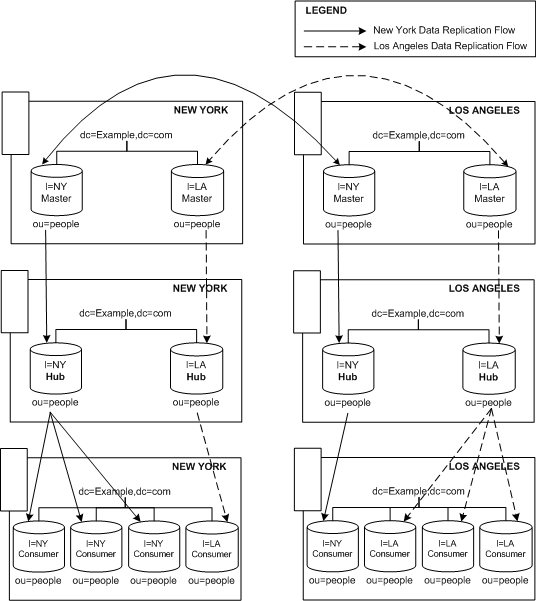
The New York office has to deal with more New York specific lookups than LA specific lookups and as a result, our example shows the New York office with three New York data consumers and one Los Angeles consumer. Following the same logic, the Los Angeles office has three Los Angeles data consumers and one New York data consumer.
This network load balancing configuration is illustrated in Figure 6-11:
Figure 6-11 Load Balancing Using Multi-Master and Cascading Replication
Example of Load Balancing for Improved Performance
Suppose that your directory must include 15,000,000 entries in support of 10,000,000 users, and that each user performs ten directory lookups a day. Also assume that you are using a messaging server that handles 250,000,000 mail messages a day, and that performs five directory lookups for every mail message that it handles. So, you can expect 1,250,000,000 directory lookups per day just as a result of mail. Your total combined traffic is, therefore, 1,350,000,000 directory lookups per day.
Assuming an eight-hour business day, and that your 10,000,000 directory users are clustered in four time zones, your business day (or peak usage) across four time zones is 12 hours long. So, you must support 1,350,000,000 directory lookups in a 12-hour day. This equates to 31,250 lookups per second (1,350,000,000 / (60*60*12)). That is:
Now, assume that you are using a combination of CPU and RAM with your Directory Servers that allows you to support 5,000 reads per second. Simple division indicates that you need at least six or seven Directory Servers to support this load. However, for enterprises with 10,000,000 directory users, you should add more Directory Servers for local availability purposes.
Note A single Directory Server 5.2 with the appropriate hardware and configuration is able to sustain much more than the 5,000 reads per second.
You could, therefore, replicate as follows:
- Place two Directory Servers in a multi-master configuration in one city to handle all write traffic.
This configuration assumes that you want a single point of control for all directory data.
- Use these masters to replicate to one or more hubs.
The read, search, and compare requests serviced by your directory should be targeted at the consumers, thereby freeing the masters to handle write requests. For a definition of a hub, refer to "Cascading Replication".
- Use the hub to replicate to local sites throughout the enterprise.
Replicating to local sites helps balance the work load of your servers and your WANs, as well as ensuring high availability of directory data. Assume that you want to replicate to four sites around the country. You then have four consumers for each hub.
- At each site, replicate at least once to ensure high availability, at least for read operations.
Use DNS sort to ensure that local users always find a local Directory Server they can use for directory lookups.
Example Replication Strategy for a Small Site
Suppose your entire enterprise is contained within a single building. This building has a very fast (100 MB per second) and lightly used network. The network is very stable and you are reasonably confident of the reliability of your server hardware and OS platforms. You are also sure that a single server's performance will easily handle your site's load.
In this case, you should replicate at least once to ensure availability in the event that your primary server is shut down for maintenance or hardware upgrades. Also, set up a DNS round robin to improve LDAP connection performance in the event that one of your Directory Servers becomes unavailable. Alternatively, use an LDAP proxy such as Sun ONE Directory Proxy Server. For more information on Sun ONE Directory Proxy Server, go to http://www.sun.com/software.
Example Replication Strategy for a Large Site
Suppose your entire enterprise is contained within two buildings. Each building has a very fast (100 MB per second) and lightly used network. The network is very stable and you are reasonably confident of the reliability of your server hardware and OS platforms. You are also sure that a single server's performance will easily handle the load placed on a server within each building.
Also assume that you have slow (ISDN) connections between the buildings, and that this connection is very busy during normal business hours.
Your replication strategy follows:
- Choose a single server in one of the two buildings to contain a master copy of your directory data.
This server should be placed in the building that contains the largest number of people responsible for the master copy of the directory data. Call this Building A.
- Replicate at least once within Building A for high availability of your directory data.
Use a multi-master replication configuration if you need to ensure write-failover.
- Create two replicas in the second building (Building B).
- If there is no need for close consistency between the master copy of the data and the replicated copies, schedule replication so that it occurs only during off peak hours.
Replication Strategy for a Large, International Enterprise
Suppose your enterprise comprises two major sites - one in France and the other site in the USA - separated by a WAN. Not only do you need to replicate over a WAN, but you do not want your partners to have access to all data and want to filter out certain data. Your connections are very busy during normal business hours.
Your replication strategy follows:
- Hold master copies of your directory data on servers in both geographical locations.
- For write-failover within your French and American sites, replicate your data to a second master located within each geographical location.
- Deploy a fully-connected, four-way, multi-master replication topology between France and the USA to provide complete high-availability and write-failover cover across your enterprise deployment.
- Deploy as many consumers as you require in each geographical location to reduce the load on your masters as far as possible in terms of lookups.
- Set up fractional replication agreements between masters and consumers in both geographical locations, to filter out the data you do not wish your partners to access.
- Schedule replication so that it occurs only during off peak hours to help optimize your bandwidth capabilities.
Using Replication with Other Directory Features
Replication interacts with other Directory Server features to provide advanced replication features. The following sections describe feature interactions to help you better design your replication strategy.
Replication and Access Control
The directory stores ACIs as attributes of entries. This means that the ACI is replicated along with other directory content. This is important because Directory Server evaluates ACIs locally.
For more information about designing access control for your directory, refer to Chapter 7, "Designing a Secure Directory".
Replication and Directory Server Plug-Ins
You can use replication with most of the plug-ins delivered with Directory Server. There are some exceptions and limitations which are listed in the following sections:
- Replication and the Retro Change Log Plug-In
- Replication and the Referential Integrity Plug-In
- Replication and Pre-Operation and Post-Operation Plug-Ins
Replication and the Retro Change Log Plug-In
The Retro Change Log Plug-in is supported to provide backward compatibility with 4.x releases of Directory Server. It can be deployed in a multi-master replication topology, but there are caveats to note about its use in this environment. If the plug-in is configured on more than one of the masters, there is no guarantee that the changes will be logged in the same order. In fact the changes will almost certainly not be logged in the same order, and the change numbers will not be the same. Applications that require consistent ordering of changes from the change log will not be able to shift from using one change log to another. The ability to use only one change log introduces a single point of failure. However, if the master with the retro change log fails, changes on other masters will be seen by applications once the failed master is brought back online.
Replication and the Referential Integrity Plug-In
You can use the referential integrity plug-in with multi-master replication provided that this plug-in is enabled on all master replicas.
Replication and Pre-Operation and Post-Operation Plug-Ins
When pre- and post-operation plug-ins are used in a replication context, replication must be able to detect the order of these pre- and post-operation plug-ins. You can decide whether or not to make changes to these replication operations, but it is worth noting that if operations are replicated operations, then changing them can result in unexpected behavior. For more information on pre- and post-operation plug-ins, refer to "Extending Client Request Handling" in the Sun ONE Directory Server Plug-In API Programming Guide.
Replication and Chained Suffixes
When you distribute entries using chaining, the server containing the chained suffix points to a remote server that contains the actual data, or the farm server. In this environment, you cannot replicate the chained suffix itself. You can, however, replicate the database that contains the actual data on the remote server.
Note You must configure the replication agreement on the farm server and not on the multiplexor.
You must not use the replication process as a backup for chained suffixes. You must back up chained suffixes manually. For more information about chaining and entry distribution, refer to Chapter 5,
Schema Replication
When Directory Server is used in a replicated environment, the schema must be consistent across all of the directory servers that participate in replication. If the schema is not consistent across servers, the replication process is likely to generate many errors.
The best way to guarantee schema consistency is to make schema modifications on a single master server, even in the case of a multi-master replication environment.
Schema replication happens automatically. If replication has been configured between a supplier and a consumer, schema replication will happen by default.
The logic used by Directory Server for schema replication is the same in every replication scenario, and can be described as follows:
- Before pushing data to the consumers, the supplier checks whether its own version of the schema is in sync with the version of the schema held by the consumers.
- If the schema entries on both supplier and consumers are the same, the replication operation proceeds.
- If the version of the schema on the supplier is more recent than the version stored on the consumer, the supplier replicates its schema to the consumer before proceeding with the data replication.
It is interesting to note that Directory Server 5.2 has an attribute which allows you to replicate only user-defined schema, that is schema which has been added over LDAP or added as a file with an X-ORIGIN value of 'user defined'. This allows you to reduce the amount of data being transferred should you so desire, and speed up the schema replication process.
Note Note that in contrast to previous versions of Directory Server, ACIs present in the schema are now replicated.
If you make schema modifications on two master servers in a multi-master set, whichever master was updated last will "win" and its schema will be propagated to the consumer. This means that you risk losing the modifications you make to one master, if different modifications are made to the other master at a later stage. To avoid losing modifications, always make sure you make schema modifications on one master only.
Note You must never update the schema on a consumer because the supplier is unable to resolve the conflicts that will occur and replication will fail. If you do update the schema on a consumer, and as a result the version of the schema on the supplier is older than the version on the consumer, you will encounter errors if you search on a consumer or try to perform an update operation on a supplier.
Schema should be maintained on a single master in a multi-master replicated topology. If you are using the standard 99user.ldif file, these changes will be replicated to all consumers. When you are using custom schema files, ensure that these files are copied to all servers after making changes on the master. After copying files, the server must be restarted. Refer to "Creating Custom Schema Files - Best Practices and Pitfalls" for more information.
Changes made to custom schema files are only replicated if the schema is updated using LDAP or the Directory Server Console. These custom schema files should be copied to each server in order to maintain the information in the same schema file on all servers. For more information, refer to "Creating Custom Schema Files - Best Practices and Pitfalls".
For more information on schema design, refer to Chapter 3 "Designing the Schema."
Replication and Multiple Password Policies
In an environment that uses multiple password policies, you need to be sure to replicate the LDAP subentry that contains the definition of the policy to apply to the replicated entries. If you fail to do so, the default password policy will be applied and will of course not work for entries that have been configured to use a non-default password policy. It is important to understand that if you replicate these entries to a 5.0/5.1 server, the replication will function correctly, but the password policy will not be enforced on the 5.0/5.1 server as the possibility of having multiple password policies is specific to Directory Server 5.2.
Replication Monitoring
Sun ONE Directory Server 5.2 provides replication monitoring tools that allow you to monitor replication between servers. Being able to monitor replication activity assists in identifying the causes of replication problems and troubleshooting. All of the Directory Server replication monitoring tools can be used when LDAPS is turned on. The three replication monitoring tools are:
For more information regarding these replication monitoring tools, refer to the Replication Monitoring Tools section of the Sun ONE Directory Server Reference Manual and for more information on the monitoring possibilities afforded to you by certain replication attributes, see the replication attributes in the Core Server Configuration Attributes chapter of the Sun ONE Directory Server Reference Manual.
Note It is important to understand that these tools constitute an LDAP client, and as such, will need to authenticate to the server and use a bind DN that has read access to cn=config.
insync
The insync tool indicates the state of synchronization between a master replica and one or more consumer replicas. Being aware of the degree of synchronization is vital when it comes to managing potential conflicts.
entrycmp
The entrycmp tool allows you to compare the same entry on two or more servers. An entry is retrieved from the master replica and the entry's nsuniqueid is used to retrieve the same entry from a given consumer. All of the entries' attributes and values are compared and if everything is identical, the entries are considered to be the same.
repldisc
The repldisc tool allows you to discover a replication topology. Topology discovery starts with one server and builds a graph of all known servers within the topology. The repldisc tool then prints an adjacency matrix describing the topology. This replication topology discovery tool is useful for large, complex deployments where it might be difficult to recall the global topology you have deployed.