| Sun ONE Portal Server 6.2 Administrator's Guide |
Chapter 9
Administering the Search Engine RobotThis chapter describes the Sun™ ONE Portal Server Search Engine robot and its corresponding configuration files. The following topics are discussed:
Search Engine Robot OverviewA Search Engine robot is an agent that identifies and reports on resources in its domains. It does so by using two kinds of filters: an enumerator filter and a generator filter.
The enumerator filter locates resources by using network protocols. It tests each resource, and, if it meets the proper criteria, it is enumerated. For example, the enumerator filter can extract hypertext links from an HTML file and use the links to find additional resources.
The generator filter tests each resource to determine if a resource description (RD) should be created. If the resource passes the test, the generator creates an RD which is stored in the Search Engine database.
How the Robot Works
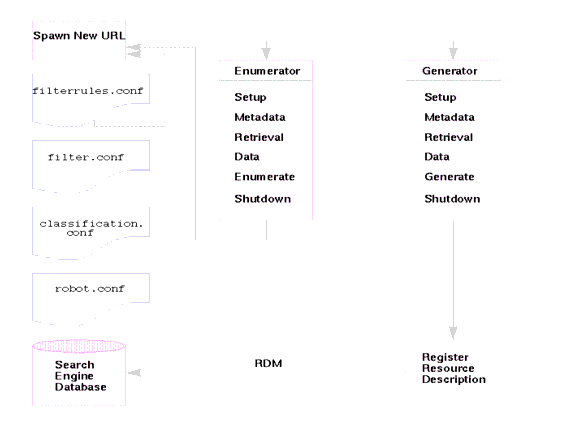
Figure 9-1 illustrates how the Search Engine robot works. In Figure 9-1, the robot examines URLs and their associated network resources. Each resource is tested by both the enumerator and the generator. If the resource passes the enumeration test, the robot checks it for additional URLs. If the resource passes the generator test, the robot generates a resource description that is stored in the Search Engine database.
Figure 9-1 How the Robot Works
Robot Configuration Files
Robot configuration files define the behavior of the Search Engine robots. These files reside in the directory /var/opt/SUNWps/http-hostname-domain/portal/config. Table 9-1 provides a description for each of the robot configuration files. The table contains two columns. The first column lists configuration file and the second column describes contents of the file.
Note
The Search service uses two other configuration files: convert.conf and import.conf. These files are generated by the Search server and in general should not be manually edited
Because you can set most parameters by using the Search Engine Administration Interface, you typically do not need to edit the robot.conf file.
However, advanced users might manually edit this file in order to set parameters that cannot be set through the interface.
Setting Robot Process ParametersThe file robot.conf defines many options for the robot, including pointing the robot to the appropriate filters in filter.conf. (For backwards-compatibility with older versions, robot.conf can also contain the seed URLs.)
The iPlanet™ Directory Server Access Management Edition administration console is used to edit the file robot.conf. Note that the few parameters you might manually edit by hand are described in detail in the "User-Modifiable Parameters"”section.
The most important parameters are enumeration-filter and generation-filter, which determine the filters the robot uses for enumeration and generation. The default values for these are enumeration-default and generation-default, which are the names of the filters provided by default in the filter.conf file.
All filters must be defined in the file filter.conf. If you define your own filters in filter.conf, you must add any necessary parameters to robot.conf.
For example, if you define a new enumeration filter named my-enumerator, you would add the following parameter to robot.conf:
enumeration-filter=my-enumerator
The Filtering ProcessThe robot uses filters to determine which resources to process and how to process them. When the robot discovers references to resources as well as the resources themselves, it applies filters to each resource in order to enumerate it and to determine whether or not to generate a resource description to store in the Search Engine database.
The robot examines one or more seed URLs, applies the filters, and then applies the filters to the URLs spawned by enumerating the seed URLs, and so on. The seed URLs are defined in the filterrules.conf file.
A filter performs any required initialization operations and applies comparison tests to the current resource. The goal of each test is to either allow or deny the resource. A filter also has a shutdown phase during which it performs any required cleanup operations.
If a resource is allowed, that means that it is allowed to continue passage through the filter. If a resource is denied, then the resource is rejected. No further action is taken by the filter for resources that are denied. If a resource is not denied, the robot will eventually enumerate it, attempting to discover further resources. The generator might also create a resource description for it.
These operations are not necessarily linked. Some resources result in enumeration; others result in RD generation. Many resources result in both enumeration and RD generation. For example, if the resource is an FTP directory, the resource typically will not have an RD generated for it. However, the robot might enumerate the individual files in the FTP directory. An HTML document that contains links to other documents can receive an RD and can lead to enumeration of the linked documents as well.
The following sections detail the filter process:
Stages in the Filter Process
Both enumerator and generator filters have five phases in the filtering process. They both have four common phases: Setup—Performs initialization operations. Occurs only once in the life of the robot., Metadata—Filters the resource based on metadata that is available about the resource. Metadata filtering occurs once per resource before the resource is retrieved over the network. Table 9-2 lists examples of common metadata types. The table contains three columns. The first column lists the metadata type, the second column provides a description, and the third column provides an example.,Data—Filters the resource based on its data. Data filtering is done once per resource after it is retrieved over the network. Data that can be used for filtering include:, and Shutdown—Performs any needed termination operations. Occurs once in the life of the robot. If the resource makes it past the Data phase, it is either in the Enumerate—Enumerates the current resource in order to determine if it points to other resources to be examined. or Generate—Generates a resource description (RD) for the resource and saves it in the Search Engine database. phase, depending on whether the filter is an enumerator or a generator.
The phases are as follows:
- Setup—Performs initialization operations. Occurs only once in the life of the robot.
- Metadata—Filters the resource based on metadata that is available about the resource. Metadata filtering occurs once per resource before the resource is retrieved over the network. Table 9-2 lists examples of common metadata types. The table contains three columns. The first column lists the metadata type, the second column provides a description, and the third column provides an example.
- Data—Filters the resource based on its data. Data filtering is done once per resource after it is retrieved over the network. Data that can be used for filtering include:
- Enumerate—Enumerates the current resource in order to determine if it points to other resources to be examined.
- Generate—Generates a resource description (RD) for the resource and saves it in the Search Engine database.
- Shutdown—Performs any needed termination operations. Occurs once in the life of the robot.
Filter Syntax
The filter.conf file contains definitions for enumeration and generation filters. This file can contain multiple filters for both enumeration and generation. Note that the robot can determine which filters to use because they are specified by the enumeration-filter and generation-filter parameters in the file robot.conf.
Filter definitions have a well-defined structure: a header, a body, and an end. The header identifies the beginning of the filter and declares its name, for example:
<Filter name="myFilter">
The body consists of a series of filter directives that define the filter’s behavior during setup, testing, enumeration or generation, and shutdown. Each directive specifies a function, and if applicable, parameters for the function.
The end is marked by </Filter>.
Code Example 9-1 shows a filter named enumeration1
Code Example 9-1 Enumeration File Syntax
Filter Directives
Filter directives use Robot Application Functions (RAFs) to perform operations. Their use and flow of execution is similar to that of NSAPI directives and Server Application Functions (SAFs) in the file obj.conf. Like NSAPI and SAF, data are stored and transferred using parameter blocks, also called pblocks.
There are six robot directives, or RAF classes, corresponding to the filtering phases and operations listed in "The Filtering Process":
Each directive has its own robot application functions. For example, use filtering functions with the Metadata and Data directives, enumeration functions with the Enumerate directive, generation functions with the Generate directive, and so on.
The built-in robot application functions, as well as instructions for writing your own robot application functions, are explained in the Sun ONE Portal Server 6.1 Developer’s Guide.
Writing or Modifying a Filter
In most cases, you should not need to write filters from scratch. You can create most of your filters using the administration console. You can then modify the filter.conf and filterrules.conf files to make any desired changes. These files reside in the directory/var/opt/SUNWps/http-hostname-domain/portal.
However, if you want to create a more complex set of parameters, you will need to edit the configuration files used by the robot.
Note the following points when writing or modifying a filter:
For a discussion of the parameters you can modify in the file robot.conf, the robot application functions that you can use in the file filter.conf, and how to create your own robot application functions, see the Sun ONE Portal Server 6.1 Developer’s Guide.
User-Modifiable ParametersThe robot.conf file defines many options for the robot, including pointing the robot to the appropriate filters in filter.conf. For backwards-compatibility with older versions, robot.conf can also contain the seed URLs.
Because you can set most parameters by using the administration console, you typically do not need to edit the robot.conf file. However, advanced users might manually edit this file in order to set parameters that cannot be set through the administration console. See "Sample robot.conf File" for an example of this file.
Table 9-3 lists the user-modifiable parameters in the robot.conf file. The first column of the table lists the parameter, the second column provides a description of the parameter, and the third column provides an example.
Table 9-3 User-Modifiable Parameters
Parameter
Description
Example
auto-proxy
Specifies the proxy setting for the robot. It can be a proxy server or a JavaScript file for automatically configuring the proxy. For more information see, the Sun ONE Portal Server 6.2 Administrator’s Guide.
auto-proxy="http://proxy_server/proxy.pac"
bindir
Specifies whether the robot will add a bind directory to the PATH environment. This is an extra PATH for users to run an external program in a robot, such as those specified by cmd-hook parameter.
bindir=path
cmd-hook
Specifies an external completion script to run after the robot completes one run. This must be a full path to the command name. The robot will execute this script from the /var/opt/SUNWps/ directory.
There is no default.
There must be at least one RD registered for the command to run.
For information about writing completion scripts, see the Sun ONE Portal Server 6.1 Developer’s Guide.
cmd-hook=”command-string”
There is no default.
command-port
Specifies the socket that the robot listens to in order to accept commands from other programs, such as the Administration Interface or robot control panels.
For security reasons, the robot can accept commands only from the local host unless remote-access is set to yes.
command-port=port_number
connect-timeout
Specifies the maximum time allowed for a network to respond to a connection request.
The default is 120 seconds.
command-timeout=seconds
convert-timeout
Specifies the maximum time allowed for document conversion.
The default is 600 seconds.
convert-timeout=seconds
depth
Specifies the number of links from the seed URLs (also referred to as starting point) that the robot will examine. This parameter sets the default value for any seed URLs that do not specify a depth.
The default is 10.
A value of negative one (depth=-1) indicates that the link depth is infinite.
depth=integer
Specifies the email address of the person who runs the robot.
The email address is sent with the user-agent in the HTTP request header, so that Web managers can contact the people who run robots at their sites.
The default is user@domain.
email=user@hostname
enable-ip
Generates an IP address for the URL for each RD that is created.
The default is true.
enable-ip=[true | yes | false | no]
enable-rdm-probe
Determines if the server supports RDM, the robot decides whether to query each server it encounters by using this parameter. If the server supports RDM, the robot will not attempt to enumerate the server’s resources, since that server is able to act as its own resource description server.
The default is false.
enable-rdm-probe=[true | false | yes | no]
enable-robots-txt
Determines if the robot should check the robots.txt file at each site it visits, if available.
The default is yes.
enable-robots-txt=[true | false | yes | no]
engine-concurrent
Specifies the number of pre-created threads for the robot to use.
The default is 10.
This parameter cannot be set interactively through the administration console.
engine-concurrent=[1..100]
enumeration-filter
Specifies the enumeration filter that is used by the robot to determine if a resource should be enumerated. The value must be the name of a filter defined in the file filter.conf.
The default is enumeration-default.
This parameter cannot be set interactively through the administration console.
enumeration-filter=enumfiltername
generation-filter
Specifies the generation filter that is used by the robot to determine if a resource description should be generated for a resource. The value must be the name of a filter defined in the file filter.conf.
The default is generation-default.
This parameter cannot be set interactively through the administration console.
generation-filter=genfiltername
index-after-ngenerated
Specifies the number of minutes that the robot should collect RDs before batching them for the Search Engine.
If you do not specify this parameter, it is set to 256 minutes.
index-after-ngenerated=30
loglevel
Specifies the levels of logging. The loglevel values are as follows:
The default value is 1.
loglevel=[0...100]
max-connections
Specifies the maximum number of concurrent retrievals that a robot can make.
The default is 8.
max-connections=[1..100]
max-filesize-kb
Specifies the maximum file size in kilobytes for files retrieved by the robot.
max-filesize-kb=1024
max-memory-per-url / max-memory
Specifies the maximum memory in bytes used by each URL. If the URL needs more memory, the RD is saved to disk.
The default is 1.
This parameter cannot be set interactively through the administration console.
max-memory-per-url=n_bytes
max-working
Specifies the size of the robot working set, which is the maximum number of URLs the robot can work on at one time.
This parameter cannot be set interactively through the administration console.
max-working=1024
onCompletion
Determines what the robot does after it has completed a run. The robot can either go into idle mode, loop back and start again, or quit.
The default is idle.
This parameter works with the cmd-hook parameter. When the robot is done, it will do the action of onCompletion and then run the cmd-hook program.
OnCompletion=[idle | loop | quit]
password
Specifies the password is used for httpd authentication and ftp connection.
password=string
referer
Specifies the parameter sent in the HTTP request if it is set to identify the robot as the referer when accessing Web pages
referer=string
register-user and register-password
Specifies the user name used to register RDs to the Search Engine database.
This parameter cannot be set interactively through the Search Engine Administration Interface.
register-user=string
register-password
Specifies the password used to register RDs to the Search Engine database.
This parameter cannot be set interactively through the administration console.
register-password=string
remote-access
This parameter determines if the robot can accept commands from remote hosts.
The default is false.
remote-access=[true | false | yes | no]
robot-state-dir
Specifies the directory where the robot saves its state. In this working directory, the robot can record the number of collected RDs and so on.
robot-state-dir="/var/opt/SUNWps/ instance/portal/robot"
server-delay
Specifies the time period between two visits to the same web site, thus preventing the robot from accessing the same site too frequently.
server-delay=delay_in_seconds
site-max-connections
Indicates the maximum number of concurrent connections that a robot can make to any one site.
The default is 2.
site-max-connections=[1..100]
smart-host-heuristics
Enables the robot to change sites that are rotating their DNS canonical host names. For example, www123.siroe.com is changed to www.siroe.com.
The default is false.
smart-host-heuristics=[true | false]
tmpdir
Specifies a place for the robot to create temporary files.
Use this value to set the environment variable TMPDIR.
tmpdir=path
user-agent
Specifies the parameter sent with the email address in the http-request to the server.
user-agent=iPlanetRobot/4.0
username
Specifies the user name of the user who runs the robot and is used for httpd authentication and ftp connection.
The default is anonymous.
username=string
Sample robot.conf FileThis section describes a sample robot.conf file. Any commented parameters in the sample use the default values shown. The first parameter, csid, indicates the Search Engine instance that uses this file; it is important not to change the value of the this parameter. See "User-Modifiable Parameters" for definitions of the parameters in this file.
Note
This sample file includes some parameters used by the Search Engine that you should not modify such as the csid parameter.
<Process csid="x-catalog://budgie.siroe.com:80/jack" \
auto-proxy="http://sesta.varrius.com:80/"
auto_serv="http://sesta.varrius.com:80/"
command-port=21445
convert-timeout=600
depth="-1"
# email="user@domain"
enable-ip=true
enumeration-filter="enumeration-default"
generation-filter="generation-default"
index-after-ngenerated=30
loglevel=2
max-concurrent=8
site-max-concurrent=2
onCompletion=idle
password=boots
proxy-loc=server
proxy-type=auto
robot-state-dir="/var/opt/SUNWps/https-budgie.siroe.com/ \
ps/robot"
server-delay=1
smart-host-heuristics=true
tmpdir="/var/opt/SUNWps/https-budgie.siroe.com/ps/tmp"
user-agent="iPlanetRobot/4.0"
username=jack
</Process>