
Using DTrace with Sun Studio Tools to Understand, Analyze, Debug, and Enhance Complex Applications
In general, a complex application is implemented by several engineers. And in most cases, the engineer who is responsible for debugging or increasing the performance of the application is not the original software designer or developer.
Hence the software engineer might encounter some difficulties in understanding, analyzing, or debugging the application for reasons such as lack of documentation, lack of good coding practices, or the complexity of the application itself.
Enhancing an existing application can be divided into two different stages:
Exploration or discovery stage
Enhancement or creation stage
In the first stage, the software developer wants to understand the behavior of the application, how the functions are being called, and how the data travel through the software stacks. The software developer has to have a good understanding of the application before advancing to next stage.
In the second stage, the software developer makes enhancements or creates a new solution based on the knowledge that is acquired in the first stage.
The Solaris Dynamic Tracing (DTrace) facility can be used by developers for the exploration or discovery stage. It helps them to funnel their attention to the problem area of a complex software system.
Sun Studio tools can be used by developers for the enhancement or creation stage. Once they have identified the problem area of a complex software system using DTrace, they can use Sun Studio tools to zoom into the problem area to pinpoint the culprits and implement the optimal solutions.
Developers will benefit most when they use Sun Studio tools during the development phase. However, once the software is deployed, DTrace becomes very instrumental at customer sites to diagnose the software and produce valuable information for developers.
This article describes how DTrace can be used in conjunction with Sun Studio tools to understand, analyze, and debug software applications. First the article describes the DTrace utility and its architecture. Next it shows how different tools can be used to fix the software deficiencies and the performance problems.
This article is not intended to describe all of the functionality of DTrace and the Sun Studio tools. It is intended to give enough information to developers so they can make wise decisions about selecting the right tool for the right task.
The NetBeans DTrace GUI Plugin is a graphical user interface (GUI) DTrace that can be installed into the Sun Studio IDE using the NetBeans Plugin Portal (choose Tools > Plugins in the IDE).
You can run D scripts from the GUI, even those that are embedded in shell scripts. In fact, the DTrace GUI Plugin runs all of the D scripts that are packaged in the DTraceToolkit. The DTraceToolkit is a collection of useful documented scripts developed by the OpenSolaris DTrace community.
You can visualize the output of DTrace using Chime. Chime is a graphical tool for visualizing DTrace aggregations. In particular, its ability to display data over time adds a missing dimension to system observability. Chime is fully integrated with the NetBeans DTrace GUI Plugin.
Documentation for the NetBeans DTrace GUI Plugin is available at http://wiki.netbeans.org/DTrace.
D Program Structure
The DTrace utility includes a new scripting language called D. The D language is derived from a large subset of C programming language combined with a special set of functions and variables to help make tracing easy.
Each D program consists of a series of clauses, each clause describing one or more probes to enable, and an optional set of actions to perform when the probe fires.
probe descriptions
/predicate /
{
action statements;
}Probe descriptions are specified using the form provider:module:function:name. Omitted fields match any value.
Provider - The name of the DTrace provider that is publishing this probe. The provider name typically corresponds to the name of the DTrace kernel module that performs the instrumentation to enable the probe.
Module - The name of the module in which the probe is located. This name is either the name of a kernel module or the name of a user library.
Function - The name of the program function in which the probe is located.
Name - The name that represents the location in the function, such as entry or return.
Predicates are expressions enclosed in slashes (/ /) that are evaluated at probe firing time to determine whether the associated actions should be executed.
Probe actions are described by a list of statements separated by semicolon (;) and enclosed in braces ({}).
DTrace Architecture
The core of DTrace - including all instrumentation, probe processing and buffering - resides in the kernel. Processes become DTrace consumers by initiating communication with the in-kernel DTrace component using the DTrace library. The dtrace command itself is a DTrace consumer, since it is built on top of the DTrace library.
Figure 1 Overview of the DTrace Architecture
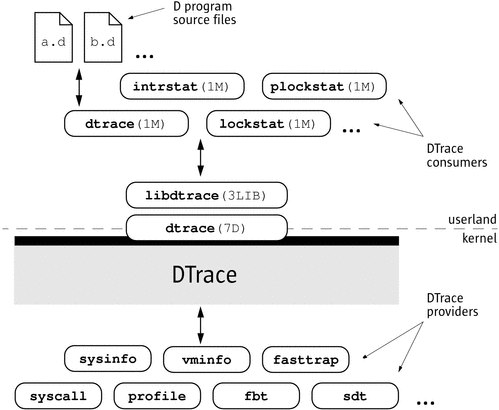
Providers and Probes
DTrace providers are loadable kernel modules that communicate with the DTrace kernel module. When you use DTrace, each provider is given an opportunity to publish the probes it can provide to the DTrace framework. You can then enable and bind your tracing actions to any of the probes that have been published.
To create a probe, the provider specifies the module name and function name of the instrumentation point; plus a semantic name for the probe. Each probe is thus uniquely identified by a 4-tuple:
< provider, module, function, name >
The DTrace framework provides sixteen different instrumentation providers that among them offer observability into many aspects of the system. The providers are named as follows:
dtrace |
provider probes related to DTrace itself |
lockstat |
lock contention probes |
profile |
probe for firing at fixed intervals |
fbt |
function boundary tracing provider |
syscall |
probes at entry/return of every syscall |
sdt |
“statically defined probes” user definable probe |
sysinfo |
probe kernel stats for mpstat and sysinfo tools |
vminfo |
probe for vm kernel stats |
proc |
process/LWP creation and termination probes |
sched |
probes for CPU scheduling |
io |
provider probes related to disk IO |
mib |
probes in network layer in kernel |
fpuinfo |
probe into kernel software FP processing |
pid |
probe into any function or instruction in user code |
plockstat |
probes user level sync and lock code |
fasttrap |
non-exposed probe, fires when DTrace probes are called |
Please refer to the Solaris Dynamic Tracing Guide at http://docs.sun.com/app/docs/doc/819–3620 for complete descriptions of these providers.
DTrace also provides a facility for developers of user applications to define customized probes in application code to augment the capabilities of the pid provider. These probes are called static probes.
Actions and Predicates
Actions are executed only when the predicate evaluates to true. Actions enable your DTrace programs to interact with system outside of DTrace. The most common actions record data to a DTrace buffer. Other actions are available, such as stopping the current process, raising a specific signal on the current process, or ceasing tracing altogether. Some of these actions are destructive in that they change the system, albeit in a well-defined way. These actions can only be used if destructive actions have been explicitly enabled. By default, data recording actions record data to the principal buffer.
The data recording actions are:
trace |
takes a D expression as its argument and traces the result to the directed buffer |
tracemem |
copies the memory from the address specified by addr into the directed buffer for the length specified by nbyte |
printf |
traces D expressions |
printa |
enables users to display and format aggregations |
stack |
records a kernel stack trace to the directed buffer |
ustack |
records a user stack trace to the directed buffer |
jstack |
an alias for ustack()(), will result in a stack with in situ Java frame translation |
The destructive actions are:
stop |
forces the process that fires the enabled probe to stop |
raise |
sends the specified signal to the currently running process |
copyout |
copies nbytes from buffer buf to address addr in the address space of the process associated with the current thread |
copyoutstr |
copies string str to address addr in the address space of the process associated with current thread |
system |
causes the program specified by program to be executed as if it were given to the shell as input |
breakpoint |
causes the system to stop and transfer control to the kernel debugger |
panic |
causes a kernel panic when triggered |
chill |
causes DTrace to spin for the specified number of nanoseconds |
exit |
immediately cease tracing, perform any final processing, and call exit(3c)() |
Principal Buffers
Each DTrace consumer has a set of in-kernel per-CPU buffers called principal buffers. The principal buffer is present in every DTrace invocation and is the buffer to which tracing actions record their data by default. These actions include:
exit |
immediately cease tracing, perform any final processing, and call exit(3C)() |
printa |
enables users to display and format aggregations |
printf |
traces D expressions |
stack |
records a kernel stack trace to the directed buffer |
trace |
takes a D expression as its argument and traces the result to the directed buffer |
tracemem |
copies the memory from the address specified by addr into the directed buffer for the length specified by nbytes |
ustack |
records a user stack trace to the directed buffer |
The amount of data recorded is always constant. Before storing data, the per-CPU buffer is checked for sufficient space. If there is not sufficient space available in per-CPU buffer, a per-buffer drop count is incremented and processing advances to the next probe. It is up to consumers to minimize drop counts by reading buffers periodically.
DTrace supports several different buffer policies. These policies include: switch, fill, fill and END probes, and ring. By default, the principal buffer has a switch buffer policy. Under this policy, per-CPU buffers are allocated in pairs: one buffer is active and the other buffer is inactive. When a DTrace consumer attempts to read a buffer, the kernel first switches the inactive and active buffers. Once the buffers are switched, the newly inactive buffer is copied out to the DTrace consumer.
Beyond principal buffers, some DTrace consumers may have additional in-kernel data buffers: an aggregation buffer, and one or more speculative buffers.
Security Privileges
The Solaris Least Privilege facility enables administrators to grant specific privileges to specific Solaris OS users. To give a user a privilege on login, insert a line into the /etc/user_attr file of the form:
user-name::::defaultpriv=basic,privilege
For example, the following is how DTrace privileges are set in the machines on which I run DTrace:
nassern::::defaultpriv=basic,dtrace_user,dtrace_proc,dtrace_kernel
To give a running process an additional privilege, use the ppriv(1) command:
ppriv -s A+privilege process-ID
The three privileges that control a user's access to DTrace features are dtrace_proc, dtrace_user, and dtrace_kernel. Each privilege permits the use of a certain set of DTrace providers, actions, and variables, and each corresponds to a particular type of use of DTrace.
DTrace and Sun Studio Tools
Engineers need to use different tools at various stages of development to resolve software issues, such as memory leaks, thread synchronization, and performance problems. Most often, they can use more than one tool to achieve the same results. However, choosing the right tool, to resolve problems that the tool is designed for, can expedite the development process extensively.
As mentioned in DTrace architecture section, DTrace provides sixteen different providers that between them offer observability into many aspects of the system. However, a few of them can be used extensively by application developers: pid, proc, and syscall. The pid provider is by far the provider most widely used by application developers. Hence, in this article, the wide range of DTrace examples are based on the pid provider.
The Sun Studio tools include compilers, the Collector and Performance Analyzer, and the dbx debugger tools.
The Collector and Performance Analyzer are tools that you can use to collect and analyze performance data for your application. Both tools can be used from the command line or from a graphical user interface.
The Collector collects performance data by using a statistical method called profiling and by tracing function calls. The data can include call stacks, microstate accounting information, thread synchronization delay data, hardware counter overflow data, Message Passing Interface (MPI) function call data, memory allocation data, and summary information for the operating system and the process.
The Performance Analyzer displays the data recorded by the Collector. The Performance Analyzer processes the data and displays various metrics of performance at the level of the program, the functions, the source lines, and the instructions.
The dbx debugger is an interactive, source-level, command-line debugging tool. You can use it to run a program in a controlled manner and to inspect the state of a stopped program. dbx gives you complete control of the dynamic execution of a program, including memory usage data, monitoring memory access, and detecting memory leaks.
Please refer to the Sun Studio Information Center for more information.
The remainder of this article describes the common usage of Solaris DTrace, and the Sun Studio Collector, Performance Analyzer, and dbx debugger tools. Several examples are used to illustrate the strength of each tool on finding the culprits in source code and helping engineers to implement the optimal solutions. Examples are categorized as follows:
Understanding the behavior of applications
Measuring the performance of applications
Memory allocations, leaks and access errors
Debugging applications
Statically defined tracing for user applications
Chime visualization tool for DTrace
Understanding the Behavior of Applications
The DTrace utility provides instrumentation of user-level program text through the pid provider, which can instrument arbitrary instructions in a specified process. The pid provider defines a class of providers. Each process can potentially have an associated pid provider. The process identifier is appended to the name of each pid provider.
For example, the probe pid1063:libc:malloc:entry corresponds to the function entry of malloc()() in process 1063. Similarly, the probe pid1063:libc:malloc:return corresponds to the function return of malloc()() in process 1063.
As was described earlier, probe descriptions are specified using the form provider:module:function:name.
provider |
pid1063 |
module |
libc |
function |
malloc |
name |
entry |
An entry probe fires when the traced function is invoked. The arguments to entry probes are the values of the arguments to the trace functions.
A return probe fires when the traced function returns or makes a tail call to another function. The value for arg0 is the offset in the function of the return instruction; arg1 holds the return value.
There are two ways to invoke the DTrace probes: from the command line, or by specifying the probe in a D script and executing the D script itself. The pid provider can be used on processes that are already running. Here is how the pid1063 provider is called for process-id 1063 from the command line:
dtrace -n pid1063:libc:malloc:entry
Or you can write a D script and execute the script itself.
The pid.d Script
#!/usr/sbin/dtrace -s
pid$1:libc:malloc:entry { }There are two ways to run the D script.
You can set the correct permissions for the script, which is named pid.d, and execute it as follows.
pid.d 1063
You can call the dtrace command and specify the pid.d script on command line.
dtrace -s pid.d 1063
The process-id 1063 is the first parameter that is passed to the pid.d script. The $1 is replaced with process-id 1063 upon invocation of the pid.d script.
You can use the $target macro variable and the dtrace -c and -p options to create and grab processes of interest and instrument them using DTrace. Here is the modified version of the pid.d script using the $target macro:
#!/usr/sbin/dtrace -s
pid$target:libc:malloc:entry { }Here is how you run the new version of the pid.d script with the UNIX date(1) command:
dtrace -s pid.d -c date
The following D script can be used to determine the distribution of user functions in a particular subject process.
The ufunc.d D Script
#!/usr/sbin/dtrace -s
pid$target:$1::entry
{
@func[probefunc] = count();
}The D script, which is named ufunc.d, utilizes the built-in probefunc DTrace variable and aggregations to collect data in memory. The DTrace count()() function stores the number of times each user function is called in a process. The dtrace command prints aggregation results by default when the process terminates.
In DTrace, the aggregating of data is a first-class operation. DTrace stores the results of aggregation functions in objects called aggregations. The aggregation results are indexed using a tuple of expressions. In D, the syntax for an aggregation is:
@name[ keys ] = aggfunc ( args );
where name is the name of the aggregation, keys is a comma-separated list of D expressions, aggfunc is one of the DTrace aggregation functions, and args is a comma-separated list of arguments appropriate for the aggregating function. The aggregation name is a D identifier that is prefixed with the special character @.
The following sample C program, test.c, is used to demonstrate the usage of the ufunc.d script.
struct S {
int a, b, c;
float f;
}s1;
void foo1(struct S s) {
int i = 100000000;
while (i > 0) i--;
s.a = 999;
};
void foo(struct S s) {
int i = 1000000
while (i > 0) i--;
foo1(s);
}
void inet_makeaddr(int x) { static int i=16; }
int main() {
foo(s1);
inet_makeaddr(2006);
int i = 100000;
while (i > 0) i--;
return 0;
}Make sure to compile the code with the -g compiler option.
The following output is generated by running the ufunc.d script with the executable:
% dtrace -s ufunc.d -c ./a.out a.out
dtrace: script 'ufunc.d' matched 5 probes
dtrace: pid 27210 has exited
inet_makeaddr 1
foo1 1
foo 1
main 1
__fsr 1 As shown above, each function is called once in process 27210.
Measuring the Performance of Applications
Both DTrace and the Sun Studio Collector and Performance Analyzer tools can be used to measure the performance of user functions in a process. Both tools can be used to answer the following kinds of questions:
Which functions or load objects are consuming the most resources?
How does the program arrive at this point in the execution?
However, if you really are interested in finding out exactly which source lines and instructions are responsible for resource consumption, you need to use the Collector and Performance Analyzer tools.
In general, you can use DTrace to isolate the area of the program that has performance bottlenecks and use the Collector and Performance Analyzer tools to pinpoint the culprits.
The test case with the test.c program was used to demonstrate the usage of both DTrace and Collector and Performance Analyzer tools.
The functime.d D script can be used to find out how much time is being spent in each function of the test.c program.
The functime.d D Script
#!/usr/sbin/dtrace -s
pid$target:$1::entry
{
ts[probefunc] = timestamp;
}
pid$target:$1::return
/ts[probefunc]/
{
@ft[probefunc] = sum(timestamp - ts[probefunc]);
ts[probefunc] = 0;
}The functime.d script uses the built-in variable timestamp and the associative array to record the time that is spent in each user function. The time unit for built-in variable timestamp is nanosecond. The following output is generated if you run the test.c program with the functime.d D script:
% dtrace -s functime.d -c ./a.out a.out
dtrace: script '/home/nassern/test/dt/functime.d' matched 15 probes<
dtrace: pid 29393 has exited
CPU ID FUNCTION:NAME
inet_makeaddr 6140
__fsr 23333
foo1 364401651
foo 368076629
main 368408675Based on the output of DTrace, the leaf function foo1()() consumes the most CPU time (364401651 nanoseconds) compared to other functions in the call chain. The CPU time reported by the functime.d script is inclusive, which means the CPU time is calculated from events which occur inside the function and any other functions it calls.
Hence, to calculate the exclusive CPU time or the CPU time for events that occur inside the function foo()() itself, we need to subtract the CPU time for foo1()() from the foo()() function.
368076629 - 364401651 = 3674978 (CPU time for function foo itself)
Similarly, you can calculate the exclusive CPU time for the main()() function.
You can get more detailed results using the Sun Studio Collector and Analyzer tools. The Collector tool collects performance data using a statistical method called profiling and by tracing function calls. The Analyzer tool displays the data recorded by the Collector in Graphical User Interface (GUI).
However, for simplicity, the er_print utility is used to present the recorded data in plain text. The er_print utility presents in plain text all the displays that presented by Analyzer, with the exception of the Timeline display. The exclusive (Excl) and inclusive (Incl) CPU time are reported automatically by the Performance Analyzer tool.
% collect a.out
Creating experiment database test.1.er ...
% er_print test.1.er
(er_print) functions
Functions sorted by metric: Exclusive User CPU Time
Excl. Incl. Name
User CPU User CPU
sec. sec.
0.340 0.340 <Total>
0.340 0.340 foo1
0. 0.340 _start
0. 0.340 foo
0. 0.340 main
(er_print) lines
Objects sorted by metric: Exclusive User CPU Time
Excl. Incl. Name
User CPU User CPU
sec. sec.
0.340 0.340 <Total>
0.340 0.340 foo1,line 12 in "1001650.c"
0. 0.340 <Function: start, instructions without line numbers>
0. 0.340 foo, line 19 in "1001650.c"
0. 0.340 main, line 27 in "1001650.c"The collect command creates the test.1.er directory. The er_print utility is used to display the recorded data. The functions command displays the exclusive and inclusive user CPU time in seconds. The lines command shows exactly which lines in the source code consumes the most CPU time. The disasm command can be used to show the metrics for assembly code that is not shown above.
Measuring the Performance of Multi-threaded Applications
Both DTrace and Sun Studio Collector and Analyzer tools can be used to measure the performance of multi-threaded applications.
The DTrace proc provider is very useful for measuring the performance of multi-threaded applications. The proc provider makes available probes pertaining to the following activities:
Process creation and termination
LWP creation and termination
Executing new program images
Sending and handling signals
Most of the probes in the proc provider have access to lwpsinfo_t, psinfo_t, and siginfo_t kernel structures. These structures are defined in the Solaris kernel and can be accessed by using the probes in the proc provider.
For instance, the lwptime.d script utilizes the lwp-create, lwp-start, and lwp-exit probes to report useful information about the lwp creation and the time is spent in each lwp.
The lwptime.d D Script
proc:::lwp-create
{
printf("%s, %d\n", stringof(args[1]->pr_fname), args[0]->pr_lwpid);
}
proc:::lwp-start
/tid != 1/
{
self->start = timestamp;
}
proc:::lwp-exit
/self->start/
{
@[tid, stringof(curpsinfo->pr_fname)] =sum(timestamp - self->start);
self->start = 0;
}The lwp-create probe has two parameters. The type of arg0 is lwpsinfo_t and the type of arg1 is psinfo_t. The pr_lwpid field of the psinfo_t structure provides the lwpid and the pr_fname field of the lwpsinfo_t structure provides the name of executable that owns the LWP.
The tid is another DTrace built-in variable that provides the ID of the current thread. The curpsinfo is also a built-in variable that provides the process state of the process associated with current thread. The special identifier self is used to define the thread-local variable start. DTrace provides the ability to declare variable storage that is local to each operating system thread, as opposed to the global variables. Thread-local variables are referenced by applying the -> operator to the special identifier self.
The lwptime.d script is used to find out how long each individual thread takes to run for the multi_thr application. This multi-threaded application spawns five threads internally to perform some work.
% dtrace -s lwptime.d
dtrace: script 'lwptime.d' matched 4 probes
CPU ID FUNCTION:NAME
2 2779 lwp_create:lwp-create csh, 1
0 2779 lwp_create:lwp-create multi_thr, 2
0 2779 lwp_create:lwp-create multi_thr, 3
2 2779 lwp_create:lwp-create multi_thr, 4
0 2779 lwp_create:lwp-create multi_thr, 5
3 2779 lwp_create:lwp-create multi_thr, 6
^C
4 multi_thr 2009914302
6 multi_thr 4009949530
2 multi_thr 4019779527
3 multi_thr 8040444787
5 multi_thr 10050000189As shown above, the multi_thr application creates five threads. It also displays the time that it takes to run each individual thread. For instance, thread 4 ran for 2009914302 nanoseconds.
More detailed information about the multi_thr application can be obtained by using the Sun Studio Collector and Analyzer tools.
% collect multi_thr
% er_print test.1.er
(er_print) fsummary
...
...
sub_d
Exclusive User CPU Time: 0. ( 0. %)
Inclusive User CPU Time: 0. ( 0. %)
Exclusive Wall Time: 0. ( 0. %)
Inclusive Wall Time: 0. ( 0. %)
Exclusive Total LWP Time: 0. ( 0. %)
Inclusive Total LWP Time: 2.011 ( 6.1%)
Exclusive System CPU Time: 0. ( 0. %)
Inclusive System CPU Time: 0. ( 0. %)
Exclusive Wait CPU Time: 0. ( 0. %)
Inclusive Wait CPU Time: 0. ( 0. %)
Exclusive User Lock Time: 0. ( 0. %)
Inclusive User Lock Time: 0. ( 0. %)
Exclusive Text Page Fault Time: 0. ( 0. %)
Inclusive Text Page Fault Time: 0. ( 0. %)
Exclusive Data Page Fault Time: 0. ( 0. %)
Inclusive Data Page Fault Time: 0. ( 0. %)
Exclusive Other Wait Time: 0. ( 0. %)
Inclusive Other Wait Time: 2.011 ( 6.1%)
Size: 433
PC Address: 2:0x000015f0
Source File: /home/nassern/test/dbx/dtrace/multi_thr.c
Object File: /tmp/multi_thr
Load Object: /tmp/multi_thr
Mangled Name:
Aliases:
sub_e
Exclusive User CPU Time: 0. ( 0. %)
Inclusive User CPU Time: 0. ( 0. %)
Exclusive Wall Time: 0. ( 0. %)
Inclusive Wall Time: 0. ( 0. %)
Exclusive Total LWP Time: 0. ( 0. %)
Inclusive Total LWP Time: 10.037 ( 30.3%)
Exclusive System CPU Time: 0. ( 0. %)
Inclusive System CPU Time: 0. ( 0. %)
Exclusive Wait CPU Time: 0. ( 0. %)
Inclusive Wait CPU Time: 0. ( 0. %)
Exclusive User Lock Time: 0. ( 0. %)
Inclusive User Lock Time: 0. ( 0. %)
Exclusive Text Page Fault Time: 0. ( 0. %)
Inclusive Text Page Fault Time: 0. ( 0. %)
Inclusive Data Page Fault Time: 0. ( 0. %)
Exclusive Other Wait Time: 0. ( 0. %)
Inclusive Other Wait Time: 10.037 ( 30.3%)
Size: 702
PC Address: 2:0x000017b0
Source File: /home/nassern/test/dbx/dtrace/multi_thr.c
Object File: /tmp/multi_thr
Load Object: /tmp/multi_thrThe partial output of the Performance Analyzer is shown above. The LWP time is reported in seconds.
The Performance Analyzer displays the detailed information about each LWP. Actually, you can match up the output of the lwptime.d script with output of the Performance Analyzer. The LWP time reported by both tools is almost the same. For instance, the LWP time (2009914302 nanoseconds) for LWP-ID 4 is the same for sub_d LWP reported by the Analyzer tool. The same is true for LWP-ID 5 (10050000189 nanoseconds) and the sub_e LWP.
Memory Allocations, Leaks, and Access Errors
A memory leak can diminish the performance of the computer by reducing the amount of available memory.
A memory leak is a dynamically allocated block of memory that has no pointers pointing to it anywhere in the data space of the program. Such blocks are orphaned memory. Because there are no pointers pointing to the blocks, programs cannot reference them, much less free them.
DTrace might be used to detect the memory leaks in applications. However, the user needs to pay close attention to the output of DTrace specially if malloc()() and free()() functions are called extensively in an application.
The hello.c program is used to show the proper usage of both DTrace and the Sun Studio dbx debugger.
The hello.c Program
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
char *hello1, *hello2
void
memory_use() {
hello1 = (char *)malloc(32);
strcpy(hello1, "hello world");
hello2 = (char *)malloc(strlen(hello1) + 1);
strcpy(hello2, hello1);
free (hello1);
}
void
memory_leak() {
char *local;
local = (char *)malloc(32);
strcpy(local, "hello world");
}
void
access_error() {
int i, j;
i = j;
}
int
main() {
memory_leak();
memory_use();
access_error();
printf("%s\n", hello2);
return 0;
}The mfs.d script uses the pid provider to match up the memory addresses for malloc()() and free()() function calls.
The mfs.d Script
#!/usr/sbin/dtrace -s
pid$target:$1:malloc:entry
{
ustack();
}
pid$target:$1:malloc:return
{
printf("%s: %x\n", probefunc, arg1);
}
pid$target:$1:free:entry
{
printf("%s: %x\n", probefunc, arg0);
}The ustack()() action records a user stack trace to the directed buffer. The arg1 in the pid$target:$1:malloc:return probe is the address of the newly allocated space that returns by the malloc()() function. The arg0 in the pid$target:$1:free:entry probe is the address of the space that needs to be deleted by the free()() function.
The Output of the mfs.d D Script
% dtrace -s mfs.d -c ./hello libc
dtrace: script 'mfs.d' matched 3 probes
hello world
dtrace: pid 7790 has exited
CPU ID FUNCTION:NAME
0 40565 malloc:entry
lib.c'malloc
hello`memory_leak+0x8
hello`main+0x4
hello`_start+0x17c
0 40566 malloc:return malloc: 1001010a0
0 40565 malloc:entry
libc`malloc
hellomemory_use+0x8
hello`main+0xc
hello`_start+0x17c
0 40566 malloc:return malloc: 1001010d0
0 40565 malloc:entry
libc`malloc
hello`memory_use+0x68
hello`main+0xc
hello`_start+0x17c
0 40566 malloc:return malloc: 1001028b0
0 40567 free:entry free: 1001010d0As shown above, the free()() function is not called for the 0x1001010a0 and 0x1001028b0 addresses. Hence, you might assume that there are memory leaks for those addresses. However, as it will be described shortly, all memory allocations might not need to be deleted before the program ends.
The address 0x1001010a0 or the local variable in the memory_leak() function is memory leak, since it has no pointers pointing to it anywhere in the data space of the program.
However, the situation is different for address 0x1001028b0 or the global variable hello2. For global variables, it is a common programming practice not to free memory if the program will terminate shortly.
The dbx debugger is a more appropriate tool to detect memory leaks. dbx includes the Runtime Checking (RTC) facility. RTC lets you automatically detect runtime errors, such as memory access errors and memory leaks, in a native code application during the development phase. It also lets you monitor memory usage.
Programs might incorrectly read or write memory in a variety of ways. These are called memory access errors. For example, the program may reference a block of memory that has been deallocated through a free()() call for a heap block. Or, a function might return a pointer to a local variable, and when that pointer is accessed, an error would result. Access errors might result in wild pointers in the program and can cause incorrect program behavior such as wrong output and segmentation violation.
% dbx hello
For information about new features see `help changes'
To remove this message, put `dbxenv suppress_startup_message 7.6'in your .dbxrc
Reading hello
Reading ld
Reading libc
(dbx) dbxenv rtc_biu_at_exitverbose
(dbx) dbxenv rtc_mel_at_exitverbose
(dbx) check -leaks
leaks checking - ON<
(dbx) check -memuse
memuse checking - ON
(dbx) check -access
access checking - ON
(dbx) run
Running: hello
process id 7823)
Reading rtcapihook.so
Reading libdl
Reading rtcaudit.so
Reading libmapmalloc
Reading libgen
Reading libm.so.2
Reading rtcboot.so
Reading librtc.so
RTC: Enabling Error Checking...
RTC: Running program...
Read from uninitialized (rui):
Attempting to read 4 bytes at address 0xffffffff7ffff588
which is 184 bytes above the current stack pointer
Variable is 'j'
stopped in access_error at line 26 in file "hello.c"
26 i = j;
(dbx) cont
hello world
Checking for memory leaks...
Actual leaks report (actual leaks: 1 total size: 32 bytes)
Memory Leak (mel):
Found leaked block of size 32 bytes at address 0x100101768
At time of allocation, the call stack was:
[1] memory_leak() at line 19 in "hello.c"
[2] main() at line 31 in "hello.c"
Possible leaks report (possible leaks: 0 total size: 0 bytes)
Checking for memory use...
Blocks in use report (blocks in use: 1 total size: 12 bytes)
Block in use (biu):
Found block of size 12 bytes at address 0x100103778 (100.00% of
At time of allocation, the call stack was:
[1] memory_use() at line 11 in "hello.c"
[2] main() at line 32 in "hello.c"
execution completed, exit code is 0As shown above, after enabling the proper actions in RTC facility, dbx reports memory usage and memory leaks. It also stops as soon as it detects memory access errors. The variable i in the access_error()() function is assigned to an uninitialized variable j.
RTC reports precisely which line in the source code has memory leaks. For example, 32 bytes are leaked in line 19 of the hello.c program. Line 19 is defined in the memory_leak()() function.
The generated report also tells users exactly how much memory is consumed by which line in the source code. For example, Line 11 in the hello.c program allocates 12 bytes. Line 11 is defined in the memory_use()() function.
Debugging Applications
The dbx debugger is an interactive, source-level, command-line debugging tool. dbx can be used standalone to debug complex applications. However, developers can use the pid, proc, and syscall providers in conjunction with dbx to expedite the debugging process.
For example, DTrace can be used to stop the server program in middle of an operation as soon as the client sends a request to server. The developer can utilize dbx to debug the stopped process. You have already seen the usage of the pid and proc providers in previous sections. More examples are given later on how to use these providers for debugging purposes. First, let's introduce the syscall provider.
The syscall provider enables you to trace every system call entry and return. System calls can be a good starting point for understanding a process's behavior, especially if the process seems to be spending a large amount of time executing or blocked in the kernel.
The syscall provider provides a pair of probes for each system call: an entry probe that fires before the system call is entered, and a return probe that fires after the system call has completed but before control has transferred back to user-level.
The stop.d D Script
syscall::open:return
/execname == "synprog"/
{
ustack();
stop_pid = 1;
printf("open file descriptor = %d", arg1);
}
syscall::close:entry
/execname == "synprog" && stop_pid != 0/
{
ustack();
printf("close file descriptor = %d\n", arg0);
printf("stopping pid %d", pid);
stop();
stop_pid = 0;
}The above script stops the synprog process just before it enters the close()() system call if the open()() system call has been called before by the synprog process.
The stop()() action can be used to stop a process at any DTrace probe point. This action can be used to capture a program in a particular state that would be difficult to achieve with a simple breakpoint, and then attach a traditional debugger like dbx to the process. You can also use the gcore(1) utility to save the state of a stopped process in a core file for later analysis using dbx.
The built-in variable execname is used in the predicate of both the syscall::open:return and syscall::close:entry probes. The string execname stands for the name of the current executable process.
The stop.d D script needs to be executed on a separate window from the synprog program itself. When the synprog program is executed, it runs until the stop()() action is called from the syscall::close:entry probe.
% dtrace -s stop.d -w
dtrace: script 'stop.d' matched 2 probes
dtrace: allowing destructive actions
...
...
1 16 open:return
0xfffffd7fff34ab5a
0xfffffd7fff33bd1c
a.out`init_micro_acct+0xf4
a.out`stpwtch_calibrate+0xa4
a.out`main+0x254
a.out`0x404a0c
open file descriptor = 4
1 17
0xfffffd7fff34a56a
a.out`init_micro_acct+0x1e5
a.out`stpwtch_calibrate+0xa4
a.out`main+0x254
a.out`0x404a0c
close file descriptor = 4
stopping pid 17522
...
...As shown above, based on the stack trace generated by DTrace, the synprog process is stopped in the init_micro_acct()() user function as soon as it enters the close()() system call. At this point you can attach the dbx debugger to process ID (pid) 17522 for further analysis.
% dbx
For information about new features see `help changes'
To remove this message, put `dbxenv suppress_startup_message 7.6'in your .dbxrc
(dbx) attach 17522
Reading synprog
Reading ld
Reading libdl
Reading libc
Attached to process 17522
stopped in _private_close at 0xfffffd7fff34a56a
0xfffffd7fff34a56a: _private_close+0x000a: jb __cerror [0xfffffd7fff2c6130, .-0x8443a ]
Current function is init_micro_acct
93 close(ctlfd);
(dbx) where
[1] _private_close(0x4, 0xfffffd7fffdfe018,0xfffffd7fff33b5f8, 0xfffffd7fff34b40a, 0x10,
0xfffffd7fffdfd87c), at 0xfffffd7fff34a56a
[2] close(0x0, 0x0, 0x0, 0x0, 0x0, 0x0), at 0xfffffd7fff33b607
=>[3] init_micro_acct(), line 93 in "stopwatch.c"
[4] stpwtch_calibrate(), line 44 in "stopwatch.c"
[5] main(argc = 1, argv = 0xfffffd7fffdff918), line 208 in"synprog.c"
(dbx) list
93 close(ctlfd);
94 fprintf(stderr,
95 " OS release %s -- enabling microstate accounting.\n",
96 arch);
97 #endif /* OS(Solaris) *
98 }
99
100 stopwatch_t *
101 stpwtch_alloc(char *name, int histo)
102 {
(dbx)
Tracing Arbitrary Instructions
You can use the pid provider to trace any instruction in any user function. Upon demand, the pid provider will create a probe for every instruction in a function. The name of each probe is the offset of its corresponding instruction in the function expressed as a hexadecimal integer.
For example, to enable a probe associated with the instruction at offset 0x1c in function foo()() of module bar.so in the process with PID 123, you can use the following command:
% dtrace -n pid123:bar.so:foo:1c
To enable all of the probes in the function foo(),() including the probe for each instruction, you can use the following command:
% dtrace -n pid123:bar.so:foo:
Infrequent errors can be difficult to debug because they can be difficult to reproduce. Often, you can identify a problem only after the failure has occurred, too late to reconstruct the code path. The following example demonstrates how to use the pid provider to solve this problem by tracing every instruction in a function.
The errorpath.d D Script
pid$target::$1:entry
{
self->spec = 1;
printf("%x %x %x %x %x", arg0, arg1, arg2, arg3, arg4);
}
pid$target::$1:
/self->spec/
{}
pid$target::$1:return
/self->spec/
{
self->spec = 0;
}
The Output of the errorpath.d Script
% dtrace -s errorpath.d -c ./hello memory_leak
dtrace: script 'errorpath3.d' matched 23 probes
hello world
dtrace: pid 17562 has exited
CPU ID FUNCTION:NAME
2 38516 memory_leak:entry 1 fffffd7fffdff928 fffffd7fffdff938 0 0
2 38516 memory_leak:entry
2 38519 memory_leak:1
2 38520 memory_leak:4
2 38521 memory_leak:8
2 38522 memory_leak:f
2 38523 memory_leak:16
2 38524 memory_leak:1a
2 38525 memory_leak:1d
2 38526 memory_leak:22
2 38527 memory_leak:27
2 38528 memory_leak:2a
2 38529 memory_leak:2e
2 38530 memory_leak:35
2 38531 memory_leak:39
2 38532 memory_leak:3e
2 38533 memory_leak:43
2 38535 memory_leak:48
2 38536 memory_leak:49
2 38517 memory_leak:returnAs shown above, the errorpath.d script is used to trace the user function memory_leak()() in the hello.c program.
dbx is equipped with two powerful commands that enables developers to trace user functions both at the source code level or at machine-instruction level.
The dbx trace command displays each line of source code as it is about to be executed. You can use the trace command to trace each call to a function, every member function of a given name, every function in a class, or each exit from a function. You can also trace changes to a variable.
(dbx) help trace
trace (command)
trace -file <filename> # Direct all trace output to the given <filename>
# To revert trace output to standard output use
# `-' for <filename>
# trace output is always appended to <filename>
# It is flushed whenever dbx prompts and when the
# app has exited. The <filename> is always re-opened
# Trace each source line, function call and return.
trace next -in <func> # Trace each source line while in the given function
trace at <line#> # Trace given source line
trace in <func> # Trace calls to and returns from the given function
trace inmember <func> # Trace calls to any member function named <func>
trace infunction <func> # Trace when any function named <func>
trace inclass <class> # Trace calls to any member function of <class>
trace change <var> # Trace changes to the variable
...
`trace' has a general syntax as follows:
trace <event-specification> [ <modifier> ]Here is how dbx is used to trace the same user function memory_leak()() in the hello.c program at source code level.
% dbx hello
For information about new features see `help changes'
To remove this message, put `dbxenv suppress_startup_message 7.6' in your .dbxrc
Reading hello
Reading ld
Reading libc
(dbx) trace next -in memory_leak
Events that require automatic single-stepping will not work properly with
multiple threads.
See also `help event specification'.
(2) trace next -in memory_leak
(dbx) run
Running: hello
(process id 17590)
trace: 19 local = (char *)malloc(32);
trace: 20 strcpy(local, "hello world");
trace: 21 }
hello world
execution completed, exit code is 0Tracing techniques at the machine-instruction level work the same as at the source code level, except you use the tracei command. For the tracei command, dbx executes a single instruction only after each check of the address being executed or the value of the variable being traced.
(dbx) help tracei
tracei (command)
tracei step # Trace each machine instruction
tracei next -in <func> # Trace each instruction while in the given function
tracei at <address> # Trace instruction at given address
tracei in <func> # Trace calls to and returns from the given function
tracei inmember <func> # Trace calls to any member function named <func>
tracei infunction <func> # Trace when any function named <func> is called
tracei inclass <class> # Trace calls to any member function of <class>
tracei change <var> # Trace changes to the variable
...
tracei is really a shorthand for `trace <event-specification> -instr'
where the -instr modifier causes tracing to happen at instruction
granularity instead of source line granularity and when the event
occurs the printed information is in disassembly format as opposed
to source line formatHere is how dbx is used to trace the same user function memory_leak()() in the hello.c program at the machine-instruction level.
% dbx hello
For information about new features see `help changes'
To remove this message, put `dbxenv suppress_startup_message 7.6' in your .dbxrc
Reading hello
Reading ld
Reading libc
(dbx) tracei next -in memory_leak
Events that require automatic single-stepping will not work properly with multiple
threads.
See also `help event specification'.
(2) tracei next -in memory_leak
(dbx) run
Running: hello (process id 17600)
0x0000000000400bf1: memory_leak+0x0001: movq %rsp,%rbp
0x0000000000400bf4: memory_leak+0x0004: subq $0x0000000000000010,%rsp
0x0000000000400bf8: memory_leak+0x0008: movl
$0x0000000000000020,0xfffffffffffffff0(%rbp)
0x0000000000400bff: memory_leak+0x000f: movl
$0x0000000000000000,0xfffffffffffffff4(%rbp)
0x0000000000400c06: memory_leak+0x0016: movq 0xfffffffffffffff0(%rbp),%r8
0x0000000000400c0a: memory_leak+0x001a: movq %r8,%rdi
0x0000000000400c0d: memory_leak+0x001d: movl $0x0000000000000000,%eax
0x0000000000400c12: memory_leak+0x0022: call malloc [PLT] [ 0x400928, .-0x2ea ]
0x0000000000400c17: memory_leak+0x0027: movq %rax,%r8
0x0000000000400c1a: memory_leak+0x002a: movq %r8,0xfffffffffffffff8(%rbp)
0x0000000000400c1e: memory_leak+0x002e: movq $_lib_version+0x14,%rsi
0x0000000000400c25: memory_leak+0x0035: movq 0xfffffffffffffff8(%rbp),%rdi
0x0000000000400c29: memory_leak+0x0039: movl $0x0000000000000000,%eax
0x0000000000400c2e: memory_leak+0x003e: call strcpy [PLT] [ 0x400938,
.-0x2f6 ]
0x0000000000400c33: memory_leak+0x0043: jmp memory_leak+0x48 [
0x400c38, .+5 ]
0x0000000000400c38: memory_leak+0x0048: leave
0x0000000000400c39: memory_leak+0x0049: ret
hello world
execution completed, exit code is 0
The signal-send Probe in the proc Provider
You can use the signal-send probe in the proc provider to determine the sending and receiving process associated with any signal, as shown in the following example:
The sig.d D Script
#pragma D option quiet
proc:::signal-send
{
@[execname, stringof(args[1]->pr_fname), args[2]] = count();
}
END
{
printf("%20s %20s %12s %s\n",
"SENDER", "RECIPIENT", "SIG", "COUNT");
printa("%20s %20s %12d %@d\n", @);
}You can set options in a D script by using #pragma D followed by the string option and the option name. If the option takes a value, the option name should be followed by an equals sign (=) and the option value. The quiet option is the same as the -q command-line option, which forces DTrace to output only explicitly traced data.
The dtrace provider provides several probes related to DTrace itself. You can use these probes to initialize state before tracing begins (BEGIN probe), process state after tracing has completed (END probe), and handle unexpected execution errors in other probes (ERROR probe).
The BEGIN probe fires before any other probe. No other probe will fire until all BEGIN clauses have completed. This probe can be used to initialize any state that is needed in other probes.
The ERROR probe fires when a run-time error occurs in executing a clause for a DTrace probe.
The END probe fires after all other probes. This probe will not fire until all other probe clauses have completed. This probe can be used to process state that has been gathered or to format the output. For example, printf()() and printa()() actions are called in the END probe of the sig.d script to format the output.
Running the sig.d D script results in output similar to the following example:
% dtrace -s sig.d
^C
SENDER RECIPIENT SIG COUNT
sched syslogd 14 1
sched dtrace 2 1
sched init 18 1
dbx test_core 9 2
sched csh 18 2
test_core test_core 11 2
sched dbx 18 2
Statically Defined Tracing for User Applications
The Dtrace utility provides a facility for user application developers to define customized probes in application code to augment the capabilities of the pid provider.
DTrace allows developers to embed static probe points in application code, including both complete applications and shared libraries.
These probes can be enabled wherever the application or library is running, either in development or in production.
You define DTrace probes in a .d source file, which is then used when compiling and linking your application. You need to augment your source code to indicate the locations that should trigger your probes. To add a probe location, you need to add a reference to the DTRACE_PROBE()() macro which is defined in the <sys/sdt.h> header file.
For example, the Sun Studio C++ compiler defines the libCrun provider for C++ exception handling. The libCrun provider provides four probes that can be enabled by developers in development or in production stage.
The libCrun.d File
provider libCrun {
probe exception_thrown();
probe exception_rethrown();
probe handler_located();
probe exception_caught();
};These probes are embedded inside of the libCrun.so library and will be triggered once the application throws an exception. The following dtrace command can be used to enable the probes for the libCrun provider.
% dtrace -n 'libCrun$target:::' -c './a.out 2'
dtrace: description 'libCrun$target:::' matched 6 probes
destructor for 3
destructor for 5
caught function returning int
dtrace: pid 5205 has exited
CPU ID FUNCTION:NAME
0 40244__1cG__CrunIex_throw6Fpvpkn0AQstatic_type_info_pF1_v_v_:exception_thrown
0 40242 _ex_throw_body:handler_located
0 40240__1cG__CrunMex_rethrow_q6F_v_:handler_located
0 40243 __1cG__CrunHex_skip6F_b_:exception_caught As shown above, the C++ testcase a.out throws an exception, which in turn triggers the probes in the libCrun provider.
Chime Visualization Tool for DTrace
Chime is a graphical tool for visualizing DTrace aggregations. It displays DTrace aggregations using bar charts and line graphs.
An important feature of Chime is the ability to add new displays without re-compiling. Chime displays are described in XML and a wizard is provided to generate the XML.
Each XML file contains a set of properties recognized by Chime. A XML description looks like this:
<?xml version="1.0" encoding="UTF-8"?>
<java version="1.5.0-beta3" class="java.beans.XMLDecoder">
<object class="org.opensolaris.chime.DisplayDescription">
display properties ...
<void property="uniqueKey">
<array class="java.loan.String" length="1">
<void index="0">
<string>Executable</string>
</void>
</array>
</void>
</object>
</java>The XML properties instruct Chime on how the DTrace aggregations data should be displayed.
By default, Chime provides eleven display traces that can be selected from the list menu. The display traces can be used to monitor the behavior of Solaris kernel and applications that are currently running on the system. Users can visualize the performance of functions defined in an application or they can visualize the kernel activities such as interrupt statistics, system calls, kernel function calls, and device I/O. The display traces are named:
Callouts
Device I/O
Kernel Function Calls
Write File Descriptor Buckets
Interrupt Statistics
Kmem_alloc Stack Counts
Time Spent In Functions
System Calls
Write Time Buckets
Write Counts
Write Counts by User Stack
The Time Spent In Functions display trace uses the DTrace pid provider to display aggregates total time spent in each function. This is the D script that is embedded in XML file of Time Spent In Functions display trace:
pid$target:::entry
{
self->ts[probefunc] = timestamp;
}
pid$target:::return
/ self->ts[probefunc] /
{
@time[probefunc] = sum(timestamp - self->ts[probefunc]);
self->ts[probefunc] = 0;
}The Time Spent In Functions display trace can be used to monitor the performance of all functions in a user specified process or application that includes defined functions in libraries linked to the executable or process.
Users might not want to display all functions. They might want to display the performance data for functions that are defined in the application itself only. They can do so using the new display wizard to create a new display.
The wizard guides users through series of questions on how DTrace aggregations need to be displayed and finally generates the XML file. The DTrace script needs to be provided by users themselves before the XML file is generated by wizard.
To display functions that are defined in the application itself, we need to create a new display trace which is very similar to the Time Spent In Functions display, with an exception that it accepts the probe module name as the parameter $1.
pid$target:$1::entry
{
self->ts[probefunc] = timestamp;
}
pid$target:$1::return
/self->ts[probefunc]/
{
@time[probefunc] = sum(timestamp -self->ts[probefunc]);
self->ts[probefunc] = 0;
}The D Script above will be embedded in the new XML file.
For example, to trace all the functions that are defined in the Unix date command, specify “date” for the probe module name shown as the parameter $1 in the script above.
The wizard questions can be categorized as follows:
Set the title and output file
Set DTrace program
Set cleared aggregations
Specify columns
Specify column data
Set column properties
Aggregation value column
Test run the display
Provide a description
Finish creating the display
The new display trace is accessible from list menu. Users should be able to utilize the newly created display trace immediately without re-compiling.
Chime is an OpenSolaris project and currently is available for download at http://hub.opensolaris.org/bin/view/Project+dtrace-chime/WebHome
In Conclusion
Developers will be benefit most when they use Sun Studio tools during the development phase. However, once the software is deployed, DTrace becomes very instrumental at customer sites to diagnose the software and produce valuable information for developers.
DTrace helps software developers to funnel their attention to the problem area of a complex software system. Once the problem area of a complex software system is identified using DTrace, they can use Sun Studio tools to zoom into the problem area to pinpoint the culprits and implement the optimal solutions.