|
| |
| Sun Java(TM) System Directory Server 5.2 2005Q1 Deployment Planning Guide | |
Chapter 2
Planning and Accessing Directory DataThe data stored in your directory may include user names, e-mail addresses, telephone numbers, and information about groups users belong to, or it may contain other types of information. The type of data in your directory determines how you structure the directory, to whom you allow access to the data, and how this access is requested and granted. Directory Server enables you to access directory data either via LDAP or DSML, extending the types of applications that can interact directly with the data.
This chapter describes the issues and strategies behind planning and accessing directory data. It includes the following sections:
Introduction to Directory DataSome types of data are better suited to a directory than others. Ideal data for a directory has the following characteristics:
For example, an employee's preference settings for a software application may not seem to be appropriate for the directory because only a single instance of the application accesses the information. However, if the application is capable of reading preferences from the directory and users interact with the application according to their preferences from different sites, it is useful to include the preference information in the directory.
What Your Directory Might Include
Examples of data you can store in your directory are:
- Contact information, such as telephone numbers, physical addresses, and e-mail addresses.
- Descriptive information, such as an employee number, job title, manager or administrator identification, and job-related interests.
- Organization contact information, such as a telephone number, physical address, administrator identification, and business description.
- Device information, such as a printer's physical location, type of printer, and the number of pages per minute that the printer can produce.
- Contact and billing information for your corporation's trading partners, clients, and customers.
- Contract information, such as the customer's name, due dates, job description, and pricing information.
- Individual software preferences or software configuration information.
- Resource sites, such as pointers to web servers or the file system of a certain file or application.
Apart from server administration data, you may want to store the following types of information in your directory:
What Your Directory Should Not Include
Directory Server is well suited to managing large quantities of data that client applications read and occasionally write, but it is not designed to handle large objects, such as images or other media. These objects should be maintained in a file system. However, your directory can store pointers to these kinds of applications through the use of FTP, HTTP, or other types of URL.
Because Directory Server works best for read operations, you should avoid placing rapidly changing information in the directory. Reducing the number of write operations improves overall search performance.
Defining Your Data NeedsWhen you design your directory data, try to think not only of the data you currently require but also what you may include in your directory in the future. Considering the future needs of your directory during the design process will influence how the data is structured and distributed.
As you plan your deployment, consider the following:
- What do you want to put in your directory today? What immediate problem do you hope to solve by deploying a directory? What are the immediate needs of the directory-enabled application you use?
- What do you want to put in your directory in the near future? For example, your enterprise might use an accounting package that does not currently support LDAP, but that you know will be LDAP-enabled or DSML-enabled in the near future. You should identify the data used by applications such as this and plan for the migration of the data into the directory when the technology becomes available.
- What do you think you might want to store in your directory in the future? For example, if you are a hosting environment, perhaps future customers will have different data requirements to your current customers. Maybe future customers will want to use your directory to store JPEG images. At a minimum, this kind of planning helps you identify data sources you might otherwise not have considered.
Performing a Site SurveyA site survey is a formal method of discovering and characterizing the contents of a directory. Budget plenty of time for performing a site survey, as data is the key to your directory architecture. The site survey consists of the following tasks, which are described briefly here and then in more detail:
Decide how available the directory data must be to client applications and design your architecture accordingly. How available your directory must be affects how you replicate data and configure chaining policies to connect data stored on remote servers.
For more information about replication, refer to Chapter 6, "Understanding Replication." For more information on chaining, refer to Chapter 5, "Distribution, Chaining, and Referrals."
If you import data from other sources, develop a strategy for bulk imports and incremental updates. As a part of this strategy, try to master data in a single place, and limit the number of applications that can change the data. Also, limit the number of people who write to any given piece of data. A smaller group ensures data integrity and reduces administrative overhead.
Because of the number of organizations that can be affected by the directory, it may be helpful to create a directory deployment team that includes representatives from each affected organization. This team performs the site survey.
Corporations generally have a human resources department, an accounting or accounts receivable department, one or more manufacturing organizations, one or more sales organizations, and one or more development organizations. Including representatives from each of these organizations can help you perform the survey. Furthermore, directly involving all the affected organizations can help build acceptance for the migration from local data stores to a centralized directory.
Identifying Client Applications
Generally, the applications that access your directory and the data needs of these applications drive the planning of directory contents. Common applications that may use your directory include:
- Directory browser applications, such as white pages. These kinds of applications generally access information such as e-mail addresses, telephone numbers, and employee names.
- Messaging applications, especially e-mail servers. All e-mail servers require e-mail addresses, user names, and some routing information. Others require more advanced information such as the place on disk where a user's mailbox is stored, vacation notification information, and protocol information (IMAP versus POP, for example).
- Directory-enabled human resources applications. These require more personal information such as government identification numbers, home addresses, home telephone numbers, birth dates, salary details, and job titles.
- Security, web portal, or personalization applications. These kinds of applications access profile information.
When you examine the applications that will use your directory, look at the types of information each application uses. The following table gives an example of applications and the information used by each:
When you have identified the applications and information used by each application, you may see that some types of data are used by more than one application. Doing this kind of exercise during the data planning stage can help you avoid data redundancy.
The data maintained in your directory, and when it starts being maintained, is affected by:
Identifying Data Sources
To identify the data to be included in your directory, perform a survey of existing data sources. Your survey should include the following:
During your survey, you may come up with a matrix that resembles the following table, identifying all of the information sources in your enterprise.
Characterizing Directory Data
The data you identify can be characterized as follows:
Study each piece of data you plan to include in your directory to determine what characteristics it shares with other pieces of data. This helps save time during the schema design stage, described in Chapter 3, "Directory Server Schema."
For example, you can create a table that characterizes your directory data as follows:
Determining Directory Availability Requirements
The level of service you provide, in terms of availability, depends on the expectations of those who rely on directory-enabled applications. To determine the level of service an application expects, first determine when and how the application is used.
As your directory evolves, it may need to support a variety of service levels. It may be difficult to raise the level of service after your directory is deployed, so make sure your initial design can meet future needs.
Considering a Data Master Server
The data master is the server that is the primary source of data. If you have more than one data center (physical site) you need to decide which server will be the data master, and which servers receives updates from this data master.
Data Mastering for Replication
If you use replication, decide which server will be the master source of your data. Directory Server supports multi-master configurations, in which more than one server can be a master for the same data. For more information about replication and multi-master replication, see Chapter 6, "Understanding Replication."
In the simplest case, put a master source of all your data on two Directory Servers and then replicate that data to one or more consumer servers. Having two master servers provides failover in the event that a server goes offline. In more complex cases, you may want to store the data in multiple databases, so that the entries are mastered by a server close to the applications that will update or search that data.
Data Mastering Across Multiple Applications
You also need to consider the master source of your data if you have applications that communicate indirectly with the directory. Keep the processes for changing data, and the places from which you can change data, as simple as possible. Once you decide on a single site to master a piece of data, use the same site to master all of the other data contained there. A single site simplifies troubleshooting if your databases get out of sync across your enterprise.
Here are some ways you can implement data mastering:
Maintaining multiple masters does not require custom scripts for moving data in and out of the directory and the other applications. However, if data changes in one place, someone has to change it on all the other sites. Maintaining master data in the directory and all applications not using the directory can result in data being unsynchronized across your enterprise (which is what your directory is supposed to prevent).
Maintaining a data master that synchronizes with other applications makes the most sense if you are using a variety of different directory and database applications. Contact your Sun Java System sales representative for more information about Meta Directory.
Master the data in some application other than the directory and then write scripts, programs, or gateways to import that data into the directory.
Mastering data in non-directory applications makes the most sense if you can identify one or two applications that you already use to master your data, and you want to use your directory only for lookups (for example, for online corporate telephone books).
How you maintain master copies of your data depends on your specific needs. However, regardless of how you maintain data masters, keep it simple and consistent. For example, you should not attempt to master data in multiple sites, then automatically exchange data between competing applications. Doing so leads to a "last change wins" scenario and increases your administrative overhead.
Suppose you want to manage an employee's home telephone number. Both the LDAP directory and a human resources (HR) database store this information. The HR database is LDAP enabled, so you can write an application that automatically transfers data from the LDAP directory to the HR database, and vice versa. However, if you attempt to master changes to the telephone number in both the LDAP directory and the HR database, the last place where the telephone number was changed overwrites the information in the other database. This is fine if the last application to write the data had the correct information. But if that information was out of date (because the HR data was reloaded from a backup, for example), the correct telephone number in the LDAP directory will be deleted.
Determining Data Ownership
Data ownership refers to the person or organization responsible for making sure the data is up to date. During the data design phase, decide who can write data to the directory. Common strategies for determining data ownership include the following:
- Allow a person's manager to write to some strategic subset of that person's information, such as contact information or job title.
- Allow an organization's administrator to create and manage entries for that organization. (This makes your organization administrators your directory content managers.)
- Create roles that give groups of people read or write access privileges.
For example, you might create roles for human resources, finance, or accounting. Allow each of these roles to have read access, write access, or both to the data needed by the group, such as salary information, government identification number (social security number), and home phone numbers and address.
For more information about roles and grouping entries, refer to Chapter 4, "The Directory Information Tree."
As you determine who can write to the data, you may find that multiple individuals require write access to the same information. For example, you will want an information systems or directory management group to have write access to employee passwords. You may also want the employees themselves to have write access to their own passwords. While you generally must give multiple people write access to the same information, try to keep this group small and easy to identify. Keeping the group small helps ensure your data's integrity.
For information on setting access control for your directory, see Chapter 7, "Access Control, Authentication, and Encryption."
Determining Data Access
After determining data ownership, decide who can read each piece of data. For example, you may decide to store an employee's home phone number in your directory. This data may be useful for a number of organizations, including the employee's manager and human resources. You may want the employee to be able to read this information for verification purposes. However, home contact information can be considered sensitive. Therefore, you must determine if you want this kind of data to be widely available across your enterprise.
For each piece of information stored in your directory, decide the following:
The LDAP protocol supports anonymous access, and allows easy lookups for common information such as office sites, e-mail addresses, and business telephone numbers. However, anonymous access gives anyone with access to the directory access to the common information. You should therefore use anonymous access sparingly.
You can set up access control so that the client must log in (or bind) to the directory to read specific information. Unlike anonymous access, this form of access control ensures that only members of your organization can view directory information. It also allows you to capture login information in the directory's access log, so you have a record of who accessed the information.
For more information about access control, refer to Designing Access Control.
Anyone who has write privileges to the data generally also needs read access (with the exception of write access to passwords). You may also have data specific to a particular organization or project group. Identifying these access needs helps you determine what groups, roles, and access controls your directory needs.
For information about groups and roles, see Chapter 4, "The Directory Information Tree." For information about access controls, see Chapter 7, "Access Control, Authentication, and Encryption."
As you make these decisions for each piece of directory data, you define a security policy for your directory. Your decisions depend on the nature of your site and the kinds of security already available. For example, if your site has a firewall or no direct access to the Internet, you may feel more free to support anonymous access than if you are placing your directory directly on the Internet.
In many countries, data protection laws govern how enterprises must maintain personal information, and restrict who has access to the personal information. For example, the laws may prohibit anonymous access to addresses and phone numbers, or may require that users have the ability to view and correct information in entries that represent them. Check with your organization's legal department to ensure that your directory deployment follows the necessary laws for the countries in which your enterprise operates.
The creation of a security policy and the way you implement it is described in detail in Chapter 7, "Access Control, Authentication, and Encryption."
Documenting Your Site Survey
Because of the complexity of data design, it is advisable that you document the results of your site surveys. During each step of the site survey we have suggested simple tables for keeping track of your data. Consider building a master table that outlines your decisions and outstanding concerns.
A basic data tracking example is provided in Table 2-4. This table identifies data ownership and data access for each piece of data identified by the site survey.
The row representing the employee name data contains the following:
Repeating the Site Survey
You may need to run more than one site survey, particularly if your enterprise has offices in multiple cities or countries. You may find your informational needs to be so complex that you have to allow several different organizations to keep information at their local offices rather than at a single, centralized site. In this case, each office that keeps a master copy of information should run its own site survey. After the site survey process has been completed, the results of each survey should be returned to a central team (probably consisting of representatives from each office) for use in the design of the enterprise-wide data schema model and directory tree.
Accessing Directory Data With DSML Over HTTP/SOAPDirectory Server 5.2 enables you to access directory data by using Directory Service Markup Language version 2 (DSMLv2) over HTTP/SOAP.
Versions of Directory Server prior to Directory Server 5.2 enable you to access directory data using the Lightweight Directory Access Protocol (LDAP).
DSMLv2 is a markup language, that is, a vocabulary and schema that enables users to describe the structure and content of directory services data operations in an eXtensible Markup Language (XML) document. DSMLv2 standardizes the way directory services information is represented in XML. Directory Server supports the use of DSMLv2 over the Hypertext Transfer Protocol (HTTP/1.1) and uses the Simple Object Access Protocol (SOAP) version 1.1 as a programming protocol to transport the DSML content.
For information on configuring the DSML frontend and on accessing and searching data using DSMLv2 over HTTP/SOAP, see "Configuring DSML" in the Directory Server Administration Guide.
DSMLv2 Over HTTP/SOAP Deployment
The following sample deployment using DSML-enabled Directory Servers and Sun Java System Web Proxy Server, enables non-LDAP clients to interact with directory data.
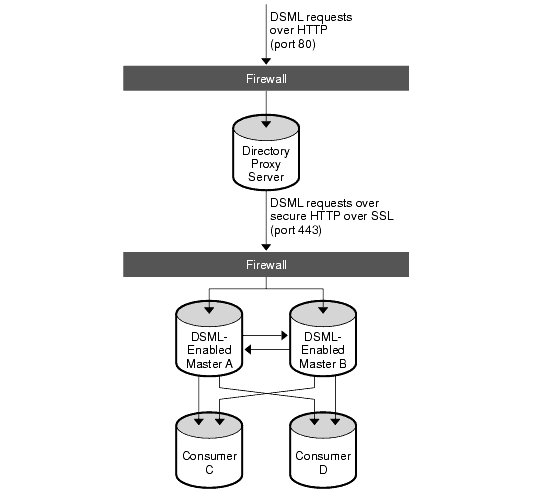
Figure 2-1 Sample DSML-Enabled Directory Deployment
In this sample deployment, update requests in DSML arriving from non-LDAP client applications cross a firewall over HTTP port 80 and enter a demilitarized zone (DMZ.) From there Directory Proxy Server configured as a reverse proxy server enforces the use of secure HTTP over port 443 for the requests to cross a second firewall and enter the intranet domain. The requests are then processed by the two master replicas on Master A and Master B, before being replicated to the non-DSML enabled Consumers C and D.
This deployment enables non-LDAP applications to perform directory operations. If the client requests are solely lookup requests, it is irrelevant whether the DSML-enabled Directory Servers hold read-only or read-write copies of the data, because both would be able to process the lookup requests. However, if a non-LDAP client issues modification requests, it is important for the DSML-enabled Directory Servers to hold read-write copies of the data. The default behavior for a consumer receiving a modification request is to return a referral with a list of LDAP URLs of the possible masters that could satisfy the request. Returning an LDAP URL over HTTP to a non-LDAP client application would not fulfill the objective of keeping client/directory traffic LDAP-free, which is why read-write copies are preferable. The deployment depicted in Figure 2-1, holds read-write copies of the data on the DSML-enabled Directory Servers Master A and Master B. These masters process modification requests and then replicate the data to the non-DSML enabled Consumers C and D.
The DSML front end constitutes a restricted HTTP server. It accepts only DSML HTTP post operations, and rejects requests that do not conform to the SOAP/DSML specification. Therefore, the threat is less extensive than for other types of HTTP web server. Nonetheless, you should take into account the following security considerations when including DSML-enabled Directory Servers in your deployment: