| Exit Print View | |
Sun OpenDS Standard Edition 2.2 Deployment Planning Guide |

|
1. Overview of Sun OpenDS Standard Edition
2. Overview of the Directory Server
3. Overview of the Proxy Server
4. Building Blocks of the Proxy Server
5. Example Deployments Using the Directory Server
The Role of Directory Servers in a Topology
The Role of Replication Servers in a Topology
Multiple Data Centers and the Window Mechanism
6. Example Deployments Using the Proxy Server
7. Simple Proxy Deployments Using the Command Line Interface
Replication groups enable you to organize a replicated topology according to specific criteria, such as data center location. A replication group is identified by a unique ID that is applied to the replication servers and the directory servers in that group. Group IDs determine how a directory server domain connects to an available replication server. From the list of configured replication servers, a directory server first tries to connect to a replication server that has the same group ID as that of the directory server.
This sample deployment shows the use of replication groups across multiple data centers. The deployment assumes two data centers, connected by a wide area network (WAN), with the following configuration:
Each replication server and directory server within a single data center has the same group ID.
There is a unique group ID for the entire data center (one group ID per data center).
The following figure shows a disaster recovery deployment that includes two data centers with different group IDs.
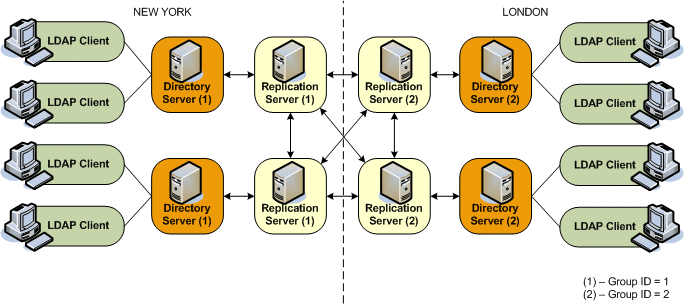
In this deployment, each directory server will attempt to connect to a replication server in its own data center, avoiding the latency associated with connection over a WAN. If all the replication servers in a data center fail, the directory server will connect to a remote replication server. This ensures that the replication service is maintained, albeit in a degraded manner (if the connection between data centers is slow). When one or more local replication servers is back online, the directory servers will automatically reconnect to a local replication server.


|