| Sun ONE Meta-Directory 5.1.1 Administration Guide |
Chapter 8
Configuring the Database ConnectorThis chapter discusses configuration factors specific to the Database Connector, which provides bi-directional synchronization between Oracle and the Meta View.
The topics in this chapter are:
Make sure you have completed the following tasks:
Configuring the Database ConnectorThere are two phases in configuring the database connector:
Note that special characters whitespace and hash(#) present in the oracle data are not escaped while constructing DN at the Meta View. If your data source contains these characters then you have to escape your data source by adding backslashes to these special characters.
Creating the Data Server
Creating the data server consists of the following tasks:
Configuring the Data Server
To display the Data Servers window
To add a new database server
To provide data server information
- Select the server to configure.
- From the General tab, provide information or change the defaults for the following fields:
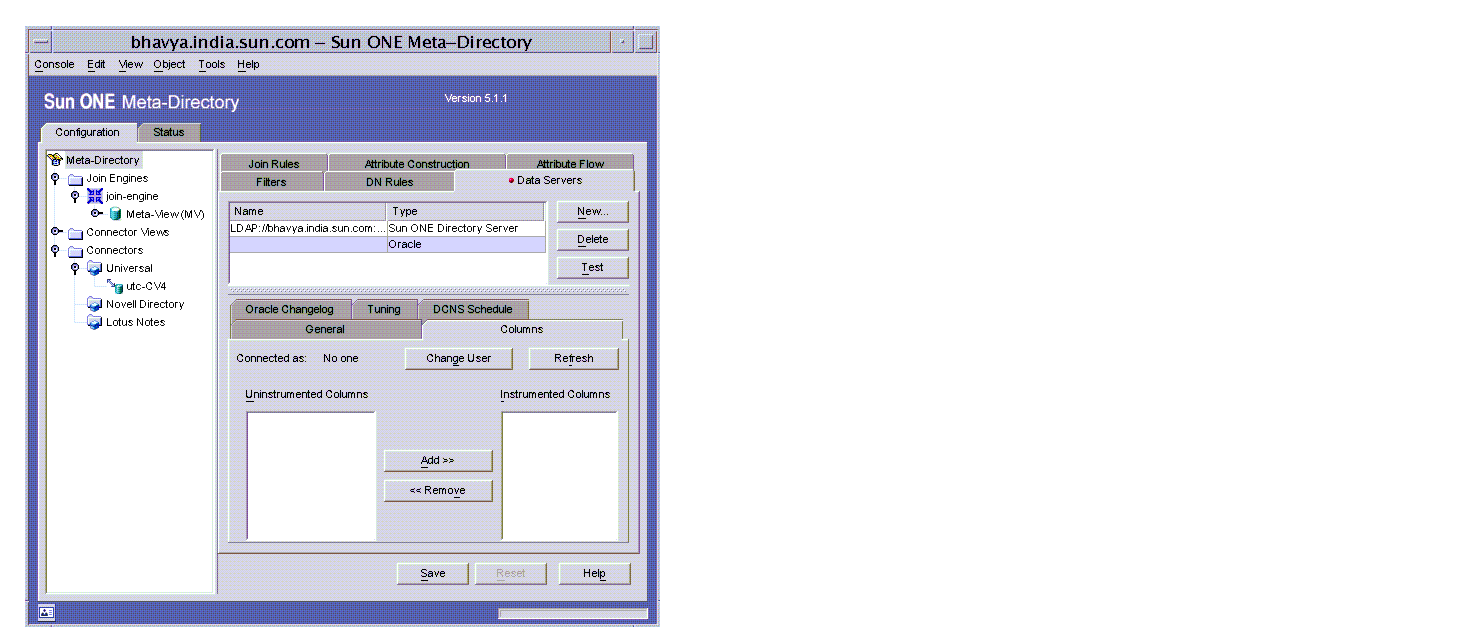
- Select the Columns tab. The ‘Database Credentials’ dialog box displays. After providing the Oracle user name and password, described in "Generating the Script", the Columns window displays. The credentials remain in effect until you leave this particular data server. Note that this is not the same user described in ‘New Oracle User Name’ above.
You can select columns or tables to participate in the flow to the Meta View. This process of selection and setting up triggers is called instrumentation. These triggers populate the changelog tables with the changes.
- Do the following to perform instrumentation:
- Select a column, table, or user from the Uninstrumented Columns list.
‘C’ precedes column names, T precedes table names, and U precedes user names. An ‘X’ is displayed for columns that cannot be instrumented.
Selecting a table instruments all the columns that belong to the table, and selecting a user instruments all the tables that belong to the user.
- Click Add or double click the node. The selection is displayed in the Instrumented Columns list.
One of the columns in the table you select for instrumentation must be a primary key, denoted with the letter ‘P’. If you have selected a table or column from a table for which there is no primary key, a ‘Nominate Primary Keys’ dialog box displays.
- Select one or more columns as the nominated keys. You can double click an un-nominated column to move it to the nominated column.
The set of nominated columns for a table must be unique for the associated row. That is, if you select FirstName and LastName as your nominated keys, there may be more than one person with the same name. A better choice would be AreaCode and PhoneNumber.
- Click Add. The column or set of columns now is displayed in the list of nominated keys.
- Click OK to close and return to the Columns window. Note that ‘N’ is now precedes the column you have nominated.
You can change any nominated key after clicking OK if the associated table is not currently instrumented, and there are no primary keys in the table. To do this, right click any node and select Change nominated keys.
- Optional: If you want to change the user credentials, click Change User, then provide a new Oracle user name and password. Meta-Directory rereads the database dictionary and rebuilds the schema. You need to change credentials whenever you instrument users, tables, or columns that a different user owns.
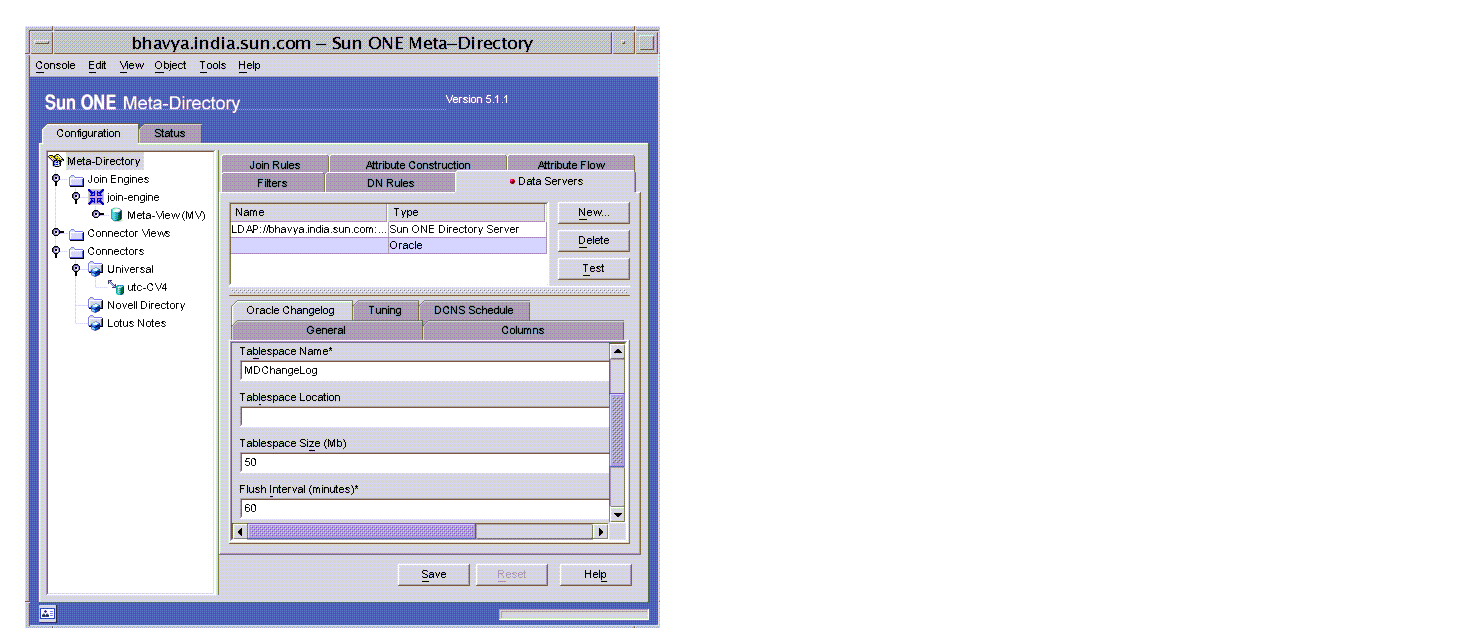
- Click the Oracle Changelog tab to display the Changelog window. You can provide input only for a new data server. For existing data servers, you can only change the Flush Interval field.
Enter appropriate values or change the defaults for these fields:
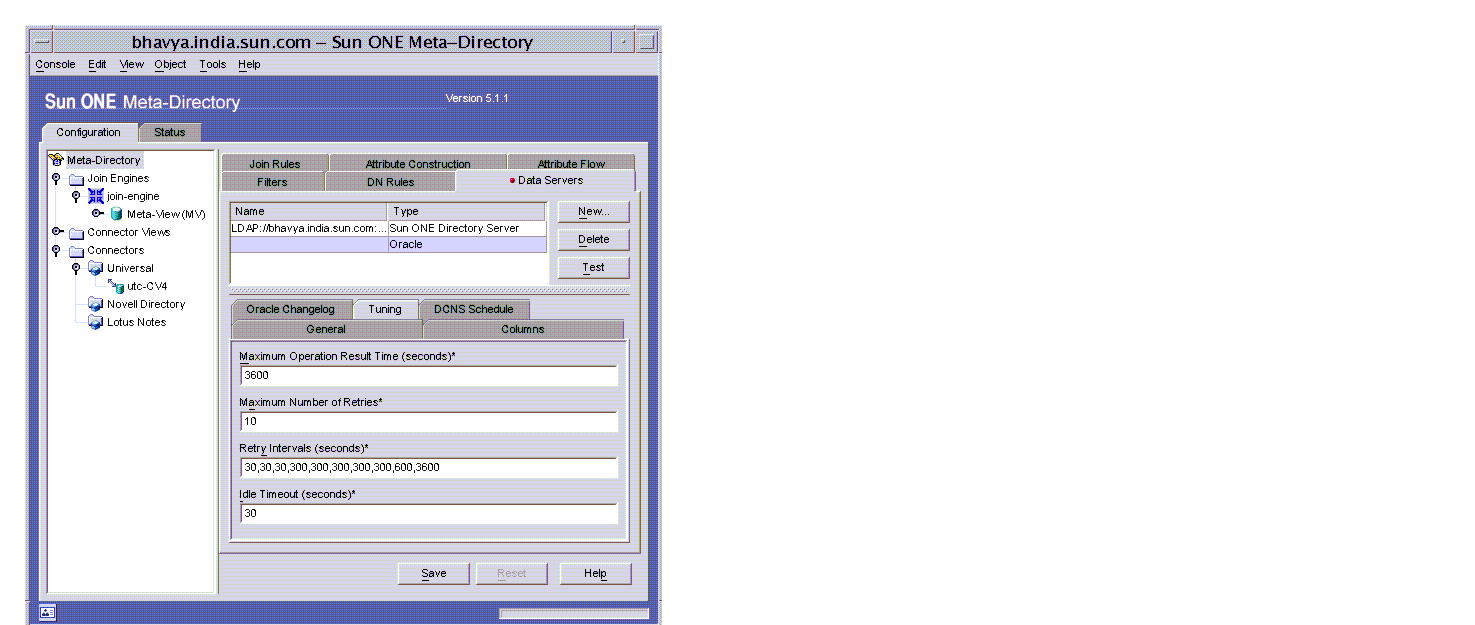
- Select the Tuning tab to display the ‘Tuning’ window.
Enter appropriate values or change the defaults for these fields:
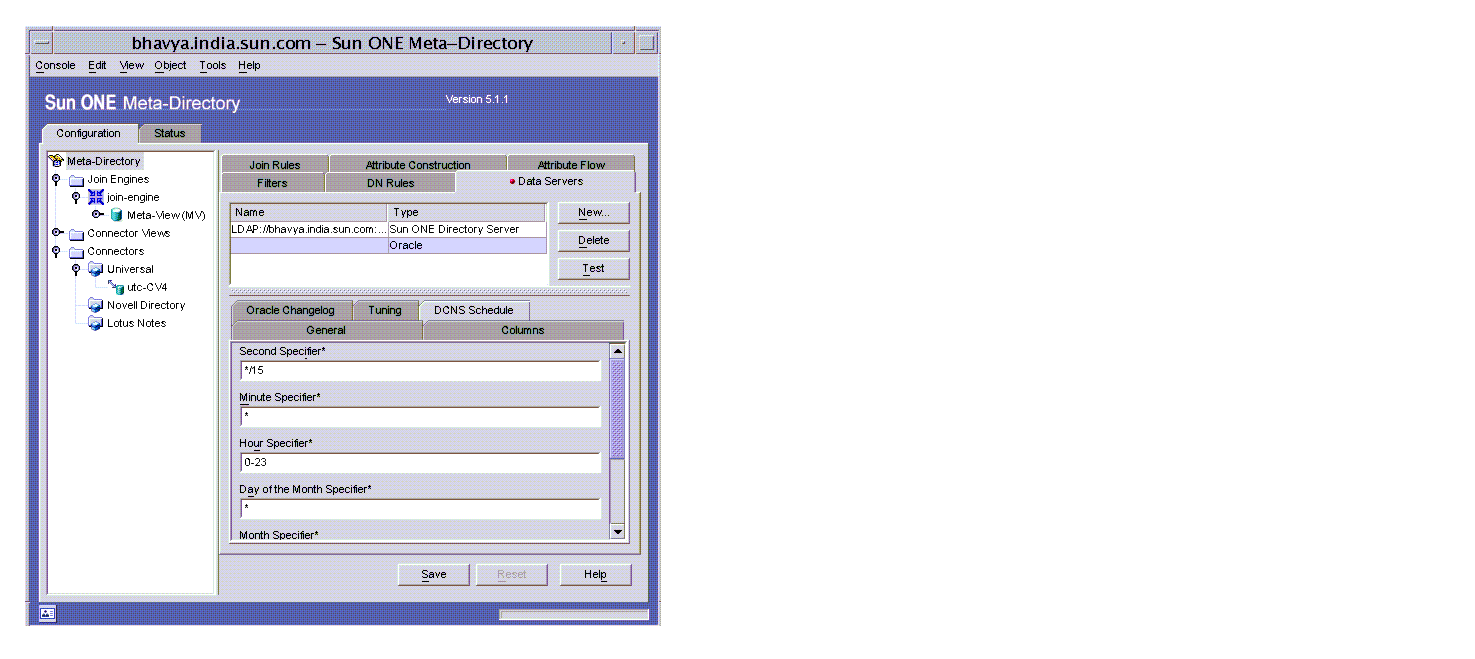
- Select the DCNS Schedule tab to display the ‘DCNS Schedule’ window.
Provide values for the following fields:
Sample data in different fields and their interpretation:
Example 1:
second specifier:12/30
minute specifier:5/15
hour specifier :7-9
day specifier:*
month specifier:*
day of week specifier:0-6Schedule starts at 5 minutes 12 seconds past 7 and runs every 30 seconds. Schedule ends at 9. This schedule runs every day. As both seconds and minute frequency were specified minute frequency was ignored.
Example 2:
second specifier:*
minute specifier:*/45
hour specifier :7-10
day specifier:*
month specifier:*
day of week specifier:0-6Schedule starts at 0 minutes past 7 and runs every 45 minutes till 10 every day. Schedule runs at 7:00, 7:45, 8:30, 9:15
Example 3:
second specifier:*
minute specifier:*/30
hour specifier :7-9, 15-17
day specifier:*
month specifier:*
day of week specifier:0Schedule runs at 7:00, 7:30, 8:00, 8:30,15:00,15:30,16:00,16:30 every sunday.
Example 4:
second specifier: *
minute specifier:10/15
hour specifier :22-3
day specifier:*
month specifier:*
day of week specifier:0-6Schedule runs at 22:10, 22:25,22:40,22:55,23:10,23:25,23:40,23:55 every day. 22-3 in hour range was rounded off to 22-23:59 as x > y in the hour range.
- Click Save to save the configuration. This generates a script that must be applied to the database. Privileges are required for generating and executing scripts. For more information, see "Issuing Privileges".
- Optional: Test the connection:
To delete a data server
- Select the data server to delete.
- Click Delete. The data server and its associated configuration is removed from the list box. A message displays the location of script.
- Execute the script to completely uninstrument the tables. When applied, the script deletes the changelog schema, changelog tablespace, and all triggers from the instrumented tables.
Running the Configuration Script
- Run the following:
inst_dataservername.sql
The script is stored in the $NETSITE_ROOT directory.
- Check the script and replace any tokens with information (that is, $TABLE_SPACE_LOCATION$). You must run the script as the system database administrator. After the script is generated, you must confirm that all fields are present and are correct.
After running the script, the tables become instrumented and the changelog tablespace is created.
Adding a Connector View Instance
To add the instance
- Select Connector Views from the Meta-Directory tree, and then right-click.
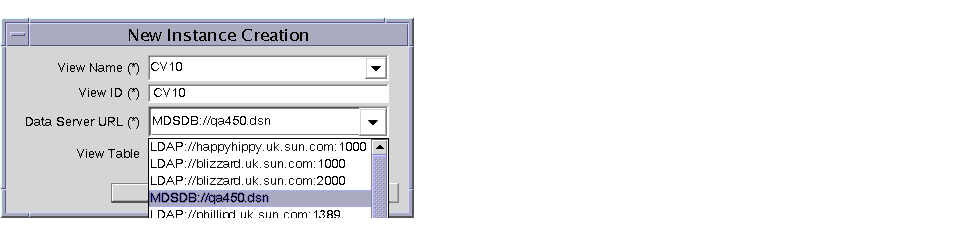
- Click New View. The ‘New Instance Creation’ dialog box displays.
- Select the newly created data server URL from the list box. The ‘New Instance Creation’ dialog box displays.
Provide information for the following fields:
- Click OK. A confirmation message ‘Instance Creation Succeeded’ displays.
To delete the instance
Adding the Instance as a Participating View
Each participating Connector View has its own settings. In addition to these settings (or in place of them), each view also has settings that specify how the Join Engine handles the view within the Meta View.
To add a participating Connector View
To remove a participating Connector View
Configuring a Connector View
Configuring the Connector View consists of the following tasks:
You can create join rules and filters, however you must create the following types of rules too:
After you create the rules, you can add them to the Connector View and flow data. The data should flow according to these rules from the Connector View (Oracle) to the Meta View and vice versa.
Creating Constructed Attribute Rules
See "Constructed Attributes" for procedures on creating constructed attribute rules.
Creating Attribute Flow Rules
See "Attribute Flow Rules" for procedures on creating attribute flow rules.
Creating DN Mapping Rules
You need to carefully write the DN mapping rules for flowing data from the Meta View to the Connector View. You might expect these to look like rules for flowing data from the Connector View to the Meta View with elements of the rule reversed, but this may not be the case.
The Meta View to Connector View DN mapping rules typically look like the following example:
<PK col name>=%mv.<mapped attribute>
Consider an employee table EMP with FIRSTNAME, LASTNAME, EMPNO and DEPT as columns in which EMPNO is the primary key. The Connector View to Meta View DN mapping rules for an inetorgperson entry would typically look like:
cn=%cv.FIRSTNAME%
However, the Meta View to Connector View DN mapping rule would need to be:
EMPNO=%mv.employeenumber%
assuming that you have mapped employeenumber to the EMPNO column.
Therefore, you need to map primary key columns to an attribute in the directory in order to correctly map a row in the database to a single entry in the directory and vice versa.
See "Distinguished Name Mapping Rules" for procedures on creating DN mapping rules.
Creating Join Filters
In case of database connector, a join filter typically replaces the ‘WHERE CLAUSE’ in the query statement. For instance
ID='%mv.uid%' and if mv.uid is say user1 the filter gets translated as ‘where ID=user1’.
Note that while creating join filters, the SQL datatype of the attribute has to be taken into consideration and accordingly the attribute value has to be enclosed within the SQL datatype specific enclosures. For instance if ID is of type SQL VARCHAR, then the filter should be created as ID='%mv.uid%' and if ID is of type NCHAR then the filter should be ID=n'%mv.uid%' and so on.
Configuring a Participating Connector View
See "Configuring a Participating View" for procedures on configuring a participating Connector View. Note that the Group Filters window is only available for UTC-based connectors or for Sun ONE Professional Services.
Starting the Join Engine
Before you start the Join Engine, ensure that you have already enabled the changelog in the Directory Server configuration.
To start the Join Engine
You can also start the server from the Sun ONE Console. To do this, select the Join Engine object and right-click. Select Start Server from the context menu.
Enabling the Connector View
- From the Sun ONE Meta-Directory software window, click on the Status tab.
- Click on the Join Engine object. The Operations tab window appears.
- Select the Participating View you want to enable.
- Select Enable from the Operation list menu, then click Start.
This option disables the Traverse drop-down menu. You can only enable the Participating View if the configuration for setting up the view is valid. Any error in the configuration automatically changes the view to a disable status.
- Select Refresh from the Operation List Window, then select either Meta View or Connector View from the Traverse menu list.
- Click Submit Request. The status changes to up.
If you are having trouble enabling the Connector View, you should check whether the proper privileges have been issued. See "Issuing Privileges" for more information.
Monitoring the Connector View
You should monitor the Connector View status while restarting the database on which you created the Connector View. When the Oracle server is restarted while the Oracle Connector View is enabled, the Join Engine requires about one to two minutes for rebinding to the Oracle server. You can adjust the DataAccess logs to level 1 to determine that the rebind has occurred; the logs would show SQLs being executed on the Oracle changelog. Subsequent to the rebind, all refresh/changelog operations would become effective.
It takes about a minute for Oracle to shut down. You can expect the Join Engine to disable the Oracle Connector View if you attempt an operation, such as add, on the database during the database shutdown. In that case, you would need to explicitly enable the Connector View after the database is up and running.
Configuration ExampleThe following example is intended as a quick reference you can use as a checklist. For complete configuration information, refer back to the earlier portions of this chapter.
Create the data server
- Configure the data server.
- Click the Meta-Directory object, then click on the Data Servers tab. The Data Servers window appears.
- Click New. The Data Server Type dialog box appears.
- Select Oracle and click OK.
- From the General tab, provide information for the fields.
- Click the Columns tab. The Database Credentials dialog box appears. After providing the Oracle user name and password, the Columns window appears.
- For the remaining tabs, use the defaults.
- Click Save to save the configuration.
- Run the following configuration script:
inst_dataservername.sql
The script is stored in the $server_root\bin\meta50\bin directory. This script grants privileges. For more information on privileges granted, see "Issuing Privileges".
- Add the Connector View instance.
- Select Connector Views from the Meta-Directory tree, then right-click. A context menu appears.
- Select New View. The New Instance Creation dialog box appears.
- Select the newly created data server URL from the drop-down list. An altered New Instance Creation dialog box appears.
- Provide the view name, view ID, and select the table you want to synchronize.
- Click OK. The message “Instance Creation Succeeded” appears after the instance has been created. The main console navigation tree will redisplay.
- Add the instance as a Participating View.
Configure the participating Connector View
- Create constructed attribute rules.
- Select Configuration > Meta-Directory > Attribute Construction.
- Click New Attribute, then provide a name, such as dbobjectclass, in the New Constructed Attribute dialog box.
- Click OK. The new attribute appears in the Attributes list.
- Select the attribute, then click New Rule. The New Constructed Attribute Rule dialog box appears.
- Configure the rule, using dbobjectclass as the name. For the Attribute Construction field, enter the following string:
top;person;organizationalperson;inetorgperson
- Click OK, then click Save from the Attribute Construction tab.
- Create attribute flow rules.
- Select Configuration > Meta-Directory > Attribute Flow.
- Click New Rule. The New Attribute Flow Configuration dialog box appears.
- Provide a name of ora2mvattrflowrule.
- For Direction, select To Meta View.
- For Selection Criteria, click “...” to go to the Compose Condition Criteria dialog box. For Type, select Attribute. For Source, select the Oracle Connector View. For Attribute, select the primary key or nominated key. For Expression, select Present. Click Insert, then OK.
- Click Add. The Add Attribute Mappings dialog box appears.
- Map attributes by doing the following:
- For Source View, select the Oracle Connector View.
- For Source Objectclass, select the Oracle table.
- For Destination View, select Meta View.
- For Destination Objectclass, select inetorgperson.
- Select one attribute from the left column, one from the right column, then click Insert. You do not need to map all attributes.
- Click OK from the New Attribute Flow Configuration dialog box. The new rule appears in the Rules section of the Attribute Flow window.
- From the Attribute Flow window, click New Set, and provide a name of ora2mvattrflowruleset in the New Set dialog box.
- Select ora2mvattrflowrule and ora2mvattrflowruleset, then click Add Member. The rule appears in the Members list box.
- Click Save, then select View > Refresh from the menubar.
- Create DN mapping rules.
- Select Configuration > Meta-Directory > DN Rules.
- Click New Rule. The New DN Mapping Rule dialog box appears.
- Provide a name of ora2mvdnmap.
- For Selection Criteria, click “...” to go to the Compose Condition Criteria dialog box. For Type, select Attribute. For Source, select the Oracle Connector View. For Attribute, select the column mapped to the RDN. For Expression, select Present. Click Insert, then OK.
- For Distinguished Name Construction, enter the RDN:
cn=%cv.ENAME%
- Click OK. The new rule for this DN mapping appears in the Rules list box.
- Click New Set and provide a name of ora2mvdnmapset in the New Set dialog box.
- Select ora2mvdnmap and ora2mvdnmapset, then click Add Member. The rule appears in the Members list box.
- Click Save, then select View > Refresh from the menubar.
- Configure the participating Connector View.
- Select the participating Oracle Connector View for the Meta View. The Configuration tab appears.
- For Attribute Flow, select None for To Connector, and select ora2mvattrflowruleset for To Meta View.
- For Join Rules, select None for both drop-down lists.
- For DN Mapping Rules, select None for To Connector, and select ora2mvdnmapset for To Meta View.
- For the remaining tabs, see "Configuring a Participating View".
- Click Save.
- Start the Join Engine.
- Enable the Connector View.
Changing InstrumentationYou can add or remove instrumentation any time after you have followed all of the procedures in this chapter to this point in the order presented.
To add instrumentation
- Click the Columns tab. The Database Credentials dialog box appears. After providing the Oracle user name and password, the Columns window appears. The credentials remain in effect until you leave this particular data server.
- Select one or more columns, tables, or users from the Uninstrumented Columns list.
- Click Add. If you selected a column, the column now appears in the Instrumented Columns list. If you selected a table, the table and its associated column(s) now appear in the Instrumented Columns list. If you selected a user, the user and its associated table(s) now appear in the Instrumented Columns list.
- Click Save.
- Run the script. The changes are now instrumented.
To remove instrumentation
- Click the Columns tab. The Database Credentials dialog box appears. After providing the Oracle user name and password, the Columns window appears. The credentials remain in effect until you leave this particular data server.
- Select one or more columns, tables, or users from the Instrumented Columns list. Note that if you select a primary key column or nominated column, the entire table will be uninstrumented.
- Click Remove.
- If you selected a column, the column now appears in the Uninstrumented Columns list.
- If you selected a table, the table and its associated column(s) now appear in the Uninstrumented Columns list.
- If you selected a user, the user and its associated table(s) now appear in the Uninstrumented Columns list.
- Click Save. After running the script, the uninstrumented columns, tables, or users are removed and the remaining columns, tables, and users become instrumented.
Note: After changing instrumentation and running the scripts, use the “Refresh” button present in the same panel, in order to refresh the console with the latest changes in the data server. If the console is not refreshed, and further changes are made to the instrumentation, the scripts generated might be incorrect. Refreshing the console is required, if the user continues to use the same session to make multiple changes to the instrumentation (i.e he has not left the particular data server).
Issuing PrivilegesOracle privileges are required for performing the following tasks:
Typically, different individuals would perform each of these tasks, but one person could perform all of the tasks if preferred. The following sections explain these tasks and the associated privileges required. Contact your database administrator or refer to your Oracle server documentation set for specific questions about privileges.
Generating the Script
The console reads the database dictionary to gather information about the database schema. The user can select tables and columns from this schema for instrumentation.
The user for which the console connects to Oracle must be given sufficient privileges to read the database dictionary tables. The associated user name and password are supplied to the Meta-Directory Console, which the console uses to read the data dictionary. The user name and password are not stored in Meta-Directory configuration.
Executing the Script
To instrument the database, a user executes the script and has privileges to do the following:
This user name and password are supplied to the tool that executes the script; they are not stored in Meta-Directory configuration, nor handled by Meta-Directory software.
Table 8-6 provides reference information for the user roles discussed above.
Synchronizing the Instrumented Tables
The Meta-Directory console generates a script to instrument the tables and columns you select. The set of tables you can select for instrumentation consists of the tables you own, and those for which you have SELECT privileges. The database schema is built by querying the data dictionary, which is accessed through public synonyms (defined in data dictionary views).
For synchronization, each data server has one user (whose user name and password are in its mdsAuthenticationDetails attribute). The Meta-Directory Database Connector authenticates this user to synchronize any associated Connector View. The generated script grants privileges to the changelog user to: