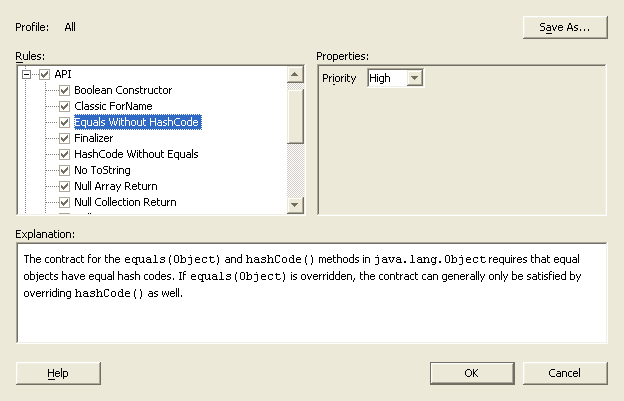
 In this view,
In this view,To perform an audit, the Audit framework applies a set of analyzers, defined by a profile, to a set of IDE nodes and collects the resulting measurements and violations into a result model. To begin an audit, Audit builds a tree of constructs. The constructs are the workspaces, projects, files, and (in the case of Java files), classes, methods, fields, statements, and so on that contain or are contained by the nodes. After building the tree, Audit walks it, depth-first, from the root (the Workspaces object), "visiting" each construct as it goes. Each analyzer can supply visitor methods for any construct type it wishes; when the framework visits a construct, it invokes the visitor method in each analyzer that best matches the construct type (if any). The visitor methods can do anything they want, but typically they either collect information for later use by some other visitor method, or report measurements or violations into the result model.
A profile is a named, persistent set of analyzer classes. An analyzer class is a concrete subclass of Analyzer. An instance of an analyzer subclass defines the rules and/or metrics that are the subject of its analysis, the properties that configure it, and the visitor methods that actually do the analysis.
The view of a profile that Audit presents to users is one of rules with properties, with no hint of analyzers: In this view,
Audit builds this view by iterating through the analyzers in the profile, getting from each analyzer the rules which it analyzes, and organizing them by their categories. The rules are themselves beans with properties, a couple of which are used by Audit. An analyzer can add extra properties to rules it defines, allowing the user to configure its analysis. User changes to property values are saved with the profile.
An analyzer also defines visitor methods. A visitor method is named either enter or exit, has two parameters, and the type of the first is AuditContext. The type of the second, the construct type, can be anything, but the method will never be called unless Audit actually traverses a construct that is an instance of the type. When called, the visitor method will typically either collect information for use by another visitor method later in the audit, or analyze collected information and report rule violations or measurements. Reporting is done through the AuditContext object passed to the visitor method. More details on the processing typical of visitor methods can be found in here.
Audit builds a tree of constructs from the nodes to be audited. A typical model is a source file containing Java, XML, or some other kind of structured text. These nodes have an associated object model that represents the structured text as a network (usually a tree) of objects. For Java nodes, the JDeveloper IDE provides the Java model, oracle.javatools.parser.java.v2.model; for generic XML nodes, it provides the DOM. org.w3c.dom; and so forth. The objects in these trees are the constructs that can be visited by Audit, given a suitable model model.
The IDE deals with file types through the model factory, oracle.ide.model.NodeFactory. The model factory maps each file type to a subclass of Node, oracle.ide.model.Node: for example, in JDeveloper it maps Java source nodes to oracle.jdeveloper.model.JavaSourceNode. Usually, the Node subclass gives access to the corresponding object model.
Audit deals with the NodeFactory and the various Node classes and object models by using an model class, specific to the model type, for each model. The model class provides Audit with a standard interface to the model and to the constructs in the object model for the model. More details on creating model models can be found here.
Audit collects the results of an Audit, violations and measurements, in an AuditModel. This is essentially a tree table model of the audited constructs, violations, and measurements. Usually only code that invokes Audit programmatically will use the AuditModel and usually not even then.
When an analyzer creates a rule, it can define fixes to be applied to source code that violates that rule. A fix is an object that defines a single (possibly complex) source transformation targeted to a specific location in a source file. At minimum, a fix must be able to apply itself to its targeted location. Ideally, however, a fix should also be able to determine if it is still applicable, since the source code can change between the time the violation is detected and the time the user attempts to apply the fix. More details on creating fixes can be found here.
Copyright © 1997, 2005, Oracle. All rights reserved.