9 Defining Classic Replication Schemes
This chapter describes how to define classic replication schemes.
Note:
For information about defining active standby pair replication schemes, see Chapter 3, "Defining an Active Standby Pair Replication Scheme". If you want to replicate a database that has cache groups, see Chapter 6, "Administering an Active Standby Pair with Cache Groups".This chapter includes these topics:
-
Table requirements and restrictions for classic replication schemes
-
Restrictions for classic replication schemes involving multiple masters
-
Configuring network operations for a classic replication scheme
Note:
To reduce the amount of bandwidth required for replication, see "Compressing replicated traffic".To replicate tables with columns in a different order or with a different number of partitions, see "Column definition options for replicated tables".
Designing a highly available system
These are the primary objectives of any replication scheme:
-
Provide one or more backup databases to ensure that the data is always available to applications
-
Provide a means to recover failed databases from their backup databases
-
Distribute workloads efficiently to provide applications with the quickest possible access to the data
-
Enable software upgrades and maintenance without disrupting service to users
In a highly available system, a subscriber database must be able to survive failures that may affect the master. At a minimum, the master and subscriber need to be on separate hosts. For some applications, you may want to place the subscriber in an environment that has a separate power supply. In certain cases, you may need to place a subscriber at an entirely separate site.
You can configure the following classic replication schemes (as described in "Types of replication schemes"):
-
Unidirectional
-
Bidirectional split workload
-
Bidirectional distributed workload
-
Propagation
In addition, consider whether you want to replicate a whole database or selected elements of the database. Also, consider the number of subscribers in the replication scheme. Unidirectional and propagation replication schemes enable you to choose the number of subscribers.
The rest of this section includes these topics:
For more information about using classic replication to facilitate online upgrades, see "Performing an online upgrade with replication" in the Oracle TimesTen In-Memory Database Installation Guide.
Considering failover and recovery scenarios
As you plan a replication scheme, consider every failover and recovery scenario. For example, subscriber failures generally have no impact on the applications connected to the master databases. Their recovery does not disrupt user service. If a failure occurs on a master database, you should have a means to redirect the application load to a subscriber and continue service with no or minimal interruption. This process is typically handled by a cluster manager or custom software designed to detect failures, redirect users or applications from the failed database to one of its subscribers, and manage recovery of the failed database. See Chapter 15, "Managing Database Failover and Recovery".
When planning failover strategies, consider which subscribers are to take on the role of the master and for which users or applications. Also, consider recovery factors. For example, a failed master must be able to recover its database from its most up-to-date subscriber, and any subscriber must be able to recover from its master. A bidirectional scheme that replicates the entire database can take advantage of automatic restoration of a failed master. See "Automatic catch-up of a failed master database".
Consider the failure scenario for the unidirectionally replicated database shown in Figure 9-1. In the case of a master failure, the application cannot access the database until it is recovered from the subscriber. You cannot switch the application connection or user load to the subscriber unless you use an ALTER REPLICATION statement to redefine the subscriber database as the master. See "Replacing a master database in a classic replication scheme".
Figure 9-1 Recovering a master in a unidirectional scheme
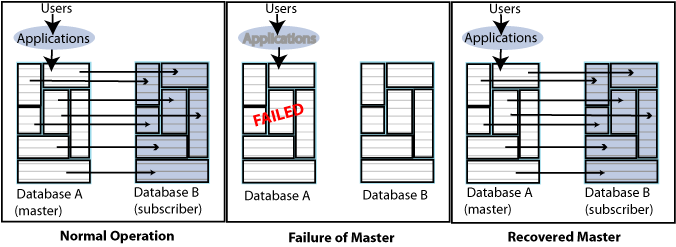
Description of "Figure 9-1 Recovering a master in a unidirectional scheme"
Figure 9-2 shows a bidirectional distributed workload scheme in which the entire database is replicated. Failover in this type of replication scheme involves shifting the users of the application on the failed database to the application on the surviving database. Upon recovery, the workload can be redistributed to the application on the recovered database.
Figure 9-2 Recovering a master in a distributed workload scheme
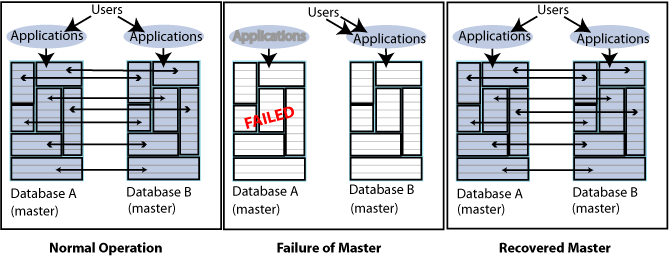
Description of "Figure 9-2 Recovering a master in a distributed workload scheme"
Similarly, the users in a split workload scheme must be shifted from the failed database to the surviving database. Because replication in a split workload scheme is not at the database level, you must use an ALTER REPLICATION statement to set a new master database. See "Replacing a master database in a classic replication scheme". Upon recovery, the users can be moved back to the recovered master database.
Propagation replication schemes also require the use of the ALTER REPLICATION statement to set a new master or a new propagator if the master or propagator fails. Higher availability is achieved if two propagators are defined in the replication scheme. See Figure 1-11 for an example of a propagation replication scheme with two propagators.
Making decisions about performance and recovery tradeoffs
When you design a replication scheme, weigh operational efficiencies against the complexities of failover and recovery. Factors that may complicate failover and recovery include the network topology that connects a master with its subscribers and the complexity of the replication scheme. For example, it is easier to recover a master that has been fully replicated to a single subscriber than recover a master that has selected elements replicated to different subscribers.
You can configure replication to work asynchronously (the default), "semi-synchronously" with return receipt service, or fully synchronously with return twosafe service. Selecting a return service provides greater confidence that your data is consistent on the master and subscriber databases. Your decision to use default asynchronous replication or to configure return receipt or return twosafe mode depends on the degree of confidence you require and the performance tradeoff you are willing to make in exchange.
Table 9-1 summarizes the performance and recover tradeoffs of asynchronous replication, return receipt service and return twosafe service.
Table 9-1 Performance and recovery tradeoffs
| Type of behavior | Asynchronous replication (default) | Return receipt | Return twosafe |
|---|---|---|---|
|
Commit sequence |
Each transaction is committed first on the master database. |
Each transaction is committed first on the master database |
Each transaction is committed first on the subscriber database. |
|
Performance on master |
Shortest response time and best throughput because there is no log wait between transactions or before the commit on the master. |
Longer response time and less throughput than asynchronous. The application is blocked for the duration of the network round-trip after commit. Replicated transactions are more serialized than with asynchronous replication, which results in less throughput. |
Longest response time and least throughput. The application is blocked for the duration of the network round-trip and remote commit on the subscriber before the commit on the master. Transactions are fully serialized, which results in the least throughput. |
|
Effect of a runtime error |
Because the transaction is first committed on the master database, errors that occur when committing on a subscriber require the subscriber to be either manually corrected or destroyed and then recovered from the master database. |
Because the transaction is first committed on the master database, errors that occur when committing on a subscriber require the subscriber to be either manually corrected or destroyed and then recovered from the master database. |
Because the transaction is first committed on the subscriber database, errors that occur when committing on the master require the master to be either manually corrected or destroyed and then recovered from the subscriber database. |
|
Failover after failure of master |
If the master fails and the subscriber takes over, the subscriber may be behind the master and must reprocess data feeds and be able to remove duplicates. |
If the master fails and the subscriber takes over, the subscriber may be behind the master and must reprocess data feeds and be able to remove duplicates. |
If the master fails and the subscriber takes over, the subscriber is at least up to date with the master. It is also possible for the subscriber to be ahead of the master if the master fails before committing a transaction it had replicated to the subscriber. |
In addition to the performance and recovery tradeoffs between the two return services, you should also consider the following:
-
Return receipt can be used in more configurations, whereas return twosafe can only be used in a bidirectional configuration or an active standby pair.
-
Return twosafe enables you to specify a "local action" to be taken on the master database in the event of a timeout or other error encountered when replicating a transaction to the subscriber database.
A transaction is classified as return receipt or return twosafe when the application updates a table that is configured for either return receipt or return twosafe. Once a transaction is classified as either return receipt or return twosafe, it remains so, even if the replication scheme is altered before the transaction completes.
For more information about return services, see "Using a return service in a classic replication scheme".
Distributing workloads
Consider configuring the databases to distribute application workloads and make the best use of a limited number of servers. For example, it may be efficient and economical to configure the databases in a bidirectional distributed workload replication scheme so that each serves as both master and subscriber, rather than as separate master and subscriber databases. However, a distributed workload scheme works best with applications that primarily read from the databases. Implementing a distributed workload scheme for applications that frequently write to the same elements in a database may diminish performance and require that you implement a solution to prevent or manage update conflicts, as described in Chapter 13, "Resolving Replication Conflicts".
Defining a classic replication scheme
After you have designed a classic replication scheme, use the CREATE REPLICATION SQL statement to apply the scheme to your databases. You must have the ADMIN privilege to use the CREATE REPLICATION statement.
Table 9-2 shows the components of a replication scheme and identifies the clauses associated with the topics in this chapter. The complete syntax for the CREATE REPLICATION statement is provided in Oracle TimesTen In-Memory Database SQL Reference.
Table 9-2 Components of a replication scheme
| Component | See... |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
"Configuring network operations for a classic replication scheme" |
Note:
Naming errors in yourCREATE REPLICATION statement are often hard to troubleshoot, so take the time to check and double-check the element, database, and host names for mistakes.The replication scheme used by a database persists across system reboots. Modify a replication scheme by using the ALTER REPLICATION statement. See Chapter 10, "Altering a Classic Replication Scheme".
Owner of the replication scheme and replicated objects
The replication scheme and the replicated objects must be owned by the same user on every database in a replication scheme. To ensure that there is a common owner across all databases, you should explicitly specify the user and replication scheme in the CREATE REPLICATION statement.
For example, create a replication scheme named repscheme owned by user repl. The first line of the CREATE REPLICATION statement for repscheme is:
CREATE REPLICATION rep1.repscheme
Database names
These are the roles of the databases in a replication scheme:
-
Master: Applications update the master database. The master sends the updates to the propagator or to the subscribers directly.
-
Propagator: The propagator database receives updates from the master database and sends them to subscriber databases.
-
Subscriber: Subscribers receive updates from the propagator or the master.
Before you define the replication scheme, you need to define the data source names (DSNs) for the databases in the replication scheme. On UNIX platforms, create an odbc.ini file. On Windows, use the ODBC Administrator to name the databases and set connection attributes. See "Step 1: Create the DSNs for the master and the subscriber" for an example.
Each database "name" specified in a replication scheme must match the prefix of the database file name without the path specified for the DataStore data store attribute in the DSN definition. Use the same name for both the DataStore and Data Source Name data store attributes in each DSN definition. If the database path is directory/subdirectory/foo.ds0, then foo is the database name that you should use. For example, this entry in an odbc.ini file shows a Data Source Name (DSN) of masterds, while the DataStore value shows the path for masterds:
[masterds] DataStore=/tmp/masterds DatabaseCharacterSet=AL32UTF8 ConnectionCharacterSet=AL32UTF8
Table requirements and restrictions for classic replication schemes
The name and owner of replicated tables participating in the replication scheme must be identical on the master and subscriber databases. However, the definition for the columns of replicated tables participating in the replication scheme do not necessarily need to be identical. For more information on the column definition options, see "Column definition options for replicated tables".
Replicated tables must have one of the following:
-
A primary key
-
A unique index over non-nullable columns
Replication uses the primary key or unique index to uniquely identify each row in the replicated table. Replication always selects the first usable index that turns up in a sequential check of the table's index array. If there is no primary key, replication selects the first unique index without NULL columns it encounters. The selected index on the replicated table in the master database must also exist on its counterpart table in the subscriber.
Note:
The keys on replicated tables are transmitted in each update record to the subscribers. Smaller keys are transmitted more efficiently.Replicated tables have these data type restrictions:
-
VARCHAR2,NVARCHAR2,VARBINARYandTT_VARCHARcolumns in replicated tables is limited to a size of 4 megabytes. For aVARCHAR2column, the maximum length when using character length semantics depends on the number of bytes each character occupies when using a particular database character set. For example, if the character set requires four bytes for each character, the maximum possible length is one million characters. For anNVARCHAR2column, which requires two bytes for each character, the maximum length when using character length semantics is two million characters. -
Columns with the
BLOBdata type in replicated tables are limited to a size of 16 megabytes. Columns with theCLOBorNCLOBdata type in replicated tables are limited to a size of 4 megabytes. -
A primary key column cannot have a LOB data type.
You cannot replicate tables with compressed columns.
If these requirements and restrictions present difficulties, you may want to consider using the Transaction Log API (XLA) as a replication mechanism. See "Using XLA as a replication mechanism" in Oracle TimesTen In-Memory Database C Developer's Guide.
Restrictions for classic replication schemes involving multiple masters
Designing bidirectional replication schemes are a commonly used design for classic replication. The original design for bidirectional replication was to include only two masters. However, you are not restricted in limiting your design to only two masters in your bidirectional replication design.
If you decide to use more than two masters (a multi-master topology) and if you decide to use ttRepAdmin -duplicate to duplicate another store, you must reset the replication states for the duplicated stores subscribers with the ttRepSubscriberStateSet built-in procedure to set all subscribers to the appropriate state.
As shown in Figure 9-3, you have three masters (master1, master2, and master3) each configured with a bidirectional replication scheme with each other. If you decide to re-create master2 from master1 by executing ttRepAdmin -duplicate on master1, then you must call the ttRepSubscriberStateSet built-in procedure on master2 to set the replication states for master3.
Figure 9-3 Multiple masters involved in bidirectional replication scheme
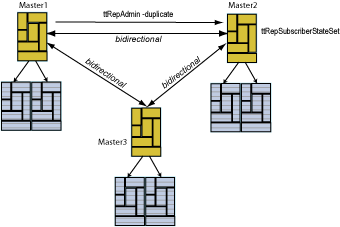
Description of "Figure 9-3 Multiple masters involved in bidirectional replication scheme"
Defining replication elements
A classic replication scheme consists of one or more ELEMENT descriptions that contain the name of the element, its type (DATASTORE, TABLE, or SEQUENCE), the master database on which it is updated, and the subscriber databases to which the updates are replicated.
Note:
If you want to replicate a database with cache groups, see Chapter 6, "Administering an Active Standby Pair with Cache Groups".These are restrictions on elements:
-
Do not include a specific object (table, sequence or database) in more than one element description.
-
Do not define the same element in the role of both master and propagator.
-
An element must include the database on the current host as either the master, subscriber or propagator.
-
Element names must be unique within a replication scheme.
The correct way to define elements in a multiple subscriber scheme is described in "Multiple subscriber classic replication schemes with return services and a log failure threshold". The correct way to propagate elements is described in "Propagation scheme".
The name of each element in a scheme can be used to identify the element if you decide later to drop or modify the element by using the ALTER REPLICATION statement.
You can add tables, sequences, and databases to an existing replication scheme. See "Altering a classic replication scheme". You can drop a table or sequence from a database that is part of a replication scheme after you exclude the table or sequence from the replication scheme. See "Dropping a table or sequence from a classic replication scheme".
The rest of this section includes the following topics:
Defining the DATASTORE element
To replicate the entire contents of the master database (masterds) to the subscriber database (subscriberds), the ELEMENT description (named ds1) might look like the following:
ELEMENT ds1 DATASTORE MASTER masterds ON "system1" SUBSCRIBER subscriberds ON "system2"
Identify a database host using the host name returned by the hostname operating system command. It is good practice to surround a host name with double quotes.
You can choose to exclude certain tables and sequences from the DATASTORE element by using the EXCLUDE TABLE and EXCLUDE SEQUENCE clauses of the CREATE REPLICATION statement. When you use the EXCLUDE clauses, the entire database is replicated to all subscribers in the element except for the objects that are specified in the EXCLUDE clauses. Use only one EXCLUDE TABLE and one EXCLUDE SEQUENCE clause in an element description. For example, this element description excludes two tables and one sequence:
ELEMENT ds1 DATASTORE MASTER masterds ON "system1" SUBSCRIBER subscriberds ON "system2" EXCLUDE TABLE ttuser.tab1, ttuser.tab2 EXCLUDE SEQUENCE ttuser.seq1
You can choose to include only certain tables and sequences in the database by using the INCLUDE TABLE and INCLUDE SEQUENCE clauses of the CREATE REPLICATION statement. When you use the INCLUDE clauses, only the objects that are specified in the INCLUDE clauses are replicated to each subscriber in the element. Use only one INCLUDE TABLE and one INCLUDE SEQUENCE clause in an element description. For example, this element description includes one table and two sequences:
ELEMENT ds1 DATASTORE MASTER masterds ON "system1" SUBSCRIBER subscriberds ON "system2" INCLUDE TABLE ttuser.tab3 INCLUDE SEQUENCE ttuser.seq2, ttuser.seq3
Defining table elements
To replicate the ttuser.tab1 and ttuser.tab2 tables from a master database (named masterds and located on a host named system1) to a subscriber database (named subscriberds on a host named system2), the ELEMENT descriptions (named a and b) might look like the following:
ELEMENT a TABLE ttuser.tab1 MASTER masterds ON "system1" SUBSCRIBER subscriberds ON "system2" ELEMENT b TABLE ttuser.tab2 MASTER masterds ON "system1" SUBSCRIBER subscriberds ON "system2"
For requirements for tables in classic replication schemes, see "Table requirements and restrictions for classic replication schemes".
Replicating tables with foreign key relationships in a classic replication scheme
In a classic replication scheme, you may choose to replicate all or a subset of tables that have foreign key relationships with one another. To do so, create the tables and the foreign key relationship on each master and subscriber. Then, add the tables to the replication scheme with the ALTER REPLICATION ADD ELEMENT statement on each master and subscriber.
However, if the foreign key relationships have been configured with ON DELETE CASCADE, then you must create all of the tables before the replication scheme is created. Then, configure the replication scheme with the CREATE REPLICATION statment to include all tables with either the DATASTORE element (that does not exclude any of the tables) or the TABLE element for every table that is involved in the relationship.
You cannot add a table with a foreign key relationship configured with ON DELETE CASCADE to the replication scheme after the replication scheme is created with the ALTER REPLICATION statement. Instead, you must drop the replication scheme, create the new table with the foreign key relationship with ON DELETE CASCADE, and then create a new replication scheme that includes all of the related tables.
If a table with a foreign key configured with ON DELETE CASCADE is replicated, then the matching foreign key on the subscriber must also be configured with ON DELETE CASCADE. In addition, you must replicate any other table with a foreign key relationship to that table. This requirement prevents foreign key conflicts from occurring on subscriber tables when a cascade deletion occurs on the master database.
TimesTen replicates a cascade deletion as a single operation, rather than replicating to the subscriber each individual row deletion which occurs on the child table when a row is deleted on the parent. As a result, any row on the child table on the subscriber database, which contains the foreign key value that was deleted on the parent table, is also deleted, even if that row did not exist on the child table on the master database.
Replicating sequences
Sequences are replicated unless you exclude them from the replication scheme or unless they have the CYCLE attribute. Replication of sequences is optimized by reserving a range of sequence numbers on the standby database each time a sequence is updated on the active database. Reserving a range of sequence numbers reduces the number of updates to the transaction log. The range of sequence numbers is called a cache. Sequence updates on the active database are replicated only when they are followed by or used in replicated transactions.
Consider a sequence my.seq with a MINVALUE of 1, an INCREMENT of 1 and the default Cache of 20. The very first time that you use my.seq.NEXTVAL, the current value of the sequence on the master database is changed to 2, and a new current value of 21 (20+1) is replicated to the subscriber. The next 19 references to my.seq.NEXTVAL on the master database result in no new current value being replicated, because the current value of 21 on the subscriber database is still ahead of the current value on the master. On the twenty-first reference to my.seq.NEXTVAL, a new current value of 41 (21+20) is transmitted to the subscriber database because the subscriber's previous current value of 21 is now behind the value of 22 on the master.
Sequence replication has these restrictions:
-
Sequences with the
CYCLEattribute cannot be replicated. -
The definition of the replicated sequence on each peer database must be identical.
-
No conflict checking is performed on sequences. If you make updates to sequences in both databases in a bidirectional replication configuration without using the
RETURN TWOSAFEservice, it is possible for both sequences to return the identicalNEXTVAL.
If you need to use sequences in a bidirectional replication scheme where updates may occur on either peer, you may instead use a nonreplicated sequence with different MINVALUE and MAXVALUE attributes on each database to avoid conflicts. For example, you may create sequence my.seq on database DS1 with a MINVALUE of 1 and a MAXVALUE of 100, and the same sequence on DS2 with a MINVALUE of 101 and a MAXVALUE of 200. Then, if you configure DS1 and DS2 with a bidirectional replication scheme, you can make updates to either database using the sequence my.seq with the guarantee that the sequence values never conflict. Be aware that if you are planning to use ttRepAdmin -duplicate to recover from a failure in this configuration, you must drop and then re-create the sequence with a new MINVALUE and MAXVALUE after you have performed the duplicate operation.
Operations on sequences such as SELECT my.seq.NEXTVAL FROM sys.dual, while incrementing the sequence value, are not replicated until they are followed by transactions on replicated tables. A side effect of this behavior is that these sequence updates are not purged from the log until followed by transactions on replicated tables. This causes ttRepSubscriberWait and ttRepAdmin -wait to fail when only these sequence updates are present at the end of the log.
To replicate the ttuser.seq sequence from a master database (named masterds and located on a host named system1) to a subscriber database (named subscriberds on a host named system2), the element description (named a) might look like the following:
ELEMENT a SEQUENCE ttuser.seq MASTER masterds ON "system1" SUBSCRIBER subscriberds ON "system2"
Views and materialized views in a replicated database
A materialized view is a summary of data selected from one or more TimesTen tables, called detail tables. Although you cannot replicate materialized views directly, you can replicate their underlying detail tables in the same manner as you would replicate regular TimesTen tables.
The detail tables on the master and subscriber databases can be referenced by materialized views. However, TimesTen replication verifies only that the replicated detail tables have the same structure on both the master and subscriber. It does not enforce that the materialized views are the same on each database.
If you replicate an entire database containing a materialized or non-materialized view as a DATASTORE element, only the detail tables associated with the view are replicated. The view itself is not replicated. A matching view can be defined on the subscriber database, but is not required. If detail tables are replicated, TimesTen automatically updates the corresponding view.
Materialized views defined on replicated tables may result in replication failures or inconsistencies if the materialized view is specified so that overflow or underflow conditions occur when the materialized view is updated.
Checking for replication conflicts on table elements
When databases are configured for bidirectional replication, there is a potential for replication conflicts to occur if the same table row in two or more databases is independently updated at the same time.
Such conflicts can be detected and resolved on a table-by-table basis by including timestamps in the replicated tables and configuring the replication scheme with the optional CHECK CONFLICTS clause in each table's element description.
See Chapter 13, "Resolving Replication Conflicts" for a complete discussion on replication conflicts and how to configure the CHECK CONFLICTS clause in the CREATE REPLICATION statement.
Setting transmit durability on DATASTORE element
A master database configured for asynchronous or return receipt replication is durable by default. This means that log records are committed to disk when transactions are committed. The master database can be set to nondurable by including the TRANSMIT NONDURABLE clause in the element description.
Transaction records in the master database log buffer are, by default, flushed to disk before they are forwarded to subscribers. If the entire master database is replicated (ELEMENT is of type DATASTORE), you can improve replication performance by eliminating the master's flush-log-to-disk operation from the replication cycle. This is done by including a TRANSMIT NONDURABLE clause in the element description. The TRANSMIT setting has no effect on the subscriber. The transaction records on the subscriber database are always flushed to disk.
Master databases configured for return twosafe replication are nondurable by default and cannot be made durable. Setting TRANSMIT DURABLE on a database that is configured for return twosafe replication has no effect on return twosafe transactions.
Example 9-1 Replicating the entire master database with TRANSMIT NONDURABLE
To replicate the entire contents of the master database (masterds) to the subscriber database (subscriberds) and to eliminate the flush-log-to-disk operation, your element description (named a) might look like the following:
ELEMENT a DATASTORE MASTER masterds ON "system1" TRANSMIT NONDURABLE SUBSCRIBER subscriberds ON "system2"
In general, if a master database fails, you have to initiate the ttRepAdmin -duplicate operation described in "Recovering a failed database" to recover the failed master from the subscriber database. This is always true for a master database configured with TRANSMIT DURABLE.
A database configured as TRANSMIT NONDURABLE is recovered automatically by the subscriber replication agent if it is configured in the specific type of bidirectional scheme described in "Automatic catch-up of a failed master database". Otherwise, you must follow the procedures described in "Recovering nondurable databases" to recover a failed nondurable database.
Using a return service in a classic replication scheme
You can configure your replication scheme with a return service to ensure a higher level of confidence that replicated data is consistent on both the master and subscriber databases. This section describes how to configure and manage the return receipt and return twosafe services.
You can specify a return service for table elements and database elements for any subscriber defined in a CREATE REPLICATION or ALTER REPLICATION statement.
For full details on how to configure a return service for your master and subscribers, see "Using a return service".
Setting STORE attributes in a classic replication scheme
The STORE attributes clause in either the CREATE REPLICATION and ALTER REPLICATION statements are used to set optional behavior for return services, compression, timeouts, durable commit behavior, conflict reporting, and table definition checking. For full details on how to use and configure the STORE attributes for a classic replication scheme, see "Setting STORE attributes". See "CREATE ACTIVE STANDBY PAIR" in the Oracle TimesTen In-Memory Database SQL Reference for a description of all STORE attributes.
Configuring network operations for a classic replication scheme
If your replication host has more than one network interface, you may want to configure replication to use an interface other than the default interface. For full details on how to configure more than one network interface for a classic replication scheme, see "Configuring network interfaces with the ROUTE clause".
Classic replication scheme syntax examples
The following examples in this section illustrate how to configure a variety of classic replication schemes:
Single classic subscriber schemes
The classic replication scheme shown in Example 9-2 is a single master and subscriber unidirectional replication scheme. The two databases are located on separate hosts, system1 and system2. We use the RETURN RECEIPT service to confirm that all transactions committed on the ttuser.tab table in the master database are received by the subscriber.
Example 9-2 Replicating one table
CREATE REPLICATION repscheme
ELEMENT e TABLE ttuser.tab
MASTER masterds ON "system1"
SUBSCRIBER subscriberds ON "system2"
RETURN RECEIPT;
The scheme shown in Example 9-3 is a single master and subscriber unidirectional replication scheme. The two databases are located on separate hosts, server1 and server2. The master database, named masterds, replicates its entire contents to the subscriber database, named subscriberds.
Multiple subscriber classic replication schemes with return services and a log failure threshold
You can create a classic replication scheme that includes up to 128 subscriber databases. If you are configuring propagator databases, you can configure up to 128 propagators. Each propagator can have up to 128 subscriber databases. See "Propagation scheme" for an example of a classic replication scheme with propagator databases.
Example 9-4 Replicating to two subscribers
This example establishes a master database, named masterds, that replicates the ttuser.tab table to two subscriber databases, subscriber1ds and subscriber2ds, located on server2 and server3, respectively. The name of the classic replication scheme is twosubscribers. The name of the replication element is e.
CREATE REPLICATION twosubscribers
ELEMENT e TABLE ttuser.tab
MASTER masterds ON "server1"
SUBSCRIBER subscriber1ds ON "server2",
subscriber2ds ON "server3";
Example 9-5 Replicating to two subscribers with RETURN RECEIPT
This example uses the basic example in Example 9-4 and adds a RETURN RECEIPT attribute and a STORE parameter. RETURN RECEIPT enables the return receipt service for both databases. The STORE parameter sets a FAILTHRESHOLD value of 10 to establish the maximum number of transaction log files that can accumulate on masterds for a subscriber before it assumes the subscriber has failed.
CREATE REPLICATION twosubscribers
ELEMENT e TABLE ttuser.tab
MASTER masterds ON "server1"
SUBSCRIBER subscriber1ds ON "server2",
subscriber2ds ON "server3"
RETURN RECEIPT
STORE masterds FAILTHRESHOLD 10;
Example 9-6 Enabling RETURN RECEIPT for only one subscriber
This example shows how to enable RETURN RECEIPT for only subscriber2ds. Note that there is no comma after the subscriber1ds definition.
CREATE REPLICATION twosubscribers
ELEMENT e TABLE ttuser.tab
MASTER masterds ON "server1"
SUBSCRIBER subscriber1ds ON "server2"
SUBSCRIBER subscriber2ds ON "server3" RETURN RECEIPT
STORE masterds FAILTHRESHOLD 10;
Example 9-7 Enabling different return services for subscribers
This example shows how to apply RETURN RECEIPT BY REQUEST to subscriber1ds and RETURN RECEIPT to subscriber2ds. In this classic replication scheme, applications accessing subscriber1ds must use the ttRepSyncSet procedure to enable the return services for a transaction, while subscriber2ds unconditionally provides return services for all transactions.
CREATE REPLICATION twosubscribers
ELEMENT e TABLE ttuser.tab
MASTER masterds ON "server1"
SUBSCRIBER subscriberds1 ON "server2" RETURN RECEIPT BY REQUEST
SUBSCRIBER subscriber2ds ON "server3" RETURN RECEIPT
STORE masterds FAILTHRESHOLD 10;
Replicating tables to different subscribers
The classic replication scheme shown in Example 9-8 establishes a master database, named centralds, that replicates four tables. ttuser.tab1 and ttuser.tab2 are replicated to the subscriber backup1ds. ttuser.tab3 and ttuser.tab4 are replicated to backup2ds. The master database is located on the finance server. Both subscribers are located on the backupsystem server.
Example 9-8 Replicating tables to different subscribers
CREATE REPLICATION twobackups ELEMENT a TABLE ttuser.tab1 MASTER centralds ON "finance" SUBSCRIBER backup1ds ON "backupsystem" ELEMENT b TABLE ttuser.tab2 MASTER centralds ON "finance" SUBSCRIBER backup1ds ON "backupsystem" ELEMENT d TABLE ttuser.tab3 MASTER centralds ON "finance" SUBSCRIBER backup2ds ON "backupsystem" ELEMENT d TABLE ttuser.tab4 MASTER centralds ON "finance" SUBSCRIBER backup2ds ON "backupsystem";
Propagation scheme
In Example 9-9, the master database sends updates on a table to a propagator that forwards the changes to two subscribers. The master database is centralds on the finance host. The propagator database is propds on the nethandler host. The subscribers are backup1ds on backupsystem1 and backup2ds on backupsystem2.
The classic replication scheme has two elements. For element a, the changes to the tab table on centralds are replicated to the propds propagator database. For element b, the changes to the tab table received by propds are replicated to the two subscribers, backup1ds and backup2ds.
Bidirectional split workload schemes
In Example 9-10, there are two databases, westds on the westcoast host and eastds on the eastcoast host. Customers are represented in two tables: waccounts contains data for customers in the Western region and eaccounts has data for customers from the Eastern region. The westds database updates the waccounts table and replicates it to the eastds database. The eaccounts table is owned by the eastds database and is replicated to the westds database. The RETURN RECEIPT attribute enables the return receipt service to guarantee that transactions on either master table are received by their subscriber.
Example 9-10 Bidirectional split workload
CREATE REPLICATION r1 ELEMENT elem_waccounts TABLE ttuser.waccounts MASTER westds ON "westcoast" SUBSCRIBER eastds ON "eastcoast" RETURN RECEIPT ELEMENT elem_eaccounts TABLE ttuser.eaccounts MASTER eastds ON "eastcoast" SUBSCRIBER westds ON "westcoast" RETURN RECEIPT;
Bidirectional distributed workload scheme
Example 9-11 shows a bidirectional general workload classic replication scheme in which the ttuser.accounts table can be updated on either the eastds or westds database. Each database is both a master and a subscriber for the accounts table.
Note:
Do not use a bidirectional distributed workload replication scheme with return twosafe return service.Example 9-11 Bidirectional distributed workload scheme
CREATE REPLICATION r1 ELEMENT elem_accounts_1 TABLE ttuser.accounts MASTER westds ON "westcoast" SUBSCRIBER eastds ON "eastcoast" ELEMENT elem_accounts_2 TABLE ttuser.accounts MASTER eastds ON "eastcoast" SUBSCRIBER westds ON "westcoast";
When elements are replicated in this manner, the applications should write to each database in a coordinated manner to avoid simultaneous updates on the same data. To manage update conflicts, include a timestamp column of type BINARY(8) in the replicated table and enable timestamp comparison by including the CHECK CONFLICTS clause in the CREATE REPLICATION statement. See Chapter 13, "Resolving Replication Conflicts" for a complete discussion on how to manage update conflicts.
Example 9-12 shows that the tstamp timestamp column is included in the ttuser.accounts table. The CREATE REPLICATION statement has been modified to include the CHECK CONFLICTS clause.
Example 9-12 Managing update conflicts
CREATE TABLE ttuser.accounts (custname VARCHAR2(30) NOT NULL,
address VARCHAR2(80),
curbalance DEC(15,2),
tstamp BINARY(8),
PRIMARY KEY (custname));
CREATE REPLICATION r1
ELEMENT elem_accounts_1 TABLE ttuser.accounts
CHECK CONFLICTS BY ROW TIMESTAMP
COLUMN tstamp
UPDATE BY SYSTEM
ON EXCEPTION ROLLBACK WORK
MASTER westds ON "westcoast"
SUBSCRIBER eastds ON "eastcoast"
ELEMENT elem_accounts_2 TABLE ttuser.accounts
CHECK CONFLICTS BY ROW TIMESTAMP
COLUMN tstamp
UPDATE BY SYSTEM
ON EXCEPTION ROLLBACK WORK
MASTER eastds ON "eastcoast"
SUBSCRIBER westds ON "westcoast";
Applying a classic replication scheme to a database
When you define the classic replication scheme, save the CREATE REPLICATION statement in a SQL file. After you have described the classic replication scheme in a SQL file, you can execute the SQL on the database using the -f option to the ttIsql utility. The syntax is:
ttIsql -f schemefile.sql -connstr "dsn=DSN"
Example 9-13 Creating a classic replication scheme by executing a SQL file
If your classic replication scheme is described in a file called repscheme.sql, you can execute the file on a DSN, called masterDSN, by entering:
> ttIsql -f repscheme.sql -connstr "dsn=masterDSN"
Under most circumstances, you should apply the same scheme to all of the replicated databases. You must invoke a separate ttIsql command on each host to apply the classic replication scheme.
Example 9-14 Executing a SQL file on each host
If your classic replication scheme includes the databases masterDSN on host S1, subscriber1DSN on host S2, and subscriber2DSN on host S3, do the following:
On host S1, enter:
> ttIsql -f repscheme.sql -connstr "dsn=masterDSN"
On host S2, enter:
> ttIsql -f repscheme.sql -connstr "dsn=subscriber1DSN"
On host S3, enter:
> ttIsql -f repscheme.sql -connstr "dsn=subscriber2DSN"
You can also execute the SQL file containing your classic replication scheme from the ttIsql command line after connecting to a database. For example:
Command> run repscheme.sql;
Creating classic replication schemes with scripts
Creating your classic replication schemes with scripts can save you time and help you avoid mistakes. This section provides some suggestions for automating the creation of replication schemes using Perl.
Consider the general workload bidirectional scheme shown in Example 9-15. Entering the element description for the five tables, ttuser.accounts, ttuser.sales, ttuser.orders, ttuser.inventory, and ttuser.customers, would be tedious and error-prone if done manually.
Example 9-15 General workload bidirectional replication scheme
CREATE REPLICATION bigscheme ELEMENT elem_accounts_1 TABLE ttuser.accounts MASTER westds ON "westcoast" SUBSCRIBER eastds ON "eastcoast" ELEMENT elem_accounts_2 TABLE ttuser.accounts MASTER eastds ON "eastcoast" SUBSCRIBER westds ON "westcoast" ELEMENT elem_sales_1 TABLE ttuser.sales MASTER westds ON "westcoast" SUBSCRIBER eastds ON "eastcoast" ELEMENT elem_sales_2 TABLE ttuser.sales MASTER eastds ON "eastcoast" SUBSCRIBER westds ON "westcoast" ELEMENT elem_orders_1 TABLE ttuser.orders MASTER westds ON "westcoast" SUBSCRIBER eastds ON "eastcoast" ELEMENT elem_orders_2 TABLE ttuser.orders MASTER eastds ON "eastcoast" SUBSCRIBER westds ON "westcoast" ELEMENT elem_inventory_1 TABLE ttuser.inventory MASTER westds ON "westcoast" SUBSCRIBER eastds ON "eastcoast" ELEMENT elem_inventory_2 TABLE ttuser.inventory MASTER eastds ON "eastcoast" SUBSCRIBER westds ON "westcoast" ELEMENT elem_customers_1 TABLE ttuser.customers MASTER westds ON "westcoast" SUBSCRIBER eastds ON "eastcoast" ELEMENT elem_customers_2 TABLE ttuser.customers MASTER eastds ON "eastcoast" SUBSCRIBER westds ON "westcoast";
It is often more convenient to automate the process of writing a classic replication scheme with scripting. For example, the perl script shown in Example 9-16 can be used to build the scheme shown in Example 9-15.
Example 9-16 Using a Perl script to create a replication scheme
@tables = qw(
ttuser.accounts
ttuser.sales
ttuser.orders
ttuser.inventory
ttuser.customers
);
print "CREATE REPLICATION bigscheme";
foreach $table (@tables) {
$element = $table;
$element =~ s/repl\./elem\_/;
print "\n";
print " ELEMENT $element\_1 TABLE $table\n";
print " MASTER westds ON \"westcoast\"\n";
print " SUBSCRIBER eastds ON \"eastcoast\"\n";
print " ELEMENT $element\_2 TABLE $table\n";
print " MASTER eastds ON \"eastcoast\"\n";
print " SUBSCRIBER westds ON \"westcoast\"";
}
print ";\n";
The @tables array shown in Example 9-16 can be obtained from some other source, such as a database. For example, you can use ttIsql and f in a Perl statement to generate a @tables array for all of the tables in the WestDSN database with the owner name repl:
@tables = 'ttIsql -e "tables; quit" WestDSN
| grep " REPL\."';
Example 9-17 shows a modified version of the script in Example 9-16 that creates a classic replication scheme for all of the repl tables in the WestDSN database. (Note that some substitution may be necessary to remove extra spaces and line feeds from the grep output.)
Example 9-17 Perl script to create a replication scheme for all tables in WestDSN
@tables = 'ttIsql -e "tables; quit" WestDSN
| grep " REPL\."';
print "CREATE REPLICATION bigscheme";
foreach $table (@tables) {
$table =~ s/^\s*//; # Remove extra spaces
$table =~ s/\n//; # Remove line feeds
$element = $table;
$element =~ s/repl\./elem\_/;
print "\n";
print " ELEMENT $element\_1 TABLE $table\n";
print " MASTER westds ON \"westcoast\"\n";
print " SUBSCRIBER eastds ON \"eastcoast\"\n";
print " ELEMENT $element\_2 TABLE $table\n";
print " MASTER eastds ON \"eastcoast\"\n";
print " SUBSCRIBER westds ON \"westcoast\"";
}
print ";\n";