3 Using Incident Management
Incident management allows you to monitor and resolve service disruptions quickly and efficiently by allowing you to focus on what is important from a broader management perspective (incidents) rather than isolated, discrete events that may point to the same underlying issue.
| In this chapter: | You will learn: |
|---|---|
| Management Concepts | Fundamental approaches to managing your monitored environment. |
| Setting Up Your Incident Management Environment | How to set up and configure key Enterprise Manager components used for incident management. |
| Working with Incidents | How to use incident management to track and resolve IT operation issues. |
| Common Tasks | Step-by-step examples illustrating how to perform common incident management tasks.. |
| Advanced Topics | How to perform specialized incident management operations. |
| Moving from Enterprise Manager 10/11g to 12c | Migrating notification rules to incident rules. |
To supplement this chapter, Oracle has created instructional videos that provide you with a fast way to learn the basics of incident management to monitor your environment.
Instructional Videos:
For video tutorials on incident management, see:https://apex.oracle.com/pls/apex/f?p=44785:24:2961267987520:::24:P24_CONTENT_ID%2CP24_PREV_PAGE:5738%2C24">>https://apex.oracle.com/pls/apex/f?p=44785:24:2961267987520:::24:P24_CONTENT_ID%2CP24_PREV_PAGE:5738%2C24
Incident Management: Create Views in Incident Manager
https://apex.oracle.com/pls/apex/f?p=44785:24:6091052115237:::24:P24_CONTENT_ID%2CP24_PREV_PAGE:5739%2C24
Incident Management: View Incident Details
https://apex.oracle.com/pls/apex/f?p=44785:24:107664888945874:::24:P24_CONTENT_ID%2CP24_PREV_PAGE:5740%2C24
Incident Management: Use Incident Rule Sets Part 1
https://apex.oracle.com/pls/apex/f?p=44785:24:114716879428375:::24:P24_CONTENT_ID%2CP24_PREV_PAGE:5758%2C24
Incident Management: Use Incident Rule Sets Part 2
https://apex.oracle.com/pls/apex/f?p=44785:24:102172707760983:::24:P24_CONTENT_ID%2CP24_PREV_PAGE:5759%2C24
3.1 Management Concepts
Enterprise Manager exposes three levels of management granularity that, when combined, provide complete monitoring/management coverage of your environment. These management levels are:
3.1.1 Event Management
Intuitively, you monitor for specific events in your monitored environment. An event is a significant occurrence on a managed target that typically indicates something has occurred outside normal operating conditions--they provide a uniform way to indicate that something of interest has occurred in an environment managed by Enterprise Manager. Examples of events are:
-
Metric Alerts
-
Compliance Violations
-
Job Events
-
Availability Alerts
Existing Enterprise Manager customers may be familiar with metric alerts and metric collection errors. For Enterprise Manager 12c, metric alerts are a type of event, one of many different event types. The notion of an event unifies the different exception conditions that are detected by Enterprise Manager, such as monitoring issues or compliance issues, into a common concept. It is backed by a consistent and uniform set of event management capabilities that can indicate something of interest has occurred in a datacenter managed by Enterprise Manager.
All events have the following attributes:
| Attribute | Description |
|---|---|
|
Type |
Type of event that is being reported. All events of a specific type share the same set of attributes that describe the exact nature of the problem. For example, Metric Alert, Compliance Standard Score Violation, or Job Status Change. |
|
Severity |
Event severity. For example, Fatal, Warning, or Critical. |
|
Internal Name |
An internal name that describes the nature of the event and can be used to search for events. For example, you can search for all tablespacePctUsed events. |
|
Entity on which the event is raised. |
An event can be raised on a target, a non-target source object (such as a job) or be related to a target and a non-target source object. Note: This attribute is important when determining what privileges are required to manage the event. |
|
Message |
Informational text associated with the event. |
|
Reported Date |
Time the event was reported. |
|
Category |
Functional or operational classification for an event. Available Categories:
|
|
Causal Analysis Update |
Used for Root Cause Analysis of target down events. Possible Values: Root Cause or Symptom |
The type of an event defines the structure and payload of an event and provides the details of the condition it is describing. For example, a metric alert raised by threshold violation has a specific payload whereas a job state change has a different structure. As shown in the following table, the range of events types greatly expands Enterprise Manager's monitoring flexibility.
| Event Type | Description |
|---|---|
| Target Availability | The Target Availability Event represents a target's availability status (Example: Up, Down, Agent Unreachable, or Blackout). |
| Metric Alert | A metric alert event is generated when an alert occurs for a metric on a specific target (Example: CPU utilization for a host target) or metric on a target and object combination Example: Space usage on a specific tablespace of a database target. |
| Metric Evaluation Error | A metric evaluation error is generated when the collection for a specific metric group fails for a target. |
| Job Status Change | All changes to the status of an Enterprise Manager job are treated as events, and these events are made available via the Job Status Change event class.
Note: A prerequisite to creating Incident Rules, is to enable the relevant job status and add required targets to job event generation criteria. To change this criteria, from the Setup menu, select Incidents, and then Job Events. |
| Compliance Standard Rule Violation | Events are generated for compliance standard rule violations. Each event corresponds to a violation of a compliance rule on a specific target. |
| Compliance Standard Score Violation | Events are generated for compliance standard score violations. An event is generated when the compliance score for a compliance standard on a specific target falls below predefined thresholds. |
| High Availability | High Availability events are generated for database availability operations (shutdown and startup), database backups and Data Guard operations (switchover, failover, and other state changes). |
| Service Level Agreement Alert | These events are generated when a service level or service level objective is violated for a service. occurs for a Service Level Agreement or a Service Level Objective. |
| User-reported | These events are created by end-users. |
| Application Dependency and Performance Alert | Alerts are raised by the Application Dependency and Performance (ADP) monitoring when metrics related to a J2EE application or component have crossed some thresholds. |
| Application Performance Management KPI Alert | An Application Performance Management (APM) Key Performance Indicator (KPI) alert event is generated when a KPI violation alert occurs for a metric on an APM managed entity associated with a Business Application target. |
| JVM Diagnostics Threshold Violation | A JVMD Diagnostics event is raised when a JVMD metric exceeds its threshold value on a Java Virtual Machine target. |
The severity of an event indicates the criticality of a specific issue. The following table shows the various event severity levels along with the associated icon.
| Icon | Severity | Description |
|---|---|---|
| Fatal | Corresponding service is no longer available. For example, a monitored target is down (target down event). A Fatal severity is the highest level severity and only applies to the Target Availability event type. | |
| Critical | Immediate action is required in a particular area. The area is either not functional or indicative of imminent problems. | |
| Warning | Attention is required in a particular area, but the area is still functional. | |
| Advisory | While the particular area does not require immediate attention, caution is recommended regarding the area's current state. This severity can be used, for example, to report Oracle best practice violations. | |
| Clear | Conditions that raised the event have been resolved. | |
| Informational | A specific condition has just occurred but does not require any remedial action.
Events with an informational severity:
|
3.1.2 Incident Management
You monitor and manage your Enterprise Manager environment via incidents and not discrete events (even though an incident can conceivably consist of a single event). Of all events raised within your managed environment, there is likely only a subset that you need to act on because they impact your business applications (such as a target down event). However, managing by incident also allows you to address more complex situations where the subset of events you are interested in are related and may indicate a higher level issue needs to be addressed as a single issue and not as individual events: A cluster of events by themselves may indicate a minor administrative issue, but when viewed together may signify a larger problem that can potentially consist of events from multiple domains/layers of your monitored infrastructure.
For example, you are monitoring a host. If you want to monitor 'load' being placed on one or more hosts you might be interested in events such as CPU utilization, memory utilization, and swap utilization exceeding acceptable metric thresholds. Individually, these events may or may not indicate an issue with the host, but together, these events form an incident indicating extreme load is being placed on a monitored host.
Incidents represent the larger service disruptions that may impact your business instead of discrete events. Managing by incidents, therefore, allows you to monitor for complex operational issues that may affect multiple domains that may impact your business. These incidents typically need to be tracked, assigned to appropriate personnel, and resolved as quickly as possible. You can effectively implement a centralized monitoring that consolidates monitoring information and more effectively allocate resource across your ecosystem to resolve or prevent issues from occurring. The end result is better implementation of your business processes that in turn lead to better performance of your IT resources.
While events indicate issues requiring attention in your managed environment, it is more efficient to work on a collective subset of related events as a single unit of work-- you can work on different events representing the same issue or you can work on one incident containing multiple space-related events. For example, you have multiple space events from various targets that indicate you are running low on space. Instead of managing numerous discrete events, you can more efficiently manage a smaller set of incidents.
An incident is a significant event or set of related significant events that need to be managed because it can potentially impact your business applications. These incidents typically need to be tracked, assigned to appropriate personnel, and resolved as quickly as possible. You perform these incident management operations through Incident Manager, an intuitive UI within Enterprise Manager.
Incident Manger provides you with a central location from which to view, manage, diagnose and resolve incidents as well as identify, resolve and eliminate the root cause of disruptions. See Section 3.1.5, "Incident Manager" for more information about this UI.
3.1.2.1 Working with Incidents
When an incident is created, Enterprise Manager makes available a rich set of incident management workflow features that let you to manage and track the incident through its complete lifecycle.
-
Assign incident ownership.
-
Track the incident resolution status.
-
Set incident priority.
-
Set incident escalation level.
-
Ability to provide a manual summary.
-
Ability to add user comments.
-
Ability to suppress/unsuppress
-
Ability to manually clear the incident.
-
Ability to create a ticket manually.
All incident management/tracking operations are carried out from Incident Manager. Creation of incidents for events, assignment of incidents to administrators, setting priority, sending notifications and other actions can be automated using (incident) rules.
The lifecycle of an incident within an organization is typically determined by two pieces of information: The current resolution state of the incident (Incident Status) and how important it is to resolve the incident relative to other incidents (Priority). As key incident attributes, the following options are available:
-
New
-
Work in Progress
-
Closed
-
Resolved
You can define additional statuses if the default options are not adequate. In addition, you can change labels using the Enterprise Manager Command Line Interface (EM CLI). See Advanced Topics for more information.
By changing the priority, you can escalate the incident and perform operations such as assigning it to a specific IT operator or notifying upper-management. The following priority options are available:
-
None
-
Low
-
Medium
-
High
-
Very High
-
Urgent
Priority is often based on simple business rules determined by the business impact and the urgency of resolution.
Every incident possesses attributes that provide information as identification, status for tracking, and ownership. The following table lists available incident attributes.
| Incident Attribute | Definition |
|---|---|
| Escalated | An escalation level signifying a escalation to raise the level of attention on the incident from your organization's IT or management hierarchy.
Available escalation levels:
|
| Category | Operational or organizational classification for an incident. Incidents (and events) can have multiple categories.
Categories for all events within an incident are aggregated. Available Categories:
|
| Summary | An intuitive message indicating what the incident is about. By default, the incident summary is pulled from the message of the last event of the incident, however, this message can be changed to a fixed summary by any administrator working on the incident. |
| Incident Created | Date and time the incident was created. |
| Last Updated | Date and time the incident was last updated or when the incident was closed. |
| Severity | Severity is based on the worst severity of the events in the incident. For example, Fatal, Warning, or Critical. |
| Source | Source entities of the incident. |
| Priority | Priority Values
|
| Status | Incident Status.
You can define additional statuses if the default options are not adequate. In addition, you can change labels using the Enterprise Manager Command Line Interface (EM CLI). Closed Status: Enterprise Manager automatically sets the status to closed when an incident severity is cleared--administrators do not manually select the Closed status. The incident severity is set to Clear when all of the events contained within the incident have been cleared. Typically the Agent sets the Clear severity, as would be the case when a metric alert value falls below a severity threshold. If an event or incident supports manual clearing, then the Clear option will be shown in the Incident Manager UI. Once an incident has been cleared by an administrator or by Enterprise Manager, only then will Enterprise Manager set the status to Closed.If you do not see the option to clear the incident in the UI, this means Enterprise Manager will automatically set the status to Clear if it detects the monitored condition no longer holds true. For example, you want to indicate that an incident has been fixed. You can set the status to Resolved and Enterprise Manager will set the status to Closed when it clears the severity. |
| Comment | Annotations added by an administrator to communicate analysis information or actions taken to resolve the incident. |
| Owner | Administrator/user currently working on the incident. |
| Acknowledged | Indicates that a user has accepted ownership of an incident or problem. Available options: Yes or No.
When an incident is acknowledged, it will be implicitly assigned to the user who acknowledged it. When a user assigns an incident to himself, it is considered 'acknowledged'. Once acknowledged, an incident cannot be unacknowledged, but can be assigned to another user. Acknowledging an incident stops any repeat notifications for that incident. |
| Causal Analysis Update | Used for Root Cause Analysis of target down incidents.
Possible Values: Root Cause or Symptom |
3.1.2.2 Incident Composed of a Single Event
The simplest incident is composed of a single event. In the following example, you are concerned whenever any production target is down. You can create an incident for the target down event which is raised by Enterprise Manager if it detects the monitored target is down. Once the incident is created, you will have all incident management functionality required to track and manage its resolution.

The figure shows how both the incident and event attributes are used to help you manage the incident. From the figure, we see that the database DB1 has gone down and an event of Fatal severity has been raised. When the event is newly generated, there is no ownership or status. An incident is opened that can be updated manually or by automated rules to set owners, status, as well as other attributes. In the example, the owner/administrator Scott is currently working to resolve the issue.
The incident severity is currently Fatal as the incident inherits the worst severity of all the events within incident. In this case there is only one event associated with the incident so the severity is Fatal.
3.1.2.3 Incident Composed of Multiple Events
Situations of interest may involve more than a single event. It is an incident's ability to contain multiple events that allows you to monitor and manage complex and more meaningful issues.
Note:
Multi-event incidents are not automatically generated. An administrator must manually create them.For example, if a monitored system is running out of space, separate multiple events such as tablespace full and filesystem full may be raised. Both, however, are related to running out of space. Another machine resource monitoring example might be the simultaneous raising of CPU utilization, memory utilization, and swap utilization events. See "Creating an Incident Manually" for more information. Together, these events form an incident indicating extreme load is being placed on a monitored host. The following figure illustrates this example.
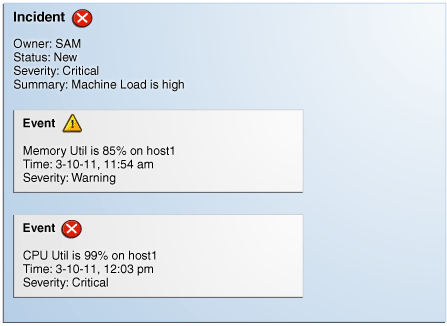
Incidents inherit the worst severity of all the events within incident. The incident summary indicates why this incident should be of interest, in this case, "Machine Load is high". This message is an intuitive indicator for all administrators looking at this incident. By default, the incident summary is pulled from the message of the last event of the incident, however, this message can be changed by any administrator working on the incident.
Because administrators are interested in overall machine load, administrator Sam has manually created an incident for these two metric events because they are related—together these events represent a host overload situation. An administrator needs to take action because memory is filling up and consumed CPU resource is too high. In its current state, this condition will impact any applications running on the host.
3.1.2.4 How are Incidents Created?
Incidents are most commonly created automatically through rules and rule sets (user-defined instructions that tell Incident Manager how to handle specific events when they occur). As shown in the preceding examples, incidents can also be created manually. Once an incident is raised, its severity is inherited from the worst severity of all events within the incident. The latest event Message, by default, becomes the Incident Summary. Incidents can also be created manually. See "Creating an Incident Manually" for more information.
3.1.3 Problem Management
Problem management involves the functionality that helps track the underlying root causes of incidents. Once the immediate service disruptions represented by incidents are resolved, you can then progress to understanding and resolving the underlying root cause of the issue.
For Enterprise Manager 12c, problems focus on the diagnostic incidents and problem diagnostic incidents/problems stored in Advanced Diagnostic Repository (ADR), which are automatically raised by Oracle software when it encounters critical errors in the software. A problem, therefore, represents the root cause of all the Oracle software incidents. For these diagnostic incidents, in order to address root cause, a problem is created that represents the root cause of these diagnostic incidents. A problem is identified by a problem key which uniquely identifies the particular error in software. Each occurrence of this error results in a diagnostic incident which is then associated with the problem object.
When a problem is raised for Oracle software, Oracle has determined that the recommended recourse is to open a service request (SR), send support the diagnostic logs, and eventually provide a solution from Oracle. As an incident, Enterprise Manager makes available all tracking, diagnostic, and reporting functions for problem management. Whenever you view all open incidents and problems, whether you are using Incident Manager, or in context of a target/group home page, you can easily determine what issues are actually affecting your monitored target.
To manage problems, you can use Support Workbench to package the diagnostic details gathered in ADR and open SR. Users should then manage the problems in Incident Manager. Access to Support Workbench functionality is available through Incident Manager (Guided Resolution area) in context of the problem.
3.1.4 Rule Sets
Incident rules and rule sets automate actions related to events, incidents and problems. They can automate the creation of incidents based on important events, perform notification actions such as sending email or opening helpdesk tickets, or perform operations to manage the incident workflow lifecycle such as changing incident ownership, priority, or escalation level.
With previous versions of Enterprise Manager, you used notification rules to choose the individual targets and conditions for which you want to perform actions or receive notifications (send email, page, open a helpdesk ticket) from Enterprise Manager. For Enterprise Manager 12c, the concept and function of notification rules has been replaced with incident rules and rule sets.
-
Rules: A rule instructs Enterprise Manager to take specific actions when incidents, events, or problems occur, such as performing notifications. Beyond notifications, rules can also instruct Enterprise Manager to perform specific actions, such as creating incidents, updating incidents and problems. The actions can also be conditional in nature. For example, a rule action can be defined to page a user when an incident severity is critical or just send email if it is warning.
-
Rule Set: An incident rule set is a collection of rules that apply to a common set of objects such as targets (hosts, databases, groups), jobs, metric extensions, or self updates and take appropriate actions to automate the business processes underlying event, incident and problem management.
Operationally, individual rules within a rule set are executed in a specified order as are the rule sets themselves. Rule sets are executed in a specified order. By default, the execution order for both rules and rule sets is the order in which they are created, but they can be reordered from the Incident Rules UI.
The following figure shows typical rule set structure and how the individual rules are applied to a heterogeneous group of targets.

The graphic illustrates a situation where all rules pertaining to a group of targets can be put into a single rule set (this is also a best practice). In the above example, a group named PROD-GROUP consists of hosts, databases, and WebLogic servers exists as part of a company's managed environment. A single rule set is created to manage the group.
In addition to the actual rules contained within a rule set, a rule set possesses the following attributes:
-
Name: A descriptive name for the rule set.
-
Description: Brief description stating the purpose of the rule set.
-
Applies To: Object to which all rules in the rule set apply: Valid rule set objects are targets, jobs, metric extensions, and self update.
-
Owner: The Enterprise Manager user who created the rule set. Rule set owners have the ability to update or delete the rule set and the rules in the rule set.
-
Enabled: Whether or not the rule set is actively being applied.
-
Type: Enterprise or Private. See "Rule Set Types"
3.1.4.1 Out-of-Box Rule Sets
Enterprise Manager provides out-of-box rule sets for incident creation and event clearing based on typical scenarios. Out-of-box rule sets cannot be edited or deleted, however, they can be disabled. As a best practice, you should create your own copies of out-of-box rule sets and then subscribe to the rule set copies rather than subscribing directly to the out-of-box rule sets. Effectively, you are making a copy of the rule set and changing the target criteria to fit your enterprise needs by selecting an appropriate group of targets (preferably an administration group).
Please note that out-of-box rule set definitions and actions they perform can be changed by Oracle at any time and will be applied during patching or software upgrade.
Regular Enterprise Manager administrators are allowed to perform the following operations on rule sets:
-
Subscribe
-
Subscribe for email notifications
-
Unsubscribe
-
Unsubscribe from email notifications
-
Enable
-
Disable
Note:
Even though administrators can subscribe to a rule set, they will only receive notification from the targets for which they have at least the View Target privilege.Enterprise Manager Super Administrators have the added ability to reorder the rule sets.
Enterprise rule sets are evaluated sequentially and may go through multiple passes as needed. When there is a change to the entity being processed - such as an incident being created for an event or an incident priority changing due to a rule - we rerun through all the rules from the beginning again until there are no matches. Any rule that is matched in a prior pass will not match again (to prevent infinite loops).
For example, when a new event, incident, or problem arises, the first rule set in the list is checked to see if any of its member rules apply and appropriate actions specified in those rules are taken. The second rule is then checked to see if its rules apply and so on. Private rule sets are only evaluated once all enterprise rule set evaluations are complete and in no particular order.
Important:
Use caution when reordering rule sets as their order defines the event, incident, and problem handling workflow. Reordering rule sets without fully understanding the impact on your system can result in unintended actions being taken on incoming events, incidents, and problems.3.1.4.2 Rule Set Types
There are two types of Rule Sets:
-
Enterprise: Used to implement all operational practices within your IT organization. All supported actions are available for this type of rule set. However, because this type of rule set can perform all actions, there are restrictions as to who can create an enterprise rule set.
In order to create or edit an enterprise rule set, an administrator must have been granted the Create Enterprise Rule Set privilege on the Enterprise Rule Set resource. However, if the rule set owner loses the Create Enterprise Rule Set system privilege at some future time, he can still edit or delete the rule set. Super Administrators can edit or delete any rule set. If the originator of the rule set wants other administrators to edit the rule set, he will need to share access in order to work collaboratively by adding co-authors. Enterprise rule sets are visible to all administrators.
-
Private: Used when an administrator wants to be notified about something he is monitoring but not as a standard business practice. The only action a private rule set can perform is to send email to the rule set owner. Any administrator can create a private rule set regardless of whether they have been granted the Create Enterprise Rule Set resource privilege. Oracle recommends that private rule sets be used only in rare or exceptional situations.
When a rule set performs actions, the privileges of the rule set creator are used. For example, a rule set owner/creator must have at least View Target privilege in order to receive notifications and at least Manage Target Events privilege in order to update the incident. The exception is when a rule set sends a notification. In this case, the privileges of the user it is sent to is used.
3.1.4.3 Rules
Rules are instructions within a rule set that automate actions on incoming events or incidents or problems. Because rules operate on incoming incidents/events/problems, if you create a new rule, it will not act retroactively on incidents/events/problems that have already occurred.
Every rule is composed of two parts:
-
Criteria: The events/incidents/problems on which the rule applies.
-
Action(s): The ordered set of one or more operations on the specified events, incidents, or problems. Each action can be executed based on additional conditions.
The following table shows how rule criteria and actions determine rule application. In this rule operation example there are three rules which take actions on selected events and incidents. Within a rule set, rules are executed in a specified order. The rule execution order can be changed at any time. By default, rules are executed in the order they are created.
| Rule Name | Execution Order | Criteria | Action | |
|---|---|---|---|---|
| Condition | Actions | |||
|
Rule 1 |
First |
CPU Util(%), Tablespace Used(%) metric alert events of warning or critical severity |
Create incident. |
|
|
Rule 2 |
Second |
Incidents of warning or critical severity |
If severity = critical If severity =warning |
Notify by page Notify by email |
|
Rule 3 |
Third |
Incidents are unacknowledged for more than six hours |
Set escalation level to 1 |
|
In the rule operation example, Rule 1 applies to two metric alert events: CPU Utilization and Tablespace Used. Whenever these events reach either Warning or Critical severity threshold levels, an incident is created.
When the incident severity level (the incident severity is inherited from the worst event severity) reaches Warning, Rule 2 is applied according to its first condition and Enterprise Manager sends an email to the administrator. If the incident severity level reaches Critical, Rule 2's second condition is applied and Enterprise Manager sends a page to the administrator.
If the incident remains open for more than six hours, Rule 3 applies and the incident escalation level is increased from None to Level 1. At this point, Enterprise Manager runs through all the rule sets and their rules from the beginning again.
3.1.4.3.1 Rule Application
Each rule within a rule set applies to an event, incident OR problem. For each of these, you can choose rule application criteria such as:
-
Apply the rule to incoming events or updated events only
-
Apply the rule to critical events only.
Rules are applied to events, incidents, and problems according to criteria selected at the time of rule creation (or update). The following situations illustrate the methodology used to apply rules.
-
If one of the rules creates a new incident in response to an incoming event, Enterprise Manager finishes matching the event to any further rules/rule sets. Once completed, Enterprise Manager then matches the newly created incident to all the rule sets from the beginning to see if any incident-specific rules match.
-
If an incoming event is already associated with an incident (for example, a Warning event creates an incident and then a Critical event is generated for the same issue), Enterprise Manager applies all the matching rules to the event and then matches all rules to the incident.
-
If, while applying a rule to an incident, changes are made to the incident (change priority. for example), Enterprise Manager stops rule application at that point and then re-applies the rules to the incident from the beginning. The conditional action that updated the incident will not be matched again in the same rule application cycle.
3.1.4.3.2 Rule Criteria
The following tables list selectable criteria for each type.
Table 3-3 Rule Criteria: Events
| Criteria | Description |
|---|---|
|
Type |
Rule applies to a specific event type. |
|
Severity |
Rule applies to a specific event severity. |
|
Category |
Rule applies to a specific event category. |
|
Target type |
Rule applies to a specific target type. |
|
Target Lifecycle Status |
Rule applies to a specific lifecycle status for a target. Lifecycle status is a target property that specifies a target's operational status. |
|
Associated with incident |
Typically, events are associated with incidents through rules. Specify Yes or No. |
|
Event name |
Rule applies to events with a specific name. The specified name can either be an exact match or a pattern match. |
|
Causal analysis update |
Upon completion of Root Cause Analysis (RCA) event, the rule applies to the event that is marked either as root cause or symptom. Alternatively, the rule can act on an RCA event when it is no longer a symptom. |
|
Associated incident acknowledged |
Rule applies to an event that is associated with a specific incident when that incident is acknowledged by an administrator. Specify Yes or No. |
|
Total occurrence count |
For duplicated events, the rule is applies when the total number of event occurrences reaches a specified number. |
|
Comment added |
Rule applies to events where an administrator adds a comment. |
For incidents, a rule can apply to all new and/or updated incidents, or newly created incidents that match specific criteria shown in the following table.
Table 3-4 Rule Criteria: Incidents
| Criteria | Description |
|---|---|
|
Rules that created the incident |
Rule applies to incidents raised by a specific rule. |
|
Category |
Rule applies to a specific incident category. |
|
Target Type |
Rule applies to a specific target type. |
|
Target Lifecycle Status |
Rule applies to a specific lifecycle status for a target. Lifecycle status is a target property that specifies a target's operational status. |
|
Severity |
Rule applies to a specific incident severity. |
|
Acknowledged |
Rule applies if the incident has been acknowledged by an administrator. Specify Yes or No. |
|
Owner |
Rule applies for a specified incident owner. |
|
Priority |
Rule applies when incident priority matches a selected priority. |
|
Status |
Rule applies when the incident status matches a selected incident status. |
|
Escalation Level |
Rule applies when the incident escalation level matches the selected level. Available escalation levels: None, Level 1, Level 2, Level 3, Level 4, Level 5 |
|
Associated with Ticket |
Rule applies when the incident is associated with a helpdesk ticket. Specify Yes or No. |
|
Associated with Service Request |
Rule applies when the incident is associated with a service request. Specify Yes or No. |
|
Diagnostic Incident |
Rule applies when the incident is a diagnostic incident. Specify Yes or No. |
|
Unassigned |
Rule applies if the newly raised incident does not have an owner. |
|
Comment Added |
Rule applies if an administrator adds a comment to the incident. |
For problems, a rule can apply to all new and/or updated problems, or newly created problems that match specific criteria shown in the following table.
Table 3-5 Rule Criteria: Problems
| Criteria | Description |
|---|---|
|
Problem key |
Each problem has a problem key, which is a text string that describes the problem. It includes an error code (such as ORA 600) and in some cases, one or more error parameters. Rule can apply to a specific problem key or a key matching a specific pattern (using a wildcard character). |
|
Category |
Rule applies to a specific problem category. |
|
Target Type |
Rule applies to a specific target type. |
|
Target Lifecycle Status |
Rule applies to a specific lifecycle status for a target. Lifecycle status is a target property that specifies a target's operational status. |
|
Acknowledged |
Rule applies when the problem is acknowledged. |
|
Owner |
Rule applies for a specified problem owner. |
|
Priority |
Rule applies when problem priority matches a selected priority. |
|
Status |
Rule applies when the problems matches a specific status. |
|
Escalation Level |
Rule applies when the problem escalation level matches the selected level. Available escalation levels: None, Level 1, Level 2, Level 3, Level 4, Level 5 |
|
Incident Count |
Rule applies when the number of incidents related to the problem reaches the specified count limit. The problem owner and the Operations manager are notified via email. |
|
Associated with Service Request |
Rule applies if the incoming problem is has an associated Service Request. Specify Yes or No. |
|
Associated with Bug |
Rule applies if the incoming problem is has an associated bug. Specify Yes or No. |
|
Unassigned |
Rule applies if the newly raised incident does not have an owner. |
|
Comment Added |
Rule applies if an administrator adds a comment to the problem. |
3.1.4.3.3 Rule Actions
For each rule, Enterprise Manager allows you to define specific actions.
Some examples of the types of actions that a rule set can perform are:
-
Create an incident based on an event.
-
Perform notification actions such as sending an email or generating a helpdesk ticket.
-
Perform actions to manage incident workflow notification via email/PL/SQL methods/ SNMP traps. For example, if a target down event occurs, create an incident and email administrator Joe about the incident. If the incident is still open after two days, set the escalation level to one and email Joe's manager.
The following table summarizes available actions for each rule application.
Table 3-6 Available Rule Actions
| Action | Event | Incident | Problem |
|---|---|---|---|
|
|
Yes |
Yes |
Yes |
|
Page |
Yes |
Yes |
Yes |
|
Advanced Notifications |
|||
|
Send SNMP Trap |
Yes |
No |
No |
|
Run OS Command |
Yes |
Yes |
Yes |
|
Run PL/SQL Procedure |
Yes |
Yes |
Yes |
|
Create an Incident |
Yes |
No |
No |
|
Set Workflow Attributes |
Yes Note: Within an event rule, the workflow attributes of the associated incident can also be updated. |
Yes |
Yes |
|
Create a Helpdesk Ticket |
Yes Note: Action performed indirectly by first creating an incident and then creating a ticket for the incident. |
Yes |
No |
Note:
you can test rule actions against targets without actually performing the actions using Enterprise Manager's event rule simulation feature. For more information, see "Testing Rule Sets".3.1.5 Incident Manager
Incident Manager provides, in one location, the ability to search, view, manage, and resolve incidents and problems impacting your environment. Use Incident Manager to perform the following tasks:
-
Filter incidents, problems, and events by using custom views
-
Search for specific incidents by properties such as target name, summary, status, or target lifecycle status
-
Respond and work on an incident
-
Manage incident lifecycle including assigning, acknowledging, tracking its status, prioritization, and escalation
-
Access (in context) My Oracle Support knowledge base articles and other Oracle documentation to help resolve the incident.
-
Access direct in-context diagnostic/action links to relevant Enterprise Manager functionality allowing you to quickly diagnose or resolve the incident.
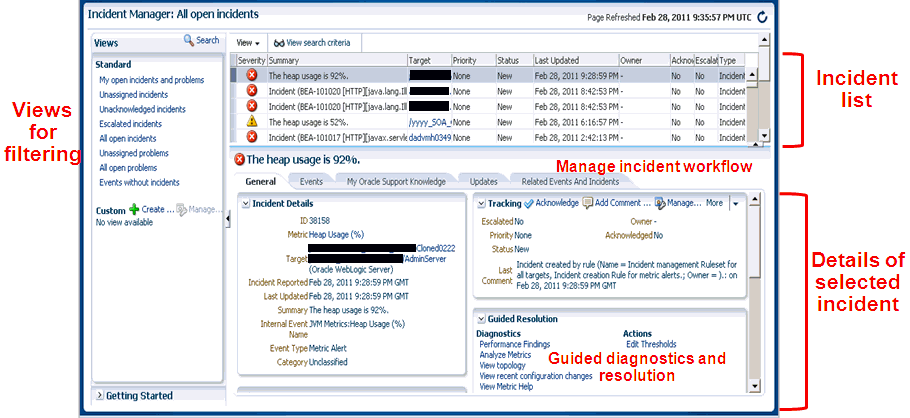
For example, you have an open incident. You can use Incident Manager to track its ownership, its resolution status, set the priority and, if necessary, add annotations to the incident to share information with others when working in a collaborative environment. In addition, you have direct access to pertinent information from MOS and links to other areas of Enterprise Manager that will help you resolve issues quickly. By drilling down on an open incident, you can access this information and modify it accordingly.
Displaying Target Information in the Context of an Incident
You can directly view information about a target for which an incident or event has been raised. The type of information shown varies depending on the target type.
To display in-context target information:
-
From the Enterprise menu, select Monitoring and then Incident Manager.
-
From the Incident Manager UI, choose an incident. Information pertaining to the incident displays.
-
From the Incident Details area of the General tab, click on the information icon "i" next to the target. Target information as it pertains to the incident displays. See Figure 3-5
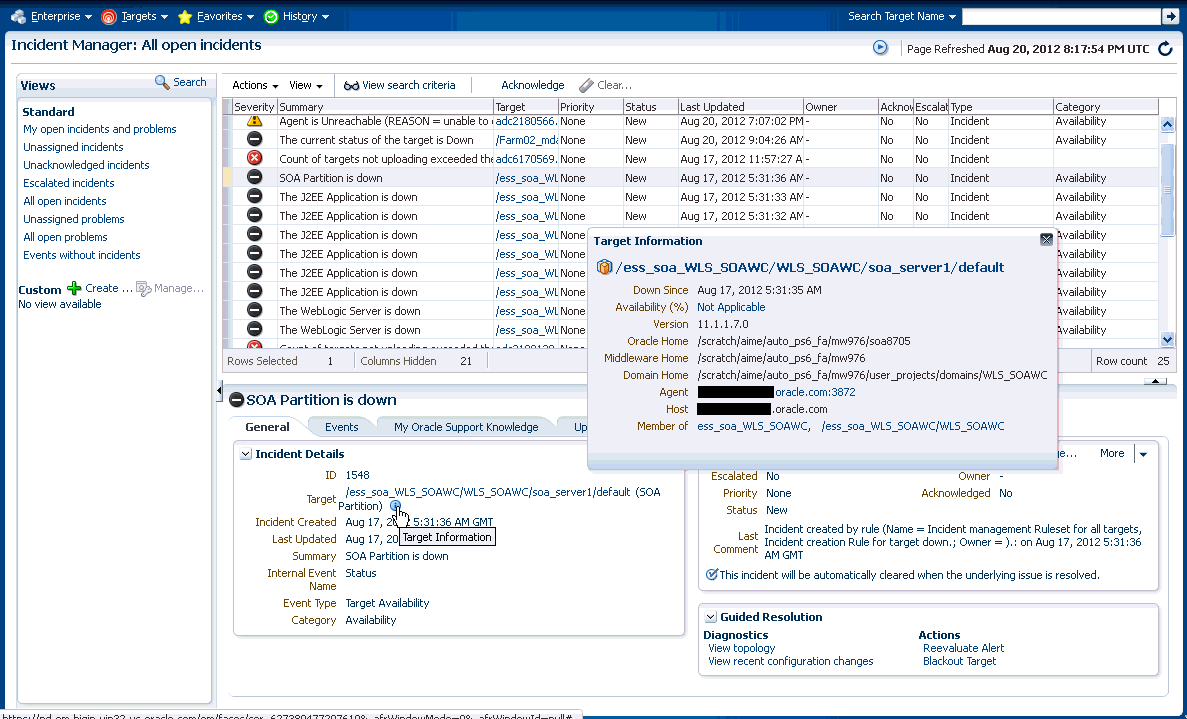
Being able to display target information in this way provides you with more operational context about the targets on which the events and incidents are raised. This in turn helps you manage the lifecycle of the incident more efficiently.
Also available is the mobile application Cloud Control Mobile, which lets you manage incidents and problems on the go using any iDevice to remotely connect to Enterprise Manager.
For more information about this mobile application, see Chapter 29, "Remote Access To Enterprise Manager"
3.1.5.1 Views
Views let you work efficiently with incidents by allowing you to categorize and focus on only those incidents of interest. A view is a set of search criteria for filtering incidents and problems in the system. Incident Manager provides a set of predefined standard views that cover the most common event, incident, and problem search scenarios. In addition, Incident Manager also allows you to create your own custom views. Custom views can be shared with other users. For instructions on creating custom views, see "Setting Up Custom Views". For instructions on sharing a custom view, see "Sharing/Unsharing Custom Views".
3.1.6 Summing Up
-
Event: A significant occurrence of interest on a target that has been detected by Enterprise Manager.
Goal: Ensure that your environment is monitored.
-
Incident: A set of significant events or combination of related events that pertain to the same issue.
Goal: Ensure that service disruptions are either avoided or resolved quickly.
-
Problems: The underlying root cause of incidents. Currently, this represents critical errors in Oracle software that represents the underlying root cause of diagnostic incidents.
Goal: Ensure underlying root causes of issues are resolved to avoid future occurrence of issues.
Events, incidents, and problems work in concert to allow you to manage your complete IT ecosystem both effectively and efficiently. The following illustration summarizes how they work within your managed environment.
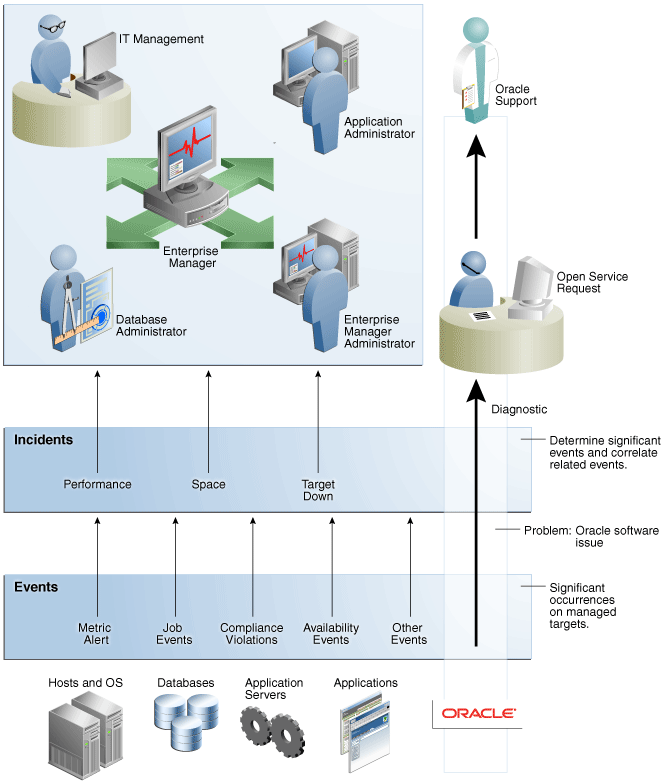
The following sections delve into events, incidents, and problems in more detail.
3.2 Setting Up Your Incident Management Environment
Before you can monitor and manage your environment using incidents, you must ensure that your monitoring environment is properly configured. Proper configuration consists of the following:
3.2.1 Setting Up Your Monitoring Infrastructure
The first step in setting up your monitoring infrastructure is to determine which conditions need to be monitored and hence are the source of events. To prevent an inordinate number of extraneous events from being generated, thus reducing system and administrator overhead, you need to determine what is of interest to you and enable monitoring based on your requirements. You can leverage Enterprise Manager features such as Administrations Groups to automatically apply management settings such as monitoring settings or compliance standards when new targets are added to your monitored environment. This greatly simplifies the task of ensuring that events are raised only for those conditions in which you are interested. For more information, see Chapter 7, "Using Administration Groups".
Example: You want to ensure that the database containing your human resource information is available round the clock. One condition you are monitoring for is whether that database target is up or down. If it goes down, you want the appropriate person to be notified and have them resolve the problem as quickly as possible. Other conditions that you may want to monitor include performance threshold violations, any changes in application configuration files, or job failures. Working with events, you are monitoring and managing individual targets and issues directly related to those targets. For example, you monitor for individual database availability, individual host threshold violations such as CPU and I/O load, or perhaps the performance of a Web service.
In general, if you are primarily interested in availability and some key performance related metrics, you should use default monitoring templates and other template features to ensure the only those specific metrics are collected and events are raised only for those metrics.
Job Events: The status of a job can change throughout its lifecycle - from the time it is submitted to the time it has executed. For each of these job statuses, events can be raised to notify administrators of the status of the job.
As a general rule, events should be generated only for job status values that require administration attention. These job status values include Action Required and Problem status values such as Failed or Stopped. However, in order to avoid overloading the system with unnecessary events, job events are not enabled for any target by default. Hence, if you would like to generate events for jobs, you must:
-
Set the appropriate job status. You can use the default settings or modify them as required.
-
Specify the set of targets for which you would like job-related events to be generated.
You can perform these operations from the Job Event Generation Criteria page. From the Setup menu, choose Incidents and then Job Events.
3.2.1.1 Rule Set Development
Before creating incident rules/rule sets, the first step is to strategically determine when incidents should be created based on the business requirements of your organization. Important questions to consider are:
-
What events should create incidents? Which service disruptions need to be tracked and resolved by IT administrators?
-
Which administrators should be notified for incoming events or incidents?
-
Are any of the events or incidents being forwarded to external systems (such as a helpdesk ticketing system)?
Once the exact business requirements are understood, you translate those into enterprise rule sets. Adhering to the following guidelines will result in efficient use of system resource as well as operational efficiency.
-
For rule sets that operate on targets (for example, hosts and databases), use groups to consolidate targets into a smaller number of monitoring entities for the rule set. Groups should be composed of targets that have similar monitoring requirements including incident management and response.
-
All the rules that apply to the same groups of targets should be consolidated into one rule set. You can create multiple rules that apply to the targets in the rule set. You can create rules for events specific to an event class, rules that apply to events of a specific event class and target type, or rules that apply to incidents on these targets.
-
Leverage the execution order of rules within the rule set. Rule sets and rules within a rule set are executed in sequential order. Therefore, ensure that rules and rule sets are sequenced with that in mind.
When creating a new rule, you are given a choice as to what object the rule will apply— events, incidents or problems. Use the following rule usage guidelines to help guide your selection.
Table 3-7 Rule Usage Guidelines
| Rule Usage | Application |
|---|---|
|
Rules on Event |
To create incidents for the events managed in Enterprise Manager. To send notifications on events. To create tickets for incidents managed by helpdesk analysts, you want to create an incident for an event, then create a ticket for the incident. Send events to third-party management systems. |
|
Rules on Incidents |
Automate management of incident workflow operations (assign owner, set priority, escalation levels..) and send notifications Create tickets based on incident conditions. For example, create a ticket if the incident is escalated to level 2. |
|
Rules on Problems |
Automate management of problem workflow operations (assign owner, set priority, escalation levels..) and send notifications |
The following example illustrates many of the implementation guidelines just discussed. All targets have been consolidated into a single group, all rules that apply to group members are part of the same rule set, and the execution order of the rules has been set. In this example, the rule set applies to a group (Production Group G) that consists of the following targets:
-
DB1 (database)
-
Host1 (host)
-
WLS1 (WebLogic Server)
All rules in the rule set perform three types of actions: incident creation, notification, and escalation.
-
Rule Set applies to target: Group Target G
-
Rules in the Rule Set:
-
Rule(s) to create incidents for specified events
-
Rule(s) that send notifications on incidents
-
Rule(s) that escalate incidents based on some condition. For example, the length of time an incident is open.
-
In a more detailed view of the rule set, we can see how the guidelines have been followed.
Example 3-2 Example Rule Set in Greater Detail
-
Rule Set for Production Group G
-
Target: Production Group G
-
Rule 1: Create an incident for all target down events.
-
Rule 2: Create an incident for specific database, host, and WebLogic Server metric alert event of critical or warning severity.
-
Rule 3: Create an incident for any problem job events.
-
Rule 4: For all critical incidents, sent a page. For all warning incidents, send email.
-
Rule 5: If a Fatal incident is open for more than 12 hours, set the excalation level to 1 and email a manager.
-
In this detailed view, there are five rules that apply to all group members. The execution sequence of the rules (rule 1 - rule 5) has been leveraged to correspond to the three types of rule actions in the rule set: Rules 1-3
-
Rules 1-3: Incident Creation
-
Rule 4: Notification
-
Rule 5: Escalation
By synchronizing rule execution order with the progression of rule action categories, execution efficiency is achieved. As shown in this example, by using conditional actions that take different actions for the same set of events based on severity, it is easier to change the event selection criteria in the future without having to change multiple rules. Note: This assumes that the action requirements for all incidents (from rules 1 - 3) are the same.
The following table illustrates explicit rule set operation for this example.
Table 3-8 Example Rule Set for Production Group G
| Rule Name | Execution Order | Criteria | Action | |
|---|---|---|---|---|
| Condition | Actions | |||
|
Rule Set: Targets within Production Group G |
||||
|
Rule 1 |
First |
DB1 goes down . Host1 goes down. WLS1 goes down. |
Create incident. |
|
|
Rule 2 |
Second |
DB1 Tablespace Full (%) Note: The warning and critical thresholds are defined in Metric and Policy settings, not from the rules UI. Host1 CPU Utilization (%) WLS1 Heap Usage (%) |
If severity=Warning If severity=Critical |
Create incident. |
|
Rule 3 |
Third |
Event generated for problem job status changes for DB1, Host1, and WLS1. |
Create incident. |
|
|
Rule 4 |
Fourth |
All incidents for Production Group G |
Severity=Warning Severity=Critical |
Send email Send page |
|
Rule 5 |
Fifth |
Incident remains open for more than 12 days. |
Status=Fatal |
Increase escalation level to 1. |
3.2.1.1.1 Before Using Rules
Before you use rules, ensure the following prerequisites have been set up:
-
User's Enterprise Manager account has notification preferences (email and schedule). This is required not just for the administrator who is creating/editing a rule, but also for any user who is being notified as a result of the rule action.
-
If you decide to use connectors, tickets, or advanced notifications, you need to configure them before using them in the actions page.
-
Ensure that the SMTP gateway has been properly configured to send email notifications.
-
User's Enterprise Manager account has been granted the appropriate privileges to manage incidents from his managed system.
3.2.1.1.2 Setting Up Notifications
After determining which events should be raised for your monitoring environment, you need to establish a comprehensive notification infrastructure for your enterprise by configuring Enterprise Manager to send out email and or pages, setting up email addresses for administrators and tagging them as email/paging. In addition, depending on the needs of your organization, notification setup may involve configuring advanced notification methods such as OS scripts, PL/SQL procedures, or SNMP traps. For detailed information and setup instructions for Enterprise Manager notifications, see Chapter 4, "Using Notifications".
3.2.2 Setting Up Administrators and Privileges
This step involves defining the appropriate administrators (which includes assigning the proper privileges for security) and then setting up notification assignments based on their defined roles and domain ownership within your organization.
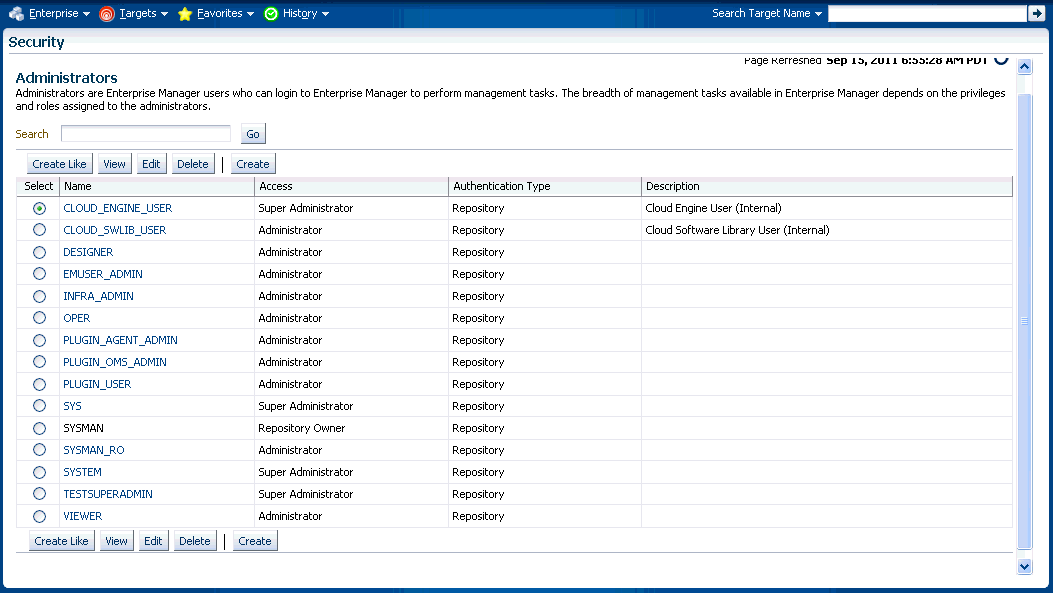
To perform user account administration, click Setup on the Enterprise Manager home page, select Security, then select Administrators to access the Administrators page.
There are two types of administrators typically involved in incident management.
-
Business Rules Architect/Analyst: Administrator who has a deep understanding of how the business works and translates this knowledge to operational rules. Once these rules have been deployed, the business architect uses their knowledge of the dynamic organization to keep these rules up-to-date.
In order to create or edit an enterprise rule set, the business architect/analyst must have been granted the Create Enterprise Rule Set privilege on the Enterprise Rule Set resource. The architect/analyst can share ownership of the rule sets with other administrators who may or may not have the Create Enterprise Rule Set privilege but are responsible for managing a specific rule set.
-
IT Operator/Manager: The IT manager is responsible for day-to-day management of incident assignment. The IT operator is assigned the incidents and is responsible for their resolution.
Privileges Required for Enterprise Rule Sets
As the owner of the rule set, an administrator can perform the following:
-
Update or delete the rule set, and add, modify, or delete the rules in the rule set.
-
Assign co-authors of the rule set. Co-authors can edit the rule set the same as the author. However, they cannot delete rule sets nor can they add additional co-authors.
-
When a rule action is to update an event, incident, or problem (for example, change priority or clear an event), the action succeeds only if the owner has the privilege to take that action on the respective event, incident, or problem.
-
Additionally, user must be granted privilege to create an enterprise rule set.
If an incident or problem rule has an update action (for example, change priority), it will take the action only if the owner of the respective rule set has manage privilege on the matching incident or problem.
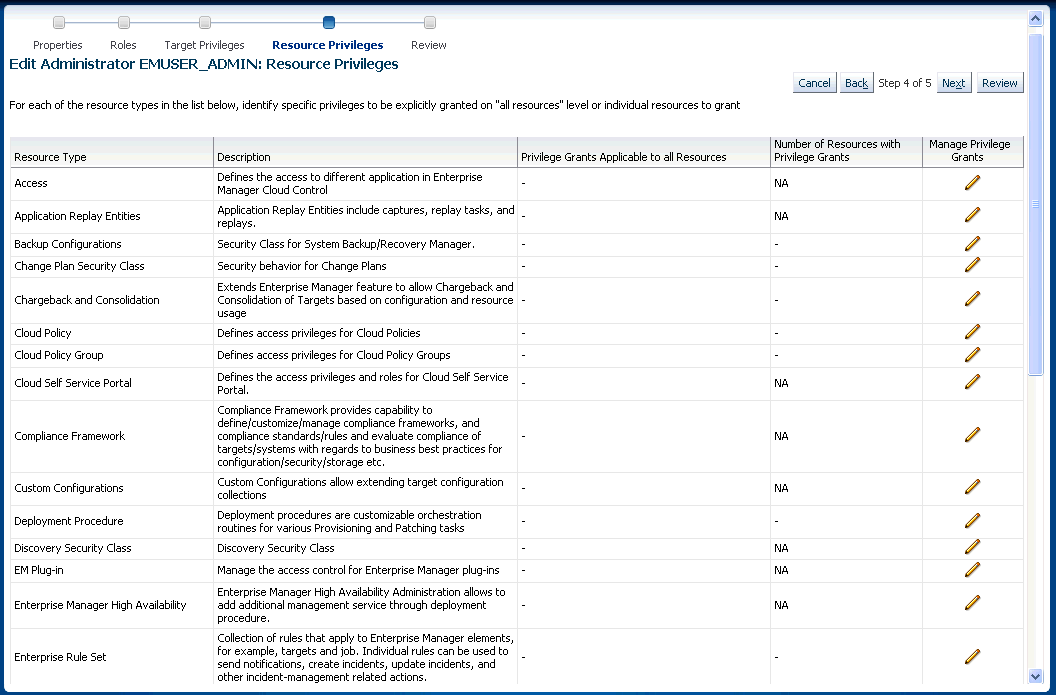
To grant privileges, from the Setup menu on the Enterprise Manager home page, select Security, then select Administrators to access the Administrators page. Select an administrator from the list, then click Edit to access the Administrator properties wizard as shown in the following graphic.
Granting User Privileges for Events, Incidents and Problems
In order to work with incidents, all relevant Enterprise Manager administrator accounts must be granted the appropriate privileges to manage incidents. Privileges for events, incidents, and problems are determined according to the following rules:
-
Privileges on events are calculated based on the privilege on the underlying source objects. For example, the user will have VIEW privilege on an event if he can view the target for the event.
-
Privileges on an incident are calculated based on the privileges on the events in the incident.
-
Similarly, problem privileges are calculated based on privileges on underlying incidents.
Users are granted privileges for events, incidents, and problems in the following situations.
For events, two privileges are defined in the system:
-
The View Event privilege allows you to view an event and add comments to the event.
-
The Manage Event privilege allows you to take update actions on an event such as closing an event, creating an incident for an event, and creating a ticket for an event. You can also associate an event with an incident.
Important:
Incident privilege is inherited from the underlying events.If an event is raised on a target alone (the majority of event types are raised on targets such as metric alerts, availability events or service level agreement), you will need the following privileges:
-
View on target to view the event.
-
Manage Target Events to manage the event.
Note: This is a sub-privilege of Operator.
If an event is raised on both a target and a job, you will need the following privileges:
-
View on target and View on the job to view the event.
-
View on target and Full on the job to manage the event.
If the event is raised on a job alone, you will need the following privileges:
-
View on the job to view the event.
-
Full on the job to manage the event.
If an event is raised on a metric extension, you will need View privilege on the metric extension to view the event. Because events raised on metric extensions are informational (and do not appear in Incident Manager) event management privileges do not apply in this situation.
If an event is raised on a Self-update, only system privilege is required. Self-update events are strictly informational.
For incidents, two privileges are defined in the system:
-
The View Incident privilege allows you to view an incident, and add comments to the incident.
-
The Manage Incident privilege allows you to take update actions on an incident. The update actions supported for an incident includes incident assignment and prioritization, resolution management, manually closing events, and creating tickets for incidents.
If an incident consists of a single event, you can view the incident if you can view the event and manage the incident if you can manage the event.
If an incident consists of more than one event, you can view the incident if you can view at least one event and manage incident if you can manage at least one of the events.
For problems, two privileges are defined:
-
The View Problem privilege allows you to view a problem and add comments to the problem.
-
The Manage Problem privilege allows you to take update actions on the problem. The update actions supported for a problem include problem assignment and prioritization, resolution management, and manually closing the problem.
In Enterprise Manager 12c, problems are always related to a single target. So the View Problem privilege, if an administrator has View privilege on the target, and the Manage Problem privilege, if an administrator has manage_target_events privilege on the target, implicitly grants management privileges on the associated event. This, in turn, grants management privileges on the incident within the problem.
3.2.3 Monitoring Privileges
The monitoring functions that an administrator can perform within the Enterprise Manager environment depend on privileges that have been granted to that user. To maintain the integrity and security of a monitored infrastructure, only the required privileges for a specific role should be granted. The following guidelines can be used to grant proper privilege levels based on user roles.
Administrators who set up monitoring
Create a role with privileges and grant it to administrators:
-
Recommend using individual user accounts instead of shared account
-
If using super administrator, do not use sysman
-
If privilege is based on targets, create privilege-propagating group containing the targets (or use administration group if it meets requirements) and grant privilege on the group to the role
Administrators who respond to events / incidents
-
Create a role and grant it to administrators
-
Create privilege-propagating group (or use administration group if it meets requirements) containing relevant targets and grant appropriate privilege on the group to the role
Example: You create the role DB_Admins and grant Manage Target Events on a the privilege-propagating group named DB-group containing relevant databases. You then grant role DB_Admins to the DBAs.
Monitoring Actions and Required Privileges
Enterprise Manager supports fine-grained privileges to enable more granular control over actions performed in Enterprise Manager.
The table below shows a (non-exhaustive) list of various job responsibilities and the corresponding privilege in Enterprise Manager required to support these
The following tables summarize the privilege levels required to perform specific monitoring responsibilities.
Table 3-9 Monitoring Operations and Required Privileges
| Monitoring Operation | Required Privilege(s) |
|---|---|
|
Monitoring Setup |
|
|
Configure SMTP gateway (email) |
Super Administrator |
|
Create Advanced Notification Methods (e.g. SNMP traps) |
Super Administrator |
|
Configure event or ticketing connector |
Super Administrator |
|
Creating Roles |
Super Administrator |
|
Create Administration Group Hierarchy |
Full Any Target Create Privilege Propagating Group |
|
Edit Administration Group Hierarchy |
Full Any Target Create Privilege Propagating Group (if adding new target property values as group criteria within a level of the administration group hierarchy) |
|
Delete Administration Group Hierarchy |
Full Any Target |
|
View entire Administration Group hierarchy in Group Administration pages |
View Any Target Note: Administrators who have privileges to only a subset of the groups can view these groups in the Groups list page accessible via Targets-->Groups |
|
Use Monitoring Templates |
No privileges required to create new monitoring templates. However if the monitoring template contains a corrective action, then Create on Job System privilege is required View on specific monitoring template to use the template created by another user (e.g. to add the monitoring template to a Template Collection |
|
Use Template Collections |
Create Template Collection (to create new Template Collections)View Template Collection on specific Template Collection to view/associate the Template Collection created by another userView Any Template Collection to view/associate any Template CollectionFull Template Collection on specific Template Collection to edit/delete the Template Collection created by another user |
|
Associate a Template Collection with an Administration Group |
Manage Template Collection Operations on the group (this includes Manage Target Compliance and Manage Target Metrics privileges) View Template Collection on the Template Collection |
|
Operations on the Administration Group |
|
|
Manage privileges on the group (for example, grant to other users) |
Group Administration on the group |
|
Add a target to an Administration Group by setting its target properties |
Configure Target (on the target to be added to the Administration Group) |
|
Perform a manual sync of the group with the associated Template Collection |
Manage Template Collection Operations on the group |
|
Operations on the members of the Administration Group |
|
|
Delete the target from Enterprise Manager |
Full on the target (Full also contains the privileges enumerated below |
|
Set blackout for planned downtime Change monitoring settings Change monitoring configuration Manage events and incidents on the target View target, receive notifications for events or incidents |
Operator on the target also contains the following privileges:
|
|
Create Incident Rule Sets |
Create Enterprise Rule Set Manage Target Events on target if rule is creating incidents for the target |
|
Granting privileges on administration group to roles |
No extra privilege required if creator of the administration group |
|
Set a target's property values |
Configure Target |
|
Edit Monitoring Template that is part of Template Collection |
Full on the Monitoring Template Manage Target Metrics on administration group |
|
Change monitoring settings on specific target |
Manage Target Metrics |
|
Receive email for events, incidents |
View on Target and/or View on source object (for example, view on job for job events) |
|
Create incident for event |
Manage Target Events |
|
Incident management actions (for example, acknowledge, assign incident, prioritize, set escalation level) |
Manage Target Events |
Note:
SYSMAN is a system account intended for Enterprise Manager infrastructure installation and maintenance. It should never be used for administrator access to Enterprise Manager as a Super Administrator.3.2.4 Setting Up Rule Sets
Rule sets automate actions in response to incoming events, incidents and problems or updates to them. This section covers the most common tasks and examples.
3.2.4.1 Creating a Rule Set
In general, to create a rule set, perform the following steps:
-
From the Setup menu, select Incidents then select Incident Rules.
-
On the Incident Rules - All Enterprise Rules page, edit the existing rule set or create a new rule set. For new rule sets, you will need to first select the targets to which the rules apply. Rules are created in the context of a rule set.
Note:
In the case where there is no existing rule set, create a rule set by clicking Create Rule Set... You then create the rule as part of creating the rule set.Narrowing Rule Set Scope Based on Target Lifecycle Status
When creating a new rule set, you can choose to have the rule set apply to a narrower set of targets based on the target's Lifecycle Status value. For example, you can create one rule set that only applies only to targets that have a Lifecycle Status of Staging and Production. As shown in the following graphic, you determine rule set scope by setting the Lifecycle Status filter.

Using this filter allows you to create rules for targets based on their Lifecycle Status without having to first create a group containing only such targets.
-
In the Rules tab of the Edit Rule Set page, click Create... and select the type of rule to create (Event, Incident, Problem) on the Select Type of Rule to Create pop-up dialog. Click Continue.
-
In the Create New Rule wizard, provide the required information.
-
Once you have finished defining the rule, click Continue to add the rule to the rule set. Click Save to save the changes made to the rule set.
3.2.4.2 Creating a Rule to Create an Incident
To create a rule that creates an incident, perform the following steps:
-
From the Setup menu, select Incidents, then select Incident Rules.
-
Determine whether there is an existing rule set that contains a rule that manages the event. In the Incident Rules page, use the Search option to find the rule/rule set name, description, target name, or target type for the target and the associated rule set. You can search by target name or the group target name to which this target belongs to locate the rule sets that manage the targets.
Note: In the case where there is no existing rule set, create a rule set by clicking Create Rule Set... You then create the rule as part of creating the rule set.
-
Select the rule set that will contain the new rule. Click Edit... In the Rules tab of the Edit Rule Set page,
-
Click Create ...
-
Select "Incoming events and updates to events"
-
Click Continue.
Provide the rule details using the Create New Rule wizard.
-
Select the Event Type the rule will apply to, for example, Metric Alert. (Metric Alert is available for rule sets of the type Targets.) Note: Only one event type can be selected in a single rule and, once selected, it cannot be changed when editing a rule.
You can then specify metric alerts by selecting Specific Metrics. The table for selecting metric alerts displays. Click the +Add button to launch the metric selector. On the Select Specific Metric Alert page, select the target type, for example, Database Instance. A list of relevant metrics display. Select the ones in which you are interested. Click OK.
You also have the option to select the severity and corrective action status.
-
Once you have provided the initial information, click Next. Click +Add to add the actions to occur when the event is triggered. One of the actions is to Create Incident.
As part of creating an incident, you can assign the incident to a particular user, set the priority, and create a ticket. Once you have added all the conditional actions, click Continue.
-
After you have provided all the information on the Add Actions page, click Next to specify the name and description for the rule. Once on the Review page, verify that all the information is correct. Click Back to make corrections; click Continue to return to the Edit (Create) Rule Set page.
-
Click Save to ensure that the changes to the rule set and rules are saved to the database.
-
-
Test the rule by generating a metric alert event on the metrics chosen in the previous steps.
3.2.4.3 Creating a Rule to Manage Escalation of Incidents
To create a rule to manage incident escalation, perform the following steps:
-
From the Setup menu, select Incidents, then select Incident Rules.
-
Determine whether there is an existing rule set that contains a rule that manages the incident. You can add it to any of your existing rule sets on incidents.
Note: In the case where there is no existing rule set, create a rule set by clicking Create Rule Set... You then create the rule as part of creating the rule set.
-
Select the rule set that will contain the new rule. Click Edit... in the Rules tab of the Edit Rule Set page, and then:
-
Click Create ...
-
Select "Newly created incidents or updates to incidents"
-
Click Continue.
-
-
For demonstration purposes, the escalation is in regards to a production database.
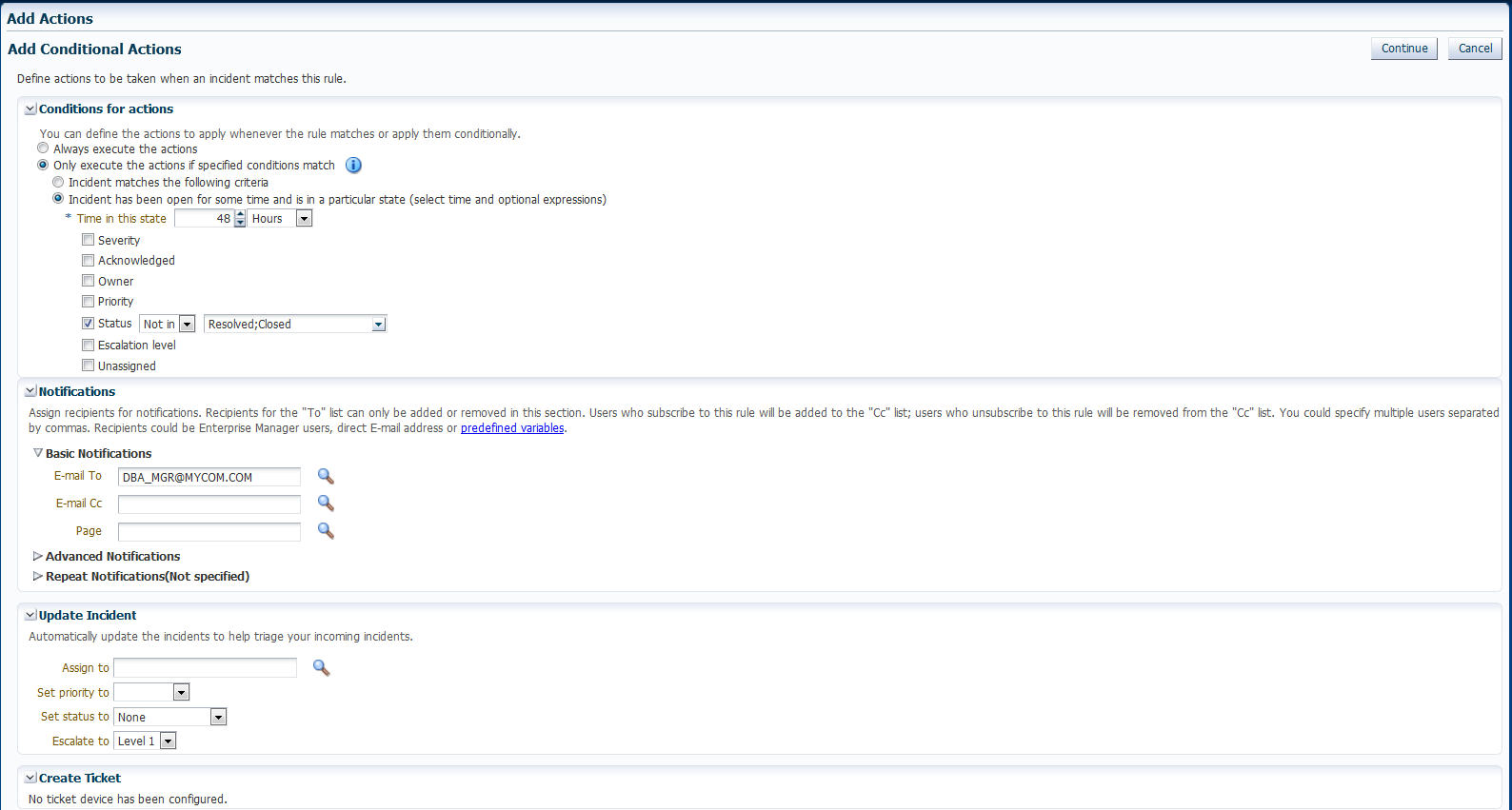
As per the organization's policy, the DBA manager is notified for escalation level 1 incidents where a fatal incident is open for 48 hours. Similarly, the DBA director is paged if the incident has been escalated to level 2, the severity is fatal and it has been open for 72 hours. If the fatal incident is still open after 96 hours, then it is escalated to level 3 and the operations VP is notified.
Provide the rule details using the Create New Rule wizard.
-
To set up the rule to apply to all newly created incidents or when the incident is updated with fatal severity, select the Specific Incidents option and add the condition Severity is Fatal .
-
In the Conditions for Actions region located on the Add Actions page, select Only execute the actions if specified conditions match.
Select Incident has been open for some time and is in a particular state (select time and optional expressions).
Select the time to be 48 hours and Status is not resolved or closed.
-
In the Notification region, type the name of the administrator to be notified by email or page. Click Continue to save the current set of conditions and actions.
-
Repeat steps b and c to page the DBA director (Time in this state is 72 hours, Status is Not Resolved or Closed). If open for more than 96 hours, set escalation level to 3, page Operations VP.
-
After reviewing added actions sets, click Next. Click Next to go to the Summary screen. Review the summary information and click Continue to save the rule.
-
-
Review the sequence of existing enterprise rules and position the newly created rule in the sequence.
In Edit Rule Set page, click on the desired rule from the Rules table and select Reorder Rules from the Actions menu to reorder rules within the rule set, then click Save to save the rule sequence changes.
To facilitate the incident escalation process, the administration manager creates a rule to escalate unresolved incidents based on their age:
-
To level 1 if the incident is open for 30 minutes
-
To level 2 if the incident is open for 1 hour
-
To level 3 if the incident is open for 90 minutes
As per the organization's policy, the DBA manager is notified for escalation level 1. Similarly, the DBA director and operations VP are paged for incidents escalated to levels "2" and "3" respectively.
Accordingly, the administration manager inputs the above logic and the respective Enterprise Manager administrator IDs in a separate rule to achieve the above notification requirement. Enterprise Manager administrator IDs represents the respective users with required target privileges and notification preferences (that is, email addresses and schedule).
3.2.4.4 Creating a Rule to Escalate a Problem
In an organization, whenever an unresolved problem has more than 20 occurrences of associated incidents, the problem should be auto-assigned to the appropriate administrator based on target type of the target on which the problem has been raised.
Accordingly, a problem rule is created to observe the count of incidents attached to the problem and notify the appropriate administrator handling that specific target type.
The problem owner and the Operations manager are notified by email.
To create a rule to escalate a problem, perform the following steps:
-
Navigate to the Incident Rules page.
From the Setup menu, select Incidents, then select Incident Rules.
-
On the Incident Rules - All Enterprise Rules page, either create a new rule set (click Create Rule Set...) or edit an existing rule set (highlight the rule set and click Edit...). Rules are created in the context of a rule set.
Note: In the case where there is no existing rule set, create a rule set by clicking Create Rule Set... You then create the rule as part of creating the rule set.
-
In the Rules section of the Edit Rule Set page, select Create...
-
From the Select Type of Rule to Create dialog, select Newly created problems or updates to problems and click Continue.
-
On the Create New Rule page, select Specific problems and add the following criteria:
The Attribute Name is Incident Count, the Operator is Greater than or equals and the Values is 20.
Click Next.
-
In the Conditions for Actions region on the Add Actions page select Always execute the action. As the actions to take when the rule matches the condition:
-
In the Notifications region, send email to the owner of the problem and to the Operations Manager.
-
In the Update Problem region, enter the email address of the appropriate administrator in the Assign to field.
Click Continue.
-
-
Review the rules summary. Make corrections as needed. Click Continue to return to Edit Rule Set page and then click Save to save the rule set.
3.2.4.5 Testing Rule Sets
When developing a rule set, it can be difficult to develop rule criteria to match all possible event conditions. Previously, the only way to test rules was to trigger an event within your monitored environment and seeing which rules match the event and what actions the rules perform. Beginning with Enterprise Manager Release 12.1.0.4, you can simulate existing events, thus allowing you to test rule actions during the rule set development phase and not waiting for specific event conditions to occur. The rule simulation feature lets you see how the rules will perform given a specific event. You immediately see which rules match for a given event and then see what actions are taken.
Note:
The simulate rule feature can only be used with event rules. Incident rules cannot be tested with this feature.To simulate rules:
This procedure assumes you have already created rule sets. See "Creating a Rule Set" for instructions on creating a rule set. Ensure that the rule type is Incoming events and updates to events.
-
From the Setup menu, select Incidents, and then Incident Rules. The Incident Rules - All Enterprise Rules page displays.
-
Click Simulate Rules. The Simulate Rules dialog displays.
-
Enter the requisite search parameters to find matching events and click Search.
-
Select an event from the list of results.
-
Click Start Simulation. The event will be passed through the rules as if the event had newly occurred. Rules will be simulated based on the current notification configuration (such as email address, schedule for the assigned administrator, or repeat notification setting).
Changing the Target Name: Under certain circumstances, an event matching rule criteria may occur on a target that is not a rule target. For testing purposes, you are only interested in the event. To use the alternate target for the simulation, click Alter Target Name and Start Simulation.
Results are displayed.
Testing Event Rules on a Production Target: Although you can generate an event on a test target, you may want to check the actions on a production target for final verification. You can safely test event rules on production targets without performing rule actions (sending email, SNMP traps, opening trouble tickets). To test your event rule on a production target, change the Target Name to a production target. When you run the simulation, you will see a list of actions to be performed by Enterprise Manager. None of these actions, however, will actually be performed on the production target.
-
If the rule actions are not what you intended, edit the rules and repeat the rule simulation process until the rules perform the desired actions. The following guidelines can help ensure predictable/expected rule simulation results.
If you do not see a rule action for email:
-
Make sure there is a rule that includes that event and has an action to send email.
-
If the specified email recipient is an Enterprise Manager administrator, make sure that administrator has an email address and notification schedule set up.
-
Make sure the email recipient has at least View privileges on the target of the event.
-
Check the SMTP gateway setup and make sure that the administrator has performed a Test Email.
If you do not see other rule actions such as creating an incident or opening a ticket:
-
Make sure there is a rule that includes the event and corresponding action (create incident, for example).
-
Make sure the target is included in the rule set.
-
Make sure the rule set owner has at least Manage Events target privilege on the target of the event.
-
For notifications such as Open Ticket, Send SNMP trap, or Call Event Connector, make sure these are specified as actions in the event rule.
-
3.2.4.6 Subscribing to Receive Email from a Rule
A DBA is aware that incidents owned by him will be escalated when not resolved in 48 hours. The DBA wants to be notified when the rule escalates the Incident. The DBA can subscribe to the Rule, which escalates the Incident and will be notified whenever the rule escalates the Incident.
Before you set up a notification subscription, ensure there exists a rule that escalates High Priority Incidents for databases that have not been resolved in 48 hours
Perform the following steps:
-
From the Setup menu, select Incidents, and then select Incident Rules.
-
On the Incident Rules - All Enterprise Rules page, click on the rule set containing incident escalation rule in question and click Edit... Rules are created in the context of a rule set.
Note: In the case where there is no existing rule set, create a rule set by clicking Create Rule Set... You then create the rule as part of creating the rule set.
-
In the Rules section of the Edit Rule Set page, highlight the escalation rule and click Edit....
-
Navigate to the Add Actions page.
-
Select the action that escalates the incident and click Edit...
-
In the Notifications section, add the DBA to the email cc list.
-
Click Continue and then navigate back to the Edit Rule Set page and click Save.
As a result of the edit to the enterprise rule, when an incident stays unresolved for 48 hours, the rule marks it to escalation level 1. An email is sent out to the DBA notifying him about the escalation of the incident.
Alternate Rule Set Subscription Method: From the Incident Rules - All Enterprise Rules page, select the rule in incident rules table. From the Actions menu, select email and then Subscribe me (or Subscribe administrator....).
3.2.4.7 Receiving Email for Private Rules
A DBA has setup a backup job on the database that he is administering. As part of the job, the DBA has subscribed to email notification for "completed" job status. Before you create the rule, ensure that the DBA has the requisite privileges to create jobs. See Chapter 11, "Utilizing the Job System and Corrective Actions" for job privilege requirements.
Perform the following steps:
-
Navigate to the Rules page.
From the Setup menu, select Incidents, then select Incident Rules.
-
On the Incident Rules - All Enterprise Rules page, either edit an existing rule set (highlight the rule set and click Edit...) or create a new rule set.
Note: The rule set must be defined as a Private rule set.
-
In the Rules tab of the Edit Rule Set page, select Create... and select Incoming events and updates to events. Click Continue.
-
On the Select Events page, select Job Status Change as the Event Type. Select the job in which you are interested either by selecting a specific job or selecting a job by providing a pattern, for example, Backup Management.
Add additional criteria by adding an attribute: Target Type as Database Instance.
-
Add conditional actions: Event matches the following criteria (Severity is Informational) and email Me for notifications.
-
Review the rules summary. Make corrections as needed. Click Save.
-
Create a database backup job and subscribe for email notification when the job completes.
When the job completes, Enterprise Manager publishes the informational event for "Job Complete" state of the job. The newly created rule is considered 'matching' against the incoming job events and email will be sent to the DBA.
The DBA receives the email and clicks the link to access the details section in Enterprise Manager console for the event.
3.3 Working with Incidents
Data centers follow operational practices that enable them to manage events and incidents by business priority and in a collaborative manner. Enterprise Manager provides the following features to enable this management and automation:
-
Send notifications to the appropriate administrators.
-
Create incidents and rules.
-
Assigning initial ownership of an incident and perhaps transferring ownership based on shift assignments or expertise.
-
Tracking its resolution status.
-
Assigning priorities based on the component affected and nature of the incident.
-
Escalating incidents.
-
Accessing My Oracle Support knowledge articles.
-
Opening Oracle Service Requests to request assistance with issues with Oracle software (Problems).
You can update resolution information for an incident by performing the following:
-
In the All Open Incidents view, select the incident.
-
In the resulting Details page, click the General tab, then click Manage. The Manage dialog displays.
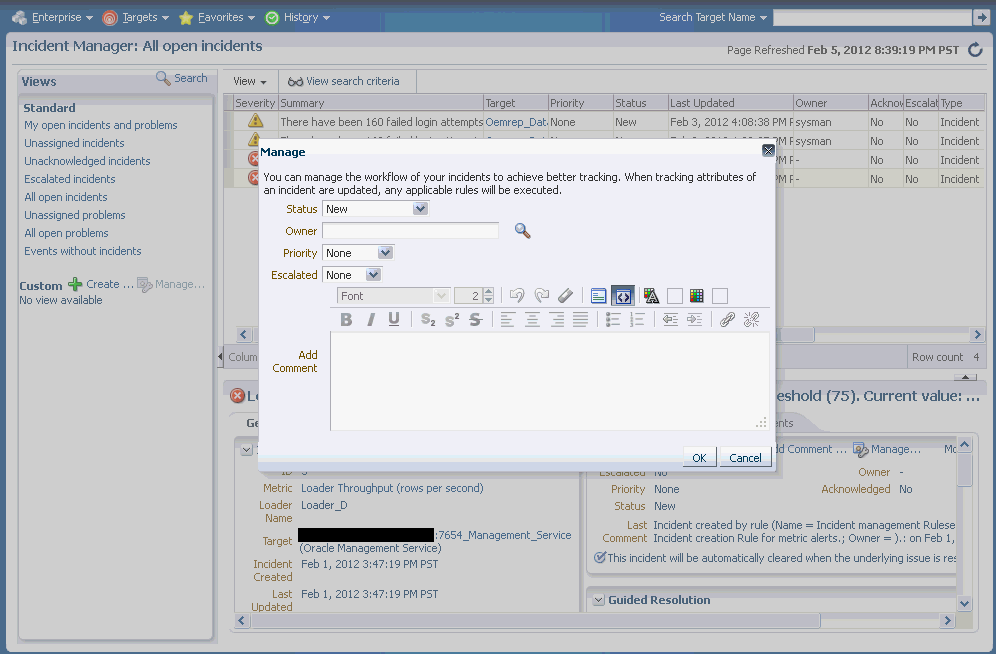
You can then adjust the priority, escalate the incident, and assign it to a specific IT operator.
Working with incidents involves the following stages:
3.3.1 Finding What Needs to be Worked On
Enterprise Manager provides multiple access points that allow you to find out what needs to be worked on. The primary focal point for incident management is the Incident Manager console, however Enterprise Manager also provides other methods of notification. The most common way to be notified that you have an issue that needs to be addressed is by email. However, incident information can also be found in the following areas:
Custom Views (See "Setting Up Custom Views") 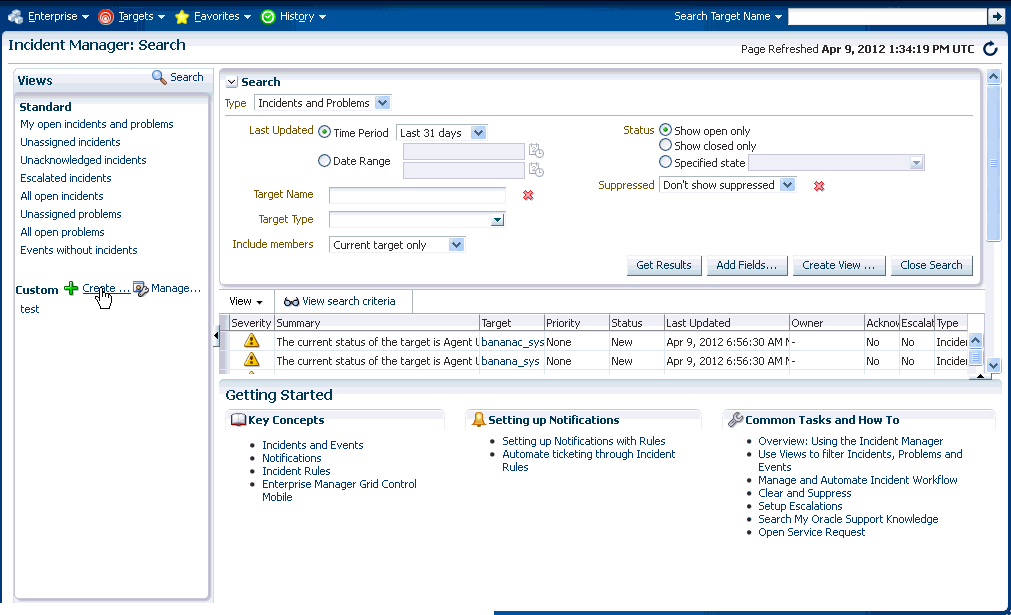
Group or System Homepages (See Chapter 6, "Managing Groups") 
Target Homepages 
Incident Manager (in context of a system or target) 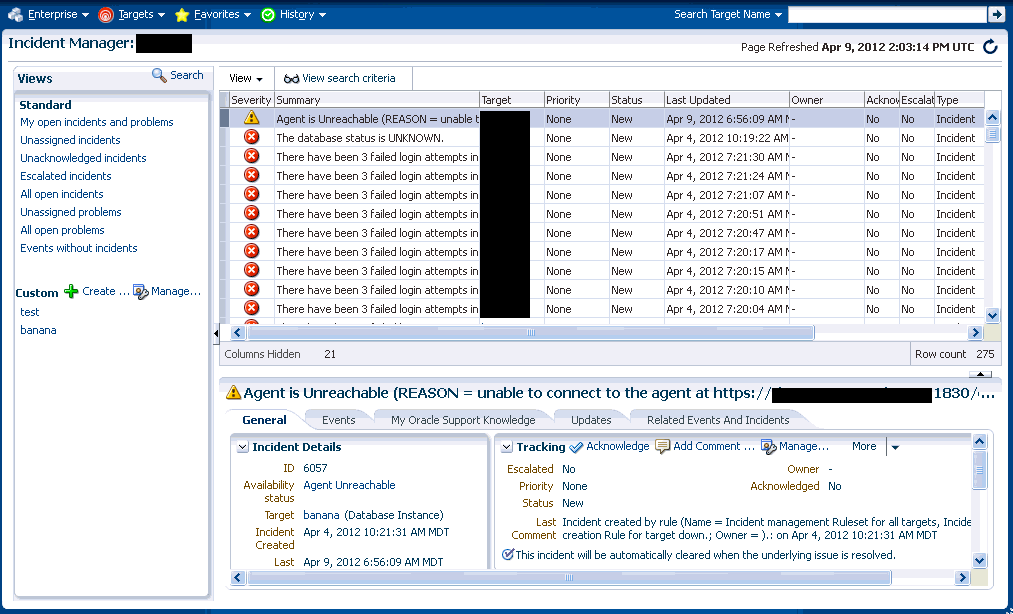
Enterprise Manager Console 
3.3.2 Searching for Incidents
You can search for incidents based on a variety of incident attributes such as the time incidents were last updated, target name, target type, or incident status.
-
Navigate to the Incident Manager page.
From the Enterprise menu on the Enterprise Manager home page, select Monitoring, then select Incident Manager.
-
In the Views region located on the left, click Search.
-
In the Search region, search for Incidents using the Type list and select Incidents.
-
In the Criteria region, choose all the criteria that are appropriate. To add fields to the criteria, click Add Fields... and select the appropriate fields.
-
After you have provided the appropriate criteria, click Get Results.
Validate that the list of incidents match what you are looking for. If not, change the search criteria as needed.
-
To view all the columns associated with this table, in the View menu, select Columns, then select Show All.
-
Searching for Incidents by Target Lifecycle Status
In addition to searching for incidents using high-level incident attributes, you can also perform more granular searches based on individual target lifecycle status. Briefly, lifecycle status is a target property that specifies a target's operational status. Status options for which you can search are:
-
All
-
Mission Critical
-
Production
-
Staging
-
Test
-
Development
For more discussion on lifecycle status, see Section 3.4.7, "Event Prioritization."
To search for incidents by target lifecycle status:
-
Navigate to the Incident Manager page.
From the Enterprise menu on the Enterprise Manager home page, select Monitoring, then select Incident Manager.
-
In the Views region located on the left, click Search.
-
In the Search region, click Add Fields. A pop-up menu appears showing the available lifecycle statuses.
-
Choose on one or more of the lifecycle status options.
-
Enter any additional search criteria.
-
Click Get Results.
3.3.3 Setting Up Custom Views
Incident Manager also allows you to define custom views to help you gain quick access to the incidents and problems on which you need to focus. For example, you may define a view to display all critical database incidents that you own. By specifying and saving view preferences to display only those incident attributes that you are interested in Enterprise Manager will show only the list of matching incidents.
You can then search the incidents for only the ones with specific attributes, such as priority 1. The view allows easy access to pertinent incidents for daily triage. Accordingly, you can save the search criteria as a filter named "All priority 1 incidents for my targets". The view becomes available in the UI for immediate use and will be available anytime you log in to access the specific incidents. The last view you used will be the default view used on your next login.
Perform the following steps:
-
Navigate to the Incident Manager page.
From the Enterprise menu on the Enterprise Manager home page, select Monitoring, then select Incident Manager.
-
In the MyViews region located on the left, click the create "+" icon.
-
In the Search region, search for Incidents using the Type list and select Incidents.
-
In the Criteria region, choose all the criteria that are appropriate. To add fields to the criteria, click Add Fields... and select the appropriate fields.
-
After you have provided the appropriate criteria, click Get Results.
Validate that the list of incidents match what you are looking for. If not, change the search criteria as needed.
-
To view all the columns associated with this table, in the View menu, select Columns, then select Show All.
To select a subset of columns to display and also the order in which to display them, from the View menu, select Columns, then Manage Columns. A dialog displays showing a list of columns available to be added in the table.
-
Click the Create View... button.
-
Enter the view name. If you want other administrators to use this view, check the Share option.
-
Click OK to save the view.
Note:
From the View creation dialog, you can also mark the view as shared. See Section 3.3.4, "Sharing/Unsharing Custom Views" for more information. -
3.3.4 Sharing/Unsharing Custom Views
When you create your own views, they are private (only you can see them). Beginning with Enterprise Manager Release 12.1.0.4, you can share your private views with other administrators. When you share a view, all Enterprise Manager users will be able to use the view.
As mentioned previously, you are given the opportunity to share a view during the view creation process. If you have already created custom views, you can share them at any time.
-
Navigate to Incident Manager.
From the Enterprise menu on the Enterprise Manager home page, select Monitoring, then select Incident Manager.
-
From the My Views region, click the Manage icon.

-
From the Manage Custom Views dialog, choose a custom view.
-
Click Share (or Unshare if the view is already shared and you want to unshare it.)
-
Click Yes to confirm the share/unshare operation.
3.3.5 Responding and Working on a Simple Incident
The following steps take you through one possible incident management scenario.
-
Navigate to Incident Manager.
From the Enterprise menu on the Enterprise Manager home page, select Monitoring, then select Incident Manager.
-
Use a view to filter the list of incidents. For example, you should use My Open Incidents and Problems view to see incidents and problems assigned to you. You can then sort the list by priority.
-
To work on an incident, select the incident. In the General tab, click Acknowledge to indicate that you are working on this incident, and to stop receiving repeat notifications for the incident.
In addition to the acknowledging the incident, you can perform other incident management operations such as:
-
Adding a comment.
-
Managing the incident. See Section 3.3.6, "Responding to and Managing Multiple Incidents, Events and Problems in Bulk" for more information on incident management options.
-
Editing the summary.
-
Manually creating a ticket.
-
Suppressing/unsuppressing the incident.
-
Clearing the incident.
Be aware that as you are working on an individual incident, new incidents might be coming in. Update the list of incidents by clicking the Refresh icon.
-
-
If the solution for the incident is unknown, use one or all of the following methods made available in the Incident page:
-
Use the Guided Resolution region and access any recommendations, diagnostic and resolution links available.
-
Check My Oracle Support Knowledge base for known solutions for the incident.
-
Study related incidents available through the Related Events and Incidents tab.
-
-
Once the solution is known and can be resolved right away, resolve the incident by using tools provided by the system, if possible.
-
In most cases, once the underlying cause has been fixed, the incident is cleared in the next evaluation cycle. However, in cases like log-based incidents, clear the incident.
Alternatively, you can work with incidents for a specific target from that target's home page. From the target menu, select Monitoring and then select Incident Manager to access incidents for that target (or group).
3.3.6 Responding to and Managing Multiple Incidents, Events and Problems in Bulk
There may be situations where you want to respond to multiple incidents in the same way. For example, you find that a cluster of incidents that are assigned to you are due to insufficient tablespace issues on several production databases. Your manager suggests that these tablespaces be transferred to a storage system being procured by another administrator. In this situation, you want to set all of the tablespace incidents to a customized resolution state "Waiting for Hardware." You also want to assign the incidents to the other administrator and add a comment to explain the scenario. In this situation, you want to update all of these incidents in bulk rather than individually.
To respond to incidents in bulk:
-
Navigate to Incident Manager.
From the Enterprise menu on the Enterprise Manager home page, select Monitoring, then select Incident Manager.
-
Use a view to filter the list of incidents to the subset of incidents you want to work on. For example, you can use My Open Incidents and Problems view to see incidents and problems assigned to you. You can then sort the list by priority.
-
Select the incidents to which you want to respond. You can select multiple incidents by holding down the Control key and selecting individual incidents or you can hold down the Shift key and select the first and last incidents to select a contiguous block of incidents.
-
From the Action menu, choose the desired response action.
-
Acknowledge: Indicate that you have viewed the incidents. This option also stops any repeat notifications sent out for the incidents. This sets the Acknowledged flag to Yes and also makes you the owner of the incident
-
Manage: Allows you to perform a multi-action response to the incidents.
-
Acknowledge: If an incident is acknowledged, it will be implicitly assigned to the user who acknowledged it. When a user assigns an incident to himself, it is considered acknowledged. Once acknowledged, an incident cannot be unacknowledged. Acknowledgement also stops any repeat notifications for that incident
-
Assign to: Assign the incident(s) to the administrator who will take ownership of the incident.
-
Prioritization: The priority level of an incident can be set by selecting one of the out-of-the-box priority values: None, Urgent, Very High, High, Medium, Low
-
Incident Status: The resolution state for the incident can be set by selecting either Work in Progress or Resolved or to any custom status defined.
-
Escalation Level: Administrators can update incidents to set an escalation level: Level 1 through 5, in addition to the default value of None. An escalated issue can be de-escalated by setting the escalation to None. The appropriate Escalation Level depends on the IT procedures you have in place.
-
Comment: You can enter comments such as those you want to pass to the owner of the incident.
-
-
Suppress: Suppressing an incident stops corresponding notifications, and removes it from out-of-the-box views and default totals (such as those presented in the summary region). Suppression is typically performed when you want to defer action on the incident until a future time and in the meantime want to visually hide them from appearing in the console. Administrators can see suppressed incidents by explicitly searching for them such as performing a search on incidents where the search criteria includes the Suppressed search field
Incidents can be suppressed until any of the following conditions are met:
-
Until the suppression is manually removed
-
Until specified date in the future
-
Until the severity state changes (incidents only)
-
Until it is closed
-
-
Clear: Administrators can clear incidents or problems manually. For incidents, this applies only to incidents containing incidents that can be manually cleared.
-
Add Comment: Users can add comments on incidents and events. Comments may be used for sharing information with other users or to provide tracking information on any actions being taken. Comments can be added even on closed issues.
Note:
The single action Acknowledge and Clear buttons are enabled for open incidents and can be used for multiple incident selection.
If any of the above actions applies only to a subset of selected incidents (for example, if an administrator tries to acknowledge multiple incidents, of which some are already acknowledged), the action will be performed only where applicable. The administrator will be informed of the success or failure of the action. When an administrator selects any of these actions, a corresponding annotation is added to the incident for future reference.
-
-
Click OK. Enterprise Manager displays a process summary and confirmation dialogs.
-
Continue working with the incidents as required.
3.3.7 Searching My Oracle Support Knowledge
To access My Oracle Support Knowledge base entries from within Incident Manager, perform the following steps:
-
Navigate to Incident Manager.
From the Enterprise menu on the Enterprise Manager home page, select Monitoring, then select Incident Manager.
-
Select one of the standard views. Choose the appropriate incident or problem in the View table.
-
In the resulting details region, click My Oracle Support Knowledge.
If your My Oracle Support (MOS) login credentials have been saved as MOS Preferred Credentials, you do not need to log in manually. If not, you will need to sign in to My Oracle Support. To save your MOS login information as Preferred Credentials.
Setting MOS Preferred Credentials: From the Setup menu, select Security and then Preferred Credentials. From the My Oracle Support Preferred Credentials region, click Set MOS Credentials.
-
On the My Oracle Support page, click the Knowledge tab to browse the knowledge base.
From this page, in addition to accessing formal Oracle documentation, you can also change the search string in to look for additional knowledge base entries.
3.3.8 Open Service Request (Problems-only)
There are times when you may need assistance from Oracle Support to resolve a problem. This procedure is not relevant for incidents or events.
To submit a service request (SR), perform the following steps:
-
Navigate to Incident Manager.
From the Enterprise menu on the Enterprise Manager home page, select Monitoring, then select Incident Manager.
-
Use one of the views to find the problem or search for it or use one of your custom views. Select the appropriate problem from table.
-
Click on the Support Workbench: Package Diagnostic link.
-
Complete the workflow for opening an SR. Upon completing the workflow, a draft SR will have been created.
-
Sign in to My Oracle Support if you are not already signed in.
-
On the My Oracle Support page, click the Service Requests tab.
-
Click Create SR button.
3.3.9 Suppressing Incidents and Problems
There are times when it is convenient to hide an incident or problem from the list in the All Open Incidents page or the All Open Problems page. For example, you need to defer work on the incident until a future date (for example, until maintenance window). In order to avoid having it appear in the UI, you want to temporarily hide or suppress the incident until a future date. In order to find a suppressed incident, you must explicitly search for the incident using either the Show all or the Only show suppressed search option. In order to unhide a suppressed incident or problem, it must be manually unsuppressed.
To suppress an incident or problem:
-
Navigate to Incident Manager.
From the Enterprise menu on the Enterprise Manager home page, select Monitoring, then select Incident Manager.
-
Select either the All Open Incidents view or the All Open Problems view.
Choose the appropriate incident or problem. Click the General tab.
-
In the resulting details region, click More, then select Suppress.
-
On the resulting Suppress pop-up, choose the appropriate suppression type.
Add a comment if desired.
-
Click OK.
3.3.10 Managing Workload Distribution of Incidents
Incident Manager enables you to manage incidents and problems to be addressed by your team.
Perform the following tasks:
-
Navigate to Incident Manager.
From the Enterprise menu on the Enterprise Manager home page, select Monitoring, then select Incident Manager.
-
Use the standard or custom views to identify the incidents for which your team is responsible. You may want to focus on unassigned and unacknowledged incidents and problems.
-
Review the list of incidents. This includes: determining person assigned to the incident, checking its status, progress made, and actions taken by the incident owner.
-
Add comments, change priority, reassign the incident as needed by clicking on the Manage button in the Incident Details region.
The DBA manager uses Incident Manager to view all the incidents owned by his team. He ensures all of them are correctly assigned; if not, he reassigns and prioritizes them appropriately. He monitors the escalated events for their status and progress, adds comments as needed for the owner of the incident. In the console, he can view how long each of the incidents has been open. He also reviews the list of unassigned incidents and assigns them appropriately.
3.3.11 Reviewing Events on a Periodic Basis
Oracle recommends managing via incidents in order to focus on important events or groups of related events. Due to the variety and sheer number of events that can be generated, it is possible that not all important events will be covered by incidents. To help you find these important yet untreated events, Enterprise Manager provides the Events without incidents standard view.
Perform the following steps:
-
From the Enterprise menu, select Monitoring, then select Incident Manager.
-
In the Views region, click Events without incidents.
-
Select the desired event in the table. The event details display.
-
In the details area, choose More and then either Create Incident or Add Event to Incident.
During the initial phase of Enterprise Manager uptake, every day the DBA manager reviews the events for the databases his team is responsible for and filters them to view only the ones which are not tracked by ticket or incident. He browses such events to ensure that none of them requires incidents to track the issue. If he feels that one such event requires an incident to track the issue, he creates an incident directly for this event.
3.3.11.1 Creating an Incident Manually
If an event of interest occurs that is not covered by any rule and you want to convert that event to an incident, perform the following:
-
Using an available view, find the event of interest.
-
Select the event in the table.
-
From the More... drop-down menu, choose Create Incident...
-
Enter the incident details and click OK.
-
Should you decide to work on the incident, set yourself as owner of the incident and update status to Work in Progress.
As per the operations policy, the DBA manager has setup rules to create incidents for all critical issues for his databases. The remainder of the issues are triaged at the event level by one of the DBAs.
One of the DBA receives email for an "SQL Response" event (not associated with an incident) on the production database. He accesses the details of the event by clicking on the link in the email. He reviews the details of the event. This is an issue that needs to be tracked and resolved, so he opens an incident to track the resolution of the issue. He marks the status of the incident as "Work in progress".
3.4 Advanced Topics
The following sections discuss incident/event management features relating advanced applications or operational areas.
3.4.1 Automatic Diagnostic Repository (ADR): Incident Flood Control
ADR is a file-based repository that stores database diagnostic data such as traces, dumps, the alert log, and health monitor reports. ADR's unified directory structure and a unified set of tools enable customers and Oracle Support to correlate and analyze diagnostic data across multiple instances and Oracle products.
Like Enterprise Manager, ADR creates and tracks incidents and problems to allow you to resolve issues.
-
A problem is a critical error in the database. Critical errors manifest as internal errors, such as ORA-00600, or other severe errors, such as ORA-07445 (operating system exception) or ORA-04031 (out of memory in the shared pool).
-
An incident is a single occurrence of a problem. When a problem (critical error) occurs multiple times, an incident is created for each occurrence. Incidents are timestamped and tracked in ADR. When an incident occurs, ADR sends a diagnostic incident alert to Enterprise Manager.
3.4.1.1 Working with ADR Diagnostic Incidents Using Incident Manager
Each diagnostic incident recorded in the ADR is also recorded as an incident in Enterprise Manager, thus providing you with a unified view of ADR/Enterprise Manager incidents and problems from within Incident Manager. For the ADR diagnostic incidents, you can access Enterprise Manager Support Workbench to take further action, such as packaging a problem or raising a service request with Oracle Support.
3.4.1.2 Incident Flood Control
Prior to Enterprise Manager Release 12.1.0.4, there was no limit to the number of diagnostic incidents recorded for a single problem in Incident Manager. It is conceivable that a problem could generate dozens or perhaps hundreds of incidents in a short period of time. While incidents generated during the early stages of a problem may be useful, after a certain point the excess diagnostic data would provide little value and possibly slow down your efforts to diagnose and resolve the problem. Because diagnostic problems typically tend to be long-lived, a significant number of incidents could be generated over time. Also, depending on the size of your monitored environment, the diagnostic data may consume considerable system resources.
For these reasons, the Enterprise Manager applies flood control limits on the number of diagnostic incidents that can be raised for a given problem in Incident Manager. Flood-controlled incidents provide a way of informing you that a critical error is ongoing, without overloading the system with diagnostic data.
Beginning with Enterprise Manager Release 12.1.0.4, two limits are placed on the number of diagnostic incidents that can be raised for a given problem in Incident Manager. A problem is identified by a unique problem signature called a problem key and is associated with a single target.
Enterprise Manager Limits on Diagnostic Incidents
Enterprise Manager enforces two limits for diagnostic incidents:
-
For any given hour, Enterprise Manager only records up to five (default value) diagnostic incidents for a given target and problem key combination.
-
On any given day, Enterprise Manager only records up to 25 (default value) diagnostic incidents for a given problem key and target combination.
When either of these limits is reached, any diagnostic incidents for the same target/problem key combination will not be recorded until the corresponding hour or day is over. Diagnostic incident recording will commence once a new hour or day begins.
Note:
Hour and day calculations are based on UTC (or GMT).These diagnostic incident limits only apply to Incident Manager and not to the underlying ADR. All incidents continue to be recorded in the ADR repository. Using Enterprise Manager Support Workbench, users can view all the incidents for a given problem at any time and take appropriate actions.
Enterprise Manager diagnostic incident limits are configurable. As mentioned earlier, the defaults for these two limits are set to 5 incidents per hour and 25 incidents per day. These defaults should not be changed unless there is a clear business reason to track all diagnostic incidents.
Changing Enterprise Manager Diagnostic Incident Limits
To update the diagnostic limits, execute the following SQL against the Enterprise Manager repository as the SYSMAN user using the appropriate limit values as shown in the following example.
Example 3-3 SQL Used to Change Diagnostic Incident Limits
exec EM_EVENT_UTIL.SET_ADR_INC_LIMITS(5,25);
The PL/SQL shown in the following example prints out the current limits.
Example 3-4 SQL Used to Print Out Current Diagnostic Incident Limits
DECLARE
l_adr_hour_limit NUMBER;
l_adr_day_limit NUMBER;
BEGIN
em_event_util. GET_ADR_INC_LIMITS
(p_hourly_limit => l_adr_hour_limit,
p_daily_limit => l_adr_day_limit);
dbms_output.put_line(l_adr_hour_limit || '-' || l_adr_day_limit);
END;
Important:
The Enterprise Manager incident limits are in addition to any diagnostic incident limits imposed by underlying applications such as Oracle database, Middleware and Fusion Applications. These limits are specific to each application. See the respective application documentation for more information.3.4.2 Defining Custom Incident Statuses
As discussed in "Working with Incidents", one of the primary incident workflow attributes is status. For most conditions, these predefined status attributes will suffice. However, the uniqueness of your monitoring and management environment may require an incident workflow requiring specialized incident states. To address this need, you can define custom states using the create_resolution_state EM CLI verb.
3.4.2.1 Creating a New Resolution State
emcli create_resolution_state
-label="Label for display"
-position="Display position"
[-applies_to="INC|PBLM"]
This verb creates a new resolution state for describing the state of incidents or problems.
Important:
This command can only be executed by Enterprise Manager Super Administrators.The new state is always added between the New and Closed states. You must specify the exact position of this state in the overall list of states by using the -position option. The position can be between 2 and 98.
By default, the new state is applicable to both incidents and problems. The -applies_to option can be used to indicate that the state is applicable only to incidents or problems.
A success message is reported if the command is successful. An error message is reported if the change fails.
Examples
The following example adds a resolution state that applies to both incidents and problems at position 25.
emcli create_resolution_state -label="Waiting for Ticket" -position=25
The following example adds a resolution state that applies to problems only at position 35.
emcli create_resolution_state -label="Waiting for SR" -position=35 -applies_to=PBLM
3.4.2.2 Modifying an Existing Resolution State
You can chance the both the display label and the position of an existing state by using the modify_resolution_state verb.
emcli modify_resolution_state
-label="old label of the state to be changed"
-new_label="New label for display"
-position="New display position"
[-applies_to=BOTH]
This verb modifies an existing resolution state that describes the state of incidents or problems. As with the create_resolution_state verb, this command can only be executed by Super Administrators.
You can optionally indicate that the state should apply to both incidents and problems using the -applies_to option.
Examples
The following example updates the resolution state with old label "Waiting for TT" with a new label "Waiting for Ticket" and if necessary, changes the position to 25.
emcli modify_resolution_state -label="Waiting for TT" -new_label="Waiting for Ticket" -position=25
The following example updates the resolution state with the old label "SR Waiting" with a new label "Waiting for SR" and if necessary, changes the position to 35. It also makes the state applicable to incidents and problems.
emcli modify_resolution_state -label="SR Waiting" -new_label="Waiting for SR" -position=35 -applies_to=BOTH
3.4.3 Clearing Stateless Alerts for Metric Alert Event Types
For metric alert event types, an event (metric alert) is raised based on the metric threshold values. These metric alert events are called stateful alerts. For those metric alert events that are not tied to the state of a monitored system (for example, snapshot too old, or resumable session suspended ), these alerts are called stateless alerts. Because stateless alerts are not cleared automatically, they need to be cleared manually. You can perform a bulk purge of stateless alerts using the clear_stateless_alerts EM CLI verb.
Note:
For large numbers of incidents, you can manually clear incidents in bulk. See "Responding to and Managing Multiple Incidents, Events and Problems in Bulk".clear_stateless_alerts clears the stateless alerts associated with the specified target. The clearing must be manually performed as the Management Agent does not automatically clear stateless alerts. To find the metric internal name associated with a stateless alert, use the EM CLI get_metrics_for_stateless_alerts verb.
emcli clear_stateless_alerts -older_than=number_in_days -target_type=target_type -target_name=target_name [-include_members][-metric_internal_name=target_type_metric:metric_name:metric_column] [-unacknowledged_only][-ignore_notifications] [-preview][ ] indicates that the parameter is optional
-
older_than
Specify the age of the alert in days. (Specify 0 for currently open stateless alerts.)
-
target_type
Internal target type identifier, such as host, oracle_database, and emrep.
-
target_name
Name of the target.
-
include_members
Applicable for composite targets to examine alerts belonging to members as well.
-
metric_internal_name
Metric to be cleaned up. Use the get_metrics_for_stateless_alerts verb to see a complete list of supported metrics for a given target type.
-
unacknowledged_only
Only clear alerts if they are not acknowledged.
-
ignore_notifications
Use this option if you do not want to send notifications for the cleared alerts. This may reduce the notification sub-system load.
-
ignore_notifications
Use this option if you do not want to send notifications for the cleared alerts. This may reduce the notification sub-system load.
-
preview
Shows the number of alerts to be cleared on the target(s).
The following example clears alerts generated from the database alert log over a week old. In this example, no notifications are sent when the alerts are cleared.
emcli clear_stateless_alerts -older_than=7 -target_type=oracle_database -tar get_name=database -metric_internal_name=oracle_database:alertLog:genericErrStack -ignore_notifications
3.4.4 Automatically Clearing "Manually Clearable" Events
There are those events that clear automatically, such as CPU Utilization and those events that must be manually cleared, either through the Incident Manager UI or automatically via rule (such as Job Failure, or Log Metric events). Auto-clear events, as the term implies, are cleared automatically by Enterprise Manager once the underlying issue is resolved. In the case of CPU Utilization, the event CPU Utilization clears automatically once the percent utilization falls below the warning threshold. However, for those events that must be cleared manually, a user must intervene and clear the event using Incident Manager either by selecting the incident/event and clicking Clear, or creating an event rule to do the job (recommended method).
As mentioned previously, an event rule automates the clearing of manually clearable events. Enterprise Manager provides a limited number of out-of-box rules that automatically clear manually clearable events, such as job failures or ADP events that remain open for seven days. However, to more accurately meet the needs of your monitoring environment, Oracle recommends creating your own event rules to automatically clear those manually clearable events that are most prevalent in your environment.
During the rule creation process, you can specify that an event be automatically cleared by selecting the Clear Event option while you are adding conditional actions.
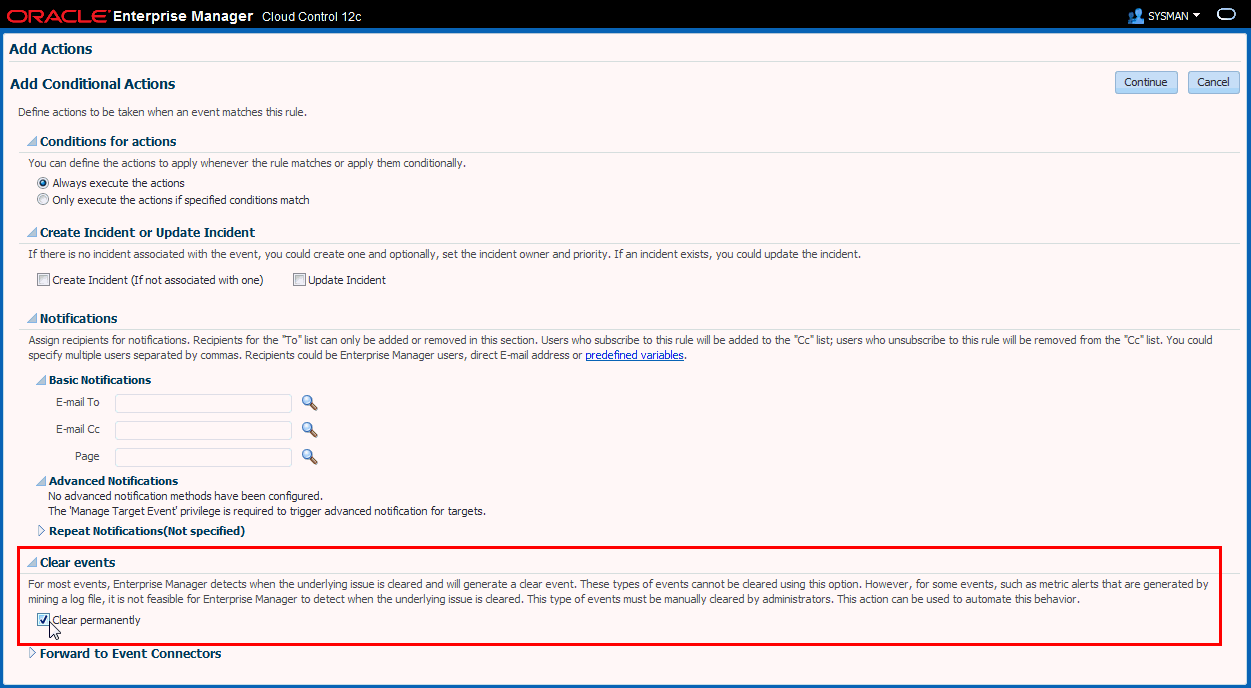
Getting Notified when the Event Clears
The event clearing action is an asynchronous operation, which means that when the rule action (clear) is initiated, the manually clearable event will be enqueued for clearing, but not actually cleared. Hence, an email notification sent upon rule execution will indicate that the event has not been cleared. Asynchronous clearing is by design as it reduces overall rule engine processing load and processing time. Subscribing to this event clearing rule with the intent to be notified when the event clears will be of little value. If you want to be notified when the event clears, you must create a new event rule and explicitly specify a Clear severity. In doing so, you will be notified once the event is actually cleared.
3.4.5 User-reported Events
Users may create (publish) events manually using the EM CLI verb publsh_event. A User-reported event is published as an event of the "User-reported event" class. Only users with Manage Target privilege can publish these events for a target. An error message is reported if the publish fails.
After an event is published with a severity other than CLEAR (see below), end-users with appropriate privileges can manually clear the event from the UI, or they can publish a new event using a severity level of CLEAR and the same details to report clearing of the underlying situation.
3.4.5.1 Format
emcli publish_event
-target_name="Target name"
-target_type="Target type internal name"
-message="Message for the event"
-severity="Severity level"
-name="event name"
[-key="sub component name"
-context="name1=value1;name2=value2;.."
-separator=context="alt. pair separator"
-subseparator=context="alt. name-value separator"]
[ ] indicates that the parameter is optional
3.4.5.2 Options
-
target_name
Target name.
-
target_type
Target type name.
-
message
Message to associate for the event. The message cannot exceed 4000 characters.
-
severity
Numeric severity level to associate for the event. The supported values for severity level are as follows:
- "CLEAR"
- "MINOR_WARNING"
- "WARNING"
- "CRITICAL"
- "FATAL"
-
name
Name of the event to publish. The event name cannot exceed 128 characters.
This is indicative of the nature of the event. Examples include "Disk Used Percentage," "Process Down," "Number of Queues," and so on. The name must be repeated and identical when reporting different severities for the same sequence of events. This should not have any identifying information about a specific event; for example, "Process xyz is down." To identify any specific components within a target that the event is about, see the key option below.
-
key
Name of the sub-component within a target this event is related to. Examples include a disk name on a host, name of a tablespace, and so forth. The key cannot exceed 256 characters.
-
context
Additional context that can be published for a given event. This is a series of strings of format name:value separated by a semi-colon. For example, it might be useful to report the percentage size of a disk when reporting space issues on the disk. You can override the default separator ":" by using the sub-separator option, and the pair separator ";" by using the separator option.
The context names cannot exceed 256 characters, and the values cannot exceed 4000 characters.
-
separator
Set to override the default ";" separator. You typically use this option when the name or the value contains ";". Using "=" is not supported for this option.
-
subseparator
Set to override the default ":" separator between the name-value pairs. You typically use this option when the name or value contains ":". Using "=" is not supported for this option.
3.4.5.3 Examples
The following example publishes a warning event for "my acme target" indicating that a HDD restore failed, and the failure related to a component called the "Finance DB machine" on this target.
emcli publish_event -target_name="my acme target" -target_type="oracle_acme" -name="HDD restore failed" -key="Finance DB machine" -message="HDD restoration failed due to corrupt disk" -severity=WARNING
The following example publishes a minor warning event for "my acme target" indicating that a HDD restore failed, and the failure related to a component called the "Finance DB machine" on this target. It specifies additional context indicating the related disk size and name using the default separators. Note the escaping of the \ in the disk name using an additional "\".
emcli publish_event -target_name="my acme target" -target_type="oracle_acme" -name="HDD restore failed" -key="Finance DB machine" -message="HDD restoration failed due to corrupt disk" -severity=MINOR_WARNING -context="disk size":800GB\;"disk name":\\uddo0111245
The following example publishes a critical event for "my acme target" indicating that a HDD restore failed, and the failure related to a component called the "Finance DB machine" on this target. It specifies additional context indicating the related disk size and name. It uses alternate separators, because the name of the disk includes the ":" default separator.
emcli publish_event -target_name="my acme target" -target_type="oracle_acme" -name="HDD restore failed" -key="Finance DB machine" -message="HDD restoration failed due to corrupt disk" -severity=CRITICAL -context="disk size"^800GB\;"disk name"^\\sdd1245:2 -subseparator=context=^
3.4.6 Additional Rule Applications
Rules can be set up to perform more complicated tasks beyond straightforward notifications. The following tasks illustrate additional rule capabilities.
-
Setting Up a Rule to Send Different Notifications for Different Severity States of an Event
-
Creating a Rule to Notify Different Administrators Based on the Event Type
3.4.6.1 Setting Up a Rule to Send Different Notifications for Different Severity States of an Event
Before you perform this task, ensure the DBA has set appropriate thresholds for the metric so that a critical metric alert is generated as expected.
Consider the following example:
The Administration Manager sets up a rule to page the specific DBA when a critical metric alert event occurs for a database in a production database group and to email the DBA when a warning metric alert event occurs for the same targets. This task occurs when a new group of databases is deployed and DBAs request to create appropriate rules to manage such databases.
Perform the following tasks to set appropriate thresholds:
-
From the Setup menu, select Incidents, then select Incident Rules.
-
On the Incident Rules - All Enterprise Rules page, highlight a rule set and click Edit.... (Rules are created in the context of a rule set. If there is no existing rule set to manage the newly added target, create a rule set.)
-
In the Edit Rule Set page, locate the Rules section. Click Create...
-
From the Select Type of Rule to Create dialog, choose Incoming events and updates to events. Click Continue.
-
Provide the rule details as follows:
-
For Type, select Metric Alerts as the Type.
-
In the criteria section, select Severity. From the drop-down list, check and Critical and Warning as the selected values. Click Next.
-
On the Add Actions page, click +Add.
In the Create Incident section, check the Create Incident option. Click Continue. The Add Action page displays with the new rule. Click Next.
-
Specify a name for the rule and a description. Click Next.
-
On the Review page, ensure your settings are correct and click Continue. A message appears informing you that the rule has been successfully created. Click OK to dismiss the message.
Next, you need to create a rule to perform the notification actions.
-
-
From the Rules section on the Edit Rules page, click Create.
-
Select Newly created incidents or updates to incidents as the rule type and click Continue.
-
Check Specific Incidents.
-
Check Severity and from the drop-down option selector, check Critical and Warning. Click Next.
-
On the Add Actions page, click Add. The Conditional Actions page displays.
-
In the Conditions for actions section, choose Only execute the actions if specified conditions match.
-
From the Incident matches the following criteria list, choose Severity and then Critical from the drop-down option selector.
-
In the Notifications section, enter the DBA in the Page field. Click Continue. The Add Actions page displays.
-
Click Add to create a new action for the Warning severity.
-
In the Conditions for actions section, choose Only execute the actions if specified conditions match.
-
From the Incident matches the following criteria list, choose Severity and then Warning from the drop-down option selector.
-
In the Notifications section, enter the DBA in the Email to field. Click Continue. The Add Actions page displays with the two conditional actions. Click Next.
-
Specify a rule name and description. Click Next.
-
On the Review page, ensure your rules have been defined correctly and click Continue. The Edit Rule Set page displays.
-
Click Save to save your newly defined rules.
3.4.6.2 Creating a Rule to Notify Different Administrators Based on the Event Type
As per operations policy for production databases, the incidents that relate to application issues should go to the application DBAs and the incidents that relate to system parameters should go to the system DBAs. Accordingly, the respective incidents will be assigned to the appropriate DBAs and they should be notified by way of email.
Before you set up rules, ensure the following prerequisites are met:
-
DBA has setup appropriate thresholds for the metric so that critical metric alert is generated as expected.
-
Rule has been setup to create incident for all such events.
-
Respective notification setup is complete, for example, global SMTP gateway, email address, and schedule for individual DBAs.
Perform the following steps:
-
Navigate to the Incident Rules page.
From the Setup menu, select Incidents, then select Incident Rules.
-
Search the list of enterprise rules matching the events from the production database.
-
On the Incident Rules - All Enterprise Rules page, highlight a rule set and click Edit....
Rules are created in the context of a rule set. If there is no existing rule set, create a rule set.
-
From the Edit Rule Set page (Rules tab), select the rule which creates the incidents for the metric alert events for the database. Click Edit
-
From the Select Events page, click Next.
-
From the Add Actions page, click +Add. The Add Conditional Actions page displays.
-
In the Notifications area, enter the email address of the DBA you want to be notified for this specific event type and click Continue to add the action. Enterprise Manager returns you to the Add Actions page. Click Next.
-
On the Specify Name and Description page, enter an intuitive rule name and a brief description.
-
Click Next.
-
On the Review page, review the Applies to, Actions and General information for correctness .
-
Click Continue to create the rule.
-
Create/Edit additional rules to handle alternate additional administrator notifications according to event type.
-
Review the rules summary and make corrections as needed. Click Save to save your rule set changes.
3.4.6.3 Creating a Rule to Create a Ticket for Incidents
If your IT process requires a helpdesk ticket be created to resolve incidents, then you can use the helpdesk connector to associate the incident with a helpdesk ticket and have Enterprise Manager automatically open a ticket when the incident is created. Communication between Incident Manager and your helpdesk system is bidirectional, thus allowing you to check the changing status of the ticket from within Incident Manager. Enterprise Manager also allows you to link out to a Web-based third-part console directly from the ticket so that you can launch the console in context directly from the ticket.
For example, according to the operations policy of an organization, all critical incidents from a production database should be tracked by way of Remedy tickets. A rule is set up to create a Remedy ticket when a critical incident occurs for the database. When such an incident occurs, the ticket is generated by the rule, the incident is associated with the ticket, and the operation is logged for future reference to the updates of the incident. While viewing the details of the incident, the DBA can view the ticket ID and, using the attached URL link, access the Remedy to get the details about the ticket.
Before you perform this task, ensure the following prerequisites are met:
-
Monitoring support has been set up.
-
Remedy ticketing connector has been configured.
Perform the following steps:
-
From the Setup menu, select Incidents, then select Incident Rules.
-
On the Incident Rules - All Enterprise Rules page, select the appropriate rule set and click Edit.... (Rules are created in the context of a rule set. If there is no applicable rule set , create a new rule set.)
-
Select the appropriate rule that covers the incident conditions for which tickets should be generated and click Edit...
-
Click Next to proceed to the Add Actions page.
-
Click +Add to access the Add Conditional Actions page.
-
Specify that a ticket should be generated for incidents covered by the rule.
-
Specify the ticket template to be used.
-
-
Click Continue to return to the Add actions page.
-
On the Add Actions page, click Next.
-
On the Review page, click Continue.
-
On the Specify Name and Description page, click Next.
-
On the Review page, click Continue. A message displays indicating that the rule has been successfully modified. Click OK to close the message.
-
Repeat steps 3 through 10 until all appropriate rules have been edited.
-
Click Save to save your changes to the rule set.
3.4.6.4 Creating a Rule to Send SNMP Traps to Third Party Systems
As mentioned in Chapter 4, "Using Notifications," Enterprise Manager supports integration with third-party management tools through the SNMP. Sending SNMP traps to third party systems is a two-step process:
Step 1: Create an advanced notification method based on an SNMP trap.
Step 2: Create an incident rule that invokes the SNMP trap notification method.
The following procedure assumes you have already created the SNMP trap notification method. For instruction on creating a notification method based on an SNMP trap, see "Sending SNMP Traps to Third Party Systems".
-
From the Setup menu, select Incidents, then select Incident Rules.
-
On the Incident Rules - All Enterprise Rules page, click Create Rule Set...
-
Enter the rule set Name, a brief Description, and select the type of source object the rule Applies to (Targets).
-
Click on the Rules tab and then click Create...
-
On the Select Type of Rule to Create dialog, select Incoming events and updates to events and then click Continue.
-
On the Create New Rule : Select Events page, specify the criteria for the events for which you want to send SNMP traps and then click Next.
Note:
You must create one rule per event type. For example, if you want to send SNMP traps for Target Availability events and Metric Alert events, you must specify two rules. -
On the Create New Rule : Add Actions page, click Add. The Add Conditional Actions page displays.
-
In the Notifications section, under Advanced Notifications, select an existing SNMP trap notification method as shown in the following graphic.
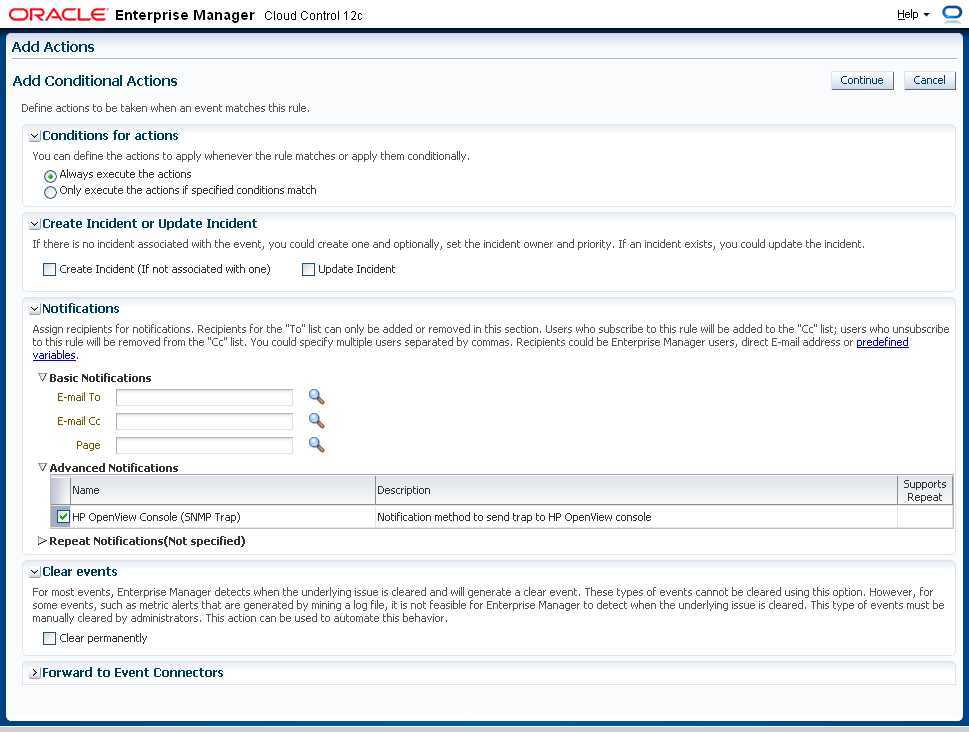
For information on creating SNMP trap notification methods, see "Sending SNMP Traps to Third Party Systems".
-
Click Continue to return to the Create New Rule : Add Actions page.
-
Click Next to go to the Create New Rule : Specify Name and Description page.
-
Specify a rule name and a concise description and then click Next.
-
Review the rule definition and then click Continue add the rule to the rule set. A message displays indicating the rule has been added to the rule set but has not yet been saved. Click OK to close the message.
-
Click Save to save the rule set. A confirmation is displayed. Click OK to close the message.
3.4.7 Event Prioritization
When working in a large enterprise, it is conceivable that when systems are under heavy load, a large number of incidents and events may be generated. All of these need to be processed in a timely and efficient manner in accordance with your business priorities. An effective prioritization scheme is needed to determine which events/incidents should be resolved first.
In order to determine which event/incidents are high priority, Enterprise Manager uses a prioritization protocol based on two incident/event attributes: Lifecycle Status of the target and the Incident/Event Type. Lifecycle Status is a target property that specifies a target's operational status. You can set/view a target's Lifecycle Status from the UI (from a target's Target Setup menu, select Properties). You can set target Lifecycle Status properties across multiple targets simultaneously by using the Enterprise Manager Command Line Interface (EM CLI) set_target_property_value verb.
A target's Lifecycle Status is set when it is added to Enterprise Manager for monitoring. At that time, you determine where in the prioritization hierarchy that target belongs—the highest level being "mission critical" and the lowest being "development."
-
Mission Critical (highest priority)
-
Production
-
Stage
-
Test
-
Development (lowest priority)
-
Availability events (highest priority)
-
Non-informational events.
-
Informational events
3.4.8 Root Cause Analysis (RCA) and Target Down Events
Root Cause Analysis (RCA) tries to identify the root causes of issues that cause operational events. Beginning with Enterprise Manager Could Control 12.1.0.3, Incident Manager automatically performs RCA over target down events, thus actively identifying whether the target down event is the cause or symptom of other target down events.The term target down event specifically pertains to Target Availability events that are raised when the targets are detected to be down.
3.4.8.1 How RCA Works
RCA is an ongoing process that identifies whether a target down event is root cause or symptom. It uses the Causal Analysis Update attribute of the event to store the results of its analysis, i.e. identifying whether or not the target down event is root cause or symptom. Whenever a new target availability event comes in, RCA is automatically performed on the incoming event and existing target down events that are related to it. Based on the analysis, it updates the Causal Analysis Update attribute value if the incoming event is a target down event. It also updates the Causal Analysis Update attribute for the related target down events if there is a change.
Two types of target relationships are used for identifying the related targets: dependency and containment.
When one target depends on another target for its availability, dependency relationship exists between them. For example, J2EE application target depends on the WebLogic Server target over which it is deployed.
The causal analysis update attribute is used only for target down events (such as a Target Availability event for target down) and can have be assigned any one of the following values by the RCA process:
-
Symptom -- The target down event has been caused by another target down event.
-
Cause - The target down event has caused another target down event and it is not the symptom of any other target down event.
-
Root Cause - The target down event has caused another target down event and it is not the symptom of any other target down event.
-
N/A - Root cause analysis is not applicable to this event. Root cause analysis applies to target down events only.
-
Not a cause and not a symptom - The target down event is not a root cause and not a symptom of other target down events. This is shown in Incident Manager as a dash (-).
The following rules describe the RCA process:
-
Rule 1: Down event on a non-container target (a target that does not have members) is marked as the cause if a dependent target is down and it is not symptom of other target down events.
Examples:
-
You have J2EE applications deployed on a standalone WebLogic Server. If both J2EE application and WebLogic Server targets are down, the WebLogic Server down event is the cause for the J2EE applications deployed on it.
-
You have a J2EE application deployed on couple of WebLogic Servers, which are part of a WebLogic Cluster. If one WebLogic Server is down along with its J2EE application, then the WebLogic Server down event is the cause of the J2EE application target down. This assumes the WebLogic Cluster is not down.
-
-
Rule 2: Down event on a non-container target (a target that does not have members) is marked as a symptom if a target it depends on is down or if the target containing it is down.
Examples:
-
You have a J2EE application deployed on a standalone WebLogic Server. If both J2EE application and WebLogic Server targets are down, J2EE application down event is the symptom of WebLogic Server being down.
-
You have a couple of WebLogic Servers which are part of a WebLogic Cluster. Each WebLogic Server has a J2EE application deployed on it. If the WebLogic Cluster is down, this means both WebLogic Servers are down. Consequently, the J2EE applications that are deployed on these servers are also down. The WebLogic Server down events would be marked as the causes of the WebLogic Cluster being down. See Rule 3 for details.
-
You have a couple of RAC database instance targets that are part of a cluster database target. If the cluster database is down, then all RAC instances are also down. The RAC instance down events would be marked as the causes of cluster database being down. See Rule 3 for details..
-
-
Rule 3: Down event on a container target is marked as symptom down if all member targets are down and any target containing it is not down.
Examples:
-
You have a couple of WebLogic Servers, which are part of a standalone WebLogic Cluster. A WebLogic Cluster down event would be marked as symptom, if both the WebLogic Servers are down.
-
You have a couple of RAC database instance targets that are part of a cluster database target. The cluster database target down event would be marked as a symptom, if both database instances are down.
-
-
Rule 4: Down event on a container target is marked as symptom if the target containing it is down.
Example:
You have a couple of WebLogic Clusters that are part of a WebLogic Domain target. If the WebLogic domain is down, this means the WebLogic Clusters are also down. The WebLogic Cluster target down events would be the cause of WebLogic Domain being down. The WebLogic Domain down event would be marked as symptom.
3.4.8.2 Leveraging RCA Results in Incident Rule Sets
As described above, RCA is an ongoing process which results in marking target down events as cause, symptom or neither as new target down events come in and are processed. So a target down event may be marked as a cause or symptom as it comes in or after some time when RCA has analyzed additional event information.
Most datacenters automatically create incidents for target down events since these are important events that need to be resolved right away. This is recommended best practice and also implemented by the out-of-the-box rule sets. However, in terms of notifying response teams or creating trouble tickets, it is not desirable to do so for symptom incidents. Some datacenters may also choose to not create incidents for symptom events.
So the RCA results can be leveraged to do the following:
-
Notify or create tickets only for non-symptom events:
This can be achieved in 2 ways:
-
Create two separate event rules , one event rule to create incidents for all relevant events, but take no further action (no notification or ticket creation) and another one to create incidents for non-symptom events only and also send notifications and create tickets. See "Creating Incidents On Non-symptom Events" for instructions.
-
Create an event rule that creates incidents for all target down events. Create another rule to update the incident priority, send notifications and create tickets only for incidents stemming from non-symptom events. Once the incident priority is set to say "Urgent", customer can also create additional incident rules to take additional actions on the Urgent priority incidents. See "Creating a Rule to Update Incident Priority for Non-symptom Events".
-
-
Only create incidents after a suitable wait for events that are not initially marked as neither a cause nor a symptom:
As mentioned previously, RCA is an iterative process whereby incoming target down events are continually being evaluated, resulting in updates to causal analysis state of existing events. Over a period of time (minutes), a target down event that was initially marked as a root cause may or may not remain a root cause depending on other incoming target down events. The original target down event may later be classified as a symptom.
To avoid prematurely creating an incident and opening a ticket for an event which may later turn out to be a symptom event, you can set up your rules as follows:
-
In addition to the rules already defined in the previous step, create an additional event rule to act upon RCA updates to events and when the RCA update indicates that the event is marked as a symptom, lower the priority of the incident to "Low". This will also send an update to the ticket automatically. This is recommended. See "Introducing a Time Delay" for instructions.
OR
-
To allow time for target down events to be reported, analyzed, and then acted upon (such as creating an incident or updating an incident), you can add a delay in the rule actions. This is useful when customer have some tolerance to take action after some minimum delay (typically 5 minutes).
-
-
Only create incidents for non-symptom events.
Some datacenters may choose not to create any incidents for symptom events. This can be achieved by changing the rules to only create incidents for events marked as cause or neither a cause nor symptom. See "Creating Incidents On Non-symptom Events" for instructions.
Please note that, even in this approach, it is possible that an event that was originally marked as cause or neither a cause nor symptom, may be marked as a symptom when more information is received. Customers can use an approach similar to that of the second option in step 2 to build some delay in creating the incidents. Even with this, it is still feasible but a bit unlikely, that newer information shows up after the pre-set delay and ends up marking the event as symptom. So it is recommended to use the approach of setting incident priority and using that as a way to manage workflow.
3.4.8.3 Leveraging RCA Results in Incident Manager
You can use the RCA results to focus on the non-symptom incidents in Incident Manager. This involves using the Causal Analysis Update incident attribute when creating custom views.
-
From the Enterprise menu, select Monitoring, and then Incidents. The Indicent Manager page displays.
-
From the Views region, click Create. The Search page displays.
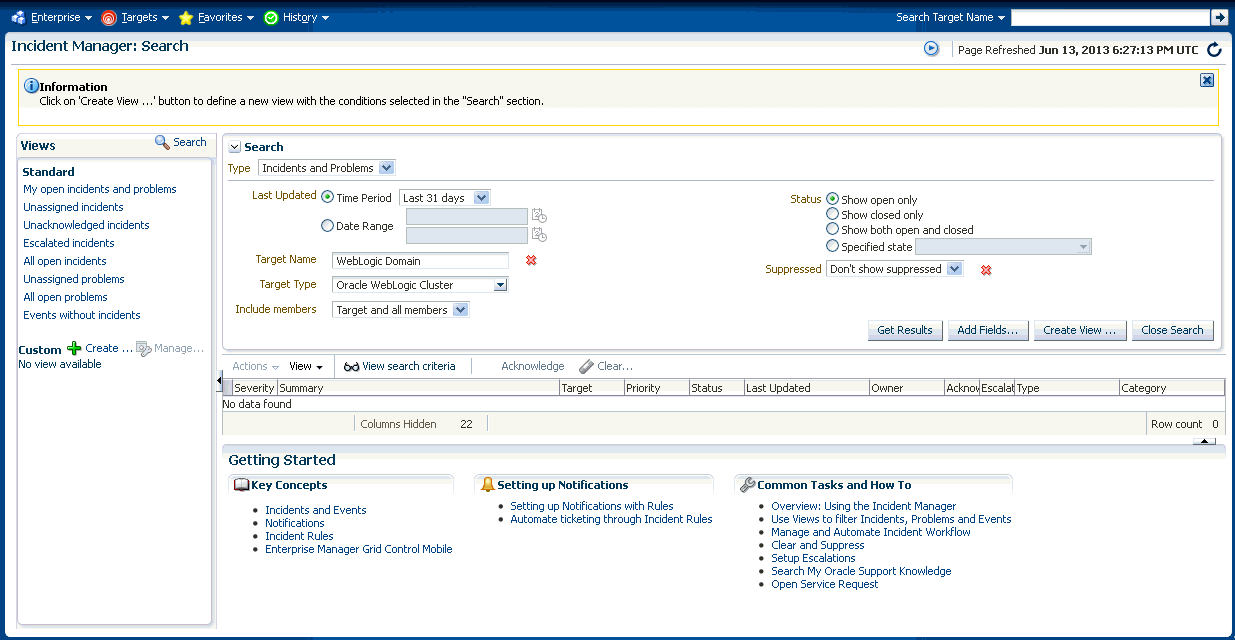
-
Click Add Fields... and then choose Causal analysis update. The Causal analysis update displays as additional search criteria.
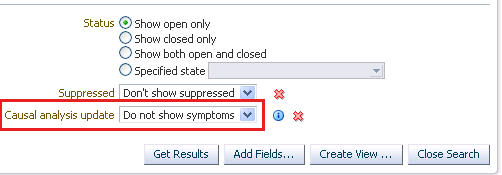
-
Choose 'Do Not Show Symptoms' from the list of available criteria. This will automatically exclude incidents that have been marked as 'symptom'. Incidents that are not marked as symptom or root cause will be included as long as it matches any other criteria you may have specified.

-
Click Create View, enter a View Name when prompted, and then click OK.
Showing RCA Results in an Incident Detail
An incident that is a root cause or symptom will be identified prominently as part of the details of the incident in Incident Manager. In addition, in case the incident is a symptom, a Causes section will be added to identify the root cause(s) of the incident. In case the incident has, in turn, caused other target down incidents, an Impacted Targets section will also be added to show the targets that have been affected, that is. other targets that are down as a result of the original target down. The following figure shows the incident detail.
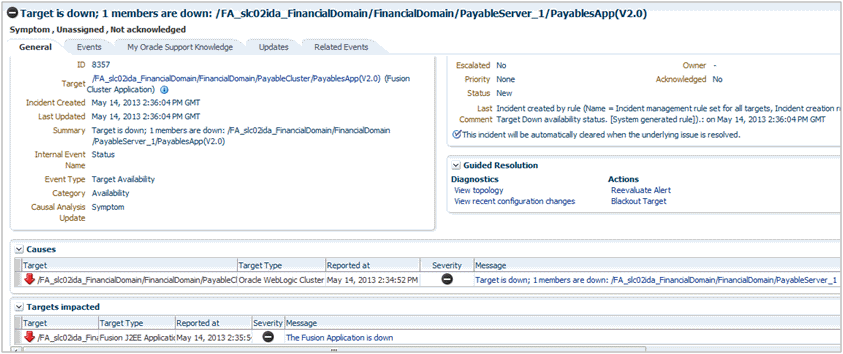
3.4.8.4 Leveraging RCA Results in the System Dashboard
In the System Dashboard, you can use the RCA results to exclude symptom incidents from the Incidents table so administrators can focus their attention on incidents that are root cause or have not been caused by other target down events.
To exclude Symptom Incidents:
-
In the System Dashboard, click on the View option that is accessible from the upper left hand corner of the Incidents and Problems table.
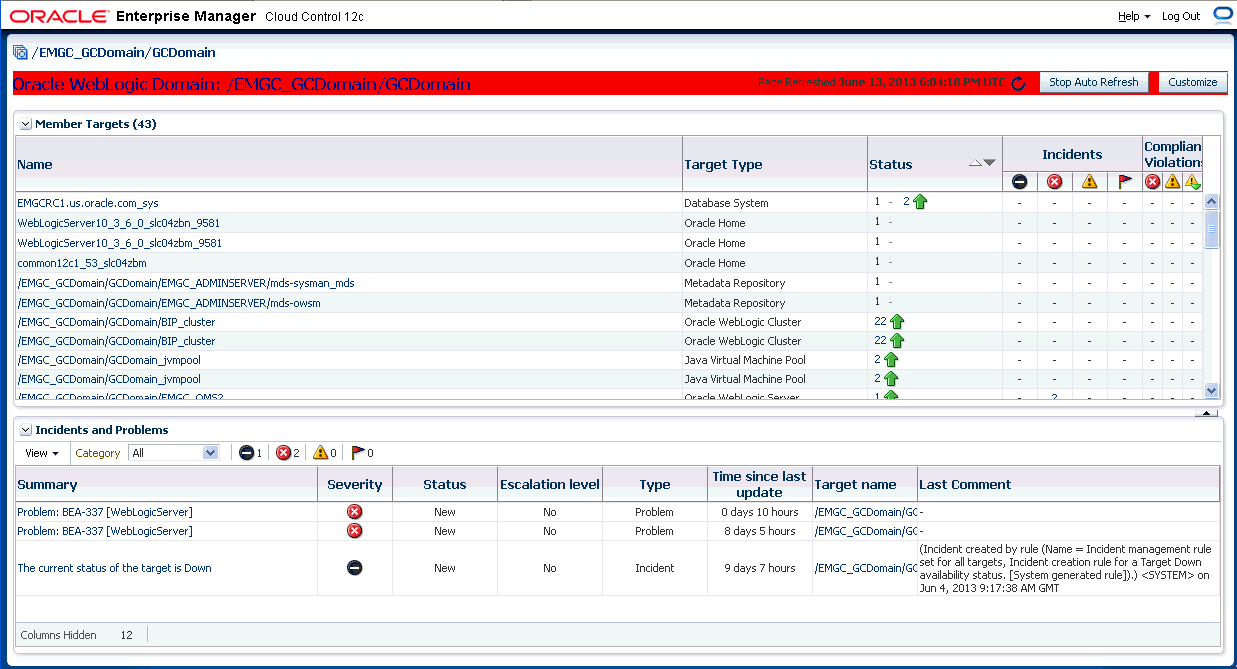
-
Choose the option to 'Exclude symptoms'. Alternatively, you can also choose the option 'Cause only' show only shows target down incidents that have been identified as cause of other target down incidents. Regardless of the option chosen, incidents that have not been marked as symptom or root cause will continue to be displayed.
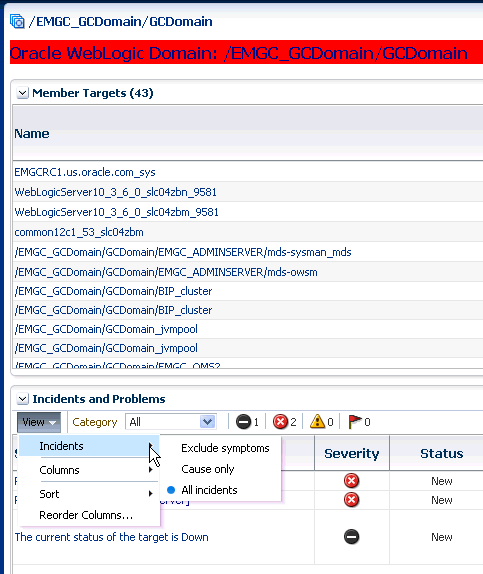
3.4.8.5 Creating a Rule to Update Incident Priority for Non-symptom Events
-
Create an event rule to select only non-symptom events.
-
When adding an action, select the priority to be set for incidents associated with the non-symptom events selected above.
3.4.8.6 Creating Incidents On Non-symptom Events
You can leverage Incident Manager's RCA capability creating rule sets that generate incidents. For monitoring situations where a high number of symptom target down events are generated, but only a few non-symptom target down events, you can create rule sets that generate incidents and send notifications only for non-symptom events.
To create a rule set that creates incidents for non-symptom target down events:
-
From the Setup menu, select Incidents, then select Incident Rules.
-
Click Create Rule Set... You then create the rule as part of creating the rule set.
-
Select the rule set that will contain the new rule. Click Edit... in the Rules tab of the Edit Rule Set page, and then:
-
Click Create ...
-
Select "Incoming events and updates to events."

-
Click Continue. The Create New Rule : Select Events dialog displays.
-
In the Advanced Selection Options region, choose Causal analysis update. Three causal event options display.
event is marked as cause: A target down is considered a cause if other targets depending on it are down.
event is marked as a symptom: A target down is considered a symptom if a target it depends on is also down.
event is not a cause and not a symptom: A target down is neither a cause or symptom.
By selecting one or more options, you can filter out extraneous target down events and focus on those target availability events that pertain to targets with interdependencies. To create an incident for only non-symptom events, choose event is marked as cause and event is not a cause and not a symptom.

Click Next.
-
On the Create New Rule : Add Actions page, click Add. The Add Conditional Actions page displays.
-
In the Create Incident or Update Incident region, choose Create Incident.
-
Specify the remaining assignment and notification details and click Continue.
-
Complete the remaining Create Rule Set wizard pages. See "Creating a Rule Set" for more information on creating rule sets.
-
3.4.8.7 Introducing a Time Delay
As mentioned previously, Incident Manager RCA is an iterative process whereby incoming target down events are continually being evaluated, resulting in updates to causal analysis states. Over a period of time (minutes), a root cause may or may not remain a root cause depending on incoming target down events. The original target down event may later be classified as a symptom. To allow time for target down events to be reported, analyzed, and then acted upon (such as creating an incident), you can define an event evaluation time delay when creating a rule set.
In the previous example, where incidents are created for non-symptom events, without a time delay in the rule, there could potentially be an incident created for a non-symptom event that eventually becomes a symptom.
To add a time delay to the rule:
-
From the Create Rule Set wizard Add Actions page, click Add or Edit (modify an existing rule). The Add Conditional Actions page displays.
-
In the Conditions for Actions region, choose Only execute the actions if specified conditions match. A list of conditions displays.
-
Choose Event has been open for specified duration.
-
Specify the desired time delay.

-
Click Continue and complete the remaining steps in the wizard.
3.5 Moving from Enterprise Manager 10/11g to 12c
Enterprise Manager 12c incident management functionality leverages your existing pre-12c monitoring setup out-of-box. Migration is seamless and transparent. For example, if your Enterprise Manager 10/11g monitoring system sends you emails based on specific monitoring conditions, you will continue to receive those emails without interruption. To take advantage of 12c features, however, you may need to perform additional migration tasks.
Important:
Alerts that were generated pre-12c will still be available. For example, critical metric alerts will be available as critical incidents.When you migrate to Enterprise Manger 12c, all of your existing notification rules are automatically converted to rules. Technically, they are converted to event rules first with incidents automatically being created for each event rule.
In general, event rules allow you to define which events should become incidents. However, they also allow you to take advantage of the Enterprise Manager's increased monitoring flexibility.
For more information on rule migration, see the following documents:
-
Appendix A, " Overview of Notification in Enterprise Manager Cloud Control" section "Migrating Notification Rules to Rule Sets" in the Enterprise Manager Cloud Control Upgrade Guide.
-
Chapter 29 "Updating Rules" in the Enterprise Manager Cloud Control Upgrade Guide.
The Create Enterprise Rule Set resource privilege is now required in order to edit/create enterprise rule sets and rules contained within. The exception to this is migrated notification rules. When pre-12c notification rules are migrated to event rules, the original notification rule owners will still be able to edit their own rules without having been granted the Create Enterprise Rule Set resource privilege. However, they must be granted the Create Enterprise Rule Set resource privilege if they wish to create new rules. Enterprise Manager Super Administrators, by default, can edit and create rule sets.
Monitoring: Common Tasks
The following sections provide "how-to" examples illustrating common tasks for incident/monitoring setup and usage.
Setting Up an Email Gateway
In order for Enterprise Manager to send email notifications to administrators, it must access an available email gateway within your organization. The instructions below step you through the process of configuring Enterprise Manager to use a designated email gateway.
-
Enterprise Manager Administrator
-
User must have Super Administrator privileges.
For more information, see "Setting Up a Mail Server for Notifications".
-
From the Setup menu, select Notifications, then select Notification Methods.
The Notification Methods page displays.
-
Enter the requisite parameters. The following examples illustrate valid parameter values.
-
Outgoing Mail (SMTP) Server - smtp01.example.com:587, smtp02.example.com
-
User Name - myadmin
-
Password - ******
-
Confirm Password - ******
-
Identify Sender As - Enterprise Manager
-
Sender's Email Address - mgmt_rep@example.com
-
Use Secure Connection - No: Email is not encrypted. SSL: Email is encrypted using the Secure Sockets Layer protocol. TLS, if available: Email is encrypted using the Transport Layer Security protocol if the mail server supports TLS. If the server does not support TLS, the email is automatically sent as plain text.
-
-
Ensure Enterprise Manager can connect to the specified email gateway. Click Test Mail Servers. Enterprise Manager displays a success/failure message. Click OK to return to the Notification Methods page.
-
Once Enterprise Manager verifies that it can successfully connect to your email gateway, click Apply.
At this point, you have configured Enterprise Manager to use your corporate email gateway. Enterprise Manager can now notify registered users while monitoring conditions within your managed environment.
"Setting Up a Notification Schedule"
Sending Email for Metric Alerts
Configure Enterprise Manager to send email to administrators when a metric alert threshold is reached. In this example, you want to send an email notification when a metric alert is raised when CPU Utilization reaches Critical severity.
-
IT Operator/Manager
-
Enterprise Manager Administrator
-
Set up an Email Gateway that allows Enterprise Manager to send email to administrators.
For more information, see "Setting Up a Mail Server for Notifications".
-
Metric thresholds have been set for CPU Utilization.
-
User's Enterprise Manager account has been granted the appropriate privileges to manage incidents from his managed system.
For information, see "Setting Up Administrators and Privileges".
-
User's Enterprise Manager account has notification preferences (email and schedule). This is required not just for the administrator who is creating/editing a rule, but also for any user who is being notified as a result of the rule action.
For more information, see "Setting Up a Notification Schedule".
-
From the Setup menu, select Incidents, then select Incident Rules.
-
Click Create Rule Set.
-
Enter a name and description for the rule set.
-
In the Targets tab, select All targets that the rule set owner can view.
Alternative:
Having the rule set apply to specific targets/group.Although we have chosen to have the rule set apply to all targets in this example, alternatively, you can have a rule set apply only to specific targets or groups.
To do this:
-
From the Targets tab, select Specific targets.
-
From the Add drop-down menu, choose Groups or Targets
-
Click Add. The Target selector dialog displays.
-
Either search for a target/group name or select one from the table.
-
Click Select once you have chosen the targets/groups of interest. The dialog closes and the targets appear in the Specific Targets list.
-
-
In the Rules tab, click Create. The Select Type of Rule to Create dialog appears.

-
Select Incoming events and updates to events, and click Continue.
-
On the Select Events page, set the criteria for events based on which the rule should act. In this case, choose Metric Alert from the drop down list.
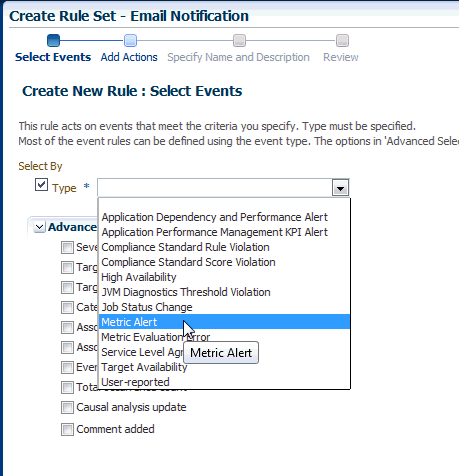
Click Next.
-
Select the Specific events of type Metric Alert option. A metric selection area displays:
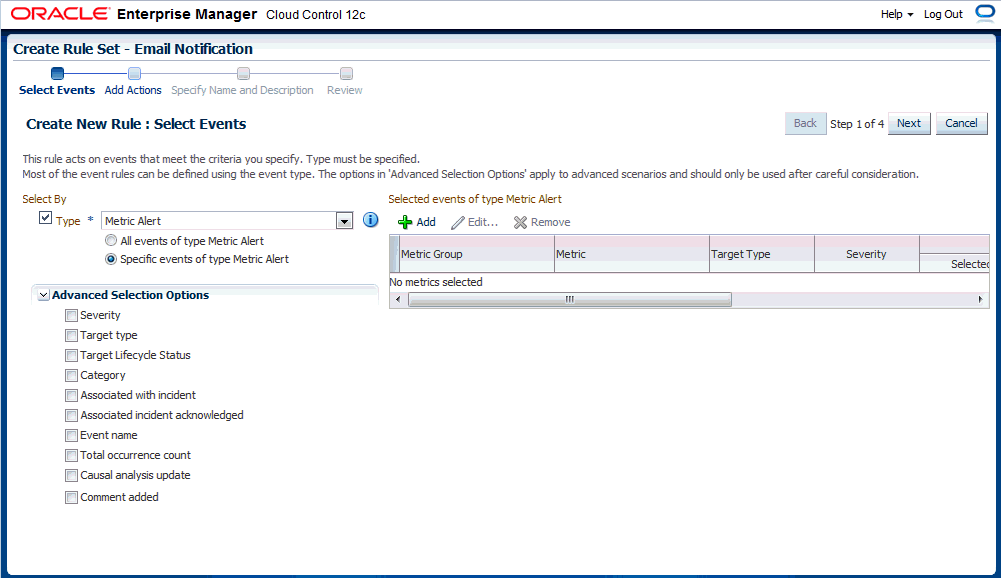
In this example, we only want to send notifications for CPU % Utilization greater reaches the defined Critical threshold.
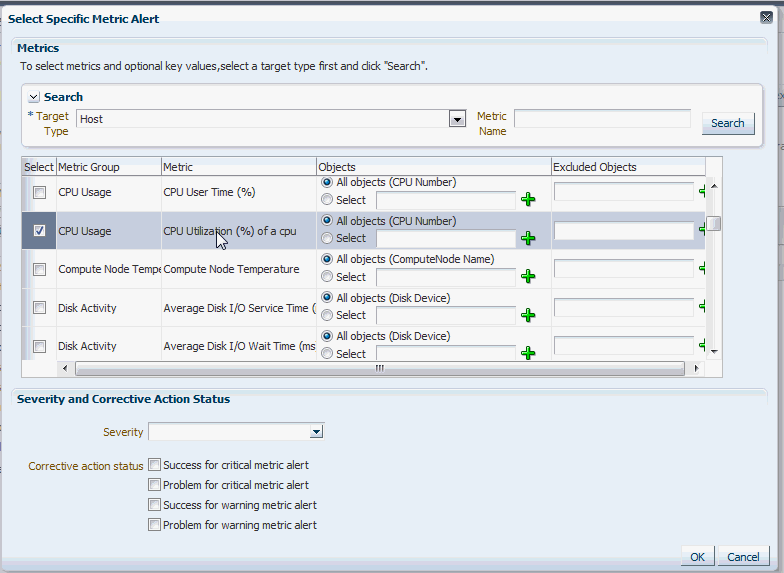
-
Choose Severity Critical from the drop down menu.
Click OK.
-
Click Next.
-
On the Add Actions page, click Add and add actions to be taken by the rule. In the Notifications section, enter the email addresses where the notifications must be send. Click Next.
Multiple conditional actions can be specified and evaluated sequentially (top down) in the order you add them.
Alternative:
Sending email notifications to mailing list.In addition to specifying email addresses, you may also specify defined Enterprise Manager administrators. Mailing distribution lists can also be specified to notify entire categories of users. Using mailing lists allows you to change who gets notified without having to update individual rule sets.
-
On the Specify Name and Description page, enter a name and description for the rule. Click Next.
-
On the review page, review the details, and click Continue.
-
On the Create Rule Set page, click Save.
At this point, you have created a new rule set that will send an administrator email a notification whenever the CPU Utilization reaches the Critical metric threshold. To subscribe to this rule set, see "Subscribing to Receive Email from a Rule" for further instructions.
-
How Do I Set Up Email Notifications for Other Administrators
-
Add/Update/Delete Email Addresses and Define a Notification Schedule
Sending SNMP Traps for Metric Alerts
You want to configure Enterprise Manager to send event information (for example, a metric alert) via SNMP trap to an HP Openview console. This is done in two phases
-
Create a notification method to send the SNMP Trap
-
Create an incident rule to send an SNMP trap when a metric alert is raised.
-
Enterprise Manager Administrator
-
User must have Super Administrator privileges.
For more information, see "Setting Up a Mail Server for Notifications".
Create a notification method based on an SNMP Trap.
-
From the Setup menu, select Notifications, then select Notification Methods.
The Notification Methods page displays.
-
From the Add drop-down menu, choose SNMP Trap and then click Go. The Add SNMP Trap page displays.
You must provide the name of the host (machine) on which the SNMP master agent is running and other details as shown in the following graphic.
The following examples illustrate valid parameter values.
-
Click Test SNMP Trap to validate the SNMP trap settings. Enterprise Manager displays a success/failure message. Click OK to return to the Add SNMP Trap page.
-
Click OK to return to the Notification Methods page.
-
Click OK to add the new SNMP Trap-based notification method.
Create an incident rule to send an SNMP trap when a metric alert is raised.
-
From the Setup menu, select Incidents, then select Incident Rules.
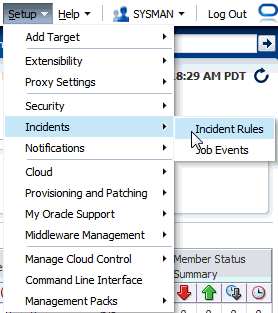
The Incident Rules - All Enterprise Rules page displays.
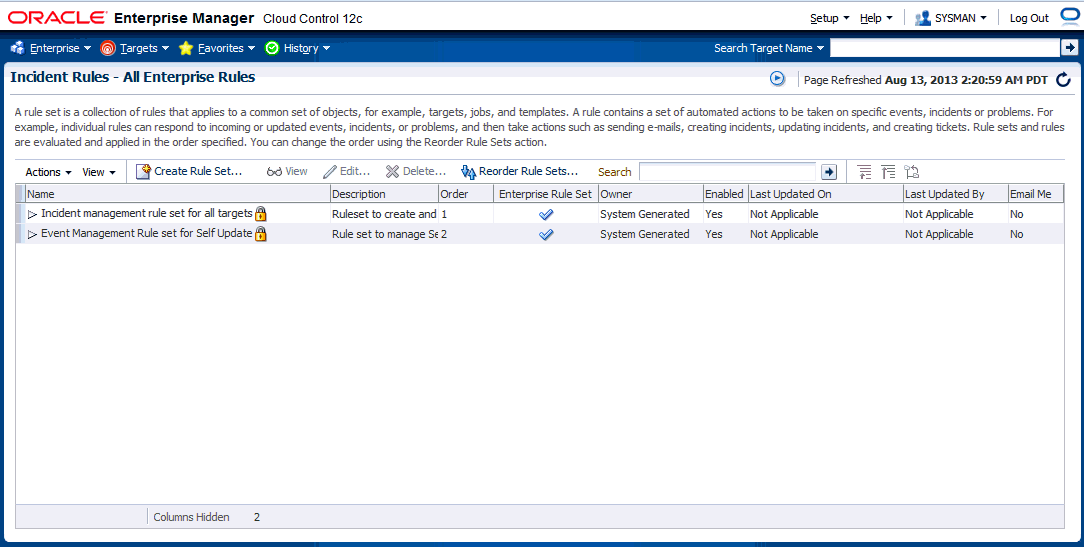
-
On the Incident Rules - All Enterprise Rules page, click Create Rule Set... The Create Rule Set page displays.
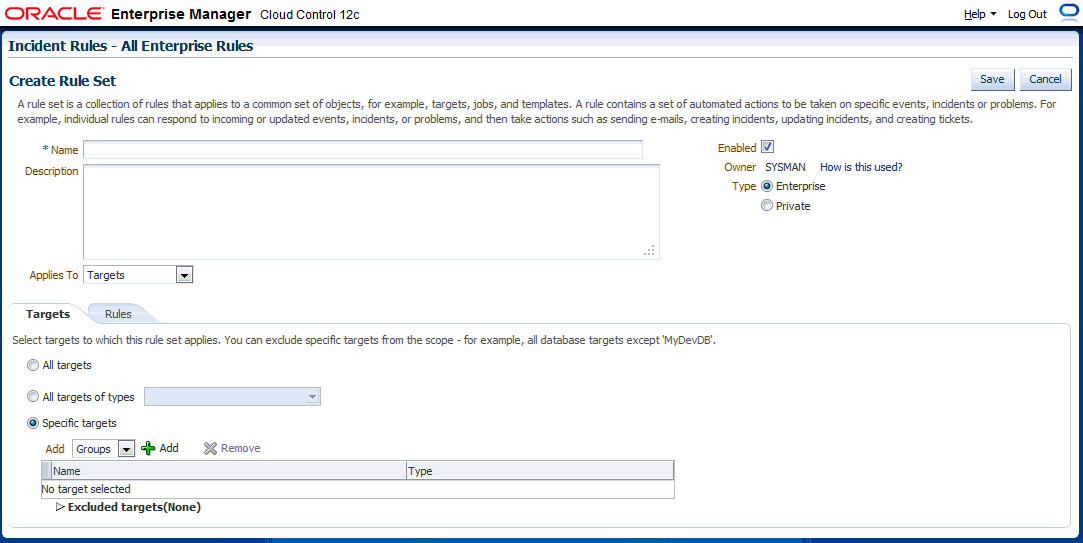
-
Enter the rule set Name, a brief Description, and select the type of source object the rule Applies to (Targets).
-
Click on the Rules tab and then click Create...
-
On the Select Type of Rule to Create dialog, select Incoming events and updates to events and then click Continue.
-
On the Select Events page, set the criteria for events based on which the rule should act. In this case, choose Metric Alert from the drop down list.
Click Next.
-
Select the Specific events of type Metric Alert option. A metric selection area displays:
In this example, we only want to send notifications for CPU % Utilization greater reaches the defined Critical threshold.
-
Choose Severity Critical from the drop down menu.
Click OK.
-
Click Next.
-
On the Create New Rule : Add Actions page, click Add. The Add Conditional Actions page displays.
-
In the Notifications section, under Advanced Notifications, select an existing SNMP trap notification method as shown in the following graphic.
For information on creating SNMP trap notification methods, see "Sending SNMP Traps to Third Party Systems".
-
Click Continue to return to the Create New Rule : Add Actions page.
-
Click Next to go to the Create New Rule : Specify Name and Description page.
-
Specify a rule name and a concise description and then click Next.
-
Review the rule definition and then click Continue add the rule to the rule set. A message displays indicating the rule has been added to the rule set but has not yet been saved. Click OK to close the message.
-
Click Save to save the rule set. A confirmation is displayed. Click OK to close the message.
At this point, you have created an incident rule set that instructs Enterprise Manager to send an SNMP trap to a third-party system whenever a metric alert is raised (%CPU Utilization).
Sending Events to an Event Connector
You want to send event information from Enterprise Manager to IBM Tivoli Netcool/OMNIbus using a connector. To do so, you must create an incident rule that invokes the IBM Tivoli Netcool/OMNIbus Connector connector.
-
System Administrator
-
IT Operator
-
User must have the Create Enterprise Rule Set resource privilege and at least View privileges on the targets where events are to be forward to Netcool/OMNIbus.
For more information, see "Setting Up a Mail Server for Notifications".
-
The IBM Tivoli Netcool/OMNIbus connector must be installed and configured.
For more information, see the Oracle® Enterprise Manager IBM Tivoli Netcool/OMNIbus Connector Installation and Configuration Guide.
-
From the Setup menu, select Incidents, then select Incident Rules.
The Incident Rules - All Enterprise Rules page displays.
-
Click Create Rule Set.
-
Enter a name and description for the rule set.
-
In the Targets tab, select All targets that the rule set owner can view.
Having the rule set apply to specific targets/groups:
Although we have chosen to have the rule set apply to all targets in this example, you can alternatively have a rule set apply only to specific targets or groups.To do this:
-
From the Targets tab, select Specific targets.
-
From the Add drop-down menu, choose Groups or Targets
-
Click Add. The Target selector dialog displays.
-
Either search for a target/group name or select one from the table.
-
Click Select once you have chosen the targets/groups of interest. The dialog closes and the targets appear in the Specific Targets list.
-
-
In the Rules tab, click Create. The Select Type of Rule to Create dialog appears.
-
Select Incoming events and updates to events, and click Continue.
-
On the Select Events page, set the criteria for events based on which the rule should act. In this case, choose Metric Alert from the drop down list.
Click Next.
-
Select the Specific events of type Metric Alert option. A metric selection area displays:
In this example, we only want to send notifications for CPU % Utilization greater reaches the defined Critical threshold.
-
Choose Severity Critical from the drop down menu.
Click OK.
-
Click Next. The Add Actions page displays.
-
Click Add. The Add Conditional Actions page displays.
-
Select one or more connector instances listed in the Forward to Event Connectors section and, click > button to add the connector to the Selected Connectors list and then click Continue.The Add Actions page appears again and lists the new action.
-
Click Next. The Specify Name and Description page displays.
-
Enter a name and description for the rule, then click Next. The Review page displays.
-
Click Continue if everything appears correct.
An information pop-up appears that states, "Rule has been successfully added to the current rule set. Newly added rules are not saved until the Save button is clicked."
You can click Back and make corrections to the rule if necessary.
At this point, you have created a rule that invokes the IBM Tivoli Netcool/OMNIbus Connector connector when a metric alert is raised.
Sending Email to Different Email Addresses for Different Periods of the Day
Your worldwide IT department operates 24/7. Support responsibility rotates to different data centers across the globe depending on the time of day. When Enterprise Manager sends an email notification, you want it sent to the administrator currently on duty (normal work day), which in this situation changes depending on the time of day.
There are four adminstrators to handle Enterprise Manager notification:
-
ADMIN_ASIA
-
ADMIN_EU
-
ADMIN_UK
-
ADMIN_US
You want the notifications to be sent to specific administrators during their normal work hours.
-
System Administrator
-
IT Operator
-
Email addresses have been defined for all administrators you want to send email nofifications.
For more information, see "Defining E-mail Addresses".
-
You must have Super Administrator privileges.
-
All administrators who are to receive email notifications have been defined.
-
From the Setup menu, select Notifications, then select My Notification Schedule.
The Notification Schedule page displays.
-
Specify the administrator who's notification schedule you wish to edit and click Change. The selected administrator's notification schedule displays. You can click the search icon (magnifying glass) for a list of available administrators.
-
Click Edit Schedule Definition. The Edit Schedule Definition: Time Period page displays. The Edit Existing Schedule option is chosen by default. If necessary, modify the rotation schedule.
-
Click Continue. The Edit Schedule Definition: Email Addresses page displays.
-
Follow the instructions on the Edit Schedule Definition: Email Addresses page to adjust the administrator's notification schedule as required.
-
Click Finish once the notification schedule changes for the selected administrator are have been made. You are returned to the Notification Schedule page.
-
Repeat this process (steps two through six) for each administrator until all four administrators' notification schedules are in sync with their normal workdays.
You have created a notification schedule where administrators in different time zones across the globe are only sent alert notifications during their assigned work hours.