5 Using Derived Associations
Effective management of IT infrastructure requires knowledge of the relationships between IT entities. Best practices such as those described by ITIL (Information Technology Infrastructure Library) rely on capturing and using such relationships.Enterprise Manager Cloud Control 12c extends the kinds of relationships being supported and adds a declarative mechanism by which these relationships can be maintained. It also determines the membership of entities in a system based on relationships. Based on accurate relationships, various Enterprise Manager applications and components can support customer uses such as:
-
Dependency analysis.
For instance, to understand the impact (to applications and infrastructure) of shutting down a host.
-
Topology viewer.
-
Change management.
For instance, tracking the source of cloned databases such as from test to production instances.
-
End-to-end performance analysis, in which interdependencies between application components must be known in order to analyze and isolate issues.
-
Change tracking of relationships, such as changes in the way VM resources are allocated.
This chapter covers the following:
5.1 Introduction
In Enterprise Manager, the concept of a relationship is internally referred to as an association. An association (association instance) represents a relationship between two managed entities and specifies three values, namely, source, destination, and association type. For instance, in ”database1 exposed_by listener1”, database1 is the source, listener1 is the destination, and ”exposed_by” is the association type.
As an plug-in developer, you are responsible for defining those association types that apply to your managed entity types and for verifying that the correct associations (association instances) are present.
5.2 Understanding Enterprise Manager Association Concepts
This section describes association derivation rules, which provide a concise declarative means of defining association types. Association derivation (so called because the existence of associations is derived from collected data) provides a mechanism by which developers can cause association instances to be created and removed based on data collected from a target.
The association derivation mechanism allows you to keep the association consistent with the collected configuration data and to determine associations centrally based on all known data (instead of being done by agent logic, which has access to less data).
5.2.1 Using Association Derivation
To use association derivation, the developer generally performs the following:
-
Specify the logic to run after the collection of target configuration.
The logic derives a set of association instances in the form of triples that specify the source managed entity GUID, association type, and destination managed entity GUID. For instance, the association derivation logic for targets of type oracle_listener could return triples that represent associations between the listener and each database for which it listens.
-
Create and run a SELECT statement that contains the logic used to derive the triples.
Each returned row contains association type, source, and destination columns and represents an association that should exist.
-
Register the derivation logic against an Enterprise Configuration Management snapshot type.
After every snapshot collection, the registered logic is invoked. Input to the logic is the GUID of the target for which the data was collected.
When the association derivation logic for snapshot S of target T is executed, the derived associations replace the previously derived associations for snapshot S of target T. For example, if associations A1 and A2 were collected yesterday and only A1 is collected today, then A2 is effectively deleted.
5.3 Using Association Derivation Rules Management
Enterprise Manager Cloud Control 12c extends the use of associations by Enterprise Manager components and enhances the overall association framework. It introduces new consumers of associations, including system stencils and the topology viewer.
Association framework enhancements include the treatment of associations as configuration data. Enterprise Configuration Management features such as change tracking and saved snapshots now apply to associations as well as to traditional configuration data. Associations can now specify source and destination target components, as well as target GUIDs.
5.3.1 About Out-of-Box Association Types
Enterprise Manager provides a common set of association types that should meet the needs of most plug-in developers. As a plug-in developer, you are encouraged to become familiar with these association types and use them if applicable. You should also update the Table of Integrators and Documents with links to the documents describing your association types and your usage of all association types (allowed_pairs).
The following diagram shows the core association type hierarchy.
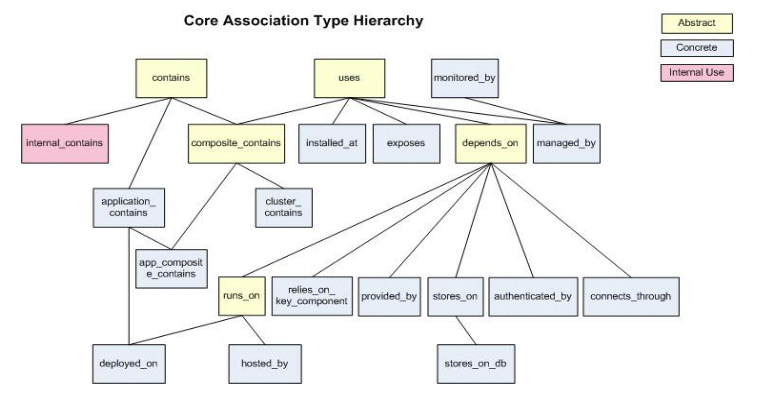
5.3.2 Overview of Plug-in Developer Responsibilities
As a plug-in developer, you are responsible for the following steps with regard to derived associations:
-
Identify all associations that need to be represented for any managed entities (MEs) that you own.
This generally includes any containment or dependency associations between an ME you own and any other MEs. For each kind of association identified, you may need to coordinate with the owner of the related ME type to determine who should be responsible for assuring that association instances of that type are kept up to date. Some associations (in particular,
hosted_byandmanaged_by) are automatically maintained by Enterprise Manager, so association derivation rules should not be used for these. -
Understand the set of out-of-box association types that are shipped with Enterprise Manager and ensure the use of the most appropriate type.
For more information, see Section 5.3.1, "About Out-of-Box Association Types".
-
Provide a query that returns the correct associations and performs acceptably.
If needed configuration data is not being collected, you must also add such collections to assure acceptable performance. Your rules must identify the configuration tables on which the rule query depends so that the evaluation is triggered when needed.
-
Ensure that association derivation rules are used to (declaratively) describe the associations that are to exist based on configuration data that resides in the repository.
Rules are triggered by configuration collections (where target property changes are also treated as a configuration collection).
5.3.3 Maintaining Performance
Because the evaluation of derivation rules may be frequent, any poor performance of the rule queries can be problematic. Rule authors must ensure that any needed indexes are present and that they test query performance based on the specific queries that are generated for each trigger.
In particular, testing of the rule query must be done for each trigger because each trigger causes the execution of a different query. Note how rule query return values are bound to a given target globally unique identifier (GUID) depending on your triggers.
You must have indexes that will make use of these bindings. Furthermore, queries should be written in such a way that they would not prevent the push of bindings from outside into your queries.
5.4 About Overlapping Associations
It is possible for more than one rule to derive the same association, although usually you should avoid creating such overlapping rules. This section describes what happens when an association is derived by multiple rules and includes suggestions on when to avoid this and how.
5.4.1 Understanding Overlap Between Associations Derived by Rules
When more than one rule derives the same association, that association continues to exist until each rule no longer derives it. Sometimes, this is what you want. For instance, suppose each of two application target types has knowledge of both the Oracle WebLogic Server on which it runs and the database it accesses. Based on that knowledge, each has a way to derive an association between the Oracle WebLogic Server and the database. If either rule derives the association, that association is real and should exist. Only when both rules no longer derive the association can you be sure that the association no longer exists.
The "exists when any rule derives it" semantics may not be what you intend. Consider two rules that could be defined for the installed_on association between the database and Oracle home. Both access the same data, but one is triggered by a property change to the Oracle home and the other by a change to the database. As soon as either rule determines the relationship is gone, the association should be deleted. In such a case, you should use a single rule with two triggers.
Suppose you did not take care to write only one rule in such cases. You may think that this mistake is not serious as, after all, the association will soon be deleted. But this is not so, and the bogus association may exist indefinitely. If in the example described above the association was derived using two rules, then the database is upgraded and its OracleHome property gets changed. The association with the old home should be removed, but this will not happen until the other rule is fired. However, nothing about the Oracle Home target has changed, so its rule is not triggered and the association remains. Indeed, it is often the case that only one target is changed and the other remains unchanged for a long period of time. As a general rule of thumb, associations based on data from a specific set of tables should be derived using a single rule with multiple triggers.
Unless there are different reasons for asserting an association exists, you should only use one rule. In such cases, the associations returned by derivation rules should be disjoint. Another way to state this is that for those associations, the set of all rows returned by all rule queries must specify no duplications. An association is identified by source, destination, and association type. So this means that the combination of these three values should be unique.
5.5 Frequently Asked Questions
This section addresses three of the most frequently asked questions:
5.5.1 Which Tables Can I Reference in a Rule Query?
In most cases, your query will just reference configuration (Enterprise Configuration Management) tables using the CM$ views, and so will your triggers. If you refer to other tables and if that data may change independently of Enterprise Configuration Management table changes, then the associations may not be updated when needed. If you have a use case in which a non Enterprise Configuration Management table is referenced where changes to that table must trigger rule evaluation, contact your Oracle representative.
Another consideration is the component in which the table is located. If the table your rule references is not part of the Enterprise Manager core SDK, your plug-in must account for the dependency on that table's plug-in. For example, you must ensure that any object that you reference already exists in the repository using a plug-in dependency mechanism.
5.5.2 Are There Guidelines for When to Use Target Properties?
Target properties are being treated as configuration data and there is an Enterprise Configuration Management snapshot table that is populated for each target type. Some care should be taken in using data from this table:
-
Many target properties are set at discovery time and never modified.
-
Querying name/value pair data can be awkward and take longer than queries on other tables where the data is more structured.
-
If the data is available from both the target properties table and an Enterprise Configuration Management snapshot table, you should use the latter.
-
If you need to add collection of configuration data, you should do so in an Enterprise Configuration Management table, not as a new row in the target properties table.
-
In general, the use of target properties should be avoided and data should be collected and modelled using standard ECM mechanisms.
However, a rule may need to refer to target properties if, for example, the target has no Enterprise Configuration Management collections that can be added. If an association to such a target is to be created, there must be some way to identify it (for example, the rule must refer to its target properties).
If you must use target properties, you should reference MGMT_TARGET_PROPERTIES in your rule query. You can also reference MGMT$TARGET_PROPERTIES in the rule query if the view already performs the join you need to do. However, in triggers you must use the GC$TARGET_PROPERTIES view for the orcl_tp_config snapshot type.
MGMT_TARGET_PROPERTIES should be used in queries because it is more efficient, but may include some properties not available in the GC$ view. Triggering is only available based on property changes in the GC$ view. For example, the GC$ view only includes those properties that are properly registered with Enterprise Manager.
5.5.3 What is the Relationship Between Discovered and Derived Associations?
This is another example of overlapping associations (for more information, see Section 5.4, "About Overlapping Associations"). For instance, you may have discovery logic that discovers an association between targets T1 and T2, plus a rule that derives the same association. Oracle recommends that you do not write two sets of logic to create the same association. In this case it is suggested that:
-
If a derivation rule is needed because the association may change, you should just write the derivation rule.
-
If the association that is discovered will not change until the source or destination is removed, then discovering the association is fine and may be simpler or more efficient.
If you do write two sets of logic to create the same association (discovery logic and derivation rule), then the discovered association will remain and the derivation logic will also assert the existence of that association. If the rule evaluation later determines that the association should no longer exist, the rule's assertion will be removed, but the association will continue to exist unless you manually delete the discovered association.