47 Managing Database Schema Changes
This chapter introduces database change management solution in the following sections:
47.1 Overview of Change Management for Databases
To manage the lifecycle of enterprise applications, an organization will need to maintain multiple copies of an application database for various purposes such as development, staging, production, and testing. Each of these databases must adhere to different processes. For example, for production databases, it is essential to ensure adherence to proper production control procedures. It is vital that administrators have the tools to detect unauthorized changes, such as an index being dropped without the requisite change approvals. In such cases, monitoring changes to production databases day over day or week over week becomes vital.
Database compliance, that is, ensuring that all databases meet the gold standard configuration, is another important aspect of life cycle management. Compliance with organizational standards or best practices ensures database efficiency, maintenance, and ease of operation.
On development databases, developers make changes that the database administrator needs to consolidate and propagate to staging or test databases. The goal is to identify the changes made to development and then make the same changes to staging or test databases taking into account any other changes already in production database.
Typically, most applications will get upgraded over time. Also, most applications are customized by the business user to suit their needs. Application customizations are usually dependent on database objects or PL/SQL modules supplied by the application vendor. The application vendor supplies the upgrade scripts and the customer has very little transparency about the impact of the upgrade procedure on their customizations. When customers test upgrade databases, they can capture a baseline of the application schema before and after the upgrade. A comparison of the before and after baselines will tell the user what modules were changed by the application. This gives them a better idea about how their customizations will be impacted as a result of upgrading their application.
The following are core capabilities of Change Management that allow developers and database administrators to manage changes in database environments:
-
Schema Baseline—A point in time of the definition of the database and its associated database objects.
-
Schema Comparison—A complete list of differences between a baseline or a database and another baseline or a database.
-
Schema Synchronization—The process of promoting changes from a database definition capture in a baseline or from a database to a target database.
-
Schema Change Plans—A means of deploying specific changes from a development environment to one or more target databases.
-
Data Comparison—A list of differences in row data between two databases.
For database versions 9.x and above, the user logged into the database target through Cloud Control must have SELECT ANY DICTIONARY privilege and SELECT_CATALOG_ROLE role for capturing or comparing databases. To perform schema synchronization, the user logging in to the destination database must have the SYSDBA privilege. To create or delete change plans, Cloud Control users need the Manage Change Plans resource privilege, EM_ALL_OPERATOR privilege, VIEW and CONNECT privilege for the targets, and Create resource privilege for the job system and Create new Named Credentials resource privilege. Users can also be granted View and Edit privileges on specific change plans.
When submitting a data comparison job, the user whose credentials are specified for the reference and candidate databases must have SELECT privilege on reference and candidate objects respectively. Additionally, the users needs these privileges: SELECT ANY DICTIONARY, SELECT_CATALOG_ROLE, and CREATE VIEW. When comparing objects with LOB type columns included, the users need to be granted EXECUTE privilege on SYS.DBMS_CRYPTO package, since cryptographic hash value of the columns will be compared instead of actual column values. And in case you specify the comparison to be performed as of a time stamp or system change number (SCN), the users must also be granted FLASHBACK privilege directly on the reference and candidate objects in their respective databases.
Further, the user whose credentials are specified as reference database credentials must be a DBA with EXECUTE privilege on DBMS_COMPARISON program and in case the reference database is not the same as candidate database, the CREATE DATABASE LINK privilege as well.
Database link, comparison definitions, and views may be created in the reference database by the data comparison job. Views may be created in the candidate database. These objects created during the comparison processing will be dropped when the comparison is deleted, unless you specify the option to skip dropping them at the time of deletion.
Data comparison cannot be performed connecting to a remote candidate database as user SYS since SYS credentials cannot be used over database links.
47.2 Using Schema Baselines
A schema baseline contains a set of database definitions captured at a certain point in time. Baselines are stored in the Cloud Control repository as XML documents.
Each baseline must be assigned a unique name. A good practice to name baselines is to match it on the scope of the database objects being captured in the baseline, for example, Financial 11.5.10 or HR Benefits or PO Check Print. A baseline can have a series of versions that have been captured at different points in time. Creating multiple versions of a baseline allows you to track changes to the definitions of a set of database objects over time. You can compare two versions of the same baseline to see the changes that have occurred between them.
When creating a baseline, you also create a corresponding baseline scope specification, which describes the names and the types of database objects and schemas from which they should be captured. When you have created the baseline definition, you can then capture the first version of the baseline by submitting an Cloud Control job. At a later time, or at regular intervals, you can capture additional versions of the same baseline. Each baseline version records the metadata definitions as they exist at the time the version is captured.
Change management schema baselines are retained in the system until you delete them. When you delete a baseline, it is deleted from the system permanently. Delete operation cannot be undone. However, if a baseline may be needed in future, you can first export the baseline to a dump file (created on the repository database server host) and then delete the baseline. Baseline can then be imported back from the file at a later time if needed.
47.2.1 Overview of Scope Specification
A scope specification identifies the database objects to be captured in a baseline. (Scope specifications also identify objects to process in schema comparisons and synchronizations.) Once you have specified the scope of a baseline, you cannot change the scope specification. This restriction ensures that all versions of the baseline are captured using the same set of rules, which means that differences between versions result from changes in the database, not scope specification changes. To capture schema objects using a different scope specification, you must create a new baseline.
Baseline scope specifications take three forms.
-
You can specify schemas and object types to capture. For example, you can capture all Tables, Indexes and Views in schemas APPL1 and APPL2. This form of scope specification is appropriate when there is a well-defined set of schemas that contain your application objects. In addition to schema objects, you can also capture non-schema objects (such as Users, Roles and Tablespaces) and privilege grants to Users and Roles.
-
You can specify schemas to exclude, and object types. This form of scope specification captures objects that are contained in all schemas other than those you specify. For example, you can capture all object types in schemas other than SYSTEM and SYS. This form of scope specification is appropriate when you want to capture all database objects, with the exception of objects contained in Oracle-provided schemas. As with the first form of scope specification, you can also capture non-schema objects and privilege grants.
-
Finally, you can capture individual schema objects by specifying the type, schema and name of each object. This form of scope specification is appropriate when you want to capture a few specific objects, rather than all objects contained within one or more schemas. While capturing individual schema objects, you can also capture non-schema objects and privilege grants.
If you include a non-schema object type, such as User or Role, in a scope specification, all objects of that type are captured. There is no way to capture individual non-schema objects. Figure 47-1 shows the Schema Baselines:Objects page where the scope can be specified.
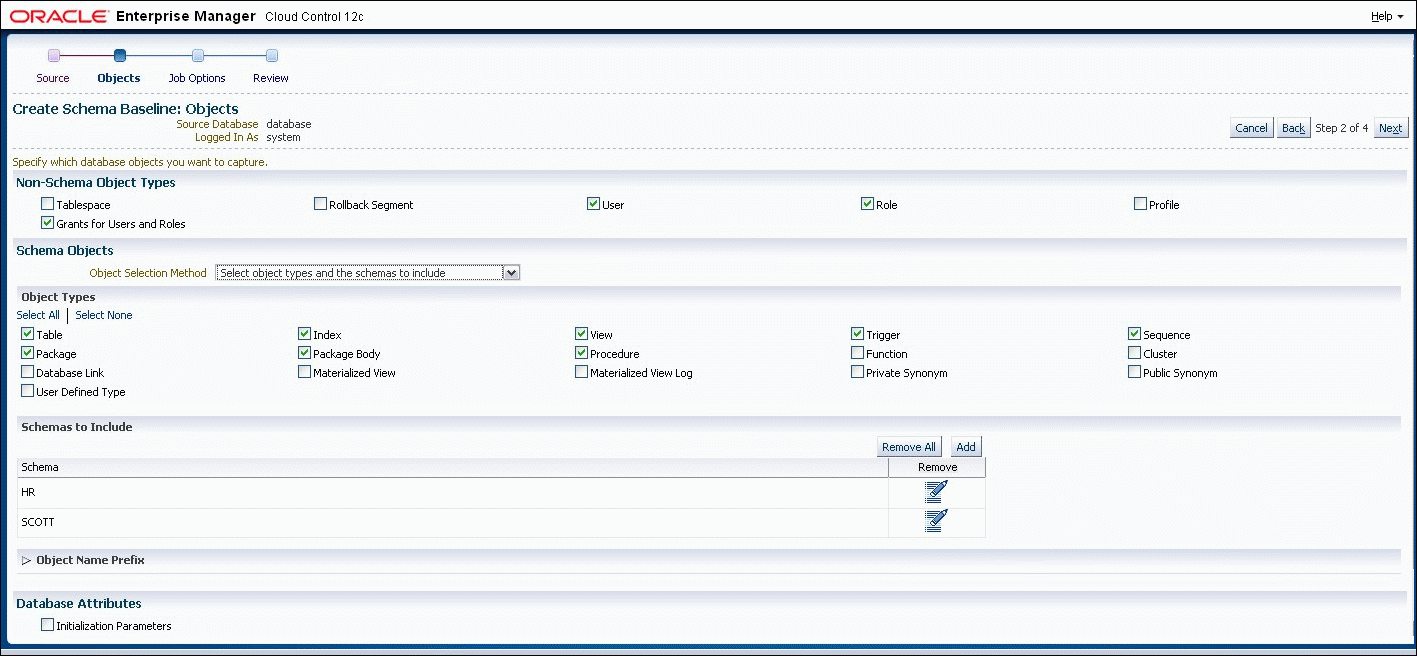
47.2.2 About Capturing a Schema Baseline Version
As the final step of defining a baseline, you specify when to capture the first version of the baseline. You can capture the first version immediately, or at a later time (for example, when the database is not being used in active development work). You can also indicate that additional versions of the baseline should be captured at regular intervals without further intervention on your part.
You can also capture a new baseline version at any time by selecting the baseline and specifying "Recapture Now."
Baselines processed after the initial version generally complete substantially faster than the initial version. Only those objects that have changed are captured in the new version. This also means that the storage required for additional baseline versions is only slightly larger than the storage used by the initial version, assuming a small percentage of objects has changed. Figure 47-2 shows the first version of a schema baseline.
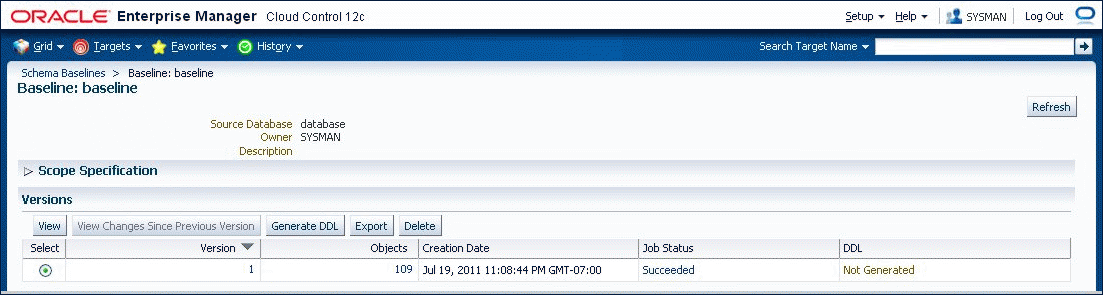
47.2.3 About Working With A Schema Baseline Version
Within a single schema baseline version, you can examine individual object attributes, generate DDL for individual objects, and generate DDL for all the objects in the baseline version. You cannot modify object definitions captured in baseline versions, since they are intended to represent the state of objects at a particular point in time.
-
Viewing a baseline object displays the object's attributes graphically.
-
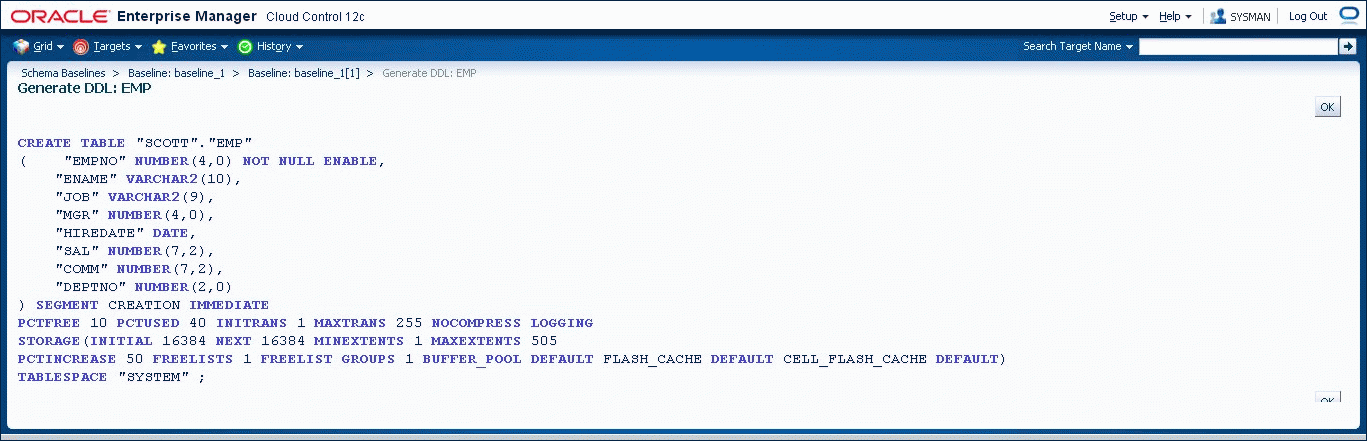
Selecting a baseline object and specifying "Generate DDL" displays the DDL used to create the object. Figure 47-3 shows the DDL generated for a baseline object.
-
Selecting a baseline version and specifying "Generate DDL" generates the DDL for all objects in the baseline version. While an effort is made to create objects in the correct order (for example, creating tables before indexes), the resulting DDL cannot necessarily be executed on a database to create the objects in the baseline version. For example, if you capture all the schema objects contained in schema APPL1, then try to execute the baseline version DDL on a database that does not contain User APPL1, the generated DDL will fail to execute.
Baseline versions are also used with other Database Lifecycle Management Pack applications, such as Compare and Synchronize. You can compare a baseline version to a database (or to another baseline version). You can also use a baseline version as the source of object definitions in Synchronize, allowing you to re-create the definitions in another database.
47.2.4 About Working With Multiple Schema Baseline Versions
When a baseline contains more than one version, you can examine the differences between the versions.
-
To see what has changed between a version and the version that precedes it, select the version and specify "View Changes Since Previous Version." The display shows which objects have changed since the previous version (Figure 47-4), which have been added or removed, and which are unchanged. Selecting an object that has changed displays the differences between the object in the two versions.
-
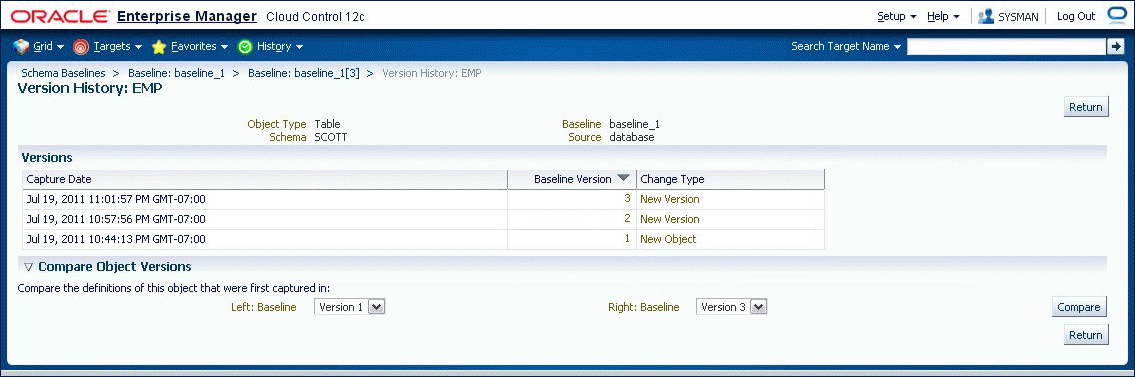
To see how an individual object has changed over all the versions of the baseline, select the object and specify "View Version History." The display identifies the versions in which the object was initially captured, modified, or dropped as shown in Figure 47-5. From this display, you can compare the definitions of the object in any two baseline versions.
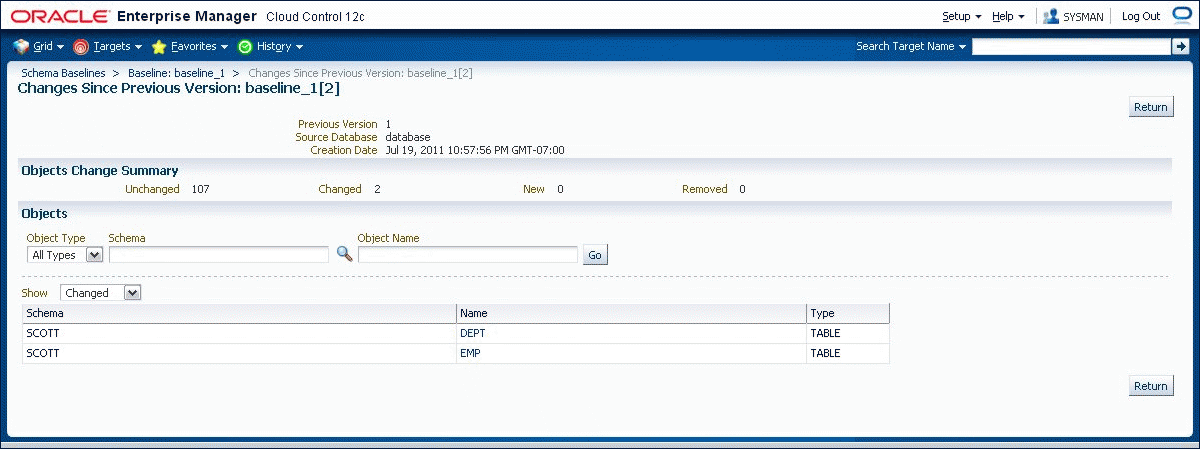
47.2.5 Exporting and Importing Schema Baselines
You can use the export/import baseline functionality for the following:
-
Transferring baselines between two Cloud Control sites with different repositories.
-
Offline storage of baselines. Baselines can be exported to files, deleted, and then imported back from files.
You can select a schema baseline or a version and then export it to a file. The system uses Data Pump for export and import. The dump files and log files are located in the Cloud Control repository database server host. They can be located in directories set up on NFS file systems, including file systems on NAS devices that are supported by Oracle.
47.2.5.1 Creating Directory Objects for Export and Import
To export a schema baseline version from the repository to an export file or import schema baselines from an import file on the repository database server, select the directory object in the repository database for the export or import and specify a name for the export or import file.
To create a new directory object for export or import, do the following:
-
Log in to the repository database as a user with
CREATE ANY DIRECTORYprivilege or the DBA role. -
Create a directory object as the alias for a directory on the repository database server's file system where the baselines are to be exported or where the import dump file is stored.
-
Grant
READandWRITEprivileges on the directory object toSYSMAN.
The newly created directory will be available for selection by Cloud Control administrators for export and import of schema baselines. Data pump log files from the export and import operations are also written to the same directory.
During import, new values can be set for name, owner, and source database. Super administrators can set another administrator as the owner at the time of import.
The export operation does not export job information associated with a baseline. On import, the job status will hence be unknown.
For non-super administrators, the following applies:
-
Non-super administrators can export their own baselines. They can also export a version of baseline owned by another administrator, provided they have the privilege to view the version and see the list of schema objects in that version.
-
At the time of import, a non-super administrator must become the owner of the baseline being imported. A non-super administrator cannot set another administrator as the owner. If the baseline in the import dump file was owned by another administrator, its new owner is set to the logged-in non-super administrator at the time of import.
-
View privileges granted on the baseline to non-super administrators are lost during import and cannot be re-granted after the import, since there is no associated job information.
47.3 Using Schema Comparisons
A schema comparison identifies differences in database object definitions between a baseline or a database and a baseline or a database, or two schemas within a single database/baseline.
A comparison specification is defined by left and right sources, scope, and owner. The scope specification describes the names and types of database object definitions to be included in the comparison and the schemas that contain these object definitions.
Comparisons identify differences in any attribute value between objects of any type. Use comparisons to create multiple versions of a comparison. Each version has a unique version number and a comparison date. Use these versions to associate comparisons of database/schemas made over time.
Comparisons show differences between definitions in the original baseline for your application and those in your current database. After creating a new comparison version, it identifies the differences between the original definitions at the start of the development cycle, and those same definitions at the current time.
Use another comparison specification to compare definitions from your most recent baseline with those in your previous baseline. With each newly created version of this comparison using the comparison specification, that comparison version identifies the differences in the definitions since the previous baseline.
47.3.1 Defining Schema Comparisons
A schema comparison definition consists of left and right sources for metadata definitions, the scope specification, an optional schema map, and comparison options. Once created, a schema comparison definition cannot be modified. This ensures that each version of the schema comparison reflects changes in the databases being compared and not in the comparison's definition.
Schema Comparison Sources
Each comparison has a left source and a right source. The comparison matches object definitions from the left and right sources. A source can be a database or a baseline version.
-
When the source is a database, object definitions are taken directly from the database at the time the comparison version is created.
-
When the source is a baseline, object definitions are taken from the specified baseline version. Using a baseline version allows you to compare a database (or another baseline version) to the database as it existed at a previous point in time. For example, a baseline version might represent a stable point in the application development cycle, or a previous release of the application.
For baseline sources, there are various ways to specify the version to be used.
-
If you want a specific baseline version to be used in all versions of the comparison, specify the baseline version number. This is appropriate for comparing a well-defined previous state of the database, such as a release, to its current state.
-
You can also request that the latest or next-to-latest version be used in the comparison. If you specify "Latest," you can also request that the baseline version be captured before the comparison takes place. This option allows you to capture a baseline and compare it to the other source in a single operation. For example, every night, you can capture a baseline version of the current state of a development database and compare it to the previous night's baseline, or to a fixed baseline representing a stable point in development.
The scope specification for a schema comparison identifies the objects to compare in the left and right sources. Creating a comparison scope specification is the same as creating a baseline scope specification, described in the "Schema Baselines" section. As with baselines, you can specify object types and schemas to compare, or individual objects to compare.
Normally, schema objects in one source are compared to objects in the same schema in the other source. For example, table APPL1.T1 in the left source is compared to APPL1.T1 in the right source.
However, there may be cases where you want to compare objects in one schema to corresponding objects in a different schema. For example, assume that there are two schemas, DEV1 and DEV2, which contain the same set of objects. Different application developers work in DEV1 and DEV2. You can use the optional schema map feature to allow you to compare objects in DEV1 to objects with the same type and name in DEV2.
To add entries to the schema map, expand the "Mapped Objects" section of the comparison "Objects" page. You can create one or more pairs of mapped schemas. Each pair designates a left-side schema and a corresponding right-side schema.
When using a schema map, you can compare objects within a single database or baseline version. In the example above, DEV1 and DEV2 can be in the same database. You specify that database as both the left and right source, and supply the schema map to compare objects in DEV1 to those in DEV2.
You can select several options to determine how objects are compared. These options allow you to disregard differences that are not significant. The options include the following:
-
"Ignore Tablespace" and "Ignore Physical Attributes" – These two options allow you to compare stored objects without regard to the tablespaces in which they are stored or the settings of their storage-related attributes. This is useful when you are comparing objects in databases having different size and storage configurations, and you are not interested in differences related to the storage of the objects.
-
"Match Constraints By Definition" or "By Name" — If you are more interested in the definitions of table constraints – for example, the columns involved in primary or unique constraints – choose "Match Constraints By Definition." This causes constraints with the same definitions to match; their names appear as differences (unless you also choose "Ignore Name Differences"). If the names of constraints are meaningful, choose "Match Constraints By Name." With this choice, constraints with the same names will match and their definitions will appear as differences.
-
"Partitioned Objects: Ignore Partitioning" — Choose this option to ignore partitioning in tables and indexes.
-
"Partitioned Objects: Ignore High Values" — Tables that are otherwise the same might have different partition high values in different environments. Choose this option to ignore differences in high values.
-
"Logical SQL Compare" — Choose this option to ignore meaningless formatting differences in source objects such packages, package bodies, procedures and functions and to ignore white space differences in comments.
-
"Compare Statistics" — Choose this option to compare optimizer statistics for tables and indexes.
-
"Ignore Table Column Position" — Choose this option if tables that differ only in column position should be considered equal.
Creating Comparison Versions
When you have finished defining the comparison, you specify when to create the first comparison version. You can create the first version immediately, or at a later time. You can also schedule new comparison versions at regular intervals.
In addition to scheduling comparison versions, you can create a new comparison version at any time by selecting the comparison and specifying "Repeat Now."
Comparisons processed after the initial version generally complete substantially faster than the initial comparison. Only those objects that have changed on the left or right side are compared in the new version. This also means that the storage required for additional comparison versions is only slightly larger than the storage used by the initial version, assuming a small percentage of objects has changed.
47.3.2 About Working with Schema Comparison Versions
A schema comparison version records the results of comparing the left and right sources in accordance with the scope specification. Objects in a comparison version have one of four states:
-
Left Only – The object is present only in the left source.
-
Right Only – The object is present only in the right source.
-
Identical – The object is present in both left and right sources, and is the same.
-
Not Identical – The object is present in both left and right sources, and is different.
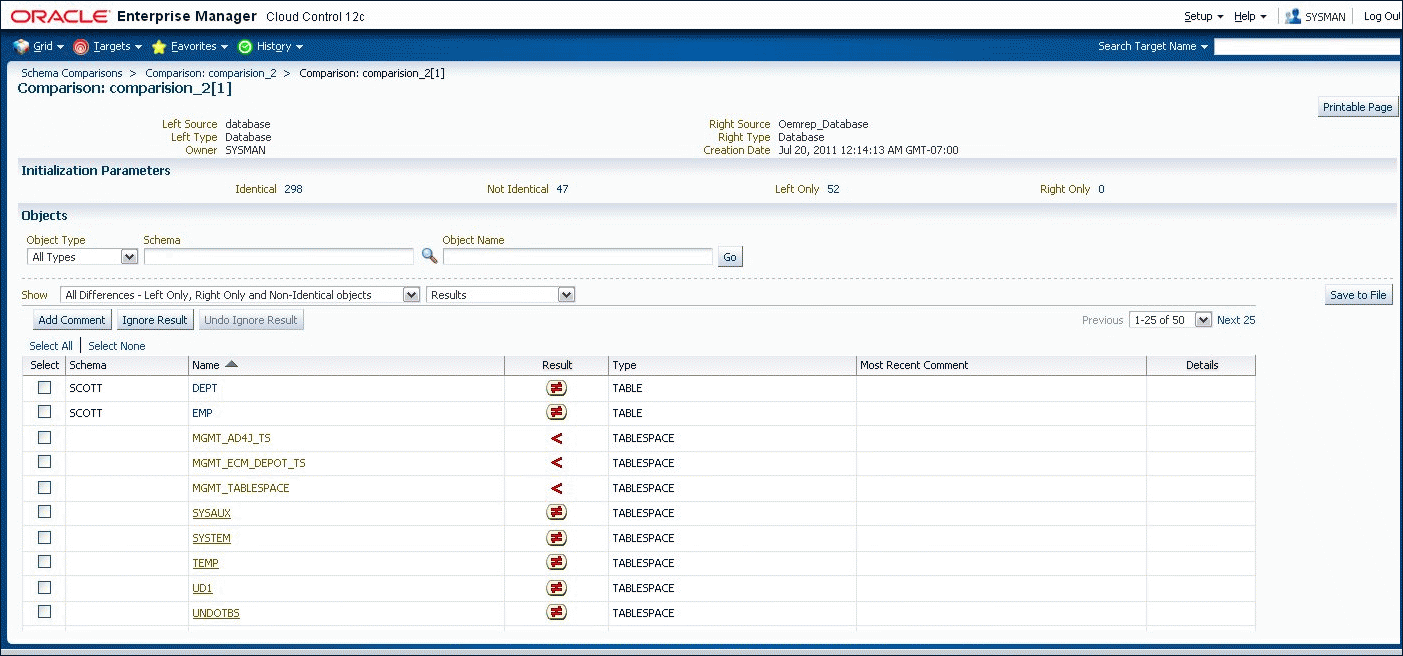
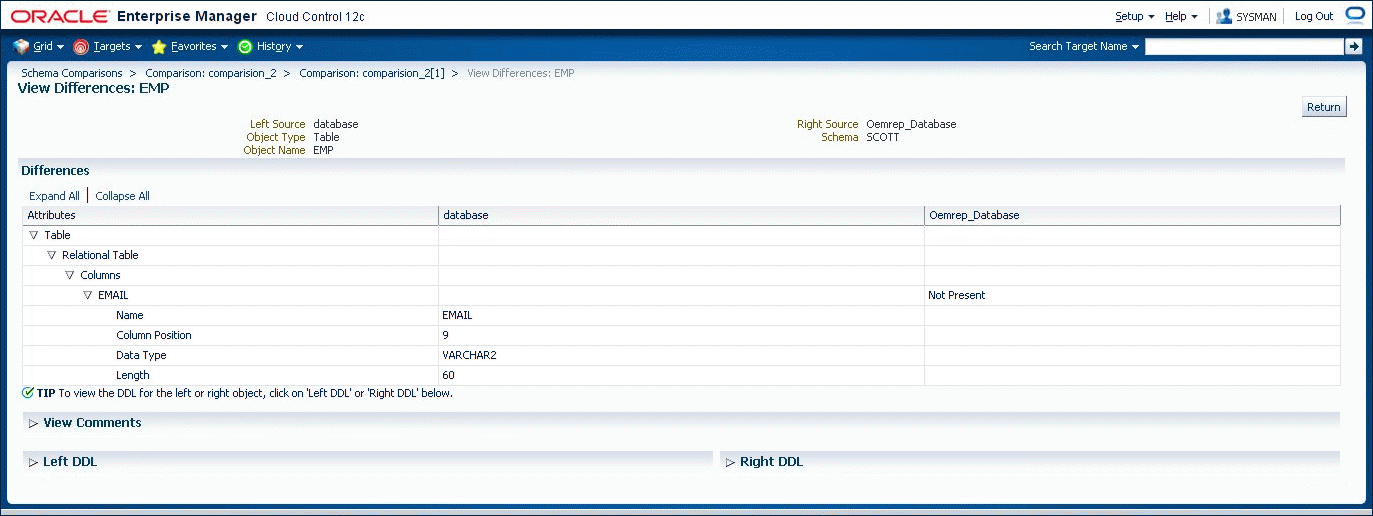
The page lists all versions of a comparison and shows the number of objects in each state within each version. On the Comparison version page shown in Figure 47-6, you can see the objects in each state individually. Objects that are "Not Identical" can be selected to view the differences, and to generate DDL for the left and right definitions as shown in Figure 47-7.
You can take two further actions to record information about objects in a comparison version:
-
You can add a comment to an object. For example, the comment might explain why two objects are different.
-
You can ignore the object. Ignoring the object removes it from lists of comparison version objects. You might ignore an object that is different if you decide that the difference is not important.
47.4 Using Schema Synchronizations
A schema synchronization synchronizes differences in database object definitions between two databases or a baseline and a database. The basic action of a database synchronization is to create or modify selected object definitions in a database to match those in another database or in a baseline.
Synchronizations are generated using synchronization specifications. For synchronizations, the scope specification does not include the names of individual objects. It can only specify the types, and the schemas to be included or excluded. You can additionally supply a prefix to limit the objects selected to those whose names start with that prefix.
Schema synchronizations synchronize differences in any attribute value between objects of any supported type. Use synchronization specifications to create multiple versions of a synchronization. Each version has a unique version number and a synchronization date. Use these versions to associate synchronizations of database/schemas made over time.
47.4.1 About Defining Schema Synchronizations
The synchronization source provides the object definitions (and optionally, the data) from which the destination database is synchronized. A synchronization source may be a database, or a baseline version. If the source is a baseline version, it is not possible to propagate data to the destination, since a baseline does not capture data.
The synchronization destination must always be a database. The purpose of synchronization is to create or modify object definitions in the destination to match those in the source.
The options for specifying which version of a source baseline to use are similar to those used with schema comparisons. You can specify a fixed baseline version, or "Latest" or "Latest-1". If you specify "Latest," you can also request that the baseline version be captured first before synchronizing the destination from it.
When defining a baseline to be used as the source for synchronization, it is important that the baseline contain all the objects to be synchronized. For this reason, the baseline's scope specification should include at least all the schemas and object types that will be synchronized. The baseline should also include User and Role objects, along with privilege grants. A baseline to database synchronization is recommended in environments where changes are expected to be applied to the source database frequently thus necessitating the need for a point-in-time snapshot of the database, i.e. a baseline as the source of the synchronization.
Defining a scope specification for a schema synchronization is similar to defining a scope specification for a schema baseline or comparison. However, there are restrictions on what you can include in the scope specification.
-
You cannot specify individual objects for synchronization. You must specify object types and either schemas to include or schemas to exclude.
-
Certain schemas, such as SYS and SYSTEM, cannot be synchronized.
-
You cannot directly include User and Role objects for synchronization. (However, Users and Roles are automatically included as needed during the synchronization process.)
-
Oracle recommends that the following object types be selected as a group: Table, Index, Cluster, Materialized View, and Materialized View Log.
The scope specification for a synchronization should be carefully tailored to the application. Do not include more schemas than are needed. For example, if you are synchronizing a module of a large application, include only those schemas that make up the module. Do not attempt to synchronize a large application (or the entire database) at one time.
The definition and use of the schema map is the same in schema synchronizations as in schema comparisons. When you use a schema map, object definitions in each schema map are synchronized to the mapped schema in the destination, rather than to the schema with the same name. In addition, schema-qualified references (other than those contained in PL/SQL blocks and view queries) are changed according to the schema map.
For example, assume the schema map has two entries, as follows:
-
DEV1A -> DEV2A
-
DEV1B -> DEV2B
Table DEV1A.T1 has an index, DEV1A.T1_IDX. It also has a foreign key constraint that refers to DEV1B.T2. Synchronize will create objects as follows:
-
Table DEV2B.T2
-
Table DEV2A.T1, with a foreign key reference to table DEV2B.T2
-
Index DEV2A.T1_IDX, on table DEV2A.T1
Schema synchronization options are similar to the options you can specify with schema comparisons. In synchronization, the options perform two functions:
-
During initial comparison of source and destination objects, the options determine whether differences are considered meaningful. For example, if the "Ignore Tablespace" option is selected, tablespace differences are ignored. If two tables are identical except for their tablespaces, no modification to the destination table will occur.
-
When generating the script that creates objects at the destination, some options control the content of the script. For example, if "Ignore Tablespace" is selected, no TABLESPACE clauses are generated.
In addition to the options provided with schema comparison, the following options are specific to Synchronize:
-
"Preserve Data In Destination" and "Copy Data From Source"—These two options control whether table data is copied from the source database to the destination database. (The option is not available if the source is a baseline.) By default, Synchronize preserves data in destination tables. Choosing "Copy Data From Source" causes Synchronize to replace the destination data with data from the source table.
-
"Drop Destination-Only Schema Objects"—Choosing this option directs Synchronize to drop schema objects that are present in the destination but not the source. For example, if the source contains table DEV1.T1 and the destination contains DEV1.T1 and DEV1.T2, Synchronize will drop DEV1.T2 if this option is chosen. This action applies only to schema objects that are within the scope specification. By default, Synchronize does not drop destination-only objects. Synchronize never drops non-schema objects.
The next step in defining a synchronization is to choose the synchronization mode. There are two options:
-
Unattended synchronization mode carries out the entire synchronization process in one step, ending with execution of the synchronization script. However, if an error is detected that makes it impossible to generate a correct script, the process will terminate without attempting to execute the script.
-
Interactive synchronization mode pauses after initial comparison of the source and destination objects, and again after generation of the synchronization script. Interactive mode gives you a chance to examine the results of comparison and script generation, and to take appropriate action before proceeding with the next step.
Creating Synchronization Versions
When you have finished defining the synchronization, you specify when to create the first synchronization version. You can create the first version immediately, or at a later time. You can also schedule new synchronization versions at regular intervals.
Depending on the synchronization mode you select, the synchronization may run to completion (unattended mode), or pause after initial object comparison (interactive mode). In the latter case, you run each subsequent phase of the synchronization in a new job.
When using interactive mode, the destination database should not be modified from the time the objects are initially compared until the synchronization script has executed. Otherwise, the script may encounter problems. For example, assume the source has a table that the destination does not have. Object comparison notes the source-only table, and the generated script includes statements to create the table. However, after object comparison but before script execution, you manually create the table at the destination database. The script will fail when it attempts to create the table because the table already exists.
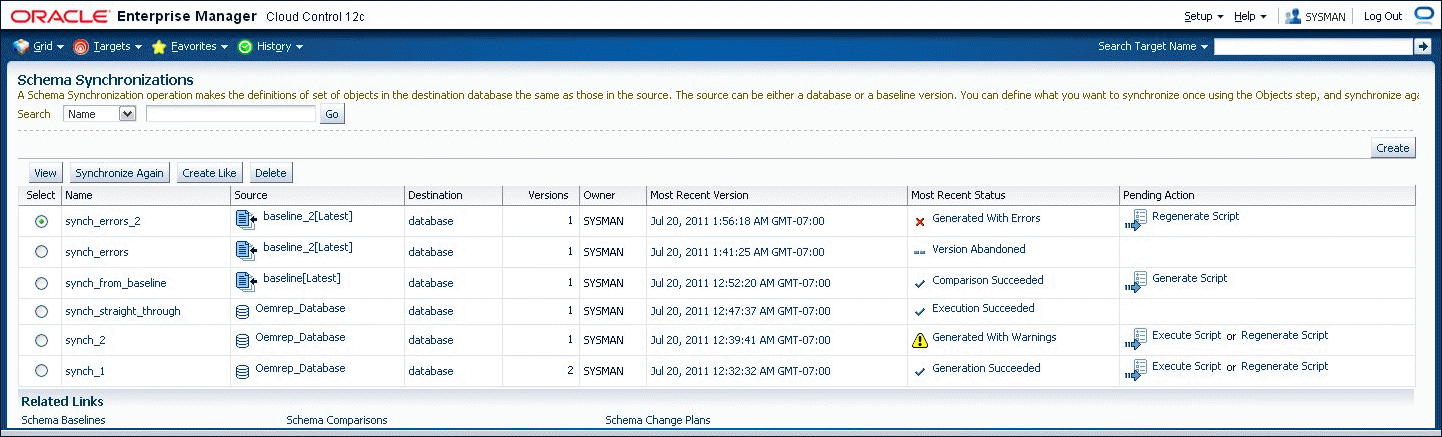
Figure 47-8 shows a list of synchronizations.
For more information about the process of synchronization, see About Working with Schema Comparison Versions.
47.4.2 Creating a Synchronization Definition from a Comparison
You can use a schema comparison as the starting point for synchronization. Select the comparison, then choose "Synchronize." This creates a new synchronization with the following initial information from the comparison:
-
Source and destination, from the comparison's left and right sources, respectively. This means that you cannot create a synchronization from a comparison whose right source is a baseline.
-
Scope specification. Note that some comparison scope specification options are not available in a synchronization. For example, you cannot synchronize individual schema objects, User objects, or Role objects.
-
Comparison options
47.4.3 Working with Schema Synchronization Versions
Each synchronization version represents an attempt to modify the destination objects selected by the scope specification to match the corresponding source objects. (It is "an attempt" because the process may not complete, for various reasons.) This section describes how a schema synchronization version is processed, and how you can monitor and control the process.
47.4.3.1 About the Schema Synchronization Cycle
There are three steps involved in processing a synchronization version. As noted previously, you can combine these steps into one (by choosing "Unattended Mode") or run each step separately (by choosing "Interactive Mode"). In either case, all three steps must be carried out when processing a successful synchronization version.
The following sections detail each of the three steps and describe what you can do following each step, when operating in interactive mode.
Object Comparison Step
The first step is to compare objects in the source to corresponding objects in the destination. Only those objects selected by the scope specification are compared. At the end of this step, the synchronization version has recorded all the objects. Each object is in one of the following states:
-
Source Only
-
Destination Only
-
Identical
-
Not Identical
In interactive mode, you can view the objects that are in each state, or all objects at once. For objects that are not identical, you can view the differences between the objects. At this stage, you can anticipate what will happen to each destination object:
-
Source-only objects will be created in the destination.
-
Destination-only objects will be unaffected, unless you chose the "Drop Destination-Only Schema Objects" option, in which case they will be dropped from the destination.
-
Identical objects will be unaffected. However, if you chose the "Copy Data From Source" option, the data in tables that are identical will be replaced with data from the source.
-
Non-identical objects will be modified to match the source object. Depending on the differences, the modification may be done with ALTER statements or by dropping and re-creating the object.
Before proceeding to script generation (Figure 47-9), you can exclude objects from the synchronization. For example, if you notice a source-only view that you do not want to create at the destination, you can exclude it now.
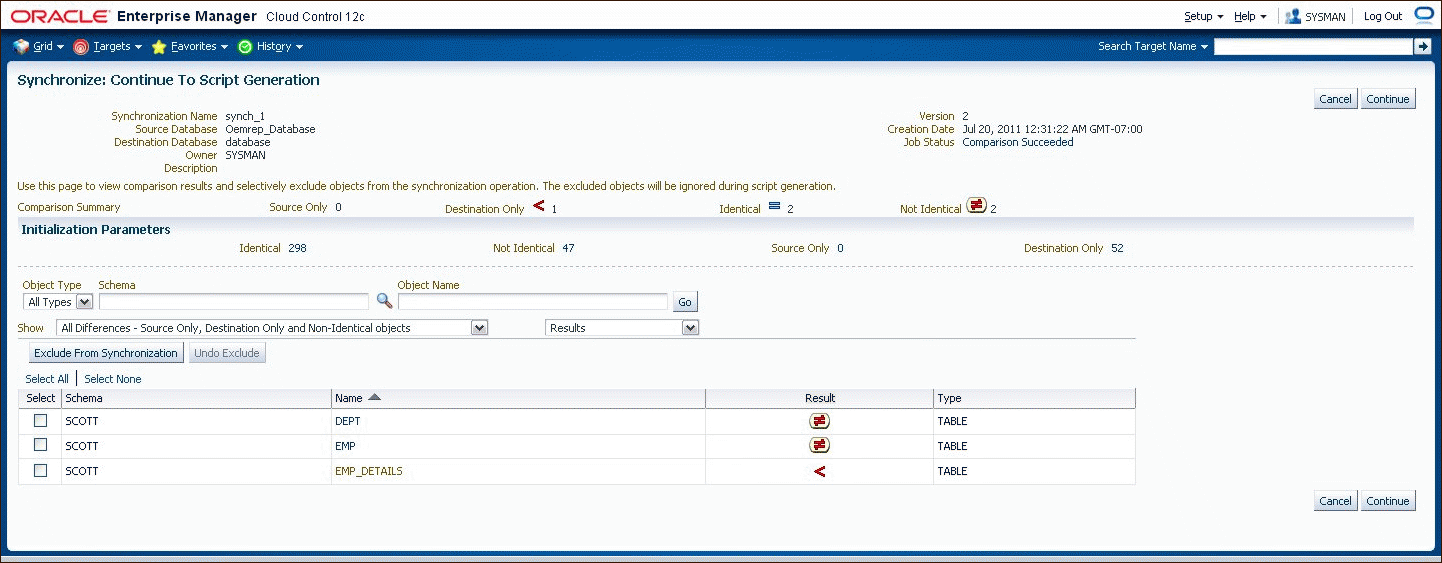
Script Generation Step
During script generation, Synchronize uses the results of the comparison step to create the PL/SQL script that will create and modify objects at the destination so that it matches the source. As part of script generation, several activities take place:
-
Dependency analysis assures that the destination database provides a suitable environment for each object and that objects are created and modified in the correct order.
-
Change analysis determines whether an object can be modified with ALTER statements or if it must be dropped and re-created.
-
Messages are placed in the impact report for the synchronization version. The messages provide information about the synchronization process, and may report one or more error conditions that make it impossible to generate a usable script.
-
The DDL statements needed to carry out the synchronization are generated and recorded in the synchronization version.
Dependency analysis examines each object to determine its relationships with other objects. It makes sure these other objects exist (or will be created) in the destination. Some examples of these relationships are:
-
A schema object depends on the User object that owns it. For example, table DEV1.T1 depends on user DEV1.
-
An index depends on the table that it is on. For example, index DEV1.T1_IDX depends on table DEV1.T1.
-
A table that has a foreign key constraint depends on the table to which the constraint refers.
-
A source object such as a package body depends on other source objects, tables, views, and so on.
-
A stored object depends on the tablespace in which it is stored, unless you choose "Ignore Tablespace."
The relationships established during dependency analysis are used later in the script generation process to make sure script statements are in the correct order.
Dependency analysis may determine that a required object does not exist in the destination database. For example, a schema object's owner may not exist in the destination database. Or, a table may have a foreign key constraint on another table that is in a different schema. There are several possible outcomes.
-
If the required object is in the source and is selected by the scope specification, Synchronize creates the object. For example, if DEV1.T1 has a foreign key constraint that refers to DEV2.T2, and both DEV1 and DEV2 are in the scope specification, Synchronize creates DEV2.T2.
-
If the required object is a user or role, and the object is available in the source, Synchronize automatically includes the user or role and creates it at the destination. This occurs even though User and Role objects are not part of the Synchronize scope specification.
-
If a required schema object is in the source but is not selected by the scope specification, Synchronize does not automatically include the object; instead, it places an Error-level message in the impact report. This restriction prevents uncontrolled synchronization of objects outside the scope specification. It is for this reason that scope specifications should include all the schemas that make up the application or module.
-
If the source is a baseline version, it may not include the required object. For example, a baseline might not capture Users and Roles. Synchronize cannot look for objects outside the baseline version, so it places an Error-level message in the impact report as shown in Figure 47-10. This is why it is important to include Users, Roles, and privilege grants in any baseline that will be used for synchronization.
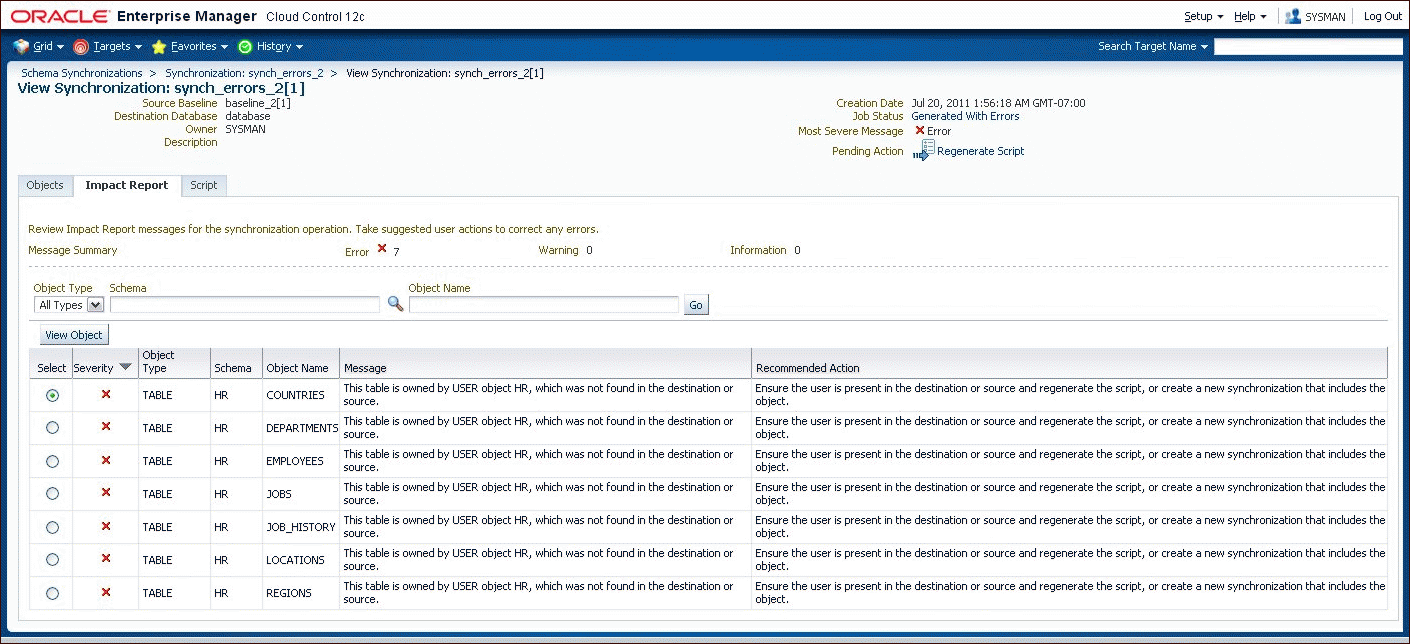
At the end of the script generation step, Synchronize has added the impact report and the script to the synchronization version. In interactive mode, you can examine the script and impact report before proceeding to script execution.
The impact report contains messages about situations that were encountered during script generation. There are three types of messages:
-
Informational messages require no action on your part. They simply report something of interest. For example, when script generation automatically includes a User object, it adds an informational message to the impact report.
-
Warning messages report a situation that requires your attention, but that may not require action. For example, if Synchronize is unable to determine if a reference in a source object can be resolved, it adds a warning message to the impact report. You need to verify that situations reported in warning messages will not prevent script execution.
-
Error messages indicate a situation that will prevent script execution if not corrected. For example, if Synchronize is unable to locate a required dependency object, it adds an error message to the impact report. Depending on the message, you may be required to create a new synchronization. For example, if the dependency object is not in the synchronization scope, or if the source is a baseline that does not contain the dependency object, you will need to create a new synchronization with an expanded scope or a different source baseline. In other cases, you can resolve the situation by excluding one or more objects from the synchronization and regenerating the script.
The script display contains the statements of the generated script in the order they will be executed. You can examine the script if you have any concerns about its correctness. The display allows you to locate statements that are associated with a particular object or object type.
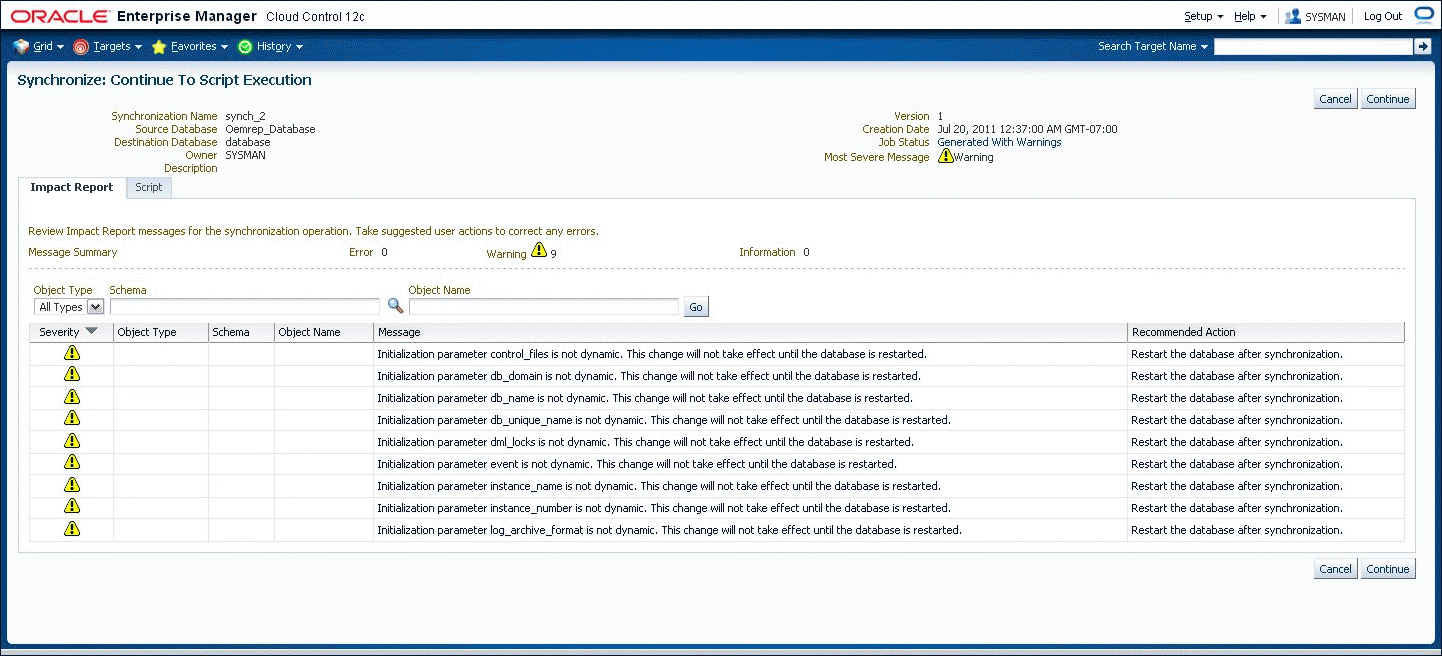
Following script generation, you can continue to script execution unless an error was encountered during the script generation step (Figure 47-11 and Figure 47-12). In this case the impact report will contain one or more Error-level messages detailing the problem and solution. In some cases, you may be able to solve the problem by selecting "Regenerate Script," excluding an object from the synchronization, and regenerating the script.
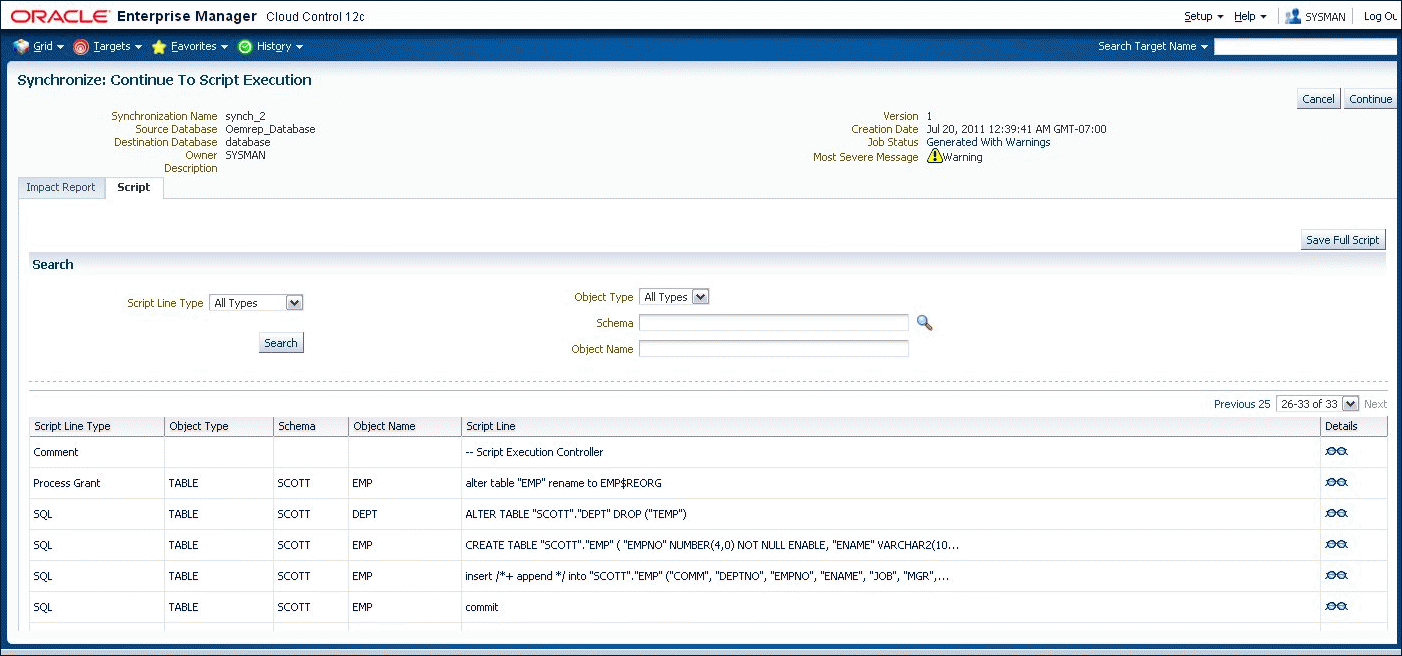
There may be cases where you need to create a new version of the synchronization in order to correct the problem. For example, if you need to modify the definition of an object in the source or destination or add an object in the destination, you will need to create a new version. This allows the new or modified object to be detected during the comparison step. In this case, the old version becomes "abandoned" since you cannot continue to script generation.
Script Execution Step
Following successful script generation, the script is ready to execute. In unattended mode, the script executes as soon as script generation completes. In interactive mode, you proceed to script execution as soon as you have reviewed the impact report and the script.
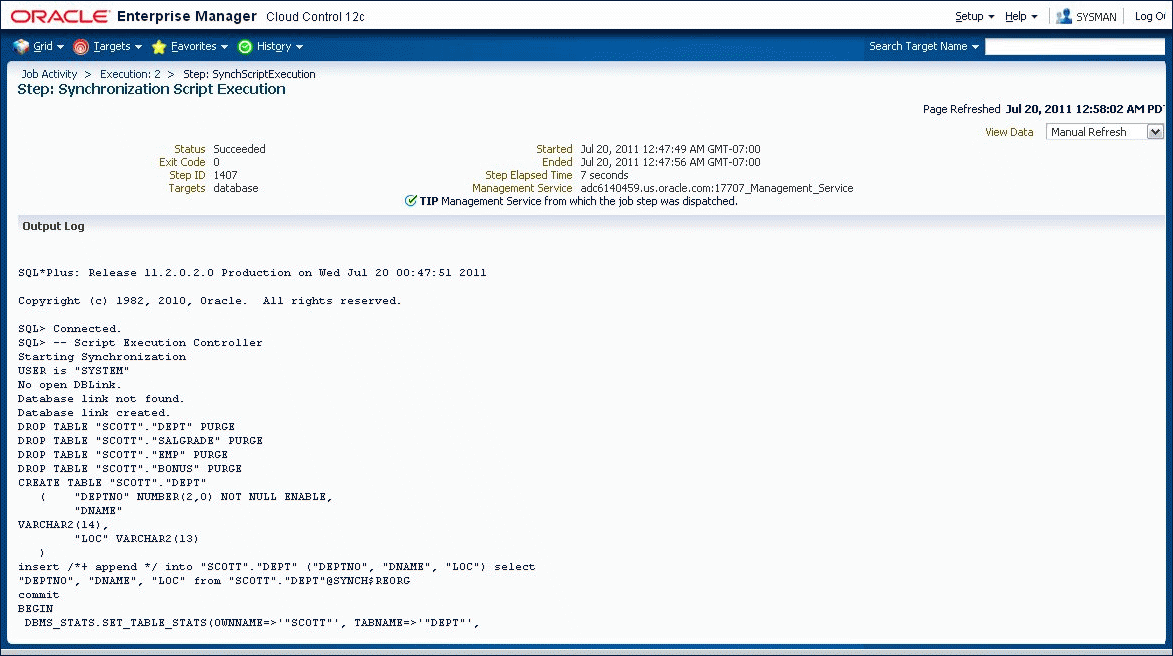
The script executes in the Cloud Control job system. Figure 47-13 shows the output of the Synchronization job. Once script execution is complete, you can view the execution log. If the script fails to execute successfully, you may be able to correct the problem and re-start the script execution from the point of failure. For example, if the script fails due to lack of space in a tablespace, you can increase the size of the tablespace, then re-start the script.
47.4.4 Creating Add itional Synchronization Versions
Following processing of the initial synchronization version, you can create additional versions of the synchronization. Select the synchronization, then choose "Synchronize Again." Note that you cannot choose a different source or destination, or modify the scope specification or synchronization options, when creating a new synchronization version. However, you can choose a different mode (Unattended or Interactive) when starting a new synchronization version.
Creating additional synchronization versions allows you to propagate incremental changes in the source to the destination. For example, you can refresh a test database from the latest changes made to a development system.
Synchronizations processed after the initial version generally complete substantially faster than the initial synchronization.
47.5 Using Change Plans
Change Plans are a new feature of the Cloud Control Database Lifecycle Management Pack. Change Plans complement and extend the capabilities of existing Change Management components by allowing users to select and package metadata changes for deployment to multiple databases. Change Plans support database application development methodologies that are not adequately supported by existing Database Lifecycle Management Pack tools such as Schema Synchronizations.
Change Plans are flexible enough to support a variety of development methodologies, yet powerful enough to automate many database administration tasks previously carried out with custom scripts. These tasks include:
-
Deploying project-specific development changes from a shared development database to one or more destination databases such as integration, test, or production staging.
-
Deploying development changes from a stand-alone project development database to an integration database that collects changes from multiple development databases.
-
Upgrading common modules in development databases from a central integration database.
Change Plans are tightly integrated with the other tools in the Database Lifecycle Management Pack. Specifically:
-
Change Plan change requests that create objects can get the object definitions from Change Management Schema Baselines.
-
Change requests that modify objects can use the contents of an object in a Change Management Schema Comparison to specify the change.
-
Change Plans complement Change Management Schema Synchronizations, allowing for finer control of changes and ”change-only” change requests.
47.5.1 About Working with Change Plans
The first phase of using a change plan to create or modify object definitions is to plan and define the changes that you want to make. For example, you may want to make one or more changes to an existing object definition in one or more databases. Or, you may want to reproduce one or more object definitions from one schema or database in another schema or database.

Figure 47-14 shows the steps in a change plan. A change plan is a named container for change requests. You can define change requests to reproduce or modify object definitions at a destination database. A destination database is a database where you want to apply the change requests in a change plan. After you finish planning and defining the changes, evaluate the impact of the changes that you want to make.
To evaluate the impact of the change requests at a particular database, generate a script and an impact report for a change plan and that destination database. The impact report explains the changes that will be made by the script when it executes at the destination database. It also describes any change requests that cannot be applied at the destination database.
To implement the change requests in a change plan at a destination database, execute the script at the destination database.
47.5.2 Creating a Change Plan
This section explains the different methods of creating change plans.
You can create change plans through any of the following ways:
-
Creating and Applying a Change Plan From a Schema Comparison
-
Using External Clients to Create and Access Change Plans in Cloud Control
47.5.2.1 Creating and Applying a Change Plan From a Schema Comparison
This section explains how to create a change plan from a schema comparison.
Prerequisites for Creating a Change Plan
Following are the prerequisites:
-
Ensure that the Application Developer (AD) is an Cloud Control user who has the following privileges:
-
Connect Target privilege to the development and production-staging databases targets or Connect Any Target privilege
-
DBA privileges to the development database
-
Create Privileges for Job System (Resource Privilege)
-
Create new Named Credential (Resource Privilege)
-
Edit Resource Privilege on the change plans
-
Execute Command Anywhere (Target Privilege)
-
EM_ALL_OPERATOR privilege
-
-
Ensure that the Database Administrator (DBA) is an Cloud Control user who has the following privileges:
-
Connect Target privilege to the development and production-staging databases targets or Connect Any Target privilege
-
DBA privileges to the development database
-
Create Privileges for Job System (Resource Privilege)
-
Create new Named Credential (Resource Privilege)
-
Manage Change Plans (Resource Privilege)
-
Execute Command Anywhere (Target Privilege)
-
EM_ALL_OPERATOR privilege
-
-
It is recommended that the development and destination databases are identical at the start of the development work. For example, they may both be at the current production version, or both updated to a common interim development version.
-
The Application Developer would have made changes in the development database. After creating a change plan, the application developer can create and update change items in the change plan through external clients such as SQL Developer. For more information, see Using External Clients to Create and Access Change Plans in Cloud Control.
Creating a Change Plan
Follow these steps to create a change plan:
-
Log in to Cloud Control as a database administrator (DBA).
-
Identify the schemas that contain application objects.
-
Use Metadata Baselines wizard to define a baseline that includes the schemas of interest. Schedule a job to capture the first version of the baseline.
-
Save the baseline.
-
Use Schema Comparisons wizard to define a comparison between the baseline version and the development database.
-
Schedule a job to create the first version of the comparison and save the comparison.
-
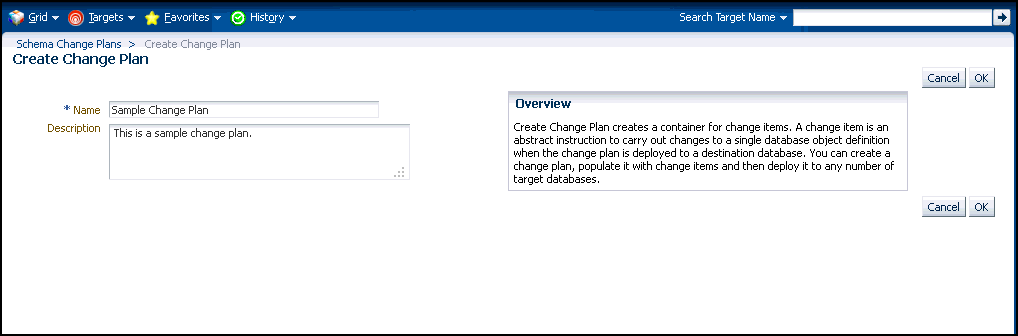
In the Schema Change Plans page, click Create.
-
Specify a Name and Description for the change plan and click OK to save the change plan.
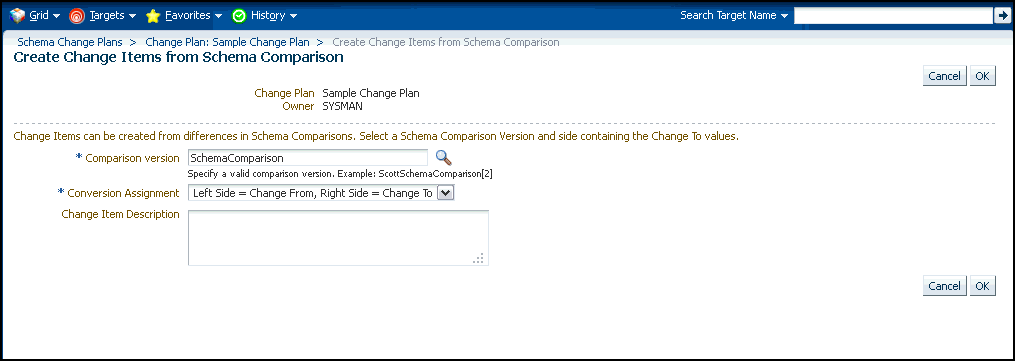
-
In the Change Items page, click Create From Comparison.
-
In the Create Change Items from Schema Comparison page, select the Comparison Version created earlier, specify the development database as the Change To side and the production-staging database as the Change From side in the Conversion Assignment and click OK.
-
In the Create Change Items from Schema Comparison: Select Differences page, select:
-
All Differences in the Schema Comparison to add all differences in the comparison to the change plan
-
Specific Differences in the Schema Comparison to select the differences in the comparison you want to add to the change plan. Select the differences.
Click Finish.
-
-
Submit request to apply the Change Plan on the destination database.
Applying a Change Plan
Follow these steps to apply a change plan:
-
Log in to Cloud Control as a database administrator (DBA).
-
In the DBA role, examine the Change Plan, evaluating its suitability for application to the proposed database. Remove individual Change requests if required.
-
From the Schema Change Plans page, select Create Synchronization from Change Plan.
-
Specify the details in the Schema Synchronization wizard with the source as the Change Plan instance created earlier. For information about using the Schema Synchronization wizard, see Synchronizing with Production Staging. By default, the synchronization created from change works in the interactive mode.
-
Schedule script generation.
-
Check Impact Report and schedule script execution.
-
Check completed script execution job for errors. If the change plan job failed, do the following:
-
If the failure is due to a condition noted in an impact report error warning, perform the suggested user action.
-
If the failure is due to a condition in the source or destination database that can be fixed manually, fix the problem and perform the operation again.
-
If the failure is in the script execution phase, view the script output in the job details. If the problem can be resolved by actions such as issuing missing grants, fix the problem manually in the database and then click Retry Script Execution.
-
-
Fix the errors and submit the change plan creation job again.
47.5.2.2 Using External Clients to Create and Access Change Plans in Cloud Control
Cloud Control provides support for external clients such as SQL Developer to create and access change plans. You can use these applications to connect to the Cloud Control repository and create change plans and add and update change items in them.
Client users are of two types:
-
Users who can create and access all change plans
-
Users who can access (view and possibly edit) specific change plans
Following are the steps:
-
Configure the repository database listener to allow access by a trusted client. It is recommended that you make the repository database inaccessible to login from non-trusted clients. For information about configuring the listener, see Oracle® Database Net Services Administrator's Guide 11g Release 2 (11.2).
-
Set up an Cloud Control administrator for use by an external client.
The following section describes how to set up administrators for change plans, for access from Cloud Control and from external clients.
Setting Up Cloud Control Administrator For Change Plans
Follow these steps:
-
Log in to Cloud Control as a super administrator.
-
From the Setup menu, click Security and then select Administrators.
-
In the Administrators page, click Create.
-
In the Create Administrator: Properties page, specify the Name and Password for the user. This creates a database user with the specified name and password, as well as creating the Cloud Control administrator. Click Next.
-
In the Create Administrator: Roles page, click Next.
-
In the Create Administrator: Target Privileges page, click Next.
-
In the Create Administrator: Resource Privileges page, select Change Plan Security Class and click the Manage Privilege Grants icon.
-
In the Create Administrator: Manage Privileges page, do the following:
-
If you want to create an administrator who has all access to all change plans, select Manage Change Plans in the Resource Type Privileges section.
-
If you want to create an administrator who has specific access to one or more change plans, click Add in the Resource Privileges section. In the list of change plans that have been created already, select one or more and click Select. The selected plans are added to the Resource Privileges section. By default, the administrator is granted View Change Plan privilege; you can edit this to grant Edit Change Plan privilege.
-
-
Click Continue.
-
In the Create Administrator: Review page, click Finish to create the new administrator.
-
For an external client to be able to access change plans using any of these privilege types, follow these steps:
-
Log in to the repository database as a user with DBA privileges.
-
Grant the CHANGE_PLAN_USER database role to the database user corresponding to the new administrator (through Schema->Users in Enterprise Manager Administrator, or in SQL Plus).
-
47.5.3 Submitting Schema Change Plans From SQL Developer Interface
To enable developers to submit their schema changes to Enterprise Manager Schema Change Plans through SQL Developer interface, perform the following manual configuration steps:
-
Ensure that the repository administrator has configured the repository database to accept remote database connection from SQL developer. You can do this by configuring the repository listener process.
-
Create a local administrator account on the OMS.
-
Provide the repository user of the local OMS account privileges to be a change plan user by running the following SQL commands on the repository database as user SYS:
grant CHANGE_PLAN_USER to PUBLIC;
or:
grant CHANGE_PLAN_USER to <repos_user>;
-
Edit the OMS users resource privileges to give the user access to edit the change plans.
47.6 Using Database Data Comparison
A data comparison operation compares data in a set of database objects in a candidate database with those in a reference database. To compare objects residing in the same database, select that database as both the reference and the candidate. You can create a comparison specifying which objects are to be compared and submit a Cloud Control job to compare them immediately or at a later time. On job completion, select the data comparison and view results. The results will be purged when you delete the comparison.
Cloud Control data comparison uses DBMS_COMPARISON package for comparison. It can compare the following types of database objects:
-
Tables
-
Single-table views
-
Materialized views
-
Synonyms for tables, single-table views, and materialized views
Database objects of different types can be compared at different databases. For example, a table at one database and a materialized view at another database can be compared.
47.6.1 Requirements for Database Data Comparisons
For data comparison, you will need to meet the requirements explained in this section.
The database character sets must be the same for the databases that contain the database objects being compared.
For index column, the number, timestamp, and interval columns datatypes are as follows:
-
Number columns are of the following datatypes: NUMBER, FLOAT, BINARY_FLOAT, and BINARY_DOUBLE.
-
Timestamp columns are of the following datatypes: TIMESTAMP, TIMESTAMP WITH TIME ZONE, and TIMESTAMP WITH LOCAL TIME ZONE
-
Interval columns are of the following datatypes: INTERVAL YEAR TO MONTH and INTERVAL DAY TO SECOND.
The database objects must have one of the following types of indexes:
-
A single-column index on a number, timestamp, interval, DATE, VARCHAR2, or CHAR datatype column
-
A composite index that only includes number, timestamp, interval, DATE, VARCHAR2, or CHAR columns. Each column in the composite index must either have a NOT NULL constraint or must be part of the primary key.
If the database objects do not have one of these types of indexes, then the EM data comparison does not support the database objects. For example, if the database objects only have a single index on an NVARCHAR2 column, then the data comparison does not support them. Or, if the database objects have only one index, and it is a composite index that includes a NUMBER column and an NCHAR column, then the data comparison does not support them.
The index columns in a comparison must uniquely identify every row involved in a comparison. The following constraints satisfy this requirement:
-
A primary key constraint
-
A unique constraint on one or more non-NULL columns.
If you specify an index, then make sure the columns in the index meet these requirements for comparison.
Data Comparison feature in Cloud Control can compare data in columns of the following datatypes:
-
VARCHAR2
-
NVARCHAR2
-
NUMBER
-
FLOAT
-
DATE
-
BINARY_FLOAT
-
BINARY_DOUBLE
-
TIMESTAMP
-
TIMESTAMP WITH TIME ZONE
-
TIMESTAMP WITH LOCAL TIME ZONE
-
INTERVAL YEAR TO MONTH
-
INTERVAL DAY TO SECOND
-
RAW
-
CHAR
-
NCHAR
If a column with datatype TIMESTAMP WITH LOCAL TIME ZONE is compared, then the two databases must use the same time zone. Also, if a column with datatype NVARCHAR2 or NCHAR is compared, then the two databases must use the same national character set.
Data comparison feature cannot compare data in columns of the following datatypes:
-
LONG
-
LONG RAW
-
ROWID
-
UROWID
-
CLOB
-
NCLOB
-
BLOB
-
BFILE
-
User-defined types (including object types, REFs, varrays, and nested tables)
-
Oracle-supplied types (including any types, XML types, spatial types, and media types)
You can compare database objects that contain unsupported columns by excluding the unsupported columns when providing comparison specification. Edit the comparison item and include only the supported columns in the Columns To Include list of column names.
Since data comparison cannot compare LOB column values directly, their cryptographic hashes will instead be used for comparison. If you include LOB type columns to be compared, make sure that the database users connecting to the reference and candidate databases have EXECUTE privilege on SYS.DBMS_CRYPTO package. For more information about DBMS_COMPARISON, see Oracle Database PL/SQL Packages and Types Reference .for the database version of your reference database
47.6.2 Comparing Database Data and Viewing Results
The following procedure enables you to specify which pairs of objects you want to compare in the reference and candidate databases, submit a job to process your choices, then view the differences after the job successfully completes.
-
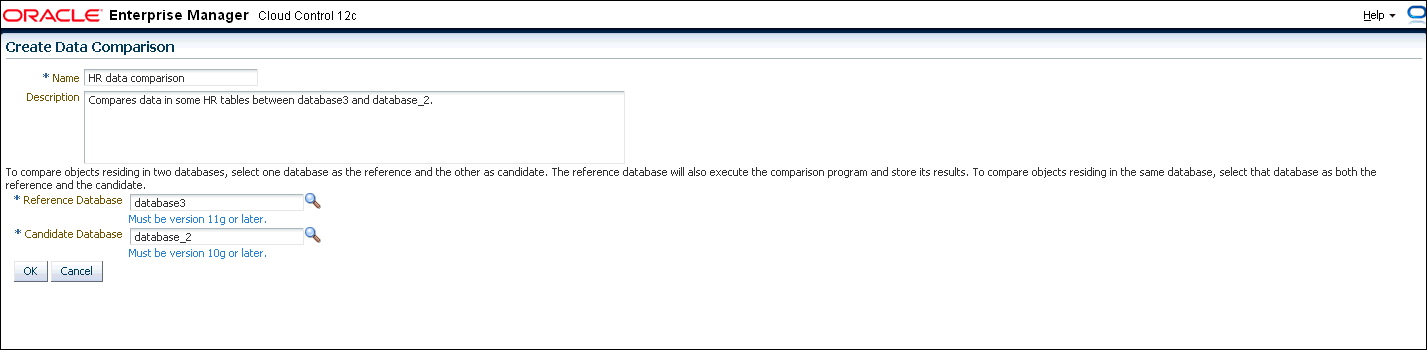
From the main Data Comparisons page, click Create. The Create Data Comparison page appears (Figure 47-15).
-
Provide the required input:
-
If you want to compare objects residing in two databases, select one database as the Reference and the other as the Candidate.
-
The Reference database always executes the comparison, so it must be version 11g or later. The Candidate database must be version 10g or later.
-
Be advised that the Reference database carries an additional processing load and requires some space to store the row IDs of differing rows (not the entire rows themselves). If you compare data between a production system and a test system, it might be appropriate to process and store the results on the test system.
-
-
Click OK when you have finished. The Data Comparison Specification page appears.
Tip:
It is recommended that you define the comparison specification once and run it many times.
-
-
Open the Actions menu, then select Add Object Pair or Add Multiple Objects. If you select Object Pair, continue with the following sub-steps. If you select Multiple Objects, go to step 4.
-
Specify the reference and candidate objects. The reference database can be the same as the candidate database. In this case, the objects are from the same database.
-
Select one or more columns in the reference or candidate databases for comparison. The columns included must be common to both objects.
-
Optionally select an index to be used for comparison. Columns in the comparison index must uniquely identify every row involved in a comparison. An index used for a primary key constraint or a unique constraint on one or more non-NULL columns satisfies this requirement. The comparison can use the specified index only if you select all of the columns in the list of Columns To Include.
You can select a composite index if you want to add multiple index columns.
-
Specify an optional Where Condition per pair of objects being compared.
-
Either specify or let the system compute the maximum number of buckets and minimum rows per bucket.
See Also:
"Comparing Database Data and Viewing Results" below. -
Specify the point in time you want to compare data.
-
The System Change Number (SCN) is a sequential counter that uniquely identifies a precise moment in the database. This is the most accurate way to identify a moment in time. Whenever you commit a transaction, Oracle records a new SCN. You can obtain SCNs from the alert log.
-
-
When you have finished the configuration, click OK.
The Data Comparison Specification page reappears, showing your selected objects in the list.
-
Click OK, then go to step 5.
-
-
Open the Actions menu, then select Add Multiple Objects.
-
Adding multiple objects enables you to conveniently perform a bulk inclusion of multiple objects from the reference database into the specification. You can search and select multiple objects, such as many tables and views, from the reference database list of values, and then edit each item as needed.
-
Specify the schema name, one or more object types, then click Search.
The table populates with object names.
-
Select the objects you want to compare, then click OK.
The Data Comparison Specification page reappears, showing your selected objects in the list.
-
-
-
Select your comparison name from the list, open the Actions menu, then select Submit Comparison Job. For information about privileges required for user credentials for the reference and candidate databases, see Overview of Change Management for Databases.
-
Provide the required credentials in the page, schedule the job, then click OK.
The Data Comparisons page reappears and displays the following confirmation message:
"The job was submitted successfully. Click the link in the Job Status column to view job status."
After the Job Status column shows Succeeded, go to the next step.
-
Select your comparison name from the list, open the Actions menu, then select View Results. The Data Comparison Results page appears.
-
Look for rows in the Result column with the =/= symbol, indicating that there are differences between reference row and candidate row data.
-
Data comparison attempts to compare all tables. If there is an error, you can see the error message by selecting the Messages tab. An error message is indicated with an X instead of the = or =/= symbol.
-
You can see the SQL statements that are running to perform the comparison by clicking the Executed Statements tab.
-
-
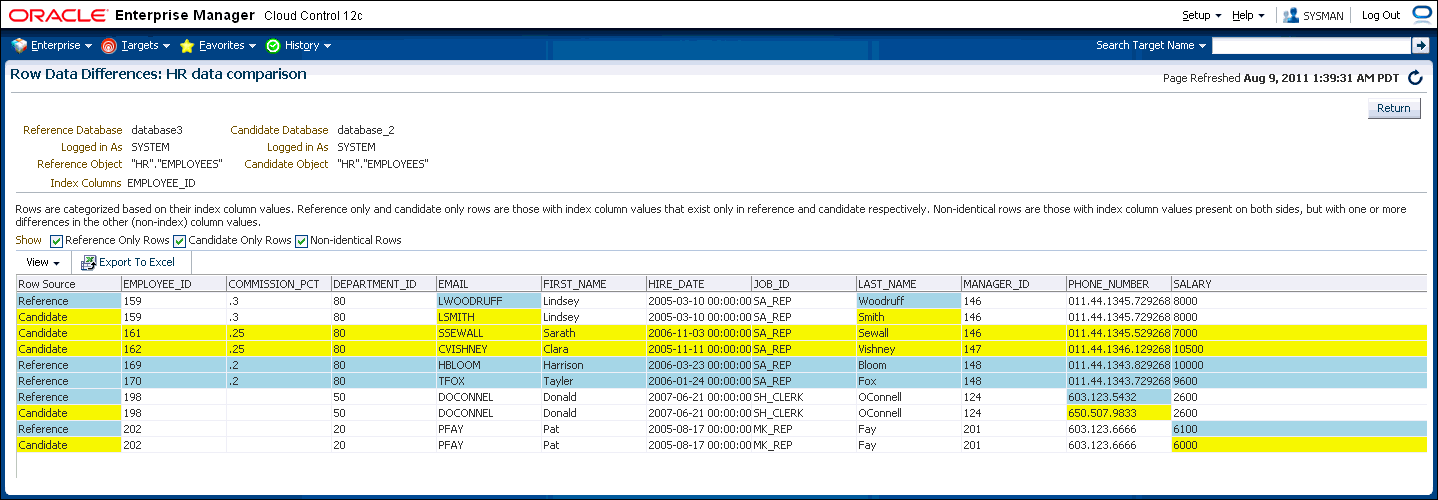
Select a dissimilar Reference/Candidate row, then click View Row Differences to see a detailed, indexed list of reference-only, candidate-only, and non-identical changed rows on the Row Data Differences page (Figure 47-16).
-
The Row Source column indicates the origin of each row of data as a whole. Furthermore, data in a row differing between reference and candidate are displayed in contrasting colors, indicating whether the source of the data is the reference or candidate database.
-
The comparison is shown based on a key column (depending on a chosen unique index). If the key column value is different, the row appears as a candidate or reference-only row. If other columns are different, the row appears as a non-identical row.
-
Schema Mapping
By default, a reference object will be compared with a candidate object in the same-named schema as the reference schema. Using schema mapping, you can optionally compare objects in a reference schema with objects in a different candidate schema. Any schema can only be mapped once. Provide reference and candidate schema names for mapping under the Schema Mapping section of the Data Comparison Specification page. Default candidate schema will then be picked from schema mapping you specified.
You may further override the candidate schema of individual item by editing the item, clicking the Override button next to the Candidate Object field, and explicitly specifying the candidate object belonging to any schema. For such items whose candidate objects are overridden in this way, schema mapping will be ignored.
Usage of Buckets
A bucket is a range of rows in a database object that is being compared. Buckets improve performance by splitting the database object into ranges and comparing the ranges independently. Every comparison divides the rows being compared into an appropriate number of buckets. The number of buckets used depends on the size of the database object and is always less than the maximum number of buckets specified for the comparison by the maximum number of buckets specified.
When a bucket is compared, the following results are possible:
-
No differences are found —
The comparison proceeds to the next bucket.
-
Differences are found —
The comparison can split the bucket into smaller buckets and compare each smaller bucket. When differences are found in a smaller bucket, the bucket is split into still smaller buckets. This process continues until the minimum number of rows allowed in a bucket is reached, whereupon a comparison reports whether there are differences in the bucket and identifies each row difference.
You can adjust the maximum number of buckets and minimum rows per bucket to achieve the best performance when comparing a particular database object.
The comparison program uses the ORA_HASH function on the specified columns in all the rows in a bucket to compute a hash value for the bucket. If the hash values for two corresponding buckets match, the contents of the buckets are assumed to match. The ORA_HASH function efficiently compares buckets, because row values are not transferred between databases. Instead, only the hash value is transferred.
Note:
If an index column for a comparison is a VARCHAR2 or CHAR column, the number of buckets might exceed the value specified for the maximum number of buckets.