F Troubleshooting Issues
This appendix provides solutions to common issues you might encounter when using provisioning and patching Deployment Procedures. In particular, this appendix covers the following:
F.1 Troubleshooting Database Provisioning Issues
This section provides troubleshooting tips for common database provisioning issues.
F.1.1 Grid Infrastructure Root Script Failure
See the details below.
F.1.1.2 Description
After Grid Infrastructure bits are laid down, the next essential step is Grid Infrastructure root script execution. This is the most process intensive phase of your deployment procedure. During this process, the GI stack configures itself and ensures all subsystems are alive and active. The root script may fail to run.
F.1.1.3 Solution
-
Visit each node that reported error and run the following command on n-1 nodes:
$GI_ORACLE_HOME/crs/install/rootcrs.pl -deconfig -force
-
If the root script did not run successfully on any of the nodes, pass the -lastNode switch on nth node (conditionally) to the final invocation as shown below.
$GI_ORACLE_HOME/crs/install/rootcrs.pl -deconfig -force -lastNode
Now, retry the failed step from the Procedure Activity page.
F.1.2 SUDO Error During Deployment Procedure Execution
See the details below.
F.1.3 Prerequisites Checks Failure
See the details below.
F.1.3.2 Cause
Perform a meticulous analysis of output from prerequisite checks. While most prerequisite failures are automatically fixed, it is likely that the deployment procedure failed due to auto-fix environment requirements. Some likely cases are:
-
Group membership for users that are not local to the system. Since users are registered with a directory service, even root access does not enable the deployment procedure to alter their attributes.
-
Zone separation in Solaris. If the execution zone of deployment procedure does not have privilege to modify system attributes, auto-fix operations of the deployment procedure will fail.
F.1.4 Oracle Automatic Storage Management (Oracle ASM) Disk Creation Failure
See the details below.
F.1.4.2 Cause
ASM disks tend to be used and purged over time. If an ASM instance is purged and physical ASM disks are left in their existing spurious state, they contain diskgroup information that can interfere with future ASM creation. This happens if the newly created ASM uses the same diskgroup name as exists in the header of such a raw disk. If such a spurious disk exists in the disk discovery path of the newly created ASM it will get consumed and raise unexpected error.
F.1.5 Oracle ASM Disk Permissions Error
See the details below.
F.1.6 Specifying a Custom Temporary Directory for Database Provisioning
To specify a temporary directory other than /tmp for placing binaries when provisioning databases, follow these steps:
-
Log in as a designer, and from the Enterprise menu, select Provisioning and Patching, then select Database Provisioning.
-
In the Database Procedures page, select the Provision Oracle Database Deployment Procedure and click Create Like.
-
In the Create Like Procedure page, in the General Information tab, provide a name for the deployment procedure.
In the Procedure Utilities Staging Path, specify the directory you want to use instead of
/tmp, for example,/u01/working. -
Click Save.
Use this deployment procedure for provisioning your Oracle databases.
F.1.7 Incident Creation When Deployment Procedure Fails
See the details below.
F.1.7.1 Issue
During deployment procedure execution, the steps to create database and Oracle ASM storage fails.
F.1.7.2 Solution
When a step in a deployment procedure executes successfully, it returns a positive exit code. If the step fails, and the exit code is not positive, it raises an incident which is stored in the OMS. All the associated log files and diagnosability information such as memory usage, disk space, running process info and so on are packaged and stored. You can access the Incident Console and package this information as a Service Request and upload it to My Oracle Support. Click Help on the Incident Manager page for more information on creating a new Service Request.
F.1.8 Reading Remote Log Files
In deployment procedure execution page, all remote log files relevant to the provisioning operation are displayed as hyperlinks in the job step. You can click on these hyperlinks and view the remote logs. The remote logs are stored in the OMS repository and can be accessed by My Oracle Support when troubleshooting.
F.1.9 Retrying Failed Jobs
See the details below.
F.1.9.2 Solution
If you deployment procedure execution has failed, check the job run details. You can retry a failed job execution or choose to ignore failed steps. For example, if your deployment procedure execution failed due to lack of disk space, you can delete files and retry the procedure execution. For certain issues which may not affect the overall deployment procedure execution, such as cluvy check failure, you may want to ignore the failed step and run the deployment procedure.
Retrying a job execution creates a new job execution with the status Running. The status of the original execution is unchanged.
To ignore a failed step and retry the procedure, follow these steps:
-
In the Procedure Activity page, click on the relevant procedure.
-
In the Job Status page, click on the status of the failed step.
-
In the Step Status page, click Ignore. In the Confirmation page, click Yes.
-
Click Retry. The failed step will be retried.
F.2 Troubleshooting Patching Issues
This section provides troubleshooting tips for common patching issues.
F.2.1 Oracle Software Library Configuration Issues
This section describes the following patching issues:
F.2.1.1 Error Occurs While Staging a File
See the details below.
F.2.1.1.1 Issue
While analyzing the patch plan, the patch plan fails with an unexpected error, although the credentials are correct and although you have write permission on the EM stage location.
For example, the following error is seen on job output page:
”Unexpected error occurred while checking the Normal Oracle Home Credentials”
F.2.1.2 Error Occurs While Uploading a Patch Set
See the details below.
F.2.1.2.1 Issue
When you upload a patch set using the Upload Patches to Software Library page, you might see an error stating that the operation failed to read the patch attributes.
For example,
ERROR:Failed to read patch attributes from the uploaded patch file <filename>.zip
F.2.1.3 OPatch Update Job Fails When Duplicate Directories Are Found in the Software Library
See the details below.
F.2.1.3.1 Issue
When you run an OPatch Update job, sometimes it might fail with the following error:
2011-11-28 10:31:19,127 RemoteJobWorker 20236 ERROR em.jobs startDownload.772- OpatchUpdateLatest: java.lang.NullPointerException: Category, 'Oracle Software Updates', has no child named, 'OPatch' at oracle.sysman.emInternalSDK.core.patch.util. ComponentUtil.getComponentCategory (ComponentUtil.java:854)
Even after applying the Cloud Control patch released in January 2012, you might see the following error:
Category, 'Oracle Software Updates' already exists.
F.2.1.3.2 Cause
The error occurs when two Patch Components directories are found in the Software Library. Particularly when you run two patch upload or download jobs, for example, an OPatch patch download job and a regular patch download job, a race condition is created, which in turn creates two directories with the name Patch Components. The Software Library does not display any error while creating these duplicate directories, but when you run the OPatch Update job, the job fails with a NullPointerException.
F.2.1.3.3 Solution
To resolve this issue, do one of the following:
If you see two Patch Components directories in the Software Library, then delete the one that has fewer entries, and retry the failed patch upload or download job. To access the Software Library, from the Enterprise menu, select Provisioning and Patching, and click Software Library.
If you see only one Patch Components directory, but yet see the error that states that the Oracle Software Updates already exists, then retry the failed patch upload or download.
F.2.2 My Oracle Support Connectivity Issues
This section describes the following issues:
F.2.2.1 Error Occurs While Testing the Proxy Server That Supports Only Digest Authentication
See the details below.
F.2.2.1.1 Issue
On the Proxy Settings page, in the My Oracle Support and Proxy Connection tab, when you provide the manual proxy configuration details, you might see an exception error as shown in Figure F-1.
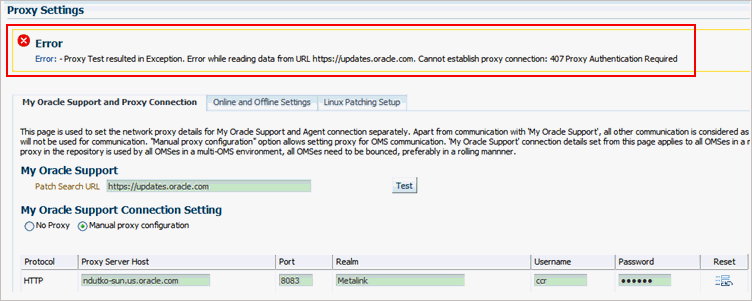
F.2.2.1.2 Cause
You might have provided the configuration details of a proxy server that supports only the Digest authentication schema. By default, the proxy server is mapped only to the Basic authentication schema, and currently there is no support for Digest authentication schema.
F.2.2.1.3 Solution
To resolve this issue, reconfigure your proxy server to make it to use the Basic authentication schema.
Tip:
For better understanding of connectivity issues related to HTTP Client Logging, you can perform the following steps:-
Locate the
startup.propertiesfile under the GC instance directory:user_projects/domains/EMGC_DOMAIN/servers/EMGC_OMS1/data/nodemanager/startup.properties -
Append the following string to the value of the property Arguments:
-DHTTPClient.log.level\=ALL -DHTTPClient.log.verbose\=true -
Restart the OMS, and the WebLogic Server Administration Manager by running the following commands:
emctl stop oms -allemctl start oms -
Navigate to the following location to check the log file:
user_projects/domains/EMGC_DOMAIN/servers/EMGC_OMS1/logs/EMGC_OMS1-diagnostic.logAlternately, you can also use the grep command to find all the HTTP connection logs as follows:
grep HTTPClient EMGC_OMS1-diagnostic*.log
F.2.3 Host and Oracle Home Credential Issues
This section describes the following security issues:
F.2.3.1 Cannot Create Log Files When You Set Privileged Credentials as Normal Oracle Home Credentials
See the details below.
F.2.3.1.1 Issue
While creating a patch plan, if you choose to override the Oracle home preferred credentials, and set privileged credentials as normal Oracle home credentials inadvertently as shown in Figure F-2, then you will see an error stating that log files cannot be created in the EMStagedPatches directory.
For example,
”Unable to create the file <RAC_HOME>/EMStagedPatches/PA_APPLY_PATCH_09_02_2011_14_27_13.log"
You might also see the following error:
ERROR: SharedDeviceException. ACTION: Please check whether the configuration is supported or not.
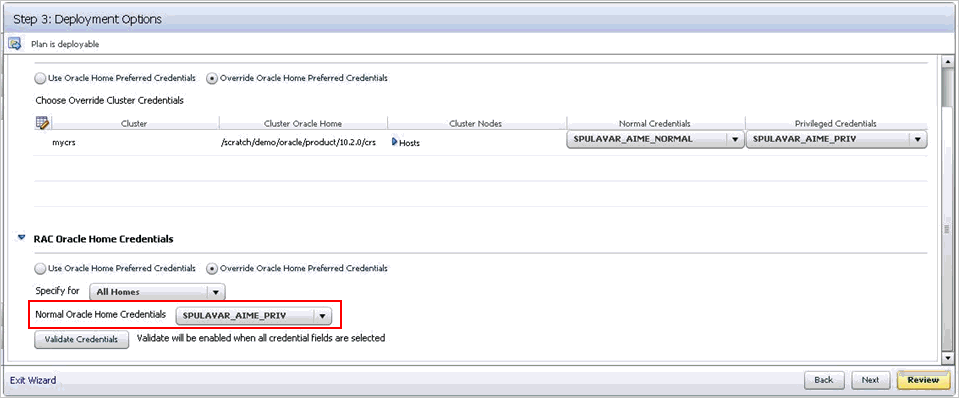
F.2.3.1.2 Cause
When a patch plan is deployed, the patch plan internally uses a deployment procedure to orchestrate the deployment of the patches. While some of the steps in the deployment procedure are run with normal Oracle home credentials, some of the steps are run with privileged Oracle home credentials. However, when you set normal Oracle home credentials as privileged Oracle home credentials, then the deployment procedure runs those steps as a root user instead of the Oracle home owner, and as a result, it encounters an error.
F.2.4 Collection Issues
This section describes the following issues:
F.2.4.1 Missing Details in Plan Wizard
See the details below.
F.2.4.1.1 Issue
When you view a patch plan, sometimes the Create Plan Wizard does not display the expected information. Some pages or sections in the wizard might be blank.
F.2.4.1.2 Cause
The issue might be with the details in the Management Repository or with the Create Plan Wizard.
F.2.4.1.3 Solution
Identify whether the issue is with the Management Repository or with the Create Plan Wizard. To do so, try retrieving some details from the Management Repository using the commands and URLs mentioned in this section.
-
If the URLs return the correct information but the console does not display it, then there might be some technical issue with the Create Plan Wizard. To resolve this issue, contact Oracle Support.
-
If the URLs return incorrect information, then there might be some issue with the Management Repository. To resolve this issue, re-create the patch plan.
To retrieve some details from the Management Repository, do the following:
-
Retrieve the GUID of the patch plan. To do so, run the following command:
select plan_guid from em_pc_plans where name='<name of the plan>”;For example,
select plan_guid from em_pc_plans where name='t8';The result of the command looks like the following. Note down the GUID of the plan.
PLAN_GUID -------------------- 96901DF943F9E3A4FF60B75FB0FAD62A
-
Retrieve general information about a patch plan such as its name, type, status, and plan privileges. To do so, use the following URL. This type of information is useful for debugging the Plan Information step and the Review and Deploy step.
https://<hostname>:<port>/em/console/CSP/main/patch/plan?planId=<plan_guid>&client=emmos&cmd=get&subset=planInfoNote:
Before retrieving any information about a patch plan using the preceding URL, log in to the Cloud Control console, and from the Enterprise menu, select Provisioning and Patching, and then click Patches & Updates. -
Retrieve information about the patches and the associated targets that are part of the patch plan. To do so, use the following URL. This type of information is useful for debugging the Patches step and the Review step.
https://<hostname>:<port>/em/console/CSP/main/patch/plan?planId=<plan_guid>&client=emmos&cmd=get&subset=patches -
Retrieve information about the deployment options selected in the patch plan. To do so, use the following URL. This type of information is useful for debugging the Deployment Options step and the Credentials step.
https://<hostname>:<port>/em/console/CSP/main/patch/plan?planId=<plan_guid>&client=emmos&cmd=get&subset=deploymentOptions -
Retrieve information about the preferred credentials set in the patch plan. To do so, use the following URL. This type of information is useful for debugging the Credentials step.
https://<hostname>:port/em/console/CSP/main/patch/plan?planId=<plan_guid>&client=emmos&cmd=get&subset=preferredCredentials -
Retrieve information about the target credentials set in the patch plan. To do so, use the following URL. This type of information is useful for debugging the Credentials step.
https://<hostname>:port/em/console/CSP/main/patch/plan?planId=<plan_guid>&client=emmos&cmd=get&subset=targetCredentials -
Retrieve information about the conflict-free patches in the patch plan. To do so, use the following URL. This type of information is useful for debugging the Validation step and the Review & Deploy step.
https://<hostname>:port/em/console/CSP/main/patch/plan?planId=<plan_guid>&client=emmos&cmd=get&subset=conflictFree -
Retrieve information about the suppressed patches in the patch plan. To do so, use the following URL. This type of information is useful for debugging the Patches step.
https://<hostname>:port/em/console/CSP/main/patch/plan?planId=<plan_guid>&client=emmos&cmd=get&subset=removedPatchList
F.2.4.2 Cannot Add Targets to a Patch Plan
See the details below.
F.2.4.2.1 Issue
While creating a new patch plan or editing an existing patch plan, when you add a new target, you might see the following error:
Wrong Platform. Expected: Oracle Solaris on SPARC (64-bit), found: null
F.2.4.2.2 Cause
The Management Repository might not have the platform information for that target. By default, for every target, the inventory details are regularly collected from the oraclehomeproperties.xml file that resides in the Oracle home of the target. Sometimes, the inventory collection might not have completed or might have failed, resulting in missing data in the Management Repository. Due to these reasons, you might not be able to add those targets.
F.2.4.2.3 Solution
To resolve this issue, forcefully recollect the inventory details from the Oracle home of the target.
To retrieve the Oracle home details, follow these steps:
-
From the Targets menu, select All Targets.
-
On the All Targets page, from the left hand Refine Search pane, click Target Type menu to expand it.
-
From the Target Type, click Others, select Oracle Home.
-
All the targets of type Oracle Home are listed. You may search for the host name to drill down to the Oracle home details you are looking for.
To retrieve the inventory details from the Oracle Home on the target host, run the following command from the $EMDROOT/bin directory:
$ emctl control agent runCollection <Oracle_Home_Target>:oracle_home oracle_home_config
Here, <Oracle_Home_Target> refers to the name of the Oracle home of the target whose platform information is missing.
For example,
$ emctl control agent runCollection db2_2_adc2170603:oracle_home oracle_home_config
F.2.5 Patch Recommendation Issues
This section describes the following issues:
F.2.5.1 Patch Recommendations Do Not Appear After Installing Oracle Management Agent on Oracle Exadata Targets
See the details below.
F.2.5.1.1 Issue
After installing the Management Agent on Oracle Exadata targets, the patch recommendations do not appear.
F.2.5.1.2 Cause
The patch recommendations do not appear because the Exadata plug-ins are not deployed.
F.2.5.1.3 Solution
To resolve this issue, explicitly deploy the Exadata plug-ins on Exadata targets. To do so, follow these steps:
-
From the Enterprise menu, select Extensibility, then select Plug-ins.
-
On the Plug-ins page, in the table, select the Oracle Exadata plug-in version you want to deploy.
-
Click Deploy On and select Management Agent.
-
In the Deploy Plug-in on Management Agent dialog, in the Selected Management Agent section, click Add and select one or more Management Agents where you want to deploy the plug-in, and click Continue. Then click Next, then Deploy.
F.2.6 Patch Plan Issues
This section describes the following issues:
-
Instances Not to Be Migrated Are Also Shown as Impacted Targets for Migration
-
Cluster ASM and Its Instances Do Not Appear as Impacted Targets While Patching a Clusterware Target
-
Error #1009 Appears in the Create Plan Wizard While Creating or Editing a Patch Plan
-
Out-of-Place Patching Fails for 11.2.0.3 Exadata Clusterware
F.2.6.1 Patch Plan Becomes Nondeployable and Fails
See the details below.
F.2.6.1.2 Cause
You can add a patch to a target in a patch plan only if the patch has the same release and platform as the target to which it is being added. You will receive a warning if the product for the patch being added is different from the product associated with the target to which the patch is being added. The warning does not prevent you from adding the patch to the patch plan, though. However, when you try to deploy, the plan might fail.
F.2.6.2 Instances Not to Be Migrated Are Also Shown as Impacted Targets for Migration
See the details below.
F.2.6.2.1 Issue
When you deploy a patch plan in out-of-place patching mode, sometimes even the instances that are not selected for migration are identified as impacted targets as shown in Figure F-3.
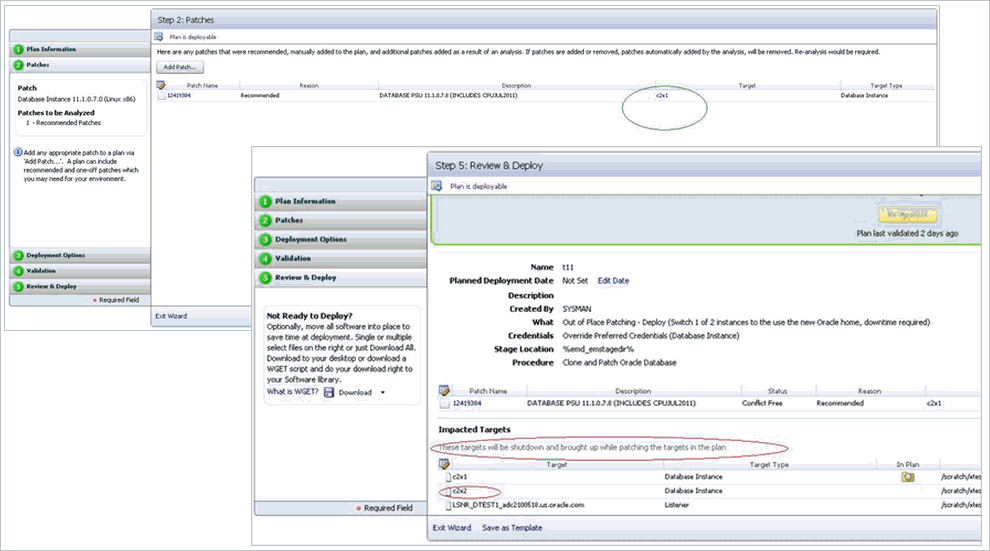
F.2.6.2.2 Cause
By default, the patch plan calculates the impacted targets based on only one mode, which in-place patching mode. Therefore, although you have selected out-of-patching mode, the patch plan ignores it and considers only the in-place patching mode as the option selected, and displays all the targets are impacted targets for migration.
F.2.6.3 Cluster ASM and Its Instances Do Not Appear as Impacted Targets While Patching a Clusterware Target
See the details below.
F.2.6.3.1 Issue
While creating a patch plan for patching a clusterware target, on the Deployment Options page, the What to Patch section does not display the cluster ASM and its instances are affected targets. They do not appear in the Impacted Targets section, either. And after deploying the patch plan in out-of-place mode, the cluster ASM and its instances show metric collection error.
F.2.6.3.2 Cause
This issue might occur if the clusterware target name in Cloud Control and the clustername target name in the mgmt$target_properties table are not matching.
F.2.6.3.3 Solution
To resolve this issue, run the following query to verify the target property ClusterName of the clusterware target:
select property_value from mgmt$target_properties where target_name=<CRS Target Name> and property_name=”ClusterName”
If the returned value is different from the clusterware target name in Cloud Control, then delete the clusterware target and other associated targets, and rediscover them. This time while rediscovering them, ensure that the clusterware target name matches with the name returned by the preceeding query.
F.2.6.4 Recovering from a Partially Prepared Plan
See the details below.
F.2.6.4.1 Issue
When you create a patch plan to patch multiple Oracle homes in out-of-place patching mode, and when you click Prepare in the Create Plan Wizard to prepare the patch plan before actually deploying it, sometimes the preparation operation fails with the message Preparation Failed.
F.2.6.4.2 Cause
The patch plan might have successfully cloned and patched some of the selected Oracle homes, but might have failed on a few Oracle homes. The overall status of the patch plan is based on the patching operation being successful on all the Oracle homes. Even if the patching operation succeeds on most of the Oracle homes and fails only on a few Oracle homes, the overall status is shown as if the patch plan has failed in one of the steps.
F.2.6.5 Error #1009 Appears in the Create Plan Wizard While Creating or Editing a Patch Plan
See the details below.
F.2.6.5.1 Issue
While creating new patch plan or editing an existing patch plan, you might see the following error in the Create Plan Wizard:
Error #1009
F.2.6.6 Analysis Succeeds But the Deploy Button is Disabled
See the details below.
F.2.6.6.1 Issue
After you successfully analyze the patch plan, when you navigate to the Review of the Create Plan Wizard, you might see the Deploy button disabled. Also, the table on the Review page appears empty (does not list any patches.) As a result, you might not be able to deploy the patch plan.
F.2.6.7 Patch Plan Fails When Patch Plan Name Exceeds 64 Bytes
See the details below.
F.2.6.7.1 Issue
On non-English locales, patch plans with long plan names fail while analyzing, preparing, or deploying, or while switching back. No error is displayed; instead the patch plan immediately reflects the Failed state, and logs an exception in the <INSTANCE_HOME>/sysman/log/emoms.log file.
F.2.6.7.2 Cause
The error occurs if the patch plan name is too long, that is, if it exceeds 64 bytes. The provisioning archive framework has a limit of 64 bytes for instance names, and therefore, it can accept only plan names that are lesser than 64 bytes. Typically, the instance name is formed using the patch plan name, the plan operation, and the time stamp (PlanName_PlanOperation_TimeStamp). If the entire instance name exceeds 64 bytes, then you are likely see this error.
F.2.6.7.3 Solution
To resolve this issue, do one of the following:
If the patch plan failed to analyze, prepare, or deploy, then edit the plan name and reduce its length, and retry the patching operation.
If the patch plan was deployed successfully, then the patch plan gets locked, and if switchback fails with this error, then you cannot edit the plan name in the wizard. Instead, run the following SQL update command to update the plan name in the Management Repository directly:
update em_pc_plans set name = 'New shorter name' where name = 'Older longer name';
commit;
F.2.6.8 Out-of-Place Patching Fails for 11.2.0.3 Exadata Clusterware
See the details below.
F.2.6.8.1 Issue
The out-of-place patching fails to unlock the cloned Oracle home in the Prepare phase of the patch plan, thus causing the patch plan to fail on the cloned Oracle home. The step Run clone.pl on Clone Oracle Home fails.
F.2.6.8.2 Cause
This issue occurs if the new Oracle home is different from the Oracle home mentioned in the files <gi_home>/crs/utl/crsconfig_dirs and crsconfig_fileperms that are present in the Grid Infrastructure home. For 11.2.0.3 Exadata Clusterware, the unlock framework works by operating on these files.
F.2.6.8.3 Solution
To resolve this issue, you can do one of the following:
-
Create a new patch plan for the Exadata Cluster, select the required patch, select In-Place in the How to Patch section, and deploy the patch plan.
-
Manually apply the patch on the Clusterware Oracle homes of all the nodes of the cluster. Then, clean up the partially cloned Oracle homes on all the nodes, and retry the Prepare operation from the patch plan.
F.2.7 Patch Plan Analysis Issues
This section covers the following issues:
-
Patch Plan Remains in Analysis State Even After the Deployment Procedure Ends
-
Patch Plan Analysis Fails When the Host's Node Name Property Is Missing
-
Link to Show Detailed Progress on the Analysis Is Not Actionable
-
Raising Service Requests When You Are Unable to Resolve Analysis Failure Issues
F.2.7.1 Patch Plan Remains in Analysis State Even After the Deployment Procedure Ends
See the details below.
F.2.7.1.1 Issue
When you analyze a patch plan, sometimes the patch plan shows that analysis is in progress even after the underlying deployment procedure or the job ended successfully.
F.2.7.1.2 Cause
This issue can be caused due to one of the following reasons:
-
Delayed or no notification from the job system about the completion of the deployment procedure. Typically, after the deployment procedure ends, the job system notifies the deployment procedure. Sometimes, there might be a delay in such notification or there might be no notification at all from the job system, and that can cause the status of the patch plan to show that is always in the analysis state.
-
Delay in changing the status of the patch plan. Typically, after the job system notifies the deployment procedure about its completion, the job system submits a new job to change the status of the patch plan. Sometimes, depending on the load, the new job might remain the execution queue for a long time, and that can cause the status of the patch plan to show that is always in the analysis state.
-
Failure of the job that changes the status of the patch plan. Sometimes, after the new job is submitted for changing the status of the patch plan, the new job might fail if there are any Management Repository update issues or system-related issues.
-
Time zone issues with the Management Repository. If the Management Repository is configured on an Oracle RAC database, and if each instance of the Oracle RAC is running on a different time zone, then when a query is run to know the current system time, it can return incorrect time details depending on which instance serviced the request. Due to incorrect time details, the job that changes the status of the patch plan might not run at all. This can cause the status of the patch plan to show that is always in the analysis state.
F.2.7.2 Patch Plan Analysis Fails When the Host's Node Name Property Is Missing
See the details below.
F.2.7.2.1 Issue
When you validate a patch plan created for patching Oracle Clusterware, the validation fails as shown in Figure F-4, stating that the node name is missing for the target <target_name> of the type host. Also, the solution mentioned on the Validation page is incorrect.
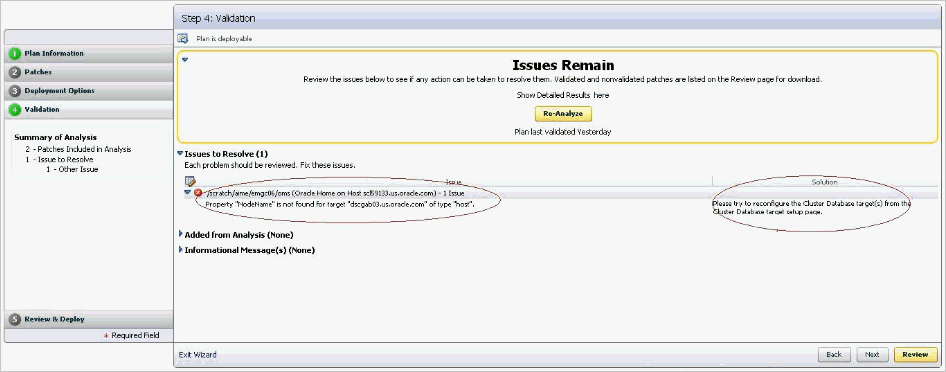
F.2.7.2.2 Cause
The error occurs because the Create Plan Wizard does not sync up with the actual query or the job you are running. Also, the property NodeName is a dynamic property for HAS target, which is not marked as a critical property, and therefore, this property could be missing from the Management Repository sometimes. Ideally, it should state that the node name property is missing for the HAS target.
F.2.7.2.3 Solution
To resolve this issue, run the following command to reload the dynamic properties for the HAS target from each node of the Oracle Clusterware.
emctl reload dynamicproperties -upload_timout 600 <target_name>:has
For example,
emctl reload dynamicproperties -upload_timout 600 <myhastarget1>:has
F.2.7.3 Link to Show Detailed Progress on the Analysis Is Not Actionable
See the details below.
F.2.7.3.1 Issue
After you analyze a patch plan, the text Analysis In Progress on the Validation page appears smaller than normal, and the here link for progress details does not work as shown in Figure F-5.

F.2.7.4 Raising Service Requests When You Are Unable to Resolve Analysis Failure Issues
As described in the preceding subsections, there can be several causes for analysis failures, including My Oracle Support connectivity issues, ARU issues, or issues while accessing the Management Repository to extract any details related to the patch plan or targets or the operation being committed. If you encounter any of these issues, follow the solution proposed in the preceding sections, and if you are still unable to resolve the issue, follow these steps, and raise a service request or a bug with the information you collect from the steps.
-
(Online Mode Only) Verify if the My Oracle Support Web site being used is currently available.
-
(Online Mode Only) If the plan analysis is failing prior to target analysis being submitted, then verify if the patch analysis is working as expected by running the following URL Replace
<em_url>with the correct EM URL, and<plan_name>with the actual patch plan name.<em_url>/em/console/CSP/main/patch/plan?cmd=getAnalysisXML&type=att&planName=<plan_name>Verify if the returned XML includes conflict check request and response XMLs for each Oracle home included in the patch plan.
-
Open the following file and check the exact error or exception being logged and communicate it to Oracle Support.
$<MIDDLEWARE_HOME>/gc_inst/em/EMGC_OMS1/sysman/log/emoms.log
F.2.8 User Account and Role Issues
This section describes the following:
F.2.8.1 Out-of-Place Patching Errors Out If Patch Designers and Patch Operators Do Not Have the Required Privileges
See the details below.
F.2.8.1.1 Issue
When you try out-of-place patching, the patch plan fails with the following error while refreshing the Oracle home configuration:
12:58:38 [ERROR] Command failed with error: Can't deploy oracle.sysman.oh on https://<hostname>:<port>/emd/main/
F.2.8.1.2 Cause
The error occurs because you might not have the following roles as a Patch Designer or a Patch Operator:
-
ORACLE_PLUGIN_USER, to view the plug-in user interface
-
ORACLE_PLUGIN_OMS_ADMIN, to deploy a plug-in on the OMS
-
ORACLE_PLUGIN_AGENT_ADMIN, to deploy a plug-in on the Management Agent
These roles are required to submit the Discover Promote Oracle Home Targets job. The job deploys the Oracle home plug-in on the Management Agent if it is not already deployed.
F.2.8.1.3 Solution
Grant these roles explicitly while creating the user accounts. Alternatively, grant the provisioning roles because EM_PROVISIONING_OPERATOR and EM_PROVISIONING_DESIGNER already include these roles. After granting the privileges, retry the failed deployment procedure step to complete the out-of-patching preparation.
F.3 Troubleshooting Linux Patching Issues
My Staging Server Setup DP fails at "Channels Information Collection" step with the error message "Could not fetch the subscribed channels properly". How do I fix this?
This error is seen if there is any network communication error between up2date and ULN. Check if up2date is configured with correct proxy setting by following https://linux.oracle.com/uln_faq.html - 9. You can verify if the issue is resolved or not by using the command, up2date –nox –show-channels. If the command lists all the subscribed channels, the issue is resolved.
My "up2date –nox –show-channels" command does not list the subscribed channels properly. How do I fix this?
Go to /etc/sysconfig/rhn/sources files, uncomment up2date default and comment out all the local RPM Repositories configured.
How can I register to channels of other architectures and releases?
Refer to >https://linux.oracle.com/uln_faq.html for this and more such related FAQs.
After visiting some other page, I come back to "Setup Groups" page; I do not see the links to the jobs submitted. How can I get it back?
Click Show in the details column.
Package Information Job fails with "ERROR: No Package repository was found" or "Unknown Host" error. How do I fix it?
Package Repository you have selected is not good. Check if metadata files are created by running yum-arch and createrepo commands. The connectivity of the RPM Repository from OMS might be a cause as well.
Even after the deployment procedure finished its execution successfully, the Compliance report still shows my Group as non-compliant, why?
Compliance Collection is a job that runs once in every 24 hour. You should wait for the next cycle of the job for the Compliance report to update itself. Alternately, you can go to the Jobs tab and edit the job to change its schedule.
Package Information Job fails with "ERROR: No Package repository was found" or "Unknown Host" error. How do I fix it?
The package repository you have selected is not good. Check if the metadata files are created by running yum-arch and createrepo commands. The connectivity of the RPM Repository from OMS might be a cause as well.
I see a UI error message saying "Package list is too long". How do I fix it?
Deselect some of the selected packages. The UI error message tells you from which package to unselect.
F.4 Troubleshooting Linux Provisioning Issues
I cannot see my stage, boot server in the UI to configure them with the provisioning application?
Either Management Agents have not been installed on the Stage or Boot Server machine, or it is not uploading data to the OMS. Refer to the Oracle Enterprise Manager Cloud Control Advanced Installation and Configuration Guide for troubleshooting information and known issues.
Bare metal machine is not coming up since it cannot locate the Boot file.
Verify the dhcp settings (/etc/dhcpd.conf) and tftp settings for the target machine. Check whether the services (dhcpd, xinted, portmap) are running. Make the necessary setting changes if required or start the required services if they are down.
Even though the environment is correctly setup, bare metal box is not getting booted over network
OR
DHCP server does not get a DHCPDISCOVER message for the MAC address of the bare metal machine.
Edit the DHCP configuration to include the IP address of the subnet where the bare metal machine is being booted up.
Agent Installation fails after operating system has been provisioned on the bare metal box?
OR
No host name is assigned to the bare metal box after provisioning the operating system?
This might happen if the get-lease-hostnames entry in the dhcpd.conf file is set to true. Edit the dhcpd.conf file to set get-lease-hostnames entry to false.
Also, ensure that length of the host name is compatible with length of the operating system host name.
Bare metal machine hangs after initial boot up (tftp error/kernel error).
This may happen if the tftp service is not running. Enable the tftp service. Go to the /etc/xinetd.d/tftp file and change the disable flag to no (disable=no). Also verify the dhcp settings.
Kernel panic occurs when the Bare Metal machine boots up.
Verify the dhcp settings and tftp settings for the target machine and make the necessary changes as required. In a rare case, the intird and vmlinuz copied may be corrupted. Copying them from RPM repository again would fix the problem.
Bare metal machine hangs after loading the initial kernel image.
This may happen if the network is half duplex. Half duplex network is not directly supported but following step will fix the problem:
-
Modify
ethtool -s eth0 duplex halftoethtool -s eth0 duplex fullin the kickstart file.
Bare metal machine cannot locate the kickstart file (Redhat screen appears for manually entering the values such as 'language', 'keyboard' etc).
This happens if STAGE_TOP_LEVEL_DIRECTORY is not mountable or not accessible. Make sure the stage top level is network accessible to the target machine. Though very rare but this might also happen because of any problem in resolving the stage server hostname. Enter the IP address of the stage or the NAS server instead of hostname on which they are located, and try the provisioning operation again.
Bare metal machine does not go ahead with the silent installation (Redhat screen appears for manually entering the network details).
Verify that DNS is configured for the stage server host name, and that DHCP is configured to deliver correct DNS information to the target machine. If the problem persists, specify the IP address of the stage or NAS server instead of hostname, and try the provisioning operation again.
After provisioning, the machine is not registered in Enterprise Manager.
This happens if Enterprise Manager Agent is not placed in the STAGE_TOP_LEVEL_DIRECTORY before provisioning operation. Place the Enterprise Manager agent in this directory, and try the operation again. It might also happen if the OMS registration password provided for securing the agents is incorrect. Go to the agent oracle home on the target machine, and run the emctl secure agent command supplying the correct OMS registration password.
Check the time zone of the OMS and the provisioned operating system. Modify the time zone of the provisioned operating system to match with the OMS time zone.
With 64-bit OS provisioning, agent is not installed.
During OS provisioning, specify the full path of the agent RPM in the Advanced Operating System Properties page.
Provisioning operations cannot be initiated since either one or all of Stage Server, Boot Server, and RPM Repository have not been configured in the Infrastructure page.
Set up at least one stage server, boot server, and RPM repository to proceed with Linux Provisioning.
Submitting the deployment operations throws an error: "An unexpected error has occured. Please check the log files for details." Logs have the corresponding message: "ComponentType with internal name BMPType not found"
Set up Software Library from the Software Library console.
The deployment procedure fails with directory permission error.
This error occurs because of insufficient user privileges on the stage server machine. STAGE_TOP_LEVEL_DIRECTORY should have write permission for the stage server user. In case of NAS, the NAS directory should be mounted on the staging server. If the error appears while writing to the boot directory, then the boot server user must have the write permission.
Bare metal box fails to boot with "reverse name lookup failed" error.
Verify that the DNS has the entry for the IP address and the host name.
Fetching properties from reference machine throws the error: " Credentials specified does not have root access"
Verify if the credentials specified for the reference machine has sudo access.
Following Package/Package Group are not available in the RPM Repository. Either update the Package List or select the correct RPM Repository in the Deployment page.
Verify that the RPM packages mentioned in the error message are present in the repository, and that they are spelled correctly. If not, either copy the packages to the repository or do not install them.
F.5 Frequently Asked Questions on Linux Provisioning
What is PXE (Pre-boot Execution Environment)?
The Pre-boot Execution Environment (PXE, aka Pre-Execution Environment) is an environment to bootstrap computers using a network interface card independently of available data storage devices (like hard disks) or installed operating systems. Refer to Appendix D, "Understanding PXE Booting and Kickstart Technology" for more information.
Can my boot server reside on a subnet other than the one on which the bare metal boxes will be added?
Yes. But it is a recommended best practice to have boot server in the same subnet on which the bare metal boxes will be added. If the network is subdivided into multiple virtual networks, and there is a separate DHCP/PXE boot server in each network, the Assignment must specify the boot server on the same network as the designated hardware server.
If one wants to use a boot server in a remote subnet then one of the following should be done:
-- Router should be configured to forward DHCP traffic to a DHCP server on a remote subnet. This traffic is broadcast traffic and routers do not normally forward broadcast traffic unless configured to do so. A network router can be a hardware-based router, such as those manufactured by the Cisco Corporation or software-based such as Microsoft's Routing and Remote Access Services (RRAS). In either case, you need to configure the router to relay DHCP traffic to designated DHCP servers.
-- If routers cannot be used for DHCP/BOOTP relay, set up a DHCP/BOOTP relay agent on one machine in each subnet. The DHCP/BOOTP relay agent relays DHCP and BOOTP message traffic between the DHCP-enabled clients on the local network and a remote DHCP server located on another physical network by using the IP address of the remote DHCP server.
Why is Agent rpm staged on the Stage server?
Agent rpm is used for installing the agent on the target machine after booting over the network using PXE. With operating system provisioning, agent bits are also pushed on the machine from the staging location specified in the Advanced Properties.
Can I use the Agent rpm for installing Agent on Stage and Boot Server?
This is true only if the operating system of the Stage or Boot Server machine is RedHat Linux 4.0, 3.1 or 3.0 or Oracle Linux 4.0 or later. Refer to section Using agent rpm for Oracle Management Agent Installation on the following page for more information:
http://www.oracle.com/technology/software/products/oem/htdocs/provisioning_agent.html
Can the yum repository be accessed by any protocol other than HTTP?
Though the rpm repository can be exposed via file:// or ftp:// as well, the recommended method is to expose it via http://. The latter is faster and more secure.
What is the significance of the Status of a directive? How can one change it?
Look at the following table to know the possible Status values and what they signify.
| Status | Description |
|---|---|
|
Incomplete |
This Status signifies that some step was not completed during the directive creation, for example uploading the actual script for the directive, or a user saved the directive while creating it and still some steps need to be performed to make complete the directive creation. |
|
Ready |
his signifies that the directive creation was successful and the directive is now ready to be used along with any component/image. |
|
Active |
A user can manually change the status of a Ready directive to Active to signify that it is ready for provisioning. Clicking Activate changes the Status to Active. |
What is a Maturity Level of a directive? How can one change it?
See Table F-2 to know the possible Status values and what they signify:
| Maturity Level | Maturity Level Description |
|---|---|
|
Untested |
This signifies that the directive has not been tested and is the default maturity level that is assigned to the directive when it is created. |
|
Beta |
A directive can be manually promoted to Beta using the Promote button after testing the directive. |
|
Production |
A directive can be manually promoted to Production using the Promote button after a user is satisfied that the directive can be used for actual provisioning on production systems. |
Can a same component be used in multiple deployments?
Yes. Components are reusable and a given component can be a part of multiple deployments at the same time.
Do I need to edit scheduled deployments associated with a component, if the component is edited?
Yes.
For creating the Linux OS component does the Reference Machine need to have a management agent running on it?
Yes. Reference Machine has to be one of the managed targets of the Enterprise Manager.
What is the significance of the Status of a component? How can one change it?
Status of a component is similar to that of a directive. Refer to What is the significance of the Status of a directive? How can one change it?.
What is a Maturity Level of a component? How can one change it?
Maturity Level of a component is similar to that of a directive. Refer to What is a Maturity Level of a directive? How can one change it?.
F.6 Refreshing Configurations
If you encounter issues and are expected to refresh the configurations in the host or the Oracle home, then follow the instructions outlined in the following sections:
F.6.1 Refreshing Host Configuration
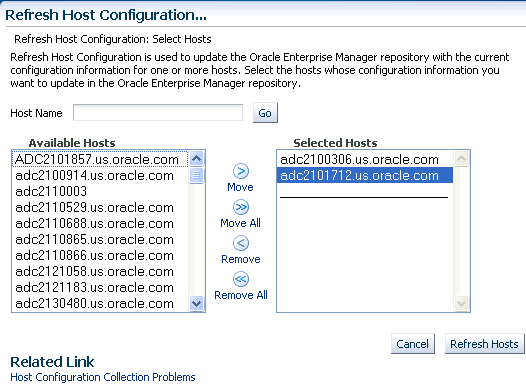
Before you run any Deployment Procedure, Oracle recommends you to refresh the configuration of the hosts. To do so, follow these steps:
-
In Cloud Control, from the Enterprise menu, select Configuration, and then, click Refresh Host Configuration.
-
On the Refresh Host Configuration page, from the Available Hosts pane, select the hosts that the Deployment Procedure will use, and move them to the Selected Hosts pane.
-
Click Refresh Hosts.
F.6.2 Refreshing Oracle Home Configuration
Although the Oracle Management Agent running on a host automatically refreshes the host configuration information every 24 hours, you can also manually refresh the host configuration information the host.
Note:
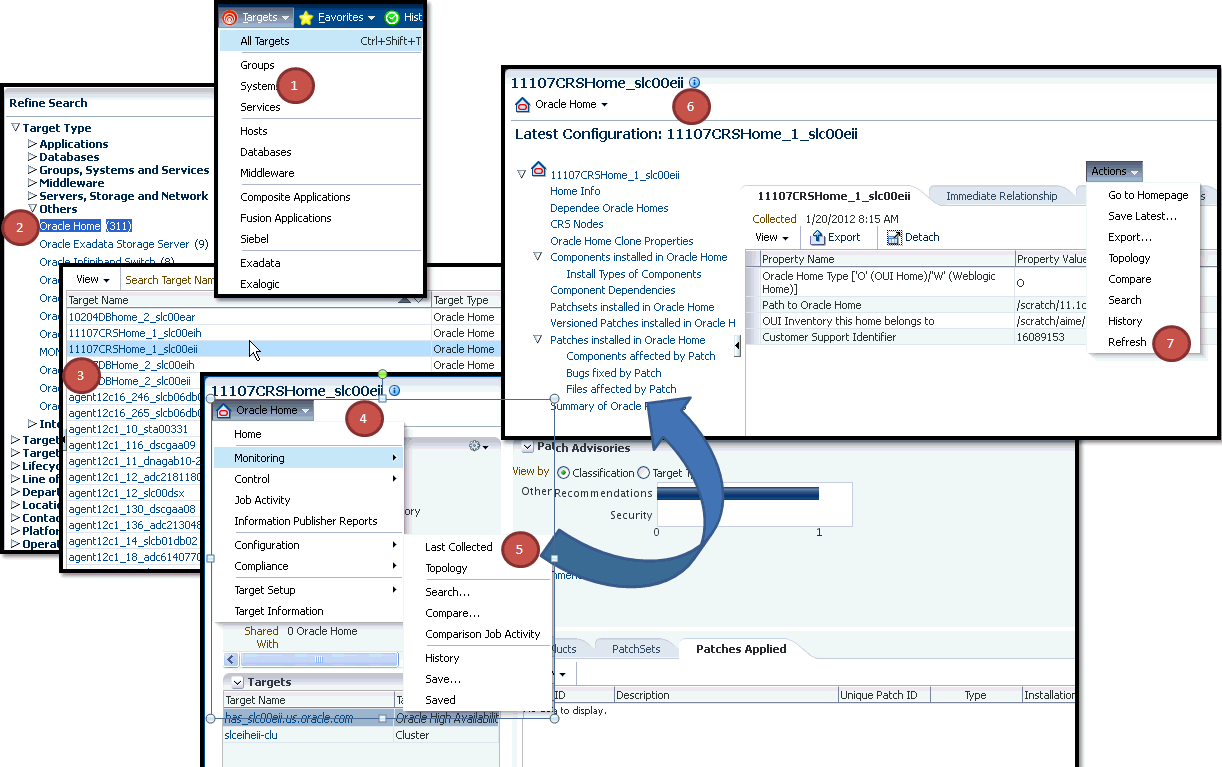
After patching the targets, refreshing the Oracle home configuration is handled internally by the deployment procedure. However if the refresh does not happen for some reason, then you can refresh the Oracle Home Configuration manually as described in this section.To manually refresh the host configuration for one host:
-
In Cloud Control, from the Targets menu, select All Targets.
-
On the All Targets page, from the Refine Search section, click Target Type to expand the menu, and from the menu click Others, and then click Oracle Home.
On the right hand side of the page gets refreshed, and only the Oracle Home targets appear.
-
Click the Target name to select it.
-
On the <target_name> home page, from the Oracle Home menu, select Configuration, and then click Last Collected.
-
On the latest Configuration:<target_name> page, from the Actions menu select Refresh to refresh the Oracle Home configuration for the host.
The following example describes the steps to refresh the Oracle home configuration for the target 11107CRSHome_1_slc00eii:
F.7 Reviewing Log Files
This section lists the log files you must review to resolve issues encountered while running a Deployment Procedure.
This section contains the following:
F.7.1 OMS-Related Log Files
The following are OMS-related log files.
Generic Enterprise Manager Trace File
<EM_INSTANCE_BASE>/em/<OMS_NAME>/sysman/log/emoms.trc
Generic Enterprise Manager Log File
<EM_INSTANCE_BASE>/em/<OMS_NAME>/sysman/log/emoms.log
Where, <EM_INSTANCE_BASE> is the OMS Instance Base directory. By default, the OMS Instance Base directory is gc_inst, which is present under the parent directory of the Oracle Middleware Home.
F.7.2 Management Agent-Related Log Files
The following are Management Agent-related log files:
EMSTATE/sysman/log/gcagent.log
EMSTATE/sysman/log/gcagent.trc
F.7.3 Advanced Options
Optionally, to capture more details, follow these steps to reset the log level and capture the logs mentioned in the previous sections.
Note:
Oracle recommends you to archive the old logs and have a fresh run after resetting the log level to capture the fresh logs.