| Oracle® Secure Enterprise Search Administrator's Guide 11g Release 2 (11.2.2) Part Number E23427-01 |
|
|
PDF · Mobi · ePub |
| Oracle® Secure Enterprise Search Administrator's Guide 11g Release 2 (11.2.2) Part Number E23427-01 |
|
|
PDF · Mobi · ePub |
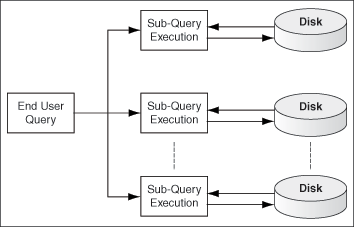
In order to scale up the indexed data size while maintaining satisfactory query response time, the indexed data can be stored in independent disks to perform disk I/O operations in parallel. The major features of this architecture are:
Oracle SES index is partitioned, so that the sub-queries are executed in parallel.
Disks perform I/O operations independent of one another. As a result, the I/O bus contention does not create a significant bottleneck on the collective I/O throughput.
Partition rules are used to control the document distribution among the partitions.
Storage areas are used to store the partitions when the partitioning option is enabled. There are two kinds of partition mechanisms for improving query performance, attribute-based partitioning and hash-based partitioning. Currently, Oracle SES supports only hash-based partitioning.
Hash-based partitioning uses a hash function to distribute a large set of documents into multiple partitions. A partition engine controls the partition logic at both crawl time and query time. When a large data set must be searched without pruning the conditions, the end user request is broken into multiple parallel sub-queries so that the I/O and CPU resources can be used in parallel. After the result sets of the sub-queries are returned by the independent query processors, a merged result set is returned to the end user.
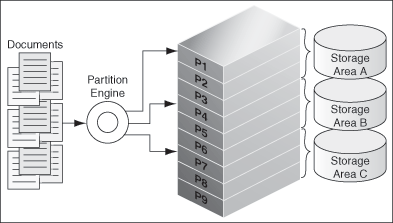
Figure 3-3 shows how the mechanism works during crawl time. The documents are partitioned and stored in different storage areas. Note that the storage areas are created on separate physical disks, so that I/O operations can be performed in parallel to improve the search turn around time.
Figure 3-3 Document Partitioning at Crawl Time
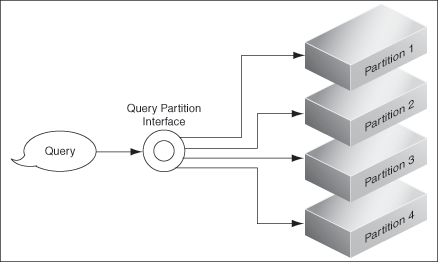
At query time, the query partition engine generates sub-queries and submits them to the storage areas, as shown in Figure 3-4.
Figure 3-4 Generation of Sub Queries at Query Time
See "Parallel Query and Index Partitioning" for more information.
|
Copyright © 2006, 2012, Oracle and/or its affiliates. All rights reserved. Legal Notices |
|