1 SQL Developer Concepts and Usage
Oracle SQL Developer is a graphical version of SQL*Plus that gives database developers a convenient way to perform basic tasks. You can browse, create, edit, and delete (drop) database objects; run SQL statements and scripts; edit and debug PL/SQL code; manipulate and export (unload) data; and view and create reports.
You can connect to any target Oracle database schema using standard Oracle database authentication. Once connected, you can perform operations on objects in the database.
You can connect to schemas for selected third-party (non-Oracle) databases, such as MySQL, Microsoft SQL Server, Sybase Adaptive Server, Microsoft Access, and IBM DB2, and view metadata and data in these databases; and you can migrate third-party databases to Oracle.
This chapter contains the following major sections:
Section 1.1, "Installing and Getting Started with SQL Developer"
Section 1.2, "SQL Developer User Interface"
Section 1.3, "Database Objects"
Section 1.4, "Database Connections"
Section 1.5, "Entering and Modifying Data"
Section 1.6, "Running and Debugging Functions and Procedures"
Section 1.7, "Using the SQL Worksheet"
Section 1.8, "Using Snippets to Insert Code Fragments"
Section 1.9, "Finding Database Objects"
Section 1.10, "Using Versioning"
Section 1.11, "Using DBA Features in SQL Developer"
Section 1.12, "Scheduling Jobs Using SQL Developer"
Section 1.13, "Deploying Objects Using the SQL Developer Cart"
Section 1.14, "Spatial Support in SQL Developer"
Section 1.15, "Change Manager Support in SQL Developer"
Section 1.16, "SQL Developer Reports"
Section 1.17, "SQL Developer Preferences"
Section 1.18, "Location of User-Related Information"
Section 1.19, "Data Modeler in SQL Developer"
Section 1.20, "Oracle TimesTen In-Memory Database Support"
Section 1.21, "Using the Help"
Section 1.22, "Tip of the Day"
Section 1.23, "For More Information"
1.1 Installing and Getting Started with SQL Developer
To install and start SQL Developer, you simply download a ZIP file and unzip it into a desired parent directory or folder, and then type a command or double-click a file name. You should read the Oracle SQL Developer Installation Guide before you perform the installation. After you have read the installation guide, the basic steps are:
-
Unzip the SQL Developer kit into a directory (folder) of your choice. This directory location will be referred to as
<sqldeveloper_install>.Unzipping the SQL Developer kit causes a directory named
sqldeveloperto be created under the<sqldeveloper_install>directory. It also causes many files and folders to be placed in and under that directory.If Oracle Database (Release 11 or later) is also installed, a version of SQL Developer is also included and is accessible through the menu system under Oracle. This version of SQL Developer is separate from any SQL Developer kit that you download and unzip on your own, so do not confuse the two, and do not unzip a kit over the SQL Developer files that are included with Oracle Database. Suggestion: Create a shortcut for the SQL Developer executable file that you install, and always use it to start SQL Developer.
-
To start SQL Developer, go to the
sqldeveloperdirectory under the<sqldeveloper_install>directory, and do one of the following:On Linux and Mac OS X systems, run sh sqldeveloper.sh.
On Windows systems, double-click
sqldeveloper.exe.If you are asked to enter the full pathname for java.exe, click Browse and find java.exe. For example, on a Windows system the path might have a name similar to
C:\Program Files\Java\jdk1.6.0_06\bin\java.exe. -
If you want to become familiar with SQL Developer concepts before using the interface, read the rest of this chapter before proceeding to the next step.
-
Create at least one database connection (or import some previously exported connections), so that you can view and work with database objects, use the SQL Worksheet, and use other features.
To create a new database connection, right-click the Connections node in the Connections navigator, select New Connection, and complete the required entries in the Create/Edit/Select Database Connection dialog box.
-
If you want to get started quickly with SQL Developer, do the short tutorial in Chapter 4, "SQL Developer Tutorial: Creating Objects for a Small Database", or work with your existing database objects.
1.2 SQL Developer User Interface
The SQL Developer window generally uses the left side for navigation to find and select objects, and the right side to display information about selected objects.
Figure 1-1 shows the main window.

Note:
This text explains the default interface. However, you can customize many aspects of the appearance and behavior of SQL Developer by setting preferences (see Section 1.17). If you ever need to restore the default interface, see Section 1.2.2, "Restoring the Original "Look and Feel"".Note:
For migration of third-party databases to Oracle, see also Section 2.3, "SQL Developer User Interface for Migration".The menus at the top contain standard entries, plus entries for features specific to SQL Developer (see Section 1.2.1, "Menus for SQL Developer"), as shown in the following figure.

You can use shortcut keys to access menus and menu items: for example Alt+F for the File menu and Alt+E for the Edit menu; or Alt+H, then Alt+S for Help, then Search. You can also display the File menu by pressing the F10 key (except in the SQL Worksheet, where F10 is the shortcut for Explain Plan).
To close a window that has focus (such as the SQL Developer main window, a wizard or dialog box, or the Help Center) and any of its dependent windows, you can press Alt+F4.
Icons under the menus perform various actions, including the following:
-
New creates a new database object (see Section 5.17, "Create New Object").
-
Open opens a file (see Section 5.123, "Open File").
-
Save saves any changes to the currently selected object.
-
Save All saves any changes to all open objects.
-
Back moves to the pane that you most recently visited. (Or use the drop-down arrow to specify a tab view.)
-
Forward moves to the pane after the current one in the list of visited panes. (Or use the drop-down arrow to specify a tab view.)
-
Open SQL Worksheet opens the SQL Worksheet (see Using the SQL Worksheet). If you do not use the drop-down arrow to specify the database connection to use, you are asked to select a connection.
The left side of the SQL Developer window has tabs and panes for the Connections and Reports navigators, icons for performing actions, and a hierarchical tree display for the currently selected navigator, as shown in the following figure.
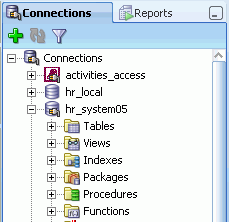
The Connections navigator lists database connections that have been created. To create a new database connection, import an XML file with connection definitions, or export or edit current connections, right-click the Connections node and select the appropriate menu item. (For more information, see Section 1.4, "Database Connections".)
The Files navigator (marked by a folder icon; not shown in the preceding figure) displays your local file system using a standard hierarchy of folders and files. You can double-click or drag and drop files to open them, and you can edit and save the files. For example, if you open a .sql file, it is displayed in a SQL Worksheet window. The Files navigator is especially useful if you are using versioning with SQL Developer (see Section 1.10, "Using Versioning").
The Reports navigator lists informative reports provided by SQL Developer, such as a list of tables without primary keys for each database connection, as well as any user-defined reports. (For more information, see Section 1.16, "SQL Developer Reports".)
Icons under the Connections tab (above the metadata tree) perform the following actions on the currently selected object:
-
Refresh queries the database for the current details about the selected object (for example, a connection or just a table).
-
Apply Filter restricts the display of objects using a filter that you specify. For example, you can right-click the Tables node and specify a filter of EM% to see only tables that start with EM and to have the Tables node label be changed to Tables (EM%). To remove the effects of applying a filter, right-click the node and select Clear Filter.
Note that for tables, the initial default node label is Tables (Filtered), to reflect the exclusion of tables that are in the Recycle Bin. To have such tables included in the display, clear the filter.
The metadata tree in the Connections pane displays all the objects (categorized by object type) accessible to the defined connections. To select an object, expand the appropriate tree node or nodes, then click the object.
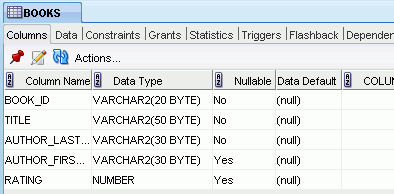
The right side of the SQL Developer window has tabs and panes for objects that you select or open, as shown in the following figure, which displays information about a table named BOOKS. (If you hold the mouse pointer over the tab label -- BOOKS in this figure -- a tooltip displays the object's owner and the database connection.)
For objects other than subprograms, icons provide the following options:
-
Freeze View (the pin) keeps that object's tab and information in the window when you click another object in the Connections navigator; a separate tab and display are created for that other object. If you click the pin again, the object's display is available for reuse.
-
Edit displays a dialog box for editing the object.
-
Refresh updates the display by querying the database for the latest information.
-
Actions displays a menu with actions appropriate for the object. The actions are the same as when you right-click an object of that type in the Connections navigator, except the Actions menu does not include Edit.
To switch among objects, click the desired tabs; to close a tab, click the X in the tab. If you make changes to an object and click the X, you are asked if you want to save the changes.
For tables and views, this information is grouped under tabs, which are labeled near the top. For example, for tables the tabs are Columns, Data (for seeing and modifying the data itself), Indexes, Constraints, and so on; and you can click a column heading under a tab to sort the grid rows by the values in that column. For most objects, the tabs include SQL, which displays the SQL statement for creating the object.
You can export (unload) data from a detail pane or from the results of a SQL Worksheet operation or a report by using the context menu and selecting Export.
The Messages - Log area is used for feedback information as appropriate (for example, results of an action, or error or warning messages). If this area is not already visible, you can display is by clicking View and then Log.
The Compiler - Log area is used for any messages displayed as a result of a Compile or Compile for Debug operation.
1.2.1 Menus for SQL Developer
This topic explains menu items that are specific to SQL Developer.
Extended Paste: Displays the Paste dialog box, in which you select a clipboard item (from potentially many) to be pasted into the current location.
Duplicate Selection: When you have selected text while editing a function or procedure, creates a copy of the selected text at the current location.
Wrap Selection: When you have selected text while editing a function or procedure, wraps the selected text.
Contains options that affect what is displayed in the SQL Developer interface.
Data Modeler: Lets you display the Browser and Thumbnail Diagram panes of the Data Modeler in SQL Developer.
Breakpoints: Displays the Breakpoints pane, which shows breakpoints, both system-defined and user-defined (see Section 1.6, "Running and Debugging Functions and Procedures").
Component Palette: Displays the Component Palette: Configure Component Palette dialog box.
Debugger: Displays panes related to debugging (see Section 1.6, "Running and Debugging Functions and Procedures").
Log: Displays the Messages - Log pane, which can contain errors, warnings, and informational messages.
Run Manager: Displays the Run Manager pane, which contains entries for any active debugging sessions.
Status: Displays the Status pane, which displays any audit violations in the document selected in the file list and provides information to help you resolve the issues.
Team: Lets you display the Versioning navigator (see Section 1.10, "Using Versioning").
Change Management: Displays the Change Management window (see .Section 1.15, "Change Manager Support in SQL Developer").
Connections: Displays the Connections navigator.
DBA: Displays the DBA navigator (see .Section 1.11, "Using DBA Features in SQL Developer").
Data Miner: Lets you display the Data Miner Navigator, Workflow Jobs, Workflow Property Inspector, and Component Palette. (For information about Oracle Data Miner, click Help, then Data Mining.).
DBMS Output: Displays the output of DBMS_OUTPUT package statements (see Section 1.7.5, "DBMS Output Pane").
Files: Displays the Files navigator, which is marked by a folder icon. You can use the Files navigator to browse, open, edit, and save files that are accessible from the local system.
Find DB Object: Displays the Find Database Object pane (see Section 1.9, "Finding Database Objects").
Map View: Displays the Map View pane (see Section 1.14.2, "Map Visualization of Spatial Data").
Migration Projects: Lets you display any captured models and converted models (see Section 2.3, "SQL Developer User Interface for Migration").
OWA Output: Displays Oracle Web Agent (MOD_PLSQL) output (see Section 1.7.6, "OWA Output Pane").
Recent Objects: Displays a pane with names of recently opened objects. You can click a name in the list to go to its editing window.
Reports: Displays the Reports navigator (see Section 1.16, "SQL Developer Reports").
SQL History: Displays information about SQL statements that you have executed. You can select statements and append them to or overwrite statements on the worksheet (see Section 1.7.7, "SQL History").
SQL Developer Cart: Displays the SQL Developer Cart window (see .Section 1.13, "Deploying Objects Using the SQL Developer Cart").
Snippets: Displays snippets (see Section 1.8, "Using Snippets to Insert Code Fragments").
Task Progress: Displays the Task Progress pane.
Unit Test: Displays the Unit Test navigator (see Chapter 3, "SQL Developer: Unit Testing").
Show Status Bar: Controls the display of the status bar at the bottom of the SQL Developer window.
Show Toolbars: Controls the display of the following toolbars: Main toolbar (under the SQL Developer menus), the Connections Navigator toolbar, the DBA navigator toolbar, the Data Miner Workflow Property Inspector toolbar, and (if a package or subprogram is open) the Code Editor toolbar.
Contains options for navigating to panes and in the execution of subprograms.
Back: Moves to the pane that you most recently visited.
Forward: Moves to the pane after the current one in the list of visited panes.
Toggle Bookmark: If you are editing a function or procedure, creates or removes a bookmark (see Section 1.6.1, "Using Bookmarks When Editing Functions and Procedures").
Remove Bookmarks from File: Removes bookmarks from the currently active editing window for a function or procedure (see Section 1.6.1, "Using Bookmarks When Editing Functions and Procedures").
Remove All Bookmarks: Removes bookmarks from open editing windows for functions and procedures (see Section 1.6.1, "Using Bookmarks When Editing Functions and Procedures").
Go to Bookmark: Displays a dialog box so that you can go to a specified bookmark (see Section 1.6.1, "Using Bookmarks When Editing Functions and Procedures").
Go to Next Bookmark: Goes to the next bookmark in the currently active editing window for a function or procedure (see Section 1.6.1, "Using Bookmarks When Editing Functions and Procedures").
Go to Previous Bookmark: Goes to the previous bookmark in the currently active editing window for a function or procedure (see Section 1.6.1, "Using Bookmarks When Editing Functions and Procedures").
Go to Line: Goes to the specified line number and highlights the line in the editing window for the selected function or procedure. (To display line numbers, enable Show Line Numbers under the Code Editor: Line Gutter preferences.)
Go to Last Edit: Goes to the last line that was edited in the editing window for a function or procedure.
Go to Recent Files: Displays the Recent Files dialog box, in which you can specify a function or procedure to go to.
Contains options relevant when a function or procedure is selected or when it is open for debugging.
Run [name]: Starts execution of the specified function or procedure.
Debug [name]: Starts execution of the specified function or procedure in debug mode.
The remaining items on the Debug menu match commands on the debugging toolbar, which is described in Section 1.6, "Running and Debugging Functions and Procedures".
Contains options related to support for the Subversion version management and source control system, and for any other such systems (such as CVS) that you have added as extensions to SQL Developer through the "check for updates" feature. See Section 1.10, "Using Versioning" for more information.
The commands on the Versioning menu depend on which version management and source control systems are available for use with SQL Developer.
Invokes SQL Developer tools.
Data Modeler: Starts the Data Modeler in SQL Developer if it not already active; otherwise, contains the commands About Data Modeler, Design Rules, and General Options (user preferences).
Migration: Displays the Migration Submenu, which contains commands related to migrating third-party databases to Oracle.
Unit Test: Displays the Unit Test Submenu, which contains commands related to unit testing.
Data Miner: Enables you to show the Data Miner navigator and drop the Data Miner repository. (For information about Data Miner, click Help, then Data Mining).
Database Copy: Enables you to copy objects, schemas, or a tablespace from one database to another (see the Database Copy wizard).
Database Diff: Enables you to compare two schemas to find differences between objects of the same type and name (for example, tables named CUSTOMERS) in two different schemas, and optionally to update the objects in the destination schema to reflect differences in the source schema (see the Database Differences interface).
Database Export: Enables you to export (unload) some or all objects of one or more object types for a database connection to a file containing SQL statements to create these objects and optionally to export table data (see the Database Export (Unload Database Objects and Data) interface).
Monitor SQL (requires the Oracle Tuning Pack): Displays information about any query currently executing and queries that are done executing for a selected connection. To see detailed information about a query, right-click its row and select Show SQL Details. The information is especially useful for real-time monitoring of long-running SQL statements. Cursor statistics (such as CPU times and IO times) and execution plan statistics (such as number of output rows, memory, and temporary space used) are updated close to real-time during statement execution. (Internally, this feature calls the DBMS_SQLTUNE.REPORT_SQL_MONITOR subprogram.)
Monitor Sessions: Displays the status of one or more sessions, using information from the V$RSRC_SESSION_INFO view, which shows how the session has been affected by the Oracle Database Resource Manager. For more information about session monitoring, see Oracle Database Administrator's Guide.
SQL Worksheet: Displays a worksheet in which you can enter and execute SQL and PL/SQL statements using a specified connection (see Section 1.7, "Using the SQL Worksheet").
External Tools: Displays the External Tools dialog box, with information about user-defined external tools that are integrated with the SQL Developer interface. From this dialog box can add external tools (see Section 5.86, "Create/Edit External Tool"). The Tools menu also contains items for any user-defined external tools.
Preferences: Enables you to customize the behavior of SQL Developer (see Section 1.17, "SQL Developer Preferences").
Displays help about SQL Developer and enables you to check for SQL Developer updates.
Search: Displays the Help Center window.
Table of Contents: Displays the Help Center window. In this window you can click these icons:
-
Keep on Top: Toggles whether to keep the Help Center window on top of the Data Modeler window.
-
Navigators: Lets you select a help navigator.
-
Print: Prints the topic.
-
Change Font Size: Lets you increase or decrease the font size for the display of the current help topic.
-
Add to Favorites: Adds the topic to the Favorites list.
-
Find: Lets you search for a string in the current help topic.
Start Page: Displays a page with links for options for learning about SQL Developer.
Data Mining: Displays an introductory help topic about Oracle Data Mining and its graphical user interface, Data Miner, which is integrated into SQL Developer.
Tip of the Day (English locales only): Displays a suggestion for efficient use of SQL Developer. (See Section 1.22, "Tip of the Day".)
Check for Updates: Checks for any updates to the selected optional SQL Developer extensions, as well as any mandatory SQL Developer extensions. The available updates may include the JTDS JDBC Driver for Microsoft SQL Server and the MySQL JDBE Driver, which enable you to create connections to third-party databases. (If the system you are using is behind a firewall, see the SQL Developer user preferences for Web Browser and Proxy.)
About: Displays version-related information about SQL Developer and its components.
1.2.2 Restoring the Original "Look and Feel"
If you have made changes to the SQL Developer user interface ("look and feel"), such as accidentally repositioning navigators and panes, you can restore the interface to the way it was after SQL Developer was installed by following these steps:
-
If you are running SQL Developer, exit.
-
Create a backup copy of the folder or directory where your SQL Developer user information is stored, in case you want to restore any old user-defined reports, snippets, code templates, or SQL history. The default location is a build-specific directory or folder under the following:
-
Windows: C:\Documents and Settings\<user-name>\Application Data\SQL Developer
-
Linux or Mac OS X: ~/.sqldeveloper
If you have specified a nondefault location for your SQL Developer user information (see Section 1.18), create the backup copy of that folder or directory instead.
(If you do not want to use any old information or settings, you can skip creating a backup copy.)
-
-
Delete the original (not the backup) folder or directory where your user information is stored (explained in step 2).
-
Start SQL Developer.
This creates a folder or directory where your user information is stored (explained in step 2), which has the same content as when SQL Developer was installed.
If you have made changes to the SQL Developer shortcut key (accelerator key) mappings, you can restore the mappings to the defaults for your system by clicking Tools, then Preferences, then Shortcut Keys, then More Actions, then Load Keyboard Scheme, and then selecting Default.
1.3 Database Objects
You can create, edit, and delete (drop) most types of objects in an Oracle database by using the context menu (right-click, or Shift+F10) in the Connections navigator or by clicking the Actions button in the detail pane display. For some objects, you can do other operations, as appropriate for the object type.
For some object types the context menu includes Open, which generates a tabular overview display of information about objects of that type. For example, selecting Open for the Tables node in the Connections navigator displays a list of all tables for the connection, and for each table the table name, the number of rows, the table status, the number of columns, the comment (if any), and other information.
Note:
The actions available from context menus and Actions buttons depend on the Oracle Database release number for the specified database connection. If an action mentioned in the text is not available with a connection, it may be that the feature was not available in that release of Oracle Database.The dialog boxes for creating and editing many objects contain a tab or pane named DDL or SQL, where you can see the statement that SQL Developer will use to perform the actions you specify (CREATE to create an object, ALTER to apply changes to an existing object).
You can search for specific objects associated with an Oracle database connection by clicking the Search icon, as explained in Section 1.9, "Finding Database Objects".
If you have connected to any third-party (non-Oracle) databases, such as MySQL, Microsoft SQL Server, Sybase Adaptive Server, Microsoft Access, or IBM DB2, you can view their objects using the Connections navigator. (For information about connecting to third-party databases, see the SQL Developer user preferences for Database: Third Party JDBC Drivers.)
1.3.1 Applications (Application Express 3.0.1 and Later)
Effective with Oracle Application Express 3.0.1, if you use SQL Developer to connect to a schema that owns any Application Express applications, the Connections navigator has an Application Express node. You can click an application name to display tabs (Application, Pages, LOVs, Lists, Templates, Breadcrumbs, and so on) with information about the application.
You can perform the following operations on an Application Express application by right-clicking the application name in the Connections navigator and selecting an item from the menu:
-
Import Application: Imports an application from a specified file and installs the application.
-
Deploy Application: Deploys an application into a specified target schema.
-
Drop: Deletes the application.
-
Modify Application: Enables you to change the alias, name (Rename), status, global notification, and proxy server for the application.
-
Export DDL: Saves the DDL statements to create the application (or the selected component) to a file, a .zip file, a worksheet, or the system clipboard.
-
Refactor (in bulk): Collects all anonymous blocks, refactors them into PL/SQL procedures, and places them in a package. The output of a refactor in bulk operation is a PL/SQL script, which you can review and save, and which you can execute to create the package.
The following operations are available only by right-clicking the Application Express node in the Connections navigator and selecting an item from the menu:
-
Start EPG: Starts the embedded PL/SQL gateway for Application Express. Displays a dialog box for executing the following statements: BEGIN DBMS_EPG.map_dad('APEX', '/apex/*'); end;
-
Stop EPG: Stops the embedded PL/SQL gateway for Application Express. Displays a dialog box for executing the following statements: BEGIN DBMS_EPG.unmap_dad('APEX'); end;
1.3.2 Cache Groups (Oracle TimesTen In-Memory Database)
A cache group describes a collection of in-memory database tables that map to all or a subset of the tables in an Oracle database. A cache group can consist of all or a subset of the rows and columns in these tables. Multiple cache groups can be used to cache different sets of related tables in the Oracle database.
1.3.3 Chains
A chain is an Oracle Scheduler object that enables you to implement dependency scheduling, in which jobs are started depending on the outcomes of one or more previous jobs. A chain consists of multiple steps that are combined using dependency rules. The dependency rules define the conditions that can be used to start or stop a step or the chain itself. Conditions can include the success, failure, or completion-codes or exit-codes of previous steps. Logical expressions, such as AND/OR, can be used in the conditions. In a sense, a chain resembles a decision tree, with many possible paths for selecting which tasks run and when.
For more information about job scheduling, see Section 1.12, "Scheduling Jobs Using SQL Developer".
1.3.4 Credentials
A credential is an Oracle Scheduler object that is a user name and password pair stored in a dedicated database object. A job uses a credential to authenticate itself with a database instance or the operating system so that it can run.
For more information about job scheduling, see Section 1.12, "Scheduling Jobs Using SQL Developer".
1.3.5 Database Destinations
A database destination is an Oracle Scheduler object that defines a location for running a job. There are two types of destinations: an external destination specifies a remote host name and IP address for running a remote external job; a database destination specifies a remote database instance for running a remote database job.
If you specify a destination when you create a job, the job runs on that destination. If you do not specify a destination, the job runs locally, on the system on which it is created.
For more information about job scheduling, see Section 1.12, "Scheduling Jobs Using SQL Developer".
1.3.6 Database Links (Public and Private)
A database link is a database object in one database that enables you to access objects on another database. The other database need not be an Oracle Database system; however, to access non-Oracle systems you must use Oracle Heterogeneous Services. After you have created a database link, you can use it to refer to tables and views in the other database. The Connections navigator has a Database Links node for all database links (public and private) owned by the user associated with the specified connection, and a Public Database Links node for all public database links on the database associated with the connection. For help with specific options in creating a database link, see Section 5.38, "Create/Edit Database Link".
You can perform the following operations on a database link by right-clicking the database link name in the Connections navigator and selecting an item from the menu:
-
Test Database Link: Validates the database link.
-
Drop: Deletes the database link.
1.3.7 Destination Groups
A destination group is an Oracle Scheduler object whose members are a list of Scheduler destination objects. In a database destination group, the members are database destinations, for running remote database jobs. In an external destination group, members are external destinations, for running remote external jobs.
For more information about job scheduling, see Section 1.12, "Scheduling Jobs Using SQL Developer".
1.3.8 Directories
A directory object specifies an alias for a directory (called a folder on Windows systems) on the server file system where external binary file LOBs (BFILEs) and external table data are located. To create a directory (that is, a directory object), you can use SQL Developer or the SQL statement CREATE DIRECTORY.
You can use directory names when referring to BFILEs in your PL/SQL code and OCI calls, rather than hard coding the operating system path name, for management flexibility. All directories are created in a single namespace and are not owned by an individual schema. You can secure access to the BFILEs stored within the directory structure by granting object privileges on the directories to specific users.
1.3.9 Editions
Edition-based redefinition, (introduced in Oracle Database 11g Release 2 (11.2), enables you to upgrade the database component of an application while it is in use, thereby minimizing or eliminating down time. To upgrade an application while it is in use, you copy the database objects that comprise the application and redefine the copied objects in isolation. Your changes do not affect users of the application—they continue to run the unchanged application. When you are sure that your changes are correct, you make the upgraded application available to all users. For more information, see the chapter about edition-based redefinition in Oracle Database Advanced Application Developer's Guide.
To specify the current edition, right-click the edition name and select Set Current Edition. To create an edition under an existing edition, right-click the edition name and select Create Edition. To delete an edition (and optionally all editions under it), right-click the edition name and select Drop Edition.
1.3.10 File Watchers
A file watcher is an Oracle Scheduler object that defines the location, name, and other properties of a file whose arrival on a system causes the Scheduler to start a job. You create a file watcher and then create any number of event-based jobs or event schedules that reference the file watcher. When the file watcher detects the arrival of the designated file, it raises a file arrival event. The job started by the file arrival event can retrieve the event message to learn about the newly arrived file.
For more information about job scheduling, see Section 1.12, "Scheduling Jobs Using SQL Developer".
1.3.11 Functions
A function is a type of PL/SQL subprogram, which is a programming object that can be stored and executed in the database server, and called from other programming objects or applications. (Functions return a value; procedures do not return a value.) For help with specific options in creating a PL/SQL subprogram, see Section 5.45, "Create PL/SQL Subprogram (Function or Procedure)".
You can perform the following operations on a function by right-clicking the function name in the Connections navigator and selecting an item from the menu:
-
Edit: Displays the function text so that you can view and edit it.
-
Run: Displays the Run/Debug/Profile PL/SQL dialog box, and then executes the function in normal (not debug) mode.
-
Compile for Debug: Performs a PL/SQL compilation of the procedure, with PL/SQL library units compiled for debugging.
-
Profile (for an Oracle Database Release 11.1 or later connection): Displays the Run/Debug/Profile PL/SQL dialog box, and then executes the function and collects execution statistics.
-
Drop: Deletes the function.
-
Grant: Enables you to grant available privileges on the function to selected users.
-
Revoke: Enables you to revoke available privileges on the function from selected users.
-
Format: Reformats the text of the function definition.
-
Create Unit Test: Creates a unit test (see Chapter 3) for the function.
-
Export DDL: Enables you to export the DDL statement for creating the function to a file, a SQL Worksheet, or the clipboard.
1.3.12 Indexes
An index is a database object that contains an entry for each value that appears in the indexed column(s) of the table or cluster and provides direct, fast access to rows. Indexes are automatically created on primary key columns; however, you must create indexes on other columns to gain the benefits of indexing. For help with specific options in creating an index, see Section 5.39, "Create/Edit Index".
You can perform the following operations on an index by right-clicking the index name in the Connections navigator and selecting an item from the menu:
-
Drop: Deletes the index.
-
Rebuild Index: Re-creates the index or one of its partitions or subpartitions. If the index is unusable, a successful rebuild operation makes the index usable. For a function-based index, rebuilding also enables the index; however, if the function on which the index is based does not exist, the rebuild operation fails.
-
Rename Index: Changes the name of the index.
-
Make Unusable: Prevents the index from being used by Oracle in executing queries. An unusable index must be rebuilt, or dropped and re-created, before it can be used again.
-
Coalesce: Merges the contents of index blocks, where possible, to free blocks for reuse.
-
Compute Statistics: For a function-based index, collects statistics on both the index and its base table using the DBMS_STATS package. Such statistics will enable Oracle Database to correctly decide when to use the index.
-
Export DDL: Saves the DDL statement to create the index to a file, a SQL Worksheet, or the system clipboard.
1.3.13 Java Sources
Java sources can be created and managed in the database. You can create a Java source object by right-clicking the Java node in the Connections navigator, selecting Load Java, and specifying the Java source name and either entering the source code or loading a Java source, class, or resource from a file (BFILE). (A CREATE OR REPLACE AND RESOLVE JAVA SOURCE statement is executed using the information you specify.) For information about Java concepts and stored procedures, see Oracle Database Java Developer's Guide.
1.3.14 Jobs
A job is an Oracle Scheduler object that is a collection of metadata that describes a user-defined task. It defines what needs to be executed (the action), when (the one-time or recurring schedule or a triggering event), where (the destinations), and with what credentials. A job has an owner, which is the schema in which it is created.
For more information about job scheduling, see Section 1.12, "Scheduling Jobs Using SQL Developer".
1.3.15 Job Classes
A job class is an Oracle Scheduler object that enables the Scheduler administrator to group jobs for logical purposes, such as to assign the same set of attribute values to member jobs, to set service affinity for member jobs, to set resource allocation for member jobs, or to group jobs for prioritization.
For more information about job scheduling, see Section 1.12, "Scheduling Jobs Using SQL Developer".
1.3.16 Materialized Views
A materialized view is a database object that contains the results of a query. The FROM clause of the query can name tables, views, and other materialized views. Collectively these objects are called master tables (a replication term) or detail tables (a data warehousing term). This reference uses "master tables" for consistency. The databases containing the master tables are called the master databases. For help with specific options in creating a materialized view, see Section 5.61, "Create/Edit View", especially the View Information or Materialized View Properties pane.
1.3.17 Materialized View Logs
A materialized view log is a table associated with the master table of a materialized view. When DML changes are made to master table data, Oracle Database stores rows describing those changes in the materialized view log and then uses the materialized view log to refresh materialized views based on the master table. This process is called incremental or fast refresh. Without a materialized view log, Oracle Database must reexecute the materialized view query to refresh the materialized view. This process is called a complete refresh. Usually, a fast refresh takes less time than a complete refresh.
1.3.18 Packages
A package is an object that contains subprograms, which are programming objects that can be stored and executed in the database server, and called from other programming objects or applications. A package can contain functions or procedures, or both. For help with specific options in creating a package, see Section 5.44, "Create PL/SQL Package".
You can perform the following operations on a package by right-clicking the package name in the Connections navigator and selecting an item from the menu:
-
Edit: Opens the package in a window, where you can modify the content and other information.
-
Run: Lets you select a member in the package and run it.
-
Compile: Performs a PL/SQL compilation of the members in the package.
-
Compile for Debug: Performs a PL/SQL compilation of the members in the package, with PL/SQL library units compiled for debugging
-
Order Members By: Orders the members of the package by location in the source, by name, or by type and by name within each type.
-
Use as Template: Lets you create a new package using the selected package as the initial content.
-
Drop Package: Deletes the package.
-
Create Body: Displays a pane in which you can enter text for the package body.
-
Grant: Lets you grant privileges on the package
-
Revoke: Lets you revoke privileges on the package.
-
Save Package Spec and Body: Saves the package specification and body to a file that you specify.
-
Export DDL: Saves the DDL statement to create the package to a file, a SQL Worksheet, or the system clipboard.
1.3.19 Procedures
A procedure is a type of PL/SQL subprogram, which is a programming object that can be stored and executed in the database server, and called from other programming objects or applications. (Procedures do not return a value; functions return a value.) For help with specific options in creating a PL/SQL subprogram, see Section 5.45, "Create PL/SQL Subprogram (Function or Procedure)".
You can perform the following operations on a procedure by right-clicking the procedure name in the Connections navigator and selecting an item from the menu:
-
Edit: Displays the procedure text so that you can view and edit it.
-
Run: Displays the Run/Debug/Profile PL/SQL dialog box, and then executes the procedure in normal (not debug) mode.
-
Compile for Debug: Performs a PL/SQL compilation of the procedure, with PL/SQL library units compiled for debugging.
-
Profile (for an Oracle Database Release 11.1 or later connection): Displays the Run/Debug/Profile PL/SQL dialog box, and then executes the procedure and collects execution statistics.
-
Drop: Deletes the procedure.
-
Grant: Enables you to grant available privileges on the procedure to selected users.
-
Revoke: Enables you to revoke available privileges on the procedure from selected users.
-
Format: Reformats the text of the procedure definition.
-
Create Unit Test: Creates a unit test (see Chapter 3) for the procedure.
-
Export DDL: Enables you to export the DDL statement for creating the procedure to a file, a SQL Worksheet, or the clipboard.
1.3.20 Programs
A program is an Oracle Scheduler object that describes what is to be run by the Scheduler. A program includes an action, a type, and the number of arguments that the stored procedure or external executable accepts. (A program is a separate entity from a job. A job runs at a certain time or because a certain event occurred, and invokes a certain program.)
For more information about job scheduling, see Section 1.12, "Scheduling Jobs Using SQL Developer".
1.3.21 Queues
A queue is an object in which messages are enqueued and dequeued. Queues are managed by Oracle Streams Advanced Queueing (AQ). For information about using queues, see Oracle Streams Advanced Queuing User's Guide.
1.3.22 Queue Tables
A queue table is a table that holds messages to be used with Oracle Streams Advanced Queueing (AQ). For information about using queue tables, see Oracle Streams Advanced Queuing User's Guide, especially the information about managing queue tables in the chapter describing the Oracle Streams AQ administrative interface.
1.3.23 Recycle Bin
The Recycle bin (applicable only to Oracle Database Release 10g and later) holds objects that have been dropped (deleted). The objects are not actually deleted until a commit operation is performed. Before the objects are actually deleted, you can "undelete" them by selecting them in the Recycle bin and selecting Flashback to Before Drop from the context menu.
The Recycle bin is available only for non-system, locally managed tablespaces. Thus, to take advantage of the Recycle bin to be able to recover dropped tables for a database user, create or edit the user to have a non-system default tablespace (for example, USERS and not SYSTEM).
You can perform the following operations on an object in the Recycle bin by right-clicking the object name in the Recycle bin in the Connections navigator and selecting an item from the menu:
-
Purge: Removes the object from the Recycle bin and deletes it.
-
Flashback to Before Drop: Moves the object from the Recycle bin back to its appropriate place in the Connections navigator display.
1.3.24 Replication Schemes (Oracle TimesTen In-Memory Database)
A replication scheme is a configuration, using SQL statements and a transaction-based log, whereby committed changes are copied from their source to one or more subscriber databases. The goal is to enable high efficiency and low overhead during the replication.
1.3.25 Schedules
A schedule is an Oracle Scheduler object that specifies when and how many times a job is run. Schedules can be shared by multiple jobs. For example, the end of a business quarter may be a common time frame for many jobs; instead of having to define an end-of-quarter schedule each time a new job is defined, job creators can point to a named schedule.
For more information about job scheduling, see Section 1.12, "Scheduling Jobs Using SQL Developer".
1.3.26 Sequences
Sequences are used to generate unique integers. You can use sequences to automatically generate primary key values. For help with specific options in creating and editing a sequence, see Section 5.49, "Create/Edit Sequence".
1.3.27 Synonyms (Public and Private)
Synonyms provide alternative names for tables, views, sequences, procedures, stored functions, packages, materialized views, Java class database objects, user-defined object types, or other synonyms. The Connections navigator has a Synonyms node for all synonyms (public and private) owned by the user associated with the specified connection, and a Public Synonyms node for all public synonyms on the database associated with the connection. For help with specific options in creating and editing a synonym, see Section 5.51, "Create/Edit Synonym".
1.3.28 Tables
Tables are used to hold data. Each table typically has multiple columns that describe attributes of the database entity associated with the table, and each column has an associated data type. You can choose from many table creation options and table organizations (such as partitioned tables, index-organized tables, and external tables), to meet a variety of enterprise needs. To create a table, you can do one of the following:
-
Create the table quickly by adding columns and specifying frequently used features. To do this, do not check the Advanced box in the Create Table dialog box. For help with options for creating a table using this quick approach, see Create Table (quick creation).
-
Create the table by adding columns and selecting from a larger set of features. To do this, check the Advanced box in the Create Table dialog box. For help with options for creating a table with advanced features, see Create/Edit Table (with advanced options).
-
Create the table automatically from a Microsoft Excel worksheet. To do this, right-click Tables under a connection in the Connections navigator, and select Import Data. When asked for the file, select a file of type .xls or .csv.
You can perform the following operations on a table by right-clicking the table name in the Connections navigator and selecting an item from the menu:
-
Edit: Displays the Create/Edit Table (with advanced options) dialog box.
-
Table: Table actions include Rename, Copy (create a copy using a different name), Drop (delete the table), Truncate (delete existing data without affecting the table definition), Lock (set the table lock mode: row share, exclusive, and so on), Comment (descriptive comment explaining the use or purpose of the table), Parallel (change the default degree of parallelism for queries and DML on the table), No Parallel (specify serial execution), and Count Rows (return the number of rows).
-
Column: Column actions include Comment (descriptive comment about a column), Add, Drop, and Normalize.
-
Constraint: Includes options for adding, dropping, enabling, and disabling constraints.
-
Index: Options include Create (create an index on specified columns), Create Text (create an Oracle Text index on a column), Create Text (create a function-based index on a column), and Drop.
-
Constraint: Options include Enable or Disable Single, Drop (delete a constraint), Add Check (add a check constraint), Add Foreign Key, and Add Unique.
-
Privileges: If you are connected as a database user with sufficient privileges, you can Grant or Revoke privileges on the table to other users.
-
Statistics: Options include Gather Statistics (compute exact table and column statistics and store them in the data dictionary) and Validate Structure (verifies the integrity of each data block and row, and for an index-organized table also generates the optimal prefix compression count for the primary key index on the table). Statistics are used by the Oracle Database optimizer to choose the execution plan for SQL statements that access analyzed objects.
-
Storage: Options include Shrink Table (shrink space in a table, for segments in tablespaces with automatic segment management) and Move Table (to another tablespace). The Shrink Table options include Compact (only defragments the segment space and compacts the table rows for subsequent release, but does not readjust the high water mark and does not release the space immediately) and Cascade (performs the same operations on all dependent objects of the table, including secondary indexes on index-organized tables).
-
Trigger: Options include Create, Create PK from Sequence (create a before-insert trigger to populate the primary key using values from a specified sequence), Enable or Disable All, Enable or Disable Single, and Drop (delete the trigger).
-
Import Data: Enables you to import data from a Microsoft Excel worksheet (.xls or .csv file).
-
Export Data: Enables you to export some or all of the table data to a file or to the system clipboard, in any of the following formats: XML (XML tags and data), CSV (comma-separated values including a header row for column identifiers), SQL Insert (INSERT statements), or SQL Loader (SQL*Loader control file). After you select a format, the Database Export (Unload Database Objects and Data) wizard is displayed.
You can perform the following operations on a column in a table by right-clicking the column name in the Connections navigator and selecting an item from the menu:
-
Rename: Renames the column.
-
Drop: Deletes the column (including all data in that column) from the table.
-
Comment: Adds a descriptive comment about the column.
-
Encrypt (for Oracle Database Release 10.2 and higher, and only if the Transparent Data Encryption feature is enabled for the database): Displays a dialog box in which you specify a supported encryption algorithm to be used for encrypting all data in the column. Current data and subsequently inserted data are encrypted.
-
Decrypt (for Oracle Database Release 10.2 and higher, and only if the Transparent Data Encryption feature is enabled for the database): Decrypts data in the column that had been encrypted, and causes data that is subsequently inserted not to be encrypted.
-
Normalize: Creates a new table using the distinct values in the specified column. You must specify names for the new table and its primary key column, as well as a sequence name and trigger name.
1.3.28.1 Flashback Table Support
For tables in Oracle Database Release 11.1 and later, the table display includes the Flashback tab, which provides a view of the modified and original data in the table. If you have appropriate privileges, you can click the Undo SQL subtab to select and review the syntax required to undo changes. For information about using the Flashback Table feature, see Oracle Database Backup and Recovery User's Guide.
1.3.29 Triggers
Triggers are stored PL/SQL blocks associated with a table, a schema, or the database, or anonymous PL/SQL blocks or calls to a procedure implemented in PL/SQL or Java. Oracle Database automatically executes a trigger when specified conditions occur. For help with specific options in creating a trigger, see Section 5.56, "Create Trigger".
A crossedition trigger is intended to fire when DML changes are made in a database while an online application that uses the database is being patched or upgraded with edition-based redefinition. The body of a crossedition trigger is designed to handle these DML changes so that they can be appropriately applied after the changes to the application code are completed. To create a crossedition trigger, you must be enabled for Editions.
1.3.30 Types
A data type associates a fixed set of properties with the values that can be used in a column of a table or in an argument of a function or procedure. These properties cause Oracle Database to treat values of one data type differently from values of another data type. Most data types are supplied by Oracle, although users can create data types.
1.3.31 Users (Other Users)
Database users are accounts through which you can log in to the database. In the Connections navigator, you can see the Other Users in the database associated with a connection, but the database objects that you are allowed to see for each user are determined by the privileges of the database user associated with the current database connection.
If you are connected as a user with the DBA role, you can create a database user by right-clicking Other Users and selecting Create User, and you can edit an existing database user by right-clicking the user under Other Users and selecting Edit User. For help on options in creating and editing users, see Create/Edit User.
1.3.32 Views
Views are virtual tables (analogous to queries in some database products) that select data from one or more underlying tables. Oracle Database provides many view creation options and specialized types of views (such as materialized views, described in Section 1.3.16, "Materialized Views"), to meet a variety of enterprise needs. For help with specific options in creating and editing a view, see Create/Edit View.
Editioning views are shown in a separate navigator node if the connection is to an Oracle Database release that supports Editions. An editioning view selects a subset of the columns from a single base table and, optionally, provides aliases for them. In providing aliases, the editioning view maps physical column names (used by the base table) to logical column names (used by the application). For more information about editioning views, see the chapter about edition-based redefinition in Oracle Database Advanced Application Developer's Guide.
You can perform the following operations on a view by right-clicking the view name in the Connections navigator and selecting an item from the menu:
-
Edit: Displays the Create/Edit View dialog box.
-
Drop: Deletes the view.
-
Compile: Recompiles the view, to enable you to locate possible errors before run time. You may want to recompile a view after altering one of its base tables to ensure that the change does not affect the view or other objects that depend on it.
1.3.33 XML DB Repository
Oracle XML DB Repository is a component of Oracle Database that is optimized for handling XML data. The Oracle XML DB repository contains resources, which can be either folders (directories, containers) or files. For more information about Oracle XML DB Repository, see Oracle XML DB Developer's Guide in the Oracle Database documentation library.
To create a subfolder of an existing folder, right-click the folder name and select Create Subfolder. To delete a folder (and optionally all subfolders under it), right-click the folder name and select Drop Folder.
1.3.34 XML Schemas
XML schemas are schema definitions, written in XML, that describe the structure and various other semantics of conforming instance XML documents. For conceptual and usage information about XML schemas, see Oracle XML DB Developer's Guide in the Oracle Database documentation library.
You can edit an XML schema by right-clicking the XML schema name in the Connections navigator and selecting Open from the menu; you can delete a selected schema by selecting Drop Schema from the menu.
1.3.35 Captured and Converted Database Objects (for Migration)
If you are migrating a third-party database to Oracle, the Captured Models and Converted Models navigators can display models that include database objects, such as tables and procedures. A captured object represents an object in the captured third-party database, and a converted object represents an Oracle model of that object as it will be created in the Oracle database.
The context menu for each captured object includes Convert to Oracle, which creates a corresponding converted object. The context menu for each converted object includes Generate, which creates the corresponding Oracle Database object. (The context menus will contain other items as appropriate for the object.)
For information about the related Oracle Database objects, see the following:
1.4 Database Connections
A connection is a SQL Developer object that specifies the necessary information for connecting to a specific database as a specific user of that database. You must have at least one database connection (existing, created, or imported) to use SQL Developer.
You can connect to any target Oracle database schema using standard Oracle database authentication. Once connected, you can perform operations on objects in the database. You can also connect to schemas for selected third-party (non-Oracle) databases, such as MySQL, Microsoft SQL Server, Sybase Adaptive Server, Microsoft Access, and IBM DB2, and view metadata and data.
When you start SQL Developer and whenever you display the database connections dialog box, SQL Developer automatically reads any connections defined in the tnsnames.ora file on your system, if that file exists. You can specify the tnsnames.ora location in the Database: Advanced preferences.By default, tnsnames.ora is located in the $ORACLE_HOME/network/admin directory, but it can also be in the directory specified by the TNS_ADMIN environment variable or registry value or (on Linux systems) the global configuration directory. On Windows systems, if the tnsnames.ora file exists but its connections are not being used by SQL Developer, define TNS_ADMIN as a system environment variable. For information about the tnsnames.ora file, see the "Local Naming Parameters (tnsnames.ora)" chapter in Oracle Database Net Services Reference.
You can create additional connections (for example, to connect to the same database but as different users, or to connect to different databases). Each database connection is listed in the Connections navigator hierarchy.
To create a new database connection, right-click the Connections node and select New Database Connection. Use the dialog box to specify information about the connection (see Section 5.21, "Create/Edit/Select Database Connection"). You can also create a new database connection by selecting an existing connection in that dialog box, changing the connection name, changing other connection attributes as needed, and clicking Save or Connect.
To create (automatically generate) a database connection for each unlocked user account in the Oracle database instance on the local system, right-click the Connections node and select Create Local Connections. The connections are placed in a folder named Auto-Generated Local Connections. Note that for these autogenerated connections (except for the one named system-<database-name>), you will always be prompted for the password when you connect, and you cannot edit the user name or password in the connection properties dialog box.
To edit the information about an existing database connection, right-click the connection name in the Connections navigator display and select Properties. Use the dialog box to modify information about the connection, but do not change the connection name. (See Section 5.21, "Create/Edit/Select Database Connection".)
To organize connection groups using folders, see Section 1.4.1, "Using Folders to Group Connections".
To export information about the existing database connections into an XML file that you can later use for importing connections, right-click Connections in the Connections navigator display and select Export Connections. Use the dialog box to specify the connections to be exported (see Section 5.35, "Export/Import Connection Descriptors").
To import connections that had previously been exported (adding them to any connections that may already exist in SQL Developer), right-click Connections in the Connections navigator display and select Import Connections. Use the dialog box to specify the connections to be imported (see Section 5.35, "Export/Import Connection Descriptors").
To perform limited database management operations if you are connected AS SYSDBA, right-click the connection name in the Connections navigator display and select Manage Database. You can click to refresh the read-only display of memory (SGA and PGA) and tablespace information. If a listener is running with a static listener configured for the database, you can also click to start and stop the database.
To perform remote debugging if you are using the Sun Microsystem's Java Platform Debugger Architecture (JPDA) and you would like the debugger to listen so that a debuggee can attach to the debugger, right-click the connection name in the Connections navigator display and select Remote Debug. Use the dialog box to specify remote debugging information (see Section 5.74, "Debugger - Attach to JPDA").
To estimate or compute statistics for objects in a database schema, right-click the connection name in the Connections navigator display and select Gather Schema Statistics. Statistics are used to optimize SQL execution.
To generate documentation (in HTML format (comparable to Javadoc for Java classes) about a schema, right-click the connection name in the Connections navigator display and select Generate DB Doc. To view the generated documentation, open the index.html file in the output directory that you specified.
(Note that Generate DB Doc is also used for migration projects: right-click the migration project name in the Migration Projects navigator display and select Migration Project Doc; you can specify whether to include child nodes of the selected node and child master-detail per-row reports.)
To reset an expired password for the database user associated with a connection, right-click the connection name in the Connections navigator display and select Reset Password (enabled only if an OCI (thick) driver is available).
To rename a connection, right-click the connection name in the Connections navigator display and select Rename Connection.
To delete a connection (that is, delete it from SQL Developer, not merely disconnect from the current connection), right-click the connection name in the Connections navigator display and select Delete. Deleting a connection does not delete the user associated with that connection.
To connect using an existing connection, expand its node in the Connections navigator, or right-click its name and select Connect. A SQL Worksheet window is also opened for the connection (see Section 1.7, "Using the SQL Worksheet"). To create a separate unshared worksheet for a connection, click in the worksheet and use Ctrl+Shift+N.
To disconnect from the current connection, right-click its name in the Connections navigator and select Disconnect.
To specify a preference for using an OCI (thick, Type 2) driver (if available) instead of a JDBC (thin) driver for basic and TNS (network alias) database connections, enable the Use OCI/Thick driver option under the Database: Advanced user preferences.
1.4.1 Using Folders to Group Connections
You can use folders in the Connections navigator to organize connections into groups: for example, one folder for connections on your local system, another for connections on the test system, and another for connections on the production system.
To create a folder to hold connections, right-click the name in the Connections navigator of a connection to be added to the folder, select Add to Folder and then New Folder, and specify the folder name (such as Local Connections).
To add more connections to a folder, right-click the name in the Connections navigator of a connection to be added to the folder, and select Add to Folder and then the name of the folder into which to add the connection.
To move a connection from one folder to another folder, right-click the connection name under its current folder, select Add to Folder, and then either the name of the destination folder or New Folder to move the connection to a new folder to be created.
To remove a connection from the folder, right-click the connection name under the folder and select Remove from Folder. (This does not delete the connection; it is moved to the top level in the Connections navigator hierarchy display.)
To remove a folder, right-click the folder name select Remove Folder. (This does not delete any connections that are in the folder; these connections are moved to the top level in the Connections navigator hierarchy display.)
To rename a folder, right-click the folder name, select Rename Folder, and specify the new name.
1.4.2 Sharing of Connections
By default, each connection in SQL Developer is shared when possible. For example, if you open a table in the Connections navigator and two SQL Worksheets using the same connection, all three panes use one shared connection to the database. In this example, a commit operation in one SQL Worksheet commits across all three panes. If you want a dedicated session, you must duplicate your connection and give it another name. Sessions are shared by name, not connection information, so this new connection will be kept separate from the original.
1.4.3 Advanced Security for JDBC Connection to the Database
You are encouraged to use Oracle Advanced Security to secure a JDBC or OCI connection to the database. Both the JDBC OCI and the JDBC Thin drivers support at least some of the Oracle Advanced Security features. If you are using the OCI driver, you can set relevant parameters in the same way that you would in any Oracle client setting. The JDBC Thin driver supports the Oracle Advanced Security features through a set of Java classes included with the JDBC classes in a Java Archive (JAR) file and supports security parameter settings through Java properties objects.
For more information about using Oracle Advanced Security, see Oracle Database JDBC Developer's Guide.
1.4.4 Connections with Operating System (OS) Authentication
When you create a connection to an Oracle database that is using operating system (OS) authentication, you can omit the user name and password; that is, specify a connection name and all the other necessary information, except do not specify a user name or password. For information about using external authentication, including the use of the OS_AUTHENT_PREFIX and REMOTE_OS_AUTHENT database initialization parameters, see Oracle Database Security Guide.
If you omit the user name and password trying to create a connection to a system that is not configured for external authentication, an error message is displayed.
1.4.5 Connections with Proxy Authentication
Proxy authentication enables one JDBC connection to act as a proxy for other JDBC connections. If you use the Proxy Connection option when you create a database connection, the connection will be used to connect as the specified user for the connection, but authenticated using the user name and either the password or distinguished name of the proxy user. For information about using a middle tier server for proxy authentication, see Oracle Database Security Guide.
For example, to create connection for a user named PROXY_USER but connecting using the user name and password of existing database user SCOTT, follow these steps.
-
Create the proxy user and grant it the appropriate privileges:
CREATE USER proxy_user IDENTIFIED BY <password>; ALTER USER proxy_user GRANT CONNECT THROUGH scott AUTHENTICATED USING PASSWORD; GRANT create session TO proxy_user; . . .<Grant other privileges as needed.>
-
Create a new database connection. For example: connection name = proxy_conn, user name = scott, password = <password for scott>.
-
Enable (check) Proxy Connection.
-
In the Oracle Proxy Connection dialog box, select User Name for Proxy Type
-
For Proxy User, enter PROXY_USER; and for Proxy Password, enter the password for the PROXY_USER database user.
-
Click OK to close the Oracle Proxy Connection dialog box.
-
Complete any other necessary connection information, and click Connect to create the connection.
In this example, when you connect using the proxy_conn connection, the user name and password for user SCOTT are used to connect to the database, but the connection sees those database objects that the PROXY_USER user is permitted to see.
The preceding instructions cause two sessions to be started (one for the proxy user and one for the proxy client) when the connection is opened. If you want to have a single session (with no second password or distinguished name required) started, you can follow these steps instead after you create the proxy user and grant it appropriate privileges:
-
Create a new database connection. For example: connection name = proxy_conn, user name = proxy_user[scott], password = <password for proxy_user>.
-
For Connection Type, specify TNS.
(Note: Do not enable Proxy Connection.)
-
For Network Alias, select the network alias for the database for the connection.
-
Complete any other necessary connection information, and click Connect to create the connection.
1.5 Entering and Modifying Data
You can use SQL Developer to enter data into Tables and to edit and delete existing table data. To do any of these operations, select the table in the Connections navigator, then click the Data tab in the table detail display. (If you click one of the other tabs -- Columns, Constraints, Grants, Statistics, Triggers, and so on -- you can view the information and perform relevant context menu (right-click) operations.)
The following figure shows the Data pane for a table named BOOKS, with a filter applied to show only books whose rating is 10, and after the user has double-clicked in the Title cell for the first book.
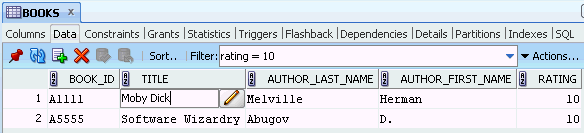
Icons and other controls under the Data tab provide the following options:
-
Freeze View (the pin) keeps that object's tab and information in the window when you click another object in the Connections navigator; a separate tab and display are created for that other object. If you click the pin again, the object's display is available for reuse.
-
Refresh queries the database to update the data display. If a filter is specified, the refresh operation uses the filter.
-
Insert Row adds an empty row after the selected row, for you to enter new data.
-
Delete Selected Row(s) marks the selected rows for deletion. The actual deletion does not occur until you commit changes.
-
Commit Changes ends the current transaction and makes permanent all changes performed in the transaction.
-
Rollback Changes undoes any work done in the current transaction.
-
Sort displays a dialog box for selecting columns to sort by. For each column, you can specify ascending or descending order, and you can specify that null values be displayed first.
-
Filter enables you to enter a SQL predicate (WHERE clause text without the WHERE keyword) for limiting the display of data. For example, to show only rows where the RATING column value is equal to 10, specify rating=10 and press Enter. (To see any previously applied filters, clear the Filter box, then either press Ctrl + spacebar or click the drop-down arrow in the Filter box.)
-
Filter Column enables you to enter a partial value (such as a number or a string; at least two characters for a string), to limit the dialog box display to items containing the partial value, so that you can then select the one item to appear in the grid. For example, entering
EMPfor column names might show a list of columns including EMPLOYEE_ID and IS_TEMP. -
Actions displays a menu with actions relevant to the table.
When you enter a cell in the grid, you can directly edit the data for many data types, and for all data types you can click the ellipsis (...) button to edit the data. For binary data you cannot edit the data in the cell, but must use the ellipsis button.
In the data grid, the context menu (right-click) includes the following commands:
-
Single Record View displays the Single Record View dialog box, which enables you to edit data for a table or view, one record at a time.
-
Auto-fit All Columns adjusts the width of all columns according to your specification (by column header, by column data, or best fit).
-
Auto-fit Selected Columns adjusts the width of the selected columns according to your specification (by column header, by column data, or best fit).
-
Count Rows displays the number of rows in the table.
-
Find/Highlight displays the Find/Highlight, which enables you to find, and optionally highlight, data value matches in the table data grid.
-
Publish to Apex (if Application Express is installed) creates a small Application Express application based on the data. It displays a dialog box in which you specify the following for the application to be created: workspace, application name, theme, page name, and SQL statement for generating the report.
-
Export enables you to export some or all of the table data to a file or to the system clipboard, in any of the following formats: XML (XML tags and data), CSV (comma-separated values including a header row for column identifiers), SQL Insert (INSERT statements), or SQL Loader (SQL*Loader control file). After you select a format, the Database Export (Unload Database Objects and Data) wizard is displayed.
You can copy and paste data between table grid cells and cells in a Microsoft Excel worksheet.
To copy table data to the clipboard, click the column header (for all column data) or select specific cells and press Ctrl+C; to copy the column header text along with the table data, press Ctrl+Shift+C.
To sort the display of rows by values within a column, double-click the column header; to switch between ascending and descending sorting, double-click the up/down arrow in the column header.
In the Data pane for a table or view, you can split the display vertically or horizontally to see two (or more) parts independently by using the split box (thin blue rectangle), located to the right of the bottom scroll bar and above the right scroll bar.
In the Data pane, the acceptable format or formats for entering dates may be different from the date format required by SQL*Plus.
1.6 Running and Debugging Functions and Procedures
You can use SQL Developer to run and debug PL/SQL subprograms (functions and procedures).
-
To run a subprogram, click its name in the Connections navigator; then either right-click and select Run, or click the Edit icon and then click the Run icon above its source listing.
-
To debug a subprogram, click its name in the Connections navigator. If the procedure in its current form has not already been compiled for debug, right-click and select Compile for Debug. Then click the Edit icon and click the Debug icon above its source listing.
In both cases, a code editing window is displayed. The following figure shows the code editing window being used to debug a procedure named LIST_A_RATING2, which is used for tutorial purposes in Section 4.8, "Debug a PL/SQL Procedure".
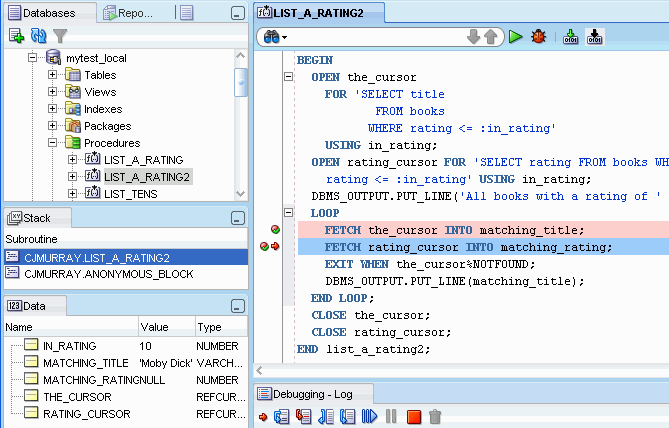
In the code editing window, under the tab with the name of the subprogram, is a toolbar, and beneath it is the text of the subprogram, which you can edit. You can set and unset breakpoints for debugging by clicking to the left of the thin vertical line beside each statement with which you want to associate a breakpoint. (When a breakpoint is set, a red circle is displayed.)
The toolbar under the tab for the subprogram name includes the icons shown in the following figure.
-
Run starts normal execution of the subprogram, and displays the results in the Running - Log tab.
-
Debug starts execution of the subprogram in debug mode, and displays the Debugging - Log tab, which includes the debugging toolbar for controlling the execution.
-
Make - Compile for Debug performs a PL/SQL compilation of the subprogram so that it can be debugged.
-
Make - Compile performs a PL/SQL compilation of the subprogram.
-
Profile displays the Run/Debug/Profile PL/SQL dialog box.
The Debugging - Log tab under the code text area contains the debugging toolbar and informational messages. The debugging toolbar has the icons shown in the following figure.
-
Find Execution Point goes to the execution point (the next line of source code to be executed by the debugger).
-
Step Over bypasses the next subprogram (unless the subprogram has a breakpoint) and goes to the next statement after the subprogram. If the execution point is located on a subprogram call, it runs that subprogram without stopping (instead of stepping into it), then positions the execution point on the statement that follows the call. If the execution point is located on the last statement of a subprogram, Step Over returns from the subprogram, placing the execution point on the line of code that follows the call to the subprogram from which you are returning.
-
Step Into executes a single program statement at a time. If the execution point is located on a call to a subprogram, Step Into steps into that subprogram and places the execution point on its first statement. If the execution point is located on the last statement of a subprogram, Step Into returns from the subprogram, placing the execution point on the line of code that follows the call to the subprogram from which you are returning.
-
Step Out leaves the current subprogram and goes to the next statement.
-
Step to End of Method goes to the last statement of the current subprogram.
-
Resume continues execution.
-
Pause halts execution but does not exit, thus allowing you to resume execution.
-
Terminate halts and exits the execution. You cannot resume execution from this point; instead, to start running or debugging from the beginning of the subprogram, click the Run or Debug icon in the Source tab toolbar.
The Breakpoints tab displays breakpoints, both system-defined and user-defined.
The Smart Data tab displays information about variables, using your Debugger: Smart Data preferences. You can also specify these preferences by right-clicking in the Smart Data window and selecting Preferences.
The Data tab displays information about variables, using your Debugger: Data preferences. You can also specify these preferences by right-clicking in the Data window and selecting Preferences.
The Watches tab displays information about watches (see Section 1.6.5, "Setting Expression Watches").
If the function or procedure to be debugged is on a remote system, see also Section 1.6.2, "Remote Debugging".
1.6.1 Using Bookmarks When Editing Functions and Procedures
When you are editing a long function or procedure, you may find it convenient to create bookmarks in the code so that you can easily navigate to points of interest.
To create or remove a bookmark, click Navigate, then Toggle Bookmark. When a bookmark is created, an icon appears to the left of the thin vertical line.
To go to a specific bookmark, click Navigate, then Go to Bookmark. To go to the next or previous bookmark, click Navigate, then Go to Next Bookmark or Go to Previous Bookmark, respectively.
To remove all bookmarks from the currently active editing window for a function or procedure or from all open editing windows, click Navigate, then Remove Bookmarks from File or Remove All Bookmarks, respectively.
You can also go to a specific line or to your last edit by clicking Navigate, then Go to Line or Go to Last Edit, respectively.
1.6.2 Remote Debugging
To debug a function or procedure for a connection where the database is on a different host than the one on which you are running SQL Developer, you can perform remote debugging. Remote debugging involves many of the steps as for local debugging; however, do the following before you start the remote debugging:
-
Use an Oracle client such as SQL*Plus to issue the debugger connection command. Whatever client you use, make sure that the session which issues the debugger connection commands is the same session which executes your PL/SQL program containing the breakpoints. For example, if the name of the remote system is remote1, use the following SQL*Plus statement to open a TCP/IP connection to that system and the port for the JDWP session:
EXEC DBMS_DEBUG_JDWP.CONNECT_TCP('remote1', '4000');The first parameter is the IP address or host name of the remote system, and the second parameter is the port number on that remote system on which the debugger is listening.
-
Right-click the connection for the remote database, select Remote Debug, and complete the information in the Debugger - Attach to JPDA dialog box.
Then, follow the steps that you would for local debugging (for example, see Section 4.8, "Debug a PL/SQL Procedure").
1.6.3 Displaying SQL Trace (.trc) Files
If you have any SQL Trace (.trc) output files, you can display them in SQL Developer as an alternative to using the TKPROF program to format the contents of the trace file. To open a .trc file in SQL Developer and see an attractive, effective display of the information, click File, then Open, and specify the file; or drag the file's name or icon into the SQL Developer window.
You can then examine the information in the List View, Statistics View, and History panes, with each pane including options for filtering and controlling the display.
For information about SQL Trace and TKPROF, see Oracle Database Performance Tuning Guide.
1.6.4 Using the PL/SQL Hierarchical Profiler
For an Oracle Database Release 11.1 or later connection, you can use the PL/SQL hierarchical profiler to identify bottlenecks and performance-tuning opportunities in PL/SQL applications. Profiling consists of the two steps: running the PL/SQL module in profiling mode, and analyzing the reports. In addition, some one-time setup work is required the first time you use profiling in SQL Developer.
To initiate profiling, right-click the name of the function or procedure in the Connections navigator hierarchy and select Profile, or click the Profile button on the PL/SQL source editor toolbar. After the function or procedure is run in profiling mode, the profiler reports are located at the Execution Profiles tab of the object viewer window. You can review subprogram-level execution summary information, such as:
-
Number of calls to the subprogram
-
Time spent in the subprogram itself (function time or self time)
-
Time spent in the subprogram itself and in its descendent subprograms (subtree time)
-
Detailed parent-children information, including all subprograms that a given subprogram called (that is, children of the given subprogram)
For more information about using the PL/SQL hierarchical profiler, see Oracle Database Advanced Application Developer's Guide.
1.6.5 Setting Expression Watches
A watch enables you to monitor the changing values of variables or expressions as your program runs. After you enter a watch expression, the Watches window displays the current value of the expression. As your program runs, the value of the watch changes as your program updates the values of the variables in the watch expression.
A watch evaluates an expression according to the current context which is controlled by the selection in the Stack window. If you move to a new context, the expression is reevaluated for the new context. If the execution point moves to a location where any of the variables in the watch expression are undefined, the entire watch expression becomes undefined. If the execution point returns to a location where the watch expression can be evaluated, the Watches window again displays the value of the watch expression.
To open the Watches window, click View, then Debugger, then Watches.
To add a watch, right-click in the Watches window and select Add Watch. To edit a watch, right-click in the Watches window and select Edit Watch.
1.7 Using the SQL Worksheet
You can use the SQL Worksheet to enter and execute SQL, PL/SQL, and SQL*Plus statements. You can specify any actions that can be processed by the database connection associated with the worksheet, such as creating a table, inserting data, creating and editing a trigger, selecting data from a table, and saving that data to a file.
You can display a SQL Worksheet by right-clicking a connection in the Connections navigator and selecting Open SQL Worksheet, by selecting Tools and then SQL Worksheet, or by clicking the Use SQL Worksheet icon under the menu bar. In the Select Connection dialog box, select the database connection to use for your work with the worksheet. You can also use that dialog box to create and edit database connections. (You can have a SQL Worksheet window open automatically when you open a database connection by enabling the appropriate SQL Developer user preference under Database Connections.)
To create a separate unshared worksheet for a connection, click in the worksheet and use Ctrl+Shift+N.
The SQL Worksheet has Worksheet and Query Builder tabs, as shown in the following figure (where the Worksheet tab is selected):
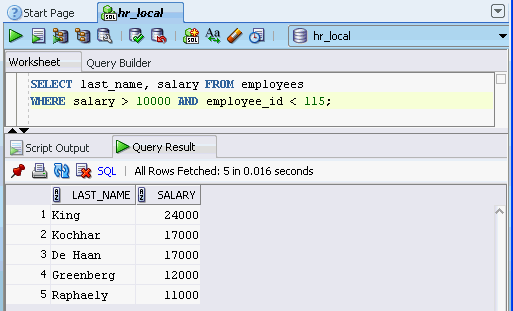
SQL Worksheet toolbar (under the Worksheet tab): Contains icons for the following operations:
-
Execute Statement executes the statement at the mouse pointer in the Enter SQL Statement box. The SQL statements can include bind variables and substitution variables of type VARCHAR2 (although in most cases, VARCHAR2 is automatically converted internally to NUMBER if necessary); a pop-up box is displayed for entering variable values.
-
Run Script executes all statements in the Enter SQL Statement box using the Script Runner. The SQL statements can include substitution variables (but not bind variables) of type VARCHAR2 (although in most cases, VARCHAR2 is automatically converted internally to NUMBER if necessary); a pop-up box is displayed for entering substitution variable values.
-
Commit writes any changes to the database, and ends the transaction; also clears any output in the Results and Script Output panes.
-
Rollback discards any changes without writing them to the database, and ends the transaction; also clears any output in the Results and Script Output panes.
-
Cancel stops the execution of any statements currently being executed.
-
Monitor SQL Status (Oracle Database Release 11.1 and later only) calls the real-time SQL monitoring feature of Oracle Database, enabling you to monitor the performance of SQL statements while they are executing.
-
Explain Plan generates the execution plan for the statement (internally executing the EXPLAIN PLAN statement). To see the execution plan, click the Explain tab. For more information, see Section 1.7.3, "Execution Plan".
-
Autotrace generates trace information for the statement. To see the Autotrace Pane, click the Autotrace tab.
-
Clear erases the statement or statements in the Enter SQL Statement box.
-
To the right of these icons is a drop-down list for changing the database connection to use with the worksheet.
The context menu (right-click, or Shift+F10) includes the preceding Worksheet toolbar operations, plus the following operations (some depending on the type of object displayed in the worksheet):
-
Print File prints the contents of the Enter SQL Statement box.
-
Cut, Copy, Paste, and Select All have the same meanings as for normal text editing operations.
-
Refactoring enables you to do the following on selected text: switch character case (to upper/lower/initcap), extract the sequence of PL/SQL statements to a procedure, or rename the local variable.
-
Format formats the SQL statement (capitalizing the names of statements, clauses, keywords, and so on). The Database: SQL Formatter preferences are used for the formatting. (You can also the Command-Line Interface for SQL Formatting.)
In addition, or as an alternative, can use the Command-Line Interface for SQL Formatting.
-
Advanced Format displays a dialog box where you can specify the output destination and output type for the formal operation.
-
Quick Outline displays the Outline pane with a graphical outline of the object displayed in the worksheet (if an outline is relevant for this type of object). You can click a node in the outline to go to the associated place in the text in the worksheet.
-
Popup Describe, if the name of a database object is completely selected, displays a window with tabs and information appropriate for that type of object (see Section 5.77, "Describe Object Window").
-
Save Snippet opens the Save Snippet (User-Defined) dialog box with the selected text as the snippet text.
Enter SQL Statement: The statement or statements that you intend to execute. For multiple statements, each non-PL/SQL statement must be terminated with either a semicolon or (on a new line) a slash (/), and each PL/SQL statement must be terminated with a slash (/) on a new line. SQL keywords are automatically highlighted. To format the statement, right-click in the statement area and select Format SQL.
You can drag some kinds of objects from the Connections navigator and drop them into the Enter SQL Statement box:
-
If you drag and drop a table or view, by default a SELECT statement is constructed with all columns in the table or view. You can then edit the statement, for example, modifying the column list or adding a WHERE clause.
-
If you drag and drop a function or procedure, a snippet-like text block is constructed for you to edit when including that object in a statement.
To view details for any object, you can select its name in the Enter SQL Statement box and select Popup Describe from the context menu (or press Shift+F4). For example, if you select a table name and press Shift+F4, information about Columns, Constraints, Grants, and so on is displayed; or if you select a procedure name and press Shift+F4, information about Code, Grants, Dependencies, References, and Details is displayed.
Tabs display panes with the following information:
-
Results: Displays the results of the most recent Execute Statement operation.
-
Explain: Displays the output if you clicked the Explain Execution Plan icon (see Section 1.7.3, "Execution Plan").
-
Script Output: Displays the output if you clicked the Run Script icon (see Section 1.7.2, "Script Runner").
-
DBMS Output: Displays the output of DBMS_OUTPUT package statements (see Section 1.7.5, "DBMS Output Pane").
-
OWA Output: Displays Oracle Web Agent (MOD_PLSQL) output (see Section 1.7.6, "OWA Output Pane").
To toggle the relative heights of the Enter SQL Statement area and the area for tabs and display panes, press Ctrl+Alt+L. You can also manually adjust the heights.
1.7.1 SQL*Plus Statements Supported and Not Supported in SQL Worksheet
The SQL Worksheet supports some SQL*Plus statements. SQL*Plus statements must be interpreted by the SQL Worksheet before being passed to the database; any SQL*Plus that are not supported by the SQL Worksheet are ignored and not passed to the database.
The following SQL*Plus statements are supported by the SQL Worksheet:
@
@@
/
acc[ept]
autotrace
clear screen
conn[ect]
def[ine]
desc[ribe]
doc[ument]
echo
errors
esc[ape]
exec[ute]
exit
feed[back]
help
ho[st]
pagesize
pau[se]
print
pro[mpt]
quit
rem[ark]
roll[back]
set pau[se] {ON | OFF}
sta[rt]
spo[ol]
term[out]
timi[ng]
undef[ine]
user
var[iable]
ver[ify]
whenever
xquery
The following SQL*Plus statements are not supported by the SQL Worksheet:
a[ppend] archive attr[ibute] bre[ak] bti[tle] c[hange] col[umn] comp[ute] copy del disc[onnect] ed[it] get i[nput] l[ist] newpage oradebug passw[ord] r[un] recover repf[ooter] reph[eader] sav[e] startup sho[w] shu[tdown] spo[ol] startup store tti[tle]
For information about SQL*Plus statements, you can enter the help statement. For information about a specific statement or topic, include it as the parameter (for example, help @, help exit, or help reserved words). If the statement is not supported in SQL Developer, or if there are restrictions or usage notes, the help display includes this information (for example, "Not currently in SQL Developer").
1.7.2 Script Runner
The script runner emulates a limited set of SQL*Plus features. You can often enter SQL and SQL*Plus statements and execute them by clicking the Run Script icon. The Script Output pane displays the output.
The SQL*Plus features available in the script runner include @, @@, CONNECT, EXIT, QUIT, UNDEFINE, WHENEVER, and substitution variables. For example, to run a script named c:\myscripts\mytest.sql, type @c:\myscripts\mytest in the Enter SQL Statement box, and click the drop-down next to the Execute Statement icon and select Run Script.
The following considerations apply to using the SQL Developer script runner:
-
You cannot use bind variables. (The Execute SQL Statement feature does let you use bind variables of type VARCHAR2, NUMBER, and DATE.)
-
For substitution variables, the syntax &&variable assigns a permanent variable value, and the syntax &variable assigns a temporary (not stored) variable value.
-
For EXIT and QUIT, commit is the default behavior, but you can specify rollback. In either case, the context is reset: for example, WHENEVER command information and substitution variable values are cleared.
-
DESCRIBE works for most, but not all, object types for which it is supported in SQL*Plus.
-
For SQL*Plus statements that are not supported, a warning message is displayed.
-
SQL*Plus comments are ignored.
-
For XMLType data, data in the column is displayed as "SYS.XMLDATA" if the database connection uses a JDBC Thin driver, but the expanded XML values are displayed if the connection uses an OCI (thick, Type 2) driver.
If you have SQL*Plus available on your system, you may want to use it instead of the script runner.
1.7.3 Execution Plan
The Execute Explain Plan icon generates the execution plan, which you can see by clicking the Explain Plan tab. The execution plan is the sequence of operations that will be performed to execute the statement. An execution plan shows a row source tree with the hierarchy of operations that make up the statement. For each operation, it shows the ordering of the tables referenced by the statement, access method for each table mentioned in the statement, join method for tables affected by join operations in the statement, and data operations such as filter, sort, or aggregation.
In addition to the row source tree, the plan table displays information about optimization (such as the cost and cardinality of each operation), partitioning (such as the set of accessed partitions), and parallel execution (such as the distribution method of join inputs). For more information, see the chapter about using EXPLAIN PLAN in Oracle Database Performance Tuning Guide.
1.7.4 Autotrace Pane
The Autotrace pane displays trace-related information when you execute the SQL statement by clicking the Autotrace icon. Most of the specific information displayed is determined by the SQL Developer Preferences for Database: Autotrace/Explain Plan. If you cancel a long-running statement, partial execution statistics are displayed.
This information can help you to identify SQL statements that will benefit from tuning. For example, you may be able to optimize predicate handling by transitively adding predicates, rewriting predicates using Boolean algebra principles, moving predicates around in the execution plan, and so on. For more information about tracing and autotrace, see the chapter about tuning in SQL*Plus User's Guide and Reference.
To use the autotrace feature, the database user for the connection must have the SELECT_CATALOG_ROLE and SELECT ANY DICTIONARY privileges.
1.7.5 DBMS Output Pane
The PL/SQL DBMS_OUTPUT package enables you to send messages from stored procedures, packages, and triggers. The PUT and PUT_LINE procedures in this package enable you to place information in a buffer that can be read by another trigger, procedure, or package. In a separate PL/SQL procedure or anonymous block, you can display the buffered information by calling the GET_LINE procedure. The DBMS Output pane is used to display the output of that buffer. This pane contains icons and other controls for the following operations:
-
Add New DBMS Output Tab: Prompts you to specify a database connection, after which a tab is opened within the DBMS Output pane for that connection, and the SET SERVEROUTPUT setting is turned on so that any output is displayed in that tab. (To stop displaying output for that connection, close the tab.)
-
Clear: Erases the contents of the pane.
-
Save: Saves the contents of the pane to a file that you specify.
-
Print: Prints the contents of the pane.
-
Buffer Size: For databases before Oracle Database 10.2, limits the amount of data that can be stored in the DBMS_OUTPUT buffer. The buffer size can be between 1 and 1000000 (1 million).
-
Poll: The interval (in seconds) at which SQL Developer checks the DBMS_OUTPUT buffer to see if there is data to print. The poll rate can be between 1 and 15.
1.7.6 OWA Output Pane
OWA (Oracle Web Agent) or MOD_PLSQL is an Apache (Web Server) extension module that enables you to create dynamic Web pages from PL/SQL packages and stored procedures. The OWA Output pane enables you to see the HTML output of MOD_PLSQL actions that have been executed in the SQL Worksheet. This pane contains icons for the following operations:
-
Add New OWA Output Tab: Prompts you to specify a database connection, after which a tab is opened within the OWA Output pane for that connection, and entries written to the OWA output buffer are displayed in that tab. (To stop displaying output for that connection, close the tab.)
-
Clear: Erases the contents of the pane.
-
Save: Saves the contents of the pane to a file that you specify.
-
Print: Prints the contents of the pane.
1.7.7 SQL History
You can click View, then History (or press F8 in the SQL Worksheet) to view a dockable window with SQL statements and scripts that you have executed, and optionally select one or more statements to have them either replace the statements currently on the SQL Worksheet or be added to the statements currently on the SQL Worksheet.
You can click on a column heading to sort the rows by the values in that column.
The SQL history list will not contain any statement that can include a password. Such statements include (but are not necessarily limited to) CONNECT, ALTER USER, and CREATE DATABASE LINK.
You can control the maximum number of statements in the history by setting the SQL History Limit preference (see Database: Worksheet preferences).
Append: Appends the selected statement or statements to any statements currently on the SQL Worksheet. You can also append the selected statement or statements by dragging them from the SQL History window and dropping them at the desired location on the SQL Worksheet.
Replace: Replaces any statements currently on the SQL Worksheet with the selected statement or statements.
Clear History: Removes the selected statement or statements (or all statements if no statements are selected) from the SQL history. (You will be asked to confirm this action.)
Filter: If you type a string in the text box and click Filter, only SQL statements containing that string are displayed.
1.7.8 Query Builder
The Query Builder pane enables you to display and build SQL queries graphically. You can create a SELECT statement by dragging and dropping table and view names and by graphically specifying columns and other elements of the query. While you are building the query, you can click the Worksheet tab to see the SELECT statement reflecting current specifications, and then click the Query Builder tab to continue building the query if you want.
In the area below the graphical display of tables and views, you can specify one or more lines with the following information:
Output: Specifies whether to include the expression in the statement output.
Expression: Column name or expression.
Aggregate: Aggregation function to be used (Avg, Avg Distinct, Count, and so on).
Alias: Column alias to be used.
Sort Type: Ascending or Descending sorting of results.
Sort Order: Order to use in sorting results if multiple columns or expressions are to be used (for example, sorting first by department and then by salary within each department).
Grouping: Specifies whether to insert a GROUP BY clause.
Criteria: An expression with one or more criteria that must be satisfied for a result to be returned. You can specify any WHERE clause (without the WHERE keyword). For example, for employees.SALARY, specifying > 10000 limits the results to employees with salaries greater than $10,000.
Or: You can specify one or more OR clauses to be added to the query criteria. For example, if Expression = employees.LAST_NAME, you could specify Or as = 'Smith' to add OR (employees.LAST_NAME = 'Smith' to the query.
1.7.9 Command-Line Interface for SQL Formatting
To format a .sql file or all .sql files in a directory or folder, you can use the format batch file (Windows) or shell script (Linux) on the operating system command line. These files are located in the sqldeveloper\sqldeveloper\bin folder or sqldeveloper/sqldeveloper/bin directory under the location where you installed SQL Developer.
Before invoking the format file or script, start the SQL Developer graphical interface, so that the Database: SQL Formatter preferences (which are used for the formatting) are loaded and available.
format.bat or format.sh has the following syntax:
format[.sh|.bat] input=<input file or directory> output=<output file or directory>
The following example takes the SQL code in c:\temp\myfile.sql and creates c:\temp\myfile_out.sql containing the formatted code. (Enter the command on one command line.)
C:\Program Files\sqldeveloper\sqldeveloper\bin>format input=c:\temp\myfile.sql output=c:\temp\myfile_out.sql
1.7.10 Gauges: In the SQL Worksheet and User-Defined Reports
You can use graphical gauges to display query results in the SQL Worksheet and in user-defined reports. In both cases, you need to specify the name of the value column for the gauge data, and minimum and maximum values on the gauge, and the values to be shown as low and high on the gauge (usually between the minimum and maximum values). In the SQL Worksheet, the required structure for the value to be selected is:
'SQLDEV:GAUGE:<min>:<max>:<low>:<high>:' || <value-column>
For example, to display the last name and the salary in gauge format, where the gauge shows from 1000 to 30000 with below 10000 as low and above 18000 as high, for employees with ID numbers less than a number to be specified, connect to the supplied HR schema and execute the following query:
SELECT last_name, 'SQLDEV:GAUGE:1000:30000:10000:18000:' || salary FROM employees WHERE employee_id < :employee_id
If you specify 104 as the bind variable value, the output appears as shown in the following figure:

For a user-defined gauge report, the query must specify only the value column, the minimum and maximum values, and the low and high values, and optionally a WHERE clause. The required structure for the query (before any optional WHERE clause) is:
SELECT <value-column>, <min>, <max>, <low>, <high> FROM <table-name>
For example, to create a report of salaries in gauge dial format, with the same values and WHERE clause as in the preceding query, right-click on User Defined Reports in the Reports navigator and select Add Report. In the Add Report dialog box, specify a report name; for Style, select Gauge; and for SQL, enter the following:
SELECT salary, 1000, 30000, 10000, 18000 FROM employees WHERE employee_id < :EMPLOYEE_ID;
Click the Chart Details tab near the bottom of the box; for Chart Type, select DIAL; for Query Based, select true; and click Apply.
Use the Reports navigator to view the newly created user-defined report. For Connection, specify one that connects to the HR sample schema. For the bind variable value, specify 104. The report shows four semicircular dials, each with a label containing the salary amount and a "needle" pointing to an appropriate place on the dial.
1.8 Using Snippets to Insert Code Fragments
Snippets are code fragments, such as SQL functions, Optimizer hints, and miscellaneous PL/SQL programming techniques. Some snippets are just syntax, and others are examples. You can insert and edit snippets when you are using the SQL Worksheet or creating or editing a PL/SQL function or procedure.
To display snippets, from the View menu, select Snippets. In the snippets window (on the right side), use the drop-down to select a group (such as Aggregate Functions or Character Functions). In most cases, the fragments in each group do not represent all available objects in that logical grouping, or all formats and options of each fragment shown. For complete and detailed information, see the Oracle Database documentation.
To insert a snippet into your code in a SQL Worksheet or in a PL/SQL function or procedure, drag the snippet from the snippets window and drop it into the desired place in your code; then edit the syntax so that the SQL function is valid in the current context. To see a brief description of a SQL function in a tooltip, hold the pointer over the function name.
For example, you could type SELECT and then drag CONCAT(char1, char2) from the Character Functions group. Then, edit the CONCAT function syntax and type the rest of the statement, such as in the following:
SELECT CONCAT(title, ' is a book in the library.') FROM books;
1.8.1 User-Defined Snippets
You can create and edit snippets. User-defined snippets are intended mainly to enable you to supplement the Oracle-supplied snippets, although you are also permitted to replace an Oracle-supplied snippet with your own version.
When you create a user-defined snippet, you can add it to one of the Oracle-supplied snippet categories (such as Aggregate Functions) or to a category that you create. If you add a snippet to an Oracle-supplied category and if your snippet has the same name as an existing snippet, your snippet definition replaces the existing one. (If you later upgrade to a new version of SQL Developer and if you choose to preserve your old settings, your old user-defined snippets will replace any Oracle-supplied snippets of the same name in the new version of SQL Developer.)
To create a snippet, do any of the following:
-
Open the Snippets window and click the Add User Snippets icon.
-
Select text for the snippet in the SQL Worksheet window, right-click, and select Save Snippet.
-
Click the Add User Snippet icon in the Edit Snippets (User-Defined) dialog box.
To edit an existing user-defined snippet, click the Edit User Snippets icon in the Snippets window.
Information about user-defined snippets is stored in a file named UserSnippets.xml under the directory for user-specific information. For information about the location of this information, see Section 1.18, "Location of User-Related Information".
1.9 Finding Database Objects
You can find various types of objects (tables, columns, declarations within functions or procedures, and so on) associated with an Oracle database connection and open editing panes to work with those objects. Click the Search icon on the left to display the Find Database Object window, where you can specify a connection name and search criteria. To display all criteria, click More. (For a connection to an Oracle Database Release 11.1 or later connection, clicking More causes SQL Developer to use PL/Scope, which enables you to search for the usage, for example, for the variable declarations.)
The following figure shows part of the Find Database Objects pane with results from a search for column definitions associated with a connection named hr_system05 where the column name starts with EM.
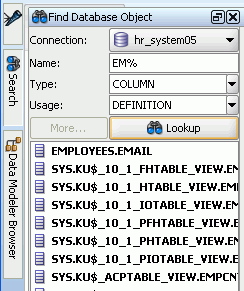
Connection: Database connection to use for the search.
Name: An object name or a string containing one or more wildcard characters. For example: EM% for all names starting with EM.
Type: Type of object for which to restrict the search.
Usage: Usage of the object. May or may not be relevant, depending on the type of object.
Click the Lookup icon to display objects that meet the specified criteria. To view or edit one of the objects (or the parent object that contains the specified object), double-click or right-click its name in the results display.
You can detach, move, and dock the Find Database Objects pane by clicking and holding the tab, and dragging and positioning the pane.
1.10 Using Versioning
SQL Developer provides integrated support for the Subversion versioning and source control system, and you can add support for other such systems as extensions by clicking Help, then Check for Updates. Available extensions include CVS (Concurrent Versions System), Serena Dimensions, and Perforce. The SQL Developer documentation does not provide detailed information about the concepts and operations of such systems; it assumes that you know them or can read about them in the product documentation.
-
For information about Subversion, see
http://subversion.tigris.org/. For Subversion documentation, seehttp://svnbook.red-bean.com/. -
For information about CVS, see
http://ximbiot.com/cvs/. For the CVS manual (by Per Cederqvist and others), seehttp://ximbiot.com/cvs/manual/.
To access the versioning features of SQL Developer, use the Versioning menu.
If you create any versioning repositories, you can use the hierarchical display in the Files navigator, which is marked by a folder icon. (If that navigator is not visible, click View, then Files.) You can also view a hierarchical display of repositories and their contents in the Versioning navigator.
1.10.1 About Subversion and SQL Developer
Before you can work with a Subversion repository through SQL Developer, you must create a connection to it. When you create a local Subversion repository, a connection to it is automatically created, and this can be seen in the Versioning navigator. You can subsequently edit the connection details.
To connect to an existing Subversion repository (if no connection to that repository exists), use the Versioning navigator, as follows:
-
If the Versioning navigator is not visible, click View, then Team, then Versioning Navigator.
-
Right-click the top-level Subversion node and select New Repository Connection.
-
Complete the information in the Subversion: Create/Edit Subversion Connection dialog box, including the URL of the existing repository.
-
Use the connection to access the repository.
Existing files must be imported into the Subversion repository to bring them under version control. Files are then checked out from the Subversion repository to a local folder known as the "Subversion working copy". Files created in (or moved into) SQL Developer must be stored in the Subversion working copy.
Files newly created within SQL Developer must be added to version control. Changed and new files are made available to other users by committing them to the SQL Developer repository. The Subversion working copy can be updated with the contents of the Subversion repository to incorporate changes made by other users.
1.10.2 About CVS and SQL Developer
CVS repositories can be created on a local PC or remote server. There can be more than one CVS repository. You need to create one or more CVS repositories.
Source files are held in a CVS repository. The source files in a CVS repository are grouped into modules. If you have new files, a wizard in SQL Developer will help you import them into the CVS repository and place them under version control. A copy is made of your original files and placed in a subdirectory (.backup) of the one from which you imported them.
Files to be worked on are checked out from the CVS repository. This makes a local copy of the files. You can see the contents of the CVS repository in the SQL Developer CVS Navigator and open read-only versions of files. You can then decide which files you want to check out and work on.
CVS creates a new directory populated with the copy of the source files. You can see the files in the System Navigator. You can also open them from here.
Source files have a status, depending on what operations have been carried out on them. A preference lets you choose whether the version control status of a file is shown in the System Navigator.
1.10.2.1 Pending Changes (CVS)
The Pending Changes window is displayed if you click Versioning, then CVS, then Pending Changes, or when you initiate an action that changes the local source control status of a file. This window shows files that have been added, modified or removed (locally or remotely), files whose content conflicts with other versions of the same file files that have not been added to source control files that are being watched, and files for which editors have been obtained. You can use this information to detect conflicts and to resolve them where possible.
The Outgoing pane shows changes made locally, the Incoming pane shows changes made remotely, and the Candidates pane shows files that have been created locally but not yet added to source control. You can double-click file names to edit them, and you can use the context menu to perform available operations.
1.11 Using DBA Features in SQL Developer
SQL Developer enables users with DBA (database administrator) privileges to view (and in some cases edit) certain information relevant to DBAs and, in some cases, to perform DBA operations. To perform DBA operations, use the DBA navigator, which is similar to the Connections navigator in that it has nodes for all defined database connections. (If the DBA navigator is not visible, select View, then DBA.)
If no connections appear in the DBA navigator display, you must add at least one connection. To add a connection to the DBA navigator, click the plus (+) icon or right-click Connections and select Add Connection; then select a connection. (You can also specify a new connection by clicking the plus (+) icon in the Select Connection dialog box.) Add only connections for which the associated database user has DBA privileges on the specified database.
The following options are available from the DBA navigator hierarchy:
Connections <connection-name> Container Database Database Configuration View Database Feature Usage Initialization Parameters Restore Points Current Database Properties Automatic Undo Management Database Status Status Data Pump Export Jobs Import Jobs RMAN Backup/Recovery Backup Jobs Backup Sets Image Copies RMAN Settings Scheduled RMAN Actions Resource Manager Consumer Groups Consumer Group Mappings Plans Settings Statistics SQL Translation Profiles Scheduler Global Attributes Job Classes External Destinations Security Audit Settings Profiles Roles Users Storage Archive Logs Control Files Datafiles Redo Log Groups Rollback Segments Tablespaces Temporary Tablespace Groups SQL Translation Profiles
To perform limited database management operations, you can right-click the connection name in the DBA navigator display and select Manage Database. For example, if a listener is running with a static listener configured for the database, you can start and stop the database, force database startup, and restrict access to the database.
You can right-click an item (node) at any level in the DBA navigator hierarchy to display a context menu with commands relevant to that item. Typical commands include the following:
-
Refresh queries the database for the current details about the selected object (for example, a connection or just a table).
-
Apply Filter restricts the display of objects using a filter that you specify. To remove the effects of applying a filter, right-click the node and select Clear Filter.
-
Open displays a pane with relevant information on the right side of the window. The pane may be read-only or editable.
-
Create New enables you to create a new object of that type.
-
Help displays a brief definition or description of objects of that type.
The pane with information about an item opened from the DBA navigator typically contains icons and other controls for the following:
-
Freeze View (the pin) keeps that object's tab and information in the window when you click another object in the Connections navigator; a separate tab and display are created for that other object. If you click the pin again, the object's display is available for reuse.
-
Run updates the display by querying the database for the latest information.
-
Refresh lets you select an interval for automatically updating the display.
-
Actions displays a menu with actions appropriate for the object. The actions are the same as when you right-click an object of that type in the Connections navigator.
With information displays that are in grid form:
-
You can often use the context (right-click) menu on a header or a data cell to perform operations like those for the table data grid, as explained in Section 1.5, "Entering and Modifying Data". For example, right-clicking on a header lets you select options like Auto-fit, Columns, Sort, Delete Persisted Settings (such as any sort order specifications), and Filter Column; right-clicking any data cell lets you select options like Save Grid as Report, Single-Record View, Count Rows, Find/Highlight (find and optionally highlight values in the grid), and Export (unload data).
-
You can click the column heading to display a Filter box to restrict the display to entries containing a string. For example, in the Database Configuration: Current Database Properties page, you can click PROPERTY_NAME and type
NLSto see only properties containing "NLS" (that is, globalization properties).
For information that is read-only (not editable) using the DBA navigator, you may have other options within SQL Developer to specify relevant values. For example, to change the value of any globalization support (NLS) parameter, you can use the Database: NLS preferences pane to change the value for use with all SQL Developer connections (current and future), or you can use the ALTER SESSION statement in the SQL Worksheet window to change the value for the current connection only.
Detailed explanations of various DBA options, including usage and reference information, are available in appropriate manuals in the Oracle Database Documentation Library on the Oracle Technology Network (OTN).
1.11.1 Container Database
(Available only for Release 12c connections.) Includes options for managing a consolidated database and the containers (pluggable databases and root) within it.
1.11.2 Database Configuration
Includes the following options related to database configuration management.
Displays database features and the number of detected usages for each.
For each database initialization parameter, displays the name, value (current value), default value, description, and other information. You can modify the values of some parameters.
For each current database initialization parameter, displays the name, value (current value), and description.
Displays restore points that can be used for recovery; lets you create and delete restore points. A restore point is a name associated with a timestamp or an SCN of the database. A restore point can be used to flash back a table or the database to the time specified by the restore point without the need to determine the SCN or timestamp. Restore points are also useful in various RMAN operations, including backups and database duplication.
Automatic undo management is a mode of the database in which undo data is stored in a dedicated undo tablespace. The only undo management that you must perform is the creation of the undo tablespace; all other undo management is performed automatically. The Automatic Undo Management option displays information about automatic undo management and any recommendations relating to its use. You can change the Retention value.
1.11.3 Database Status
Includes options for displaying status information about the database.
Includes tabs for displaying information about the Database Status, Oracle Host, Oracle Home, and TNS Listener.
1.11.4 Data Pump
Includes options for using the Oracle Data Pump Export and Import utilities, which are described in detail in Oracle Database Utilities.
Displays any Data Pump Export jobs. You can right-click and select Data Pump Export Wizard to create a Data Pump Export job.
Displays any Data Pump Import jobs. You can right-click and select Data Pump Import Wizard to create a Data Pump Import job.
1.11.5 RMAN Backup/Recovery
Includes options related to database backup and recovery. The options use the Oracle Database Recovery Manager (RMAN) feature, which is described in detail in Oracle Database Backup and Recovery User's Guide. You should be familiar with RMAN concepts and techniques before using these options.
Displays the backup jobs that have been previously run; lets you create and run new backup. (Note that backup jobs are complete distinct from action jobs.)
Displays the backup sets that have been created by previous backup jobs and that can be used for recovery.
Displays the image copies that have been created by previous backup jobs and that can be used for recovery.
Lets you view and modify settings for backup and recovery. (These settings are stored in the server and are used and managed by RMAN.)
For Oracle Database 11.1 and later connections: Displays DBMS_SCHEDULER jobs that have been used to execute RMAN scripts; lets you view log files. For more information, see Section 1.11.5.1, "Using Action Jobs".
1.11.5.1 Using Action Jobs
Action jobs are applicable to connections to an Oracle Database Release 11.1 or later database.
Most backup and recovery actions involve RMAN scripts. The action jobs dialog boxes let you save the generated RMAN to a disk; you can then copy the script to the server system and run the script there.
Before you can execute the script for an action job, you must create a DBMS_SCHEDULER credential by running a procedure in the following format:
BEGIN
DBMS_SCHEDULER.CREATE_CREDENTIAL(
username => 'user-name',
password => 'password',
database_role => NULL,
windows_domain => NULL,
comments => NULL,
credential_name => 'credential-name'
);
END;
/
Then, run the Action Jobs, Configure action. This action places some scripts in the server-side database home (in <home>/sqldeveloper/dbascripts) and creates some DBMS_SCHEDULER program objects in the database. (If you want to unconfigure an action job, you can use the Action Jobs, Unconfigure action, which removes the server-side directory containing the script and log files and drops the DBMS_SCHEDULER program objects.)
After you perform the configuration, the Run Scheduler Job action of the Script Processing control becomes available in the RMAN dialog boxes, and you can click Apply to cause the RMAN script to be executed in the server using a DBMS_SCHEDULER job.
After an RMAN job has been run, you can view the log file containing the output from RMAN by using the Action Jobs, View Latest Log action. This lets you check for any errors that may have occurred during the running of the RMAN script.
Some RMAN jobs involve performing a database restart. Examples are setting the archive log mode and some whole database backup and restore operations. In such cases, after you click Apply you are asked to confirm that you want to proceed; and if you do proceed, the job is queued (with no waiting for the completion). Because of the restart, the SQL Developer connection must be disconnected and then connected again after the database is restarted. After the reconnection, examine the log file to see whether the job completed successfully.
1.11.6 Resource Manager
Includes the following options related to database resource management.
A resource consumer group is a group of sessions that are grouped together based on resource requirements. The Resource Manager allocates resources to resource consumer groups, not to individual sessions. The Consumer Groups option displays, for each consumer group, its description and whether it is mandatory.
A consumer group mapping specifies mapping rules that enable the Resource Manager to automatically assign each session to a consumer group upon session startup, based upon session attributes. The Consumer Group Mappings option displays, for each attribute, its priority, value, and associated consumer group.
A resource plan is a container for directives that specify how resources are allocated to resource consumer group; you specify how the database allocates resources by activating a specific resource plan. The Plans option displays, for each plan, its description and if its status is Active.
Lists any active resource plans.
Lists various resource-related statistics (if applicable).
1.11.7 Scheduler
Includes the following options related to Scheduling Jobs Using SQL Developer. (The objects under Scheduler in the DBA navigator are for objects that owned by the SYS user and that can be created and modified only by users with DBA privileges. Other objects are listed under Scheduler for users in the Connections navigator.)
The Global Attributes display lets you view and edit attributes such as the default time zone, the e-mail sender and server, event expiry time, log history retention, and maximum job slave processes.
The Job Classes display lets you view and edit information about Job Classes. The information for each job class includes the job class name, logging level, log history, resource consumer group, service, and comments.
The External Destinations display lets you view and edit information about external destinations for jobs.
1.11.8 Security
Includes the following options related to database security management.
The Audit Settings display includes the audit trail setting, whether SYS user operations are audited, and the directory or folder for the audit file.
A profile is a set of limits on database resources. If you assign the profile to a user, then that user cannot exceed these limits.The Profiles option displays any limits on activities and resource usage for each profile.
A role is a set of privileges that can be granted to users or to other roles; you can use roles to administer database privileges. The Roles option displays the roles and their authentication settings.
A database user is an account through which you can connect to the database. The Users option displays status and usage information about each database user.
1.11.9 Storage
Includes the following options related to database storage management.
An archived redo log is a copy of one of the filled members of an online redo log group made when the database is in ARCHIVELOG mode. After the LGWR process fills each online redo log with redo records, the archiver process copies the log to one or more redo log archiving destinations; this copy is the archived redo log.
A control file is a binary file that records the physical structure of a database and contains the names and locations of redo log files, the time stamp of the database creation, the current log sequence number, checkpoint information, and so on. The Control Files option displays, for each control file, its status, file name, and file directory.
A data file is a physical file on disk that was created by Oracle Database and contains the data for a database. The data files can be located either in an operating system file system or Oracle ASM disk group. The Datafiles option displays, for each data file, its file name, tablespace, status, and other information.
A redo log group contains one or more members: each online redo log member (which corresponds to an online redo log file) belongs to a redo log group. The contents of all members of a redo log group are identical.The Redo Log Groups option displays, for each redo log group, its status, number of members, and other information.
A rollback segment records the before-images of changes to the database. The Rollback Segments option displays, for each rollback segment, its name, status, tablespace, and other information.
A tablespace is a database storage unit that groups related logical structures together. The database data files are stored in tablespaces. The Tablespaces option displays, for each tablespace, its name; megabytes allocated, free, and used; and other information.
A temporary tablespace group is a tablespace group that is assigned as the default temporary tablespace for the database. (A tablespace group enables a database user to consume temporary space from multiple tablespaces. Using a tablespace group, rather than a single temporary tablespace, can alleviate problems caused where one tablespace is inadequate to hold the results of a sort, particularly on a table that has many partitions.) The Temporary Tablespace Groups option displays, for each tablespace group, its name, the number of tablespaces in the group, the total size of the tablespaces, and whether the group is the default temporary tablespace.
1.11.10 SQL Translation Profiles
(Available only for Release 12c connections.) Includes options for creating and managing SQL translation profiles. A SQL translation profile is a database schema object that directs how non-Oracle SQL statements are translated into Oracle SQL dialects.
1.12 Scheduling Jobs Using SQL Developer
SQL Developer provides a graphical interface for using the DBMS_SCHEDULER PL/SQL package to work with Oracle Scheduler objects. To use the SQL Developer scheduling features, you must first understand the concepts and essential tasks for job scheduling, which are explained in the chapters about Oracle Scheduler concepts and scheduling jobs in Oracle Database Administrator's Guide.
The Scheduler node for a connection appears in the Connections navigator and in the DBA navigator. The DBA navigator displays Scheduler objects owned by the SYS user and requiring DBA privileges for creating and modifying; the Connections navigator displays other Scheduler objects that may require specific privileges for creating and modifying. The Oracle Scheduler objects are grouped under object types that include:
You can right-click an item (node) at any level in the Scheduler hierarchy to display a context menu with commands relevant to that item. Typical commands include the following:
-
New [object-type] enables you to create a new object of that type.
-
Refresh queries the database for the current details about the selected object (for example, a connection or just a table).
-
Apply Filter restricts the display of objects using a filter that you specify. To remove the effects of applying a filter, right-click the node and select Clear Filter.
-
Open displays a pane with relevant information on the right side of the window. The pane may be read-only or editable.
-
Help displays a brief definition or description of objects of that type.
-
Drop (with an object selected) drops (deletes) the object.
-
Create Like (with an object selected) creates an object of that type using information from the selected object. You must specify a name for the newly created object, and you can change other properties as needed.
If you right-click the top-level Scheduler node, you can create an object of a specified type, and you can display the Scheduler Design Editor.
The pane with information about an item opened from the Scheduler hierarchy typically contains icons and other controls for the following:
-
Freeze View (the pin) keeps that object's tab and information in the window when you click another object in the Connections navigator; a separate tab and display are created for that other object. If you click the pin again, the object's display is available for reuse.
-
Run updates the display by querying the database for the latest information.
-
Refresh lets you select an interval for automatically updating the display.
-
Actions displays a menu with actions appropriate for the object. For example, the actions for a job include New Job, Drop, Run Job Now, and Create Like.
With information displays that are in grid form, you can often use the context (right-click) menu on a header or a data cell to perform operations like those for the table data grid, as explained in Section 1.5, "Entering and Modifying Data". For example, right-clicking on a header lets you select options like Auto-fit, Columns, Sort, Delete Persisted Settings (such as any sort order specifications), and Filter Column; right-clicking any data cell lets you select options like Save Grid as Report, Single-Record View, Count Rows, Find/Highlight (find and optionally highlight values in the grid), and Export (unload data).
Several Scheduler reports are also available.
1.12.1 Scheduler Design Editor
The scheduler design editor is a graphical interface for Scheduling Jobs Using SQL Developer. To create, edit, or delete any Oracle Scheduler objects in the editor, you must be in write mode. You can use the editor toolbar toggle button or the right-click command to Switch to write mode and Switch to read-only mode.
To copy existing objects to the schedule design editor, drag the objects from the Connections navigator onto the editing canvas.
To create a new object, right-click in the canvas and select the context menu command for creating a new object of the desired type.
To open an object, double-click it or right-click it and select Open.
To delete an object, right-click it and select Drop. You will be prompted to confirm that you want to drop the object.
To remove the object from the editing canvas without deleting the object itself, right-click it and select Clear.
To enable a disabled object, right-click it and select Enable; to disable an enabled object, right-click it and select Disable.
You can click, drag, and release to set a relationship between compatible objects. For example, to set a schedule for a job, you can drag the schedule onto the job, which causes a line to be drawn between the objects. You can unset (remove) that relationship by right-clicking the line and selecting the appropriate command (such as Unset Schedule), and then clicking OK when you are prompted to confirm the action.
1.13 Deploying Objects Using the SQL Developer Cart
The SQL Developer Cart is a convenient tool for deploying Oracle Database objects from one or more database connections to a destination connection. You drag and drop objects from the Connections navigator into the SQL Developer Cart window, specify any desired options, and click the Deploy icon to display the Deploy Objects dialog box. After you complete the information in that dialog box, SQL Developer creates a file containing scripts (including a master script) to create the objects in the schema of a desired destination connection.
To display the SQL Developer Cart window, click View, then SQL Developer Cart. The following figure shows that window after some objects have been added.
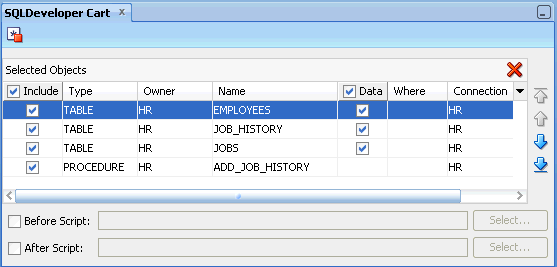
Deploy icon (active if one or more objects are included): After you have added the objects to be deployed and specified any desired options, click this icon to display the Deploy Objects dialog box, where you can specify further options and generate the deployment scripts and a file that contains them.
Open Cart icon: Lets you open a saved cart by specifying the XML file with the cart contents.
Save Cart icon (active if one of more objects are selected): Displays the Save Cart dialog box, where you specify the File (XML) and the Encoding.
Selected Objects: Contains objects that have been selected for potential deployment. To add objects, select them in the Connections navigator and drag and drop them into the Selected Objects area.
Delete Row icon (red X): Lets you delete selected objects from the Selected Objects area.
Include: Lets you select and deselect all objects or selected objects for inclusion in the deployment.
Type: Type of database object.
Owner: Owner of the database object.
Name: Name of the database object.
Data: For tables and views, lets you include or exclude the associated data for the deployment.
Where: Optional WHERE clause (without the WHERE keyword) to filter the data rows from a table or view.
Connection: Connection from which the object was selected.
Arrow buttons: Let you move objects up or down in the order of Selected Objects. This affects the order in which objects are created in the generated scripts.
Before Script: Optionally specify a .sql script to be executed first in the generated master deployment script (before the other generated scripts).
After Script: Optionally specify a .sql script to be executed last in the generated master deployment script (after the other generated scripts).
1.14 Spatial Support in SQL Developer
SQL Developer lets you work with Oracle Spatial data and metadata. Oracle Spatial (referred to as Spatial) facilitates the storage, retrieval, update, and query of collections of spatial features in an Oracle database. Spatial includes a schema (MDSYS), a data type (SDO_GEOMETRY), a spatial indexing mechanism and index type, and operators, functions, and procedures for performing area-of-interest queries, spatial join queries, and other spatial analysis operations.
For complete information about Oracle Spatial, including the differences between Spatial and Oracle Locator (a subset of Spatial), see Oracle Spatial Developer's Guide.
SQL Developer support for Spatial includes the following:
1.14.1 Context Menu Operations on Spatial Data and Metadata
In the Connections navigator display, the context menu (right-click) for a table includes a Spatial submenu, which includes the following commands:
-
Update Spatial Metadata displays the Maintain Spatial Metadata dialog box, which enables you to update the spatial metadata for data in columns of type SDO_GEOMETRY in the table.
-
Validate Geometry Using Tolerance performs a consistency check, based on the tolerance value that you specify, for valid geometry types in the spatial data in the table, and returns context information if any geometries are invalid. Displays the Validate Geometry dialog box.
-
Validate Geometry Using Dimension Information performs a consistency check, based on the dimensional information associated with the spatial data (using the USER_SDO_GEOM_METADATA view), for valid geometry types in the spatial data in the table, and returns context information if any geometries are invalid. Displays the Validate Geometry dialog box.
-
Drop Spatial Metadata deletes the spatial metadata for the specified spatial column (but does not delete the column definition or the data).
-
Create Spatial Index creates a spatial index (INDEXTYPE IS MDSYS.SPATIAL_INDEX) on the specified spatial geometry column.
-
Drop Spatial Index deletes the specified spatial index.
1.14.2 Map Visualization of Spatial Data
You can use the Map View window for displaying spatial geometry objects that are returned by a query. The SQL Developer Map View display lacks the rich features of a visualizing tool such as Oracle MapViewer, but it provides a quick and flexible way to see simple representations of spatial data.
To display the Map View, click View, then Map View. You can resize and reposition the Map View window so that it adequately displays the geometries you want to see.
The following figure show the Map View window display of a query that returns all geometries for counties in the U.S. state of South Carolina. On the left is a map display pane with some icons above it. On the right is a Query List pane with one query (named South Carolina Counties) and some icons above it. (Not shown is the database connection drop-down selector to the right of the Query List.)
You can visualize geometries in the Map View window by creating and executing a SQL query, or by selecting a geometry in a table data grid cell and using the context menu:
1.14.2.1 Visualizing Geometries by Creating and Executing a Query
To visualize geometries by creating and executing a SQL query, follow these steps:
-
Click View, then Map View to display the Map View window.
-
Optionally, resize and reposition the Map View window.
-
Using the connection selector drop-down on the right above Query List (not shown in the figure), select the database connection to be used for the query.
-
Click the Add New Query (+) icon above Query List to display a query dialog box, and specify the information for the query:
Map Title: Short descriptive name for the display to result from the query. Example:
South Carolina CountiesMap Query: SELECT statement to return the desired geometries. Example (for a table named COUNTIES that includes a geometry column named GEOM and a STATE_ABRV column for 2-character state abbreviations):
SELECT geom FROM counties WHERE state_abrv = 'SC'Map Styles: Optionally, customize the Line Color and Fill Color for the geometries, and select an Annotation Column. For the colors, you can click the square to display a dialog box for specifying a color using a swatch or an HSB or RGB value.
-
Click OK to complete the definition.
-
Optionally, repeat steps 4 and 5 to create one or more additional queries. (For a query using a different database connection, repeat steps 3 through 5.)
To execute the query and display the map in the left pane of the window, select (check mark) the query and click the Execute Checked Queries icon above Query List.
To modify a query, select (check mark) it and click the Edit Query (pencil) icon above Query List.
To delete a query from the list, select (check mark) it and click the Remove Query (X) icon above Query List.
In the map display pane on the left, you can click icons above the pane to control aspects of the display:
-
Zoom In expands the display and makes the objects appear larger.
-
Zoom Out contracts the display and makes the objects appear smaller.
-
Fit adjusts the display so that all objects fit in the pane.
-
Marquee Zoom lets you select a rectangle (press, drag, release), after which the display zooms to fit the selected rectangle in the pane.
1.14.2.2 Visualizing Geometries from the Table Data Grid
To visualize one or more geometries by from the table data grid, follow these steps:
-
Display the information for a spatial table by clicking its name in the Connections navigator hierarchy display.
-
Click the Data tab to display the data in the table.
-
In the grid display of table data, click the cell with the spatial data for a geometry object. For example, if the spatial column is named
GEOM, click one of the cells underGEOM. (The cell content will start withMDSYS.SDO_GEOMETRY.) -
Right-click, and select one of the following from the context menu:
-
Display Geometry Shape displays the selected geometry object in a standalone box.
-
Identify Geometry Shape in Map View highlights the selected geometry object in the Map View window (if it is included in the window).
-
Invoke Map View on Result Set displays all geometry objects in the column (that is, it displays the layer).
-
For information about icons and options in the Map View window, see Section 1.14.2.1, "Visualizing Geometries by Creating and Executing a Query".
1.15 Change Manager Support in SQL Developer
A change plan is an Oracle Change Manager container for schema object changes. Using SQL Developer, you can create change plans and populate them change information. Later, a database administrator deploys the change plan to one or more destination databases using Oracle Enterprise Manager.
A change plan can contain multiple change items, each of which describes changes to be made to a single schema object. There are three types of change item, reflecting three basic actions to be carried out at the destination database:
-
An Add change item adds a database object.
-
A Drop change item drops the database object. (The definition of the object to be dropped is copied into the change item, enabling Change Manager to check the definition in the destination database to ensure that the object definitions are the same.)
-
A Modify change item makes one or more changes to a database object (for example, adding a column or a constraint to a table).
To deploy a change plan to a destination database, the DBA uses Enterprise Manager to create a Change Manager Schema Synchronization from the contents of the change plan. During this process, Change Manager detects and reports conflicts between the change plan and the database. (For example, the database may already contain an object that the change plan is trying to add.) The generated script carries out operations in the correct order.
The Change Management Parameters user preferences affect Change Manager support in SQL Developer, especially how objects are compared to determine if a change has occurred and how extensive the DDL statements are when the script for deploying changes is generated.
See the following subtopics for more information related to support for Change Manager:
1.15.1 Change Plan Administrators and Developers
Change plans are stored in the Enterprise Manager repository. An Enterprise Manager super administrator has unlimited access to all change plans. However, in most cases, it is preferable to create Enterprise Manager administrators with specific Change Plan privileges and limited access to other Enterprise Manager facilities. There are two general types of Change Plan privilege:
-
A Change Plan Administrator has unlimited access to change plans: the administrator can create, edit, and delete any change plan. A Change Plan Administrator is typically a DBA.
-
A Change Plan Developer has access to specific change plans. The access may be view-only, or view and edit. A Change Plan Developer is typically a developer of database applications.
To create a Change Plan Administrator or one or more Change Plan Developers, you muse Enterprise Manager, as explained in Section 1.15.4, "Change Manager Actions to Perform with Enterprise Manager".
1.15.2 User Interface for Change Manager Support
The SQL Developer user interface support for Change Manager includes the Change Management window and the Change Management Parameters user preferences.
To display the Change Management window, click View, then Change Management. The Change Management window is displayed within the SQL Developer main window.
1.15.3 Developing Change Plans with SQL Developer
You can use the Map View window for displaying spatial geometry objects that are returned by a query. The SQL Developer Map View display lacks the rich features of a visualizing tool such as Oracle MapViewer, but it provides a quick and flexible way to see simple representations of spatial data.
To display the Map View, click View, then Map View. You can resize and reposition the Map View window so that it adequately displays the geometries you want to see.
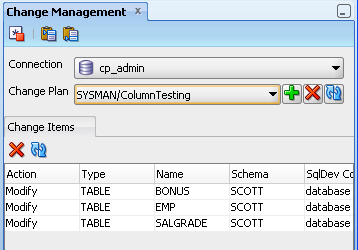
At the top of the Change Management window are icons for the following operations:
-
Disconnect disconnects the selected Change Plan connection.
-
Pre Script lets you enter a script with statements to be executed before the selected change plan is deployed.
-
Post Script lets you enter a script with statements to be executed after the selected change plan is deployed.
Connection: Database connection for the Change Management repository.
Change Plan: A change plan within the selected repository. To the right of the Change Plan are icons for the following operations: Add Plan (+) to create a new change plan to the repository, Remove Plan (X) to delete the selected plan from the repository, and Refresh to refresh the window with the current contents of the repository.
Change Items: A list of change items for the selected change plan, with the following information about each item: Action, Database Object Type, Object Name, Schema, SQL Developer Connection, Enterprise Manager Connection, Global Name, Description.
To delete a change item, select its row and click the Remove Item(s) (X) icon. To update the change items display to reflect the contents of the repository, click the Refresh icon.
Related subtopics:
1.15.3.1 Creating a Repository Connection
To store and retrieve change plans, you must create a SQL Developer database connection to the Enterprise Manager repository database. This connection typically logs in as one of the repository database users created as a Change Plan administrator or developer. Create the database connection specifying the user name and password of a suitably privileged user, and the connection details for the schema Enterprise Manager repository.
1.15.3.2 Creating and Deleting Change Plans
To create a change plan:
-
If the Change Management window is not visible, Click View, then Change Management to display the window.
-
For Connection, select the database connection for the Enterprise Manager repository.
-
To the right of Change Plan, click the Add Plan (+) icon.
-
In the Create Plan dialog box, specify a name for the plan, and click Apply.
To delete a change plan.
-
For Connection, select the database connection for the Enterprise Manager repository.
-
For Change Plan, select the change plan to be deleted.
-
To the right of Change Plan, click the Remove Plan (X) icon.
-
In the Delete Plan dialog box, click Apply to confirm that you want to delete the change plan.
1.15.3.3 Adding and Updating Change Items
To add a change item to a change plan or to update (refresh) the change items in a change plan, you must be connected to the Enterprise repository as a user that has Edit privileges on the plan (or that has the Manage Change Plans resource privilege). In the Change Management window, select the relevant change plan from the Change Plan list. The current contents of the plan (if any) are listed in the Change Items display.
To add a change item to the selected change plan, drag a database object from the Connections navigator (for example, a table named EMPLOYEES from a connection named HR) into the Change Items pane. In the dialog box, specify the type of change item to be created: Add Change Item, Drop Change Item, or Modify Change Item.
1.15.3.4 Using Change Plans to Capture Change in SQL Developer
There are two basic approaches to capturing changes in change plans: single database or multiple databases. The approach chosen may depend on the complexity of the work and the number of developers involved.
-
Single database: Before development starts, the developer creates Monitor change items for all objects that might be modified or dropped. The developer then begins development work in the database -- adding, modifying, and dropping objects. As this work progresses, the developer updates Monitor change items to make them into Modify change items, or converts them to Drop change items, and creates new Add change items. At the end of development work, the change plan contains the changes that took place during the development cycle.
-
Multiple databases: One database represents the pre-development state and is not modified during development work. All work takes place in one or more development databases. Monitor and Drop change items are created as needed from the pre-development database, and then updated from the development database(s). Changes from multiple developers working in multiple databases can be combined into a single change plan.
1.15.4 Change Manager Actions to Perform with Enterprise Manager
You must use Enterprise Manager to perform any of the following operations related to change plans:
-
Creating change plan administrators and developers
-
Creating change plans from Change Manager schema comparisons
-
Deploying change plans
For information about performing these operations, see the Enterprise Manager help and documentation.
1.15.4.1 Creating Change Plans from Change Manager Schema Comparisons
You can create change plans in Enterprise Manager and populate them from Change Manager schema comparisons. On the Databases page, select Schema Change Plans, then Create. Enter the name of the new change plan and click OK. In the resulting Change Plan page, click Create from Comparison. Select a version of a Schema Comparison, and a Conversion Assignment as follows:
-
For the Change From side, select the side of the comparison that represents the original state of the schema objects.
-
For the Change To side, select the side of the comparison that represents the developed (or evolved) state of the schema objects.
Based on your selection, Change Manager populates the change clan with Add, Drop, and Modify change items that, if applied to the Change From objects, will convert them into the Change To objects.
1.15.4.2 Deploying Change Plans
To deploy change plans, Change Manager uses the script generation capability contained in its Schema Synchronizations application. You deploy a change plan by creating a synchronization that applies the changes in the change plan to a database that you select. To reduce the chance of incompatible change conflicts, the objects in the database should be identical or similar to the initial objects from which the change plan's change items were created.
To deploy a change clan to a database, select the plan on the Change Plans page, and then click Create Synchronization from Change Plan. This takes you to the first page of the Create Schema Synchronization wizard. The process of creating a synchronization from a Change Plan is similar to creating a synchronization from scratch. However, in the first phase of synchronization processing, rather than comparing the source database (or baseline version) to the destination database, Change Manager applies the changes contained in the change plan to the destination database definitions (not to the actual objects). The result of this operation provides the basis for script generation and execution, the second and third phases of schema synchronization processing.
During change plan processing, Change Manager may detect conflicts between change items and the destination database. In general, a conflict means that the state of the destination database is not what was expected. Examples of conflicts include:
-
A table that is to be added already exists, and has a different definition than that contained in the change item.
-
A table to be modified does not exist.
-
A column to be added to a table already exists and has a different data type than the column added by the change item.
-
A constraint to be dropped from a table does not exist.
-
A view to be dropped exists, but has a different definition than that stored in the change item.
-
A procedure to be dropped does not exist.
After changes have been applied to the destination definitions, Change Manager reports the results of the operations, including any conflicts encountered.
Change Plans and Schema Synchronizations: Comparison
Schema change plans and schema synchronizations are similar in some ways, and use some of the same underlying technology. However, they have different purposes and uses:
-
The purpose of a schema synchronization is to make the set of objects at the destination database identical to those at the source database or baseline version. Schema synchronization compares the objects at the source and destination, and then generates a script to reconcile all the differences.
-
The purpose of a change plan is to carry out a specific set of changes at any destination database. The changes may apply to an entire object (Add or Drop), or to attributes of an object (Modify, for example, add a column).
In other words, schema synchronization picks up any changes that have been made to the destination object or schema and makes those changes at the destination. Change plan deployment, however, makes only those changes specified in the change items.
With schema synchronizations, there is no chance of conflict because the source definition always overrides the destination definition. With change plans, however, there is a possibility of conflict, because the specified changes might not be applicable at a destination database or might conflict with other changes.
1.16 SQL Developer Reports
SQL Developer provides many reports about the database and its objects. You can also create your own user-defined reports. To display reports, click the Reports tab on the left side of the window (see SQL Developer User Interface). If this tab is not visible, select View and then Reports.
Individual reports are displayed in tabbed panes on the right side of the window; and for each report, you can select (in a drop-down control) the database connection for which to display the report. For reports about objects, the objects shown are only those visible to the database user associated with the selected database connection, and the rows are usually ordered by Owner. The detail display pane for a report includes the following icons at the top:
-
Freeze View (the pin) keeps that report in the SQL Developer window when you click another report in the Reports navigator; a separate tab and detail view pane are created for that other report. If you click the pin again, the report's detail view pane is available for reuse.
-
Run Report updates the detail view pane display by querying the database for the latest information.
-
Run Report in SQL Worksheet displays the SQL statement used to retrieve the information for a report in a SQL Worksheet pane, where you can view, edit, and run the statement (see Section 1.7, "Using the SQL Worksheet").
The time required to display specific reports will vary, and may be affected by the number and complexity of objects involved, and by the speed of the network connection to the database.
For most reports that contain names of database objects, you can double-click the object name in the report display pane (or right-click the object name and select Go To) to display that object in a detail view pane, just as if you had selected that object using the Connections navigator.
To export a report into an XML file that can be imported later, right-click the report name in the Reports navigator display and select Export. To import a report that had previously been exported, select the name of the report folder name (such as a user-defined folder) in which to store the imported report, right-click, and select Import.
You can create a shared report from an exported report by clicking Tools, then Preferences, and using the Database: User Defined Extensions pane to add a row with Type as REPORT and Location specifying the exported XML file. The next time you restart SQL Developer, the Reports navigator will have a Shared Reports folder containing that report.
Reports are grouped in the following categories:
About Your Database reports list release information about the database associated with the connection.
All Objects reports list information about all objects accessible to the user associated with the specified database connection, not just objects owned by the user.
Application Express reports list information about Oracle Application Express 3.0.1 (or later) applications, pages, schemas, UI defaults, and workspaces.
ASH and AWR reports list information provided by the Active Session History (ASH) and Automated Workload Repository (AWR) features.
Database Administration reports list usage information about system resources.
Data Dictionary reports list information about the data dictionary views that are accessible in the database. Examples of data dictionary views are ALL_OBJECTS and USER_TABLES.
PL/SQL reports list information about your PL/SQL objects and allow you to search the source of those objects.
Scheduler reports list information about jobs running on the database.
Security reports list privilege-related information about the database.
Streams reports list information about stream rules.
Table reports list information about tables owned by the user associated with the specified connection. These reports can help you to better understand the metadata and data. The table reports include Quality Assurance reports that indicate possible logical design flaws and sources of run-time performance problems.
XML reports list information about XML objects.
Data Modeler reports list information about design objects that have been exported to the Data Modeler reporting repository.
TimesTen reports list information about Oracle TimesTen In-Memory Database objects (see Section 1.20, "Oracle TimesTen In-Memory Database Support").
User Defined reports are any customized reports that you have created.
For some reports, you are prompted for bind variables before the report is generated. These bind variables enable you to further restrict the output. The default value for all bind variables is null, which implies no further restrictions. To specify a bind variable, select the variable name and type an entry in the Value field. Any bind variable values that you enter are case insensitive, all matches are returned where the value string appears anywhere in the name of the relevant object type.
1.16.1 About Your Database reports
The About Your Database reports list release information about the database associated with the selected connection. The reports include Version Banner (database settings) and National Language Support Parameters (NLS_xxx parameter values for globalization support).
1.16.2 All Objects reports
All Objects reports list information about objects visible to the user associated with the database connection.
All Objects: For each object, lists the owner, name, type (table, view, index, and so on), status (valid or invalid), the date it was created, and the date when the last data definition language (DDL) operation was performed on it. The Last DDL date can help you to find if any changes to the object definitions have been made on or after a specific time.
Collection Types: Lists information about for each collection type. The information includes the type owner, element type name and owner, and type-dependent specific information.
Dependencies: For each object with references to it, lists information about references to (uses of) that object.
Invalid Objects: Lists all objects that have a status of invalid.
Object Count by Type: For each type of object associated with a specific owner, lists the number of objects. This report might help you to identify users that have created an especially large number of objects, particularly objects of a specific type.
Public Database Links: Lists all public database links.
Public Synonyms: Lists all public synonyms.
1.16.3 Application Express reports
If you select a connection for a schema that owns any Oracle Application Express 3.0.1 (or later) applications, the Application Express reports list information about applications, pages, schemas, UI defaults, and workspaces. For information about Oracle Application Express, see the documentation for that product.
1.16.4 ASH and AWR reports
The ASH and AWR reports list information provided by the Active Session History (ASH) and Automated Workload Repository (AWR) features, which require special licensing. For information about using AWR, including how to use ASH reports, see the information about automatic performance statistics in Oracle Database Performance Tuning Guide.
1.16.5 Charts reports
Charts reports include a chart showing the distribution of objects of various object types (number of tables, indexes, and so on).
1.16.6 Database Administration reports
Database Administration reports list usage information about system resources. This information can help you to manage storage, user accounts, and sessions efficiently. (The user for the database connection must have the DBA role to see most Database Administration reports.)
All Tables: Contains the reports that are also grouped under Table reports, including Quality Assurance reports.
Cursors: Provide information about cursors, including cursors by session (including open cursors and cursor details.
Database Parameters: Provide information about all database parameters or only those parameters that are not set to their default values.
Locks: Provide information about locks, including the user associated with each.
Sessions: Provide information about sessions, selected and ordered by various criteria.
Storage: Provide usage and allocation information for tablespaces and data files.
Top SQL: Provide information about SQL statements, selected and ordered by various criteria. This information might help you to identify SQL statements that are being executed more often than expected or that are taking more time than expected.
Users: Provide information about database users, selected and ordered by various criteria. For example, you can find out which users were created most recently, which user accounts have expired, and which users use object types and how many objects each owns.
Waits and Events: Provide information about waits and events, selected by criteria related to time and other factors. For Events in the Last x Minutes, specify the number of minutes in the Enter Bind Values dialog box.
1.16.7 Data Dictionary reports
Data Dictionary reports list information about the data dictionary views that are accessible in the database. Examples of data dictionary views are ALL_OBJECTS and USER_TABLES.
Dictionary View Columns: For each Oracle data dictionary view, lists information about the columns in the view.
Dictionary Views: Lists each Oracle data dictionary view and (in most cases) a comment describing its contents or purpose.
1.16.8 Scheduler reports
Jobs reports list information about jobs and other objects related to Scheduling Jobs Using SQL Developer.
DBMS Jobs: Lists information about all jobs, DBA jobs (jobs for which a DBA user is associated with the database connection), and your jobs (jobs for which the user associated with the database connection is the log user, privilege user, or schema user). The information for each job includes the start time of its last run, current run, and next scheduled run.
Definitions: Lists information about all objects of types associated with job scheduling.
Executions: Lists information about the executions of jobs.
1.16.9 PL/SQL reports
PL/SQL reports list information about PL/SQL packages, function, and procedures, and about types defined in them.
Program Unit Arguments: For each argument (parameter) in a program unit, lists the program unit name, the argument position (1, 2, 3, and so on), the argument name, and whether the argument is input-only (In), output-only (Out), or both input and output (In/Out).
Search Source Code: For each PL/SQL object, lists the source code for each line, and allows the source to be searched for occurrences of the specified variable.
Unit Line Counts: For each PL/SQL object, lists the number of source code lines. This information can help you to identify complex objects (for example, to identify code that may need to be simplified or divided into several objects).
1.16.10 Security reports
Security reports list information about users that have been granted privileges, and in some cases about the users that granted the privileges. This information can help you (or the database administrator if you are not a DBA) to understand possible security issues and vulnerabilities, and to decide on the appropriate action to take (for example, revoking certain privileges from users that do not need those privileges).
Auditing: Lists information about audit policies.
Encryption: Lists information about encrypted columns.
Grants and Privileges: Includes the following reports:
-
Column Privileges: For each privilege granted on a specific column in a specific table, lists the user that granted the privilege, the user to which the privilege was granted, the table, the privilege, and whether the user to which the privilege was granted can grant that privilege to other users.
-
Object Grants: For each privilege granted on a specific table, lists the user that granted the privilege, the user to which the privilege was granted, the table, the privilege, and whether the user to which the privilege was granted can grant that privilege to other users.
-
Role Privileges: For each granted role, lists the user to which the role was granted, the role, whether the role was granted with the ADMIN option, and whether the role is designated as a default role for the user.
-
System Privileges: For each privilege granted to the user associated with the database connection, lists the privilege and whether it was granted with the ADMIN option.
Policies: Lists information about policies.
Public Grants: Lists information about privileges granted to the PUBLIC role.
1.16.11 Streams reports
Streams reports list information about stream rules.
All Stream Rules: Lists information about all stream rules. The information includes stream type and name, rule set owner and name, rule owner and name, rule set type, streams rule type, and subsetting operation.
Your Stream Rules: Lists information about each stream rule for which the user associated with the database connection is the rule owner or rule set owner. The information includes stream type and name, rule set owner and name, rule owner and name, rule set type, streams rule type, and subsetting operation.
1.16.12 Table reports
Table reports list information about tables owned by the user associated with the specified connection. This information is not specifically designed to identify problem areas; however, depending on your resources and requirements, some of the information might indicate things that you should monitor or address.
For table reports, the owner is the user associated with the database connection.
Columns: For each table, lists each column, its data type, and whether it can contain a null value. Also includes Datatype Occurrences: For each table owner, lists each data type and how many times it is used.
Comments for tables and columns: For each table and for each column in each table, lists the descriptive comments (if any) associated with it. Also includes a report of tables without comments. If database developers use the COMMENT statement when creating or modifying tables, this report can provide useful information about the purposes of tables and columns
Constraints: Includes the following reports related to constraints:
-
All Constraints: For each table, lists each associated constraint, including its type (unique constraint, check constraint, primary key, foreign key) and status (enabled or disabled).
-
Check Constraints: For each check constraint, lists information that includes the owner, the table name, the constraint name, the constraint status (enabled or disabled), and the constraint specification.
-
Enabled Constraints and Disabled Constraints: For each constraint with a status of enabled or disabled, lists the table name, constraint name, constraint type (unique constraint, check constraint, primary key, foreign key), and status. A disabled constraint is not enforced when rows are added or modified; to have a disabled constraint enforced, you must edit the table and set the status of the constraint to Enabled (see the appropriate tabs for the Create/Edit Table (with advanced options) dialog box).
-
Foreign Key Constraints: For each foreign key constraint, lists information that includes the owner, the table name, the constraint name, the column that the constraint is against, the table that the constraint references, and the constraint in the table that is referenced.
-
Primary Key Constraints: For primary key constraint, lists information that includes the owner, the table name, the constraint name, the constraint status (enabled or disabled), and the column name.
-
Unique Constraints: For each unique constraint, lists information that includes the owner, the table name, the constraint name, the constraint status (enabled or disabled), and the column name.
Indexes: Includes information about all indexes, indexes by status, indexes by type, and unused indexes.
Organization: Specialized reports list information about partitioned tables, clustered tables, and index-organized tables.
Quality Assurance: (See Quality Assurance reports.)
Statistics: For each table, lists statistical information, including when it was last analyzed, the total number of rows, the average row length, and the table type. In addition, specialized reports order the results by most rows and largest average row length.
Storage: Lists information about the table count by tablespace and the tables in each tablespace.
Triggers: Lists information about all triggers, disabled triggers, and enabled triggers.
User Synonyms: Displays information about either all user synonyms or those user synonyms containing the string that you specify in the Enter Bind Variables dialog box (uncheck Null in that box to enter a string).
User Tables: Displays information about either all tables or those tables containing the string that you specify in the Enter Bind Variables dialog box (uncheck Null in that box to enter a string).
Quality assurance reports are table reports that identify conditions that are not technically errors, but that usually indicate flaws in the database design. These flaws can result in various problems, such as logic errors and the need for additional application coding to work around the errors, as well as poor performance with queries at run time.
Tables without Primary Keys: Lists tables that do not have a primary key defined. A primary key is a column (or set of columns) that uniquely identifies each row in the table. Although tables are not required to have a primary key, it is strongly recommended that you create or designate a primary key for each table. Primary key columns are indexed, which enhances performance with queries, and they are required to be unique and not null, providing some "automatic" validation of input data. Primary keys can also be used with foreign keys to provide referential integrity.
Tables without Indexes: Lists tables that do not have any indexes. If a column in a table has an index defined on it, queries that use the column are usually much faster and more efficient than if there is no index on the column, especially if there are many rows in the table and many different data values in the column.
Tables with Unindexed Foreign Keys: Lists any foreign keys that do not have an associated index. A foreign key is a column (or set of columns) that references a primary key: that is, each value in the foreign key must match a value in its associated primary key. Foreign key columns are often joined in queries, and an index usually improves performance significantly for queries that use a column. If an unindexed foreign key is used in queries, you may be able to improve run-time performance by creating an index on that foreign key.
1.16.13 XML reports
XML reports list information about XML objects.
XML Schemas: For each user that owns any XML objects, lists information about each object, including the schema URL of the XSD file containing the schema definition.
1.16.14 Data Modeler reports
Data Modeler reports list information about objects that have been exported to the Data Modeler reporting repository. For information about exporting designs to the reporting repository, see the "Data Modeler Reports" topic in the Data Modeler help or the Oracle SQL Developer Data Modeler User's Guide. (To export to the reporting repository, you must use the full Data Modeler product; you cannot use the Data Modeler in SQL Developer that is included in SQL Developer.)
To use any Data Modeler reports in SQL Developer, you must have created a database connection to the schema that contains the Data Modeler reporting repository.
To view any Data Modeler report, expand the Data Modeler Reports hierarchy and double-click the desired report. If you are prompted for a database connection, select the one containing the reporting repository. If you are prompted for bind variables, follow the guidelines in "Bind Variables for Reports".
Design Content: Includes reports about the data types and the logical and relational models.
Design Rules: Includes reports about potential violations of the Data Modeler design rules. For example, for logical model attributes, you can see attributes without data types and attributes not based on domains; and for relational model tables, you can see tables without columns, primary keys, foreign key links, and unique constraints.
1.16.15 User Defined reports
User Defined reports are any reports that are created by SQL Developer users. To create a user-defined report, right-click the User Defined node under Reports and select Add Report. A dialog box is displayed in which you specify the report name and the SQL query to retrieve information for the report (see Section 5.59, "Create/Edit User Defined Report").
You can organize user-defined reports in folders, and you can create a hierarchy of folders and subfolders. To create a folder for user-defined reports, right-click the User Defined node or any folder name under that node and select Add Folder (see Section 5.60, "Create/Edit User Defined Report Folder").
Information about user-defined reports, including any folders for these reports, is stored in a file named UserReports.xml under the directory for user-specific information. For information about the location of this information, see Section 1.18, "Location of User-Related Information".
For examples of creating user-defined reports, see:
-
Section 1.16.15.2, "User-Defined Report Example: Dynamic HTML"
-
Section 1.7.10, "Gauges: In the SQL Worksheet and User-Defined Reports"
1.16.15.1 User-Defined Report Example: Chart
This example creates a report displayed as a chart. It uses the definition of the EMPLOYEES table from the HR schema, which is a supplied sample schema.
Right-click on User Defined Reports and select Add Report. In the Add Report dialog box, specify a report name; for Style, select Chart; and for SQL, enter the following:
select m.department_id, e.last_name, e.salary from employees m, employees e where e.employee_id = m.employee_id order by 1
The preceding query lists the last name and salary of each employee in each department, grouping the results by department ID (10, 20, 30, ... 110). Note that the expected syntax for the SQL statement for a chart report is:
SELECT <group>,<series>,<value> FROM <table(s)>
Click the Chart Details tab near the bottom of the box; for Chart Type, select BAR_VERT_STACK (bar chart, stacked vertically); and click Apply.
Use the Reports navigator to view the newly created user-defined report. For Connection, specify one that connects to the HR sample schema.
The report is displayed as a chart, part of which is shown in the following illustration. For example, as you can see, department 50 has mainly employees with the lowest salaries, and department 90 consists of the three highest-paid employees.
1.16.15.2 User-Defined Report Example: Dynamic HTML
This example creates a report using one or more PL/SQL DBMS_OUTPUT statements, so that the report is displayed as dynamic HTML.
Right-click on User Defined Reports and select Add Report. In the Add Report dialog box, specify a report name; for Style, select plsql-dbms_output; and for SQL, enter the following:
begin
dbms_output.put_line ('<H1> This is Level-1 Heading </H1>');
dbms_output.put_line ('<H2> This is a Level-2 Heading </H2>');
dbms_output.put_line ('<p> This is regular paragraph text. </p>');
end;
Click Apply.
Use the Reports navigator to view the newly created user-defined report. For Connection, specify any from the list. (This report does not depend on a specific connection of table.).
The report is displayed as formatted HTML output.
1.17 SQL Developer Preferences
You can customize many aspects of the SQL Developer interface and environment by modifying SQL Developer preferences according to your preferences and needs. To modify SQL Developer preferences, select Tools, then Preferences.
Information about SQL Developer preferences is stored under the directory for user-specific information. For information about the location of this information, see Section 1.18, "Location of User-Related Information".
Most preferences are self-explanatory, and this topic explains only those whose meaning and implications are not obvious. Some preferences involve performance or system resource trade-offs (for example, enabling a feature that adds execution time), and other preferences involve only personal aesthetic taste. The preferences are grouped in the following categories.
1.17.1 Environment
The Environment pane contains options that affect the startup and overall behavior and appearance of SQL Developer. You can specify that certain operations be performed automatically at specified times, with the trade-off usually being the extra time for the operation as opposed to the possibility of problems if the operation is not performed automatically (for example, if you forget to perform it when you should).
The undo level (number of previous operations that can be undone) and navigation level (number of open files) values involve slight increases or decreases system resource usage for higher or lower values.
Automatically Reload Externally Modified Files: If this option is checked, any files open in SQL Developer that have been modified by an external application are updated when you switch back to SQL Developer, overwriting any changes that you might have made. If this option is not checked, changes that you make in SQL Developer overwrite any changes that might have been made by external applications.
Silently Reload When File Is Unmodified: If this option is checked, you are not asked if you want to reload files that have been modified externally but not in SQL Developer. If this option is not checked, you are asked if you want to reload each file that has been modified externally, regardless of whether it has been modified in SQL Developer.
The Dockable Windows pane configures the behavior of dockable windows and the shapes of the four docking areas of SQL Developer: top, bottom, left, and right.
Dockable Windows Always on Top: If this option is checked, dockable windows always remain visible in front of other windows.
Windows Layout: Click the corner arrows to lengthen or shorten the shape of each docking area.
The Local History pane controls whether information about editing operations on files opened within SQL Developer is kept. If local history is enabled, you can specify how long information is retained and the maximum number of revisions for each file.
The Log pane configures the colors of certain types of log messages and the saving of log messages to log files.
Save Logs to File: If this option is checked, all output to the Messages - Log window is saved to log files, where the file name reflects the operation and a timestamp. You are also asked to specify a Log Directory; and if the specified directory does not already exist, it is created if and when it is needed. Note that if you save log information to files, the number of these files can become large.
Maximum Log Lines: The maximum number of lines to store in each log file.
1.17.2 Change Management Parameters
The Change Management Parameters pane contains options that affect Change Manager Support in SQL Developer, especially how objects are compared to determine if a change has occurred and how extensive the DDL statements are when the script for deploying changes is generated.
Ignore physical attributes: Causes differences in physical attributes to be ignored when objects are compared.
Ignore tablespace: Causes differences in the tablespace specified for the object to be ignored when objects are compared.
Ignore segment attributes: Causes differences in segment specification to be ignored when objects are compared.
Ignore storage: Causes differences in storage specification to be ignored when objects are compared.
Ignore table column positions: Causes differences in the positions of table columns to be ignored when objects are compared. For example, if this option is enabled (checked), two tables would not be considered different in the only difference is that Column1 and Column2 appear first and second in one table but second and first in the other table.
Match Constraints: Controls whether constraints are matched for comparison by the names or definitions or the constraints (Match constraints by name or Match constraints by definition).
Report constraint name difference: If Match constraints by definition is selected, causes the constraint name to be displayed when differences are reported.
Generate constraint indexes: Causes constraint indexes to be generated in the DDL for the deployment script.
Generate constraints: Causes constraints to be generated in the DDL for the deployment script.
Generate password values: Causes password values to be generated in the DDL for the deployment script.
Generate referential constraints: Causes referential constraints to be generated in the DDL for the deployment script.
Generate SQL terminator: Causes the SQL statement terminator character to be generated at the end of each statement in the DDL for the deployment script.
Change Management Parameters: Conflict Resolution
The Conflict Resolution pane contains options for resolving conflicts when the old or existing item's value is different from the potential new or modified value or when the existing item would be removed.
Item to be added already exists, or the item to be removed is different. Apply Exists Different: FALSE causes the item to be added or the existing item to be removed; TRUE causes the item not to be added or the existing item not to be removed.
Item to be modified has already been modified to a different value. Apply Exists Different: FALSE causes the item to be modified so as to replace the existing (different) value; TRUE causes the item to keep the existing (different) value.
Item to be modified has already been modified to the old value recorded in the difference. Apply Exists Different: FALSE causes the item to be changed to the new value; TRUE causes the item to keep the existing value (the old value recorded in the difference).
1.17.3 Code Editor
The Code Editor pane contains general options that affect the appearance and behavior of SQL Developer when you edit functions, procedures, and packages.
Autopin PL/SQL Editors: Keeps the current PL/SQL editor open when you open another function, procedure, or package.
Max Open PL/SQL Editors: Specifies the maximum number of PL/SQL editors that can be kept open ("pinned").
Auto-Indent New Lines: Automatically indents a new line when you press Enter at the end of a line. The new line will automatically be indented at the same initial indentation as the line preceding it.
Perform Block Indent or Outdent for Selections: Performs a block indent or block outdent on a selection when your press Tab or Shift+Tab, respectively. With this option selected, when you press Tab on a selected block of text, the entire block will be indented to the current tab size. Shift+Tab on the same block would outdent it, as a block, to the current tab size.
Use Smart Home: Contextualizes the cursor's understanding of home (the beginning of the line). With this setting selected, pressing Home positions the cursor at the start of the line after any leading spaces or tabs. Pressing Home again repositions the cursor at the start of the line before any leading spaces or tabs. Continuing to press Home toggles the cursor between these two locations.
With this setting deselected, pressing Home simply places the cursor at the start of the line.
Use Smart End: Contextualizes the cursor's understanding of end of line. The behavior is analogous to that for Smart Home, except that the cursor responds to the End key, and its behavior regarding the end of the line and any trailing spaces is altered.
Use Jump Scrolling for Keyboard Navigation: Implement jump scrolling, which involves behavior of the keyboard arrow keys. With this setting selected, when you navigate off-screen using the keyboard arrow keys, the editor view will "jump" to recenter the cursor location in the middle of the editor view.
With this setting deselected, the editor view will scroll the editor view the minimum amount to bring the cursor back into view.
Use Change of Case As Word Boundary: Has change of case regarded as the boundary of a word, for example, when you double-click to select a word.
Enable Cut or Copy of Current Line with No Selection: Applies all cut and copy operations to the current line whenever there is no text selection in the editor.
Automatically Copy Paste Imports: Automatically add imports when references are introduced to objects that have not yet been imported.
Adjust Indentation When Pasting: Corrects the indentation of a pasted in item that includes indentation.
Reformat Code Block When Pasting: Reformats the code correctly when you paste it into a new location.
Escape When Pasting in String Literals: Includes the correct escape characters in pasted-in string literals.
The Bookmarks pane contains options that determine the persistence and search behavior for bookmarks that you create when using the code editor.
The Caret Behavior pane contains options that determine the shape, color, and blinking characteristics of the caret (cursor) in the code editor.
Code Editor: Completion Insight
The Completion Insight pane contains options for the logical completion (autocomplete options) of keywords and names while you are coding in the SQL Worksheet.
When you pause for the auto-popup time (if the auto-popup is enabled) or when you press Ctrl+Space, code insight provides a context-sensitive popup window that can help you select parameter names. Completion insight provides you with a list of possible completions at the insertion point that you can use to auto-complete code you are editing. This list is based on the code context at the insertion point. To exit code insight at any time, press Esc or continue typing.
You can enable or disable automatic completion and parameter insight, as well as set the time delay for the popup windows.
Generate Column/Table Aliases Automatically: Automatically generates table aliases if you select multiple tables from the popup window; and if you then edit the column list, each column name in the popup window is prefixed with a table alias.
Autogenerate GROUP BY Clause: Automatically generates a GROUP BY clause if you manually enter (not copy/paste) a SELECT statement containing a COUNT function, and then edit the SELECT query.
The Display pane contains general options for the appearance and behavior of the code editor.
Enable Text Anti-Aliasing allows smooth-edged characters where possible.
Show Whitespace Characters renders spaces, new lines, carriage returns, non-breaking spaces, and tab characters as alternate visible characters.
Show Breadcrumbs shows the breadcrumb bar, which shows the hierarchy of nodes from the current caret position up to the top of the file. Hover the mouse cursor over a node to display information about the node.
Show Scroll Tip enables the Tip window that displays the methods in view while scrolling.
Show Code Folding Margin allows program blocks in procedures and functions to be expanded and collapsed in the display.
Show visible Right Margin renders a right margin that you can set to control the length of lines of code.
Enable Automatic Brace Matching controls the highlighting of opening parentheses and brackets and of blocks when a closing parenthesis or bracket is typed.
The Fonts pane specifies text font options for the code editor.
Display Only Fixed-Width Fonts: If this option is checked, the display of available font names is restricted to fonts where all characters have the same width. (Fixed-width fonts are contrasted with proportional-width fonts.)
The Line Gutter pane specifies options for the line gutter (left margin of the code editor).
Show Line Numbers: If this option is checked, lines are numbered. (To go to a line number while you are using the SQL Worksheet, press Ctrl+G.)
Enable Line Selection by Click-Dragging: If this option is checked, you can select consecutive lines in the editor by clicking in the gutter and dragging the cursor without releasing the mouse button.
Code Editor: PL/SQL Syntax Colors
The PL/SQL Syntax Colors pane specifies colors for different kinds of syntax elements.
The Printing pane specifies options for printing the contents of the code editor. The Preview pane sample display changes as you select and deselect options.
The Printing HTML pane specifies options for printing HTML files from the code editor.
The Undo Behavior pane specifies options for the behavior of undo operations (Ctrl+Z, or Edit, then Undo). Only consecutive edits of the same type are considered; for example, inserting characters and deleting characters are two different types of operation.
Allow Navigation-Only Changes to be Undoable: If this option is checked, navigation actions with the keyboard or mouse can be undone. If this option is not checked, navigation actions cannot be undone, and only actual changes to the text can be undone.
1.17.4 Compare and Merge
The Compare and Merge pane defines options for comparing and merging two source files. For more information, see Comparing Source Files.
For each type of option, you can specify a Maximum File Size (KB): the maximum size of the file (number of kilobytes) for which the operation will be performed.
Ignore Whitespace: If this option is enabled, leading and trailing tabs and letter spacing are ignored when comparing files. Carriage returns are not ignored. Enabling this option makes comparing two files easier when you have replaced all the space with hard tabs, or vice versa. Otherwise, every line in the two documents might be shown as different in the Compare window.
Show Character Differences: If this option is enabled, characters that are present in one file and not in another are highlighted. Red highlighting indicates a character that has been removed. Green highlighting indicates a character that has been added. The highlighting is shown only when you click into a comparison block that contains character differences.
Enable Java Compare: If this option is enabled, Java source files can be compared in a structured format.
Enable XML Compare: If this option is enabled, XML files can be compared.
Enable XML Merge: If this option is enabled, XML files can be merged.
Reformat Result: If this option is enabled, merged XML files can be reformatted.
Validate Result (May require Internet access): If this option is enabled, merged XML files will be validated.
You can compare source files in the following ways:
-
A file currently being edited with its saved version: Place the focus on the current version open in the editor; from the main menu, select File, then Compare With, then File on Disk.
-
One file with another file: Place the focus on the file in the editor to be compared; from the main menu, select File, then Compare With, then Other File. In the Select File to Compare With dialog, navigate to the file and click Open.
1.17.5 Database
The Database pane sets properties for the database connection.
Validate date and time default values: If this option is checked, date and time validation is used when you open tables.
Default path to store export in: Default path of the directory or folder under which to store output files when you perform an export operation. To see the current default for your system, click the Browse button next to this field.
Filename for connection startup script: File name for the startup script to run when an Oracle database connection is opened. You can click Browse to specify the location. The default location is the default path for scripts (see the Database: Worksheet preferences pane).
The Advanced pane specifies options such as the SQL array fetch size and display options for null values.
You can also specify Kerberos thin driver configuration parameters, which enables you to create database connections using Kerberos authentication and specifying the user name and password. For more information, see the Kerberos Authentication explanation on the Oracle tab in the Create/Edit/Select Database Connection dialog box. For information about configuring Kerberos authentication, see Oracle Database Advanced Security Administrator's Guide.
Use OCI/Thick driver: If this option is checked, and if an OCI (thick, Type 2) driver is available, that driver will be used instead of a JDBC (thin) driver for basic and TNS (network alias) database connections. If any connections use a supported Remote Authentication Dial In User Service (RADIUS) server, check this option.
Autocommit: If this option is checked, a commit operation is automatically performed after each INSERT, UPDATE, or DELETE statement executed using the SQL Worksheet. If this option is not checked, a commit operation is not performed until you execute a COMMIT statement.
Kerberos Thin Config: Config File: Kerberos configuration file (for example, krb5.conf). If this is not specified, default locations will be tried for your Java and system configuration.
Kerberos Thin Config: Credential Cache File: Kerberos credential cache file (for example, krb5_cc_cache). If this is not specified, a cache will not be used, and a principal name and password will be required each time.
Tnsnames Directory: Enter or browse to select the location of the tnsnames.ora file. If no location is specified, SQL Developer looks for this file as explained in Section 1.4, "Database Connections". Thus, any value you specify here overrides any TNS_ADMIN environment variable or registry value or (on Linux systems) the global configuration directory.
Database: Autotrace/Explain Plan
The Autotrace/Explain Plan pane specifies information to be displayed on the Autotrace and Explain Plan panes in the SQL Worksheet.
The Drag and Drop Effects pane determines the type of SQL statement created in the SQL Worksheet when you drag an object from the Connections navigator into the SQL Worksheet. The SQL Developer preference sets the default, which you can override in the Drag and Drop Effects dialog box.
The type of statement (INSERT, DELETE, UPDATE, or SELECT) applies only for object types for which such a statement is possible. For example, SELECT makes sense for a table, but not for a trigger. For objects for which the statement type does not apply, the object name is inserted in the SQL Worksheet.
Some SQL Developer features require that licenses for specific Oracle Database options be in effect for the database connection that will use the feature. The Licensing pane enables you to specify, for each defined connection, whether the database has the Oracle Change Management Pack, the Oracle Tuning Pack, and the Oracle Diagnostics Pack.
For each cell in this display (combination of license and connection), the value can be true (checked box), false (cleared box), or unspecified (solid-filled box).
If an option is specified as true for a connection in this pane, you will not be prompted with a message about the option being required when you use that connection for a feature that requires the option.
The NLS pane specifies values for globalization support parameters, such as the language, territory, sort preference, and date format. These parameter values are used for SQL Developer session operations, such as for statements executed using the SQL Worksheet and for the National Language Support Parameters report. Specifying values in this preferences pane does not apply those values to the underlying database itself. To change the database settings, you must change the appropriate initialization parameters and restart the database.
Note that SQL Developer does not use default values from the current system for globalization support parameters; instead, SQL Developer, when initially installed, by default uses parameter values that include the following:
NLS_LANG,"AMERICAN" NLS_TERR,"AMERICA" NLS_CHAR,"AL32UTF8" NLS_SORT,"BINARY" NLS_CAL,"GREGORIAN" NLS_DATE_LANG,"AMERICAN" NLS_DATE_FORM,"DD-MON-RR"
Database: ObjectViewer Parameters
The ObjectViewer Parameters pane specifies whether to freeze object viewer windows, and display options for the output. The display options will affect the generated DDL on the SQL tab. The Data Editor Options affect the behavior when you are using the Data tab to edit table data.
Data Editor Options
Post Edits on Row Change: If this option is checked, posts DML changes when you perform edits using the Data tab (and the Set Auto Commit On option determines whether or not the changes are automatically committed). If this option is not checked, changes are posted and committed when you press the Commit toolbar button.
Set Auto Commit On (available only if Post Edit on Row Changes is enabled): If this option is checked, DML changes are automatically posted and committed when you perform edits using the Data tab.
Clear persisted table column widths, order, sort, and filter settings: If you click Clear, then any customizations in the Data tab display for table column widths, order, sort, and filtering are not saved for subsequent openings of the tab, but instead the default settings are used for subsequent openings.
Use ORA_ROWSCN for DataEditor insert and update statements: If this option is checked, SQL Developer internally uses the ORA_ROWSCN pseudocolumn in performing insert and update operations when you use the Data tab. If you experience any errors trying to update data, try unchecking (disabling) this option.
The PL/SQL Compiler pane specifies options for compilation of PL/SQL subprograms.
Generate PL/SQL Debug Information: If this option is checked, PL/SQL debug information is included in the compiled code; if this option is not checked, this debug information is not included. The ability to stop on individual code lines and debugger access to variables are allowed only in code compiled with debug information generated.
Types of messages: You can control the display of informational, severe, and performance-related messages. (The ALL type overrides any individual specifications for the other types of messages.) For each type of message, you can specify any of the following:
-
No entry (blank): Use any value specified for ALL; and if none is specified, use the Oracle default.
-
Enable: Enable the display of all messages of this category.
-
Disable: Disable the display of all messages of this category.
-
Error: Enable the display of only error messages of this category.
Optimization Level: 0, 1, or 2, reflecting the optimization level that will be used to compile PL/SQL library units. The higher the setting of this parameter, the more effort the compiler makes to optimize PL/SQL library units. However, for a module to be compiled with PL/SQL debugging information, the level must be 0 or 1.
PLScope Identifiers: Specifies the amount of PL/Scope identifier data to collect and use (All or None).
The Reports pane specifies options relating to SQL Developer Reports.
Close all reports on disconnect: If this option is checked, all reports for any database connection are automatically closed when that connection is disconnected.
Database: SQL Editor Code Templates
The SQL Editor Code Templates pane enables you to view, add, and remove templates for editing SQL and PL/SQL code. Code templates assist you in writing code more quickly and efficiently by inserting text for commonly used statements. You can then modify the inserted text.
The template ID string is not used by SQL Developer; only the template content (Description text) is used, in that it is considered by completion insight (explained in Code Editor: Completion Insight) in determining whether a completion popup should be displayed and what the popup should contain. For example, if you define code template ID mydate as SELECT sysdate FROM dual, then if you start typing select in the SQL Worksheet, the auto-popup includes SELECT sysdate FROM dual.
Add Template: Adds an empty row in the code template display. Enter an ID value, then move to the Template cell; you can enter template content in that cell, or click the pencil icon to open an editing box to enter the template content.
Remove Template: Deletes the selected code template.
The SQL Formatter pane controls how statements in the SQL Worksheet are formatted when you click Format SQL. The options include whether to insert space characters or tab characters when you press the Tab key (and how many characters), uppercase or lowercase for keywords and identifiers, whether to preserve or eliminate empty lines, and whether comparable items should be placed or the same line (if there is room) or on separate lines.
Import: Lets you import code style profile settings that you previously exported.
Export: Exports the current code profile settings to an XML file.
Autoformat PL/SQL in Procedures, Packages, Views, and Triggers: If this option is checked, the SQL Formatter options are applied automatically as you enter and modify PL/SQL code in procedures, packages, views, and triggers; if this option is not checked, the SQL Formatter options are applied only when you so request.
Panes for product-specific formatting options: Individual panes let you specify formatting options for Oracle and for other vendors (Microsoft Access, IBM DB2, Microsoft SQL Server, Sybase Adaptive Server). In each of these panes, you can click Edit to specify input/output, alignment, indentation, line breaks, CASE line breaks, white space, and other options.
Database: Third Party JDBC Drivers
The Third Party JDBC Drivers pane specifies drivers to be used for connections to third-party (non-Oracle) databases, such as IBM DB2, MySQL, Microsoft SQL Server, or Sybase Adaptive Server. (You do not need to add a driver for connections to Microsoft Access databases.) To add a driver, click Add Entry and select the path for the driver:
-
For IBM DB2: the
db2jcc.jaranddb2jcc_license_cu.jarfiles, which are available from IBM -
For MySQL: a file with a name similar to
mysql-connector-java-5.0.4-bin.jar, in a directory under the one into which you unzipped the download for the MySQL driver -
For Microsoft SQL Server or Sybase Adaptive Server:
jtds-1.2.jar, which is included in thejtds-1.2-dist.zipdownload -
For Teradata:
tdgssconfig.jarandterajdbc4.jar, which are included (along with areadme.txtfile) in theTeraJDBC__indep_indep.12.00.00.110.ziporTeraJDBC__indep_indep.12.00.00.110.tardownload
Alternative:
As an alternative to using this preference, you can click Help, then Check for Updates to install the JTDS JDBC Driver for Microsoft SQL Server and the MySQL JDBE Driver as extensions.To find a specific third-party JDBC driver, see the appropriate Web site (for example, http://www.mysql.com for the MySQL Connector/J JDBC driver for MySQL, http://jtds.sourceforge.net/ for the jTDS driver for Microsoft SQL Server and Sybase Adaptive Server, or search at http://www.teradata.com/ for the JDBC driver for Teradata). For MySQL, use the MySQL 5.0 driver, not 5.1 or later, with SQL Developer release 1.5.
You must specify a third-party JDBC driver or install a driver using the Check for Updates feature before you can create a database connection to a third-party database of that associated type. (See the tabs for creating connections to third-party databases in the Create/Edit/Select Database Connection dialog box.)
Database: User Defined Extensions
The User Defined Extensions pane specifies user-defined extensions that have been added. You can use this pane to add extensions that are not available through the Check for Updates feature. These extensions can be for user-defined reports, actions, editors, and navigators. (For more information about extensions and checking for updates, see Section 1.17.7, "Extensions".)
One use of the Database: User-Defined Extensions pane is to create a Shared Reports folder and to include an exported report under that folder: click Add Row, specify Type as REPORT, and for Location specify the XML file containing the exported report. The next time you restart SQL Developer, the Reports navigator will have a Shared Reports folder containing that report.
For more information about creating user-defined extensions, see:
-
How To create an XML User Defined Extension:
http://wiki.oracle.com/page/SQL+Dev+SDK+How+To+create+an+XML+User+Defined+Extension -
Creating XML Extensions in Oracle SQL Developer 3.0: Access the learning library at
http://www.oracle.com/technetwork/tutorials/and search for: Creating XML Extensions in Oracle SQL Developer 3.0
The Utilities pane specifies options that affect the behavior of Database Utilities, such as Export and Import, when they are invoked using SQL Developer.
The Cart and Cart Deploy panes specify options that affect the behavior of the SQL Developer Cart (see Section 1.13, "Deploying Objects Using the SQL Developer Cart").
Database: Utilities: Difference
The Difference pane specifies options that affect the behavior of the Database Differences Wizard (see Section 5.71, "Database Differences").
The Export pane determines the default values used for the Database Export (Unload Database Objects and Data) wizard and for some other.interfaces.
See also the panes for Database: Utilities: Export: Formats (CSV, Delimited, Excel, Fixed, HTML, PDF, SQL*Loader, Text, XML)
Export DDL: If this option is checked, the data definition language (DDL) statements for the database objects to be exported are included in the output file, and the other options in this group affect the content and format of the DDL statements.
Pretty Print: If this option is checked, the statements are attractively formatted in the output file, and the size of the file will be larger than it would otherwise be.
Terminator: If this option is checked, a line terminator character is inserted at the end of each line.
Show Schema: If this option is checked, the schema name is included in CREATE statements. If this option is not checked, the schema name is not included in CREATE and INSERT statements, which is convenient if you want to re-create the exported objects and data under a schema that has a different name.
Include Dependents: If this option is checked, objects that are dependent on the objects specified for export are also exported. For nonprivileged users, only dependent objects in their schema are exported; for privileged users, all dependent objects are exported.
Include BYTE Keyword: If this option is checked, column length specifications refer to bytes; if this option is not checked, column length specifications refer to characters.
Add Force to Views: If this option is checked, the FORCE keyword is added to any CREATE VIEW statements (resulting in CREATE OR REPLACE FORCE VIEW...) in the generated DDL during a database export operation. When the script is run later, the FORCE keyword causes the view to be created regardless of whether the base tables of the view or the referenced object types exist or the owner of the schema containing the view has privileges on them.
Include Grants: If this option is checked, GRANT statements are included for any grant objects on the exported objects. (However, grants on objects owned by the SYS schema are never exported.)
Include Drop Statement: If this option is checked, a DROP statement is included before each CREATE statement, to delete any existing objects with the same names. However, you may want to uncheck this option, and create a separate drop script that can be run to remove an older version of your objects before creation. This avoids the chance of accidentally removing an object you did not intend to drop.
Cascade Drops: If this option is checked, the DROP statements include the CASCADE keyword to cause dependent objects to be deleted also.
Storage: If this option is checked, any STORAGE clauses in definitions of the database objects are preserved in the exported DDL statements. If you do not want to use the current storage definitions (for example, if you will re-create the objects in a different system environment), uncheck this option.
Export Data: If this option is checked, the output file or files contain appropriate statements or data for inserting the data for an exported table or view; the specific output format is determined by the Export Data: Format setting. If this option is not checked, the data for an exported table or view is not exported; that is, only the DDL statements are included. If you check Export Data, all data in all tables in the selected schema is exported, unless you use the Filter Data tab to limit the data to be migrated.
Export Data: Format: Specifies the format to be used for exporting data for a table or view. For example, insert causes SQL INSERT statements to be included to insert the data, loader causes SQL*Loader files to be created, and xls causes a Microsoft Excel .xls file to be created.
Save As: Specifies how the output of an export operation is to be generated. You can also click Browse to find and select the location for the output:
-
Single File: A single file contains both DDL and data.
-
Separate Files: Each object is saved to a separate file in the specified directory.
-
Type Files: Objects of the same type are saved to a single file in the specified directory.
-
Separate Directories: A directory for each object type being exported is created. Files are created in the appropriate directory.
-
Worksheet: Statements are sent to a SQL Worksheet window.
-
Clipboard: Statements are copied to the clipboard.
Encoding: Character set to be used for encoding of the output file or files.
Open SQL File When Exported: If this option is checked, the output file is opened automatically when the export operation is complete.
Generate Controlling Script for Multiple SQL Files: If this option is checked, then if statements are generated in multiple .sql script files, a controlling (or master) .sql script file is also generated to run all the individual script files.
Database: Utilities: Export: Formats (CSV, Delimited, Excel, Fixed, HTML, PDF, SQL*Loader, Text, XML)
A separate pane is provided for specifying default attributes for each supported format for exported data. The displayed and editable attributes depend on the specific format.
Right Enclosure in Data is Doubled (CSV, Delimited, and Text formats) If this option if checked, then for CSV, delimited, and text format, if the right enclosure occurs in the data, it is doubled in the exported data file.
The PDF Format options include panes for options specific to cell, column, and table layout, headers and footers, and security. Note that if a table has multiple columns and the columns do not fit horizontally on a PDF page, then the Table Layout Horizontal Alignment option does not apply, but instead the table is split vertically spanning multiple pages and the information on each page is left-aligned.
PDF Format: Column Layout: Binary Large Object Column specifies whether to include BLOBs in the PDF document, to exclude BLOBs from the PDF document (and have the BLOB column be blank), or to create the BLOBs as separate files (in a filename_blob subdirectory) and create relative links in the PDF file to the BLOB files. (In this case, if you copy the PDF file, you must also remember to copy the filename_blob subdirectory and its files.) For the relative links option, you have the option to create instead only a .zip file that contains the PDF file and BLOB files.
If a pane includes Header, this option controls whether the first row is a header row or the first row of data.
The Import pane determines the default values used for the Data Import Wizard (Load Data) wizard.
See also the panes for Database: Utilities: Import: File Formats (CVS, Delimited, Text) and Database: Utilities: Import: Import Methods (External Table, Insert, SQL Loader).
Default Import Directory: The default folder or directory for files containing data to be imported. You can click Browse to find and select the folder or directory.
File Encoding: Default character set used for encoding of the data to be imported.
Preview Limit: If this option is checked, it specifies the maximum number of rows of data to be displayed in the preview pane before you proceed with the import operation. The lower the value, the faster the preview pane is populated. When the wizard creates a new table, the preview data is used to calculate the size of the columns; therefore, ensure that the preview is a good sample of the data.
Preview File Read Maximum: Specifies the maximum number of bytes of data to be displayed in the preview pane (if the specified preview row limit has not already been reached) before you proceed with the import operation. (You should set some maximum to ensure that very large files are not inadvertently read into memory.)
Database: Utilities: Import: File Formats (CVS, Delimited, Text)
A separate pane is provided for specifying default attributes for each supported format for imported data. The displayed and editable attributes depend on the specific format.
If a pane includes Header, this option controls whether the first row is a header row or the first row of data.
Delimiter: Identifies the character used to separate the data into columns. The delimiter character is not included in the data loaded. If the preview page does not show the data separated into columns, the correct delimiter is probably not specified. Examine the data in the preview area to determine the correct delimiter.
Line Terminator: Identifies the terminator for each line. The line terminator is not included in the data loaded. If the preview page shows the data in one single row, the correct terminator is not specified.
Left Enclosure and Right Enclosure: Enclosures are used for character data and are optional. Enclosures are not included in the data loaded.
Right Enclosure in Data is Doubled: If this option if checked, then for CSV, delimited, and text format, any right enclosure that is doubled in the data is loaded (imported) as a single right enclosure; also, the data preview will show such data as it will be loaded (that is, double right enclosures will be displayed as single right enclosures in the preview if this option is checked).
Database: Utilities: Import: Import Methods (External Table, Insert, SQL Loader)
The Import Methods pane lets you specify the default mode for importing data in the following situations:
-
Existing Table Import Method: For importing data into an existing table, specifies the default method to be used for loading data.
-
New Table Import Method: For creating a new table to hold the data to be imported, specifies the default method to be used for loading data.
A separate pane is provided for specifying default attributes for each supported method or tool to be used for exporting the data. The displayed and editable attributes depend on the specific method.
External Table Method preferences apply to both the External Table method and the Staging External Table method.
Identify Oracle directories for default, log, bad, and discard directories to be used as defaults for the data load. If any of the optional directories are not specified here or in the wizard, the default directory is used. Note these are Oracle directory objects that must be created before the external table can be used, and the appropriate permissions must be granted.
Staging Table Suffix: For Staging External Table, the suffix will be appended to the name of the table to create the name of the external table used as the staging table.
Commit and Drop Staging Table: Indicates the default setting for the commit and drop staging table option. If this option is enabled, the staging table will be dropped and the data will be committed at the end of the load.
The Worksheet pane specifies options that affect the behavior of the SQL Worksheet.
Open a worksheet on connect: If this option is checked, a SQL Worksheet window for the connection is automatically opened when you open a database connection. If this option is not checked, you must use the Open SQL Worksheet right-click command or toolbar icon to open a SQL Worksheet.
New Worksheet to use unshared connection: If this option is checked, a separate unshared connection to the database is used for each new SQL Worksheet window that connects to a given database. If this option is not checked, the existing connection to the database is used for subsequent SQL Worksheet windows that connect to the database.
Close all worksheets on disconnect: If this option is checked, all SQL Worksheet windows for any database connection are automatically closed when that connection is disconnected.
Prompt for Save File on Close: If this option is checked, you are prompted to save changes when you close a SQL Worksheet if it contains any unsaved changes. If this option is not checked, any unsaved changes are discarded.
Grid in checker board or zebra pattern: If this option is checked, two different light-colored backgrounds are used for alternating rows of grid displays, to provide some visual contrast. If this option is not checked, all grid rows have a white background.
Max rows to print in a script: Limits the number of rows displayed.
Max lines in script output: Limits the number of lines output.
SQL History Limit: Maximum number of statements that can be stored in the SQL History. Must be greater than 0 (zero). If you enter an invalid value, no value is stored in this field.
Default path to look for scripts: The default directory where SQL Developer looks when you run a script (using @). If you type a path, you can specify multiple delimited locations; if you click Browse, you can select a single location. In addition to any path that you specify, SQL Developer looks in the location specified by the SQLPATH environment variable.
Save bind variables to disk on exit: If this option is checked, bind variables that you enter when running a script are saved on disk for reuse. If you do not want bind variable values stored on disk (for security or other reasons), be sure not to check this option.
Automatically Freeze Result Tabs: If this option is checked, each pane showing the result of a Script Runner query is "pinned" and a new tab is created for each new query's results. If this option is not checked, the results pane is reused for all queries.
Re-initialize on script exit command: If this option is checked, Script Runner context settings, such as a WHENEVER SQLERROR directive and substitution variables, are cleared when the script exits. If this option is not checked, these context settings are retained. For example, uncheck this option if you want to keep any WHENEVER SQLERROR setting specified in a script after the script exits.
1.17.6 Debugger
The Debugger pane contains general options for the SQL Developer debugger. Other panes contain additional specific kinds of debugger options.
The Breakpoints pane sets the columns to appear in the Breakpoints pane and the scope of each breakpoint.
Debugger: Breakpoints: Default Actions
The Breakpoints: Default Actions pane sets defaults for actions to occur at breakpoints. These actions are the same as on the Actions tab in the Create/Edit Breakpoint dialog box.
The Data pane enables you to control the columns to appear in the debugger Data pane and aspects of how the data is displayed.
The Inspector pane enables you to control the columns to appear in the debugger Inspector pane and aspects of how the data is displayed.
The Smart Data pane enables you to control the columns to appear in the debugger Smart Data pane and aspects of how the data is displayed.
The Stack pane enables you to control the columns to appear in the debugger Stack pane and other options.
The ToolTip pane enables you to control the columns to appear in the debugger ToolTip pane.
The Watches pane enables you to control the columns to appear in the debugger Watches pane and aspects of how the data is displayed.
1.17.7 Extensions
The Extensions pane determines which optional extensions SQL Developer uses when it starts. (SQL Developer also uses some mandatory extensions, which users cannot remove or disable.) If you change any settings, you must exit SQL Developer and restart it for the new settings to take effect.
For Versioning Support, the settings (selected or not, and configuration options if selected) affect whether the Versioning menu is displayed and the items on that menu.
Extensions: Controls the specific optional SQL Developer extensions to use at startup. To cause an extension not to be used at the next startup, uncheck its entry. (To completely remove an extension, you must go to sqldeveloper\extensions under the SQL Developer installation folder and delete the .jar files associated with that extension.)
Check for Updates: Checks for any updates to the selected optional SQL Developer extensions, as well as any mandatory extensions. (If the system you are using is behind a firewall, see the SQL Developer user preferences for Web Browser and Proxy.)
Automatically Check for Updates: If this option is checked, SQL Developer automatically checks for any updates to the selected optional SQL Developer extensions and any mandatory extensions at startup. (Enabling this option might increase SQL Developer startup time. You can manually check for updates by clicking Help, then Check for Updates.)
1.17.8 External Editor
The External Editor pane determines which external editor is called by SQL Developer when you try to edit binary large object (BLOB) data, such as image files, video files, and other files created by certain applications. For each combination of MIME type and file extension, you can specify the executable application to be used to open and edit associated files.
MIME Type: MIME type of the data.
File Extension: File extension for files that contain BLOB data and that are associated with the MIME type.associated
Editor Location: Path to the editor to be used to open and edit files associated with this MIME type and file extension. To edit an existing path or to specify one if the cell is empty, click in the cell, and either modify the existing text or click Browse to find and select the executable file for the editor.
1.17.9 File Types
The File Types pane determines which file types and extensions will be opened by default by SQL Developer. The display shows each file extension, the associated file type, and a check mark if files with that extension are to be opened by SQL Developer be default, such as when a user double-clicks the file name.
Details area at bottom: You can modify the file type, content type (text or binary), and whether to open files with this extension automatically by SQL Developer.
To have files with a specific extension be opened by default by SQL Developer, click the file extension in the list, then check Open with SQL Developer in the Details area. This overrides any previous application association that may have been in effect for that file extension.
To add a file extension, click Add and specify the file extension (including the period). After adding the extension, you can modify its associated information by selecting it and using the Details area.
1.17.10 Global Ignore List
The Global Ignore List pane specifies filters that determine which files and file types will not be used in any processing.
New Filter: A file name or file type that you want to add to the list of files and file types (in the Filter box) that SQL Developer will ignore during all processing (if the filter is enabled, or checked). You can exclude a particular file by entering its complete file name, such as mumble.txt, or you can exclude all files of the same type by entering a construct that describes the file type, such as *.txt.
Add: Adds the new filter to the list in the Filter box.
Remove: Deletes the selected filter from the list in the Filter box.
Restore Defaults: Restores the contents of the Filter box to the SQL Developer defaults.
Filter: Contains the list of files and file types. For each item, if it is enabled (checked), the filter is enforced and the file or file type is ignored by SQL Developer; but if it is disabled (unchecked), the filter is not enforced.
1.17.11 Migration
The Migration pane contains options that affect the behavior of SQL Developer when you migrate schema objects and data from third-party databases to an Oracle database.
Default Repository: Migration repository to be used for storing the captured models and converted models. For information about migrating third-party databases to Oracle, including how to create a migration repository, see Chapter 2.
The Data Move Options pane contains options that affect the behavior when you migrate data from third-party databases to Oracle Database tables generated by the migration. This pane includes options that can be used for online data migration for all supported third-party databases, and for offline data migration for MySQL, SQL Server, and Sybase Adaptive Server.
Oracle Representation for Zero Length String: The value to which Oracle converts zero-length strings in the source data. Can be a space (' ') or a null value (NULL). Specific notes:
-
For Microsoft Access offline migrations, a null value and a space are considered the same.
-
For Sybase offline migrations, '' is considered the same as a space (' ').
-
For MySQL offline migrations, a null value is exported as 'NULL', which is handled as type VARCHAR2. You can specify another escape character by using the --fields-escaped-by option with the mysqldump command (for example, specifying
\Nfor null or\\for \). For information about the mysqldump command, see Section 2.2.8.1.3, "Creating Data Files From MySQL".For MySQL offline migrations, the data is exported to a file named table-name.txt; so if you are moving data from two or more tables with the same name but in different schemas, rename files as needed so that they are all unique, and modify the SQL*Loader .ctl file accordingly.
Online: The online data move options determine the results of files created when you click Migration, then Migrate Data.
Number of Parallel Data Move Streams (online data moves): The number of internal connections created for simultaneous movement of data from the source database to the Oracle tables. Higher values may shorten the total time required, but will use more database resources during that time.
Number of Rows to Commit After (online data moves): During the data move operation, Oracle pauses to perform an automatic internal commit operation after each number of rows that you specify are moved from the source database to Oracle tables.
Lower values will cause a successful move operation to take more time; but if a failure occurs, it is likely that more source records will exist in the Oracle tables and that if the move operation is resumed, fewer source records will need to be moved. Higher values will cause a successful move operation to take less time; but if a failure occurs, it is likely that fewer source records will exist in the Oracle tables and that is the move operation is resumed, more source records will need to be moved.
Offline: The offline data move options determine the results of files created, such as when you click Tools, then Migration, then Create Database Capture Scripts.
End of Column Delimiter (offline data moves): String to indicate end of column.
End of Row Delimiter (offline data moves): String to indicate end of row.
Generic Date Mask (offline data moves): Format mask for dates, unless overridden by user-defined custom preferences.
Generic Timestamp Mask (offline data moves): Format mask for timestamps, unless overridden by user-defined custom preferences.
User-Defined Custom Preferences by Source Type (offline data moves): Lets you specify, for one or more source data types, a custom mapping for the function and format mask. Add one row for each mapping. For example, the following rows specify the Source Type, Function, and Mask for custom mappings for the Sybase data types datetime, smalldatetime, and time:
datetime TO_TIMESTAMP mon dd yyyy hh:mi:ss:ff3am smalldatetime TO_DATE Mon dd yyyy hh:miam time TO_TIMESTAMP hh:mi:ss:ff3am
The Generation Options pane contains options that are used when generating .sql script files for creating migrated database objects in the target schema.
One single file or A file per object: Determines how many files are created and their relative sizes. Having more files created might be less convenient, but may allow more flexibility with complex migration scenarios.
Generate Comments: Generates comments in the Oracle SQL statements.
Generate Controlling Script: Generates a "master" script for running all the required files.
Least Privilege Schema Migration: For migrating schema objects in a converted model to Oracle, causes CREATE USER, GRANT, and CONNECT statements not to be generated in the output scripts. You must then ensure that the scripts are run using a connection with sufficient privileges. You can select this option if the database user and connection that you want to use to run the scripts already exist, or if you plan to create them.
Generate Data Move User: For data move operations, creates an additional database user with extra privileges to perform the operation. It is recommended that you delete this user after the operation. This option is provided for convenience, and is suggested unless you want to perform least privilege migrations or unless you want to grant privileges manually to a user for the data move operations. This option is especially recommended for multischema migrations, such as when not all tables belong to a single user.
Generate Failed Objects: Causes objects that failed to be converted to be included in the generation script, so that you can make any desired changes and then run the script. If this option is not checked, objects that failed to be converted are not included in the generation script.
Generate Stored Procedure for Migrate Blobs Offline: Causes a stored procedure named CLOBtoBLOB_sqldeveloper (with execute access granted to public) to be created if the schema contains a BLOB (binary large object); this procedure is automatically called if you perform an offline capture. If this option is not checked, you will need to use the manual workaround described in Section 2.2.8.1.4, "Populating the Destination Database Using the Data Files". (After the offline capture, you can delete the CLOBtoBLOB_sqldeveloper procedure or remove execute access from public.)
Generate Separate Emulation User: Causes a separate database user named EMULATION to be created. The emulation package is created in the new EMULATION schema and is referenced by all other migrated users. If this option is not checked, no separate EMULATION user is created, and the emulation package is created within each migrated user. Generating a separate emulation user is usually the best practice because the emulation package is defined in one place, rather than having multiple copies of it. However, if you prefer each migrated user to be standalone and not need to reference anything from another user, then uncheck this option.
(Sybase) To Index-Organized Tables: Controls whether Sybase clustered unique constraints or clustered primary keys are converted to Oracle index-organized tables. NONE causes neither to be converted to index-organized tables (they are converted to Oracle unique constraints and primary keys, respectively). From Clustered Unique Constraints converts each clustered constraint into a primary key and creates an index-organized table if there is no primary key already. From Clustered Primary Keys creates an index-organized table if the primary key is clustered (the Sybase default).
The Identifier Options pane contains options that apply to object identifiers during migrations.
Prepended to All Identifier Names (Microsoft Access, Microsoft SQL Server, and Sybase Adaptive Server migrations only): A string to be added at the beginning of the name of migrated objects. For example, if you specify the string as XYZ_, and if a source table is named EMPLOYEES, the migrated table will be named XYZ_EMPLOYEES. (Be aware of any object name length restrictions if you use this option.)
Is Quoted Identifier On (Microsoft SQL Server and Sybase Adaptive Server migrations only): If this option is enabled, quotation marks (double-quotes) can be used to refer to identifiers (for example, SELECT "Col 1" from "Table 1"); if this option is not enabled, quotation marks identify string literals. Important: The setting of this option must match the setting in the source database to be migrated, as explained in Section 2.2.4.2, "Before Migrating From Microsoft SQL Server or Sybase Adaptive Server".
The Translators pane contains options that relate to conversion of stored procedures and functions from their source database format to Oracle format. (These options apply only to migrations from Microsoft Access, Microsoft SQL Server, and Sybase Adaptive Server.)
Default Source Date Format: Default date format mask to be used when casting string literals to dates in stored procedures and functions.
Variable Name Prefix: String to be used as the prefix in the names of resulting variables.
In Parameter Prefix: String to be used as the prefix in the names of resulting input parameters.
Query Assignment Translation: Option to determine what is generated for a query assignment: only the assignment, assignment with exception handling logic, or assignment using a cursor LOOP ... END LOOP structure to fetch each row of the query into variables.
Display AST: If this option is checked, the abstract syntax tree (AST) is displayed in the Source Tree pane of the Translation Scratch Editor window (described in Section 2.3.5) if you perform a translation.
Generate Compound Triggers: If this option is checked, then depending on the source code, SQL Developer can convert a Sybase or SQL Server trigger to an Oracle compound trigger, which uses two temporary tables to replicate the inserted and deleted tables in Sybase and SQL Server. In such cases, this can enable the conversion of logic that cannot otherwise be converted.
1.17.12 Mouseover Popups
The Mouseover Popups pane specifies text to be displayed on hover-related mouse actions over relevant object names.
Popup Name: The type of information to be displayed: Data Values (value of the item under the mouse pointer, such as the value of a variable during a debugging operation), Documentation (documentation on the item under the mouse pointer, such as Javadoc on a method call), or Source (source code of the item under the mouse pointer, such as the source code of a method).
Activate Via: Use action with the mouse cursor to activate the display: Hover, or Hover while pressing one or two specified modifier keys.
Description: Description of the associated Popup Name entry.
Smart Enabled: If this option is checked, then the text for the relevant type of information is displayed if Smart Popup is also checked.
Smart Popup: If this option is checked, the relevant text for the first smart-enabled popup is displayed for the item under the mouse pointer.
1.17.13 Shortcut Keys (Accelerator Keys)
The Shortcut Keys pane enables you to view and customize the shortcut key (also called accelerator key) mappings for SQL Developer.
Hide Unmapped Commands: If this option is checked, only shortcut keys with mappings are displayed.
More Actions:
-
Export: Exports the shortcut key definitions to an XML file.
-
Import: Imports the shortcut key definitions from a previously exported XML file.
-
Load Keyboard Scheme: Drops all current shortcut key mappings and sets the mappings in the specified scheme. (This option was called Load Preset in previous releases.) If you have made changes to the mappings and want to restore the default settings, select Default.
Category: Select All or a specific category (Code Editor, Database, Debug, Edit, and so on), to control which actions are displayed.
Command: The actions for the selected category. When you select an action, any existing shortcut key mappings are displayed.
Shortcut: Any existing key mappings for the selected action. To remove an existing key mapping, select it and click Remove.
New Shortcut: The new shortcut key to be associated with the action. Press and hold the desired modifier key, then press the other key. For example, to associate Ctrl+J with an action, press and hold the Ctrl key, then press the j key. If any actions are currently associated with that shortcut key, they are listed in the Current Assignment box.
Conflicts: A read-only display of the current action, if any, that is mapped to the shortcut key that you specified in the New Shortcut box.
1.17.14 Unit Test Parameters
Unit Test Parameters preferences affect the behavior of the SQL Developer unit testing feature (described in Chapter 3).
Configuration set to use for lookups: Lookup category to be used for automatically generating test implementations when you create a unit test, as explained in Section 3.6.2. The list includes the default category and any user-added categories (see the Unit Testing: Add Category dialog box).
1.17.15 Versioning
Versioning preferences affect the behavior of the version control and management systems that you can use with SQL Developer. You can specify preferences for CVS and Subversion. For information about using versioning with SQL Developer, see Section 1.10, "Using Versioning".
The CVS pane specifies options for use with CVS (Concurrent Versions System).
CVS Client: Internal to Oracle SQL Developer (installed with SQL Developer) or External Executable (separately installed CVS client, for which you must specify the name or path).
-
Name on System Path: Name of the CVS server executable. The default (cvs) is correct for most installations. This option assumes that the name of the CVS server executable is on the system path.
-
Path from Environment: Location of the CVS server executable, especially if there is more than one on the system path. The selection area will list all instances of the CVS server executable known to the local system. You may have more than one version of CVS installed: this option lets you specify which of them to use with SQL Developer.
-
Other Path: Location of the CVS server executable, if it is not on the system path at all.
Run CVS in Edit/Watch Mode: If this option is enabled, you coordinate access to files by declaring an editor for them through CVS, after which they may be modified. Only those files that you check out after changing this preference will be affected. If this option is disabled, the edit and watch commands on the Versioning menu are disabled.
State Overlay Scheme: Scheme for the icons displayed alongside folder and file names in the navigators to indicate their versioning status.
The CVS: Commands pane sets options for CVS source control. Some options are not available when using the internal CVS client.
Enable Advanced Controls: If this option is enabled, advanced CVS controls are shown in dialog boxes. If you find that you use only basic CVS features, you might wish to use SQL Developer without advanced controls, to reduce complexity and save screen space.
Global Options: Run Quietly: If this option is enabled, informational messages are suppressed.
Global Options: Do not Log Commands: If this option is enabled, CVS commands are not logged in the repository command history.
Global Options: Encrypt: If this option is enabled, all communication between the client and the server is encrypted. Encryption support is not available in CVS by default; it must be enabled using a special configuration option when you build CVS.
Set Compression Level (z): If this option is enabled, you can set the compression level for files sent between client and server. The level can be set from Minimum (high speed, low compression) to Maximum (low speed, high compression).
Keyword Substitution Mode: CVS uses keyword substitution modes to insert revision information into files when they are checked out or updated. This option controls the mode of replacement for keyword substitution in versioned files:
-
Automatic: The default, recommended option.
-
Keyword-Only Mode: Generates only keyword names in keyword strings and omits their values. This option is useful for disregarding differences due to keyword substitution when comparing different revisions of a file.
-
Keyword-Value Mode: Generates keyword strings using the default form.
-
Keyword-Value-Locker Mode: Like the keyword-value mode, except that the name of the locker is always inserted if the given revision is currently locked.
-
Old-Contents Mode: Generates the old keyword string, present in the working file just before it was checked in.
-
Value-Only Mode: Generates only keyword values for keyword strings. This can help generate files in programming languages where it is hard to strip keyword delimiters from a string. However, further keyword substitution cannot be performed once the keyword names are removed, so this option should be used with care.
On Commit: Use Comment Templates: If this option is enabled, your commit comments will be entered through template forms. The forms are set up by the CVS system administrator. There may be different forms for different circumstances and installations, and it may be that none of them are suitable for your commit comments. In this case, this preference lets you disable the use of all forms.
On Commit: Automatically Add Files: If this option is enabled, local files are added to the CVS repository whenever you perform a commit action.
Create Backup Files on Remove: If this option is enabled, backup copies are made of files that are removed through actions of the source control system.
The CVS: General pane specifies environment settings and the operation timeout.
Use Navigator State Overlay Icons: If this option is enabled, state overlay icons are used. State overlay icons are small symbols associated with object names in the navigators. They indicate the state of version-controlled files (for example, "up to date").
Use Navigator State Overlay Labels: If this option is enabled, state overlay labels are used. State overlay labels are tooltips associated with object names in the navigators.
Automatically Make Files Editable: If this option is enabled, an editor is automatically used on a data file when you start to change it. (If you edit a file unintentionally, immediately use Versioning, then Unedit to revert.)
Operation Timeout: Maximum time allowed for CVS operations to complete.
Versioning: CVS: Navigator Labels
The CVS: Navigator Labels pane specifies formatting for CVS information appears on navigator nodes and tool tips. For a full explanation of keyword substitution modes, see the CVS documentation.
Versioning: CVS: Version Tools
The CVS: Version Tools pane specifies options for the pending changes window and the merge editor.
Use Outgoing Changes Commit Dialog: Enables you to make optimum use of limited screen space when the Pending Changes window is open. You can save screen space by not showing the Comments area of the Pending Changes window, but you might still want to add comments before a commit action. You can choose the circumstances under which the Commit dialog is opened: always, only when the Comments area of the Pending Changes window is hidden, or never.
Incoming Changes Timer Interval: The frequency at which the change status of files is checked.
Merge Editor: Specifies whether files are merged locally or at the server.
The Subversion pane specifies the Subversion client to use with SQL Developer.
Versioning: Subversion: Comment Templates
The Subversion: Comment Templates pane specifies templates for comments to be used with commit operations. For example, a template might contain text like the following:
Problem Description (with bug ID if any): Fix Description:
You can add, edit, and remove comment templates, and you can export templates to an XML file or import templates that had previously been exported.
Versioning: Subversion: General
The Subversion: General pane specifies environment settings and the operation timeout.
Use Navigator State Overlay Icons: If this option is enabled, state overlay icons are used. State overlay icons are small symbols associated with object names in the navigators. They indicate the state of version-controlled files (for example, "up to date").
Use Navigator State Overlay Labels: If this option is enabled, state overlay labels are used. State overlay labels are tooltips associated with object names in the navigators.
Automatically Make Files Editable: If this option is enabled, an editor is automatically used on a data file when you start to change it. (If you edit a file unintentionally, immediately use Versioning, then Unedit to revert.)
Operation Timeout: Maximum time allowed for Subversion operations to complete.
Edit Subversion Configuration File: To modify the Subversion file directly, click Edit "server".
Versioning: Subversion: Version Tools
The Subversion: Version Tools pane specifies options for the pending changes window and the merge editor.
Use Outgoing Changes Commit Dialog: Enables you to make optimum use of limited screen space when the Pending Changes window is open. You can save screen space by not showing the Comments area of the Pending Changes window, but you might still want to add comments before a commit action. You can choose the circumstances under which the Commit dialog is opened: always, only when the Comments area of the Pending Changes window is hidden, or never.
Incoming Changes Timer Interval: The frequency at which the change status of files is checked.
Merge Editor: Specifies whether files are merged locally or at the server.
1.17.16 Web Browser and Proxy
The Web Browser and Proxy pane settings are relevant only when you use the Check for Updates feature (click Help, then Check for Updates), and only if your system is behind a firewall.
Browser Command Line: To specify a Web browser other than your default browser, specify the executable file to start that browser. To use your default browser, leave this field blank.
Use HTTP Proxy Server: Check your Web browser options or preferences for the appropriate values for these fields.
1.17.17 XML Schemas
The XML Schemas pane lets you view all the currently registered XML schemas, add new schemas to support additional namespaces and elements, remove existing schemas, and unload schemas from memory.
SQL Developer Schemas for XML Editing: Lists the names and locations of the pre-registered schemas currently available when editing XML documents and the file extension with which each schema is associated.
User Schemas for XML Editing: Lists the names and locations of the schemas you have added since installing SQL Developer that are available when editing XML documents, and the file extension with which each schema is associated.
Add: Displays a dialog box for specify a new schema to add to the list of User Schemas.
Remove: Removes the selected schema from the list.
Edit: Displays a dialog box in which you can modify a previously registered schema.
For adding or editing, you can specify the location (file system or URL) and the file extension to register the schema for a specific file type.
Clear Cache: Unloads all currently loaded schemas from memory when you modify a schema. Any needed schemas will then be reloaded, including the modified schema.
1.18 Location of User-Related Information
SQL Developer stores user-related information in several places, with the specific location depending on the operating system and certain environment specifications. User-related information includes user-defined reports, user-defined snippets, SQL Worksheet history, code templates, and SQL Developer user preferences. In most cases, your user-related information is stored outside the SQL Developer installation directory hierarchy, so that it is preserved if you delete that directory and install a new version.
The user-related information is stored in or under the IDE_USER_DIR environment variable location, if defined; otherwise as indicated in the following table, which shows the typical default locations (under a directory or in a file) for specific types of resources on different operating systems. (Note the period in the name of any directory named .sqldeveloper.)
Table 1-1 Default Locations for User-Related Information
| Resource Type | System (Windows, Linux, or Mac OS X) |
|---|---|
|
User-defined reports |
Windows: C:\Documents and Settings\<user-name>\Application Data\SQL Developer\UserReports.xml Linux or Mac OS X: ~/.sqldeveloper/UserReports.xml |
|
User-defined snippets |
Windows: C:\Documents and Settings\<user-name>\Application Data\SQL Developer\UserSnippets.xml Linux: ~/.sqldeveloper/UserSnippets.xml Mac OS X: /Users/<Your user>/Library/Application Support/ SQLDeveloper/UserSnippets.xml |
|
SQL history |
Windows: C:\Documents and Settings\<user-name>\Application Data\SQL Developer\SqlHistory.xml Linux: ~/.sqldeveloper/SqlHistory.xml Mac OS X: /Users/<Your user>/Library/Application Support/ SQLDeveloper/ SqlHistory.xml |
|
Code templates |
Windows: C:\Documents and Settings\<user-name>\Application Data\SQL Developer\ CodeTemplate.xml Linux: ~/.sqldeveloper/CodeTemplate.xml Mac OS X: /Users/<Your user>/Library/Application Support/ SQLDeveloper/ CodeTemplate.xml |
|
SQL Developer user preferences |
Windows: C:\Documents and Settings\<user-name>\Application Data\SQL Developer\systemn.n.n.n.n Linux or Mac OS X: ~/.sqldeveloper/systemn.n.n.n.n |
If you want to prevent other users from accessing your user-specific SQL Developer information, you must ensure that the appropriate permissions are set on the directory where that information is stored or on a directory above it in the path hierarchy. For example, on a Windows system you may want to ensure that the SQL Developer folder and the \<user-name>\Application Data\SQL Developer folder under Documents and Settings are not shareable; and on a Linux or Mac OS X system you may want to ensure that the ~/.sqldeveloper directory is not world-readable.
1.19 Data Modeler in SQL Developer
SQL Developer includes an integrated version of SQL Developer Data Modeler. You can create, open, import, and save a database design, and you can create, modify, and delete Data Modeler objects.
To display Data Modeler in a pane, click Tools, then Data Modeler. After that, the Data Modeler menu under Tools includes additional commands, for example, enabling you to specify design rules and general options (user preferences).
1.20 Oracle TimesTen In-Memory Database Support
When you connect to an Oracle TimesTen In-Memory Database, the available types of objects that you can work with include several that apply to an Oracle Database, and the following that are specific to TimesTen:
-
Cache groups
-
Replication schemes
To create a connection to a TimesTen database, use the TimesTen tab in the Create/Edit/Select Database Connection dialog box.
For additional usage and reference information, see the following:
-
Oracle SQL Developer TimesTen In-Memory Database Support User's Guide for information about using TimesTen-specific features in SQL Developer
-
http://www.oracle.com/technetwork/database/timesten/timesten-sqldeveloper-overview-158942.htmlfor an overview SQL Developer support for Oracle TimesTen In-Memory Database and Oracle In-Memory Database Cache, and links to related information -
http://www.oracle.com/technetwork/database/timesten/for links to TimesTen documentation, white papers, tutorials, case studies, and other resources
1.21 Using the Help
SQL Developer provides a Help menu and context-sensitive help (click the Help button or press the F1 key in certain contexts). Much of the help content is also in Oracle SQL Developer User's Guide, which is in the SQL Developer Documentation Library.
Help is displayed in the Help Center window, which has a Contents pane on the left, a Search box at the top right, and a help topic display pane under the Search box. You can move the horizontal divider to change the pane sizes (for example, to make the Contents pane narrower, to allow more room for the help topic content). You can also resize and reposition the Help Center window.
For Search, you can click the icon (binoculars) to see search options: case sensitive (Match case) or case insensitive; and whether to match topics based on all specified words, any specified words, or a Boolean expression.
The Keep on Top button toggles whether the Help Center window is kept on top of the display when you switch focus (click) back in the SQL Developer window.
To print a help topic, display it in the topic display pane and click the Print icon at the top of the pane.
To increase or decrease the size of the font in the help topic viewer, click the Change Font Size (A) icon in the Help Center topic display area toolbar, then select Increase Font Size of Decrease Font Size. This setting is preserved only for the duration of the current help pane or window; therefore, you may want to keep the Help Center window open after setting the help text font to your preferred size.
1.22 Tip of the Day
For English locales, you can display a random suggestion for effective use of SQL Developer by clicking Help, then Tip of the Day. The tip window is also displayed automatically when you start SQL Developer, unless you disable the Show tips at startup option in the tip window.
For convenience, this section lists the available tip topics. (There is no special order or organization for these topics.)
1.22.1 SQL History Shortcuts
Using Ctrl+up-arrow or Ctrl+down-arrow in the SQL Worksheet replaces the contents of the SQL Worksheet with lines of code from the SQL History. You can step up and down through the SQL History.
To view the SQL History in the SQL Worksheet, press F8 or click View, then History.
1.22.2 Unshared Worksheets
To create a separate unshared worksheet for a connection, press Ctrl+Shift+N.
1.22.3 SQL Worksheet Bookmarks
If you have many SQL Worksheets open, you can assign a bookmark number to each and then easily navigate among them. To create a bookmark, click the worksheet's tab and press Alt+Shift+number (for example, Alt+Shift+1). The number now appears as a small superscript in the tab.
To switch to a worksheet that has a bookmark, press Alt+number (for example, Alt+1).
1.22.5 Formatted Display of SQL Trace (.trc) Files
To see a formatted display of a SQL Trace file, drag the *.trc file onto the area above the SQL Worksheet (or open it by clicking File, then Open).
1.22.6 Keyboard Navigation: Alt + Page Down/Up to Move Among Tabs
You can press Alt + Page Down to move to the next tab, and Alt + Page Up to move to the previous tab, in a tabbed editor or display window, such as with the tabs for Table and View grid displays (Columns, Data, and so on).
1.22.7 Folders for Organizing Connections
You can group connections into folders. Right-click a connection name and select Add to Folder. See the help topic Using Folders to Group Connections.
1.22.8 Third-Party Databases and SQL Developer
In addition to Oracle databases, SQL Developer works with several third-party databases, such as MySQL, Sybase, Microsoft Access, Microsoft SQL Server, and IBM DB2.
For information about connecting to third-party databases, or about migrating a third-party database to Oracle, see the help topics Database Connections and SQL Developer: Migrating Third-Party Databases.
1.22.9 Debugger Ports and Firewalls
The SQL Debugger by default uses ports 40000 to 49000. If you cannot get the debugger to start, make sure that you are not being blocked by a firewall on these ports.
1.22.10 Viewing Multiple Tables
You can have tabs open for more than one table. Just click the Freeze View button (it looks like a push pin) when you are viewing a table; and when you click to display another table, the tab for the first table will remain open.
1.22.11 Customizing SQL Developer Appearance
You can use the Look and Feel (platform) and Theme (color scheme) options under Environment preferences to customize the appearance of the SQL Developer window.
1.22.12 Maximizing Tab Panes
You can often maximize a display pane (such as a SQL Worksheet) by double-clicking its tab.
To restore the SQL Developer window to its original display, double-click the tab again.
1.22.13 Default Path for Running Scripts
You can set a default path for SQL Developer to use if you run a SQL script file (for example, @my_script.sql) without specifying the path. See the Database: Worksheet Parameters preferences.
1.22.14 Shutting Down and Restarting the Database
A user with SYSDBA privileges can shut down and restart the database from within SQL Developer, if a listener is running with a static listener configured for the database. Right-click the connection name and select Manage Database.
1.22.15 Feature Requests
Do you have a SQL Developer feature request? Log it at the Oracle Technology Network: go to http://sqldeveloper.oracle.com and select the Feature Requests link.
1.22.16 Discussion Forums
Would you like to share and search information, questions, and comments about SQL Developer and Data Miner? Visit our discussion forums:
SQL Developer: http://forums.oracle.com/forums/forum.jspa?forumID=260
Data Mining: http://forums.oracle.com/forums/forum.jspa?forumID=55
1.22.17 Help Text Font Size
You can use a button in the Help Center window display pane (right side) to change the help text display size: click Increase Font Size or Decrease Font Size (repeatedly if necessary) until the size is right for you. (If the text appears blurry, try decreasing the size.)
Suggestion: Don't close the Help Center window, because font size changes will be in effect only for as long as the current window is open. Consider using the Keep on Top toggle in the Help Center window.
1.22.18 Procedure and Function Signatures
To see the signature (format, including parameters) of a procedure or function in a PL/SQL package, expand the package (under Packages in the Connections navigator), and place the mouse pointer over the procedure or function name.
1.22.19 Type-Ahead in Navigators
Many navigators that use a tree support type-ahead to find and open an object. For example, expand the Tables node under a connection and start typing a table name.
Note: This works only on nodes when the child nodes are visible. For example, if the Tables node is not expanded to display the individual tables, typing the name of a table will not find and open it.
1.22.20 Extended Paste
If you have cut or copied multiple things to the clipboard and want to paste something other than the most recent copy, you can use extended paste to display a dialog box to select which one to paste. Press Ctrl+Shift+V; or click Edit, then Extended Paste.
1.22.21 Closing Tabbed Windows Using the Mouse Wheel
To close a tabbed editor or display window, click its tab with the mouse wheel.
1.22.22 Go to Last Edit Location
If you have made edits in several editing windows and are now in a different window, and if you want to return to where you made the last edit, press Ctrl+Shift+Backspace; or click Navigate, then Go to Last Edit.
1.22.23 Closing Tabbed Windows Using the Context Menu
To close a tabbed editor or display window, right-click and select Close from the context menu.
1.22.24 List of All Open Windows
To see a list of all open tabbed windows, click the small button with the drop-down arrow, located to the right of the tabs and over the tabbed window vertical scroll bar.
To go to one of the listed windows, select it from the drop-down list.
1.22.25 Go to Subprogram Implementation from Package Window
In the window for a package definition, you can press Ctrl+click on a procedure or function name to perform the Open Declaration command, which opens the procedure or function implementation (body specification) in a new window.
1.22.26 Select Multiple Table or Column Names in Completion Insight
When entering or editing a SELECT query, you can select multiple tables and columns from the completion insight popup window. Aliases are provided for column and table names if the Generate Column/Table Aliases Automatically preference for Code Editor: Completion Insight is enabled.
1.22.27 Startup Time and Automatic Check for Updates
If the startup time for SQL Developer seems too slow, consider disabling the Automatically Check for Updates option (Tools, Preferences, Extensions).
If this option is enabled, it can increase the startup time. You can manually check for updates by clicking Help, then Check for Updates.
1.23 For More Information
For more information about SQL Developer and related topics, you may find the following resources helpful:
-
SQL Developer Start Page, which contains links for tutorials and OBE (Oracle By Example) lessons, online demonstrations, documentation, and other resources. (If the Start Page tab is not visible, click Help, then Start Page).
-
SQL Developer home page (OTN), which includes links for downloads, white papers, tutorials, viewlets (demonstrations), blogs, a discussion forum, and other sources of information:
http://www.oracle.com/technetwork/developer-tools/sql-developer/ -
PL/SQL page on OTN:
http://www.oracle.com/technetwork/database/features/plsql/ -
Oracle Accessibility site:
http://www.oracle.com/accessibility/ -
Oracle Corporate site:
http://www.oracle.com/