Overview of Value Chain Planning Collections
This chapter covers the following topics:
Overview
Oracle Value Chain Planning (VCP) has a component architecture that allows a single instance of Oracle VCP to plan one or more EBS source instances. The EBS source instances can be a mixture of releases. The Oracle VCP destination instance (referred to as the planning server) can sit on the same instance as one of the EBS source instances, or be a separate instance altogether. In either case (even if the planning server shares an instance with the EBS source instance to be planned), data to be planned is brought from the EBS source instance(s) to the planning server via a process called Planning Data Collection.
This section describes the architecture used in the collection of planning data from multiple operational sources into Oracle VCP. These sources could be different versions/instances of Oracle applications or other legacy systems. Oracle VCP uses a data store based on the planning data model that is exposed through interface tables. The data is pulled from the designated data sources into its data store; Collections are then responsible for synchronization as changes are made to the data sources. The configurability of the collections is enabled through a pull program based on AOL concurrent program architecture. Thus, for example, different business objects can be collected at different frequencies. Supplies and demands, which change frequently, can be collected frequently. Routings and resources, which change relatively less often, can be collected less frequently.
When collecting from an EBS source instance, the data collection process is performed in two steps: a data pull from the execution module tables on the EBS source instance to the staging tables and a load from the staging tables to Operational Data Store (ODS) load on the APS Planning Destination instance. The collection process lets you collect across several Oracle application versions. It supports several configurations. Types of data collection processes supported:
-
Standard: Using the standard collections process, you can manually run three types of data collection methods including a complete refresh, a net change refresh, or a targeted refresh on specific business entities.
-
Continuous: The continuous collections process is an automated process of data collection that efficiently synchronizes the data on the planning server by looking up the sources. If you opt for continuous collections, the system automatically determines whether to perform a net change collection of the entity or a targeted collection of the entity on an entity-by-entity basis. The continuous collections process collects data from the sources with the least user intervention. The Continuous Collections concurrent program performs continuous collections.
-
ATP: Used by customers using only simple ATP for Order Management in a centralized instance, and not using any other Value Chain Planning applications such as Global Order Promising (GOP). The ATP data collection is a simplified version of the Planning Data Collection with preset program parameters to collect only the data required for ATP based on collected data. Running ATP data collections in complete refresh mode removes the data required for Planning applications. Do NOT use ATP Data Collections when you are using any of the VCP Planning Applications.
-
Legacy: The legacy collections process provides an open framework for consulting and system integrators to bring data from legacy systems into Oracle VCP. You can upload data by batch upload of flat files. This is achieved in part by extending the interface table capabilities. A preprocessing engine validates the incoming data from a legacy application and ensures that referential integrity is maintained. Business objects can be imported into VCP using flat files. The legacy collection process can be launched using a form, or through a self-service process.
Collection Diagrams
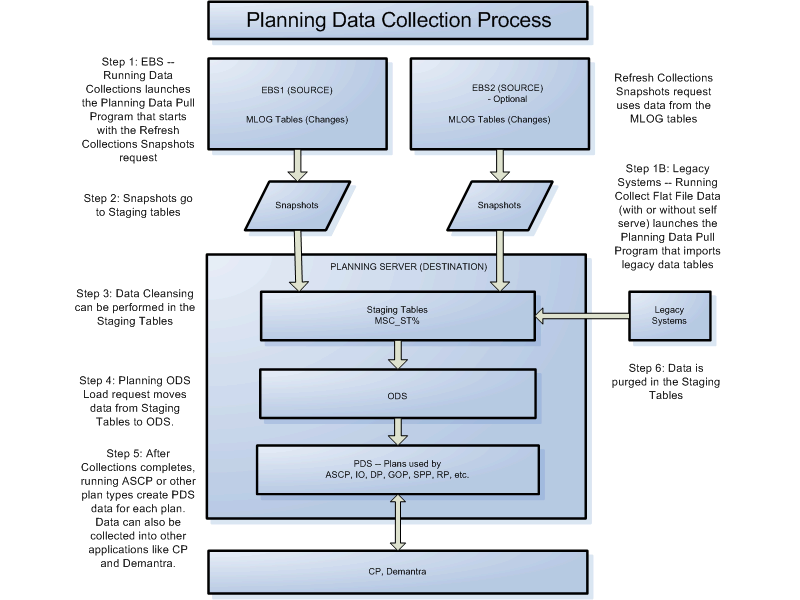
Important: ATP based on collected data uses the ODS data. ATP based on planning data (GOP) requires that you run a plan to generate PDS data.
More details about the steps:
Step IB: For Legacy Collections - Collect Flat File data inserts data into the MSC_ST% staging tables the ODS and then launches the pre-processor that validates the data and reports any errors. The pre-processor then launches the ODS Load.
Step 2: After refreshing the snapshots, the Planning Data Pull resumes and uses snapshots and MRP_AP% views to load data into the staging tables.
Step 3: After the Data Pull completes, ODS Load is launched as first calls the custom hook MSC_CL_CLEANSE which can be used to manipulate data for business purposes. See My Oracle Support Note 976328.1 for more information.
Step 4: ODS data is stored in tables with PLAN_ID=-1 and can be viewed in the Collections Workbench.
Step 5: After ODS Load completes, Purge Staging Tables launches. If set up to use Collaborative Planning, the Collaboration ODS Load is launched.
Step 6: After Collections completes, then ASCP or other plan types are launched to create PDS data which is stored in tables with PLAN_ID>0 and can be viewed in the Planner Workbench. The collected data can also be used on other applications like Demantra, Collaborative Planning, Production Scheduling, etc.
Process
There are three key stages to the Data Collections Process:
-
Refresh Collection Snapshots
-
Planning Data Pull
-
Planning ODS Load
Refresh Collections Snapshots
Initially, if the setup profile MSC: Source Setup Required = Yes, then the Refresh Collections Snapshots process launches Setup Requests that create all the objects used by Data Collections in the EBS source applications. When deployed in a distributed installation, these processes are launched on the EBS source instance. When Setup Requests complete successfully, then the profile is set to No by the snapshot process and it continues with standard process flow to refresh the snapshots. In a centralized/single instance installation, all requests are launched on the same instance.
After a complete refresh of a snapshot, when data is subsequently inserted, updated, or deleted in the master table, these changes are inserted into the snapshot log tables (MLOG$_ tables). A snapshot refresh updates the snapshot table with all of the transactions that were logged in the MLOG$ table. This makes the transaction data available for the Planning Data Pull.
The Planning Data Pull program has a list of parameters (entities) that correspond to one or more of these snapshots. When the Planning Data Pull program is run, it spawns the Refresh Collection Snapshots (RCS) program. Based on the parameters passed to the Planning Data Pull program, the Refresh Collection Snapshots program begins refreshing the snapshots located on the source instance. There are two ways to refresh a snapshot during data collections:
-
Fast refresh (most cases): Refreshes the snapshot based on the contents of the MLOG$_table.
-
Complete Refresh: The snapshot is updated by getting all data directly from the application module tables.
When launching Refresh Collection Snapshots as a standalone program, you can also choose type - Automatic Refresh. This truncates the snapshot log when you set the parameter Threshold = 0 and performs a complete refresh of the snapshots. The truncation of the MLOG$ helps with performance and space allocation for the RDBMS.
Planning Data Pull
Once the data in the snapshot tables is refreshed, the Planning Data Pull code on the VCP destination instance "reads" the data from the snapshots, filtered by views on the EBS source instance, into the MSC_ST% staging tables on the VCP destination instance. The Planning Data Pull process spawns workers to help manage the many tasks (40+) that gather the data into the staging tables.
Planning ODS Load
The Planning ODS Load process starts to move the data from the MSC_ST Staging tables to the MSC planning tables.
The Planning ODS Load performs key transformations of critical data into unique keys for the VCP applications. For example, since VCP can collect from multiple instances, the INVENTORY_ITEM_ID from one instance will likely represent a different item than on another instance. Since the planning process needs one unified unique set of INVENTORY_ITEM_IDs, local ID tables are used to track the instance and INVENTORY_ITEM_ID from a given source instance and the corresponding unique value that is used throughout the rest of the planning process. This happens for item-related entities and for trading partner-related entities (customers, suppliers, organizations). The source instance key values are stored in columns with the prefix SR_. For example, SR_INVENTORY_ITEM_ID in MSC_SYSTEM_ITEMS.
Then, the Planning ODS launches workers to handle the many different load tasks that move data from the MSC_ST% staging tables to the base MSC tables. The Alter Temporary ODS Table concurrent program is launched after the Planning ODS Load workers are finished.
There are three collections methods that can be used to update the ODS data:
-
Complete: Replaces all data for the entities except items and trading partners. Items are replaced, but item name is kept in the Key ID tables. Trading partners and partner sites can be used across multiple instances are never removed.
-
Target: Collects one or more entities in complete refresh mode.
-
Net Change: Picks up only the changes to the transactional entities like WIP, PO, OM and some setup entities like items, BOM, etc. See Data Changes That Can Be Collected in Net Change Mode for more information about the entities that can be collected in Net Change mode.
ODS Loads creates TEMP tables, then copies data from MSC_ST% staging tables into the TEMP tables, then uses Exchange Partition technology to flip this temporary table into the partitioned table.
For example, if your instance code is TST, you can see in the log file where the temp table SYSTEM_ITEMS_TST is created. Data is then moved into the SYSTEMS_ITEMS_TST table from MSC_ST_SYSTEM_ITEMS. The SYSTEM_ITEMS_TST temporary table is exchanged with the partition of MSC_SYSTEM_ITEMS used for collected data. In this example, if the INSTANCE_ID is 2021, the partition name shown is SYSTEM_ITEMS_2021.
Finally, the Planning ODS Load launches the Planning Data Collections - Purge Staging Tables process to remove data from the MSC_ST% staging tables. If the MSC: Configuration profile is set to 'CP' or 'CP & APS', then the Collaboration ODS Load process is launched to populate data for Collaborative Planning.
Collection Example
For example, the Items parameter corresponds with the snapshot MTL_SYS_ITEMS_SN. When a change is made to an item (MTL_SYSTEM_ITEMS_B table) or a new item is created, data is inserted into MLOG$_MTL_SYSTEM_ITEMS_B.
When the Refresh Collection Snapshot runs as a fast refresh, the data in MLOG$_MTL_SYSTEM_ITEMS_B is used to update MTL_SYS_ITEMS_SN and then the data in MLOG$_MTL_SYSTEM_ITEMS_B is deleted. The Data Pull process moves this data via views (MRP_AP_SYS_ITEMS_V and MRP_AP_SYSTEM_ITEMS_V) into the staging table MSC_ST_SYSTEM_ITEMS, then the Planning ODS Load moves the data from the staging table to the base table MSC_SYSTEM_ITEMS.
VCP Collections Terminology
You should be familiar with the following terms before examining the data collections architecture:
Oracle Applications Data Store (ADS): The set of source data tables in each transaction instance that contain data relevant to planning.
Operational Data Store (ODS): The planning data tables in the planning server that act as the destination for the collected data from each of the data sources (both ADS and Legacy).
Planning Data Store (PDS): The outputs of the planning process. The PDS resides in the same data tables as the ODS. PDS data is stored with plan ID > 0 corresponding to the plan_id assigned to that plan. ODS data is stored with plan ID = -1..
Standard Data Collection: The standard data collection process enables you to select the mode of data collection. You can use a complete refresh, a net change (incremental) refresh, or a targeted refresh. Standard data collection consists of the following processes:
-
Planning Data Pull: Collects the data from the ADS and stores the data into the staging tables. This pull program is a registered AOL concurrent program that can be scheduled and launched by a system administrator. If you are using a legacy program, you must write your own pull program.
-
Planning ODS Load: A PL/SQL program which performs the data transformation and moves the data from the staging tables to the ODS. This collection program is a registered AOL concurrent program that can be scheduled and launched by the system administrator.
Continuous Data Collection: The continuous data collection process automates the process of looking up the sources to populate the tables on the planning server. With the least user intervention, the continuous data collection process determines the type of collection to perform on each type of entity. The Continuous Collections concurrent process performs continuous collections.
Entity: During Planning Data Collection, data is collected and processed together from each EBS application as a business entity. Running a Planning Data Collection Request Set involves selecting which entities will be collected and which will not be collected. There are two types of entities: Setup and Transactional. Calendars are a setup entity. While calendar information is stored across a number of related tables, all of the calendar information is collected together as a single business entity. Similarly, Purchase Orders/Purchase Requisitions are an transactional entity that are always collected together.
Collection Workbench: The Collection Workbench is a user interface for viewing data collected over to the planning server from the transaction instances. The functionality here is similar to Planner Workbench functionality. For more information on the Planner Workbench, see Overview of Planner Workbench, Oracle Advanced Supply Chain Planning Implementation and User's Guide.