|
|

|

|

|

|
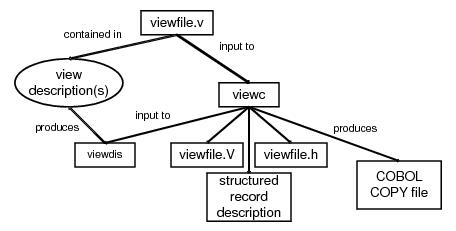
A field identifier (fieldid) is defined (with typedef) as a FLDID (FLDID32 for FML32), and is composed of two parts: a field type and a field number. The number uniquely identifies the field.Field number 0 and the corresponding field identifier 0 are reserved to indicate a bad field identifier (BADFLDID). When FML is used with other software that also uses fields, additional restrictions may be imposed on field numbers.