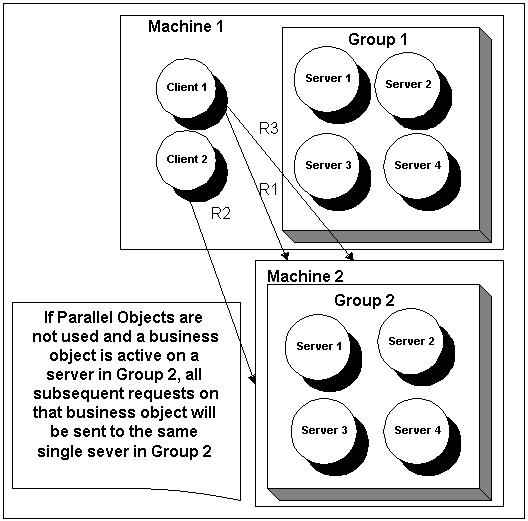
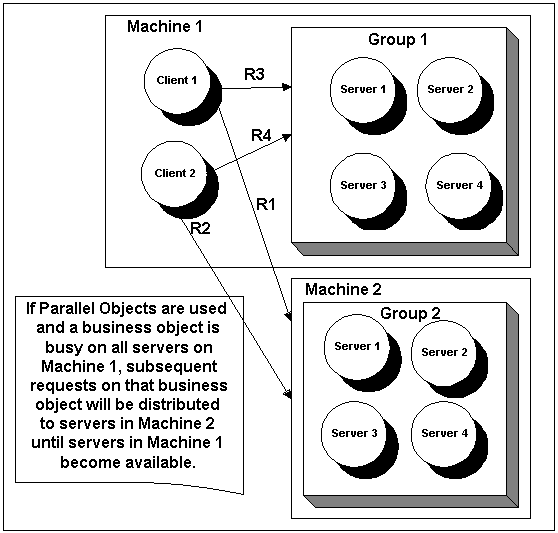
|
|

|

|

|

|
For more detailed information and examples for Oracle Tuxedo CORBA applications, see Chapter 2, “Scaling CORBA Server Applications.”Object state management is a fundamental concern of large-scale client/server systems because it is critical that such systems achieve optimized throughput and response time. For more detailed information about using object state management, see “Using a Stateless Object Model” on page 2‑3 and the technical article Process-Entity Design Pattern.For more information about these models, see “Server Application Concepts” in Creating CORBA Server ApplicationsProcess-bound objects remain in memory beginning when they are first invoked until the server process in which they are running is shut down. A process-bound object can be activated upon a client invocation or explicitly before any client invocation (a preactivated object). Applications can control the deactivation of process-bound objects. In this document, a process-bound object is considered to be a stateful object.By managing object state in a way that is efficient and appropriate for your application, you can maximize your application’s ability to support large numbers of simultaneous client applications that use large numbers of objects. The way that you manage object state depends on the specific characteristics and requirements of your application. For CORBA applications, you manage object state by assigning the method activation policy to these objects, which has the effect of deactivating idle object instances so that machine resources can be allocated to other object instances.