| Oracle® Enterprise Manager Cloud Control管理者ガイド 12c リリース5 (12.1.0.5) B65081-16 |
|


 前 |
 次 |
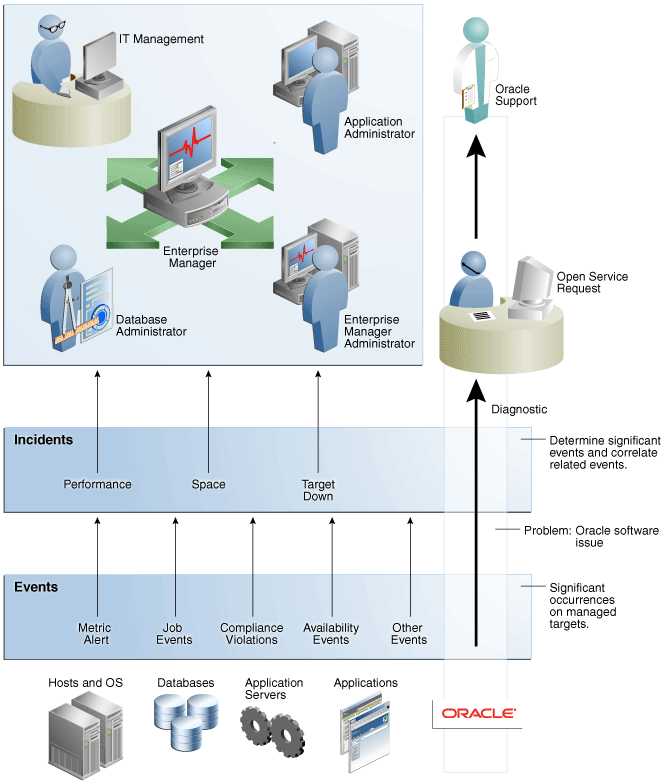
インシデント管理によって、根本的な問題が同じである可能性のある個別のイベントではなく、より広い管理の観点(インシデント)から重要な事項に焦点をあてることで、サービス中断を迅速かつ効率的に監視し解決できます。
| この章の項: | 学習内容: |
|---|---|
| 管理の概念 |
管理対象の環境を管理するための基本的な方法。 |
| インシデント管理環境の設定 |
インシデント管理に使用するEnterprise Managerの主要コンポーネントの設定および構成方法。 |
| インシデントの処理 |
IT操作の問題を追跡および解決するためのインシデント管理の使用方法。 |
| 一般的なタスク | インシデント管理の一般的なタスクを実行する方法を説明するサンプル手順。 |
| 高度なトピック | 特別なインシデント管理操作の実行方法。 |
| Enterprise Manager 10/11gから12cへの移行 |
通知ルールのインシデント・ルールへの移行 |
オラクル社はこの章の説明を補完するために、環境を監視するためのインシデント管理の基本について速習する手段を提供する説明用ビデオを作成しています。
Enterprise Managerでは、3レベルの管理の精度を公開し、それらを組み合せて、環境を完全に監視および管理できます。次の管理レベルがあります。
直感的に、監視環境内の特定のイベントを監視します。イベントは、管理対象ターゲットについての重要な事象であり、一般的には、通常の運用状態から逸脱した出来事の発生を示します。これにより、Enterprise Managerにより管理された環境内で、関心のある何かが発生したことを示す共通の方法を提供します。イベントの例は次のとおりです。
メトリック・アラート
コンプライアンス違反
ジョブ・イベント
可用性アラート
既存のEnterprise Managerのユーザーは、メトリック・アラートおよびメトリック・コレクション・エラーについてよく知っているかもしれません。Enterprise Manager 12cでは、メトリック・アラートはイベントの一種であり、数多くあるイベント・タイプの1つです。イベントの概念は、監視の問題やコンプライアンスの問題などのEnterprise Managerにより検知される様々な例外条件を、共通の概念に統一します。これは、Enterprise Managerにより管理されたデータセンター内で関心のある何かが発生したことを示すことができる、イベント管理機能の一貫性のある共通のセットにより裏付けられています。
表3-1 イベント属性
| 属性 | 説明 |
|---|---|
|
Type |
報告されるイベントのタイプ。特定のタイプのすべてのイベントは、問題の性質を正確に記述する同じ属性のセットを共有します。たとえば、「メトリック・アラート」、「コンプライアンス標準スコア違反」、「ジョブ・ステータスの変更」があります。 |
|
Severity |
イベントの重大度。たとえば、「致命的」、「警告」、「クリティカル」があります。 |
|
内部名 |
内部名はイベントの性質を記述するもので、イベントの検索に使用できます。たとえば、すべてのtablespacePctUsedイベントを検索することができます。 |
|
イベントが発生するエンティティ。 |
イベントは、ターゲット、非ターゲット・ソース・オブジェクト(ジョブなど)で発生、またはターゲットおよび非ターゲット・ソース・オブジェクトに関係する可能性があります。注意: この属性はイベントの管理に必要な権限を決定するときに重要です。 |
|
メッセージ |
イベントに関連付けられた情報テキスト。 |
|
報告日 |
イベントが報告された時刻。 |
|
カテゴリ |
イベントの機能上または操作上の分類。 使用可能なカテゴリ
|
|
原因分析の更新 |
ターゲットの停止イベントの根本原因分析に使用します。 可能な値: 根本原因または兆候 |
イベントのタイプは、イベントの構造およびペイロードを定義し、記述する条件の詳細を提供します。たとえば、しきい値違反により発生したメトリック・アラートが特定のペイロードを持つのに対し、ジョブ状態の変更は別の構造を持ちます。次の表に示すように、様々なイベント・タイプにより、Enterprise Managerの監視の柔軟性が大幅に拡張されています。
| イベント・タイプ | 説明 |
|---|---|
| ターゲット可用性 | ターゲット可用性イベントは、ターゲットの可用性ステータス(「稼働中」、「停止中」、「エージェント使用不可」、「ブラックアウト」など)を表します。 |
| メトリック・アラート | 特定のターゲットのメトリック(ホスト・ターゲットのCPU使用率など)またはターゲットとオブジェクトの組合せのメトリック(データベース・ターゲットの特定表領域の領域使用率など)でアラートが発生した場合に、メトリック・アラート・イベントが生成されます。 |
| メトリック評価エラー | ターゲットに対して特定のメトリック・グループを収集できなかった場合に、メトリック評価エラーが生成されます。 |
| ジョブ・ステータスの変更 | Enterprise Managerジョブのステータス変更はすべてイベントとして処理され、これらのイベントは「ジョブ・ステータスの変更」イベント・クラスによって使用できます。
注意: インシデント・ルールの作成の前提条件は、関連するジョブ・ステータスが有効になっていることと、必要なターゲットがジョブ・イベント生成基準に追加されていることです。この条件を変更するには、「設定」メニューから、「インシデント」、「ジョブ・イベント」の順に選択します。 |
| コンプライアンス標準ルール違反 | コンプライアンス基準ルールの違反に対して生成されるイベント。各イベントは、特定のターゲットに関するコンプライアンス・ルールの違反に対応します。 |
| コンプライアンス標準スコア違反 | コンプライアンス基準スコアの違反に対して生成されるイベント。特定のターゲットに関するコンプライアンス基準について、コンプライアンス・スコアが事前定義済のしきい値を下回ると、イベントが生成されます。 |
| 高可用性 | 高可用性イベントがデータベースの可用性操作(停止、起動)、データベースのバックアップおよびData Guard操作(スイッチオーバー、フェイルオーバーおよびその他の状態の変更)に対して生成されます。 |
| サービス・レベル合意のアラート | これらのイベントは、サービス・レベルまたはサービス・レベル目標がサービスに対して違反すると生成されます。サービス・レベル合意またはサービス・レベル目標に対して発生します。 |
| ユーザー報告 | これらのイベントはエンドユーザーによって作成されます。 |
| アプリケーションの依存性とパフォーマンスのアラート | J2EEアプリケーションまたはコンポーネント関連のメトリックでしきい値を超えた場合に、アプリケーションの依存性とパフォーマンス(ADP)監視によってアラートが生成されます。 |
| アプリケーション・パフォーマンス管理KPIアラート | アプリケーション・パフォーマンス管理(APM)のキー・パフォーマンス・インジケータ(KPI)アラート・イベントは、ビジネス・アプリケーション・ターゲットに関連付けられているAPM管理対象エンティティでメトリックのKPI違反アラートが発生したときに生成されます。 |
| JVM診断しきい値違反 | Java仮想マシン・ターゲットでJVMDメトリックがしきい値を超えると、JVMD診断イベントが発生します。 |
イベントの重大度は特定の問題の重要性を示します。次の表に、様々なイベントの重大度レベルをそれに対応するアイコンとともに示します。
| アイコン | Severity | 説明 |
|---|---|---|
 |
致命的 | 対応するサービスはすでに使用不可となっています。たとえば、監視対象ターゲットは停止しています(ターゲット停止イベント)。「致命的」は最高レベルの重大度で、イベント・タイプ「ターゲット可用性」にのみ適用されます。 |
 |
クリティカル | 特定の領域で即時のアクションが必要です。その領域は、機能していないか、緊急の問題が発生しています。 |
 |
警告 | 特定の領域で注意が必要ですが、その領域は機能を続けています。 |
 |
アドバイザ | 特定の領域に即時のアクションは不要ですが、領域の現在の状態について注意することをお薦めします。この重大度は、たとえばOracleのベスト・プラクティス違反を報告するのに使用できます。 |
 |
クリア | イベントを発生させた条件が解決されました。 |
 |
情報 | 特定の条件が発生しましたが、改善処置は必要ありません。
重大度が情報のイベントは
|
Enterprise Manager環境は、(インシデントが単一のイベントで構成されていたとしても)個々のイベントではなくインシデントを介して監視および管理します。管理対象環境で生成されるすべてのイベントの中には、ビジネス・アプリケーションに影響を与えるため、対処を必要とするイベントのサブセットが存在します(ターゲットの停止イベントなど)。しかし、インシデントによる管理では、関心のあるイベントのサブセットが関連している、個別のイベントとしてではなく1つの問題として対応する必要のあるより高いレベルの問題を示す可能性のある、より複雑な状況に対応できます。イベントの1つのクラスタはそれ自身では小さな管理上の問題であっても、一緒に見てみると、監視インフラストラクチャの複数のドメイン/レイヤーからイベントを構成する可能性のある、より大きい問題を表している可能性があります。
たとえば、ホストを監視中とします。1つ以上のホストの負荷を監視する場合、興味を引かれるイベントとしては、許容可能なメトリックしきい値を超過しているCPU使用率、メモリー使用率、スワップ使用量などのイベントなどがあります。個別では、これらのイベントはホストの問題を示している場合もそうでない場合もありますが、全体として、これらのイベントは監視対象のホストの負荷が非常に高くなっていることを示すインシデントを形成します。
インシデントは、個別のイベントではなく、ビジネスに影響を与える可能性のあるより大きなサービスの中断を表します。そのためインシデントによる管理では、ビジネスに影響を与える可能性のある、複数のドメインに関連する可能性のある複雑な操作の問題を監視できます。これらのインシデントは、通常、追跡され、適切な人員が割り当てられ、できるだけ早く解決する必要があります。監視情報を統合し、エコシステム間でリソースをより効果的に割り当てる集中管理監視を効果的に実装して、問題を解決または問題の発生を防ぐことができます。最終的な成果は、ITリソースのより高いパフォーマンスを導く、ビジネス・プロセスをより適切に実装することです。
イベントが管理対象の環境で対応が必要な問題を示している間は、関連するイベントをまとめたサブセットを1つの作業単位として処理する方が効率的です。同じ問題を表している異なるイベントを処理したり、複数の領域関連のイベントを含む1つのインシデントを処理したりできます。たとえば、実行中に領域が少なくなっていることを示す複数のスペース・イベントを様々なターゲットから受け取ります。多数の個別のイベントを管理するかわりに、より小さいインシデントのセットをより効果的に管理できます。
インシデントは、潜在的にビジネス・アプリケーションに影響を与える可能性があり、その管理を必要とする重要なイベントまたは関連する重要なイベントのセットです。これらのインシデントは、通常、追跡され、適切な人員が割り当てられ、できるだけ早く解決する必要があります。これらのインシデント管理操作を、Enterprise Manager内の直感的なUIであるインシデント・マネージャを使用して実行します。
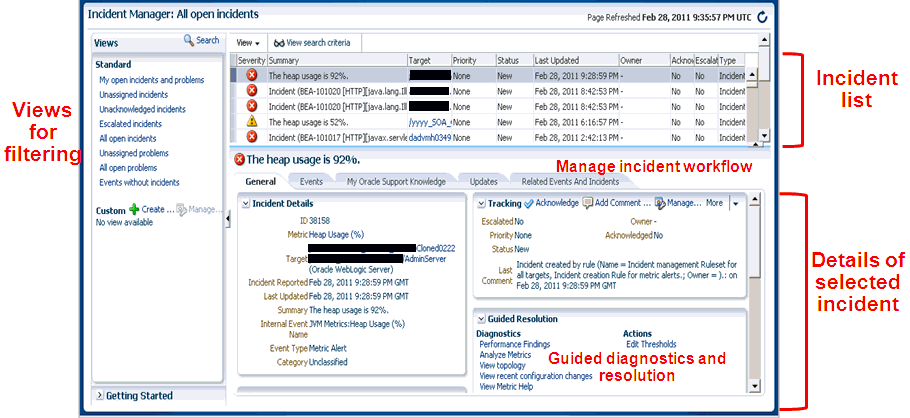
インシデント・マネージャは、インシデントを表示、管理、診断および解決し、混乱の根本原因を識別、解決および排除する中枢となる場所を提供します。このUIの詳細は、第3.1.5項「インシデント・マネージャ」を参照してください。
インシデントが作成されると、Enterprise Managerの豊富なインシデント管理ワークフロー機能群が使用できるようになり、インシデントをライフサイクル全体を通して管理および追跡できます。
インシデント所有権の割当て。
インシデント解決ステータスの追跡。
インシデント優先度の設定。
インシデントのエスカレーション・レベルの設定。
手動での要約を提供する機能。
ユーザー・コメントを追加する機能。
抑止および抑止解除する機能。
手動でインシデントをクリアする機能。
手動でチケットを作成する機能。
すべてのインシデント管理/追跡操作は、インシデント・マネージャから実行します。イベントに対するインシデントの作成では、管理者へのインシデントの割当て、優先度の設定、通知の送信およびその他のアクションが、(インシデント)ルールを使用して自動化できます。
インシデントのステータス。
組織内でのインシデントのライフサイクルは、通常、2つの部分の情報で決定されます。インシデントの現在の解決状態(インシデント・ステータス)と、他のインシデントと比較したインシデントの解決の重要度(優先度)です。主要なインシデント属性として、次のオプションを使用できます。
新規
処理中
クローズ
解決
デフォルトのオプションが適切でない場合に、追加のステータスを定義できます。また、Enterprise Manageコマンドライン・インタフェース(EM CLI)を使用して、ラベルを変更できます。詳細は、「高度なトピック」を参照してください。
優先度を変更することで、インシデントをエスカレートし、特定のITオペレータへの割当てや上級管理者への通知などの操作を実行できます。次の優先度オプションを使用できます。
なし
低
中
高
非常に高
緊急
優先度は多くの場合、ビジネスへの影響と解決の緊急性によって決まる単純なビジネス・ルールに基づいています。
すべてのインシデントには、ID、追跡用のステータス、所有権などの情報を提供する属性があります。次の表に、使用可能なインシデント属性を示します。
| インシデント属性 | 定義 |
|---|---|
| エスカレート済 | 組織のITまたは管理階層からのインシデントでの注意のレベルを上げるためのエスカレーションを示すエスカレーション・レベル。
使用可能なエスカレーションのレベルは次のとおりです。
|
| カテゴリ | インシデントの操作上または組織上の分類。インシデント(およびイベント)は複数のカテゴリを持つことができます。
インシデント内のすべてのイベントのカテゴリが集計されます。 使用可能なカテゴリ
|
| サマリー | インシデントの内容を示す直感的なメッセージ。デフォルトでは、インシデント・サマリーはインシデントの最後のイベントのメッセージから取得されますが、このメッセージはインシデントを操作している管理者が修正されたサマリーに変更できます。 |
| インシデント作成 | インシデントが作成された日時。 |
| 最終更新 | インシデントが最後に更新された、またはインシデントがクローズした日時。 |
| Severity | 重大度はインシデント内のイベントの最悪の重大度に基づきます。たとえば、「致命的」、「警告」、「クリティカル」があります。 |
| ソース | インシデントのソース・エンティティ。 |
| 優先度 | 優先度の値
|
| ステータス | インシデントのステータス。
デフォルトのオプションが適切でない場合に、追加のステータスを定義できます。また、Enterprise Manageコマンドライン・インタフェース(EM CLI)を使用して、ラベルを変更できます。 クローズ・ステータス: インシデント重大度がクリアされると、Enterprise Managerによってステータスが自動的にクローズに設定され、管理者が手動でクローズ・ステータスを選択することはありません。インシデント内に含まれるすべてのイベントがクリアされると、インシデント重大度はクリアに設定されます。一般的に、メトリック・アラート値が重大度しきい値未満になるときと同様に、エージェントがクリアの重大度を設定します。イベントまたはインシデントが手動のクリアをサポートする場合、インシデント・マネージャUIに「クリア」オプションが表示されます。インシデントが管理者またはEnterprise Managerによってクリアされたときのみ、Enterprise Managerによってステータスがクローズに設定されます。UIにインシデントをクリアするオプションが表示されない場合、Enterprise Managerが、監視対象の条件が真でないことを検出したときに自動的にステータスをクリアに設定することを意味します。たとえば、インシデントが修正されたことを示すとします。ステータスを解決に設定することができ、Enterprise Managerは重大度をクリアしたときにステータスをクローズに設定します。 |
| コメント | 分析情報またはインシデントを解決するためのアクションを伝えるために管理者によって追加される注釈。 |
| owner | 現在、そのインシデントについて作業中の管理者/ユーザー。 |
| 確認済 | ユーザーがインシデントまたは問題の所有権を受け入れたことを示します。使用可能なオプションは「はい」または「いいえ」です。
インシデントが確認された場合、そのインシデントは暗黙的にそれを確認したユーザーに割り当てられます。ユーザーがインシデントを自分自身に割り当てた場合、そのインシデントは「確認済」とみなされます。一度確認済となったインシデントを未確認にはできませんが、別のユーザーに割り当てることはできます。インシデントを確認することで、そのインシデントについての通知が繰り返されることを停止します。 |
| 原因分析の更新 | ターゲットの停止インシデントの根本原因分析に使用します。
可能な値: 根本原因または兆候 |
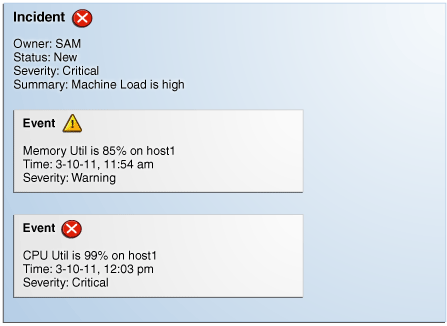
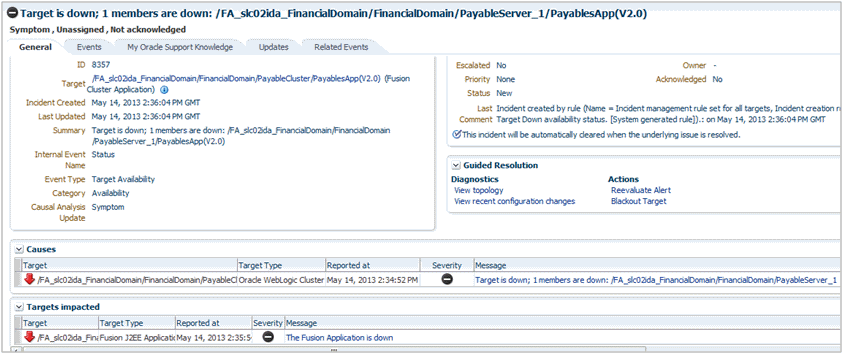
最も単純なインシデントは、単一イベントから構成されます。次の例では、ユーザーはなんらかの製品ターゲットの停止に関心があります。管理対象ターゲットの停止を検出したときにEnterprise Managerによって生成される、ターゲットの停止イベント用のインシデントを作成できます。インシデントが作成されると、ソリューションの追跡と管理に必要なすべてのインシデント管理が使用可能になります。
図は、インシデント属性とイベント属性の両方を使用してインシデントを管理する方法を示しています。図から、データベースDB1が停止し、「致命的」重大度のイベントが発生したことがわかります。イベントが新しく生成されるときには、所有権やステータスはありません。インシデントがオープンされ、手動で更新、または所有者、ステータスやその他の属性を設定する、自動化されたルールで更新できます。例では、所有者/管理者Scottが現在問題の解決作業を行っています。
インシデントはインシデント内のすべてのイベントの最悪の重大度を継承するため、インシデントの重大度は現在「致命的」です。この場合、インシデントに関連付けられているイベントは1つのみであるため、重大度は「致命的」です。
関心の対象に複数のイベントが関連する場合があります。複数イベントを収容できるインシデントの機能により、複雑でより意味のある問題を監視および管理できます。
|
注意: 複数イベントのインシデントは、自動的に生成されません。管理者が手動で作成する必要があります。 |
たとえば、管理対象システムの領域が枯渇した場合、表領域フルおよびファイルシステム・フルという、別々の複数イベントが生成されます。しかし、両方とも領域の枯渇に関連しています。また別のマシン・リソースの監視例として、CPU使用状況、メモリー使用状況およびスワップ使用状況のイベントの同時生成があります。詳細は、「インシデントの手動作成」を参照してください。これらのイベントは1つにまとめられ、管理対象ホストに非常に高い負荷がかかっていることを示す1つのインシデントになります。次の図は、この例を示しています。
インシデントはインシデント内のすべてのイベントの最悪の重大度を継承します。インシデント・サマリーは、このインシデントが関心の対象である理由(この場合はマシンの負荷が高い)を示します。このメッセージは、このインシデントを参照するすべての管理者にとって直感的なインジケータです。デフォルトでは、インシデント・サマリーはインシデントの最後のイベントのメッセージから取得されますが、このメッセージはインシデントを操作している管理者が変更できます。
管理者はマシン全体の負荷に関心があり、2つのイベントは両方ともホストの過負荷状況を表しているため、管理者Samは、この2つのメトリック・イベントに対して1つのインシデントを手動で作成しました。メモリーが一杯になり、消費されているCPUリソースが多すぎるため、管理者はアクションを実行する必要があります。現在の状態では、この条件はホストで実行されているアプリケーションに影響を与えます。
インシデントはルールおよびルール・セット(特定のイベントの発生時にその処理方法をインシデント・マネージャに伝えるユーザー定義の手順)により自動的に作成されることが最も一般的です。前述の例のように、インシデントは手動で作成することもできます。インシデントが発生すると、その重大度はインシデント内のすべてのイベントの最悪の重大度を継承します。最新のイベント・メッセージはデフォルトでインシデント・サマリーになります。インシデントは手動で作成することもできます。詳細は、「インシデントの手動作成」を参照してください。
問題管理には、インシデントの基礎となる根本原因の追跡を支援する機能が含まれます。インシデントで表される即時サービス中断が解決されると、問題の基礎となる根本原因の理解と解決に進むことができます。
Enterprise Manager 12cにおける問題は、診断インシデントおよび拡張診断リポジトリ(ADR)に格納される問題診断インシデント/問題に照準が絞られており、そのような問題は、ソフトウェアにクリティカルなエラーが発生したときにOracleソフトウェアにより自動的に生成されます。このため、問題は、すべてのOracleソフトウェア・インシデントの根本原因を表します。診断インシデントでは、根本原因に対処するため、診断インシデントの根本原因を表す問題オブジェクトが作成されます。問題は、ソフトウェアにおける個別のエラーを一意に識別する問題キーで識別されます。エラーは発生するたびに診断インシデントとなり、問題オブジェクトと関連付けられます。
Oracleソフトウェアに問題が発生した場合、オラクル社の推奨する問題解決の手続きは、サービス・リクエスト(SR)をオープンしてサポートに診断ログを送信してもらい、最終的にオラクル社からソリューションを提供することです。インシデントとして、Enterprise Managerは問題管理のためにすべての追跡、診断およびレポート機能を使用可能にします。インシデント・マネージャまたはターゲット/グループのホームページのいずれを使用するにしても、オープンしているすべてのインシデントおよび問題を表示すれば、管理対象ターゲットに実際に影響を与えている問題を簡単に判断できます。
問題を管理するには、サポート・ワークベンチを使用して、ADRで収集された診断詳細をまとめてSRをオープンできます。ユーザーはインシデント・マネージャで問題を管理する必要があります。サポート・ワークベンチ機能は、問題のコンテキストに応じて、インシデント・マネージャを介して(「ガイドされた解決」領域)使用できます。
インシデント・ルールおよびルール・セットはイベント、インシデントおよび問題に関連するアクションを自動化します。重要なイベントに基づくインシデントの作成を自動化し、電子メールの送信やヘルプディスク・チケットのオープンなどの通知アクションを実行したり、インシデントの所有権、優先度またはエスカレーション・レベルなどのインシデント・ワークフロー・ライフサイクルの管理操作を実行できます。
以前のバージョンのEnterprise Managerでは、通知ルールを使用して、アクションの実行またはEnterprise Managerからの通知の受信(電子メールの送信、ページ、ヘルプディスク・チケットのオープン)を行う個々のターゲットと条件を選択しました。Enterprise Manager 12cでは、通知ルールの概念と機能は、インシデント・ルールとルール・セットに置き換えられました。
ルール: ルールは、Enterprise Managerに対して、インシデント、イベントまたは問題が発生したときに、通知の実行などの特定のアクションの実行を指示します。ルールでは、通知のみではなく、インシデントの生成、インシデントや問題の更新などのアクションの実行をEnterprise Managerに指示することもできます。アクションには、条件的な性質も含まれます。たとえば、ルール・アクションを定義して、インシデントの重大度がクリティカルの場合にページを表示し、警告の場合には電子メールを送信するのみにできます。
ルール・セット: インシデント・ルール・セットは、ターゲット(ホスト、データベース、グループ)、ジョブ、メトリック拡張、または自己更新などのオブジェクトの共通セットに適用され、基礎となるイベント、インシデントおよび問題管理のビジネス・プロセスを自動化する適切なアクションをとる、ルールのコレクションです。
運用では、ルール・セット内の各ルールは、ルール・セット自体と同様に指定された順序で実行されます。ルール・セットは指定された順序で実行されます。デフォルトでは、ルールおよびルール・セットの実行順序はどちらも作成された順序ですが、インシデント・ルールのUIから並替えが可能です。
次の図は、標準的なルール・セットの構造、および個々のルールがどのように異種のターゲット・グループに適用されるかを示しています。
この図は、ターゲット・グループに関係するすべてのルールを、1つのルール・セットにまとめることのできる様子を表しています(これがベスト・プラクティスでもあります)。前述の例では、PROD-GROUPという名前のグループは、ある会社の管理対象環境に存在するホスト、データベースおよびWebLogicサーバーから構成されています。このグループを管理する単一のルール・セットが作成されています。
ルール・セットは、実際のルールを含むのに加え、次の属性を持ちます。
名前: ルール・セットを説明する名前。
説明: ルール・セットの目的を示す簡単な説明。
適用先: ルール・セット内のすべてのルールを適用するオブジェクト。有効なルール・セットのオブジェクトは、ターゲット、ジョブ、メトリック拡張および自己更新です。
所有者: ルール・セットを作成したEnterprise Managerのユーザー。ルール・セットの所有者は、ルール・セットおよびルール・セット内のルールを更新または削除できます。
有効: そのルール・セットが、現在適用されているかどうか。
タイプ: エンタープライズまたはプライベート。「ルール・セット・タイプ」を参照してください。
Enterprise Managerは、一般的なシナリオに基づくインシデント作成やイベントのクリア用に即時利用可能なルール・セットを提供します。即時利用可能なルール・セットは編集も削除もできませんが、無効にすることができます。ベスト・プラクティスとして、即時利用可能なルール・セットの独自のコピーを作成し、即時利用可能なルール・セットに直接サスブクライブするのではなく、そのルール・セットのコピーにサブスクライブする必要があります。事実上、ルール・セットのコピーを作成し、適切なターゲットのグループ(管理グループが望ましい)を選択することによって企業のニーズに合うようターゲット基準を変更しています。
即時利用可能なルール・セット定義および実行するアクションは、Oracleによりいつでも変更される可能性があり、パッチ適用中またはソフトウェアのアップグレード中に適用されることに注意してください。
通常のEnterprise Manager管理者はルール・セットで次の操作を実行できます。
サブスクライブ
電子メール通知をサブスクライブ
サブスクライブ解除
電子メール通知をサブスクライブ解除
有効化
無効化
|
注意: 管理者はルール・セットにサブスクライブできますが、少なくとも「ターゲットの表示」権限のあるターゲットから通知を受信するのみです。 |
Enterprise Managerスーパー管理者にはルール・セットを並べ替えできる機能が追加されています。
エンタープライズ・ルール・セットは順次評価され、必要に応じて複数のパスを通過します。処理中のエンティティに変更があるとき(イベントに作成中のインシデントや、ルールのために変更中のインシデント優先度など)、一致がなくなるまですべてのルールを最初から再実行します。前のパスで一致したルールは、もう一致しません(無限ループを防ぐため)。
たとえば、新しいイベント、インシデントまたは問題が発生したときに、リストの最初のルール・セットがチェックされ、そのメンバー・ルールのいずれかが適用されるかどうかが判断され、それらのルールで指定されている適切なアクションが実行されます。2番目のルールがチェックされ、ルールが適用されるかが判断される、などと続きます。プライベート・ルール・セットは、すべてのエンタープライズ・ルール・セットの評価が完了してからのみ評価され、特定の順番はありません。
|
重要: ルール・セットの順番はイベント、インシデントおよび問題の処理ワークフローを定義しているため、並べ替えるときは注意してください。システムへの影響を十分に理解せずにルール・セットを並べ替えると、発生するイベント、インシデントおよび問題に対して意図しないアクションが実行されてしまうことがあります。 |
ルール・セットには次の2つのタイプがあります。
エンタープライズ: IT組織内のすべての操作手順の実装に使用します。サポートされるすべてのアクションを、このタイプのルール・セットに使用できます。ただし、このタイプのルール・セットはすべてのアクションを実行できるため、エンタープライズ・ルール・セットを作成できるユーザーには制限があります。
エンタープライズ・ルール・セットを作成または編集するには、管理者に「エンタープライズ・ルール・セット」リソースに対する「エンタープライズ・ルール・セットの作成」権限が付与されている必要があります。ただし、今後、ルール・セットの所有者が「エンタープライズ・ルール・セットの作成」システム権限を喪失しても、そのルール・セットを引き続き編集または削除できます。スーパー管理者はどのルール・セットも編集または削除できます。ルール・セットの最初の作成者が他の管理者にルール・セットを編集させる場合は、共同作成者を追加することで、共同作業するためにアクセスを共有する必要があります。エンタープライズ・ルール・セットはすべての管理者から参照できます。
プライベート: 管理者が、標準のビジネス・プラクティスとしてではないが、なんらかの監視対象について通知される必要がある場合に使用します。プライベート・ルール・セットが実行できるアクションは、ルール・セット所有者への電子メールの送信のみです。管理者は「エンタープライズ・ルール・セットの作成」リソース権限が付与されているかどうかにかかわらず、プライベート・ルール・セットを作成できます。プライベート・ルール・セットはまれにのみ、または例外的な状況でのみ使用することをお薦めします。
ルール・セットがアクションを実行するときは、そのルール・セットの作成者の権限が使用されます。たとえば、ルール・セットの所有者および作成者は、通知を受け取るためには少なくとも「ターゲットの表示」権限が、インシデントを更新するためには少なくとも「ターゲット・イベントの管理」権限が必要です。例外はルール・セットが通知を送信するときです。この場合、送信先のユーザーの権限が使用されます。
ルールは、着信イベント、インシデントまたは問題に対するアクションを自動化するルール・セット内の手順です。ルールは着信インシデント/イベント/問題を操作するため、新しいルールを作成した場合、そのルールはすでに発生したインシデント/イベント/問題を遡って操作しません。
各ルールは次の2つの部分から構成されます。
基準: ルールが適用されるイベント/インシデント/問題。
アクション: 指定したイベント、インシデントまたは問題に対する1つ以上の操作の順序付きセット。各アクションは、追加の条件に基づいて実行できます。
次の表に、ルールの基準とアクションがルールの適用を決定する方法を示します。このルール操作の例では、選択したイベントおよびインシデントで実行される3つのルールがあります。ルール・セット内で、ルールは指定された順序で実行されます。ルールの実行順序はいつでも変更可能です。デフォルトでは、ルールは作成された順番に実行されます。
表3-2 ルール操作
| ルール名 | 実行順序 | 基準 | アクション | |
|---|---|---|---|---|
| 条件 | アクション | |||
|
ルール1 |
1番目 |
警告またはクリティカル重大度のCPU使用率(%)、使用済表領域(%)メトリック・アラート・イベント |
インシデントを作成します。 |
|
|
ルール2 |
2番目 |
警告またはクリティカル重大度のインシデント |
重大度=クリティカルの場合 重大度=警告の場合 |
ページャによる通知 電子メールによる通知 |
|
ルール3 |
3番目 |
インシデントが6時間以上未確認 |
エスカレーション・レベルを1に設定 |
|
このルール操作の例では、ルール1は「CPU使用率」と使用済表領域の2つのメトリック・アラート・イベントに適用されます。これらのイベントが「警告」または「クリティカル」重大度しきい値レベルに達すると、インシデントが作成されます。
インシデントの重大度レベル(インシデントの重大度は最悪のイベントの重大度から継承されます)が「警告」に達すると、その1番目の条件に従ってルール2が適用され、Enterprise Managerにより電子メールが管理者に送信されます。インシデントの重大度レベルが「クリティカル」に達すると、ルール2の2番目の条件が適用され、Enterprise Managerによりページャが管理者に送信されます。
そのインシデントが6時間を超えてもオープンのまま残っている場合は、ルール3が適用され、インシデントのエスカレーション・レベルが「なし」から「1」にアップします。この時点で、Enterprise Managerはすべてのルール・セットおよびそのルールを最初から再び実行します。
ルール・セット内の各ルールは、イベント、インシデントまたは問題に適用されます。それぞれに対し、次のようなルール適用条件を選択できます。
ルールを着信イベントまたは更新されたイベントのみに適用
ルールをクリティカルなイベントのみに適用。
ルールは、ルールの作成(または更新)時に選択された基準に従ってイベント、インシデントおよび問題に適用されます。次の状況で、ルールの適用に使用される手法を示します。
ルールの1つが着信イベントへの応答で新しいインシデントを作成すると、Enterprise Managerはそれ以上イベントをルールおよびルール・セットを一致させるのを終了します。完了すると、Enterprise Managerは新しく作成したインシデントを最初からすべてのルール・セットと照合し、インシデント特有のルールが一致するかどうかを判断します。
着信イベントがすでにインシデントと関連付けられている場合(たとえば警告イベントがインシデントを作成してからクリティカル・イベントが同じ問題から生成される場合)、Enterprise Managerはすべての一致するルールをイベントに適用してから、すべてのルールをインシデントと照合します。
ルールをインシデントに適用中に、インシデントが変更された(優先度の変更など)場合、Enterprise Managerはその時点でルールの適用を停止し、そのルールを最初からインシデントに再度適用します。インシデントを更新した条件付きアクションは、同じルール適用サイクルで再び一致することはありません。
次の表に、それぞれのタイプで選択可能な基準を示します。
表3-3 ルールの基準: イベント
| 基準 | 説明 |
|---|---|
|
Type |
特定のイベント・タイプにルールを適用します。 |
|
Severity |
特定のイベント重大度にルールを適用します。 |
|
カテゴリ |
特定のイベント・カテゴリにルールを適用します。 |
|
ターゲット・タイプ |
特定のターゲット・タイプにルールを適用します。 |
|
ターゲットのライフサイクル・ステータス |
ターゲットの特定のライフサイクル・ステータスにルールを適用します。ライフサイクル・ステータスは、ターゲットの運用ステータスを示すターゲット・プロパティです。 |
|
インシデントと関連付け |
通常、イベントはルールを介してインシデントと関連付けられます。「はい」または「いいえ」を指定します。 |
|
イベント名 |
特定の名前のイベントにルールを適用します。名前は、完全一致またはパターン一致のどちらでも指定できます。 |
|
原因分析の更新 |
根本原因分析(Root Cause Analysis: RCA)イベントの完了により、「根本原因」または「兆候」のいずれかとマークされたイベントにルールが適用されます。または、もはや兆候ではない場合は、ルールはRCAイベントに作用します。 |
|
関連インシデントの確認 |
インシデントが管理者によって確認されている場合、特定のインシデントと関連付けられているイベントにルールを適用します。「はい」または「いいえ」を指定します。 |
|
発生件数合計 |
重複するイベントで、イベントの発生件数合計が特定の数に達した場合にルールを適用します。 |
|
コメント追加済 |
管理者がコメントを追加したイベントにルールを適用します。 |
インシデントの場合、すべての新規または更新(あるいはその両方)のインシデント、または次の表に示す特定の基準に一致する新たに作成されたインシデントにルールを適用できます。
表3-4 ルールの基準: インシデント
| 基準 | 説明 |
|---|---|
|
インシデントを作成したルール |
特定のルールによって生成されたインシデントにルールを適用します。 |
|
カテゴリ |
特定のインシデント・カテゴリにルールを適用します。 |
|
ターゲット・タイプ |
特定のターゲット・タイプにルールを適用します。 |
|
ターゲットのライフサイクル・ステータス |
ターゲットの特定のライフサイクル・ステータスにルールを適用します。ライフサイクル・ステータスは、ターゲットの運用ステータスを示すターゲット・プロパティです。 |
|
Severity |
特定のインシデント重大度にルールを適用します。 |
|
確認済 |
インシデントが管理者によって確認されている場合にルールを適用します。「はい」または「いいえ」を指定します。 |
|
owner |
特定のインシデント所有者にルールを適用します。 |
|
優先度 |
選択した優先度と一致する優先度のインシデントにルールを適用します。 |
|
ステータス |
選択したステータスと一致するステータスのインシデントにルールを適用します。 |
|
エスカレーション・レベル |
選択したレベルと一致するエスカレーション・レベルのインシデントにルールを適用します。使用可能なエスカレーション・レベル: なし、レベル1、レベル2、レベル3、レベル4、レベル5。 |
|
チケットと関連付け |
ヘルプデスク・チケットに関連付けられているインシデントにルールを適用します。「はい」または「いいえ」を指定します。 |
|
サービス・リクエストと関連付け |
サービス・リクエストに関連付けられているインシデントにルールを適用します。「はい」または「いいえ」を指定します。 |
|
診断インシデント |
診断インシデントにルールを適用します。「はい」または「いいえ」を指定します。 |
|
未割当て |
新たに生成された所有者のないインシデントにルールを適用します。 |
|
コメント追加済 |
管理者がコメントを追加したインシデントにルールを適用します。 |
問題の場合、すべての新規または更新(あるいはその両方)の問題、または次の表に示す特定の基準に一致する新たに作成された問題にルールを適用できます。
表3-5 ルールの基準: 問題
| 基準 | 説明 |
|---|---|
|
問題キー |
各問題には問題キーが含まれます。問題キーは問題を説明するテキスト文字列です。これには、エラー・コード(ORA600など)、場合によってはさらに1つ以上のエラー・パラメータが含まれます。 特定のキーまたは指定したパターン(ワイルドカード文字を使用します)に一致するキーを持つ問題にルールを適用できます。 |
|
カテゴリ |
特定の問題カテゴリにルールを適用します。 |
|
ターゲット・タイプ |
特定のターゲット・タイプにルールを適用します。 |
|
ターゲットのライフサイクル・ステータス |
ターゲットの特定のライフサイクル・ステータスにルールを適用します。ライフサイクル・ステータスは、ターゲットの運用ステータスを示すターゲット・プロパティです。 |
|
確認済 |
確認されている問題にルールを適用します。 |
|
owner |
特定の問題所有者にルールを適用します。 |
|
優先度 |
選択した優先度と一致する優先度の問題にルールを適用します。 |
|
ステータス |
特定のステータスと一致するステータスの問題にルールを適用します。 |
|
エスカレーション・レベル |
選択したレベルと一致するエスカレーション・レベルの問題にルールを適用します。使用可能なエスカレーション・レベル: なし、レベル1、レベル2、レベル3、レベル4、レベル5。 |
|
インシデント数 |
その問題に関連するインシデントの数が、指定した制限数に達した問題にルールを適用します。問題の所有者とオペレーション・マネージャには、電子メールで通知されます。 |
|
サービス・リクエストと関連付け |
受信した問題がサービス・リクエストに関連付けられている場合にルールを適用します。「はい」または「いいえ」を指定します。 |
|
バグと関連付け |
受信した問題が不具合に関連付けられている場合にルールを適用します。「はい」または「いいえ」を指定します。 |
|
未割当て |
新たに生成された所有者のないインシデントにルールを適用します。 |
|
コメント追加済 |
管理者がコメントを追加した問題にルールを適用します。 |
それぞれのルールに応じて、Enterprise Managerで特定のアクションを定義できます。
ルール・セットで実行できるアクション・タイプの例をいくつか示します。
イベントに基づくインシデントの作成。
電子メールの送信、ヘルプデスク・チケットの生成などの通知アクションの実行。
電子メール/PL/SQLメソッド/SNMPトラップを介したインシデント・ワークフロー通知の管理アクションの実行。たとえば、ターゲットの停止イベントが発生した場合、インシデントを作成し、そのインシデントについての電子メールを管理者Joeに送信します。2日後、まだそのインシデントがオープンしている場合は、エスカレーション・レベルを1に設定し、Joeの上司に電子メールを送信します。
次の表に、ルールの適用ごとに使用可能なアクションを要約しています。
表3-6 使用可能なルールのアクション
| アクション | イベント | インシデント | 問題 |
|---|---|---|---|
|
電子メール |
はい |
はい |
はい |
|
ページ |
はい |
はい |
はい |
|
高度な通知 |
|||
|
SNMPトラップの送信 |
はい |
いいえ |
いいえ |
|
OSコマンドの実行 |
はい |
はい |
はい |
|
PL/SQLプロシージャの実行 |
はい |
はい |
はい |
|
インシデントの作成 |
はい |
いいえ |
いいえ |
|
ワークフロー属性の設定 |
はい 注意: イベント・ルール内で、関連付けられたインシデントのワークフロー属性も更新できます。 |
はい |
はい |
|
ヘルプデスク・チケットの作成 |
はい 注意: アクションは、最初にインシデントの作成、次にインシデントのチケットの作成により、間接的に実行されました。 |
はい |
いいえ |
|
注意: Enterprise Managerのイベント・ルール・シミュレーション機能を使用することで、アクションを実際に実行することなく、ターゲットに対するルール・アクションをテストできます。詳細は「ルール・セットのテスト」を参照してください。 |
インシデント・マネージャを使用すると、環境に影響するインシデントと問題を1か所で検索、表示、管理および解決できます。インシデント・マネージャを使用して、次のタスクを実行します。
カスタム・ビューの使用によるインシデント、問題およびイベントのフィルタ処理
ターゲット名、サマリー、ステータス、またはターゲットのライフサイクル・ステータスなどのプロパティによる特定のインシデントの検索
インシデントの応答および処理
割当て、確認、ステータスの追跡、優先度付け、およびエスカレーションといったインシデントのライフサイクル管理
インシデントの解決には、My Oracle Supportのナレッジ・ベースの記事へのアクセス(コンテキスト依存)、およびその他のオラクル社のドキュメントが役立ちます。
インシデントをすばやく診断または解決するには、関連するEnterprise Manager機能へのコンテキスト依存の診断/アクション・リンクに直接アクセスします。
たとえば、オープン・インシデントがあるとします。インシデント・マネージャを使用して所有者と解決ステータスを追跡し、優先度を設定し、必要に応じてインシデントに注釈を追加して、共同作業環境で作業している他のユーザーと情報を共有できます。また、MOSから関連情報に直接アクセスし、問題の迅速な解決に役立つEnterprise Managerの他の領域にリンクできます。オープン・インシデントのドリルダウンによりこの情報にアクセスし、必要に応じて変更できます。
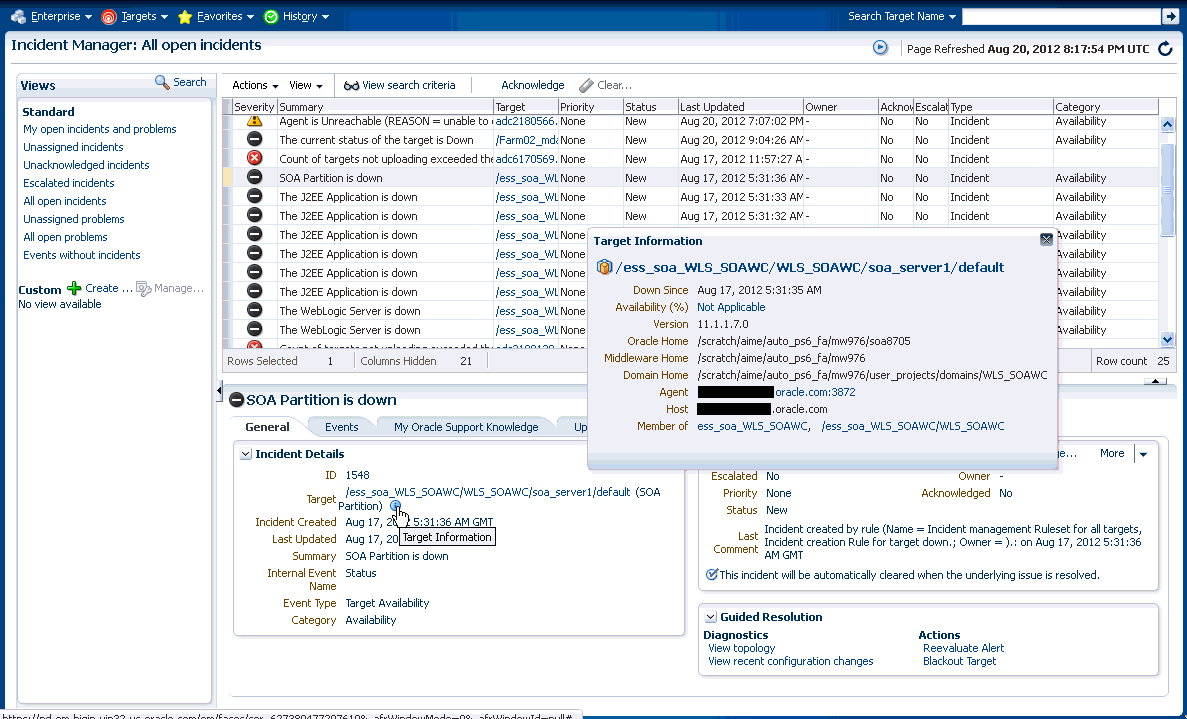
インシデントのコンテキストでのターゲット情報の表示
インシデントまたはイベントが発生したターゲットに関する情報を直接表示できます。表示される情報のタイプは、ターゲット・タイプに応じて異なります。
コンテキスト内ターゲット情報を表示するには、次の手順に従います。
「エンタープライズ」メニューから、「監視」、「インシデント・マネージャ」の順に選択します。
「インシデント・マネージャ」のUIからインシデントを選択します。インシデントに関する情報が表示されます。
「一般」タブの「インシデントの詳細」領域で、ターゲットの横にある情報アイコン"i"をクリックします。インシデントに関するターゲット情報が表示されます。図3-5を参照してください。
この方法でターゲット情報を表示できることで、イベントおよびインシデントが発生するターゲットに関するより多くの操作コンテキストが提供されます。さらにインシデントのライフサイクルをより効率的に管理できます。
Cloud Control Mobile
さらにモバイル・アプリケーションCloud Control Mobileも使用可能で、これにより、Enterprise Managerにリモートで接続するiDeviceを使用して出先でインシデントおよび問題を管理できます。
このモバイル・アプリケーションの詳細は、第29章「Enterprise Managerへのリモート・アクセス」を参照してください。
ビューにより、関心のあるインシデントのみを分類して焦点を当てることができるので、インシデントを効率的に処理できます。ビューは、システムでインシデントおよび問題をフィルタリングするための検索基準のセットです。インシデント・マネージャでは、最も一般的なイベント、インシデントおよび検索の検索シナリオをカバーする事前定義済の標準ビューが用意されています。さらに、インシデント・マネージャでは、独自のカスタム・ビューを作成することもできます。カスタム・ビューは他のユーザーと共有できます。カスタム・ビューの作成の手順については、「カスタム・ビューの設定」を参照してください。カスタム・ビューの共有については、「カスタム・ビューの共有/共有解除」を参照してください。
イベント: Enterprise Managerにより検知されたターゲットでの重大な出来事の発生。
目標: 環境が確実に監視される。
インシデント: 同じ問題に関する、重要なイベントのセット、または関連するイベントの組合せ。
目標: サービス中断が回避されるか、迅速に解決される。
問題: インシデントの基礎となる根本原因。現在、これは診断インシデントの基礎となる根本原因を表す、Oracleソフトウェアでのクリティカルなエラーを表しています。
目標: 問題の基礎となる根本原因を解決し、今後の問題の発生を防ぐ。
イベント、インシデント、および問題は連携して動作し、ITエコシステム全体を効果的かつ効率的に管理することができます。次の図に、これらが管理環境内でどのように動作するかを要約します。
次の項ではイベント、インシデントおよび問題について詳細に説明します。
インシデントを使用して環境を監視および管理する前に、監視環境が適切に構成されていることを確認する必要があります。適切な構成は次のとおりです。
監視インフラストラクチャの設定の最初の手順は、監視の必要があり、そのためイベントのソースとなる条件を特定することです。無関係なイベントが過度に生成されるのを防ぎ、システムおよび管理者のオーバーヘッドを減少させるために、要件に基づいて、関心があり監視可能な対象を特定する必要があります。管理グループなどのEnterprise Manager機能を使用して、新しいターゲットが監視環境に追加されたときに、監視設定やコンプライアンス標準などの管理設定を自動的に適用できます。これにより、関心のある条件に対してのみイベントが発生するようにタスクが大幅に簡略化されます。詳細は、第7章「管理グループの使用」を参照してください。
例: 人事管理情報を含むデータベースを24時間使用可能にする必要があるとします。監視する条件の1つは、データベース・ターゲットが稼働中または停止のいずれであるかです。停止であれば、適切な担当者に通知し、できるだけ早く問題を解決してもらう必要があります。監視する条件にはその他に、パフォーマンスしきい値の違反、アプリケーション構成ファイルの変更、ジョブの失敗などがあります。イベントを使用して、これらのターゲットに直接関連する個別のターゲットおよび問題を監視および管理しています。たとえば、個別のデータベースの可用性、CPUおよびI/O負荷などの、個別のホストのしきい値違反を監視します。またはWebサービスのパフォーマンスも含まれる可能性があります。
通常、主に可用性やキー・パフォーマンス関連メトリックに関心がある場合は、デフォルトの監視テンプレートを使用し、特定のメトリックのみを収集し、それらのメトリックに対してのみイベントが発生するようにするには、別のテンプレート機能を使用する必要があります。
ジョブ・イベント: ジョブのステータスは、発行されたときから実行済まで、そのライフサイクルを通じて変更できます。各ジョブ・ステータスで、イベントを発生させ、ジョブのステータスを管理者に通知することができます。
一般的なルールとして、イベントは管理者の対応を必要とするジョブ・ステータス値に対してのみ生成される必要があります。これらのジョブ・ステータス値には、「失敗」または「停止中」などの「操作必須」および「問題」ステータス値が含まれます。しかし、不要なイベントでシステムがオーバーロードになるのを防ぐために、ジョブ・イベントは、デフォルトではターゲットに対して有効になっていません。そのため、ジョブに対してイベントを生成する場合には、次の操作を行う必要があります。
適切なジョブ・ステータスを設定します。デフォルトの設定を使用することも、必要に応じて変更することもできます。
ジョブ関連のイベントを生成するターゲットのセットを指定します。
これらの操作はジョブ・イベント生成基準ページで行うことができます。「設定」メニューで「インシデント」、「ジョブ・イベント」の順に選択します。
インシデントのルールおよびルール・セットを作成する前の最初の手順は、組織のビジネス要求に応じていつインシデントが作成される必要があるかを戦略的に決定することです。考慮すべき重要な質問は次のとおりです。
何のイベントでインシデントを作成する必要があるか。どのサービス中断がIT管理者により追跡され解決される必要があるか。
どの管理者が着信イベントまたはインシデントに対し通知される必要があるか。
イベントまたはインシデントが外部システム(ヘルプデスク・チケット・システムなど)へ転送されるか。
正確にビジネス要件が理解されたら、それをエンタープライズ・ルール・セットに変換します。次のガイドラインに従うと、システム・リソースを効率的に使用し、効率よく運用できます。
ターゲット(ホストやデータベースなど)を操作するルール・セットの場合は、グループを使用してターゲットをルール・セットのより少ない数の監視エンティティに統合します。グループは、インシデント管理および応答を含む、同様の監視要件を持つターゲットで構成される必要があります。
同じターゲットのグループに適用されるすべてのルールは、1つのルール・セットに統合される必要があります。同じターゲットのグループに適用されるすべてのルールは、1つのルール・セットに統合される必要があります。1つのイベント・クラスに特有のイベントに対するルール、特定のイベント・クラスおよびターゲット・タイプのイベントに適用されるルール、またはそれらのターゲットのインシデントに適用されるルールを作成できます。
ルール・セット内のルールの実行順序を活用します。ルール・セットとルール・セット内のルールは順次実行されます。そのため、ルールおよびルール・セットはその点に留意して順番を決めてください。
新規ルールを作成するとき、イベント、インシデントおよび問題のうち、どのオブジェクトにそのルールを適用するかを選択できます。次のルール使用のガイドラインは、どれを選択するかのガイドとして使用できます。
表3-7 ルール使用のガイドライン
| ルール使用 | アプリケーション |
|---|---|
|
イベントに関するルール |
Enterprise Managerで管理されているイベントのインシデントの作成。 イベントに関する通知の送信。 ヘルプデスクのアナリストによって管理されるインシデントのチケットを作成するには、イベントのインシデントを作成し、そのインシデントにチケットを作成します。 イベントをサード・パーティ管理システムに送信。 |
|
インシデントに関するルール |
インシデント・ワークフロー操作の管理(所有者の割当て、優先度の設定、エスカレーション・レベル)を自動化し、通知を送信 インシデント条件に基づくチケットの作成。たとえば、インシデントがレベル2にエスカレートされた場合にチケットを作成します。 |
|
問題に関するルール |
問題ワークフロー操作の管理(所有者の割当て、優先度の設定、エスカレーション・レベル)を自動化し、通知を送信 |
ルール・セットの例
次の例は、説明した実装ガイドラインの多くを示しています。すべてのターゲットは単一のグループに統合され、グループ・メンバーに適用されるすべてのルールは同じルール・セットに属し、ルールの実行順序が設定されています。この例では、次のようなターゲットから構成されるグループ(製品グループG)にルール・セットを適用します。
DB1(データベース)
Host1(ホスト)
WLS1(WebLogic Server)
ルール・セット内のすべてのルールは、インシデント作成、通知およびエスカレーションの3種類のアクションを実行します。
例3-1 ルール・セットの例
ルール・セットは、ターゲット: グループ・ターゲットGに適用されます。
ルール・セットのルール:
指定されたイベントでインシデントを作成するためのルール
インシデント発生時に通知を送信するルール
いくつかの条件に基づいてインシデントをエスカレーションするルール。たとえば、インシデントがオープンな時間の長さです。
ルール・セットのより詳細なビューでは、ガイドラインにどのように従ったかを確認できます。
例3-2 ルール・セットのより詳細な例
製品グループGのルール・セット
ターゲット: 製品グループG
ルール1: すべてのターゲット停止イベントのインシデントを作成します。
ルール2: 重大度がクリティカルまたは警告の特定のデータベース、ホストおよびWebLogic Serverのメトリック・アラート・イベントのインシデントを作成します。
ルール3: すべての問題ジョブ・イベントのインシデントを作成します。
ルール4: すべてのクリティカル・インシデントについてページを送信します。すべての警告インシデントについて電子メールを送信します。
ルール5: 致命的インシデントが12時間を超えてオープンされている場合は、エスカレーション・レベルを1に設定し、マネージャに電子メールを送信します。
この詳細ビューでは、すべてのグループ・メンバーに適用される5つのルールがあります。ルールの実行順序(ルール1からルール5)は、ルール・セット内の3種類のルール・アクション(ルール1から3)に対応します。
ルール1-3: インシデントの作成
ルール4: 通知
ルール5: エスカレーション
ルールの実行順序をルール・アクション・カテゴリの進行状況と同期することで、実行効率が達成されます。この例に示すように、同じイベントのセットに対し重大度に基づき異なるアクションをとる条件付きアクションを使用することで、今後、複数のルールを変更する必要なく、イベント選択条件を変更することが容易になります。注意: これは、すべてのインシデント(ルール1から3)のアクション要件が同じであることを前提としています。
次の表は、この例における明示的なルール・セット操作を示しています。
表3-8 製品グループGのためのルール・セットの例
| ルール名 | 実行順序 | 基準 | アクション | |
|---|---|---|---|---|
| 条件 | アクション | |||
|
ルール・セット: 製品グループG内のターゲット |
||||
|
ルール1 |
1番目 |
DB1の停止 Host1の停止 WLS1の停止 |
インシデントを作成します。 |
|
|
ルール2 |
2番目 |
DB1 表領域フル(%) 注意: 警告およびクリティカルのしきい値は、ルールUIではなく、メトリックおよびポリシー設定で定義されます。 Host1 CPU使用率(%) WLS1 ヒープ使用量(%) |
重大度=警告の場合 重大度=クリティカルの場合 |
インシデントを作成します。 |
|
ルール3 |
3番目 |
DB1、Host1およびWLS1での、問題ジョブのステータス変更イベントの生成 |
インシデントを作成します。 |
|
|
ルール4 |
4番目 |
製品グループGのすべてのインシデント |
重大度=警告 重大度=クリティカル |
電子メールを送信します。 ページを送信します。 |
|
ルール5 |
5番目 |
12日を超えてインシデントがオープンのまま残存 |
ステータス=致命的 |
エスカレーション・レベルを「1」にアップします。 |
ルールを使用する前に、次の前提条件が設定されていることを確認してください。
ユーザーのEnterprise Managerアカウントに通知プリファレンス(電子メールおよびスケジュール)が設定されていること。これはルールを作成および編集する管理者だけではなく、ルール・アクションの結果として通知されるユーザーにも必要です。
コネクタ、チケットまたは拡張通知を使用する場合、これらはアクション・ページで使用する前に構成する必要があります。
電子メールの通知ができるように、SMTPゲートウェイが適切に構成されていること。
ユーザーのEnterprise Managerアカウントに管理対象システムからのインシデントの管理に必要な適切な権限が付与されていること。
監視環境に対してどのイベントを発生させる必要があるかを決定した後、Enterprise Managerを電子メールおよびページを送信するように構成し、管理者用電子メール・アドレスを設定し、それらを電子メール/ページングとしてタグ付けすることで、企業の包括的な通知インフラストラクチャを構築する必要があります。さらに、組織のニーズに応じて、通知の設定に、OSスクリプト、PL/SQLプロシージャ、またはSNMPトラップのような、高度な通知方法の構成を含めることができます。Enterprise Managerの通知の詳細と設定手順については、第4章「通知の使用」を参照してください。
この手順には、適切な管理者の定義(セキュリティに対する適切な権限の割当てを含む)と、組織内で定義されたロールとドメイン所有権に基づく通知割当ての設定が含まれます。
ユーザー・アカウントの管理を実行するには、Enterprise Managerのホームページの「設定」をクリックし、「セキュリティ」、「管理者」の順に選択して管理者ページにアクセスします。
通常、インシデント管理に含まれる管理者には2つのタイプがあります。
ビジネス・ルール・アーキテクト/アナリスト: 業務の動きを深く理解し、その知識を操作上のルールに変換する管理者。これらのルールがデプロイされると、ビジネス・アーキテクトは動的組織の知識を使用して、それらのルールを最新に維持します。
エンタープライズ・ルール・セットを作成または編集するには、ビジネス・アーキテクト/アナリストに「エンタープライズ・ルール・セット」リソースに対する「エンタープライズ・ルール・セットの作成」権限が付与されている必要があります。アーキテクト/アナリストは、特定のルール・セットの管理に責任を持つ別の管理者(「エンタープライズ・ルール・セットの作成」権限がある場合もない場合もあります)とルール・セットの所有権を共有できます。
ITオペレータ/マネージャ: ITマネージャはインシデント割当ての毎日の管理に責任を負います。ITオペレータはインシデントに割り当てられ、その解決に責任を負います。
エンタープライズ・ルール・セットに必要な権限
ルール・セットの所有者として、管理者は次を実行できます。
ルール・セットを更新または削除し、ルール・セット内のルールを追加、変更または削除します。
ルール・セットの共同作成者を割り当てます。共同作成者は作成者と同じようにルール・セットを編集できます。ただし、ルール・セットを削除したり、別の共同作成者を追加することはできません。
ルール・アクションがイベント、インシデントまたは問題の更新(優先度の変更やイベントのクリアなど)である場合、アクションが成功するのは、各イベント、インシデントまたは問題に対してこのアクションを実行する権限が所有者にある場合のみです。
また、エンタープライズ・ルール・セットを作成する権限がユーザーに付与されている必要があります。
インシデントまたは問題のルールに更新アクション(優先度の変更など)がある場合、アクションが行われるのは、対応するインシデントまたは問題に対する管理権限が各ルール・セットの所有者にある場合のみです。
権限を付与するには、Enterprise Managerホームページ上の「設定」メニューから、「セキュリティ」、「管理者」の順に選択して管理者ページにアクセスします。リストから管理者を選択し、「編集」をクリックして、次の図に示すように管理者のプロパティ・ウィザードにアクセスします。
ユーザーへのイベント、インシデントおよび問題に対する権限の付与
インシデントを処理するために、関連するすべてのEnterprise Manager管理者アカウントにはインシデントの管理に必要な適切な権限が付与されている必要があります。イベント、インシデントおよび問題に対する権限は、次のルールに従い決定されます。
イベントに対する権限は、基礎となるソース・オブジェクトに対する権限に基づいて計算されます。たとえば、イベントのターゲットを表示できる場合、イベントに対する表示権限が割り当てられます。
インシデントに対する権限は、インシデント内のイベントに対する権限に基づいて計算されます。
同様に、問題に対する権限は、基礎となるインシデントに対する権限に基づいて計算されます。
ユーザーには、次の状況下でイベント、インシデントおよび問題に対する権限が付与されます。
イベントの場合、2つの権限がシステムで定義されています。
イベントの表示権限を使用すると、イベントを表示し、イベントにコメントを追加できます。
イベントの管理権限を使用すると、イベントのクローズ、イベントのインシデントの作成、イベントのチケットの作成など、イベントに対する更新アクションを実行できます。イベントをインシデントに関連付けることもできます。
|
重要: インシデントの権限は基礎となるイベントから継承されます。 |
イベントが1つのターゲットのみに発生した場合(大部分のイベント・タイプはメトリック・アラート、可用性イベントまたはサービス・レベル合意などの複数のターゲットに発生します)、次の権限が必要です。
イベントを表示するためのターゲットの「表示」。
イベントを管理するための「ターゲット・イベントの管理」。
注意: これはオペレータのサブ権限です。
イベントがターゲットとジョブの両方で発生した場合、次の権限が必要です。
ターゲットの「表示」およびイベントを表示するジョブの「表示」。
ターゲットの「表示」およびイベントを管理するジョブの「完全」。
イベントが1つのジョブでのみ発生した場合、次の権限が必要です。
イベントを表示するには、ジョブの「表示」。
イベントを管理するには、ジョブの「完全」。
イベントがメトリック拡張で発生した場合、イベントを表示するメトリック拡張に「表示」権限が必要です。メトリック拡張で発生したイベントが情報なので(インシデント・マネージャに表示されない)、イベント管理権限はこの状況では適用されません。
イベントが自己更新で発生した場合、システム権限のみが必要です。自己更新イベントは完全に情報です。
インシデントの場合、2つの権限がシステムで定義されています。
イベントの表示権限を使用すると、インシデントを表示し、インシデントにコメントを追加できます。
インシデントの管理権限を使用すると、インシデントに対する更新アクションを実行できます。インシデントに対してサポートされている更新アクションには、インシデントの割当ておよび優先度付け、解決管理、イベントの手動クローズおよびインシデントのチケットの作成が含まれます。
インシデントが1つのイベントで構成されている場合、イベントを表示できるならばインシデントを表示することができ、イベントを管理できるならばインシデントを管理できます。
インシデントが複数のイベントで構成されている場合、少なくとも1つのイベントを表示できるならばインシデントを表示することができ、少なくとも1つのイベントを管理できるならばインシデントを管理できます。
問題の場合、2つの権限が定義されています。
問題の表示権限を使用すると、問題を表示し、問題にコメントを追加できます。
問題の管理権限を使用すると、問題に対する更新アクションを実行できます。問題に対してサポートされている更新アクションには、問題の割当ておよび優先度付け、解決管理、問題の手動クローズが含まれます。
Enterprise Manager 12cでは、問題は常に1つのターゲットと関連します。それで、管理者がターゲットの表示権限を持っている場合は問題の表示権限、管理者がターゲットのmanage_target_events権限を持っている場合は問題の管理権限が、関連付けられたイベントの管理権限を暗黙的に付与します。これが次に、問題内のインシデントの管理権限を付与します。
Enterprise Manager環境で管理者が実行できる監視機能は、そのユーザーに付与されている権限に依存します。管理対象のインフラストラクチャの整合性およびセキュリティを保持するには、特定のロールの必須権限のみ付与する必要があります。ユーザー・ロールに基づいて適切な権限レベルを付与するには、次のガイドラインを使用できます。
監視を設定する管理者
権限でロールを作成し、管理者に付与します。
共有アカウントではなく、個別のユーザー・アカウントを使用することをお薦めします。
スーパー管理者を使用する場合は、sysmanを使用しないでください。
権限がターゲットに基づく場合は、ターゲットを含む権限伝播グループを作成し(または、要件を満たす場合は管理グループを使用し)、そのグループへの権限をロールに付与します。
イベント/インシデントに応答する管理者
ロールを作成し、管理者に付与します。
関連するターゲットを含む権限伝播グループを作成し(または、要件を満たす場合は管理グループを使用し)、そのグループへの適切な権限をロールに付与します。
例: ロールDB_Adminsを作成し、関連データベースを含む権限伝播グループDB-groupに対する「ターゲット・イベントの管理」を付与します。その後、ロールDB_AdminsをDBAに付与します。
監視操作および必要な権限
Enterprise Managerは、Enterprise Managerで実行される操作をより詳細に制御できる細分化された権限をサポートしています。
次の表に、これらをサポートするために必要なEnterprise Managerでの様々なジョブ職責および対応する権限をいくつか示します。
次の表に、特定の監視職責を実施するために必要な権限レベルの概要を示します。
表3-9 監視操作および必要な権限
| 監視操作 | 必要な権限 |
|---|---|
|
監視設定 |
|
|
SMTPゲートウェイの構成(email) |
スーパー管理者 |
|
拡張通知メソッドの作成(SNMPトラップなど) |
スーパー管理者 |
|
イベントまたはチケッティング・コネクタの構成 |
スーパー管理者 |
|
ロールの作成 |
スーパー管理者 |
|
管理グループ階層の作成 |
完全な任意のターゲット 権限伝播グループの作成 |
|
管理グループ階層の編集 |
完全な任意のターゲット 権限伝播グループの作成(管理グループ階層のレベル内でグループ基準としてターゲット・プロパティ値を追加する場合) |
|
管理グループ階層の削除 |
完全な任意のターゲット |
|
「グループ管理」ページでの管理グループ階層全体の表示 |
任意のターゲットの表示 注意: グループの一部に対する権限のみを持つ管理者は、「ターゲット」 -> 「グループ」でアクセスできる「グループ」リスト・ページにあるグループのみ表示できます。 |
|
監視テンプレートの使用 |
新しい監視テンプレートを作成するために必要な権限はありません。ただし、監視テンプレートに修正処理が含まれている場合は、ジョブ・システムでの作成権限が必要です。 別のユーザーが作成したテンプレートを使用するための、特定の監視テンプレートでの表示(たとえば、監視テンプレートをテンプレート・コレクションに追加する場合など) |
|
テンプレート・コレクションの使用 |
テンプレート・コレクションの作成(新しいテンプレート・コレクションを作成するため)、別のユーザーが作成したテンプレート・コレクションに対する表示/関連付けを行うための特定のテンプレート・コレクションの表示、任意のテンプレート・コレクションに対する表示/関連付けを行うためのテンプレート・コレクションの表示、別のユーザーが作成したテンプレート・コレクションを編集/削除するための特定のテンプレート・コレクションでのフル・テンプレート・コレクション |
|
管理グループへのテンプレート・コレクションの関連付け |
グループでのテンプレート・コレクション操作の管理(「ターゲット・コンプライアンスの管理」および「ターゲット・メトリックの管理」権限を含む) テンプレート・コレクションでのテンプレート・コレクションの表示 |
|
管理グループでの操作 |
|
|
グループに対する権限の管理(他のユーザーへの権限付与など) |
グループに対するグループ管理 |
|
ターゲット・プロパティの設定による管理グループへのターゲットの追加 |
ターゲットの構成(管理グループに追加するターゲット上) |
|
グループと関連付けられたテンプレート・コレクションの手動での同期化の実行 |
グループでのテンプレート・コレクション操作の管理 |
|
管理グループのメンバーに対する操作 |
|
|
Enterprise Managerからのターゲットの削除 |
ターゲットに対するフル権限(フルにも次の権限が含まれます) |
|
計画停止のためのブラックアウトの設定 監視設定の変更 監視構成の変更 ターゲットでのイベントおよびインシデントの管理 ターゲットの表示、イベントまたはインシデントの通知の受信 |
ターゲットに対して実行する演算子にも次の権限が含まれます。
|
|
インシデント・ルール・セットの作成 |
エンタープライズ・ルール・セットの作成 ターゲットでのターゲット・イベントの管理(ルールがターゲットのインシデントを作成している場合) |
|
ロールへの管理グループに対する権限付与 |
管理グループの作成者の場合、追加の権限は必要ありません。 |
|
ターゲットのプロパティ値の設定 |
ターゲットの構成 |
|
テンプレート・コレクションの一部である監視テンプレートの編集 |
監視テンプレートに対するフル権限 管理グループでのターゲット・メトリックの管理 |
|
特定のターゲットでの監視設定の変更 |
ターゲット・メトリックの管理 |
|
イベント、インシデントの電子メールの受信 |
ターゲットでの表示 ソース・オブジェクトでの表示(ジョブ・イベントのジョブでの表示など) |
|
イベントのインシデントの作成 |
ターゲット・イベントの管理 |
|
インシデント管理操作(確認、インシデントの割当て、優先順位付け、エスカレーション・レベルの設定など) |
ターゲット・イベントの管理 |
|
注意: SYSMANは、Enterprise Managerインフラストラクチャのインストールおよび保守を目的としたシステム・アカウントです。スーパー管理者としてのEnterprise Managerへの管理者アクセスには使用しないでください。 |
ルール・セットは受信イベント、インシデントおよび問題、またはそれらの更新に応答して、アクションを自動化します。この項では、最も一般的なタスクと例について説明します。
通常、ルール・セットを作成するには、次の手順を実行します。
「設定」メニューで「インシデント」、「インシデント・ルール」の順に選択します。
インシデント・ルール - すべてのエンタープライズ・ルール・ページで、既存のルール・セットを編集するか、または新しいルール・セットを作成します。新しいルール・セットの場合、ルールを適用するターゲットを最初に選択する必要があります。ルールはルール・セットのコンテキストで作成されます。
|
注意: 既存のルール・セットがない場合は、「ルール・セットの作成...」をクリックしてルール・セットを作成します。次に、ルール・セットの作成の一環としてルールを作成します。 |
ターゲット・ライフサイクル・ステータスに基づくルール・セットの範囲の絞り込み
新しいルール・セットの作成時に、ターゲットの「ライフサイクル・ステータス」値に基づいて、絞り込まれたターゲットのセットに、ルール・セットを適用することを選択できます。たとえば、「ライフサイクル・ステータス」が「ステージング」および「本番」のターゲットにのみ適用するだけの1つのルール・セットを作成できます。次の図に示すように、「ライフサイクル・ステータス」フィルタを設定することで、ルール・セットの範囲を決定します。

このフィルタを使用することで、その「ライフサイクル・ステータス」に基づくターゲット用のルールを作成できます。そのようなターゲットのみを含むグループを先に作成する必要はありません。
ルール・セットの編集ページの「ルール」タブで、「作成...」をクリックし、「作成するルールのタイプを選択」ポップアップ・ダイアログで作成するルールのタイプ(「イベント」、「インシデント」、「問題」)を選択します。「続行」をクリックします。
新規ルールの作成ウィザードで、必要な情報を指定します。
ルールの定義が終了したら、「続行」をクリックし、ルールをルール・セットに追加します。「保存」をクリックし、ルール・セットに対して行った変更を保存します。
インシデントを作成するルールを作成するには、次の手順を実行します。
「設定」メニューで「インシデント」、「インシデント・ルール」の順に選択します。
イベントを管理するルールが含まれる既存のルール・セットがあるかどうかを確認します。インシデント・ルール・ページで「検索」オプションを使用して、ルール/ルール・セットの名前、説明、ターゲット名またはターゲットのターゲット・タイプおよび関連ルール・セットを検索します。ターゲット名またはこのターゲットが属するグループ・ターゲット名で検索し、ターゲットを管理するルール・セットを見つけることができます。
注意: 既存のルール・セットがない場合は、「ルール・セットの作成」をクリックしてルール・セットを作成します。次に、ルール・セットの作成の一環としてルールを作成します。
新規ルールを含むルール・セットを選択します。ルール・セットの編集ページの「ルール」タブで、「編集...」をクリックします。
「作成...」をクリックします。
「受信イベントおよびイベントの更新」を選択します。
「続行」をクリックします。
新規ルールの作成ウィザードを使用してルール詳細を指定します。
ルールの適用先である「イベント・タイプ」(「メトリック・アラート」など)を選択します。(「メトリック・アラート」は、タイプ「ターゲット」のルール・セットに対して使用可能です)。注意: 1つのルールでは1つのイベント・タイプしか選択できません。一度選択すると、ルールの編集中は変更できません。
次に、「特定のメトリック」を選択することにより、メトリック・アラートを指定できます。メトリック・アラートを選択するための表が表示されます。「+」(追加)ボタンをクリックし、メトリック・セレクタを起動します。特定のメトリック・アラートの選択ページで、ターゲット・タイプ(「データベース・インスタンス」など)を選択します。関連するメトリックのリストが表示されます。興味のあるメトリックを選択します。「OK」をクリックします。
重大度および修正処理ステータスを選択することもできます。
初期情報を指定した後、「次へ」をクリックします。「+」(追加)をクリックし、イベントのトリガー時に実行するアクションを追加します。アクションの1つとして「インシデントの作成」があります。
インシデントの作成の一環として、インシデントを特定のユーザーに割り当て、重要度を設定し、チケットを作成できます。すべての条件処理を追加した後、「続行」をクリックします。
アクションの追加ページのすべての情報を指定した後で、「次へ」をクリックしてルールの名前と説明を指定します。確認ページで、すべての情報が正しいことを確認します。修正するには「戻る」をクリックします。ルール・セットの編集(ルール・セットの作成)ページに戻るには「続行」をクリックします。
「保存」をクリックし、ルール・セットおよびルールの変更がデータベースに保存されるようにします。
前のステップで選択したメトリックでメトリック・アラート・イベントを生成し、ルールをテストします。
インシデントのエスカレーションを管理するルールを作成する手順:
「設定」メニューで「インシデント」、「インシデント・ルール」の順に選択します。
インシデントを管理するルールが含まれる既存のルール・セットがあるかどうかを確認します。それをインシデントについての任意の既存ルール・セットに追加できます。
注意: 既存のルール・セットがない場合は、「ルール・セットの作成」をクリックしてルール・セットを作成します。次に、ルール・セットの作成の一環としてルールを作成します。
新規ルールを含むルール・セットを選択します。ルール・セットの編集ページの「ルール」タブで、「編集」をクリックし、次の操作を行います。
「作成...」をクリックします。
「新たに作成されたインシデントおよびインシデントの更新」を選択します。
「続行」をクリックします。
ここでは、デモ用として、エスカレーションは本番データベースに基づいています。
組織のポリシーに従って、エスカレーション・レベル1のインシデントになるとDBAマネージャに通知され、致命的なインシデントは48時間の間オープンされます。同様に、インシデントがレベル2にエスカレートし、重大度が致命的で、72時間の間オープンされている場合、DBAディレクタにページで通知されます。致命的インシデントが96時間後までオープンされたままだと、レベル3にエスカレートし、業務VPに通知されます。
新規ルールの作成ウィザードを使用してルール詳細を指定します。
ルールを設定して新しく作成したすべてのインシデントに適用する場合、またはインシデントが「致命的」重大度に更新されるときには、「特定のインシデント」オプションを選択し、条件に重大度が致命的」を追加します。
アクションの追加ページの「アクションの条件」リージョンで、「指定された条件に一致する場合のみアクションを実行」を選択します。
「インシデントは一定の時間オープンであり、特定の状態にあります(時間とオプションで式を選択)」を選択します。
時間に48時間を選択し、ステータスは「解決されていません」または「クローズ済」です。
「通知」リージョンに、電子メールまたはページによって通知する管理者の名前を入力します。「続行」をクリックし、現在の条件とアクションのセットを保存します。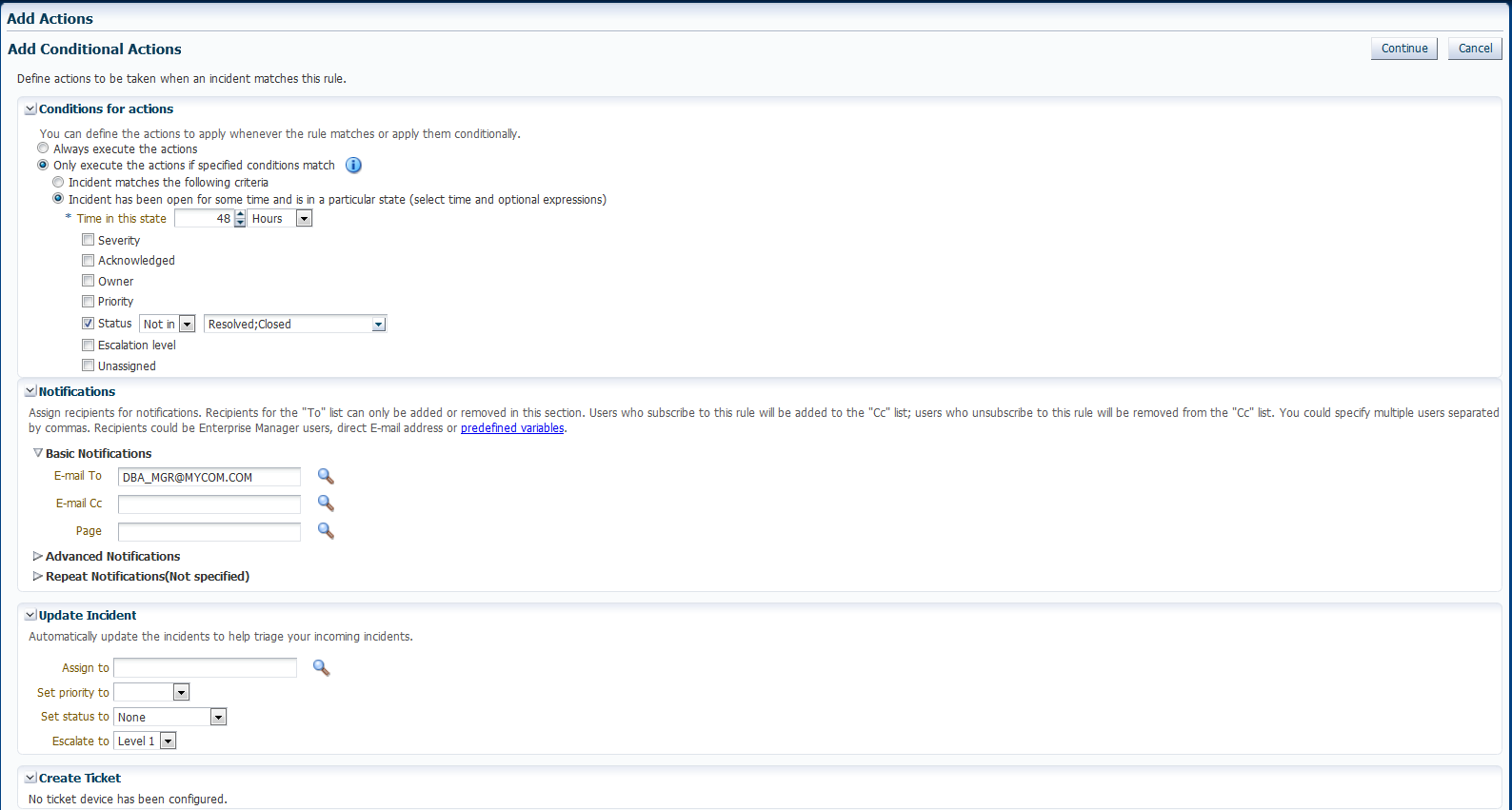
手順bおよびcを繰り返して、DBAディレクタにページで通知します(こ「この状態での時間」は72時間、ステータスは「解決されていません」または「クローズ済」)。96時間以上オープンされている場合、エスカレーション・レベルを3に設定し、業務VPにページで通知します。
追加されたアクション・セットを確認して、「次へ」をクリックします。「次へ」をクリックして「サマリー」画面に移動します。サマリー情報を確認し、「続行」をクリックしてルールを保存します。
既存のエンタープライズ・ルールのシーケンスを確認し、新しく作成したルールをそのシーケンスに配置します。
ルール・セットの編集ページでdesired rule from the Rules表をクリックし、「アクション」メニューから「ルールの並替え」を選択して、ルール・セット内のルールの順序を変更してから、「保存」をクリックして、ルールの順序の変更を保存します。
シナリオ例
インシデントのエスカレーション・プロセスを簡略化するには、運用管理者が未解決のインシデントを、その期間に基づいてエスカレートするルールを次のように作成します。
インシデントが30分間オープンの場合にはレベル1へ
インシデントが1時間オープンの場合にはレベル2へ
インシデントが90分間オープンの場合にはレベル3へ
組織のポリシーに従って、エスカレーション・レベル1になるとDBAマネージャに通知されます。同じように、DBAディレクタとオペレーションVPは、インシデントがそれぞれレベル2、レベル3にエスカレートすると呼び出されます。
そこで、運用管理者は前述のロジックと、通知要件を達成する個々のルールのEnterprise Manager管理者IDを入力します。Enterprise Manager管理者IDは、必要なターゲット権限と通知プリファレンス(つまり、電子メール・アドレスとスケジュール)を持つ各ユーザーを表します。
1つの問題に付随して20を超えるインシデントが発生するような組織では、未解決の問題は、問題が発生したターゲットのターゲット・タイプに基づいて、適切な管理者に自動的に割り当てることが必要になります。
そこで、問題に伴うインシデントの件数を監視し、特定のターゲット・タイプを処理するのに適した管理者に通知する問題ルールを作成します。
問題の所有者とオペレーション・マネージャには、電子メールで通知されます。
問題をエスカレートするルールを作成する手順:
インシデント・ルール・ページにナビゲートします。
「設定」メニューで「インシデント」、「インシデント・ルール」の順に選択します。
インシデント・ルール - すべてのエンタープライズ・ルール・ページで、新規のルール・セットを作成(「ルール・セットの作成...」をクリック)するか既存のルール・セットを編集(ルール・セットをハイライトして「編集...」をクリック)します。ルールはルール・セットのコンテキストで作成されます。
注意: 既存のルール・セットがない場合は、「ルール・セットの作成」をクリックしてルール・セットを作成します。次に、ルール・セットの作成の一環としてルールを作成します。
ルール・セットの編集ページの「ルール」セクションで、「作成...」をクリックします。
「作成するルールのタイプを選択」ダイアログで、「新たに作成された問題および問題の更新」を選択し、「続行」をクリックします。
新規ルールの作成ページで、「特定の問題」を選択し、次の基準を追加します。
「属性名」は「インシデント数」、「演算子」は「次以上」、および「値」は「20」です。
「次」をクリックします。
アクションの追加ページのアクションの条件リージョンで、「常にアクションを実行」を選択します。ルールが条件を満たすときに実行するアクションは、次のとおりです。
「通知」リージョンで、問題の所有者およびオペレーション・マネージャに電子メールを送信します。
「問題の更新」リージョンの「割当て先」フィールドに、適切な管理者の電子メール・アドレスを入力します。
「続行」をクリックします。
ルール・サマリーを検討します。必要に応じて修正します。「続行」をクリックしてルール・セットの編集ページに戻り、「保存」をクリックして、ルール・セットを保存します。
ルール・セットを開発する際、考えられるすべてのイベント条件に一致するルールを作成することが困難になる可能性があります。以前は、ルールをテストする唯一の方法は、監視対象の環境でイベントをトリガーし、イベントに一致するルールとルールが実行する操作を確認することでした。Enterprise Managerリリース12.1.0.4以上では、既存のイベントをシミュレートできるため、ルール・セットの開発フェーズでルール操作をテストでき、特定のイベント条件が発生するまで待機することはありません。ルールのシミュレーション機能によって、特定のイベントがルールでどのように実行されるかを確認できます。特定のイベントに一致するルールをすぐに確認し、どのような操作を実行するかを確認します。
|
注意: ルールのシミュレート機能は、イベント・ルールでのみ使用できます。この機能でインシデント・ルールをテストすることはできません。 |
ルールをシミュレートするには:
この手順では、ルール・セットが作成済であることが前提になります。ルール・セットの作成の詳細は、「ルール・セットの作成」を参照してください。ルール・タイプが「受信イベントおよびイベントの更新」であることを確認します。
「設定」メニューで「インシデント」、「インシデント・ルール」の順に選択します。「インシデント・ルール - すべてのエンタープライズ・ルール」ページが表示されます。
「ルールのシミュレート」をクリックします。「ルールのシミュレート」ダイアログが表示されます。
一致するイベントを検索するために必要な検索パラメータを入力し、「検索」をクリックします。
結果のリストからイベントを選択します。
「シミュレーションの開始」をクリックします。イベントが新しく発生したかのように、ルールによってイベントが渡されます。ルールは、現在の通知構成に基づいてシミュレートされます(電子メール・アドレス、割り当てられた管理者のスケジュール、繰返し通知設定など)。
ターゲット名の変更: 特定の状況下では、ルール・ターゲットではないターゲットで、ルール基準に一致するイベントが発生する可能性があります。イベントは、テストを目的としているだけです。シミュレーション用に別のターゲットを使用するには、「ターゲット名の変更およびシミュレーションの開始」をクリックします。
結果が表示されます。
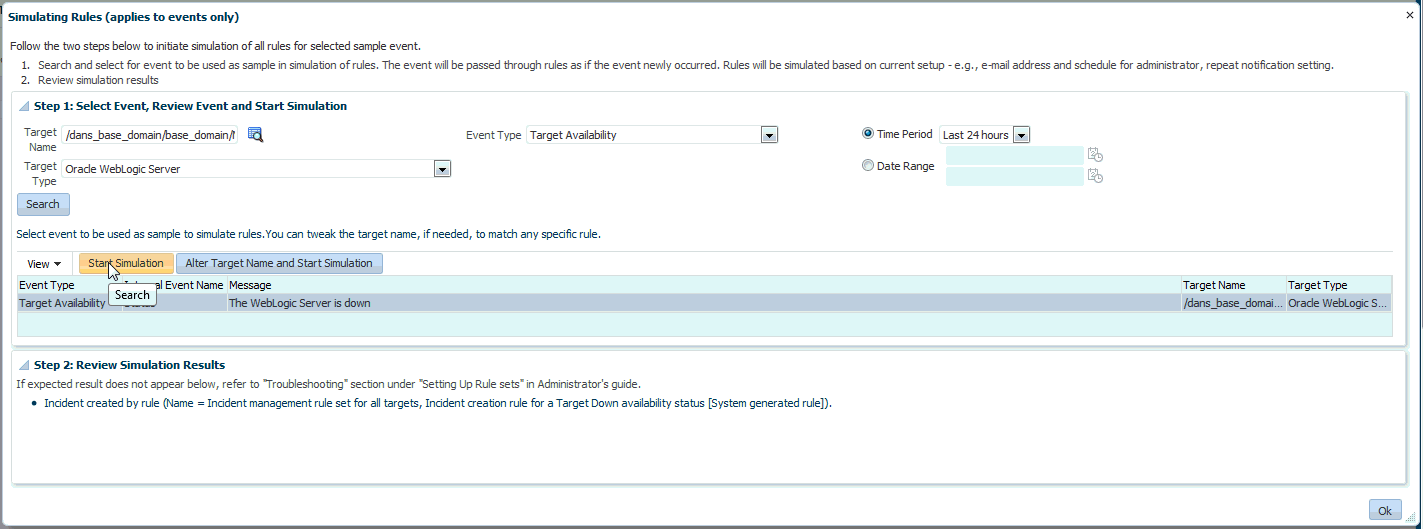
本番ターゲットに対するイベント・ルールのテスト: テスト・ターゲットに対してイベントを生成することもできますが、最終確認のために本番ターゲットで動作を確認したい場合もあるでしょう。本番ターゲットに対するイベント・ルールのテストを、ルール・アクション(電子メールの送信、SNMPトラップ、トラブル・チケットのオープン)を実行することなく安全に行うことができます。本番ターゲットに対しイベント・ルールをテストするには、「ターゲット名」を本番ターゲットに変更します。シミュレーションの実行中、Enterprise Managerによって実行されるアクションのリストが表示されます。ただし、実際にはこれらのアクションが本番ターゲットで実行されることはありません。
ルール操作が意図しないものの場合は、ルールを編集し、目的の操作が実行されるまで、ルールのシミュレーション・プロセスを繰り返します。予想または期待したとおりのシミュレーション結果を得るために、次のガイドラインを参考にしてください。
電子メールに関するルール・アクションが実行されない場合の対処は次のとおりです。
当該イベントを対象にして電子メールを送信するアクションを実行するルールが存在することを確認します。
Enterprise Managerの管理者が電子メールの受信者として指定されている場合、管理者に電子メール・アドレスが与えられ、通知スケジュールが設定されていることを確認します。
イベントのターゲットに対して、電子メールの受信者が少なくとも表示権限を持っていることを確認します。
SMTPのゲートウェイ設定を確認し、さらに管理者で「電子メールのテスト」が実行済であることを確認します。
インシデントの作成やチケットのオープンのようなその他のルール・アクションが実行されない場合の対処は次のとおりです。
当該イベントを対象にして対応するアクション(インシデントの作成など)を実行するルールが存在することを確認します。
ルール・セットがターゲットを対象にしていることを確認します。
イベントのターゲットに対して、ルール・セット所有者が少なくともターゲットのイベント管理権限を持っていることを確認します。
チケットのオープン、SNMPトラップの送信またはイベント・コネクタの呼出しのような通知に関して、これらがイベント・ルールのアクションとして指定されていることを確認します。
DBAは、48時間以内に解決しないと自分の所有するインシデントがエスカレートすることを知っています。ルールによってインシデントがエスカレートされたとき、このDBAに通知する必要があります。インシデントをエスカレートするルールにサブスクライブすると、このDBAはルールによってインシデントがエスカレートされたとき常に通知を受けるようになります。
通知サブスクリプションを設定する前に、48時間以内に解決されなかったデータベースの高優先度インシデントをエスカレートするルールが存在していることを確認します。
次の手順を実行してください。
「設定」メニューから、「インシデント」、「インシデント・ルール」の順に選択します。
インシデント・ルール - すべてのエンタープライズ・ルール・ページで、該当するインシデントのエスカレーション・ルールを含むルール・セットをクリックし、「編集」をクリックします。ルールはルール・セットのコンテキストで作成されます。
注意: 既存のルール・セットがない場合は、「ルール・セットの作成」をクリックしてルール・セットを作成します。次に、ルール・セットの作成の一環としてルールを作成します。
ルール・セットの編集ページの「ルール」セクションで、変更するエスカレーション・ルールをハイライトして「編集」をクリックします。
アクションの追加ページに移動します。
インシデントをエスカレートするアクションを選択し、「編集」をクリックします。
「通知」セクションで、「電子メールCc」リストにDBAを追加します。
「続行」をクリックしてルール・セットの編集ページに戻り、「保存」をクリックします。
エンタープライズ・ルールを編集した結果、インシデントが48時間未解決のままになると、ルールによってエスカレーション・レベルが1とマークされます。インシデントのエスカレーションを通知する電子メールが、DBAに送信されます。
代替ルール・セット・サブスクリプション方法: インシデント・ルール: すべてのエンタープライズ・ルール・ページで、インシデント・ルール表のルールを選択します。「アクション」メニューで、「電子メール」、「自分をサブスクライブ」(または「管理者をサブスクライブ....」)の順に選択します。
あるDBAが、管理しているデータベースに対してバックアップ・ジョブを設定しました。このジョブの一部として、DBAは「完了」のジョブ・ステータスに関する電子メール通知にサブスクライブしました。ルールを作成する前に、DBAがジョブの作成に必要な権限を持っていることを確認します。ジョブ権限の要件については、第11章「ジョブ・システムと修正処理の使用」を参照してください。
次の手順を実行してください。
ルール・ページに移動します。
「設定」メニューで「インシデント」、「インシデント・ルール」の順に選択します。
インシデント・ルール - すべてのエンタープライズ・ルール・ページで、既存のルール・セットを編集(ルール・セットをハイライトして「編集」をクリック)するか、新規ルール・セットを作成します。
注意: このルール・セットはプライベート・ルール・セットとして定義されている必要があります。
ルール・セットの編集ページの「ルール」タブで、「作成...」、「受信イベントおよびイベントの更新」の順に選択します。「続行」をクリックします。
イベントの選択ページで、「ジョブ・ステータスの変更」として「イベント・タイプ」を選択します。特定のジョブを選択するか、パターン(「バックアップ管理」など)を指定することにより、興味のあるジョブを選択します。
属性を追加することにより、別の基準を追加します(「ターゲット・タイプ」として「データベース・インスタンス」)。
条件アクションを追加します。たとえば、イベントが満たす基準として「重大度」は「情報」、通知は「電子メールを送信」にします。
ルール・サマリーを検討します。必要に応じて修正します。「保存」をクリックします。
データベース・バックアップ・ジョブを作成し、ジョブが完了したときの電子メール通知にサブスクライブします。
ジョブが完了すると、そのジョブのジョブ完了状態を示す情報イベントが発行されます。新しく作成したルールは、受信ジョブ・イベントに一致しているとみなされ、電子メールがDBAに送信されます。
電子メールを受信したDBAはリンクをクリックし、Enterprise Managerコンソールでイベントの詳細セクションにアクセスできます。
データ・センターは、ビジネスの優先度に応じて協力しながらイベントおよびインシデントを管理できる作業手法に従います。Enterprise Managerには、この管理および自動化を実現するために次の機能が用意されています。
適切な管理者に対する通知の送信。
インシデントおよびルールの作成。
インシデントの初期所有権の割当て、および場合によってはシフト割当てまたは専門知識に基づいた所有権の委譲
解決ステータスの追跡
影響を受けるコンポーネントおよびインシデントの性質に基づいた優先度の割当て
インシデントのエスカレート。
My Oracle Supportのナレッジ記事へのアクセス
Oracleソフトウェアの問題に関するサポートをリクエストするためのOracle Service Requestのオープン。
次の操作を実行することで、インシデントの解決情報を更新できます。
「すべてのオープン・インシデント」ビューで、インシデントを選択します。
詳細ページが表示されたら「一般」タブをクリックし、「管理」をクリックします。「管理」ダイアログが表示されます。
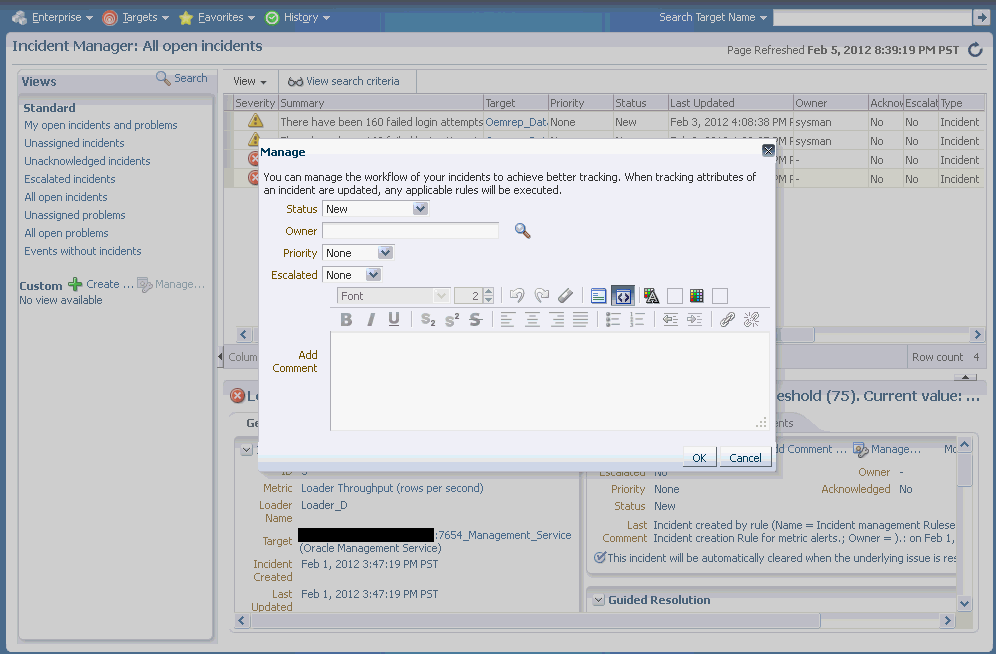
これで、優先順位を調整し、インシデントをエスカレートし、特定のITオペレータに割り当てることが可能になります。
インシデントの処理には次のステージが含まれます。
Enterprise Managerには、処理が必要な事項を発見できるアクセス・ポイントが複数用意されています。インシデント管理の主な焦点は、インシデント・マネージャ・コンソールですが、Enterprise Managerにも、別の通知方法が用意されています。対応が必要な問題があることを通知する最も一般的な方法は電子メールです。しかし、インシデント情報は次の場所にもあります。
カスタム・ビュー(「カスタム・ビューの設定」を参照)
グループまたはシステム・ホームページ(第6章「グループの管理」参照)
ターゲット・ホームページ
インシデント・マネージャ(システムまたはターゲットのコンテキスト)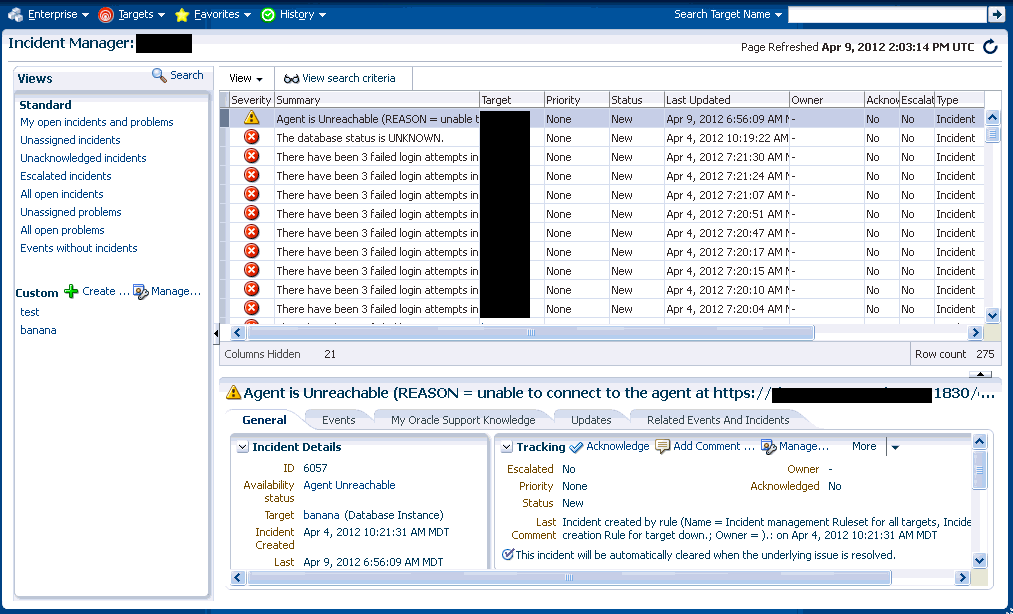
Enterprise Managerコンソール 
インシデントの最終更新時間、ターゲット名、ターゲット・タイプまたはインシデント・ステータスなどの様々なインシデント属性に基づき、インシデントを検索できます。
インシデント・マネージャ・ページにナビゲートします。
Enterprise Managerホームページ上の「エンタープライズ」メニューから、「監視」を選択し、「インシデント・マネージャ」を選択します。
左側の「表示」リージョンで、「検索」をクリックします。
「検索」リージョンで、「タイプ」列を使用してインシデントを検索し、「インシデント」を選択します。
「基準」リージョンで、適切な基準をすべて選択します。基準にフィールドを追加するには、「フィールドの追加」をクリックして適切なフィールドを選択します。
適切な基準を指定した後、「結果取得」をクリックします。
インシデントのリストが求めているものと一致することを確認します。一致しない場合は、必要に応じて検索基準を変更します。
この表に関連付けられているすべての列を表示する場合には、「表示」メニューで「列」、「すべて表示」の順に選択します。
ターゲットのライフサイクル・ステータスによるインシデントの検索
高レベルのインシデント属性を使用した検索に加えて、個別のライフサイクル・ステータスに基づくさらに詳細な検索を実行することもできます。簡単に言うと、ライフサイクル・ステータスは、ターゲットの運用ステータスを示すターゲット・プロパティです。検索できるステータス・オプションは次のとおりです。
すべて
基幹
本番
ステージング
テスト
開発
ライフサイクル・ステータスの詳細は、第3.4.7項「イベントの優先度付け」を参照してください。
ターゲットのライフサイクル・ステータスによりインシデントを検索するには、次の手順に従います。
インシデント・マネージャ・ページにナビゲートします。
Enterprise Managerホームページ上の「エンタープライズ」メニューから、「監視」を選択し、「インシデント・マネージャ」を選択します。
左側の「表示」リージョンで、「検索」をクリックします。
「検索」リージョンで「フィールドの追加」をクリックします。ポップアップ・メニューが表示されて、使用可能なライフサイクル・ステータスを示します。
1つ以上のライフサイクル・ステータス・オプションを選択します。
追加の検索基準を入力します。
「結果取得」をクリックします。
インシデント・マネージャでも、焦点を当てる必要のあるインシデントや問題にすばやくアクセスできるカスタム・ビューを定義できます。たとえば、所有するすべてのクリティカル・データベース・インシデントを表示するビューを定義できます。関心のあるインシデント属性のみを表示するビュー・プリファレンスを指定および保存することで、Enterprise Managerで一致するインシデントのリストのみを表示します。
優先度1など、特定の属性を持つインシデントのみを検索できます。このビューにより、毎日の優先順位決定のために適切なインシデントに容易にアクセスできます。検索基準を「All priority 1 incidents for my targets」という名前のフィルタとして保存できます。このビューはすぐにUIで使用可能となり、ログインして特定のインシデントにアクセスするときに、いつでも使用できます。最後に使用したビューは、次にログインするときに使用されるデフォルトのビューになります。
次の手順を実行してください。
インシデント・マネージャ・ページにナビゲートします。
Enterprise Managerホームページ上の「エンタープライズ」メニューから、「監視」を選択し、「インシデント・マネージャ」を選択します。
左側にある「マイ・ビュー」リージョンで、作成アイコン(+)をクリックします。
「検索」リージョンで、「タイプ」列を使用してインシデントを検索し、「インシデント」を選択します。
「基準」リージョンで、適切な基準をすべて選択します。基準にフィールドを追加するには、「フィールドの追加」をクリックして適切なフィールドを選択します。
適切な基準を指定した後、「結果取得」をクリックします。
インシデントのリストが求めているものと一致することを確認します。一致しない場合は、必要に応じて検索基準を変更します。
この表に関連付けられているすべての列を表示する場合には、「表示」メニューで「列」、「すべて表示」の順に選択します。
表示する列のサブセットを選択と、それらを表示する順番を選択するには、「ビュー」メニューで、「列」、「列の管理」の順に選択します。表に追加できる列のリストを示すダイアログが表示されます。
「ビューの作成」ボタンをクリックします。
ビュー名を入力します。このビューを他の管理者が使用する場合は、「共有」オプションをチェックします。
「OK」をクリックして、ビューを保存します。
独自のビューを作成すると、それらはプライベートになります(表示のみ可能)。Enterprise Managerリリース12.1.0.4以上では、他の管理者とプライベート・ビューを共有できます。ビューを共有すると、すべてのEnterprise Managerユーザーがそのビューを使用できるようになります。
前述のとおり、ビュー作成プロセスでビューを共有する機会があります。カスタム・ビューを作成済の場合は、いつでも共有が可能です。
インシデント・マネージャにナビゲートします。
Enterprise Managerホームページ上の「エンタープライズ」メニューから、「監視」を選択し、「インシデント・マネージャ」を選択します。
「マイ・ビュー」リージョンから、「管理」アイコンをクリックします。
「カスタム・ビューの管理」ダイアログから、カスタム・ビューを選択します。
「共有」 (ビューがすでに共有されており、共有を解除する場合は「共有解除」)をクリックします。
「はい」をクリックして、共有/共有解除操作を確定します。
次に、考えられる1つのインシデント管理シナリオを順を追って説明します。
インシデント・マネージャにナビゲートします。
Enterprise Managerホームページ上の「エンタープライズ」メニューから、「監視」を選択し、「インシデント・マネージャ」を選択します。
ビューを使用したインシデントのリストのフィルタリング。たとえば、「オープンなインシデントと問題」ビューを使用して、自分に割り当てられているインシデントおよび問題を確認します。次に、優先度に従ってリストをソートできます。
インシデントを選択して、インシデントを処理します。「一般」タブで「確認」をクリックし、自分がこのインシデントで作業中であることを示し、このインシデントの通知を繰り返し受信することを停止します。
インシデントの確認に加えて、次のようなその他のインシデント管理操作を実行できます。
コメントの追加。
インシデントの管理。インシデント管理オプションの詳細は、第3.3.6項「複数のインシデント、イベントおよび問題への一括応答」を参照してください。
サマリーの編集。
チケットの手動作成。
インシデントの抑制/抑制解除。
インシデントのクリア。
個々のインシデントを処理している間にも、新しいインシデントが発生する可能性があります。「リフレッシュ」アイコンをクリックしてインシデントのリストを更新してください。
インシデントに対する解決策がわからない場合には、インシデントのページで使用できる次の方法をいずれか、またはすべて使用してください。
「ガイドされた解決」リージョンを使用して、使用可能な任意の推奨、診断および解決リンクにアクセスします。
My Oracle Supportのナレッジ・ベースで、インシデントに対する既知の解決策を確認します。
関連するイベントおよびインシデント・タブで、関連するインシデントを調べます。
解決策が判明し、すぐに解決できる場合には、システムに付属しているツールを使用してインシデントを解決します。
多くの場合、基礎となる原因が修正されると、インシデントは次の標準サイクルで解消されます。ただし、ログ・ベースのインシデントの場合はインシデントをクリアしてください。
または、ターゲットのホームページから特定のターゲットのインシデントを処理できます。「ターゲット」メニューから、「監視」、「インシデント・マネージャ」の順に選択し、そのターゲット(またはグループ)のインシデントにアクセスします。
複数のインシデントに同じ方法で応答する必要がある場合があります。たとえば、いくつかの本番データベースで表領域が不足している問題により、自分に割り当てられたインシデントのクラスタがあるとします。上司はその表領域を別の管理者が調達した記憶域システムに転送することを提案しています。この状況で、表領域のすべてのインシデントをカスタマイズされた解決状態の"Waiting for Hardware"に設定します。また、インシデントを別の管理者に割り当て、シナリオを説明するコメントを追加します。この状況で、これらのすべてのインシデントを個別にではなく一括で更新します。
インシデントに一括で応答するには、次の手順に従います。
インシデント・マネージャにナビゲートします。
Enterprise Managerホームページ上の「エンタープライズ」メニューから、「監視」を選択し、「インシデント・マネージャ」を選択します。
ビューを使用して、インシデントのリストを処理するインシデントのサブセットへとフィルタします。たとえば、「オープンなインシデントと問題」ビューを使用して、自分に割り当てられているインシデントおよび問題を確認できます。次に、優先度に従ってリストをソートできます。
応答するインシデントを選択します。[Ctrl]キーを押しながら個別のインシデントを選択することで、複数の項目を選択できます。または[Shift]キーを押しながら最初と最後のインシデントを選択することで、インシデントの連続したブロックを選択できます。
「アクション」メニューで目的の応答アクションを選択します。
確認: インシデントを表示したことを示します。このオプションはまた、インシデントについての通知が繰り返し送信されることを停止します。これにより「確認」フラグが「はい」に設定され、自分がインシデントの所有者になります。
管理: インシデントに対し複数処理の応答を実行できます。
確認: インシデントが確認された場合、そのインシデントは暗黙的にそれを確認したユーザーに割り当てられます。ユーザーがインシデントを自分自身に割り当てた場合、そのインシデントは確認済とみなされます。一度確認済となったインシデントを未確認にはできません。確認することにより、そのインシデントについての通知が繰り返されることも停止します。
割当て先: インシデントをインシデントの所有権を持つ管理者に割り当てます。
優先度付け: インシデントの優先度レベルは、「なし」、「緊急」、「非常に高」、「高」、「中」、「低」の、そのまま使用できる優先度の値のいずれかを選択することで設定できます。
インシデント・ステータス: インシデントの解決状態を、「調査中」、「解決」またはカスタム定義のステータスのいずれかを選択することで設定できます。
エスカレーション・レベル: 管理者はエスカレーション・レベルを、デフォルト値の「なし」に加えてレベル1から5まで設定して、インシデントを更新できます。エスカレートされた問題は、エスカレーションを「なし」に設定することで、エスカレートを解除できます。適切なエスカレーション・レベルは作成したITプロシージャにより異なります。
コメント: インシデントの所有者に伝える内容などのコメントを入力できます。
抑止: インシデントを抑止することで、対応する通知を停止し、即時使用可能なビューおよびデフォルトの合計(サマリー・リージョンに表示されるものなど)から削除します。抑止は、通常、インシデントに対するアクションを将来の時点まで遅らせて、その間、コンソールに表示しないようする場合に実行されます。管理者は抑止されたインシデントを、検索条件に「抑止」検索フィールドを含む、インシデントの検索の実行など、明示的にそれらを検索することにより表示できます。
インシデントは、次の条件のいずれかが満たされるまで抑止できます。
抑止が手動で削除されるまで
将来の指定した日付まで
重大度の状態が変更されるまで(インシデントのみ)
クローズされるまで
クリア: 管理者はインシデントまたは問題を手動でクリアできます。インシデントの場合、これは手動でクリアできるインシデントを含むインシデントにのみ適用されます。
コメントの追加: ユーザーはインシデントおよびイベントにコメントを追加できます。コメントは他のユーザーと情報を共有するのに使用したり、実行しているアクションの追跡情報を提供するのに使用できます。コメントはクローズした問題にも追加できます。
|
注意: シングル・アクションの「確認」および「クリア」ボタンは、インシデントのオープンや、複数のインシデントの選択に使用できます。 |
前述のアクションのいずれかが、選択したインシデントのサブセットにのみ適用される場合(たとえば、管理者が複数のインシデントを確認しようとし、そのうちの一部がすでに確認済の場合)、アクションは適用可能な場合にのみ実行されます。管理者にはアクションの成功または失敗が通知されます。管理者がこれらのアクションのいずれかを選択する場合、対応する注釈が今後の参照用に追加されます。
「OK」をクリックします。プロセスのサマリーと確認のダイアログが表示されます。
必要に応じて、インシデントの処理を続行します。
My Oracle Supportナレッジ・ページのエントリにインシデント・マネージャからアクセスするには、次の手順を実行します。
インシデント・マネージャにナビゲートします。
Enterprise Managerホームページ上の「エンタープライズ」メニューから、「監視」を選択し、「インシデント・マネージャ」を選択します。
標準ビューの1つを選択します。「表示」表で適切なインシデントまたは問題を選択します。
表示された「詳細」リージョンで、「My Oracle Supportのナレッジ」をクリックします。
My Oracle Support (MOS)ログイン資格証明がMOS優先資格証明として保存された場合、手動でログインする必要はありません。そうでない場合、My Oracle Supportにサインインする必要があります。MOSログイン情報を優先資格証明として保存するには、次を実行します。
MOS優先資格証明の設定: 「設定」メニューで、「セキュリティ」、「優先資格証明」の順に選択します。「My Oracle Support優先資格証明」リージョンで、「MOS資格証明の設定」をクリックします。
My Oracle Supportページで「ナレッジ」タブをクリックし、ナレッジ・ベースを参照します。
このページから公式なOracleドキュメントにアクセスできるだけでなく、検索文字列を変更してその他のナレッジ・ベースのエントリを探すこともできます。
問題を解決するためにOracleサポートの支援が必要な場合があります。この手順はインシデントおよびイベントには関係ありません。
サービス・リクエスト(SR)を発行するには、次の手順を実行します。
インシデント・マネージャにナビゲートします。
Enterprise Managerホームページ上の「エンタープライズ」メニューから、「監視」を選択し、「インシデント・マネージャ」を選択します。
問題を検索して発見するいずれかのビュー、またはカスタムのビューを使用します。表中の適切な問題を選択します。
「サポート・ワークベンチ\: パッケージ診断」リンクをクリックします。
SRをオープンするワークフローを完了します。ワークフローの完了により、SRのドラフトが作成されます。
まだサインインしていない場合、My Oracle Supportにサインインします。
My Oracle Supportページで、「サービス・リクエスト」タブをクリックします。
「SRの作成」ボタンをクリックします。
インシデントまたは問題を、すべてのオープン・インシデント・ページまたはすべてのオープンな問題ページのリストで非表示にすると便利なことがあります。たとえば、インシデントの処理を将来に日付まで(たとえばメンテナンス・ウィンドウまで)遅らせる必要があるとします。UIに表示しないために、インシデントを一時的に非表示にするか、または将来の日付まで抑止します。抑止されたインシデントを見つけるためには、「すべて表示」または「抑止されたイベントのみ表示」検索オプションのいずれかを使用してインシデントを明示的に検索する必要があります。抑止されたインシデントまたは問題の非表示を解除するためには、手動で抑止を解除する必要があります。
インシデントと問題を抑止するには:
インシデント・マネージャにナビゲートします。
Enterprise Managerホームページ上の「エンタープライズ」メニューから、「監視」を選択し、「インシデント・マネージャ」を選択します。
すべてのオープン・インシデント・ビューまたはすべてのオープンな問題ビューを選択します。
適切なインシデントまたは問題を選択します。「一般」タブをクリックします。
「詳細」リージョンが表示されたら、「詳細」タブをクリックして「抑止」を選択します。
「抑止」ポップアップが開いたら、適切な抑止タイプを選択します。
必要に応じてコメントを追加します。
「OK」をクリックします。
インシデント・マネージャを使用すると、自分のチームで対応するインシデントおよび問題を管理できます。
次のタスクを実行します。
インシデント・マネージャにナビゲートします。
Enterprise Managerホームページ上の「エンタープライズ」メニューから、「監視」を選択し、「インシデント・マネージャ」を選択します。
標準ビューまたはカスタム・ビューを使用して、自分のチームが担当するインシデントを識別します。未割当てで未確認のインシデントおよび問題に注目する必要があります。
インシデントのリストを確認します。これには、インシデントに割り当てられた担当者の確認、ステータス、進捗状況およびインシデントの所有者によるアクションの確認が含まれます。
「インシデントの詳細」リージョンの「管理」ボタンをクリックし、必要に応じてコメントを追加し、優先度を変更し、インシデントを再割当てします。
シナリオ例
DBAマネージャは、インシデント・マネージャを使用して、チームが所有しているすべてのインシデントを表示し、すべてが適切に割り当てられていることを確認します。適切に割り当てられていない場合は、再度割当てを行い、適切に優先度を付けます。また、エスカレーションされたイベントのステータスと進捗状況を監視し、インシデントの所有者用に必要に応じてコメントを追加します。コンソールで、各インシデントがオープン状態であった期間を表示できます。割り当てられていないインシデントのリストも確認し、適切に割り当てます。
オラクル社では、重要なイベントまたは関連イベントのグループに注意を集中するため、インシデントによる管理をお薦めします。生成されるイベントの多様性およびその数の多さのため、重要なイベントのすべてをインシデントでカバーすることは現実的ではありません。重要でありながら対応していないイベントを検索できるように、Enterprise Managerには「インシデントのないイベント」という標準のビューが用意されています。
次の手順を実行してください。
「エンタープライズ」メニューから、「監視」、「インシデント・マネージャ」の順に選択します。
「ビュー」リージョンで、「インシデントのないイベント」をクリックします。
表から、目的とするイベントを選択します。イベントの詳細が表示されます。
詳細の領域で、「詳細」を選択し、「インシデントの作成」または「インシデントにイベントを追加」のいずれかを選択します。
シナリオ例
Enterprise Managerの初期フェーズで、DBAマネージャは毎日、自身が管理しているデータベースでイベントを確認し、フィルタを設定してチケットまたはインシデントで追跡されていないイベントのみを表示します。そのようなイベントを参照して、どれも問題を追跡するインシデントが必要ないことを確認します。いずれかのイベントで問題を追跡するインシデントが必要と判断した場合には、このイベントに対して直接インシデントを作成します。
関心のあるイベントが発生し、それがどのルールでもカバーされておらず、そのイベントをインシデントに変換する場合は、次の手順に従います。
使用可能なビューを使用し、関心のあるイベントを検索します。
表中のイベントを選択します。
「詳細」ドロップダウン・メニューから「インシデントの作成」を選択します。
インシデントの詳細を入力し、「OK」をクリックします。
そのインシデントを自分で処理することに決めた場合は、自身をインシデントの所有者として設定し、ステータスを「調査中」に更新します。
シナリオ例
オペレーション・ポリシーに従って、あるDBAマネージャはこのデータベースのクリティカルな問題すべてに対してインシデントを作成するルールを設定しています。残りの問題には、DBAのいずれかがイベント・レベルで優先順位を付けます。
DBAの1人が、本番データベースに対する「SQLレスポンス」イベント(インシデントには関連付けられていない)に関する電子メールを受信します。DBAは、電子メールのリンクをクリックしてイベントの詳細にアクセスします。イベントの詳細を確認します。これは追跡と解決が必要な問題であるため、DBAはインシデントをオープンし、問題の解決策を追跡します。インシデントのステータスを、「調査中」に設定します。
次の項では、高度なアプリケーションまたは操作領域に関連するインシデント/イベント管理機能について説明します。
ADRは、トレース、ダンプ、アラート・ログ、状態モニター・レポートなどデータベース診断データを格納するファイルベース・リポジトリです。ADRの統一されたディレクトリ構造および統一されたツール・セットにより、ユーザーおよびOracleサポートは、複数のインスタンスおよびOracle製品間の診断データの相関関係を確認して分析できます。
Enterprise Managerと同様、ADRは、問題を解決するためのインシデントを作成し、問題を追跡します。
問題はデータベースにおけるクリティカル・エラーです。クリティカル・エラーには、内部エラー(ORA-00600など)やその他の深刻なエラー(ORA-07445(オペレーティング・システム例外)またはORA-04031(共有プールのメモリー不足))が含まれます。
インシデントとは、問題の1回の発生です。問題(クリティカル・エラー)が複数回発生すると、インシデントはそれぞれの発生分に対して作成されます。インシデントにはタイムスタンプが付与され、ADRで追跡されます。インシデントが発生すると、ADRでは診断インシデント・アラートをEnterprise Managerに送信します。
ADRに記録された各診断インシデントは、Enterprise Managerでもインシデントとして記録されるため、インシデント・マネージャからADR/Enterprise Managerのインシデントおよび問題の統一されたビューが提供されます。ADR診断インシデントの場合は、Enterprise Managerのサポート・ワークベンチにアクセスして、問題のパッケージ化、Oracleサポートへのサービス・リクエストの発行など、さらに処理を行うことができます。
Enterprise Managerリリース12.1.0.4より前では、インシデント・マネージャで1つの問題に対して記録される診断インシデントの数に制限はありませんでした。問題によって、短期間の間に数十、場合によっては数百ものインシデントが生成されることも考えられます。問題が発生して早い段階で生成されたインシデントは有効ですが、特定の時点を過ぎると、過剰な診断データはほとんど価値がなく、問題の診断と解決の処理速度が低下する可能性があります。通常、診断の問題は長時間かかることが多く、一定期間に大量のインシデントが生成される可能性があります。また、管理対象の環境のサイズによっては、診断データが膨大なシステム・リソースを消費する場合もあります。
これらの理由から、Enterprise Managerは、インシデント・マネージャで特定の問題に対して発生する可能性のある診断インシデントの数にフラッド制御制限を適用します。フラッド制御インシデントは、診断データによりシステムに過大な負荷をかけることなく、クリティカル・エラーが継続的に発生していることを知らせる手段となります。
Enterprise Managerリリース12.1.0.4以上では、インシデント・マネージャの特定の問題に対して発生する可能性のある診断インシデントの数に2つの制限が適用されます。1つの問題は、問題キーと呼ばれる一意の問題シグネチャによって識別され、1つのターゲットに関連付けられます。
Enterprise Managerによる診断インシデントの制限
Enterprise Managerは、診断インシデントに2つの制限を適用します。
いずれかの1時間について、Enterprise Managerは、指定したターゲットと問題キーの組合せに対し、最大で5つ(デフォルト値)の診断インシデントを記録します。
いずれかの1日について、Enterprise Managerは、指定したターゲットと問題キーの組合せに対し、最大で25(デフォルト値)の診断インシデントを記録します。
いずれかの制限に到達すると、同じターゲット/問題キーの組合せの診断インシデントは、対応する時間または日を超えるまで記録されなくなります。新しい時間または日が始まると、診断インシデントの記録が開始されます。
|
注意: 時間および日の計算はUTC (またはGMT)をベースに行われます。 |
これらの診断インシデントの制限は、インシデント・マネージャにのみ適用され、基礎となっているADRには適用されません。ADRリポジトリでは、引き続きすべてのインシデントが記録されます。Enterprise Managerのサポート・ワークベンチを使用すると、いつでも問題のインシデントをすべて表示でき、適切な処理を行うことができます。
Enterprise Managerの診断インシデント制限は構成可能です。前述のとおり、これらの2つの制限のデフォルトは1時間に5つ、1日に25のインシデントに設定されています。これらのデフォルトは、すべての診断インシデントを追跡するというビジネス上の特別な理由がないかぎり、変更しないでください。
Enterprise Managerの診断インシデント制限の変更
診断制限を更新するには、次の例に示すとおり、適切な制限値を使用し、SYSMANユーザーでEnterprise Managerリポジトリに対して次のSQLを実行します。
次の例に示すPL/SQLは、現在の制限を出力します。
例3-4 現在の診断インシデント制限を出力するSQL
DECLARE
l_adr_hour_limit NUMBER;
l_adr_day_limit NUMBER;
BEGIN
em_event_util. GET_ADR_INC_LIMITS
(p_hourly_limit => l_adr_hour_limit,
p_daily_limit => l_adr_day_limit);
dbms_output.put_line(l_adr_hour_limit || '-' || l_adr_day_limit);
END;
|
重要: Enterprise Managerのインシデント制限は、Oracle Database、Middleware and Fusion Applicationsなどの基礎となるアプリケーションによって適用される診断インシデント制限に追加されるものです。これらの制限は、各アプリケーションに固有です。詳細は、それぞれのアプリケーションのドキュメントを参照してください。 |
「インシデントの処理」で説明したとおり、主なインシデント・ワークフロー属性の1つは「ステータス」です。ほとんどの条件に対し、この事前定義済のステータス属性は十分です。しかし、監視および管理環境の独自性により、インシデント・ワークフローに特別なインシデント・ステータスが必要な場合があります。この必要性に対処するために、create_resolution_state EM CLI動詞を使用して、カスタム・ステータスを定義できます。
emcli create_resolution_state
-label="Label for display"
-position="Display position"
[-applies_to="INC|PBLM"]
この動詞は、新規解決状態を作成して、インシデントまたは問題の状態を記述します。
|
重要: このコマンドを実行できるのは、Enterprise Managerのスーパー管理者のみです。 |
新しい状態は常に、「新規」と「クローズ済」の状態の間に追加されます。-positionオプションを使用して、状態のリスト全体におけるこの状態の正確な位置を指定する必要があります。指定できる位置は、2と98の間です。
デフォルトでは、新しい状態はインシデントと問題の両方に適用されます。-applies_toオプションを使用して、状態をインシデントと問題のいずれかのみに適用する指定が可能です。
コマンドが正常に実行されると、成功メッセージが報告されます。変更が失敗すると、エラー・メッセージが報告されます。
例
次の例では、位置25でインシデントと問題の両方に適用する解決状態を追加します。
emcli create_resolution_state -label="Waiting for Ticket" -position=25
次の例では、位置35で問題のみに適用する解決状態を追加します。
emcli create_resolution_state -label="Waiting for SR" -position=35 -applies_to=PBLM
modify_resolution_state動詞を使用して、既存の状態の表示ラベルと位置の両方を変更できます。
emcli modify_resolution_state
-label="old label of the state to be changed"
-new_label="New label for display"
-position="New display position"
[-applies_to=BOTH]
この動詞はインシデントまたは問題の状態を定義する既存の解決ステータスを変更します。create_resolution_state動詞と同じく、このコマンドを実行できるのはスーパー管理者のみです。
-applies_toオプションを使用して、状態がインシデントと問題の両方に適用されるように指定することができます。
例
次の例では、古いラベルWaiting for TTを持つ解決状態を新しいラベルWaiting for Ticketで更新します。必要に応じて、位置を25に変更します。
emcli modify_resolution_state -label="Waiting for TT" -new_label="Waiting for Ticket" -position=25
次の例では、古いラベルSR Waitingを持つ解決状態を新しいラベルWaiting for SRで更新します。必要に応じて、位置を35に変更します。状態をインシデントと問題に適用します。
emcli modify_resolution_state -label="SR Waiting" -new_label="Waiting for SR" -position=35 -applies_to=BOTH
「メトリック・アラート」イベント・タイプの場合、イベント(メトリック・アラート)はメトリックしきい値に基づいて発生します。これらのメトリック・アラートはステートフル・アラートと呼ばれます。監視対象システムの状態に関連付けられていないメトリック・アラート・イベント(たとえば、「スナップショットが古すぎます」または再開可能セッションが一時停止されました)の場合、これらのアラートはステートレス・アラートと呼ばれます。ステートレス・アラートは自動的にクリアされないので、手動でクリアする必要があります。clear_stateless_alerts EM CLI動詞を使用して、ステートレス・アラートの一括パージを実行できます。
clear_stateless_alertsは指定したターゲットに関連付けられたステートレス・アラートをクリアします。管理エージェントはステートレス・アラートを自動的にクリアしないので、クリアは手動で実行する必要があります。ステートレス・アラートに関連付けられたメトリックの内部名を見つけるには、EM CLI get_metrics_for_stateless_alerts動詞を使用します。
構文
emcli clear_stateless_alerts -older_than=number_in_days -target_type=target_type -target_name=target_name [-include_members][-metric_internal_name=target_type_metric:metric_name:metric_column] [-unacknowledged_only][-ignore_notifications] [-preview][ ] indicates that the parameter is optional
オプション
older_than
アラートの経過時間を日数で指定します。(現在オープンしているステートレス・アラートを対象とするには、0を指定します。)
target_type
内部ターゲット・タイプの識別子(host、oracle_database、emrepなど)。
target_name
ターゲットの名前。
include_members
コンポジット・ターゲットに適用され、メンバーに属しているアラートも調査されます。
metric_internal_name
クリーンアップされるメトリック。get_metrics_for_stateless_alerts verbを使用して、特定のターゲット・タイプでサポートされるメトリックの完全なリストを表示できます。
unacknowledged_only
アラートが未確認の場合にのみ、それらのアラートを消去します。
ignore_notifications
このオプションは、消去したアラートに関する通知を送信しない場合に使用します。これにより、通知サブシステムの負荷が軽減される可能性があります。
ignore_notifications
このオプションは、消去したアラートに関する通知を送信しない場合に使用します。これにより、通知サブシステムの負荷が軽減される可能性があります。
preview
ターゲットで消去されるアラートの数が表示されます。
例
次の例では、1週間より前の古いデータベース・アラート・ログから生成されるアラートを消去します。この例では、アラートの消去時に通知は送信されません。
emcli clear_stateless_alerts -older_than=7 -target_type=oracle_database -tar get_name=database -metric_internal_name=oracle_database:alertLog:genericErrStack -ignore_notifications
自動的にクリアされるイベント(CPU使用率)と、インシデント・マネージャのUIまたはルールによって手動でクリアする必要のあるイベント(ジョブ障害やログ・メトリックなど)があります。自動クリア・イベントは、元になる問題が解決されるとEnterprise Managerによって自動的にクリアされます。CPU使用率の場合、使用率が警告しきい値を下回ると、CPU使用率のイベントは自動的にクリアされます。ただし、手動でクリアする必要のあるイベントの場合は、ユーザーが介入し、インシデント/イベントを選択して「クリア」をクリックするか、またはイベント・ルールを作成してジョブを実行する(推奨)ことによって、インシデント・マネージャを使用してイベントをクリアする必要があります。
前述のとおり、イベント・ルールによって手動でクリア可能なイベントのクリアを自動化できます。Enterprise Managerでは、手動でクリア可能なイベント(ジョブ障害やADPイベント(7日間オープンされている))を自動的にクリアする、アウトオブボックス・ルールがいくつか提供されます。ただし、監視する環境のニーズをより的確に満たすために、独自のイベント・ルールを作成して、その環境に最もよく見られる手動でクリア可能なイベントを自動的にクリアすることをお薦めします。
ルールの作成プロセスでは、条件付きの処理を追加するときに「イベントのクリア」オプションを選択することによって、イベントが自動的にクリアされるように指定できます。
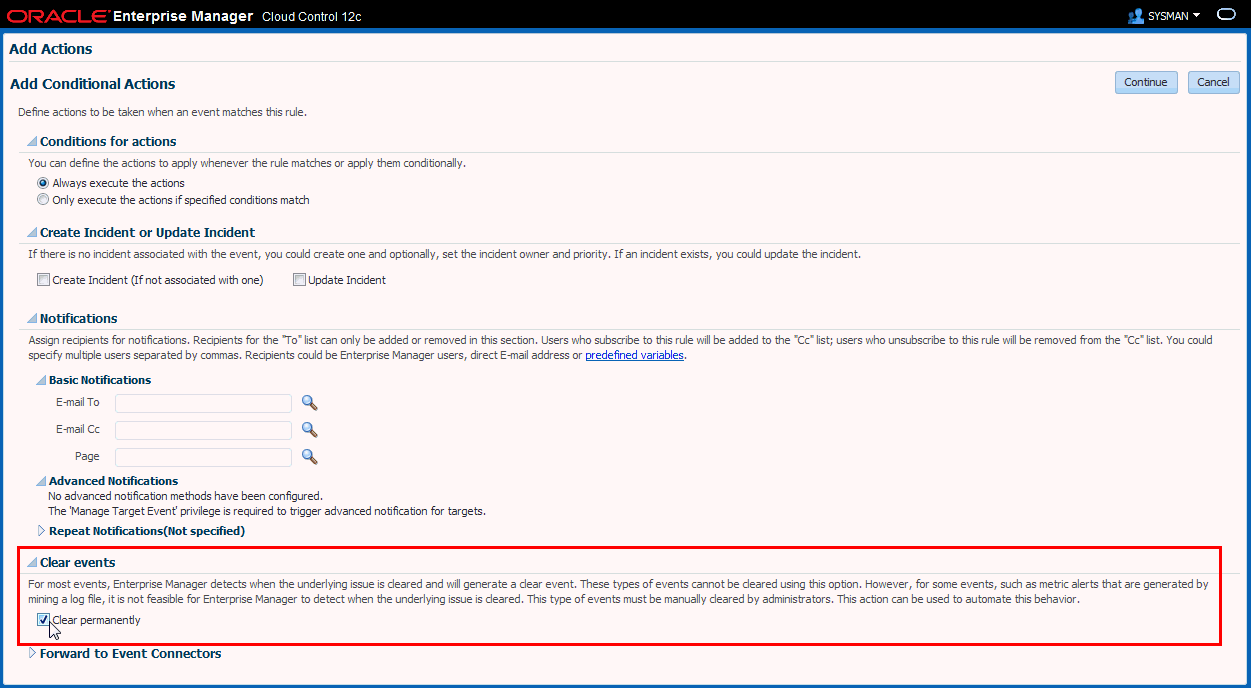
イベントがクリアされたときの通知
イベントのクリア処理は非同期操作であり、ルール・アクション(クリア)が開始されると、手動でクリア可能なイベントがクリアのためにキューにエンキューされますが、実際にはクリアされないことを意味します。つまり、ルールの実行時に送信された電子メール通知は、イベントがまだクリアされていないことを示します。非同期のクリアは、ルール・エンジン全体の処理負荷および処理時間を減らすことを目的としています。このイベントのクリア・ルールを、イベントがクリアされたときに通知されるようにサブスクライブしても、ほとんど意味がありません。イベントがクリアされたときに通知されるようにする場合は、新しいイベント・ルールを作成し、重大度を明示的に「クリア」に指定する必要があります。そうすることで、イベントが実際にクリアされたときに通知されるようになります。
ユーザーはEM CLI動詞publsh_eventを使用してイベントを手動で作成(公開)できます。ユーザー報告のイベントは、"User-reported event"クラスのイベントとして公開されます。ターゲットの管理権限のあるユーザーのみがターゲットに対するこれらのイベントを公開できます。公開が失敗すると、エラー・メッセージが報告されます。
「クリア」以外の重大度でイベントを公開した後で(後述)、適切な権限のあるエンド・ユーザーはUIからイベントを手動でクリアできます。または「クリア」の重大度レベルおよび同じ詳細を使用して新しいイベントを公開し、基礎となる状況のクリアを報告できます。
emcli publish_event
-target_name="Target name"
-target_type="Target type internal name"
-message="Message for the event"
-severity="Severity level"
-name="event name"
[-key="sub component name"
-context="name1=value1;name2=value2;.."
-separator=context="alt. pair separator"
-subseparator=context="alt. name-value separator"]
[ ] indicates that the parameter is optional
target_name
ターゲット名。
target_type
ターゲット・タイプ名。
message
イベントに関連付けるメッセージ。メッセージの長さは4000文字までです。
重大度
イベントに関連付ける、数値による重大度レベル。サポートされている重大度レベルの値は次のとおりです。
名前
発行するイベントの名前。イベント名は128文字以下です。
イベントの性質がわかるようにします。たとえば、"ディスク使用率"、"プロセス停止"、"キュー数"などです。同じ連続のイベントについて異なる重大度を報告する場合にも、同じこの名前を繰り返す必要があります。"プロセスxyzが停止"のように、特定のイベントに関する具体的な情報を表す名前にはしないでください。イベントの対象となるターゲット内で特定のコンポーネントを識別するには、次に示す「キー」オプションを参照してください。
キー
このイベントが関係するターゲット内のサブ・コンポーネントの名前。たとえば、ホスト上のディスク名、表領域の名前などを指定します。キーの長さは256文字までです。
コンテキスト
任意のイベントについて発行できる追加のコンテキスト。name:valueという書式の一連の文字列で、複数の場合はセミコロンで区切ります。たとえば、ディスク上の領域の問題を報告するときには、ディスクの比率のサイズを報告すると便利な場合があります。デフォルトのセパレータ":"はsub-separatorオプションを使用して、ペア・セパレータ";"はseparatorオプションを使用して、それぞれオーバーライドできます。
コンテキスト名の長さは256文字までで、値は4000文字までです。
セパレータ
デフォルトのセパレータ";"をオーバーライドするときに設定します。このオプションは通常は、名前や値に";"が含まれる場合に使用します。このオプションに"="は使用できません。
サブセパレータ
名前と値のペアを区切るデフォルトのセパレータ":"をオーバーライドするときに設定します。このオプションは通常は、名前や値に":"が含まれる場合に使用します。このオプションに"="は使用できません。
例1
この例は、"my acme target"について、HDDのリストアに失敗したことと、その失敗がこのターゲット上の"Finance DB machine"というコンポーネントに関係していることを示す警告イベントを発行します。
emcli publish_event -target_name="my acme target" -target_type="oracle_acme" -name="HDD restore failed" -key="Finance DB machine" -message="HDD restoration failed due to corrupt disk" -severity=WARNING
例2
この例は、"my acme target"について、HDDのリストアに失敗したことと、その失敗がこのターゲット上の"Finance DB machine"というコンポーネントに関係していることを示すマイナー警告イベントを発行します。関連するディスクのサイズと名前をデフォルトのセパレータで示す追加のコンテキストも指定しています。ディスク名で「\」をエスケープするために追加の"\"を使用していることに注意してください。
emcli publish_event -target_name="my acme target" -target_type="oracle_acme" -name="HDD restore failed" -key="Finance DB machine" -message="HDD restoration failed due to corrupt disk" -severity=MINOR_WARNING -context="disk size":800GB\;"disk name":\\uddo0111245
例3
この例は、"my acme target"について、HDDのリストアに失敗したことと、その失敗がこのターゲット上の"Finance DB machine"というコンポーネントに関係していることを示すクリティカル・イベントを発行します。関連するディスクのサイズと名前を示す追加のコンテキストも指定しています。ディスクの名前に、デフォルトのセパレータである":"が使用されているため、別のセパレータを使用しています。
emcli publish_event -target_name="my acme target" -target_type="oracle_acme" -name="HDD restore failed" -key="Finance DB machine" -message="HDD restoration failed due to corrupt disk" -severity=CRITICAL -context="disk size"^800GB\;"disk name"^\\sdd1245:2 -subseparator=context=^
簡単な通知を超えた、より複雑なタスクを実行するようにルールを設定できます。次のタスクで、追加のルールの機能を説明します。
このタスクを実行する前に、クリティカルなメトリック・アラートが設定どおりに生成されるように、DBAが適切なしきい値を設定していることを確認します。
次に例を示します。
運用管理者が、本番データベース・グループのデータベースにクリティカルのメトリック・アラート・イベントが発生したときには特定のDBAを呼び出し、また同じターゲットについて警告のメトリック・アラート・イベントしたときにはDBAに電子メールを送信するというルールを設定します。このタスクは、データベースの新しいグループがデプロイされ、DBAがこのようなデータベースを管理する適切なルールを作成すると発生します。
適切なしきい値を設定するには、次のタスクを実行します。
「設定」メニューで「インシデント」、「インシデント・ルール」の順に選択します。
インシデント・ルール - すべてのエンタープライズ・ルール・ページで、ルール・セットをハイライトして「編集...」をクリックします。ルール・セットをハイライトして 「編集」 をクリックします(ルールはルール・セットのコンテキストで作成されます。新規に追加したターゲットを管理する既存のルール・セットがない場合は、ルール・セットを作成します。)
ルール・セットの編集ページで、「ルール」セクションを探します。「作成...」をクリックします。
「作成するルールのタイプを選択」ダイアログで、「受信イベントおよびイベントの更新」を選択します。「続行」をクリックします。
次のようにルールの詳細を入力します。
「タイプ」については、「タイプ」として「メトリック・アラート」を選択します。
基準のセクションで「重大度」を選択します。ドロップダウン・リストから、選択値として「クリティカル」および「警告」をクリックします。「次へ」をクリックします。
アクションの追加ページで、「+」(「追加」)をクリックします。
「インシデントの作成」セクションで、「インシデントの作成」を選択します。「続行」をクリックします。アクションの追加ページに新規のルールが表示されます。「次」をクリックします。
ルール名と説明を指定します。「次」をクリックします。
確認ページで、設定が正しいことを確認し、「続行」をクリックします。ルールが正常に作成されたことを示すメッセージが表示されます。「OK」をクリックして、メッセージを閉じます。
次に、通知のアクションを実行するルールを作成する必要があります。
ルールの編集ページの「ルール」セクションで、「作成」をクリックします。
ルールのタイプに「新たに作成されたインシデントおよびインシデントの更新」を選択し、「続行」をクリックします。
「特定のインシデント」をクリックします。
「重大度」を選択し、ドロップダウン・リストから「クリティカル」および「警告」を選択します。「次へ」をクリックします。
アクションの追加ページで、「追加」をクリックします。条件付きアクション・ページが表示されます。
「アクションの条件」セクションで、「指定された条件に一致する場合のみアクションを実行」を選択します。
「インシデントは次の基準に一致」リストから「重大度」を選択し、ドロップダウン・リストから「クリティカル」を選択します。
「通知」セクションの「ページ」フィールドにDBAを入力します。「続行」をクリックします。アクションの追加ページが表示されます。
「追加」をクリックし、重大度が緊急用の新規アクションを作成します。
「アクションの条件」セクションで、「指定された条件に一致する場合のみアクションを実行」を選択します。
「インシデントは次の基準に一致」リストから「重大度」を選択し、ドロップダウン・リストから「警告」を選択します。
「通知」セクションの「電子メール宛先」フィールドにDBAを入力します。「続行」をクリックします。アクションの追加ページに2つの条件付きアクションが表示されます。「次へ」をクリックします。
ルール名と説明を指定します。「次」をクリックします。
確認ページで、ルールが正しく定義されていることを確認して「続行」をクリックします。ルール・セットの編集ページが表示されます。
「保存」をクリックし、新たに定義したルールを保存します。
本番データベースのオペレーション・ポリシーに従って、アプリケーションの問題に関連するインシデントはアプリケーションDBAに通知され、システム・パラメータに関連するインシデントはシステムDBAに通知されるようにする必要があります。そこで、個々のインシデントを適切なDBAに割り当て、電子メールで通知するようにします。
ルールを設定する前に、次の前提条件が満たされていることを確認してください。
クリティカルのメトリック・アラートが設定どおりに生成されるように、DBAが適切なしきい値を設定していること。
そのようなすべてのイベントについてインシデントを作成するルールが設定されていること。
グローバルSMTPゲートウェイ、電子メール・アドレス、各DBAのスケジュールなど、個々の通知設定が完了していること。
次の手順を実行してください。
インシデント・ルール・ページにナビゲートします。
「設定」メニューで「インシデント」、「インシデント・ルール」の順に選択します。
本番データベースからのイベントに一致するエンタープライズ・ルールのリストを検索します。
インシデント・ルール - すべてのエンタープライズ・ルール・ページで、ルール・セットをハイライトして「編集...」をクリックします。
ルールはルール・セットのコンテキストで作成されます。既存のルール・セットがない場合、ルール・セットを作成します。
「ルール・セットの編集」ページ(「ルール」タブ)で、データベースのメトリック・アラート・イベントに対してインシデントを作成するルールを選択します。「編集」をクリックします。
イベントの選択ページで「次へ」をクリックします。
「アクションの追加」ページで、追加をクリックします。条件付きアクションの追加ページが表示されます。
「通知」領域で、この特定のイベント・タイプに対して通知するDBAの電子メール・アドレスを入力し、「続行」をクリックして、アクションを追加します。アクションの追加ページに戻ります。「次へ」をクリックします。
名前と説明の指定ページに、直感的なルールの名前と簡単な説明を入力します。
「次」をクリックします。
確認ページで、「適用先」、「アクション」および「一般」情報が正しいかどうかを確認します。
「続行」をクリックして、ルールを作成します。
追加のルールを作成/編集して、イベント・タイプに応じた、別の追加の管理者通知を処理します。
ルールの概要を確認し、必要に応じて修正します。「保存」をクリックし、ルール・セットの変更を保存します。
お客様のITプロセスでインシデント解決にヘルプデスク・チケットの作成を必要とする場合は、ヘルプデスク・コネクタを使用してヘルプデスク・チケットとインシデントを関連付け、インシデントの作成時にEnterprise Managerで自動的にチケットをオープンします。インシデント・マネージャとヘルプデスク・システム間の通信は双方向なので、インシデント・マネージャ内からチケットのステータス変更を確認できます。Enterprise Managerでは、チケットからWebベースのサード・パーティ・コンソールに直接リンクして、チケットから直接コンテキスト内でコンソールを起動することもできます。
たとえば、組織の運用ポリシーに従い、本番データベースのすべてのクリティカル・インシデントは処置チケットを使用して追跡する必要があります。ルールは、データベースに対してクリティカル・インシデントが発生した場合に、処置チケットを作成するように設定されます。このようなインシデントが発生した場合、ルールによってチケットが生成され、インシデントがチケットに関連付けられ、インシデントの更新を後で参照できるように操作がログに記録されます。インシデントの詳細を表示しながら、DBAはチケットIDを確認し、添付されたURLリンクを使用して、チケットに関する詳細を取得するために処置にアクセスできます。
このタスクを実行する前に、次の前提条件が満たされていることを確認してください。
監視のサポートが設定されていること。
チケットの処置コネクタが構成されていること。
次の手順を実行してください。
「設定」メニューで「インシデント」、「インシデント・ルール」の順に選択します。
インシデント・ルール - すべてのエンタープライズ・ルール・ページで、適切なルール・セットを選択して「編集」をクリックします。ルール・セットをハイライトして 「編集」 をクリックします(ルールはルール・セットのコンテキストで作成されます。適切なルール・セットがない場合は、新規のルール・セットを作成します)。
チケットが生成されるインシデント条件に対応する適切なルールを選択し、「編集...」をクリックします。
「次へ」をクリックしてアクションの追加ページに進みます。
追加をクリックして条件付きアクションの追加ページにアクセスします。
このルールが対応するインシデントに対してチケットが生成されるように指定します。
使用するチケットのテンプレートを指定します。
「続行」をクリックし、アクションの追加ページに戻ります。
アクションの追加ページで、「次へ」をクリックします。
「確認」ページで「続行」をクリックします。
名前と説明の指定ページで、「次へ」をクリックします。
「確認」ページで「続行」をクリックします。ルールが正常に変更されたことを表すメッセージが表示されます。「OK」をクリックして、メッセージを閉じます。
手順3から10を繰り返して、適切なルールをすべて編集します。
「保存」をクリックし、ルール・セットに対して行った変更を保存します。
第4章「通知の使用」に示したように、Enterprise Managerは、SNMPを介したサード・パーティ管理ツールとの統合をサポートしています。サード・パーティ・システムへのSNMPトラップの送信には、次の2つの処理手順があります。
手順1: SNMPトラップに基づく高度な通知メソッドを作成します。
手順2: SNMPトラップの通知メソッドを起動するインシデント・ルールを作成します。
次の手順は、SNMPトラップの通知メソッドが作成済であることを前提としています。SNMPトラップに基づく通知メソッドの作成手順については、「サード・パーティ・システムへのSNMPトラップの送信」を参照してください。
「設定」メニューで「インシデント」、「インシデント・ルール」の順に選択します。
インシデント・ルール: すべてのエンタープライズ・ルール・ページで「ルール・セットの作成...」をクリックします。
ルール・セットの「名前」、簡単な「説明」を入力し、ルールの「適用先」(ターゲット)ソース・オブジェクトのタイプを選択します。
「ルール」タブをクリックした後、「作成...」をクリックします。
「作成するルールのタイプを選択」ダイアログで、「受信イベントおよびイベントの更新」を選択し、「続行」をクリックします。
新規ルールの作成: イベントの選択ページで、SNMPトラップを送信するイベントの条件を指定して、「次へ」をクリックします。
|
注意: イベント・タイプごとに1つルールを作成する必要があります。たとえば、SNMPトラップを「ターゲット可用性」イベントおよび「メトリック・アラート」イベントに送信する場合、2つのルールを指定する必要があります。 |
新規ルールの作成: アクションの追加ページで、「追加」をクリックします。条件付きアクションの追加ページが表示されます。
次の図に示すように、「通知」セクションの「拡張通知」で、既存のSNMPトラップ通知メソッドを選択します。
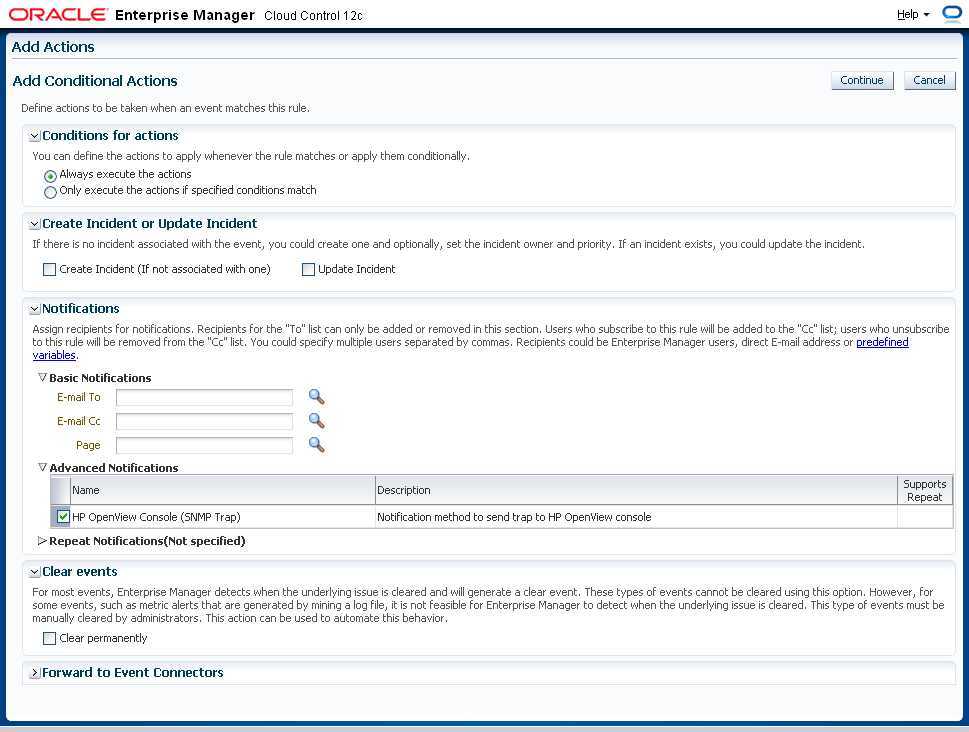
SNMPトラップの通知メソッドの作成については、「サード・パーティ・システムへのSNMPトラップの送信」を参照してください。
「続行」をクリックし、新規ルールの作成: アクションの追加ページに戻ります。
「次へ」をクリックし、新規ルールの作成: 名前と説明の指定ページに移動します。
ルール名および簡潔な説明を指定して、「次へ」をクリックします。
ルール定義を確認し、「続行」をクリックしてルールをルール・セットに追加します。ルールがルール・セットに追加されたがまだ保存されていないことを表すメッセージが表示されます。「OK」をクリックして、メッセージを閉じます。
「保存」をクリックしてルール・セットを保存します。確認メッセージが表示されます。「OK」をクリックして、メッセージを閉じます。
大企業では、システムの負荷が高いときに多くのインシデントとイベントが生成されると考えられます。ビジネスの優先度に従って、これらすべてをタイミングよく効率的な方法で処理する必要があります。どのイベント/インシデントを最初に解決する必要があるかを判断する効果的な優先度付けの方法が必要です。
どのイベント/インシデントの優先度が高いかを判断するために、Enterprise Managerは、ターゲットの「ライフサイクル・ステータス」と「インシデント・タイプ/イベント・タイプ」の2つのインシデント/イベント属性に基づく優先度付けプロトコルを使用します。ライフサイクル・ステータスは、ターゲットの運用ステータスを示すターゲット・プロパティです。ターゲットのライフサイクル・ステータスは、UIから設定/表示できます(ターゲットの「ターゲット設定」メニューから「プロパティ」を選択)。ターゲットのライフサイクル・ステータス・プロパティは、Enterprise Managerコマンドライン・インタフェース(EM CLI)のset_target_property_value動詞を使用して、複数のターゲットに対して同時に設定できます。
ターゲットの「ライフサイクル・ステータス」は、そのターゲットが監視のためにEnterprise Managerに追加されたときに設定されます。その時点で、ターゲットが属する優先度階層(最高レベルは「基幹」、最低レベルは「開発」)を決定します。
ターゲットのライフサイクル・ステータス
基幹(最高の優先度)
本番
ステージング
テスト
開発(最低の優先度)
インシデント/イベント・タイプ
可用性イベント(最高の優先度)
非情報イベント。
情報イベント
根本原因分析(RCA)は、操作イベントを発生させた問題の根本原因を特定しようとします。Enterprise Manager Could Control 12.1.0.3から、インシデント・マネージャがターゲットの停止イベント上で自動的にRCAを実行するようになり、ターゲットの停止イベントが他のターゲットの停止イベントの原因または兆候であるかどうかが積極的に特定されるようになりました。ターゲットの停止イベントという用語は、ターゲットが停止していると検出されたときに発生するターゲット可用性イベントに特に関係します。
RCAは、ターゲットの停止イベントが根本原因または兆候であるかどうかを特定する持続プロセスです。イベントの原因分析の更新属性が使用されて分析の結果が格納され、つまり、ターゲットの停止イベントが根本原因または兆候であるかどうかが特定されます。新しいターゲットの可用性イベントが入ってくると必ず、受信イベント上およびそれが関連付けられている既存のターゲットの停止イベント上でRCAが自動的に実行されます。分析に基づいて、受信イベントがターゲットの停止イベントである場合は原因分析の更新属性値が更新されます。変更がある場合は、関連するターゲットの停止イベントの原因分析の更新属性も更新されます。
関連ターゲットの特定に2つのタイプのターゲット関係、依存性および包含が使用されます。
あるターゲットが可用性に関して別のターゲットに依存する場合、それらの間に依存関係が存在します。たとえば、J2EEアプリケーション・ターゲットは、デプロイ先のWebLogic Serverターゲットに依存します。
原因分析の更新属性は、ターゲットの停止イベント(ターゲットの停止に関するターゲット可用性イベントなど)に対してのみ使用され、RCAプロセスによって次の値のいずれかを割り当てることができます。
兆候 -- ターゲットの停止イベントが別のターゲットの停止イベントによって引き起こされています。
原因 -- ターゲットの停止イベントが別のターゲットの停止イベントを引き起こし、他のターゲットの停止イベントの兆候ではありません。
根本原因 -- ターゲットの停止イベントが別のターゲットの停止イベントを引き起こし、他のターゲットの停止イベントの兆候ではありません。
N/A - 根本原因分析はこのイベントには適用されません。根本原因分析は、ターゲットの停止イベントにのみ適用されます。
原因および兆候ではない - ターゲットの停止イベントは、他のターゲットの停止イベントの根本原因ではなく兆候でもありません。これは、インシデント・マネージャでダッシュ(-)と表示されます。
次のルールはRCAプロセスを説明しています。
ルール1: 非コンテナ・ターゲット(メンバーを持たないターゲット)の停止イベントは、依存ターゲットが停止しており、他のターゲットの停止イベントの兆候ではない場合、原因としてマークされます。
次に例を示します。
スタンドアロンWebLogic ServerにデプロイされたJ2EEアプリケーションがあるとします。J2EEアプリケーションとWebLogic Serverターゲットの両方が停止している場合、WebLogic Serverの停止イベントが、デプロイされているJ2EEアプリケーションに対する原因になります。
Weblogicクラスタの一部である2つのWebLogic ServerにデプロイされているJ2EEアプリケーションがあるとします。1つのWebLogic ServerがそのJ2EEアプリケーションとともに停止している場合、そのWebLogic Serverの停止イベントは、J2EEアプリケーション・ターゲットの停止の原因になります。これはWebLogicクラスタが停止していないと仮定しています。
ルール2: 非コンテナ・ターゲット(メンバーを持たないターゲット)の停止イベントは、それが依存するターゲットがダウンしているかそれを含むターゲットがダウンしている場合、兆候としてマークされます。
次に例を示します。
スタンドアロンWebLogic ServerにデプロイされたJ2EEアプリケーションがあるとします。J2EEアプリケーションとWebLogic Serverターゲットの両方が停止している場合、J2EEアプリケーションの停止イベントは、停止しているWebLogic Serverの兆候になります。
WebLogicクラスタの一部である2つのWebLogic Serverがあるとします。各WebLogic ServerにJ2EEアプリケーションがデプロイされています。Weblogicクラスタが停止している場合、両方のWebLogic Serverが停止していることを意味します。その結果、これらのサーバーにデプロイされるJ2EEアプリケーションも停止します。WebLogic Serverの停止イベントは、停止しているWeblogicクラスタの原因であるとマークされます。詳細は、ルール3を参照してください。
クラスタ・データベース・ターゲットの一部である、2つのRACデータベース・インスタンス・ターゲットがあるとします。クラスタ・データベースが停止している場合、すべてのRACインスタンスも停止します。RACインスタンスの停止イベントは、停止しているクラスタ・データベースの原因としてマークされます。詳細は、ルール3を参照してください。
ルール3: コンテナ・ターゲットの停止イベントは、すべてのメンバー・ターゲットが停止しており、それを含むターゲットが停止していない場合、兆候としてマークされます。
次に例を示します。
スタンドアロンWebLogicクラスタの一部である2つのWebLogic Serverがあるとします。WebLogicクラスタの停止イベントは、両方のWebLogic Serverが停止している場合は兆候としてマークされます。
クラスタ・データベース・ターゲットの一部である、2つのRACデータベース・インスタンス・ターゲットがあるとします。クラスタ・データベース・ターゲットの停止イベントは、両方のデータベース・インスタンスが停止している場合、兆候としてマークされます。
ルール4: コンテナ・ターゲットの停止イベントは、それを含むターゲットが停止している場合、兆候としてマークされます。
例:
WebLogicドメイン・ターゲットの一部である、2つのWebLogicクラスタがあるとします。WebLogicドメインが停止している場合、WebLogicクラスタも停止していることを意味します。WebLogicクラスタ・ターゲットの停止イベントは、停止しているWebLogicドメインの原因です。WebLogicドメインの停止イベントは兆候としてマークされます。
前述のように、RCAは持続プロセスであり、新しいターゲットの停止イベントが受信されて処理される間に、ターゲットの停止イベントを原因、兆候またはいずれでもないとしてマークします。そのため、ターゲットの停止イベントは、受信されたときまたはその後RCAが追加のイベント情報を分析したときに、原因または兆候としてマークされる場合があります。
ターゲットの停止イベントはただちに解決する必要がある重要なイベントであるため、ほとんどのデータセンターでは、ターゲットの停止イベントのインシデントを自動的に作成します。これはお薦めのベスト・プラクティスであり、即時使用可能ルール・セットによって実装もされています。しかし、レスポンス・チームへの通知またはトラブル・チケットの作成に関しては、兆候インシデントの場合にそのようにすることは望ましくありません。一部のデータセンターでは、兆候イベントについてインシデントを作成しないことを選択する場合もあります。
そのため、RCAの結果は次のように活用できます。
兆候以外のイベントについて通知またはチケットを作成します。
これは2つの方法で実施できます。
2つの別々のイベント・ルールを作成し、1つのイベント・ルールではすべての関連イベントのインシデントを作成するが、それ以上のアクションをとらない(通知やチケット作成は行わない)ようにし、もう1つのルールでは兆候以外のイベントのみについてインシデントを作成し、通知の送信およびチケットの作成を行うようにします。手順については、「兆候以外のイベントのインシデントの作成」を参照してください。
ターゲットの停止イベントのすべてについてインシデントを作成するイベント・ルールを作成します。インシデント優先度を更新する別のルールを作成し、兆候以外のイベントから発生したインシデントについてのみ通知の送信およびチケットの作成を行うようにします。インシデント優先度が「緊急」に設定されると、顧客は、緊急優先度のインシデントに対する追加アクションを実行する追加のインシデント・ルールを作成することもできます。「兆候以外のイベントのインシデント優先度を更新するルールの作成」を参照してください。
最初に原因と兆候のどちらでもないとマークされなかったイベントを待機した後にのみ、インシデントを作成します。
前述のように、RCAは、受信するターゲットの停止イベントが継続的に評価され、既存イベントの原因分析の状態が更新される反復プロセスです。最初に根本原因としてマークされたターゲットの停止イベントは、受信する他のターゲットの停止イベントに応じて、一定の時間(分)、根本原因のままである場合も根本原因ではなくなる場合もあります。元のターゲットの停止イベントが、後で兆候として分類されることがあります。
後で兆候イベントという結果になる可能性のあるイベントに対して、時期尚早にインシデントを作成しチケットをオープンすることがないように、次のようにルールを設定できます。
前述の手順ですでに定義したルールに加えて、追加のイベント・ルールを作成し、イベントに対するRCAが更新され、イベントが兆候としてマークされてインシデントの優先度が「低」に下げられることがRCAの更新によって示されるときに機能するようにします。これによって、チケットに対する更新も自動的に送信されます。これがお薦めの方法です。手順については、「遅延時間の概要」を参照してください。
または
ターゲットの停止イベントが報告、分析され、それについてのアクション(インシデントの作成やインシデントの更新など)が実行される時間を見越すために、ルール・アクションに遅延を追加できます。これは、顧客が最小遅延(通常は5分)の後にアクションを実行する許容差を持つ場合に便利です。
兆候以外のイベントに対してのみインシデントを作成します。
一部のデータセンターでは、兆候イベントについてインシデントを作成しないことを選択する場合があります。これは、原因としてマークされた、または原因と兆候のどちらでもないとマークされたイベントについてのみインシデントを作成するルールを変更することによって実施できます。手順については、「兆候以外のイベントのインシデントの作成」を参照してください。
この方法でも、最初に原因としてまたは原因と兆候のどちらでもないとマークされていたイベントが、追加情報を受け取ったときに兆候としてマークされる場合もあることに注意してください。顧客は、手順2の2番目のオプションと類似した方法を使用して、インシデントの作成に遅延を作成することができます。この場合でも、事前設定の遅延後に新しい情報が現れ、イベントが結局兆候としてマークされることもありえます。そのため、インシデント優先度を使用し、ワークフローを管理する1つの方法としてそれを使用する方法の使用をお薦めします。
RCAの結果を使用して、インシデント・マネージャで兆候以外のインシデントに焦点を当てることができます。これには、カスタム値を作成するときに原因分析の更新インシデント属性を使用することが含まれます。
「エンタープライズ」メニューから、「監視」、「インシデント」の順に選択します。インシデント・マネージャ・ページが表示されます。
「ビュー」リージョンから「作成」をクリックします。検索ページが表示されます。
「フィールドの追加...」をクリックし、「原因分析の更新」を選択します。追加の検索基準として原因分析の更新が表示されます。
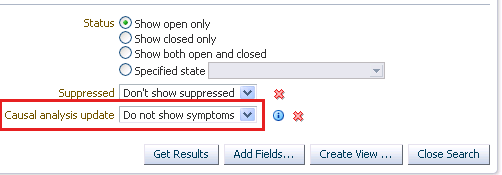
選択可能な基準のリストから「兆候を表示しない」を選択します。これによって、「兆候」とマークされたインシデントが自動的に除外されます。兆候または根本原因としてマークされていないインシデントは、指定した他の基準に一致するかぎり含まれます。

「ビューの作成」をクリックし、「ビュー名」を求められたら入力し、OKをクリックします。
インシデントの詳細におけるRCA結果の表示
根本原因または兆候であるインシデントは、インシデント・マネージャでインシデントの詳細の一部として目立つように識別されます。さらに、インシデントが兆候である場合、インシデントの根本原因を識別するために「原因」セクションが追加されます。同様に、インシデントが他のターゲットの停止インシデントを発生させた場合、影響されたターゲット(つまり、元のターゲットの停止の結果として停止している他のターゲット)を表示するために「影響されるターゲット」セクションも追加されます。次の図にインシデントの詳細を示します。
システム・ダッシュボードで、RCA結果を使用して、インシデント表から兆候インシデントを除外し、根本原因であり他のターゲットの停止イベントによって発生したものではないインシデントに管理者が焦点を当てることができるようにすることができます。
兆候インシデントを除外する手順:
システム・ダッシュボードで、「インシデントと問題」表の左上隅からアクセスできる「ビュー」オプションをクリックします。
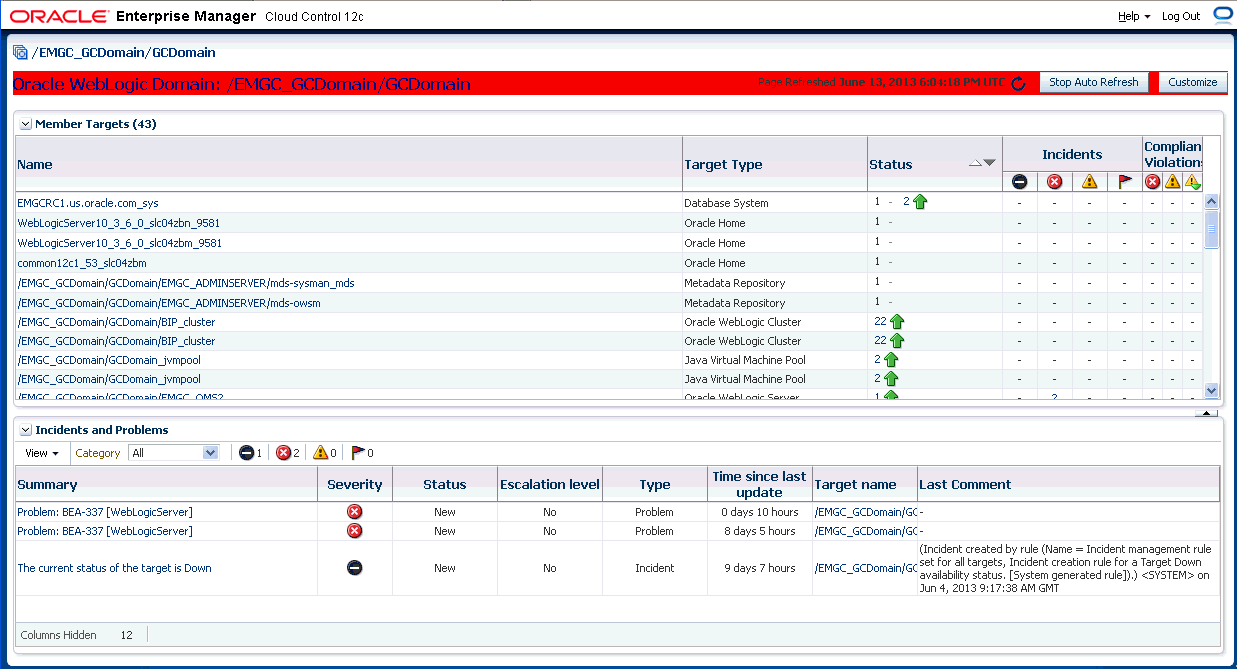
「兆候の除外」オプションを選択します。かわりに「原因のみ」オプションを選択して、他のターゲットの停止インシデントの原因として識別されたターゲットの停止インシデントのみを表示することもできます。選択したオプションにかかわらず、兆候または根本原因としてマークされていないインシデントは表示されたままです。
兆候以外のイベントのみを選択するイベント・ルールを作成します。
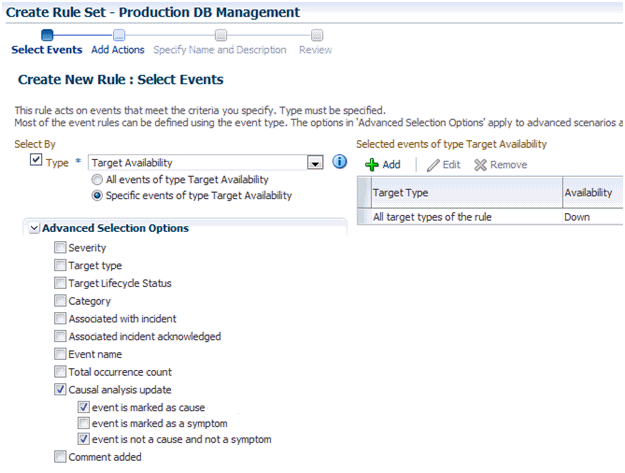
アクションを追加するとき、選択した兆候以外のイベントに関連付けられているインシデントに設定する優先度を選択します。
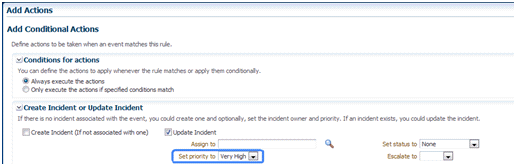
インシデント生成のルール・セットを作成するインシデント・マネージャのRCA機能を活用できます。多数の兆候のターゲットの停止イベントが生成され、兆候以外のターゲットの停止イベントが少しだけである状況の監視では、兆候以外のイベントについてのみインシデントを生成し通知を送信するルール・セットを作成できます。
兆候以外のターゲットの停止イベントについてインシデントを作成するルール・セットを作成する手順:
「設定」メニューで「インシデント」、「インシデント・ルール」の順に選択します。
「ルール・セットの作成...」をクリックします。ルール・セットの作成の一部としてルールを作成します。
新規ルールを含むルール・セットを選択します。ルール・セットの編集ページの「ルール」タブで、「編集」をクリックし、次の操作を行います。
「作成...」をクリックします。
「受信イベントおよびイベントの更新」を選択します。

「続行」をクリックします。「新規ルールの作成 : イベントの選択」ダイアログが表示されます。
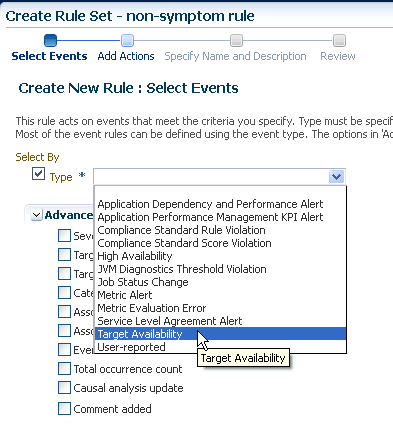
「詳細な選択オプション」リージョンで、「原因分析の更新」を選択します。3つの原因イベント・オプションが表示されます。
イベントは原因としてマークされます: このターゲットに依存する他のターゲットが停止している場合、このターゲットの停止は原因とみなされます。
イベントは兆候としてマークされます: 依存するターゲットも停止している場合、停止中のターゲットは兆候とみなされます。
イベントは原因と兆候のどちらでもありません: ターゲットの停止は原因でも兆候でもありません。
1つ以上のオプションを選択することによって、余分なターゲットの停止イベントをフィルタ処理し、相互依存性のあるターゲットに関するターゲットの可用性イベントに焦点を当てることができます。兆候以外のイベントについてのみインシデントを作成するには、「イベントは原因としてマークされます」およびイベントは原因と兆候のどちらでもありませんを選択します。

「次」をクリックします。
新規ルールの作成: アクションの追加ページで、「追加」をクリックします。条件付きアクションの追加ページが表示されます。
「インシデントの作成またはインシデントの更新」リージョンで、「インシデントの作成」を選択します。
残りの割当ておよび通知の詳細を指定して「続行」をクリックします。
「ルール・セットの作成」ウィザード・ページの残りを完了します。ルール・セットの作成の詳細は、「ルール・セットの作成」を参照してください。
前述のように、インシデント・マネージャのRCAは、受信するターゲットの停止イベントが継続的に評価され、原因分析の状態が更新される反復プロセスです。受信するターゲットの停止イベントに応じて、一定の時間(分)、根本原因は根本原因のままである場合も根本原因ではなくなる場合もあります。元のターゲットの停止イベントが、後で兆候として分類されることがあります。ターゲットの停止イベントが報告、分析され、それについてのアクション(インシデントの作成など)が実行される時間を見越すために、ルール・セットの作成時にイベント評価の遅延時間を定義できます。
前述の例では、ルールに遅延時間を設定せずに、兆候以外のイベントについてインシデントが作成されましたが、最終的に兆候になった兆候以外のイベントに作成されたインシデントが存在する可能性があります。
ルールに遅延時間を追加する手順:
「ルール・セットの作成」ウィザードの「アクションの追加」ページから、「追加」または「編集」(既存のルールの変更)をクリックします。「条件付きアクションの追加」ページが表示されます。
「アクションの条件」リージョンで、「指定された条件に一致する場合のみアクションを実行」を選択します。条件のリストが表示されます。
「指定された期間の間オープン状態になっていたイベント」を選択します。
必要な遅延時間を指定します。

「続行」をクリックして、ウィザードの残りのステップを完了します。
Enterprise Manager 12cのインシデント管理機能は、12cの前から存在する、即時利用可能な監視設定を強化するものです。移行はシームレスで透過的です。たとえば、Enterprise Manager 10/11g監視システムが特定の監視条件に基づいて電子メールを送信する場合、中断なしでそれらの電子メールの受信を継続できます。ただし、12cの機能を利用するには、追加の移行タスクの実行が必要な場合があります。
|
重要: 12cより前に生成されたアラートも使用できます。たとえば、クリティカル・メトリック・アラートはクリティカル・インシデントとして使用可能です。 |
ルール
Enterprise Manger 12cに移行すると、既存のすべての通知ルールが自動的にルールに変換されます。技術的には、最初にイベント・ルールに変換され、各イベント・ルールに対してインシデントが自動的に作成されます。
一般に、イベント・ルールでは、どのイベントがインシデントになるかを定義できます。一方で、Enterprise Managerの強化された監視の柔軟性も利用できます。
ルールの移行の詳細は、次のドキュメントを参照してください。
付録Aの「Enterprise Manager Cloud Controlの通知の概要」、『Oracle Enterprise Manager Cloud Controlアップグレード・ガイド』の通知ルールからルール・セットへの移行に関する項
『Oracle Enterprise Manager Cloud Controlアップグレード・ガイド』の第29章「ルールの更新」
権限の要件
エンタープライズ・ルール・セットおよびそれに含まれるルールの編集/作成には、リソース権限「エンタープライズ・ルール・セットの作成」が必要です。これに対する例外は、移行された通知ルールです。12cより前の通知ルールがイベント・ルールに移行されている場合、元の通知ルールの所有者は、「エンタープライズ・ルール・セットの作成」リソース権限を付与されていなくても自身のルールを編集できます。ただし、新規ルールを作成する場合は、「エンタープライズ・ルール・セットの作成」リソース権限が付与されている必要があります。Enterprise Managerのスーパー管理者は、デフォルトでルール・セットを編集および作成できます。
次の項で、インシデント/監視の設定および使用に関する一般的なタスクの操作例を示します。
タスク
Enterprise Managerから管理者に電子メール通知を送信するには、組織内で利用可能な電子メール・ゲートウェイにアクセスする必要があります。次の手順で、指定した電子メール・ゲートウェイを使用するようにEnterprise Managerを構成します。
ユーザー・ロール
Enterprise Manager管理者
前提条件
ユーザーには、スーパー管理者権限が必要です。
詳細は、「通知用のメール・サーバーの設定」を参照してください。
次の手順を実行します。
「設定」メニューから、「通知」、「通知メソッド」の順に選択します。
「通知メソッド」ページが表示されます。
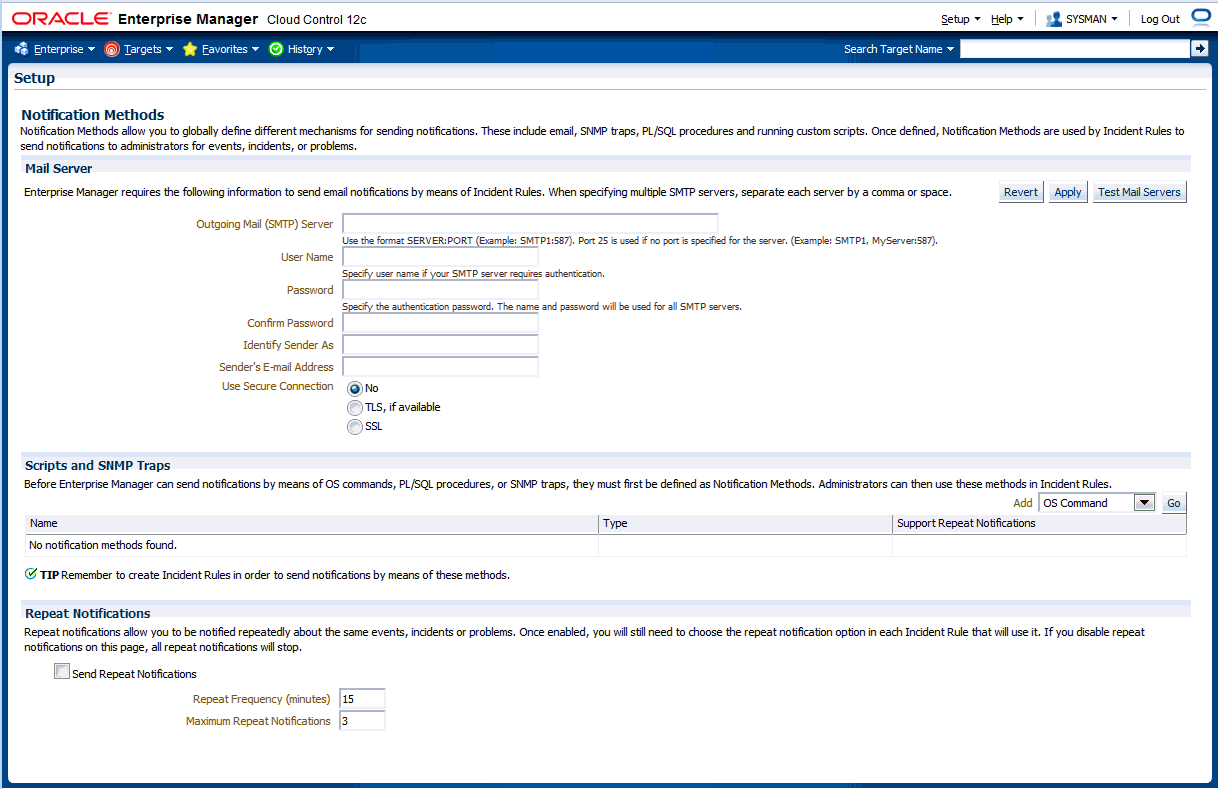
必要なパラメータを入力します。次に、有効なパラメータ値の例を示します。
送信メール(SMTP)サーバー - smtp01.example.com:587, smtp02.example.com
ユーザー名 - myadmin
パスワード - ******
パスワードの確認 - ******
送信者ID - Enterprise Manager
送信者の電子メール・アドレス - mgmt_rep@example.com
セキュアな接続を使用: いいえ: 電子メールは暗号化されません。SSL: 電子メールはSecure Sockets Layer protocolを使用して暗号化されます。使用可能な場合はTLS: メール・サーバーがTransport Layer Security(TLS)プロトコルをサポートしている場合、電子メールはTLSを使用して暗号化されます。サーバーがTLSをサポートしない場合、電子メールは自動的にプレーン・テキストで送信されます。
指定した電子メール・ゲートウェイにEnterprise Managerが接続できることを確認します。「メール・サーバーのテスト」をクリックします。Enterprise Managerが成功/失敗メッセージを表示します。「OK」をクリックして、「通知メソッド」ページに戻ります。
Enterprise Managerが電子メール・ゲートウェイに正常に接続できることを確認したら、「適用」をクリックします。
これまでに実施したこと:
ここまでで、会社の電子メール・ゲートウェイを使用するようにEnterprise Managerを構成しました。Enterprise Managerは、管理対象の環境の状況を監視しながら、登録ユーザーに通知ができます。
次の操作
タスク
メトリック・アラートのしきい値に到達した時点で管理者に電子メールを送信するようにEnterprise Managerを構成します。この例では、CPU使用率が重大度「クリティカル」に到達してメトリック・アラートが発生したときに電子メール通知を送信します。
ユーザー・ロール
ITオペレータ/マネージャ
Enterprise Manager管理者
前提条件
Enterprise Managerが管理者に電子メールを送信できるように電子メール・ゲートウェイを設定すること。
詳細は、「通知用のメール・サーバーの設定」を参照してください。
CPU使用率のメトリックしきい値が設定されていること。
ユーザーのEnterprise Managerアカウントに管理対象システムからのインシデントの管理に必要な適切な権限が付与されていること。
詳細は、「管理者および権限の設定」を参照してください。
ユーザーのEnterprise Managerアカウントに通知プリファレンス(電子メールおよびスケジュール)が設定されていること。これはルールを作成および編集する管理者だけではなく、ルール・アクションの結果として通知されるユーザーにも必要です。
詳細は、「通知スケジュールの設定」を参照してください。
次の手順を実行します。
「設定」メニューから、「インシデント」、「インシデント・ルール」の順に選択します。
「ルール・セットの作成」をクリックします。
ルール・セットの名前および説明を入力します。
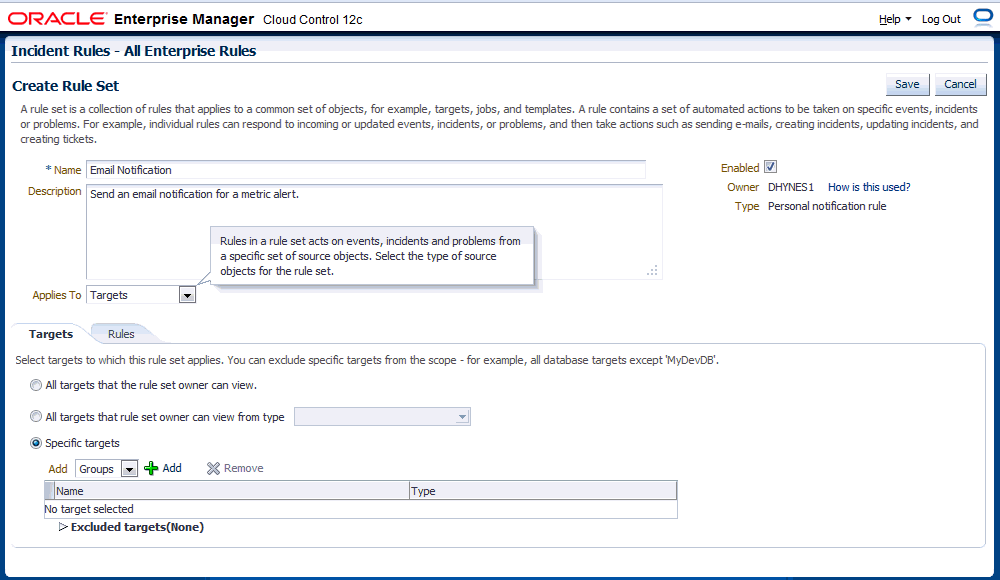
「ターゲット」タブで、「ルール・セット所有者が表示できるすべてのターゲットです。」を選択します。
|
代替方法: 特定のターゲット/グループにルール・セットを適用します。この例のすべてのターゲットにルール・セットを適用するように選択しましたが、特定のターゲットまたはグループにのみ適用することもできます。 手順は次のとおりです。
|
「ルール」タブで「作成」をクリックします。「作成するルールのタイプを選択」ダイアログが表示されます。
「受信イベントおよびイベントの更新」を選択し、「続行」をクリックします。
「イベント」ページで、ルールのアクションの基礎となるイベントの基準を設定します。この場合、ドロップダウン・リストから「メトリック・アラート」を選択します。
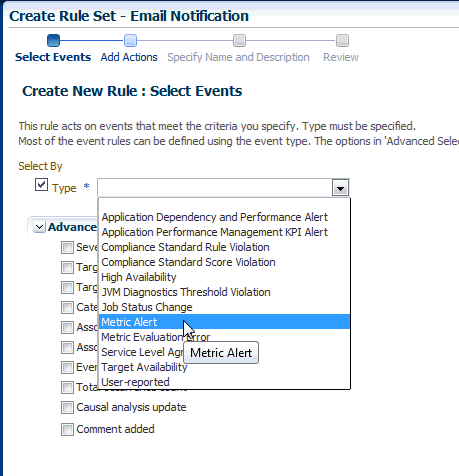
「次へ」をクリックします。
「タイプ メトリック・アラートの特定のイベント」オプションを選択します。メトリック選択領域が表示されます。
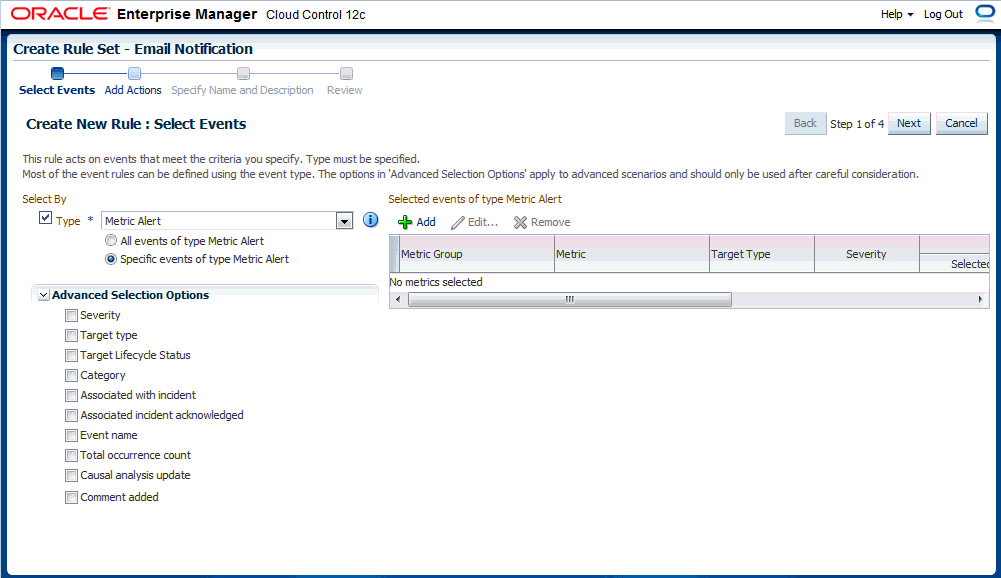
この例では、CPU使用率が定義した「クリティカル」しきい値を大幅に超えた場合にのみ通知を送信します。
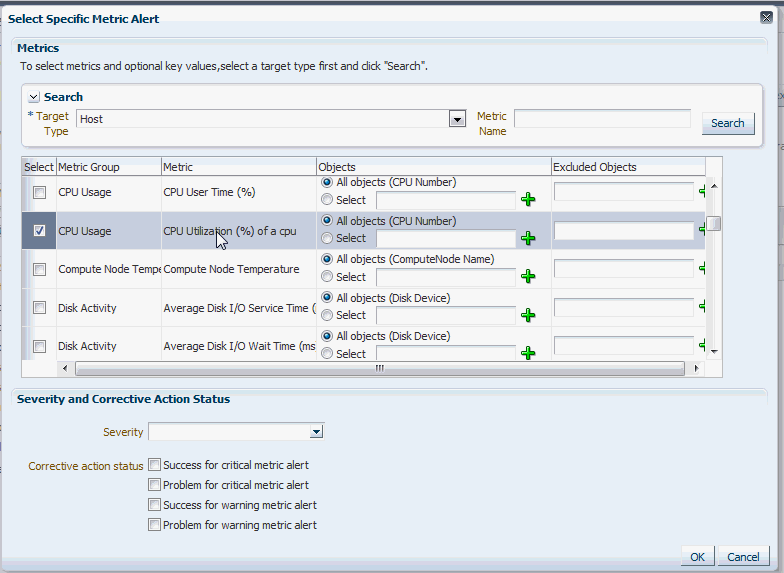
ドロップダウン・リストから重大度「クリティカル」を選択します。
「OK」をクリックします。
「次」をクリックします。
「アクションの追加」にある「追加」をクリックして、ルールに適用するアクションを追加します。「通知」セクションで、通知を送信する電子メール・アドレスを入力します。「次」をクリックします。
複数の条件付きアクションを指定したり、追加した順番に順次(上から下に)評価できます。
|
代替方法: メーリング・リストに電子メール通知を送信します。電子メール・アドレスを指定する他に、定義済のEnterprise Manager管理者を指定できます。ユーザーのカテゴリ全体に通知するために、メール配信リストを指定することもできます。メーリング・リストを使用すると、個々のルール・セットを更新しなくても、通知の受信者を変更できます。 |
「名称と説明の指定」ページに、ルールの名前と説明を入力します。「次へ」をクリックします。
「確認」ページで詳細を確認し、「続行」をクリックします。
「ルール・セットの作成」ページで「保存」をクリックします。
これまでに実施したこと:
ここまでで、CPU使用率が「クリティカル」メトリックしきい値に到達したとき、管理者の電子メールに通知を送信するという新しいルール・セットを作成しました。このルール・セットをサブスクラウブする手順の詳細は、「ルールからの電子メールを受信するためのサブスクライブ」を参照してください。
次の操作
他の管理者のために電子メールの設定をする方法
電子メール・アドレスの追加/更新/削除、および通知スケジュールの定義
タスク
SNMPトラップ経由でHPオープンビュー・コンソールにイベント情報(メトリック・アラートなど)を送信するようにEnterprise Managerを構成します。これには2つのフェーズがあります。
SNMPトラップを送信するための通知メソッドの作成
メトリック・アラートが発生したときにSNMPトラップを送信するインシデント・ルールの作成
ユーザー・ロール
Enterprise Manager管理者
前提条件
ユーザーには、スーパー管理者権限が必要です。
詳細は、「通知用のメール・サーバーの設定」を参照してください。
次の手順を実行します。
SNMPトラップに基づく通知メソッドの作成
「設定」メニューから、「通知」、「通知メソッド」の順に選択します。
「通知メソッド」ページが表示されます。
「追加」ドロップダウン・メニューから、「SNMPトラップ」を選択し、「実行」をクリックします。「SNMPトラップの追加」ページが表示されます。
SNMPマスター・エージェントが実行されているホスト(マシン)の名前およびその他の詳細を、次の図のように指定する必要があります。
次に、有効なパラメータ値の例を示します。
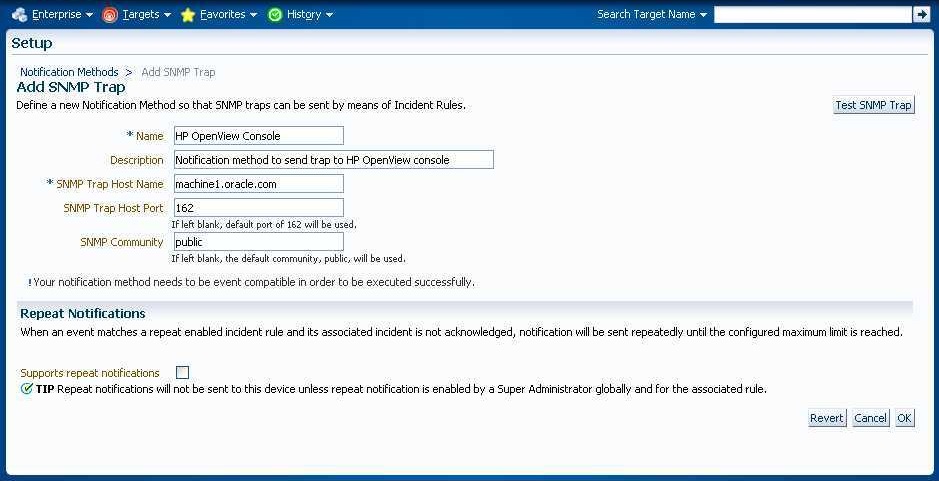
「SNMPトラップのテスト」をクリックして、SNMPトラップ設定を検証します。Enterprise Managerが成功/失敗メッセージを表示します。「OK」をクリックして、「SNMPトラップの追加」ページに戻ります。
「OK」をクリックして、「通知メソッド」ページに戻ります。
「OK」をクリックして、新しいSNMPトラップ・ベースの通知メソッドを追加します。
メトリック・アラートが発生したときにSNMPトラップを送信するインシデント・ルールの作成
「設定」メニューで「インシデント」、「インシデント・ルール」の順に選択します。
「インシデント・ルール - すべてのエンタープライズ・ルール」ページが表示されます。
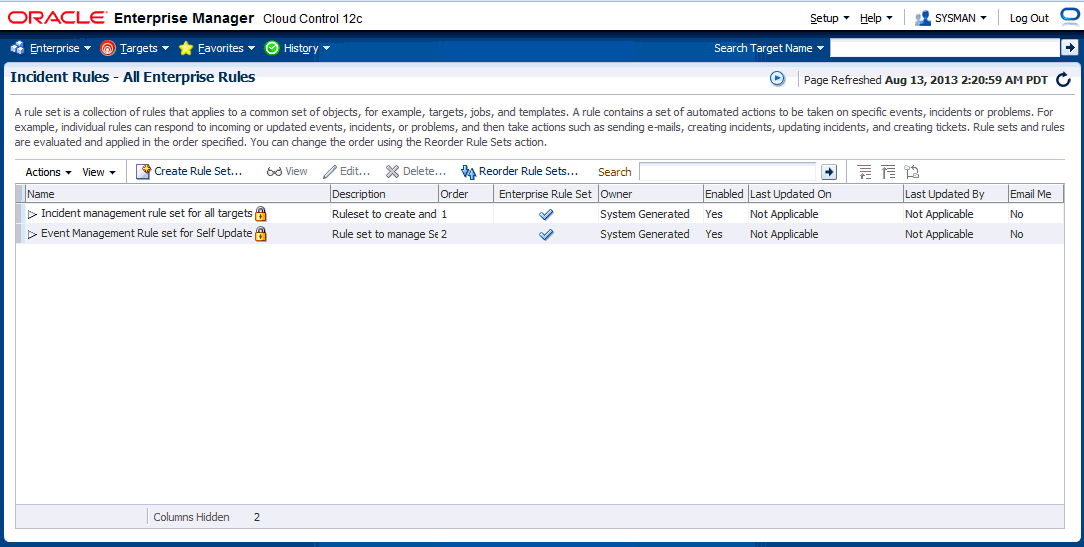
「インシデント・ルール: すべてのエンタープライズ・ルール」ページで「ルール・セットの作成...」をクリックします。「ルール・セットの作成」ページが表示されます。
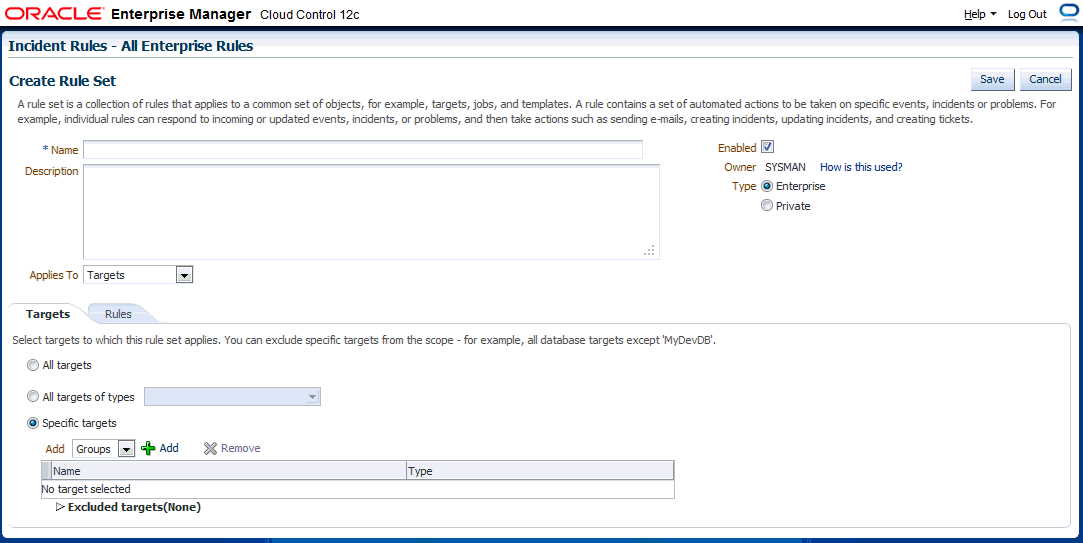
ルール・セットの「名前」、簡単な「説明」を入力し、ルールの「適用先」(ターゲット)ソース・オブジェクトのタイプを選択します。
「ルール」タブをクリックした後、「作成...」をクリックします。
「作成するルールのタイプを選択」ダイアログで、「受信イベントおよびイベントの更新」を選択し、「続行」をクリックします。
「イベント」ページで、ルールのアクションの基礎となるイベントの基準を設定します。この場合、ドロップダウン・リストから「メトリック・アラート」を選択します。
「次へ」をクリックします。
「タイプ メトリック・アラートの特定のイベント」オプションを選択します。メトリック選択領域が表示されます。
この例では、CPU使用率が定義した「クリティカル」しきい値を大幅に超えた場合にのみ通知を送信します。
ドロップダウン・リストから重大度「クリティカル」を選択します。
「OK」をクリックします。
「次」をクリックします。
新規ルールの作成: アクションの追加ページで、「追加」をクリックします。条件付きアクションの追加ページが表示されます。
次の図に示すように、「通知」セクションの「拡張通知」で、既存のSNMPトラップ通知メソッドを選択します。
SNMPトラップの通知メソッドの作成については、「サード・パーティ・システムへのSNMPトラップの送信」を参照してください。
「続行」をクリックし、新規ルールの作成: アクションの追加ページに戻ります。
「次へ」をクリックし、新規ルールの作成: 名前と説明の指定ページに移動します。
ルール名および簡潔な説明を指定して、「次へ」をクリックします。
ルール定義を確認し、「続行」をクリックしてルールをルール・セットに追加します。ルールがルール・セットに追加されたがまだ保存されていないことを表すメッセージが表示されます。「OK」をクリックして、メッセージを閉じます。
「保存」をクリックしてルール・セットを保存します。確認メッセージが表示されます。「OK」をクリックして、メッセージを閉じます。
これまでに実施したこと:
ここまでで、メトリック・アラート(%CPU使用率)が発生したときに、サード・パーティのシステムにSNMPトラップを送信するようにEnterprise Managerに指示するインシデント・ルール・セットを作成しました。
次の操作
タスク
コネクタを使用して、イベント情報をEnterprise ManagerからIBM Tivoli Netcool/OMNIbusに送信します。それには、IBM Tivoli Netcool/OMNIbus Connectorコネクタを起動するインシデント・ルールを作成する必要があります。
ユーザー・ロール
システム管理者
ITオペレータ
前提条件
ユーザーには、「エンタープライズ・ルール・セットの作成」リソース権限と、少なくともイベントがNetcool/OMNIbusに転送されるターゲットに対する「表示」権限が必要です。
詳細は、「通知用のメール・サーバーの設定」を参照してください。
IBM Tivoli Netcool/OMNIbusコネクタがインストール済で構成されている必要があります。
詳細は、Oracle® Enterprise Manager IBM Tivoli Netcool/OMNIbus Connectorのインストレーションおよび構成ガイドを参照してください。
次の手順を実行します。
「設定」メニューで「インシデント」、「インシデント・ルール」の順に選択します。
「インシデント・ルール - すべてのエンタープライズ・ルール」ページが表示されます。
「ルール・セットの作成」をクリックします。
ルール・セットの名前および説明を入力します。
「ターゲット」タブで、「ルール・セット所有者が表示できるすべてのターゲットです。」を選択します。
|
特定のターゲット/グループにルール・セットを適用します。 この例のすべてのターゲットにルール・セットを適用するように選択しましたが、特定のターゲットまたはグループにのみ適用することもできます。手順は次のとおりです。
|
「ルール」タブで「作成」をクリックします。「作成するルールのタイプを選択」ダイアログが表示されます。
「受信イベントおよびイベントの更新」を選択し、「続行」をクリックします。
「イベント」ページで、ルールのアクションの基礎となるイベントの基準を設定します。この場合、ドロップダウン・リストから「メトリック・アラート」を選択します。
「次へ」をクリックします。
「タイプ メトリック・アラートの特定のイベント」オプションを選択します。メトリック選択領域が表示されます。
この例では、CPU使用率が定義した「クリティカル」しきい値を大幅に超えた場合にのみ通知を送信します。
ドロップダウン・リストから重大度「クリティカル」を選択します。
「OK」をクリックします。
「次」をクリックします。アクションの追加ページが表示されます。
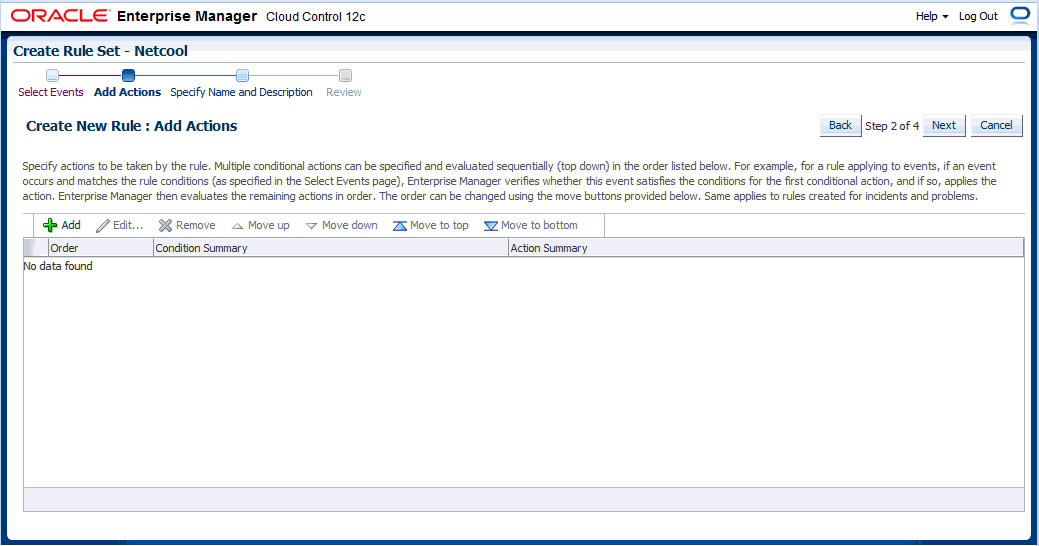
「追加」をクリックします。条件付きアクションの追加ページが表示されます。
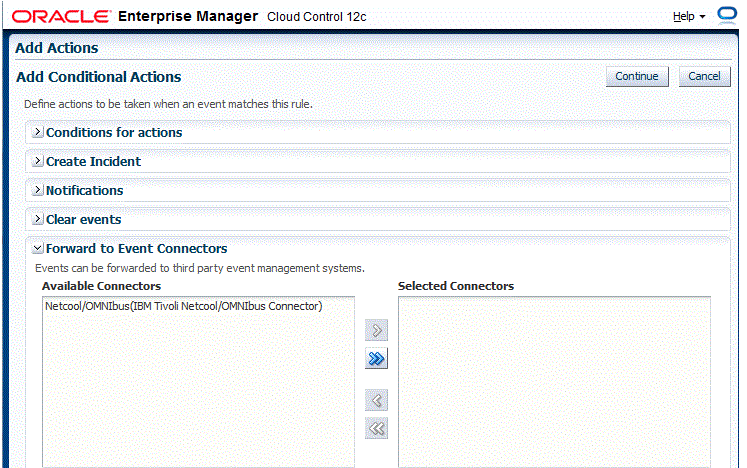
「イベント・コネクタに転送」セクションにリストされている1つ以上のコネクタ・インスタンスを選択し、「>」ボタンをクリックして、コネクタを「選択したコネクタ」リストに追加してから、「続行」をクリックします。「アクションの追加」ページが再度表示され、新しい処理がリストされます。
「次」をクリックします。「名前と説明の指定」ページが表示されます。
ルールの名前と説明を入力し、「次」をクリックします。確認ページが表示されます。
すべて正しく表示されたら、「続行」をクリックします。
ルールが正しいルール・セットに追加されたことを示す情報ポップアップが表示されます。新しく追加されたルールは、「保存」ボタンをクリックするまで保存されないことも示されます。
必要に応じて、「戻る」をクリックしてルールを修正することもできます。
これまでに実施したこと:
ここまでで、メトリック・アラートが発生したときにIBM Tivoli Netcool/OMNIbus Connectorコネクタを起動するルールを作成しました。
次の操作
タスク
あなたの企業の世界各地にあるIT部門は24時間365日稼働しています。サポート業務は、時間によって世界中の異なるデータ・センターがローテーションで担当します。Enterprise Managerが電子メール通知を送信すると、稼働中(通常の出勤日)の管理者に送信され、時間によって送信先が変わります。
Enterprise Managerからの通知を処理する管理者は次の4つです。
ADMIN_ASIA
ADMIN_EU
ADMIN_UK
ADMIN_US
通知を、通常の稼働時間にある特定の管理者に送信します。
ユーザー・ロール
システム管理者
ITオペレータ
前提条件
電子メール・アドレスは、電子メール通知の送信先とするすべての管理者用に定義されています。
詳細は、「電子メール・アドレスの定義」を参照してください。
スーパー管理者権限が必要です。
電子メール通知を受信するすべての管理者が定義済である必要があります。
次の手順を実行します。
「設定」メニューから、「通知」、「通知スケジュール」の順に選択します。
通知スケジュール・ページが表示されます。
編集する通知スケジュールを所有する管理者を指定し、「変更」をクリックします。選択された管理者の通知スケジュールが表示されます。使用可能な管理者のリストは、検索アイコン(拡大鏡)をクリックできます。
「スケジュール定義の編集」をクリックします。スケジュール定義の編集: 期間ページが表示されます。デフォルトで「既存のスケジュールの編集」オプションが選択されます。必要に応じて、ローテーション・スケジュールを変更します。
「続行」をクリックします。スケジュール定義の編集: 電子メール・アドレス・ページが表示されます。
スケジュール定義の編集: 電子メール・アドレス・ページ上の指示に従って、必要に応じて管理者の通知スケジュールを調整します。
選択された管理者の通知スケジュールの変更が行われた後、「終了」をクリックします。通知スケジュール・ページに戻ります。
すべての4つの管理者の通知スケジュールが通常の仕事日と同期化するまで、各管理者に対してこのプロセス(手順2から6)を繰り返します。
これまでに実施したこと:
世界の別のタイムゾーンの管理者に割り当てられた作業時間中にのみアラート通知が送信される通知スケジュールを作成しました。
次の操作