| Oracle® Communications Converged Application Server Concepts Release 5.1 Part Number E27705-01 |
|
|
PDF · Mobi · ePub |
| Oracle® Communications Converged Application Server Concepts Release 5.1 Part Number E27705-01 |
|
|
PDF · Mobi · ePub |
This chapter describes the Oracle Communications Converged Application Server cluster architecture.
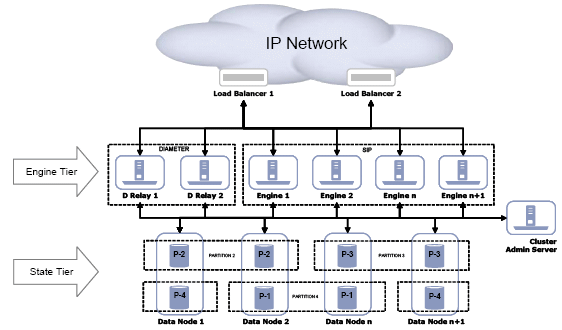
Converged Application Server provides a multi-tier cluster architecture in which a stateless “Engine Tier” processes all traffic and distributes all transaction and session state to a “Data Tier.” The SIP data tier is comprised of one or more partitions, labeled as “Data Nodes” in Figure 4-1 below.
Each partition may contain one or more replicas of all state assigned to it and may be distributed across multiple physical servers or server blades. A standard load balancing appliance is used to distribute traffic across the Engines in the cluster. It is not necessary that the load balancer be SIP-aware; there is no requirement that the load balancer support affinity between Engines and SIP dialogs or transactions. However, SIP-aware load balancers can provide higher performance by maintaining a client's affinity to a particular engine tier server.
Figure 4-1 shows an example Converged Application Server cluster.
There is no arbitrary limit to the number of engines, partitions or physical servers within a cluster, and there is no fixed ratio of engines to partitions. When dimensioning the cluster, however, a number of factors should be considered, such as the typical amount of memory required to store the state for a given session and the increasing overhead of having more than two replicas within a partition.
Converged Application Server has demonstrated linear scalability from 2 to 16 hosts (up to 32 CPUs) in both laboratory and field tests and in commercial deployments. This characteristic is likely to be evident in larger clusters as well, up to the ability of the cluster interconnect (or alternatively the load balancer) to support the total traffic volume. Gigabit Ethernet is recommended as a minimum for the cluster interconnect.
In some cases, it is advantageous to have SIP data tier instances and engine tier instances running on the same physical host. For example, during development it is usually more convenient to deploy and test applications on a single server rather than a cluster of servers. This may also be the case for physical servers or server blades based on Symmetrical Multi-Processing (SMP) architectures, now common for platforms such as Advance Telecom Computing Architecture (ATCA).
In a combined-tier configuration, the same Converged Application Server instance provides SIP Servlet container functionality and manages the call state for applications hosted on the server. Although the combined-tier configuration is most commonly used for development and testing purposes, it can be used in any production environment in which replication is not required for call state data. In such cases, the signaling throughput of individual Converged Application Server instances will be substantially higher due to the elimination of the computing overhead of the clustering mechanism. Non-clustered configurations are appropriate for development environments or for cases where all deployed services are stateless and/or session retention is not considered important to the user experience (where users are not disturbed by failure of established sessions).
Converged Application Server can be installed in a geographically-redundant configuration for implementations that employ distributed data centers, and require continuing operation even after a catastrophic site failure.
The geographically-redundant configuration enables multiple Converged Application Server installations (complete with engine and SIP data tier clusters) to replicate call state transactions between one another. If a particular site's installation were to suffer a critical failure, the administrator could choose to redirect all network traffic to the secondary, replicated site to minimize lost calls.
When an initial SIP message is received, Converged Application Server uses Servlet mapping rules to direct the message to the appropriate SIP Servlet deployed in the engine tier. The engine tier maintains no stateful information about SIP dialogs, but instead persists the call state to the engine tier at SIP transaction boundaries. A hashing algorithm is applied to the call state to select a single SIP data tier partition in which to store the call state data. The engine tier server then "writes" the call state to each replica within that partition and locks the call state. For example, if the SIP data tier is configured to use two servers within each partition, the engine tier opens a connection to both replicas in the partition, and writes and locks the call state on each replica.
In a default configuration, the replicas maintain the call state information only in memory (available RAM). Call state data can also be configured for longer-term storage in an RDBMS, and it may also be persisted to an off-site Converged Application Server installation for geographic redundancy.
When subsequent SIP messages are generated for the SIP dialog, the engine tier must first retrieve the call state data from the SIP data tier. The hashing algorithm is again applied to determine the partition that stores the call state data. The engine tier then asks each replica in the partition to unlock and retrieve the call state data, after which a Servlet on the engine tier can update the call state data.
You manage a Converged Application Server domain using an Administration Server. The Administration Server hosts the Administration Console interface, which you use to configure, deploy, and monitor the Converged Application Server installation.
Oracle recommends the following best practices for configuring Administration Server and Managed Server instances in your Converged Application Server domain:
Run the Administration Server instance on a dedicated machine. The Administration Server machine should have a memory capacity similar to Managed Server machines, although a single CPU is generally acceptable for administration purposes.
Configure all Managed Server instances to use Managed Server Independence. This feature allows the Managed Servers to restart even if the Administration Server is unavailable. For more information, see Oracle Fusion Middleware Managing Server Startup and Shutdown for Oracle WebLogic Server in the Oracle Fusion Applications Technology book set for more information.
Configure the Node Manager utility to automatically restart all Managed Servers in the Converged Application Server domain. See Oracle WebLogic Scripting Tool in the Oracle WebLogic Server 11g documentation for more information.
If an Administration Server fails, only configuration, deployment, and monitoring features are affected, but Managed Servers continue to operate and process client requests. See Oracle Communications Converged Application Server Administration Guide for more information.
The engine tier is a cluster of Converged Application Server instances that hosts the SIP Servlets and other applications that provide features to SIP clients. The engine tier is a stateless cluster of servers, and it stores no permanent or transient information about the state of SIP dialogs. Instead, all stateful information about SIP dialogs is stored and retrieved from the SIP Data Tier, which also provides replication and failover services for SIP session data.
Engine tier servers can optionally cache a portion of the session data managed by the SIP data tier. Caching is most useful in configurations that use a SIP-aware load balancer.
The primary goal of the engine tier is to provide maximum throughput and low response time to SIP clients. As the number of calls, or the average duration of calls to your system increases, you can easily add additional server instances to the engine tier to manage the additional load.
Although the engine tier consists of multiple Converged Application Server instances, you manage the engine tier as a single, logical entity; SIP Servlets are deployed uniformly to all server instances (by targeting the cluster itself) and the load balancer need not maintain an affinity between SIP clients and servers in the engine tier.
Note:
Converged Application Server start scripts use default values for many JVM parameters that affect performance. For example, JVM garbage collection and heap size parameters may be omitted, or may use values that are acceptable only for evaluation or development purposes. In a production system, you must rigorously profile your applications with different heap size and garbage collection settings in order to realize adequate performance. See the Oracle Communications Converged Application Administrator's Guide for suggestions about maximizing JVM performance in a production domain.Because the engine tier relies on SIP data tier servers in order to retrieve call state data, Oracle recommends using dual, Gigabit Ethernet Network Interface Cards (NICs) on engine and SIP data tier machines to provide redundant network connections.
The Converged Application Server SIP data tier is an in-memory, peer-replicated store. The store also functions as a lock manager, whereby call state access follows a simple “library book” model (a call state can only be checked out by one SIP engine at a time).
The goals of the SIP data tier are as follows:
To provide reliable, performant storage for session data required by SIP applications in the Converged Application Server engine tier.
To enable administrators to easily scale hardware and software resources as necessary to accommodate the session state for all concurrent calls.
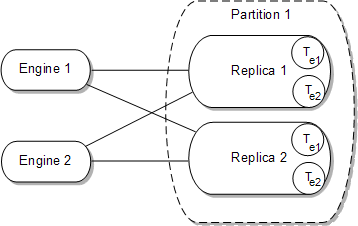
The nodes in the SIP data tier are called replicas. To increase the capacity of the SIP data tier, the data is split evenly across a set of partitions. Each partition has a set of 1-8 replicas which maintain a consistent state. (Oracle recommends using no more than 3 replicas per partition.) The number of replicas in the partition is the replication factor.
Replicas can join and leave the partition. Any given replica serves in exactly one partition at a time. The total available call state storage capacity of the cluster is determined by the capacity of each partition.
In a system that uses two partitions, the first partition manages one half of the concurrent call state (sessions A through M) while the second partition manages another half of the concurrent call states (sessions N through Z). With three partitions, each partition manages a third of the call state, and so on. Additional partitions can be added as necessary to manage a large number of concurrent calls. A simple hashing algorithm is used to ensure that each call state is uniquely assigned to only one SIP data tier partition.
Within each partition, multiple servers can be added to provide redundancy and failover should other servers in the partition fail. When multiple servers participate in the same partition, the servers are referred to as "replicas" because each server maintains a duplicate copy of the partition's call state. For example, if a two-partition system has two servers in the first partition, each server manages a replica of call states A through M. If one or more servers in a partition fails or is disconnected from the network, any available replica can automatically provide call state data to the engine tier. The SIP data tier can have a maximum of three replicas, providing two levels of redundancy.
Note:
Because the engine tier relies on SIP data tier servers in order to retrieve call state data, Oracle recommends using dual Network Interface Cards (NICs) on engine and SIP data tier machines to provide redundant network connections.The call state store is peer-replicated. This means that clients perform all operations (reads and writes) to all replicas in a partition. Peer replication stands in contrast to the more common primary-secondary replication architecture, wherein one node acts as a primary and the all other nodes act as secondaries. With primary-secondary replication, clients only talk directly to the current primary node. Peer-replication is roughly equivalent to the synchronous primary-secondary architecture with respect to failover characteristics, peer replication has lower latency during normal operations on average. Lower latency is achieved because the system does not have to wait for the synchronous 2nd hop incurred with primary-secondary replication.
Peer replication also provides better failover characteristics than asynchronous primary-secondary systems because there is no change propagation delay.
The operations supported by all replicas for normal operations are: “lock and get call state,” “put and unlock call state,” and “lock and get call states with expired timers.” The typical message processing flow is simple:
Lock and get the call state.
Process the message.
Put and unlock the call state.
Additional management functions deal with bootstrapping, registration, and failure cases.
The current set of replicas in a partition is referred to as the partition view. The view contains an increasing ID number. A view change signals that either a new replica has joined the partition, or that a replica has left the partition. View changes are submitted to engines when they perform and operation against the SIP data tier.
When faced with a view change, engine nodes performing a lock/get operation must immediately retry their operations with the new view. Each SIP engine schedules a 10ms interval for retrying the lock/get operation against the new view. In the case of a view change on a put request, the new view is inspected for added replicas (in the case that the view change derives from a replica join operation instead of replica failure or shutdown). If there is an added replica, that replica also gets the put request to ensure consistency.
An additional function of the SIP data tier is timer processing. The replicas set timers for the call states when call states perform put operations. Engines then poll for and “check out” timers for processing. Should an engine fail at this point, this failure is detected by the replica and the set of checked-out timers is forcefully checked back in and rescheduled so that another engine may check them out and process them.
As an optimization, if a given call state contains only timers required for cleaning up the call state, the SIP data tier itself expires the timers. In this special case, the call state is not returned to an engine tier for further processing, because the operation can be completed wholly within the SIP data tier.
The SIP engine node clients perform failure detection for replicas, or for failed network connections to replicas.
During the course of message processing, an engine communicates with each replica in the current partition view. Normally all operations succeed, but occasionally a failure (a dropped socket or an invocation timeout) is detected. When a failure is detected the engine sends a “replica died” message to any of the remaining live replicas in the partition. (If there is no remaining live replica, the partition is declared “dead” and the engines cannot process calls hashing to that partition until the partition is restored). The replica that receives the failed replica notification proposes a new partition view that excludes the reportedly dead replica. All clients will then receive notification of the view change (see "Partition Views" for more information).
To handle partitioned network scenarios where one client cannot talk to the supposedly failed replica but another replica can, the “good” replica removes the reportedly failed replica offline, ensuring safe operation in the face of network partition.
An engine tier server failure can affect the validity of replicated data in the following cases:
Engine processes fail in the middle of a lock/get or put/unlock operation
Engine processes fail to unlock call states for messages they are currently processing
Engine processes abandon the set of timers that they are currently processing
Replicas are responsible for detecting engine failure. In the case of failures during lock/get and put/unlock operations, there is risk of lock state and data inconsistency between the replicas (data inconsistency in the case of put/unlock only). To handle this, the replicas break locks for call states if they are requested by another engine and the current lock owner is deemed dead. This allows progress with that call state.
Additionally, to deal with possible data inconsistency in scenarios where locks had to be broken, the call state is marked as “possibly stale”. When an engine evaluates the response of a lock/get operation, it wants to choose the best data. If any one replica reports that it has non-stale data, that data is used. Otherwise, the “possibly stale” data is used (it is only actually stale in the case that the single replica that had the non-stale version died in the intervening period).
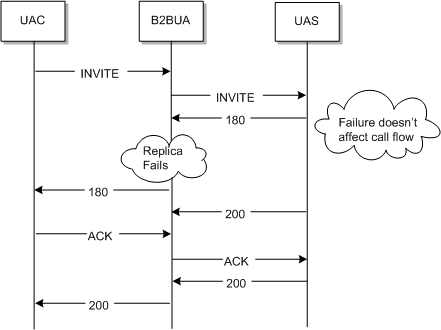
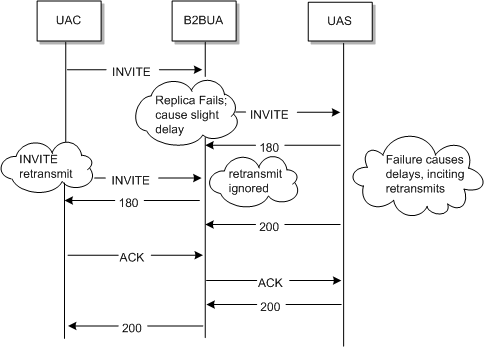
Because of the automatic failure recovery of the replicated store design, failures don't affect call flow unless the failure is of a certain duration or magnitude.
In some cases, failure recovery causes “blips” in the system where the engine's coping with view changes causes message processing to temporarily back-up. This is usually not dangerous, but may cause UAC or UAS re-transmits if the backlog created is substantial.
Catastrophic failure of a partition (whereby no replica is remaining) causes a fraction of the cluster to be unable to process messages. If there are four partitions, and one is lost, 25% of messages will be rejected. This situation will resolve once any of the replicas are put back in the service of that partition.
Converged Application Server enables you to store long-lived call state data in an Oracle RDBMS in order to conserve RAM. The SIP data tier persists a call state's data to the RDBMS after the call dialog has been established, and retrieves or deletes the persisted call state data as necessary to modify or remove the call state.
A load balancer is an essential component of any production Converged Application Server deployment. A load balancer enhances the reliability and scalability of a deployment by distributing the workload among a group of servers and monitoring server availability. By distributing workload among multiple servers, a load balancer increases overall system throughput.
You can use the Converged Load Balancer or a third-party load balancer with the Converged Application Server deployment. The Converged Load Balancer is included with the Converged Application Server as an optionally installed component.
The Converged Load Balancer is a SIP-aware load balancer that accepts HTTP/HTTPS and SIP/SIPS requests and forwards them to application server instances in the cluster.
The Converged Load Balancer can monitor servers in the domain to ensure traffic is directed to healthy servers only. If an application server instance becomes unavailable or unresponsive, the converged load balancer bypasses the server until it is available again.
The Converged Load Balancer runs as a standalone component, operating in a separate container from the application servers. For high availability, you can deploy multiple Converged Load Balancer in a WebLogic domain. This improves the performance of the system and ensures that service continues if a load balancer fails.
Converged Load Balancers are stateless. They achieve server session affinity through the use of message headers that identify the server instance associated with an active session.
In addition to improving system reliability and scalability, a load balancer is useful for performing maintenance activities, such as upgrading individual servers or upgrading deployed applications without disrupting existing SIP clients.
While using the included Converged Load Balancer provides a common administration interface for your deployment, as well as other conveniences, you can use any third-party load balancer with your system, including non-SIP aware load balancers.
However, note that if you are using a combined-tier server deployment, the load balancer must be fully SIP aware. This is because each server in a combined-tier server deployment manages only the call state for the applications it hosts. Therefore, the load balancer must actively route multiple requests for the same call to the same Converged Application Server instance. If requests in the same call are not pinned to the same server, the call state cannot be retrieved.
Converged Application Server supports the Diameter base protocol. It supports the IMS Sh interface provider on engine tier servers, which then act as Diameter Sh client nodes. SIP Servlets deployed on the engines can use the profile service API to initiate requests for user profile data, or to subscribe to and receive notification of profile data changes. The Sh interface is also used to communicate between multiple IMS Application Servers.
One or more server instances may be also be configured as Diameter relay agents, which route Diameter messages from the client nodes to a configured Home Subscriber Server (HSS) in the network, but do not modify the messages. Oracle recommends configuring one or more servers to act as relay agents in a domain. The relays simplify the configuration of Diameter client nodes, and reduce the number of network connections to the HSS. Using at least two relays ensures that a route can be established to an HSS even if one relay agent fails.
The relay agents included in Converged Application Server perform only stateless proxying of Diameter messages; messages are not cached or otherwise processed before delivery to the HSS.
Note:
In order to support multiple HSSs, the 3GPP defines the Dh interface to look up the correct HSS. Converged Application Server does not provide a Dh interface application, and can be configured only with a single HSS.Note that relay agent servers do not function as either engine or SIP data tier instances—they should not host applications, store call state data, maintain SIP timers, or even use SIP protocol network resources (sip or sips network channels).
In summary, Converged Application Server supports the following Diameter functions:
Diameter Sh interface client node (for querying a Home Subscriber Service)
Diameter Rf interface client node (for offline charging)
Diameter Ro interface client node (for online charging)
Diameter relay node
HSS simulator node (suitable for testing and development only, not for production deployment)
Converged Application Server also provides a simple HSS simulator that you can use for testing Sh client applications. You can configure a Converged Application Server instance to function as an HSS simulator by deploying the appropriate application.
|
Copyright © 2005, 2012, Oracle and/or its affiliates. All rights reserved. Legal Notices |
|