11 Clustering Best Practices
This chapter provides recommended design and deployment practices that maximize the scalability, reliability, and performance of applications hosted by a cluster in WebLogic Server 10.3.6.
This chapter includes the following sections:
General Design Considerations
The following sections describe general design guidelines for clustered applications.
Strive for Simplicity
Distributed systems are complicated by nature. For a variety of reasons, make simplicity a primary design goal. Minimize "moving parts" and do not distribute algorithms across multiple objects.
Minimize Remote Calls
You improve performance and reduce the effects of failures by minimizing remote calls.
Session Facades Reduce Remote Calls
Avoid accessing EJB entity beans from client or servlet code. Instead, use a session bean, referred to as a facade, to contain complex interactions and reduce calls from Web applications to RMI objects. When a client application accesses an entity bean directly, each getter method is a remote call. A session facade bean can access the entity bean locally, collect the data in a structure, and return it by value.
Transfer Objects Reduce Remote Calls
EJBs consume significant system resources and network bandwidth to execute—they are unlikely to be the appropriate implementation for every object in an application.
Use EJBs to model logical groupings of an information and associated business logic. For example, use an EJB to model a logical subset of the line items on an invoice—for instance, items to which discounts, rebates, taxes, or other adjustments apply.
In contrast, an individual line item in an invoice is fine-grained—implementing it as an EJB wastes network resources. Implement objects that simply represents a set of data fields, which require only get and set functionality, as transfer objects.
Transfer objects (sometimes referred to as value objects or helper classes) are good for modeling entities that contain a group of attributes that are always accessed together. A transfer object is a serializable class within an EJB that groups related attributes, forming a composite value. This class is used as the return type of a remote business method.
Clients receive instances of this class by calling coarse-grained business methods, and then locally access the fine-grained values within the transfer object. Fetching multiple values in one server round-trip decreases network traffic and minimizes latency and server resource usage.
Web Application Design Considerations
The following sections describe design considerations for clustered servlets and JSPs.
Configure In-Memory Replication
To enable automatic failover of servlets and JSPs, session state must persist in memory. For instructions to configure in-memory replication for HTTP session states, see Requirements for HTTP Session State Replication, and Configure In-Memory HTTP Replication.
EJB Design Considerations
The following sections describe design considerations for clustered RMI objects.
Design Idempotent Methods
It is not always possible to determine when a server instance failed with respect to the work it was doing at the time of failure. For instance, if a server instance fails after handling a client request but before returning the response, there is no way to tell that the request was handled. A user that does not get a response retries, resulting in an additional request.
Failover for RMI objects requires that methods be idempotent. An idempotent method is one that can be repeated with no negative side-effects.
Follow Usage and Configuration Guidelines
Table 11-1 summarizes usage and configuration guidelines for EJBs. For a list of configurable cluster behaviors and resources and information on how to configure them, see Table 11-2.
Table 11-1 EJB Types and Guidelines
| Object Type | Usage | Configuration |
|---|---|---|
|
EJBs of all types |
Use EJBs to model logical groupings of an information and associated business logic. See Transfer Objects Reduce Remote Calls. |
Configure clusterable homes. See Table 11-2. |
|
Stateful session beans |
Recommended for high volume, heavy-write transactions. Remove stateful session beans when finished to minimize EJB container overhead. A stateful session bean instance is associated with a particular client, and remains in the container until explicitly removed by the client, or removed by the container when it times out. Meanwhile, the container may passivate inactive instances to disk. This consumes overhead and can affect performance. Note: Although unlikely, the current state of a stateful session bean can be lost. For example, if a client commits a transaction involving the bean and there is a failure of the primary server before the state change is replicated, the client will fail over to the previously-stored state of the bean. If it is critical to preserve bean state in all possible failover scenarios, use an entity EJB rather than a stateful session EJB. |
Configure clusterable homes. See Table 11-2. Configure in-memory replication for EJBs. See Table 11-2. |
|
Stateless Session Beans |
Scale better than stateful session beans which are instantiated on a per client basis, and can multiply and consume resources rapidly. When a home creates a stateless bean, it returns a replica-aware stub that can route to any server where the bean is deployed. Because a stateless bean holds no state on behalf of the client, the stub is free to route any call to any server that hosts the bean. |
Configure clusterable homes. See Table 11-2. Configure Cluster Address. See Table 11-2. Configure methods to be idempotence (see Table 11-2) to support failover during method calls. (Failover is default behavior if failure occurs between method calls.or if the method fails to connect to a server). The methods on stateless session bean homes are automatically set to be idempotent. It is not necessary to explicitly specify them as idempotent. |
|
Read-only Entity Beans |
Recommended whenever stale data is tolerable—suitable for product catalogs and the majority of content within many applications. Reads are performed against a local cache that is invalided on a timer basis. Read-only entities perform three to four times faster than transactional entities. Note: A client can successfully call setter methods on a read-only entity bean, however the data will never be moved into the persistent store. |
Configure clusterable homes. See Table 11-2. Configure Cluster Address. See Table 11-2. Methods are configured to be idempotent by default. |
|
Read-Write Entity Beans |
Best suited for shared persistent data that is not subject to heavy request and update.If the access/update load is high, consider session beans and JDBC. Recommended for applications that require high data consistency, for instance, customer account maintenance. All reads and writes are performed against the database. Use the For read-mostly applications, characterized by frequent reads, and occasional updates (for instance, a catalog)—a combination of read-only and read-write beans that extend the read-only beans is suitable. The read-only bean provides fast, weakly consistent reads, while the read-write bean provides strongly consistent writes. |
Configure clusterable homes. See Table 11-2. Configure methods to be idempotence (see Table 11-2) to support failover during method calls. (Failover is default behavior if failure occurs between method calls.or if the method fails to connect to a server). The methods on read-only entity beans are automatically set to be idempotent. |
Cluster-Related Configuration Options
Table 11-2 lists key behaviors that you can configure for a cluster, and the associated method of configuration.
Table 11-2 Cluster-Related Configuration Options
| Configurable Behavior or Resource | How to Configure |
|---|---|
|
Set |
|
|
At bean level, set At method level, set |
|
|
Set |
|
|
The cluster address identifies the Managed Servers in the cluster. The cluster address is used in entity and stateless beans to construct the host name portion of URLs. The cluster address can be assigned explicitly, or generated automatically by WebLogic Server for each request. For more information, see Cluster Address. |
|
clients-on-same-server |
Set If |
|
Load balancing algorithm for entity bean and entity EJBs homes |
|
|
Custom load balancing for entity EJBs, stateful session EJBs, and stateless session |
Use |
|
Custom load balancing for stateless session bean |
Use |
|
Configure stateless session bean as clusterable |
Set |
|
Load balancing algorithm for stateless session beans. |
Use |
|
Machine |
The WebLogic Server Machine resource associates server instances with the computer on which it runs. For more information, see Configure Machine Names. |
|
Replication groups |
Replication groups allow you to control where HTTP session states are replicated. For more information, see Configure Replication Groups. |
State Management in a Cluster
Different services in a WebLogic Server cluster provide varying types and degrees of state management. This list defines four categories of service that are distinguished by how they maintain state in memory or persistent storage:
-
Stateless services—A stateless service does not maintain state in memory between invocations.
-
Conversational services—A conversational service is dedicated to a particular client for the duration of a session. During the session, it serves all requests from the client, and only requests from that client. Throughout a session there is generally state information that the application server must maintain between requests. Conversational services typically maintain transient state in memory, which can be lost in the event of failure. If session state is written to a shared persistent store between invocations, the service is stateless. If persistent storage of state is not required, alternatives for improving performance and scalability include:
-
Session state can be sent back and forth between the client and server under the covers, again resulting in a stateless service. This approach is not always feasible or desirable, particularly with large amounts of data.
-
More commonly, session state may be retained in memory on the application server between requests. Session state can be paged out from memory as necessary to free up memory. Performance and scalability are still improved in this case because updates are not individually written to disk and the data is not expected to survive server failures.
-
-
Cached services—A cached service maintains state in memory and uses it to process requests from multiple clients. Implementations of cached services vary in the extent to which they keep the copies of cached data consistent with each other and with associated data in the backing store.
-
Singleton services—A singleton service is active on exactly one server in the cluster at a time and processes requests from multiple clients. A singleton service is generally backed by private, persistent data, which it caches in memory. It may also maintain transient state in memory, which is either regenerated or lost in the event of failure. Upon failure, a singleton service must be restarted on the same server or migrated to a new server.
Table 11-3 summarizes how Java EE and WebLogic support each of these categories of service. Support for stateless and conversational services is described for two types of clients:
-
Loosely-coupled clients include browsers or Web Service clients that communicate with the application server using standard protocols.
-
Tightly-coupled clients are objects that run in the application tier or in the client-side environment, and communicate with the application server using proprietary protocol.
Table 11-3 Java EE and WebLogic Support for Service Types
| Service | Java EE Support | WebLogic Server Scalability and Reliability Features for... |
|---|---|---|
|
All Java EE APIs are either stateless or may be implemented in a stateless manner by writing state information to a shared persistent store between invocations. Java EE does not specify a standard for load balancing and failover. For loosely coupled clients, load balancing must be must be performed by external IP-based mechanisms |
WebLogic Server increases the availability of stateless services by deploying multiple instances of the service to a cluster. For loosely-coupled clients of a stateless service, WebLogic Server supports external load balancing solutions, and provides proxy plug-ins for session failover and load balancing. For more information, see: |
|
|
Stateless Service with tightly-coupled clients |
These Java EE APIs support tightly coupled access to stateless services:
|
WebLogic Server increases the availability of stateless services by deploying multiple instances of the service to a cluster. For tightly-coupled clients of a stateless service, WebLogic Server supports load balancing and failover in its RMI implementation. The WebLogic Server replica-aware stub for a clustered RMI object lists the server instances in the cluster that currently offer the service, and the configured load balancing algorithm for the object. WebLogic Server uses the stub to make load balancing and failover decisions. For more information, see: |
|
Conversational services with loosely-coupled clients |
These Java EE APIs support loosely-coupled access to conversational services:
Java EE does not specify a standard for load balancing and failover. Load balancing can be accomplished with external IP-based mechanisms or application server code in the presentation tier. Because protocols for conversations services are stateless, load balancing should occur only when the session is created. Subsequent requests should stick to the selected server. |
WebLogic Server increases the reliability of sessions with:
For more information, see |
|
Conversational services with tightly-coupled clients |
The Java EE standard provides EJB stateful session beans to support conversational services with tightly-coupled clients. |
WebLogic Server increases the availability and reliability of stateful session beans with these features:
For more information, see Stateful Session Beans. |
|
Cached Services |
Java EE does not specify a standard for cached services. Entity beans with Bean-Managed-Persistence can implement custom caches. |
Weblogic Server supports caching of: Stateful session beans For a list of WebLogic features that increase scalability and reliability of stateful session beans, see description in the previous row. Entity beans Weblogic Server supports these caching features for entity beans.
Consistency between the cache and the external data store can be increased by:
"read-mostly pattern" WebLogic Server supports the "read-mostly pattern" by combining read-only and read-write EJBs. JSPs WebLogic Server provides custom JSP tags to support caching at fragment or page level. |
|
Singleton Services |
Java EE APIs used to implement singleton services include:
Scalability can be increased by "partitioning" the service into multiple instances, each of which handles a different slice of the backing data and its associated requests |
WebLogic Server features for increasing the availability of singleton services include:
|
Application Deployment Considerations
Deploy clusterable objects to the cluster, rather than to individual Managed Servers in the cluster. For information and recommendations, see Deploying Applications to Oracle WebLogic Server.
Architecture Considerations
For information about alternative cluster architectures, load balancing options, and security options, see Chapter 9, "Cluster Architectures."
Avoiding Problems
The following sections present considerations to keep in mind when planning and configuring a cluster.
Naming Considerations
For guidelines for how to name and address server instances in cluster, see Identify Names and Addresses.
Administration Server Considerations
To start up WebLogic Server instances that participate in a cluster, each Managed Server must be able to connect to the Administration Server that manages configuration information for the domain that contains the cluster. For security purposes, the Administration Server should reside within the same DMZ as the WebLogic Server cluster.
The Administration Server maintains the configuration information for all server instances that participate in the cluster. The config.xml file that resides on the Administration Server contains configuration data for all clustered and non-clustered servers in the Administration Server's domain. You do not create a separate configuration file for each server in the cluster.
The Administration Server must be available in order for clustered WebLogic Server instances to start up. Note, however, that once a cluster is running, a failure of the Administration Server does not affect ongoing cluster operation.
The Administration Server should not participate in a cluster. The Administration Server should be dedicated to the process of administering servers: maintaining configuration data, starting and shutting down servers, and deploying and undeploying applications. If the Administration Server also handles client requests, there is a risk of delays in accomplishing administration tasks.
There is no benefit in clustering an Administration Server; the administrative objects are not clusterable, and will not failover to another cluster member if the administrative server fails. Deploying applications on an Administration Server can reduce the stability of the server and the administrative functions it provides. If an application you deploy on the Administration Server behaves unexpectedly, it could interrupt operation of the Administration Server.
For these reasons, make sure that the Administration Server's IP address is not included in the cluster-wide DNS name.
Firewall Considerations
If your configuration includes a firewall, locate your proxy server or load-balancer in your DMZ, and the cluster, both Web and EJB containers, behind the firewall. Web containers in DMZ are not recommended. See Basic Firewall for Proxy Architectures.
If you place a firewall between the servlet cluster and object cluster in a multi-tier architecture, bind all servers in the object cluster to public DNS names, rather than IP addresses. Binding those servers with IP addresses can cause address translation problems and prevent the servlet cluster from accessing individual server instances.
If the internal and external DNS names of a WebLogic Server instance are not identical, use the ExternalDNSName attribute for the server instance to define the server's external DNS name. Outside the firewall the ExternalDNSName should translate to external IP address of the server. Set this attribute in the Administration Console using the Servers > Configuration > General page. See Servers > Configuration > General in Oracle WebLogic Server Administration Console Help.
In any cluster architecture that utilizes one or more firewalls, it is critical to identify all WebLogic Server instances using publicly-available DNS names, rather than IP addresses. Using DNS names avoids problems associated with address translation policies used to mask internal IP addresses from untrusted clients.
Note:
Use ofExternalDNSName is required for configurations in which a firewall is performing Network Address Translation, unless clients are accessing WebLogic Server using t3 and the default channel. For instance, ExternalDNSName is required for configurations in which a firewall is performing Network Address Translation, and clients are accessing WebLogic Server using HTTP via a proxy plug-in.Figure 11-1 describes the potential problem with using IP addresses to identify WebLogic Server instances. In this figure, the firewall translates external IP requests for the subnet "xxx" to internal IP addresses having the subnet "yyy."
Figure 11-1 Translation Errors Can Occur When Servers are Identified by IP Addresses
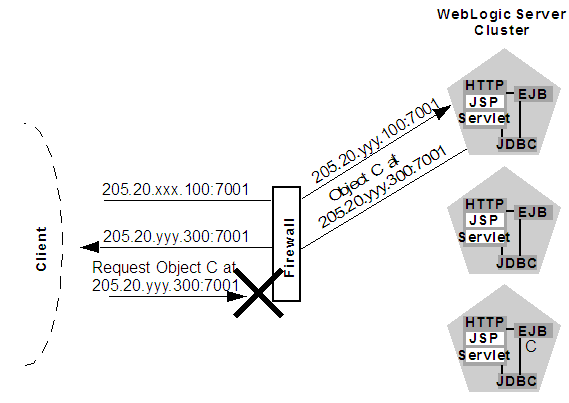
Description of "Figure 11-1 Translation Errors Can Occur When Servers are Identified by IP Addresses"
The following steps describe the connection process and potential point of failure:
-
The client initiates contact with the WebLogic Server cluster by requesting a connection to the first server at 205.20.xxx.100:7001. The firewall translates this address and connects the client to the internal IP address of 205.20.yyy.100:7001.
-
The client performs a JNDI lookup of a pinned Object C that resides on the third WebLogic Server instance in the cluster. The stub for Object C contains the internal IP address of the server hosting the object, 205.20.yyy.300:7001.
-
When the client attempts to instantiate Object C, it requests a connection to the server hosting the object using IP address 205.20.yyy.300:7001. The firewall denies this connection, because the client has requested a restricted, internal IP address, rather than the publicly-available address of the server.
If there was no translation between external and internal IP addresses, the firewall would pose no problems to the client in the above scenario. However, most security policies involve hiding (and denying access to) internal IP addresses.
Evaluate Cluster Capacity Prior to Production Use
The architecture of your cluster will influence the capacity of your system. Before deploying applications for production use, evaluate performance to determine if and where you may need to add servers or server hardware to support real-world client loads. Testing software such as LoadRunner from Mercury Interactive allows you to simulate heavy client usage.