26 Prerequisites for Installing Analytics
This chapter contains prerequisites for installing and configuring Analytics to run on the WebCenter Sites web application.
This chapter contains the following sections:
26.1 Pre-Installation Checklist
To install Analytics, you will run a silent installer (a Java-based script). Before running the silent installer, verify the availability and configuration of all components that support Analytics.
-
Section 26.1.5, "WebCenter Sites and Supporting Documentation"
-
Section 26.1.6, "WebCenter Sites: Analytics Silent Installer"
-
Section 26.1.7, "WebCenter Sites: Analytics Supporting Software"
26.1.1 Required Experience
To install Analytics, you must have experience installing and configuring enterprise-level software (such as application servers and databases), and setting system operating parameters.
26.1.2 System Architecture
-
Read Chapter 25, "Overview of Analytics Architecture" to familiarize yourself with the architecture of the Analytics product and the supported installation options.
-
Read the release notes and the Oracle WebCenter Sites Certification Matrix to ensure that you are using certified versions of the third-party software that supports Analytics.
26.1.3 WebCenter Sites: Analytics Kit
Make sure you have a licensed Analytics Kit (analytics2.5.zip). The kit is organized as shown in Figure 26-1.
Figure 26-1 Analytics Kit's Directory Structure
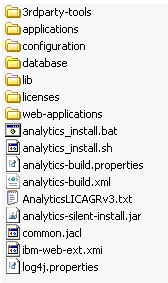
Description of ''Figure 26-1 Analytics Kit's Directory Structure''
The kit contains the Analytics silent installer files, supporting third-party software, and the Analytics suite. The Analytics suite consists of the following applications:
-
Analytics Data Capture web application (also called "sensor")
-
Analytics Administrator web application
-
Analytics Reporting web application (reporting engine and interface)
-
Hadoop Distributed File System (HDFS) Agent
-
Hadoop Jobs (scheduler)
26.1.4 Installing Hadoop
Note:
In the Analytics Kit, the3rdparty-tools folder contains Hadoop binaries. Use the Hadoop binaries to install Hadoop (and not the files that are available on the Hadoop web site).-
In this section, you will install and configure Hadoop in one of the following modes: local, pseudo-distributed, or fully distributed (recommended), whichever is best suited to meet your development, scalability, and performance requirements. The modes are described as follows:
-
The local (standalone) mode is used for development and debugging. By default, Hadoop is configured to run in a non-distributed mode, as a single Java process.
-
The pseudo-distributed mode is used in single-server installations. In this mode, all the Hadoop services (for example,
NameNode,JobTracker,DataNodeandTaskTracker) run on a single node, and each service runs as a separate Java process. -
The fully distributed mode is used for enterprise-level installations. In this mode, Hadoop runs on multiple nodes in a parallel and distributed manner. A minimum of two nodes is required to set up Hadoop: One machine acts as the master node, while the remaining machines act as slave nodes. On the master node, the
NameNodeandJobTrackerservices will be running. On the slave nodes, theDataNodeandTaskTrackerservices will be running.
-
-
For Hadoop installation instructions, refer to the Hadoop Quick Start site. The URL at the time of this writing is:
http://hadoop.apache.org/docs/r0.18.3/quickstart.pdfIf you install Hadoop in either pseudo- or fully distributed mode, you must configure a property file called
hadoop-site.xmlon all master and slave computers. Recommended property values and a sample file are available in this section.To configure hadoop-site.xml
-
Configure the
hadoop-site.xmlfile as shown in Table 26-1. Your configured file should look similar to the samplehadoop-site.xmlfile shown. -
If you are installing in fully distributed mode, copy the configured
hadoop-site.xmlto all master and slave computers.Table 26-1 Properties in
hadoop-site.xmlProperty Description Sample Value fs.default.nameName of the default file system. A URI whose scheme and authority determine the
FileSystemimplementation.The URI's scheme determines the configuration property (
fs.SCHEME.impl) that names theFileSystemimplementation class.The URI's authority is used to determine the host, port (and so on) for a file system.
hdfs://<ipaddress>:<port1>
where
<ipaddress>is the IP address of the master node, and<port1>is the port on which NameNodewill listen for incoming connections.For example:
hdfs://192.0.2.1:9090
mapred.job.trackerHost and port on which the
MapReducejob tracker runs.If this property is set to
local, then jobs are run in-process, as a single map and reduce task.<ipaddress>:<port2> local
For example:
192.0.2.1:7070
Note: In fully distributed mode, enter the IP address of the master node.
dfs.replicationDefault block replication. The number of replications for any file that is created in HDFS.
The value should be equal to the number of
DataNodesin the cluster. The default is used ifdfs.replicationis not set.<equal to the number of data nodes>
dfs.permissionsEnables/disables permission checking in HDFS.
-
trueenables permission checking in HDFS. -
falsedisables permission checking, but leaves all other behavior unchanged.
Switching from one value to the other does not change the mode, owner or group of files, or directories.
true | false
hadoop.tmp.dirHadoop file system location on the local file system.
/work/hadoop/hadoop-0.18.2/tmp/hadoop-${user.name}mapred.child.java.opts
Java options for the
TaskTrackerchild processes.The following parameter, if present, will be interpolated:
@taskid@will be replaced by the currentTaskID. Any other occurrences of@will be unchanged.For example:
To enable verbose gc logging to a file named for the
taskidin/tmpand to set the heap maximum to a gigabyte, pass a value of:-Xmx1024m -verbose:gc -Xloggc:/tmp/@taskid@.gc
The configuration variable
mapred.child.ulimitcan be used to control the maximum virtual memory of child processes.-Xmx1024m
mapred.tasktracker. expiry.interval
Time interval, in milliseconds, after which a TaskTracker is declared 'lost' if it does not send heartbeats.
60000000
mapred.task.timeout
Number of milliseconds before a task is terminated if it neither reads an input, writes an output, nor updates its status string.
60000000
mapred.map.tasks
Default number of map tasks per job. Typically set to a prime number, several times greater than the number of available hosts. Ignored when
mapred.job.trackerspecifies the local IP address.11
mapred.reduce.tasks
Default number of reduce tasks per job. Typically set to a prime number, close to the number of available hosts.Ignored when
mapred.job.trackerspecifies the local IP address.7
mapred.tasktracker .map.tasks.maximum
Maximum number of
maptasks that will be run simultaneously by a TaskTracker.Specify a number that
exceeds the value of
mapred.map.tasks.Integer that exceeds the value of
mapred.map.tasksmapred.tasktracker .reduce.tasks.maximum
Maximum number of
reducetasks that will be run simultaneously by a TaskTracker.Specify a number that
exceeds the value of
mapred.reduce.tasks.Integer that exceeds the value of
mapred.reduce.tasks<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Put site-specific property overrides in this file. --> <configuration> <property> <name>fs.default.name</name> <value>hdfs://192.0.2.1:9090</value> <description>The name of the default file system.A URI whose scheme and authority determine the FileSystem implementation. The uri's scheme determines the config property (fs.SCHEME.impl) naming the FileSystem implementation class.The uri's authority is used to determine the host, port, etc. for a filesystem.</description> </property> <property> <name>mapred.job.tracker</name> <value>192.0.2.1:7090</value> <description>The host and port that the MapReduce job tracker runs at.If "local", then jobs are run in-process as a single map and reduce task. </description> </property> <property> <name>dfs.replication</name> <value>1</value> <description>Default block replication. The actual number of replications can be specified when the file is created. The default is used if replication is not specified in create time. </description> </property> <property> <name>dfs.permissions</name> <value>false</value> <description> If "true", enable permission checking in HDFS. If "false", permission checking is turned off, but all other behavior is unchanged. Switching from one parameter value to the other does not change the mode,owner or group of files or directories. </description> </property> <property> <name>hadoop.tmp.dir</name> <value/work/hadoop/hadoop-0.18.2/tmp/hadoop-${user.name}</value> <description>A base for other temporary directories.</description> </property> <property> <name>mapred.child.java.opts</name> <value>-Xmx200m</value> <description>Java opts for the task tracker child processes. The following symbol, if present, will be interpolated: @taskid@ is replaced by current TaskID. Any other occurrences of '@' will go unchanged. For example, to enable verbose gc logging to a file named for the taskid in /tmp and to set the heap maximum to be a gigabyte, pass a 'value' of: -Xmx1024m -verbose:gc -Xloggc:/tmp/@taskid@.gc The configuration variable mapred.child.ulimit can be used to control the maximum virtual memory of the child processes. </description> </property> <property> <name>mapred.tasktracker.expiry.interval</name> <value>600000</value> <description>Expert: The time-interval, in miliseconds, after which a tasktracker is declared 'lost' if it doesn't send heartbeats. </description> </property> <property> <name>mapred.task.timeout</name> <value>600000</value> <description>The number of milliseconds before a task will be terminated if it neither reads an input, writes an output, nor updates its status string. </description> </property> <property> <name>mapred.map.tasks</name> <value>2</value> <description>The default number of map tasks per job.Typically set to a prime several times greater than number of available hosts. Ignored when mapred.job.tracker is "local". </description> </property> <property> <name>mapred.reduce.tasks</name> <value>1</value> <description>The default number of reduce tasks per job.Typically set to a prime close to the number of available hosts.Ignored when mapred.job.tracker is "local". </description> </property> <property> <name>mapred.tasktracker.map.tasks.maximum</name> <value>2</value> <description>The maximum number of map tasks that will be run simultaneously by a task tracker. </description> </property> <property> <name>mapred.tasktracker.reduce.tasks.maximum</name> <value>2</value> <description>The maximum number of reduce tasks that will be run simultaneously by a task tracker. </description> </property> </configuration> -
-
-
Once Hadoop is installed and configured, verify the Hadoop cluster:
-
To determine whether your distributed file system is running across multiple machines, open the Hadoop HDFS interface on your master node:
http://<hostname_MasterNode>:50070/
The HDFS interface provides a summary of the cluster's status, including information about total/remaining capacity, active nodes, and dead nodes. Additionally, it allows you to browse the HDFS namespace and view the content of its files in the web browser. It also provides access to the local machine's Hadoop log files.
-
View your MapReduce setup, using the MapReduce monitoring web app that comes with Hadoop and runs on your master node:
http://<hostname_MasterNode>:50030/
-
26.1.5 WebCenter Sites and Supporting Documentation
-
Ensure that you have a licensed version of the WebCenter Sites web application and it is powering a fully functional online site.
-
Have WebCenter Sites documentation handy. Various steps in the installation process require you to create and configure third-party components, and integrate Analytics with WebCenter Sites. Download the following guides:
-
Oracle Fusion Middleware WebCenter Sites: Installing and Configuring Supporting Software – contains instructions for creating and configuring the Oracle database for the WebCenter Sites environment.
-
Oracle Fusion Middleware WebCenter Sites Administrator's Guide – contains instructions for creating and assigning roles during the integration process.
-
Oracle Fusion Middleware WebCenter Sites Developer's Guide – contains instructions for using CatalogMover in the integration process.
-
26.1.6 WebCenter Sites: Analytics Silent Installer
The Analytics silent installer is a Java-based script (developed on Ant) that installs Analytics. The silent installer is provided in the Analytics Kit.
-
Ensure that the currently supported version of Ant (required by the silent installer) is running on each server where the silent installer, itself, will be running.
-
Familiarize yourself with the installation scenarios that are covered in this guide and select the scenario that is appropriate for your operations. The scenarios are:
-
Single-server installation: Figure 25-1
-
Dual-server installation: Figure 25-2
-
Enterprise-level installation: Figure 25-3
Note:
The silent installer script installs Analytics locally (on the computer where it is executed) and non-interactively. A silent installation involves all the steps from preparing the installation folders and setting up the database to deploying the web applications and utility programs.
-
26.1.7 WebCenter Sites: Analytics Supporting Software
26.1.7.1 Databases
-
Install the Oracle database management system (DBMS) and the SQL Plus utility. Analytics schema will be installed on the Oracle database by SQL Plus.(If you need installation instructions, refer to the product vendor's documentation.)
-
Create and configure an Oracle database as the Analytics database.
If your WebCenter Sites installation runs on Oracle DBMS, you can use the same DBMS to create a database for Analytics, assuming the server has the capacity to support an additional database. Space requirements depend on the amount of site traffic data you expect to capture within a given time frame, the volume of statistics that will be computed on the captured data, and whether you plan to archive any of the raw data and statistics.
The steps for creating and configuring an Oracle database are given below:
-
Follow the procedures in the Oracle Fusion Middleware WebCenter Sites: Installing and Configuring Supporting Software.
Note:
Remember the following points:-
When setting the Global name and SID, do not create names longer than 8 characters.
-
When creating the user, create the
analyticsuser.
-
-
Set the encoding to Unicode (
AL32UTF8). Change the environment variablenls_langto:NLS_LANG=AMERICAN_AMERICA.AL32UTF8, using one of the following commands:-
In Windows, enter the command
set NLS_LANG=AMERICAN_AMERICA.AL32UTF8
-
In Linux, the command depends on the shell you are using:
For Korn and Bourne shells:
NLS_LANG=AMERICAN_AMERICA.AL32UTF8 export NLS_LANG
For C shell:
setenv NLS_LANG AMERICAN_AMERICA.AL32UTF8
-
-
26.1.7.2 Application Servers
-
Install a supported application server to host the Analytics web applications (i.e., data capture, administrator application, and reporting application). For the list of supported application servers, see the Oracle WebCenter Sites Certification Matrix.
Note:
A single-server installation requires a single application server.A multi-server installation requires up to three application servers, depending on its configuration (for example, three application servers if the data capture application, administrator application, and reporting application are installed on separate computers).
-
Make sure that each application server provides a JDBC driver that works with the Analytics database. (Analytics does not ship with a JDBC driver.)
26.1.7.2.1 All Application Servers
-
Configure each application server for UTF-8 character encoding.
Note:
The application server's encoding setting must match the value of theencodingparameter inglobal.xml. The value isUTF-8.-
In Tomcat:
Edit the file
$CATALINA_HOME/conf/server.xmland set theURIEncodingattribute to UTF-8:<Connector port="8080" URIEncoding="UTF-8"/>
-
In WebSphere:
Set the value of system property
default.client.encodingon the JVM settings of the application server to UTF-8.
-
-
For the application server, set the JVM parameter to:
-Djava.awt.headless=true
-
Enable DNS lookups on your application server. Your DNS server must perform DNS lookups in order for the "Hosts" report to display host names of the machines from which visitors access your site. For instructions, consult your application server's documentation.
Note:
If the application server is not configured to perform DNS lookups, the "Hosts" report will display IP addresses instead (just like the "IP Addresses" report).
26.1.7.2.2 JBoss Application Server
Perform the following:
-
Delete the common
jarfiles from thelibfolder used by JBoss (in order for the Analytics Administrator application to run).
26.1.7.2.3 WebLogic Application Server
Perform the following:
-
Add the
log4j jarfile to thelibfolder for the WebLogic domain in order for the Analytics applications to create log files. -
Add the
antlr.jarfile to thePRE_CLASSPATHin the application server's startup command. For example:C:/bea/wlserver_10.3/samples/domains/wl_server/bin/setDomainEnv.cmd
26.1.8 Environment Variables
Perform the following:
-
SetJAVA_HOMEto the path of the currently supported JDK and thePATHvariable to$JAVA_HOME/bin. These settings are required by Hadoop (Hadoop-env.sh), the HDFS Agent, and Hadoop-jobs (all of which, otherwise, will not run).Note:
On Windows, setJAVA_HOMEto its canonical form:C:\PROGRA~1\<path_to_jdk>
Otherwise, if the path contains spaces (for example,
C:\Program Files), the path must be enclosed in double quotes (for example,"C:\Program Files"). -
On Solaris systems, add the following line to
hadoop-env.sh:export PATH=$PATH:/usr/ucb
-
Set
ANT_HOME(required by the silent installer) to the correct path.
26.1.9 Support for Charts
Perform the following:
-
The Swiff Chart Generator is used to render charts within Analytics reports. Install the Swiff Chart Generator either on the Analytics host (single-server installation), or on the reporting server (in multi-server installations. The reporting server hosts
analytics.war.)Copies of the Swiff Chart Generator can be purchased at:
http://www.globfx.com/
Evaluation copies are available at:
http://www.globfx.com/downloads/swfchartgen/
-
Install Adobe Flash Player on the computers on which reports will be viewed. A free copy of Adobe Flash Player is available at:
http://www.adobe.com/go/getflashplayer
If you choose not to install Adobe Flash Player, you can still generate reports. However, the charts they might contain will be replaced by the download plugin link.
26.2 Next Step
Install Analytics, using the silent installer. For instructions, see Chapter 27, "Procedures for Installing Analytics."