2 Administration Object Types
This chapter describes the object types in the Oracle SES Administration API. It contains these topics:
Alphabetic List of Administration Object Types
altWord authorizedPrincipal autoSuggestion
boostedUrl
classification classificationMappings clustering clusterTree crawlerSettings
docServiceInstance docServiceManager docServicePipeline
facetTree
globalBoundaryRules globalDocumentTypes
identityPlugin index indexOptimizer indexProfile
languageBasedTokenization lexer
partitionConfig proxy proxyLogin
queryConfig queryUIConfig queryUIFacets queryUISourceGroups
relevanceRanking resultList
schedule searchAttr singleSignOnSetting skinBundle source sourceGroup sourceType storageArea suggContent suggContentProvider suggestion suggLink
tagging tag thesaurus
Document Formats Supported
Table 2-1 lists the document formats supported by Oracle SES.
Table 2-1 Document Formats Supported by Oracle SES
| Document Format | MIME Type |
|---|---|
|
Adobe Framemaker Interchange Format (MIF) Document |
application/vnd.mif |
|
Corel Presentations Document |
application/vnd.corel-presentations |
|
DICOM Image |
application/dicom |
|
GIF Image |
image/gif |
|
GNU ZIP Archive |
application/x-gzip |
|
Haansoft Hangul Document |
application/x-hwp |
|
HTML |
text/html |
|
JPEG 2000 Image |
image/jp2 |
|
JPEG Image |
image/jpeg |
|
JustSystems Ichitaro |
application/x-js-taro |
|
Lotus 1-2-3 Document |
application/x-lotus123 application/vnd.lotus-1-2-3 |
|
Lotus Freelance Document |
application/x-freelance application/vnd.lotus-freelance |
|
Lotus Word Pro Document |
application/vnd.lotus-wordpro |
|
LHA Archive |
application/x-lzh-compressed |
|
Microsoft Excel Document |
application/x-msexcel application/vnd.ms-excel, application/ms-excel application/vnd.openxmlformats-officedocument.spreadsheetml.sheet |
|
Microsoft Project Document |
application/vnd.ms-project |
|
Microsoft PowerPoint Document |
application/x-mspowerpoint application/vnd.ms-powerpoint application/vnd.openxmlformats-officedocument.presentationml.presentation |
|
Microsoft Visio Document |
application/vnd.visio |
|
Microsoft Word Document |
application/msword application/vnd.openxmlformats-officedocument.wordprocessingml.document |
|
Microsoft Works Word Processor Document |
application/x-msworks-wp |
|
MS Write |
application/x-mswrite |
|
PDF Document |
application/pdf |
|
Plain Text |
text/plain |
|
PostScript Document |
application/postscript, application/ps, application/x-postscript, application/x-ps |
|
Quattro Pro for Windows Document |
application/x-quattro-win |
|
Rich Text Format (RTF) Document |
application/rtf |
|
StarOffice/OpenOffice Calc Document |
application/vnd.stardivision.calc |
|
StarOffice/OpenOffice Impress Document |
application/vnd.stardivision.impress |
|
StarOffice/OpenOffice Draw Document |
application/vnd.stardivision.draw |
|
StarOffice/OpenOffice Writer Document |
application/vnd.stardivision.writer |
|
TIF Image |
image/tiff |
|
WordPerfect 5.1 Document |
application/wordperfect5.1 |
|
WordPerfect 6 Document |
application/x-wordperfect6 |
|
X-Ami Document |
application/amipro, application/x-amipro, application/sam, application/x-sam application/x-ami |
|
XML |
text/xml |
|
XyWrite Document |
application/x-xywrite |
|
ZIP Archive |
application/zip |
Note:
Oracle SES uses Oracle Text to convert binary documents to HTML. See "Appendix B" of Oracle Text Reference for more information about the document formats supported by Oracle SES.Globalization Support
Oracle SES provides localization support for source documents, metadata translation, and user queries. You can specify this information in the configuration of administration objects.
Product Languages
Oracle SES user interface components are translated into the languages listed in Table 2-2. The locale of the Oracle SES host system sets the default language for error messages, as well as the Administration GUI and the Search Application. In the Web services interface, you can set the language for error messages in individual operations.
Crawlable Documents
For Oracle SES to crawl and index source documents, they must be stored in a supported language and character set.
Table 2-3 lists the codes for languages supported by the crawler.
Table 2-3 Languages Supported by the Crawler
| Language | Code |
|---|---|
|
Arabic |
|
|
Chinese |
|
|
Czech |
|
|
Danish |
|
|
Dutch |
|
|
English |
|
|
Finnish |
|
|
French |
|
|
German |
|
|
Greek |
|
|
Hebrew |
|
|
Hungarian |
|
|
Italian |
|
|
Japanese |
|
|
Korean |
|
|
Norwegian |
|
|
Polish |
|
|
Portuguese |
|
|
Romanian |
|
|
Russian |
|
|
Slovak |
|
|
Spanish |
|
|
Swedish |
|
|
Turkish |
|
Table 2-4 lists the codes for character sets supported by the crawler.
Table 2-4 Crawlable Character Sets
| Character Set | Code |
|---|---|
|
Standard UTF-8 |
|
|
16-Bit UCS Transformation Format |
|
|
Big 5 Traditional Chinese |
|
|
CNS 11643 Traditional Chinese |
|
|
GB 18030 Simplified Chinese |
|
|
GB2312-80 Simplified Chinese |
|
|
GBK Simplified Chinese |
|
|
ISO Latin/Arabic |
|
|
ISO Latin/Cyrillic |
|
|
ISO Latin/Greek |
|
|
ISO Latin/Hebrew |
|
|
ISO Latin-1 |
|
|
ISO Latin-2 |
|
|
ISO Latin-3 |
|
|
ISO Latin-4 |
|
|
ISO Latin-5 |
|
|
Japanese (Auto-Detect) |
|
|
Japanese (EUC) |
|
|
Japanese (JIS) |
|
|
Japanese (Shift-JIS) |
|
|
KSC5601 Korean |
|
|
Macintosh Arabic |
|
|
Macintosh Croatian |
|
|
Macintosh Cyrillic |
|
|
Macintosh Dingbat |
|
|
Macintosh Greek |
|
|
Macintosh Hebrew |
|
|
Macintosh Iceland |
|
|
Macintosh Latin-2 |
|
|
Macintosh Roman |
|
|
Macintosh Romania |
|
|
Macintosh Symbol |
|
|
Macintosh Thai |
|
|
Macintosh Turkish |
|
|
Macintosh Ukraine |
|
|
PC Arabic |
|
|
PC Baltic |
|
|
PC Canadian French |
|
|
PC Cyrillic |
|
|
PC Greek |
|
|
PC Hebrew |
|
|
PC Icelandic |
|
|
PC Latin-1 |
|
|
PC Latin-2 |
|
|
PC Modern Greek |
|
|
PC Nordic |
|
|
PC Original |
|
|
PC Portuguese |
|
|
PC Russian |
|
|
PC Turkish |
|
|
Windows Arabic |
|
|
Windows Baltic |
|
|
Windows Cyrillic |
|
|
Windows Eastern Europe/Latin-2 |
|
|
Windows Greek |
|
|
Windows Hebrew |
|
|
Windows Japanese |
|
|
Windows Thai |
|
|
Windows Turkish |
|
|
Windows Vietnamese |
|
|
Windows Western Europe/Latin-1 |
|
Providing Translations of Object Names
The names of some administration objects are displayed to users in the Search interface, such as source, sourceGroup, and clusterTree. You can provide a display name in one or more languages by using the <search:translations> element, as shown here:
<search:name> <search:translations> <search:translation> <search:translatedValue>
Element Descriptions
- <search:name>
-
Name of the administration object.
- <search:translations>
-
Contains one or more
<search:translation>elements. - <search:translation>
-
Contains a
<search:translatedValue>element.Attribute Value languageA code identifying the language of the translated value. The codes are not case sensitive. See Table 2-5, "Query Language Codes". - <search:translatedValue>
-
Contains a description of the object in the translation language. This value is displayed in the Search Application.
Table 2-5 Query Language Codes
| Language | Code |
|---|---|
|
Arabic |
|
|
Catalan |
|
|
Chinese, Simplified |
|
|
Chinese, Traditional |
|
|
Czech |
|
|
Danish |
|
|
Dutch |
|
|
English |
|
|
Finnish |
|
|
French |
|
|
German |
|
|
Greek |
|
|
Hebrew |
|
|
Hungarian |
|
|
Italian |
|
|
Japanese |
|
|
Korean |
|
|
Norwegian |
|
|
Polish |
|
|
Portuguese |
|
|
Portuguese, Brazilian |
|
|
Romanian |
|
|
Russian |
|
|
Slovak |
|
|
Spanish |
|
|
Swedish |
|
|
Thai |
|
|
Turkish |
|
Encryption
The Administration API provides an encryption system to safeguard sensitive information, such as passwords, contained in the XML description of an object.
When you import an XML document using an operation such as create or update, you can indicate in the XML whether a value is encrypted. In this example, the password is in plain text, which either sets it for the first time or changes it to a new value:
<search:password encrypted="false">password</search:password>
Oracle SES stores the password in an encrypted form. The next example shows an encrypted password, which was exported in an XML document from Oracle SES:
<search:password encrypted="true"> 128b6b43091659ffa1ff068666b8eb6445dabd361871b6a5b97941f00ee8c842e76bcc1eb3c0806fd0f6ee2e3ab371febcf053255ffd4e46888909cdd553914bfabe99eda51861d7 </search:password>
When exporting an XML document containing a password, Oracle SES requires you to provide an encryption key. If you use this document as input to an operation (encrypted="true"), then you must use the same encryption key as the export operation so that Oracle SES can decrypt the password.
XML Description of State Properties
Both universal and creatable objects can have state properties. The getState, getStateList, and getAllStates commands return an XML document describing the current state of one or more objects.
The <search:state> element describes the current state of an object.
<search:state> <search:objectStates> <search:objectState> <search:objectState> <search:objectType> <!-- For creatable objects --> <search:objectKey> <search:keyPairs> <search:keyPair> <search:name> <search:value> <!-- For all objects --> <search:stateProperties> <search:stateProperty> <search:propertyName> <search:propertyValues> <search:propertyValue> <search:propertyValue>
Element Descriptions
- <search:state>
-
Contains a
<search:objectStates>element.Attribute Value productVersionOracle SES product version xmlns:searchNamespace for the Oracle SES Administration API - <search:objectStates>
-
Contains one or more
<search:objectState>elements. - <search:objectState>
-
Describes the state properties of a particular object, using these child elements:
<search:objectType> <search:objectKey> <search:stateProperties>
- <search:objectType>
-
Contains an object type with one or more state properties:
clustering clusterTree identityPlugin index indexOptimizer resultList schedule skinBundle suggContentProvider
- <search:objectKey>
-
Contains the object key that identifies a specific instance of a creatable object type. It contains a
<search:keyPairs>element. - <search:keyPairs>
-
Contains one or more
<search:keyPair>elements. - <search:keyPair>
-
Contains these child elements:
<search:name> <search:value>
- <search:name>
-
Contains a key name for this object type.
- <search:value>
-
Contains the key value for this object.
- <search:stateProperties>
-
Contains one or more
<search:stateProperty>elements. - <search:stateProperty>
-
Contains a
<search:propertyName>element. - <search:propertyName>
-
Contains the name of a property.
- <search:propertyValues>
-
Contains one or more
<search:propertyValue>elements. - <search:propertyValue>
-
Contains a
<search:value>element.Attribute Value keyProvides additional context, such as the name of the data source associated with the property for a schedule that crawls multiple sources. - <search:value>
-
Contains the current value of the property.
Search Interface Customization: Skin Bundles
You can alter the look and feel of the Search application by creating a custom "skin" -- or user interface -- with different graphics, fonts, and colors. The files composing a custom skin are called, collectively, a skin bundle.
Support Bundles
All of the files associated with the Search application user interface for a particular release are supplied in a support bundle. These files include FreeMarker templates, images, style sheets, and JavaScript libraries.
The templates that you modify or replace are included in your skin bundle. When Oracle SES does not find a template file in the skin bundle that is needed to display a page in the Search application, then it uses the template file in the support bundle.
Both support bundles and skin bundles are associated with a particular release. This association enables you to migrate skin bundles to future releases of Oracle SES, even though the default user interface might change. When rendering the Search application pages, Oracle SES can still combine files from the skin bundle with files in the support bundle for the same release.
The current support bundle is located in this directory:
wls_domain_home/ses_domain_name/servers/search_server1/tmp/_WL_user/search_query/curkae/war/WEB-INF/templates
FreeMarker Templates
FreeMarker is an open-source tool that generates text from templates. The templates replace HTML files for generating a page in a browser. Oracle SES uses FreeMarker to isolate the look-and-feel of the Search Application from the search software.
The FreeMarker templates are located in the templates directory of the support bundle and have an ftl extension to the file name, such as templates/results.ftl. Before editing the template files, you should become familiar with FreeMarker.
See Also:
FreeMarker Web site athttp://www.freemarker.org/.The templates contain HTML and two other types of tags:
-
FreeMarker tags: These tags are predefined in FreeMarker and begin with
<#. For example, this tag appears at the beginning of most templates:<#import "/lib/oracle.com/seslib.ftl" as ses>
The FreeMarker Manual describes these tags, which invoke predefined directives, at
http://freemarker.org/docs/ref_directives.html. -
Oracle SES tags: These tags are specific to Oracle SES and begin with
<@. For example, this tag references a graphic file named logo.gif in the skin bundle:<@ses.skin_asset 'images/logo.gif'/>
Oracle SES tags invoke macros (also called user-defined directives) defined in seslib.ftl, so any template that uses them must import that file. The Oracle Secure Enterprise Search Administrator's Guide describes these macros.
Asset Files
Cascading style sheets, graphics, and JavaScript files are assets. You can revise an asset file from the support bundle like a template file, or you can create your own custom asset files.
When using custom asset files, you must include references to them using macros within standard HTML. For example, you might create a style sheet named mystyles.css with redefined tags from the support bundle, then include it in your skin bundle templates with a tag like the following. Note the use of the <@ses.skin_asset> macro, which identifies the location of mystyles.css in the skin bundle.
<link rel="stylesheet" type="text/css" href="<@ses.skin_asset filename='css/mystyles.css'/>">
Similarly, the next tag references a graphics file named mylogo.gif:
<img src="<@ses.skin_asset filename='images/mylogo.gif'/>" ALT="Example, Inc."/>
Alternatively, you might copy search.css and oraclelogo_medium.gif into your skin bundle and modify their contents. Then you would modify references to these files to use the <@ses.skin_asset> macro, which points to the version of the asset in your skin bundle instead of the file in the support bundle.
Tip:
To trace the styles formatting a particular element on the page, use the development tools of your browser, such as the Firebug extension to Mozilla Firefox, the Inspect Element tool in Google Chrome, or the Developer Toolbar extension to Microsoft Internet Explorer.JavaScript Libraries
The Oracle SES 11.2.2.2.0 support bundle contains two JavaScript libraries:
-
Yahoo! User Interface (YUI) Library: A set of utilities and controls for building interactive Web applications.
-
Bubbling Library extension to YUI: A set of plug-ins and widgets.
See Also:
-
YUI Library section of the Yahoo! Developer Network site at
http://developer.yahoo.com/yui/ -
Bubbling Library Web site at
http://sourceforge.net/projects/bubbling/
Template Library
The support library contains a file named seslib.ftl that references all of the resources available to the templates: JavaScript files, style sheets, macros, and so forth. The Freemaker templates import seslib.ftl using this tag at the top of each file:
<#import "/lib/oracle.com/seslib.ftl" as ses>
The tag makes these resources available for use in the template. You can delete the tag if you do not need these resources to generate a particular page, but do not modify the file.
Assembling the Skin Bundle Files
To assemble the skin bundle files:
-
Decide on the changes to make to the Search application, such as replacing the logo or the icons, changing the default font or background color, or adding an RSS feed.
-
Create the following directory structure for storing the files composing the skin bundle:
/skinBundle_name /templates /assets /images /css /js -
Identify the template files that render the changed pages.
For descriptions of the template files, see the Oracle Secure Enterprise Search Administrator's Guide.
-
Copy the ftl files from the support bundle for the current release of Oracle SES into the templates directory. Do not change the names of these files.
-
Modify the templates as desired, using a text editor. Templates can include HTML tags, FreeMarker tags, and Oracle SES tags. You can change text and various settings, and reference custom graphics, style sheets, and JavaScript. See "FreeMarker Templates".
-
Create the graphic files, cascading style sheets, and JavaScript files as desired. Copy the graphics files into the images directory, the cascading style sheets into the css directory, and the JavaScript files into the js directory.
-
Create an XML document that describes the skin bundle. See skinBundle.
Creating a skinBundle Object
To create a skinBundle object using the command-line API:
-
Assemble the files composing the skin bundle, as previously described.
-
Create a text file that lists all of the files in the skin bundle. See the Notes for create skinBundle.
-
Issue a
createcommand to create theskinBundleobject.
To create a skinBundle object using the Web service API:
-
Assemble the files composing the skin bundle, as previously described.
-
Compose the SOAP message for a
createoperation, as described in Chapter 4, "Web Service Operations." Include an<attachments>element for each file in the skin bundle. -
Submit the request to the Web service to create the
skinBundleobject.
To create a skinBundle object using the Java client, see the Oracle Secure Enterprise Search Java API Reference.
Using a Skin Bundle to Render the Search Application User Interface
To use a skin bundle when rendering the Search interface:
-
Issue an
activateoperation for theskinBundle. When you activate a default skin bundle, it can be used immediately to render the Search Application interface. -
To use a skin bundle that is not the default, add a
skin=skin_nameattribute to the URL for the Search Application interface:http://host:port/search/query/search?skin=skin_name
If the modified pages fail to open in a browser or appear with errors, read the middle-tier log file at
wls_domain_home/ses_domain_name/servers/AdminServer/logs/AdminServer.out
After updating the skin bundle, restart the middle tier.
Skin Bundle Example
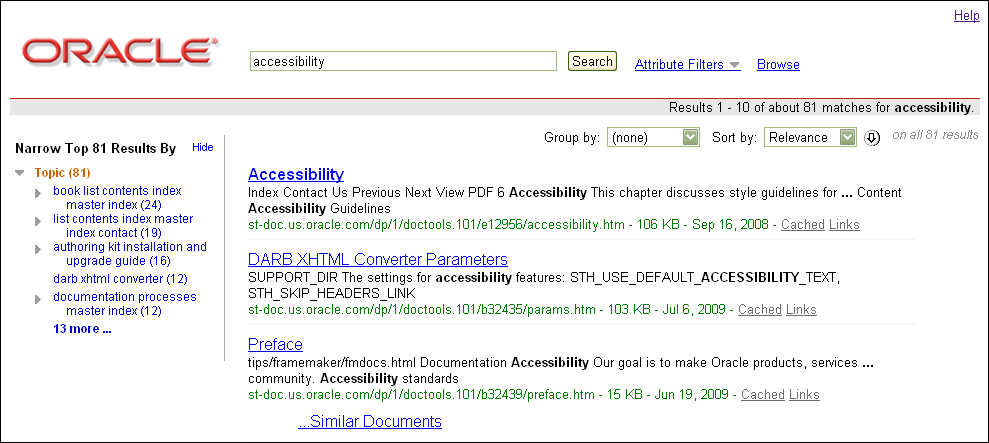
This example makes a few changes to the default results page, which is shown in Figure 2-1.
Changes to the Example Results Page
Table 2-6 identifies the changes that this example makes to the default results page. You can see these differences by comparing Figure 2-1 and Figure 2-2. The title in the browser title bar is not shown.
Changes to results.ftl do not affect any other pages of the Search application, which continue to use the default skin. However, the example makes changes to inc_logo_querybox.ftl and inc_footer.ftl, which affect all of the pages that include those templates.
Table 2-6 Differences Between the Default Skin and the Example Skin
| Default Skin | Example Skin | Template Rendering the Element |
|---|---|---|
|
Oracle logo |
Example Inc. logo |
inc_logo_querybox.ftl |
|
Search button |
Search icon |
inc_logo_querybox.ftl |
|
Sidebar on left |
Sidebar on right |
results.ftl |
|
Title of Oracle Secure Enterprise Search |
Title of Example Inc. |
results.ftl |
|
No RSS feed |
RSS feed icon on the Results bar |
results.ftl |
|
No corporate identifier |
Example, Inc. above the copyright |
inc_footer.ftl |

Changes to the Example Footer
The only change to the footer is the addition of Example Inc., as shown in Figure 2-3. The following pages use the same footer template, so all of them are affected by this change:
-
Initial splash screen: query.ftl
-
Results page: results.ftl
-
No results page: noresults.ftl
-
Error page: error.ftl

Creating the Example Directory Structure
To make the changes to the skin shown in the previous section, the skin bundle must contain these files:
-
inc_logo_querybox.ftl: A template included by results.ftl to generate the logo and the query box.
-
inc_footer.ftl: A template included by results.ftl (and other templates) to generate the footer.
-
example.gif: A graphic file with the logo for a fictitious company named Example Inc.
-
search.jpg: a graphic file with the search icon.
-
rss.jpg: A graphic file with the standard RSS icon.
To create the example skin bundle directory structure:
-
On the Oracle SES host, create these directories:
/example/templates /example/assets/images
-
Copy the ftl files to the
templatesdirectory from:wls_domain_home/ses_domain_name/servers/search_server1/tmp/_WL_user/search_query/curkae/war/WEB-INF/templates -
Copy the graphics file (created or acquired elsewhere) into the
imagesdirectory.
The resulting directories have this structure:
/example
/templates
/inc_footer.ftl
/inc_logo_querybox.ftl
/results.ftl
/assets
/images
/example.gif
/rss.jpg
/search.jpg
Customizing results.ftl
The results page contains numerous elements. Some elements appear by default, while you must define others, such as source groups and suggested links, for a specific installation. The results.ftl template uses the FreeMarker <#include> tag to include the following template files, which define distinct areas of the results page:
This example uses the default inc_header.ftl, but alters the other templates. Figure 2-0 identifies the altered elements that are generated directly by results.ftl.
To customize results.ftl:
-
Open example/templates/results.ftl in a text editor.
-
To move the sidebar to the right, change:
<#assign sidebarPageAlign = "left">
to
<#assign sidebarPageAlign = "right">
-
To replace the page title, change:
<title>${msg("ORACLE_ENTERPRISE_SEARCH")} <#if req.displayQuery??> - ${req.displayQuery} </#if> </title>to
<title>Example Inc.</title>
-
For the RSS feed, add the following immediately after
<@ses.hit_stats/>:<#assign feed_img_src><@ses.skin_asset 'images/rss.jpg'/></#assign> <@ses.feed_icon title="Results Feed" img_src="${feed_img_src}"> <@ses.feed_href/> </@ses.feed_icon> -
Save and close the file.
Customizing inc_logo_querybox.ftl
The inc_logo_querybox.ftl template renders a section of the results page immediately following the header. This section includes these elements in the default user interface:
-
Oracle logo
-
Query box
-
Search button
-
Attribute filters, both the link and the form
-
Browse link
-
Optional source group tab links above the query box, such as E-mail, Calendar, and Sales.
To customize inc_logo_querybox.ftl:
-
Open example/templates/inc_logo_querybox.ftl in a text editor.
-
To replace the Oracle logo with the Example logo, change:
<@ses.oracle_logo size="small" href="${logoHref}"/>to
<img src="<@ses.skin_asset filename='images/example.gif'/>">
-
To replace the Search button with an icon, change:
<input type="submit" name="btnSearch" value="${msg("SEARCH")}">to
<input type="image" src="<@ses.skin_asset filename="images/search.jpg" />" name="${msg("SEARCH")}" alt="${msg("SEARCH")}" style="vertical-align: bottom;"> -
Save and close the file.
Customizing inc_footer.ftl
The inc_footer.ftl template renders the links, such as Help, and the copyright information at the bottom of the page.
To customize inc_footer.ftl:
-
Open example/templates/inc_footer.ftl in a text editor.
-
For the company name, add the following immediately before
<!-- Bottom Line -->:<div style="padding-top:10px;font-size:16px;font-weight:bold; font-style:italic;color:red;font-family:'Book Antigua',Palatino,serif; text-align:center"> Example Inc. </div>
-
Save and close the file.
Creating the Example Skin Bundle File List
Create a text file that identifies all of the files in the skin bundle. In this example, the file list is named /scratch/skins/example.lst. Substitute the actual path you are using for /scratch/skins.
assets/images/example.gif::/scratch/skins/example/assets/images/example.gif assets/images/search.jpg::/scratch/skins/example/assets/images/search.jpg assets/images/rss.jpg::/scratch/skins/example/assets/images/rss.jpg templates/inc_footer.ftl::/scratch/skins/example/templates/inc_footer.ftl templates/inc_logo_querybox.ftl::/scratch/skins/example/templates/inc_logo_querybox.ftl templates/results.ftl::/scratch/skins/example/templates/results.ftl
Creating an XML Description of the Example Skin Bundle
Create an XML file that describes the Example skin bundle. In this example, the XML file is named /scratch/skins/example.xml.
<?xml version="1.0" encoding="UTF-8" ?>
<search:config productVersion="11.2.2.2.0" xmlns:search="http://xmlns.oracle.com/search">
<search:skinBundles>
<search:skinBundle>
<search:name>example</search:name>
<search:isDefault>false</search:isDefault>
<search:linkedVersion>11.2.2.2.0</search:linkedVersion>
<search:files>
<search:file path="templates/inc_footer.ftl"/>
<search:file path="templates/inc_logo_querybox.ftl"/>
<search:file path="templates/results.ftl"/>
<search:file path="assets/images/example.gif"/>
<search:file path="assets/images/search.jpg"/>
<search:file path="assets/images/rss.jpg"/>
</search:files>
</search:skinBundle>
</search:skinBundles>
</search:config>
Creating the Example skinBundle Object
To create the Example skin bundle:
-
At the host command prompt, navigate to the /scratch/skins directory.
-
Open
searchadminin session mode, as described in "Opening an Interactive Session". -
To create the skin bundle, issue this command:
create skinBundle --NAME=example --INPUT_FILE=example.xml --ATTACHMENT_LIST=example.lst
-
To activate the skin bundle, issue this command:
activate skinBundle --NAME=example
Using the Example Skin Bundle to Render the Search Application
Because the example skin bundle is not defined as the default, you must include the skin attribute in the URL to view the Search application.
To use the Example skin bundle:
-
In a browser, enter a URL like the following, substituting the appropriate host and port:
http://host:port/search/query/search?skin=exampleThe footer displays Example Inc., while the rest of the page uses the default skin.
-
Enter a search string. The results page has the changes shown in Figure 2-2, "Example Results Page".
altWord
Oracle SES uses alternate words to provide suggestions to users or to expand the search results. Alternate words are useful for correcting common typing errors and for including synonyms in a search. You can create up to four alternates for the same word.
create createAll delete deleteAll deleteList export exportAll exportList getAllObjectKeys update updateAll
The <search:altWords> element describes alternate word pairs:
<search:altWords> <search:altWord> <search:keyword> <search:altKeyword> <search:autoExpand>
Element Descriptions
- <search:altWords>
-
Contains one or more
<search:altWord>elements. - <search:altWord>
-
Contains one of each of these elements:
<search:keyword> <search:altKeyword> <search:autoExpand>
- <search:keyword>
-
Contains a search word or phrase. Keywords are not case sensitive. Required.
- <search:altKeyword>
-
Contains a word or phrase that is suggested when users enter the keyword. Alternate words are displayed exactly as they appear here. Required.
- <search:autoExpand>
-
Controls the display of alternative words in the search results: Set to
trueto include the alternative words automatically in the search, or set tofalseto display alternative word matches in a "do you mean..." message. The default isfalse.
This XML document defines alternate words for OSES, text, and RAC:
<?xml version="1.0" encoding="UTF-8"?>
<search:config productVersion="11.2.2.2.0" xmlns:search="http://xmlns.oracle.com/search">
<search:altWords>
<search:altWord>
<search:keyword>oses</search:keyword>
<search:altKeyword>Oracle Secure Enterprise Search</search:altKeyword>
<search:autoExpand>true</search:autoExpand>
</search:altWord>
<search:altWord>
<search:keyword>rac</search:keyword>
<search:altKeyword>Real Application Clusters</search:altKeyword>
<search:autoExpand>false</search:autoExpand>
</search:altWord>
<search:altWord>
<search:keyword>text</search:keyword>
<search:altKeyword>Oracle Text</search:altKeyword>
<search:autoExpand>false</search:autoExpand>
</search:altWord>
</search:altWords>
</search:config>
authorizedPrincipal
The authorizedPrincipal object is used to provide various privileges, such as tagging, to the required Oracle SES users.
create createAll delete deleteAll deleteList export exportAll exportList getAllObjectKeys update updateAll
The <search:authorizedPrincipals> element describes privileges for Oracle SES users:
<search:authorizedPrincipals> <search:authorizedPrincipal> <search:name> <search:privileges> <search:privilege>
Element Descriptions
- <search:authorizedPrincipals>
-
Contains one or more <search:authorizedPrincipal> elements.
- <search:authorizedPrincipal>
-
Describes the previleges for a user. It contains these elements:
<search:name> <search:privileges>
- <search:name>
-
Name of the user to whom the required privileges are assigned using the
<search:privileges>element. - <search:privileges>
-
Contains one or more
<search:privilege>elements. - <search:privilege>
-
Describes a privilege for a user.
Attribute Value typeType of privilege, such as TAGGING. Required.
This example assigns tagging privilege to users - user1 and user2:
<search:config productVersion="11.2.2.2.0" xmlns:search="http://xmlns.oracle.com/search">
<search:authorizedPrincipals>
<search:authorizedPrincipal>
<search:name>user1</search:name>
<search:privileges>
<search:privilege type="TAGGING"/>
</search:privileges>
</search:authorizedPrincipal>
<search:authorizedPrincipal>
<search:name>user2</search:name>
<search:privileges>
<search:privilege type="TAGGING"/>
</search:privileges>
</search:authorizedPrincipal>
</search:authorizedPrincipals>
</search:config>
autoSuggestion
The autoSuggestion object is used to configure general settings for auto suggestions.
| Property | Value |
|---|---|
filterStatus |
ACTIVE INACTIVE |
filterError |
An error value is assigned to this property by Oracle SES in case of any error while processing auto suggestions. |
The <search:autoSuggestions> element describes auto suggestion configurations:
<search:autoSuggestion> <search:maxSuggestions> <search:maxTotalSuggestions> <search:maxSuggestionLength> <search:populateFromQueries> <search:minOccurrenceOfPhrase> <search:filterExpression> <search:populateFromSecureQueries> <search:minDistinctUsers>
Element Descriptions
- <search:autoSuggestion>
-
Contains these elements:
<search:maxSuggestions> <search:maxTotalSuggestions> <search:maxSuggestionLength> <search:populateFromQueries>
- <search:maxSuggestions>
-
The maximum number of suggestion keywords to display in the search box of the query application. It must be a numeric value greater than 0 and less than 16.
- <search:maxTotalSuggestions>
-
The maximum number of suggestion keywords to store in Oracle SES.
- <search:maxSuggestionLength>
-
The maximum length of a suggestion keyword.
- <search:populateFromQueries>
-
Contains these elements:
<search:minOccurenceOfPhrase> <search:filterExpression> <search:populateFromSecureQueries>
Controls whether the auto suggestion keywords are populated from queries.
Attribute Value enabledSet to trueto populate auto suggestion keywords from queries, or set tofalseotherwise. Required. - <search:minOccurrenceOfPhrase>
-
The minimum number of times a phrase must be searched so as to add it to the suggestion keywords list while populating the list from queries.
- <search:filterExpression>
-
A regular expression for filtering out undesired keywords from the suggestion keywords list while populating the list from queries.
- <search:populateFromSecureQueries>
-
Contains the
<search:minDistinctUsers>element.Controls whether the keywords are populated from secure queries.
Attribute Value enabledSet to trueto populate auto suggestion keywords from query log for secure queries, or set tofalseotherwise. Required. - <search:minDistinctUsers>
-
The minimum number of distinct users that must search for a phrase in order for that phrase to be added to the suggestion keywords list while populating the list from secure queries.
This XML document configures auto suggestions in Oracle SES:
<?xml version="1.0" encoding="UTF-8"?>
<search:config productVersion="11.2.2.2.0" xmlns:search="http://xmlns.oracle.com/search">
<search:autoSuggestion>
<search:maxSuggestions>15</search:maxSuggestions>
<search:maxTotalSuggestions>1000000</search:maxTotalSuggestions>
<search:maxSuggestionLength>60</search:maxSuggestionLength>
<search:populateFromQueries enabled="true">
<search:minOccurrenceOfPhrase>100</search:minOccurrenceOfPhrase>
<search:populateFromSecureQueries enabled="true">
<search:minDistinctUsers>25</search:minDistinctUsers>
</search:populateFromSecureQueries>
</search:populateFromQueries>
</search:autoSuggestion>
</search:config>
boostedUrl
The boostedUrl object is used to increase the relevancy of specific URLs so that those URLs are displayed on the top of search results.
create createAll delete deleteAll deleteList export exportAll exportList getAllObjectKeys update updateAll
The <search:boostedUrl> element describes configurations related to relevancy boosting for specific URLs:
<search:boostedUrls> <search:boostedUrl> <search:url> <search:query> <search:score>
Element Descriptions
- <search:boostedUrls>
-
Contains one or more <search:boostedUrl> elements.
- <search:boostedUrl>
-
Describes the boosted score for a URL. It contains these elements:
<search:url> <search:query> <search:score>
- <search:url>
-
Contains the valid URL of a document whose relevancy requires boosting.
- <search:query>
-
Contains the query term for which
<search:url>is boosted. Oracle SES requires an exact match for boosting. - <search:score>
-
Contains an integer from 0 to 100 for the score. Boosted documents are listed in descending order in the search results, before the unboosted documents.
This example boosts two URLs for the search term "indexing":
<search:config productVersion="11.2.2.2.0" xmlns:search="http://xmlns.oracle.com/search">
<search:boostedUrls>
<search:boostedUrl>
<search:url>
http://example.com/doctools/b32440/xref_foot_in.htm
</search:url>
<search:query>indexing</search:query>
<search:score>90</search:score>
</search:boostedUrl>
<search:boostedUrl>
<search:url>
http://example.com/doctools/b32439/markers.htm
</search:url>
<search:query>indexing</search:query>
<search:score>80</search:score>
</search:boostedUrl>
</search:boostedUrls>
</search:config>
classification
The classification object is used to specify classifications for categorizing suggestion keywords.
create createAll delete deleteAll deleteList export exportAll exportList getAllObjectKeys update updateAll
The <search:classifications> element contains classification details:
<search:classifications> <search:classification> <search:name> <search:description>
Element Descriptions
This XML document configures classification:
<?xml version="1.0" encoding="UTF-8"?>
<search:config productVersion="11.2.2.2.0" xmlns:search="http://xmlns.oracle.com/search">
<search:classifications>
<search:classification>
<search:name>Reports</search:name>
<search:description>Generic Reports</search:description>
</search:classification>
</search:classifications>
</search:config>
classificationMappings
The classificationMappings object is used to specify source group specific classifications, thus determining the categories of suggestion keywords that are available for each source group.
The <search:classificationMappings> element describes details related to the mappings between source groups and classifications:
<search:classificationMappings> <search:classificationMapping> <search:sourceGroup> <search:classifications> <search:classification>
Element Descriptions
- <search:classificationMappings>
-
Contains one or more
<search:classificationMapping>elements. - <search:classificationMapping>
-
Describes a classification mapping. Contains the following elements:
<search:source> <search:classifications>
- <search:sourceGroup>
-
Describes the source group.
Attribute Value nameName of the source group. - <search:classifications>
-
Contains one or more
<search:classification>elements mapped to the source group. - <search:classification>
-
Name of the classification.
Attribute Value prioritySpecifies the priority of the classification. A classification with priority of 1 has higher precedence over a classification with priority of 2.
This XML document configures a source group specific classification:
<?xml version="1.0" encoding="UTF-8"?>
<search:config productVersion="11.2.2.2.0" xmlns:search="http://xmlns.oracle.com/search">
<search:classificationMappings>
<search:classificationMapping>
<search:sourceGroup name="people"/>
<search:classifications>
<search:classification priority="1">Names</search:classification>
<search:classification priority="2">Addresses</search:classification>
</search:classifications>
</search:classificationMapping>
</search:classificationMappings>
</search:config>
clustering
Query-time clustering dynamically organizes search results into groups to provide end users with different views of the top results. Clustered documents within one group, called a cluster node, share the same common topics or property values. A cluster node for a large document set can be categorized into child cluster nodes, creating a hierarchy. Users can navigate directly to a specific cluster node. Effective real-time clustering balances clustering quality and clustering time.
The <search:clustering> element describes configurations related to clustering:
<search:clustering> <search:maxTreeDepth> <search:maxChildrenPerNode> <search:minDocsPerNode> <search:minOccurrenceWords> <search:maxExtractWords> <search:minOccurrencePhrases> <search:maxExtractPhrases> <search:maxPhraseLength> <search:numFirstLevelNode> <search:showEmptyCluster> <search:topic> <search:metaData>
Element Descriptions
- <search:clustering>
-
Contains the elements for clustering parameters that are described in the following paragraphs.
- <search:maxTreeDepth>
-
Maximum number of levels in a cluster node hierarchy (Optional).
A cluster node with a large document set can be categorized into child cluster nodes. A cluster hierarchy gives end users a quick overview of the results. They can navigate directly to a specific cluster node or refine their query by combining the original query and cluster results.
- <search:maxChildrenPerNode>
-
Maximum number of cluster nodes on each level.
- <search:minDocsPerNode>
-
Minimum number of documents in a cluster node.
- <search:minOccurrenceWords>
-
Minimum occurrences of a word to be extracted for topic clustering.
- <search:maxExtractWords>
-
Maximum number of words to be extracted for topic clustering.
- <search:minOccurrencePhrases>
-
Minimum occurrences of a phrase to be extracted for topic clustering.
- <search:maxExtractPhrases>
-
Maximum number of phrases to be extracted for topic clustering.
- <search:maxPhraseLength>
-
Maximum word length of phrases to be extracted for topic clustering.
- <search:numFirstLevelNode>
-
Number of cluster nodes to display in the first level of a cluster tree on the search results page.
- <search:showEmptyCluster>
-
Controls whether to show empty clusters on the search results page.
Attribute Value enabledSet to trueto show empty clusters on the search results page, or set tofalseotherwise. Required. - <search:topic>
-
Settings related to
topiccluster trees only. It contains the elements<maxTreeDepth>, <maxChildrenPerNode>,and<minDocsPerNode>, which when specified, override the corresponding global settings. - <search:metaData>
-
Settings related to
metaDatacluster trees only. It contains the elements<maxTreeDepth>, <maxChildrenPerNode>,and<minDocsPerNode>, which when specified, override the corresponding global settings.
This XML document configures clustering:
<?xml version="1.0" encoding="UTF-8"?>
<search:config productVersion="11.2.2.2.0" xmlns:search="http://xmlns.oracle.com/search">
<search:clustering>
<search:maxTreeDepth>4</search:maxTreeDepth>
<search:maxChildrenPerNode>50</search:maxChildrenPerNode>
<search:minDocsPerNode>3</search:minDocsPerNode>
<search:minOccurrenceWords>3</search:minOccurrenceWords>
<search:maxExtractWords>20</search:maxExtractWords>
<search:minOccurrencePhrases>2</search:minOccurrencePhrases>
<search:maxExtractPhrases>10</search:maxExtractPhrases>
<search:maxPhraseLength>6</search:maxPhraseLength>
<search:numFirstLevelNode>5</search:clusterMoreLimit>
<search:topic>
<search:maxTreeDepth>2</search:maxTreeDepth>
<search:maxChildrenPerNode>20</search:maxChildrenPerNode>
<search:minDocsPerNode>2</search:minDocsPerNode>
</search:topic>
<search:metaData>
<search:maxTreeDepth>3</search:maxTreeDepth>
<search:maxChildrenPerNode>30</search:maxChildrenPerNode>
<search:minDocsPerNode>3</search:minDocsPerNode>
</search:metaData>
</search:clustering>
</search:config>
clusterTree
Clusters provide users with a tree structure to navigate the top n results by organizing search results into groups. Documents in the same group share the same common topics or property values. Effective real-time clustering balances clustering quality and clustering time.
Clustering does not change the order of the documents. When users select a cluster, the result view is limited to the documents in that cluster. All operations, such as sorting or next page, are limited to the cluster.
activate create createAll deactivate delete deleteAll deleteList export exportAll exportList getAllObjectKeys getAllStates getState getStateList update updateAll
Global Settings - Clustering Configuration - Create or Edit Metadata Clustering Tree
Global Settings - Clustering Configuration - Create or Edit Topic Clustering Tree
The <search:clusterTrees> element describes topic cluster trees, metadata cluster trees, or both:
<search:clusterTrees> <search:topicClusterTree> <search:name> <search:translations> <search:clusteringAttrs> <search:clusteringAttr> <search:name> <search:metadataClusterTree> <search:name> <search:translations> <search:clusteringAttrs> <search:clusteringAttr> <search:name> <search:type> <search:tokenized> <search:tokenDelimiter> <search:hierarchical> <search:hierarchyDelimiter>
Element Descriptions
- <search:clusterTrees>
-
Contains one or more
<search:topicClusterTree>elements,<search:metadataClusterTree>elements, or both. - <search:topicClusterTree>
-
Describes a topic cluster tree. It contains these elements:
<search:name> <search:translations> <search:clusteringAttrs>
- <search:metadataClusterTree>
-
Describes a metadata cluster tree. It contains these elements:
<search:name> <search:translations> <search:clusteringAttr> <search:tokenized> <search:tokenDelimiter> <search:hierarchical> <search:hierarchyDelimiter>
- <search:name>
-
Contains the unique name of the cluster tree. Required.
- <search:translations>
-
Contains one or more translations of the object name. See "Providing Translations of Object Names".
- <search:clusteringAttrs>
-
Contains one or more
<search:clusteringAttr>elements. - <search:clusteringAttr>
-
Contains a
<search:name>element and, for metadata trees, a<search:type>element.These attributes can be default search attributes, custom search attributes, or Oracle SES internal attributes. Topic tree attributes are String only. For metadata trees, you must specify the data type.
- <search:name>
-
Contains the search attribute used to generate the tree.
- <search:type>
-
Contains the data type of the attribute values. Set to
STRING,NUMBER, orDATE. - <search:tokenized>
-
Controls tokenizing of a String attribute value in a
metadataClusterTree. Set totrueto separate the string into several values where indicated by a delimiter, or set tofalseto handle the string as a single value. - <search:tokenDelimiter>
-
Identifies the delimiter used to separate tokens in a String attribute value. Set to a character, such as a comma (
,) or a hash mark (#). The default delimiter is whitespace ( - <search:hierarchical>
-
Controls whether a metadata cluster tree for String attributes has a hierarchical structure. Set to
trueto generate the tree based on a hierarchy implicit in the attribute values, or set tofalseto generate the tree without a hierarchy. - <search:hierarchyDelimiter>
-
Identifies the delimiter used to separate the categories in a hierarchy for a metadata cluster tree. Set to a character, such as a slash (
/). The default delimiter is whitespace (The following example shows a comma-delimited tokens, and both tokens have a three-level, slash-delimited hierarchy:
java/j2ee/jdbc, oracle/search/connector
This XML document defines both a topic cluster tree and a metadata cluster tree:
<?xml version="1.0" encoding="UTF-8" ?>
<search:config productVersion="11.2.2.2.0" xmlns:search="http://xmlns.oracle.com/search">
<search:clusterTrees>
<search:topicClusterTree>
<search:name>Topic Tree</search:name>
<search:translations>
<search:translation language="es">
<search:translatedValue>Árbol del Asunto
</search:translatedValue>
</search:translation>
</search:translations>
<search:clusteringAttrs>
<search:clusteringAttr>
<search:name>eqtopphrases</search:name>
</search:clusteringAttr>
<search:clusteringAttr>
<search:name>eqsnippet</search:name>
</search:clusteringAttr>
</search:clusteringAttrs>
</search:topicClusterTree>
<search:metadataClusterTree>
<search:name>Metadata Tree</search:name>
<search:translations>
<search:translation language="es">
<search:translatedValue>Árbol de los Meta Datos
</search:translatedValue>
</search:translation>
</search:translations>
<search:clusteringAttr>
<search:name>Infosource</search:name>
<search:type>STRING</search:type>
</search:clusteringAttr>
<search:tokenized>true</search:tokenized>
<search:tokenDelimiter>,</search:tokenDelimiter>
</search:metadataClusterTree>
</search:clusterTrees>
</search:config>
crawlerSettings
This object configures the global crawler settings that are used by default for new data sources. You can also configure the crawler settings for individual sources, as described in source.
The Oracle SES crawler is a Java process activated by a schedule. When activated, the crawler spawns a configurable number of processor threads that fetch information from various sources and index the documents. This index is used for searching sources.
The <search:crawlerSettings> element describes configurations related to the crawler:
<search:crawlerSettings> <search:numThreads> <search:numProcessors> <search:crawlDepth> <search:limit> <search:languageDetection> <search:defaultLanguage> <search:crawlTimeout> <search:maxDocumentSize> <search:charSetDetection> <search:defaultCharset> <search:preserveDocumentCache> <search:servicePipeline> <search:pipelineName> <search:verboseLogging> <search:logLanguage> <search:logLevel> <search:badTitles> <search:badTitle> <search:minCacheQueue> <search:maxCacheQueue> <search:fileWriteBufferSize> <search:idmUserCacheSize> <search:idmGroupCacheSize> <search:portalIndexContainerPage> <search:portalSmartIncrCrawl> <search:zipFilePackage> <search:archiveFileTraverseDepth>
Element Descriptions
- <search:crawlerSettings>
-
Contains the elements for configuring the crawler that are described in the following paragraphs.
- <search:numThreads>
-
Contains the number of processes the crawler starts to crawl sources.
- <search:numProcessors>
-
Contains the number of CPUs (or cores in a multi-core processor) on the computer where the crawler runs. This setting determines the optimal number of processes used for document conversion. A document conversion process converts formatted documents into HTML documents for indexing.
- <search:crawlDepth>
-
Controls whether crawling is limited to the number of nested links set by
<search:limit>.Attribute Value haslimitSet to trueto restrict crawling to the depth limit, or set tofalseotherwise. Required. - <search:limit>
-
Contains the number of nested links the crawler follows. Crawling depth starts at 0, so that the crawler only fetches the starting URL. With a crawling depth of 1, the crawler also fetches any document that it linked from the starting URL, and so forth.
- <search:languageDetection>
-
Controls whether the crawler attempts to detect the language of documents that do not specify the language in their metadata.
Language detection involves these steps:
-
The crawler determines the language code by checking the HTTP header content-language or the LANGUAGE column of a table source.
-
If the crawler cannot determine the language, then the language recognizer attempts to determine a language. The language recognizer operates on the Latin-1 alphabet and any language with a deterministic Unicode range of characters, such as Chinese, Japanese, and Korean.
-
If the language recognizer cannot identify the language, then the default language is used.
Attribute Value enabledSet to trueto attempt to detect a language, or set tofalseto use the default language. Required.
-
- <search:defaultLanguage>
-
Contains the code for the default language. The default language is used when language detection is disabled or when the crawler and language detector cannot determine the document language. See Table 2-3, "Languages Supported by the Crawler".
- <search:crawlTimeout>
-
Contains the number of seconds allowed for the crawler to access a document.
- <search:maxDocumentSize>
-
Contains the maximum document size in megabytes. Larger documents are not crawled.
- <search:charSetDetection>
-
Controls whether to detect the character set automatically.
Attribute Value enabledSet to trueto detect the character set automatically, or set tofalseotherwise. Required. - <search:defaultCharset>
-
Contains the default character set. The crawler uses this character set for indexing documents when the character set cannot be determined. See Table 2-4, "Crawlable Character Sets".
- <search:preserveDocumentCache>
-
Controls whether the cache is saved after indexing.
Attribute Value enabledSet to trueto preserve the cache, or set tofalseto discard it. Required. - <search:servicePipeline>
-
Controls use of a document service pipeline. A document service pipeline is used for search result clustering. If your installation does not use result clustering for any source, then disable the pipeline.
Attribute Value enabledSet to trueto enable the pipeline, or set tofalseto disable it. Required. - <search:pipelineName>
-
Contains the name of the document service pipeline used when the pipeline is enabled.
- <search:verboseLogging>
-
Controls the level of detail in logging messages.
Logging everything can create very large log files when crawling a large number of documents. However, in certain situations, it can be beneficial to configure the crawler to record detailed activity.
The crawler maintains the last seven versions of its log file. The format of the log file name is ids.MMDDhhmm.log, where i is a system-generated ID, ds is the source ID, MM is the month, DD is the date, hh is the launching hour in 24-hour format, and mm is the minutes. For example, if a schedule for source 23 is launched at 10 pm, July 8th, then the log file name is i3ds23.07082200.log. Each successive schedule launching has a unique log file name. When the total number of log files for a source reaches seven, the oldest log file is deleted.
Attribute Value enabledSet to trueto record all information, or set tofalseto record only summary information. Required. - <search:logLanguage>
-
Contains the language code for messages written to the log file. See Table 2-3, "Languages Supported by the Crawler".
- <search:logLevel>
-
Contains the log level for the crawler. The following are the valid log levels:
Logging Level Description TRACETrace messages DEBUGDebug messages INFOInformational messages (Default) WARNWarning messages ERRORError messages FATALFatal messages - <search:badTitles>
-
Contains one or more
<search:badTitle>elements. This parameter can be set at the global level. - <search:badTitle>
-
Contains an exact character string for a document title that the crawler omits from the index. These bad titles are defined by default:
PowerPoint Presentation Slide 1
- <search:minCacheQueue>
-
Minimum size of the cache queue. The default size is 1MB.
- <search:maxCacheQueue>
-
Maximum size of the cache queue. The default size is 10MB.
- <search:fileWriteBufferSize>
-
Buffer size for writing files to disk.
- <search:idmUserCacheSize>
-
Size of the user cache. This cache is used to avoid repeated lookups. The default size is 5000MB.
- <search:idmGroupCacheSize>
-
Size of the group cache. This cache is used to avoid repeated lookups. The default size is 5000MB.
- <search:portalIndexContainerPage>
-
Controls whether the portal container pages should be indexed, or they should be only used as seeds to crawl other portal items.
- <search:portalSmartIncrCrawl>
-
Controls whether the portal container pages should be crawled incrementally, that is, only the portal container pages that were changed since the last re-crawl date should be crawled.
- <search:zipFilePackage>
-
Specifies the Java package to use for processing zip files. The available options are
JDKandApache. - <search:archiveFileTraverseDepth>
-
Specifies the crawling depth for recursively traversing the nested archive files, such as, zip files.
This XML document configures the crawler:
<?xml version="1.0" encoding="UTF-8"?>
<search:config productVersion="11.2.2.2.0" xmlns:search="http://xmlns.oracle.com/search">
<search:crawlerSettings>
<search:numThreads>5</search:numThreads>
<search:numProcessors>3</search:numProcessors>
<search:crawlDepth haslimit="true">
<search:limit>2</search:limit>
</search:crawlDepth>
<search:languageDetection enabled="true"/>
<search:defaultLanguage>en</search:defaultLanguage>
<search:crawlTimeout>30</search:crawlTimeout>
<search:maxDocumentSize>10</search:maxDocumentSize>
<search:charSetDetection enabled="true"/>
<search:defaultCharSet>8859_1</search:defaultCharSet>
<search:preserveDocumentCache enabled="true"/>
<search:servicePipeline enabled="true">
<search:pipelineName>Default pipeline</search:pipelineName>
</search:servicePipeline>
<search:verboseLogging enabled="true"/>
<search:logLanguage>en-US</search:logLanguage>
<search:logLevel>INFO</search:logLevel>
<search:badTitles>
<search:badTitle>PowerPoint Presentation</search:badTitle>
<search:badTitle>Slide 1</search:badTitle>
</search:badTitles>
<search:minCacheQueue>1</search:minCacheQueue>
<search:maxCacheQueue>10</search:maxCacheQueue>
<search:fileWriteBufferSize>32K</search:fileWriteBufferSize>
<search:idmUserCacheSize>5000</search:idmUserCacheSize>
<search:idmGroupCacheSize>5000</search:idmGroupCacheSize>
<search:portalIndexContainerPage>true</search:portalIndexContainerPage>
<search:portalSmartIncrCrawl>true</search:portalSmartIncrCrawl>
<search:zipFilePackage>JDK</search:zipFilePackage>
<search:archiveFileTraverseDepth>3</search:archiveFileTraverseDepth>
</search:crawlerSettings>
</search:config>
docServiceInstance
A document service instance is a Java class that implements the document service API. It accepts input from documents and performs an operation on it. For example, you could create a document service for auditing or to show custom metatags.
create createAll delete deleteAll deleteList export exportAll exportList getAllObjectKeys update updateAll
Global Settings - Document Services - Create or Edit Document Service Instance
The <search:docServiceInstances> element describes the document service instances:
<search:docServiceInstances> <search:docServiceInstance> <search:name> <search:instanceManagerName> <search:parameters> <search:parameter> <search:value> <search:description>
Element Descriptions
- <search:docServiceInstances>
-
Describes all document service instances. It contains one or more
<search:docServiceInstance>elements, each defining a document service instance. - <search:docServiceInstance>
-
Describes a document service instance. It contains these elements:
<search:name> <search:instanceManagerName> <search:parameters>
- <search:name>
-
Contains the name of the document service instance.
- <search:instanceManagerName>
-
Contains the name of the manager for the document service instance. (Read only)
- <search:parameters>
-
Contains one or more
<search:parameter>elements, each describing a parameter of the document service instance. - <search:parameter>
-
Describes a parameter. It contains these elements:
<search:value> <search:description>
Attribute Value nameName of the parameter. (Read only) - <search:value>
-
Contains the value of the parameter.
Attribute Value encryptedIndicates whether the value of <search:value>is encrypted. Set totrueif the value is encrypted, or set tofalseif it is plain text. - <search:description>
-
Contains a description of the parameter. (Read only)
This XML document describes the default image service:
<?xml version="1.0" encoding="UTF-8"?>
<search:config productVersion="11.2.2.2.0" xmlns:search="http://xmlns.oracle.com/search">
<search:docServiceInstances>
<search:docServiceInstance>
<search:name>Default image service instance</search:name>
<search:instanceManagerName>
Secure Enterprise Search Image Document Service
</search:instanceManagerName>
<search:parameters>
<search:parameter name="attributes configuration file">
<search:value>attr-config.xml</search:value>
<search:description>EQG-12011:en-US:</search:description>
</search:parameter>
</search:parameters>
</search:docServiceInstance>
</search:docServiceInstances>
</search:config>
docServiceManager
A document service manager identifies the parameters for one or more document service instances.
create createAll delete deleteAll deleteList export exportAll exportList getAllObjectKeys
The <search:docServiceManagers> element describes all document service managers:
<search:docServiceManagers> <search:docServiceManager> <search:managerClassName> <search:jarFilePath> <search:name> <search:description> <search:parameterInfos> <search:parameterInfo> <search:defaultValue> <search:encrypted> <search:description>
Element Descriptions
- <search:docServiceManagers>
-
Describes all document service managers. It contains one or more
<search:docServiceManager>elements, each defining a document service manager. - <search:docServiceManager>
-
Describes a document service manager. It contains these elements:
<search:managerClassName> <search:jarFilePath> <search:name> <search:description> <search:parameterInfo>
- <search:managerClassName>
-
Contains the class name of the manager plug-in.
- <search:jarFilePath>
-
Contains the qualified name of the jar file. Paths can be absolute or relative path to the ses_home/search/lib/plugins/doc directory.
- <search:name>
-
Contains the name of the document service manager. (Read only)
- <search:description>
-
Contains a description of the object. (Read only)
- <search:parameterInfos>
-
Contains one or more
<search:parameterInfo>elements, each describing a parameter of the document service manager. (Read only) - <search:parameterInfo>
-
Describes a parameter. (Read only)
This element contains these child elements:
<search:defaultValue> <search:encrypted> <search:description>
Attribute Value nameName of the parameter. (Read only) - <search:defaultValue>
-
Contains the default value of the parameter. (Read only)
- <search:encrypted>
-
Indicates whether the parameter represents a value that should be encrypted (Read only).
- <search:description>
-
Description of the parameter.
This XML document describes the Image Document Service Manager.
<?xml version="1.0" encoding="UTF-8"?>
<search:config productVersion="11.2.2.2.0" xmlns:search="http://xmlns.oracle.com/search">
<search:docServiceManager>
<search:managerClassName>
oracle.search.plugin.doc.ordim.ImageDocumentServiceManager
</search:managerClassName>
<search:jarFilePath>ordim/ordimses.jar</search:jarFilePath>
<search:name>ImageDocumentService</search:name>
<search:description>
document service that processes JPEG, GIF, TIFF, JPEG 2000 andDICOM image metadata for search
</search:description>
<search:parameterInfos>
<search:parameterInfo name="attributes configuration file">
<search:defaultValue>attr-config.xml</search:defaultValue>
<search:encrypted>false</search:encrypted>
<search:description>
name of the configuration file that defined search attributes for image documents. The file must exist at search/lib/plugins/doc/ordim/config.
</search:description>
</search:parameterInfo>
</search:parameterInfos>
</search:docServiceManager>
</search:docServiceManagers>
</search:config>
docServicePipeline
A document service pipeline is a list of document service instances that are invoked in the order of the list. The same instance can be assigned to different pipelines, but it cannot be assigned twice in the same pipeline. You can have multiple pipeline definitions; for example, one pipeline could be used globally and another pipeline used for certain sources. An instance does not need to be in a pipeline.
create createAll delete deleteAll deleteList export exportAll exportList getAllObjectKeys update updateAll
Global Settings - Document Services - Create or Edit Document Service Pipeline
The <search:docServicePipelines> element describes the document service pipelines:
<search:docServicePipelines> <search:docServicePipeline> <search:name> <search:description> <search:assignedSources> <search:assignedSource> <search:serviceInstances> <search:serviceInstance>
Element Descriptions
- <search:docServicePipelines>
-
Describes all document service pipelines. It contains one or more
<search:docServicePipeline>elements, each defining a document service pipeline. - <search:docServicePipeline>
-
Describes a document service pipeline. It contains these elements:
<search:name> <search:description> <search:assignedSources> <search:serviceInstances>
- <search:name>
-
Contains the name of the document service pipeline.
- <search:description>
-
Contains a description of the pipeline.
- <search:assignedSources>
-
Contains one or more
<search:assignedSource>element, each describing a source that the document service pipeline is assigned to. (Read only) - <search:assignedSource>
-
Contains the name of a source crawled using this pipeline. (Read only)
- <search:serviceInstances>
-
Contains one or more
<search:serviceInstance>elements, each describing an existing document service instance to be invoked by the document service pipeline. - <search:serviceInstance>
-
Contains the name of an existing document service instance to be invoked by the document service pipeline.
This XML document describes a document service pipeline:
<?xml version="1.0" encoding="UTF-8"?>
<search:config productVersion="11.2.2.2.0" xmlns:search="http://xmlns.oracle.com/search">
<search:docServicePipelines>
<search:docServicePipeline>
<search:name>My pipeline</search:name>
<search:description>
My document service pipeline
</search:description>
<search:assignedSources>
<search:assignedSource>
this_web_source
</search:assignedSource>
<search:assignedSource>
that_web_source
</search:assignedSource>
</search:assignedSources>
<search:serviceInstances>
<search:serviceInstance>
My web service instance
</search:serviceInstance>
</search:serviceInstances>
</search:docServicePipeline>
</search:docServicePipelines>
</search:config>
facetTree
Facets are a way of categorizing the search result data, so that the search results can be filtered based on various categories and sub-catgories. A facet tree is a hierarchy of categories and sub-catgories, where each category is called as a facet node, and can be used to narrow the number of matching documents.
A facet tree (facet name and facet node names) can be translated into different languages.
create createAll delete deleteAll deleteList export exportAll exportList getAllObjectKeys update updateAll
The <search:facetTrees> element describes facet trees:
<search:facetTrees> <search:facetTree> <!-- Properties --> <search:facetName> <search:facetType> <search:mappedSearchAttribute> <search:pathDelimiter> <!-- Facet Name Translations --> <search:translations> <search:translation> <search:translatedValue> <!-- Facet Nodes --> <search:facetNodes> <search:facetNode> <search:nodeName> <search:matchExpression> <!-- Facet Node Name Translations --> <search:translations> <search:translation> <search:translatedValue>
Element Descriptions
- <search:facetTrees>
-
Contains one or more
<search:facetTree>elements. - <search:facetTree>
-
Describes a facet tree. It contains these elements:
<search:facetName> <search:facetType> <search:mappedSearchAttribute> <search:translations> <search:facetNodes>
- <search:facetName>
-
Name of the facet. The maximum length is 2000 bytes in UTF-8. Required.
- <search:facetType>
-
Data type of
<search:mappedSearchAttribute>. Set toSTRINGonly. Required. - <search:mappedSearchAttribute>
-
Name of the search attribute whose values are used as the facet values. The data type must be the same as
<search:facetType>. The maximum length of a string facet is 2000 bytes in UTF-8 format. - <search:pathDelimiter>
-
Facet tree path delimiter, which is a slash (/) by default. The backslash (\) is the escape character, thus you must enter two backslashes (\\) to set the delimiter to a backslash.
- <search:translations>
-
Contains one or more
<search:translation>elements. - <search:translation>
-
Controls the translation language for the facet name. It contains
<search:translatedValue>element.Attribute Value languageA code identifying the language of the translated value. The codes are not case sensitive. See Table 2-5, "Query Language Codes". Default is en, that is, English. - <search:translatedValue>
-
The translated value of the facet name in the specified language.
- <search:facetNodes>
-
Describes the facet nodes for number and date data types. It contains one or more
<search:facetNode>elements. - <search:facetNode>
-
Describes a facet node. It contains these elements:
<search:nodeName> <search:matchExpression> <search:translations>
- <search:nodeName>
-
Name of the facet node. It can be a full path, starting from the root node. Any node in the path that does not exist is created automatically. The name must be unique within the parent node. The maximum length is 2000 bytes in UTF-8.
- <search:matchExpression>
-
Provides an optional, conditional expression for number and date facets in the form:
type = [range | system], option operator expression, ...Note:
Some of these characters have special significance in XML, so you must enter the entity references instead of the characters as element values:
"for"(quotation marks)
&for&(ampersand)The expression can be one of these types:
-
range: Uses thebeginValueandendValueparameters to identify a range of values. You can specify one or both of these parameters. Use theincludeparameter to identify whether the range value includes or excludes the beginning value and the end value of the range. Use theintervalparameter to indicate the time interval in days, months, or years.beginValue [ = ] [expression]: Identifies the beginning of the range. Optional ifendValueis specifiedendValue [ = ] [expression]: Identifies the end of the range. Optional ifbeginValueis specified.include [ = ] [begin | end | both | none]: Identifies whether the range value includes or excludes the beginning value and the end value of the range. Specifybeginto include the beginning value, specifyendto include the end value, specifybothto include beginning value as well as end value of the range, and specifynoneto exclude beginning value as well as end value of the range. If theincludeparameter for the range expression type is not specified, then the default processing is same as that ofbegin, that is, the beginning value of the range is included.interval [ = ] [DAY | MONTH | YEAR]: This range parameter can be used only for the date type facets. It indicates the time interval in days, months, or years. -
system: This expression type can be used only with the date type facets. Uses thevalueparameter to specify a predefined date range using the keywords described as follows:value = [Today | Yesterday | This Week | This Month | This Year | Before This Year]
-
- <search:translations>
-
Contains one or more
<search:translation>elements. - <search:translation>
-
Controls the translation language for the facet node name. It contains
<search:translatedValue>element.Attribute Value languageA code identifying the language of the translated value. The codes are not case sensitive. See Table 2-5, "Query Language Codes". Default is en, that is, English. - <search:translatedValue>
-
The translated value of the facet node name in the specified language.
This XML document describes three facet trees. Books is a string facet tree. Price is a number facet tree with three nodes: Under $20, Under $35, and $35 and up. Published Date is a date facet tree with three nodes also: New Releases, Recent Titles, and Timeless Treasures.
<search:config productVersion="11.2.2.2.0" xmlns:search="http://xmlns.oracle.com/search">
<search:facetTrees>
<search:facetTree>
<search:facetName>Books</search:facetName>
<search:facetType>STRING</search:facetType>
<search:mappedSearchAttribute>Title</search:mappedSearchAttribute>
</search:facetTree>
<search:facetTree>
<search:facetName>Price</search:facetName>
<search:facetType>NUMBER</search:facetType>
<search:mappedSearchAttribute>Price</search:mappedSearchAttribute>
<search:facetNodes>
<search:facetNode>
<search:nodeName>Under $20</search:nodeName>
<search:matchExpression>
type=range, endValue=20, include=none
</search:matchExpression>
</search:facetNode>
<search:facetNode>
<search:nodeName>Under $35</search:nodeName>
<search:matchExpression>
type=range, endValue=35, beginValue=20,include=begin
</search:matchExpression>
</search:facetNode>
<search:facetNode>
<search:nodeName>$35 and up</search:nodeName>
<search:matchExpression>
type=range, beginValue=35, include=begin
</search:matchExpression>
</search:facetNode>
</search:facetNodes>
</search:facetTree>
<search:facetTree>
<search:facetName>Published Date</search:facetName>
<search:facetType>DATE</search:facetType>
<search:mappedSearchAttribute>Year</search:mappedSearchAttribute>
<search:facetNodes>
<search:facetNode>
<search:nodeName>New Releases</search:nodeName>
<search:matchExpression>
type=system, value=This Year
</search:matchExpression>
</search:facetNode>
<search:facetNode>
<search:nodeName>Recent Titles</search:nodeName>
<search:matchExpression>
type=system, value=Before This Year
</search:matchExpression>
</search:facetNode>
<search:facetNode>
<search:nodeName>Timeless Treasures</search:nodeName>
<search:matchExpression>
type=range, endValue=today - 2, interval=YEAR, include=end
</search:matchExpression>
</search:facetNode>
</search:facetNodes>
</search:facetTree>
</search:facetTrees>
</search:config>
Example Contents of <search:matchExpression>
Following are the examples of the content of the <search:matchExpression> element.
- Example 1 Number Data Type
-
For range
[10 - 20]where 10 is inclusive and 20 is exclusive:type=range, beginValue=10, endValue=20
or
type=range, beginValue=10, endValue=20, include=begin
For range
[10 - 20]where both 10 and 20 are inclusive:type=range, beginValue=10, endValue=20, include=both
For range
[* - 100]for any number less than 100 (exclusive):type=range, endValue=100, include=none
For range
[100 - *]for any number greater than or equal to 100:type=range, beginValue=100, include=begin
For range [100 - 100] where every element in the range has a value of 100:
type=range, beginValue=100
- Example 2 Date Data Type: Absolute Value
-
Specify absolute values for dates using the format
mm/dd/yyyy.For range [year 2001- year 2011] for years 2001 and 2011 inclusive:
type=range, beginValue=01/01/2001, endValue=12/31/2011, include=both
For range [* - year 2010] for any date before or in year 2010:
type=range, endValue=12/31/2010, include=end
For range [year 2000 - *] for any date in or after year 2001:
type=range, beginValue=01/01/2001, include=begin
For range [year 2001] for any date that matches year 2001:
type=range, beginValue=01/01/2001, endValue=01/01/2002
For range [01/01/2011 - 01/01/2011] for any date that exactly matches the date January 1, 2011:
type=range, beginValue=01/01/2011, endValue=01/01/2011, include=both
- Example 3 Date Data Type: Relative Value
-
Last three years including this year up to today:
type=range, beginValue=today - 3, endValue=today, include=end, interval=YEAR
Last seven days including today:
type=range, beginValue=today - 7, endValue=today, include=end, interval=DAY
Last six months including this month up to today:
type=range, beginValue=today - 6, endValue=today, include=end, interval=MONTH
- Example 4 Date Data Type: Predefined Constants
-
Today:
type = system, value = Today
This year:
type = system, value = This Year
globalBoundaryRules
The default boundary rules specified in this object are copied to new sources that are created with no other boundary rules.
Boundary rules restrict the crawler to those URLs that match the specified rules. Exclusion rules override inclusion rules. The order in which the rules are listed has no impact.
For file sources with no boundary rules, crawling is limited to the underlying file system access privileges. Files accessible from the specified seed file URL are crawled to the default crawling depth.
The <search:globalBoundaryRules> element describes the rules limiting the scope of the crawler. It contains these elements:
<search:globalBoundaryRules> <search:boundaryRules> <search:boundaryRule> <search:ruleType> <search:ruleOperation> <search:rulePattern>
Element Descriptions
- <search:globalBoundaryRules>
-
Contains one or more
<search:boundaryRule>elements, each describing a boundary rule. - <search:boundaryRules>
-
Contains one or more
<search:boundaryRule>elements. - <search:boundaryRule>
-
Describes a boundary rule. It contains these child elements:
<search:ruleType> <search:ruleOperation> <search:rulePattern>
- <search:ruleType>
-
Type of URL boundary rule:
-
INCLUSION: The URL matches <search:rulePattern>. -
EXCLUSION: The URL does not match <search:rulePattern>.
-
- <search:ruleOperation>
-
Matching operation for a search rule pattern:
-
CONTAINS: The URL contains the rule pattern for a case-insensitive match. -
STARTSWITH: The URL starts with the rule pattern for a case-insensitive match. -
ENDSWITH: The URL ends with the rule pattern for a case-insensitive match. -
REGEX: The URL matches the regular expression in a case-sensitive match.
-
- <search:rulePattern>
-
The pattern of characters in the URL. You can use these special characters:
-
Caret (
^) denotes the beginning of a URL. -
Dollar sign (
$) denotes the end of a URL. -
A period (
.) matches any one character. -
Question mark (
?) matches zero or one occurrence of the character that it follows. -
Asterisk (
*) matches zero or more occurrences of the pattern that it follows. Enclose the pattern in parentheses(), brackets[], or braces{}. -
A backslash (
\) precedes a literal use of a special character, such as\?to match a question mark in a URL.
Files with the following filename extensions are excluded by the default boundary rule patterns:
-
Image: bmp, png, tif
-
Audio: wav, wma, mp3
-
Video: avi, wmv, mpeg, mpg
-
Binary: bin, cab, dll, dmp, ear, exe, iso, jar, scm, so, tar, war, wmv
-
This XML document defines the default global boundary rules:
<?xml version="1.0" encoding="UTF-8"?>
<search:config productVersion="11.2.2.2.0" xmlns:search="http://xmlns.oracle.com/search">
<search:globalBoundaryRules>
<search:boundaryRules>
<search:boundaryRule>
<search:ruleType>EXCLUSION</search:ruleType>
<search:ruleOperation>REGEX</search:ruleOperation>
<search:rulePattern>
(?i:(?:\.jar)|(?:\.bmp)|(?:\.war)|(?:\.ear)|(?:\.mpg)|(?:\.wmv)|(?:\.mpeg)|(?:\.scm)|(?:\.iso)|(?:\.dmp)|(?:\.dll)|(?:\.cab)|(?:\.so)|(?:\.avi)|(?:\.wav)|(?:\.mp3)|(?:\.wma)|(?:\.bin)|(?:\.exe)|(?:\.iso)|(?:\.tar)|(?:\.png))$
</search:rulePattern>
</search:boundaryRule>
<search:boundaryRule>
<search:ruleType>EXCLUSION</search:ruleType>
<search:ruleOperation>REGEX</search:ruleOperation>
<search:rulePattern>\?.*(.*\+)\1{3}</search:rulePattern>
</search:boundaryRule>
</search:boundaryRules>
</search:globalBoundaryRules>
</search:config>
globalDocumentTypes
This object defines the default document types for each new source.
The <search:documentTypes> element describes the default document types:
<search:globalDocumentTypes> <search:documentTypes> <search:documentType> <search:mimeType>
Element Descriptions
- <search:globalDocumentTypes>
-
Contains one or more
<search:documentTypes>elements. - <search:documentTypes>
-
Contains one or more
<search:documentType>elements.Attribute Value processAllSet to trueto process all the MIME types by default, or set tofalseotherwise. - <search:documentType>
-
Contains a
<search:mimeType>element. - <search:mimeType>
-
Contains a supported MIME type, as described in Table 2-1, "Document Formats Supported by Oracle SES". These MIME types are defined by default:
application/msword application/pdf application/x-msexcel application/x-mspowerpoint text/html text/plain
This XML document describes the default global document types:
<?xml version="1.0" encoding="UTF-8"?>
<search:config productVersion="11.2.2.2.0" xmlns:search="http://xmlns.oracle.com/search">
<search:globalDocumentTypes>
<search:documentTypes>
<search:documentType>
<search:mimeType>text/html</search:mimeType>
</search:documentType>
<search:documentType>
<search:mimeType>text/plain</search:mimeType>
</search:documentType>
<search:documentType>
<search:mimeType>application/msword</search:mimeType>
</search:documentType>
<search:documentType>
<search:mimeType>application/pdf</search:mimeType>
</search:documentType>
<search:documentType>
<search:mimeType>application/x-msexcel</search:mimeType>
</search:documentType>
<search:documentType>
<search:mimeType>application/x-mspowerpoint</search:mimeType>
</search:documentType>
</search:documentTypes>
</search:globalDocumentTypes>
</search:config>
To process all the supported MIME types by default, specify processAll=true for <search:documentTypes> element:
<?xml version="1.0" encoding="UTF-8"?>
<search:config productVersion="11.2.2.2.0"
xmlns:search="http://xmlns.oracle.com/search">
<search:globalDocumentTypes>
<search:documentTypes processAll="true"/>
<search:globalDocumentTypes/>
</search:config>
identityPlugin
An identity plug-in provides an interface between Oracle Secure Enterprise Search and an identity management system to validate and authenticate users. An identity plug-in is required for secure searches. Secure searches return only the results that the user is allowed to view based on access privileges.
Only one identity plug-in can be active. It is responsible for all authentication and validation activity in Oracle SES. See "activate identityPlugin".
activate create createAll deactivate delete deleteAll deleteList export exportAll exportList getAllObjectKeys getAllStates getState getStateList
The <search:identityPlugins> element describes identity plug-ins:
<search:identityPlugins> <search:identityPlugin> <search:managerClassName> <search:jarFilePath> <search:description> <search:version> <search:authAttribute> <!-- Include parameters for activate operation --> <search:parameters> <search:parameter> <search:value> <search:description>
The implementation of the identity plug-in determines the parameters. You cannot create new parameters in the XML document.
Element Descriptions
- <search:identityPlugins>
-
Contains one or more
<search:identityPlugin>elements. - <search:identityPlugin>
-
Describes an identity plug-in. It contains these elements:
<search:managerClassName> <search:jarFilePath> <search:description> <search:version> <search:authAttribute> <search:parameters>
- <search:managerClassName>
-
Contains the class name of the plug-in.
- <search:jarFilePath>
-
Contains the qualified name of the jar file. Paths can be absolute or relative to the ses_home/search/lib/plugins/identity directory.
- <search:description>
-
Contains a description of the plug-in. (Read only)
- <search:version>
-
Contains the Oracle SES version of the plug-in. (Read only)
- <search:authAttribute>
-
Contains the authentication attribute for the plug-in.
- <search:parameters>
-
Contains one or more
<search:parameter>elements. The parameter are used only by activate identityPlugin, not by create identityPlugin. - <search:parameter>
-
Describes a plug-in parameter. Each plug-in has its own parameters. This element contains these child elements:
<search:value> <search:description>
Attribute Value nameName of the parameter. - <search:value>
-
Value of the parameter.
Attribute Value encryptedIndicates whether the value of <search:value>is encrypted. Set totrueif the password is encrypted, or set tofalseif it is plain text. The default value isfalse. - <search:description>
-
Description of the parameter.
This XML document defines an Oracle Internet Directory plug-in:
<?xml version="1.0" encoding="UTF-8" ?>
<search:config productVersion="11.2.2.2.0" xmlns:search="http://xmlns.oracle.com/search">
<search:identityPlugins>
<search:identityPlugin>
<search:managerClassName>
oracle.search.plugin.security.identity.oid.OIDPluginManager
</search:managerClassName>
<search:jarFilePath>OIDPlugins.jar</search:jarFilePath>
<search:description>Oracle Internet Directory identity plug-in manager
</search:description>
<search:version>11.1.0.0.0</search:version>
<search:authAttribute>nickname</search:authAttribute>
<search:parameters>
<search:parameter name="Host name">
<search:value>my_computer</search:value>
<search:description>OID host on my computer</search:description>
</search:parameter>
<search:parameter name="Port">
<search:value>7789</search:value>
<search:description>OID port</search:description>
</search:parameter>
<search:parameter name="Use SSL">
<search:value>false</search:value>
<search:description>SSL encryption
</search:description>
</search:parameter>
<search:parameter name="Realm">
<search:value>dc=us,dc=example,dc=com</search:value>
<search:description>OID realm</search:description>
</search:parameter>
<search:parameter name="User name">
<search:value>cn=orcladmin</search:value>
<search:description>OID user name</search:description>
</search:parameter>
<search:parameter name="Password">
<search:value encrypted="false">mypassword</search:value>
<search:description>Password</search:description>
</search:parameter>
<search:parameter name="Use User Cache">
<search:value>false</search:value>
<search:description> </search:description>
</search:parameter>
<search:parameter name="User Cache Source Name">
<search:description> </search:description>
</search:parameter>
</search:parameters>
</search:identityPlugin>
</search:identityPlugins>
</search:config>
index
The index is a metadata repository for crawled documents and provides the search results list.
| Property | Value |
|---|---|
estimatedFragmentation |
Decimal number representing the percent of fragmentation; optimize the index when fragmentation is greater than 50%. |
The <search:index> element describes indexing:
<search:index> <search:indexingBatchSize> <search:indexingMemorySize>
Element Descriptions
- <search:index>
-
Describes the indexing parameters. It contains these elements:
<search:indexingBatchSize> <search:indexingMemorySize>
- <search:indexingBatchSize>
-
Contains the size in megabytes of the crawled documents before indexing begins. Crawling and indexing run concurrently after the initial batch size is reached. While the index is running, the crawler continues to crawl documents.
The default size is 250 MB.
- <search:indexingMemorySize>
-
Contains the number of megabytes of memory used for indexing before swapping to disk. A large amount of memory improves both indexing and query performance.
The default size is 275 MB.
This XML document configures the indexing properties:
<?xml version="1.0" encoding="UTF-8"?>
<search:config productVersion="11.2.2.2.0" xmlns:search="http://xmlns.oracle.com/search">
<search:index>
<search:indexingBatchSize>250</search:indexingBatchSize>
<search:indexingMemorySize>275</search:indexingMemorySize>
</search:index>
</search:config>
indexOptimizer
Optimizing the index reduces fragmentation and may significantly increase the speed of searches. In general, the fragmentation percentage should be less than 50%. A higher percentage indicates that search performance is compromised. If it is over 75%, then you should optimize the index as soon as possible.
Optimization of a very large index may take several hours. Schedule optimization during hours of low usage to ensures minimal disruption to users.
| Property | Value |
|---|---|
endTime |
The date and time that the last optimization ended, in the form
Day, DD Mon YYYY, HH:MM:SS GMT |
startTime |
The date and time that the last optimization started, in the same form as endTime |
status |
DISABLED, EXECUTING, FAILED, LAUNCHING, SCHEDULED, or STOPPED |
The <search:indexOptimizer> element describes index optimization:
<search:indexOptimizer> <search:frequency> <!-- For hourly optimization --> <search:hourly> <search:hoursBtwnLaunches> <!-- For daily optimization --> <search:daily> <search:daysBtwnLaunches> <search:startHour> <!-- For weekly optimization --> <search:weekly> <search:weeksBtwnLaunches> <search:startDayOfWeek> <search:startHour> <!-- For monthly optimization --> <search:monthly> <search:monthsBtwnLaunches> <search:startDayOfMonth> <search:startHour> <!-- For all frequencies --> <search:duration> <search:maxHours>
Element Descriptions
- <search:indexOptimizer>
-
Describes index optimization schedule. It contains these elements:
<search:frequency> <search:duration>
- <search:frequency>
-
Describes the optimization schedule. It contains one of these elements:
<search:hourly> <search:daily> <search:weekly> <search:monthly>
- <search:hourly>
-
Describes an hourly schedule. It contains a
<search:hoursBtwnLaunches>element. - <search:hoursBtwnLaunches>
-
The number of hours between optimizations.
- <search:daily>
-
Describes a daily schedule. It contains these elements:
<search:daysBtwnLaunches> <search:startHour>
- <search:daysBtwnLaunches>
-
The number of days between optimizations.
- <search:startHour>
-
The time the crawl begins using a 24-hour clock, such as
9for 9:00 a.m. or23for 11:00 p.m. - <search:weekly>
-
Describes a weekly schedule. It contains these elements:
<search:weeksBtwnLaunches> <search:startDayOfWeek> <search:startHour>
- <search:weeksBtwnLaunches>
-
The number of weeks between optimizations.
- <search:startDayOfWeek>
-
The day of the week that the crawl begins, such as
MONDAYorTUESDAY. - <search:monthly>
-
Describes a monthly schedule. It contains these elements:
<search:monthsBtwnLaunches> <search:startDayOfMonth> <search:startHour>
- <search:monthsBtwnLaunches>
-
The number of time periods between starting a crawl.
- <search:startDayOfMonth>
-
An integer value for the day of the month that the crawl begins, such as
1or15. - <search:duration>
-
Controls the duration of the optimization process. It contains a
<search:maxhours>element.Attribute Value haslimitSet to trueto enforce the time limit, or set tofalseto allow the process to finish. Required. - <search:maxHours>
-
The number of hours the optimization process is allowed to continue. For best results, allow the optimization to finish.
This XML document contains the index optimizer settings:
<?xml version="1.0" encoding="UTF-8"?>
<search:config productVersion="11.2.2.2.0" xmlns:search="http://xmlns.oracle.com/search">
<search:indexOptimizer>
<search:frequency>
<search:weekly>
<search:weeksBtwnLaunches>3</search:weeksBtwnLaunches>
<search:startDayOfWeek>MONDAY</search:startDayOfWeek>
<search:startHour>23</search:startHour>
</search:weekly>
</search:frequency>
<search:duration haslimit="true">
<search:maxHours>8</search:maxHours>
</search:duration>
</search:indexOptimizer>
</search:config>
indexProfile
An index profile is a group of index settings that can be used by multiple data sources. All newly created sources use the default index profile, which you can configure in the crawlerSettings object.
create createAll delete deleteAll deleteList export exportAll exportList getAllObjectKeys update updateAll
The <search:indexProfiles> element describes all the index profiles:
<search:indexProfiles> <search:indexProfile> <search:name> <search:description> <search:tokenization> <search:languageBasedTokenization> <search:userDefinedTokenization> <search:mappingRules> <search:mappingRule> <search:rule> <search:lexerName> <search:defaultMappingRule> <search:lexerName>
Element Descriptions
- <search:indexProfiles>
-
Contains one or more
<search:indexProfile>elements. - <search:indexProfile>
-
Describes an index profile. It contains these elements:
<search:name> <search:description> <search:tokenization>
- <search:name>
-
Contains the name of the index profile. Required.
- <search:description>
-
Contains a description of the index profile.
- <search:tokenization>
-
Identifies the type of tokenization used by the index profile. It contains one of these elements:
<search:userDefinedTokenization> <search:languageBasedTokenization
- <search:languageBasedTokenization>
-
Tokenization is performed using the language mapping rules defined in a languageBasedTokenization object. Default.
- <search:userDefinedTokenization>
-
Tokenization is performed using a set of prioritized mapping rules that you define in this element. It contains a
<search:mappingRules>element. - <search:mappingRules>
-
Contains one or more
<search:mappingRule>elements. - <search:mappingRule>
-
Associates a rule with lexer and identifies the priority of the rule. It contains these elements:
<search:rule> <search:lexerName>
priorityA positive integer that identifies the priority of the rule. Each rule must have a unique priority number. Rules are evaluated in numeric order: If the first rule does not match the document, then the second rule is evaluated, and so forth. - <search:rule>
-
A text string in the form
attribute=value:attributeis the name of a String document attribute.valueis a value of the attribute. It can contain an asterisk (*) as a wildcard. To use an asterisk or a backslash (\) as literal values, precede them with a backslash as an escape (\* or \\).Both parts of the string are case-insensitive.
- <search:lexerName>
-
Contains the name of a lexer object.
- <search:defaultMappingRule>
-
Identifies the lexer for a document that does not match any of the other mapping rules. It contains a
<search:lexerName>element. Required. - <search:lexerName>
-
Contains the name of the default lexer object.
This XML document describes the default index profile, which uses language-based tokenization and a custom index profile, which defines the tokenization rules.
<?xml version="1.0" encoding="UTF-8"?>
<search:config productVersion="11.2.2.2.0" xmlns:search="http://xmlns.oracle.com/search">
<search:indexProfiles>
<search:indexProfile>
<search:name>Oracle Default Index Profile</search:name>
<search:description>
Oracle Secure Enterprise Search Default index profile.
</search:description>
<search:tokenization>
<search:languageBasedTokenization/>
</search:tokenization>
</search:indexProfile>
<search:indexProfile>
<search:name>This Index Profile</search:name>
<search:description>Alternate index profile</search:description>
<search:tokenization>
<search:userDefinedTokenization>
<search:mappingRules>
<search:mappingRule priority="1">
<search:rule>Language=en</search:rule>
<search:lexerName>OracleDefaultLanguageLexer</search:lexerName>
</search:mappingRule>
<search:mappingRule priority="2">
<search:rule>Language=de</search:rule>
<search:lexerName>OracleDefaultGermanLexer</search:lexerName>
</search:mappingRule>
<search:mappingRule priority="3">
<search:rule>Mimetype=text/html</search:rule>
<search:lexerName>OracleDefaultLanguageLexer</search:lexerName>
</search:mappingRule>
</search:mappingRules>
<search:defaultMappingRule>
<search:lexerName>OracleDefaultLanguageLexer</search:lexerName>
</search:defaultMappingRule>
</search:userDefinedTokenization>
</search:tokenization>
</search:indexProfile>
</search:indexProfiles>
</search:config>
languageBasedTokenization
Language-based tokenization associates each document language with a lexer.
The <search:languageBasedTokenization> element describes language-based tokenization:
<search:languageBasedTokenization> <search:languageMappingRules> <search:languageMappingRule> <search:language> <search:lexerName> <search:defaultLanguageMappingRule> <search:lexerName>
Element Descriptions
- <search:languageBasedTokenization>
-
Contains a
<search:languageMappingRules>element. - <search:languageMappingRules>
-
Contains one or more
<search:languageMappingRule>elements. - <search:languageMappingRule>
-
Identifies the lexer used to tokenize a document language.
- <search:language>
-
Contains a two-letter language code from Table 2-3. A language can be mapped only once.
- <search:lexerName>
-
Contains the name of the lexer to use to tokenize documents in the specified language.
- <search:defaultLanguageMappingRule>
-
Identifies the lexer to use for document languages without a language mapping rule. It contains a
<search:lexerName>element. (Required) - <search:lexerName>
-
Contains the name of the default lexer to use to tokenize documents in the specified language.
This XML document describes the mapping rules for language-based tokenization:
<?xml version="1.0" encoding="UTF-8"?>
<search:config productVersion="11.2.2.2.0" xmlns:search="http://xmlns.oracle.com/search">
<search:languageBasedTokenization>
<search:languageMappingRules>
<search:languageMappingRule>
<search:language>de</search:language>
<search:lexerName>OracleDefaultGermanLexer</search:lexerName>
</search:languageMappingRule>
<search:languageMappingRule>
<search:language>ja</search:language>
<search:lexerName>OracleDefaultJapaneseLexer</search:lexerName>
</search:languageMappingRule>
<search:languageMappingRule>
<search:language>ko</search:language>
<search:lexerName>OracleDefaultKoreanLexer</search:lexerName>
</search:languageMappingRule>
<search:languageMappingRule>
<search:language>zh</search:language>
<search:lexerName>OracleDefaultChineseLexer</search:lexerName>
</search:languageMappingRule>
</search:languageMappingRules>
<search:defaultLanguageMappingRule>
<search:lexerName>OracleDefaultLanguageLexer</search:lexerName>
</search:defaultLanguageMappingRule>
</search:languageBasedTokenization>
</search:config>
lexer
Lexers convert a sequence of characters into tokens. Different languages and different data sets require different tokenization rules. Oracle SES uses lexers to tokenize documents for indexing and to tokenize queries. For indexing, the crawler identifies the document language and determines the correct lexer to tokenize each document. For queries, Oracle SES uses a single lexer based on the user's browser language.
create createAll delete * deleteAll * deleteList * export exportAll exportList getAllObjectKeys update updateAll
* A lexer cannot be deleted when a languageBasedTokenization object is using it.
The <search:lexers> element describes the language lexers:
<search:lexers> <search:lexer> <search:name> <search:type> <search:description> <search:parameters> <search:parameter> <search:value>
Element Descriptions
- <search:lexers>
-
Contains one or more
<search:lexer>elements. - <search:lexer>
-
Describes a lexer. It contains these elements:
<search:name> <search:type> <search:description> <search:parameters>
- <search:name>
-
Contains a case-insensitive name that uniquely identifies the lexer. The name cannot contain spaces, be more than 26 bytes in UTF-8, or begin with the string
Oracle. - <search:type>
-
Contains a supported lexer type. You cannot change the type after the lexer is created.
Oracle SES uses a subset of Oracle Text lexers. For more information about these lexers, refer to the Oracle Text Reference.
- <search:description>
-
Contains a description of the lexer.
- <search:parameters>
-
Contains one or more
<search:parameter>elements. - <search:parameter>
-
Contains the name of a supported attribute for the lexer type, which are described in the following topics. All attribute names are case-insensitive.
- <search:value>
-
Contains the value of the attribute. All attribute values are case-insensitive.
To specify white space in a parameter value, enter the string
SPACE.
The BASIC_LEXER type identifies tokens for English and all other supported whitespace-delimited languages. You can use it with any database character set.
BASIC_LEXER Attributes
- continuation
-
One or more characters that indicate a word continues on the next line and should be indexed as a single token. The most common continuation characters are hyphen '-' and backslash '\'.
- numgroup
-
A single character that, when it appears in a string of digits, indicates that the digits are groupings within a larger single unit. For example, comma ',' might be defined as a
numgroupcharacter because it often indicates a grouping of thousands when it appears in a string of digits.The globalization support initialization parameters for the database determine the default value.
- numjoin
-
One or more characters that, when they appear in a string of digits, indicates that the string should be indexed as a single unit or word. For example, period '.' might be defined as
numjoincharacters because it often serves as a decimal point when it appears in a string of digits.The globalization support initialization parameters for the database determine the default value.
- printjoins
-
One or more nonalphanumeric characters that, when they appear anywhere in a word, are processed as alphanumeric and included with the token in the index. This includes
printjoinscharacters that occur consecutively.For example, if the hyphen '-' and underscore '_' are defined as
printjoinscharacters, then terms such as pseudo-intellectual and _file_ are stored in the index aspseudo-intellectualand_file_.Printjoinsdiffer fromendjoinsandstartjoinsin that position does not matter. For example, $35 is indexed as one token if $ is astartjoinor aprintjoin, but as two tokens if it is defined as anendjoin.If a
printjoinscharacter is also defined as apunctuationscharacter, it is processed as aprintjoinscharacter only if the character immediately following it is a standard alphanumeric character, or it has been defined as aprintjoinsorskipjoinscharacter. - punctuations
-
One or more nonalphanumeric characters that, when they appear at the end of a word, indicate the end of a sentence. The defaults are period '.', question mark '?', and exclamation point '!'.
Characters that are defined as
punctuationsare removed from a token before indexing. However, if apunctuationscharacter is also defined as aprintjoinscharacter, then the character is removed only when it is the last character in the token.For example, if the period (.) is defined as both a
printjoinsand apunctuationscharacter, then the following transformations take place during indexing and querying as well:Token Indexed Token .doc .doc dog.doc dog.doc dog..doc dog..doc dog. dog dog... dog.. BASIC_LEXERusepunctuationscharacters withnewlineandwhitespacecharacters to determine sentence and paragraph delimiters for sentence/paragraph searching. - skipjoins
-
One or more nonalphanumeric characters that, when they appear within a word, identify the word as a single token; however, the characters are not stored with the token in the index.
For example, if the hyphen '-' is defined as a
skipjoinscharacter, then the word pseudo-intellectual is stored in the index aspseudointellectual.Printjoinsandskipjoinsare mutually exclusive. The same characters cannot be specified for both attributes. - startjoins
-
One or more nonalphanumeric characters that, when encountered as the first character in a token, identify the start of the token. The character and any trailing
startjoinscharacters are included in the index entry for the token. In addition, the firststartjoinscharacter in a string ofstartjoinscharacters implicitly ends the previous token.The following rules apply:
-
The specified characters cannot occur in any of the other attributes for
BASIC_LEXER. -
The characters can occur only at the beginning tokens.
-
- endjoins
-
One or more nonalphanumeric characters that, when encountered as the last character in a token, identify the end of the token. The character and any trailing
startjoinscharacters are included in the Text index entry for the token.The following rules apply:
-
The characters cannot occur in any of the other attributes for
BASIC_LEXER. -
The characters can occur only at the end of tokens.
-
- whitespace
-
One or more characters that are treated as blank spaces between tokens.
BASIC_LEXERuseswhitespacecharacters withpunctuationsandnewlinecharacters to identify character strings that serve as sentence delimiters for sentence and paragraph searching.The predefined default values for
whitespacearespaceandtab. These values cannot be changed. Specifying characters aswhitespacecharacters adds to these defaults. - newline
-
Characters that indicate the end of a line of text.
BASIC_LEXERusesnewlinecharacters with punctuation and whitespace characters to identify character strings that serve as paragraph delimiters for sentence and paragraph searching.The only valid values for
newlineareNEWLINEandCARRIAGE_RETURN(for carriage returns). The default isNEWLINE. - base_letter
-
YESto convert characters that have diacritical marks (umlauts, cedillas, acute accents, and so on) to their base form before being stored in the index. The default isNO, which disables base-letter conversion. - base_letter_type
-
The transformation table for base-letter transformations:
GENERICuses one transformation table for all languages for base-letter transformation (default).SPECIFICuses different transformation tables for different languages. - override_base_letter
-
TRUEprevents unexpected results from serial transformations whenbase_letteris enabled at the same time asalternate_spelling. Default isFALSE. - composite
-
DUTCHandGERMANenable composite word indexing for the specified language.DEFAULTdisables composite word indexing (default).Words that are usually one entry in a German dictionary are not split into composite stems, while words that are not dictionary entries are split into composite stems.
- alternate_spelling
-
DANISH,GERMAN, andSWEDISHenable alternate spelling in the specified language. Users can then query a word in any of its alternate forms.NONEdisables alternate spelling in all languages.Alternate spelling is typically off by default, but may be on for some German-, Danish-, and Swedish-language installations.
- new_german_spelling
-
YESreturns both traditional and reformed (new) spellings of German words.NOmatches words only as they are entered in the query (default).
The CHINESE_LEXER type identifies tokens in traditional and simplified Chinese text. It generates a smaller index and supports better query response time than the CHINESE_VGRAM_LEXER type, but indexing takes longer.
You can use this lexer if your database uses a Chinese or Unicode character sets supported by Oracle. See the Oracle Database Globalization Support Guide.
The CHINESE_LEXER type has no attributes.
The CHINESE_VGRAM_LEXER type identifies tokens in Chinese text. Indexing is quicker than the CHINESE_LEXER type, but the index is larger and querying is slower.
You can use this lexer if your database uses one of these character sets:
AL32UTF8
UTF8
ZHS16CGB231280
ZHS16GBK
ZHS32GB18030
ZHT32EUC
ZHT16BIG5
ZHT32TRIS
ZHT16HKSCS
ZHT16MSWIN950
The CHINESE_VGRAM_LEXER type has no attributes.
The JAPANESE_LEXER type identifies tokens in Japanese. It generates a smaller index and supports better query response time than the JAPANESE_VGRAM_LEXER type, but indexing takes longer.
You can use this lexer if your database uses one of these character sets:
AL32UTF8
UTF8
JA16SJIS
JA16EUC
JA16EUCTILDE
JA16EUCYEN
JA16SJISTILDE
JA16SJISYEN
JAPANESE_LEXER Attributes
- delimiter
-
Specify
NONEorALLto ignore certain Japanese blank characters, such as a full-width slash or a full-width middle dot. Default isNONE.
The JAPANESE_VGRAM_LEXER type identifies tokens in Japanese. Indexing is quicker than the JAPANESE_LEXER type, but the index is larger and querying is slower.
You can use this lexer if the database uses one of these character sets:
AL32UTF8
UTF8
JA16SJIS
JA16EUC
JA16EUCTILDE
JA16EUCYEN
JA16SJISTILDE
JA16SJISYEN
JAPANESE_VGRAM_LEXER Attributes
- delimiter
-
Specify
NONEorALLto ignore certain Japanese blank characters, such as a full-width slash or a full-width middle dot. Default isNONE.
The KOREAN_MORPH_LEXER type identifies tokens in Korean text.
You can use this lexer if the database uses one of these character sets:
AL32UTF8
UTF8
KO16KSC5601
KO16MSWIN949
KOREAN_MORPH_LEXER Attributes
- verb_adjective
-
TRUEto index verbs, adjectives, and adverbs, orFALSEto skip them (default). - one_char_word
-
TRUEto index one syllable tokens, orFALSEto skip them (default). - number
-
TRUEto index numbers, orFALSEto skip them (default). - composite
-
The indexing style of composite nouns:
COMPOSITE_ONLYindexes only composite nouns.NGRAMindexes all noun components of a composite noun.COMPONENT_WORDindexes single noun components of composite nouns and the composite noun itself (default). - morpheme
-
TRUEfor morphological analysis (default), orFALSEto create tokens from words that are delimited, for example, by white space. - to_upper
-
TRUEto convert English to uppercase (default), orFALSEto retain mixed case. - hanja
-
TRUEto index hanja characters, orFALSEto convert hanja characters to hangul characters (default). - long_word
-
TRUEto index long words that have more than 16 syllables in Korean, orFALSEto skip them (default). - japanese
-
TRUEto index Japanese characters in Unicode (only in the 2-byte area), orFALSEto skip them (default). - english
-
TRUEto index alphanumeric strings (default), orFALSEto skip them.
This XML document describes the default lexer for Oracle SES:
<?xml version="1.0" encoding="UTF-8"?>
<search:config productVersion="11.2.2.2.0" xmlns:search="http://xmlns.oracle.com/search">
<search:lexers>
<search:lexer>
<search:name>OracleDefaultLanguageLexer</search:name>
<search:type>BASIC_LEXER</search:type>
<search:description>Oracle Secure Enterprise Search default lexer for all languages except Chinese, German, Japanese and Korean.</search:description>
<search:parameters>
<search:parameter name="BASE_LETTER">
<search:value>YES</search:value>
</search:parameter>
</search:parameters>
</search:lexer>
</search:lexers>
</search:config>
partitionConfig
Partitioning is used to improve the query performance of large data sets. You can use multiple partitions to distribute the document index across physical storage devices. I/O is then performed in parallel to gain the best query performance.
You can enable partitioning only on a freshly installed, empty Oracle SES instance.
See Also:
"Parallel Querying and Index Partitioning" in Oracle Secure Enterprise Search Administrator's GuideThe <search:partitionConfig> element describes partitioning:
<search:partitionConfig> <search:partitionAttrs> <search:partitionAttr> <search:name> <search:partitionRules> <search:partitionRule> <search:partitionValue> <search:valueType> <search:ruleType> <search:ruleSetting> <search:storageArea>
Element Descriptions
- <search:partitionConfig>
-
Describes the partition configuration rules. It contains these elements:
<search:partitionAttrs> <search:partitionRules>
- <search:partitionAttrs>
-
Contains a
<search:partitionAttr>element. - <search:partitionAttr>
-
Describes an attribute on which partitioning is based. It contains a
<search:name>element. - <search:name>
-
Contains the name of any String-type search attribute, or one of the following system-defined values:
-
EQ_SOURCE_NAME: Data source name. -
EQ_SOURCE_TYPE: Data source type. To know all the data source types, export the sourceType object.
-
- <search:partitionRules>
-
Contains one or more
<search:partitionRule>elements. - <search:partitionRule>
-
Describes a partition rule for the expected values of the partitioning attribute. It contains these elements:
<search:partitionValue> <search:valueType> <search:ruleType> <search:ruleSetting> <search:storageArea>
- <search:partitionValue>
-
Contains an expected value of the partitioning attribute or one of these values:
-
EQ_DEFAULT: Identifies the partition rule when no partition attribute is defined. -
EQ_OTHER: Identifies the partition rule when none of the other defined values of<search:partitionValue>match the attribute value of the document. -
EQ_OWNER: Identifies the partition rule with the document owner information, such as, e-mail ID and global user ID.
-
- <search:valueType>
-
Contains the type of partition value. Specify
ATTRif it is an attribute value or specifyMETAif it is a system-defined value, such as,EQ_OTHERorEQ_DEFAULT. Required. - <search:ruleType>
-
Contains the type of partition rule. Required.
-
HASH: Evenly distributes the index values for a large set of documents across the list of storage areas. Each partition is located in one storage area. -
VALUE: Maps the specified partition value to one partition. Oracle SES assigns this rule initially when partitioning is enabled and only one storage area is defined out of the box. -
BUCKETING: The number of partitions are created based on the bucket size specified. While crawling, if the number of distinct partition attribute values extend beyond the specified bucket size, then the new partitions are created according to the bucket size specified. Only theEQ_OWNERandEQ_OTHERpartition values can haveBUCKETINGrule type.
-
- <search:ruleSetting>
-
Contains the rule setting for the
BUCKETINGrule type. It defines the bucket size for each partition. The bucket size denotes the maximum number of unmapped values for each partition. The format for specifying rule setting is:bucket_size/storage_area_list
where,
bucket_sizeis the maximum number of unmapped values for each partition.storage_area_listis the comma-delimited list of storage areas associated with a partition.For example, the following rule setting for
BUCKETINGrule type specifies the bucket size of 10 for the two storage areas SA1 and SA2.10/SA1,SA2
This rule will create the first partition (bucket) in SA1, the second partition in SA2, the third partition in SA1, the fourth partition in SA2, and so on. Thus, the partitions will be created in sequence of the list of storage areas defined. A new rule of
BUCKETtype will be automatically created for any new partition value encountered. - <search:storageArea>
-
For a
VALUErule, specify the name of a singlestorageAreaobject.For a
HASHrule, specify a comma-delimited list ofstorageAreaobjects used by this partition rule. Repeat the name of astorageAreaobject to create multiple partitions within a single tablespace. Remember that astorageAreaobject is a tablespace in Oracle Database that is registered for use with Oracle SES.For example, this list creates one partition in each tablespace:
SA1, SA2, SA3
The next list creates three partitions in
SA1and two partitions inSA2:SA1, SA1, SA1, SA2, SA2
This XML document describes partitioning of the document index across six storage areas named SA1 to SA6:
<search:config productVersion="11.2.2.2.0" xmlns:search="http://xmlns.oracle.com/search">
<search:partitionConfig>
<search:partitionRules>
<search:partitionRule>
<search:partitionValue>EQ_DEFAULT</search:partitionValue>
<search:valueType>META</search:valueType>
<search:ruleType>HASH</search:ruleType>
<search:storageArea>SA1, SA2, SA3, SA4, SA5, SA6</search:storageArea>
</search:partitionRule>
</search:partitionRules>
</search:partitionConfig>
</search:config>
This example creates a partitioning rule based on the Language attribute. Documents with value of en (English) or ja (Japanese) for the Language attribute are indexed in the SA1 storage area. All the other documents are hashed into the SA2 and SA3 storage areas.
<search:config productVersion="11.2.2.2.0" xmlns:search="http://xmlns.oracle.com/search">
<search:partitionConfig>
<search:partitionAttrs>
<search:partitionAttr>
<search:name>Language</search:name>
</search:partitionAttr>
</search:partitionAttrs>
<search:partitionRules>
<search:partitionRule>
<search:partitionValue>en,ja</search:partitionValue>
<search:valueType>ATTR</search:valueType>
<search:ruleType>VALUE</search:ruleType>
<search:storageArea>SA1</search:storageArea>
</search:partitionRule>
<search:partitionRule>
<search:partitionValue>EQ_DEFAULT</search:partitionValue>
<search:valueType>META</search:valueType>
<search:ruleType>HASH</search:ruleType>
<search:ruleSetting></search:ruleSetting>
<search:storageArea>SA2,SA3</search:storageArea>
</search:partitionRule>
</search:partitionRules>
</search:partitionConfig>
</search:config>
The next example stores the document index from the Doc Library source in SA1, from My Web Site source in SA2, and from all the other sources in SA3:
<search:config xmlns:search="http://xmlns.oracle.com/search" productVersion="11.2.2.2.0">
<search:partitionConfig>
<search:partitionAttrs>
<search:partitionAttr>
<search:name>EQ_SOURCE_NAME</search:name>
</search:partitionAttr>
</search:partitionAttrs>
<search:partitionRules>
<search:partitionRule>
<search:partitionValue>Doc Library</search:partitionValue>
<search:valueType>ATTR</search:valueType>
<search:ruleType>VALUE</search:ruleType>
<search:storageArea>SA1</search:storageArea>
</search:partitionRule>
<search:partitionRule>
<search:partitionValue>My Web Site</search:partitionValue>
<search:valueType>ATTR</search:valueType>
<search:ruleType>VALUE</search:ruleType>
<search:storageArea>SA2</search:storageArea>
</search:partitionRule>
<search:partitionRule>
<search:partitionValue>EQ_OTHER</search:partitionValue>
<search:valueType>META</search:valueType>
<search:ruleType>VALUE</search:ruleType>
<search:storageArea>SA3</search:storageArea>
</search:partitionRule>
</search:partitionRules>
</search:partitionConfig>
</search:config>
The next example creates a partition rule of BUCKETING type with the bucket size of 10 for the two storage areas SA1 and SA2:
<search:config productVersion="11.2.2.2.0" xmlns:search="http://xmlns.oracle.com/search">
<search:partitionConfig>
<search:partitionRules>
<search:partitionRule>
<search:partitionValue>EQ_OWNER</search:partitionValue>
<search:valueType>META</search:valueType>
<search:ruleType>BUCKETING</search:ruleType>
<search:ruleSetting>10/SA1,SA2</search:ruleSetting>
<search:storageArea></search:storageArea>
</search:partitionRule>
</search:partitionRules>
</search:partitionConfig>
</search:config>
proxy
The proxy object defines the HTTP proxy server settings.
The <search:proxy> element describes the HTTP proxy server parameters:
<search:proxy> <search:server> <search:port> <search:proxyExceptions> <search:proxyException>
Element Descriptions
- <search:proxy>
-
Describes HTTP proxy server parameters. It contains these elements:
<search:server> <search:port> <search:proxyExceptions>
- <search:server>
-
URL of HTTP proxy server.
- <search:port>
-
Port number of HTTP proxy server.
- <search:proxyExceptions>
-
Contains one or more
<search:proxyException>elements. It contains a list of domain names that should not go through HTTP proxy server. - <search:proxyException>
-
A proxy exception, that is, a domain name that should not go through HTTP proxy server.
This XML document contains HTTP proxy server configuration:
<?xml version="1.0" encoding="UTF-8"?>
<search:config productVersion="11.2.2.2.0" xmlns:search="http://xmlns.oracle.com/search">
<search:proxy>
<search:server>www-proxy.us.xyz.com</search:server>
<search:port>80</search:port>
<search:proxyExceptions>
<search:proxyException>*.us.example.com</search:proxyException>
<search:proxyException>www.abc.com</search:proxyException>
</search:proxyExceptions>
</search:proxy>
</search:config>
proxyLogin
When performing a secure search on a federation endpoint, the federation broker must transmit the identity of the user to the federation endpoint. If the endpoint instance trusts the broker instance, then the broker instance can proxy as the end user. To establish this trust relationship, Oracle SES instances exchange a secret. This secret is exchanged in the form of a trusted entity.
A trusted entity consists of two values: an entity name and an entity password. Each Oracle SES instance can have one or more trusted entities that it can use to participate in secure federated search. A federated trusted entity is also referred to as a proxy user or a proxy log-in.
create createAll delete deleteAll deleteList export exportAll exportList getAllObjectKeys update updateAll
The <search:proxyLogins> element describes proxy log-ins:
<search:proxyLogins> <search:proxyLogin> <search:name> <search:password> <search:useIdentityPlugin>
Element Descriptions
- <search:proxyLogins>
-
Describes proxy log-ins. It contains one or more
<search:proxyLogin>elements. - <search:proxyLogin>
-
Describes a proxy log-in. It contains these elements:
<search:name> <search:password> <search:useIdentityPlugin>
- <search:name>
-
Name of the proxy. Required.
- <search:password>
-
Password for the proxy server. Required when
<search:useIdentityPlugin>isfalse.Attribute Value encryptedIndicates whether the value of <search:password>is encrypted. Set totrueif the password is encrypted, or set tofalseif it is plain text. - <search:useIdentityPlugin>
-
Controls use of an identity plug-in. Set to
trueto use the active identity plug-in for authentication, or set tofalseotherwise. Required.
This XML document describes two proxy log-ins:
<?xml version="1.0" encoding="UTF-8" ?>
<search:config productVersion="11.2.2.2.0" xmlns:search="http://xmlns.oracle.com/search">
<search:proxyLogins>
<search:proxyLogin>
<search:name>this_proxy</search:name>
<search:useIdentityPlugin>true</search:useIdentityPlugin>
</search:proxyLogin>
<search:proxyLogin>
<search:name>that_proxy</search:name>
<search:password encrypted="false">password</search:password>
<search:useIdentityPlugin>false</search:useIdentityPlugin>
</search:proxyLogin>
</search:proxyLogins>
</search:config>
queryConfig
Query configuration enables you to customize the search results and tune the search engine.
The <search:queryConfig> element sets the query configuration parameters:
<search:queryConfig> <search:maxNumResults> <search:lastCrawlDatesMergeRange> <search:searchTimeout> <search:enableWildcardQueries> <search:displayUrls> <search:tableDisplayUrl> <search:fileDisplayUrl> <search:mailingListDisplayUrl> <search:emailDisplayUrl> <<search:relevancyBoosting> <search:spellingCorrection> <search:useLanguageDictionary> <search:useIndexedDocsAndQueryLog> <search:hitCount> <search:countMethod> <search:maxExactHitCount> <search:queryStatistics> <search:loggingPeriod> <search:urlSubmission> <search:sourceName> <search:checkUrlBoundaryRules> <search:federation> <search:timeout> <search:minNumThreads> <search:maxNumThreads> <search:queryTimeAuthorization> <search:timeout> <search:minNumThreads> <search:maxNumThreads> <search:logFilteredDocs> <search:secureSearch> <search:loginRequirement> <search:securityFilterLifespan> <search:securityFilterRefreshWaitTimeout> <search:authenticationTimeout> <search:authorizationTimeout> <search:minNumThreads> <search:maxNumThreads> <search:preserveStaleSecurityFilterOnError>
Element Descriptions
- <search:queryConfig>
-
Describes query configuration parameters. It contains these elements:
<search:maxNumResults> <search:displayUrls> <search:relevancyBoosting> <search:spellingCorrection> <search:hitCount> <search:queryStatistics> <search:urlSubmission> <search:federation> <search:queryTimeauthorization> <search:secureSearch>
- <search:maxNumResults>
-
Maximum number of search results returned by a query.
- <search:lastCrawlDatesMergeRange>
-
Threshold for merging last crawl dates from different data sources. The default value is 86,400,000.
- <search:searchTimeout>
-
Number of milliseconds allowed for processing each parallel query phase. The default value is 1,200,000.
- <search:enableWildcardQueries>
-
Controls whether question marks (?) and asterisks (*) in queries are used as wildcards or literal characters for matching documents.
Attribute Value enabledSet to trueto enable wildcards, or set tofalseotherwise. Default isfalse. Required. - <search:displayUrls>
-
Describes the display URLs. It contains these elements:
<search:tableDisplayUrl> <search:fileDisplayUrl> <search:mailingListDisplayUrl> <search:emailDisplayUrl>
- <search:tableDisplayUrl>
-
URL used to display the retrieved data for a table source.
- <search:fileDisplayUrl>
-
URL used to display the retrieved data for a file source.
- <search:mailingListDisplayUrl>
-
URL used to display the retrieved data for a mailing list source.
- <search:emailDisplayUrl>
-
URL used to display the retrieved data for an e-mail source.
- <search:relevancyBoosting>
-
Attribute Value enabledSet to trueto enable relevancy boosting, or set tofalseotherwise. Required. - <search:spellingCorrection>
-
Controls spelling correction. When enabled, this element contains these child elements:
<search:useLanguageDictionary> <search:useIndexedDocsAndQueryLog>
Attribute Value enabledSet to trueto enable spelling correction, or set tofalseotherwise. Required. - <search:useLanguageDictionary>
-
Controls use of an English dictionary for spelling suggestions. Set to
trueto use an English dictionary, or set tofalseto derive spelling suggestions only from terms in indexed documents and the query log. Considerfalseif users typically search for non-English terms. - <search:useIndexedDocsAndQueryLog>
-
Contains a value of
trueorfalseto control use of terms from indexed documents and the query log for spelling suggestions. Terms that occur frequently are extracted to the Oracle SES dictionary. Set totrueto use terms from these sources, or set tofalseto use only the English dictionary for suggestions. Considerfalseif suggestions from crawled documents to all search users may breach security. - <search:hitCount>
-
Contains a
<search:countMethod>element. - <search:countMethod>
-
-
APPROX_COUNT: Displays an estimated number of matching documents. This method supports better performance thanEXACT_COUNT. (Default) -
EXACT_COUNT: Displays the exact number of matching documents. -
EXACT_COUNT_QTA: Displays the exact number of matching documents adjusted for query-time filtering.
-
- <search:maxExactHitCount>
-
The maximum number of exact results. An estimated number is returned for a higher number of results.
- <search:queryStatistics>
-
Controls the collection of search statistics. SEt to
trueto collect statistics, or set tofalseotherwise. This operation degrades search performance, so you should disable it during peak hours.Attribute Value enabledSet to trueto enable collection or set tofalseotherwise. Required. - <search:loggingPeriod>
-
Number of days the data is saved. Statistics are compiled for this number of days.
- <search:urlSubmission>
-
Controls the submission of URLs. When enabled, this element contains these child elements:
<search:sourceName> <search:checkUrlBoundaryRules>
Attribute Value enabledSet to trueto enable URL submission, or set tofalseotherwise. Required. - <search:sourceName>
-
A Web source to which user-suggested URLs are added.
- <search:checkUrlBoundaryRules>
-
Controls the enforcement of boundary rules for URLs submitted by users. Set to
trueto accept only URLs that match the rules, or set tofalseto ignore the boundary rules. - <search:federation>
-
Describes the querying parameters of federated sources. It contains these child elements:
<search:timeout> <search:minNumThreads> <search:maxNumThreads>
- <search:timeout>
-
Contains the number of milliseconds for search results to be returned.
- <search:minNumThreads>
-
Contains the minimum number of processes to use for searching when demand is low.
- <search:maxNumThreads>
-
Contains the maximum number of processes to use for searching when demand is high.
- <search:queryTimeAuthorization>
-
Describes authorization. It contains these optional child elements:
<search:timeout> <search:minNumThreads> <search:maxNumThreads> <search:logFilteredDocs>
- <search:logFilteredDocs>
-
Controls document logging. Set to
trueto record all filtered documents in the query application log file, or set tofalseotherwiseQuery-time filtering errors are always logged.
- <search:secureSearch>
-
Describes secure search. It contains these child elements:
<search:loginRequirement> <search:securityFilterLifespan> <search:securityFilterRefreshWaitTimeout> <search:authenticationTimeout> <search:authorizationTimeout> <search:minNumThreads> <search:maxNumThreads> <search:preserveStaleSecurityFilterOnError>
- <search:loginRequirement>
-
A log-in method:
-
ALL_CONTENT: Users must log in to view any content, whether public or secure. -
SECURE_CONTENT: Users must log in to view secure content.
-
- <search:securityFilterLifespan>
-
Number of minutes a stored security filter is retained. Set to a value between
0(no cache) and526500(one-year cache retention). - <search:securityFilterRefreshWaitTimeout>
-
Number of milliseconds to block a query for a security filter refresh before returning no results or using an expired security filter, depending on the value of <search:preserveStaleSecurityFilterOnError>. The default value is 1000 ms.
- <search:authenticationTimeout>
-
Number of milliseconds for authentication.
- <search:authorizationTimeout>
-
Number of milliseconds for authorization.
- <search:minNumThreads>
-
Contains the minimum number of processes to use for searching when demand is low.
- <search:maxNumThreads>
-
Contains the maximum number of processes to use for searching when demand is high.
- <search:preserveStaleSecurityFilterOnError>
-
Controls the response to queries when an expired security filter is being refreshed. Set to
trueto use the expired security filter, or set tofalseto return no results. The default value isfalse.When the security filter is expired, Oracle SES triggers a security filter refresh. During the refresh, if there is any error from any data source, then the user's existing security filter is preserved or overwritten, depending on this setting.
This XML document describes the query parameters:
<?xml version="1.0" encoding="UTF-8"?>
<search:config xmlns:search="http://xmlns.oracle.com/search" productVersion="11.2.2.2.0">
<search:queryConfig>
<search:maxNumResults>200</search:maxNumResults>
<search:lastCrawlDatesMergeRange>8640000</search:lastCrawlDatesMergeRange>
<search:searchTimeout>120000</search:searchTimeout>
<search:enableWildcardQueries enabled="false"/>
<search:displayUrls>
<search:tableDisplayUrl>
/search/query/display.jsp?type=table</search:tableDisplayUrl>
<search:fileDisplayUrl>
/search/query/display.jsp?type=file</search:fileDisplayUrl>
<search:mailingListDisplayUrl>
/search/query/mail.jsp</search:mailingListDisplayUrl>
<search:emailDisplayUrl>
/search/query/pmail.jsp</search:emailDisplayUrl>
</search:displayUrls>
<search:relevancyBoosting enabled="true"/>
<search:spellingCorrection enabled="false"/>
<search:hitCount>
<search:countMethod>APPROX_COUNT</search:countMethod>
</search:hitCount>
<search:queryStatistics enabled="true">
<search:loggingPeriod>7</search:loggingPeriod>
</search:queryStatistics>
<search:urlSubmission enabled="false"/>
<search:federation>
<search:timeout>30000</search:timeout>
<search:minNumThreads>5</search:minNumThreads>
<search:maxNumThreads>20</search:maxNumThreads>
</search:federation>
<search:queryTimeAuthorization>
<search:timeout>30000</search:timeout>
<search:minNumThreads>5</search:minNumThreads>
<search:maxNumThreads>20</search:maxNumThreads>
<search:logFilteredDocs>false</search:logFilteredDocs>
</search:queryTimeAuthorization>
<search:secureSearch>
<search:loginRequirement>SECURE_CONTENT</search:loginRequirement>
<search:securityFilterLifespan>60</search:securityFilterLifespan>
<search:authenticationTimeout>10000</search:authenticationTimeout>
<search:authorizationTimeout>10000</search:authorizationTimeout>
<search:minNumThreads>5</search:minNumThreads>
<search:maxNumThreads>20</search:maxNumThreads>
<search:securityFilterRefreshWaitTimeout>
1000</search:securityFilterRefreshWaitTimeout>
<search:preserveStaleSecurityFilterOnError>
false</search:preserveStaleSecurityFilterOnError>
</search:secureSearch>
</search:queryConfig>
</search:config>
queryUIConfig
Query UI configuration enables you to customize the search results.
The <search:queryUIConfig> element sets the query UI configuration parameters:
<search:queryUIConfig> <search:convertTimezone> <search:convertTimeZoneAttrs> <search:convertTimeZoneAttr> <search:defaultTopNDocuments> <search:maxTopNDocuments> <search:similarDocumentHandling> <search:resultsInNewWindow> <search:numVisibleGroupTabs> <search:groupTabOrder> <search:groupTabName> <search:displayQueryExpansionMessage> <search:fetchBrowseSourceGroupsOnPageload> <search:displayQuerySplashPage> <search:defaultSourceGroupName> <search:suppressedSourceGroupList> <search:suppressedSourceGroupName> <search:displayErrorPageOnInvalidSourceGroup> <search:showSidebarForFreshUser> <search:autoLoadTopNResults> <search:cacheLogoImage> <search:cacheLogoImagePath> <search:displayAutoSuggestions> <search:minCharBeforeAutoSuggestion> <search:absoluteSorting> <search:sortableAttrs> <search:sortableAttr>
Element Descriptions
- <search:queryUIConfig>
-
Describes query UI configuration parameters. It contains these elements:
<search:convertTimezone> <search:defaultTopNDocuments> <search:maxTopNDocuments> <search:similarDocumentHandling> <search:resultsInNewWindow> <search:numVisibleGroupTabs> <search:groupTabOrder> <search:displayQueryExpansionMessage> <search:fetchBrowseSourceGroupsOnPageload> <search:displayQuerySplashPage> <search:defaultSourceGroupName> <search:suppressedSourceGroupList> <search:displayErrorPageOnInvalidSourceGroup> <search:showSidebarForFreshUser> <search:autoLoadTopNResults> <search:cacheLogoImage> <search:displayAutoSuggestions> <search:minCharBeforeAutoSuggestion> <search:absoluteSorting>
- <search:convertTimezone>
-
Controls whether the date values in query application should be converted to the user's time zone.
Attribute Value enabledSet to trueto convert the date values in query application to the user's time zone, or set tofalseotherwise. Required.Contains the element
<search:convertTimeZoneAttrs>. - <search:convertTimeZoneAttrs>
-
Identifies date attributes that appear in the search results, that need to be converted to user's time zone. It contains one or more
<search:convertTimeZoneAttr>elements. - <search:convertTimeZoneAttr>
-
Identifies a date attribute to be converted to user's time zone.
- <search:defaultTopNDocuments>
-
Controls the number of documents to retrieve by default as part of the top N search results.
- <search:maxTopNDocuments>
-
Controls the maximum number of documents to retrieve by default as part of the top N search results.
- <search:similarDocumentHandling>
-
Controls how similar documents should be handled. The available options are:
-
detect: Detect and display similar documents under the Similar Documents link in a search result page. -
remove: Detect and remove similar documents from a search result page. -
disabled: Do not detect similar documents, that is, similar documents will be displayed in a search result page along with all the other documents.
-
- <search:resultsInNewWindow>
-
Controls whether clicking the search result link should display search results in a new window, or in the same window.
Attribute Value enabledSet to trueto display search results in a new window, or set tofalseto display search results in the same window. Required.Note:
This setting has no effect if XSLT is used for rendering search results. - <search:numVisibleGroupTabs>
-
Controls the number of source group tabs to display above the query box. If the number of source groups are more than this value, then you can click the more >> link to view the remaining source group tabs.
- <search:groupTabOrder>
-
Controls the ordering of source group tabs that are displayed above the query box. It contains one or more
<search:groupTabName>elements. - <search:groupTabName>
-
Source group tab name to display above the query box.
- <search:displayQueryExpansionMessage>
-
Controls whether to display alternate keywords message in the query application.
Attribute Value enabledSet to trueto display alternate keywords message, or set tofalseotherwise. Required. - <search:fetchBrowseSourceGroupsOnPageload>
-
Controls whether to fetch the source group list each time the Browse popup window is displayed, otherwise the source group list is fetched only once when the Browse popup window is displayed for the first time, and for the subsequent display of the Browse popup window the cached source group list is displayed.
Attribute Value enabledSet to trueto fetch the source group list each time the Browse popup window is displayed, or set tofalseotherwise. Required. - <search:displayQuerySplashPage>
-
Controls whether to display the splash page in the query application when the query application is started.
Attribute Value enabledSet to trueto display the splash page in the query application when the query application is started, or set tofalseotherwise. Required. - <search:defaultSourceGroupName>
-
Default source group to display on the query page. Select All (System) to display All source group (that is, source group containing all the sources) by default on the query page.
- <search:suppressedSourceGroupList>
-
List of source groups that should not be displayed in the query application.
Contains the element
<search:suppressedSourceGroupName>. - <search:suppressedSourceGroupName>
-
Source group name that should not be displayed in the query application.
- <search:displayErrorPageOnInvalidSourceGroup>
-
Controls whether to display an error page if an invalid source group name is specified in the query URL parameters.
Attribute Value enabledSet to trueto display an error page, if an invalid source group is specified in the query URL parameters. If set tofalse, the invalid source group is ignored, and the query uses the default source group, if no other valid source groups are specified. Required. - <search:showSidebarForFreshUser>
-
Controls whether to display sidebar on the query results page, when the query search is used for the first time (that is, when the cookie is not available).
Attribute Value enabledSet to trueto display sidebar on the query results page, when the query search is used for the first time (that is, when the cookie is not available), or set tofalseotherwise. Required. - <search:autoLoadTopNResults>
-
Controls whether to automatically load the top-N results on the search results page.
Attribute Value enabledSet to trueto automatically load the top-N results on the search results page. If set tofalse, a button is displayed on the search page, which you can click to load the top-N results. Default isfalse. Required. - <search:cacheLogoImage>
-
Controls whether to display the cached page logo image.
Attribute Value enabledSet to trueto display the cached page logo image, or set tofalseotherwise. Required.Contains the element
<search:cacheLogoImagePath>. - <search:cacheLogoImagePath>
-
Path of the cached page logo image.
- <search:displayAutoSuggestions>
-
Controls whether to display auto suggestions.
Attribute Value enabledSet to trueto display auto suggestions in the query application, or set tofalseotherwise. Required. - <search:minCharBeforeAutoSuggestion>
-
The minimum number of characters a user has to enter into the search box so as to display auto suggestion keywords.
See Also:
autoSuggestion object. - <search:absoluteSorting>
-
Defines sortable search attributes to show in the Sort by list in the query application. Contains the element
<search:sortableAttrs>. - <search:sortableAttrs>
-
Contains one or more
<search:sortableAttr>elements. - <search:sortableAttr>
-
Sortable search attribute to show in the Sort by list in the query application.
Note:
When the sortable search attributes are provided, the first attribute fromsortConditionselement specified inrelevanceRankingobject (at the global level) ordefaultSortConditionselement specified inqueryUISourceGroupsobject (at the source group level), will be added, along withRelevance, to the Sort by list in the query application.
This XML document defines the query UI configuration:
<?xml version="1.0" encoding="UTF-8"?>
<search:config productVersion="11.2.2.2.0" xmlns:search="http://xmlns.oracle.com/search">
<search:queryUIConfig>
<search:convertTimezone enabled="false"/>
<search:defaultTopNDocuments>100</search:defaultTopNDocuments>
<search:maxTopNDocuments>300</search:maxTopNDocuments>
<search:similarDocHandling>detect</search:similarDocHandling>
<search:resultsInNewWindow>true</search:resultsInNewWindow>
<search:numVisibleGroupTabs>5</search:numVisibleGroupTabs>
<search:groupTabOrder/>
<search:displayQueryExpansionMessage>true</search:displayQueryExpansionMessage>
<search:useMultipleAlternateKeywords>false</search:useMultipleAlternateKeywords>
<search:fetchBrowseSourceGroupsOnPageload>false</search:fetchBrowseSourceGroupsOnPageload>
<search:displayQuerySplashPage>false</search:displayQuerySplashPage>
<search:absoluteSorting>
<search:sortableAttrs>
<search:sortableAttr>price</search:sortableAttr>
<search:sortableAttr>author</search:sortableAttr>
</search:sortableAttrs>
</search:absoluteSorting>
</search:queryUIConfig>
</search:config>
queryUIFacets
Facets are used to refine the search results. The queryUIFacets object contains the configuration settings for controlling the display properties of facets in the query application.
The <search:queryUIFacets> element describes facets display configurations:
<search:queryUIFacets> <search:numVisibleFacets> <search:facetTrees> <search:facetTree>
Element Descriptions
- <search:queryUIFacets>
-
Contains one or more
<search:facetTrees>elements.Attribute Value enabledSet to trueto enable facets, or set tofalseotherwise. Required. - <search:numVisibleFacets>
-
Number of facets to display on the query application screen.
- <search:facetTrees>
-
Contains one or more
<search:facetTree>elements. - <search:facetTree>
-
Controls the following display properties of a facet:
Attribute Value nameName of the facet. enabledSet to trueto enable, that is, to display this facet, or set tofalseotherwise.sortByControls the sorting order of documents matching this facet. The following are the available sorting criteria: -
COUNT_DESCENDING -
COUNT_ASCENDING -
ALPHA_DESCENDING(for String type facet only) -
ALPHA_ASCENDING(for String type facet only) -
TREE_STRUCTURE(for Number or Date type facet only)
minDocPerNodeThe minimum number of documents that should contain the match for a facet node of this facet. If the documents matching a facet nodes are less than minDocPerNodevalue, then that facet node is not displayed in the query application.numOfVisibleValuesNumber of facet nodes to display for the facet in the query application. If the number of facet nodes returned for a search result are more than this value, then you need to click the More ... link to see the next set of facet nodes in the facet panel. The number of additional facet nodes to display by clicking the More ... link is controlled by the value provided in this attribute. For example, if numOfVisibleValuesis set to 5, then each time More ... link is clicked, the additional five facet nodes are displayed. -
This XML document configures display propertied of facets:
<?xml version="1.0" encoding="UTF-8"?>
<search:config productVersion="11.2.2.2.0" xmlns:search="http://xmlns.oracle.com/search">
<search:queryUIFacets enabled="true">
<search:numVisible>4</search:numVisible>
<search:facetTrees>
<search:facetTree name="Author" enabled="true"
sortBy="COUNT_DESCENDING" numOfVisibleValues="5"
minDocPerNode="1"/>
<search:facetTree name="LastModified" enabled="false"
sortBy="TREE_STRUCTURE" numOfVisibleValues="10"
minDocPerNode="1"/>
</search:facetTrees>
</search:facetUIConfig>
</search:config>
queryUISourceGroups
This object contains the source group related configuration settings, such as, facets, cluster trees, top-N sortable attributes, top-N groupable attributes, and sortable attributes for absolute sort.
The <search:queryUISourceGroups> element describes source group specific configuration settings, such as, facets, cluster trees, top-N sortable attributes, top-N groupable attributes, and sortable attributes for absolute sorting:
<search:queryUISourceGroups> <search:sourceGroups> <search:sourceGroup> <search:facetTrees> <search:facetTree> <search:all> <search:none> <search:clusterTrees> <search:clusterTree> <search:all> <search:none> <search:topNSortableAttrs> <search:topNSortableAttr> <search:defaults> <search:none> <search:topNGroupableAttrs> <search:topNGroupableAttr> <search:defaults> <search:none> <search:absoluteSorting> <search:defaultSortConditions> <search:sortCondition> <search:sortableAttrs> <search:sortableAttr>
Element Descriptions
- <search:queryUISourceGroups>
-
Contains one or more
<search:sourceGroups>elements. - <search:sourceGroups>
-
Collection of source groups. Contains one or more
<search:sourceGroup>elements. - <search:sourceGroup>
-
A source group specific configurations. Contains one or more
<search:facetTrees>elements. - <search:facetTrees>
-
Facets related to the source group. Contains
<search:all>or<search:none>or one or more<search:facetTree>elements. - <search:facetTree>
-
Facet to display for the source group.
- <search:all>
-
Indicates that all the facets must be displayed for the source group in the query application.
- <search:none>
-
Indicates that no facets should be displayed for the source group in the query application.
- <search:clusterTrees>
-
Cluster trees to display in the query application for the source group. Contains
<search:all>or<search:none>or one or more<search:clusterTree>elements. - <search:clusterTree>
-
Name of the cluster tree to display for the source group in the query application.
- <search:all>
-
Indicates that all the cluster trees must be displayed for the source group in the query application.
- <search:none>
-
Indicates that no cluster trees should be displayed for the source group in the query application.
- <search:topNSortableAttrs>
-
Contains one or more
<search:topNSortableAttr>elements. - <search:topNSortableAttr>
-
Attribute to show in the Sort by list in the query application for the source group.
- <search:defaults>
-
Indicates that all the default attributes should be displayed in the Sort by list in the query application for the source group. The default top-n sortable attributes are:
-
Author
-
File Format
-
Title
-
Relevance
-
Path
-
Language
-
Date
-
- <search:none>
-
Indicates that no attributes should be displayed in the Sort by list in the query application for the source group.
Note:
The system attribute Relevance will still be shown in the Sort by list. - <search:topNGroupableAttrs>
-
Contains one or more
<search:topNGroupableAttr>elements. - <search:topNGroupableAttr>
-
Attribute to show in the Group by list in the query application for the source group.
- <search:defaults>
-
Indicates that all the default attributes should be displayed in the Group by list in the query application for the source group. The default top-n groupable attributes are:
-
(none)
-
Author
-
File Format
-
Source
-
Date
-
- <search:none>
-
Indicates that no attributes should be displayed in the Group by list in the query application for the source group.
Note:
The system attributes (none) and Source will still be shown in the Group by list. - <search:absoluteSorting>
-
Contains
<search:defaultSortConditions>and<search:sortableAttrs>elements. - <search:defaultSortConditions>
-
Defines the default sort conditions for the query application. Contains one or more
<search:sortCondition>elements. - <search:sortCondition>
-
Defines a default sort condition.
Attribute Value nameName of the sortable attribute. orderSort order of the specified attribute. The available options are ascendinganddescending. Default isascending.typeSortable attribute type. For sortable search attribute, specify ATTRIBUTE, and for sortable system attribute, specifySYSTEM. Default isATTRIBUTE. - <search:sortableAttrs>
-
Defines the sortable search attributes to display in the Sort by list in the query application. Contains one or more
<search:sortableAttr>elements. - <search:sortableAttr>
-
Sortable attribute to display in the Sort by list in the query application.
Attribute Value nameName of the sortable attribute. Note:
When the sortable search attributes are provided, the first attribute fromdefaultSortConditionselement specified inqueryUISourceGorupsobject (at the source group level) orsortConditionselement specified inrelevanceRankingobject (at the global level), will be added, along withRelevance, to the Sort by list in the query application.
This XML document defines the source group sourceGroup1:
<?xml version="1.0" encoding="UTF-8"?>
<search:config productVersion="11.2.2.2.0" xmlns:search="http://xmlns.oracle.com/search">
</search:queryUISourceGroups>
<search:sourceGroup name="sourceGroup1">
<search:facetTrees>
<search:facetTree name="Tree 1"/>
<search:facetTree name="Tree 2"/>
<search:facetTree name="Tree 3"/>
</search:facetTrees>
<search:clusterTrees>
<search:all/>
</search:clusterTrees>
<search:topNSortableAttrs>
<search:topNSortableAttr name="sort attribute 1"/>
<search:topNSortableAttr name="sort attribute 2"/>
</search:topNSortableAttrs>
<search:topNGroupableAttrs>
<search:topNGroupableAttr name="group attribute 1"/>
</search:topNGroupableAttrs>
<search:absoluteSorting>
<search:defaultSortConditions>
<search:sortCondition name="price" order="ascending"/>
<search:sortCondition name="LastModifiedDate" order="descending"/>
</search:defaultSortConditions>
<search:sortableAttrs>
<search:sortableAttr name="price"/>
<search:sortableAttr name="author"/>
</search:sortableAttrs>
</search:absoluteSorting>
</search:sourceGroup>
</search:queryUISourceGroups>
</search:config>
relevanceRanking
Relevance ranking controls the importance given to various document attributes when ordering the search results. By customizing the ranking rules, you can produce more relevant search results for your enterprise.
In Oracle SES 11.1.2.2 and earlier releases, these parameters were stored in a file named ranking.xml.
Search - Forced Ranking
Search - Inline Result Grouping
Search - Ranking Factor
The <search:relevanceRanking> element describes the relevance ranking of search attributes:
<search:relevanceRanking> <search:defaultFactors> <search:defaultFactor> <search:name> <search:weight> <search:customFactors> <search:customFactor> <search:attributeName> <search:attributeType> <search:factorType> <search:queryFactor> <search:weight> <search:staticFactor> <search:matches> <search:match> <search:value> <search:weight> <search:docScoreFactors> <search:docScoreFactor> <search:attributeName> <search:weight> <search:sortConditions> <search:sortCondition> <search:queryModels> <search:macros> <search:macro> <search:queryModel> <search:triggers> <search:trigger> <search:includeQueries> <search:includeQuery> <search:includeUrls> <search:includeUrl> <search:resultGroupings> <search:maxResultGroupsReturned> <search:positions> <search:position> <search:resultGroupingList> <search:resultGrouping> <search:name> <search:key> <search:value> <search:teasers>
Element Descriptions
- <search:relevanceRanking>
-
Contains these elements:
<search:defaultFactors> <search:customFactors> <search:docScoreFactors> <search:sortConditions> <search:queryModels> <search:resultGroupings>
- <search:defaultFactors>
-
Sets the weights for the default attributes used for ranking. It contains one or more
<search:defaultFactor>elements.Attribute Value enabledSet to trueto enable default factors (default), or set tofalseotherwise. Required. - <search:defaultFactor>
-
Identifies a default search attribute and its weight. It contains these elements:
<search:name> <search:weight>
The following table lists the default attributes and weights:
Attribute Weight TitleHighDescriptionMediumReftextHighKeywordsMediumSubjectLowAuthorMediumH1headlineLowH2headlineVery lowUrlLowUrldepthHighLanguageMatchHighLinkscoreHigh - <search:name>
-
Name of the attribute, such as
TitleorDescription. - <search:weight>
-
Contains the weight assigned to an attribute:
very high,high,medium,low,very low, andnone. If the weight is not specified, the default weight for the attribute is used. - <search:customFactors>
-
Adds other attributes for ranking. It contains one or more
<search:customFactor>elements. - <search:customFactor>
-
Describes an attribute used for ranking. Any indexed search attribute can be a custom ranking attribute. This element contains these child elements:
<search:attributeName> <search:attributeType> <search:factorType>
- <search:attributeName>
-
The exact name of a search attribute defined in Oracle SES. This name is case-insensitive.
- <search:attributeType>
-
The data type of the attribute. Only
Stringis supported. - <search:factorType>
-
Identifies the type of ranking. It contains one of these elements:
<search:queryFactor> <search:staticFactor>
- <search:queryFactor>
-
Matches the attribute value against query terms. For example, if a custom attribute has the value "Terry Francona," then a query for "Terry Francona" is given the relevancy ranking of the attribute.
This element contains a
<search:weight>element. - <search:weight>
-
Contains the weight assigned to an attribute:
very high,high,medium,low,very low, andnone. If the weight is not specified, the default weight for the attribute is used. - <search:staticFactor>
-
Matches the attribute value against an attribute of the documents. For example, assume a company identifies its documents as good or poor and defines a custom search attribute for quality. If a custom attribute for quality ranks good documents
very highand poor documentslow, then a good document appears higher than a poor document in the list of search results.This element contains a
<search:matches>element. - <search:matches>
-
Contains one or more
<search:match>elements. - <search:match>
-
Identifies a matching search attribute and value. It contains these elements:
<search:value> <search:weight>
- <search:value>
-
The value of the search attribute specified in
<search:name>being given a weight. - <search:weight>
-
Contains the weight assigned to an attribute:
very high,high,medium,low,very low, andnone. If the weight is not specified, the default weight for the attribute is used. - <search:docScoreFactors>
-
Sets the weights for the document score attributes used for ranking. It contains one or more
<search:docScoreFactor>elements. - <search:docScoreFactor>
-
Describes a document score factor. It contains these elements:
<search:attributeName> <search:weight>
- <search:attributeName>
-
Name of the document score attribute.
- <search:weight>
-
Weight of the document score attribute. This is a float value.
- <search:sortConditions>
-
Defines the default sort criteria for the query application. Contains one or more
<search:sortCondition>elements. - <search:sortCondition>
-
This can be either a sortable search attribute name or a system defined sortable attribute name, such as,
RELEVANCEandABSOLUTE_DATE. It can have a sort order of either ascending or descending. This sort condition is used as a default sort criteria for ordering the search results.Attribute Value orderSort order of the specified attribute. The available options are ascendinganddescending. Default isascending.typeSortable attribute type. For sortable search attribute, specify ATTRIBUTE, and for sortable system attribute, specifySYSTEM. Default isATTRIBUTE. - <search:queryModels>
-
Contains these elements:
<search:macros> <search:queryModel>
- <search:macros>
-
Contains one or more
<search:macro>elements. - <search:macro>
-
Defines a macro. It contains the following attributes.
Attribute Value defineDefinition of a macro. A macro has the syntax of macro_name(parameter1, parameter2, ..., parameterN). Macro parameters must be specified using a single letter. Parameters can be referenced in the macro definition by prefixing them with a % sign. Macros can be used in both triggers and query expressions.The following macros are provided by Oracle SES by default.
Macro Purpose <macro define='prefix(P)'> ^%P </macro>Prefix match (used for triggers) <macro define='suffix(S)'> %S$ </macro>Suffix match (used for triggers) <macro define='exact(E)'> ^%E$ </macro>Exact match (used for triggers) - <search:queryModel>
-
Defines a query model. It contains these elements:
<search:triggers> <search:includeQueries> <search:includeUrls>
It contains the following attributes.
Attribute Value nameName of the query model. inheritName of the inherited query model (optional). Query models support single inheritance. The most common usage of this is to support default models for common query-independent filter expressions. Example of query model inheritance:
<!-- Parent query model --> <queryModel name="default"> <includeQueries> <includeQuery>mimetype:=text/html or mimetype:=application/pdf or mimetype:=text/plain</includeQuery> </includeQueries> </queryModel> <!-- Child query model --> <queryModel name='whitepaper' inherit='default'> <triggers> <trigger>((\w+\s+)+)whitepapers?</trigger> <trigger>((\w+\s+)+)white\s+papers?</trigger> </triggers> <includeQueries> <includeQuery>TAG:$1 and TAG:"white papers"</includeQuery> </includeQueries> </queryModel>Here, "whitepaper" query model inherits "default" query model. The parent model (default) is connected with the child model (whitepaper) using AND operator. This has the effect of limiting the whitepaper query model hits to mime-types of html, pdf, and plain text. A parent query model cannot contain any triggers; it must contain only query-independent filter expressions.
- <search:triggers>
-
Contains one or more
<search:trigger>elements. - <search:trigger>
-
Defines a trigger to be issued on a user query string. It should contain a regular expression confirming to POSIX standard. For example, use
<trigger>oracle.*</trigger>for matching all the query terms starting with the word "oracle". - <search:includeQueries>
-
Contains one or more
<search:includeQuery>elements that define a set of query expressions to use to generate and score the top-ranking hits. - <search:includeQuery>
-
Defines a query expression to generate and score the top-ranking hits. For example:
<queryModel name='titles'> <triggers> <trigger>Title:(.*)</trigger> </triggers> <includeQueries> <includeQuery>Title:"$1" and Host:"oracle.com"</includeQuery> </includeQueries> </queryModel>Here, whenever an attribute search is done for a
Title, the top results will be shown only from the documents present on the hostoracle.com.When one or more query expressions are specified, the order of defining the query expressions correspond to their weights, that is, a query expression defined first has a higher rank as compared to query expressions defined subsequently. The query expressions are evaluted together using OR operation. A query expression should be an attribute only query. For example,
<queryModel name='gym'> <triggers> <trigger>gym</trigger> </triggers> <includeQueries> <includeQuery>TAG:"gym" AND TAG:"landing page"</includeQuery> <includeQuery>TAG:"gym" AND TAG:"news"</includeQuery> </includeQueries> </queryModel>Here, the query model assumes that someone had tagged the gym landing page as well as news about the gym. It ranks the gym landing page first followed by news pages by creating the following Oracle Text query:
(( (MDATA(TAG,gym)) AND (MDATA(TAG,landing page)) )*1.0)| (( (MDATA(TAG,gym)) AND (MDATA(TAG,news)) )*0.99)
- <search:includeUrls>
-
Contains one or more
<search:includeUrl>elements that define a set of URLs to be shown on top of search results in the order of their definition. - <search:includeUrl>
-
URL to be shown on top of search results in the order of its definition.
- <search:resultGroupings>
-
Describes result grouping configuration. It contains these elements:
<search:maxResultGroupsReturned> <search:positions> <search:resultGroupingList>
- <search:maxResultGroupsReturned>
-
Maximum number of result groupings to show in search results.
- <search:positions>
-
Contains one or more
<search:position>elements that define the position of result groupings to display in search results. - <search:position>
-
Postion of a result grouping to show in search results.
- <search:resultGroupingList>
-
Contains one or more
<search:resultGrouping>elements that define a list of result groupings configuration. - <search:resultGrouping>
-
Defines a result grouping configuration. It contains these elements:
<search:name> <search:key> <search:value> <search:teasers>
- <search:name>
-
Name of result grouping.
- <search:key>
-
Type of result grouping. It can be either "Source Group" or "URL".
- <search:value>
-
Value of the result grouping name, that is, either the source group name or the URL. This is optional.
- <search:teasers>
-
Number of teaser links to show within the result grouping. If the number of teasers is set to 0, then the result grouping will not be shown in search results.
This XML document describes relevance ranking configuration:
<?xml version="1.0" encoding="UTF-8"?>
<search:config productVersion="11.2.2.2.0" xmlns:search="http://xmlns.oracle.com/search">
<search:relevanceRanking>
<!-- defaultFactors -->
<search:defaultFactors enabled="true">
<search:defaultFactor>
<search:name>TITLE</search:name>
<search:weight>MEDIUM</search:weight>
</search:defaultFactor>
</search:defaultFactors>
<!-- sortConditions -->
<search:sortConditions>
<search:sortCondition order="ascending" type="attribute">Attribute_1</search:sortCondition>
<search:sortCondition order="descending" type="system">RELEVANCE</search:sortCondition>
</search:sortConditions>
<!-- resultGroupings -->
<search:resultGroupings>
<search:maxResultGroupsReturned>10</search:maxResultGroupsReturned>
<search:positions>
<search:position>2</search:position>
<search:position>3</search:position>
<search:position>7</search:position>
</search:positions>
<search:resultGroupingList>
<search:resultGrouping>
<search:name>oracle</search:name>
<search:key>url</search:key>
<search:value>http://www.oracle.com</search:value>
<search:teasers>2</search:teasers>
</search:resultGrouping>
</search:resultGroupingList>
</search:resultGroupings>
<!-- queryModels -->
<search:queryModels>
<search:queryModel name="default">
<search:includeQueries>
<search:includeQuery>mimetype:=text/html or mimetype:=application/pdf or mimetype:=text/plain</search:includeQuery>
</search:includeQueries>
</search:queryModel>
<search:queryModel name="ses" inherit="default">
<search:triggers>
<search:trigger>@EXACT(secure enterprise search)</search:trigger>
<search:trigger>@EXACT(ses)</search:trigger>
<search:trigger>@EXACT(secure search)</search:trigger>
</search:triggers>
<search:includeQueries>
<!-- show landing pages first by tag -->
<search:includeQuery>TAG:"secure enterprise search" AND TAG:"landing page"</search:includeQuery>
<!-- show downloads by tag -->
<search:includeQuery>TAG:"secure enterprise search" AND TAG:"downloads"</search:includeQuery>
</search:includeQueries>
</search:queryModel>
</search:queryModels>
</search:relevanceRanking>
</search:config>
resultList
The result list settings enable you to select the attributes included in the search results and customize the look-and-feel of the Oracle SES Search Application.
The <search:resultList> element describes the search results lists:
<search:resultList> <search:renderingAttrs> <search:renderingAttr> <search:name> <search:xsltContent> <search:cssContent>
Element Descriptions
- <search:resultList>
-
Contains these elements:
<search:renderingAttrs> <search:xsltContent> <search:cssContent>
- <search:renderingAttrs>
-
Identifies attributes that appear in the search results, including local search attributes, federated search attributes, and Oracle SES internal attributes. It contains one or more
<search:renderingAttr>elements. - <search:renderingAttr>
-
Identifies an attribute. It contains a
<search:name>element. - <search:name>
-
Contains the name of an attribute. Required.
- <search:xsltContent>
-
Contains the content of an XSLT style sheet in XML-escaped format or wrapped in a CDATA element. The XSLT operates on the attributes by transforming the XML content into an HTML fragment for display in the result list. To return HTML, include this in the XSLT:
<xsl:output method="html" />If the XSLT is blank, then the search results are displayed as untransformed XML.
- <search:cssContent>
-
Content of a cascading style sheet (CSS) wrapped in a CDATA element. These styles format the HTML returned by the XSLT style sheet.
This CSS is used with other style sheets installed with the Oracle SES and has the highest priority.
This XML document contains the result list properties and style sheets:
<?xml version="1.0" encoding="UTF-8"?>
<search:config productVersion="11.2.2.2.0" xmlns:search="http://xmlns.oracle.com/search">
<search:resultList>
<search:renderingAttrs>
<search:renderingAttr>
<search:name>Subject</search:name>
</search:renderingAttr>
<search:renderingAttr>
<search:name>eqdatasourcename</search:name>
</search:renderingAttr>
<search:renderingAttr>
<search:name>eqdatasourcetype</search:name>
</search:renderingAttr>
</search:renderingAttrs>
<search:xsltContent>
<![CDATA[<?xml version="1.0" encoding="UTF-8" ?>
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<!-- XSLT content appears here-->
</xsl:stylesheet>]]>
</search:xsltContent>
<search:cssContent>
<![CDATA[.title
{
font-size: 12pt;
}]]>
</search:cssContent>
</search:resultList>
</search:config>
schedule
Schedules define the frequency of updating the index with information about each source.
| Property | Value |
|---|---|
lastCrawled |
The date of the last scheduled crawl in the format Day, DD MMM YYYY HH:MM:SS GMT |
logFilePath |
The full path to the crawler log files |
nextCrawl |
The date of the next scheduled crawl in the same format as lastCrawled. |
scheduleError |
The text of the last error message |
status |
DISABLED, EXECUTING, FAILED, LAUNCHING, PARTIALLY_FAILED, SCHEDULED, or STOPPED |
activate create createAll deactivate delete deleteAll deleteList export exportAll exportList getAllObjectKeys getAllStates getState getStateList start stop update updateAll
A <search:schedules> element describes the schedules for crawling sources:
<search:schedules> <search:schedule> <search:name> <search:crawlingMode> <search:recrawlPolicy> <search:frequency> <!-- For hourly crawls: --> <search:hourly> <search:hoursBtwnLaunches> <!-- For daily crawls: --> <search:daily> <search:daysBtwnLaunches> <search:startHour> <!-- For weekly crawls: --> <search:weekly> <search:weeksBtwnLaunches> <search:startDayOfWeek> <search:startHour> <!-- For monthly crawls: --> <search:monthly> <search:monthsBtwnLaunches> <search:startDayOfMonth> <search:startHour> <!-- For manual crawls: --> <search:manual> <!-- For all crawls: --> <search:assignedSources> <search:assignedSource>
Element Descriptions
- <search:schedules>
-
Contains one or more
<search:schedule>elements, one for each schedule. - <search:schedule>
-
Describes a schedule for crawling sources. It contains these elements:
<search:name> <search:crawlingMode> <search:recrawlPolicy> <search:frequency> <search:assignedSources>
- <search:name>
-
The name of the schedule. Required.
- <search:crawlingMode>
-
A crawling mode:
-
ACCEPT_ALL: Crawls and indexes all URLs in the source, and extracts and indexes any links found in the URLs of Web sources. If the URL has been crawled before, then it is reindexed only after it changes. -
EXAMINE_URLS: Crawls but does not index any URLs in the source. It also crawls any links found in those URLs. Use this mode when first crawling a new source, so that you can examine the documents and refine the crawling parameters if necessary before indexing. -
INDEX_ONLY: Crawls and indexes all URLs in the source. It does not extract any links from those URLs. In general, select this option for a source that has been crawled previously usingEXAMINE_URLS.
-
- <search:recrawlPolicy>
-
A recrawl policy:
-
PROCESS_ALL: Recrawls all documents in the source. -
PROCESS_CHANGED: Crawls only documents that changed after the last crawl. For file sources, documents are also crawled if the parent directory changed.
-
- <search:frequency>
-
Controls the intervals between starting a schedule. It contains one of these elements:
<search:hourly> <search:daily> <search:weekly> <search:monthly> <search:manual>
- <search:hourly>
-
Describes an hourly schedule. It contains a
<search:hoursBtwnLaunches>element. - <search:hoursBtwnLaunches>
-
Number of hours between starting crawls, in the range of
1to23. - <search:daily>
-
Describes a daily schedule. It contains these elements:
<search:daysBtwnLaunches> <search:startHour>
- <search:daysBtwnLaunches>
-
Number of days between starting crawls, in the range of
1to99. - <search:startHour>
-
The time the crawl begins using a 24-hour clock, such as
9for 9:00 a.m. or23for 11:00 p.m. - <search:weekly>
-
Describes a weekly schedule. It contains these elements:
<search:weeksBtwnLaunches> <search:startDayOfWeek> <search:startHour>
- <search:weeksBtwnLaunches>
-
Number of weeks between starting crawls, in the range of
1to12. - <search:startDayOfWeek>
-
The day of the week that the crawl begins, such as
MONDAYorTUESDAY. - <search:monthly>
-
Describes a monthly schedule. It contains these elements:
<search:monthsBtwnLaunches> <search:startDayOfMonth> <search:startHour>
- <search:monthsBtwnLaunches>
-
Number of months between starting crawls, in the range of
1to12. - <search:startDayOfMonth>
-
An integer value for the day of the month that the crawl begins, such as
1or15. - <search:manual>
-
Describes a manual search.
- <search:assignedSources>
-
Contains one or more
<search:assignedSource>elements, one for each source that is crawled using this schedule. - <search:assignedSource>
-
The name of a source crawled using this schedule. The source cannot be a mailing-list source or a federated source.
This XML document creates a schedule for mySource that runs every third Monday at 11:00 p.m.:
<?xml version="1.0" encoding="UTF-8"?>
<search:config productVersion="11.2.2.2.0" xmlns:search="http://xmlns.oracle.com/search">
<search:schedules>
<search:schedule>
<search:name>schedule1</search:name>
<search:crawlingMode>INDEX_ONLY</search:crawlingMode>
<search:recrawlPolicy>PROCESS_ALL</search:recrawlPolicy>
<search:frequency>
<search:weekly>
<search:weeksBtwnLaunches>3</search:weeksBtwnLaunches>
<search:startDayOfWeek>MONDAY</search:startDayOfWeek>
<search:startHour>23</search:startHour>
</search:weekly>
</search:frequency>
<search:assignedSources>
<search:assignedSource>mySource</search:assignedSource>
</search:assignedSources>
</search:schedule>
</search:schedules>
</search:config>
searchAttr
Search attributes are attributes exposed to the search user. Oracle Secure Enterprise Search (SES) provides system-defined attributes, such as author and description, and enables administrators to create custom attributes.
When the indexed documents contain metadata, such as author and date information, you can let users refine their searches based on this information. For example, users can search for all documents by a particular author, that is, where the author attribute has a particular value.
Oracle Secure Enterprise Search has several default search attributes. They can be incorporated in search applications for a more detailed search and richer presentation. If an attribute List of Values (LOV) is available, then the crawler registers the LOV definition, which includes attribute value, attribute value display name, and its translation.
You can create, delete, and update custom attributes, and update the default attributes.
create createAll delete deleteAll deleteList export exportAll exportList getAllObjectKeys update updateAll
Global Settings - Search Attributes
Global Settings - Search Attributes - Manage LOVs for Attribute
Global Settings - Translate Search Attribute Name
Global Settings - Translate LOV Display Name
The <search:Attrs> element describes search attributes:
<search:searchAttrs> <search:searchAttr> <search:name> <search:type> <search:properties> <search:property> <search:translations> <search:lovEntries> <search:lovEntry>> <search:lovValue> <search:sourceName> <search:translations>
Element Descriptions
- <search:searchAttrs>
-
Contains one or more
<search:searchAttr>elements. - <search:searchAttr>
-
Describes a search attribute. It contains these elements:
<search:name> <search:type> <search:properties> <search:translations> <search:lovEntries>
- <search:name>
-
Name of the search attribute.
- <search:type>
-
Data type of the attribute values. Set to
STRING,NUMBER, orDATE. - <search:properties>
-
Defines a list of attribute properties. Contains one or more
<search:property>elements. - <search:property>
-
Defines an attribute property. Currently, the only property supported is
sortable, which takes the value of eithertrueorfalse.Attribute Value nameYou can only specify sortable.valueSpecify trueto enable sorting, else specifyfalse. - <search:translations>
-
Provides a display name. See "Providing Translations of Object Names".
- <search:lovEntries>
-
Contains one or more
<search:lovEntry>elements, each describing a list of values (LOV).<search:lovValue> <search:sourceName> <search:translations>
- <search:lovEntry>
-
Describes a list of values. It contains these child elements:
- <search:lovValue>
-
Name of the list of values.
- <search:sourceName>
-
Name of the source for a source-specific list of values.
This XML document defines a search attribute named Copyright:
<?xml version="1.0" encoding="UTF-8"?>
<search:config productVersion="11.2.2.2.0" xmlns:search="http://xmlns.oracle.com/search">
<search:searchAttrs>
<search:searchAttr>
<search:name>Copyright</search:name>
<search:type>DATE</search:type>
</search:searchAttr>
</search:searchAttrs>
</search:config>
singleSignOnSetting
The Single Sign-On (SSO) settings are used to configure SSO types, such as, Oracle Access Manager (OAM), Oracle Single Sign-On (OSSO), and Windows Native Authentication (WNA).
OAM is supported by both the admin application and the query application, while OSSA and WNA are supported only by the query application.
activate deactivate export exportAll exportList getAllObjectKeys getAllStates getState getStateList update updateAll
The <search:singleSignOnSettings> element describes the configuration settings for SSO:
<search:singleSignOnSettings> <search:singleSignOnSetting> <search:name> <search:parameters> <search:parameters> <search:parameter> <search:value>
Element Descriptions
- <search:singleSignOnSettings>
-
Contains one or more
<search:singleSignOnSetting>elements, which contain the SSO options that can be activated. - <search:singleSignOnSetting>
-
Contains SSO settings for an SSO type. It contains these elements:
<search:name> <search:description> <search:parameters>
- <search:name>
-
The SSO type. The supported values are
OAM,OSSO, andWNA. - <search:description>
-
Description of the SSO type.
- <search:parameters>
-
Contains one or more
<search:parameter>elements. - <search:parameter>
-
Name of the SSO configuration parameter. These parameters vary for different SSO types. The supported parameters are:
-
For OAM:
Query invalid session return URL – URL to display when the query application session expires.
Query logout return URL – URL to display after logging out of the query application.
Admin logout return URL – URL to display after logging out of the administration application.
-
For OSSO:
Hint cookie enabled – whether hint cookie should be enabled (true/false).
Hint cookie name – name of the hint cookie.
Query invalid session return URL – URL to display when the query application session expires.
Query logout return URL – URL to display after logging out of the query application.
-
For WNA:
There are no parameters for WNA SSO type.
-
- <search:value>
-
Value of the SSO configuration parameter.
The following is the default XML for Single Sign-On configuration settings:
<?xml version="1.0" encoding="UTF-8"?>
<search:config productVersion="11.2.2.2.0" xmlns:search="http://xmlns.oracle.com/search">
<singleSignOnSettings>
<singleSignOnSetting>
<search:name>OAM</search:name>
</singleSignOnSetting>
<singleSignOnSetting>
<search:name>OSSO</search:name>
</singleSignOnSetting>
<singleSignOnSetting>
<search:name>WNA</search:name>
</singleSignOnSetting>
</singleSignOnSettings>
</search:config>
skinBundle
A skin bundle is a set of files that customize the look and feel of the Oracle SES default query application.
See Also: "Search Interface Customization: Skin Bundles"
activate create deactivate delete deleteAll deleteList export exportAll exportList getAllObjectKeys getAllStates getState getStateList update
The <search:skinBundles> element describes skin bundles:
<search:skinBundles> <search:skinBundle> <search:name> <search:isDefault> <search:linkedVersion> <search:files> <search:file>
Element Descriptions
- <search:skinBundles>
-
Contains one or more
<search:skinBundle>elements. - <search:skinBundle>
-
Describes a skin bundle. It contains these elements:
<search:name> <search:isDefault> <search:linkedVersion> <search:files>
- <search:name>
-
Contains the name of the skin bundle. (Required)
- <search:isDefault>
-
Identifies whether this is the default skin bundle. Set to
trueto make this the default skin bundle; otherwise, set it tofalse. - <search:linkedVersion>
-
Contains the version number of Oracle SES.
- <search:files>
-
Contains one or more
<search:file>elements. - <search:file>
-
Identifies the path to a file composing the skin bundle, such as a template (ftl), cascading style sheet (css), JavaScript (js), or graphic (gif).
Attribute Value pathRelative path of the file in the skin bundle. (Required)
This example describes a skin bundle named acme.
<?xml version="1.0" encoding="UTF-8" ?>
<search:config productVersion="11.2.2.2.0" xmlns:search="http://xmlns.oracle.com/search">
<search:skinBundles>
<search:skinBundle>
<search:name>acme</search:name>
<search:isDefault>false</search:isDefault>
<search:linkedVersion>11.2.2.2.0</search:linkedVersion>
<search:files>
<search:file path="templates/query.ftl"/>
<search:file path="templates/inc_footer.ftl"/>
<search:file path="assets/images/logo.gif"/>
<search:file path="assets/css/acme.css"/>
</search:files>
</search:skinBundle>
</search:skinBundles>
</search:config>
source
Sources are collections of data to be searched, such as Web sites, files, database tables, content management repositories, collaboration repositories, and applications.
Note:
The current release of the Oracle SES Administration API supports these source types:-
File
-
Federated
-
User Defined
-
Web
create createAll delete deleteAll deleteList export exportAll exportList getAllObjectKeys update updateAll
Home - Sources - Create or Edit Source
Home - Sources - Customize Federated Source
Each supported source type has a unique XML description:
XML Description: Federated Sources
For a federated source, the <search:sources> element contains a <search:federatedSource> element:
<search:sources> <search:federatedSource> <search:name> <search:url> <search:security> <search:entityName> <search:entityPassword> <search:authAttribute> <search:queryRouting> <search:filterRule> <search:searchRestrictions> <search:groupRestrictedEnabled> <search:searchedGroups> <search:fedSourceGroup> <search:attributeRetrieval> <search:retrievedAttrs> <search:fedSearchAttr> <search:attributeMappings> <search:attributeMapping> <search:localAttribute> <search:localAttribute>
Element Descriptions
- <search:sources>
-
Contains one or more source descriptions.
- <search:federatedSource>
-
Describes a federated source. It contains these elements:
<search:name> <search:url> <search:security> <search:queryRouting> <search:searchRestrictions> <search:attributeRetrieval>
- <search:name>
-
Contains the name of the source. (Required)
- <search:url>
-
Contains the Web service URL.
- <search:security>
-
Describes security for connecting to the federated source. It contains these child elements:
<search:entityName> <search:entityPassword> <search:authAttribute>
- <search:entityName>
-
Contains the name of the federation trusted entity on the federation endpoint. Contact the administrator of the federated endpoint for this information
- <search:entityPassword>
-
Contains the password for the entity name.
Attribute Value encryptedIndicates whether the value of <search:entityPassword>is encrypted. Set totrueif the password is encrypted, or set tofalseif it is plain text. - <search:authAttribute>
-
Contains the name of an attribute that identifies and can authenticate a user on the federation endpoint.
- <search:queryRouting>
-
Describes the rules for routing queries to the federated source. Without any rules, Oracle SES routes all queries to the federated source. This element is optional, but can improve scalability. It contains a
<search:filterRule>element. - <search:filterRule>
-
Contains the rules within a
CDATAelement. Rules consist of an attribute, a colon (:), and an expression. Attributes can beDATE,STRING, orNUMBER.DATEandNUMBERattributes can include these operators:-,=,>,>=,<,<=. TheANDorORoperators separate multiple rules. - <search:searchRestrictions>
-
Restricts searches to a list of source groups. It contains these child elements:
<search:groupRestrictedEnabled> <search:searchedGroups>
- <search:groupRestrictedEnabled>
-
Controls whether source groups are restricted during searches. Set to
trueto restrict searches, or set tofalseotherwise. The default value isfalse. (Optional) - <search:searchedGroups>
-
Describes the source groups to be searched on the federated source. It contains one or more
<search:fedSourceGroup>elements. - <search:fedSourceGroup>
-
Empty element that uses parameters to identify source group. (Read only)
Attribute Value isAvailableIdentifies whether the source group is currently available in the federated source. nameName of a federated source group. (Required) - <search:attributeRetrieval>
-
Describes the attributes to be retrieved from the federated source. It contains a
<search:retrieveAttrs>element. - <search:retrievedAttrs>
-
Contains one or more
<search:fedSearchAttr>elements. - <search:fedSearchAttr>
-
Empty element that uses parameters to identify a search attribute.
Attribute Value nameName of a search attribute. (Required) typeData type of the attribute: STRING,NUMBER, orDATE.isAvailableIdentifies whether the attribute is currently available in the federated source: trueif it is available, orfalseotherwise.isMandatoryIdentifies whether retrieval of the attribute is mandatory: trueif it must be listed in the<search:retrievedAttrs>element, orfalseif it can be omitted without causing an error. - <search:attributeMappings>
-
Contains one or more <search:attributeMapping> elements.
- <search:attributeMapping>
-
Maps a local attribute to a remote attribute. It contains one of each of these elements:
<search:localAttribute> <search:remoteAttribute>
- <search:localAttribute>
-
Identifies the local attribute being mapped.
Attribute Value nameName of the local attribute. (Required) typeData type of the local attribute: STRING,NUMBER, orDATE. (Required) - <search:remoteAttribute>
-
Identifies the remote attribute being mapped.
Attribute Value nameName of the remote attribute. (Required) typeData type of the remote attribute: STRING,NUMBER, orDATE. (Required)isAvailableIdentifies whether the remote attribute is currently available in the federated source: trueif it is available, orfalseotherwise.
Example 2-1 Federated Source Description
This XML document describes a federated source:
<?xml version="1.0" encoding="UTF-8"?>
<search:config productVersion="11.2.2.2.0" xmlns:search="http://xmlns.oracle.com/search">
<search:sources>
<search:federatedSource>
<search:name>fed1</search:name>
<search:url>http://example:7777/search/query/OracleSearch</search:url>
<search:security>
<search:entityName>entity2</search:entityName>
<search:entityPassword encrypted="false">password</search:entityPassword>
<search:authAttribute>nickname</search:authAttribute>
</search:security>
<search:queryRouting>
<search:filterRule>
<![CDATA[
(language:en) AND (idm::mail:a.*)
]]>
</search:filterRule>
</search:queryRouting>
<search:searchRestrictions>
<search:groupRestrictedEnabled>true</search:groupRestrictedEnabled>
<search:searchedGroups>
<search:fedSourceGroup isAvailable="true" name="FILE"/>
<search:fedSourceGroup isAvailable="true" name="Web"/>
</search:searchedGroups>
</search:searchRestrictions>
<search:attributeRetrieval>
<search:retrievedAttrs>
<search:fedSearchAttr type="STRING" isAvailable="true"
isMandatory="true" name="Author"/>
<search:fedSearchAttr type="STRING" isAvailable="true"
isMandatory="true" name="Description"/>
<search:fedSearchAttr type="STRING" isAvailable="true"
isMandatory="true" name="Infosource"/>
<search:fedSearchAttr type="STRING" isAvailable="true"
isMandatory="true" name="Infosource Path"/>
<search:fedSearchAttr type="STRING" isAvailable="true"
isMandatory="true" name="Language"/>
<search:fedSearchAttr type="DATE" isAvailable="true"
isMandatory="true" name="LastModifiedDate"/>
<search:fedSearchAttr type="STRING" isAvailable="true"
isMandatory="true" name="Mimetype"/>
<search:fedSearchAttr type="STRING" isAvailable="true"
isMandatory="true" name="Title"/>
<search:fedSearchAttr type="STRING" isAvailable="true"
isMandatory="true" name="Url"/>
<search:fedSearchAttr type="STRING" isAvailable="true"
isMandatory="false" name="custom1"/>
<search:fedSearchAttr type="STRING" isAvailable="true"
isMandatory="false" name="custom2"/>
<search:fedSearchAttr type="NUMBER" isAvailable="true"
isMandatory="true" name="eqdocid"/>
<search:fedSearchAttr type="STRING" isAvailable="true"
isMandatory="true" name="eqfedid"/>
<search:fedSearchAttr type="STRING" isAvailable="true"
isMandatory="true" name="eqsnippet"/>
</search:retrievedAttrs>
</search:attributeRetrieval>
</search:federatedSource>
</search:sources>
</search:config>
For a file source, the <search:sources> element contains a <search:fileSource> element:
<search:sources> <search:fileSource> <search:name> <search:fileDisplayUrl> <search:fileUrlPrefix> <search:displayUrlPrefix> <search:startingUrls> <search:startingUrl> <search:url> <search:aclPolicy> <search:authorizationPlugin> <search:boundaryRules> <search:attributeMappings> <search:attributeMapping> <search:documentAttr> <search:searchAttr> <search:crawlerSettings> <search:followSymlinks> <search:documentTypes> <search:documentType> <search:mimeType>
Element Descriptions
- <search:sources>
-
Contains one or more source descriptions.
- <search:fileSource>
-
Describes a file source. It contains these elements:
<search:name> <search:fileDisplayUrl> <search:startingUrls> <search:aclPolicy> <search:boundaryRules> <search:attributeMappings> <search:crawlerSettings> <search:documentTypes>
- <search:name>
-
Contains the name of the file source.
- <search:fileDisplayUrl>
-
Identifies a physical path that is replaced by a display URL for security reasons when the file is retrieved during a search.
Attribute Value enabledControls whether the display URL prefix is used for security reasons. Set to trueto use the display URL, or set tofalseto display the physical location of the file. (Required) - <search:fileUrlPrefix>
-
Contains the physical file URL to be replaced by the display URL.
- <search:displayUrlPrefix>
-
Contains a URL prefix displayed instead of the file URL.
- <search:startingUrls>
-
Identifies the file path where the crawler begins. It consists of one or more of these child elements:
- <search:startingUrl>
-
Contains a
<search:url>element. - <search:url>
-
Contains an entry point for starting to crawl files. The URL must be in its original form as an unencoded file path.
- <search:aclPolicy>
-
Describes an authorization policy for the source. See "XML Description: Web Sources".
- <search:authorizationPlugin>
-
Describes the authorization plug-in. See "XML Description: User-Defined Sources".
- <search:boundaryRules>
-
Describes the boundary rules for the source. See "XML Description: Web Sources".
- <search:attributeMappings>
-
Maps the document attributes to search attributes. It contains one or more
<search:attributeMapping>elements. - <search:attributeMapping>
-
Contains a document attribute and a search attribute for mapping. It contains one of each of these child elements:
<search:documentAttr> <search:searchAttr>
- <search:documentAttr>
-
Identifies a document attribute by its name and data type.
Attribute Value nameName of a document attribute typeData type of the attribute: DATE,NUMBER, orSTRING - <search:searchAttr>
-
Identifies a search attribute by its name and data type. Search attributes are displayed to users in the Oracle SES Search interface.
Attribute Value nameName of a search attribute typeData type of the attribute: DATE,NUMBER, orSTRING - <search:crawlerSettings>
-
Configures the crawler. It contains these child elements:
<search:numThreads> <search:languageDetection> <search:defaultLanguage> <search:crawlTimeout> <search:maxDocumentSize> <search:preserveDocumentCache> <search:charSetDetection> <search:defaultCharSet> <search:servicePipeline> <search:indexNullTitleFallback> <search:badTitles> <search:logLevel> <search:followSymlinks>
See the <search:crawlerSettings> for Web sources for description for all these elements, except the
<search:followSymlinks>element, which is described as follows. - <search:followSymlinks>
-
Contains
trueto prevent the crawler from following links to the absolute path, orfalseotherwise. The default value istrue.Applies only to file sources on Linux and UNIX systems.
- <search:documentTypes>
-
Identifies the types of documents to be crawled. It contains one or more
<search:documentType>elements. - <search:documentType>
-
Contains one or more
<search:mimeType>elements. - <search:mimeType>
-
Contains the Internet media type of the content in the form
type/subtype. See Table 2-1, "Document Formats Supported by Oracle SES" for supported MIME types.
Example 2-2 File Source Description
This XML document describes a file source:
<?xml version="1.0" encoding="UTF-8"?>
<search:config productVersion="11.2.2.2.0" xmlns:search="http://xmlns.oracle.com/search">
<search:sources>
<search:fileSource>
<search:name>Document Library</search:name>
<search:fileDisplayUrl enabled="false"/>
<search:startingUrls>
<search:startingUrl>
<search:url>file://localhost/startingDirectory/</search:url>
</search:startingUrl>
</search:startingUrls>
<search:aclPolicy>
<search:noACL/>
</search:aclPolicy>
<search:attributeMappings>
<search:attributeMapping>
<search:documentAttr name="AUTHOR" type="STRING"/>
<search:searchAttr name="Author" type="STRING"/>
</search:attributeMapping>
<search:attributeMapping>
<search:documentAttr name="CREATOR" type="STRING"/>
<search:searchAttr name="Author" type="STRING"/>
</search:attributeMapping>
<search:attributeMapping>
<search:documentAttr name="DESCRIPTION" type="STRING"/>
<search:searchAttr name="Description" type="STRING"/>
</search:attributeMapping>
<search:attributeMapping>
<search:documentAttr name="HOST" type="STRING"/>
<search:searchAttr name="Host" type="STRING"/>
</search:attributeMapping>
<search:attributeMapping>
<search:documentAttr name="INFOSOURCE" type="STRING"/>
<search:searchAttr name="Infosource" type="STRING"/>
</search:attributeMapping>
<search:attributeMapping>
<search:documentAttr name="KEYWORD" type="STRING"/>
<search:searchAttr name="Keywords" type="STRING"/>
</search:attributeMapping>
<search:attributeMapping>
<search:documentAttr name="KEYWORDS" type="STRING"/>
<search:searchAttr name="Keywords" type="STRING"/>
</search:attributeMapping>
<search:attributeMapping>
<search:documentAttr name="LANGUAGE" type="STRING"/>
<search:searchAttr name="Language" type="STRING"/>
</search:attributeMapping>
<search:attributeMapping>
<search:documentAttr name="LASTMODIFIEDDATE" type="DATE"/>
<search:searchAttr name="LastModifiedDate" type="DATE"/>
</search:attributeMapping>
<search:attributeMapping>
<search:documentAttr name="MIMETYPE" type="STRING"/>
<search:searchAttr name="Mimetype" type="STRING"/>
</search:attributeMapping>
<search:attributeMapping>
<search:documentAttr name="SUBJECT" type="STRING"/>
<search:searchAttr name="Subject" type="STRING"/>
</search:attributeMapping>
<search:attributeMapping>
<search:documentAttr name="SUBJECTS" type="STRING"/>
<search:searchAttr name="Subject" type="STRING"/>
</search:attributeMapping>
<search:attributeMapping>
<search:documentAttr name="TITLE" type="STRING"/>
<search:searchAttr name="Title" type="STRING"/>
</search:attributeMapping>
</search:attributeMappings>
<search:crawlerSettings>
<search:numThreads>5</search:numThreads>
<search:languageDetection enabled="false"/>
<search:defaultLanguage>en</search:defaultLanguage>
<search:crawlTimeout>30</search:crawlTimeout>
<search:maxDocumentSize>10</search:maxDocumentSize>
<search:preserveDocumentCache enabled="true"/>
<search:defaultCharSet>8859_1</search:defaultCharSet>
<search:servicePipeline enabled="true">
<search:pipelineName>Default pipeline</search:pipelineName>
</search:servicePipeline>
</search:crawlerSettings>
<search:documentTypes>
<search:documentType>
<search:mimeType>text/html</search:mimeType>
</search:documentType>
<search:documentType>
<search:mimeType>text/plain</search:mimeType>
</search:documentType>
<search:documentType>
<search:mimeType>text/xml</search:mimeType>
</search:documentType>
</search:documentTypes>
</search:fileSource>
</search:sources>
</search:config>
XML Description: User-Defined Sources
For a user-defined source, a <search:sources> element contains a <search:userDefinedSource> element:
<search:sources> <search:userDefinedSource> <search:name> <search:sourceTypeName> <search:aclPolicy> <search:authorizationPlugin> <search:managerClassName> <search:jarFilePath> <search:parameters> <search:parameter> <search:securityAttrs> <search:securityAttr> <search:parameters> <search:parameter> <search:value> <search:boundaryRules> <search:attributeMappings> <search:crawlerSettings> <search:documentTypes> <search:documentType> <search:mimeType>
Element Descriptions
- <search:sources>
-
Describes one or more sources.
- <search:userDefinedSource>
-
Describes a user-defined source. It contains these child elements:
<search:name> <search:sourceTypeName> <search:boundaryRules> <search:aclPolicy> <search:attributeMappings> <search:documentTypes> <search:parameters>
- <search:name>
-
Name of the user-defined source.
- <search:sourceTypeName>
-
Type of user-defined source. For a complete list of user-defined source types, issue an
exportAll sourceTypecommand. Set to the source type exactly as shown.Database EMC Documentum Content Server Federated User Authorization Cache Lotus Notes Microsoft Exchange) Microsoft SharePoint 2007 NTFS Oracle Calendar Oracle Collaboration Suite E-Mail Oracle Content Database Oracle Content Database (JDBC) Oracle Content Server Oracle E-Business Suite Oracle Fusion Oracle WebCenter Push Feed Siebel 7.8 Siebel 7.8(Public) Siebel 8 User Authorization Cache User-Defined Source Type - <search:aclPolicy>
- <search:authorizationPlugin>
-
Describes an authorization plug-in. It contains these elements:
<search:managerClassName> <search:jarFilePath> <search:parameters>
- <search:managerClassName>
-
Contains the name of the plug-in manager Java class.
- <search:jarFilePath>
-
Contains the qualified name of the jar file. Paths can be absolute or relative to the ses_home/search/lib/plugins/identity directory.
- <search:parameters>
-
Contains one or more
<search:parameter>elements, each one setting a parameter. This element appears in a<search:userDefinedSource>element to define parameters supported by the source. It also appears in a<search:authorizationPlugin>to define parameters supported by the plug-in. - <search:parameter>
-
Describes a parameter. It contains the following elements:
<search:value> <search:description>
Attribute Value nameName of a parameter. - <search:value>
-
Contains the value of the parameter.
Attribute Value encryptedIndicates whether the value of <search:value>is encrypted. Set totrueif the value is encrypted, or set tofalseif it is plain text. - <search:description>
-
Contains a description of the parameter.
- <search:securityAttrs>
-
Contains one or more
<search:securityAttr>elements. - <search:securityAttr>
-
Contains a user or a group that is granted or denies access to the data source, depending on the value of the type attribute. (Read only)
Attribute Value typeSet to GRANTif the user or group has access to the source, or set toDENYotherwise. - <search:boundaryRules>
-
Describes the boundary rules. See "XML Description: Web Sources".
- <search:attributeMappings>
-
Maps the document attributes to search attributes. See "XML Description: File Sources".
- <search:crawlerSettings>
-
Configures the crawler. It contains these child elements:
<search:numThreads> <search:languageDetection> <search:defaultLanguage> <search:crawlTimeout> <search:maxDocumentSize> <search:preserveDocumentCache> <search:defaultCharSet> <search:servicePipeline>
- <search:documentTypes>
-
Identifies the types of documents to be crawled. It contains one or more
<search:documentType>elements. - <search:documentType>
-
Contains a
<search:mimeType>element. - <search:mimeType>
-
Contains the Internet media type of the content in the form
type/subtype. See Table 2-1, "Document Formats Supported by Oracle SES".
Example 2-3 User-Defined Source Description for Oracle Content Database source
The following XML document describes an Oracle Content Database source.
<?xml version="1.0"?>
<search:config productVersion="11.2.2.2.0" xmlns:search="http://xmlns.oracle.com/search">
<search:sources>
<search:userDefinedSource>
<search:name>contentdb</search:name>
<search:sourceTypeName>Oracle Content Database</search:sourceTypeName>
<search:aclPolicy>
<search:noACL/>
</search:aclPolicy>
<search:parameters>
<search:parameter name="Oracle Content Database URL">
<search:value>http://contentDBUrl.com:7777/content</search:value>
</search:parameter>
<search:parameter name="Starting paths">
<search:value>/us</search:value>
</search:parameter>
<search:parameter name="Depth">
<search:value>-1</search:value>
</search:parameter>
<search:parameter name="Oracle Content Database admin user">
<search:value>myUserName</search:value>
</search:parameter>
<search:parameter name="Entity name">
<search:value>
orclapplicationcommonname=ocscsplugin,cn=ifs,cn=products,cn=oraclecontext
</search:value>
</search:parameter>
<search:parameter name="Entity password">
<search:value encrypted="false">password</search:value>
</search:parameter>
<search:parameter name="Crawl only">
<search:value>false</search:value>
</search:parameter>
<search:parameter name="Use e-mail for authorization">
<search:value>false</search:value>
</search:parameter>
</search:parameters>
</search:userDefinedSource>
</search:sources>
</search:config>
Example 2-4 User-Defined Source Description for Push Feed source
The following XML document describes a Push Feed source:
<?xml version="1.0" encoding="UTF-8"?>
<search:config productVersion="11.2.2.2.0" xmlns:search="http://xmlns.oracle.com/search">
<search:sources>
<search:userDefinedSource>
<search:name>pshsrc3</search:name>
<search:sourceTypeName>Push Feed</search:sourceTypeName>
<search:aclPolicy>
<search:documentLevelACL/>
</search:aclPolicy>
<search:authorizationPlugin>
<search:managerClassName>oracle.search.plugin.security.auth.db.DBAuthManager</search:managerClassName>
<search:jarFilePath>oracleapplications/DBCrawler.jar</search:jarFilePath>
<search:parameters>
<search:parameter name="Authorization Database Connection String">
<search:value>DBCONNECTSTR1</search:value>
<search:description>JDBC connection string for the database</search:description>
</search:parameter>
<search:parameter name="Authorization Query">
<search:value>select EQ_GROUPS1 from pushtestuseracl where username like upper(?)</search:value>
<search:description>SQL query to retrieve values of all the security attributes for a given user. The user ID in the WHERE clause should be specified as '?'. For example, SELECT attr1, attr2 FROM table1, table2 WHERE table1.f1=table2.f2 AND table1.user=?.</search:description>
</search:parameter>
<search:parameter name="Authorization User ID Format">
<search:value>nickname</search:value>
<search:description>Format of user ID to be used in the authorization query. This format should be one of the supported authentication attributes of the active ID plugin. The canonical form will be used if format is not specified.</search:description>
</search:parameter>
<search:parameter name="JDBC Driver Class">
<search:value>oracle.jdbc.driver.OracleDriver</search:value>
<search:description>JDBC driver class to connect to the database. For example, oracle.jdbc.driver.OracleDriver</search:description>
</search:parameter>
<search:parameter name="Password">
<search:value encrypted="true">b911a0fa2b08f209c53f50131339e06b62526a22cd205807</search:value>
<search:description>Password to connect to the database</search:description>
</search:parameter>
<search:parameter name="Single Record Query">
<search:value>false</search:value>
<search:description>Enter true if the query returns single record for each user with attribute values separated by spaces. Else, enter false.</search:description>
</search:parameter>
<search:parameter name="User ID">
<search:value>scott</search:value>
<search:description>User ID to connect to the database</search:description>
</search:parameter>
</search:parameters>
</search:authorizationPlugin>
<search:securityAttrs>
<search:securityAttr type="GRANT">EQ_GROUPS1</search:securityAttr>
</search:securityAttrs>
<search:parameters>
<search:parameter name="Attachment Auth Type">
<search:value>NATIVE</search:value>
<search:description>Authentication Type for Attachments</search:description>
</search:parameter>
<search:parameter name="Attachment Realm">
<search:description>Realm for attachments</search:description>
</search:parameter>
<search:parameter name="HTTP Error Log URL">
<search:description>The HTTP URL where the status feeds are sent after batch feed is processed.</search:description>
</search:parameter>
<search:parameter name="Scratch Directory">
<search:description>Scratch Directory</search:description>
</search:parameter>
<search:parameter name="Security Attributes">
<search:value>EQ_GROUPS1,true</search:value>
<search:description>Security attributes, comma separated list of name, (grant/deny)</search:description>
</search:parameter>
<search:parameter name="Source Password">
<search:value encrypted="true">42fde84db62dcd4eccfe438d941fe0f854e7580f584926e2</search:value>
<search:description>Password for fetching Attachments</search:description>
</search:parameter>
<search:parameter name="Source Username">
<search:value>aime</search:value>
<search:description>Username for fetching Attachments</search:description>
</search:parameter>
<search:parameter name="Trusted Entity Password">
<search:value encrypted="true">ef38accc4d3185115bc12913edb3570cf68fcdb90f15eb43</search:value>
<search:description>Trusted Entity Password</search:description>
</search:parameter>
<search:parameter name="Trusted Entity Username">
<search:value>testuser1</search:value>
<search:description>Trusted Entity Username</search:description>
</search:parameter>
</search:parameters>
</search:userDefinedSource>
</search:sources>
</search:config>
For a Web source, the <search:source> element contains a <search:webSource> element:
<search:sources> <search:webSource> <search:name> <search:selfService> <search:startingUrls> <search:startingUrl> <search:url> <search:aclPolicy> <!-- No ACL policy --> <search:noACL> <!-- Document-level ACL policy --> <search:documentLevelACL> <!-- Source-level ACL policy --> <search:sourceLevelACL> <search:accessControlEntries> <search:accessControlEntry> <search:name> <search:privilege> <search:authorizationPlugin> <!-- Boundary rules --> <search:boundaryRules> <search:boundaryRule> <search:ruleType> <search:ruleOperation> <search:rulePattern> <search:metatagMappings> <search:metatagMapping> <search:documentAttr> <search:searchAttr> <search:crawlerSettings> <search:numThreads> <search:languageDetection> <search:defaultLanguage> <search:crawlDepth> <search:limit> <search:crawlTimeout> <search:maxDocumentSize> <search:preserveDocumentCache> <search:charsetDetection> <search:defaultCharSet> <search:servicePipeline> <search:pipelineName> <search:indexNullTitleFallback> <search:badTitles> <search:badTitle> <search:honorRobotsExclusion> <search:sitemap> <search:indexDynamicPages> <search:urlRewriter> <search:urlRewriterClass> <search:urlRewriterJar> <search:httpCharSetOverride> <search:cookies> <search:cookieContentInLog> <search:maxCookieSize> <search:maxCookies> <search:maxCookiesPerHost> <search:agentString> <search:duplicateDetection> <search:connections> <search:timeout> <search:retries> <search:retryInterval> <search:logLevel> <search:documentTypes> <search:documentType> <search:mimeType> <search:httpAuthentications> <search:httpAuthentication> <search:host> <search:realm> <search:username> <search:password> <search:htmlForms> <search:htmlForm> <search:name> <search:formUrl> <search:action> <search:successUrl> <search:formControls> <search:formControl> <search:name> <search:value> <search:isPasswordField> <search:ssoAuthentication> <search:username> <search:password>
Element Descriptions
- <search:sources>
-
Contains one or more source descriptions.
- <search:webSource>
-
Describes a Web source. It contains these child elements:
<search:name> <search:selfService <search:startingUrls> <search:aclPolicy> <search:boundaryRules> <search:metatagMappings> <search:crawlerSettings> <search:documentTypes> <search:httpAuthentications> <search:htmlForms> <search:ssoAuthentication>
- <search:name>
-
Name of the Web source.
- <search:selfService>
-
Contains a value of
trueto enable self-service authentication, or a value offalseto disable it. Self-service authentication lets users enter authentication credentials at run time, instead of the administrator entering credentials at the time the source is created. - <search:startingUrls>
-
Contains one or more
<search:startingUrl>elements. - <search:startingUrl>
-
Contains a
<search:url>element. - <search:url>
-
Contains the URL-encoded Web address that is an entry point for starting to crawl Web pages.
- <search:aclPolicy>
-
Describes an ACL policy for the source. It contains one of these child elements:
<search:noACL> <search:documentLevelACL> <search:sourceLevelACL>
- <search:noACL>
-
Indicates no ACL policy. All documents are visible and searchable.
- <search:documentLevelACL>
-
Describes a document-level ACL policy.
- <search:sourceLevelACL>
-
Describes an Oracle SES ACL policy used when crawling private content. It preserves authorizations specified in OracleAS Portal. For user-defined sources, crawler plug-ins (or connectors) can supply ACL information with documents for indexing, which provides finer control document protection. That is, each document within one source may be viewed by a different set of users or groups.
This element contains a
<search:accessControlEntries>element. - <search:accessControlEntries>
-
Contains one or more
<search:accessControlEntry>elements. - <search:accessControlEntry>
-
Provides a list of users and groups that have access to the source or are restricted from access. It contains these child elements:
<search:name> <search:privilege>
- <search:name>
-
Contains the name or a user or group that is valid for the currently active identity plug-in.
- <search:privilege>
-
Set to
GRANTEDto allow access to the source, or set toDENIEDto restrict access. - <search:authorizationPlugin>
-
Describes an authorization plug-in. See "XML Description: User-Defined Sources".
- <search:boundaryRules>
-
Contains one or more
<search:boundaryRule>elements, each describing a boundary rule. - <search:boundaryRule>
-
Describes a boundary rule. It contains these child elements:
<search:ruleType> <search:ruleOperation> <search:rulePattern>
- <search:ruleType>
-
Type of URL boundary rule. Set to one of these keywords:
-
INCLUSION: The URL matches <search:rulePattern>. -
EXCLUSION: The URL does not match <search:rulePattern>.
-
- <search:ruleOperation>
-
Matching operation for a search rule pattern. Set to one of these operations:
-
CONTAINS: The URL contains the rule pattern for a case-insensitive match. -
STARTSWITH: The URL starts with the rule pattern for a case-insensitive match. -
ENDSWITH: The URL ends with the rule pattern for a case-insensitive match. -
REGEX: The URL contains the regular expression in a case-sensitive match.
-
- <search:rulePattern>
-
The pattern of characters in the URL. You can use these special characters:
-
Caret (
^) denotes the beginning of a URL. -
Dollar sign (
$) denotes the end of a URL. -
A period (
.) matches any one character. -
Question mark (
?) before a character matches 0 or 1 occurrences of that character. -
Asterisk (
*) before a pattern matches 0 or more occurrences of that pattern. Enclose the pattern in parentheses(), brackets[], or braces{}. -
A backslash (
\) precedes a literal use of a special character, such as\?to match a question mark in a URL.
-
- <search:metatagMappings>
-
Contains one or more
<search:metataMappings>elements. - <search:metatagMapping>
-
Contains a mapped pair of attributes in these child elements:
<search:documentAttr> <search:searchAttr>
- <search:documentAttr>
-
Identifies a document attribute by its name and data type. Document attributes are among the properties of a document.
Attribute Value nameName of a document attribute. (Required) typeData type of the attribute: DATE,NUMBER, orSTRING. - <search:searchAttr>
-
Identifies a search attribute by its name and data type. Search attributes are displayed to users in the Oracle SES Search interface.
Attribute Value nameName of a search attribute. (Required) typeData type of the attribute: DATE,NUMBER, orSTRING. - <search:crawlerSettings>
-
Configures the crawler. It contains these child elements:
<search:numThreads> <search:languageDetection> <search:defaultLanguage> <search:crawlDepth> <search:crawlTimeout> <search:maxDocumentSize> <search:preserveDocumentCache> <search:charsetDetection> <search:defaultCharSet> <search:servicePipeline> <search:indexNullTitleFallback> <search:badTitles> <search:honorRobotsExclusion> <search:sitemap> <search:indexDynamicPages> <search:urlRewriter> <search:httpCharSetOverride> <search:cookies> <search:logLevel>
- <search:numThreads>
-
Number of processes to use for crawling the source.
- <search:languageDetection>
-
Controls the use of a language detector when the metadata for a document does not identify the language.
Attribute value enabledControls use of language detection when a source document does not indicate the language in the header. Set to trueto enable language detection, or set tofalseotherwise. (Required) - <search:defaultLanguage>
-
Default language used by the crawler when the document language cannot be detected.
- <search:crawlDepth>
-
Controls use of a limit on crawling nested links. It contains a
<search:limit>element.Attribute Value haslimitControls whether the search limit is enforced. Set to trueto impose the limit, or set tofalseotherwise. (Required) - <search:limit>
-
Contains the maximum number of nested links to be crawled.
- <search:crawlTimeout>
-
Number of milliseconds for search results to be returned.
- <search:maxDocumentSize>
-
Maximum document size in megabytes. Larger documents are not crawled.
- <search:preserveDocumentCache>
-
Controls retention of the document cache after indexing.
Attribute Value enabledSet to trueto retain the cache, or set tofalseotherwise. (Required) - <search:charsetDetection>
-
Contains a value of
trueto enable automatic character set detection, orfalseto disable it. The default value istrue. This parameter can be set at the global level. - <search:defaultCharSet>
-
Code for the default character set, which is used when a source document does not identify its character set in the header. See Table 2-4, "Crawlable Character Sets".
- <search:servicePipeline>
-
Controls use of a document service pipeline.
Attribute Value enabledSet to trueto use the pipeline, or set tofalseotherwise. Whentrue,<search:servicePipeline>contains a<search:pipelineName>element. - <search:pipelineName>
-
Contains the name of a pipeline.
- <search:indexNullTitleFallback>
-
Controls whether the default title is included in the index for documents with null titles:
-
indexForAll: Includes the default title in the index. (Default) -
noIndex: Does not include the default title in the index.
-
- <search:badTitles>
-
Contains one or more
<search:badTitle>elements. This parameter can be set at the global level. - <search:badTitle>
-
Contains an exact character string for a document title that the crawler omits from the index. These bad titles are defined by default:
PowerPoint Presentation Slide 1
- <search:honorRobotsExclusion>
-
Controls visits by robots to the Web site.
Attribute Value enabledSet to trueto exclude robots, or set tofalseotherwise. - <search:sitemap>
-
Controls the Sitemap processing. The available options are:
-
SITEMAP_ONLY: Crawler indexes only those URLs extracted from the Sitemap files. The non-Sitemap URLs that are specified as Starting URLs in the Basic Settings page for a Web source are also indexed, but not crawled. All the Sitemap URLs are not crawled further down the URL hierarchy. -
SITEMAP_PREFERRED: If a Sitemap URL is present inrobots.txtfile orSitemap.xmlfile, or at least one Sitemap URL is specified as a Starting URL in the Basic Settings page for a Web source, then the crawling is done according to the Sitemap Only Crawl option.When no Sitemap URL is found, then the regular crawling is done, that is, each Starting URL is crawled further down the URL hierarchy till the last level.
-
SITEMAP_FULL: Regular crawling is done for all the Sitemap URLs present inrobots.txtfile,Sitemap.xmlfile, and all the Starting URLs, including the Sitemap URLs, that are specified in the Basic Settings page for a Web source. Thus, each Sitemap URL as well as non-Sitemap URL is crawled further down the URL hierarchy till the last level.
-
- <search:indexDynamicPages>
-
Controls whether dynamic pages are crawled and indexed.
Attribute Value enabledSet to trueto crawl dynamic pages, or set tofalseotherwise. - <search:urlRewriter>
-
Controls whether the URL Rewriter is used to filter and rewrite URL links. It contains these elements:
<search:urlRewriterClass> <search:urlRewriterJar>
Attribute Value enabledSet to trueto use the URL Rewriter, or set tofalseotherwise. - <search:urlRewriterClass>
-
Contains the class name of the URL Rewriter.
- <search:urlRewriterJar>
-
Contains the absolute path to the JAR file for the URL Rewriter.
- <search:httpCharSetOverride>
-
Controls the character set used for a Web page.
Attribute Value enabledSet to trueto exclude robots, or set tofalseotherwise. - <search:cookies>
-
Controls whether cookies are used to remember context. It contains these child elements:
<search:cookiecontentInLog> <search:maxCookieSize> <search:maxCookies> <search:maxCookiesPerHost>
Attribute Value enabledSet to trueto enable cookies (default), orfalseotherwise. - <search:cookieContentInLog>
-
Controls whether information about cookies appears in the log file.
Attribute Value enabledSet to trueto log cookie messages, or set tofalseotherwise (default). - <search:maxCookieSize>
-
Contains the maximum size in bytes of a cookie.
- <search:maxCookies>
-
Contains the total number of cookies allowed in a crawl.
- <search:maxCookiesPerHost>
-
Contains the maximum number of cookies permitted for a Web site.
- <search:agentString>
-
Contains the browser agent string presented to the Web server. The default value is "Oracle Secure Enterprise Search". Applies only to Web and Portal sources.
- <search:duplicateDetection>
-
Contains a value of
trueto enable duplicate detection during a Web crawl, orfalseto disable it. The default value istrue. - <search:connections>
-
Sets limits on a connection to Web and Portal sources. It contains these elements:
<search:timeout> <search:retries> <search:retryInterval>
- <search:timeout>
-
Contains the maximum number of milliseconds to make a connection to a data source. The default value is 10.
- <search:retries>
-
Contains the maximum number of connection attempts to a data source. The default value is 10.
- <search:retryInterval>
-
Contains the number of milliseconds between connection retry attempts. The default value is 5.
- <search:logLevel>
-
Contains the log level for the crawler. The following are the valid log levels:
Logging Level Description TRACETrace messages DEBUGDebug messages INFOInformational messages (Default) WARNWarning messages ERRORError messages FATALFatal messages - <search:documentTypes>
-
Identifies the types of documents to be crawled. It contains one or more
<search:documentType>elements. - <search:documentType>
-
Contains one or more
<search:mimeType>elements. - <search:mimeType>
-
Contains the Internet media type of the content in the form
type/subtype. See Table 2-1, "Document Formats Supported by Oracle SES". - <search:httpAuthentications>
-
Contains one or more
<search:httpAuthentication>elements. - <search:httpAuthentication>
-
Describes HTTP authentication. For proxy authentication, it contains these elements:
<search:host> <search:realm> <search:username> <search:password>
- <search:host>
-
Contains the address of the target computer.
- <search:realm>
-
Contains a name associated with the protected area of a Web site.
- <search:username>
-
Contains the name of the log-in user.
- <search:password>
-
Contains the password associated with the user name.
Attribute Value encryptedIndicates whether the value of <search:password>is encrypted. Set totrueif the password is encrypted, or set tofalseif it is plain text. - <search:htmlForms>
-
Contains one or more
<search:htmlForm>elements, each one describing an HTML form. - <search:htmlForm>
-
Describes an HTML form. It contains these elements:
<search:name> <search:formUrl> <search:action> <search:successUrl> <search:formControls>
- <search:name>
-
Contains the name of the HTML form object.
- <search:formUrl>
-
Contains the Web address of the HTML form.
- <search:action>
-
Contains the address where the browser sends the form.
- <search:successUrl>
-
Contains the URL displayed after the user successfully submits the form.
- <search:formControls>
-
Contains one or more
<search:formControl>elements. - <search:formControl>
-
Describes a form control. It contains these elements:
<search:name> <search:value> <search:isPasswordField>
- <search:name>
-
Contains the name of the form control.
- <search:value>
-
Contains the value of the form control.
Attribute Value encryptedIndicates whether the value of <search:value>is encrypted. Set totrueif the value is encrypted, or set tofalseif it is plain text. - <search:isPasswordField>
-
Identifies whether the field contains a password. Set to
truefor a password field, orfalseotherwise. - <search:ssoAuthentication>
-
Describes OracleAS Single Sign-On authentication. It contains these elements:
<search:username> <search:password>
Attribute Value enabledControls use of OracleAS Single Sign-On for authentication. Set to trueto enable Single Sign-On, orfalseotherwise. - <search:username>
-
Contains a user name for OracleAS Single Sign-On.
- <search:password>
-
Contains the password for the OracleAS Single Sign-On user.
Attribute Value encryptedIndicates whether the value of <search:password>is encrypted. Set totrueif the password is encrypted, or set tofalseif it is plain text. - <search:userAgent>
-
Contains an authentication value that overrides the default User Agent value for OracleAS Single Sign-On. The default value is null.
Example 2-5 Sample Web Source Description
This XML document describes a sample Web source.
<?xml version="1.0" encoding="UTF-8"?>
<search:config productVersion="11.2.2.2.0" xmlns:search="http://xmlns.oracle.com/search">
<search:sources>
<search:webSource>
<search:name>websource_1</search:name>
<search:startingUrls>
<search:startingUrl>
<search:url>http://www.example.com/</search:url>
</search:startingUrl>
</search:startingUrls>
<search:aclPolicy>
<search:noACL/>
</search:aclPolicy>
<search:boundaryRules>
<search:boundaryRule>
<search:ruleType>EXCLUSION</search:ruleType>
<search:ruleOperation>STARTSWITH</search:ruleOperation>
<search:rulePattern>
<![CDATA[http://www.example.com?test=test val3]]>
</search:rulePattern>
</search:boundaryRule>
<search:boundaryRule>
<search:ruleType>INCLUSION</search:ruleType>
<search:ruleOperation>CONTAINS</search:ruleOperation>
<search:rulePattern>
<![CDATA[http://www.example.com?test=test val]]>
</search:rulePattern>
</search:boundaryRule>
<search:boundaryRule>
<search:ruleType>INCLUSION</search:ruleType>
<search:ruleOperation>REGEX</search:ruleOperation>
<search:rulePattern>
<![CDATA[^https?://www\.example\.com(?:\:\d{1,5})?(?:$|/)]]>
</search:rulePattern>
</search:boundaryRule>
</search:boundaryRules>
<search:metatagMappings>
<search:metatagMapping>
<search:documentAttr name="AUTHOR" type="STRING"/>
<search:searchAttr name="Author" type="STRING"/>
</search:metatagMapping>
<search:metatagMapping>
<search:documentAttr name="CREATOR" type="STRING"/>
<search:searchAttr name="Author" type="STRING"/>
</search:metatagMapping>
<search:metatagMapping>
<search:documentAttr name="DESCRIPTION" type="STRING"/>
<search:searchAttr name="Description" type="STRING"/>
</search:metatagMapping>
<search:metatagMapping>
<search:documentAttr name="KEYWORD" type="STRING"/>
<search:searchAttr name="Keywords" type="STRING"/>
</search:metatagMapping>
<search:metatagMapping>
<search:documentAttr name="KEYWORDS" type="STRING"/>
<search:searchAttr name="Keywords" type="STRING"/>
</search:metatagMapping>
<search:metatagMapping>
<search:documentAttr name="SUBJECT" type="STRING"/>
<search:searchAttr name="Subject" type="STRING"/>
</search:metatagMapping>
<search:metatagMapping>
<search:documentAttr name="SUBJECTS" type="STRING"/>
<search:searchAttr name="Subject" type="STRING"/>
</search:metatagMapping>
</search:metatagMappings>
<search:crawlerSettings>
<search:numThreads>7</search:numThreads>
<search:languageDetection enabled="true"/>
<search:defaultLanguage>fr</search:defaultLanguage>
<search:crawlDepth haslimit="true">
<search:limit>2</search:limit>
</search:crawlDepth>
<search:crawlTimeout>100</search:crawlTimeout>
<search:maxDocumentSize>1000</search:maxDocumentSize>
<search:preserveDocumentCache enabled="true"/>
<search:defaultCharSet>JIS</search:defaultCharSet>
<search:servicePipeline enabled="false"/>
<search:honorRobotsExclusion enabled="false"/>
<search:indexDynamicPages enabled="true"/>
<search:httpCharSetOverride enabled="false"/>
<search:cookies enabled="true">
<search:cookieContentInLog enabled="false"/>
<search:maxCookieSize>1</search:maxCookieSize>
<search:maxCookies>2</search:maxCookies>
<search:maxCookiesPerHost>3</search:maxCookiesPerHost>
</search:cookies>
</search:crawlerSettings>
<search:documentTypes>
<search:documentType>
<search:mimeType>application/msword</search:mimeType>
</search:documentType>
<search:documentType>
<search:mimeType>application/pdf</search:mimeType>
</search:documentType>
<search:documentType>
<search:mimeType>application/x-msexcel</search:mimeType>
</search:documentType>
<search:documentType>
<search:mimeType>application/x-mspowerpoint</search:mimeType>
</search:documentType>
<search:documentType>
<search:mimeType>text/html</search:mimeType>
</search:documentType>
<search:documentType>
<search:mimeType>text/plain</search:mimeType>
</search:documentType>
</search:documentTypes>
<search:httpAuthentications>
<search:httpAuthentication>
<search:host>testhost1</search:host>
<search:realm>testrealm1</search:realm>
<search:username>testusername1</search:username>
<search:password encrypted="false">
password
</search:password>
</search:httpAuthentication>
</search:httpAuthentications>
<search:htmlForms>
<search:htmlForm>
<search:name>testformname1</search:name>
<search:formUrl>http://test2.oracle.com</search:formUrl>
<search:action>test</search:action>
<search:successUrl>
http://successurl.oracle.com
</search:successUrl>
<search:formControls>
<search:formControl>
<search:name>testcontrol1</search:name>
<search:value encrypted="false">testvalue1</search:value>
<search:isPasswordField>false</search:isPasswordField>
</search:formControl>
<search:formControl>
<search:name>testcontrol2</search:name>
<search:value encrypted="false">
this_value
</search:value>
<search:isPasswordField>true</search:isPasswordField>
</search:formControl>
</search:formControls>
</search:htmlForm>
</search:htmlForms>
<search:ssoAuthentication enabled="true">
<search:username>testsso</search:username>
<search:password encrypted="false">
password
</search:password>
</search:ssoAuthentication>
</search:webSource>
</search:sources>
</search:config>
Example 2-6 Sample Web Source Description for Configuring Sitemap
This XML document describes Sitemap configuration for a Web source.
<?xml version="1.0" encoding="UTF-8"?>
<search:config productVersion="11.2.2.2.0" xmlns:search="http://xmlns.oracle.com/search">
<search:sources>
<search:webSource>
<search:name>websource_2</search:name>
<search:crawlerSettings>
<search:sitemap>SITEMAP_ONLY</search:sitemap>
</search:crawlerSettings>
</search:webSource>
</search:sources>
</search:config>
sourceGroup
A source group consists of one or more sources. When entering a search, users can select the source groups to search instead of searching all available sources. A source can belong to multiple source groups.
create createAll delete deleteAll deleteList export exportAll exportList getAllObjectKeys update updateAll
Global Settings - Translate Source Group Name
Search - Source Groups - Create or Edit Source Group
The <search:sourceGroups> element describes source groups:
<search:sourceGroups> <search:sourceGroup> <search:name> <search:translations> <search:assignedSources> <search:assignedSource>
Schema Descriptions
- <search:sourceGroups>
-
Contains one or more
<search:sourceGroup>elements, each defining a source group. - <search:sourceGroup>
-
Describes a source group. It contains these elements:
<search:name> <search:translations> <search:assignedSources>
- <search:name>
-
Contains the name of the source group. (Required)
- <search:translations>
-
Contains translations of the object name for display. See "Providing Translations of Object Names".
- <search:assignedSources>
-
Contains one or more
<search:assignedSource>elements, each identifying a source assigned to this source group. - <search:assignedSource>
-
Contains the name of a source in this source group.
This XML document defines two source groups, Web and Calendar:
<search:config productVersion="11.2.2.2.0" xmlns:search="http://xmlns.oracle.com/search">
<search:sourceGroups>
<search:sourceGroup>
<search:name>Web</search:name>
</search:sourceGroup>
<search:sourceGroup>
<search:name>Calendar</search:name>
<search:translations>
<search:translation language="de">
<search:translatedValue>Kalender</search:translatedValue>
</search:translation>
<search:translation language="fi">
<search:translatedValue>kalenteri</search:translatedValue>
</search:translation>
<search:translation language="es">
<search:translatedValue>calendario</search:translatedValue>
</search:translation>
<search:translation language="pt-br">
<search:translatedValue>calendario</search:translatedValue>
</search:translation>
</search:translations>
</search:sourceGroup>
</search:sourceGroups>
</search:config>
sourceType
A source type identifies where the information for a source is stored, such as on a Web site or in a database table. Oracle SES provides several built-in source types.
create createAll delete deleteAll deleteList export exportAll exportList getAllObjectKeys update updateAll
The <search:sourceTypes> element describes the source types:
<search:sourceTypes> <search:sourceType> <search:name> <search:managerClassName> <search:jarFilePath> <search:description> <search:securityCapability> <search:parameterInfos> <search:parameterInfo> <search: defaultValue> <search:encrypted> <search: description>
Element Descriptions
- <search:sourceTypes>
-
Describes all source types. It contains one or more
<search:sourceType>elements, each defining a source type. - <search:sourceType>
-
Describes a source type. It contains these elements:
<search:name> <search:managerClassName> <search:jarFilePath> <search:description> <search:securityCapability> <search:parameterInfos>
- <search:name>
-
Contains the name of the source type.
- <search:managerClassName>
-
Contains the name of the plug-in manager Java class.
- <search:jarFilePath>
-
Contains the qualified name of the jar file. Paths can be absolute or relative to the ses_home/search/lib/plugins directory.
- <search:description>
-
Contains a description of the source type.
- <search:securityCapability>
-
Contains one of these values from the plug-in:
IDENTITY_BASED,USER_DEFINED, orUNKNOWN. (Read only) - <search:parameterInfos>
-
Contains one or more
<search:parameterInfo>elements, each describing a parameter of the source type. - <search:parameterInfo>
-
Describes a parameter. It contains these elements:
<search:defaultValue> <search:encrypted> <search:description>
Attribute Value NameName of the parameter. (Required) - <search: defaultValue>
-
Default value of the parameter.
- <search:encrypted>
-
Indicates whether the parameter represents a value that should be encrypted. Set to
trueto encrypt the value, or set tofalseotherwise. The default value isfalse(Optional). - <search: description>
-
Description of the parameter.
This XML document describes the Oracle Content Database source type:
<?xml version="1.0" encoding="UTF-8"?>
<search:config productVersion="11.2.2.2.0" xmlns:search="http://xmlns.oracle.com/search">
<search:sourceTypes>
<search:sourceType>
<search:name>Oracle Content Database</search:name>
<search:managerClassName>
oracle.search.plugin.ocs.cservices.OCSCSPluginMgr
</search:managerClassName>
<search:jarFilePath>cservices/ocscsrvV2.jar</search:jarFilePath>
<search:description>
Oracle Content Database crawler plug-in
</search:description>
<search:securityCapability>USER_DEFINED</search:securityCapability>
<search:parameterInfos>
<search:parameterInfo name="CDB Server public key alias">
<search:encrypted>false</search:encrypted>
<search:description>
Oracle Content Database Server public key alias
</search:description>
</search:parameterInfo>
<search:parameterInfo name="Crawl only">
<search:defaultValue>false</search:defaultValue>
<search:encrypted>false</search:encrypted>
<search:description>
True will perform a crawl without indexing the documents
</search:description>
</search:parameterInfo>
<search:parameterInfo name="Depth">
<search:defaultValue>-1</search:defaultValue>
<search:encrypted>false</search:encrypted>
<search:description>
Depth from starting paths ("-1" for no limit)
</search:description>
</search:parameterInfo>
<search:parameterInfo name="Entity name">
<search:encrypted>false</search:encrypted>
<search:description>
Name of the trusted entity in Oracle Internet Directory (OID)
</search:description>
</search:parameterInfo>
<search:parameterInfo name="Entity password">
<search:encrypted>true</search:encrypted>
<search:description>
Password of the trusted entity in OID
</search:description>
</search:parameterInfo>
<search:parameterInfo name="Oracle Content Database URL">
<search:encrypted>false</search:encrypted>
<search:description>Oracle Content Database Web services endpoint; for example, "http://contentserver:7777/content"</search:description>
</search:parameterInfo>
<search:parameterInfo name="Oracle Content Database Version">
<search:defaultValue>10.1.2.3.0</search:defaultValue>
<search:encrypted>false</search:encrypted>
<search:description>Oracle Content Database version; for example, "10.1.2.3.0"</search:description>
</search:parameterInfo>
<search:parameterInfo name="Oracle Content Database admin user">
<search:encrypted>false</search:encrypted>
<search:description>Name of administrator user for Oracle Content Database; for example, orcladmin</search:description>
</search:parameterInfo>
<search:parameterInfo name="SES keystore location">
<search:encrypted>false</search:encrypted>
<search:description>
SES keystore location for WS security
</search:description>
</search:parameterInfo>
<search:parameterInfo name="SES keystore password">
<search:encrypted>true</search:encrypted>
<search:description>SES keystore password</search:description>
</search:parameterInfo>
<search:parameterInfo name="SES keystore type">
<search:encrypted>false</search:encrypted>
<search:description>SES keystore type</search:description>
</search:parameterInfo>
<search:parameterInfo name="SES private key alias">
<search:encrypted>false</search:encrypted>
<search:description>
SES client private key alias
</search:description>
</search:parameterInfo>
<search:parameterInfo name="SES private key password">
<search:encrypted>true</search:encrypted>
<search:description>
SES client private key password
</search:description>
</search:parameterInfo>
<search:parameterInfo name="Starting paths">
<search:defaultValue>/</search:defaultValue>
<search:encrypted>false</search:encrypted>
<search:description>
Paths (not encoded) to start crawling (separated by ";" )
</search:description>
</search:parameterInfo>
<search:parameterInfo name="Use e-mail for authorization">
<search:defaultValue>false</search:defaultValue>
<search:encrypted>false</search:encrypted>
<search:description>Use e-mail to resolve the user privilege. Set this to true if the Oracle Internet Directory has been configured to use "mail" as the nickname attribute.</search:description>
</search:parameterInfo>
</search:parameterInfos>
</search:sourceType>
</search:sourceTypes>
</search:config>
storageArea
A storage area is equivalent to an Oracle ASSM tablespace that must be created by the Oracle SES database administrator. The storageArea object just registers the existing tablespace with Oracle SES.
See Also:
"Parallel Querying and Index Partitioning" in Oracle Secure Enterprise Search Administrator's Guidecreate createAll delete deleteAll deleteList export exportAll exportList getAllObjectKeys update updateAll
A <search:storageAreas> element describes a storage area:
<search:storageAreas> <search:storageArea> <search:name> <search:description> <search:usage>
Element Contents:
- <search:storageAreas>
-
Contains one or more
<search:storageArea>elements, each defining a storage area for use by Oracle SES. - <search:storageArea>
-
Describes a storage area. It contains these elements:
<search:name> <search:description> <search:usage>
- <search:name>
-
Name of the storage area. (Required)
Enter the name of an existing ASSM tablespace and specify
PARTITIONfor the usage type. An ASSM (Automatic Segment Space Management) tablespace can be created with the SQLCREATE TABLESPACEclauseEXTENT MANAGEMENT LOCAL SEGMENT SPACE MANAGEMENT AUTO.The default tablespaces for Oracle SES are SEARCH_DATA, SEARCH_INDEX, and SEARCH_TEMP.
- <search:description>
-
Description of the storage area. (Required)
- <search:usage>
-
-
PARTITION: Stores document index. -
CACHE_FILE: Stores secure cache. You cannot create or delete the cache file storage area. -
CRAWLER: Stores tokens for index. This storage type is used by the Push crawler. -
SYSTEM: Stores index data. You cannot create or delete the system storage area.
-
This XML document describes the default SEARCH_DATA storage area:
<?xml version="1.0" encoding="UTF-8"?>
<search:config productVersion="11.2.2.2.0" xmlns:search="http://xmlns.oracle.com/search">
<search:storageAreas>
<search:storageArea>
<search:name>SEARCH_DATA</search:name>
<search:description>Default storage area</search:description>
<search:usage>PARTITION</search:usage>
</search:storageArea>
</search:storageAreas>
</search:config>
suggContent
The suggContent object contains the suggested content configuration settings.
The <search:suggContent> element describes suggested content:
<search:suggContent> <search:timeout> <search:numProviders>
Element Descriptions
- <search:suggContent>
-
Describes suggested content parameters. It contains these elements:
<search:timeout> <search:numProviders>
- <search:timeout>
-
Time limit, in milliseconds, for Oracle SES to fetch the content. If search result contains suggested content, then the result page is not rendered until the content is available or until the timeout period has expired.
- <search:numProviders>
-
Maximum number of suggested content results (up to 20) to be included with the Oracle SES result list. The results are rendered on a first-come, first-served basis.
This XML document contains the suggested content configuration settings.
<?xml version="1.0" encoding="UTF-8"?>
<search:config productVersion="11.2.2.2.0" xmlns:search="http://xmlns.oracle.com/search">
<search:suggContent>
<search:timeout>2000</search:timeout>
<search:numProviders>2</search:numProviders>
</search:suggContent>
</search:config>
suggContentProvider
The suggContentProvider object contains the information about suggested content providers.
activate create createAll deactivate delete deleteAll deleteList export exportAll exportList getAllObjectKeys getAllStates getState getStateList update updateAll
The <search:suggContentProviders> element describes suggested content providers:
<search:suggContentProviders> <search:suggContentProvider> <search:name> <search:queryPattern> <search:providerUrl> <search:xsltStyleSheet> <search:securitySettings> <!-- securitySettings element can have only one of the following child elements - none, cookie, or serviceToService> <search:none> <search:cookie> <search:name> <search:unauthenticatedUserAction> <search:loginUrl> <search:serviceToService> <search:entityName> <search:entityPassword> <search:format>
Element Descriptions
- <search:suggContentProviders>
-
Contains one or more
<search:suggContentProvider>elements. - <search:suggContentProvider>
-
Describes a suggested content provider. It contains these elements:
<search:name> <search:queryPattern> <search:providerUrl> <search:xsltStyleSheet> <search:securitySettings>
- <search:name>
-
Name of the suggested content provider.
- <search:queryPattern>
-
Query pattern for the suggested content provider. The query pattern is defined using regular expressions as supported in the Java regular expression API
java.util.regex. The query pattern must be specified in a CDATA section. - <search:providerUrl>
-
URL of the suggested content provider.
- <search:xsltStyleSheet>
-
XSLT style sheet that defines rules (for example, the size and style) for transforming XML content from a provider into HTML format. The XSLT style sheet must be specified in a CDATA section.
- <search:securitySettings>
-
Describes how Oracle SES passes end user's authentication information to the suggested content provider. It contains one of the following child elements:
<search:none> <search:cookie> <search:serviceToService>
- <search:none>
-
Describes the option of using no security settings.
- <search:cookie>
-
Describes the option of using security settings by using a cookie to pass user authentication information to the suggested content provider. It contains the following elements.
<search:name> <search:unauthenticatedUserAction> <search:loginUrl>
- <search:name>
-
Name of the cookie.
- <search:unauthenticatedUserAction>
-
Describes what should happen when suggested content is available but the user is not logged in to the content provider or the cookie for the suggested content provider is not available. It can have one of the following values:
-
IGNORE_CONTENT- Oracle SES returns the result list with no suggested content. -
DISPLAY_LOGIN_MESSAGE- Oracle SES returns a message that there is content available from this provider but the user is not logged in. The message also provides a link to log in to that provider. Specify the link for the suggested content provider login in the <search:loginUrl> element.
-
- <search:loginUrl>
-
When
DISPLAY_LOGIN_MESSAGEvalue is specified for the <search:unauthenticatedUserAction> element, then specify the URL to log in to the suggested content provider in the <search:loginUrl> element. - <search:serviceToService>
-
Describes the option of using security settings by establishing one-way trusted relationship between Oracle SES and the suggested content provider. It contains the following elements.
<search:entityName> <search:entityPassword> <search:format>
- <search:entityName>
-
User name for logging in to the suggested content provider application.
- <search:entityPassword>
-
Password for logging in to the suggested content provider application.
- <search:format>
-
Authentication format for the user logging in to the suggested content provider application.
This XML document contains the definition for a suggested content provider.
<?xml version="1.0" encoding="UTF-8"?>
<search:config productVersion="11.2.2.2.0" xmlns:search="http://xmlns.oracle.com/search">
<search:suggContentProviders>
<search:suggContentProvider>
<search:name>Provider1</search:name>
<search:queryPattern><![CDATA[dir (\S+)]]></search:queryPattern>
<search:providerUrl>http://www.xyz.com:8810/OASearchProvider?query=dir%20john&p0=dir&p1=john&authType=sso</search:providerUrl>
<search:xsltStyleSheet>
<![CDATA[<?xml version="1.0" encoding="ISO-8859-1"?>
<xsl:stylesheet version="2.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output method="html" indent="no"/>
<xsl:template match="/OneBoxResults">
<HTML>
<table border="0" cellpadding="1" cellspacing="0">
<tr>
<td>
<a>
<xsl:attribute name="href">
<xsl:value-of select="title/urlLink"/>
</xsl:attribute>
<b>
App HR:<xsl:value-of select="title/urlText"/>
</b>
</a>
<table width="100%" border="0" cellspacing="0" cellpadding="0">
<tr>
<td style="vertical-align:middle;width:20px">
<img alt="Service">
<xsl:attribute name="src">
<xsl:value-of select="IMAGE_SOURCE"/>
</xsl:attribute>
</img>
</td>
<td style="padding-left:6px;vertical-align:top;">
<xsl:for-each select="MODULE_RESULT">
<table width="100%" border="0" cellspacing="0" cellpadding="1">
<tr valign="top" align="left">
<td colspan="5" align="left">
<font size="-1">
<b>
<xsl:value-of select="Field[@name='DisplayName']"/>
</b>
</font>
</td>
<td align="right">
<font size="-1">Phone:</font>
</td>
<td align="left">
<font size="-1">
<nobr>
<b>
<xsl:value-of select="Field[@name='WorkTelephone']"/>
</b>
</nobr>
</font>
</td>
<td style="padding-left:6px">
</td>
<td align="right">
<font size="-1">Email:</font>
</td>
<td align="left">
<font size="-1">
<nobr>
<b>
<xsl:value-of select="Field[@name='EmailAddress']"/>
</b>
</nobr>
</font>
</td>
<td align="right">
<font size="-1">
<nobr>location:</nobr>
</font>
</td>
<td align="left">
<font size="-1">
<nobr>
<b>
<xsl:value-of select="Field[@name='DerivedLocale']"/>
</b>
</nobr>
</font>
</td>
<td>
</td>
</tr>
</table>
</xsl:for-each>
</td>
</tr>
</table>
</td>
</tr>
</table>
</HTML>
</xsl:template>
</xsl:stylesheet>]]>
</search:xsltStyleSheet>
<search:securitySettings>
<search:cookie>
<search:name>testcookie1</search:name>
<search:unauthenticatedUserAction>DISPLAY_LOGIN_MESSAGE</search:unauthenticatedUserAction>
<search:loginUrl>http://www.xyz.com:8810/OASearchProvider?query=dir%20john&p0=dir&p1=john&authType=sso</search:loginUrl>
</search:cookie>
</search:securitySettings>
</search:suggContentProvider>
</search:suggContentProviders>
</search:config>
suggestion
The suggestion object is used to create, update, delete, and export suggestions.
create createAll delete deleteAll deleteList export exportAll exportList getAllObjectKeys update updateAll
The <search:suggestions> element describes suggestions:
<search:suggestions> <search:suggestion> <search:name> <search:classification> <search:language> <search:weight>
Element Descriptions
- <search:suggestions>
-
Contains one or more
<search:suggestion>element. - <search:suggestion>
-
Contains these elements:
<search:name> <search:classification> <search:language> <search:weight>
- <search:name>
-
The suggestion keyword.
- <search:classification>
-
The classification for the suggestion keyword.
- <search:language>
-
The language for which this suggestion keyword should be displayed. It is pecified using a two letter code. The language codes are not case sensitive. See Table 2-3, "Languages Supported by the Crawler". The value
anycan also be specified for the language, denoting that the suggestion is language independent. - <search:weight>
-
Specify weight for the suggestion keyword, based on which Oracle SES retrieves and sorts suggestions, with the highest weighted suggestions being displayed first in the search results.
This XML document contains the definition for the suggestion keyword ses.
<?xml version="1.0" encoding="UTF-8"?>
<search:config productVersion="11.2.2.2.0" xmlns:search="http://xmlns.oracle.com/search">
<search:suggestions>
<search:suggestion>
<search:name>ses</search:name>
<search:classification>OracleGeneric</search:classification>
<search:language>en</search:language>
<search:weight>10</search:weight>
</search:suggestion>
</search:suggestions>
</search:config>
suggLink
Suggested links direct users to a designated Web site for particular query keywords. For example, a suggested link might be http://www.oracle.com/technetwork/search/oses/overview/index.html for 'Oracle Secure Enterprise Search documentation', 'Enterprise Search documentation', and 'Search documentation'.
create createAll delete deleteAll deleteList export exportAll exportList getAllObjectKeys update updateAll
The <search:suggLinks> element describes suggested links:
<search:suggLinks> <search:suggLink> <search:keyword> <search:linkUrl> <search:linkText>
Element Descriptions
- <search:suggLinks>
-
Contains one or more
<search:suggLink>elements, each describing a suggested link. - <search:suggLink>
-
Describes a suggested link. It contains one of each of these child elements:
<search:keyword> <search:linkUrl> <search:linkText>
- <search:keyword>
-
A word or phrase with optional operators that identifies which search queries display this suggested link. (Required)
Do not enter special characters, such as
#,$,=,&. You can include the following operators:Operation Syntax Example about ABOUT(term)about(dogs) and termANDtermdog and cat near term;termdog ; cat or termORtermdog or cat phrase phrasedog sled stem $term$dog thesaurus {BT | NT | SYN} (term)SYN(dog) within termWITHINtermdog within title - <search:linkUrl>
-
A link to the suggested page, which appears in the result list., such as
http://www.example.com. (Required) - <search:linkText>
-
The linked text that appears in the result list, such as
Example Corp. (Required)
This XML document defines a suggested link for a query on the term "oracle":
<search:config productVersion="11.2.2.2.0" xmlns:search="http://xmlns.oracle.com/search">
<search:suggLinks>
<search:suggLink>
<search:keyword>oracle</search:keyword>
<search:linkUrl>http://www.oracle.com</search:linkUrl>
<search:linkText>Oracle</search:linkText>
</search:suggLink>
</search:suggLinks>
</search:config>
tagging
The tagging object contains the tagging related configuration settings.
The <search:tagging> element describes the tagging configurations:
<search:tagging> <search:maxTagPerDoc> <search:maxTagPerSession> <search:tagCleanupInterval> <search:authorizationMode>
Element Descriptions
- <search:tagging>
-
Contains the following elements:
<search:maxTagPerDoc> <search:maxTagPerSession> <search:tagCleanupInterval> <search:authorizationMode>
- <search:maxTagPerDoc>
-
Maximum number of tags that can be assigned to a document (not specific to a user). The default value is 100.
- <search:maxTagPerSession>
-
Maximum number of tags that can be added in a session. The default value is 100.
- <search:tagCleanupInterval>
-
Number of days for which any tag should be available in the query application, even if it is not being used. When the number of days specified in tagCleanupInterval elapse, the tags that are unused for the specified number of days are removed from Oracle SES. The default value is 30.
- <search:authorizationMode>
-
Specify one of the following authorization modes:
Tagging Mode Description loggedInUsersTagging is enabled only for the users who are logged-in. This is default. allUsersTagging is enabled for all the users (anonymous tagging). authorizedPrincipalsTagging is enabled only for specific users having tagging privilege.
This XML document defines the tagging configuration:
<?xml version="1.0" encoding="UTF-8"?>
<search:config productVersion="11.2.2.2.0" xmlns:search="http://xmlns.oracle.com/search">
<search:tagging>
<search:maxTagPerDoc>100</search:maxTagPerDoc>
<search:maxTagPerSession>100</search:maxTagPerSession>
<search:tagCleanupInterval>30</search:tagCleanupInterval>
<search:authorizationMode><search:loggedInUsers/></search:authorizationMode>
</search:tagging>
</search:config>
tag
The tag object can be used to upload tags in bulk in Oracle SES.
create createAll delete deleteAll deleteList export exportAll exportList getAllObjectKeys update updateAll
The <search:tags> element describes the tags for bulk upload:
<search:tags> <search:tag> <search:name> <search:docURL> <search:owner>
Element Descriptions
- <search:tags>
-
Contains one or more
<search:tag>elements. - <search:tag>
-
Contains information for each tag. It contains the following elements:
<search:name> <search:docURL> <search:owner>
- <search:name>
-
Name of the tag.
- <search:docURL>
-
URL of the document that needs to be tagged.
- <search:owner>
-
Owner of the document.
This XML document contains the tags for bulk upload:
<?xml version="1.0" encoding="UTF-8"?>
<search:config productVersion="11.2.2.2.0" xmlns:search="http://xmlns.oracle.com/search">
<search:tags>
<search:tag>
<search:name>oses</search:name>
<search:docUrl>http://www.oracle.com/xyz.html</search:docUrl>
<search:owner>abc@oracle.com</search:owner>
</search:tag>
</search:tags>
</search:config>
thesaurus
A thesaurus is a list of terms or phrases with relationships specified among them, such as a synonym, a broader term, and a narrower term. When a user issues a search query, Oracle SES can expand the search results to include matches for the related terms.
A thesaurus contains domain-specific knowledge. You can build a thesaurus, buy an industrial-specific thesaurus, or use utilities to extract a thesaurus from a specific corpus of documents. The thesaurus must be compliant with both the ISO-2788 and ANSI Z39.19(1993) standards.
A thesaurus must be loaded in Oracle SES for thesaurus-based query expansion. If no thesaurus is loaded or if the specified term or phrase cannot be found in the loaded thesaurus, then query expansion is not possible. Oracle SES only returns documents containing the original term or phrase. The default expansion level is one.
The proper encoding of an XML document for thesaurus configuration is UTF-8, which is the Oracle SES default language setting. Ensure that the NLS_LANG environment variable setting is consistent with the XML document encoding.
The <search:thesauruses> element defines a thesaurus:
<search:thesauruses> <search:thesaurus> <search:name> <search:thesaurusContent>
Element Descriptions
- <search:thesauruses>
-
Contains a
<search:thesaurus>element, which describes a thesaurus. - <search:thesaurus>
-
Describes a thesaurus. It contains these child elements:
<search:name> <search:thesaurusContent>
- <search:name>
-
The name of the thesaurus. This name must be
DEFAULT. (Required) - <search:thesaurusContent>
-
The thesaurus content. (Required)
Enter each term on a separate line within a CDATA element. You can identify broader terms (
BT), narrower terms (NT) and synonyms (SYN). Note the one-space indentation of the related terms:dog BT mammal NT domestic dog NT wild dog SYN canine
This XML document defines the default thesaurus:
<?xml version="1.0" encoding="UTF-8"?>
<search:config productVersion="11.2.2.2.0" xmlns:search="http://xmlns.oracle.com/search">
<search:thesauruses>
<search:thesaurus>
<search:name>DEFAULT</search:name>
<search:thesaurusContent>
<![CDATA[
cat
SYN feline
NT domestic cat
NT wild cat
BT mammal
mammal
BT animal
domestic cat
NT Persian cat
NT Siamese cat
wild cat
NT tiger
tiger
NT Bengal tiger
dog
BT mammal
NT domestic dog
NT wild dog
SYN canine
domestic dog
NT German Shepard
wild dog
NT Dingo
]]>
</search:thesaurusContent>
</search:thesaurus>
</search:thesauruses>
</search:config>