| Oracle® Enterprise Data Quality for Product Data Knowledge Studio Reference Guide Release 11g R1 (11.1.1.6) Part Number E29134-02 |
|
|
PDF · Mobi · ePub |
| Oracle® Enterprise Data Quality for Product Data Knowledge Studio Reference Guide Release 11g R1 (11.1.1.6) Part Number E29134-02 |
|
|
PDF · Mobi · ePub |
Regular Expressions use character pattern matching to find and capture the information you need. Regular Expressions are used most frequently in the Knowledge Studio when creating Terminology rules.
To use Regular Expressions, you must learn the syntax. Regular Expressions use special characters, wildcards, to match a range of other characters. A Regular Expression found in a Terminology rule is surrounded by forward slashes.
The following table lists of many of the special characters used in a regular expression and some example expressions:
| Wildcard or Meta-Characters | Description and Examples |
|---|---|
| . | The dot character matches any single character.
For example, the terminology rule regular expression, "/a.b/", matches all text where there is an "a" followed by any single character, followed by a "b", as in, "a5b". |
| * | The asterisk matches the preceding pattern or character zero or more times.
For example, "/fo*/" matches the following text fragments: "f", "fo", "foo", "fooo" Combining the period and asterisk, "/a.*b/" will match "a5b", "a55b", "a123b", and so on. |
| + | The plus sign matches the preceding pattern or character one or more times.
For example, /ca+r/ matches the following text fragments: "car", "caar" and "caaar", but will not match "cr". |
| ? | The question mark character matches the preceding pattern or character zero or once.
For example, "/ca?r/" matches both "car" and "cr"; it will not match "caar". |
| {n} | The curly brackets are used to match exactly n instances of the proceeding character or pattern.
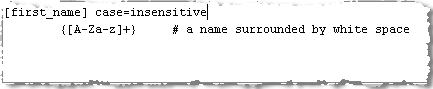
For example, "/x{2}/" matches "xx". Note: The curly brackets are used in the application to differentiate white space bounded text or characters from text or characters that are embedded among other characters with no identifiable white space. |
| {n,m} | This form of the curly brackets is used to match the preceding character or pattern from n to m times, with n greater than m. If m is not present then the pattern is matched n or more times.
For example, "/x{2,3}/" matches "xx" and "xxx". |
| […] | The square brackets match any one of characters inside the brackets. A range of characters in the alphabet can be matched using the hyphen.
For example, "/[xyz]/ "will match any of "x", "y", or "z". Also, "/[xyz]+/" will match "x", "xx", "y", "yy", and so on. Within square brackets, a range of characters can be defined using the dash (-). For example, "[a-z]" matches any lowercase letter, and "[A-Z]" matches any uppercase letter. When using the dash to define a range of characters, the first character must precede the second character in alphabetic or numeric order. For example, "[0-9]" is valid, but "[9-0]" is not valid. |
| (…) | The parentheses are used to group characters.
For example, "(cars?)|bus" will match "car", "cars", or "bus". Note: The parentheses are equivalent to "(?:…)" |
| x|y | The pipe (|) character matches either "x" or "y", where "x" or "y" are blocks of characters.
For example, "car|bus" will match either "car" or "bus". |
| \ | Backslash has two meanings:
Matches against characters that normally have special meaning such as star (*) and dot (.), see preceding descriptions. In this case a "\*" matches the star character. Similarly "" matches the dot character. Used to define a meta-character. The character "w" will normally match "w". A "\w" will match a sequence of alphanumeric characters not interrupted by white space, see the following description. |
| \w | Matches any alphanumeric character or the underscore. This is identical to "[A-Za-z0-9_]". |
| \W | Matches any character that is not alphanumeric and not underscore. |
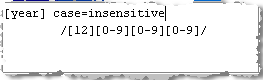
| \d | Matches all digits. Identical to "[0-9]".
For example, "/\d+/" will match one or more digits. For example, positive integers. |
| \D | Matches all non-digits including white space. |
| \s | Matches any white space character including a tab or a space. |
| \S | Matches any character other than white space characters. |
| (?i) | The "(?i)" meta-characters indicate that the following pattern should ignore the case of letters when performing the match.
For example, the pattern "(?i)car" will match "Car", "car", "cAR", and so on. And "(?i)cars?" will match "Car", "Cars", "CarS", and so on. Note: The syntax differences between this match rule and the following three are where the pattern is inside the parentheses. |
| (?!pattern1)pattern2 | The "(?!…)… meta-characters say that if the first pattern is not present, pattern1, then accept the second pattern, pattern2.
For example, /(?!x)car/ matches "car"; it will not match "xcar". Note: Both pattern1 and pattern2 are required. |
|
Copyright © 2001, 2013, Oracle and/or its affiliates. All rights reserved. Legal Notices |
|