2 Administering Oracle Big Data Appliance
This chapter provides information about the software and services installed on Oracle Big Data Appliance. It contains these sections:
2.1 Monitoring a Cluster Using Oracle Enterprise Manager
An Oracle Enterprise Manager plug-in enables you to use the same system monitoring tool for Oracle Big Data Appliance as you use for Oracle Exadata Database Machine or any other Oracle Database installation. With the plug-in, you can view the status of the installed software components in tabular or graphic presentations, and start and stop these software services. You can also monitor the health of the network and the rack components.
After selecting a target cluster, you can drill down into these primary areas:
-
InfiniBand network: Network topology and status for InfiniBand switches and ports. See Figure 2-1.
-
Hadoop cluster: Software services for HDFS, MapReduce, and ZooKeeper.
-
Oracle Big Data Appliance rack: Hardware status including server hosts, Oracle Integrated Lights Out Manager (Oracle ILOM) servers, power distribution units (PDUs), and the Ethernet switch.
Figure 2-1 shows some of the information provided about the InfiniBand switches.
Figure 2-1 InfiniBand Home in Oracle Enterprise Manager
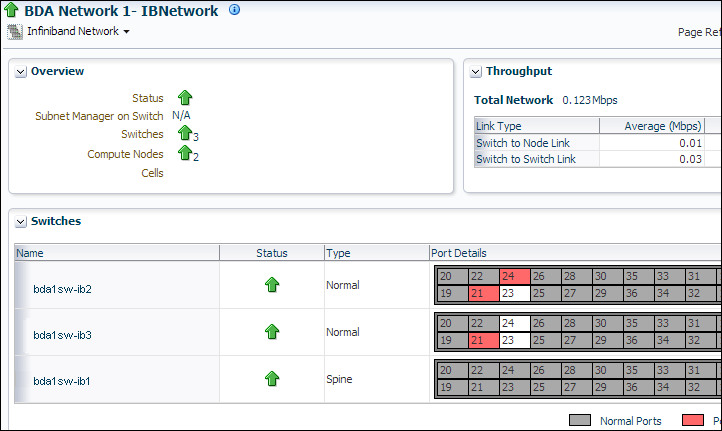
Description of "Figure 2-1 InfiniBand Home in Oracle Enterprise Manager"
To monitor Oracle Big Data Appliance using Oracle Enterprise Manager:
-
Download and install the plug-in. See Oracle Enterprise Manager System Monitoring Plug-in Installation Guide for Oracle Big Data Appliance.
-
Log in to Oracle Enterprise Manager as a privileged user.
-
From the Targets menu, choose Big Data Appliance to view the Big Data page. You can see the overall status of the targets already discovered by Oracle Enterprise Manager.
-
Select a target cluster to view its detail pages.
-
Expand the target navigation tree to display the components. Information is available at all levels.
-
Select a component in the tree to display its home page.
-
To change the display, choose an item from the drop-down menu at the top left of the main display area.
See Also:
Oracle Enterprise Manager System Monitoring Plug-in Installation Guide for Oracle Big Data Appliance for installation instructions and use cases.2.2 Managing CDH Operations Using Cloudera Manager
Cloudera Manager is installed on Oracle Big Data Appliance to help you with Cloudera's Distribution including Apache Hadoop (CDH) operations. Cloudera Manager provides a single administrative interface to all Oracle Big Data Appliance servers configured as part of the Hadoop cluster.
Cloudera Manager simplifies the performance of these administrative tasks:
-
Monitor jobs and services
-
Start and stop services
-
Manage security and Kerberos credentials
-
Monitor user activity
-
Monitor the health of the system
-
Monitor performance metrics
-
Track hardware use (disk, CPU, and RAM)
Cloudera Manager runs on the JobTracker node (node03) of the primary rack and is available on port 7180.
To use Cloudera Manager:
-
Open a browser and enter a URL like the following:
http://bda1node03.example.com:7180
In this example,
bda1is the name of the appliance,node03is the name of the server,example.comis the domain, and7180is the default port number for Cloudera Manager. -
Log in with a user name and password for Cloudera Manager. Only a user with administrative privileges can change the settings. Other Cloudera Manager users can view the status of Oracle Big Data Appliance.
See Also:
Cloudera Manager User Guide athttp://ccp.cloudera.com/display/ENT/Cloudera+Manager+User+Guide
or click Help on the Cloudera Manager Help menu
2.2.1 Monitoring the Status of Oracle Big Data Appliance
In Cloudera Manager, you can choose any of the following pages from the menu bar across the top of the display:
-
Services: Monitors the status and health of services running on Oracle Big Data Appliance. Click the name of a service to drill down to additional information.
-
Hosts: Monitors the health, disk usage, load, physical memory, swap space, and other statistics for all servers.
-
Activities: Monitors all MapReduce jobs running in the selected time period.
-
Logs: Collects historical information about the systems and services. You can search for a particular phrase for a selected server, service, and time period. You can also select the minimum severity level of the logged messages included in the search: TRACE, DEBUG, INFO, WARN, ERROR, or FATAL.
-
Events: Records a change in state and other noteworthy occurrences. You can search for one or more keywords for a selected server, service, and time period. You can also select the event type: Audit Event, Activity Event, Health Check, or Log Message.
-
Reports: Generates reports on demand for disk and MapReduce use.
Figure 2-2 shows the opening display of Cloudera Manager, which is the Services page.
Figure 2-2 Cloudera Manager Services Page
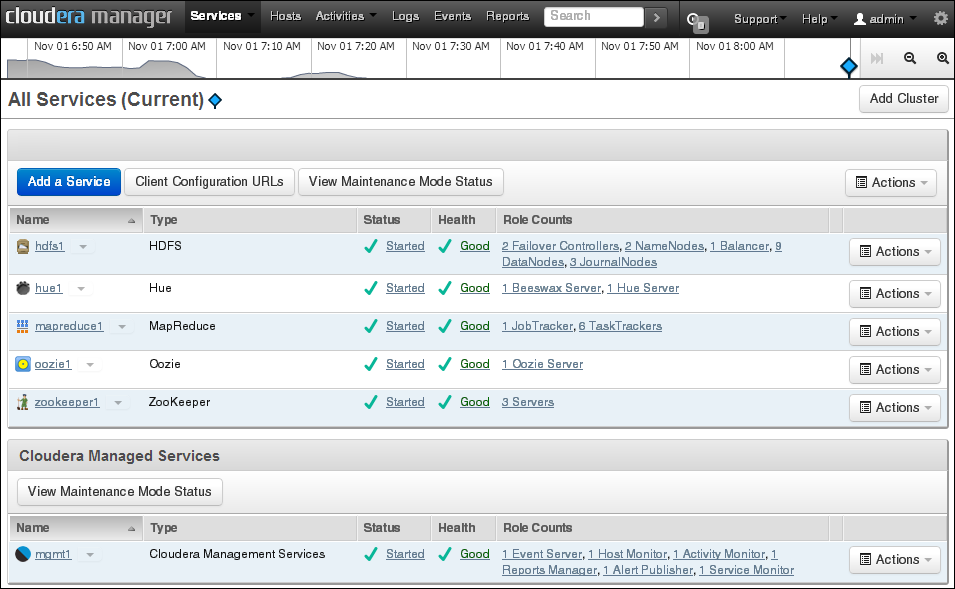
Description of "Figure 2-2 Cloudera Manager Services Page"
2.2.2 Performing Administrative Tasks
As a Cloudera Manager administrator, you can change various properties for monitoring the health and use of Oracle Big Data Appliance, add users, and set up Kerberos security.
To access Cloudera Manager Administration:
-
Log in to Cloudera Manager with administrative privileges.
-
Click Welcome admin at the top right of the page.
2.2.3 Managing Services With Cloudera Manager
Cloudera Manager provides the interface for managing these services:
-
HDFS
-
Hue
-
MapReduce
-
Oozie
-
ZooKeeper
You can use Cloudera Manager to change the configuration of these services, stop, and restart them.
Note:
Manual edits to Linux service scripts or Hadoop configuration files do not affect these services. You must manage and configure them using Cloudera Manager.2.3 Using Hadoop Monitoring Utilities
Users can monitor MapReduce jobs without providing a Cloudera Manager user name and password.
2.3.1 Monitoring the JobTracker
Hadoop Map/Reduce Administration monitors the JobTracker, which runs on port 50030 of the JobTracker node (node03) on Oracle Big Data Appliance.
To monitor the JobTracker:
-
Open a browser and enter a URL like the following:
http://bda1node03.example.com:50030
In this example,
bda1is the name of the appliance,node03is the name of the server, and50030is the default port number for Hadoop Map/Reduce Administration.
Figure 2-3 shows part of a Hadoop Map/Reduce Administration display.
Figure 2-3 Hadoop Map/Reduce Administration
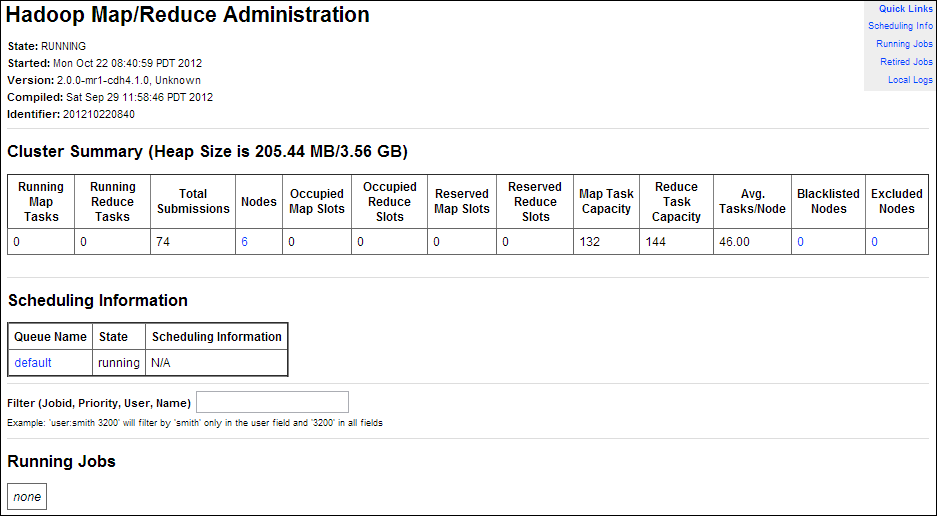
Description of "Figure 2-3 Hadoop Map/Reduce Administration"
2.3.2 Monitoring the TaskTracker
The Task Tracker Status interface monitors the TaskTracker on a single node. It is available on port 50060 of all noncritical nodes (node04 to node18) in Oracle Big Data Appliance. On six-node clusters, the TaskTracker also runs on node01 and node02.
To monitor a TaskTracker:
-
Open a browser and enter the URL for a particular node like the following:
http://bda1node13.example.com:50060
In this example,
bda1is the name of the rack,node13is the name of the server, and50060is the default port number for the Task Tracker Status interface.
Figure 2-4 shows the Task Tracker Status interface.
2.4 Using Hue to Interact With Hadoop
Hue runs in a browser and provides an easy-to-use interface to several applications to support interaction with Hadoop and HDFS. You can use Hue to perform any of the following tasks:
-
Query Hive data stores
-
Create, load, and delete Hive tables
-
Work with HDFS files and directories
-
Create, submit, and monitor MapReduce jobs
-
Monitor MapReduce jobs
-
Create, edit, and submit workflows using the Oozie dashboard
-
Manage users and groups
Hue runs on port 8888 of the JobTracker node (node03).
To use Hue:
-
Open Hue in a browser using an address like the one in this example:
http://bda1node03.example.com:8888In this example,
bda1is the cluster name,node03is the server name, andexample.comis the domain. -
Log in with your Hue credentials.
Oracle Big Data Appliance is not configured initially with any Hue user accounts. The first user who connects to Hue can log in with any user name and password, and automatically becomes an administrator. This user can create other user and administrator accounts.
-
Use the icons across the top to open a utility.
Figure 2-5 shows the Beeswax Query Editor for entering Hive queries.
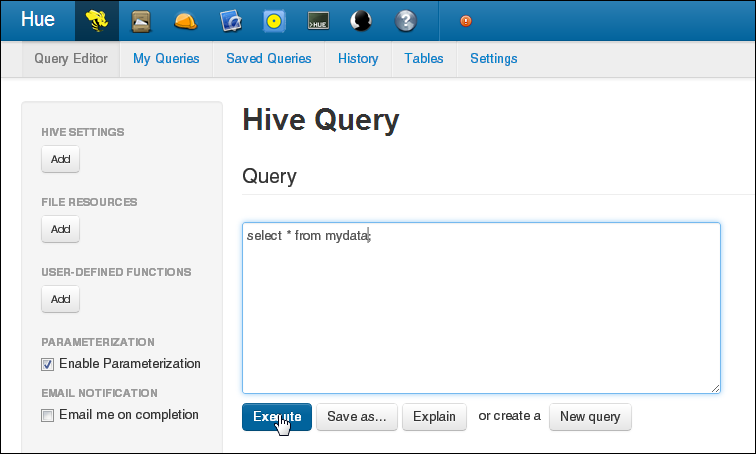
See Also:
Hue Installation Guide for information about using Hue, which is already installed and configured on Oracle Big Data Appliance, at2.5 About the Oracle Big Data Appliance Software
The following sections identify the software installed on Oracle Big Data Appliance and where it runs in the rack. Some components operate with Oracle Database 11.2.0.2 and later releases.
2.5.1 Software Components
These software components are installed on all 18 servers in Oracle Big Data Appliance Rack. Oracle Linux, required drivers, firmware, and hardware verification utilities are factory installed. All other software is installed on site using the Mammoth Utility. The optional software components may not be configured in your installation.
Note:
You do not need to install additional software on Oracle Big Data Appliance. Doing so may result in a loss of warranty and support. See the Oracle Big Data Appliance Owner's Guide.Base image software:
-
Java HotSpot Virtual Machine 6 Update 37
-
Oracle R Distribution 2.15.1
-
MySQL Server 5.5.17 Advanced Edition
-
Puppet, firmware, utilities
Mammoth installation:
-
Cloudera's Distribution including Apache Hadoop Release 4 Update 1.2 (CDH)
-
Oracle Database Instant Client 11.2.0.3
-
Oracle NoSQL Database Community Edition or Enterprise Edition 11g Release 2.0 (optional)
-
Oracle Big Data Connectors 2.1 (optional):
See Also:
Oracle Big Data Appliance Owner's Guide for information about the Mammoth UtilityFigure 2-6 shows the relationships among the major components.
Figure 2-6 Major Software Components of Oracle Big Data Appliance

Description of "Figure 2-6 Major Software Components of Oracle Big Data Appliance"
2.5.2 Logical Disk Layout
Each server has 12 disks. The critical operating system is stored on disks 1 and 2.
Table 2-1 describes how the disks are partitioned.
2.6 About the Software Services
This section contains the following topics:
2.6.1 Monitoring the CDH Services
You can use Cloudera Manager to monitor the CDH services on Oracle Big Data Appliance.
To monitor the services:
-
In Cloudera Manager, click the Services tab at the top of the page to display the Services page.
-
Click the name of a service to see its detail pages. The service opens on the Status page.
-
Click the link to the page that you want to view: Status, Instances, Commands, Configuration, or Audits.
2.6.2 Where Do the Services Run?
All services are installed on all servers, but individual services run only on designated nodes in the Hadoop cluster.
Table 2-2 identifies the nodes where the services run on the primary rack. Services that run on all nodes run on all racks of a multirack installation.
Table 2-2 Software Service Locations
| Service Type | Role | Node Name | Initial Node Position |
|---|---|---|---|
|
Cloudera Management Services |
All nodes |
Node01 to node18 |
|
|
Cloudera Management Services |
JobTracker node |
Node03 |
|
|
HDFS |
First NameNode |
Node01 |
|
|
HDFS |
All nodes |
Node01 to node18 |
|
|
HDFS |
Failover controller |
First NameNode and second NameNode |
Node01 and node02 |
|
HDFS |
First NameNode |
First NameNode |
Node01 |
|
HDFS |
JournalNode |
First NameNode, second NameNode, JobTracker node |
Node01 to node03 |
|
HDFS |
Second NameNode |
Node02 |
|
|
Hive |
Hive server |
JobTracker node |
Node03 |
|
Hue |
JobTracker node |
Node03 |
|
|
Hue |
Hue server |
JobTracker node |
Node03 |
|
MapReduce |
JobTracker node |
Node03 |
|
|
MapReduce |
All noncritical nodes |
Node04 to node18 |
|
|
MySQL |
MySQL Backup ServerFoot 1 |
Second NameNode |
Node02 |
|
MySQL |
MySQL Primary ServerFootref 1 |
JobTracker node |
Node03 |
|
NoSQL |
Oracle NoSQL Database AdministrationFootref 2 |
Second NameNode |
Node02 |
|
NoSQL |
Oracle NoSQL Database Server processesFootref 2 |
All nodes |
Node01 to node18 |
|
ODI |
Oracle Data Integrator agentFoot 2 |
JobTracker node |
Node03 |
|
Puppet |
Puppet agents |
All nodes |
Node01 to node18 |
|
Puppet |
First NameNode |
Node01 |
|
|
ZooKeeper |
ZooKeeper server |
First NameNode, second NameNode, JobTracker node |
Node01 to node03 |
Footnote 1 If the software was upgraded from version 1.0, then MySQL Backup remains on node02 and MySQL Primary Server remains on node03.
Footnote 2 Started only if requested in the Oracle Big Data Appliance Configuration Worksheets
2.6.3 Automatic Failover of the NameNode
The NameNode is the most critical process because it keeps track of the location of all data. Without a healthy NameNode, the entire cluster fails. Apache Hadoop v0.20.2 and earlier are vulnerable to failure because they have a single name node.
Cloudera's Distribution including Apache Hadoop Version 4 (CDH4) reduces this vulnerability by maintaining redundant NameNodes. The data is replicated during normal operation as follows:
-
CDH maintains redundant NameNodes on the first two nodes. One of the NameNodes is in active mode, and the other NameNode is in hot standby mode. If the active NameNode fails, then the role of active NameNode automatically fails over to the standby NameNode.
-
The NameNode data is written to a mirrored partition so that the loss of a single disk can be tolerated. This mirroring is done at the factory as part of the operating system installation.
-
The active NameNode records all changes in at least two JournalNode processes, which the standby NameNode reads. There are three JournalNodes, which run on node01 to node03.
Note:
Oracle Big Data Appliance 2.0 and later releases do not support the use of an external NFS filer for backups and do not use NameNode federation.Figure 2-7 shows the relationships among the processes that support automatic failover on Oracle Big Data Appliance.
Figure 2-7 Automatic Failover of the NameNode on Oracle Big Data Appliance
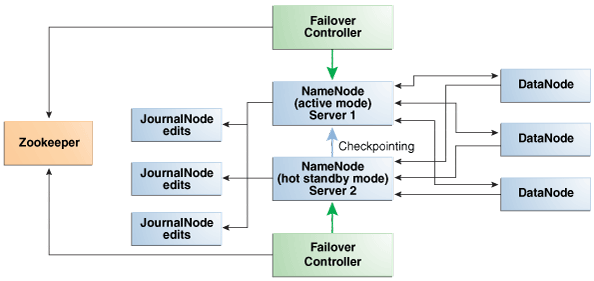
Description of "Figure 2-7 Automatic Failover of the NameNode on Oracle Big Data Appliance"
2.6.4 Unconfigured Software
The RPM installation files for the following tools are available on Oracle Big Data Appliance. Do not download them from the Cloudera website. However, you must install and configure them.
You can find the RPM files on Oracle Big Data Appliance in /opt/oracle/BDAMammoth/bdarepo/RPMS/noarch.
See Also:
CDH4 Installation and Configuration Guide for configuration procedures at2.7 Configuring HBase
HBase is an open-source, column-oriented database provided with CDH. HBase is not configured automatically on Oracle Big Data Appliance. You must set up and configure HBase before you can access it from an HBase client on another system.
To create an HBase service:
-
Open Cloudera Manager in a browser, using a URL like the following:
http://bda1node03.example.com:7180
In this example,
bda1is the name of the appliance,node03is the name of the server,example.comis the domain, and7180is the default port number for Cloudera Manager. -
On the All Services page, click Add a Service.
-
Select HBase from the list of services, then click Continue.
-
Select zookeeper, then click Continue.
-
Click Continue on the host assignments page.
-
Click Accept on the review page.
HBase is now ready for you to configure.
To configure HBase on Oracle Big Data Appliance:
-
On the All Services page of Cloudera Manager, click hbase1.
-
On the hbase1 page, click Configuration.
-
In the Category pane on the left, select Advanced under Service-Wide.
-
In the right pane, locate the HBase Service Configuration Safety Valve for hbase-site.xml property and click the Value cell.
-
Enter the following XML property descriptions:
<property> <name>hbase.master.ipc.address</name> <value>0.0.0.0</value> </property> <property> <name>hbase.regionserver.ipc.address</name> <value>0.0.0.0</value> </property>
-
Click the Save Changes button.
-
From the Actions menu, select either Start or Restart, depending on the current status of the HBase server.
-
Log out of Cloudera Manager.
2.8 Effects of Hardware on Software Availability
The effects of a server failure vary depending on the server's function within the CDH cluster. Oracle Big Data Appliance servers are more robust than commodity hardware, so you should experience fewer hardware failures. This section highlights the most important services that run on the various servers of the primary rack. For a full list, see Table 2-2.
2.8.1 Critical and Noncritical Nodes
Critical nodes are required for the cluster to operate normally and provide all services to users. In contrast, the cluster continues to operate with no loss of service when a noncritical node fails.
The critical services are installed initially on the first three nodes of the primary rack. Table 2-3 identifies the critical services that run on these nodes. The remaining nodes (initially node04 to node18) only run noncritical services. If a hardware failure occurs on one of the critical nodes, then the services can be moved to another, noncritical server. For example, if node02 fails, its critical services might be moved to node05. Table 2-3 provides names to identify the nodes providing critical services.
Moving a critical node requires that all clients be reconfigured with the address of the new node. The other alternative is to wait for the repair of the failed server. You must weigh the loss of services against the inconvenience of reconfiguring the clients.
| Node Name | Initial Node Position | Critical Functions |
|---|---|---|
|
First NameNode |
Node01 |
ZooKeeper, first NameNode, failover controller, balancer, puppet master |
|
Second NameNode |
Node02 |
ZooKeeper, second NameNode, failover controller, MySQL backup server |
|
JobTracker Node |
Node03 |
ZooKeeper, JobTracker, Cloudera Manager server, Oracle Data Integrator agent, MySQL primary server, Hue, Hive, Oozie |
2.8.2 First NameNode
One instance of the NameNode initially runs on node01. If this node fails or goes offline (such as a reboot), then the second NameNode (node02) automatically takes over to maintain the normal activities of the cluster.
Alternatively, if the second NameNode is already active, it continues without a backup. With only one NameNode, the cluster is vulnerable to failure. The cluster has lost the redundancy needed for automatic failover of the active NameNode.
These functions are also disrupted:
-
Balancer: The balancer runs periodically to ensure that data is distributed evenly across the cluster. Balancing is not performed when the first NameNode is down.
-
Puppet master: The Mammoth utilities use Puppet, and so you cannot install or reinstall the software if, for example, you must replace a disk drive elsewhere in the rack.
2.8.3 Second NameNode
One instance of the NameNode initially runs on node02. If this node fails, then the function of the NameNode either fails over to the first NameNode (node01) or continues there without a backup. However, the cluster has lost the redundancy needed for automatic failover if the first NameNode also fails.
These services are also disrupted:
-
MySQL Master Database: Cloudera Manager, Oracle Data Integrator, Hive, and Oozie use MySQL Database. The data is replicated automatically, but you cannot access it when the master database server is down.
-
Oracle NoSQL Database KV Administration: Oracle NoSQL Database database is an optional component of Oracle Big Data Appliance, so the extent of a disruption due to a node failure depends on whether you are using it and how critical it is to your applications.
2.8.4 JobTracker Node
The JobTracker assigns MapReduce tasks to specific nodes in the CDH cluster. Without the JobTracker node (node03), this critical function is not performed.
These services are also disrupted:
-
Cloudera Manager: This tool provides central management for the entire CDH cluster. Without this tool, you can still monitor activities using the utilities described in "Using Hadoop Monitoring Utilities".
-
Oracle Data Integrator: This service supports Oracle Data Integrator Application Adapter for Hadoop. You cannot use this connector when the JobTracker node is down.
-
Hive: Hive provides a SQL-like interface to data that is stored in HDFS. Most of the Oracle Big Data Connectors can access Hive tables, which are not available if this node fails.
-
MySQL Backup Database: MySQL Server continues to run, although there is no backup of the master database.
-
Oozie: This workflow and coordination service runs on the JobTracker node, and is unavailable when the node is down.
2.8.5 Noncritical Nodes
The noncritical nodes (node04 to node18) are optional in that Oracle Big Data Appliance continues to operate with no loss of service if a failure occurs. The NameNode automatically replicates the lost data to maintain three copies at all times. MapReduce jobs execute on copies of the data stored elsewhere in the cluster. The only loss is in computational power, because there are fewer servers on which to distribute the work.
2.9 Collecting Diagnostic Information for Oracle Customer Support
If you need help from Oracle Support to troubleshoot CDH issues, then you should first collect diagnostic information using the bdadiag utility with the cm option.
To collect diagnostic information:
-
Log in to an Oracle Big Data Appliance server as
root. -
Run
bdadiagwith at least thecmoption. You can include additional options on the command line as appropriate. See the Oracle Big Data Appliance Owner's Guide for a complete description of thebdadiagsyntax.# bdadiag cm
The command output identifies the name and the location of the diagnostic file.
-
Go to My Oracle Support at
http://support.oracle.com. -
Open a Service Request (SR) if you have not already done so.
-
Upload the bz2 file into the SR. If the file is too large, then upload it to
ftp.oracle.com, as described in the next procedure.
To upload the diagnostics to ftp.oracle.com:
-
Open an FTP client and connect to
ftp.oracle.com.See Example 2-1 if you are using a command-line FTP client from Oracle Big Data Appliance.
-
Log in as user
anonymousand leave the password field blank. -
In the bda/incoming directory, create a directory using the SR number for the name, in the format SRnumber. The resulting directory structure looks like this:
bda incoming SRnumber -
Set the binary option to prevent corruption of binary data.
-
Upload the diagnostic bz2 file to the new directory.
-
Update the SR with the full path, which has the form bda/incoming/SRnumber, and the file name.
Example 2-1 shows the commands to upload the diagnostics using the FTP command interface on Oracle Big Data Appliance.
Example 2-1 Uploading Diagnostics Using FTP
# ftp ftp> open ftp.oracle.com Connected to bigip-ftp.oracle.com. 220-*********************************************************************** 220-Oracle FTP Server . . . 220-**************************************************************************** 220- 220 530 Please login with USER and PASS. 530 Please login with USER and PASS. KERBEROS_V4 rejected as an authentication type Name (ftp.oracle.com:root): anonymous 331 Please specify the password. Password: 230 Login successful. Remote system type is UNIX. Using binary mode to transfer files. ftp> cd bda/incoming 250 Directory successfully changed. ftp> mkdir SR12345 257 "/bda/incoming/SR12345" created ftp> cd SR12345 250 Directory successfully changed. ftp> bin 200 Switching to Binary mode. ftp> put /tmp/bdadiag_bda1node01_1216FM5497_2013_01_18_07_33.tar.bz2 local: bdadiag_bda1node01_1216FM5497_2013_01_18_07_33.tar.bz2 remote: bdadiag_bda1node01_1216FM5497_2013_01_18_07_33.tar.bz2 227 Entering Passive Mode (141,146,44,21,212,32) 150 Ok to send data. 226 File receive OK. 2404836 bytes sent in 1.8 seconds (1.3e+03 Kbytes/s)
2.10 Security on Oracle Big Data Appliance
You can take precautions to prevent unauthorized use of the software and data on Oracle Big Data Appliance.
This section contains these topics:
2.10.1 About Predefined Users and Groups
Every open-source package installed on Oracle Big Data Appliance creates one or more users and groups. Most of these users do not have login privileges, shells, or home directories. They are used by daemons and are not intended as an interface for individual users. For example, Hadoop operates as the hdfs user, MapReduce operates as mapred, and Hive operates as hive.
You can use the oracle identity to run Hadoop and Hive jobs immediately after the Oracle Big Data Appliance software is installed. This user account has login privileges, a shell, and a home directory.
Oracle NoSQL Database and Oracle Data Integrator run as the oracle user. Its primary group is oinstall.
Note:
Do not delete or modify the users created during installation, because they are required for the software to operate.Table 2-4 identifies the operating system users and groups that are created automatically during installation of Oracle Big Data Appliance software for use by CDH components and other software packages.
Table 2-4 Operating System Users and Groups
| User Name | Group | Used By | Login Rights |
|---|---|---|---|
|
|
Flume parent and nodes |
No |
|
|
|
HBase processes |
No |
|
|
|
No |
||
|
|
No |
||
|
|
Hue processes |
No |
|
|
|
JobTracker, TaskTracker, Hive Thrift daemon |
Yes |
|
|
|
|
Yes |
|
|
|
Oozie server |
No |
|
|
Oracle NoSQL Database, Oracle Loader for Hadoop, Oracle Data Integrator, and the Oracle DBA |
Yes |
||
|
|
Puppet parent (puppet nodes run as |
No |
|
|
|
Sqoop metastore |
No |
|
|
Auto Service Request |
No |
||
|
|
ZooKeeper processes |
No |
2.10.2 Port Numbers Used on Oracle Big Data Appliance
Table 2-5 identifies the port numbers that might be used in addition to those used by CDH. For the full list of CDH port numbers, go to the Cloudera website at
http://ccp.cloudera.com/display/CDH4DOC/Configuring+Ports+for+CDH4
To view the ports used on a particular server:
-
In Cloudera Manager, click the Hosts tab at the top of the page to display the Hosts page.
-
In the Name column, click a server link to see its detail page.
-
Scroll down to the Ports section.
See Also:
The Cloudera website for CDH port numbers:-
Hadoop Default Ports Quick Reference at
http://www.cloudera.com/blog/2009/08/hadoop-default-ports-quick-reference/ -
Configuring Ports for CDH3 at
https://ccp.cloudera.com/display/CDHDOC/Configuring+Ports+for+CDH3
2.10.3 About CDH Security Using Kerberos
Apache Hadoop is not an inherently secure system. It is protected only by network security. After a connection is established, a client has full access to the system.
Cloudera's Distribution including Apache Hadoop (CDH) supports Kerberos network authentication protocol to prevent malicious impersonation. You must install and configure Kerberos and set up a Kerberos Key Distribution Center and realm. Then you configure various components of CDH to use Kerberos.
CDH provides these securities when configured to use Kerberos:
-
The CDH master nodes, NameNode, and JobTracker resolve the group name so that users cannot manipulate their group memberships.
-
Map tasks run under the identity of the user who submitted the job.
-
Authorization mechanisms in HDFS and MapReduce help control user access to data.
See Also:
http://oracle.cloudera.com for these manuals:
-
CDH4 Security Guide
-
Configuring Hadoop Security with Cloudera Manager
-
Configuring TLS Security for Cloudera Manager
2.10.4 About Puppet Security
The puppet node service (puppetd) runs continuously as root on all servers. It listens on port 8139 for "kick" requests, which trigger it to request updates from the puppet master. It does not receive updates on this port.
The puppet master service (puppetmasterd) runs continuously as the puppet user on the first server of the primary Oracle Big Data Appliance rack. It listens on port 8140 for requests to push updates to puppet nodes.
The puppet nodes generate and send certificates to the puppet master to register initially during installation of the software. For updates to the software, the puppet master signals ("kicks") the puppet nodes, which then request all configuration changes from the puppet master node that they are registered with.
The puppet master sends updates only to puppet nodes that have known, valid certificates. Puppet nodes only accept updates from the puppet master host name they initially registered with. Because Oracle Big Data Appliance uses an internal network for communication within the rack, the puppet master host name resolves using /etc/hosts to an internal, private IP address.