20 Using the Archival and Purge Utilities for Controlling Data Growth
The application capabilities in Oracle Identity Manager generate a large volume of data. To meet the standards of performance and scalability, maintaining the data generated for the life cycle management of Oracle Identity Manager entities is a challenge. Oracle Identity Manager meets this challenge by providing online and continuous as well as offline data purge and archival solutions.
Table 20-1 lists the archival and purge solutions provided by Oracle Identity Manager for its entities and their dependent data.
For more information about specific methods to purge the corresponding SOA data, see "Developing a Database Growth Management Strategy" and "Managing Database Growth" in Oracle Fusion Middleware Administrator's Guide for Oracle SOA Suite and Oracle Business Process Management Suite Guide.
For mor information about how to purge SOA data, see SOA Suite 11g Purging Guide at https://blogs.oracle.com/soaproactive/entry/soa_suite_11g_purging_guide.
Table 20-1 Archival and Purge Solutions
| Archival and Purge for Entities | Real-time Online Mode | Operated via Command Line | Available via Other Modes |
|---|---|---|---|
|
Reconciliation |
Yes |
Yes |
|
|
Provisioning Tasks |
Yes |
Yes |
|
|
Request |
Yes |
Yes |
|
|
Orchestration |
Yes |
No |
|
|
Audit |
No |
No |
Set of instructions for purge via partitioning of audit table. For more information, see "Using the Audit Archival and Purge Utility". |
This chapter describes how to use the various archival and purge utilities and the concepts related to them. It contains the following topics:
-
Using Real-Time Purge and Archival Option in Oracle Identity Manager
-
Using Command-Line Option of the Archival Purge Utilities in Oracle Identity Manager
Note:
Oracle recommends that you use the real-time purge and archival option rather than the offline command-line utilities.20.1 Understanding Archival and Purge Concepts
The concepts related to archival and purge solutions in Oracle Identity Manager are described in the following sections.
20.1.1 Categorization: Purge Only Solution Versus Purge and Archive Solution for Entities
The purge-only solution and the purge plus archive solution is applicable to the real-time purge and archival feature. Oracle Identity Manager entities are divided into the following on the basis of how the data related to them are purged and archived from the perspective of Real-time Purge Archival feature:
-
Purge only: Entities for which data is directly purged but not archived. These entities are Reconciliation, Provisioning Tasks, and Orchestration.
-
Purge and archive: Entities for which data is purged as well as archived. This is applicable to the Request entity.
Note:
The real-time purge and archival solution provides data purge capabilities on a continuous basis. In addition, you can use the command-line archival utilities periodically to archive data, if required. There is no such categorization of entities in their command-line archive purge utilities version. They essentially archive prior to purge. For details about the command-line archival utilities, see "Using Command-Line Option of the Archival Purge Utilities in Oracle Identity Manager".20.1.2 Archival of Data
Archival (prior to purge) is the standard mechanism followed in Oracle Identity Manager command-line utilities that offer for deleting data from the Active Feature or Entity tables. This is done by copying the data to a shadow copy or replica of the original table, typically with a suffix ARCH_TABLE_NAME. Archive operation precedes purge in data purge solutions for entities in the Purge and Archive category.
20.1.3 Purge
The mechanism to delete or purge data from the Active Feature or Entity tables without any preceding archive operation. Data purged is non-recoverable in Oracle Identity Manager.
20.1.4 Real-Time Purge
Real-time purge denotes that data is deleted or purged when Oracle Identity Manager is up and running and is available irrespective of the feature invocation, concurrency, or workload. However, in contrast to the literal meaning of real-time, entity data created in the system is not deleted immediately.
20.1.5 Retention Period
Retention period defines the age of the data that needs to be retained in Oracle Identity Manager for functional usage and compliance purpose. Data is deleted based on the age defined by the retention period value for the entity data in question. The Retention Period attribute must be defined for the real-time purge feature via the OIM Data Purge scheduled job user interface.
20.1.6 Modes of Archival Purge Operations
Archival purge operations can be performed in the following modes:
-
Offline mode: In this mode, archival and purge of data renders Oracle Identity Manager unusable for the time period it is being run. Because the entire operation being database-intensive, it disables the constraints/indexes at the beginning, copies, deletes the data from the entity tables, and re-enables the post deletion. This is for attaining the maximum performance in the delete operation and eliminating possibilities of functional inconsistencies in the data entered in the window of deletion with table-level constraints disabled. Therefore, any transactional-level changes from Oracle Identity Manager usage is not advised, and as a result, the system is offline from the usage perspective.
-
Online mode: In this mode, archival and purge of data happens with the entire database-level indexes/constraints enabled as usual. Therefore, Oracle Identity Manager usage can be continued in online mode from the operational perspective.
Note:
Real-time purge supports online mode only. Command-line Archival Purge Utilities support both online and offline modes based on the user input.
20.2 Using Real-Time Purge and Archival Option in Oracle Identity Manager
The application capabilities in Oracle Identity Manager generate a large volume of data. To meet the standards of performance and scalability, maintaining the data generated for the life cycle management of Oracle Identity Manager entities is a challenge. Oracle Identity Manager meets this challenge by providing a real-time and continuous data purge solution, which is described in the following sections:
20.2.1 Understanding Real-Time Data Purge and Archival
The real-time purge and archival capability is provided by default in Oracle Identity Manager. Entity data can be continuously purged through this based on the options or choices made. Figure 20-1 shows the flow of the real-time purge and archival capability in Oracle Identity Manager.
Figure 20-1 Real-Time Purge and Archival Flow
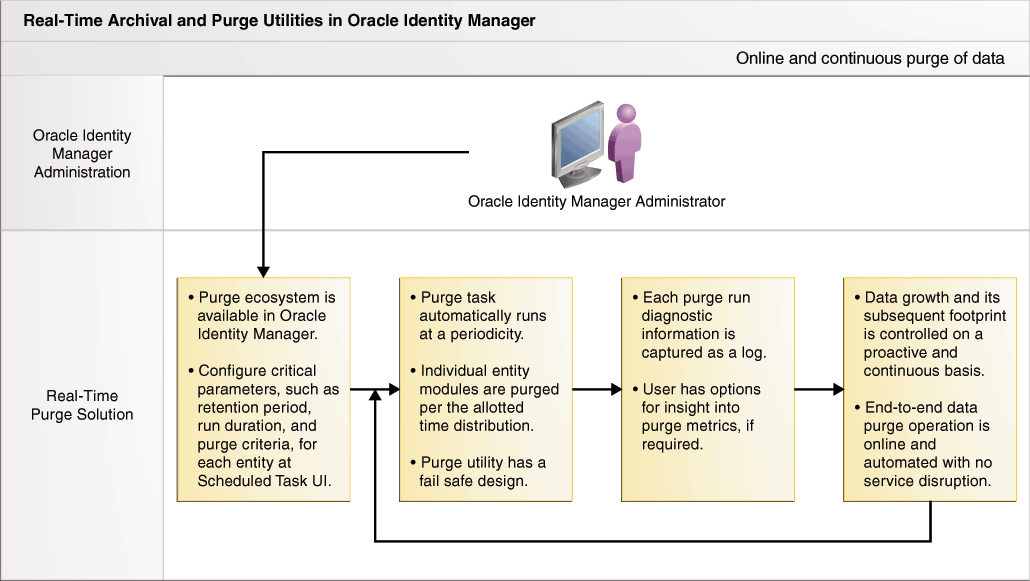
Description of "Figure 20-1 Real-Time Purge and Archival Flow"
The configuration is one time and the purge solution works automatically without any intervention from the administrator.
The real-time purge and archival has the following features:
-
The administrators provides values for some critical parameters, such as retention period, run duration, and purge criteria, for entities by using the Scheduled Tasks section of Oracle Identity System Administration.
-
Diagnostic information about each purge run is captured as a log.
-
Purge tasks run periodically.
-
The entity modules, such as Request, Reconciliation, Task, and Orchestration, is purged according to the allotted time duration.
-
The purge solution is fail safe. This means that in the event of a situation, the system does not endlessly consume CPU cycles. A fail-safe design has a minimum impact on other modules. The fail-safe capability is provided by:
-
Maximum Run Time for Auto-Cutoff in Purge Run for each Entity: Each run of the purge utility is governed by the value of the Maximum Purge Run Time parameter, the value of which is in minutes. Purge automatically stops when this maximum purge run duration is exceeded. This is provided at the each entity level so that you can control the Purge Time Period allocation at the feature level.
Each batch picked up for deletion is aware of the time factor. When the time factor exceeds, the next batch is skipped and the utility's flow of control comes to completion.
The Maximum Purge Run Time in minutes for each entity can be specified in the scheduled task UI.
-
Single-threaded batching: The purge operation accepts a batch size, which is the maximum number of rows to delete before a commit is issued. This keeps the redo log segments from growing too large when purge is applied to a large number of rows. The batch size is accepted from the scheduled task interface for the purge run operation.
-
-
Data growth and subsequent footprint is controlled on an on-going basis.
-
It operates online with no disruption of service.
-
The purge operation via an automated scheduled task runs silently at a predefined periodicity and is non-interactive. Various metrices related to the purge operation, such as names of the entity modules, success or failure status, and number of rows targeted for deletion, are logged. These logs are diagnostic pointers for the purge operation for every run.
-
The volume of data purged through the Real-time Purge Utilities Framework is a function of a few inputs, such as time duration window, entities selected, and existing workload.There might be instances when outflow of data in Oracle Identity Manager via this purge functionality is less than the inflow, which means that there would be some data volume accumulating in the system. This can be then purged via the Command-Line Archival/Purge Utilities at a reasonable point in time.
20.2.2 Configuring Real-Time Purge and Archival
Entity data via the Purge solution is continuously purged based on the options or choices that you make when you configure running of the utility. You can modify these options based on data retention policies and maintenance requirements.
To configure real-time purge and archival:
-
Log in to Oracle Identity System Administration.
-
Under System Management, click Scheduler.
-
Search and open the 'OIM Data Purge Job' scheduled job.
-
In the Parameters section, specify values for the parameters, as described in Table 20-2:
Table 20-2 Purge Configuration Parameters
Category Parameter Description Default Value Global parameters
Batch Size
The purge operation runs in batches. It represents the maximum number of rows to delete before a commit is issued.
5000
Maximum Purge Run Duration Per Entity (in Mins)
This is the maximum run duration in minutes for purge processing for each entity.
30 mins
Orchestration purge parameters
Orchestration Entity Selection
This specifies whether or not data is to be purged from orchestration tables.
Yes
Orchestration Purge Criteria
This takes the following values:
-
1 for completed orchestrations
-
2 for failed, compensated, canceled, or canceled with compensation orchestrations
-
3 for both 1 and 2
1
Orchestration[COMPLETED] Retention Period (in days)
This indicates the retention period in days for completed orchestrations.
1 day
Orchestration[OTHERS] Retention Period (in days)
This indicates the retention period in days for failed, compensated, or other orchestrations
30 days
Provisioning task purge parameters
Provisioning Task Entity Selection
This specifies whether or not data is to be purged from provisioning task tables.
No
Provisioning Tasks Purge Criteria
This takes the following values:
-
1 for completed provisioning tasks
-
2 for completed and canceled provisioning tasks
1
Provisioning Tasks Retention Period (in days)
This indicates the retention period in days for provisioning tasks.
90 days
Reconciliation purge parameters
Recon Entity Selection
This specified whether or not data is to be purged from reconciliation tables.
No
Recon Purge Criteria
This takes the following values:
-
1 for completed reconciliation events
-
2 for linked reconciliation events
-
3 for both 1 and 2
1
Recon Retention Period (in days)
This indicates the retention period in days for reconciliation events.
30 days
Request purge parameters
Request Entity Selection
This specifies whether or not data is to be purged from request tables.
No
Request Purge Criteria
This takes the following values:
-
1 for completed requests
-
2 for completed and failed requests
-
3 for all requests
1
Request Retention Period (in days)
This indicates the retention period in days for requests.
90 days
Note:
By default, the 'OIM Data Purge Job' scheduled job is available in the enabled state with a retention period of 90 days. You must revisit the job parameters to disable or to change the purge interval as required. -
-
Click Apply.
In addition to the steps on the Scheduled Task UI for configuration inputs documented in this section, there are no further steps required manually, such as archival tablespace creation. All the steps in the subsequent sections are for running the command-line version of the utilities.
Note:
-
For Real-time Archival Purge operation via Scheduled Task interface, Retention Period must not be specified as ZERO as this can cause inconsistencies in purge operation.
-
Simultaneous runs of multiple 'OIM Data Purge Job' scheduled jobs is not supported via instantiation of the Scheduled Task functionality.
-
There should be no overlap of archival/purge utility run for an entity from both modes in Oracle Identity Manager, which are scheduled task and command-line modes.
-
For details of the purge internals, such as tables that undergo purge for Request, Reconciliation, and Provisioning Tasks, refer to the subsequent sections of the command-line utilities. Both real-time scheduled job-based purge and command-line archival utilities purge data from the same set of table for an entity.
20.2.3 Understanding the Orchestration Purge Utility
Orchestration data purge takes place from the active orchestration tables via the unified 'OIM Data Purge Job' scheduled job interface. It is based on the following criteria:
Note:
Orchestration purge is available only in online mode and via the scheduled job interface.-
Orchestration process status, such as Completed, Failed, Compensated, Canceled, or Canceled with Compensation.
-
Time-based criteria, which is specified via the retention period value specified in days on the scheduled job interface.
The following active orchestration tables undergo purge via the Orchestration Purge feature:
-
ORCHPROCESS
-
ORCHEVENTS
-
ORCHFAILEDEVENTS
-
ORCH_BENEFICIARIES
-
CALLBACK_INVOCATION_RESULT
20.2.4 Collecting Diagnostic Data of the Online Archival and Purge Operations
The Real-Time Purge and Archival operation via the automated scheduled task runs silently at a predefined periodicity and is non-interactive. However, you can capture and communicate the various metrics related to the purge operation, such as:
-
Names of the Entity modules that were picked
-
Success/failure status
-
Exceptions encountered during the run
-
Number of rows targeted for deletion
-
Actual number of rows purged
At a minimum, these metrics are logged for every run. At any point in time, data of the most recent 500 runs is available.
The following diagnostic logging tables are part of the Real-Time Purge and Archival operation to store the diagnostic information of the entity purge runs:
-
OIM_DATAPURGE_TASK_LOG: Stores the critical information related to the purge runs controlled by the scheduled task for the deletion of Entity data.
Table 20-3 lists the columns of the OIM_DATAPURGE_TASK_LOG table.
Table 20-3 Columns of the OIM_DATAPURGE_TASK_LOG Table
Column Description OIM_DATAPRGTASK_KEY
Stores keys to uniquely identify tasks
OIM_DATAPRG_ID
Stores unique purge name
SCH_JOB_ID
Stores the Job ID of the scheduled task as assigned by the Scheduler
EXECUTION_MODE
The execution mode of the purge run, which is SCH for scheduled task mode.
PURGERUN_START_TIME
Stores the start time of the entire purge run
PURGERUN_END_TIME
Stores the end time of the entire purge run
PURGERUN_STATUS
Stores the overall status of the purge run, which can be any one of the following during the run:
-
STARTED
-
COMPLETED
-
ERRORED_OUT
Task-level purge run could not proceed due to run-time errors. The root cause can be further probed into via the PURGE_RUN_NOTE column that stores the exception stack trace.
-
COMPLETED WITH ERROR
Task-level purge run has completed but one of its modules could not get completed within the allotted time or encountered some run-time errors. The root cause can be further probed into via the PURGE_RUN_NOTE column that stores the exception stack trace.
PURGE_RUN_NOTE
Stores the task-level exception details at the purge run
-
-
OIM_DATAPRG_TASKS_LOGDTLS: Stores the critical information related to the Module or Entity-level purge runs controlled by the scheduled task.
Table 20-4 lists the columns of the OIM_DATAPRG_TASKS_LOGDTLS table.
Table 20-4 Columns of the OIM_DATAPRG_TASKS_LOGDTLS Table
Column Description OIM_DATPRGLOGDET_KEY
Stores keys to uniquely identify a module in a task
OIM_DATAPRGTASK_KEY
Stores the logical foreign key for the OIM_ENTITYPURGE_TASK_LOG table
MOD_NAME
Stores the module name, such as:
-
RECON
-
REQUEST
-
ORCH
-
PROVTASKS
EST_ALLOCT_TIME
Stores the time allocated for the module purge run
MOD_STATUS
Stores the module status, which can be any one of the following during the run:
-
STARTED
-
COMPLETED
-
COMPLETED WITH ERROR
Module or Entity purge run has completed within the allotted time duration but encountered errors during its execution. The root cause can be further probed into via the MOD_PURGE_RUN_NOTE column that stores the exception stack trace.
-
ERRORED_OUT
Module or Entity purge run could not proceed because of run-time errors. The root cause can be further probed into via the MOD_PURGE_RUN_NOTE column that stores the exception stack trace.
-
PARTIALLY COMPLETED
Module or Entity purge run is unable to complete within the allotted time duration. This is an acceptable functional state of completion. The root cause can be further probed into via the MOD_PURGE_RUN_NOTE column that stores the exception stack trace.
-
PARTIALLY_COMPLETED WITH ERROR
Module or Entity purge run could not complete within the allotted time duration but also encountered errors during its execution. The root cause can be further probed into via the MOD_PURGE_RUN_NOTE column that stores the exception stack trace.
MODPURGERUN_START_TIME
Stores the start time of the module purge run
MODPURGERUN_END_TIME
Stores the end time of the module purge run
EST_PURGE_ROW_CNT
Stores the driving table target row count for purge run for the module
ACTUAL_PURGE_ROW_CNT
Stores the actual driving table rows deleted during purge run
MOD_PURGE_RUN_NOTE
Stores the exception or other information encountered at module level
-
-
OIM_DATAPRG_FAILED_KEYS: Stores the entity keys for each Module or Entity that have failed during the scheduled purge run.
Table 20-5 lists the columns of the OIM_DATAPRG_FAILED_KEYS table.
Table 20-5 Columns of the OIM_DATAPRG_FAILED_KEYS Table
Column Description OIM_DATAPRGFAILED_KEY
Stores keys to uniquely identify a failed task
OIM_DATAPRGTASK_KEY
Stores the logical foreign key for the OIM_ENTITYPURGE_TASK_LOG table
MOD_NAME
Stores the module name for which the purge run fails
MOD_ENTITY_KEY
Stores the driving table key for each module
ERROR_NOTE
Stores the exception stack trace
The OIM_DATAPURGE_TASK_LOG and OIM_DATAPRG_TASKS_LOGDTLS tables contain the data of the last 500 runs. The OIM_DATAPRG_FAILED_KEYS table stores the failed keys data for the last run only.
20.3 Using Command-Line Option of the Archival Purge Utilities in Oracle Identity Manager
This section describes how to use the command-line archival purge utilities. It contains the following topics:
Note:
You can use the Reconciliation Archival utility, the Task Archival utility, and the Requests Archival utility in both offline and online modes.20.3.1 Understanding Command-Line Utilities
Oracle Identity Manager provides archival and purge of entity data via command-line utilities option for three entities, namely Reconciliation, Provisioning Tasks, and Requests. All the command-line utilities are part of Oracle Identity Manager installation and are interactive to capture user-specified parameters to archive and purge entity data. These utilities are available for both Linux and Microsoft Windows operating system environments.
20.3.2 Using the Reconciliation Archival Utility
This section describes how to use the Reconciliation Archival utility. It contains the following topics:
20.3.2.1 Understanding the Reconciliation Archival Utility
Oracle Identity Manager stores reconciliation data from target systems in Oracle Identity Manager tables called active reconciliation tables:
During the reconciliation process, Reconciliation Manager reconciles data in the active reconciliation tables with the Oracle Identity Manager core tables. Because Reconciliation Manager does not remove reconciled data from the active reconciliation tables, they might eventually grow very large, resulting in decreased performance during the reconciliation process. You can use the Reconciliation Archival utility to archive data that has been reconciled with Oracle Identity Manager. The Reconciliation Archival utility stores archived data in the archive reconciliation tables, which have the same structure as the active reconciliation tables.
Table 20-6 lists the active reconciliation tables with the corresponding archive reconciliation tables in which data from the active reconciliation tables are archived.
Table 20-6 Active and Archive Reconciliation Tables
| Active Reconciliation Tables (Oracle Identity Manager Tables) | Archive Reconciliation Tables |
|---|---|
|
RECON_EVENTS |
ARCH_RECON_EVENTS |
|
RECON_JOBS |
ARCH_RECON_JOBS |
|
RECON_BATCHES |
ARCH_RECON_BATCHES |
|
RECON_EVENT_ASSIGNMENT |
ARCH_RECON_EVENT_ASSIGNMENT |
|
RECON_EXCEPTIONS |
ARCH_RECON_EXCEPTIONS |
|
RECON_HISTORY |
ARCH_RECON_HISTORY |
|
RECON_USER_MATCH |
ARCH_RECON_USER_MATCH |
|
RECON_ACCOUNT_MATCH |
ARCH_RECON_ACCOUNT_MATCH |
|
RECON_CHILD_MATCH |
ARCH_RECON_CHILD_MATCH |
|
RECON_ORG_MATCH |
ARCH_RECON_ORG_MATCH |
|
RECON_ROLE_MATCH |
ARCH_RECON_ROLE_MATCH |
|
RECON_ROLE_HIERARCHY_MATCH |
ARCH_RECON_ROLE_HIER_MATCH |
|
RECON_ROLE_MEMBER_MATCH |
ARCH_RECON_ROLE_MEMBER_MATCH |
|
RA_LDAPUSER |
ARCH_RA_LDAPUSER |
|
RA_MLS_LDAPUSER |
ARCH_RA_MLS_LDAPUSER |
|
RA_LDAPROLE |
ARCH_RA_LDAPROLE |
|
RA_MLS_LDAPROLE |
ARCH_RA_MLS_LDAPROLE |
|
RA_LDAPROLEMEMBERSHIP |
ARCH_RA_LDAPROLEMEMBERSHIP |
|
RA_LDAPROLEHIERARCHY |
ARCH_RA_LDAPROLEHIERARCHY |
|
All horizontal tables mentioned under RECON_TABLES |
"ARCH_ "first 25 characters of the horizontal tables (RA_* tables) |
The Reconciliation Archival utility performs the following tasks:
-
Archives all or specific data from the active reconciliation tables to the archive reconciliation tables
-
Deletes all data from the active reconciliation tables
The Reconciliation Archival Utility archives data by moving it from the active reconciliation tables to the archive reconciliation tables based on the following two-fold criteria per the user inputs:
-
The date- based criteria, which is the reconciliation event creation date. This must be specified in the YYYYMMDD format. All records on or before this date will be archived.
-
The functional reconciliation event state-based criteria, which is the reconciliation event status. This must be selected from the prompted status options when the utility is run.
For information about the archiving criteria, refer to "Archival Criteria".
If you choose to archive selective data, then the utility archives reconciliation data based on selected event status that have been created on or before the specified date and event status.
When you archive all data from the active reconciliation tables to the archive reconciliation tables, the Reconciliation Archival utility archives all reconciliation data that have been created on or before the specified date.
The files that constitute the Oracle Database version of the Reconciliation Archival utility are located in the following directory:
OIM_ORACLE_HOME/server/db/oim/oracle/Utilities/Recon11gArchival
You can run the Reconciliation Archival utility in offline mode with Oracle Identity Manager stopped, or in online mode with Oracle Identity Manager running.
Before running the utility in offline mode, you must stop Oracle Identity Manager.
20.3.2.2 Prerequisite for Running the Reconciliation Archival Utility
Before running the Reconciliation Archival utility, the OIM_RECON_ARCH tablespace must be created in the database. To do so, you can run the following sample command as a DBA privilege user, for instance SYS or SYSTEM.
CREATE TABLESPACE OIM_RECON_ARCH
LOGGING DATAFILE 'ORADATA/OIM_RECON_ARCH.dbf'
SIZE 500M REUSE AUTOEXTEND ON NEXT 10M;
Note:
-
You must replace ORADATA in the preceding sample command with the full path to your ORADATA directory.
-
You must set LD_LIBRARY_PATH to start Oracle utilities such as SQL*Plus in the environment where you want to run Oracle Identity Manager utilities.
-
Data that has been archived from the active reconciliation tables to the archive reconciliation tables will no longer be available through Oracle Identity Manager. To access this data, you must query the archive reconciliation tables in your Oracle Identity Manager database.
If you are using ASM, Exadata (ASM) or Oracle Managed Files (OMF), then follow the instructions described here.
If you are using ASM, then you can use the name of a diskgroup say DATA 1 to create the tablespace in the database as follows:
CREATE TABLESPACE OIM_RECON_ARCH
LOGGING DATAFILE '+DATA1'
SIZE 500M AUTOEXTEND ON NEXT 10M;
If you are using Oracle Managed Files, then you can omit the data file and run the command as follows:
CREATE TABLESPACE OIM_RECON_ARCH
LOGGING DATAFILE
SIZE 500M AUTOEXTEND ON NEXT 10M;
If you want to run the utility in offline mode, then you must stop Oracle Identity Manager before running the utility.
20.3.2.3 Archival Criteria
To select reconciliation data to archive, provide the following criteria. Data with matching values will be archived.
-
Date must be in the format YYYYMMDD. All records on or before this date that match the specified reconciliation event parameter value will be archived.
-
Select Closed, Linked, Closed or Linked, or All for the reconciliation event parameter.
-
Closed describes events that have been manually closed in Reconciliation Manager.
-
Linked describes events that were reconciled in Oracle Identity Manager, including the following states:
-
Creation Succeeded
-
Update Succeeded
-
Delete Succeeded
-
Creation Failed
-
Update Failed
-
Delete Failed
-
-
Closed or Linked
-
Select status for reconciliation events to be archived.
-
Enter 1 for Closed
-
Enter 2 for Linked
-
Enter 3 for Closed and Linked
-
Enter 4 for Exit
-
-
20.3.2.4 Running the Reconciliation Archival Utility
To run the Reconciliation Archival utility:
-
Ensure that the Oracle Identity Manager database is available and that no reconciliation processes are running.
Note:
Oracle recommends that you run the Reconciliation Archival utility during off-peak hours. -
If you want to run the utility in offline mode, then stop Oracle Identity Manager by following the instructions in the "Starting and Stopping Servers" chapter.
To run the utility in online mode, ignore this step and proceed to step 3.
-
On Microsoft Windows platforms, you must specify the short date format as M/d/yyyy. In addition, you must specify the time format as H:mm:ss. To customize the date and time formats, use the Regional and Language Options command in Control Panel.
Note:
-
When you change the date and time format, the change is applied to all the applications running on the Microsoft Windows platform.
-
Minimal validation is done on date before calling the utility, and you can scan logs files for any ORA-18xx errors for invalid date-related errors.
-
-
On Linux or UNIX platforms, run the following commands to set execution permission for the oim_recon_archival.sh file and to ensure that the file is a valid Linux or UNIX text file:
chmod 755 path/oim_recon_archival.sh dos2unix path/oim_recon_archival.sh
-
On Linux or UNIX platforms, run the path/oim_recon_archival.sh file to run the utility.
On Microsoft Windows platforms, run the path\oim_recon_archival.bat file to run the utility.
-
For Oracle Database installations, enter values for the following parameters when prompted:
-
Oracle home directory
-
Oracle Identity Manager database user name and password
-
-
Enter the reconciliation creation date in the YYYYMMDD format. All records on or before this date with required status value will be archived.
-
When prompted, select a reconciliation event status for the data that you want to archive:
-
Enter 1 for Closed
-
Enter 2 for Linked
-
Enter 3 for Closed or Linked
-
Enter 4 for Exit
-
-
When prompted to specify the mode of running the utility, enter 1 if you want to run the utility in online mode. Otherwise, enter 2 to run the utility in offline mode.
-
Enter the batch size for processing.
The default batch size is 5000.
Note:
Batch size is a value for the number of records to be processed in a single iteration of archival/purge, also as an internal commit at the database level. You must provide the batch size as an input parameter value while starting the operation of Archival Utilities at run time.This batch size by default is 5000. When purging greater than few hundred thousand recon_events, a higher batch size can be opted for. This may need more resources from RDBMS, such as more space from the TEMP and UNDO tablespaces.
The utility archives the reconciliation data and provides an execution summary in a log file.
-
On Microsoft Windows platforms, reset the short date format to the date format for your region or locale after you run the utility. Use the Regional and Language Options command in Control Panel to reset the date format.
-
Because the data from active reconciliation tables are removed, your DBA must analyze the active reconciliation tables and their indexes in order to update the statistics.
20.3.2.5 Log File Generated by the Reconciliation Archival Utility
After running the Reconciliation Archival utility, the following log file is generated:
./logs/oim_recon_archival_summary_TIMESTAMP.log
If running the utility fails, then the log file records the batch number at which the utility fails along with the error messages.
20.3.3 Using the Task Archival Utility
This section describes how to use the Task Archival utility. It contains the following topics:
20.3.3.1 Understanding the Task Archival Utility
In Oracle Identity Manager, a task refers to one or more activities that comprise a process, which handles the provisioning of a resource. For example, a process for requesting access to a resource may include multiple provisioning tasks. Oracle Identity Manager stores task data in the active task tables.
By default, Oracle Identity Manager does not remove completed tasks from the active task tables. As the size of the active task tables increases, you might experience a reduction in performance, especially when managing provisioning tasks. After a task executes successfully, you can use the Task Archival utility to archive the task data and remove it from the active task tables. Archiving task data with the Task Archival utility improves performance and ensures that the data is safely stored.
The Task Archival utility stores archived task data in the archive task tables, which have the same structure as the active task tables.
Table 20-7 lists the active task tables with the corresponding archive task tables in which data from the active task tables are archived.
Table 20-7 Active and Archive Task Tables
| Active Task Tables | Archive Task Tables |
|---|---|
|
OSI |
ARCH_OSI |
|
OSH |
ARCH_OSH |
|
SCH |
ARCH_SCH |
You can use the Task Archival utility to archive the following types of tasks:
-
Provisioning tasks that have been completed
-
Provisioning tasks that have been completed and canceled
The Task Archival Utility archives provisioning tasks by moving it from the active task tables to the archive task tables. This is based on the following two-fold criteria per the user inputs provided:
-
The date-based criteria, which is the provisioning task creation date. This must be specified in the YYYYMMDD format. All records on or before this date will be archived
-
The functional criteria task status, which is the provisioning task status, for example, provisioning tasks with Completed or Completed and Canceled status. This must be selected from the prompted status options when the utility is run.
The archive operation represents the type of task data to archive and the user status determines whether to archive data for users who have been deleted, disabled, or both. The task execution date represents the date on which a task is executed and must be in the format YYYYMMDD.
All executed tasks, up to the task execution date you specify, will be archived. To reduce the time that the archiving process takes, the utility drops the indexes on all active task tables when the number of records to be archived is greater than 200000. The indexes are re-created after the archived data is deleted from the active task tables. You can change the value 200000 to your preferred value. You can change the value in the following lines of code in the OIM_TasksArch.bat file or in the OIM_TasksArch.sh file:
In the .bat file, set INDXRESP=200000
In the .sh file, indxopt=200000
The files that constitute the Oracle Database version of the Task Archival utility are located in the following directory:
OIM_HOME/db/oim/oracle/Utilities/TaskArchival
Note:
Data that has been archived from the active task tables to the archive task tables will no longer be available through Oracle Identity Manager. To access this data, you must query the archive task tables in your Oracle Identity Manager database.You can run the Task Archival utility in offline mode with Oracle Identity Manager stopped, or in online mode with Oracle Identity Manager running.
Before running the utility in offline mode, you must stop Oracle Identity Manager.
20.3.3.2 Preparing Oracle Database for the Task Archival Utility
Before you can use the Task Archival utility with Oracle Database, you must perform the following steps:
-
Start SQL*Plus and connect to Oracle Database as a SYS user.
-
Create a separate tablespace for the archival task tables by entering the following command. Replace DATA_DIR with the directory in which you want to store the data file and adjust the size and other parameters as necessary for your environment.
CREATE TABLESPACE TasksArch DATAFILE 'DATA_DIR\tasksarch_01.dbf' SIZE 1000M REUSE EXTENT MANAGEMENT LOCAL SEGMENT SPACE MANAGEMENT AUTO;Note:
Oracle recommends that you allocate a large UNDO tablespace when archiving large amounts of data. In addition, turn on parallel execution by configuring the parallel_max_servers and parallel_min_servers initialization parameters. Parallel execution helps improve the performance of the archival process. -
Connect to Oracle Database as the Oracle Identity Manager database user.
Note:
You must set LD_LIBRARY_PATH to start Oracle utilities such as SQL*Plus in the environment where you want to run Oracle Identity Manager utilities.20.3.3.3 Running the Task Archival Utility
Perform the following steps to run the Task Archival utility:
-
Ensure that the Oracle Identity Manager database is available but it is not open to other Oracle Identity Manager transactions.
Note:
Oracle recommends that you run the Task Archival utility during off-peak hours. -
Ensure that you have created a backup of the OSI, SCH, and OSH tables.
-
If you want to run the utility in offline mode, then stop Oracle Identity Manager by following the instructions in the "Starting and Stopping Servers" chapter.
To run the utility in online mode, ignore this step and proceed to step 4.
-
On Microsoft Windows platforms, you must specify the short date format as dddd M/d/yyyy. In addition, you must specify the time format as H:mm:ss. To customize the date and time formats, select the Regional and Language Options command in the Control Panel.
Note:
-
When you change the date and time format, the change is applied to all the applications running on the Microsoft Windows platform
-
Minimal validation is done on date before calling the utility, and you can scan logs files for any ORA-18xx errors for invalid date-related errors
-
-
On Linux and UNIX platforms, run the path/OIM_TasksArch.sh file. On Microsoft Windows platforms, run the path
\OIM_TasksArch.batfile. -
For Oracle Database installations, enter values for the following parameters when prompted:
-
Oracle home directory
-
Oracle Identity Manager database name or TNS string if the Oracle Identity Manager database is running on a remote computer
-
Oracle Identity Manager database user name and password
-
-
When prompted, select one of the following options:
-
Archive Provisioning Tasks which have been Completed.
-
Archive Provisioning Tasks which have been Completed and Cancelled.
-
Exit.
-
-
When prompted to specify the mode of running the utility, enter 1 if you want to run the utility in online mode. Otherwise, enter 2 to run the utility in offline mode.
-
Enter a task execution date in the format YYYYMMDD when prompted. All executed tasks, up to the task execution date you specify, will be archived. To archive all tasks that were executed on or before the current date, press Enter without entering a date.
-
Summary information is displayed before the utility starts the archival process. The summary information gives you the total number of tasks to be archived. Read the summary information carefully and make sure your database can support the delete volume listed in the summary.
Enter a value of y or Y when prompted to archive the tasks. Otherwise, enter a value of n or N to exit the utility.
Note:
You must enter the value of Y or N when prompted. If you press Enter without selecting a value, then the utility again counts the number of tasks to be archived and prompts you without beginning the archive. -
On Microsoft Windows platforms, reset the short date format to the date format for your region or locale after the Task Archival utility finishes running. Use the Regional and Language Options command in the Control Panel to reset the date format.
Note:
You must analyze the active task tables and their indexes for updated statistics, because the data from active task tables is removed. Perform this step only if you are using Oracle Database as the database for Oracle Identity Manager.
20.3.3.4 Reviewing the Output Files Generated by the Task Archival Utility
Table 20-8 describes the output files that are generated by the Task Archival utility.
Table 20-8 Output Files Generated by the Task Archival Utility
| File | Description |
|---|---|
|
|
Generated when the utility is unable to connect to the database with the specified credentials |
|
|
Generated when the archival or deletion processes fail |
|
|
Generated when the archival or deletion processes succeed |
Note:
These error log files are deleted when you run the utility again.20.3.4 Using the Requests Archival Utility
This section describes how to use the Requests Archival utility. It contains the following topics:
20.3.4.1 Understanding the Requests Archival Utility
By default, Oracle Identity Manager does not remove closed or withdrawn requests from the active request tables. To archive these requests and free up the disk space and thereby enhance database performance, the Requests Archival utility is used. You can archive request data based on request creation date and request status. Archiving requests based on the request status is optional. By using request status, you can archive:
-
Completed requests such as requests with status Withdrawn, Closed, and Completed. This is specified by selecting the 1 for Completed option.
-
Completed and failed requests such as requests with status Withdrawn, Closed, Completed, Failed, and Partially Failed. This is specified by selecting option 2 for Completed and Failed.
-
All requests based on request creation date. This is specified by selecting option 3 for All.
Table 20-9 lists the names of the tables which are to be archived and the corresponding archival table names.
| Main Table | Archival Table |
|---|---|
|
REQUEST |
ARCH_REQUEST |
|
REQUEST_HISTORY |
ARCH_REQUEST_HISTORY |
|
REQUEST_APPROVALS |
ARCH_REQUEST_APPROVALS |
|
REQUEST_ENTITIES |
ARCH_REQUEST_ENTITIES |
|
REQUEST_ENTITY_DATA |
ARCH_REQUEST_ENTITY_DATA |
|
REQUEST_BENEFICIARY |
ARCH_REQUEST_BENEFICIARY |
|
REQUEST_BENEFICIARY_ENTITIES |
ARCH_REQUEST_BE |
|
REQUEST_BENEFICIARY_ENTITYDATA |
ARCH_REQUEST_BED |
|
REQUEST_TEMPLATE_ATTRIBUTES |
ARCH_REQUEST_TA |
|
WF_INSTANCE |
ARCH_WF_INSTANCE |
|
REQUEST_COMMENTS |
ARCH_REQUEST_COMMENTS |
The files that constitute the Oracle Database version of the Requests Archival utility are located in the following directory:
OIM_HOME/db/oim/oracle/Utilities/RequestArchival
You can run the Requests Archival utility in offline mode with Oracle Identity Manager stopped, or in online mode with Oracle Identity Manager running.
Before running the utility in offline mode, you must stop Oracle Identity Manager.
20.3.4.2 Prerequisites for Running the Requests Archival Utility
If you want to run the utility in offline mode, then you must stop Oracle Identity Manager before running the utility.
Note:
You must set LD_LIBRARY_PATH to start Oracle utilities such as SQL*Plus in the environment where you want to run Oracle Identity Manager utilities.20.3.4.3 Input Parameters
Table 20-10 lists the input parameters used by the Requests Archival utility:
| Parameter | Description |
|---|---|
|
Oracle Home |
The value of ORACLE_HOME environment variable on the system. |
|
Oracle SID |
The SID of the Oracle Identity Manager database, which is a TNS name or TNS alias. |
|
OIM DB User |
The database login ID of the Oracle Identity Manager database user. |
|
OIM DB Pwd |
The password of the Oracle Identity Manager database user. |
|
Request Status |
The request status based on the user inputs 1, 2, or 3. |
|
Request Creation Date |
The utility archives all requests created on or before this request creation date with the required request status. |
|
Batch Size |
The utility processes a group of records or batch as a single transaction. The batch size can influence the performance of the utility. Default value of Batch Size is |
|
Utility Running Mode |
The mode in which you want to run the utility, online or offline. You must enter 1 for online mode, or 2 for offline mode. The utility runs faster when you run it in offline mode than online mode. However, running the utility in offline mode requires downtime. The archival operation can be speeded up by running in offline mode, but Oracle Identity Manager is not usable until the utility completes the archival operation. Therefore, make sure that Oracle Identity Manager is not running before choosing this option. |
20.3.4.4 Running the Requests Archival Utility
To run the Requests Archival utility:
-
Ensure that the Oracle Identity Manager database is available.
Note:
It is recommended that you run the Requests Archival utility during off-peak hours. -
If you want to run the utility in offline mode, then stop Oracle Identity Manager by following the instructions in the "Starting and Stopping Servers" chapter.
To run the utility in online mode, ignore this step and proceed to step 3.
-
On Microsoft Windows platform, you must specify the short date format as
dddd M/d/yyyy. In addition, you must specify the time format asH:mm:ss. To customize the date and time formats, use the Regional and Language Options command in Control Panel.Note:
-
When you change the date and time format, the change is applied to all the applications running on the Microsoft Windows platform.
-
Minimal validation is done on date before calling the utility, and you can scan logs files for any ORA-18xx errors for invalid date-related errors.
-
-
On UNIX platform, run the following commands to set execution permission for the
OIM_request_archival.shfile and to ensure that the file is a valid UNIX text file:chmod 755 path/OIM_request_archival.sh dos2unix path/OIM_request_archival.sh
-
On UNIX platform, run the path/
OIM_request_archival.shfile. On Microsoft Windows platform, run the path\OIM_request_archival.batfile.The oim_request_archival script validates the database input and establishes a connection with the database. It then calls the oim_request_archival.sql script, the script is used to compile PL/SQL procedures related to the utility.
-
For Oracle Database installations, enter values for the following parameters when prompted:
-
Oracle home directory.
-
Oracle Identity Manager database name or TNS string if the Oracle Identity Manager database is running on a remote computer. Otherwise, enter ORACLE SID.
-
Oracle Identity Manager database user name and password.
-
-
When prompted, enter one of the following options:
-
Enter 1 to archive the requests with status Request Withdrawn, Request Closed, or Request Completed, and requests with creation date on or before the request creation date specified by the user in the format YYYYMMDD.
-
Enter 2 to archive the requests with status Request Withdrawn, Request Closed, Request Completed, or Request Partially Failed, and requests with creation date on or before the request creation date specified by the user in the format YYYYMMDD.
-
Enter 3 to archive all the requests with request creation date on or before the request creation date specified by the user in the format YYYYMMDD.
-
-
When prompted to specify the mode of running the utility, enter 1 if you want to run the utility in online mode. Otherwise, enter 2 to run the utility in offline mode.
-
Specify the batch size, when prompted.
Note:
Batch size is a value for the number of records to be processed in a single iteration of archival/purge also an internal commit at the database level. You must provide the batch size as an input parameter value while starting the operation of Archival Utilities at run time.This batch size by default is 2000. A higher batch size can be opted for, but this might require more resources from the database, such as more space from the TEMP and UNDO tablespaces.
The utility archives the request data and provides an execution summary in a log file.
-
On Microsoft Windows platforms, reset the short date format to the date format for your region or locale after you run the utility. Use the Regional and Language Options command in Control Panel to reset the date format.
-
Because the data from active request tables are removed, your DBA must analyze the active request tables and their indexes in order to update the statistics. Perform this step only if you are using Oracle Database as the database for Oracle Identity Manager.
20.3.4.5 Log Files Generated by the Utility
All the logs are written to the logs/ directory created in the current folder. Table 20-11 lists the log files generated by the utility.
Table 20-11 Logs Generated by the DB Archival Utility
| Log File | Description |
|---|---|
|
validate_date.log |
Created when the input REQUEST_CREATION_DATE is invalid |
|
oim_request_archival_summary_TIMESTAMP.log |
Contains the summary of the run |
|
Err_DB_Conn_TIMESTAMP_ATTEMPTNUMBER.log |
Created when the utility is unable to connect to the database with the credentials provided |
20.3.5 Using the Audit Archival and Purge Utility
This section describes how to use the Audit Archival and Purge utility. It contains the following topics:
Note:
The partitioning feature of Oracle Database Enterprise Edition is required for implementing audit archival and purge.20.3.5.1 Overview
Continuous data generation in the Oracle Identity Manager database schema and the audit data growth results in a gradual increase in the storage consumption of the database server. The audit data is populated in the UPA table. The growth of data in the UPA table can pose disk space and maintenance issues. Therefore, old audit data in the UPA table must be cleaned or archived.
To keep this disk space consumption in control, you can use the Audit Archival and Purge utility. This utility controls the growth of the audit data by purging the data in a logical and consistent manner.
Note:
-
The audit archival and purge solution is only applicable to the UPA table. It is not applicable to audit reporting tables, which are tables with the UPA_ prefix.
-
The utility is compatible with Oracle Identity Manager release 9.1.0 and later.
You must shut down Oracle Identity Manager to fetch the latest data, which is to retrieve EFF_TO_DATE as null records. You can retrieve the remaining data later when Oracle Identity Manager is running with the new partitioned UPA.
Oracle recommends partitioning of the UPA table on the basis of calendar year, which allows you to archive or drop partitions. The advantage of partitioning is that the old partitions can be archived or purged because Oracle Identity Manager does not use old audit data lying in those partitions. Oracle Identity Manager uses the latest audit data and the current calendar year data. Therefore, the UPA table is partitioned based on date range-partitioning approach by calender year using EFF_TO_DATE column. After partitioning, the latest audit data where EFF_TO_DATE is NULL, can be grouped in one partition, and there will be one partition for each calendar year. Oracle Identity Manager do not read or write into any other partitions except the latest and current year partitions.
For instance, if you are using Oracle Identity Manager audit feature since 2005 and implementing the audit archive and purge solution in calendar year 2011, then you will have seven partitions after this exercise, assuming that you create a partition for each calendar year. In those seven partitions, Oracle Identity Manager will only read or write the following partitions:
-
The latest partition
-
The partition for the current year, for example 2011
All the previous year partitions can be archived and then purged. If you do not want to archive, then you can purge those old partitions. You can reclaim the space by archiving and purging those old partitions. You must keep the latest and current year partitions untouched for Oracle Identity Manager to continue working.
20.3.5.2 Prerequisites for Using the Utility
The following prerequisites must be met before or when using the Audit Archival and Purge utility:
-
Database partitioning is supported only on Enterprise Edition of Oracle Database. Therefore, to implement the audit archival and purge solution, you must run Enterprise Edition of Oracle Database.
-
The UPA table must be range-partitioned. Time interval can be any value as per data distribution. Other modes of partition methods are not supported.
-
Make sure that the latest backup of the UPA table is available. Creating a backup of the UPA table is a compulsory prerequisite before applying this solution. It is recommended to try out this solution in the development or staging environment before implementing it on the production database.
-
Decide how many previous year's of audit data you require to keep online before implementing this solution. This helps in creating partitions beforehand.
-
Each partition should be placed on its own tablespace. Do not share the tablespace between partitions of different year or with some other data.
-
During partitioning, the audit data for each calendar year is copied into a table before it is moved into a final destination. You must have provision for disk space to hold the copied data.
20.3.5.3 Preparing the UPA Table for Archival and Purge
To prepare the UPA table for the audit and purge solution:
-
Make sure that Oracle Identity Manager database has no transaction against it until the UPA table is partitioned.
-
Query the UPA table to get the minimum and maximum calendar year for the audit data. Following queries can help you get the minimum and maximum year. The maximum year should be the current calendar year.
SELECT EXTRACT (YEAR FROM MIN (eff_to_date)) min_year,EXTRACT (YEAR FROM MAX (eff_to_date)) running_year FROM upa;
This helps in deciding the partitions for each calendar year starting from minimum year.
-
Make sure that Oracle Identity Manager is not running and is not available for off-line utilities.
-
Create a new partition table.
Assuming 2005 as minimum year and 2011 as running or current calendar year, the following decisions are to be made before creating a newly partition table:
-
How many years of old audit data you want to keep? If it is important to keep only three years of audit data, then you have to create newly partitioned table starting from year 2008. The data older than 2008 will get cleaned up when the original UPA table gets dropped.
-
After deciding the years of old data to keep, the next question is how and where the old data should be kept? Do you want to keep all the old data partitions in the active UPA table, or create backup of the old partitions and then drop the old partitions? Oracle recommends moving the old partitions into tapes and then purging them from the UPA table. As stated earlier, you must keep the latest and running calendar year partition untouched.
The following sample assumes that you want to keep three years of audit data in UPA table and current calendar year is 2011:
SQL> SELECT 'Create Table UPA_PART ( UPA_KEY NUMBER (19) Not Null, USR_KEY NUMBER (19) Not Null, EFF_FROM_DATE TIMESTAMP (6) Not Null, EFF_TO_DATE TIMESTAMP (6), SRC VARCHAR2 (4000), SNAPSHOT CLOB, DELTAS CLOB, SIGNATURE CLOB ) PARTITION BY RANGE (EFF_TO_DATE) (PARTITION UPA_2008 VALUES LESS THAN (TO_DATE(''01/01/2009'', ''DD/MM/YYYY'')) Tablespace upa_2008, PARTITION UPA_2009 VALUES LESS THAN (TO_DATE(''01/01/2010'', ''DD/MM/YYYY'')) Tablespace upa_2009, PARTITION UPA_2010 VALUES LESS THAN (TO_DATE(''01/01/2011'', ''DD/MM/YYYY'')) Tablespace upa_2010, PARTITION UPA_2011_PART1 VALUES LESS THAN (TO_DATE('''||TO_CHAR(SYSDATE,'DD/MM/YYYY HH24:MI:SS')||''',''DD/MM/YYYY HH24:MI:SS'')) TABLESPACE UPA_2011_PART1, PARTITION UPA_2011_PART2 VALUES LESS THAN (TO_DATE(''01/01/2012'',''DD/MM/YYYY'')) TABLESPACE UPA_2011_PART2, PARTITION UPA_LATEST VALUES LESS THAN (MAXVALUE) TABLESPACE UPA_MAX ) ENABLE ROW MOVEMENT;' FROM DUAL; -
-
Create another non-partitioned table with similar structure as the UPA table, by running the following statement:
SQL> Create table upa_non_part Tablespace TBS_NAME as select * from upa where 1=2;Here, TBS_NAME is the name of the same tablespace as of partition, which is to be exchanged.
This table is temporary in nature. The purpose of this table is to facilitate the loading of audit data to a newly partitioned UPA table.
Note:
UPA_NON_PART or temporary non-partitioned table must be created on same tablespace as the partition to be exchanged. -
Load the latest audit data into the non-partitioned UPA table, as shown:
SQL> Insert /*+ parallel */ into upa_non_part select /*+ parallel */ * from upa where eff_to_date is null; SQL> COMMIT;
Note:
Using hint /*+parallel*/ in the INSERT statement is optional and you can use other hints also to improve performance according to the available resources. -
Swap the data into the partitioned table by using the ALTER TABLE command, as shown:
SQL> ALTER TABLE upa_part EXCHANGE PARTITION UPA_LATEST WITH TABLE UPA_NON_PART WITH VALIDATION UPDATE GLOBAL INDEXES;
-
Drop the upa_non_part table, as shown:
SQL> DROP TABLE upa_non_part;
While exchanging partitions, the data dictionary is updated instead of writing data physically. Therefore, it is necessary to drop and re-create the temporary non-partitioned UPA_NON_PART table in the same tablesapce associated to the partition to be exchanged.
-
Rename the original non-partitioned UPA table to UPA_OLD, as shown:
SQL> ALTER TABLE upa rename TO upa_old;
-
Rename the newly partitioned UPA_PART table to UPA:
SQL> RENAME UPA_PART to UPA;
-
Manage the constraints for the new UPA table. To do so:
-
Rename the constraint from old UPA table to some other name, as shown:
ALTER TABLE UPA_old RENAME CONSTRAINT PK_UPA TO PK_UPA_old; ALTER INDEX IDX_UPA_EFF_FROM_DT RENAME TO IDX_UPA_EFF_FROM_DT_old; ALTER INDEX IDX_UPA_EFF_TO_DT RENAME TO IDX_UPA_EFF_TO_DT_old; ALTER INDEX IDX_UPA_USR_KEY RENAME TO IDX_UPA_USR_KEY_old; ALTER INDEX PK_UPA RENAME TO PK_UPA_OLD;
-
Create the necessary indexes and primary key constraint on the newly partitioned UPA table. Make sure to add storage characteristics, such as tablespace and size. To do so, run the following SQL query:
SQL>create index IDX_UPA_EFF_FROM_DT on UPA (EFF_FROM_DATE) Local; SQL>create index IDX_UPA_EFF_TO_DT on UPA (EFF_TO_DATE) Local; SQL>create index IDX_UPA_USR_KEY on UPA (USR_KEY) Local; SQL>ALTER TABLE UPA add constraint PK_UPA primary key (UPA_KEY) using index;
Note:
The global non-partitioned index is created to support the primary key. Global index becomes unusable every time a partition is touched. You must rebuild the index when required.
-
-
Run the statistics collection for the UPA table, as shown:
SQL>Exec dbms_stats.gather_table_stats(ownname => 'SCHEMA_NAME',tabname => 'UPA',cascade => TRUE,granularity => 'GLOBAL and PARTITION');Note:
Global statistics must be gathered by default. Oracle 11g includes improvements to statistics collection for partitioned objects so untouched partitions are not rescanned. This significantly increases the speed of statistics collection on large tables where some of the partitions contain static data. When a new partition is added to the table, you need to collect statistics only for the new partition. The global statistics is automatically updated by aggregating the new partition synopsis with the existing partitions synopsis. -
Start Oracle Identity Manager. The database is ready to be opened for transactions. Test and make sure that applications are running as expected.
-
Bring current year data in UPA_2011_PART1 to have all data and maintain consistency for current year. To do so, run the following SQL queries in sequence:
SQL> CREATE TABLE upa_non_part Tablespace TBS_NAME AS SELECT * FROM upa WHERE 1=2;Here, TBS_NAME is the same tablespace name as of the partition, which is to be exchanged.
SQL> Alter Table UPA_NON_PART add constraint PK_UPA_NON_PART primary key (UPA_KEY) using index; ............. ............. SQL> Insert into upa_non_part select * from upa_old where eff_to_date >= to_date('01/01/2011', 'mm/dd/yyyy'); ............. ............. SQL> COMMIT; ............. ............. SQL> ALTER TABLE upa_part exchange partition UPA_2011_PART1 WITH table upa_non_part WITH VALIDATION UPDATE GLOBAL INDEXES; ............. ............. SQL> Drop table upa_non_part; -
If required, bring previous year's data into the newly partitioned UPA table. To do so:
-
Run the following SQL queries in sequence:
SQL> CREATE TABLE upa_non_part Tablespace TBS_NAME AS SELECT * FROM upa WHERE 1=2;Here, TBS_NAME is the same tablespace as of the partition, which is to be exchanged.
............. ............. SQL> Alter Table UPA_NON_PART add constraint PK_UPA_NON_PART primary key (UPA_KEY) using index; ............. ............. SQL> Insert into upa_non_part select * from upa_old where eff_to_date >= to_date('01/01/YEAR', 'mm/dd/yyyy') and eff_to_date < to_date('01/01/<YEAR+1>', 'mm/dd/yyyy');Here, YEAR is the year for which you want to bring the data into newly partitioned UPA table.
............. ............. SQL>COMMIT; ............. ............. SQL> Alter table upa exchange partition UPA_<year> with table upa_non_part with validation Update global indexes; -
Rebuild indexes if they are unusable. The Following SQL query shows the indexes that are unusable:
SQL> Select index_name, partition_name, tablespace_name, status from user_ind_partitions;
-
Drop the table upa_non_part, as shown:
SQL> Drop table upa_non_part;
Note:
Repeat step 15 for each old year. -
-
All partition operations against UPA table are done and all the data is brought into. Run the statistics collection for the UPA table, as shown:
SQL>Exec dbms_stats.gather_table_stats(ownname => '<Schem_name>',tabname => 'UPA',cascade => TRUE,granularity => 'GLOBAL and PARTITION');
-
Drop the UPA_OLD table if it is not required. You can create a backup of this table before dropping.
20.3.5.4 Archiving or Purging the UPA Table
Archiving and purging the UPA table is described in the following sections:
20.3.5.4.1 Partitions That Must Not Be Archived or Purged
Oracle Identity Manager always requires the latest and the current calendar year audit data. The following are the names of latest and calendar year partitions:
-
UPA_LATEST: The latest partition
-
UPA_2011_PART1 and UPA_2011_PART2: Partitions for the current year if current year is 2011
You must keep these two partitions untouched for Oracle Identity Manager to continue working. These two partitions should never be archived or purged.
20.3.5.4.2 Ongoing Partition Maintenance
A new partition must be added to the UPA table before the new calendar year arrives. To do so, use the following SQL template:
SQL> Alter table UPA split partition UPA_LATEST at (TO_DATE('01/01/YEAR+1','DD/MM/YYYY')) into (partition UPA_YEAR tablespace UPA_YEAR,partition UPA_LATEST tablespace UPA_MAX) update global indexes;
Here, YEAR in the TO_DATE function represents the new calendar year plus one. YEAR for partition name and tablespace name represents new upcoming calendar year.
An example of SQL statement for adding new partition for new calendar year 2012 is as follows:
SQL> Alter table UPA split partition UPA_LATEST at (TO_DATE('01/01/2013','DD/MM/YYYY')) into (partition UPA_2012 tablespace UPA_2012,partition UPA_LATEST tablespace UPA_MAX) update global indexes;
Oracle recommends adding new partition with the given SQL template before the new calendar year arrives. However, if you do not add the same before the arrival of the next calender year, then the same can be done after the next year has started by using the same SQL command.
20.3.5.4.3 Archiving or Purging Partitions in the UPA Table
To archive or purge partitions in the UPA table:
-
If you use the attestation feature of Oracle Identity Manager, then make sure that the partition to be archived or purged does not have any active attestation records. You can use the following SQL to verify that.
SQL> SELECT COUNT(1) FROM UPA PARTITION(<PARTITION_TO_BE_DROPPED>) WHERE UPA_KEY IN (select distinct (upa_key) from apt apt, atr atr, atd atd where apt.atr_key=atr.atr_key and atr.atr_completion_time is NULL and apt.apt_key = atd.apt_key);
This query should return zero records, which means there are no active attestation records. If this returns non-zero value, then it means that there are still active attestations pointing to the partition to be dropped. This is not common, but you must make sure that there are no active attestation records before dropping an old year partition.
-
Make sure that there are no custom reports or queries that needs the data from partition to be dropped.
-
Archive the partition to be dropped to tape or any other media. There are many ways to archive a partition. One of the ways is to use data pump or export utility to archive the partition to be dropped. Choose a way that works best in your environment.
-
Purge the partition. To do so:
SQL> Alter table UPA drop partition PARTITION_NAME UPDATE GLOBAL INDEXES; SQL>Drop tablespace TBS_NAME including contents and datafiles;
Here, TBS_NAME is the tablespace associated with the partition to be dropped, and it must not contain any other data.
Note:
-
The current year contains two partitions named UPA_2011_PART1 and UPA_2011_PART2. When current year becomes an old year and the data for that is ready to be archived or purged, make sure to archive or purge these two partitions.
-
It is your responsibility to restore the archived data later, if required.
-