5 Using Oracle XQuery for Hadoop
This chapter explains how to use Oracle XQuery for Hadoop to extract and transform large volumes of semistructured data. It contains the following sections:
5.1 What Is Oracle XQuery for Hadoop?
Oracle XQuery for Hadoop is a transformation engine for semi-structured big data. Oracle XQuery for Hadoop runs transformations expressed in the XQuery language by translating them into a series of MapReduce jobs, which are executed in parallel on the Apache Hadoop cluster. You can focus on data movement and transformation logic, instead of the complexities of Java and MapReduce, without sacrificing scalability or performance.
The input data can be located in a file system accessible through the Hadoop File System API, including the Hadoop Distributed File System (HDFS), or stored in Oracle NoSQL Database. Oracle XQuery for Hadoop can write the transformation results to Hadoop files, Oracle NoSQL Database, or Oracle Database.
Oracle XQuery for Hadoop also provides extensions to Apache Hive to support massive XML files. These extensions are available only on Oracle Big Data Appliance.
Oracle XQuery for Hadoop is based on mature industry standards including XPath, XQuery, and XQuery Update Facility. It is fully integrated with other Oracle products, and so it:
-
Loads data efficiently into Oracle Database using Oracle Loader for Hadoop.
-
Provides read and write support to Oracle NoSQL Database.
Figure 5-1 provides an overview of the data flow using Oracle XQuery for Hadoop.
Figure 5-1 Oracle XQuery for Hadoop Data Flow
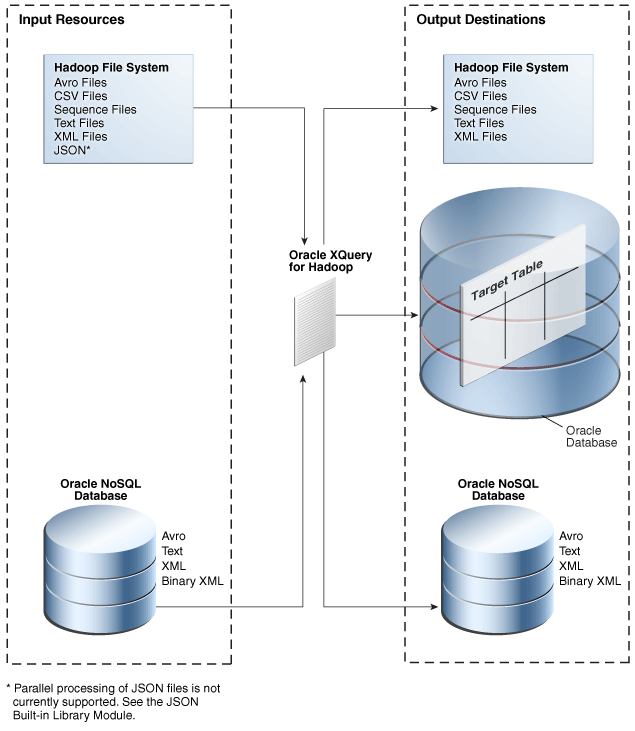
Description of "Figure 5-1 Oracle XQuery for Hadoop Data Flow"
5.2 Getting Started With Oracle XQuery for Hadoop
Oracle XQuery for Hadoop is designed for use by XQuery developers. If you are already familiar with XQuery, then you are ready to begin. However, if you are new to XQuery, then you must first acquire the basics of the language. This guide does not attempt to cover this information.
See Also:
-
"XQuery Tutorial" by W3Schools at
-
"XQuery 3.0: An XML Query Language" at
5.2.1 Basic Steps
Take the following basic steps when using Oracle XQuery for Hadoop:
-
The first time you use Oracle XQuery for Hadoop, ensure that the software is installed and configured.
-
Log in to either a node in the Hadoop cluster or a system set up as a Hadoop client for the cluster.
-
Create an XQuery transformation that uses the Oracle XQuery for Hadoop functions. It can use various adapters for input and output.
See "About the Adapters" and "Creating an XQuery Transformation."
-
Execute the XQuery transformation.
5.2.2 Example: Hello World!
Follow these steps to create and run a simple query using Oracle XQuery for Hadoop:
-
Create a text file named hello.txt in the current directory that contains the line
Hello.$ echo "Hello" > hello.txt
-
Copy the file to HDFS:
$ hdfs dfs -copyFromLocal hello.txt
-
Create a query file named hello.xq in the current directory with the following content:
import module "oxh:text"; for $line in text:collection("hello.txt") return text:put($line || " World!") -
Run the query:
$ hadoop jar $OXH_HOME/lib/oxh.jar hello.xq -output ./myout -print
-
Check the output file:
$ hdfs dfs -cat ./myout/part-m-00000 Hello World!
5.3 About the Adapters
This section contains the following topics:
5.3.1 About the Oracle XQuery for Hadoop Functions
Oracle XQuery for Hadoop reads from and writes to big data sets using collection and put functions:
-
A collection function reads data from Hadoop files or Oracle NoSQL Database as a collection of items. A Hadoop file is one that is accessible through the Hadoop File System API. On Oracle Big Data Appliance and most Hadoop clusters, this file system is Hadoop Distributed File System (HDFS).
-
A put function adds a single item to a data set stored in Oracle Database, Oracle NoSQL Database, or a Hadoop file.
The following is a simple example of an Oracle XQuery for Hadoop query that reads items from one source and writes to another:
for $x in collection(...) return put($x)
Oracle XQuery for Hadoop comes with a set of adapters that you can use to define put and collection functions for specific formats and sources. Each adapter has two components:
-
A set of built-in put and collection functions that are predefined for your convenience.
-
A set of XQuery function annotations that you can use to define custom put and collection functions.
5.3.2 About the Avro File Adapter
The Avro file adapter provides access to Avro container files stored in HDFS. It includes collection and put functions for reading from and writing to Avro container files.
See Also:
"Avro File Adapter"5.3.3 About the Oracle Database Adapter
The Oracle Database adapter loads data into Oracle Database. This adapter supports a custom put function for direct output to a table in an Oracle database using JDBC or OCI. If a live connection to the database is not available, the adapter also supports output to Data Pump or delimited text files in HDFS; the files can be loaded into the Oracle database with a different utility, such as SQL*Loader, or using external tables. This adapter does not move data out of the database, and therefore does not have collection or get functions.
See Also:
-
"Software Requirements" for the supported versions of Oracle Database
5.3.4 About the Oracle NoSQL Database Adapter
The Oracle NoSQL Database adapter provides access to data stored in Oracle NoSQL Database. The data can be read from or written as Avro, XML, binary XML, or text. This adapter includes collection, get, and put functions.
See Also:
"Oracle NoSQL Database Adapter"5.3.5 About the Sequence File Adapter
The sequence file adapter provides access to Hadoop sequence files. A sequence file is a Hadoop format composed of key-value pairs.
This adapter includes collection and put functions for reading from and writing to HDFS sequence files that contain text, XML, or binary XML.
See Also:
"Sequence File Adapter"5.3.6 About the Text File Adapter
The text file adapter provides access to text files, such as CSV files. It contains collection and put functions for reading from and writing to text files.
The JSON library module extends the support for JSON objects stored in text files.
See Also:
5.3.7 About the XML File Adapter
The XML file adapter provides access to XML files stored in HDFS. It contains collection functions for reading large XML files. You must use another adapter to write the output.
See Also:
"XML File Adapter"5.3.8 About Other Modules for Use With Oracle XQuery for Hadoop
You can use functions from these additional modules in your queries:
- Standard XQuery Functions
-
The standard XQuery math functions are available.
See "Functions and Operators on Numerics" in W3C XPath and XQuery Functions and Operators 3.0 at
- Hadoop Functions
-
The Hadoop module is a collection of functions that are specific to Hadoop.
See "Hadoop Module."
- JSON Functions
-
The JSON module is a collection of helper functions for parsing JSON data.
See "JSON Module."
- Duration, Date, and Time Functions
-
These functions parse duration, date, and time values.
- String-Processing Functions
-
These functions add and remove white space that surrounds data values.
5.4 Creating an XQuery Transformation
This chapter describes how to create XQuery transformations using Oracle XQuery for Hadoop. It contains the following topics:
5.4.1 XQuery Transformation Requirements
You create a transformation for Oracle XQuery for Hadoop the same way as any other XQuery transformation, except that you must comply with these additional requirements:
-
The main XQuery expression (the query body) must be in one of the following forms:
FLWOR1or
(FLWOR1, FLWOR2,... , FLWORN)
In this syntax FLWOR is a top-level "For, Let, Where, Order by, Return" expression.
See Also:
"FLWOR Expressions" in W3C XQuery 3.0: An XML Query Language at -
Each top-level FLWOR expression must have a
forclause that iterates over an Oracle XQuery for Hadoopcollectionfunction. Thisforclause cannot have a positional variable.See Chapter 6 for the
collectionfunctions. -
Each top-level FLWOR expression must return one or more results from calling the Oracle XQuery for Hadoop
putfunction. See Chapter 6 for theputfunctions.The query body must be an updating expression. Because all
putfunctions are classified as updating functions, all Oracle XQuery for Hadoop queries are updating queries.In Oracle XQuery for Hadoop, a
%*:putannotation indicates that the function is updating. The%updatingannotation orupdatingkeyword is not required with it.See Also:
For a description of updating expressions, "Extensions to XQuery 1.0" in W3C XQuery Update Facility 1.0 athttp://www.w3.org/TR/xquery-update-10/#dt-updating-expression -
Each top-level FLOWR expression can have optional
let,where, andgroup byclauses. Other types of clauses are invalid, such asorder by,count, andwindowclauses.
5.4.2 About XQuery Language Support
Oracle XQuery for Hadoop supports the XQuery 1.0 specification:
-
For the language, see
http://www.w3.org/TR/xquery/ -
For the functions, see
http://www.w3.org/TR/xpath-functions/
In addition, Oracle XQuery for Hadoop supports the following XQuery 3.0 features. The links are to the relevant sections of W3C XQuery 3.0: An XML Query Language.
-
group byclause -
forclause with theallowing emptymodifier -
Annotations
-
String concatenation expressions
-
Standard functions:
fn:analyze-string fn:unparsed-text fn:unparsed-text-lines fn:unparsed-text-available fn:serialize fn:parse-xml
-
Trigonometric and exponential functions
5.4.3 Accessing Data in the Hadoop Distributed Cache
You can use the Hadoop distributed cache facility to access auxiliary job data. This mechanism can be useful in a join query when one side is a relatively small file.
The query might execute faster if the smaller file is accessed from the distributed cache.
To place a file into the distributed cache, use the -files Hadoop command line option when calling Oracle XQuery for Hadoop.
For a query to read a file from the distributed cache, it must call the fn:doc function for XML, and either fn:unparsed-text or fn:unparsed-text-lines for text files.
See Example 7.
5.4.4 Calling Custom Java Functions from XQuery
Oracle XQuery for Hadoop is extensible with custom external functions implemented in the Java language.
The Java implementation must be a static method with the parameter and return types as defined by the XQuery API for Java (XQJ) specification.
The custom Java function binding is defined in Oracle XQuery for Hadoop by annotating an external function definition with the %ora-java:binding annotation. This annotation has the following syntax:
%ora-java:binding("java.class.name[#method]")
- java.class.name
-
The fully qualified name of a Java class that contains the implementation method.
- method
-
A Java method name. It defaults to the XQuery function name. Optional.
See Example 8 for an example of %ora-java:binding.
All JAR files that contain custom Java functions must be listed in the -libjars command line option. For example:
hadoop jar $OXH_HOME/lib/oxh.jar -libjars myfunctions.jar query.xq
See Also:
"XQuery API for Java (XQJ)" at5.4.5 Accessing User-Defined XQuery Library Modules and XML Schemas
Oracle XQuery for Hadoop supports user-defined XQuery library modules and XML schemas when you comply with these criteria:
-
Locate the library module or XML schema file in the same directory where the main query resides on the client calling Oracle XQuery for Hadoop.
-
Import the library module or XML schema from the main query using the location URI parameter of the import module/schema statement.
-
Specify the library module or XML schema file in the
-filescommand line option when calling Oracle XQuery for Hadoop.
See Example 9.
See Also:
"Location URIs" in the W3C XQuery 3.0: An XML Query Language athttp://www.w3.org/TR/xquery-30/#id-module-handling-location-uris
5.4.6 XQuery Transformation Examples
For these examples, the following text files are in HDFS. The files contain a log of visits to different web pages. Each line represents a visit to a web page and contains the time, user name, page visited, and the status code.
mydata/visits1.log 2013-10-28T06:00:00, john, index.html, 200 2013-10-28T08:30:02, kelly, index.html, 200 2013-10-28T08:32:50, kelly, about.html, 200 2013-10-30T10:00:10, mike, index.html, 401 mydata/visits2.log 2013-10-30T10:00:01, john, index.html, 200 2013-10-30T10:05:20, john, about.html, 200 2013-11-01T08:00:08, laura, index.html, 200 2013-11-04T06:12:51, kelly, index.html, 200 2013-11-04T06:12:40, kelly, contact.html, 200
- Example 1 Basic Filtering
-
This query filters out pages visited by user
kellyand writes those files into a text fileimport module "oxh:text"; for $line in text:collection("mydata/visits*.log") let $split := fn:tokenize($line, "\s*,\s*") where $split[2] eq "kelly" return text:put($line)The query creates text files in the output directory that contain the following lines:
2013-11-04T06:12:51, kelly, index.html, 200 2013-11-04T06:12:40, kelly, contact.html, 200 2013-10-28T08:30:02, kelly, index.html, 200 2013-10-28T08:32:50, kelly, about.html, 200
- Example 2 Group By and Aggregation
-
The next query computes the number of page visits per day:
import module "oxh:text"; for $line in text:collection("mydata/visits*.log") let $split := fn:tokenize($line, "\s*,\s*") let $time := xs:dateTime($split[1]) let $day := xs:date($time) group by $day return text:put($day || " => " || fn:count($line))The query creates text files that contain the following lines:
2013-10-28 => 3 2013-10-30 => 3 2013-11-01 => 1 2013-11-04 => 2
- Example 3 Inner Joins
-
This example queries the following text file in HDFS, in addition to the other files. The file contains user profile information such as user ID, full name, and age, separated by a colon (:).
mydata/users.txt john:John Doe:45 kelly:Kelly Johnson:32 laura:Laura Smith: phil:Phil Johnson:27
The following query performs a join between users.txt and the log files. It computes how many times users older than 30 visited each page.
import module "oxh:text"; for $userLine in text:collection("mydata/users.txt") let $userSplit := fn:tokenize($userLine, "\s*:\s*") let $userId := $userSplit[1] let $userAge := xs:integer($userSplit[3][. castable as xs:integer]) for $visitLine in text:collection("mydata/visits*.log") let $visitSplit := fn:tokenize($visitLine, "\s*,\s*") let $visitUserId := $visitSplit[2] where $userId eq $visitUserId and $userAge gt 30 group by $page := $visitSplit[3] return text:put($page || " " || fn:count($userLine))The query creates text files that contain the following lines:
about.html 2 contact.html 1 index.html 4
The next query computes the number of visits for each user who visited any page; it omits users who never visited any page.
import module "oxh:text"; for $userLine in text:collection("mydata/users.txt") let $userSplit := fn:tokenize($userLine, "\s*:\s*") let $userId := $userSplit[1] for $visitLine in text:collection("mydata/visits*.log") [$userId eq fn:tokenize(., "\s*,\s*")[2]] group by $userId return text:put($userId || " " || fn:count($visitLine))The query creates text files that contain the following lines:
john 3 kelly 4 laura 1
Note:
When the results of two collection functions are joined, only equijoins are supported. If one or both sources are not from acollectionfunction, then any join condition is allowed. - Example 4 Left Outer Joins
-
This example is similar to the second query in Example 3, but also counts users who did not visit any page.
import module "oxh:text"; for $userLine in text:collection("mydata/users.txt") let $userSplit := fn:tokenize($userLine, "\s*:\s*") let $userId := $userSplit[1] for $visitLine allowing empty in text:collection("mydata/visits*.log") [$userId eq fn:tokenize(., "\s*,\s*")[2]] group by $userId return text:put($userId || " " || fn:count($visitLine))The query creates text files that contain the following lines:
john 3 kelly 4 laura 1 phil 0
- Example 5 Semijoins
-
The next query finds users who have ever visited a page.
import module "oxh:text"; for $userLine in text:collection("mydata/users.txt") let $userId := fn:tokenize($userLine, "\s*:\s*")[1] where some $visitLine in text:collection("mydata/visits*.log") satisfies $userId eq fn:tokenize($visitLine, "\s*,\s*")[2] return text:put($userId)The query creates text files that contain the following lines:
john kelly laura
- Example 6 Multiple Outputs
-
The next query finds web page visits with a 401 code and writes them to
trace*files using the XQuerytext:trace()function. It writes the remaining visit records into the default output files.import module "oxh:text"; for $visitLine in text:collection("mydata/visits*.log") let $visitCode := xs:integer(fn:tokenize($visitLine, "\s*,\s*")[4]) return if ($visitCode eq 401) then text:trace($visitLine) else text:put($visitLine)The query generates a
trace*text file that contains the following line:2013-10-30T10:00:10, mike, index.html, 401
The query also generates default output files that contain the following lines:
2013-10-30T10:00:01, john, index.html, 200 2013-10-30T10:05:20, john, about.html, 200 2013-11-01T08:00:08, laura, index.html, 200 2013-11-04T06:12:51, kelly, index.html, 200 2013-11-04T06:12:40, kelly, contact.html, 200 2013-10-28T06:00:00, john, index.html, 200 2013-10-28T08:30:02, kelly, index.html, 200 2013-10-28T08:32:50, kelly, about.html, 200
- Example 7 Accessing Auxiliary Input Data
-
The next query is an alternative version of the second query in Example 3, but it uses the
fn:unparsed-text-linesfunction to access a file in the Hadoop distributed cache.import module "oxh:text"; for $visitLine in text:collection("mydata/visits*.log") let $visitUserId := fn:tokenize($visitLine, "\s*,\s*")[2] for $userLine in fn:unparsed-text-lines("users.txt") let $userSplit := fn:tokenize($userLine, "\s*:\s*") let $userId := $userSplit[1] where $userId eq $visitUserId group by $userId return text:put($userId || " " || fn:count($visitLine))The
hadoopcommand to run the query must use the Hadoop-filesoption. See "Accessing Data in the Hadoop Distributed Cache."hadoop jar $OXH_HOME/lib/oxh.jar -files users.txt query.xq
The query creates text files that contain the following lines:
john 3 kelly 4 laura 1
- Example 8 Calling a Custom Java Function from XQuery
-
The next query formats input data using the
java.lang.String#formatmethod.import module "oxh:text"; declare %ora-java:binding("java.lang.String#format") function local:string-format($pattern as xs:string, $data as xs:anyAtomicType*) as xs:string external; for $line in text:collection("mydata/users*.txt") let $split := fn:tokenize($line, "\s*:\s*") return text:put(local:string-format("%s,%s,%s", $split))The query creates text files that contain the following lines:
john,John Doe,45 kelly,Kelly Johnson,32 laura,Laura Smith, phil,Phil Johnson,27
See Also:
Java Platform Standard Edition 7 API Specification for Class String at - Example 9 Using User-defined XQuery Library Modules and XML Schemas
-
This example uses a library module named mytools.xq.
module namespace mytools = "urn:mytools"; declare %ora-java:binding("java.lang.String#format") function mytools:string-format($pattern as xs:string, $data as xs:anyAtomicType*) as xs:string external;The next query is equivalent to the previous one, but it calls a string-format function from the mytools.xq library module:
import module namespace mytools = "urn:mytools" at "mytools.xq"; import module "oxh:text"; for $line in text:collection("mydata/users*.txt") let $split := fn:tokenize($line, "\s*:\s*") return text:put(mytools:string-format("%s,%s,%s", $split))The query creates text files that contain the following lines:
john,John Doe,45 kelly,Kelly Johnson,32 laura,Laura Smith, phil,Phil Johnson,27
5.5 Running a Query
To run a query, call the OXH utility using the hadoop jar command.
The following is the basic syntax:
hadoop jar $OXH_HOME/lib/oxh.jar [generic options] query.xq -output directory [-clean] [-ls] [-print] [-skiperrors] [-version]
5.5.1 Oracle XQuery for Hadoop Options
- query.xq
-
Identifies the XQuery file. See "Creating an XQuery Transformation."
- -clean
-
Deletes all files from the output directory before running the query.
- -ls
-
Lists the contents of the output directory after the query executes.
- -output directory
-
Specifies the output directory of the query. The put functions of the file adapters create files in this directory. Written values are spread across one or more files. The number of files created depends on how the query is distributed among tasks. By default, each output file has a name that starts with
part, such as part-m-00000.See "About the Oracle XQuery for Hadoop Functions" for a description of put functions.
-
Prints the contents of all files in the output directory to the standard output (your screen). When printing Avro files, each record prints as JSON text.
- -skiperrors
-
Turns on error recovery, so that an error does not halt processing.
All errors that occur during query processing are counted, and the total is logged at the end of the query. The error messages of the first 20 errors per task are also logged. See
oracle.hadoop.xquery.skiperrors.counters,oracle.hadoop.xquery.skiperrors.max, andoracle.hadoop.xquery.skiperrors.log.max. - -version
-
Displays the Oracle XQuery for Hadoop version and exits without running a query.
5.5.2 Generic Options
You can include any generic hadoop command-line option. OXH implements the org.apache.hadoop.util.Tool interface and follows the standard Hadoop methods for building MapReduce applications.
The following generic options are commonly used with Oracle XQuery for Hadoop:
- -conf job_config.xml
-
Identifies the job configuration file. See "Oracle XQuery for Hadoop Configuration Properties."
When you are working with the Oracle Database or Oracle NoSQL Database adapters, you can set various job properties in this file. See "%oracle-property Annotations and Corresponding Oracle Loader for Hadoop Configuration Properties" and "Oracle NoSQL Database Adapter Configuration Properties".
- -D property=value
-
Identifies a configuration property. See "Oracle XQuery for Hadoop Configuration Properties."
- -files
-
Specifies a comma-delimited list of files that are added to the distributed cache. See "Accessing Data in the Hadoop Distributed Cache."
See Also:
For full descriptions of the generic options:http://hadoop.apache.org/docs/r1.1.2/commands_manual.html#Generic+Options
5.5.3 About Running Queries Locally
When developing queries, you can run them locally before submitting them to the cluster. A local run enables you to see how the query behaves on small data sets and diagnose potential problems quickly.
In local mode, relative URIs resolve against the local file system instead of HDFS, and the query runs in a single process.
To run a query in local mode:
-
Set the Hadoop
-jtand-fsgeneric arguments tolocal. This example runs the query described in "Example: Hello World!" in local mode:$ hadoop jar $OXH_HOME/lib/oxh.jar -jt local -fs local ./hello.xq -output ./myoutput -print
-
Check the result file in the local output directory of the query, as shown in this example:
$ cat ./myoutput/part-m-00000 Hello World!
5.6 Oracle XQuery for Hadoop Configuration Properties
Oracle XQuery for Hadoop uses the generic methods of specifying configuration properties in the hadoop command. You can use the -conf option to identify configuration files, and the -D option to specify individual properties. See "Running a Query."
See Also:
Hadoop documentation for job configuration files at- oracle.hadoop.xquery.output
-
Type: String
Default Value: Not defined
Description: Sets the output directory for the query. This property is equivalent to the
-outputcommand line option. - oracle.hadoop.xquery.scratch
-
Type: String
Default Value: /tmp/user_name/oxh. The user_name is the name of the user running Oracle XQuery for Hadoop.
Description: Sets the HDFS temp directory for Oracle XQuery for Hadoop to store temporary files.
- oracle.hadoop.xquery.timezone
-
Type: String
Default Value: Client system time zone
Description: The XQuery implicit time zone, which is used in a comparison or arithmetic operation when a date, time or dateTime value does not have a time zone. The value must be in the format described by the Java TimeZone class. See the Java 7 API Specification at
http://docs.oracle.com/javase/7/docs/api/java/util/TimeZone.html - oracle.hadoop.xquery.skiperrors
-
Type: Boolean
Default Value:
falseDescription: Set to
trueto turn on error recovery, or set tofalseto stop processing when an error occurs. This property is equivalent to the-skiperrorscommand line option. - oracle.hadoop.xquery.skiperrors.counters
-
Type: Boolean
Default Value:
trueDescription: Set to
trueto group errors by error code, or set tofalseto report all errors in a single counter. - oracle.hadoop.xquery.skiperrors.max
-
Type: Integer
Default Value: Unlimited
Description: Sets the maximum number of errors that a single MapReduce task can recover from (skip).
- oracle.hadoop.xquery.skiperrors.log.max
-
Type: Integer
Default Value: 20
Description: Sets the maximum number of errors that a single MapReduce task logs.
- log4j.logger.oracle.hadoop.xquery
-
Type: String
Default Value: Not defined
Description: Configures the
log4jlogger for each task with the specified threshold level. Set the property to one of these values:OFF,FATAL,ERROR,WARN,INFO,DEBUG,ALL. If this property is not set, then Oracle XQuery for Hadoop does not configurelog4j.
5.7 Third-Party Licenses for Bundled Software
Oracle XQuery for Hadoop installs the following third-party products:
Unless otherwise specifically noted, or as required under the terms of the third party license (e.g., LGPL), the licenses and statements herein, including all statements regarding Apache-licensed code, are intended as notices only.
5.7.1 Apache Licensed Code
The following is included as a notice in compliance with the terms of the Apache 2.0 License, and applies to all programs licensed under the Apache 2.0 license:
You may not use the identified files except in compliance with the Apache License, Version 2.0 (the "License.")
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
A copy of the license is also reproduced in "Apache Licensed Code."
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and limitations under the License.
5.7.2 ANTLR 3.2
[The BSD License]
Copyright © 2010 Terence Parr
All rights reserved.
Redistribution and use in source and binary forms, with or without modification, are permitted provided that the following conditions are met:
-
Redistributions of source code must retain the above copyright notice, this list of conditions and the following disclaimer.
-
Redistributions in binary form must reproduce the above copyright notice, this list of conditions and the following disclaimer in the documentation and/or other materials provided with the distribution.
-
Neither the name of the author nor the names of its contributors may be used to endorse or promote products derived from this software without specific prior written permission.
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT OWNER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
5.7.3 Apache Ant 1.7.1
Copyright 1999-2008 The Apache Software Foundation
This product includes software developed by The Apache Software Foundation (http://www.apache.org).
This product includes also software developed by:
-
the W3C consortium (
http://www.w3c.org) -
the SAX project (
http://www.saxproject.org)
The <sync> task is based on code Copyright (c) 2002, Landmark Graphics Corp that has been kindly donated to the Apache Software Foundation.
Portions of this software were originally based on the following:
-
software copyright (c) 1999, IBM Corporation, http://www.ibm.com.
-
software copyright (c) 1999, Sun Microsystems, http://www.sun.com.
-
voluntary contributions made by Paul Eng on behalf of the Apache Software Foundation that were originally developed at iClick, Inc., software copyright (c) 1999
W3C® SOFTWARE NOTICE AND LICENSE
http://www.w3.org/Consortium/Legal/2002/copyright-software-20021231
This work (and included software, documentation such as READMEs, or other related items) is being provided by the copyright holders under the following license. By obtaining, using and/or copying this work, you (the licensee) agree that you have read, understood, and will comply with the following terms and conditions.
Permission to copy, modify, and distribute this software and its documentation, with or without modification, for any purpose and without fee or royalty is hereby granted, provided that you include the following on ALL copies of the software and documentation or portions thereof, including modifications:
-
The full text of this NOTICE in a location viewable to users of the redistributed or derivative work.
-
Any pre-existing intellectual property disclaimers, notices, or terms and conditions. If none exist, the W3C Software Short Notice should be included (hypertext is preferred, text is permitted) within the body of any redistributed or derivative code.
-
Notice of any changes or modifications to the files, including the date changes were made. (We recommend you provide URIs to the location from which the code is derived.)
THIS SOFTWARE AND DOCUMENTATION IS PROVIDED "AS IS," AND COPYRIGHT HOLDERS MAKE NO REPRESENTATIONS OR WARRANTIES, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO, WARRANTIES OF MERCHANTABILITY OR FITNESS FOR ANY PARTICULAR PURPOSE OR THAT THE USE OF THE SOFTWARE OR DOCUMENTATION WILL NOT INFRINGE ANY THIRD PARTY PATENTS, COPYRIGHTS, TRADEMARKS OR OTHER RIGHTS.
COPYRIGHT HOLDERS WILL NOT BE LIABLE FOR ANY DIRECT, INDIRECT, SPECIAL OR CONSEQUENTIAL DAMAGES ARISING OUT OF ANY USE OF THE SOFTWARE OR DOCUMENTATION.
The name and trademarks of copyright holders may NOT be used in advertising or publicity pertaining to the software without specific, written prior permission. Title to copyright in this software and any associated documentation will at all times remain with copyright holders.
This formulation of W3C's notice and license became active on December 31 2002. This version removes the copyright ownership notice such that this license can be used with materials other than those owned by the W3C, reflects that ERCIM is now a host of the W3C, includes references to this specific dated version of the license, and removes the ambiguous grant of "use". Otherwise, this version is the same as the previous version and is written so as to preserve the Free Software Foundation's assessment of GPL compatibility and OSI's certification under the Open Source Definition. Please see our Copyright FAQ for common questions about using materials from our site, including specific terms and conditions for packages like libwww, Amaya, and Jigsaw. Other questions about this notice can be directed to site-policy@w3.org.
Joseph Reagle <site-policy@w3.org>
This license came from: http://www.megginson.com/SAX/copying.html
However please note future versions of SAX may be covered under http://saxproject.org/?selected=pd
SAX2 is Free!
I hereby abandon any property rights to SAX 2.0 (the Simple API for XML), and release all of the SAX 2.0 source code, compiled code, and documentation contained in this distribution into the Public Domain. SAX comes with NO WARRANTY or guarantee of fitness for any purpose.
David Megginson, david@megginson.com
2000-05-05
5.7.4 Apache Avro 1.7.3, 1.7.4
Copyright 2010 The Apache Software Foundation
This product includes software developed at The Apache Software Foundation (http://www.apache.org/).
C JSON parsing provided by Jansson and written by Petri Lehtinen. The original software is available from http://www.digip.org/jansson/.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use Apache Avro except in compliance with the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License.
License for the Jansson C JSON parser used in the C implementation:
Copyright (c) 2009 Petri Lehtinen <petri@digip.org>
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
License for the Json.NET used in the C# implementation:
Copyright (c) 2007 James Newton-King
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
License for msinttypes used in the C implementation:
Source from:
http://code.google.com/p/msinttypes/downloads/detail?name=msinttypes-r26.zip
Copyright (c) 2006-2008 Alexander Chemeris
Redistribution and use in source and binary forms, with or without modification, are permitted provided that the following conditions are met:
-
Redistributions of source code must retain the above copyright notice, this list of conditions and the following disclaimer.
-
Redistributions in binary form must reproduce the above copyright notice, this list of conditions and the following disclaimer in the documentation and/or other materials provided with the distribution.
-
The name of the author may be used to endorse or promote products derived from this software without specific prior written permission.
THIS SOFTWARE IS PROVIDED BY THE AUTHOR "AS IS'' AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE AUTHOR BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
License for Dirent API for Microsoft Visual Studio used in the C implementation:
Source from:
http://www.softagalleria.net/download/dirent/dirent-1.11.zip
Copyright (C) 2006 Toni Ronkko
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the ``Software''), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS'', WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL TONI RONKKO BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
5.7.5 Apache Xerces
Xerces Copyright © 1999-2002 The Apache Software Foundation. All rights reserved. Licensed under the Apache 1.1 License Agreement.
The names "Xerces" and "Apache Software Foundation must not be used to endorse or promote products derived from this software or be used in a product name without prior written permission. For written permission, please contact apache@apache.org.
This software consists of voluntary contributions made by many individuals on behalf of the Apache Software Foundation. For more information on the Apache Software Foundation, please see http://www.apache.org.
The Apache Software License, Version 1.1
Redistribution and use in source and binary forms, with or without modification, are permitted provided that the following conditions are met:
-
Redistributions of source code must retain the above copyright notice, this list of conditions and the following disclaimer.
-
Redistributions in binary form must reproduce the above copyright notice, this list of conditions and the following disclaimer in the documentation and/or other materials provided with the distribution.
-
The end-user documentation included with the redistribution, if any, must include the acknowledgements set forth above in connection with the software ("This product includes software developed by the ….) Alternately, this acknowledgement may appear in the software itself, if and wherever such third-party acknowledgements normally appear.
-
The names identified above with the specific software must not be used to endorse or promote products derived from this software without prior written permission. For written permission, please contact apache@apache.org.
-
Products derived from this software may not be called "Apache" nor may "Apache" appear in their names without prior written permission of the Apache Group.
THIS SOFTWARE IS PROVIDED "AS IS" AND ANY EXPRESSED OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE APACHE SOFTWARE FOUNDATION OR ITS CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
5.7.6 Apache XMLBeans 2.5
This product includes software developed by The Apache Software Foundation (http://www.apache.org/).
Portions of this software were originally based on the following:
-
software copyright (c) 2000-2003, BEA Systems, <http://www.bea.com/>.
Aside from contributions to the Apache XMLBeans project, this software also includes:
-
one or more source files from the Apache Xerces-J and Apache Axis products, Copyright (c) 1999-2003 Apache Software Foundation
-
W3C XML Schema documents Copyright 2001-2003 (c) World Wide Web Consortium (Massachusetts Institute of Technology, European Research Consortium for Informatics and Mathematics, Keio University)
-
resolver.jar from Apache Xml Commons project, Copyright (c) 2001-2003 Apache Software Foundation
-
Piccolo XML Parser for Java from
http://piccolo.sourceforge.net/, Copyright 2002 Yuval Oren under the terms of the Apache Software License 2.0 -
JSR-173 Streaming API for XML from
http://sourceforge.net/projects/xmlpullparser/, Copyright 2005 BEA under the terms of the Apache Software License 2.0
5.7.7 Jackson 1.8.8
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License.
5.7.8 Woodstox XML Parser 4.2
This copy of Woodstox XML processor is licensed under the Apache (Software) License, version 2.0 ("the License"). See the License for details about distribution rights, and the specific rights regarding derivate works.
You may obtain a copy of the License at:
http://www.apache.org/licenses/
A copy is also included with both the downloadable source code package and jar that contains class bytecodes, as file "ASL 2.0". In both cases, that file should be located next to this file: in source distribution the location should be "release-notes/asl"; and in jar "META-INF/"
This product currently only contains code developed by authors of specific components, as identified by the source code files.
Since product implements StAX API, it has dependencies to StAX API classes.
For additional credits (generally to people who reported problems) see CREDITS file.