1 Getting Started with Oracle Big Data Connectors
This chapter describes the Oracle Big Data Connectors and provides installation instructions.
This chapter contains the following sections:
1.1 About Oracle Big Data Connectors
Oracle Big Data Connectors facilitate data access to data stored in an Apache Hadoop cluster. It can be licensed for use on either Oracle Big Data Appliance or a Hadoop cluster running on commodity hardware.
These are the connectors:
-
Oracle SQL Connector for Hadoop Distributed File System (previously Oracle Direct Connector for HDFS): Enables an Oracle external table to access data stored in Hadoop Distributed File System (HDFS) files or a table in Apache Hive. The data can remain in HDFS or the Hive table, or it can be loaded into an Oracle database. Oracle SQL Connector for HDFS is a command-line utility that accepts generic command line arguments supported by the org.apache.hadoop.util.Tool interface. It also provides a preprocessor for Oracle external tables.
-
Oracle Loader for Hadoop: Provides an efficient and high-performance loader for fast movement of data from a Hadoop cluster into a table in an Oracle database. Oracle Loader for Hadoop prepartitions the data if necessary and transforms it into a database-ready format. It optionally sorts records by primary key or user-defined columns before loading the data or creating output files. Oracle Loader for Hadoop is a MapReduce application that is invoked as a command-line utility. It accepts the generic command-line options that are supported by the org.apache.hadoop.util.Tool interface.
-
Oracle Data Integrator Application Adapter for Hadoop: Extracts, transforms, and loads data from a Hadoop cluster into tables in an Oracle database, as defined using a graphical user interface.
-
Oracle XQuery for Hadoop: Runs transformations expressed in the XQuery language by translating them into a series of MapReduce jobs, which are executed in parallel on the Hadoop cluster. The input data can be located in a file system accessible through the Hadoop File System API, such as the Hadoop Distributed File System (HDFS), or stored in Oracle NoSQL Database. Oracle XQuery for Hadoop can write the transformation results to HDFS, Oracle NoSQL Database, or Oracle Database.
-
Oracle R Advanced Analytics for Hadoop: Provides an interface between a local R environment, Oracle Database, and Hadoop, allowing speed-of-thought, interactive analysis on all three platforms. Oracle R Advanced Analytics for Hadoop is designed to work independently, but if the enterprise data for your analysis is also stored in Oracle Database, then the full power of this connector is achieved when it is used with Oracle R Enterprise.
Individual connectors may require that software components be installed in Oracle Database and either the Hadoop cluster or an external system set up as a Hadoop client for the cluster. Users may also need additional access privileges in Oracle Database.
See Also:
My Oracle Support Information Center: Big Data Connectors (ID 1487399.2) and its related information centers.1.2 Big Data Concepts and Technologies
Enterprises are seeing large amounts of data coming from multiple sources. Click-stream data in web logs, GPS tracking information, data from retail operations, sensor data, and multimedia streams are just a few examples of vast amounts of data that can be of tremendous value to an enterprise if analyzed. The unstructured and semi-structured information provided by raw data feeds is of little value in and of itself. The data must be processed to extract information of real value, which can then be stored and managed in the database. Analytics of this data along with the structured data in the database can provide new insights into the data and lead to substantial business benefits.
1.2.1 What is MapReduce?
MapReduce is a parallel programming model for processing data on a distributed system. It can process vast amounts of data quickly and can scale linearly. It is particularly effective as a mechanism for batch processing of unstructured and semi-structured data. MapReduce abstracts lower level operations into computations over a set of keys and values.
A simplified definition of a MapReduce job is the successive alternation of two phases, the map phase and the reduce phase. Each map phase applies a transform function over each record in the input data to produce a set of records expressed as key-value pairs. The output from the map phase is input to the reduce phase. In the reduce phase, the map output records are sorted into key-value sets so that all records in a set have the same key value. A reducer function is applied to all the records in a set and a set of output records are produced as key-value pairs. The map phase is logically run in parallel over each record while the reduce phase is run in parallel over all key values.
Note:
Oracle Big Data Connectors do not support the Yet Another Resource Negotiator (YARN) implementation of MapReduce.1.2.2 What is Apache Hadoop?
Apache Hadoop is the software framework for the development and deployment of data processing jobs based on the MapReduce programming model. At the core, Hadoop provides a reliable shared storage and analysis systemFoot 1 . Analysis is provided by MapReduce. Storage is provided by the Hadoop Distributed File System (HDFS), a shared storage system designed for MapReduce jobs.
The Hadoop ecosystem includes several other projects including Apache Avro, a data serialization system that is used by Oracle Loader for Hadoop.
Cloudera's Distribution including Apache Hadoop (CDH) is installed on Oracle Big Data Appliance. You can use Oracle Big Data Connectors on a Hadoop cluster running CDH or the equivalent Apache Hadoop components, as described in the setup instructions in this chapter.
See Also:
-
For conceptual information about the Hadoop technologies, the following third-party publication:
Hadoop: The Definitive Guide, Third Edition by Tom White (O'Reilly Media Inc., 2012, ISBN: 978-1449311520).
-
For information about Cloudera's Distribution including Apache Hadoop (CDH4), the Oracle Cloudera website at
-
For information about Apache Hadoop, the website at
1.3 Downloading the Oracle Big Data Connectors Software
You can download Oracle Big Data Connectors from Oracle Technology Network or Oracle Software Delivery Cloud.
To download from Oracle Technology Network:
-
Use any browser to visit this website:
http://www.oracle.com/technetwork/bdc/big-data-connectors/downloads/index.html -
Click the name of each connector to download a zip file containing the installation files.
To download from Oracle Software Delivery Cloud:
-
Use any browser to visit this website:
-
Accept the Terms and Restrictions to see the Media Pack Search page.
-
Select the search terms:
Select a Product Pack: Oracle Database
Platform: Linux x86-64
-
Click Go to display a list of product packs.
-
Select Oracle Big Data Connectors Media Pack for Linux x86-64 (B65965-0x), and then click Continue.
-
Click Download for each connector to download a zip file containing the installation files.
1.4 Oracle SQL Connector for Hadoop Distributed File System Setup
You install and configure Oracle SQL Connector for Hadoop Distributed File System (HDFS) on the system where Oracle Database runs. If Hive tables are used as the data source, then you must also install and run Oracle SQL Connector for HDFS on a Hadoop client where users access Hive.
Oracle SQL Connector for HDFS is installed already on Oracle Big Data Appliance if it was configured for Oracle Big Data Connectors. This installation supports users who connect directly to Oracle Big Data Appliance to run their jobs.
This section contains the following topics:
-
Installing and Configuring a Hadoop Client on the Oracle Database System
-
Using Oracle SQL Connector for HDFS on a Secure Hadoop Cluster
1.4.1 Software Requirements
Oracle SQL Connector for HDFS requires the following software:
On the Hadoop cluster:
-
Cloudera's Distribution including Apache Hadoop version 3 (CDH3) or version 4 (CDH4), Apache Hadoop 1.0 (formerly 0.20.2), or Apache Hadoop 1.1.
-
Java Development Kit (JDK) 1.6_08 or later. Consult the distributor of your Hadoop software (Cloudera or Apache) for the recommended version.
-
Hive 0.7.0, 0.7.1, 0.8.1, 0.9.0, or 0.10 (required for Hive table access, otherwise optional)
This software is already installed on Oracle Big Data Appliance.
On the Oracle Database system and Hadoop client systems:
-
Oracle Database 12c, Oracle Database 11g release 2 (11.2.0.2 or 11.2.0.3), or Oracle Database 10g release 2 (10.2.0.5) for Linux.
-
To support the Oracle Data Pump file format in Oracle Database release 11.2.0.2 or 11.2.0.3, an Oracle Database one-off patch. To download this patch, go to
http://support.oracle.comand search for bug 14557588.Release 11.2.0.4 and later releases do not require this patch.
-
The same version of Hadoop as your Hadoop cluster: CDH3, CDH4, Apache Hadoop 1.0, or Apache Hadoop 1.1.
If you have a secure Hadoop cluster configured with Kerberos, then the Hadoop client on the database system must be set up to access a secure cluster. See "Using Oracle SQL Connector for HDFS on a Secure Hadoop Cluster."
-
The same version of JDK as your Hadoop cluster.
1.4.2 Installing and Configuring a Hadoop Client on the Oracle Database System
Oracle SQL Connector for HDFS works as a Hadoop client. You must install Hadoop on the Oracle Database system and minimally configure it for Hadoop client use only. You do not need to perform a full configuration of Hadoop on the Oracle Database system to run MapReduce jobs for Oracle SQL Connector for HDFS.
For Oracle RAC systems including Oracle Exadata Database Machine, you must install and configure Oracle SQL Connector for HDFS using identical paths on all systems running Oracle instances.
You can optionally set up additional Hadoop client systems by following these instructions.
To configure the Oracle Database system as a Hadoop client:
-
Install and configure the same version of CDH or Apache Hadoop on the Oracle Database system as on the Hadoop cluster. If you are using Oracle Big Data Appliance, then complete the procedures for providing remote client access in the Oracle Big Data Appliance Software User's Guide. Otherwise, follow the installation instructions provided by the distributor (Cloudera or Apache).
Note:
Do not start Hadoop on the Oracle Database system. If it is running, then Oracle SQL Connector for HDFS attempts to use it instead of the Hadoop cluster. Oracle SQL Connector for HDFS just uses the Hadoop JAR files and the configuration files from the Hadoop cluster on the Oracle Database system. -
If your cluster is secured with Kerberos, then you must configure the Oracle system to permit Kerberos authentication. See "Using Oracle SQL Connector for HDFS on a Secure Hadoop Cluster."
-
Ensure that Oracle Database has access to HDFS:
-
Log in to the system where Oracle Database is running by using the Oracle Database account.
-
Open a Bash shell and enter this command:
hdfs dfs -ls /user
You might need to add the directory containing the Hadoop executable file to the
PATHenvironment variable. The default path for CDH is /usr/bin.You should see the same list of directories that you see when you run the
hdfs dfscommand directly on the Hadoop cluster. If not, then first ensure that the Hadoop cluster is up and running. If the problem persists, then you must correct the Hadoop client configuration so that Oracle Database has access to the Hadoop cluster file system.
-
-
For an Oracle RAC system, repeat this procedure for every Oracle instance.
The Hadoop client is now ready for use. No other Hadoop configuration steps are needed.
1.4.3 Installing Oracle SQL Connector for HDFS
Follow this procedure to install Oracle SQL Connector for HDFS on the Oracle Database system. In addition, you can install Oracle SQL Connector for HDFS on any system configured as a Hadoop client.
To install Oracle SQL Connector for HDFS:
-
Download the zip file to a directory on the system where Oracle Database runs.
-
Unpack the content of
oraosch-version.zip.$ unzip oraosch-2.3.0.zip Archive: oraosch-2.3.0.zip extracting: orahdfs-2.3.0.zip inflating: README.txt -
Unpack
orahdfs-version.zipinto a permanent directory:$ unzip orahdfs-2.3.0.zip Archive: orahdfs-2.3.0.zip creating: orahdfs-2.3.0/ creating: orahdfs-2.3.0/bin/ inflating: orahdfs-2.3.0/bin/hdfs_stream . . .The unzipped files have the structure shown in Example 1-1.
-
Open the
orahdfs-2.3.0/bin/hdfs_streamBash shell script in a text editor, and make the changes indicated by the comments in the script, if necessaryThe hdfs_stream script does not inherit any environment variable settings, and so they are set in the script if Oracle SQL Connector for HDFS needs them:
-
PATH: If thehadoopscript is not in/usr/bin:bin(the path initially set inhdfs_stream), then add the Hadoop bin directory, such as /usr/lib/hadoop/bin. -
JAVA_HOME: If Hadoop does not detect Java, then set this variable to the Java installation directory. For example,/usr/bin/java.
See the comments in the script for more information about these environment variables.
The
hdfs_streamscript is the preprocessor for the Oracle Database external table created by Oracle SQL Connector for HDFS. -
-
If your cluster is secured with Kerberos, then obtain a Kerberos ticket:
> kinit > password -
Run
hdfs_streamfrom the Oracle SQL Connector for HDFS/bindirectory. You should see this usage information:$ ./hdfs_stream Usage: hdfs_stream locationFileIf you do not see the usage statement, then ensure that the operating system user that Oracle Database is running under (such as
oracle) has the following permissions:-
Read and execute permissions on the hdfs_stream script:
$ ls -l OSCH_HOME/bin/hdfs_stream -rwxr-xr-x 1 oracle oinstall Nov 27 15:51 hdfs_stream
-
Read permission on orahdfs.jar.
$ ls -l OSCH_HOME/jlib/orahdfs.jar -rwxr-xr-x 1 oracle oinstall Nov 27 15:51 orahdfs.jar
If you do not see these permissions, then enter a
chmodcommand to fix them, for example:$ chmod 755 OSCH_HOME/bin/hdfs_stream
In the previous commands,
OSCH_HOMErepresents the Oracle SQL Connector for HDFS home directory. -
-
For an Oracle RAC system, repeat the previous steps for every Oracle instance, using identical path locations.
-
Log in to Oracle Database and create a database directory for the
orahdfs-version/bindirectory where hdfs_stream resides. For Oracle RAC systems, this directory must be on a shared disk that all Oracle instances can access.In this example, Oracle SQL Connector for HDFS is installed in
/etc:SQL> CREATE OR REPLACE DIRECTORY osch_bin_path AS '/etc/orahdfs-2.3.0/bin';
-
To support access to Hive tables:
-
Ensure that the system is configured as a Hive client.
-
Add the Hive JAR files and the Hive conf directory to the
HADOOP_CLASSPATHenvironment variable. To avoid JAR conflicts among the various Hadoop products, Oracle recommends that you setHADOOP_CLASSPATHin your local shell initialization script instead of making a global change toHADOOP_CLASSPATH.
-
The unzipped files have the structure shown in Example 1-1.
Example 1-1 Structure of the orahdfs Directory
orahdfs-version
bin/
hdfs_stream
doc/
README.txt
jlib/
ojdbc6.jar
ora-hadoop-common.jar
oraclepki.jar
orahdfs.jar
osdt_cert.jar
osdt_core.jar
log/
Figure 1-1 illustrates shows the flow of data and the components locations.
Figure 1-1 Oracle SQL Connector for HDFS Installation for HDFS and Data Pump Files
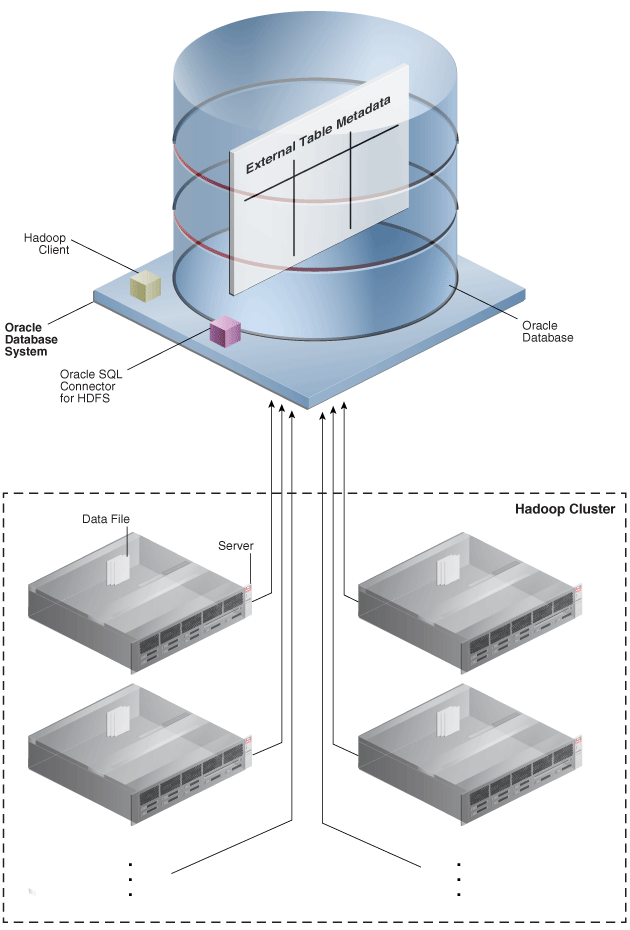
Description of "Figure 1-1 Oracle SQL Connector for HDFS Installation for HDFS and Data Pump Files"
1.4.4 Granting User Privileges in Oracle Database
Oracle Database users require these privileges when using Oracle SQL Connector for HDFS to create external tables:
-
READandEXECUTEon theOSCH_BIN_PATHdirectory created during the installation of Oracle SQL Connector for HDFS. Do not grant write access to anyone. GrantEXECUTEonly to those who intend to use Oracle SQL Connector for HDFS. -
READandWRITEon a database directory for storing external tables, or theCREATE ANY DIRECTORYsystem privilege. For Oracle RAC systems, this directory must be on a shared disk that all Oracle instances can access. -
A tablespace and quota for copying data into the Oracle database. Optional.
Example 1-2 shows the SQL commands granting these privileges to HDFSUSER.
Example 1-2 Granting Users Access to Oracle SQL Connector for HDFS
CONNECT / AS sysdba;
CREATE USER hdfsuser IDENTIFIED BY password
DEFAULT TABLESPACE hdfsdata
QUOTA UNLIMITED ON hdfsdata;
GRANT CREATE SESSION, CREATE TABLE TO hdfsuser;
GRANT EXECUTE ON sys.utl_file TO hdfsuser;
GRANT READ, EXECUTE ON DIRECTORY osch_bin_path TO hdfsuser;
GRANT READ, WRITE ON DIRECTORY external_table_dir TO hdfsuser;
Note:
To query an external table that uses Oracle SQL Connector for HDFS, users only need theSELECT privilege on the table.1.4.5 Setting Up User Accounts on the Oracle Database System
To create external tables for HDFS and Data Pump format files, users can log in to either the Oracle Database system or another system set up as a Hadoop client.
You can set up an account on these systems the same as you would for any other operating system user. HADOOP_CLASSPATH must include path/orahdfs-2.3.0/jlib/*. You can add this setting to the shell profile as part of this installation procedure, or users can set it themselves. The following example alters HADOOP_CLASSPATH in the Bash shell where Oracle SQL Connector for HDFS is installed in /usr/bin:
export HADOOP_CLASSPATH="$HADOOP_CLASSPATH:/usr/bin/orahdfs-2.3.0/jlib/*
1.4.6 Using Oracle SQL Connector for HDFS on a Secure Hadoop Cluster
When users access an external table that was created using Oracle SQL Connector for HDFS, the external table acts like a Hadoop client running on the system where the Oracle database is running. It uses the identity of the operating system user where Oracle is installed.
A secure Hadoop cluster has Kerberos installed and configured to authenticate client activity. You must configure Oracle SQL Connector for HDFS for use with a Hadoop cluster secured by Kerberos.
For a user to authenticate using kinit:
-
A Hadoop administrator must register the operating system user (such as
oracle) and password in the Key Distribution Center (KDC) for the cluster. -
A system administrator for the Oracle Database system must configure
/etc/krb5.confand add a domain definition that refers to the KDC managed by the secure cluster.
These steps enable the operating system user to authenticate with the kinit utility before submitting Oracle SQL Connector for HDFS jobs. The kinit utility typically uses a Kerberos keytab file for authentication without an interactive prompt for a password.
The system should run kinit on a regular basis, before letting the Kerberos ticket expire, to enable Oracle SQL Connector for HDFS to authenticate transparently. Use cron or a similar utility to run kinit. For example, if Kerberos tickets expire every two weeks, then set up a cron job to renew the ticket weekly.
Be sure to schedule the cron job to run when Oracle SQL Connector for HDFS is not actively being used.
Do not call kinit within the Oracle SQL Connector for HDFS preprocessor script (hdfs_stream), because it could trigger a high volume of concurrent calls to kinit and create internal Kerberos caching errors.
Note:
Oracle Big Data Appliance configures Kerberos security automatically as a configuration option. For details about setting up client systems for a secure Oracle Big Data Appliance cluster, see Oracle Big Data Appliance Software User's Guide.1.5 Oracle Loader for Hadoop Setup
Follow the instructions in these sections for setting up Oracle Loader for Hadoop:
1.5.1 Software Requirements
Oracle Loader for Hadoop requires the following software:
-
A target database system running one of the following:
-
Oracle Database 12c
-
Oracle Database 11g release 2 (11.2.0.3)
-
Oracle Database 11g release 2 (11.2.0.2) with required patch
-
Oracle Database 10g release 2 (10.2.0.5)
Note:
To use Oracle Loader for Hadoop with Oracle Database 11g release 2 (11.2.0.2), you must first apply a one-off patch that addresses bug number 11897896. To access this patch, go tohttp://support.oracle.comand search for the bug number. -
-
Cloudera's Distribution including Apache Hadoop version 3 (CDH3) or version 4 (CDH4), or Apache Hadoop 1.0 (formerly 0.20.2).
-
Apache Hive 0.7.0, 0.8.1, 0.9.0, or 0.10.0 if you are loading data from Hive tables.
1.5.2 Installing Oracle Loader for Hadoop
Oracle Loader for Hadoop is packaged with the Oracle Database 11g release 2 client libraries and Oracle Instant Client libraries for connecting to Oracle Database 11.2.0.2 or 11.2.0.3.
To install Oracle Loader for Hadoop:
-
Unpack the content of
oraloader-version.x86_64.zipinto a directory on your Hadoop cluster or on a system configured as a Hadoop client. This archive contains two archives:-
oraloader-version-h1.x86_64.zip: Use with CDH3 and Apache Hadoop 1.0 -
oraloader-version-h2.x86_64.zip: Use with CDH4
-
-
Unzip the appropriate archive into a directory on your Hadoop cluster.
A directory named
oraloader-version-hnis created with the following subdirectories:doc jlib lib examples
-
Create a variable named
OLH_HOMEand set it to the installation directory. -
Add the following paths to the
HADOOP_CLASSPATHvariable:-
For all installations:
$OLH_HOME/jlib/*
-
To support data loads from Hive tables:
path/orahdfs-2.3.0/jlib/* /usr/lib/hive/lib/* /etc/hive/conf
-
To read data from Oracle NoSQL Database Release 2:
$KVHOME/lib/kvstore.jar
-
1.5.3 Providing Support for Offline Database Mode
In a typical installation, Oracle Loader for Hadoop can connect to the Oracle Database system from the Hadoop cluster or a Hadoop client. If this connection is impossible—for example, the systems are located on distinct networks—then you can use Oracle Loader for Hadoop in offline database mode. See "About the Modes of Operation."
To support offline database mode, you must install Oracle Loader for Hadoop on two systems:
-
The Hadoop cluster or a system set up as a Hadoop client, as described in "Installing Oracle Loader for Hadoop."
-
The Oracle Database system or a system with network access to Oracle Database, as described in the following procedure.
To support Oracle Loader for Hadoop in offline database mode:
-
Unpack the content of
oraloader-version.zipinto a directory on the Oracle Database system or a system with network access to Oracle Database. -
Unzip the same version of the software as you installed on the Hadoop cluster, either for CDH3 or CDH4.
-
Create a variable named
OLH_HOMEand set it to the installation directory. This example uses the Bash shell syntax:$ export OLH_HOME="/usr/bin/oraloader-2.3.0-h2/"
-
Add the Oracle Loader for Hadoop JAR files to the
CLASSPATHenvironment variable. This example uses the Bash shell syntax:$ export CLASSPATH=$CLASSPATH:$OLH_HOME/jlib/*
1.5.4 Using Oracle Loader for Hadoop on a Secure Hadoop Cluster
A secure Hadoop cluster has Kerberos installed and configured to authenticate client activity. An operating system user must be authenticated before initiating an Oracle Loader for Hadoop job to run on a secure Hadoop cluster. For authentication, the user must log in to the operating system where the job will be submitted and use the standard Kerberos kinit utility.
For a user to authenticate using kinit:
-
A Hadoop administrator must register the operating system user and password in the Key Distribution Center (KDC) for the cluster.
-
A system administrator for the client system, where the operating system user will initiate an Oracle Loader for Hadoop job, must configure
/etc/krb5.confand add a domain definition that refers to the KDC managed by the secure cluster.
Typically, the kinit utility obtains an authentication ticket that lasts several days. Subsequent Oracle Loader for Hadoop jobs authenticate transparently using the unexpired ticket.
Note:
Oracle Big Data Appliance configures Kerberos security automatically as a configuration option. For details about setting up client systems for a secure Oracle Big Data Appliance cluster, see Oracle Big Data Appliance Software User's Guide.1.6 Oracle Data Integrator Application Adapter for Hadoop Setup
Installation requirements for Oracle Data Integrator (ODI) Application Adapter for Hadoop are provided in these topics:
1.6.1 System Requirements and Certifications
To use Oracle Data Integrator Application Adapter for Hadoop, you must first have Oracle Data Integrator, which is licensed separately from Oracle Big Data Connectors. You can download ODI from the Oracle website at
http://www.oracle.com/technetwork/middleware/data-integrator/downloads/index.html
Oracle Data Integrator Application Adapter for Hadoop requires a minimum version of Oracle Data Integrator 11.1.1.6.0.
Before performing any installation, read the system requirements and certification documentation to ensure that your environment meets the minimum installation requirements for the products that you are installing.
The list of supported platforms and versions is available on Oracle Technology Network:
http://www.oracle.com/technetwork/middleware/data-integrator/overview/index.html
1.6.2 Technology-Specific Requirements
The list of supported technologies and versions is available on Oracle Technical Network:
http://www.oracle.com/technetwork/middleware/data-integrator/overview/index.html
1.6.3 Location of Oracle Data Integrator Application Adapter for Hadoop
Oracle Data Integrator Application Adapter for Hadoop is available in the xml-reference directory of the Oracle Data Integrator Companion CD.
1.6.4 Setting Up the Topology
To set up the topology, see Chapter 4, "Oracle Data Integrator Application Adapter for Hadoop."
1.7 Oracle XQuery for Hadoop Setup
You install and configure Oracle XQuery for Hadoop on the Hadoop cluster. If you are using Oracle Big Data Appliance, then the software is already installed.
The following topics describe the software installation:
1.7.1 Software Requirements
Oracle Big Data Appliance 2.3 meets the following software requirements. However, if you are installing Oracle XQuery for Hadoop on a third-party cluster, then you must ensure that these components are installed.
-
Java 6.x or 7.x
-
Cloudera's Distribution including Apache Hadoop Version 3 (CDH 3.3 or above) or Version 4 (CDH 4.1.2 or above)
-
Oracle NoSQL Database 2.x to support reading and writing to Oracle NoSQL Database
-
Oracle Loader for Hadoop 2.3 to support writing tables in Oracle databases
1.7.2 Installing Oracle XQuery for Hadoop
Take the following steps to install Oracle XQuery for Hadoop.
To install Oracle XQuery for Hadoop:
-
Unpack the contents of
oxh-version.zipinto the installation directory:$ unzip oxh-2.3.0-cdh-4.4.0.zip Archive: oxh-2.3.0-cdh-4.4.0.zip creating: oxh-2.3.0-cdh-4.4.0/ creating: oxh-2.3.0-cdh-4.4.0/lib/ inflating: oxh-2.3.0-cdh-4.4.0/lib/ant-launcher.jar inflating: oxh-2.3.0-cdh-4.4.0/lib/ant.jar inflating: oxh-2.3.0-cdh-4.4.0/lib/apache-xmlbeans.jar inflating: oxh-2.3.0-cdh-4.4.0/lib/avro-mapred-1.7.4-hadoop2.jar . . .You can now run Oracle XQuery for Hadoop.
-
To support data loads into Oracle Database, install Oracle Loader for Hadoop as follows:
-
Unpack the content of
oraloader-version.x86_64.zipinto a directory on your Hadoop cluster or on a system configured as a Hadoop client. This archive contains two archives:oraloader-version-h1.x86_64.zip: Use with CDH3 and Apache Hadoop 1.0oraloader-version-h2.x86_64.zip: Use with CDH4 -
Unzip the appropriate archive into a directory on your Hadoop cluster.
A directory named
oraloader-version-hnis created with the following subdirectories:doc jlib lib examples
-
Create an environment variable named
OLH_HOMEand set it to the installation directory. Do not setHADOOP_CLASSPATH.
-
-
To support data loads into Oracle NoSQL Database, install it, and then set an environment variable named
KVHOMEto the Oracle NoSQL Database installation directory.
1.7.3 Troubleshooting the File Paths
If Oracle XQuery for Hadoop fails to find its own or third-party libraries when running queries, then first ensure that the environment variables are set, as described in "Installing Oracle XQuery for Hadoop."
If they are set correctly, then you may need to edit lib/oxh-lib.xml. This file identifies the location of Oracle XQuery for Hadoop system JAR files and other libraries, such as Avro, Oracle Loader for Hadoop, and Oracle NoSQL Database.
If necessary, you can reference environment variables in this file as ${env.variable}, such as ${env.OLH_HOME}. You can also reference Hadoop properties as ${property}, such as ${mapred.output.dir}.
1.8 Oracle R Advanced Analytics for Hadoop Setup
Oracle R Advanced Analytics for Hadoop requires the installation of a software environment on the Hadoop side and on a client Linux system.
1.8.1 Installing the Software on Hadoop
Oracle Big Data Appliance supports Oracle R Advanced Analytics for Hadoop without any additional software installation or configuration. However, you do need to verify whether certain R packages are installed. See "Installing Additional R Packages."
However, to use Oracle R Advanced Analytics for Hadoop on any other Hadoop cluster, you must create the necessary environment.
1.8.1.1 Software Requirements for a Third-Party Hadoop Cluster
You must install several software components on a third-party Hadoop cluster to support Oracle R Advanced Analytics for Hadoop.
Install these components on third-party servers:
-
Cloudera's Distribution including Apache Hadoop version 4 (CDH4) or Apache Hadoop 2.0.0, using MapReduce 1.
Complete the instructions provided by the distributor.
-
Apache Hive 0.7.1 or 0.9.0
-
Sqoop for the execution of functions that connect to Oracle Database. Oracle R Advanced Analytics for Hadoop does not require Sqoop to install or load.
-
Mahout for the execution of (
orch_lmf_mahout_als.R). -
Java Virtual Machine (JVM), preferably Java HotSpot Virtual Machine 6.
Complete the instructions provided at the download site at
http://www.oracle.com/technetwork/java/javase/downloads/index.html -
Oracle R Distribution 3.0.1 with all base libraries on all nodes in the Hadoop cluster.
-
The ORCH package on each R engine, which must exist on every node of the Hadoop cluster.
-
Oracle Loader for Hadoop to support the OLH driver (optional). See "Oracle Loader for Hadoop Setup."
Note:
Do not setHADOOP_HOME on the Hadoop cluster. CDH4 does not need it, and it interferes with Oracle R Advanced Analytics for Hadoop when it checks the status of the JobTracker. This results in the error "Something is terribly wrong with Hadoop MapReduce."
If you must set HADOOP_HOME for another application, then also set HADOOP_LIBEXEC_DIR in the /etc/bashrc file. For example:
export HADOOP_LIBEXEC_DIR=/usr/lib/hadoop/libexec
1.8.1.2 Installing Sqoop on a Hadoop Cluster
Sqoop provides a SQL-like interface to Hadoop, which is a Java-based environment. Oracle R Advanced Analytics for Hadoop uses Sqoop for access to Oracle Database.
Note:
Sqoop is required even when using Oracle Loader for Hadoop as a driver for loading data into Oracle Database. Sqoop performs additional functions, such as copying data from a database to HDFS and sending free-form queries to a database. The driver also uses Sqoop to perform operations that Oracle Loader for Hadoop does not support.To install and configure Sqoop for use with Oracle Database:
-
Install Sqoop if it is not already installed on the server.
For Cloudera's Distribution including Apache Hadoop, see the Sqoop installation instructions in the CDH Installation Guide at
-
Download the appropriate Java Database Connectivity (JDBC) driver for Oracle Database from Oracle Technology Network at
http://www.oracle.com/technetwork/database/features/jdbc/index-091264.html -
Copy the driver JAR file to
$SQOOP_HOME/lib, which is a directory such as/usr/lib/sqoop/lib. -
Provide Sqoop with the connection string to Oracle Database.
$ sqoop import --connect jdbc_connection_stringFor example,
sqoop import --connect jdbc:oracle:thin@myhost:1521/orcl.
1.8.1.3 Installing Hive on a Hadoop Cluster
Hive provides an alternative storage and retrieval mechanism to HDFS files through a querying language called HiveQL. Oracle R Advanced Analytics for Hadoop uses the data preparation and analysis features of HiveQL, while enabling you to use R language constructs.
To install Hive:
-
Follow the instructions provided by the distributor (Cloudera or Apache) for installing Hive.
-
Verify that the installation is working correctly:
-
$ hive -H usage: hive -d,--define <key=value> Variable subsitution to apply to hive commands. e.g. -d A=B or --define A=B --database <databasename> Specify the database to use -e <quoted-query-string> SQL from command line -f <filename> SQL from files -H,--help Print help information -h <hostname> connecting to Hive Server on remote host --hiveconf <property=value> Use value for given property --hivevar <key=value> Variable subsitution to apply to hive commands. e.g. --hivevar A=B -i <filename> Initialization SQL file -p <port> connecting to Hive Server on port number -S,--silent Silent mode in interactive shell -v,--verbose Verbose mode (echo executed SQL to the console) -
If the command fails or you see warnings in the output, then fix the Hive installation.
1.8.1.4 Installing R on a Hadoop Cluster
You can download Oracle R Distribution 3.0.1 and get the installation instructions from the website at
http://www.oracle.com/technetwork/indexes/downloads/r-distribution-1532464.html
Alternatively, you can download R from a Comprehensive R Archive Network (CRAN) website at
1.8.1.5 Installing the ORCH Package on a Hadoop Cluster
ORCH is the name of the Oracle R Advanced Analytics for Hadoop package.
To install the ORCH package:
-
Set the environment variables for the supporting software:
$ export JAVA_HOME="/usr/lib/jdk7" $ export R_HOME="/usr/lib64/R" $ export SQOOP_HOME "/usr/lib/sqoop"
-
Unzip the downloaded file:
$ unzip orch-version.zip $ unzip orch-linux-x86_64-2.3.0.zip Archive: orch-linux-x86_64-2.3.0.zip creating: ORCH2.3.0/ extracting: ORCH2.3.0/ORCH_2.3.0_R_x86_64-unknown-linux-gnu.tar.gz inflating: ORCH2.3.0/ORCHcore_2.3.0_R_x86_64-unknown-linux-gnu.tar.gz extracting: ORCH2.3.0/ORCHstats_2.3.0_R_x86_64-unknown-linux-gnu.tar.gz inflating: ORCH2.3.0/OREbase_1.4_R_x86_64-unknown-linux-gnu.tar.gz inflating: ORCH2.3.0/OREmodels_1.4_R_x86_64-unknown-linux-gnu.tar.gz inflating: ORCH2.3.0/OREserver_1.4_R_x86_64-unknown-linux-gnu.tar.gz inflating: ORCH2.3.0/OREstats_1.4_R_x86_64-unknown-linux-gnu.tar.gz inflating: ORCH2.3.0/libOrdBlasLoader.so
-
Change to the new directory:
$ cd ORCH2.3.0
-
Install the packages in the exact order shown here:
R --vanilla CMD INSTALL OREbase_1.4_R_x86_64-unknown-linux-gnu.tar.gz R --vanilla CMD INSTALL OREstats_1.4_R_x86_64-unknown-linux-gnu.tar.gz R --vanilla CMD INSTALL OREmodels_1.4_R_x86_64-unknown-linux-gnu.tar.gz R --vanilla CMD INSTALL OREserver_1.4_R_x86_64-unknown-linux-gnu.tar.gz R --vanilla CMD INSTALL ORCHcore_2.3.0_R_x86_64-unknown-linux-gnu.tar.gz R --vanilla CMD INSTALL ORCHstats_2.3.0_R_x86_64-unknown-linux-gnu.tar.gz R --vanilla CMD INSTALL ORCH_2.3.0_R_x86_64-unknown-linux-gnu.tar.gz
-
You must also install these packages on all other nodes of the cluster:
-
OREbase
-
OREmodels
-
OREserver
-
OREstats
The following examples use the
dcliutility, which is available on Oracle Big Data Appliance but not on third-party clusters, to copy and install theOREserverpackage:$ dcli -C -f OREserver_1.4_R_x86_64-unknown-linux-gnu.tar.gz -d /tmp/ OREserver_1.4_R_x86_64-unknown-linux-gnu.tar.gz $ dcli -C " R --vanilla CMD INSTALL /tmp/OREserver_1.4_R_x86_64-unknown-linux-gnu.tar.gz"
-
1.8.2 Installing Additional R Packages
Your Hadoop cluster must have libpng-devel installed on every node. If you are using a cluster running on commodity hardware, then you can follow the same basic procedures. However, you cannot use the dcli utility to replicate the commands across all nodes. See Oracle Big Data Appliance Owner's Guide for the syntax of the dcli utility.
To install libpng-devel:
-
Log in as
rootto any node in your Hadoop cluster. -
Check whether
libpng-develis already installed:# dcli rpm -qi libpng-devel bda1node01: package libpng-devel is not installed bda1node02: package libpng-devel is not installed . . .If the package is already installed on all servers, then you can skip this procedure.
-
If you need a proxy server to go outside a firewall, then set the
HTTP_PROXYenvironment variable. This example uses dcli, which is available only on Oracle Big Data Appliance:# dcli export HTTP_PROXY="http://proxy.example.com" -
Change to the
yumdirectory:# cd /etc/yum.repos.d
-
Download and configure the appropriate configuration file for your version of Linux:
For Enterprise Linux 5 (EL5):
-
Download the yum configuration file:
# wget http://public-yum.oracle.com/public-yum-el5.repo
-
Open
public-yum-el5.repoin a text editor and make these changes:Under
el5_latest, setenabled=1Under
el5_addons, setenabled=1 -
Save your changes and exit.
-
Copy the file to the other Oracle Big Data Appliance servers:
# dcli -d /etc/yum.repos.d -f public-yum-el5.repo
For Oracle Linux 6 (OL6):
-
Download the yum configuration file:
# wget http://public-yum.oracle.com/public-yum-ol6.repo
-
Open
public-yum-ol6.repoin a text editor and make these changes:Under
ol6_latest, setenabled=1Under
ol6_addons, setenabled=1 -
Save your changes and exit.
-
Copy the file to the other Oracle Big Data Appliance servers:
# dcli -d /etc/yum.repos.d -f public-yum-ol6.repo
-
-
Install the package on all servers:
# dcli yum -y install libpng-devel bda1node01: Loaded plugins: rhnplugin, security bda1node01: Repository 'bda' is missing name in configuration, using id bda1node01: This system is not registered with ULN. bda1node01: ULN support will be disabled. bda1node01: http://bda1node01-master.us.oracle.com/bda/repodata/repomd.xml: bda1node01: [Errno 14] HTTP Error 502: notresolvable bda1node01: Trying other mirror. . . . bda1node01: Running Transaction bda1node01: Installing : libpng-devel 1/2 bda1node01: Installing : libpng-devel 2/2 bda1node01: Installed: bda1node01: libpng-devel.i386 2:1.2.10-17.el5_8 ibpng-devel.x86_64 2:1.2.10-17.el5_8 bda1node01: Complete! bda1node02: Loaded plugins: rhnplugin, security . . . -
Verify that the installation was successful on all servers:
# dcli rpm -qi libpng-devel bda1node01: Name : libpng-devel Relocations: (not relocatable) bda1node01: Version : 1.2.10 Vendor: Oracle America bda1node01: Release : 17.el5_8 Build Date: Wed 25 Apr 2012 06:51:15 AM PDT bda1node01: Install Date: Tue 05 Feb 2013 11:41:14 AM PST Build Host: ca-build56.us.oracle.com bda1node01: Group : Development/Libraries Source RPM: libpng-1.2.10-17.el5_8.src.rpm bda1node01: Size : 482483 License: zlib bda1node01: Signature : DSA/SHA1, Wed 25 Apr 2012 06:51:41 AM PDT, Key ID 66ced3de1e5e0159 bda1node01: URL : http://www.libpng.org/pub/png/ bda1node01: Summary : Development tools for programs to manipulate PNG image format files. bda1node01: Description : bda1node01: The libpng-devel package contains the header files and static bda1node01: libraries necessary for developing programs using the PNG (Portable bda1node01: Network Graphics) library. . . .
1.8.3 Providing Remote Client Access to R Users
Whereas R users will run their programs as MapReduce jobs on the Hadoop cluster, they do not typically have individual accounts on that platform. Instead, an external Linux server provides remote access.
1.8.3.1 Software Requirements for Remote Client Access
To provide access to a Hadoop cluster to R users, install these components on a Linux server:
-
The same version of Hadoop as your Hadoop cluster; otherwise, unexpected issues and failures can occur
-
The same version of Sqoop as your Hadoop cluster; required only to support copying data in and out of Oracle databases
-
Mahout; required only for the
orch.lsfunction with the Mahout ALS-WS algorithm -
The same version of the Java Development Kit (JDK) as your Hadoop cluster
-
ORCH R package
To provide access to database objects, you must have the Oracle Advanced Analytics option to Oracle Database. Then you can install this additional component on the Hadoop client:
-
Oracle R Enterprise Client Packages
1.8.3.2 Configuring the Server as a Hadoop Client
You must install Hadoop on the client and minimally configure it for HDFS client use.
To install and configure Hadoop on the client system:
-
Install and configure CDH3 or Apache Hadoop 0.20.2 on the client system. This system can be the host for Oracle Database. If you are using Oracle Big Data Appliance, then complete the procedures for providing remote client access in the Oracle Big Data Appliance Software User's Guide. Otherwise, follow the installation instructions provided by the distributor (Cloudera or Apache).
-
Log in to the client system as an R user.
-
Open a Bash shell and enter this Hadoop file system command:
$HADOOP_HOME/bin/hdfs dfs -ls /user
-
If you see a list of files, then you are done. If not, then ensure that the Hadoop cluster is up and running. If that does not fix the problem, then you must debug your client Hadoop installation.
1.8.3.3 Installing Sqoop on a Hadoop Client
Complete the same procedures on the client system for installing and configuring Sqoop as those provided in "Installing Sqoop on a Hadoop Cluster".
1.8.3.4 Installing R on a Hadoop Client
You can download R 2.13.2 and get the installation instructions from the Oracle R Distribution website at
When you are done, ensure that users have the necessary permissions to connect to the Linux server and run R.
You may also want to install RStudio Server to facilitate access by R users. See the RStudio website at
1.8.3.5 Installing the ORCH Package on a Hadoop Client
Complete the procedures on the client system for installing ORCH as described in "Installing the Software on Hadoop".
1.8.3.6 Installing the Oracle R Enterprise Client Packages (Optional)
To support full access to Oracle Database using R, install the Oracle R Enterprise Release 1.3.1 or later client packages. Without them, Oracle R Advanced Analytics for Hadoop does not have access to the advanced statistical algorithms provided by Oracle R Enterprise.
See Also:
Oracle R Enterprise User's Guide for information about installing R and Oracle R EnterpriseFootnote Legend
Footnote 1: Hadoop: The Definitive Guide, Third Edition by Tom White (O'Reilly Media Inc., 2012, 978-1449311520).