3 Oracle Loader for Hadoop
This chapter explains how to use Oracle Loader for Hadoop to copy data from Apache Hadoop into tables in an Oracle database. It contains the following sections:
3.1 What Is Oracle Loader for Hadoop?
Oracle Loader for Hadoop is an efficient and high-performance loader for fast movement of data from a Hadoop cluster into a table in an Oracle database. It prepartitions the data if necessary and transforms it into a database-ready format. It can also sort records by primary key or user-specified columns before loading the data or creating output files. Oracle Loader for Hadoop uses the parallel processing framework of Hadoop to perform these preprocessing operations, which other loaders typically perform on the database server as part of the load process. Offloading these operations to Hadoop reduces the CPU requirements on the database server, thereby lessening the performance impact on other database tasks.
Oracle Loader for Hadoop is a Java MapReduce application that balances the data across reducers to help maximize performance. It works with a range of input data formats that present the data as records with fields. It can read from sources that have the data already in a record format (such as Avro files or Apache Hive tables), or it can split the lines of a text file into fields.
You run Oracle Loader for Hadoop using the hadoop command-line utility. In the command line, you provide configuration settings with the details of the job. You typically provide these settings in a job configuration file.
If you have Java programming skills, you can extend the types of data that the loader can handle by defining custom input formats. Then Oracle Loader for Hadoop uses your code to extract the fields and records.
3.2 About the Modes of Operation
Oracle Loader for Hadoop operates in two modes:
3.2.1 Online Database Mode
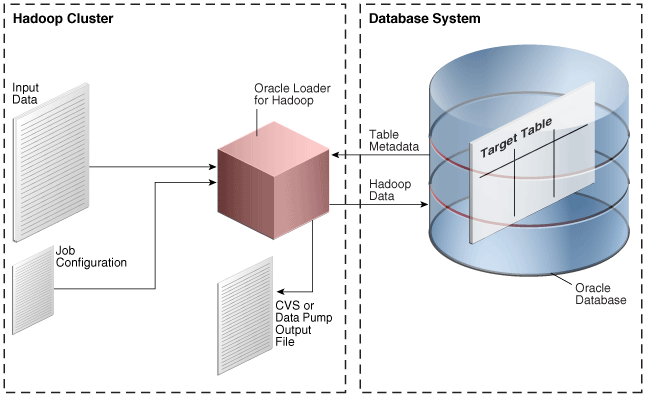
In online database mode, Oracle Loader for Hadoop can connect to the target database using the credentials provided in the job configuration file or in an Oracle wallet. The loader obtains the table metadata from the database. It can insert new records directly into the target table or write them to a file in the Hadoop cluster. You can load records from an output file when the data is needed in the database, or when the database system is less busy.
Figure 3-1 shows the relationships among elements in online database mode.
3.2.2 Offline Database Mode
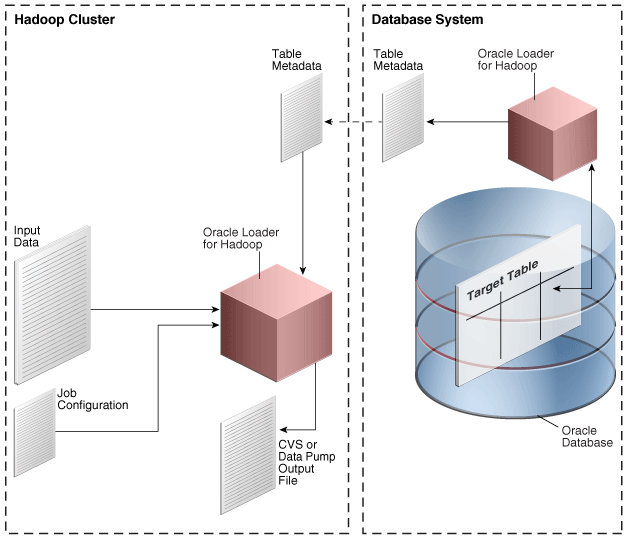
Offline database mode enables you to use Oracle Loader for Hadoop when the Oracle Database system is on a separate network from the Hadoop cluster, or is otherwise inaccessible. In this mode, Oracle Loader for Hadoop uses the information supplied in a table metadata file, which you generate using a separate utility. The loader job stores the output data in binary or text format output files on the Hadoop cluster. Loading the data into Oracle Database is a separate procedure using another utility, such as Oracle SQL Connector for Hadoop Distributed File System (HDFS) or SQL*Loader.
Figure 3-2 shows the relationships among elements in offline database mode. The figure does not show the separate procedure of loading the data into the target table.
3.3 Getting Started With Oracle Loader for Hadoop
You take the following basic steps when using Oracle Loader for Hadoop:
-
The first time you use Oracle Loader for Hadoop, ensure that the software is installed and configured.
-
Connect to Oracle Database and create the target table.
-
If you are using offline database mode, then generate the table metadata.
See "Generating the Target Table Metadata for Offline Database Mode."
-
Log in to either a node in the Hadoop cluster or a system set up as a Hadoop client for the cluster.
-
If you are using offline database mode, then copy the table metadata to the Hadoop system where you are logged in.
-
Create a configuration file. This file is an XML document that describes configuration information, such as access to the target table metadata, the input format of the data, and the output format.
-
Create an XML document that maps input fields to columns in the Oracle database table. Optional.
-
Create a shell script to run the Oracle Loader for Hadoop job.
-
If you are connecting to a secure cluster, then you run
kinitto authenticate yourself. -
Run the shell script.
-
If the job fails, then use the diagnostic messages in the output to identify and correct the error.
See "Job Reporting."
-
After the job succeeds, check the command output for the number of rejected records. If too many records were rejected, then you may need to modify the input format properties.
-
If you generated text files or Data Pump-format files, then load the data into Oracle Database using one of these methods:
-
Create an external table using Oracle SQL Connector for HDFS (online database mode only).
See Chapter 2.
-
Copy the files to the Oracle Database system and use SQL*Loader or external tables to load the data into the target database table. Oracle Loader for Hadoop generates scripts that you can use for these methods.
See "About DelimitedTextOutputFormat" or "About DataPumpOutputFormat."
-
-
Connect to Oracle Database as the owner of the target table. Query the table to ensure that the data loaded correctly. If it did not, then modify the input or output format properties as needed to correct the problem.
-
Before running the OraLoader job in a production environment, employ these optimizations:
3.4 Creating the Target Table
Oracle Loader for Hadoop loads data into one target table, which must exist in the Oracle database. The table can be empty or contain data already. Oracle Loader for Hadoop does not overwrite existing data.
Create the table the same way that you would create one for any other purpose. It must comply with the following restrictions:
3.4.1 Supported Data Types for Target Tables
You can define the target table using any of these data types:
-
BINARY_DOUBLE -
BINARY_FLOAT -
CHAR -
DATE -
FLOAT -
INTERVAL DAY TO SECOND -
INTERVAL YEAR TO MONTH -
NCHAR -
NUMBER -
NVARCHAR2 -
RAW -
TIMESTAMP -
TIMESTAMP WITH LOCAL TIME ZONE -
TIMESTAMP WITH TIME ZONE -
VARCHAR2
The target table can contain columns with unsupported data types, but these columns must be nullable, or otherwise set to a value.
3.4.2 Supported Partitioning Strategies for Target Tables
Partitioning is a database feature for managing and efficiently querying very large tables. It provides a way to decompose a large table into smaller and more manageable pieces called partitions, in a manner entirely transparent to applications.
You can define the target table using any of the following single-level and composite-level partitioning strategies.
-
Hash
-
Hash-Hash
-
Hash-List
-
Hash-Range
-
Interval
-
Interval-Hash
-
Interval-List
-
Interval-Range
-
List
-
List-Hash
-
List-List
-
List-Range
-
Range
-
Range-Hash
-
Range-List
-
Range-Range
Oracle Loader for Hadoop does not support reference partitioning or virtual column-based partitioning.
3.5 Creating a Job Configuration File
A configuration file is an XML document that provides Hadoop with all the information it needs to run a MapReduce job. This file can also provide Oracle Loader for Hadoop with all the information it needs. See "Oracle Loader for Hadoop Configuration Property Reference".
Configuration properties provide the following information, which is required for all Oracle Loader for Hadoop jobs:
-
How to obtain the target table metadata.
-
The format of the input data.
-
The format of the output data.
OraLoader implements the org.apache.hadoop.util.Tool interface and follows the standard Hadoop methods for building MapReduce applications. Thus, you can supply the configuration properties in a file (as shown here) or on the hadoop command line. See "Running a Loader Job."
You can use any text or XML editor to create the file. Example 3-1 provides an example of a job configuration file.
Example 3-1 Job Configuration File
<?xml version="1.0" encoding="UTF-8" ?>
<configuration>
<!-- Input settings -->
<property>
<name>mapreduce.inputformat.class</name>
<value>oracle.hadoop.loader.lib.input.DelimitedTextInputFormat</value>
</property>
<property>
<name>mapred.input.dir</name>
<value>/user/oracle/moviedemo/session/*00000</value>
</property>
<property>
<name>oracle.hadoop.loader.input.fieldTerminator</name>
<value>\u0009</value>
</property>
<!-- Output settings -->
<property>
<name>mapreduce.outputformat.class</name>
<value>oracle.hadoop.loader.lib.output.OCIOutputFormat</value>
</property>
<property>
<name>mapred.output.dir</name>
<value>temp_out_session</value>
</property>
<!-- Table information -->
<property>
<name>oracle.hadoop.loader.loaderMapFile</name>
<value>file:///home/oracle/movie/moviedemo/olh/loaderMap_moviesession.xml</value>
</property>
<!-- Connection information -->
<property>
<name>oracle.hadoop.loader.connection.url</name>
<value>jdbc:oracle:thin:@${HOST}:${TCPPORT}/${SERVICE_NAME}</value>
</property>
<property>
<name>TCPPORT</name>
<value>1521</value>
</property>
<property>
<name>HOST</name>
<value>myoraclehost.example.com</value>
</property>
<property>
<name>SERVICE_NAME</name>
<value>orcl</value>
</property>
<property>
<name>oracle.hadoop.loader.connection.user</name>
<value>MOVIEDEMO</value>
</property>
<property>
<name>oracle.hadoop.loader.connection.password</name>
<value>oracle</value>
<description> A password in clear text is NOT RECOMMENDED. Use an Oracle wallet instead.</description>
</property>
</configuration>
3.6 About the Target Table Metadata
You must provide Oracle Loader for Hadoop with information about the target table. The way that you provide this information depends on whether you run Oracle Loader for Hadoop in online or offline database mode. See "About the Modes of Operation."
3.6.1 Providing the Connection Details for Online Database Mode
Oracle Loader for Hadoop uses table metadata from the Oracle database to identify the column names, data types, partitions, and so forth. The loader automatically fetches the metadata whenever a JDBC connection can be established.
Oracle recommends that you use a wallet to provide your credentials. To use an Oracle wallet, enter the following properties in the job configuration file:
Oracle recommends that you do not store passwords in clear text; use an Oracle wallet instead to safeguard your credentials. However, if you are not using an Oracle wallet, then enter these properties:
3.6.2 Generating the Target Table Metadata for Offline Database Mode
Under some circumstances, the loader job cannot access the database, such as when the Hadoop cluster is on a different network than Oracle Database. In such cases, you can use the OraLoaderMetadata utility to extract and store the target table metadata in a file.
To provide target table metadata in offline database mode:
-
Log in to the Oracle Database system.
-
The first time you use offline database mode, ensure that the software is installed and configured on the database system.
-
Export the table metadata by running the
OraLoaderMetadatautility program. See "OraLoaderMetadata Utility." -
Copy the generated XML file containing the table metadata to the Hadoop cluster.
-
Use the
oracle.hadoop.loader.tableMetadataFileproperty in the job configuration file to specify the location of the XML metadata file on the Hadoop cluster.When the loader job runs, it accesses this XML document to discover the target table metadata.
3.6.2.1 OraLoaderMetadata Utility
Use the following syntax to run the OraLoaderMetadata utility on the Oracle Database system. You must enter the java command on a single line, although it is shown here on multiple lines for clarity:
java oracle.hadoop.loader.metadata.OraLoaderMetadata -user userName -connection_url connection [-schema schemaName] -table tableName -output fileName.xml
To see the OraLoaderMetadata Help file, use the command with no options.
Options
- -user userName
-
The Oracle Database user who owns the target table. The utility prompts you for the password.
- -connection_url connection
-
The database connection string in the thin-style service name format:
jdbc:oracle:thin:@//hostName:port/serviceName
If you are unsure of the service name, then enter this SQL command as a privileged user:
SQL> show parameter service NAME TYPE VALUE ------------------------------------ ----------- ------------------------------ service_names string orcl - -schema schemaName
-
The name of the schema containing the target table. Unquoted values are capitalized, and unquoted values are used exactly as entered. If you omit this option, then the utility looks for the target table in the schema specified in the
-useroption. - -table tableName
-
The name of the target table. Unquoted values are capitalized, and unquoted values are used exactly as entered.
- -output fileName.xml
-
The output file name used to store the metadata document.
Example 3-2 shows how to store the target table metadata in an XML file.
Example 3-2 Generating Table Metadata
Run the OraLoaderMetadata utility:
$ java -cp '/tmp/oraloader-2.3.0-h1/jlib/*' oracle.hadoop.loader.metadata.OraLoaderMetadata -user HR -connection_url jdbc:oracle:thin://@localhost:1521/orcl.example.com -table EMPLOYEES -output employee_metadata.xml
The OraLoaderMetadata utility prompts for the database password.
Oracle Loader for Hadoop Release 2.3.0 - Production
Copyright (c) 2011, 2013, Oracle and/or its affiliates. All rights reserved.
[Enter Database Password:] password
OraLoaderMetadata creates the XML file in the same directory as the script.
$ more employee_metadata.xml
<?xml version="1.0" encoding="UTF-8"?>
<!--
Oracle Loader for Hadoop Release 2.3.0 - Production
Copyright (c) 2011, 2013, Oracle and/or its affiliates. All rights reserved.
-->
<DATABASE>
<ROWSET><ROW>
<TABLE_T>
<VERS_MAJOR>2</VERS_MAJOR>
<VERS_MINOR>5 </VERS_MINOR>
<OBJ_NUM>78610</OBJ_NUM>
<SCHEMA_OBJ>
<OBJ_NUM>78610</OBJ_NUM>
<DATAOBJ_NUM>78610</DATAOBJ_NUM>
<OWNER_NUM>87</OWNER_NUM>
<OWNER_NAME>HR</OWNER_NAME>
<NAME>EMPLOYEES</NAME>
.
.
.
3.7 About Input Formats
An input format reads a specific type of data stored in Hadoop. Several input formats are available, which can read the data formats most commonly found in Hadoop:
You can also use your own custom input formats. The descriptions of the built-in formats provide information that may help you develop custom Java InputFormat classes. See "Custom Input Formats."
You specify a particular input format for the data that you want to load into a database table, by using the mapreduce.inputformat.class configuration property in the job configuration file.
Compressed data is automatically decompressed when Oracle Loader for Hadoop reads it.
Note:
The built-in text formats do not handle header rows or newline characters (\n) embedded in quoted values.3.7.1 Delimited Text Input Format
To load data from a delimited text file, set mapreduce.inputformat.class to
oracle.hadoop.loader.lib.input.DelimitedTextInputFormat
3.7.1.1 About DelimitedTextInputFormat
The input file must comply with these requirements:
-
Records must be separated by newline characters.
-
Fields must be delimited using single-character markers, such as commas or tabs.
A null replaces any empty-string token, whether enclosed or unenclosed.
DelimitedTextInputFormat emulates the tokenization method of SQL*Loader: Terminated by t, and optionally enclosed by ie, or by ie and te. DelimitedTextInputFormat uses the following syntax rules, where t is the field terminator, ie is the initial field encloser, te is the trailing field encloser, and c is one character.
-
Line = Token t Line | Token\n
-
Token = EnclosedToken | UnenclosedToken
-
EnclosedToken = (white-space)* ie [(non-te)* te te]* (non-te)* te (white-space)*
-
UnenclosedToken = (white-space)* (non-t)*
-
white-space = {c | Character.isWhitespace(c) and c!=t}
White space around enclosed tokens (data values) is discarded. For unenclosed tokens, the leading white space is discarded, but not the trailing white space (if any).
This implementation enables you to define custom enclosers and terminator characters, but it hard codes the record terminator as a newline, and white space as Java Character.isWhitespace. A white space can be defined as the field terminator, but then that character is removed from the class of white space characters to prevent ambiguity.
Hadoop automatically decompresses compressed delimited text files when they are read.
3.7.1.2 Required Configuration Properties
None. The default format separates fields with commas and has no field enclosures.
3.7.2 Complex Text Input Formats
To load data from text files that are more complex than DelimitedTextInputFormat can handle, set mapreduce.inputformat.class to
oracle.hadoop.loader.lib.input.RegexInputFormat
For example, a web log might delimit one field with quotes and another field with square brackets.
3.7.2.1 About RegexInputFormat
RegexInputFormat requires that records be separated by newline characters. It identifies fields in each text line by matching a regular expression:
-
The regular expression must match the entire text line.
-
The fields are identified using the capturing groups in the regular expression.
RegexInputFormat uses the java.util.regex regular expression-based pattern matching engine. Hadoop automatically decompresses compressed regex files when they are read.
See Also:
Java Platform Standard Edition 6 Java Reference for more information aboutjava.util.regex:
http://docs.oracle.com/javase/6/docs/api/java/util/regex/package-summary.html
3.7.2.2 Required Configuration Properties
Use the following property to describe the data input file:
3.7.3 Hive Table Input Format
To load data from a Hive table, set mapreduce.inputformat.class to
oracle.hadoop.loader.lib.input.HiveToAvroInputFormat
3.7.3.1 About HiveToAvroInputFormat
HiveToAvroInputFormat imports the entire table, which includes all the files in the Hive table directory or, for partition tables, all files in each partition directory.
Oracle Loader for Hadoop rejects all rows with complex (non-primitive) column values. UNIONTYPE fields that resolve to primitive values are supported. See "Handling Rejected Records."
HiveToAvroInputFormat transforms rows in the Hive table into Avro records, and capitalizes the Hive table column names to form the field names. This automatic capitalization improves the likelihood that the field names match the target table column names. See "Mapping Input Fields to Target Table Columns".
Hive tables are automatically decompressed when they are read.
3.7.4 Avro Input Format
To load data from binary Avro data files containing standard Avro-format records, set mapreduce.inputformat.class to
oracle.hadoop.loader.lib.input.AvroInputFormat
To process only files with the .avro extension, append *.avro to directories listed in the mapred.input.dir configuration property.
The Avro reader automatically decompresses compressed Avro files.
3.7.5 Oracle NoSQL Database Input Format
To load data from Oracle NoSQL Database, set mapreduce.inputformat.class to
oracle.kv.hadoop.KVAvroInputFormat
This input format is defined in Oracle NoSQL Database 11g, Release 2 and later releases.
3.7.5.1 About KVAvroInputFormat
Oracle Loader for Hadoop uses KVAvroInputFormat to read data directly from Oracle NoSQL Database.
KVAvroInputFormat passes the value but not the key from the key-value pairs in Oracle NoSQL Database. If you must access the Oracle NoSQL Database keys as Avro data values, such as storing them in the target table, then you must create a Java InputFormat class that implements oracle.kv.hadoop.AvroFormatter. Then you can specify the oracle.kv.formatterClass property in the Oracle Loader for Hadoop configuration file.
The KVAvroInputFormat class is a subclass of org.apache.hadoop.mapreduce.InputFormat<oracle.kv.Key, org.apache.avro.generic.IndexedRecord>
See Also:
Javadoc for theKVInputFormatBase class at
3.7.6 Custom Input Formats
If the built-in input formats do not meet your needs, then you can write a Java class for a custom input format. The following information describes the framework in which an input format works in Oracle Loader for Hadoop.
3.7.6.1 About Implementing a Custom Input Format
Oracle Loader for Hadoop gets its input from a class extending org.apache.hadoop.mapreduce.InputFormat. You must specify the name of that class in the mapreduce.inputformat.class configuration property.
The input format must create RecordReader instances that return an Avro IndexedRecord input object from the getCurrentValue method. Use this method signature:
public org.apache.avro.generic.IndexedRecord getCurrentValue() throws IOException, InterruptedException;
Oracle Loader for Hadoop uses the schema of the IndexedRecord input object to discover the names of the input fields and map them to the columns of the target table.
3.7.6.2 About Error Handling
If processing an IndexedRecord value results in an error, Oracle Loader for Hadoop uses the object returned by the getCurrentKey method of the RecordReader to provide feedback. It calls the toString method of the key and formats the result in an error message. InputFormat developers can assist users in identifying the rejected records by returning one of the following:
-
Data file URI
-
InputSplitinformation -
Data file name and the record offset in that file
Oracle recommends that you do not return the record in clear text, because it might contain sensitive information; the returned values can appear in Hadoop logs throughout the cluster. See "Logging Rejected Records in Bad Files."
If a record fails and the key is null, then the loader generates no identifying information.
3.7.6.3 Supporting Data Sampling
Oracle Loader for Hadoop uses a sampler to improve performance of its MapReduce job. The sampler is multithreaded, and each sampler thread instantiates its own copy of the supplied InputFormat class. When implementing a new InputFormat, ensure that it is thread-safe. See "Balancing Loads When Loading Data into Partitioned Tables."
3.7.6.4 InputFormat Source Code Example
Oracle Loader for Hadoop provides the source code for an InputFormat example, which is located in the examples/jsrc/ directory.
The sample format loads data from a simple, comma-separated value (CSV) file. To use this input format, specify oracle.hadoop.loader.examples.CSVInputFormat as the value of mapreduce.inputformat.class in the job configuration file.
This input format automatically assigns field names of F0, F1, F2, and so forth. It does not have configuration properties.
3.8 Mapping Input Fields to Target Table Columns
Mapping identifies which input fields are loaded into which columns of the target table. You may be able to use the automatic mapping facilities, or you can always manually map the input fields to the target columns.
3.8.1 Automatic Mapping
Oracle Loader for Hadoop can automatically map the fields to the appropriate columns when the input data complies with these requirements:
-
All columns of the target table are loaded.
-
The input data field names in the
IndexedRecordinput object exactly match the column names. -
All input fields that are mapped to
DATEcolumns can be parsed using the same Java date format.
Use these configuration properties for automatic mappings:
-
oracle.hadoop.loader.loaderMap.targetTable: Identifies the target table. -
oracle.hadoop.loader.defaultDateFormat: Specifies a default date format that applies to allDATEfields.
3.8.2 Manual Mapping
For loads that do not comply with the requirements for automatic mapping, you must define additional properties. These properties enable you to:
-
Load data into a subset of the target table columns.
-
Create explicit mappings when the input field names are not identical to the database column names.
-
Specify different date formats for different input fields.
Use these properties for manual mappings:
-
oracle.hadoop.loader.loaderMap.targetTableconfiguration property to identify the target table. Required. -
oracle.hadoop.loader.loaderMap.columnNames: Lists the columns to be loaded. -
oracle.hadoop.loader.defaultDateFormat: Specifies a default date format that applies to allDATEfields. -
oracle.hadoop.loader.loaderMap.column_name.format: Specifies the data format for a particular column. -
oracle.hadoop.loader.loaderMap.column_name.field: Identifies the name of an Avro record field mapped to a particular column.
3.8.3 Converting a Loader Map File
The following utility converts a loader map file from earlier releases to a configuration file:
hadoop oracle.hadoop.loader.metadata.LoaderMap -convert map_file conf_file
Options
- map_file
-
The name of the input loader map file on the local file system (not HDFS).
- conf_file
-
The name of the output configuration file on the local file system (not HDFS).
Example 3-3 shows a sample conversion.
Example 3-3 Converting a Loader File to Configuration Properties
$ HADOOP_CLASSPATH="$HADOOP_CLASSPATH:$OLH_HOME/jlib/*" $ hadoop oracle.hadoop.loader.metadata.LoaderMap -convert loadermap.xml conf.xml Oracle Loader for Hadoop Release 2.3.0 - Production Copyright (c) 2011, 2013, Oracle and/or its affiliates. All rights reserved.
Input Loader Map File loadermap.xml
<?xml version="1.0" encoding="UTF-8"?> <LOADER_MAP> <SCHEMA>HR</SCHEMA> <TABLE>EMPLOYEES</TABLE> <COLUMN field="F0">EMPLOYEE_ID</COLUMN> <COLUMN field="F1">LAST_NAME</COLUMN> <COLUMN field="F2">EMAIL</COLUMN> <COLUMN field="F3" format="MM-dd-yyyy">HIRE_DATE</COLUMN> <COLUMN field="F4">JOB_ID</COLUMN> </LOADER_MAP>
Output Configuration File conf.xml
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<configuration>
<property>
<name>oracle.hadoop.loader.loaderMap.targetTable</name>
<value>HR.EMPLOYEES</value>
</property>
<property>
<name>oracle.hadoop.loader.loaderMap.columnNames</name>
<value>EMPLOYEE_ID,LAST_NAME,EMAIL,HIRE_DATE,JOB_ID</value>
</property>
<property>
<name>oracle.hadoop.loader.loaderMap.EMPLOYEE_ID.field</name>
<value>F0</value>
</property>
<property>
<name>oracle.hadoop.loader.loaderMap.EMPLOYEE_ID.format</name>
<value></value>
</property>
<property>
<name>oracle.hadoop.loader.loaderMap.LAST_NAME.field</name>
<value>F1</value>
</property>
<property>
<name>oracle.hadoop.loader.loaderMap.LAST_NAME.format</name>
<value></value>
</property>
<property>
<name>oracle.hadoop.loader.loaderMap.EMAIL.field</name>
<value>F2</value>
</property>
<property>
<name>oracle.hadoop.loader.loaderMap.EMAIL.format</name>
<value></value>
</property>
<property>
<name>oracle.hadoop.loader.loaderMap.HIRE_DATE.field</name>
<value>F3</value>
</property>
<property>
<name>oracle.hadoop.loader.loaderMap.HIRE_DATE.format</name>
<value>MM-dd-yyyy</value>
</property>
<property>
<name>oracle.hadoop.loader.loaderMap.JOB_ID.field</name>
<value>F4</value>
</property>
<property>
<name>oracle.hadoop.loader.loaderMap.JOB_ID.format</name>
<value></value>
</property>
</configuration>
3.9 About Output Formats
In online database mode, you can choose between loading the data directly into an Oracle database table or storing it in a file. In offline database mode, you are restricted to storing the output data in a file, which you can load into the target table as a separate procedure. You specify the output format in the job configuration file using the mapreduce.outputformat.class property.
Choose from these output formats:
-
JDBC Output Format: Loads the data directly into the target table.
-
Oracle OCI Direct Path Output Format: Loads the data directly into the target table.
-
Delimited Text Output Format: Stores the data in a local file.
-
Oracle Data Pump Output Format: Stores the data in a local file.
3.9.1 JDBC Output Format
You can use a JDBC connection between the Hadoop system and Oracle Database to load the data. The output records of the loader job are loaded directly into the target table by map or reduce tasks as part of the OraLoader process, in online database mode. No additional steps are required to load the data.
A JDBC connection must be open between the Hadoop cluster and the Oracle Database system for the duration of the job.
To use this output format, set mapreduce.outputformat.class to
oracle.hadoop.loader.lib.output.JDBCOutputFormat
3.9.1.1 About JDBCOutputFormat
JDBCOutputFormat uses standard JDBC batching to optimize performance and efficiency. If an error occurs during batch execution, such as a constraint violation, the JDBC driver stops execution immediately. Thus, if there are 100 rows in a batch and the tenth row causes an error, then nine rows are inserted and 91 rows are not.
The JDBC driver does not identify the row that caused the error, and so Oracle Loader for Hadoop does not know the insert status of any of the rows in the batch. It counts all rows in a batch with errors as "in question," that is, the rows may or may not be inserted in the target table. The loader then continues loading the next batch. It generates a load report at the end of the job that details the number of batch errors and the number of rows in question.
One way that you can handle this problem is by defining a unique key in the target table. For example, the HR.EMPLOYEES table has a primary key named EMPLOYEE_ID. After loading the data into HR.EMPLOYEES, you can query it by EMPLOYEE_ID to discover the missing employee IDs.Then you can locate the missing employee IDs in the input data, determine why they failed to load, and try again to load them.
3.9.2 Oracle OCI Direct Path Output Format
You can use the direct path interface of Oracle Call Interface (OCI) to load data into the target table. Each reducer loads into a distinct database partition in online database mode, enabling the performance gains of a parallel load. No additional steps are required to load the data.
The OCI connection must be open between the Hadoop cluster and the Oracle Database system for the duration of the job.
To use this output format, set mapreduce.outputformat.class to
oracle.hadoop.loader.lib.output.OCIOutputFormat
3.9.2.1 About OCIOutputFormat
OCIOutputFormat has the following restrictions:
-
It is available only on the Linux x86.64 platform.
-
The MapReduce job must create one or more reducers.
-
The target table must be partitioned.
-
For Oracle Database 11g (11.2.0.3), apply the patch for bug 13498646 if the target table is a composite interval partitioned table in which the subpartition key contains a
CHAR,VARCHAR2,NCHAR, orNVARCHAR2column. Later versions of Oracle Database do not require this patch.
3.9.3 Delimited Text Output Format
You can create delimited text output files on the Hadoop cluster. The map or reduce tasks generate delimited text files, using the field delimiters and enclosers that you specify in the job configuration properties. Afterward, you can load the data into an Oracle database as a separate procedure. See "About DelimitedTextOutputFormat."
This output format can use either an open connection to the Oracle Database system to retrieve the table metadata in online database mode, or a table metadata file generated by the OraloaderMetadata utility in offline database mode.
To use this output format, set mapreduce.outputformat.class to
oracle.hadoop.loader.lib.output.DelimitedTextOutputFormat
3.9.3.1 About DelimitedTextOutputFormat
Output tasks generate delimited text format files, and one or more corresponding SQL*Loader control files, and SQL scripts for loading with external tables.
If the target table is not partitioned or if oracle.hadoop.loader.loadByPartition is false, then DelimitedTextOutputFormat generates the following files:
-
A data file named
oraloader-taskId-csv-0.dat. -
A SQL*Loader control file named oraloader-csv.ctl for the entire job.
-
A SQL script named
oraloader-csv.sqlto load the delimited text file into the target table.
For partitioned tables, multiple output files are created with the following names:
-
Data files:
oraloader-taskId-csv-partitionId.dat -
SQL*Loader control files:
oraloader-taskId-csv-partitionId.ctl -
SQL script:
oraloader-csv.sql
In the generated file names, taskId is the mapper or reducer identifier, and partitionId is the partition identifier.
If the Hadoop cluster is connected to the Oracle Database system, then you can use Oracle SQL Connector for HDFS to load the delimited text data into an Oracle database. See Chapter 2.
Alternatively, you can copy the delimited text files to the database system and load the data into the target table in one of the following ways:
-
Use the generated control files to run SQL*Loader and load the data from the delimited text files.
-
Use the generated SQL scripts to perform external table loads.
The files are located in the ${map.output.dir}/_olh directory.
3.9.3.2 Configuration Properties
The following properties control the formatting of records and fields in the output files:
Example 3-4 shows a sample SQL*Loader control file that might be generated by an output task.
Example 3-4 Sample SQL*Loader Control File
LOAD DATA CHARACTERSET AL32UTF8 INFILE 'oraloader-csv-1-0.dat' BADFILE 'oraloader-csv-1-0.bad' DISCARDFILE 'oraloader-csv-1-0.dsc' INTO TABLE "SCOTT"."CSV_PART" PARTITION(10) APPEND FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"' ( "ID" DECIMAL EXTERNAL, "NAME" CHAR, "DOB" DATE 'SYYYY-MM-DD HH24:MI:SS' )
3.9.4 Oracle Data Pump Output Format
You can create Data Pump format files on the Hadoop cluster. The map or reduce tasks generate Data Pump files. Afterward, you can load the data into an Oracle database as a separate procedure. See "About DataPumpOutputFormat."
This output format can use either an open connection to the Oracle Database system in online database mode, or a table metadata file generated by the OraloaderMetadata utility in offline database mode.
To use this output format, set mapreduce.outputformat.class to
oracle.hadoop.loader.lib.output.DataPumpOutputFormat
3.9.4.1 About DataPumpOutputFormat
DataPumpOutputFormat generates data files with names in this format:
oraloader-taskId-dp-partitionId.dat
In the generated file names, taskId is the mapper or reducer identifier, and partitionId is the partition identifier.
If the Hadoop cluster is connected to the Oracle Database system, then you can use Oracle SQL Connector for HDFS to load the Data Pump files into an Oracle database. See Chapter 2.
Alternatively, you can copy the Data Pump files to the database system and load them using a SQL script generated by Oracle Loader for Hadoop. The script performs the following tasks:
-
Creates an external table definition using the
ORACLE_DATAPUMPaccess driver. The binary format Oracle Data Pump output files are listed in theLOCATIONclause of the external table. -
Creates a directory object that is used by the external table. You must uncomment this command before running the script. To specify the directory name used in the script, set the
oracle.hadoop.loader.extTabDirectoryNameproperty in the job configuration file. -
Insert the rows from the external table into the target table. You must uncomment this command before running the script.
The SQL script is located in the ${map.output.dir}/_olh directory.
See Also:
-
Oracle Database Administrator's Guide for more information about creating and managing external tables
-
Oracle Database Utilities for more information about the
ORACLE_DATAPUMPaccess driver
3.10 Running a Loader Job
To run a job using Oracle Loader for Hadoop, you use the OraLoader utility in a hadoop command.
The following is the basic syntax:
hadoop jar $OLH_HOME/jlib/oraloader.jar oracle.hadoop.loader.OraLoader \ -conf job_config.xml \ -libjars input_file_format1.jar[,input_file_format2.jar...]
You can include any generic hadoop command-line option. OraLoader implements the org.apache.hadoop.util.Tool interface and follows the standard Hadoop methods for building MapReduce applications.
Basic Options
- -conf job_config.xml
-
Identifies the job configuration file. See "Creating a Job Configuration File."
- -libjars
-
Identifies the JAR files for the input format.
-
When using the example input format, specify
$OLH_HOME/jlib/oraloader-examples.jar. -
When using the Hive or Oracle NoSQL Database input formats, you must specify additional JAR files, as described later in this section.
-
When using a custom input format, specify its JAR file. (Also remember to add it to
HADOOP_CLASSPATH.)
-
Separate multiple file names with commas, and list each one explicitly. Wildcard characters and spaces are not allowed.
Oracle Loader for Hadoop prepares internal configuration information for the MapReduce tasks. It stores table metadata information and the dependent Java libraries in the distributed cache, so that they are available to the MapReduce tasks throughout the cluster.
The following example uses a built-in input format and a job configuration file named MyConf.xml:
HADOOP_CLASSPATH="$HADOOP_CLASSPATH:$OLH_HOME/jlib/*" hadoop jar $OLH_HOME/jlib/oraloader.jar oracle.hadoop.loader.OraLoader \ -conf MyConf.xml -libjars $OLH_HOME/jlib/oraloader-examples.jar
See Also:
-
For the full
hadoopcommand syntax and generic options:http://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-common/CommandsManual.html
3.10.1 Specifying Hive Input Format JAR Files
When using HiveToAvroInputFormat, you must add the Hive configuration directory to the HADOOP_CLASSPATH environment variable:
HADOOP_CLASSPATH="$HADOOP_CLASSPATH:$OLH_HOME/jlib/*:hive_home/lib/*:hive_conf_dir"
You must also add the following Hive JAR files, in a comma-separated list, to the -libjars option of the hadoop command. Replace the stars (*) with the complete file names on your system:
-
hive-exec-*.jar -
hive-metastore-*.jar -
libfb303*.jar
This example shows the full file names in Cloudera's Distribution including Apache Hadoop (CDH) 4.4:
# hadoop jar $OLH_HOME/jlib/oraloader.jar oracle.hadoop.loader.OraLoader \
-conf MyConf.xml \
-libjars hive-exec-0.10.0-cdh4.4.0.jar,hive-metastore-0.10.0-cdh4.4.0.jar,libfb303-0.9.0.jar
3.10.2 Specifying Oracle NoSQL Database Input Format JAR Files
When using KVAvroInputFormat from Oracle NoSQL Database 11g, Release 2, you must include $KVHOME/lib/kvstore.jar in your HADOOP_CLASSPATH and you must include the -libjars option in the hadoop command:
hadoop jar $OLH_HOME/jlib/oraloader.jar oracle.hadoop.loader.OraLoader \ -conf MyConf.xml \ -libjars $KVHOME/lib/kvstore.jar
3.10.3 Job Reporting
Oracle Loader for Hadoop consolidates reporting information from individual tasks into a file named ${map.output.dir}/_olh/oraloader-report.txt. Among other statistics, the report shows the number of errors, broken out by type and task, for each mapper and reducer.
3.11 Handling Rejected Records
Oracle Loader for Hadoop may reject input records for a variety of reasons, such as:
-
Errors in the mapping properties
-
Missing fields in the input data
-
Records mapped to invalid table partitions
-
Badly formed records, such as dates that do not match the date format or records that do not match regular expression patterns
3.11.1 Logging Rejected Records in Bad Files
By default, Oracle Loader for Hadoop does not log the rejected records into Hadoop logs; it only logs information on how to identify the rejected records. This practice prevents user-sensitive information from being stored in Hadoop logs across the cluster.
You can direct Oracle Loader for Hadoop to log rejected records by setting the oracle.hadoop.loader.logBadRecords configuration property to true. Then Oracle Loader for Hadoop logs bad records into one or more "bad" files in the _olh/ directory under the job output directory.
3.11.2 Setting a Job Reject Limit
Some problems can cause Oracle Loader for Hadoop to reject every record in the input. To mitigate the loss of time and resources, Oracle Loader for Hadoop aborts the job after rejecting 1000 records.
You can change the maximum number of rejected records allowed by setting the oracle.hadoop.loader.rejectLimit configuration property. A negative value turns off the reject limit and allows the job to run to completion regardless of the number of rejected records.
3.12 Balancing Loads When Loading Data into Partitioned Tables
The goal of load balancing is to generate a MapReduce partitioning scheme that assigns approximately the same amount of work to all reducers.
The sampling feature of Oracle Loader for Hadoop balances loads across reducers when data is loaded into a partitioned database table. It generates an efficient MapReduce partitioning scheme that assigns database partitions to the reducers.
The execution time of a reducer is usually proportional to the number of records that it processes—the more records, the longer the execution time. When sampling is disabled, all records from a given database partition are sent to one reducer. This can result in unbalanced reducer loads, because some database partitions may have more records than others. Because the execution time of a Hadoop job is usually dominated by the execution time of its slowest reducer, unbalanced reducer loads slow down the entire job.
3.12.1 Using the Sampling Feature
You can turn the sampling feature on or off by setting the oracle.hadoop.loader.sampler.enableSampling configuration property. Sampling is turned on by default.
3.12.2 Tuning Load Balancing
These job configuration properties control the quality of load balancing:
The sampler uses the expected reducer load factor to evaluate the quality of its partitioning scheme. The load factor is the relative overload for each reducer, calculated as (assigned_load - ideal_load)/ideal_load. This metric indicates how much a reducer's load deviates from a perfectly balanced reducer load. A load factor of 1.0 indicates a perfectly balanced load (no overload).
Small load factors indicate better load balancing. The maxLoadFactor default of 0.05 means that no reducer is ever overloaded by more than 5%. The sampler guarantees this maxLoadFactor with a statistical confidence level determined by the value of loadCI. The default value of loadCI is 0.95, which means that any reducer's load factor exceeds maxLoadFactor in only 5% of the cases.
There is a trade-off between the execution time of the sampler and the quality of load balancing. Lower values of maxLoadFactor and higher values of loadCI achieve more balanced reducer loads at the expense of longer sampling times. The default values of maxLoadFactor=0.05 and loadCI=0.95 are a good trade-off between load balancing quality and execution time.
3.12.3 Tuning Sampling Behavior
By default, the sampler runs until it collects just enough samples to generate a partitioning scheme that satisfies the maxLoadFactor and loadCI criteria.
However, you can limit the sampler running time by setting the oracle.hadoop.loader.sampler.maxSamplesPct property, which specifies the maximum number of sampled records.
3.12.4 When Does Oracle Loader for Hadoop Use the Sampler's Partitioning Scheme?
Oracle Loader for Hadoop uses the generated partitioning scheme only if sampling is successful. A sampling is successful if it generates a partitioning scheme with a maximum reducer load factor of (1+ maxLoadFactor) guaranteed at a statistical confidence level of loadCI.
The default values of maxLoadFactor, loadCI, and maxSamplesPct allow the sampler to successfully generate high-quality partitioning schemes for a variety of different input data distributions. However, the sampler might be unsuccessful in generating a partitioning scheme using custom property values, such as when the constraints are too rigid or the number of required samples exceeds the user-specified maximum of maxSamplesPct. In these cases, Oracle Loader for Hadoop generates a log message identifying the problem, partitions the records using the database partitioning scheme, and does not guarantee load balancing.
Alternatively, you can reset the configuration properties to less rigid values. Either increase maxSamplesPct, or decrease maxLoadFactor or loadCI, or both.
3.12.5 Resolving Memory Issues
A custom input format may return input splits that do not fit in memory. If this happens, the sampler returns an out-of-memory error on the client node where the loader job is submitted.
To resolve this problem:
-
Increase the heap size of the JVM where the job is submitted.
-
Adjust the following properties:
If you are developing a custom input format, then see "Custom Input Formats."
3.12.6 What Happens When a Sampling Feature Property Has an Invalid Value?
If any configuration properties of the sampling feature are set to values outside the accepted range, an exception is not returned. Instead, the sampler prints a warning message, resets the property to its default value, and continues executing.
3.13 Optimizing Communications Between Oracle Engineered Systems
If you are using Oracle Loader for Hadoop to load data from Oracle Big Data Appliance to Oracle Exadata Database Machine, then you can increase throughput by configuring the systems to use Sockets Direct Protocol (SDP) over the InfiniBand private network. This setup provides an additional connection attribute whose sole purpose is serving connections to Oracle Database to load data.
To specify SDP protocol:
-
Add JVM options to the
HADOOP_OPTSenvironment variable to enable JDBC SDP export:HADOOP_OPTS="-Doracle.net.SDP=true -Djava.net.preferIPv4Stack=true"
-
Configure standard Ethernet communications. In the job configuration file, set
oracle.hadoop.loader.connection.urlusing this syntax:jdbc:oracle:thin:@(DESCRIPTION=(ADDRESS_LIST= (ADDRESS=(PROTOCOL=TCP)(HOST=hostName)(PORT=portNumber))) (CONNECT_DATA=(SERVICE_NAME=serviceName))) -
Configure the Oracle listener on Exadata to support the SDP protocol and bind it to a specific port address (such as 1522). In the job configuration file, specify the listener address as the value of
oracle.hadoop.loader.connection.oci_urlusing this syntax:(DESCRIPTION=(ADDRESS=(PROTOCOL=SDP) (HOST=hostName) (PORT=portNumber)) (CONNECT_DATA=(SERVICE_NAME=serviceName)))Replace hostName, portNumber, and serviceName with the appropriate values to identify the SDP listener on your Oracle Exadata Database Machine.
See Also:
Oracle Big Data Appliance Software User's Guide for more information about configuring communications over InfiniBand3.14 Oracle Loader for Hadoop Configuration Property Reference
OraLoader uses the standard methods of specifying configuration properties in the hadoop command. You can use the -conf option to identify configuration files, and the -D option to specify individual properties. See "Running a Loader Job."
This section describes the OraLoader configuration properties, the Oracle NoSQL Database configuration properties, and a few generic Hadoop MapReduce properties that you typically must set for an OraLoader job:
A configuration file showing all OraLoader properties is in $OLH_HOME/doc/oraloader-conf.xml.
See Also:
Hadoop documentation for job configuration files atMapReduce Configuration Properties
- mapred.job.name
-
Type: String
Default Value:
OraLoaderDescription: The Hadoop job name. A unique name can help you monitor the job using tools such as the Hadoop JobTracker web interface and Cloudera Manager.
- mapred.input.dir
-
Type: String
Default Value: Not defined
Description: A comma-separated list of input directories.
- mapreduce.inputformat.class
-
Type: String
Default Value: Not defined
Description: Identifies the format of the input data. You can enter one of the following built-in input formats, or the name of a custom
InputFormatclass:-
oracle.hadoop.loader.lib.input.AvroInputFormat -
oracle.hadoop.loader.lib.input.DelimitedTextInputFormat -
oracle.hadoop.loader.lib.input.HiveToAvroInputFormat -
oracle.hadoop.loader.lib.input.RegexInputFormat -
oracle.kv.hadoop.KVAvroInputFormat
See "About Input Formats" for descriptions of the built-in input formats.
-
- mapred.output.dir
-
Type: String
Default Value: Not defined
Description: A comma-separated list of output directories, which cannot exist before the job runs. Required.
- mapreduce.outputformat.class
-
Type: String
Default Value: Not defined
Description: Identifies the output type. The values can be:
-
oracle.hadoop.loader.lib.output.DataPumpOutputFormatWrites data records into binary format files that can be loaded into the target table using an external table.
-
oracle.hadoop.loader.lib.output.DelimitedTextOutputFormatWrites data records to delimited text format files such as comma-separated values (CSV) format files.
-
oracle.hadoop.loader.lib.output.JDBCOutputFormatInserts rows into the target table using a JDBC connection.
-
oracle.hadoop.loader.lib.output.OCIOutputFormatInserts rows into the target table using the Oracle OCI Direct Path interface.
-
OraLoader Configuration Properties
- oracle.hadoop.loader.badRecordFlushInterval
-
Type: Integer
Default Value:
500Description: Sets the maximum number of records that a task attempt can log before flushing the log file. This setting limits the number of records that can be lost when the record reject limit (
oracle.hadoop.loader.rejectLimit) is reached and the job stops running.The
oracle.hadoop.loader.logBadRecordsproperty must be set totruefor a flush interval to take effect. - oracle.hadoop.loader.compressionFactors
-
Type: Decimal
Default Value:
BASIC=5.0,OLTP=5.0,QUERY_LOW=10.0,QUERY_HIGH=10.0,ARCHIVE_LOW=10.0,ARCHIVE_HIGH=10.0Description: Defines the Oracle Database compression factor for different types of compression during parallel, direct-path loads into a partition. The value is a comma-delimited list of name=value pairs. The name can be one of the following keywords:
ARCHIVE_HIGH ARCHIVE_LOW BASIC OLTP QUERY_HIGH QUERY_LOW
- oracle.hadoop.loader.connection.defaultExecuteBatch
-
Type: Integer
Default Value:
100Description: The number of records inserted in one trip to the database. It applies only to
JDBCOutputFormatandOCIOutputFormat.Specify a value greater than or equal to 1. Although the maximum value is unlimited, very large batch sizes are not recommended because they result in a large memory footprint without much increase in performance.
A value less than 1 sets the property to the default value.
- oracle.hadoop.loader.connection.oci_url
-
Type: String
Default Value: Value of
oracle.hadoop.loader.connection.urlDescription: The database connection string used by
OCIOutputFormat. This property enables the OCI client to connect to the database using different connection parameters than the JDBC connection URL.The following example specifies Socket Direct Protocol (SDP) for OCI connections.
(DESCRIPTION=(ADDRESS_LIST= (ADDRESS=(PROTOCOL=SDP)(HOST=myhost)(PORT=1521))) (CONNECT_DATA=(SERVICE_NAME=my_db_service_name)))
This connection string does not require a "jdbc:oracle:thin:@" prefix. All characters up to and including the first at-sign (@) are removed.
- oracle.hadoop.loader.connection.password
-
Type: String
Default Value: Not defined
Description: Password for the connecting user. Oracle recommends that you do not store your password in clear text. Use an Oracle wallet instead.
- oracle.hadoop.loader.connection.sessionTimeZone
-
Type: String
Default Value:
LOCALDescription: Alters the session time zone for database connections. Valid values are:
-
[+|-]hh:mm: Hours and minutes before or after Coordinated Universal Time (UTC), such as
-5:00for Eastern Standard Time -
LOCAL: The default time zone of the JVM -
time_zone_region: A valid JVM time zone region, such as EST (for Eastern Standard Time) or America/New_York
This property also determines the default time zone for input data that is loaded into
TIMESTAMP WITH TIME ZONEandTIMESTAMP WITH LOCAL TIME ZONEdatabase column types. -
- oracle.hadoop.loader.connection.tns_admin
-
Type: String
Default Value: Not defined
Description: File path to a directory on each node of the Hadoop cluster, which contains SQL*Net configuration files such as
sqlnet.oraandtnsnames.ora. Set this property so that you can use TNS entry names in database connection strings.You must set this property when using an Oracle wallet as an external password store. See
oracle.hadoop.loader.connection.wallet_location. - oracle.hadoop.loader.connection.tnsEntryName
-
Type: String
Default Value: Not defined
Description: A TNS entry name defined in the
tnsnames.orafile. Use this property withoracle.hadoop.loader.connection.tns_admin. - oracle.hadoop.loader.connection.url
-
Type: String
Default Value: Not defined
Description: The URL of the database connection. This property overrides all other connection properties.
If an Oracle wallet is configured as an external password store, then the property value must start with the
jdbc:oracle:thin:@driver prefix, and the database connection string must exactly match the credential in the wallet. Seeoracle.hadoop.loader.connection.wallet_location.The following examples show valid values of connection URLs:
-
Oracle Net Format:
jdbc:oracle:thin:@(DESCRIPTION=(ADDRESS_LIST= (ADDRESS=(PROTOCOL=TCP)(HOST=myhost)(PORT=1521))) (CONNECT_DATA=(SERVICE_NAME=example_service_name))) -
TNS Entry Format:
jdbc:oracle:thin:@myTNSEntryName
-
Thin Style:
jdbc:oracle:thin:@//myhost:1521/my_db_service_name jdbc:oracle:thin:user/password@//myhost:1521/my_db_service_name
-
- oracle.hadoop.loader.connection.user
-
Type: String
Default Value: Not defined
Description: A database user name. When using online database mode, you must set either this property or
oracle.hadoop.loader.connection.wallet_location. - oracle.hadoop.loader.connection.wallet_location
-
Type: String
Default Value: Not defined
Description: File path to an Oracle wallet directory on each node of the Hadoop cluster, where the connection credentials are stored.
When using an Oracle wallet, you must also set the following properties:
- oracle.hadoop.loader.defaultDateFormat
-
Type: String
Default Value:
yyyy-MM-dd HH:mm:ssDescription: Parses an input field into a
DATEcolumn using ajava.text.SimpleDateformatpattern and the default locale. If the input file requires different patterns for different fields, then use the manual mapping properties. See "Manual Mapping." - oracle.hadoop.loader.enableSorting
-
Type: Boolean
Default Value:
trueDescription: Controls whether output records within each reducer group are sorted. Use the
oracle.hadoop.loader.sortKeyproperty to identify the columns of the target table to sort by. Otherwise, Oracle Loader for Hadoop sorts the records by the primary key. - oracle.hadoop.loader.extTabDirectoryName
-
Type: String
Default Value:
OLH_EXTTAB_DIRDescription: The name of the database directory object for the external table
LOCATIONdata files. Oracle Loader for Hadoop does not copy data files into this directory; the file output formats generate a SQL file containing external table DDL, where the directory name appears.This property applies only to
DelimitedTextOutputFormatandDataPumpOutputFormat. - oracle.hadoop.loader.input.fieldNames
-
Type: String
Default Value:
F0,F1,F2,...Description: A comma-delimited list of names for the input fields.
For the built-in input formats, specify names for all fields in the data, not just the fields of interest. If an input line has more fields than this property has field names, then the extra fields are discarded. If a line has fewer fields than this property has field names, then the extra fields are set to null. See "Mapping Input Fields to Target Table Columns" for loading only selected fields.
The names are used to create the Avro schema for the record, so they must be valid JSON name strings.
- oracle.hadoop.loader.input.fieldTerminator
-
Type: String
Default Value:
,(comma)Description: A character that indicates the end of an input field for
DelimitedTextInputFormat. The value can be either a single character or\uHHHH, whereHHHHis the character's UTF-16 encoding. - oracle.hadoop.loader.input.hive.databaseName
-
Type: String
Default Value: Not defined
Description: The name of the Hive database where the input table is stored.
- oracle.hadoop.loader.input.hive.tableName
-
Type: String
Default Value: Not defined
Description: The name of the Hive table where the input data is stored.
- oracle.hadoop.loader.input.initialFieldEncloser
-
Type: String
Default Value: Not defined
Description: A character that indicates the beginning of a field. The value can be either a single character or
\uHHHH, whereHHHHis the character's UTF-16 encoding. To restore the default setting (no encloser), enter a zero-length value. A field encloser cannot equal the terminator or white-space character defined for the input format.When this property is set, the parser attempts to read each field as an enclosed token (value) before reading it as an unenclosed token. If the field enclosers are not set, then the parser reads each field as an unenclosed token.
If you set this property but not
oracle.hadoop.loader.input.trailingFieldEncloser, then the same value is used for both properties. - oracle.hadoop.loader.input.regexCaseInsensitive
-
Type: Boolean
Default Value:
falseDescription: Controls whether pattern matching is case-sensitive. Set to
trueto ignore case, so that "string" matches "String", "STRING", "string", "StRiNg", and so forth. By default, "string" matches only "string".This property is the same as the
input.regex.case.insensitiveproperty oforg.apache.hadoop.hive.contrib.serde2.RegexSerDe. - oracle.hadoop.loader.input.regexPattern
-
Type: Text
Default Value: Not defined
Description: The pattern string for a regular expression.
The regular expression must match each text line in its entirety. For example, a correct regex pattern for input line
"a,b,c,"is"([^,]*),([^,]*),([^,]*),". However,"([^,]*),"is invalid, because the expression is not applied repeatedly to a line of input text.RegexInputFormatuses the capturing groups of regular expression matching as fields. The special group zero is ignored because it stands for the entire input line.This property is the same as the
input.regexproperty oforg.apache.hadoop.hive.contrib.serde2.RegexSerDe.See Also:
For descriptions of regular expressions and capturing groups, the entry forjava.util.regexin the Java Platform Standard Edition 6 API Specification athttp://docs.oracle.com/javase/6/docs/api/java/util/regex/Pattern.html - oracle.hadoop.loader.input.trailingFieldEncloser
-
Type: String
Default Value: The value of
oracle.hadoop.loader.input.initialFieldEncloserDescription: Identifies a character that marks the end of a field. The value can be either a single character or
\uHHHH, whereHHHHis the character's UTF-16 encoding. For no trailing encloser, enter a zero-length value.A field encloser cannot be the terminator or a white-space character defined for the input format.
If the trailing field encloser character is embedded in an input field, then the character must be doubled up to be parsed as literal text. For example, an input field must have
''(two single quotes) to load'(one single quote).If you set this property, then you must also set
oracle.hadoop.loader.input.initialFieldEncloser. - oracle.hadoop.loader.loadByPartition
-
Type: Boolean
Default Value:
trueDescription: Specifies a partition-aware load. Oracle Loader for Hadoop organizes the output by partition for all output formats on the Hadoop cluster; this task does not impact the resources of the database system.
DelimitedTextOutputFormatandDataPumpOutputFormatgenerate multiple files, and each file contains the records from one partition. ForDelimitedTextOutputFormat, this property also controls whether thePARTITIONkeyword appears in the generated control files for SQL*Loader.OCIOutputFormatrequires partitioned tables. If you set this property tofalse, thenOCIOutputFormatturns it back on. For the other output formats, you can setloadByPartitiontofalse, so that Oracle Loader for Hadoop handles a partitioned table as if it were unpartitioned. - oracle.hadoop.loader.loaderMap.columnNames
-
Type: String
Default Value: Not defined
Description: A comma-separated list of column names in the target table, in any order. The names can be quoted or unquoted. Quoted names begin and end with double quotes (") and are used exactly as entered. Unquoted names are converted to upper case.
You must set
oracle.hadoop.loader.loaderMap.targetTable, or this property is ignored. You can optionally setoracle.hadoop.loader.loaderMap.column_name.fieldandoracle.hadoop.loader.loaderMap.column_name.format. - oracle.hadoop.loader.loaderMap.column_name.field
-
Type: String
Default Value: Normalized column name
Description: The name of a field that contains Avro records, which is mapped to the column identified in the property name. The column name can be quoted or unquoted. A quoted name begins and ends with double quotes (") and is used exactly as entered. An unquoted name is converted to upper case. Optional.
You must set
oracle.hadoop.loader.loaderMap.columnNames, or this property is ignored. - oracle.hadoop.loader.loaderMap.column_name.format
-
Type: String
Default Value: Not defined
Description: Specifies the data format of the data being loaded into the column identified in the property name. Use a
java.text.SimpleDateformatpattern for a date format or regular expression patterns for text. Optional.You must set
oracle.hadoop.loader.loaderMap.columnNames, or this property is ignored. - oracle.hadoop.loader.loaderMap.targetTable
-
Type: String
Default Value: Not defined
Description: A schema-qualified name for the table to be loaded. This property takes precedence over
oracle.hadoop.loader.loaderMapFile.To load a subset of columns, set the
oracle.hadoop.loader.loaderMap.columnNamesproperty. WithcolumnNames, you can optionally setoracle.hadoop.loader.loaderMap.column_name.fieldto specify the names of the fields that are mapped to the columns, andoracle.hadoop.loader.loaderMap.column_name.formatto specify the format of the data in those fields. If all the columns of a table will be loaded, and the input field names match the database column names, then you do not need to setcolumnNames. - oracle.hadoop.loader.loaderMapFile
-
Loader maps are deprecated in Release 2.3. The
oracle.hadoop.loader.loaderMap.*configuration properties replace loader map files. See "Manual Mapping." - oracle.hadoop.loader.logBadRecords
-
Type: Boolean
Default Value:
falseDescription: Controls whether Oracle Loader for Hadoop logs bad records to a file.
This property applies only to records rejected by input formats and mappers. It does not apply to errors encountered by the output formats or by the sampling feature.
- oracle.hadoop.loader.log4j.propertyPrefix
-
Type: String
Default Value:
log4j.logger.oracle.hadoop.loaderDescription: Identifies the prefix used in Apache
log4jproperties loaded from its configuration file.Oracle Loader for Hadoop enables you to specify
log4jproperties in thehadoopcommand using the-confand-Doptions. For example:-D log4j.logger.oracle.hadoop.loader.OraLoader=DEBUG -D log4j.logger.oracle.hadoop.loader.metadata=INFO
All configuration properties starting with this prefix are loaded into
log4j. They override the settings for the same properties thatlog4jloaded from${log4j.configuration}. The overrides apply to the Oracle Loader for Hadoop job driver, and its map and reduce tasks.The configuration properties are copied to
log4jwithRAWvalues; any variable expansion is done forlog4j. Any configuration variables to be used in the expansion must also start with this prefix. - oracle.hadoop.loader.olh_home
-
Type: String
Default Value: Value of the
OLH_HOMEenvironment variableDescription: The path of the Oracle Loader for Hadoop home directory on the node where you start the OraLoader job. This path identifies the location of the required libraries.
- oracle.hadoop.loader.olhcachePath
-
Type: String
Default Value:
${mapred.output.dir}/../olhcacheDescription: Identifies the full path to an HDFS directory where Oracle Loader for Hadoop can create files that are loaded into the MapReduce distributed cache.
The distributed cache is a facility for caching large, application-specific files and distributing them efficiently across the nodes in a cluster.
See Also:
The description oforg.apache.hadoop.filecache.DistributedCachein the Java documentation at - oracle.hadoop.loader.output.dirpathBufsize
-
Type: Integer
Default Value:
131072(128 KB)Description: Sets the size in bytes of the direct path stream buffer for
OCIOutputFormat. Values are rounded up to the next multiple of 8 KB. - oracle.hadoop.loader.output.escapeEnclosers
-
Type: Boolean
Default Value:
falseDescription: Controls whether the embedded trailing encloser character is handled as literal text (that is, escaped). Set this property to
truewhen a field may contain the trailing enclosure character as part of the data value. Seeoracle.hadoop.loader.output.trailingFieldEncloser. - oracle.hadoop.loader.output.fieldTerminator
-
Type: String
Default Value:
,(comma)Description: A character that indicates the end of an output field for
DelimitedTextInputFormat. The value can be either a single character or\uHHHH, whereHHHHis the character's UTF-16 encoding. - oracle.hadoop.loader.output.granuleSize
-
Type: Integer
Default Value:
10240000Description: The granule size in bytes for generated Data Pump files.
A granule determines the work load for a parallel process (PQ slave) when loading a file through the
ORACLE_DATAPUMPaccess driver. - oracle.hadoop.loader.output.initialFieldEncloser
-
Type: String
Default Value: Not defined
Description: A character generated in the output to identify the beginning of a field. The value must be either a single character or
\uHHHH, whereHHHHis the character's UTF-16 encoding. A zero-length value means that no enclosers are generated in the output (default value).Use this property when a field may contain the value of
oracle.hadoop.loader.output.fieldTerminator. If a field may also contain the value oforacle.hadoop.loader.output.trailingFieldEncloser, then setoracle.hadoop.loader.output.escapeEncloserstotrue.If you set this property, then you must also set
oracle.hadoop.loader.output.trailingFieldEncloser. - oracle.hadoop.loader.output.trailingFieldEncloser
-
Type: String
Default Value: Value of
oracle.hadoop.loader.output.initialFieldEncloserDescription: A character generated in the output to identify the end of a field. The value must be either a single character or
\uHHHH, whereHHHHis the character's UTF-16 encoding. A zero-length value means that there are no enclosers (default value).Use this property when a field may contain the value of
oracle.hadoop.loader.output.fieldTerminator. If a field may also contain the value oforacle.hadoop.loader.output.trailingFieldEncloser, then setoracle.hadoop.loader.output.escapeEncloserstotrue.If you set this property, then you must also set
oracle.hadoop.loader.output.initialFieldEncloser. - oracle.hadoop.loader.rejectLimit
-
Type: Integer
Default Value:
1000Description: The maximum number of rejected or skipped records allowed before the job stops running. A negative value turns off the reject limit and allows the job to run to completion.
If
mapred.map.tasks.speculative.executionistrue(the default), then the number of rejected records may be inflated temporarily, causing the job to stop prematurely.Input format errors do not count toward the reject limit because they are irrecoverable and cause the map task to stop. Errors encountered by the sampling feature or the online output formats do not count toward the reject limit either.
- oracle.hadoop.loader.sampler.enableSampling
-
Type: Boolean
Default Value:
trueDescription: Controls whether the sampling feature is enabled. Set this property to
falseto disable sampling.Even when
enableSamplingis set totrue, the loader automatically disables sampling if it is unnecessary, or if the loader determines that a good sample cannot be made. For example, the loader disables sampling if the table is not partitioned, the number of reducer tasks is less than two, or there is too little input data to compute a good load balance. In these cases, the loader returns an informational message. - oracle.hadoop.loader.sampler.hintMaxSplitSize
-
Type: Integer
Default Value:
1048576(1 MB)Description: Sets the Hadoop
mapred.max.split.sizeproperty for the sampling process; the value ofmapred.max.split.sizedoes not change for the job configuration. A value less than1is ignored.Some input formats (such as
FileInputFormat) use this property as a hint to determine the number of splits returned bygetSplits. Smaller values imply that more chunks of data are sampled at random, which results in a better sample.Increase this value for data sets with tens of terabytes of data, or if the input format
getSplitsmethod throws an out-of-memory error.Although large splits are better for I/O performance, they are not necessarily better for sampling. Set this value small enough for good sampling performance, but no smaller. Extremely small values can cause inefficient I/O performance, and can cause
getSplitsto run out of memory by returning too many splits.The
org.apache.hadoop.mapreduce.lib.input.FileInputFormatmethod always returns splits at least as large as the minimum split size setting, regardless of the value of this property. - oracle.hadoop.loader.sampler.hintNumMapTasks
-
Type: Integer
Default Value:
100Description: Sets the value of the Hadoop
mapred.map.tasksconfiguration property for the sampling process; the value ofmapred.map.tasksdoes not change for the job configuration. A value less than1is ignored.Some input formats (such as
DBInputFormat) use this property as a hint to determine the number of splits returned by thegetSplitsmethod. Higher values imply that more chunks of data are sampled at random, which results in a better sample.Increase this value for data sets with more than a million rows, but remember that extremely large values can cause
getSplitsto run out of memory by returning too many splits. - oracle.hadoop.loader.sampler.loadCI
-
Type: Decimal
Default Value:
0.95Description: The statistical confidence indicator for the maximum reducer load factor.
This property accepts values greater than or equal to
0.5and less than1(0.5 <=value< 1). A value less than0.5resets the property to the default value. Typical values are0.90,0.95, and0.99. - oracle.hadoop.loader.sampler.maxHeapBytes
-
Type: Integer
Default Value:
-1Description: Specifies in bytes the maximum amount of memory available to the sampler.
Sampling stops when one of these conditions is true:
-
The sampler has collected the minimum number of samples required for load balancing.
-
The percent of sampled data exceeds
oracle.hadoop.loader.sampler.maxSamplesPct. -
The number of sampled bytes exceeds
oracle.hadoop.loader.sampler.maxHeapBytes. This condition is not imposed when the property is set to a negative value.
-
- oracle.hadoop.loader.sampler.maxLoadFactor
-
Type: Float
Default Value:
0.05(5%)Description: The maximum acceptable load factor for a reducer. A value of
0.05indicates that reducers can be assigned up to 5% more data than their ideal load.This property accepts values greater than
0. A value less than or equal to 0 resets the property to the default value. Typical values are0.05and0.1.In a perfectly balanced load, every reducer is assigned an equal amount of work (or load). The load factor is the relative overload for each reducer, calculated as (assigned_load - ideal_load)/ideal_load. If load balancing is successful, the job runs within the maximum load factor at the specified confidence.
- oracle.hadoop.loader.sampler.maxSamplesPct
-
Type: Float
Default Value:
0.01(1%)Description: Sets the maximum sample size as a fraction of the number of records in the input data. A value of
0.05indicates that the sampler never samples more than 5% of the total number of records.This property accepts a range of 0 to 1 (0% to 100%). A negative value disables it.
Sampling stops when one of these conditions is true:
-
The sampler has collected the minimum number of samples required for load balancing, which can be fewer than the number set by this property.
-
The percent of sampled data exceeds
oracle.hadoop.loader.sampler.maxSamplesPct. -
The number of sampled bytes exceeds
oracle.hadoop.loader.sampler.maxHeapBytes. This condition is not imposed when the property is set to a negative value.
-
- oracle.hadoop.loader.sampler.minSplits
-
Type: Integer
Default Value:
5Description: The minimum number of input splits that the sampler reads from before it makes any evaluation of the stopping condition. If the total number of input splits is less than
minSplits, then the sampler reads from all the input splits.A number less than or equal to
0is the same as a value of1. - oracle.hadoop.loader.sampler.numThreads
-
Type: Integer
Default Value:
5Description: The number of sampler threads. A higher number of threads allows higher concurrency in sampling. A value of
1disables multithreading for the sampler.Set the value based on the processor and memory resources available on the node where you start the Oracle Loader for Hadoop job.
- oracle.hadoop.loader.sortKey
-
Type: String
Default Value: Not defined
Description: A comma-delimited list of column names that forms a key for sorting output records within a reducer group.
The column names can be quoted or unquoted identifiers:
-
A quoted identifier begins and ends with double quotation marks (
"). -
An unquoted identifier is converted to uppercase before use.
-
- oracle.hadoop.loader.tableMetadataFile
-
Type: String
Default Value: Not defined
Description: Path to the target table metadata file. Set this property when running in offline database mode.
Use the
file://syntax to specify a local file, for example:file:///home/jdoe/metadata.xml
To create the table metadata file, run the
OraLoaderMetadatautility. See "OraLoaderMetadata Utility." - oracle.hadoop.loader.targetTable
-
Deprecated. Use
oracle.hadoop.loader.loaderMap.targetTable.
Oracle NoSQL Database Configuration Properties
- oracle.kv.kvstore
-
Type: String
Default Value: Not defined
Description: The name of the KV store with the source data.
- oracle.kv.hosts
-
Type: String
Default Value: Not defined
Description: An array of one or more hostname:port pairs that identify the hosts in the KV store with the source data. Separate multiple pairs with commas.
- oracle.kv.batchSize
-
Type: Key
Default Value: Not defined
Description: The desired number of keys for
KVAvroInputFormatto fetch during each network round trip. A value of zero (0) sets the property to a default value. - oracle.kv.parentKey
-
Type: String
Default Value: Not defined
Description: Restricts the returned values to only the child key-value pairs of the specified key. A major key path must be a partial path, and a minor key path must be empty. A null value (the default) does not restrict the output, and so
KVAvroInputFormatreturns all keys in the store. - oracle.kv.subRange
-
Type: KeyRange
Default Value: Not defined
Description: Further restricts the returned values to a particular child under the parent key specified by
oracle.kv.parentKey. - oracle.kv.depth
-
Type: Depth
Default Value:
PARENT_AND_DESCENDENTSDescription: Restricts the returned values to a particular hierarchical depth under the value of
oracle.kv.parentKey. The following keywords are valid values:-
CHILDREN_ONLY: Returns the children, but not the specified parent. -
DESCENDANTS_ONLY: Returns all descendants, but not the specified parent. -
PARENT_AND_CHILDREN: Returns the children and the parent. -
PARENT_AND_DESCENDANTS: Returns all descendants and the parent.
-
- oracle.kv.consistency
-
Type: Consistency
Default Value:
NONE_REQUIREDDescription: The consistency guarantee for reading child key-value pairs. The following keywords are valid values:
-
ABSOLUTE: Requires the master to service the transaction so that consistency is absolute. -
NONE_REQUIRED: Allows replicas to service the transaction, regardless of the state of the replicas relative to the master.
-
- oracle.kv.timeout
-
Type: Long
Default Value:
Description: Sets a maximum time interval in milliseconds for retrieving a selection of key-value pairs. A value of zero (0) sets the property to its default value.
- oracle.kv.formatterClass
-
Type: String
Default Value: Not defined
Description: Specifies the name of a class that implements the
AvroFormatterinterface to formatKeyValueVersioninstances into AvroIndexedRecordstrings.Because the Avro records from Oracle NoSQL Database pass directly to Oracle Loader for Hadoop, the NoSQL keys are not available for mapping into the target Oracle Database table. However, the formatter class receives both the NoSQL key and value, enabling the class to create and return a new Avro record that contains both the value and key, which can be passed to Oracle Loader for Hadoop.
3.15 Third-Party Licenses for Bundled Software
Oracle Loader for Hadoop installs the following third-party products:
-
Apache Avro
-
Apache Commons Mathematics Library
-
Jackson JSON Processor
Oracle Loader for Hadoop includes Oracle 11g Release 2 (11.2) client libraries. For information about third party products included with Oracle Database 11g Release 2 (11.2), refer to Oracle Database Licensing Information.
Unless otherwise specifically noted, or as required under the terms of the third party license (e.g., LGPL), the licenses and statements herein, including all statements regarding Apache-licensed code, are intended as notices only.
3.15.1 Apache Licensed Code
The following is included as a notice in compliance with the terms of the Apache 2.0 License, and applies to all programs licensed under the Apache 2.0 license:
You may not use the identified files except in compliance with the Apache License, Version 2.0 (the "License.")
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
A copy of the license is also reproduced below.
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and limitations under the License.
Version 2.0, January 2004
http://www.apache.org/licenses/
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
-
Definitions
"License" shall mean the terms and conditions for use, reproduction, and distribution as defined by Sections 1 through 9 of this document.
"Licensor" shall mean the copyright owner or entity authorized by the copyright owner that is granting the License.
"Legal Entity" shall mean the union of the acting entity and all other entities that control, are controlled by, or are under common control with that entity. For the purposes of this definition, "control" means (i) the power, direct or indirect, to cause the direction or management of such entity, whether by contract or otherwise, or (ii) ownership of fifty percent (50%) or more of the outstanding shares, or (iii) beneficial ownership of such entity.
"You" (or "Your") shall mean an individual or Legal Entity exercising permissions granted by this License.
"Source" form shall mean the preferred form for making modifications, including but not limited to software source code, documentation source, and configuration files.
"Object" form shall mean any form resulting from mechanical transformation or translation of a Source form, including but not limited to compiled object code, generated documentation, and conversions to other media types.
"Work" shall mean the work of authorship, whether in Source or Object form, made available under the License, as indicated by a copyright notice that is included in or attached to the work (an example is provided in the Appendix below).
"Derivative Works" shall mean any work, whether in Source or Object form, that is based on (or derived from) the Work and for which the editorial revisions, annotations, elaborations, or other modifications represent, as a whole, an original work of authorship. For the purposes of this License, Derivative Works shall not include works that remain separable from, or merely link (or bind by name) to the interfaces of, the Work and Derivative Works thereof.
"Contribution" shall mean any work of authorship, including the original version of the Work and any modifications or additions to that Work or Derivative Works thereof, that is intentionally submitted to Licensor for inclusion in the Work by the copyright owner or by an individual or Legal Entity authorized to submit on behalf of the copyright owner. For the purposes of this definition, "submitted" means any form of electronic, verbal, or written communication sent to the Licensor or its representatives, including but not limited to communication on electronic mailing lists, source code control systems, and issue tracking systems that are managed by, or on behalf of, the Licensor for the purpose of discussing and improving the Work, but excluding communication that is conspicuously marked or otherwise designated in writing by the copyright owner as "Not a Contribution."
"Contributor" shall mean Licensor and any individual or Legal Entity on behalf of whom a Contribution has been received by Licensor and subsequently incorporated within the Work.
-
Grant of Copyright License. Subject to the terms and conditions of this License, each Contributor hereby grants to You a perpetual, worldwide, non-exclusive, no-charge, royalty-free, irrevocable copyright license to reproduce, prepare Derivative Works of, publicly display, publicly perform, sublicense, and distribute the Work and such Derivative Works in Source or Object form.
-
Grant of Patent License. Subject to the terms and conditions of this License, each Contributor hereby grants to You a perpetual, worldwide, non-exclusive, no-charge, royalty-free, irrevocable (except as stated in this section) patent license to make, have made, use, offer to sell, sell, import, and otherwise transfer the Work, where such license applies only to those patent claims licensable by such Contributor that are necessarily infringed by their Contribution(s) alone or by combination of their Contribution(s) with the Work to which such Contribution(s) was submitted. If You institute patent litigation against any entity (including a cross-claim or counterclaim in a lawsuit) alleging that the Work or a Contribution incorporated within the Work constitutes direct or contributory patent infringement, then any patent licenses granted to You under this License for that Work shall terminate as of the date such litigation is filed.
-
Redistribution. You may reproduce and distribute copies of the Work or Derivative Works thereof in any medium, with or without modifications, and in Source or Object form, provided that you meet the following conditions:
-
You must give any other recipients of the Work or Derivative Works a copy of this License; and
-
You must cause any modified files to carry prominent notices stating that You changed the files; and
-
You must retain, in the Source form of any Derivative Works that You distribute, all copyright, patent, trademark, and attribution notices from the Source form of the Work, excluding those notices that do not pertain to any part of the Derivative Works; and
-
If the Work includes a "NOTICE" text file as part of its distribution, then any Derivative Works that You distribute must include a readable copy of the attribution notices contained within such NOTICE file, excluding those notices that do not pertain to any part of the Derivative Works, in at least one of the following places: within a NOTICE text file distributed as part of the Derivative Works; within the Source form or documentation, if provided along with the Derivative Works; or, within a display generated by the Derivative Works, if and wherever such third-party notices normally appear. The contents of the NOTICE file are for informational purposes only and do not modify the License. You may add Your own attribution notices within Derivative Works that You distribute, alongside or as an addendum to the NOTICE text from the Work, provided that such additional attribution notices cannot be construed as modifying the License.
You may add Your own copyright statement to Your modifications and may provide additional or different license terms and conditions for use, reproduction, or distribution of Your modifications, or for any such Derivative Works as a whole, provided Your use, reproduction, and distribution of the Work otherwise complies with the conditions stated in this License.
-
-
Submission of Contributions. Unless You explicitly state otherwise, any Contribution intentionally submitted for inclusion in the Work by You to the Licensor shall be under the terms and conditions of this License, without any additional terms or conditions. Notwithstanding the above, nothing herein shall supersede or modify the terms of any separate license agreement you may have executed with Licensor regarding such Contributions.
-
Trademarks. This License does not grant permission to use the trade names, trademarks, service marks, or product names of the Licensor, except as required for reasonable and customary use in describing the origin of the Work and reproducing the content of the NOTICE file.
-
Disclaimer of Warranty. Unless required by applicable law or agreed to in writing, Licensor provides the Work (and each Contributor provides its Contributions) on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied, including, without limitation, any warranties or conditions of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A PARTICULAR PURPOSE. You are solely responsible for determining the appropriateness of using or redistributing the Work and assume any risks associated with Your exercise of permissions under this License.
-
Limitation of Liability. In no event and under no legal theory, whether in tort (including negligence), contract, or otherwise, unless required by applicable law (such as deliberate and grossly negligent acts) or agreed to in writing, shall any Contributor be liable to You for damages, including any direct, indirect, special, incidental, or consequential damages of any character arising as a result of this License or out of the use or inability to use the Work (including but not limited to damages for loss of goodwill, work stoppage, computer failure or malfunction, or any and all other commercial damages or losses), even if such Contributor has been advised of the possibility of such damages.
-
Accepting Warranty or Additional Liability. While redistributing the Work or Derivative Works thereof, You may choose to offer, and charge a fee for, acceptance of support, warranty, indemnity, or other liability obligations and/or rights consistent with this License. However, in accepting such obligations, You may act only on Your own behalf and on Your sole responsibility, not on behalf of any other Contributor, and only if You agree to indemnify, defend, and hold each Contributor harmless for any liability incurred by, or claims asserted against, such Contributor by reason of your accepting any such warranty or additional liability.
END OF TERMS AND CONDITIONS
APPENDIX: How to apply the Apache License to your work
To apply the Apache License to your work, attach the following boilerplate notice, with the fields enclosed by brackets "[]" replaced with your own identifying information. (Do not include the brackets!) The text should be enclosed in the appropriate comment syntax for the file format. We also recommend that a file or class name and description of purpose be included on the same "printed page" as the copyright notice for easier identification within third-party archives.
Copyright [yyyy] [name of copyright owner]
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License.
This product includes software developed by The Apache Software Foundation (http://www.apache.org/) (listed below):
3.15.2 Apache Avro 1.7.3
Licensed under the Apache License, Version 2.0 (the "License"); you may not use Apache Avro except in compliance with the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License.
3.15.3 Apache Commons Mathematics Library 2.2
Copyright 2001-2011 The Apache Software Foundation
Licensed under the Apache License, Version 2.0 (the "License"); you may not use the Apache Commons Mathematics library except in compliance with the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License.
3.15.4 Jackson JSON 1.8.8
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this library except in compliance with the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License.