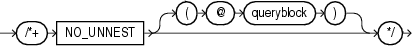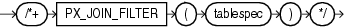| Oracle® Database SQL言語リファレンス 12cリリース1 (12.1) B71278-13 |
|


 前 |
 次 |
次の2種類のコメントを作成できます。
SQL文中のコメントは、SQL文を実行するアプリケーション・コードの一部として格納されます。
個別のスキーマ・オブジェクトまたは非スキーマ・オブジェクトに付けたコメントは、オブジェクト自体のメタデータとともにデータ・ディクショナリに格納されます。
コメントは、アプリケーションを読みやすく、メンテナンスしやすくします。たとえば、文にはアプリケーションでのその文の目的を記述したコメントを含めることができます。SQL文中のコメントは文の実行には影響しませんが、ヒントは例外です。この特殊なコメント形式を使用する場合の詳細は、「ヒント」を参照してください。
コメントは、文中のキーワード、パラメータまたは句読点の間に入れることができます。次のいずれかの方法を使用します。
スラッシュとアスタリスク(/*)を使用してコメントを開始します。コメントのテキストを続けます。このテキストは複数行にまたがってもかまいません。アスタリスクとスラッシュ(*/)を使用してコメントを終了します。開始文字と終了文字は、空白や改行によってテキストから切り離す必要はありません。
--(ハイフン2個)を使用してコメントを開始します。コメントのテキストを続けます。このテキストは複数行にまたがることはできません。改行によってコメントを終了します。
SQLの入力に使用するツール製品には、追加の制限事項があるものもあります。たとえば、SQL*Plusを使用している場合、デフォルトでは複数行のコメント内に空白行を入れることはできません。詳細は、データベースのインタフェースとして使用するツール製品のドキュメントを参照してください。
SQL文の中に両方のスタイルのコメントが複数あってもかまいません。コメントのテキストには、使用しているデータベース・キャラクタ・セットの印字可能文字を含めることができます。
例 次の文には多くのコメントが含まれています。
SELECT last_name, employee_id, salary + NVL(commission_pct, 0),
job_id, e.department_id
/* Select all employees whose compensation is
greater than that of Pataballa.*/
FROM employees e, departments d
/*The DEPARTMENTS table is used to get the department name.*/
WHERE e.department_id = d.department_id
AND salary + NVL(commission_pct,0) > /* Subquery: */
(SELECT salary + NVL(commission_pct,0)
/* total compensation is salary + commission_pct */
FROM employees
WHERE last_name = 'Pataballa')
ORDER BY last_name, employee_id;
SELECT last_name, -- select the name
employee_id -- employee id
salary + NVL(commission_pct, 0), -- total compensation
job_id, -- job
e.department_id -- and department
FROM employees e, -- of all employees
departments d
WHERE e.department_id = d.department_id
AND salary + NVL(commission_pct, 0) > -- whose compensation
-- is greater than
(SELECT salary + NVL(commission_pct,0) -- the compensation
FROM employees
WHERE last_name = 'Pataballa') -- of Pataballa
ORDER BY last_name -- and order by last name
employee_id -- and employee id.
;
COMMENTコマンドを使用して、スキーマ・オブジェクト(表、ビュー、マテリアライズド・ビュー、演算子、索引タイプ、マイニング・モデル)または非スキーマ・オブジェクト(エディション)にCOMMENTコマンドでコメントを付けることができます。表スキーマ・オブジェクトの一部である列にもコメントを作成できます。スキーマ・オブジェクトおよび非スキーマ・オブジェクトに付けたコメントは、データ・ディクショナリに格納されます。このコメントの形式の詳細は、「COMMENT」を参照してください。
ヒントとは、Oracle Databaseのオプティマイザに指示を与えるためにSQL文中に記述するコメントのことです。オプティマイザは、オプティマイザの動作を阻止する条件が存在しないかぎり、これらのヒントを使用して文の実行計画を選択します。
ヒントが導入されたのはOracle7からですが、当時は、オプティマイザによって生成された計画が最善ではない場合にユーザーが取れる手段はほとんどありませんでした。現在では、オプティマイザでは解決されないパフォーマンスの問題の解決に役立つように、OracleはSQLチューニング・アドバイザ、SQL計画管理、SQLパフォーマンス・アナライザをはじめとする多数のツールを提供しています。ヒントではなく、これらのツールを使用することをお薦めします。これらのツールはヒントに比べてはるかに優れていますが、その理由は、これらのツールを継続的に使用すれば、データやデータベース環境の変化に合せた最新の解決策が得られるからです。
ヒントの多用は避けるとともに、使用する場合は必ず事前に、関係する表の統計情報を収集して、ヒントなしのオプティマイザ計画をEXPLAIN PLAN文を使用して評価してください。データベースの状態の変化や以降のリリースにおける問合せパフォーマンスの向上によって、コード内のヒントがパフォーマンスに及ぼす影響が大きく変化することもあります。
この後は、使用頻度の高い一部のヒントについて説明します。他の高度なチューニング・ツールではなくヒントを使用する場合は、ヒントの使用によって短期的な効果が得られても、長期にわたるパフォーマンスの向上にはつながらない場合があることに注意してください。
ヒントの使用方法
文ブロックには、ヒントを含むコメントは1つのみ指定できます。このコメントは、SELECT、UPDATE、INSERT、MERGEまたはDELETEのいずれかのキーワードの後でのみ指定できます。
次の構文図は、Oracleが文ブロック内でサポートする両方のスタイルのコメントに含まれるヒントの構文です。ヒント構文は、文ブロックを開始するINSERT、UPDATE、DELETE、SELECTまたはMERGEのいずれかのキーワードの直後でのみ指定できます。
hint::=
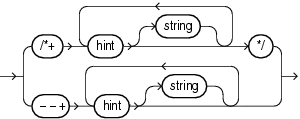
それぞれの意味は、次のとおりです。
+(プラス記号)は、コメントをヒントのリストとして、Oracleに解析させます。プラス記号は、コメント・デリミタの直後に置く必要があります。空白を入れてはいけません。
hintは、この項で説明するヒントの1つです。プラス記号とヒントの間の空白は入れても入れなくてもかまいません。コメントに複数のヒントが含まれている場合は、1つ以上の空白で区切る必要があります。
stringは、ヒントに含めることができるその他のコメント・テキストです。
--+構文では、コメント全体を単一行で指定する必要があります。
Oracle Databaseは、次の状況ではヒントを無視し、エラーを戻しません。
ヒントにスペルの誤りまたは構文エラーがある場合。ただし、データベースは、同一コメント内に正しく指定された他のヒントがある場合はそれを採用します。
ヒントを含むコメントが、DELETE、INSERT、MERGE、SELECTまたはUPDATEのいずれかのキーワードの後で指定していない場合。
ヒントの組合せが互いに競合している場合。ただし、データベースは、同一コメント内に他のヒントがあればそれを採用します。
データベース環境が、Formsバージョン3トリガー、Oracle Forms 4.5、Oracle Reports 2.5など、PL/SQLバージョン1を使用している場合。
1つのグローバル・ヒントが複数の問合せブロックを参照している場合。詳細は、「1つのグローバル・ヒントでの複数問合せブロックの指定」を参照してください。
多くのヒントでオプションの問合せブロック名を指定して、ヒントが適用される問合せブロックを指定できます。この構文によって、インライン・ビューに適用されるヒントを外部問合せ内で指定できます。
問合せブロックの引数の構文は、@queryblockの形式になります。ここでqueryblockは問合せ内の問合せブロックを指定する識別子です。queryblock識別子は、システムで生成されたものでも、ユーザーが指定したものでもかまいません。ヒントを、そのヒントが適用される問合せブロック自体の中で指定するときは、@queryblock構文を省略してください。
システム生成の識別子は、問合せに対するEXPLAIN PLAN文を使用して取得できます。変換前の問合せブロック名は、NO_QUERY_TRANSFORMATIONヒントを使用している問合せに対してEXPLAIN PLANを実行することで調べることができます。「NO_QUERY_TRANSFORMATIONヒント」を参照してください。
ユーザー指定の名前はQB_NAMEヒントで指定できます。「QB_NAMEヒント」を参照してください。
グローバル・ヒントの指定
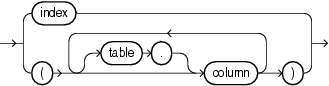
多くのヒントは、特定の表や索引に適用することも、ビュー内の表や、索引の一部である列によりグローバルに適用することもできます。このようなグローバル・ヒントは、構文要素tablespecおよびindexspecによって定義します。
tablespec::=
アクセスする表は、文で示されるとおり正確に指定する必要があります。文が表の別名を使用している場合は、ヒントでも表名を使用せずに別名を使用します。ただし、文でスキーマ名を指定している場合でも、ヒント内ではスキーマ名を表名に含めないでください。
|
注意: 解析時にオプティマイザが追加のビューを生成するため、tablespec句を使用したグローバル・ヒントの指定は、ANSI結合を使用する問合せに対しては無効です。かわりに、@queryblockを指定してヒントが適用される問合せブロックを指定してください。 |
indexspec::=
ヒントの指定の中で、tablespecの後にindexspecがある場合は、表名と索引名を区切るカンマを使用できますが、このカンマは必須ではありません。indexspecが複数回出現するときも、区切るためのカンマを使用できますが、必須ではありません。
1つのグローバル・ヒントでの複数問合せブロックの指定 Oracle Databaseは、複数問合せブロックを参照するグローバル・ヒントは無視します。この問題を回避するために、ヒントの中ではtablespecとindexspecを使用するかわりにオブジェクト別名を指定することをお薦めします。
たとえば、次のビューvと表tがあるとします。
CREATE VIEW v AS SELECT e.last_name, e.department_id, d.location_id FROM employees e, departments d WHERE e.department_id = d.department_id; CREATE TABLE t AS SELECT * from employees WHERE employee_id < 200;
|
注意: 次に示す例ではEXPLAIN PLAN文が使用されており、これによって実行計画が表示されるので、ヒントが遵守されているか無視されているかがわかります。詳細は、「EXPLAIN PLAN」を参照してください。 |
次の問合せのLEADINGヒントは無視されますが、これは複数の問合せブロック(表tが含まれるメイン問合せブロックと、ビュー問合せブロックv)を参照しているためです。
EXPLAIN PLAN
SET STATEMENT_ID = 'Test 1'
INTO plan_table FOR
(SELECT /*+ LEADING(v.e v.d t) */ *
FROM t, v
WHERE t.department_id = v.department_id);
次のSELECT文を実行すると実行計画が戻され、これを見るとLEADINGヒントが無視されたことがわかります。
SELECT id, LPAD(' ',2*(LEVEL-1))||operation operation, options, object_name, object_alias
FROM plan_table
START WITH id = 0 AND statement_id = 'Test 1'
CONNECT BY PRIOR id = parent_id AND statement_id = 'Test 1'
ORDER BY id;
ID OPERATION OPTIONS OBJECT_NAME OBJECT_ALIAS
--- -------------------- ---------- ------------- --------------------
0 SELECT STATEMENT
1 HASH JOIN
2 HASH JOIN
3 TABLE ACCESS FULL DEPARTMENTS D@SEL$2
4 TABLE ACCESS FULL EMPLOYEES E@SEL$2
5 TABLE ACCESS FULL T T@SEL$1
次の問合せのLEADINGヒントは遵守されますが、これはオブジェクト別名を参照しているからであり、このことは前の問合せで戻された実行計画に現れています。
EXPLAIN PLAN
SET STATEMENT_ID = 'Test 2'
INTO plan_table FOR
(SELECT /*+ LEADING(E@SEL$2 D@SEL$2 T@SEL$1) */ *
FROM t, v
WHERE t.department_id = v.department_id);
次のSELECT文から戻される実行計画は、LEADINGヒントが遵守されたことを示しています。
SELECT id, LPAD(' ',2*(LEVEL-1))||operation operation, options,
object_name, object_alias
FROM plan_table
START WITH id = 0 AND statement_id = 'Test 2'
CONNECT BY PRIOR id = parent_id AND statement_id = 'Test 2'
ORDER BY id;
ID OPERATION OPTIONS OBJECT_NAME OBJECT_ALIAS
--- -------------------- ---------- ------------- --------------------
0 SELECT STATEMENT
1 HASH JOIN
2 HASH JOIN
3 TABLE ACCESS FULL EMPLOYEES E@SEL$2
4 TABLE ACCESS FULL DEPARTMENTS D@SEL$2
5 TABLE ACCESS FULL T T@SEL$1
|
関連項目: EXPLAIN PLANを使用してオプティマイザが問合せをどのように実行しているかを知る方法の詳細は、『Oracle Database SQLチューニング・ガイド』を参照してください。 |
機能のカテゴリに分類したヒント
表2-21に、機能のカテゴリに分類したヒントと、各ヒントの構文とセマンティクスの参照先を示します。表の後には、ヒントをアルファベット順に説明します。
表2-21 機能のカテゴリに分類したヒント
| ヒント | 構文とセマンティクスの参照先 |
|---|---|
|
最適化目標と方法 |
|
|
アクセス・パスのヒント |
|
|
-- |
|
|
-- |
|
|
-- |
|
|
-- |
|
|
-- |
|
|
-- |
|
|
-- |
|
|
-- |
|
|
-- |
|
|
-- |
|
|
-- |
|
|
-- |
|
|
-- |
|
|
-- |
|
|
-- |
|
|
インメモリー列ストアヒント |
|
|
-- |
|
|
結合順序のヒント |
|
|
-- |
|
|
結合操作のヒント |
|
|
-- |
|
|
-- |
|
|
-- |
|
|
パラレル実行のヒント |
|
|
-- |
|
|
-- |
|
|
-- |
|
|
-- |
|
|
-- |
|
|
-- |
|
|
オンライン・アプリケーション・アップグレードのヒント |
|
|
-- |
|
|
-- |
|
|
問合せ変換のヒント |
|
|
-- |
|
|
-- |
|
|
-- |
|
|
-- |
|
|
-- |
|
|
-- |
|
|
XMLのヒント |
|
|
-- |
|
|
その他のヒント |
|
|
-- |
|
|
-- |
|
|
-- |
|
|
-- |
|
|
-- |
GATHER_OPTIMIZER_STATISTICSヒント NO_GATHER_OPTIMIZER_STATISTICSヒント |
|
-- |
|
|
-- |
|
|
-- |
|
|
-- |
|
|
-- |
|
|
-- |
|
|
-- |
|
|
-- |
|
|
-- |
|
この項では、すべてのヒントの構文とセマンティクスをアルファベット順に説明します。

ALL_ROWSヒントは、文ブロックが最高のスループットになるよう(リソースの消費が最小になるよう)、オプティマイザに最適化の指示をします。たとえば、オプティマイザは問合せの最適化アプローチを使用して、この文を最高のスループットに最適化します。
SELECT /*+ ALL_ROWS */ employee_id, last_name, salary, job_id FROM employees WHERE employee_id = 107;
ALL_ROWSまたはFIRST_ROWSヒントのいずれかをSQL文で指定する場合に、この文でアクセスする表の統計情報がデータ・ディクショナリにないと、オプティマイザは該当する表に割り当てられている記憶域など、デフォルトの統計値を使用して欠落している統計値を推定し、実行計画を選択します。このような推定値は、DBMS_STATSパッケージで収集した値ほど正確でない場合があるため、統計情報の収集にはDBMS_STATSパッケージを使用する必要があります。
アクセス・パスまたは結合操作のヒントをALL_ROWSまたはFIRST_ROWSヒントとともに指定する場合、オプティマイザでは、ヒントで指定されたアクセス・パスまたは結合操作が優先されます。

APPENDヒントは、INSERT文の副問合せ構文とともにダイレクト・パスINSERT文を使用するようオプティマイザに指示します。
従来型のINSERTはシリアル・モードでのデフォルトです。シリアル・モードでは、ダイレクト・パスはAPPENDヒントを指定する場合にのみ使用できます。
ダイレクト・パスINSERTはパラレル・モードでのデフォルトです。パラレル・モードでは、従来型INSERTはNOAPPENDヒントを指定する場合にのみ使用できます。
INSERTをパラレルにするかどうかの決定は、APPENDヒントとは関係ありません。
ダイレクト・パスINSERTでは、データは現在表に割り当てられている既存の空き領域を使用せず、表の最後に追加されます。その結果、ダイレクト・パスINSERTは、従来型INSERTよりも高速に処理されます。
APPENDヒントは、INSERT文の副問合せ構文でのみサポートされています。VALUES句ではサポートされていません。APPENDヒントをVALUES句とともに指定した場合、ヒントは無視され、従来型INSERTが使用されます。VALUES句とともにダイレクト・パスINSERTを使用する方法については、「APPEND_VALUESヒント」.を参照してください。

APPEND_VALUESヒントは、VALUES句とともにダイレクト・パスINSERTを使用するようオプティマイザに指示します。このヒントを指定しない場合、従来型INSERTが使用されます。
ダイレクト・パスINSERTでは、データは現在表に割り当てられている既存の空き領域を使用せず、表の最後に追加されます。その結果、ダイレクト・パスINSERTは、従来型INSERTよりも高速に処理されます。
APPEND_VALUESヒントを使用すると、パフォーマンスを大幅に向上できます。次に使用方法の例を示します。
Oracle Call Interface(OCI)を使用するプログラムで、大規模な配列バインドまたは行コールバックを伴う配列バインドを使用する場合
PL/SQLで、VALUES句とともにINSERT文を使用するFORALLループを伴う多くの行をロードする場合
APPEND_VALUESヒントは、INSERT文のVALUES句でのみサポートされています。APPEND_VALUESヒントをINSERT文の副問合せ構文とともに指定した場合、ヒントは無視され、従来型INSERTが使用されます。副問合せとともにダイレクト・パスINSERTを使用する方法については、「APPENDヒント」を参照してください。
|
関連項目: ダイレクト・パス・インサートの詳細は、『Oracle Database管理者ガイド』を参照してください。 |
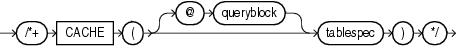
(「ヒントでの問合せブロックの指定」、tablespec::=を参照)
CACHEヒントは、全表スキャンの実行時に、この表に対して取り出されたブロックを、バッファ・キャッシュ内のLRUリストの最高使用頻度側に入れるようオプティマイザに指定します。このヒントは、小規模な参照表で有効です。
次の例では、CACHEヒントが表のデフォルト・キャッシュ仕様を上書きします。
SELECT /*+ FULL (hr_emp) CACHE(hr_emp) */ last_name FROM employees hr_emp;
CACHEおよびNOCACHEヒントは、V$SYSSTATデータ・ディクショナリ・ビューで示すように、システム統計情報table scans (long tables)およびtable scans (short tables)に影響を与えます。

|
注意: CHANGE_DUPKEY_ERROR_INDEXヒント、IGNORE_ROW_ON_DUPKEY_INDEXヒントおよびRETRY_ON_ROW_CHANGEヒントは、セマンティクスに影響を与えるという点で他のヒントとは異なります。これら3つのヒントには、「ヒント」で説明されている一般的な原則は当てはまりません。 |
CHANGE_DUPKEY_ERROR_INDEXヒントは、指定した列セットまたは指定した索引に対する一意キー違反を明確に識別するメカニズムを提供します。指定した索引に対して一意キー違反が発生すると、ORA-001のかわりにORA-38911エラーが報告されます。
このヒントは、INSERT操作およびUPDATE操作に適用されます。索引を指定する場合は、その索引が存在するとともに一意であることが必要です。索引のかわりに列リストを指定する場合は、列の数と順序が列リストのものと一致する一意索引が存在する必要があります。
特定の規則に違反した場合、このヒントの使用によってエラー・メッセージが戻されます。詳細は、「IGNORE_ROW_ON_DUPKEY_INDEXヒント」を参照してください。
|
注意: このヒントを使用すると、APPENDモードおよびパラレルDMLの両方が無効になります。 |
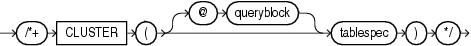
(「ヒントでの問合せブロックの指定」、tablespec::=を参照)
CLUSTERヒントは、クラスタ・スキャンを使用して、指定した表にアクセスするようオプティマイザに指示します。このヒントは、索引クラスタ内の表にのみ適用されます。
|
注意: CLUSTERINGヒントは、Oracle Database 12cリリース1(12.1.0.2)から使用可能です。 |

このヒントは、属性クラスタリングに対して有効な表のINSERTおよびMERGE操作にのみ有効です。CLUSTERINGヒントは、ダイレクト・パス・インサート(シリアルまたはパラレル)の属性クラスタリングを有効化します。これにより、部分的にクラスタリングされるデータになります。つまり、挿入またはマージ操作ごとにデータがクラスタリングされます。このヒントは、表を作成または変更したDDLのNO ON LOAD設定をオーバーライドします。このヒントは、属性クラスタリングに有効化されていない表には影響しません。

Oracleでは、置換しても安全な場合には、SQL文内のリテラルをバインド変数に置き換えることができます。この置換処理は、CURSOR_SHARING初期化パラメータを使用して制御します。CURSOR_SHARING_EXACTヒントは、この動作を行わないようオプティマイザに指示します。このヒントを指定すると、Oracleは、リテラルのバインド変数への置換を試行せずにSQL文を実行します。

DISABLE_PARALLEL_DMLヒントは、DELETE、INSERT、MERGEおよびUPDATE文のパラレルDMLを無効化します。ALTER SESSION ENABLE PARALLEL DML文を使用したセッションでパラレルDMLが有効化されている場合、このヒントを使用して、個別の文のパラレルDMLを無効化できます。
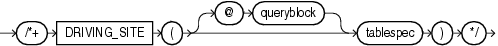
(「ヒントでの問合せブロックの指定」、tablespec::=を参照)
DRIVING_SITEヒントは、データベースによって選択されたサイトとは異なるサイトで問合せを実行するようオプティマイザに指示します。このヒントは、分散化された問合せの最適化を使用している場合に有効です。
次に例を示します。
SELECT /*+ DRIVING_SITE(departments) */ * FROM employees, departments@rsite WHERE employees.department_id = departments.department_id;
この問合せがヒントなしで実行されている場合、departmentsからの行がローカル・サイトに送信され、そこで結合が実行されます。このヒントを使用している場合、employeesからの行がリモート・サイトに送信され、そこで問合せが実行されて結果セットがローカル・サイトに戻されます。

(「ヒントでの問合せブロックの指定」、tablespec::=を参照)
DYNAMIC_SAMPLINGヒントは、動的なサンプリングを制御する方法をオプティマイザに指示し、より正確な述語の選択性と表および索引に対する統計情報を調べることでサーバーのパフォーマンスを改善します。
DYNAMIC_SAMPLINGの値は、0から10の範囲で設定できます。このレベルが高いほど、コンパイラは多くのリソースを動的なサンプリングに費やし、その適用範囲も広がります。tablespecを指定しない場合、サンプリングのデフォルトは、カーソルのレベルになります。
integerの値は0から10となり、サンプリングの度合いを示します。
カーディナリティ統計情報が表にすでに存在する場合、オプティマイザはその情報を使用します。存在しない場合、オプティマイザは動的なサンプリングによってカーディナリティ統計情報を推定します。
tablespecを指定しており、カーディナリティ統計情報がすでに存在している場合は、次のようになります。
単一表述語(1つの表のみを評価するWHERE句)がない場合、オプティマイザは既存の統計情報を信頼し、このヒントを無視します。たとえば、employeesが分析される場合、次の問合せは動的なサンプリングにはなりません。
SELECT /*+ DYNAMIC_SAMPLING(e 1) */ count(*) FROM employees e;
単一表述語がある場合、オプティマイザは既存のカーディナリティ統計情報を使用し、この既存の統計情報を使用して述語の選択性を推定します。
動的なサンプリングを特定の表に適用するには、次の形式のヒントを使用します。
SELECT /*+ DYNAMIC_SAMPLING(employees 1) */ * FROM employees WHERE ...
|
関連項目: 動的なサンプリングおよび設定可能なサンプリング・レベルの詳細は、『Oracle Database SQLチューニング・ガイド』を参照してください。 |

ENABLE_PARALLEL_DMLヒントは、DELETE、INSERT、MERGEおよびUPDATE文のパラレルDMLを有効化します。ALTER SESSION ENABLE PARALLEL DML文を使用したセッションでパラレルDMLが有効化されている場合、このヒントを使用して、個別の文のパラレルDMLを有効化できます。
|
関連項目: パラレルDMLの有効化およびパラレルDMLの制限詳細は、『Oracle Database VLDBおよびパーティショニング・ガイド』を参照 |

(「ヒントでの問合せブロックの指定」、tablespec::=を参照)
FACTヒントは、スター型変換のコンテキストで使用されます。これは、tablespecで指定された表をファクト表とみなすようオプティマイザに指示するためのものです。
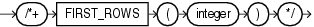
FIRST_ROWSヒントは、最初のn行を最も効率的に戻す計画を選択し、個々のSQL文を最適化して応答時間を速くするようOracleに指示します。integerには、戻される行数を指定します。
たとえば、オプティマイザは問合せの最適化アプローチを使用して、次の文を最善の応答時間に最適化します。
SELECT /*+ FIRST_ROWS(10) */ employee_id, last_name, salary, job_id FROM employees WHERE department_id = 20;
この例では、各部門に多数の従業員がいます。ユーザーは、部門20の最初の10人の従業員を迅速に表示する必要があります。
オプティマイザは、DELETEおよびUPDATEの文ブロック、およびソートまたはグループ化などのブロッキング操作を含むSELECT文ブロックではこのヒントを無視します。Oracle Databaseでは最初の行を戻す前に、この文でアクセスされるすべての行を取り出す必要があるため、このような文は最善の応答時間に最適化することができません。このヒントをこのような文で指定する場合は、データベースを最善のスループットに最適化します。

(「ヒントでの問合せブロックの指定」、tablespec::=を参照)
FULLヒントは、指定した表に対して全表スキャンを実行するようオプティマイザに指示します。次に例を示します。
SELECT /*+ FULL(e) */ employee_id, last_name FROM hr.employees e WHERE last_name LIKE :b1;
Oracle Databaseは、WHERE句内の条件によって使用可能になるlast_name列に索引がある場合でも、employees表に対して全表スキャンを実行し、この文を実行します。
employees表は、FROM句の中に別名eを持つため、ヒントは表名ではなく別名で表を参照する必要があります。スキーマ名がFROM句の中で指定されている場合でも、ヒントではスキーマ名を指定しないでください。

GATHER_OPTIMIZER_STATISTICSヒントは、次のタイプのバルク・ロード操作中に統計収集を有効にするようオプティマイザに指示します。
CREATE TABLE ... AS SELECT
ダイレクト・パス・インサートを使用した、空の表へのINSERT INTO ... SELECT
|
関連項目: バルク・ロードに関する統計収集の詳細は、『Oracle Database SQLチューニング・ガイド』を参照してください。 |
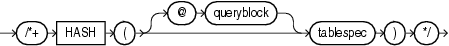
(「ヒントでの問合せブロックの指定」、tablespec::=を参照)
HASHヒントは、ハッシュ・スキャンを使用して、指定した表にアクセスするようオプティマイザに指示します。このヒントは、ハッシュ・クラスタ内の表にのみ適用されます。

|
注意: CHANGE_DUPKEY_ERROR_INDEXヒント、IGNORE_ROW_ON_DUPKEY_INDEXヒントおよびRETRY_ON_ROW_CHANGEヒントは、セマンティクスに影響を与えるという点で他のヒントとは異なります。これら3つのヒントには、「ヒント」で説明されている一般的な原則は当てはまりません。 |
IGNORE_ROW_ON_DUPKEY_INDEXヒントが適用されるのは、単一表INSERT操作のみです。UPDATE、DELETE、MERGEおよびマルチテーブル・インサート操作に対してはサポートされません。IGNORE_ROW_ON_DUPKEY_INDEXを指定すると、その文では、指定の列セットまたは指定の索引に対する一意キー違反が無視されます。一意キー違反が発生したときは、行レベルのロールバックが行われ、実行は次の入力行から再開します。データを挿入するときにこのヒントを指定した場合は、DMLエラー・ロギングが有効になっていても、一意キー違反はログに記録されず、文は終了しません。
特定の規則に違反した場合、このヒントによるセマンティクスへの影響によってエラー・メッセージが戻されます。
索引を指定する場合は、その索引が存在するとともに一意であることが必要です。そうでない場合は、ORA-38913が発生します。
索引は、1つのみ指定する必要があります。索引を指定しなかった場合、ORA-38912が発生します。複数の索引を指定した場合、ORA-38915が発生します。
INSERT文にCHANGE_DUPKEY_ERROR_INDEXまたはIGNORE_ROW_ON_DUPKEY_INDEXのいずれかのヒントを指定できますが、両方を指定することはできません。両方を指定した場合、ORA-38915が発生します。
すべてのヒントと同様に、ヒント内の構文エラーは特に警告もなく無視されます。その結果、ヒントを使用しなかった場合と同じように、ORA-00001が発生します。
|
注意: このヒントを使用すると、APPENDモードおよびパラレルDMLの両方が無効になります。 |

(「ヒントでの問合せブロックの指定」、tablespec::=、indexspec::=を参照)
INDEXヒントは、指定した表について索引スキャンを使用するようオプティマイザに指示します。ファンクション索引、ドメイン索引、Bツリー索引、ビットマップ索引およびビットマップ結合索引について、INDEXヒントを使用できます。
ヒントの動作は、indexspecの仕様によって異なります。
INDEXヒントが使用可能な単一の索引を指定すると、データベースはこの索引でスキャンを実行します。オプティマイザは、全表スキャンおよび表上の別の索引のスキャンを考慮しません。
複数の索引の組合せに対してヒントを指定する場合は、INDEXではなく、より多目的なヒントであるINDEX_COMBINEを使用することをお薦めします。INDEXヒントで索引のリストが指定されている場合は、オプティマイザはこのリスト内の各索引のスキャンのコストを計算してから、コストが最低である索引スキャンを実行します。あるいは、このリストの複数の索引をスキャンしてその結果をマージするというアクセス・パスが選択されることもあります(そのようなアクセス・パスのコストが最低になる場合)。全表スキャンや、ヒントで指定されていない索引のスキャンが検討されることはありません。
INDEXヒントが索引を指定しない場合、オプティマイザは、表にある使用可能な各索引でのスキャンのコストを検討し、最低のコストで索引スキャンを実行します。アクセス・パスのコストが最低となる場合、データベースは複数の索引をスキャンするように選択し、結果をマージすることもあります。オプティマイザは全表スキャンを検討しません。
次に例を示します。
SELECT /*+ INDEX (employees emp_department_ix)*/ employee_id, department_id FROM employees WHERE department_id > 50;
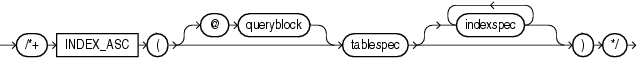
(「ヒントでの問合せブロックの指定」、tablespec::=、indexspec::=を参照)
INDEX_ASCヒントは、指定した表について索引スキャンを使用するようオプティマイザに指示します。文で索引レンジ・スキャンを使用する場合、Oracle Databaseは索引付きの値の昇順で索引エントリをスキャンします。各パラメータは、「INDEXヒント」と同じ目的で使用されます。
レンジ・スキャンのデフォルトの動作は、索引エントリを索引値の昇順で(降順索引の場合は降順で)スキャンするというものです。このヒントを指定しても、索引のデフォルトの順序が変わることはなく、したがってINDEXヒントを指定したのと同じことになります。ただし、INDEX_ASCヒントを使用すると、デフォルトの動作が変更された場合に昇順レンジ・スキャンを明示的に指定できます。

(「ヒントでの問合せブロックの指定」、tablespec::=、indexspec::=を参照)
INDEX_COMBINEヒントは、表へのビットマップ・アクセス・パスを使用するようオプティマイザに指示します。indexspecがINDEX_COMBINEヒントから省略されている場合、オプティマイザは、表のスキャンにかかるコスト効率が最大になる索引のブールの組合せを使用します。indexspecを指定すると、オプティマイザは、指定した索引のブールのいくつかの組合せの使用を試行します。各パラメータは、「INDEXヒント」と同じ目的で使用されます。次に例を示します。
SELECT /*+ INDEX_COMBINE(e emp_manager_ix emp_department_ix) */ *
FROM employees e
WHERE manager_id = 108
OR department_id = 110;

(「ヒントでの問合せブロックの指定」、tablespec::=、indexspec::=を参照)
INDEX_DESCヒントは、指定した表に降順索引スキャンを使用するようオプティマイザに指示します。文で索引レンジ・スキャンを使用しており、索引が昇順の場合、Oracleは索引付きの値の降順で索引エントリをスキャンします。パーティション索引では、結果は各パーティション内で降順になります。降順索引の場合、このヒントは降順を効果的に取り消すため、索引エントリは昇順でスキャンされます。各パラメータは、「INDEXヒント」と同じ目的で使用されます。次に例を示します。
SELECT /*+ INDEX_DESC(e emp_name_ix) */ * FROM employees e;
|
関連項目: 全体スキャンの詳細は、『Oracle Database SQLチューニング・ガイド』を参照してください。 |
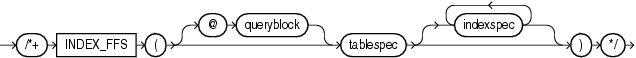
(「ヒントでの問合せブロックの指定」、tablespec::=、indexspec::=を参照)
INDEX_FFSヒントは、全表スキャンではなく高速全索引スキャンを実行するようオプティマイザに指示します。
各パラメータは、「INDEXヒント」と同じ目的で使用されます。次に例を示します。
SELECT /*+ INDEX_FFS(e emp_name_ix) */ first_name FROM employees e;
(「ヒントでの問合せブロックの指定」、tablespec::=、indexspec::=を参照)
INDEX_JOINヒントは、アクセス・パスとして索引結合を使用するようオプティマイザに指示します。ヒントが正しく機能するためには、問合せの解決に必要なすべての列を含む索引が最小限の数だけ存在している必要があります。
各パラメータは、「INDEXヒント」と同じ目的で使用されます。たとえば、次に示す問合せでは索引結合を使用してmanager_id列とdepartment_id列にアクセスしています(どちらの列もemployees表内で索引が付けられています)。
SELECT /*+ INDEX_JOIN(e emp_manager_ix emp_department_ix) */ department_id
FROM employees e
WHERE manager_id < 110
AND department_id < 50;

(「ヒントでの問合せブロックの指定」、tablespec::=、indexspec::=を参照)
INDEX_SSヒントは、指定した表について索引スキップ・スキャンを実行するようオプティマイザに指示します。文で索引レンジ・スキャンを使用する場合、Oracleは索引付きの値の昇順で索引エントリをスキャンします。パーティション索引では、結果は各パーティション内で昇順になります。
各パラメータは、「INDEXヒント」と同じ目的で使用されます。次に例を示します。
SELECT /*+ INDEX_SS(e emp_name_ix) */ last_name FROM employees e WHERE first_name = 'Steven';
|
関連項目: 索引スキップ・スキャンの詳細は、『Oracle Database SQLチューニング・ガイド』を参照してください。 |

(「ヒントでの問合せブロックの指定」、tablespec::=、indexspec::=を参照)
INDEX_SS_ASCヒントは、指定した表について索引スキップ・スキャンを実行するようオプティマイザに指示します。文で索引レンジ・スキャンを使用する場合、Oracle Databaseは索引付きの値の昇順で索引エントリをスキャンします。パーティション索引では、結果は各パーティション内で昇順になります。各パラメータは、「INDEXヒント」と同じ目的で使用されます。
レンジ・スキャンのデフォルトの動作は、索引エントリを索引値の昇順で(降順索引の場合は降順で)スキャンするというものです。このヒントを指定しても、索引のデフォルトの順序が変わることはなく、したがってINDEX_SSヒントを指定したのと同じことになります。ただし、INDEX_SS_ASCヒントを使用すると、デフォルトの動作が変更された場合に昇順レンジ・スキャンを明示的に指定できます。
|
関連項目: 索引スキップ・スキャンの詳細は、『Oracle Database SQLチューニング・ガイド』を参照してください。 |

(「ヒントでの問合せブロックの指定」、tablespec::=、indexspec::=を参照)
INDEX_SS_DESCヒントは、指定した表について索引スキップ・スキャンを実行するようオプティマイザに指示します。文で索引レンジ・スキャンを使用しており、索引が昇順の場合、Oracleは索引付きの値の降順で索引エントリをスキャンします。パーティション索引では、結果は各パーティション内で降順になります。降順索引の場合、このヒントは降順を効果的に取り消すため、索引エントリは昇順でスキャンされます。
各パラメータは、「INDEXヒント」と同じ目的で使用されます。次に例を示します。
SELECT /*+ INDEX_SS_DESC(e emp_name_ix) */ last_name FROM employees e WHERE first_name = 'Steven';
|
関連項目: 索引スキップ・スキャンの詳細は、『Oracle Database SQLチューニング・ガイド』を参照してください。 |
|
注意: INMEMORYヒントは、Oracle Database 12cリリース1(12.1.0.2)から使用可能です。 |
(「ヒントでの問合せブロックの指定」、tablespec::=を参照)
INMEMORYヒントは、インメモリー問合せを有効化します。
このヒントは、オプティマイザに全表スキャンを実行するようには指示しません。全表スキャンが必要な場合は、「FULLヒント」も指定してください。
|
注意: INMEMORY_PRUNINGヒントは、Oracle Database 12cリリース1(12.1.0.2)から使用可能です。 |

(「ヒントでの問合せブロックの指定」、tablespec::=を参照)
INMEMORY_PRUNINGヒントは、インメモリー問合せのプルーニングを有効化します。

(「ヒントでの問合せブロックの指定」、tablespec::=を参照)
LEADINGヒントは、実行計画において、指定した一連の表を接頭辞として使用するようオプティマイザに指示します。このヒントは、ORDEREDヒントより多目的なヒントです。次に例を示します。
SELECT /*+ LEADING(e j) */ *
FROM employees e, departments d, job_history j
WHERE e.department_id = d.department_id
AND e.hire_date = j.start_date;
図形結合の依存性により、指定の表を指定の順序の最初に結合できない場合、LEADINGヒントは無視されます。2つ以上の競合するLEADINGヒントを指定すると、指定したすべてのヒントが無視されます。ORDEREDヒントを指定すると、このヒントがすべてのLEADINGヒントに優先します。

(「ヒントでの問合せブロックの指定」、tablespec::=を参照)
MERGEヒントを使用すると、問合せ内のビューをマージできます。
ビューの問合せブロックにGROUP BY句、またはSELECTリスト内のDISTINCT演算子が含まれている場合、複雑なビューのマージが可能であれば、オプティマイザはビューをアクセス文のみにマージできます。複雑なマージは、副問合せに相関関係がない場合、IN副問合せをアクセス文にマージする際に使用することもできます。
次に例を示します。
SELECT /*+ MERGE(v) */ e1.last_name, e1.salary, v.avg_salary
FROM employees e1,
(SELECT department_id, avg(salary) avg_salary
FROM employees e2
GROUP BY department_id) v
WHERE e1.department_id = v.department_id
AND e1.salary > v.avg_salary
ORDER BY e1.last_name;
引数なしでMERGEヒントを使用する場合、ビューの問合せブロック内に配置する必要があります。ビュー名を引数としてMERGEヒントを使用する場合、周囲の問合せに挿入する必要があります。

MODEL_MIN_ANALYSISヒントは、スプレッドシート・ルールのコンパイル時間の最適化(主に、詳細な依存グラフ分析)を省略するようオプティマイザに指示します。スプレッドシートのアクセス構造に選択的に移入するためのフィルタの作成や制限されたルールのプルーニングなど、他のスプレッドシートの最適化は、引き続きオプティマイザによって使用されます。
スプレッドシート・ルールの数が数百を超えると、スプレッドシート分析に長い時間がかかることがあるため、このヒントによってコンパイル時間を減らします。

MONITORヒントは、文の実行時間が長くない場合でも、問合せのリアルタイムのSQL監視を強制します。このヒントは、パラメータCONTROL_MANAGEMENT_PACK_ACCESSがDIAGNOSTIC+TUNINGに設定されている場合にのみ有効です。
|
関連項目: リアルタイムのSQL監視の詳細は、『Oracle Database SQLチューニング・ガイド』を参照してください。 |

NATIVE_FULL_OUTER_JOINヒントは、ネイティブ完全外部結合を使用するようオプティマイザに指示します。ネイティブ完全外部結合は、ハッシュ結合に基づくネイティブ実行メソッドです。

NOAPPENDヒントは、INSERT文が有効な間、パラレル・モードを無効にして従来型のINSERTを使用するようにオプティマイザに指示します。従来型のINSERTはシリアル・モードでのデフォルトです。また、ダイレクト・パスINSERTはパラレル・モードでのデフォルトです。

(「ヒントでの問合せブロックの指定」、tablespec::=を参照)
NOCACHEヒントは、全表スキャンの実行時に、この表に対して取り出されたブロックを、バッファ・キャッシュ内のLRUリストの最低使用頻度側に入れるようオプティマイザに指定します。これは、バッファ・キャッシュ内のブロックの通常動作です。次に例を示します。
SELECT /*+ FULL(hr_emp) NOCACHE(hr_emp) */ last_name FROM employees hr_emp;
CACHEおよびNOCACHEヒントは、V$SYSSTATビューで示すように、システム統計情報table scans(long tables)およびtable scans(short tables)に影響を与えます。
|
注意: NO_CLUSTERINGヒントは、Oracle Database 12cリリース1(12.1.0.2)から使用可能です。 |

このヒントは、属性クラスタリングに対して有効な表のINSERTおよびMERGE操作にのみ有効です。NO_CLUSTERINGヒントは、ダイレクト・パス・インサート(シリアルまたはパラレル)の属性クラスタリングを無効化します。このヒントは、表を作成または変更したDDLのYES ON LOAD設定をオーバーライドします。このヒントは、属性クラスタリングに有効化されていない表には影響しません。
(「ヒントでの問合せブロックの指定」を参照)
NO_EXPANDヒントは、OR条件を持つ問合せ用のOR拡張、またはWHERE句内にあるINリストを検討しないようオプティマイザに指示します。通常、オプティマイザは、OR拡張を使用しない場合よりもコストが低減できると判断すると、OR拡張の使用を検討します。次に例を示します。
SELECT /*+ NO_EXPAND */ *
FROM employees e, departments d
WHERE e.manager_id = 108
OR d.department_id = 110;
(「ヒントでの問合せブロックの指定」、tablespec::=を参照)
NO_FACTヒントは、スター型変換のコンテキストで使用されます。これは、問合せ対象の表をファクト表とみなさないようオプティマイザに指示するためのものです。

NO_GATHER_OPTIMIZER_STATISTICSヒントは、次のタイプのバルク・ロード操作中に統計収集を無効にするようオプティマイザに指示します。
CREATE TABLE AS SELECT
ダイレクト・パス・インサートを使用した、空の表へのINSERT INTO ... SELECT
|
関連項目: バルク・ロードに関する統計収集の詳細は、『Oracle Database SQLチューニング・ガイド』を参照してください。 |

(「ヒントでの問合せブロックの指定」、tablespec::=、indexspec::=を参照)
NO_INDEXヒントは、指定した表について1つ以上の索引を使用しないようオプティマイザに指示します。次に例を示します。
SELECT /*+ NO_INDEX(employees emp_empid) */ employee_id FROM employees WHERE employee_id > 200;
各パラメータは「INDEXヒント」と同じ目的で使用されますが、次の変更が加えられています。
このヒントが使用可能な単一の索引を指定すると、オプティマイザはこの索引でのスキャンを検討しません。その他の指定されていない索引については、スキャンを検討します。
このヒントが使用可能な索引のリストを指定すると、オプティマイザは指定された索引でのスキャンを検討しません。リスト内に指定されていないその他の索引については、スキャンを検討します。
このヒントが索引を指定しない場合、オプティマイザは表のいずれの索引でのスキャンを考慮しません。この動作は、表について使用可能なすべての索引のリストを指定するNO_INDEXヒントと同様になります。
NO_INDEXヒントは、ファンクション索引、Bツリー索引、ビットマップ索引、クラスタ索引およびドメイン索引に適用されます。NO_INDEXヒントと索引ヒント(INDEX、INDEX_ASC、INDEX_DESC、INDEX_COMBINEまたはINDEX_FFS)の両方が同じ索引を指定する場合、データベースは、NO_INDEXヒントと、指定した索引の索引ヒントの両方を無視し、これらの索引を文の実行中に使用することを検討します。

(「ヒントでの問合せブロックの指定」、tablespec::=、indexspec::=を参照)
NO_INDEX_FFSヒントは、指定された表の指定された索引の高速全索引スキャンを除外するようオプティマイザに指示します。各パラメータの目的は、「NO_INDEXヒント」と同じです。次に例を示します。
SELECT /*+ NO_INDEX_FFS(items item_order_ix) */ order_id FROM order_items items;
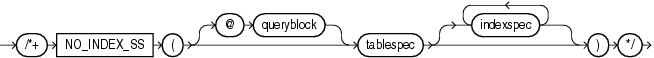
(「ヒントでの問合せブロックの指定」、tablespec::=、indexspec::=を参照)
NO_INDEX_SSヒントは、指定された表の指定された索引のスキップ・スキャンを除外するようオプティマイザに指示します。各パラメータの目的は、「NO_INDEXヒント」と同じです。
|
関連項目: 索引スキップ・スキャンの詳細は、『Oracle Database SQLチューニング・ガイド』を参照してください。 |
|
注意: NO_INMEMORYヒントは、Oracle Database 12cリリース1(12.1.0.2)から使用可能です。 |

(「ヒントでの問合せブロックの指定」、tablespec::=を参照)
NO_INMEMORYヒントは、インメモリー問合せを無効化します。
|
注意: NO_INMEMORY_PRUNINGヒントは、Oracle Database 12cリリース1(12.1.0.2)から使用可能です。 |

(「ヒントでの問合せブロックの指定」、tablespec::=を参照)
NO_INMEMORY_PRUNINGヒントは、インメモリー問合せのプルーニングを無効化します。

(「ヒントでの問合せブロックの指定」、tablespec::=を参照)
NO_MERGEヒントは、外部問合せとインライン・ビュー問合せを結合して単一の問合せにしないようオプティマイザに指示します。
このヒントを使用すると、ビューへのアクセス方法に強い影響を与えることができます。たとえば、次の文は、ビューseattle_deptがマージされないようにします。
SELECT /*+ NO_MERGE(seattle_dept) */ e1.last_name, seattle_dept.department_name
FROM employees e1,
(SELECT location_id, department_id, department_name
FROM departments
WHERE location_id = 1700) seattle_dept
WHERE e1.department_id = seattle_dept.department_id;
ビューの問合せブロック内でNO_MERGEヒントを使用する場合は、引数なしで指定します。また、周囲の問合せでNO_MERGEを指定する場合には、ビュー名を引数として指定します。

NO_NATIVE_FULL_OUTER_JOINヒントは、指定された各表を結合する場合にネイティブ実行メソッドを除外するようオプティマイザに指示します。かわりに、完全外部結合は、左側外部結合とアンチ結合の論理和として実行されます。
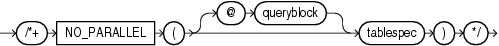
(「ヒントでの問合せブロックの指定」、tablespec::=を参照)
NO_PARALLELヒントは、文をシリアルで実行するようにオプティマイザに指示します。このヒントは、PARALLEL_DEGREE_POLICY初期化パラメータの値をオーバーライドします。また、表を作成するか変更したDDL内のPARALLELパラメータを上書きします。たとえば、次のSELECT文はシリアルで実行されます。
ALTER TABLE employees PARALLEL 8; SELECT /*+ NO_PARALLEL(hr_emp) */ last_name FROM employees hr_emp;
|
関連項目:
|

(「ヒントでの問合せブロックの指定」、tablespec::=、indexspec::=を参照)
NO_PARALLEL_INDEXヒントは、索引を作成するか変更したDDL内のPARALLELパラメータを上書きし、パラレル索引スキャン操作を防止します。

(「ヒントでの問合せブロックの指定」を参照)
NO_PQ_CONCURRENT_UNIONヒントは、UNION操作とUNION ALL操作の同時処理を無効にするようオプティマイザに指示します。
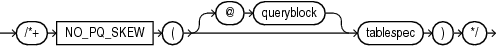
(「ヒントでの問合せブロックの指定」、tablespec::=を参照)
NO_PQ_SKEWヒントは、パラレル結合の結合キーの値の分散が偏っていない(つまり、同じ結合キー値を持つ行の割合が大きくない)ことをオプティマイザに知らせます。tablespecで指定される表は、ハッシュ結合のプローブ表です。

(「ヒントでの問合せブロックの指定」、tablespec::=を参照)
NO_PUSH_PREDヒントは、結合述語をビューにプッシュしないようオプティマイザに指示します。次に例を示します。
SELECT /*+ NO_MERGE(v) NO_PUSH_PRED(v) */ *
FROM employees e,
(SELECT manager_id
FROM employees) v
WHERE e.manager_id = v.manager_id(+)
AND e.employee_id = 100;
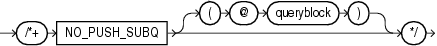
(「ヒントでの問合せブロックの指定」を参照)
NO_PUSH_SUBQヒントは、実行計画における最後の手順として、マージされていない副問合せを評価するようオプティマイザに指示します。これにより、副問合せのコストが比較的高い場合や、副問合せによって行数が大幅に減少しない場合に、パフォーマンスが向上する場合があります。

NO_QUERY_TRANSFORMATIONヒントは、すべての問合せ変換(OR拡張、ビュー・マージ、副問合せのネスト解除、スター型変換、マテリアライズド・ビュー・リライトなど)をスキップするようオプティマイザに指示するためのものです。次に例を示します。
SELECT /*+ NO_QUERY_TRANSFORMATION */ employee_id, last_name FROM (SELECT * FROM employees e) v WHERE v.last_name = 'Smith';

RESULT_CACHE_MODE初期化パラメータがFORCEに設定されていると、オプティマイザは、問合せ結果を結果キャッシュにキャッシュします。この場合、NO_RESULT_CACHEヒントにより、このような現行の問合せのキャッシュが無効になります。
問合せがOCIクライアントから実行され、OCIクライアントの結果キャッシュが有効になっている場合、NO_RESULT_CACHEヒントにより現行の問合せキャッシュが無効になります。
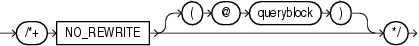
(「ヒントでの問合せブロックの指定」を参照)
NO_REWRITEヒントは、パラメータQUERY_REWRITE_ENABLEDの設定を上書きして、問合せブロック用のクエリー・リライトを無効にするようオプティマイザに指示します。次に例を示します。
SELECT /*+ NO_REWRITE */ sum(s.amount_sold) AS dollars FROM sales s, times t WHERE s.time_id = t.time_id GROUP BY t.calendar_month_desc;

(「ヒントでの問合せブロックの指定」を参照)
NO_STAR_TRANSFORMATIONヒントは、問合せのスター型問合せ変換を実行しないようオプティマイザに指示します。

NO_STATEMENT_QUEUINGヒントは、パラレル文のキューイングによって文がキューに入れられるかどうかに影響します。
PARALLEL_DEGREE_POLICYがAUTOに設定されている場合、このヒントにより文がパラレル文キューをバイパスできるようになります。ただし、キューを回避した文が原因となって、PARALLEL_SERVERS_TARGET初期化パラメータの値で定義されたパラレル実行サーバーの最大数をシステムが超過する可能性があります(この初期化パラメータで定義された制限値を超えるとパラレル文のキューイングが開始されます)。
パラレル文キューを回避した文が要求どおりの数のパラレル実行サーバーを受け取れる保証はありません。割当てが可能なのは、システム上で使用可能なパラレル実行サーバーのみであり、その数は最大でPARALLEL_MAX_SERVERS初期化パラメータの値までです。
次に例を示します。
SELECT /*+ NO_STATEMENT_QUEUING */ emp.last_name, dpt.department_name FROM employees emp, departments dpt WHERE emp.department_id = dpt.department_id;

(「ヒントでの問合せブロックの指定」、tablespec::=を参照)
NO_USE_CUBEヒントは、指定された表を内部表として使用して、指定された各表を別の行のソースに結合する際にキューブ結合を除外するようオプティマイザに指示します。

(「ヒントでの問合せブロックの指定」、tablespec::=を参照)
NO_USE_HASHヒントは、指定された表を内部表として使用して、指定された各表を別の行のソースに結合する際にハッシュ結合を除外するようオプティマイザに指示します。次に例を示します。
SELECT /*+ NO_USE_HASH(e d) */ * FROM employees e, departments d WHERE e.department_id = d.department_id;
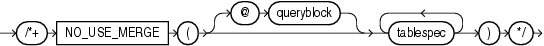
(「ヒントでの問合せブロックの指定」、tablespec::=を参照)
NO_USE_MERGEヒントは、指定された表を内部表として使用して、指定された各表を別の行のソースに結合する際にソート/マージ結合を除外するようオプティマイザに指示します。次に例を示します。
SELECT /*+ NO_USE_MERGE(e d) */ * FROM employees e, departments d WHERE e.department_id = d.department_id ORDER BY d.department_id;
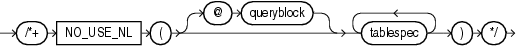
(「ヒントでの問合せブロックの指定」、tablespec::=を参照)
NO_USE_NLヒントは、指定された表を内部表として使用して、指定された各表を別の行のソースに結合する際に、ネストしたループ結合を除外するようオプティマイザに指示します。次に例を示します。
SELECT /*+ NO_USE_NL(l h) */ *
FROM orders h, order_items l
WHERE l.order_id = h.order_id
AND l.order_id > 2400;
このヒントを指定すると、指定された表についてハッシュ結合とソート/マージ結合のみが検討されます。ただし、ネストしたループのみを使用して表を結合する場合もあります。この場合、オプティマイザは、それらの表に関するヒントを無視します。

NO_XML_QUERY_REWRITEヒントは、SQL文のXPath式のリライトを禁止するようオプティマイザに指示します。このヒントは、XPath式のリライトを禁止することで、現行の問合せでのXMLIndex索引の使用も禁止します。次に例を示します。
SELECT /*+NO_XML_QUERY_REWRITE*/ XMLQUERY('<A/>' RETURNING CONTENT)
FROM DUAL;

NO_XMLINDEX_REWRITEヒントは、現行の問合せにXMLIndex索引を使用しないようにオプティマイザに指示します。次に例を示します。
SELECT /*+NO_XMLINDEX_REWRITE*/ count(*) FROM warehouses WHERE existsNode(warehouse_spec, '/Warehouse/Building') = 1;
|
注意: NO_ZONEMAPヒントは、Oracle Database 12cリリース1(12.1.0.2)から使用可能です。 |

(「ヒントでの問合せブロックの指定」、tablespec::=を参照)
NO_ZONEMAPヒントは、異なるタイプのプルーニングのゾーン・マップの使用を無効化します。このヒントは、ゾーン・マップを作成または変更したDDLのENABLE PRUNING設定をオーバーライドします。
次のいずれかのオプションを指定します。
SCAN - スキャン・プルーニングのゾーン・マップの使用を無効化します。
JOIN - 結合プルーニングのゾーン・マップの使用を無効化します。
PARTITION - パーティション・プルーニングのゾーン・マップの使用を無効化します。
|
関連項目:
|

OPT_PARAMヒントを使用すると、現行の問合せ中にのみ初期化パラメータを設定できます。このヒントは、パラメータOPTIMIZER_DYNAMIC_SAMPLING、OPTIMIZER_INDEX_CACHING、OPTIMIZER_INDEX_COST_ADJ、OPTIMIZER_SECURE_VIEW_MERGINGおよびSTAR_TRANSFORMATION_ENABLEDに対してのみ有効です。たとえば、次のヒントは、ヒントを追加した文のパラメータSTAR_TRANSFORMATION_ENABLEDをTRUEに設定します。
SELECT /*+ OPT_PARAM('star_transformation_enabled' 'true') */ *
FROM ... ;
文字列のパラメータ値は、一重引用符で囲まれます。数値のパラメータ値は、一重引用符で囲まずに指定されます。

ORDEREDヒントは、FROM句に現れる順序で表を結合するようOracleに指示します。ORDEREDヒントより多目的なLEADINGヒントを使用することをお薦めします。
結合を要求するSQL文からORDEREDヒントを削除すると、オプティマイザが表の結合順序を選択します。各表から選択した行数をオプティマイザが把握していないと考えられる場合、ORDEREDヒントを使用して結合順序を指定することがあります。この情報を使用すると、オプティマイザによる選択よりも効率良く内部表と外部表を選択できます。
次の問合せは、ORDEREDヒントの使用例です。
SELECT /*+ ORDERED */ o.order_id, c.customer_id, l.unit_price * l.quantity
FROM customers c, order_items l, orders o
WHERE c.cust_last_name = 'Taylor'
AND o.customer_id = c.customer_id
AND o.order_id = l.order_id;
パラレル・ヒントの注意事項 Oracle Database 11gリリース2以降では、PARALLELヒントとNO_PARALLELヒントは文レベルのヒントであり、以前のオブジェクト・レベルのPARALLEL_INDEXヒントとNO_PARALLEL_INDEXヒント、および以前に指定したPARALLELヒントとNO_PARALLELヒントより優先されます。PARALLELでintegerを指定すると、並列度は文に対して使用されます。integerを指定しない場合は、データベースで並列度が計算されます。パラレル化を使用できるすべてのアクセス・パスで、指定した並列度または計算された並列度が使用されます。
次の構文図で、parallel_hint_statementは文レベルのヒントの構文を示し、parallel_hint_objectはオブジェクト・レベルのヒントの構文を示します。オブジェクト・レベルのヒントは下位互換性のためにサポートされており、文レベルのヒントの方が優先されます。
parallel_hint_statement::=
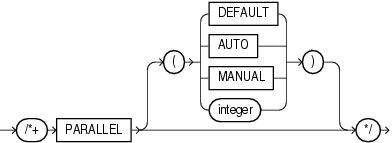
parallel_hint_object::=

(「ヒントでの問合せブロックの指定」、tablespec::=を参照)
PARALLELヒントは、指定された数の同時サーバーをパラレル操作に使用するようオプティマイザに指示します。このヒントは、PARALLEL_DEGREE_POLICY初期化パラメータの値をオーバーライドします。このヒントは、文のSELECT、INSERT、MERGE、UPDATEおよびDELETE部分と表のスキャン部分に適用されます。パラレル制限に違反すると、ヒントは無視されます。
|
注意: ソート操作またはグループ操作も実行する場合、使用可能なサーバー数はPARALLELヒントの値の2倍となります。 |
文レベルのPARALLELヒントでは、次のように動作します。
PARALLEL: 文は常にパラレルで実行され、データベースは並列度(2以上)を計算します。
PARALLEL (DEFAULT): オプティマイザは並列度を計算します。並列度は、すべての関係するインスタンスで使用可能なCPUの数に、初期化パラメータPARALLEL_THREADS_PER_CPUの値を掛けたものです。
PARALLEL (AUTO): データベースは並列度を計算します(結果は1以上になります)。計算された並列度が1の場合、文はシリアルで実行されます。
PARALLEL (MANUAL): オプティマイザは強制的に、文の中のオブジェクトのパラレル設定を使用します。
PARALLEL (integer): オプティマイザは、integerに指定された並列度を使用します。
次の例では、オプティマイザは並列度を計算します。文は常にパラレルで実行されます。
SELECT /*+ PARALLEL */ last_name FROM employees;
次の例では、オプティマイザは並列度を計算しますが、並列度は1の場合があります。その場合、文はシリアルで実行されます。
SELECT /*+ PARALLEL (AUTO) */ last_name FROM employees;
次の例では、PARALLELヒントは、表自体に現在適用されている並列度(5)を使用するようオプティマイザに指示します。
CREATE TABLE parallel_table (col1 number, col2 VARCHAR2(10)) PARALLEL 5; SELECT /*+ PARALLEL (MANUAL) */ col2 FROM parallel_table;
オブジェクト・レベルのPARALLELヒントでは、次のように動作します。
PARALLEL: 問合せコーディネータはデフォルトの並列度を決定するために初期化パラメータの設定を検証する必要があります。
PARALLEL (integer): オプティマイザは、integerに指定された並列度を使用します。
PARALLEL (DEFAULT): オプティマイザは並列度を計算します。並列度は、すべての関係するインスタンスで使用可能なCPUの数に、初期化パラメータPARALLEL_THREADS_PER_CPUの値を掛けたものです。
次の例では、PARALLELヒントが、employees表定義内で指定された並列度を上書きします。
SELECT /*+ FULL(hr_emp) PARALLEL(hr_emp, 5) */ last_name FROM employees hr_emp;
次の例では、PARALLELヒントが、employees表定義内で指定された並列度を上書きし、並列度を計算するようにオプティマイザに指示します。並列度は、すべての関係するインスタンスで使用可能なCPUの数に初期化パラメータPARALLEL_THREADS_PER_CPUの値を掛けたものです。
SELECT /*+ FULL(hr_emp) PARALLEL(hr_emp, DEFAULT) */ last_name FROM employees hr_emp;
パラレル実行の詳細は、「CREATE TABLE」および『Oracle Database概要』を参照してください。
|
関連項目:
|
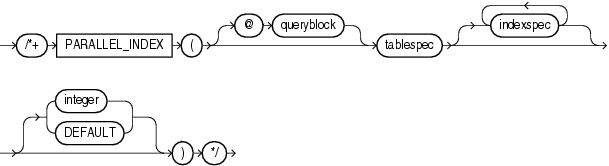
(「ヒントでの問合せブロックの指定」、tablespec::=、indexspec::=を参照)
PARALLEL_INDEXヒントは、パーティション索引について索引レンジ・スキャン、全体スキャンおよび高速全体スキャンをパラレル化するために、指定された数の同時サーバーを使用するようオプティマイザに指示します。
integer値は、指定された索引の並列度を示します。DEFAULTを指定するか、いかなる値も指定しない場合、問合せコーディネータはデフォルトの並列度を決定するために初期化パラメータの設定を検証する必要があります。たとえば、次のヒントは、3つのパラレル実行プロセスが使用されることを示します。
SELECT /*+ PARALLEL_INDEX(table1, index1, 3) */

(「ヒントでの問合せブロックの指定」を参照)
PQ_CONCURRENT_UNIONヒントは、UNION操作とUNION ALL操作の同時処理を有効にするようオプティマイザに指示します。

(「ヒントでの問合せブロックの指定」、tablespec::=を参照)
PQ_DISTRIBUTEヒントは、プロデューサおよびコンシューマ問合せサーバーに行を分散させる方法をオプティマイザに指示します。結合またはロードのいずれかで行の分散を制御できます。
ロードでの分散の制御 パラレルINSERT ... SELECT文およびパラレルCREATE TABLE ... AS SELECT文で行の分散を制御し、プロデューサ(問合せ)およびコンシューマ(ロード)サーバー間で行を分散する方法を指示できます。構文の上位ブランチを使用するには、1つの分散方法を指定します。表2-22に、分散方法の値とそのセマンティクスを示します。
表2-22 ロードでの分散処理の値
| 分散 | 説明 |
|---|---|
|
|
分散処理なし。したがって、問合せおよびロード操作は、問合せサーバーごとに組み合されます。すべてのサーバーがすべてのパーティションをロードします。分散を行わないことで、偏りがない場合に行の分散によって発生するオーバーヘッドを避けることができます。偏りは、空のセグメントによって発生したり、文の条件で問合せによって評価されるすべての行が排除される場合に発生することがあります。この方法を使用することで偏りが発生する場合、かわりに 注意: この分散方法は、慎重に使用してください。ロードされる各パーティションに対し、プロセスごとに512 KB以上のPGAメモリーが必要です。圧縮も同時に使用している場合、サーバーごとに約1.5 MBのPGAメモリーが消費されます。 |
|
|
この方法は、 |
|
|
この方法は、プロデューサの行をラウンドロビン法でコンシューマに分散します。この分散方法は、入力データの偏りが大きい場合に使用します。 |
|
|
この方法は、特定のパーティションの集合を保持する役割を果たすサーバーの集合に対して、プロデューサの行を分散します。2つ以上のサーバーが同じパーティションをロードする可能性はありますが、すべてのパーティションをロードするサーバーは存在しません。この分散方法は、入力データが偏っており、メモリーの制約によって問合せおよびロード操作を組み合せることができない場合に使用します。 |
たとえば、次のダイレクト・パス・インサート操作の問合せおよびロード部分は、問合せサーバーごとに組み合されます。
INSERT /*+ APPEND PARALLEL(target_table, 16) PQ_DISTRIBUTE(target_table, NONE) */ INTO target_table SELECT * FROM source_table;
次の表を作成する例では、オプティマイザは、target_tableのパーティション化を使用して行を分散します。
CREATE /*+ PQ_DISTRIBUTE(target_table, PARTITION) */ TABLE target_table NOLOGGING PARALLEL 16 PARTITION BY HASH (l_orderkey) PARTITIONS 512 AS SELECT * FROM source_table;
結合での分散の制御 構文図の下位ブランチに示すように、2つの分散方法(外部表への分散処理と内部表への分散処理)を指定することで、結合での分散方法を制御できます。
outer_distributionは、外部表への分散処理です。
inner_distributionは、内部表への分散処理です。
分散の値は、HASH、BROADCAST、PARTITIONおよびNONEです。表2-23で説明するとおり、6つの組合せの表分散のみが有効です。
表2-23 結合での分散処理の値
| 分散 | 説明 |
|---|---|
|
|
各表の行は、結合キーにハッシュ関数を使用して、コンシューマ問合せサーバーにマップされます。マッピングが完了すると、各問合せサーバーは、結果として生成されるパーティションの組で結合を実行します。この分散は、表のサイズがほぼ等しく、結合操作がハッシュ結合またはソート/マージ結合で実施される場合にお薦めします。 |
|
|
外部表のすべての行が各問合せサーバーにブロードキャストされます。内部表の行は、ランダムにパーティション化されます。この分散は、外部表のサイズが内部表よりもきわめて小さい場合にお薦めします。一般的に、内部表のサイズに問合せサーバーの数を乗じた数値が外部表のサイズよりも大きい場合、この分散を使用します。 |
|
|
内部表のすべての行が各コンシューマ問合せサーバーにブロードキャストされます。外部表の行は、ランダムにパーティション化されます。この分散は、内部表のサイズが外部表よりもきわめて小さい場合にお薦めします。一般的に、内部表のサイズに問合せサーバーの数を乗じた数値が外部表のサイズより小さい場合、この分散を使用します。 |
|
|
外部表の行は、内部表のパーティション化を使用してマップされます。内部表は、結合キーでパーティション化されている必要があります。この分散は、外部表のパーティションの数が問合せサーバーの数と等しいかほぼ等しい(たとえば、パーティション数が14で問合せサーバー数が15)場合にお薦めします。 注意: オプティマイザは、内部表がパーティション化されていないか、パーティション化キーと等価結合関係にない場合、このヒントを無視します。 |
|
|
内部表の行は、外部表のパーティション化を使用してマップされます。外部表は、結合キーでパーティション化されている必要があります。この分散は、外部表のパーティションの数が問合せサーバーの数と等しいかほぼ等しい(たとえば、パーティション数が14で問合せサーバー数が15)場合にお薦めします。 注意: オプティマイザは、外部表がパーティション化されていないか、パーティション化キーと等価結合関係にない場合、このヒントを無視します。 |
|
|
各問合せサーバーは、各表から抽出した一致パーティションの組で結合操作を実行します。両方の表は、結合キーに基づいて同一レベルでパーティション化されている必要があります。 |
たとえば、rとsという2つの表がハッシュ結合によって結合されている場合、次の問合せには、ハッシュ分散を使用するためのヒントが含まれます。
SELECT /*+ORDERED PQ_DISTRIBUTE(s HASH, HASH) USE_HASH (s)*/ column_list
FROM r,s
WHERE r.c=s.c;
外部表rをブロードキャストするための問合せは、次のとおりです。
SELECT /*+ORDERED PQ_DISTRIBUTE(s BROADCAST, NONE) USE_HASH (s) */ column_list
FROM r,s
WHERE r.c=s.c;
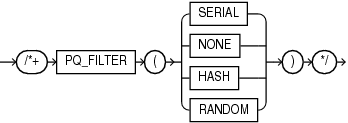
PQ_FILTERヒントは、相関副問合せをフィルタリングするときの行の処理方法についてオプティマイザに指示します。
SERIAL: フィルタの左側と右側で行を逐次処理します。このオプションは、問合せにとってパラレル化のオーバーヘッドが大きすぎる場合(たとえば左側の行が非常に少ない場合など)に使用します。
NONE: フィルタの左側と右側で行をパラレル処理します。このオプションは、フィルタの左側でデータの分散に偏りがなく、左側の分散を回避する(たとえば左側のサイズが大きいため)場合に使用します。
HASH: フィルタの左側でハッシュ分散を使用して行をパラレル処理します。フィルタの右側では行を逐次処理します。このオプションは、フィルタの左側でデータの分散に偏りがない場合に使用します。
RANDOM: フィルタの左側でランダム分散を使用して行をパラレル処理します。フィルタの右側では行を逐次処理します。このオプションは、フィルタの左側でデータの分散に偏りがある場合に使用します。

(「ヒントでの問合せブロックの指定」、tablespec::=を参照)
PQ_SKEWヒントは、パラレル結合の結合キーの値の分散が著しく偏っている(つまり、同じ結合キー値を持つ行の割合が大きい)ことをオプティマイザに知らせます。tablespecで指定される表は、ハッシュ結合のプローブ表です。

(「ヒントでの問合せブロックの指定」、tablespec::=を参照)
PUSH_PREDヒントは、結合述語をビューにプッシュするようオプティマイザに指示します。次に例を示します。
SELECT /*+ NO_MERGE(v) PUSH_PRED(v) */ *
FROM employees e,
(SELECT manager_id
FROM employees) v
WHERE e.manager_id = v.manager_id(+)
AND e.employee_id = 100;
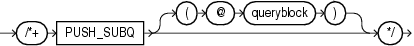
(「ヒントでの問合せブロックの指定」を参照)
PUSH_SUBQヒントは、実行計画の初期段階で実行可能な手順で、マージされていない副問合せを評価するようオプティマイザに指示します。通常、マージされていない副問合せは、実行計画の最終手順で実行されます。副問合せのコストが比較的低く、副問合せによって行数が大幅に減少する場合、副問合せの早期評価によってパフォーマンスが向上する可能性があります。
このヒントは、副問合せがリモート表か、マージ結合によって結合されている表に適用される場合には効果がありません。
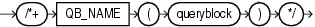
(「ヒントでの問合せブロックの指定」を参照)
QB_NAMEヒントを使用すると、問合せブロックの名前を定義できます。この名前は外部問合せ内のヒントまたはインライン・ビュー内のヒントで使用でき、名前が付けられた問合せブロックにある表で実行する問合せに影響をおよぼします。
2つ以上の問合せブロックに同じ名前が付いている場合や、同じ問合せブロックに対して2回、それぞれ異なる名前でヒントが適用されている場合は、オプティマイザはすべての名前を無視し、その問合せブロックを参照しているヒントも無視します。このヒントを使用して名前が付けられてはいない問合せブロックには、システムによって生成された一意の名前が付けられます。この名前は計画表に表示できます。また、問合せブロック内のヒントや問合せブロック・ヒントでも使用できます。次に例を示します。
SELECT /*+ QB_NAME(qb) FULL(@qb e) */ employee_id, last_name FROM employees e WHERE last_name = 'Smith';

RESULT_CACHEヒントは、メモリー内の現行の問合せまたは問合せのフラグメントの結果をキャッシュし、今後の問合せまたは問合せのフラグメントの実行時にキャッシュした結果を使用するようデータベースに指示します。このヒントは、トップレベル問合せ、subquery_factoring_clauseまたはFROM句のインライン・ビューで認識されます。キャッシュ結果は、共有プールの結果のキャッシュ・メモリー部分に保存されます。
作成に使用されたデータベース・オブジェクトが正常に修正されると、キャッシュ結果は自動的に無効化されます。このヒントは、RESULT_CACHE_MODE初期化パラメータの設定よりも優先されます。
問合せが結果キャッシュに使用できるのは、問合せで必要とされるすべてのファンクション(たとえば、組込みファンクション、ユーザー定義ファンクションまたは仮想列)が決定的である場合にかぎられます。
問合せがOCIクライアントから実行され、OCIクライアントの結果キャッシュが有効になっている場合、RESULT_CACHEヒントにより現行の問合せのクライアントのキャッシュが有効になります。
|
関連項目: このヒントの使用方法については『Oracle Databaseパフォーマンス・チューニング・ガイド』、RESULT_CACHE_MODE初期化パラメータの詳細は『Oracle Databaseリファレンス』、OCI結果キャッシュの詳細および使用のガイドラインについては『Oracle Call Interfaceプログラマーズ・ガイド』を参照してください。 |

|
注意: CHANGE_DUPKEY_ERROR_INDEXヒント、IGNORE_ROW_ON_DUPKEY_INDEXヒントおよびRETRY_ON_ROW_CHANGEヒントは、セマンティクスに影響を与えるという点で他のヒントとは異なります。これら3つのヒントには、「ヒント」で説明されている一般的な原則は当てはまりません。 |
このヒントが有効になるのは、UPDATE操作およびDELETE操作に対してのみです。INSERT操作およびMERGE操作に対してはサポートされません。このヒントを指定すると、変更対象の行セットが決定された時点から、ブロックが実際に変更される時点までの間に、セット内の1つ以上の行のORA_ROWSCNが変更された場合に、操作が再試行されます。
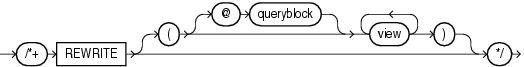
(「ヒントでの問合せブロックの指定」を参照)
REWRITEヒントは、可能な場合、コストを考慮することなく、マテリアライズド・ビューに関する問合せをリライトするようオプティマイザに指示します。REWRITEヒントは、ビュー・リストとともに、またはビュー・リストなしで使用します。ビュー・リストとともにREWRITEを使用し、リストに適切なマテリアライズド・ビューが含まれている場合、Oracleはコストを考慮せずにそのビューを使用します。
Oracleでは、リスト外のビューを検討しません。ビュー・リストを指定しない場合、Oracleは適切なマテリアライズド・ビューを検索し、最終計画のコストを考慮することなく常にそのビューを使用します。
|
関連項目:
|

(「ヒントでの問合せブロックの指定」を参照)
STAR_TRANSFORMATIONヒントは、変換を行う際に最適な計画を使用するようオプティマイザに指示します。このヒントを使用しない場合、オプティマイザは、変換された問合せ用の最適な計画のかわりに、変換なしで生成された最適な計画を使用するという、問合せの最適化に関する決定を行う場合があります。次に例を示します。
SELECT /*+ STAR_TRANSFORMATION */ s.time_id, s.prod_id, s.channel_id
FROM sales s, times t, products p, channels c
WHERE s.time_id = t.time_id
AND s.prod_id = p.prod_id
AND s.channel_id = c.channel_id
AND c.channel_desc = 'Tele Sales';
ヒントが指定された場合でも、変換が実行される保証はありません。オプティマイザは、妥当と考えられる場合にかぎって副問合せを生成します。副問合せが生成されない場合には、変換された問合せが存在しないため、ヒントに関係なく、未変換の問合せに関する最適な計画が使用されます。
|
関連項目:
|

NO_STATEMENT_QUEUINGヒントは、パラレル文のキューイングによって文がキューに入れられるかどうかに影響します。
PARALLEL_DEGREE_POLICYをAUTOに設定しない場合は、このヒントによって文がパラレル文キューイング用として認識され、リクエストされたDOPで十分なパラレル処理が可能な場合にのみ実行できるようにします。キューイングが有効にされる前の時点で使用可能なパラレル実行サーバーの数は、PARALLEL_SERVERS_TARGET初期化パラメータで定義されたシステム内で許可されるパラレル実行サーバーの最大数と使用中のパラレル実行サーバーの数との差です。
次に例を示します。
SELECT /*+ STATEMENT_QUEUING */ emp.last_name, dpt.department_name FROM employees emp, departments dpt WHERE emp.department_id = dpt.department_id;
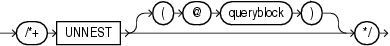
(「ヒントでの問合せブロックの指定」を参照)
UNNESTヒントは、副問合せの本体のネストを解除し、その副問合せを含む問合せブロック本体にマージするようオプティマイザに指示します。これによって、アクセス・パスおよび結合の評価時に、オプティマイザが副問合せと問合せブロックを総合して考慮できるようになります。
副問合せのネストを解除する前に、オプティマイザは、文が有効かどうかをまず検討します。文は、経験則に基づくテストと問合せ最適化テストに合格する必要があります。UNNESTヒントは、副問合せブロックの有効性のみをチェックするようオプティマイザに指示します。副問合せブロックが有効な場合、経験則またはコストをチェックすることなく副問合せのネストを解除できます。
|
関連項目:
|
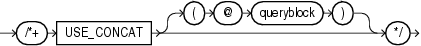
(「ヒントでの問合せブロックの指定」を参照)
USE_CONCATヒントは、問合せのWHERE句内で組み合されたOR条件を、集合演算子UNION ALLを使用して複合問合せに変換するようオプティマイザに指示します。このヒントを使用しない場合、この変換は、連結を使用した問合せのコストが、使用しない場合よりも低い場合にのみ実行されます。USE_CONCATヒントは、コストより優先します。次に例を示します。
SELECT /*+ USE_CONCAT */ *
FROM employees e
WHERE manager_id = 108
OR department_id = 110;

(「ヒントでの問合せブロックの指定」、tablespec::=を参照)
結合の右側がキューブの場合、USE_CUBEヒントは、指定された各表を、キューブ結合を使用して別の行のソースに結合するようにオプティマイザに指示します。オプティマイザが統計分析に基づいてキューブ結合を使用しないことを決定したときには、USE_CUBEを使用するとオプティマイザの決定を無視できます。

(「ヒントでの問合せブロックの指定」、tablespec::=を参照)
USE_HASHヒントは、指定された各表を、ハッシュ結合を使用して別の行のソースに結合するようオプティマイザに指示します。次に例を示します。
SELECT /*+ USE_HASH(l h) */ *
FROM orders h, order_items l
WHERE l.order_id = h.order_id
AND l.order_id > 2400;
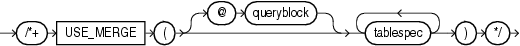
(「ヒントでの問合せブロックの指定」、tablespec::=を参照)
USE_MERGEヒントは、指定された各表を、ソート/マージ結合を使用して別の行のソースに結合するようオプティマイザに指示します。次に例を示します。
SELECT /*+ USE_MERGE(employees departments) */ * FROM employees, departments WHERE employees.department_id = departments.department_id;
LEADINGおよびORDEREDヒントとともに、USE_NLおよびUSE_MERGEヒントを使用することをお薦めします。オプティマイザは、参照表を結合の内部表にする必要がある場合に、これらのヒントを使用します。参照表が外部表の場合、ヒントは無視されます。
USE_NLヒントは、指定された表を内部表として使用し、指定された各表をネストしたループ結合とともに別の行のソースに結合するようオプティマイザに指示します。

(「ヒントでの問合せブロックの指定」、tablespec::=を参照)
USE_NLヒントは、指定された表を内部表として使用し、指定された各表をネストしたループ結合とともに別の行のソースに結合するようオプティマイザに指示します。
LEADINGおよびORDEREDヒントとともに、USE_NLおよびUSE_MERGEヒントを使用することをお薦めします。オプティマイザは、参照表を結合の内部表にする必要がある場合に、これらのヒントを使用します。参照表が外部表の場合、ヒントは無視されます。
次の例では、ネストしたループがヒントによって強制される場合、全表スキャンを介してordersがアクセスされ、各行にフィルタ条件l.order_id = h.order_idが適用されます。フィルタ条件を満たす各行については、索引order_idを介してorder_itemsがアクセスされます。
SELECT /*+ USE_NL(l h) */ h.customer_id, l.unit_price * l.quantity FROM orders h, order_items l WHERE l.order_id = h.order_id;
INDEXヒントを問合せに追加すると、ordersの全表スキャンを回避し、より大規模なシステムで使用される実行計画と同様の実行計画を生成できる場合があります。ただし、ここでは特に効果的ではない場合があります。

(「ヒントでの問合せブロックの指定」、tablespec::=、indexspec::=を参照)
USE_NL_WITH_INDEXヒントは、指定された表を内部表として使用し、指定された表をネストしたループ結合とともに別の行のソースに結合するようオプティマイザに指示します。次に例を示します。
SELECT /*+ USE_NL_WITH_INDEX(l item_product_ix) */ *
FROM orders h, order_items l
WHERE l.order_id = h.order_id
AND l.order_id > 2400;
次の条件が適用されます。
索引を指定しない場合、オプティマイザは、1つ以上の結合述語とともに、索引キーとして一部の索引を使用できる必要があります。
索引を指定する場合、オプティマイザは、1つ以上の結合述語とともに、索引キーとしてその索引を使用できる必要があります。