| Oracle® Big Data Applianceソフトウェア・ユーザーズ・ガイド リリース4 (4.0) E57728-01 |
|


 前 |
 次 |
この章では、Oracle Big Data Applianceの概要およびシステムにインストールされるソフトウェアについて説明します。この章は次の項で構成されています:
トランザクション型データをビジネス・インテリジェンスのソースとして使用する方法は、何年にもわたって一般的に利用されてきました。デジタル・テクノロジとワールド・ワイド・ウェブが現代生活のあらゆる局面に浸透するにつれ、これ以外のデータ・ソースがビジネスの意思決定に大きく貢献する可能性があります。多くの企業がそのような新しいデータ・ソースを求めています。つい最近まで捨てられていた大量のデータを分析することに商機を見いだそうとしているのです。
ビッグ・データの特徴は次のとおりです。
これらの特徴によって、ビッグ・データから価値を生み出す上での課題と、ビッグ・データと従来のデータ・ソース(主に高度に構造化されたトランザクション型データを提供)との違いが明らかになります。
ビッグ・データは次のような様々なソースから取得されます。
機器センサー: 医療、製造、輸送などの機械センサーからの伝送
機械: 通話詳細レコード、Webログ、スマート・メーター読取り、グローバル・ポジショニング・システム(GPS)伝送、取引システム・レコード
ソーシャル・メディア: Facebookなどのソーシャル・メディア・サイトやTwitterなどのブログ・サイトからのデータ・ストリーム
アナリストはこのデータのマイニングを繰り返すことで、有益な洞察を抽出する新しい方法を考案できます。現在は無関係のように見える情報でも、将来的にはビジネスに深く関係する可能性があります。
課題: このような多様性に対応できる柔軟なシステムを導入する
データの種類が増えるにつれて、システムはますます複雑になります。データの種類が複雑になると、あまり構造化されていない性質のために、ビッグ・データの量も増加します。
課題: 幅広いデータ・タイプに適用できるソリューションを見つけること。
ソーシャル・メディアでは、毎日TB単位のデータが生成される可能性があります。機器センサーやその他の機械では、同量のデータが1時間足らずで生成される場合があります。
たとえば顧客関係管理(CRM)システムからの顧客プロファイル、トランザクション型の統合基幹業務システム(ERP)データ、ストア・トランザクション、総勘定元帳データといった、従来のデータ・ウェアハウスのデータ・ソースでさえも、過去10年間で容量が10倍に増加しています。
課題: 拡大するシステムに拡張性と使いやすさをもたらす
Oracle Big Data Applianceは、ハードウェアとソフトウェアのコンポーネントを組み合せたエンジアド・システムです。ハードウェアはビッグ・データ用ソフトウェア・コンポーネントの拡張機能を実行するために最適化されています。
Oracle Big Data Applianceでは、次のことを実現します。
ビッグ・データ用に最適化された完全なソリューション
ハードウェアとソフトウェアを1つのベンダーでサポート
デプロイが容易なソリューション
Oracle DatabaseおよびOracle Exadata Database Machineとの緊密な連携
Oracleでは、様々なデータ・ソースから企業内に流入する膨大で複雑なデータ・ストリームの取得、体系化および深い分析のサポートを可能にする、ビッグ・データ用プラットフォームを提供しています。データ構造、ワークロードの特性、およびエンドユーザー要件に基づいて、最適なストレージ・ロケーションと処理ロケーションを選択できます。
Oracle Databaseによって、大規模なユーザー・コミュニティは同じ方法を使用して、すべてのデータにアクセスし分析することが可能です。Oracle Databaseの前にOracle Big Data Applianceを追加することで、既存のデータ・ウェアハウスに新しい情報ソースを提供できます。Oracle Big Data Applianceは、真のビジネス価値を持つ関連情報をOracle Databaseで分析できるように、ビッグ・データを取得および体系化するためのプラットフォームです。
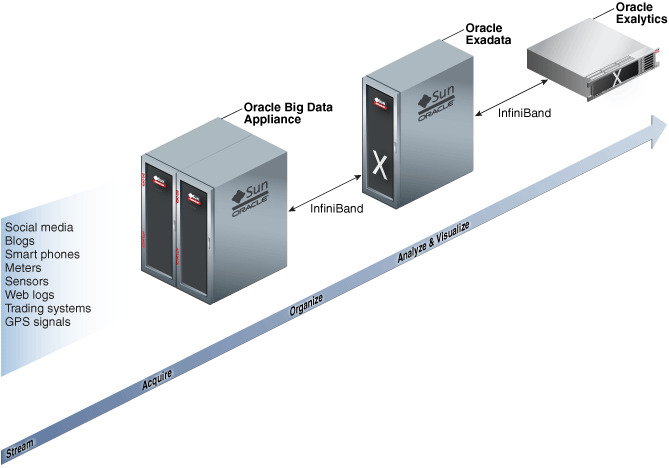
高速度と効率性を最大化するため、Oracle Big Data Applianceは、Oracle Databaseを実行しているOracle Exadata Database Machineに接続できます。Oracle Exadata Database Machineは、データ・ウェアハウスのホスティングやデータベースのトランザクション処理に卓越したパフォーマンスを発揮します。さらに、Oracle Exalytics In-Memory Machineに接続して、ビジネス・インテリジェンスおよびビジネス・プランニング・アプリケーションに最適なパフォーマンスを実現できます。このようなエンジニアド・システム間の接続はインフィニバンドを経由しているため高度に並列化され、バッチや問合せワークロードの高速データ転送が可能です。
図1-1は、このようなエンジニアド・システム間の関係を示しています。
Oracle Linuxオペレーティング・システムおよびCloudera's Distribution including Apache Hadoop (CDH)は、Oracle Big Data Applianceにインストールされたその他すべてのソフトウェア・コンポーネントの基礎となります。CDHは、連携して機能するようにテストおよびパッケージ化された各種コンポーネントの包括的なスタックです。
CDHはバッチ処理インフラストラクチャを備え、ファイルの格納と複数のコンピュータにまたがったワークロードの分散が可能です。データは格納されているコンピュータ上で処理されます。Oracle Big Data Applianceの単一ラック環境では、CDHによって、クラスタを構成している18台のサーバー全体にファイルとワークロードが分散されます。各サーバーはクラスタ内のノードです。
ソフトウェア・フレームワークは次の主要コンポーネントで構成されます。
ファイル・システム: Hadoop Distributed File System (HDFS)は、サイズの大きいファイルを複数のサーバーにまたがって格納する、拡張性に優れたファイル・システムです。RAIDテクノロジを使用せずに、複数のサーバー間でデータをレプリケートすることにより、信頼性を実現します。Oracle Big Data Appliance上のLinuxファイル・システムの最上位で実行されます。
MapReduceエンジン: MapReduceエンジンは、Javaで記述されたアルゴリズムの大規模な並列実行に対応したプラットフォームを提供します。Oracle Big Data Appliance 3.0は、デフォルトでYARNを実行します。
管理フレームワーク: Cloudera Managerは、CDHのための包括的な管理ツールです。Oracle Enterprise Managerを使用すると、Oracle Big Data Appliance上のハードウェアとソフトウェアの両方を監視することもできます。
Apacheプロジェクト: CDHには、Hive、Pig、Oozie、ZooKeeper、HBase、Sqoop、Sparkなど、MapReduceおよびHDFS用のApacheプロジェクトが含まれています。
Clouderaアプリケーション: Oracle Big Data Applianceは、Cloudera Enterprise Data Hub Editionに含まれるすべての製品(Impala、Search、Navigatorなど)をインストールします。
CDHはJavaで記述され、Javaはアプリケーション開発言語です。ただし、一部のCDHユーティリティやOracle Big Data Applianceで使用可能なその他のソフトウェアは、使いやすいように、別の言語を使用したWebベースのグラフィカル・インタフェースを備えています。
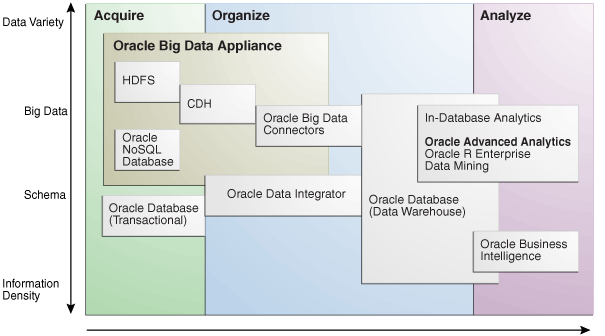
主要ソフトウェア・コンポーネントは、次に示す3つの基本タスクを実行します。
取得
体系化
分析と視覚化
それぞれのタスクに最適なツールは、情報の密度と構造化の程度によって異なります。図1-2は、ツール間の関係とそれぞれが実行するタスクを示しています。
オンライン・トランザクション処理(OLTP)に使用されているデータベースは、従来のデータ・ウェアハウスのデータ・ソースです。Oracleのソリューションでは、同じOracleデータ・ウェアハウス内で従来のデータ・ストアとビッグ・データの分析が可能です。リレーショナル・データは、Oracle Big Data Applianceとは別のハードウェア上で実行されていても、ビジネス・インテリジェンスの重要なソースであることにかわりありません。
Oracle Big Data Applianceは、ビッグ・データを取得および格納するための次の機能を備えています。
Oracle Big Data Appliance上のCloudera's Distribution including Apache Hadoop (CDH)では、Hadoop Distributed File System (HDFS)を使用します。HDFSは、レコード指向データを含む非常に大きなファイルを格納します。Oracle Big Data Appliance上で、HDFSは大きなデータ・ファイルを256メガバイト(MB)のチャンクに分割し、各チャンクをクラスタ内の3つの異なるノードにレプリケートします。チャンクのサイズとレプリケーション数は構成可能です。
チャンク化により、HDFSでは、1つのサーバーの物理ストレージよりも大きなファイルを格納できるようになります。また、複数のコンピュータを使用し、マルチ・プロセッサでデータを並列処理(それぞれがローカルに格納されているデータを処理)することも可能です。レプリケーションにより、1台のサーバーに障害が発生しても、別のサーバーがそのワークロードを自動的に引き継ぐので、データの高可用性が実現します。
HDFSは通常、あらゆるタイプのビッグ・データの格納に使用されます。
|
関連項目:
|
Hiveはオープンソース・データ・ウェアハウスで、HDFS内に格納されているデータのデータ要約、アドホック問合せおよびデータ分析をサポートします。HiveQLと呼ばれるSQLライクな言語を使用します。インタプリタによって、HiveQL問合せからMapReduceコードが生成されます。Hiveにデータを格納することにより、MapReduceプログラムをJavaで記述しないですみます。
HiveはCDHのコンポーネントで、常にOracle Big Data Applianceにインストールされます。Oracle Big Data Connectorsは、Hive表にアクセスできます。
Oracle NoSQL Databaseは、実績が証明されているストレージ・テクノロジBerkeley DB Java Editionに基づく分散キー/値データベースです。HDFSが非構造化データの非常に大きなファイルを格納するのに対して、Oracle NoSQL Databaseでは、データの索引付けとトランザクションをサポートします。ただし、高度に構造化されたデータを格納するOracle Databaseとは異なり、Oracle NoSQL Databaseは、特にストレージ・ノード全体にわたって、一貫性のルールも緩やかで、スキーマ構造はなく、結合に対してごく限られたサポートしかしていません。
NoSQLデータベース(Not Only SQLデータベース)は、過去10年間にわたりビッグ・データの格納に特化して開発されてきました。ただし、実装方法は様々です。Oracle NoSQL Databaseには、次の特徴があります。
システム定義で一貫性のあるハッシュ索引を使用したデータ分散
レプリケーションによる高可用性のサポート
緩やかな一貫性保証による単一レコード、単一操作のトランザクションの実現
Java APIを搭載
Oracle NoSQL Databaseは、信頼性、拡張性、予測可能性および可用性に優れたデータ格納を実現するように設計されています。キー/値のペアは、主キーに基づき、断片またはパーティション(データのサブセットのこと)に格納されます。各断片上のデータを複数のストレージ・ノードにレプリケートすることで高可用性を確保します。Oracle NoSQL Databaseは、一般にはキー検索によるデータの高速問合せをサポートします。
インテリジェント・ドライバによってNoSQLデータベースとクライアント・アプリケーションが接続され、ストレージ・ノード上の要求されたキー/値に最小の待機時間でアクセスできるようになります。
Oracle NoSQL Databaseは、適切なデータ分散と最適なロード・バランシングを実現するハッシング・アルゴリズムとバランシング・アルゴリズム、ストレージ・ノードの障害とリカバリを処理するレプリケーション管理コンポーネント、およびデータベースの状態を監視する使いやすい管理インタフェースを備えています。
Oracle NoSQL Databaseは通常、ビッグ・データの識別と分析のための、顧客プロファイルや類似するデータの格納に使用されます。たとえば、Webサイトにログインすると、格納されている顧客プロファイル(Oracle NoSQL Databaseのレコード)と最近のサイト上でのアクティビティ(現在HDFSにストリーミングされているWebログ)に基づいて広告が表示されるような場合に使用されます。
Oracle NoSQL Databaseは、Oracle Big Data Applianceのオプションのコンポーネントであり、CDHとは別のクラスタ上で実行されます。
|
関連項目:
|
Oracle Big Data Applianceは、次のような、ビッグ・データを分析用に体系化、変換およびリデュースする方法を備えています。
MapReduceエンジンは、Javaで記述されたアルゴリズムの大規模な並列実行に対応したプラットフォームを提供します。MapReduceは、並列プログラミング・モデルを使用して、分散システムのデータ処理を行います。大量のデータを迅速に処理し、線形的に拡張できます。非構造化および半構造化データのバッチ処理メカニズムとして特に有効です。MapReduceは、低レベルの操作を一連のキーと値の計算に抽象化します。
ビッグ・データは通常、非構造化と説明されていますが、入力データは常になんらかの構造を持っています。ただし、HDFSに書き込まれるときは、固定の事前定義された構造は持っていません。かわりに、MapReduceでは、特定のジョブのデータを読み込む際に、必要な構造を作成します。同じデータでも、MapReduceのジョブが異なれば、様々な構造を持っている可能性があります。
MapReduceジョブを簡単に説明すると、2つのフェーズ(MapフェーズとReduceフェーズ)の交互の繰返しといえます。各Mapフェーズでは、入力データのレコードごとに変換関数を適用し、キー/値のペアで表された一連のレコードが生成されます。Mapフェーズからの出力がReduceフェーズへの入力になります。Reduceフェーズでは、Mapの出力レコードがキー/値のセットにソートされ、1つのセット内ではすべてのレコードが同じキー値を持ちます。リデューサ関数がセット内の全レコードに適用され、キー/値のペアからなる一連の出力レコードが生成されます。Mapフェーズがレコードごとに論理的に並列実行されるのに対して、Reduceフェーズはすべてのキー値にわたって並列実行されます。
Oracle Big Data Connectorsを使用すると、CDHとOracle Databaseに格納されているデータ間のデータ・アクセスが簡単になります。コネクタはOracle Big Data Applianceとは別にライセンス供与され、次のものが含まれます。
|
関連項目: 『Oracle Big Data Connectorsユーザーズ・ガイド』 |
Oracle SQL Connector for Hadoop Distributed File System (Oracle SQL Connector for HDFS)は、外部表を使用してOracleデータベースからHDFSへの読取りアクセスを提供します。
外部表は、データベース外のデータの場所を識別するOracle Databaseオブジェクトです。Oracle Databaseは、外部表の作成時に指定されたメタデータを使用してデータにアクセスします。外部表への問合せによって、ユーザーは、データがデータベースの表に格納されている場合と同様に、HDFSに格納されているデータにアクセスできます。外部表は、データベースのロード時にデータをステージングして変換するために使用されることが多くあります。
Oracle SQL Connector for HDFSを使用すると、次のことができます。
Oracle Loader for Hadoopは、HadoopクラスタからOracle Databaseの表にデータをすばやく移動するための効率的でパフォーマンスのよいローダーです。様々な形式からデータを読取りおよびロードできます。Oracle Loader for Hadoopはデータをパーティション化し、Hadoop内でデータベースに対応した形式に変換します。必要に応じて、データのロードや出力ファイルの作成の前に主キーでレコードをソートします。ロードは、Hadoopクラスタ上でMapReduceジョブとして実行されます。
Oracle Data Integrator(ODI)は、様々なソースからOracle Databaseにデータを抽出、変換およびロードします。
ODIでは、ナレッジ・モジュール(KM)は、データ統合処理における特定のタスク専用のコード・テンプレートです。Oracle Data Integrator Studioを使用すると、特定のアプリケーション用にKMをロード、選択および構成できます。使用可能なKM数は150を超え、様々なサードパーティ製データベースやその他のデータ・リポジトリからデータを取得できます。ユーザーは、特定のジョブに対してKMをいくつかロードするだけですみます。
Oracle Data Integrator Application Adapter for Hadoopには、ビッグ・データ専用のKMが含まれています。
Oracle XQuery for Hadoopは、XQuery言語で表された変換を、Hadoopクラスタで並行して実行される一連のMapReduceジョブに変換して実行します。入力データは、HDFSまたはOracle NoSQL Databaseにあります。Oracle XQuery for Hadoopは、変換結果をHDFS、Oracle NoSQL DatabaseまたはOracle Databaseに書き込みます。
Oracle R Advanced Analytics for HadoopはRパッケージのコレクションであり、次の機能を提供します。
Hive表、Apache Hadoopの計算インフラストラクチャ、ローカルR環境およびデータベース表を操作するインタフェース
Hadoop MapReduceジョブとしてRまたはJavaで記述された予測分析手法(HDFSファイルのデータに適用可能)
単純なR関数を使用して、Rメモリー、ローカル・ファイル・システム、HDFS、Hive間でデータをコピーできます。Rでマッパーおよびリデューサを記述して、Hadoop MapReduceジョブとして実行し、それらの場所に結果を返すよう、Rプログラムをスケジュールできます。
Rは、統計分析とグラフ作成のためのオープンソース言語および環境です。Rでは、線形および非線形モデリング、標準統計メソッド、時系列分析、分類、クラスタリングおよびグラフィカル・データ表示の機能が提供されます。Comprehensive R Archive Network (CRAN)内に数千ものオープンソース・パッケージが用意されており、バイオインフォマティクス、空間統計、財務/マーケティング分析など、幅広いアプリケーションに使用できます。Rは、その機能の成熟化を受けて人気が高まっており、現在では、高コストなプロプライエタリ統計パッケージにも匹敵するほど進化しています。
アナリストは通常PC上でRを使用しますが、PCによって分析に使用できるデータの量と処理能力が制限されます。Oracle Big Data Applianceを直接利用するようRプラットフォームを拡張することで、この制限はなくなります。Oracle R Distributionは、Oracle Big Data Applianceのすべてのノードにインストールされます。
Oracle R Advanced Analytics for Hadoopを使用すると、RユーザーはHDFSとMapReduceプログラミング・フレームワークに、優れたパフォーマンスでネイティブにアクセスできます。これにより、Rプログラムを膨大なデータに対するMapReduceジョブとして実行できるようになります。Oracle R Advanced Analytics for HadoopはOracle Big Data Connectorsに付属しています。「Oracle R Advanced Analytics for Hadoop」を参照してください。
Oracle R Enterpriseは、Oracle DatabaseへのOracle Advanced Analyticsオプションのコンポーネントです。次のものを提供します。
Rからのデータ準備および統計分析のためのデータベース・データへの透過的アクセス
RとSQLの両方からアクセスできる、データベース・サーバーでのRスクリプトの実行
様々な予測およびデータ・マイニングのインデータベース・アルゴリズム
Oracle R Enterpriseを使用すると、Oracleデータベースにビッグ・データの分析の結果を格納することや、ダッシュボードおよびアプリケーションに表示するためにアクセスすることができます。
Oracle R Advanced Analytics for HadoopとOracle R Enterpriseの両方によって、統計のユーザーは、Oracle DatabaseやHadoopのネイティブ・プログラミング言語を習得することなく、これらの計算インフラストラクチャを使用できます。
|
関連項目:
|
ビッグ・データの変換とOracle Databaseへのロードが終了したら、Oracleのビジネス・インテリジェンス・ソリューションと意思決定を支援する製品を駆使して、すべてのデータの詳細な分析と視覚化を行うことができます。
|
関連項目:
|