4 Planning a Messaging Server Sizing Strategy
When you design your deployment, you must decide how to configure your Oracle Communications Messaging Server to provide optimum performance, scalability, and reliability.
Sizing is an important part of this effort. The sizing process enables you to identify what hardware and software resources are needed so that you can deliver your desired level of service or response time according to the estimated workload that your Messaging Server users generate. Sizing is an iterative effort.
This chapter provides information on the basics of sizing your Messaging Server deployment to enable you to obtain the right sizing data by which you can make deployment decisions. It also provides the context and rationale for the Messaging Server sizing process.
This chapter includes the following topics:
Note:
Because each deployment has its own set of unique features, this chapter does not provide detailed sizing information for your specific site. Rather, this chapter explains what you need to consider when you architect your sizing plan. Work with consulting for your deployment hardware and software needs.Collecting Messaging Server Sizing Data
Use this section to identify the data you need to size your Messaging Server deployment. The following topics are covered in this section:
Determining Messaging Peak Volume
Your peak volume is the largest concentrated numbers of transactions to your messaging system within a given period in a day. The volume can vary from site to site as well as across different classes of users. For example, peak volume among a certain class of managers in a medium-sized enterprise might occur from 9 a.m. to 10 a.m. in the morning, 12 p.m. to 1 p.m. in the afternoon, and 5 p.m. to 6 p.m. in the evening.
Analyzing peak volume involves three basic operations:
-
Determining when and for how long the peaks occur.
-
Sizing your deployment against peak volume load assumptions.
Once patterns are analyzed, choices can be made to help the system handle the load and provide the services that users demand.
-
Making sure that your Messaging Server deployment can support the peak volume that you have determined.
Creating Your Messaging Usage Profile
Measuring your load is important for accurate sizing. Your usage profile determines the factors that programs and processes place on your Messaging Server hosts.
This section helps you create your usage profile to measure the amount of load that is placed on your deployment.
To create a usage profile, answer the following questions:
-
What is the number of users on your system? When counting the number of users on your system, account for not only the users who have mail accounts and can log in to the mail system, but also the users with mail accounts who are currently not logged onto the system. In particular, note the difference between active and inactive users:
Table 4-1 Active and Inactive User Definitions
User Description Active User
A user who is logged into mail systems through mail access protocols like POP, IMAP, or HTTP. Depending on the type of access protocol, active users might or might not have connections to the mail server at any given time. For example, POP users can have a mail client open, but the POP connection established by the mail client to the server is short in duration and periodic. Active users in this discussion are not the same as mail attributes with active status, such as mailuserstatus or inetuserstatus. For more information, see the discussion on mail attributes in the Schema Reference.
Inactive User
A user with a mail account who currently is not using the mail system.
If you have a very small deployment (for example, under 300 users), you might not need to go through this process of planning a sizing strategy. Work with consulting to determine your individual needs.
-
How many connections are on your system during your peak volume for your POP, IMAP, and web client access services? Specifically, note the number of concurrent, idle, and busy connections for each client access service that you support:
Table 4-2 Messaging Server Connections
Connection Description Concurrent Connection
Number of unique TCP connections or sessions (HTTP, POP, or IMAP) that are established on your mail system at any given time. An active user can have multiple concurrent IMAP sessions, whereas a user with a POP or web client can only have one connection per client. Furthermore, because POP and web connections connect to the server, retrieve data, disconnect from the server, display data, get user input, and reconnect to the mail server, it is possible for active users on POP and web client access services not to have active connections at a given moment in time.
Idle Connection
An established IMAP connection where no information is being sent between the mail client and Messaging Server, except the occasional check or noop command.
Busy Connection
A connection that is in progress. An example of a busy connection is a mail server that is processing the command a mail client has just sent; the mail server is sending back a response to the mail client.
To determine the number of concurrent connections in your deployment, do one of the following:
-
Count the number of established TCP connections by using the netstat command on UNIX platforms.
-
Obtain the last login and logout times for web or for IMAP users. For more information, see the discussion on the imsconnutil command in the Messaging Server System Administrator's Guide.
-
-
If you have a large deployment, how will you organize your users? Some options include but are not limited to:
-
Placing active users and inactive users together on separate machines from one another. If an inactive user becomes an active user, that user can be moved to the active user machines. This approach could decrease the amount of needed hardware, rather than placing inactive and active users together on a machine.
-
Separating users by Class of Service. You might separate individual contributors, managers, and executives on machines that offer different mail storage space allocation for each class of service, different privileges, and specialized services.
-
-
What is the amount of storage used on each mailbox? When you measure the amount of storage per mailbox, you should estimate real usage per mailbox, not the specified quota. Messages in trash or wastebasket folders still take up disk space and quota.
-
How many messages enter your messaging system from the Internet? The number of messages should be measured in messages per second during your peak volume.
-
How many messages are sent by your users to:
-
End users on your mail system?
-
The Internet? This number of messages is also measured in messages per second during the peak volume.
-
-
What is the distribution of messages in different size ranges? For example:
-
Less than 5 Kbytes?
-
Between 5 Kbytes - 10 Kbytes?
-
Between 10 Kbytes - 100 Kbytes?
-
Between 100 Kbytes - 500 Kbytes?
-
Between 500 Kbytes - 10 MB?
-
Greater than 10 MB? If the distribution of message sizes is not available, use the average message size on your mail system, however it is not as effective as size ranges. The size of messages is particularly important, because it affects the rate of delivery of the MTA, the rate of delivery into the Message Store, the rate of message retrieval, and processing by anti-virus or anti-spam filters.
-
-
Will you be using SSL/TLS? If yes, what percentage of users and what type of users? For example, in a particular organization, 20 percent of IMAP connections during peak hours will enable SSL.
-
Do you plan on using any SSL crypto accelerator hardware?
-
Will you be using virus scanning or other specialized message processing and will this processing be enabled for all users? Depending on your Messaging Server configuration, the MTA will need to scan all messages to match criteria specified in specialized processing, thus increasing load on the system.
-
For POP users, will you have a policy restricting how often they can access mail? If so, how often?
-
For IMAP users, will you enforce a standard client or allow users to choose their own? Different IMAP clients make different numbers of concurrent connections to the server. Thus, a power user with many open folders might have many concurrent connections.
-
Will you allow users to share folders? If so, will you allow all users or only some?
Answering these questions provides a preliminary usage profile for your deployment. You can refine your usage profile as your Messaging Server needs change.
Additional Questions
While the following questions are not applicable to creating your usage profile, they are important to developing your sizing strategy. How you answer these questions might require you to consider additional hardware.
-
How much redundancy do you want in your deployment? For example, you might consider high availability. Consider how much down time is allowed, and if you need clustering technology.
-
What backup and restore strategy do you have in place (such as disaster recovery, mailbox restores, and site failover)? What are the expected times to accomplish recovery tasks?
-
Do you need a DMZ to separate your internal and external networks? Are all users using the internal network? Or do some of them connect by using the Internet? You might need MMP proxy servers and separate MTA layers.
-
What are your response time requirements? What are your throughput requirements?
-
What is your specific criteria for resource utilization? Can your CPUs be 80 percent busy on average? Or only at peak?
-
Will you have messaging servers at different geographic locations? Do you expect users' mail to be located geographically?
-
Do you have archiving requirements for keeping mail messages for a certain length of time?
-
Do you have legal requirements to log all messages? Do you need to keep a copy of every message sent and received?
Defining Your Messaging User Base
Once you establish a usage profile, compare it to sample pre-defined user bases that are described in this section. A user base is made up of the types of messaging operations that your users will perform along with a range of message sizes that your users will send and receive. Messaging users fall into one of five user bases:
The sample user bases described in this section broadly generalize user behavior. Your particular usage profile might not exactly match the user bases. You will be able to adjust these differences when you run your load simulator (as described in "Using a Messaging Server Load Simulator").
Lightweight POP
A lightweight POP user base typically consists of residential dial-up users with simple messaging requirements. Each concurrent client connection sends approximately four messages per hour. These users read and delete all of their messages within a single login session. In addition, these users compose and send few messages of their own with just single recipients. Approximately 80 percent of messages are 5 Kbytes or smaller in size, and about 20 percent of messages are 10 Kbytes or larger.
Heavyweight POP
A heavyweight POP user base typically consists of premium broadband users or small business accounts with more sophisticated messaging requirements than the lightweight POP user base. This group uses cable modem or DSL to access its service provider. Each concurrent client connection sends approximately six messages per hour. Messages average about two recipients per message. Sixty-five percent of messages are 5 Kbytes or smaller in size. Thirty percent of messages in this user base are between 5-10 Kbytes. Five percent of messages are larger than 1 Mbyte. Of these users, 85 percent delete all of their messages after reading them. However, 15 percent of users leave messages on the server through several logins before they delete them. Mail builds up in a small portion of those mailboxes. In some cases, the same message can be fetched several times from the server.
Lightweight IMAP
A lightweight IMAP user base represents users that enable premium broadband Internet services, including most of the advanced features of their messaging systems like message searching and client filters. This user base is similar to heavyweight POP with regard to message sizes, number of recipients, and number of messages sent and received by each concurrent connection. Lightweight IMAP users typically log in for hours at a time and delete most or all mail before log out. Consequently, mail stacks up in a mailbox during a login session, but user generally do not store more than 20 to 30 messages in their mailboxes. Most inboxes contain less than 10 messages.
Mediumweight IMAP
A mediumweight IMAP user base represents sophisticated enterprise users with login sessions lasting most of an eight hour business day. These users send, receive, and keep a large amount of mail. Furthermore, these users have unlimited or very large message quotas. Their inboxes contain a large amount of mail that grows during the day, and is fully or partially purged in large spurts. They regularly file messages into folders and search for messages multiple times per hour. Each concurrent client connection sends approximately eight messages per hour. These users send messages with an average of four recipients and have the same message size mix as the Heavyweight POP and Lightweight IMAP user bases.
Mediumweight Convergence
A mediumweight Convergence user base is similar to Mediumweight IMAP. This user base has the same message size mix as Mediumweight IMAP, Lightweight IMAP, and Heavyweight POP. And, the message delivery rates are the same as Mediumweight IMAP users.
It is likely that you will have more than one type of user base in your organization, particularly if you offer more than one client access option. Once you identify your user bases from these categories, you will test them with your usage profile and with a load simulator, described in "Using a Messaging Server Load Simulator."
Using a Messaging Server Load Simulator
To measure the performance of your Messaging Server, use your messaging user base (described in "Defining Your Messaging User Base") and your messaging usage profile (described in "Creating Your Messaging Usage Profile") as inputs into a load simulator.
A load simulator creates a peak volume environment and calibrates the amount of load placed on your servers. You can determine if you need to alter your hardware, throughput, or deployment architecture to meet your expected response time, without overloading your system.
To Use a Load Simulator
-
Define the user base that you want to test (for example, Lightweight IMAP). If necessary, adjust individual parameters to best match your usage profile.
-
Define the hardware that will be tested.
-
Run the load simulator and measure the maximum number of concurrent connections on the tested hardware with the user base.
-
Publish your results and compare those results with production deployments.
-
Repeat this process using different user bases and hardware until you get the response time that is within an acceptable range for your organization under peak load conditions.
Note:
Contact consulting for recommended load simulators and support.
Assessing Your Messaging Server System Performance
Once you evaluate your hardware and user base with a load simulator, you need to assess your system performance. The following topics address methods by which you can improve your overall system performance.
Messaging Server Memory Utilization
Make sure you have an adequate amount of physical memory on each machine in your deployment. Additional physical memory improves performance and enables the server to operate at peak volume. Without sufficient memory, Messaging Server cannot operate efficiently without excessive swapping.
At minimum, be sure to have 1 GB of memory per CPU. For most deployments, you will want 2 GB of memory per CPU.
Messaging Server Disk Throughput
Disk throughput is the amount of data that your system can transfer from memory to disk and from disk to memory. The rate at which this data can be transferred is critical to the performance of Messaging Server. To create efficiencies in your system's disk throughput:
-
Consider your maintenance operations, and ensure you have enough bandwidth for backup. Backup can also affect network bandwidth particularly with remote backups. Private backup networks might be a more efficient alternative.
-
Carefully partition the store and separate store data items (such as tmp and db) to improve throughput efficiency.
-
Ensure the user base is distributed across RAID (Redundant Array of Independent Disks) environments in large deployments.
-
Stripe data across multiple disk spindles in order to speed up operations that retrieve data from disk.
-
Allocate enough CPU resources for RAID support, if RAID does not exist on your hardware.
You want to measure disk I/O in terms of IOPS (total I/O operations per second) not bandwidth. You need to measure the number of unique disk transactions the system can handle with a very low response time (less than 10 milliseconds).
Messaging Server Disk Capacity
When planning server system disk space, you need to be sure to include space for operating environment software, Messaging Server software, and message content and tracking. Be sure to use an external disk array if availability is a requirement. For most systems, external disks are required for performance because the internal system disks supply no more than four spindles.
For the Message Store partitions, the storage requirement is the total size of all messages plus 30 percent overhead.
In addition, user disk space needs to be allocated. Typically, this space is determined by your site's policy.
Note:
Your deployment planning needs to include how you want to back up the Message Store for disaster recovery. Messaging Server supports Solstice Backup (Legato Networker), the imsbackup utility, and file system snapshot backup. You might want to store your backup media remotely. The more frequently you perform a backup, the better, as long as it does not impact server operations.Disk Sizing for MTA Message Queues
The behavior of the Messaging Server MTA Queue is to provide a transient store for messages waiting to be delivered. Messages are written to disk in a persistent manner to maintain guaranteed service delivery. If the MTA is unable to deliver the message, it will retry until it finally gives up and returns the message to the sender.
Message Queue Performance
Sizing the MTA Queue disks are an important step for improving MTA performance. The MTA's performance is directly tied to disk I/O first above any other system resource. This means that you should plan on disk volume that consists of multiple disk spindles, which are concatenated and stripped by using a disk RAID system.
End users are quickly affected by the MTA performance. As users press the SEND button on their email client, the MTA will not fully accept receipt of the message until the message has been committed to the Message Queue. Therefore, improved performance on the Message Queue results in better response times for the end-user experience.
Message Queue Availability
SMTP services are considered a guaranteed message delivery service. This is an assurance to end users that the Messaging Server will not lose messages that the service is attempting to deliver. When you architect the design of the MTA Queue system, all effort should be made to ensure that messages will not be lost. This guarantee is usually made by implementing redundant disk systems through various RAID technologies.
Message Queue Available Disk
The queue will grow excessively if one of the following conditions occurs:
-
The site has excessive network connectivity issues
-
The MTA configuration is holding on to messages too long
-
There are valid problems with those messages (not covered in this document)
The following sections address these issues.
Planning for Network Connectivity Issues
Occasionally the MTA is unable to deliver messages due to network connectivity issues. In these cases, the messages will be stored on the queue until the next time the MTA is able to attempt to deliver (as defined by the retry interval).
Planning on disk space for these outages is based on a simple rule, the ”General Rule for Message Queue Sizing:”
-
Determine average number of messages/minute expected to be delivered (N).
-
Determine average size (kb) of messages (S).
-
Determine maximum duration (minutes) of typical network connectivity outages (T).
Thus, the formula for estimating the Disk Queue Size is:
Disk Queue Size (kb) = N x S x T
Tuning MTA for Reattempts of Delivery
Occasionally, the system will not be able to deliver any messages. In this state, messages will reside on the message queue while the MTA attempts to set aside the messages for a period of time (retry interval) until it reattempts the delivery. This will continue until the MTA gives up and returns the message to the sender. The reason a message is undeliverable is fairly unpredictable. A number of reasons such as network connectivity, busy destination server, network throttles, and so on, could explain why the message is undeliverable.
On a busy server, these temporarily stored messages can build up during periods of high volume activities. Such a build-up can potentially cause problems with disk space. To avoid these build-ups, tune the MTA to retry delivery at a faster rate.
The retry interval is set within the Channel Block configurations of the imta.cnf file. The structure of this file consists of two parts: rewrite rules and channel blocks. The channel blocks define the behavior of a particular disk queue and related processes. This discussion refers to the tcp_local channel. The tcp_local channel provides delivery to sites outside an enterprise's local network, in other words, to places over the Internet.
The retry interval setting of the tcp_local channel is initially set by the default channel block. The default channel block allows settings to be duplicated to avoid having repeated settings.
The following is the default channel block:
defaults notices 1 2 4 7 copywarnpost copysendpost postheadonly noswitchchannel immnonurgent maxjobs 7 defaulthost red.example.com red.example.com
First, the structure of the channel block consists of the channel name. In the example above, this is the default channel block, which will be applied to channels without these settings. The second part is a list of channel keywords.
The notices keyword specifies the amount of time that can elapse before message delivery notices (MDNs) are sent back to the sender. This keyword starts with the notices keyword followed by a set of numbers, which set the retry period. By default, the MTA will attempt delivery and send notices back to the sender. These notices come from ”postmaster” to end-user inboxes.
In this example, the MTA will retry at a period of 1 day, 2 days, and 4 days. At 7 days, the MTA will return the message and regard the message as a failed delivery.
In many cases, the default setting of the MTA provides adequate performance. In some cases, you need to tune the MTA to avoid potential resource exhaustions, such as running out disk space for message queues. This is not a product limitation, but a limitation of the total Messaging Server system, which includes hardware and network resources.
In consideration of these possible disk size issues, deployments with a large number of users may not want to attempt message deliveries for much shorter intervals. If this is the case, study the documentation listed below.
Further Readings
Refer to the following documentation for more information.
-
See the discussion on how to set notification message delivery in the Messaging Server System Administrator's Guide.
-
See the discussion on configuring channel definitions in the Messaging Server System Administrator's Guide.
Messaging Server Network Throughput
Network throughput is the amount of data at a given time that can travel through your network between your client application and server. When a networked server is unable to respond to a client request, the client typically retransmits the request a number of times. Each retransmission introduces additional system overhead and generates more network traffic.
You can reduce the number of retransmissions by improving data integrity, system performance, and network congestion:
-
To avoid bottlenecks, ensure that the network infrastructure can handle the load.
-
Partition your network. For example, use 100 Mbps Ethernet for client access and 1 GB Ethernet for the backbone.
-
To ensure that sufficient capacity exists for future expansion, do not use theoretical maximum values when configuring your network.
-
Separate traffic flows on different network partitions to reduce collisions and to optimize bandwidth use.
Performance Tuning Considerations for a Messaging Server Architecture
This information describes how to evaluate the performance characteristics of Messaging Server components to accurately develop your architecture and ensure proper tuning of the deployment.
The topics in this section include:
Message Store Performance Considerations
Message Store performance is affected by a variety of factors, including:
-
Disk I/O
-
Inbound message rate (also known as message insertion rate)
-
Message sizes
-
Use of S/MIME
-
Login rate (POP/IMAP/HTTP)
-
Transaction rate for IMAP and HTTP
-
Concurrent number of connections for the various protocols
-
Network I/O
-
Use of SSL
The preceding factors list the approximate order of impact to the Message Store. Most performance issues with the Message Storage arise from insufficient disk I/O capacity. Additionally, the way in which you lay out the store on the physical disks can also have a performance impact. For smaller standalone systems, it is possible to use a simple stripe of disks to provide sufficient I/O. For most larger systems, segregate the file system and provide I/O to the various parts of store.
In addition to tuning the Message Store, you need to protect the Message Store from loss of data. The level of loss and continuous availability that is necessary varies from simple disk protection such as RAID5, to mirroring, to routine backup, to real time replication of data, to a remote data center. Data protection also varies from the need for Automatic System Recovery (ASR) capable machines, to local HA capabilities, to automated remote site failover. These decisions impact the amount of hardware and support staff required to provide service.
Messaging Server Directories
Messaging Server uses six directories that receive a significant amount of input and output activity. If you require a deployment that is scalable, responsive, and resilient to variations in load, provide each of those directories with sufficient I/O bandwidth. When you provide separate file systems for these directories, each composed of multiple drives, you can more readily diagnose I/O bottlenecks and problems. Also, you can isolate the effect of storage failures and simplify the resulting recovery operations. In addition, place a seventh directory for DB snapshots on a file system separate from the active DB to preserve it in the event of a storage failure of the active DB file system.
Table 4-3 describes these directories.
Table 4-3 High Access Messaging Server Directories
| High I/O Directory | Description and Defining Options |
|---|---|
|
MTA queue directory |
In this directory, many files are created, one for each message that passes through each MTA channel. After the file is sent to the next destination, the file is then deleted. The directory is located at /var/MessagingServer_home/queue. After moving it to another file system, replace /var/MessagingServer_home/queue with a softlink. Also see the subdirs channel option. |
|
Messaging Server log directory |
This directory contains log files which are constantly being appended with new logging information. The number of changes will depend on the logging level set. The directory location is controlled by the msconfig option *.logfile.logdir (Unified Configuration) or the configutil option logfile.*.logdir (legacy configuration), where * can be a log-generating component such as admin, default, HTTP, IMAP, or POP. To change the location of the MTA log files, replace /var/MessagingServer_home/log with a softlink. |
|
Mailbox database files |
These files require constant updates as well as cache synchronization. Put this directory on your fastest disk volume. These files are always located in the /var/MessagingServer_home/store/mboxlist directory. |
|
Message store index files |
These files contain meta information about mailboxes, messages, and users. By default, these files are stored with the message files. The msconfig option partition:*.path (Unified Configuration) or configutil option store.partition.*.path (legacy configuration), where * is the name of the partition, controls the directory location. If you have the resources, put these files on your second fastest disk volume. Default location: /var/MessagingServer_home/store/partition/primary |
|
Message files |
These files contain the messages, one file per message. Files are frequently created, never modified, and eventually deleted. By default, they are stored in the same directory as the message store index files. The location can be controlled with the msconfig option partition:*.messagepath (Unified Configuration) or the configutil option store.partition.*.messagepath (legacy configuration), where * is the name of the partition. Some sites might have a single message store partition called primary specified by partition:primary.path (Unified Configuration) or store.partition.primary.path (legacy configuration). Large sites might have additional partitions that can be specified with store.partition.partition_name.messagepath, where partition_name is the name of the partition. Default location: /var/MessagingServer_home/store/partition/primary |
|
Mailbox list database temporary directory |
The directory used by the Message Store for database temporary files. To maximize performance, this directory should be located under the fastest file system. The default value is /tmp/.ENCODED_SERVERROOT/store/, where ENCODED_SERVERROOT is composed of the mail server user plus the value of $SERVERROOT with the backslash (\) replaced by _. |
|
Lock directory |
DB temporary files used for locking other resources. Use a tmpfs directory similar to store.dbtmpdir, but do NOT use the same directory. For example, msconfig uses base.lockdir (Unified Configuration), or configutil -o local.lockdir -v /tmp/msgDBlockdir for legacy configuration. Be sure to use a unique name so the same directory cannot be used by any other instance of Messaging Server. Default location: /var/MessagingServer_home/lock |
The following sections provide more detail on Messaging Server high access directories.
MTA Queue Directories
In non-LMTP environments, the MTA queue directories in the Message Store system are also heavily used. LMTP works such that inbound messages are not put in MTA queues but directly inserted into the store. This message insertion lessens the overall I/O requirements of the Message Store machines and greatly reduces use of the MTA queue directory on Message Store machines. If the system is standalone or uses the local MTA for Webmail sends, significant I/O can still result on this directory for outbound mail traffic. In a two-tiered environment using LMTP, this directory will be lightly used, if at all. In prior releases of Messaging Server, on large systems this directory set needs to be on its own stripe or volume.
MTA queue directories should usually be on their own file systems, separate from the message files in the Message Store. The Message Store has a mechanism to stop delivery and appending of messages if the disk space drops below a defined threshold. However, if both the log and queue directories are on the same file system and keep growing, you will run out of disk space and the Message Store will stop working.
Also, refer to the subdirs channel option. If a channel will often contain many messages, it may be necessary to increase the number of subdirectories for that channel queue directory.
Log Files Directory
The log files directory requires varying amounts of I/O depending on the level of logging that is enabled. The I/O on the logging directory, unlike all of the other high I/O requirements of the Message Store, is asynchronous. For typical deployment scenarios, do not dedicate an entire Logical Unit Number (LUN) for logging. For very large store deployments, or environments where significant logging is required, a dedicated LUN is in order.
mboxlist Directory
The mboxlist directory is highly I/O intensive but not very large. The mboxlist directory contains the databases that are used by the stores and their transaction logs. Because of its high I/O activity, and due to the fact that the multiple files that constitute the database cannot be split between different file systems, you should place the mboxlist directory on its own stripe or volume in large deployments. This is also the most likely cause of a loss of vertical scalability, as many procedures of the Message Store access the databases. For highly active systems, this can be a bottleneck. Bottlenecks in the I/O performance of the mboxlist directory decrease not only the raw performance and response time of the store but also impact the vertical scalability. For systems with a requirement for fast recovery from backup, place this directory on Solid State Disks (SSD) or a high performance caching array to accept the high write rate that an ongoing restore with a live service will place on the file system.
Multiple Store Partitions
The Message Store supports multiple store partitions. Place each partition on its own stripe or volume. The number of partitions that should be put on a store is determined by a number of factors. The obvious factor is the I/O requirements of the peak load on the server. By adding additional file systems as additional store partitions, you increase the available IOPS (total IOs per second) to the server for mail delivery and retrieval. In most environments, you will get more IOPS out of a larger number of smaller stripes or LUNs than a small number of larger stripes or LUNs.
With some disk arrays, it is possible to configure a set of arrays in two different ways. You can configure each array as a LUN and mount it as a file system. Or, you can configure each array as a LUN and stripe them on the server. Both are valid configurations. However, multiple store partitions (one per small array or a number of partitions on a large array striping sets of LUNs into server volumes) are easier to optimize and administer.
Raw performance, however, is usually not the overriding factor in deciding how many store partitions you want or need. In corporate environments, it is likely that you will need more space than IOPS. Again, it is possible to software stripe across LUNs and provide a single large store partition. However, multiple smaller partitions are generally easier to manage. The overriding factor of determining the appropriate number of store partitions is usually recovery time.
Recovery times for store partitions fall into a number of categories:
-
First of all, the fsck command can operate on multiple file systems in parallel on a crash recovery caused by power, hardware, or operating system failure. If you are using a journaling file system (highly recommended and required for any HA platform), this factor is small.
-
Secondly, backup and recovery procedures can be run in parallel across multiple store partitions. This parallelization is limited by the vertical scalability of the mboxlist directory as the Message Store uses a single set of databases for all of the store partitions. Store cleanup procedures (expire and purge) run in parallel with one thread of execution per store partition.
-
Lastly, mirror or RAID re-sync procedures are faster with smaller LUNs. There are no hard and fast rules here, but the general recommendation in most cases is that a store partition should not encompass more than 10 spindles.
The size of drive to use in a storage array is a question of the IOPS requirements versus the space requirements. For most residential ISP POP environments, use ”smaller drives.” Corporate deployments with large quotas should use ”larger” drives. Again, every deployment is different and needs to examine its own set of requirements.
Message Store Processor Scalability
The Message Store scales well, due to its multiprocess, multithreaded nature. The Message Store actually scales more than linearly from one to four processors. This means that a four processor system will handle more load than a set of four single processor systems. The Message Store also scales fairly linearly from four to 12 processors. From 12 to 16 processors, there is increased capacity but not a linear increase. The vertical scalability of a Message Store is more limited with the use of LMTP although the number of users that can be supported on the same size store system increases dramatically.
Setting the Mailbox Database Cache Size
Messaging Server makes frequent calls to the mailbox database. For this reason, it helps if this data is returned as quickly as possible. A portion of the mailbox database is cached to improve Message Store performance. Setting the optimal cache size can make a big difference in overall Message Store performance. You set the size of the cache with the store.dbcachesize option.
The store.dbcachesize option defaults to /tmp/.ENCODED_SERVERROOT/store/, where ENCODED_SERVERROOT is composed of the mail server user plus the value of $SERVERROOT with the backslash (\) replaced by _. For example: /tmp/.mailsrv_opt_sun_comms_messaging64/store/
The files stored in the store.dbtmpdir location are temporarily memory mapped files used by all processes connecting to the database. Due to their usage pattern, the pages of these files will most likely be in memory all the time. So setting this to be on a tempfs will not really increase memory usage. What it will do is save I/O. When the Oracle Solaris virtual memory system sees a memory mapped file is on a tempfs, it knows it does not really need to write the modified pages back to the file. So there is only one copy in memory and it saves I/O.
The mailbox database is stored in data pages. When the various daemons make calls to the database (stored, imapd, popd), the system checks to see if the desired page is stored in the cache. If it is, the data is passed to the daemon. If not, the system must write one page from the cache back to disk, and read the desired page and write it in the cache. Lowering the number of disk read/writes helps performance, so setting the cache to its optimal size is important.
If the cache is too small, the desired data will have to be retrieved from disk more frequently than necessary. If the cache is too large, dynamic memory (RAM) is wasted, and it takes longer to synchronize the disk to the cache. Of these two situations, a cache that is too small will degrade performance more than a cache that is too large.
Cache efficiency is measured by hit rate. Hit rate is the percentage of times that a database call can be handled by cache. An optimally sized cache will have a 98 to 99 percent hit rate (that is, 98 to 99 percent of the desired database pages will be returned to the daemon without having to grab pages from the disk). The goal is to set the smallest cache so that it holds a number of pages such that the cache will be able to return at least 98 to 99 percent of the requested data. If the direct cache return is less than 98 percent, then you need to increase the cache size.
To Adjust the Mailbox Database Cache Size
Set the size of the cache with the msconfig option (Unified Configuration) or configutil option (legacy configuration) to store.dbcachesize.
It is important to tune the cache size to smallest size that will accomplish the desired hit rate.
The store.dbcachesize controls the size of a shared memory segment used by all processes connected to the database, including stored, imap, popd, imsbackup, imsrestore, ims_master, tcp_lmtp_server, and so on. While the maximum value for store.dbcachesize is 2 GB, setting it to the maximum consumes half of the 32-bit address space of your those processes. Instead, start with the default value of 16 MB and monitor the cache hit rate over a period of days. Increase the value only if the hit rate is under 98 percent.
Also consider the transaction checkpoint function (performed by stored). Set the msconfig option (Unified Configuration) or configutil option (legacy configuration) to store.checkpoint.debug and refresh stored to see log messages to provide more exact data about transaction checkpoint function time. This process must examine all buffers in the cache and hold a region lock during the checkpoint. Other threads needing the lock must wait.
To Monitor the Mailbox Database Cache Size
Use the imcheck command to measure the cache hit rate:
imcheck -s mpool > imcheck-s.out
In this example, Messaging Server is installed in /opt/sun/comms/messaging64 and store.dbtmpdir is set to /tmp/msgDBtmpdir.
su mailsrv LD_LIBRARY_PATH=/opt/sun/comms/messaging64/lib export LD_LIBRARY_PATH /opt/sun/comms/messaging64/lib/db_stat -m -h /tmp/msgDBtmpdir > dbstat-m.out
Find the cache information section in the output file, for example:
2MB 513KB 604B Total cache size. 1 Number of caches. 1 Maximum number of caches 2MB 520KB Pool individual cache size.
There will be several blocks of output- a summary and one for each database file- look for these lines in each block:
0 Requested pages mapped into the process' address space. 55339 Requested pages found in the cache (99%).
In this case, the hit rate is 99 percent. This could be optimal or, more likely, it could be that the cache is too large. To test, lower the cache size until the hit rate moves to below 99 percent. When you hit 98 percent, you have optimized the DB cache size. Conversely, if see a hit rate of less than 95 percent, then you should increase the cache size with the store.dbcachesize option.
As your user base changes, the hit rate can also change. Periodically check and adjust this option as necessary.
Setting Disk Stripe Width
When setting disk striping, the stripe width should be about the same size as the average message passing through your system. A stripe width of 128 blocks is usually too large and has a negative performance impact. Instead, use values of 8, 16, or 32 blocks (4, 8, or 16 kilobyte message respectively).
MTA Performance Considerations
MTA performance is affected by a number of factors including, but not limited to:
-
Disk performance
-
Use of SSL
-
The number of messages/connections inbound and outbound
-
The size of messages
-
The number of target destinations/messages
-
The speed and latency of connections to and from the MTA
-
The need to do spam or virus filtering
-
The use of Sieve rules and the need to do other message parsing (like use of the conversion channel)
The MTA is both CPU and I/O intensive. The MTA reads from and writes to two different directories: the queue directory and the logging directory. For a small host (four processors or less) functioning as an MTA, you do not need to separate these directories on different file systems. The queue directory is written to synchronously with fairly large writes. The logging directory is a series of smaller asynchronous and sequential writes. On systems that experience high traffic, consider separating these two directories onto two different file systems.
In most cases, you will want to plan for redundancy in the MTA in the disk subsystem to avoid permanent loss of mail in the event of a spindle failure. (A spindle failure is by far the single most likely hardware failure.) This implies that either an external disk array or a system with many internal spindles is optimal.
MTA and Raid Trade-offs
There are trade-offs between using external hardware RAID controller devices and using JBOD arrays with software mirroring. The JBOD approach is sometimes less expensive in terms of hardware purchase but always requires more rack space and power. The JBOD approach also marginally decreases server performance, because of the cost of doing the mirroring in software, and usually implies a higher maintenance cost. Software RAID5 has such an impact on performance that it is not a viable alternative. For these reasons, use RAID5 caching controller arrays if RAID5 is preferred.
MTA and Processor Scalability
The MTA does scale linearly beyond eight processors, and like the Message Store, more than linearly from one processor to four.
MTA and High Availability
It is rarely advisable to put the MTA under HA control, but there are exceptional circumstances where this is warranted. If you have a requirement that mail delivery happens in a short, specified time frame, even in the event of hardware failure, then the MTA must be put under HA software control. In most environments, simply increase the number of MTAs that are available by one or more over the peak load requirement. This ensures that proper traffic flow can occur even with a single MTA failure, or in very large environments, when multiple MTAs are offline for some reason.
In addition, with respect to placement of MTAs, you should always deploy the MTA inside your firewall.
MMP Performance Considerations
The MMP runs as a single multithreaded process and is CPU and network bound. It uses disk resources only for logging. The MMP scales most efficiently on two processor machines, scales less than linearly from two to four processors and scales poorly beyond four processors. Two processor, rack mounted machines are good candidates for MMPs.
In deployments where you choose to put other component software on the same machine as the MMP (Messaging Server front end, Convergence web container, LDAP proxy, and so on), look at deploying a larger, four processor SPARC machine. Such a configuration reduces the total number of machines that need to be managed, patched, monitored, and so forth.
MMP sizing is affected by connection rates and transaction rates. POP sizing is fairly straight forward, as POP connections are rarely idle. POP connections connect, do some work, and disconnect. IMAP sizing is more complex, as you need to understand the login rate, the concurrency rate, and the way in which the connections are busy. The MMP is also somewhat affected by connection latency and bandwidth. Thus, in a dial up environment, the MMP will handle a smaller number of concurrent users than in a broadband environment, as the MMP acts as a buffer for data coming from the Message Store to the client.
If you use SSL in a significant percentage of connections, install a hardware accelerator.
MMP and High Availability
Never deploy the MMP under HA control. An individual MMP has no static data. In a highly available environment, add one or more additional MMP machines so that if one or more are down there is still sufficient capacity for the peak load. If you are using Sun Fire Blade Server hardware, take into account the possibility that an entire Blade rack unit can go down and plan for the appropriate redundancy.
MMP and Webmail Server
You can put the MMP and Webmail Server on the same set of servers. The advantage of doing so is if a small number of either MMPs or Webmail Servers is required, the amount of extra hardware for redundancy is minimized. The only possible downside to co-locating the MMP and Webmail Server on the same set of servers is that a denial of service attack on one protocol can impact the others.
File System Performance Considerations
For a small but perceptible performance gain, you should enable noatime on your Messaging Server file systems. By default, the file system is mounted with normal access time (atime) recording. If you specify noatime, then the file system ignores the access time updates on files, reducing disk activity.
To enable noatime, edit the /ect/vfstab file's options field, for example:
/dev/dsk/c1d0s0 /dev/rdsk/c1d0s0 / ufs 1 no noatime
ZFS also has atime on by default as well, so you should change that to off. Use the zfs set command, for example:
zfs set atime=off tank/home
CPU Considerations
-
For sites which use IMAP heavily, set service.imap.numprocesses to the number of CPUs (or cores on CMT systems) divided by 4.
-
For POP sites, set service.pop.numprocesses to the number of CPUs (or cores on CMT systems) divided by 2.
Performance Tuning Realtime BlockLists (RBL) Lookups
The dns_verify.so Messaging Server plugin provides a mechanism to block emails based on DNS Realtime Blocklists (RBL) data. RBL Blocklists provided by organizations such as Spamhaus (see http://www.spamhaus.org/) provide an excellent mechanism to reduce the number of emails that are sent from IP addresses of hosts that are known or highly-likely to send spam or bulk unsolicited emails.
This section contains the following topics:
Performance Discussion
The use of DNS RBL lookups to reduce spam email comes at the cost of some additional CPU and network utilisation plus increased time to accept email messages due to DNS resolution delays.
The additional CPU and network utilisation tends to be negated by the overall reduction in email processing due to less spam emails – and therefore less overall emails. The increased time to accept email messages due to DNS resolution delays is a very-real issue that results in a bottleneck in the rate that emails can be accepted.
The most efficient point to see if the IP address of the connecting host is listed in a DNS Realtime Blocklists is at the initial connection state. The PORT_ACCESS mapping table is the first table that is checked, and therefore this is the table most commonly used to perform the dns_verify.so library callout.
In Messaging Server 6.2 and below, the PORT_ACCESS mapping table is only checked by the dispatcher process by default. The dispatcher process uses a single-thread-per-listen-port model e.g. port 25 (SMTP) is one thread, port 587 (SMTP_SUBMIT) is another thread.
As the dispatcher uses a single-thread-per-listen-port, the rate at which an initial email connection can be accepted, compared against the PORT_ACCESS mapping table and then handed off to the multi-threaded tcp_smtp_server process will depend on the time taken for the PORT_ACCESS mapping table comparison to be performed.
Large DNS resolution times in the dns_verify.so callout will therefore cause a bottleneck in the rate connections can be accepted and handed off. The common symptom of this bottleneck is for a system to take a long time to return the initial SMTP banner when the system is either under heavy client connection load or experiencing large DNS resolution times.
Relevant Changes in Messaging Server
Two changes made in Messaging Server 6.3 directly impact the overall performance of dns_verify.so lookups.
Messaging Server 6.3
RFE (Request For Enhancement) #6322877 - ”Have SMTP server processes respect the overall result of their PORT_ACCESS probes” was implemented in Messaging Server 6.3. This resulted in the PORT_ACCESS mapping table being unconditionally checked twice for any given connection. Once in the dispatcher, and a second time in the tcp_smtp_server process.
Two newly documented flags, $:A and $:S, control whether a PORT_ACCESS rule should only be checked at the dispatcher or tcp_smtp_server level.
As a result of this change, dns_verify.so callouts in the PORT_ACCESS table may be called twice, thus increasing load on DNS resolution infrastructure.
Messaging Server 6.3 (patch 120228-25 and above)
Bug #6590888 - ”MS6.3: SMTP server processes not respecting result of PORT_ACCESS probes” was fixed in 120228-25 and above. Prior to this bug fix, it was not possible to have a dns_verify.so callout drop (reject) an email connection if the callout was only performed at the tcp_smtp_server level (i.e. the $:S flag was used).
Hints and Tips
This section discusses the following topics:
Prevention is better then cure. Careful rearrangement and modification of mapping table rules can assist in reducing the overall number of DNS lookups that are performed and therefore improve the rate that emails can be accepted.
-
Use absolute DNS lookups by adding a ”.” to the end of the domain
Using a relative domain lookup e.g. zen.spamhaus.org vs. an absolute lookup e.g. zen.spamhaus.org. will result in unnecessary lookups. The number of additional lookups will depend on the systems /etc/resolv.conf configuration. A configuration with numerous 'search' domains defined will result in an equivalent number of additional lookups.
(relative domain lookup - a single search domain defined: aus.sun.com)
TCP|*|25|*|* $C$[IMTA_LIB:dns_verify.so,dns_verify_domain_port,$1,zen.spamhaus.org,Your$ host$ ($1)$ found$ on$ spamhaus.org$ RBLblock$ list]$T$E
mailserver.aus.sun.com -> dns.Aus.Sun.COM DNS C 3.100.168.192.zen.spamhaus.org. Internet TXT ? dns.Aus.Sun.COM -> mailserver.aus.sun.com DNS R Error: 3(Name Error) mailserver.aus.sun.com -> dns.Aus.Sun.COM DNS C 3.100.168.192.zen.spamhaus.org. Internet Addr ? dns.Aus.Sun.COM -> mailserver.aus.sun.com DNS R Error: 3(Name Error) mailserver.aus.sun.com -> dns.Aus.Sun.COM DNS C 3.100.168.192.zen.spamhaus.org.aus.sun.com. Internet Addr ? dns.Aus.Sun.COM -> mailserver.aus.sun.com DNS R Error: 3(Name Error)
(absolute domain lookup - one less lookup compared to relative domain lookup)
TCP|*|25|*|* $C$[IMTA_LIB:dns_verify.so,dns_verify_domain_port,$1,zen.spamhaus.org.,Your$ host$ ($1)$ found$ on$ spamhaus.org$ RBLblock$ list]$T$E
mailserver.aus.sun.com -> dns.Aus.Sun.COM DNS C 3.100.168.192.zen.spamhaus.org. Internet TXT ? dns.Aus.Sun.COM -> mailserver.aus.sun.com DNS R Error: 3(Name Error) mailserver.aus.sun.com -> dns.Aus.Sun.COM DNS C 3.100.168.192.zen.spamhaus.org. Internet Addr ? dns.Aus.Sun.COM -> mailserver.aus.sun.com DNS R Error: 3(Name Error)
-
Restrict the rule to port 25 and non-internal IP addresses (after the INTERNAL_IP)
To avoid unnecessary lookups for internal systems, place the RBL DNS lookup rule after the default INTERNAL_IP PORT_ACCESS rule and restrict the rule to port 25 only as this prevents internal systems from being accidentally blocked and stops email submission (port 587/465) from being checked e.g.
PORT_ACCESS ! TCP|server-address|server-port|client-address|client-port *|*|*|*|* $C$|INTERNAL_IP;$3|$Y$E TCP|*|25|*|* $C$:S$[IMTA_LIB:dns_verify.so,dns_verify_domain_port,$1,zen.spamhaus.org.,Your$ host$ ($1)$ found$ on$ spamhaus.org$ RBLblock$ list]$T$E * $YEXTERNAL
-
Use the appropriate mapping table modifier for your version of Messaging Server
If you have MS6.3 patch 120228-24 or below:
Use $:A to halve the number of lookups e.g.
TCP|*|25|*|* $C$:A$[IMTA_LIB:dns_verify.so,dns_verify_domain_port,$1,zen.spamhaus.org.,Your$ host$ ($1)$ found$ on$ spamhaus.org$ RBLblock$ list]$T$E
If you have MS6.3 patch 120228-25 and above:
Use $:S to move lookups to the multi-threaded smtp-server process e.g.
TCP|*|25|*|* $C$:S$[IMTA_LIB:dns_verify.so,dns_verify_domain_port,$1,zen.spamhaus.org.,Your$ host$ ($1)$ found$ on$ spamhaus.org$ RBLblock$ list]$T$E
(Not using $:S or $:A modifier - twice the number of lookups)
02:30:15.629216 IP mailserver.Aus.Sun.COM.41249 > dns.Aus.Sun.COM.domain: 27201+ TXT? 3.100.168.192.zen.spamhaus.org. (46) 02:30:15.629222 IP mailserver.Aus.Sun.COM.41249 > dns.Aus.Sun.COM.domain: 27201+ TXT? 3.100.168.192.zen.spamhaus.org. (46) 02:30:15.631251 IP dns.Aus.Sun.COM.domain > mailserver.Aus.Sun.COM.41249: 27201 NXDomain 0/1/0 (110) 02:30:15.631474 IP mailserver.Aus.Sun.COM.41250 > dns.Aus.Sun.COM.domain: 27202+ A? 3.100.168.192.zen.spamhaus.org. (46) 02:30:15.631480 IP mailserver.Aus.Sun.COM.41250 > dns.Aus.Sun.COM.domain: 27202+ A? 3.100.168.192.zen.spamhaus.org. (46) 02:30:15.632386 IP dns.Aus.Sun.COM.domain > mailserver.Aus.Sun.COM.41250: 27202 NXDomain 0/1/0 (110) 02:30:15.633410 IP mailserver.Aus.Sun.COM.41251 > dns.Aus.Sun.COM.domain: 28805+ TXT? 3.100.168.192.zen.spamhaus.org. (46) 02:30:15.633418 IP mailserver.Aus.Sun.COM.41251 > dns.Aus.Sun.COM.domain: 28805+ TXT? 3.100.168.192.zen.spamhaus.org. (46) 02:30:15.634324 IP break.Aus.Sun.COM.domain > mailserver.Aus.Sun.COM.41251: 28805 NXDomain 0/1/0 (110) 02:30:15.634526 IP mailserver.Aus.Sun.COM.41252 > dns.Aus.Sun.COM.domain: 28806+ A? 3.100.168.192.zen.spamhaus.org. (46) 02:30:15.634531 IP mailserver.Aus.Sun.COM.41252 > dns.Aus.Sun.COM.domain: 28806+ A? 3.100.168.192.zen.spamhaus.org. (46) 02:30:15.635325 IP break.Aus.Sun.COM.domain > mailserver.Aus.Sun.COM.41252: 28806 NXDomain 0/1/0 (110)
(Using $:S or $:A modifier)
02:32:07.923587 IP mailserver.Aus.Sun.COM.41253 > dns.Aus.Sun.COM.domain: 63100+ TXT? 3.100.168.192.zen.spamhaus.org. (46) 02:32:07.923599 IP mailserver.Aus.Sun.COM.41253 > dns.Aus.Sun.COM.domain: 63100+ TXT? 3.100.168.192.zen.spamhaus.org. (46) 02:32:07.924979 IP dns.Aus.Sun.COM.domain > mailserver.Aus.Sun.COM.41253: 63100 NXDomain 0/1/0 (110) 02:32:07.927616 IP mailserver.Aus.Sun.COM.41254 > dns.Aus.Sun.COM.domain: 63101+ A? 3.100.168.192.zen.spamhaus.org. (46) 02:32:07.927627 IP mailserver.Aus.Sun.COM.41254 > dns.Aus.Sun.COM.domain: 63101+ A? 3.100.168.192.zen.spamhaus.org. (46) 02:32:07.928609 IP dns.Aus.Sun.COM.domain > mailserver.Aus.Sun.COM.41254: 63101 NXDomain 0/1/0 (110)
-
Place rate-limiting mechanisms (metermaid, conn_throttle etc.) *before DNS RBL lookups*
If you use one of the email rate-limiting mechanisms e.g. MeterMaid or conn_throttle.so, placing these PORT_ACCESS rate-limiting lookups prior to the dns_verify.so lookup will help reduce the impact of a Denial of Service on Messaging Server. For more information, see the discussion on MeterMaid in the Messaging Server System Administrator's Guide. e.g.
PORT_ACCESS ! TCP|server-address|server-port|client-address|client-port *|*|*|*|* $C$|INTERNAL_IP;$3|$Y$E *|*|*|*|* $C$:A$[IMTA_LIB:check_metermaid.so,throttle,ext_throttle,$3]$N421$ Connection$ declined$ at$ this$ time$E TCP|*|25|*|* $C$:S$[IMTA_LIB:dns_verify.so,dns_verify_domain_port,$1,zen.spamhaus.org.,Your$ host$ ($1)$ found$ on$ spamhaus.org$ RBLblock$ list]$T$E * $YEXTERNAL
-
Use most successful lookup first (multiple lookups)
By placing the RBL lookups in most-successful to least-successful order, the overall number DNS lookups will be reduced as Messaging Server will terminate the PORT_ACCESS mapping table processing after the first RBL lookup returns a DNS TXT or A record.
Adding the ”$T” PORT_ACCESS mapping table flag to the dns_verify.so callout will provide additional logging information to help determine which RBL is the most successful e.g.
TCP|*|25|*|* $C$:S$[IMTA_LIB:dns_verify.so,dns_verify_domain_port,$1,zen.spamhaus.org.,Your$ host$ ($1)$ found$ on$ spamhaus.org$ RBLblock$ list]$T$E
Adding ”LOG_CONNECTION=7” to the Messaging Server MTA option.dat configuration file will result in an additional ”T” record in the mail.log file when a connection is dropped due to the connecting host being listed in a DNS RBL e.g.
12-Mar-2008 10:06:52.09 78f.4.686597 ** + T TCP|1.2.3.4|25|5.6.7.8|39802 571 http://www.spamhaus.org/query/bl?ip=5.6.7.8
In the above case the SpamHaus lookup returned a TXT record ”http://www.spamhaus.org/query/bl?ip=5.6.7.8” which was returned to the connecting client.
By using this log information, and re-ordering the DNS RBL lookups to provide the best first-lookup match rate, your DNS lookups will be reduced therefore improving overall performance.
-
Don't use too many lookups
If your site uses multiple DNS RBL lookups to increase the chances of blocking IP addresses that are known to send spam, reordering those rules as per the previous Hint/Tip may show that the latter lookups block negligible additional hosts and can therefore be removed.
-
Don't use DNS_VERIFY_DOMAIN dispatcher configuration
The DNS_VERIFY_DOMAIN dispatcher option doesn't provide sufficient granularity and therefore dns_verify.so PORT_ACCESS lookups should be used instead as discussed throughout this guide.
-
Avoid lookups for known 'Friendly' IP ranges
IP addresses for an organization can usually be split into three distinct categories:
=> Internal IP addresses of trusted email upload systems (e.g. other Messaging Server MTA relays, mailstores). These are usually defined in the INTERNAL_IP mapping table and which you never want to be blocked if the IP address of a host happens to be listed in Realtime Blacklist.
=> 'Friendly' IP addresses of trusted hosts which your organization has direct control over (e.g. user's PC), and can therefore take action to quarantine if the systems are found to be a source of spam email. These systems are unlikely to ever be listed on a DNS RBL blacklist and if they are you don't want them to be blocked. They are not trusted enough to consider 'Internal'.
=> External IP addresses which cannot be trusted and whose IP addresses definitely need to be verified against Realtime Blacklists.
To define a range of 'Friendly' IP addresses, add a new mapping table called FRIENDLY_IP, this table will have the same format as the INTERNAL_IP mapping table e.g.
FRIENDLY_IP $(192.168.100.0/24) $Y * $N
Add a new 'FRIENDLY_IP' check to the PORT_ACCESS mapping table. This check should be above any dns_verify.so lookups, but below any rate-limiting checks (to protect Messaging Server from Denial of Service attacks) e.g.
PORT_ACCESS ! TCP|server-address|server-port|client-address|client-port *|*|*|*|* $C$|INTERNAL_IP;$3|$Y$E *|*|*|*|* $C$:A$[IMTA_LIB:check_metermaid.so,throttle,ext_throttle,$3]$N421$ Connection$ declined$ at$ this$ time$E *|*|*|*|* $C$|FRIENDLY_IP;$3|$YEXTERNAL$E TCP|*|25|*|* $C$:S$[IMTA_LIB:dns_verify.so,dns_verify_domain_port,$1,zen.spamhaus.org.,Your$ host$ ($1)$ found$ on$ spamhaus.org$ RBLblock$ list]$T$E * $YEXTERNAL
-
Have customers use 'submit' port or SSL port for sending emails
The dns_verify.so lookups used in this guide are restricted to port 25 server connections only.
If a customer uploading emails (e.g. using Mozilla Thunderbird) to your Messaging Server uses a submit port (e.g. port 587) they will avoid the DNS RBL lookup – although they will still be required to authenticate so this mechanism does not provide a means of spammers to easily bypass the RBL checks.
Using the 'submit' port reduces the number of RBL checks that need to be performed and also stops your email customers from being accidentally blocked.
Improve Performance of DNS Lookups
If you need to perform a DNS RBL lookup, they should be as fast-as-possible to reduce the impact on overall email delivery and processing performance.
-
Use a local-caching name-server process
A local-caching name-server will keep a local cache of DNS lookups; thus reducing network overhead (and delay) and reducing the impact of any network infrastructure/DNS infrastructure problems.
The following guides provide information on how to install and configure Bind 9 on the messaging server to operate as a caching name-server.
http://www.learning-solaris.com/index.php/configuring-a-dns-server/
http://www.logiqwest.com/dataCenter/Demos/RunBooks/DNS/DNSsetup.html
-
Use local copy of Realtime Blacklist DNS tables
Organizations such as SpamHaus provide the option to keep a local copy of the RBL DNS tables. This can then be used to provide a local copy of the RBL Blacklist data which is much faster and potentially more reliable then relying on an external DNS servers.
spamhaus.org data feed. (See http://www.spamhaus.org/faq/)
-
Use fast and reliable Realtime Blacklist DNS providers only
Smaller DNS Realtime Blacklist providers may not have sufficient or local DNS mirrors to provide quick lookup times or they may be prone to periods of outages when heavily loaded.
Prior to using any RBL, make sure you search the Internet using your preferred web-search engine for any existing reviews, problems etc.
The consequences of an incorrect choice can be severe.
For example, the ordb.org RBL list shutdown in 2006. System administrators that didn't notice that the ordb.org list was no longer blocking emails received a rude shock on the 25th March 2008 when lookups using the ORDB list now returned a successful value for all lookups – therefore causing all emails to be blocked as a result.
Developing Messaging Server Architectural Strategies
Once you have identified your system performance needs, the next step in sizing your Messaging Server deployment is to size specific components based on your architectural decisions.
The following sections point out sizing considerations when you deploy two-tiered and one-tiered architectures.
Note:
For more information, see the discussion on planning your architecture in "Developing a Messaging Server Architecture."Two-tiered Messaging Server Architecture
A two-tiered architecture splits the Messaging Server deployment into two layers: an access layer and a data layer. In a simplified two-tiered deployment, you might add an MMP and an MTA to the access layer. The MMP acts as a proxy for POP and IMAP mail readers, and the MTA relays transmitted mail. The data layer holds the Message Store and Directory Server. Figure 4-1 shows a simplified two-tiered architecture.
Figure 4-1 Simplified Messaging Server Two-Tiered Architecture
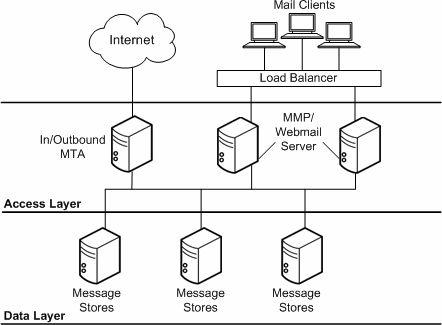
Description of ''Figure 4-1 Simplified Messaging Server Two-Tiered Architecture ''
Two-tiered architectures have advantages over one-tiered architectures that might impact your sizing decisions. Two-tiered architectures permit:
-
Easier maintenance than one-tiered architectures
-
Offloading of load-intensive processes like SSL, virus scanning, message reprocessing, and denial of service
-
Easier growth management and system upgrade with limited overall downtime
The next several sections describe how to size specific components in a two-tiered deployment.
To Size the Message Store
The goals of sizing your Message Store are to identify the maximum number of concurrent connections your store can handle and to determine the number of messages that can be delivered to the store per second.
-
Determine the number of store machines and concurrent connections per machine based on the figures you gather by using a load simulator. For more information on sizing tools, see "Using a Messaging Server Load Simulator."
-
Determine the amount of storage needed for each store machine.
-
Use multiple store partitions or store machines, if it is appropriate for your backup and restoration of file system recovery times.
Consulting is often asked to specify a recommendation for the maximum number of users on a message store. Such a recommendation cannot be given without understanding:
-
Usage patterns (as described in "Using a Messaging Server Load Simulator.")
-
The maximum number of active users on any given piece of hardware within the deployment.
-
Backup, restore, and recovery times. These times increase as the size of a message store increases.
To Size Inbound and Outbound MTAs
In general, separate your MTA services into inbound and outbound services. You can then size each in a similar fashion. The goal of sizing your MTAs is to determine the maximum number of messages that can be relayed per second.
To size inbound MTAs, you need to know the raw performance of your inbound MTA in a real-world environment.
-
From the raw performance of the inbound MTA, add SSL, virus scanning processes, and other extraordinary message processing.
-
Account for denial of service attacks at peak volume in the day.
-
Add enough MTAs for load balancing and for redundancy as appropriate. With redundancy, one or more of each type of machine can still handle peak load without a substantial impact to throughput or response time.
-
In addition, calculate sufficient disk capacity for network problems or non-functioning remote MTAs for transient messages.
To Size Your MMP
When you size your MMP, the calculation is based on your system load, particularly the number of POP and IMAP concurrent connections for the MMP.
In addition, you must:
-
Add CPU or a hardware accelerator for SSL.
-
Add more disks for an SMTP proxy.
-
Account for denial of service.
-
Add capacity for load balancing and redundancy, if appropriate.
As with inbound MTA routers, one or more of each type of machine should still handle peak load without a substantial impact to throughput or response time when you plan for redundancy in your deployment.
Single-tiered Messaging Server Architecture
In a single-tiered architecture, there is no separation between access and data layers. The MTA, Message Store, and sometimes the Directory Server are installed in one layer. Figure 4-2 shows a single-tiered architecture.
Figure 4-2 Simplified Messaging Server Single-Tiered Architecture
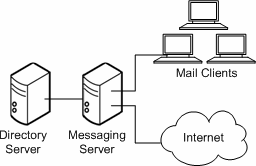
Description of ''Figure 4-2 Simplified Messaging Server Single-Tiered Architecture''
Single-tiered architectures have lower up-front hardware costs than two-tiered architectures. However, if you choose a one-tiered architecture, you need to allow for significant maintenance windows.
To Size a Single-tiered Messaging Server Architecture
-
Size your message stores like you size message stores in a "Two-tiered Messaging Server Architecture."
-
Add CPU for SSL, if necessary.
-
Account for denial of service attacks.
-
Add more disks for the increased number of SMTP connections.
-
Add more disks for outbound MTA routing.
Note:
For specific instructions on sizing Messaging components in single-tiered or two-tiered architectures, contact your Oracle representative.Analyzing Your Messaging Server Requirements
Planning your Messaging Server deployment requires that you first analyze your organization's business and technical requirements. This section helps you to gather and access your requirements, which you then use to determine you Messaging Server design.
Determining Messaging Server Project Goals
Your investigation and analysis should reveal your Messaging Server project's requirements. Next, you should be able to determine a clearly measurable set of goals. Specify these goals in such a manner that personnel not directly associated with the project can understand the goals and how to measure the project against them.
Stake holders need to accept the project goals. The project goals need to be measured in a post-implementation review to determine the success of the project.
Planning for Growth
In addition to determining what capacity you need today, assess what capacity you need in the future, within a time frame that you can plan for. Typically, a growth time line is in the range of 12 to 18 months. Growth expectations and changes in usage characteristics are factors that you need to take into account to accommodate growth.
As the number of users and messages increase, you should outline successful guidelines for capacity planning. You need to plan for increases in message traffic for the various servers, a larger volume of users, larger mailbox sizes, more calendar appointments, and so forth. As growth occurs in the user population, usage characteristics change over time. Your deployment goals (and therefore deployment design) must respond accordingly to be viable into the future.
Ideally, you should design your architecture to easily accommodate future growth. For example, use logical names for the Messaging Server services themselves. For more information, see the discussion on designing your deployment around logical service names in "Using Logical Service Names." Monitoring the deployment, once it enters its production phase, is also crucial to being able to understand when and by how much a deployment needs to grow.
Understanding Total Cost of Ownership
Total Cost of Ownership (TCO) is another factor that affects capacity planning. This includes choosing the hardware upon which to deploy Messaging Server. Table 4-4 presents some factors to consider as to whether to deploy more smaller hardware systems or fewer larger hardware systems.
The table below lists the considerations for total cost of ownership.
Table 4-4 Considerations for Total Cost of Ownership
| Hardware Choices | Pros | Cons |
|---|---|---|
|
More, smaller hardware systems |
|
|
|
Fewer, larger hardware systems |
|
|
Identifying Messaging Server Deployment Goals
Before you purchase or deploy Messaging Server hardware or software, you need to identify your deployment goals. Deployment requirements can come from various sources within an organization. In many cases, requirements are expressed in vague terms, requiring you to clarify them towards determining a specific goal.
The outcome of your requirements analysis should be a clear, succinct, and measurable set of goals by which to gauge the deployment's success. Proceeding without clear goals that have been accepted by the stake holders of the project is precarious at best.
Some of the requirements you need to examine before you can plan your deployment include:
Defining Business Requirements
Your business objectives affect deployment decisions. Specifically, you need to understand your users' behavior, your site distribution, and the potential political issues that could affect your deployment. If you do not understand these business requirements, you can easily make wrong assumptions that impact the accuracy of your deployment design.
Operational Requirements
Express operational requirements as a set of functional requirements with straightforward goals. Typically, you might come across informal specifications for:
-
End-user functionality
-
End-user response times
-
Availability/uptime
-
Information archival and retention
For example, translate a requirement for adequate end-user response time into measurable terms such that all stake holders understand what is adequate and how the response time is measured.
Culture and Politics
A deployment needs to take into account your corporate culture and politics. Demands can arise from areas that end up representing a business requirement. For example:
-
Some sites might require their own management of the deployed solution. Such demands can raise the project's training costs, complexities, and so forth.
-
Given that the LDAP directory contains personnel data, the Human Resources department might want to own and control the directory.
Defining Technical Requirements
Technical requirements (or functional requirements) are the details of your organization's system needs.
Supporting Existing Usage Patterns
Express existing usage patterns as clearly measurable goals for the deployment to achieve. Here are some questions that will help you determine such goals.
-
How are current services utilized?
-
Can your users be categorized (for example, as sporadic, frequent, or heavy users)?
-
How do users access services (from their desktop, from a shared PC or factory floor, from a roaming laptop)?
-
What size messages do users commonly send?
-
How many invitees are usually on calendar appointments?
-
How many messages do users send?
-
How many calendar events and tasks do users typically create per day or per hour?
-
To which sites in your company do your users send messages?
-
What level of concurrency, the number of users who can be connected at any given time, is necessary?
Study the users who will access your services. Factors such as when they will use existing services are keys to identifying your deployment requirements and therefore goals. If your organization's experience cannot provide these patterns, study the experience of other organizations to estimate your own.
Regions in organizations that have heavy usage might need their own servers. Generally, if your users are far away from the actual servers (with slow links), they will experience slower response times. Consider whether the response times will be acceptable.
Site Distribution
Use these questions to understand how site distribution impacts your deployment goals:
-
How are your sites geographically distributed?
-
What is the bandwidth between the sites?
Centralized approaches will require greater bandwidth than de-centralized. Mission critical sites might need their own servers.
Network Requirements
Here are some questions to help you understand your network requirements:
-
Do you want to obfuscate internal network information?
-
Do you want to provide redundancy of network services?
-
Do you want to limit available data on access layer hosts?
-
Do you want to simplify end-user settings, for example, have end users enter a single mail host that does not have to change if you move them?
-
Do you want to reduce network HTTP traffic?
Note:
Answering yes to these questions suggests a two-tiered architecture.Existing Infrastructure
You might be able to centralize servers if you have more reliable and higher available bandwidth.
-
Will the existing infrastructure and facilities prove adequate to enable this deployment?
-
Can the DNS server cope with the extra load? Directory Server? Network? Routers? Switches? Firewall?
Support Personnel
24-hour, seven-day-a-week (24 x 7) support might only be available at certain sites. A simpler architecture with fewer servers will be easier to support.
-
Is there sufficient capacity in operations and technical support groups to facilitate this deployment?
-
Can operations and technical support groups cope with the increased load during deployment phase?
Defining Financial Requirements
Financial restrictions impact how you construct your deployment. Financial requirements tend to be clearly defined from an overall perspective providing a limit or target of the deployment.
Beyond the obvious hardware, software, and maintenance costs, a number of other costs can impact the overall project cost, including:
-
Training
-
Upgrade of other services and facilities, for example, network bandwidth or routers
-
Deployment costs, such as personnel and resources required to prove the deployment concept
-
Operational costs, such as personnel to administer the deployed solution
You can avoid financial issues with the project by applying sufficient attention and analysis to the many factors associated with the project requirements.
Defining Service Level Agreements (SLAs)
You should develop SLAs for your deployment around such areas as uptime, response time, message delivery time, and disaster recovery. An SLA itself should account for such items as an overview of the system, the roles and responsibilities of support organizations, response times, how to measure service levels, change requests, and so forth.
Identifying your organization's expectations around system availability is key in determining the scope of your SLAs. System availability is often expressed as a percentage of the system uptime. A basic equation to calculate system availability is:
Availability = uptime / (uptime + downtime) * 100
For instance, a service level agreement uptime of four nines (99.99 percent) means that in a month the system can be unavailable for about four minutes.
Furthermore, system downtime is the total time the system is not available for use. This total includes not only unplanned downtime, such as hardware failures and network outages, but also planned downtime, preventive maintenance, software upgrade, patches, and so on. If the system is supposed to be available 7x24 (seven days a week, 24 hours a day), the architecture needs to include redundancy to avoid planned and unplanned downtime to ensure high availability.