Release 8.1.5
A68002-01
Library |
Product |
Contents |
Index |
| Oracle8i Data Cartridge Developer's Guide Release 8.1.5 A68002-01 |
|
![]()
![]()
This chapter describes extensible indexing, including:
What is extensible indexing? Why is it important to you as a cartridge developer? How should you go about implementing it?
To answer these questions we first need to understand the modes of indexing provided by the Oracle, which in turn requires that we first consider the role of indexing in information management systems.
The impetus to index data arises because of the need to locate specific information and then to retrieve it as efficiently as possible. If you could keep the entire dataset in main memory (equivalent to a person memorizing a book), there would be no need for indexing. Since this is not possible, and since disk access times are much slower than main memory access times, you are forced to wrestle with the art of indexing.
If you think of the form of indexing with which we are most familiar -- the index at the back of a technical book -- you will note that every index token has three characteristics which refer to the item being indexed:
There has many implications. For one, it means that the same data can be subject to different indexing schemes. For another, it means that the indexing scheme provides a pathway of access to the information. The index in the back of the book gives you access to the entire range of topics covered in the book. Provided that its structure meets your needs, its presorting of the data means that you do not have to sift through every iota of information.
10296 HELEN: If you really loved me you wouldn't go to war. 10297 PARIS: If you really loved me you wouln't stand in the way of my duty.
The upshot is that you can retrieve the information much quicker than if you had to page through the entire book (equivalent to sequential scanning of a file)! However, note that while indexing speeds up retrieval, it slows down inserts because you have to update the index.
An index can be any structure which can be used to represent information that can be used to efficiently evaluate a query.
There is no single structure that is optimal for all applications.
Regions contain a city named Metropolis, you will deploy an equality operator that will return an exact match (or not).
In each case, you will want to organize the data in a different index structure since different queries require that information be indexed in different ways. As we will discuss below, a Hash structure is best suited for determining exact match, whereas a B-tree is much better suited for range queries.
Moreover, these are not the only kind of queries. What if you want to discover whether Power Station A or B can best service Quadrant 3, or to determine the overlapping coverage zones derived from different distributions of power stations? In these cases, you will want to create operators (inRangeOf, servesArea, etc.) that meet your specific requirements. Unfortunately, you cannot do this by means of either the Hash or B-tree indextypes.
The limitation of Hash and B-tree indextypes is important because one criterion that distinguishes cartridges from other database applications is that data often incorporates many different kinds of information. While database systems are accomplished in processing scalar values, they cannot encompass the domain-specific data of interest to cartridge developers. Information in these contexts may be made up of text, images, audio, video -- and combinations of these that comprise domain-specific datatypes.
One way to resolve this problem is to create an index that serves as an intermediate structure. This is a logical extension of the basic idea underlying software-based indexing, namely that pointers refer to data (records, pages, files). In this scheme, keywords used to index video may be stored as an index. Going one step further, an intermediate structure may itself be indexed, as you might index abstracts (capsule text descriptions) of films.The advantage of this approach is that it may be easier to construct an index based on textual description of film than it is to index video footage. Employing this strategy you can scan the index without ever referring to the primary data (the film).
Unfortunately, intermediate structures in which text or scalars are used to represent unstructured data cannot satisfy all requirements. For one thing, they are always slower than direct indexing of the data because they introduce a level of indirection. More importantly, if the task is to analyze the density of bone in x-rays, or to categorize primate gestures, or to record the radio emissions of stars, there is no efficient substitute for direct indexing of unstructured data.
While there is no single indextype that can satisfy all needs, the B-tree indextype comes closest to meeting the requirement. Here we describe the Knuth variation in which the index consists of two parts: a sequence set that provides fast sequential access to the data, and an index set that provides direct access to the sequence set.
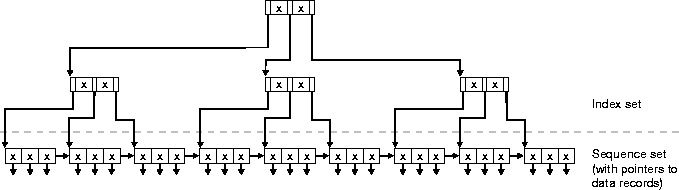
While the nodes of a B-tree will generally not contain the same number of data values, and will usually contain a certain amount of unused space, the B-tree algorithm ensures that it remains balanced (the leaf nodes will all be at the same level).
Hashing gives fast direct access to a specific stored record based on a given field value. Each record is placed at a location whose address is computed as some function of some field of that record. The same function is used both at the time of insertion and retrieval.
The problem with hashing is that the physical ordering of records has little if any relation to their logical ordering. Also, there may be large unused areas on the disk.

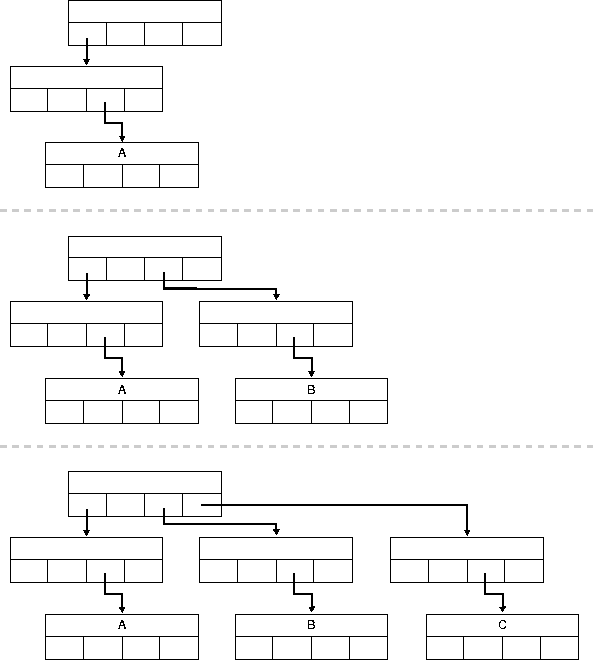
Our sample scenario integrates geographic data with other kinds of data. Insofar as we are interested in points that can be defined with two dimensions (latitude and longitude), such as geographic location of power stations, we can use a variation on the k-d tree known as the 2-d tree.
In this structure, each node is a datatype with fields for information, the two co-ordinates, a left-link and a right-link which can point to two children.

The structure allows for range queries. That is, if the user specifies a point (xx, xx) and a distance, the query will return the set of all points within the specified distance of the point.
2-d trees are very easy to implement. However,the fact that a 2-d tree containing k nodes may have a height of k means that insertion and querying may be complex.
The point quadtree is also used to represent point data in a two dimensional spaces. But these structures divide regions into four parts while 2-d trees divide regions into two. The fields of the record type for this node are comprised of an attribute for information, two co-ordinates, and four compass points (NW, SW, NE, SE) that can therefore point to four children.
Like 2-d trees, point quadtrees are very easy to implement. Also like 2-d trees, the fact that a point quadtree containing k nodes may have a height of k means that insertion and querying may be complex. Each comparison requires comparisons on at least two co-ordinates. However, in practice the lengths from root to leaf tend to be shorter in point quadtrees.
The fact is that Oracle provides a limited number of indextypes, so that if (for instance) you wish to utilize either the k-d tree or the point quadtree, you will have to implement this yourself. As you consider your need to access your data, you need to keep in mind the following restrictions that pertain to the standard indextypes:
Oracle's standard modes of indexing do not permit indexing a column that contains LONG or LOB values.
You may not be able to index a column object using Oracle's standard indexing schemes or the elements of a collection type.
Oracle object types may be compared using either a map function or an order function. If the object utilizes a map function, then you can define a functional index that can be used implicitly to evaluate relational predicates. However, if an order function is used, you will not be able to use this to construct an index.
Further, you cannot utilize functions in predicates in which the range of the parameters is infinite. With Oracle8i functional indexes allow you to include a function in a predicate, provided you can precompute the function values for all the rows. Typically the index would store the rowid and the functional value. Queries that apply relational operators to values based on derived values utilize the index.
However, you can use functional indexes only if the function is so designed that there are a finite number of input combinations. Put another way: you cannot use functional indexes in cases in which the input parameters do not have a limited cardinality.
This SQL-based interface allows you to define domain-specific operators and indexing schemes, and integrate these into the Oracle8i server.
Oracle8i provides a set of pre-defined operators which include arithmetic operators (+, -, *, /), comparison operators (=, >, <) and logical operators (NOT, AND, OR). These operators take as input one or more arguments (or operands) and return a result. They are represented by special characters (+) or keywords (AND).
Like built-in operators, user-defined operators (e.g., Contains) take a set of operands as input and return a result. The implementation of the operator is provided by the user. After a user has defined a new operator, it can be used in SQL statements like any other built-in operator.
For instance, suppose you define a new operator Contains, which takes as input a text document and a keyword, and returns 1 if the document contains the specified keyword. You can then write an SQL query as:
SELECT * FROM Employees WHERE Contains(resume, 'Oracle and UNIX')=1;
Oracle8i uses indexes to efficiently evaluate some built-in operators. For example, a B-tree index can be used to evaluate the comparison operators =, > and <. Similarly, user-defined domain indexes can be used to efficiently evaluate user-defined operators.
Typical database management systems support a few types of access methods (B+Trees, Hash Index) on some set of data types (numbers, strings, etc.). In recent years, databases are more and more being used to store different types of data, such as text, spatial, image, video and audio. In these complex domains, there is a need for indexing complex data types and also specialized indexing techniques. For instance, R-trees are an efficient method of indexing spatial data. No database server can be built with support for all possible kinds of complex data and indexing. The solution is to provide an extensible server which allows the user to define new index types.
The framework to develop new index types is based on the concept of cooperative indexing where an application and the Oracle server cooperate to build and maintain indexes for data types such as text, spatial and On-line-Analytical Processing (OLAP). The application software, in the form of a cartridge, is responsible for defining the index structure, maintaining the index content during load and update operations, and searching the index during query processing. The index structure itself can either be stored in an Oracle database as an Index-Organized Table, etc., or externally as a file.
The extensible indexing framework consists of the following components:
Overlaps operator in the spatial domain. In general, user-defined operators can be bound to functions. However, operators can also be evaluated using indexes. For instance, the equality operator can be evaluated using a hash index. An indextype provides index-based implementation for the operators listed in the indextype definition.
To illustrate the role of each of these components, let us consider a text domain application. Suppose a new indextype TextIndexType be defined as part of the text cartridge. It contains routines for managing and accessing the text index. The text index is an inverted index storing the occurrence list for each token in each of the text documents. The text cartridge also defines the Contains operator for performing content-based search on textual data. It provides both a functional implementation (a simple number function) and an index implementation (using the text index) for the Contains operator.
Now, let Employees be an employee table with a resume column containing textual data.
CREATE TABLE Employees (name VARCHAR(128), id INTEGER, resume VARCHAR2(1024));
A domain index can be created on resume column as follows:
CREATE INDEX ResumeTextIndex ON Employees(resume) INDEXTYPE IS TextIndexType;
The Oracle server invokes the routine corresponding to the create method in the TextIndexType, which results in the creation of an index-organized table to store the occurrence list of all tokens in the resumes (essentially, the inverted index data). The inverted index modeled by ResumeTextIndex is automatically maintained by invoking routines defined in TextIndexType, whenever an Employees row is inserted, updated, or deleted.
Content-based search on the resume column can be performed as follows:
SELECT * FROM Employees WHERE Contains(resume, 'Oracle and UNIX')=1;
Index-based implementation of the Contains operator can take advantage of the previously built inverted index. Specifically, the Oracle server can invoke routines specified in TextIndexType to search the domain index for identifying candidate rows, and then do further processing such as filtering, selection, and fetching of rows. Note that the above query can also be evaluated using the non-index implementation of the Contains operator, if the Oracle server chooses to not use the index defined on resume column. In such a case, the filtering of rows will be done by applying the non-index implementation on each resume instance of the table.
In summary, the extensible indexing interface will
This interface will enable a domain index to operate essentially the same way as any other Oracle Server index, the primary difference being that the Oracle Server will invoke application code specified as part of the indextype to create, drop, truncate, modify, and search a domain index.
It should be noted that an index designer may choose to store the index data in files, rather than in index-organized tables. The SQL interface for extensible indexing makes no restrictions on the location of the index data, only that the application adhere to the protocol for index definition, maintenance and search operations.
This section describes the key concepts of the Extensible Indexing Framework.
For simple data types such as integers and small strings, all aspects of indexing can be easily handled by the database system. This is not the case for documents, images, video clips and other complex data types that require content-based retrieval (CBR). The essential reason is that complex data types have application specific formats, indexing requirements, and selection predicates. For example, there are many different document encodings (e.g., ODA, SGML, plain text) and information retrieval (IR) techniques (e.g., keyword, full-text boolean, similarity, probabilistic, and so on). To effectively accommodate the large and growing number of complex data objects, the database system must support application specific indexing. The approach that we employ to satisfy this requirement is termed extensible indexing.
With Extensible indexing,
In effect, the application controls the structure and semantic content of the domain index. The database system interacts with the application to build, maintain, and employ the domain index. It is highly desirable for the database to handle the physical storage of domain indexes. In the following discussion, we implicitly make the assumption that the index is stored in an index-organized table. Note however, that the extensible indexing paradigm does not impose this requirement. The index could be stored in one or more external files.
To illustrate the notion of extensible indexing, we consider a textual database application with IR functionality. For such applications, document indexing involves parsing the text and inserting the words, or tokens, into an inverted index. Such index entries typically have the following logical form
(token, <docid, data>)
where token is the key, docid is a unique identifier (e.g., object identification) for the related document, and data is a segment containing IR specific quantities. For example, a probabilistic IR scheme could have a data segment with token frequency and occurrence list attributes. The occurrence list identifies all locations within the related document where the token appears. Assuming an IR scheme such as this, each index entry would be of the form:
(token, <docid, frequency, occlist> ..)
The following sample index entry for the token Archimedes illustrates the associated logical content.
(Archimedes, <5, 3, [7 62 225]>, <26, 2, [33, 49]>, ...);
In this sample index entry, the token "Archimedes" appears in document 5 at 3 locations(7, 62, and 225), and in document 26 at 2 locations(33 and 49). Note that the index would contain one entry for every document with the word "Archimedes".
IR applications can use domain indexes to locate documents that satisfy some given selection criteria. After consulting the index, the documents of interest are retrieved with the related docid values. It should be noted that the occurrence lists are required for queries that contain proximity expressions (e.g., the phrase "Oracle Corporation").
When the database system handles the physical storage of domain indexes, applications must be able to:
In the following section, we illustrate the extensible indexing framework by building a text domain index.
This section presents an example of adding a text indexing scheme to Oracle RDBMS using the extensible indexing framework. It describes:
'The sequence of steps required to define the Text Indextype are:
The text cartridge intends to support an operator Contains, that takes as parameters a text value and a key and returns a number value indicating whether the text contained the key. The functional implementation of this operator is a regular function defined as:
CREATE FUNCTION TextContains(Text IN VARCHAR2, Key IN VARCHAR2) RETURN NUMBER AS BEGIN ....... END TextContains;
CREATE OPERATOR Contains BINDING (VARCHAR2, VARCHAR2) RETURN NUMBER USING TextContains;
ODCIIndex. This involves implementing routines for index definition, index maintenance, and index scan operations.
The index definition routines (ODCIIndexCreate, ODCIIndexAlter, ODCIIndexDrop, ODCIIndexTruncate) build the text index when index is created, alter the index information when index is altered, remove the index information when the index is dropped, and truncate the text index when the base table is truncated.
The index maintenance routines (ODCIIndexInsert, ODCIIndexDelete, ODCIIndexUpdate) maintain the text index when the table rows are inserted, deleted, or updated.
The index scan routines (ODCIIndexStart, ODCIIndexFetch, ODCIIndexClose) implement access to the text index to retrieve rows of the base table that satisfy the operator predicate. In this case, the Contains(...) =1, whose arguments are passed to the index scan routines. The index scan routines scan the text index and return the qualifying rows to the system.
CREATE TYPE TextIndexMethods ( FUNCTION ODCIIndexCreate(...) ... ); CREATE TYPE BODY TextIndexMethods ( ... );
Text Indextype schema object. The Indextype definition also specifies all the operators supported by the new indextype and specifies the type that implements the index interface.
CREATE INDEXTYPE TextIndexType FOR Contains(VARCHAR2, VARCHAR2) USING TextIndexMethods;
Suppose that the text indextype presented in the previous section has been defined in the system. You can define text indexes on text columns and use the associated Contains operator to query text data.
Consider the Employees table defined as follows:
CREATE TABLE Employees (name VARCHAR2(64), id INTEGER, resume VARCHAR2(2000));
A text domain index can be built on the resume column as follows:
CREATE INDEX ResumeIndex ON Employees(resume) INDEXTYPE IS TextIndexType;
The text data in the resume column can be queried as:
SELECT * FROM Employees WHERE Contains(resume, 'Oracle') =1;
The query execution will use the text index on resume to efficiently evaluate the Contains predicate.
The following sections describe the concepts of indextypes, domain indexes and operators in greater detail.
The purpose of an indextype is to enable efficient search and retrieval functions for complex domains such as text, spatial, image, and OLAP using external software. An indextype is analogous to the sorted or bit-mapped indextype that are supplied internally within the Oracle Server. The essential difference is that the implementation for an indextype is provided by application software, as opposed to the Oracle Server internal routines.
A set of routine specifications. It does not refer to a separate schema object but rather a logical set of documented method specifications.
The set of index definition, maintenance and scan routine specifications.
The interface specifies all the routines which have to be implemented by the index designer. The routines are implemented as type methods.
After the type implementing the ODCIIndex interface has been defined, a new indextype can be created by specifying the list of operators supported by the indextype and referring to the type that implements the index interface.
Using the information retrieval example, the DDL statement for defining the new indextype TextIndexType which supports the Contains operator and whose implementation is provided by the type TextIndexMethods (implemented in the previous section) is as follows:
CREATE INDEXTYPE TextIndexTypeFOR Contains (VARCHAR2, VARCHAR2) USING TextIndexMethods;
In addition to the ODCIIndex interface routines, the implementation type must always implement the ODCIGetInterfaces routine. This function returns the list of names of the interfaces implemented by the type. The routine is invoked by Oracle when CREATE INDEXTYPE is executed. In Oracle8i there is only one set of extensible indexing interface routines called SYS.ODCIINDEX1. Thus, the ODCIGetInterfaces routine must return 'SYS'.'ODCIINDEX1' as one of the implemented interfaces.
A corresponding DROP statement is supported to remove the definition of an indextype. For our example, this statement would be of the following form:
DROP INDEXTYPE TextIndexType;
The default DROP behavior is DROP RESTRICT semantics, that is, if one or more domain indexes exist that uses the indextype then the DROP operation is disallowed. User can override the default behavior with the FORCE option, which drops the indextype and marks dependent domain indexes (if any) invalid. For more details on object dependencies and drop semantics see "Object Dependencies, Drop Semantics, and Validation".
The ODCIIndex (Oracle Data Cartridge Interface Index) interface consists of the following classes of methods:
Index definition methods allow specification of CREATE, ALTER, DROP, and TRUNCATE behaviors.
The ODCIIndexCreate procedure is called when a CREATE INDEX statement is issued that references the indextype. Upon invocation, any physical parameters specified as part of the CREATE INDEX... PARAMETERS (...) statement are passed in along with the description of the index.
A typical action of this procedure is to create tables/files to store index data. Further, if the base table is not empty, this routine should build the index for the existing data in the indexed columns.
The ODCIIndexAlter procedure is invoked when a domain index is altered using an ALTER INDEX statement. The description of the domain index to be altered is passed in along with any specified physical parameters.
In addition, this procedure is allowed to handle ALTER with REBUILD option, which supports rebuilding of domain index. The precise behavior in these two cases is defined by the person who implements indextype.
The ODCIIndexAlter routine is also invoked when a domain index is renamed using the ALTER INDEX ... RENAME command.
The ODCIIndexTruncate procedure is called when a TRUNCATE statement is issued against a table that contains a column or OBJECT type attribute indexed by the indextype. After this procedure executes, the domain index should be empty.
The ODCIIndexDrop procedure is invoked when a domain index is destroyed using a DROP INDEX statement.
Index maintenance methods allow specification of index INSERT, UPDATE, and DELETE behaviors.
The ODCIIndexInsert procedure in the indextype is called when a record is inserted in a table that contains columns or OBJECT attributes indexed by the indextype. The new values in the indexed columns are passed in as arguments along with the corresponding row identifier.
The ODCIIndexDelete procedure in the indextype is called when a record is deleted from a table that contains columns or OBJECT attributes indexed by the indextype. The old values in the indexed columns are passed in as arguments along with the corresponding row identifier.
The ODCIIndexUpdate procedure in the indextype is called when a record is updated in a table that contains columns or OBJECT attributes indexed by the indextype. The old and new values in the indexed columns are passed in as arguments along with the row identifier.
Index scan methods allow specification of an index-based implementation for evaluating predicates containing operators.
An index scan is specified through three routines, ODCIIndexStart, ODCIIndexFetch, and ODCIIndexClose, which can perform initialization, fetch rows (essentially row identifiers) satisfying the predicate, and clean-up once all rows satisfying the predicate are returned.
ODCIIndexStart() is invoked to initialize any data structures and start an index scan. The index related information and the operator related information are passed in as arguments.
A typical action performed when ODCIIndexStart() is invoked is to parse and execute SQL statements that query the tables storing the index data. It could also generate some set of result rows to be returned later when ODCIIndexFetch() is invoked (see below).
Since the index and operator related information are passed in as arguments to ODCIIndexStart() and not to the other index scan routines (ODCIIndexFetch() and ODCIIndexClose()), any information needed in the later routines must be saved. This is referred to as the state that has to be shared among the index scan routines. There are two ways of doing this:
SELF parameter.
In both cases, Oracle RDBMS will pass the SELF value to subsequent ODCIIndexFetch() and ODCIIndexClose() calls which can then use the to access the relevant context information.
There are two modes of evaluating the operator predicate to return the result set of rows.
ODCIIndexStart(). Iterate over the results returning a row at a time in ODCIIndexFetch(). This mode is required for operators involving some sort of ranking over the entire collection, etc. Evaluating such operators would require looking at the entire result set to compute the ranking, relevance, etc. for each candidate row.
ODCIIndexFetch(). This mode is applicable for operators which can determine the candidate rows one at a time without having to look at the entire result set.
The choice of evaluating modes as well as what gets saved is left to the index designer. In either case, the Oracle RDBMS simply executes the ODCIIndexStart() routine as part of processing query containing operators which returns the context as an output SELF value.The returned value is passed back to subsequent ODCIIndexFetch() and ODCIIndexClose() calls.
ODCIIndexFetch() returns the "next" row identifier of the row that satisfies the operator predicate.The operator predicate is specified in terms of the operator expression (name and arguments) and a lower and upper bound on the operator return values. Thus, a ODCIIndexFetch() call returns the row identifier of the rows for which the operator return value falls within the specified bounds. A NULL is returned to indicate end of index scan. The fetch method supports returning a batch of rows in each call. The state returned by ODCIIndexStart() or a previous call to ODCIIndexFetch() is passed in as an argument.
ODCIIndexClose() is invoked when the cursor is closed or reused. In this call the Indextype can perform any clean-ups, etc. The current state is passed in as an argument.
The ODCIIndexGetMetadata routine, if it is implemented, is called by the export utility to write implementation-specific metadata into the export dump file. This metadata might be policy information, version information, per-user settings, and so on, which are not stored in the system catalogs. The metadata is written to the dump files as anonymous PL/SQL blocks that get executed at import time immediately prior to the creation of the associated index.
This method on the ODCIIndex interface is required in version 8.1.3 and must be implemented by all domain index implementation types. If ODCIIndexGetMetadata is not found, export will abort the creation of the index. However, for the final release of 8.1, this method will be optional if no implementation-specific metadata is required.
The index interface routines (with the exception of index definition methods, namely, ODCIIndexCreate(), ODCIIndexAter(), ODCIIndexTruncate(), ODCIIndexDrop()) are invoked under the same transaction that triggered these actions. Thus, the changes made by these routines are atomic and are committed or aborted based on the parent transaction. To achieve this, there are certain restrictions on the nature of the actions that can be performed in the different indextype routines.
For example, if an INSERT statement caused the ODCIIndexInsert() routine to be invoked, ODCIIndexInsert() runs under the same transaction as INSERT. The ODCIIndexInsert() routine can execute any number of DML statements (for example, insert into index-organized tables). If the original transaction aborts, all the changes made by the indextype routines are rolled back.
However, if the indextype routines cause changes external to the database (like writing to external files), transaction semantics are not assured.
The index definition routines do not have any restrictions on the nature of actions within them. Consider ODCIIndexCreate() to understand this difference. A typical set of actions to be performed in ODCIIndexCreate() could be:
To allow ODCIIndexCreate() to execute an arbitrary sequence of DDL and DML statements, we consider each statement to be an independent operation. Consequently, the changes made by ODCIIndexCreate() are not guaranteed to be atomic. The same is true for other index-definition routines.
The index maintenance (and scan routines) execute with the same snapshot as the top level SQL statement performing the DML (or query) operation. This enables the index data processed by the index method to be consistent with the data in the base tables.
Indextype routines always execute as the owner of the index. To support this, the index access driver will dynamically change user mode to index owner before invoking the indextype routines.
For certain operations, indextype routines may require to store information in tables owned by indextype designer. Indextype implementation must code those actions in a separate routine which will be executed using definer's privileges. For more information on syntax, see CREATE TYPE in the Oracle8i SQL Reference.
This section describes the domain index operations and how metadata associated with the domain index can be obtained.
A domain index can be created on a column of a table just like a B-tree index. However, an indextype must be explicitly specified. For example:
CREATE INDEX ResumeTextIndex ON Employees(resume) INDEXTYPE IS TextIndexType PARAMETERS (':Language English :Ignore the a an');
The INDEXTYPE clause specifies the indextype to be used. The PARAMETERS clause identifies any parameters for the domain index, specified as a string. This string is passed uninterpreted to the ODCIIndexCreate routine for creating the domain index. In the above example, the parameters string identifies the language of the text document (thus identifying the lexical analyzer to use) and the list of stop words which are to be ignored while creating the text index.
A domain index can be altered using ALTER INDEX statement. For example:
ALTER INDEX ResumeTextIndex PARAMETERS (':Ignore on');
The parameter string is passed uninterpreted to ODCIIndexAlter() routine, which takes appropriate actions to alter the domain index. In the above example, additional stop words to ignore in the text index are specified.
The ALTER statement can be used to rename a domain index.
ALTER INDEX ResumeTextIndex RENAME TO ResumeTIdx;
The ODCIIndexAlter() routine is invoked, which takes appropriate actions to rename the domain index.
In addition, the ALTER statement can be used to rebuild a domain index.
ALTER INDEX ResumeTextIndex REBUILD PARAMETERS (':Ignore of');
The same ODCIIndexAlter() routine is called but with additional information about the ALTER option.
There is no explicit statement for truncating a domain index. However, when the corresponding table is truncated the truncate procedure specified as part of the indextype is invoked. For example:
TRUNCATE TABLE Employees;
will result in truncating ResumeTextIndex by calling ODCIIndexTruncate() routine.
To drop an instance of a domain index, the DROP INDEX statement is used. For our example, this statement would be of the form:
DROP INDEX ResumeTextIndex;
This results in calling the ODCIIndexDrop() routine and passing information about the index.
For B-tree indexes, users can query the USER_INDEXES view to get index information. To provide similar support for domain indexes, indextype designers can add any domain-specific metadata in the following manner:
schema.index). The remainder of the column definitions are at the discretion of the index designer.
Like B-tree and bitmap indexes, domain indexes are exported and subsequently imported when their base tables are exported. However, domain indexes can have implementation-specific metadata associated with them that are not stored in the system catalogs. For example, a text domain index can have associated policy information, a list of irrelevant words, and so on. Export/Import provides a mechanism to opaquely move this metadata from the source platform to target platform.
To move the domain index metadata, the indextype needs to implement the ODCIIndexGetMetadata interface routine (see the reference chapters for details). This interface routine gets invoked when a domain index is being exported. The domain index information is passed in as a parameter. It can return any number of anonymous PL/SQL blocks that are written into the dump file and executed on import. If present, these anonymous PL/SQL blocks are executed immediately before the creation of the associated domain index.
Note that the ODCIIndexGetMetadata is an optional interface routine. It is needed only if the domain index has extra metadata to be moved.
A user-defined operator is a top-level schema object. It is identified by a name which is in the same namespace as tables, views, types and stand-alone functions.
An operator binding identifies the operator with a unique signature (via argument data types), and allows associating a function that provides an implementation for the operator. This enables Oracle to execute the function when the operator is invoked. Multiple operator bindings can be defined as long as they differ in their signatures.
Thus, any operator has an associated set of one or more bindings. Each of this binding can be evaluated using an user-defined function which could be one of
An operator created in a schema can be evaluated using functions defined in the same or different schemas. The operator bindings can be specified at the time of creating the operator. It is ensured that the signatures of the bindings are unique.
An operator can be created by specifying the operator name and its bindings.
For example, an operator Contains can be created in the Ordsys schema with two bindings and the corresponding functions that providing the implementation in Text and Spatial domains.
CREATE OPERATOR Ordsys.Contains BINDING (VARCHAR2, VARCHAR2) RETURN NUMBER USING text.contains, (Spatial.Geo, Spatial.Geo) RETURN NUMBER USING Spatial.contains;
An existing operator and all its bindings can be dropped using the DROP OPERATOR statement as follows:
DROP OPERATOR Contains;
The default DROP behavior is DROP RESTRICT semantics. Namely, if there are any dependent indextypes for any of the operator bindings, then the DROP operation is disallowed.
However, users can override the default behavior by using the FORCE option. For example,
DROP OPERATOR Contains FORCE;
drops operator Contains and all its binding marks any dependent indextype objects (if any) invalid.
User-defined operators can be invoked anywhere built-in operators can be used. i.e. wherever expressions can occur. For example, user-defined operators can be used in the following:
SELECT command
WHERE clause
ORDER BY and GROUP BY clauses
When an operator is invoked, the evaluation of the operator is transformed to the execution of one of the functions bound to it. This transformation is based on the datatypes of the arguments to the operator. If none of the functions bound to the operator satisfy the signature with which the operator is invoked, an error is raised. There might be some implicit type conversions present during the transformation process.
Consider the operator created with the following statement:
CREATE OPERATOR Ordsys.Contains BINDING (VARCHAR2, VARCHAR2) RETURN NUMBER USING text.contains, (spatial.geo, spatial.geo) RETURN NUMBER USING spatial.contains;
Consider the operator Contains being used in the following SQL statements:
SELECT * FROM Employee WHERE Contains(resume, 'Oracle')=1 AND Contains(location, :bay_area)=1;
The invocation of the operator Contains(resume, 'Oracle') is transformed into the execution of the function text.contains(resume, 'Oracle') since the signature of the function matches the datatypes of the operator arguments. Similarly, the invocation of the operator Contains(location, :bay_area) is transformed into the execution of the function spatial.contains(location, :bay_area).
The following statement would raise an error since none of the operator bindings satisfy the argument datatypes:
SELECT * FROM Employee WHERE Contains(salary, 10000)=1;
There are system privileges for operator schema objects. They are:
See the Oracle8i SQL Reference for details.
To use a user-defined operator in an expression, you must own the operator or have EXECUTE privilege on it.
An operator can be optionally supported by one or more user-defined indextypes. An indextype can "support" one or more operators. This means that a domain index of this indextype can be used in efficiently evaluating these operators. For example, B-tree indexes can be used to evaluate the relational operators like =, < and >. Operators can also be bound to regular functions. For example, an operator Equal can be bound to a function eq(number, number) that compares two numbers. The DDL for this would be:
CREATE OPERATOR Equal BINDING(NUMBER, NUMBER) RETURN NUMBER USING eq;
Thus, an indextype designer should first design the set of operators to be supported by the indextype. For each of these operators, a functional implementation should be provided.
The list of operators supported by an indextype are specified when the indextype schema object is created (as described above). The evaluation of operators using indextype is different for operators occurring in WHERE clause compared to operators occurring elsewhere in a SQL statement. Below we consider index-based evaluation of the operators in both these cases.
The operators appearing in the WHERE clause can be evaluated efficiently by performing an index scan using the scan methods provided as part of indextype implementation. This involves recognizing operator predicates of a certain form, selection of a domain index, setting up of appropriate index scan, and finally, execution of index scan methods. Let's consider each one of these steps in detail.
Indextype "supports" efficient evaluation of those operator predicates, which can be represented by a range of lower and upper bounds on the operator return values. Specifically, predicates of the form
op(...) relop <value expression>, where relop in {<, <=, =, >=,>} op(...) LIKE <value_expression>
are possible candidates for index scan based evaluation.
Use of the operators in any expression, for example
op(...) + 2 = 3
precludes index-scan based evaluation.
Predicates of the form,
op() is NULL
will not be evaluated using index scan. It will always be evaluated using the functional implementation.
Finally, any other operator predicates which can internally be converted into one of the above forms by Oracle can also make use of the index scan based evaluation.
The index scan based evaluation of the operator is a possible candidate for predicate evaluation only if the operator occurring in the predicate (as described above) operates on a column or OBJECT attribute indexed using an indextype. The final decision to choose between the indexed implementation and the functional implementation is made by the optimizer. The optimizer takes into account the selectivity and cost while generating the query execution plan.
As an example, consider the query
SELECT * FROM Employees WHERE Contains(resume, 'Oracle') = 1;
The optimizer can choose to use a domain index in evaluating the Contains operator if
TextIndexType.
TextIndexType supports the appropriate Contains() operator.
If any of the above conditions do not hold, a complete scan of the Employees table is performed and the functional implementation of Contains is applied as a post-filter. If the above conditions are met, the optimizer uses selectivity and cost functions to compare the cost of index-based evaluation with the full table scan and appropriately generates the execution plan.
Consider a slightly different query,
SELECT * FROM Employees WHERE Contains(resume, 'Oracle') =1 AND id =100;
In this query, the Employees table could be accessed through an index on the id column or one on the resume column. The optimizer estimates the costs of the two plans and picks the cheaper one, which could be to use the index on id and apply the Contains operator on the resulting rows. In this case, the functional implementation of Contains() is used and the domain index is not used.
If a domain index is selected for the evaluation of an operator predicate, an index scan is set-up. The index scan is performed by the scan methods (ODCIIndexStart(), ODCIIndexFetch(), ODCIIndexClose()) specified as part of the corresponding indextype implementation. The ODCIIndexStart() method is invoked with the operator related information including name and arguments and the lower and upper bounds describing the predicate. After the ODCIIndexStart() call, a series of fetches are performed to obtain row identifiers of rows satisfying the predicate, and finally the ODCIIndexClose() is called when the SQL cursor is destroyed.
The index scan routines must be implemented with an understanding of how the routines' invocations are ordered and how multiple sets of invocations can be interleaved.
As an example, consider the query
SELECT * FROM Emp1, Emp2 WHERE Contains(Emp1.resume, 'Oracle') =1 AND Contains(Emp2.resume, 'Unix') =1 AND Emp1.id = Emp2.id;
If the optimizer decides to use the domain indexes on the resume columns of both tables, the indextype routines may be invoked in the following sequence:
start(ctx1, ...); /* corr. to Contains(Emp1.resume, 'Oracle') */ start(ctx2, ...); /* corr. to Contains(Emp2.resume, 'Unix'); fetch(ctx1, ...); fetch(ctx2, ...); fetch(ctx1, ...); ... close(ctx1); close(ctx2);
Thus, the same indextype routine may be invoked but for different instances of operators. At any time, many operators are being evaluated through the same indextype routines. In case of routines that do not need to maintain any state across calls i.e. all the information is obtained through its parameters (like the create routine), this is not a problem. However, in case of routines needing to maintain state across calls (like the fetch routine which needs to know which row to return next), the state should be maintained in the SELF parameter that is passed in to each call. The SELF parameter (which is an instance of the implementation type) can be used to store either the entire state (if it is not too big) or a handle to the cursor-duration memory that stores the state.
Operators occurring in expressions other than in the WHERE clause are evaluated using the functional implementation. For example,
SELECT Contains(resume, 'Oracle') FROM Employee;
would be executed by scanning the Employee table and invoking the functional implementation for Contains on each instance of resume. The function is invoked by passing it the actual value of the resume (text data) in the current row. Note that this function would not make use of any domain indexes that may have been built on the resume column.
However, it's possible to have a functional implementation for an operator that makes use of a domain index. The following sections discuss how functions that use domain indexes can be written and how they are invoked by the system.
For many domain-specific operators, such as Contains, the functional implementation can work in two ways:
OBJECT attribute) that has a domain index of a particular indextype, the function can evaluate the operator by looking at the index data rather than the actual argument value.
For example, when Contains(resume, 'Oracle') is invoked on a particular row of the Employee table, it is easier for the function to look up the text domain index defined on the resume column and evaluate the operator based on the row identifier for the row containing the resume - rather than work on the resume text data argument.
To achieve both the behaviors of (1) and (2) above, the functional implementation is provided using a regular function which has three additional arguments - in addition to all the original arguments to the operator. The additional arguments are:
For example, the index-based functional implementation for the Contains operator is provided by the following function.
CREATE FUNCTION TextContains (Text IN VARCHAR2, Key IN VARCHAR2, indexctx IN ODCIIndexCtx, scanctx IN OUT TextIndexMethods, scanflg IN NUMBER) RETURN NUMBER AS BEGIN ....... END TextContains;
The Contains operator is bound to the above functional implementation as follows:
CREATE OPERATOR Contains BINDING (VARCHAR2, VARCHAR2) RETURN NUMBER WITH INDEX CONTEXT, SCAN CONTEXT TextIndexMethods USING TextContains;
The WITH INDEX CONTEXT clause specifies that the functional implementation can make use of any applicable domain indexes. The SCAN CONTEXT specifies the datatype of the scan context argument. It must be the same as the implementation type of the relevant indextype that supports this operator.
Oracle will invoke the functional implementation for the operator if the operator appears elseWHERE i.e. anywhere other than the WHERE clause. If the functional implementation is index-based (i.e. defined to use an indextype), the additional index information will be passed in as arguments only if the operator's first argument is a column (or OBJECT attribute) with a domain index of the appropriate indextype defined on it.
For example, in the query
SELECT Contains(resume, 'Oracle & Unix') FROM Employees;
the Operator Contains will be evaluated using the index-based functional implementation by passing the index information about the domain index on resume column instead of the resume data.
To execute the index-based functional implementation, Oracle RDBMS will set-up the arguments in the following manner:
ODCIIndexCtx attributes are set to NULL.
ODCIIndexCtx attributes are set up as follows.
NULL to the first invocation of the operator. Since it is an IN/OUT parameter, the return value from the first invocation is passed in to the second invocation and so on.
RegularCall for all normal invocations of the operator. After the last invocation, the functional implementation is invoked once more during which any cleanup actions can be performed. During this call, the scan flag is set to CleanupCall and all other arguments except the scan context are set to NULL.
When index information is passed in, the implementation can compute the operator value by doing a domain index lookup using the row identifier as key. The index metadata is used to identify the index structures associated with the domain index. The scan context is typically used to share state with the subsequent invocations of the same operator.
Apart from filtering rows, the operator occurring in WHERE clause might need to support returning ancillary data. The ancillary data is modeled as an operator (or multiple operators) with a single literal number argument. It has a functional implementation that has access to state generated by the index-scan based implementation of the primary operator occurring in the WHERE clause.
For example, in the following query,
SELECT Score(1) FROM Employees WHERE Contains(resume, 'OCI & UNIX', 1) =1;
Contains is the primary operator which can be evaluated using an index-scan which in addition to determining the rows that satisfy the predicate, also computes a score value for each row. The functional implementation for Score operator simply accesses the state generated by the index-scan to obtain score for a given row identified by its row identifier. The literal argument 1 associates the ancillary operator Score to the corresponding primary operator Contains which generates the ancillary data.
In summary, ancillary data is modeled as independent operator(s), which is invoked by the user with a single number argument that ties it with the corresponding primary operator. Its functional implementation makes use of either the domain index or the state generated by the primary operator occurring in WHERE clause. The functional implementation is invoked with extra arguments: the index context containing the domain index information and the scan context which provides access to the state generated by the primary operator. The following sections discuss how operators modeling ancillary data are defined and invoked.
An indextype designer needs to specify that an operator binding computes ancillary data. Such a binding is referred to as a primary binding. For example, a primary binding for Contains can be defined as follows:
CREATE OPERATOR Contains BINDING (VARCHAR2, VARCHAR2) RETURN NUMBER WITH INDEX CONTEXT, SCAN TextIndexMethods COMPUTE ANCILLARY DATA USING TextContains;
The above definition registers two bindings for Contains, namely:
CONTAINS(VARCHAR2, VARCHAR2) -- This can be used as before.
CONTAINS(VARCHAR2, VARCHAR2, NUMBER) -- When ancillary data is required elsewhere in SQL query, the operator can be invoked with the above signature. The NUMBER argument is used to associate the corresponding ancillary operator binding.
However, the indextype designer needs to define a single functional implementation:
TextContains(VARCHAR2,VARCHAR2,ODCIIndexCtx,TextIndexMethods, NUMBER).
An indextype designer has to implement the functional implementation for ancillary data operators in a manner similar to the index-based functional implementation. As discussed earlier, the function takes extra arguments. After the function is defined, the indextype designer can bind it to the operator with an additional ANCILLARY TO attribute, which indicates that the functional implementation needs to share state with the primary operator binding. The binding that is used for modeling ancillary data is referred to as the ancillary operator binding.
For example, let TextScore() function contain code to evaluate the Score ancillary operator.
CREATE FUNCTION TextScore (Text IN VARCHAR2, Key IN VARCHAR2, indexctx IN ODCIIndexCtx, scanctx IN OUT TextIndexMethods, scanflg IN NUMBER) RETURN NUMBER AS BEGIN ....... END TextScore;
An ancillary operator binding can be created as follows:
CREATE OPERATOR Score BINDING (NUMBER) RETURN NUMBER ANCILLARY TO Contains(VARCHAR2, VARCHAR2) USING TextScore;
ANCILLARY TO clause specifies that it shares state with the implementation of corresponding primary operator binding CONTAINS(VARCHAR2, VARCHAR2).
Score(1), Score(2), etc.
The operators corresponding to ancillary data are invoked by the user with a single number argument.
The corresponding primary operator invocation in the query is determined by matching it with the number passed in as the last argument to the primary operator. After the matching primary operator invocation is found (it is an error to find zero or more than one matching primary operator invocation):
For example, consider the query
SELECT Score(1) FROM Employees WHERE Contains(resume, ' Oracle & Unix', 1) =1;
The invocation of Score is determined to be ancillary to Contains based on the number argument "1" and the functional implementation for Score gets the following operands: (resume, 'Oracle&Unix', indexctx, scanctx, scanflg) where scanctx is shared with the invocation of Contains.
The execution would involve using an index scan to process the Contains operator. For each of the rows returned by the fetch() call of the index scan, the functional implementation of Score is invoked by passing it the ODCIIndexCtx argument, which contains the index information, row identifier, and a handle to the index scan state. The functional implementation can use the handle to the index scan state to compute the score.
The dependencies between various objects are as follows:
Thus, the order in which these objects must be created, or their definitions exported for future Import are:
The drop behavior for an object is as follows:
RESTRICT semantics: If there are any dependent objects the drop operation is disallowed.
FORCE semantics: The object is dropped even in the presence of dependent objects and the dependent objects if any are recursively marked invalid.
The table below shows the default and explicit drop options supported for operators and indextypes. The other schema objects are included for completeness and the corresponding drop behavior already available in Oracle8i.
| Schema Object | Default Drop Behavior | Explicit Options Supported |
|---|---|---|
|
Function |
|
None |
|
Package |
|
None |
|
Object Types |
|
|
|
Operator |
|
|
|
Indextype |
|
|
Invalid object are automatically revalidated whenever the object is subsequently referenced.
EXECUTE privilege on the function, operator, package, or the type referenced in addition to CREATE OPERATOR or CREATE ANY OPERATOR privilege.
EXECUTE privilege on the type that implements the indextype in addition to CREATE INDEXTYPE or CREATE ANY INDEXTYPE privilege. Also, the user must have EXECUTE privileges on the operators that the indextype supports.
EXECUTE privilege on the indextype in addition to CREATE INDEX or CREATE ANY INDEX privilege.
EXECUTE privilege on the operator and the associated function/package/type.