|
|
Adding Directory Support |
![]()
![]()
The javax.naming.directorypackage contains the following methods (plus their java.lang.String overloads) for dealing with directory schema:
How an API user uses these methods is discussed in the Schema
- DirContext.getSchema(Name name)
- DirContext.getSchemaClassDefinition(Name name)
- Attribute.getAttributeDefinition()
- Attribute.getAttributeSyntaxDefinition()
lesson.
getSchema(), getAttributeDefinition(), and getAttributeSyntaxDefinition() return a pointer to the schema tree, whereas getSchemaClassDefinition() returns a context whose children are from the schema tree. The following figure depicts the relationship between the directory tree and the schema tree.
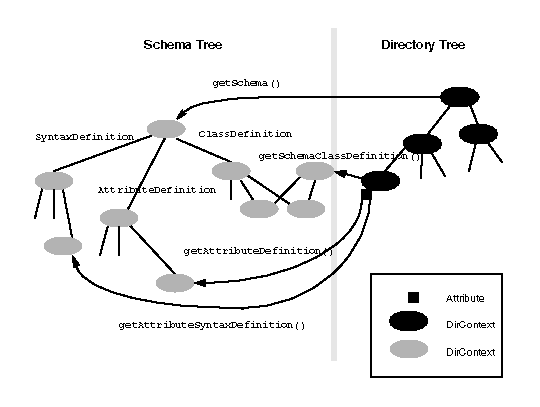
If a context implementation does not support returning schema information, then these methods should throw an OperationNotSupportedException
Implementation Strategies
A context implementation that supports schema methods should follow the recommendations in the Guideline for LDAP Service Providers when choosing the names of attributes to use to describe schema data.A common strategy is to build an in-memory schema tree that mirrors the one depicted in the figure. More than one schema tree per context implementation might exist because getSchema() accepts a Name
Each node in the tree is a DirContext
For getSchemaClassDefinition(), you need to create a new DirContext instance and bind as children nodes that represent the named object's class definitions. For example, if the named object is of classes "top" and "person", the DirContext instance will have two child DirContext nodes, one representing the definition for "top" and the other for "person". The "top" and "person" DirContexts are nodes in the "ClassDefinition" branch of the schema tree (the one pointed to by getSchema()).
Attribute Definitions
To implement the schema methods in the AttributeAdvanced Features
The DirContext nodes returned by the schema methods are full-fledged DirContext objects. This means that they are free to implement, or not, all of the methods available in the DirContext interface.A context implementation should support updates to the schema objects only to the extent that corresponding updates are reflected in the schema data of the underlying directory service. For example, you should never allow a DirContext to be removed from the schema tree unless the corresponding schema definition is removed from the underlying directory service.
To the degree possible, a context implementation should support basic searches (that is, single context level, attribute matches) on the schema tree. Support for the advanced search is nice, but its return on investment is not as great because the schema tree is not very deep.
Optimizations
The schema tree is typically very expensive to generate. Generating it involves first reading schema data from the directory service and parsing the data and then constructing an in-memory tree. To improve performance, a context implementation can cache the schema tree so that it can be shared by multiple contexts. Of course, such sharing should be allowed only if doing so does not compromise correctness and security.
|
|
Adding Directory Support |