7 Whole Server Migration
This chapter describes the different migration mechanisms supported by WebLogic Server.
This chapter includes the following sections:
These sections focus on whole server-level migration, where a migratable server instance, and all of its services, is migrated to a different physical machine upon failure. WebLogic Server also supports service-level migration, as well as replication and failover at the application level. For more information, see Chapter 8, "Service Migration" and Chapter 6, "Failover and Replication in a Cluster."
Understanding Server and Service Migration
In a WebLogic Server cluster, most services are deployed homogeneously on all server instances in the cluster, enabling transparent failover from one server to another. In contrast, "pinned services" such as JMS and the JTA transaction recovery system are targeted at individual server instances within a cluster—for these services, WebLogic Server supports failure recovery with migration, as opposed to failover.
Migration in WebLogic Server is the process of moving a clustered WebLogic Server instance or a component running on a clustered instance elsewhere in the event of failure. In the case of whole server migration, the server instance is migrated to a different physical machine upon failure. In the case of service-level migration, the services are moved to a different server instance within the cluster. See Chapter 8, "Service Migration."
WebLogic Server provides this feature for making JMS and the JTA transaction system highly available: migratable servers. Migratable servers provide for both automatic and manual migration at the server-level, rather than the service level.
When a migratable server becomes unavailable for any reason, for example, if it hangs, loses network connectivity, or its host machine fails—migration is automatic. Upon failure, a migratable server is automatically restarted on the same machine if possible. If the migratable server cannot be restarted on the machine where it failed, it is migrated to another machine. In addition, an administrator can manually initiate migration of a server instance.
Migration Terminology
The following terms apply to server and service migration:
-
Migratable server—a clustered server instance that migrates in its entirety, along with all the services it hosts. Migratable servers are intended to host pinned services, such as JMS servers and the JTA transaction recovery servers, but they can also host clusterable services. All services that run on a migratable server are highly available.
-
Whole server migration— a WebLogic Server instance to be migrated to a different physical machine upon failure, either manually or automatically.
-
Service migration:
-
Manual Service Migration—the manual migration of pinned JTA and JMS-related services (for example, JMS server, SAF agent, path service, and custom store) after the host server instance fails. See Chapter 8, "Service Migration."
-
Automatic Service Migration—JMS-related services, singleton services, and the JTA Transaction Recovery Service can be configured to automatically migrate to another member server when a member server fails or is restarted. See Chapter 8, "Service Migration."
-
-
Cluster leader—one server instance in a cluster, elected by a majority of the servers, that is responsible for maintaining the leasing information. See Non-database Consensus Leasing.
-
Cluster master—one server instance in a cluster that contains migratable servers acts as the cluster master and orchestrates the process of automatic server migration, in the event of failure. Any Managed Server in a cluster can serve as the cluster master, whether it hosts pinned services or not. See Cluster Master Role in Whole Server Migration.
-
Singleton master—a lightweight singleton service that monitors other services that can be migrated automatically. The server that currently hosts the singleton master is responsible for starting and stopping the migration tasks associated with each migratable service. See Singleton Master.
-
Candidate machines—a user-defined list of machines within a cluster that can be a potential target for migration.
-
Target machines—a set of machines that are designated as allowable or preferred hosts for migratable servers.
-
Node Manager—a WebLogic Server utility used by the Administration Server or a standalone Node Manager client, to start and stop migratable servers, and is invoked by the cluster master to shut down and restart migratable servers, as necessary. For background information about Node Manager and how it fits into a WebLogic Server environment, see "General Node Manager Configuration" in Administering Node Manager for Oracle WebLogic Server.
-
Lease table—a database table in which migratable servers persist their state, and which the cluster master monitors to verify the health and liveness of migratable servers. For more information on leasing, see Leasing.
-
Administration Server—used to configure migratable servers and target machines, to obtain the run-time state of migratable servers, and to orchestrate the manual migration process.
-
Floating IP address—an IP address that follows a server from one physical machine to another after migration.
Leasing
Leasing is the process WebLogic Server uses to manage services that are required to run on only one member of a cluster at a time. Leasing ensures exclusive ownership of a cluster-wide entity. Within a cluster, there is a single owner of a lease. Additionally, leases can failover in case of server or cluster failure. This helps to avoid having a single point of failure.
Features That Use Leasing
The following WebLogic Server features use leasing:
-
Automatic Whole Server Migration—Uses leasing to elect a cluster master. The cluster master is responsible for monitoring other cluster members. It is also responsible for restarting failed members hosted on other physical machines.
Leasing ensures that the cluster master is always running, but is only running on one server at a time within a cluster. For information on the cluster master, see Cluster Master Role in Whole Server Migration.
-
Automatic Service Migration—JMS-related services, singleton services, and the JTA Transaction Recovery Service can be configured to automatically migrate from an unhealthy hosting server to a healthy active server with the help of the health monitoring subsystem. When the migratable target is migrated, the pinned service hosted by that target is also migrated. Migratable targets use leasing to accomplish automatic service migration. See Chapter 8, "Service Migration."
-
Singleton Services—A singleton service is, by definition, a service running within a cluster that is available on only one member of the cluster at a time. Singleton services use leasing to accomplish this. See Singleton Master.
-
Job Scheduler—The Job Scheduler is a persistent timer that is used with in a cluster. The Job Scheduler uses the timer master to load balance the timer across a cluster.
Although you can use the non-database version, consensus leasing, with the Job Scheduler, this feature requires an external database to maintain failover and replication information.
Note:
Beyond basic configuration, most leasing functionality is handled internally by WebLogic Server.
Types of Leasing
WebLogic Server provides two types of leasing functionality. Which one you use depends on your requirements and your environment.
-
High-availability database leasing—This version of leasing requires a high-availability database to store leasing information. For information on general requirements and configuration, see High-availability Database Leasing.
-
Non-database consensus leasing—This version of leasing stores the leasing information in-memory within a cluster member. This version of leasing requires that all servers in the cluster are started by Node Manager. For more information, see Non-database Consensus Leasing.
Within a WebLogic Server installation, you can use only one type of leasing. Although it is possible to implement multiple features that use leasing within your environment, each must use the same kind of leasing.
When switching from one leasing type to another, you must restart the entire cluster, not just the Administration Server. Changing the leasing type cannot be done dynamically.
Determining Which Type of Leasing To Use
The following considerations will help you determine which type of leasing is appropriate for your WebLogic Server environment:
-
High-availability database leasing
Database leasing basis is useful in environments that are already invested in a high-availability database, like Oracle RAC, for features like JMS store recovery. The high-availability database instance can also be configured to support leasing with minimal additional configuration. This is particularly useful if Node Manager is not running in the system.
-
Non-database consensus leasing
This type of leasing provides a leasing basis option (consensus) that does not require the use of a high-availability database. This has a direct benefit in automatic whole server migration. Without the high-availability database requirement, consensus leasing requires less configuration to enable automatic server migration.
Consensus leasing requires Node Manager to be configured and running. Automatic whole server migration also requires the Node Manager for IP migration and server restart on another machine. Hence, consensus leasing works well since it does not impose additional requirements, but instead takes away an expensive one.
High-availability Database Leasing
In this version of leasing, lease information is maintained within a table in a high-availability database. A high-availability database is required to ensure that the leasing information is always available to the servers. Each member of the cluster must be able to connect to the database in order to access leasing information, update and renew their leases. Servers will fail if the database becomes unavailable and they are not able to renew their leases.
This method of leasing is useful for customers who already have a high-availability database within their clustered environment. This method allows you to use leasing functionality without being required to use Node Manager to manage servers within your environment.
The following procedures outline the steps required to configure your database for leasing.
-
Configure the database for server migration. The database stores leasing information that is used to determine whether or not a server is running or needs to be migrated.
Your database must be reliable. The server instances will only be as reliable as the database. For experimental purposes, a regular database will suffice. For a production environment, only high-availability databases are recommended. If the database goes down, all the migratable servers will shut themselves down.
Create the leasing table in the database. This is used to store the machine-server associations used to enable server migration. The schema for this table is located in
WL_HOME/server/db/dbname/leasing.ddl, wheredbnameis the name of the database vendor.Note:
The leasing table should be stored in a highly available database. Migratable servers are only as reliable as the database used to store the leasing table. -
Set up and configure a data source. This data source should point to the database configured in the previous step.
Note:
XA data sources are not supported for server migration.For more information on creating a JDBC data source, see "Configuring JDBC Data Sources" in Administering JDBC Data Sources for Oracle WebLogic Server.
Server Migration with Database Leasing on RAC Clusters
When using server migration with database leasing on RAC Clusters, Oracle recommends synchronizing all RAC nodes in the environment. If the nodes are not synchronized, it is possible that a managed server that is renewing a lease will evaluate that the value of the clock on the RAC node is greater than the timeout value of leasing table. If it is more than 30 seconds, the server will fail and restart with the following log message:
<Mar 29, 2013 2:39:09 PM EDT> <Error> <Cluster> <BEA-000150> <Server failed to get a connection to the database in the past 60 seconds for lease renewal. Server will shut itself down.>
See "Configuring Time Synchronization for the Cluster" in the Oracle Grid Infrastructure Installation Guide.
Non-database Consensus Leasing
Note:
Consensus leasing requires that you use Node Manager to control servers within the cluster. Node Manager must be running on every machine hosting Managed Servers within the cluster, including any candidate machines for failed migratable servers. For more information, see "Using Node Manager to Control Servers" in Administering Node Manager for Oracle WebLogic Server.In Consensus leasing, there is no highly available database required. The cluster leader maintains the leases in-memory. All the servers renew their leases by contacting the cluster leader, however, the leasing table is replicated to other nodes of the cluster to provide failover.
The cluster leader is elected by all the running servers in the cluster. A server becomes a cluster leader only when it has received acceptance from the majority of the servers. If the Node Manager reports a server as shutdown, the cluster leader assumes that server to have accepted it as leader when counting the majority.
Consensus leasing requires a majority of servers to continue functioning. Any time there is a network partition, the servers in the majority partition will continue to run while those in the minority partition will voluntarily shut down since they cannot contact the cluster leader or elect a new cluster leader since they will not have the majority of servers. If the partition results in an equal division of servers, then the partition that contains the cluster leader will survive while the other one will fail. Consensus leasing depends on the ability to contact Node Manager to get the status of the servers it is managing in order to count them as part of the majority of reachable servers. If Node Manager running on a machine cannot be contacted, due to loss of network connectivity or a hardware failure, the servers it manages are not counted as part of the majority, even if they are running.
Note:
If your cluster only contains two servers, the cluster leader will be the majority partition if a network partition occurs. If the cluster leader fails, the surviving server will attempt to verify its status through Node Manager. If the surviving server is able to determine the status of the failed cluster leader, it assumes the role of cluster leader. If the surviving server cannot check the status of the cluster leader, due to machine failure or a network partition, it will voluntarily shut down as it cannot reliably determine if it is in the majority.To avoid this scenario, Oracle recommends that you use a minimum of three servers running on different machines.
If automatic server migration is enabled, the servers are required to contact the cluster leader and renew their leases periodically. Servers will shut themselves down if they are unable to renew their leases. The failed servers will then be automatically migrated to the machines in the majority partition.
Automatic Whole Server Migration
This section outlines the procedures for configuring automatic whole server migration and provides a general discussion of how whole server migration functions within a WebLogic Server environment.
The following topics are covered:
Preparing for Automatic Whole Server Migration
Before configuring automatic whole server migration, be aware of the following requirements:
-
Verify that whole server migration is supported on your platform. See Support for Server Migration in Oracle WebLogic Server, WebLogic Portal and WebLogic Integration 10gR3 (10.3)
Caution:
Support for automatic whole server migration on Solaris 10 systems using the Solaris Zones feature can be found in Note 3: Support For Sun Solaris 10 In Multi-Zone Operation athttp://www.oracle.com/technetwork/middleware/ias/oracleas-supported-virtualization-089265.html. -
Each Managed Server uses the same subnet mask. Unicast and multicast communication among servers requires each server to use the same subnet. Server migration will not work without multicast or unicast communication being configured.
For information on using multicast, see Using IP Multicast. For information on using unicast, see One-to-Many Communication Using Unicast.
-
All servers hosting migratable servers are time-synchronized. Although migration works when servers are not time-synchronized, time-synchronized servers are recommended in a clustered environment.
-
If you are using different operating system versions among migratable servers, make sure that all versions support identical functionality for
ifconfig. -
Automatic whole server migration requires Node Manager to be configured and running, for IP migration and server restart on another machine.
-
The primary interface names used by migratable servers are the same. If your environment requires different interface names, then configure a local version of
wlscontrol.shfor each migratable server.For more information on wlscontrol.sh, see "Using Node Manager to Control Servers" in Administering Node Manager for Oracle WebLogic Server.
-
See "Databases Supporting WebLogic Server Features" in Oracle WebLogic Server, WebLogic Portal and WebLogic Integration 10gR3 (10.3) for a list of databases for which WebLogic Server supports automatic server migration.
-
There is no built-in mechanism for transferring files that a server depends on between machines. Using a disk that is accessible from all machines is the preferred way to ensure file availability. If you cannot share disks between servers, you must ensure that the contents of
domain_dir/binare copied to each machine. -
Ensure that the Node Manager security files are copied to each machine using the
nmEnroll()WLST command. For more information, see "Using Node Manager to Control Servers" in Administering Node Manager for Oracle WebLogic Server. -
Use high availability storage for state data. For highest reliability, use a shared storage solution that is itself highly available—for example, a storage area network (SAN). See Using High Availability Storage for State Data.
-
For capacity planning in a production environment, keep in mind that server startup during migration taxes CPU utilization. You cannot assume that because a machine can handle x number of servers running concurrently that it also can handle that same number of servers starting up on the same machine at the same time.
Configuring Automatic Whole Server Migration
Before configuring server migration, ensure that your environment meets the requirements outlined in Preparing for Automatic Whole Server Migration.
To configure server migration for a Managed Server within a cluster, perform the following tasks:
-
Obtain floating IP addresses for each Managed Server that will have migration enabled.
Each migratable server must be assigned a floating IP address which follows the server from one physical machine to another after migration. Any server that is assigned a floating IP address must also have
AutoMigrationEnabledset to true.Note:
The migratable IP address should not be present on the interface of any of the candidate machines before the migratable server is started. -
Configure Node Manager. Node Manager must be running and configured to allow server migration.
The Java version of Node Manager can be used for server migration on Windows or UNIX. The SSH version of Node Manager can be used for server migration on UNIX only.
When using the Java Node Manager, you must edit
nodemanager.propertiesto add your environment Interface and NetMask values.nodemanager.propertiesis located in the directory specified inNodeManagerHome, typicallyORACLE_HOME\user_projects\domains\domain_name\nodemanagerorORACLE_HOME\oracle_common\common\nodemanager. For information aboutnodemanager.properties, see "Reviewing nodemanager.properties" in Administering Node Manager for Oracle WebLogic Server.If you are using the SSH version of Node Manager, edit
wlscontrol.shand set the Interface variable to the name of your network interface.For general information on using Node Manager in server migration, see Node Manager Role in Whole Server Migration. For general information on configuring Node Manager, "General Node Manager Configuration" in Administering Node Manager for Oracle WebLogic Server.
-
If you are using a database to manage leasing information, configure the database for server migration according to the procedures outlined in High-availability Database Leasing. For general information on leasing, see Leasing.
-
If you are using database leasing within a test environment and you need to reset the leasing table, you should re-run the
leasing.ddlscript. This causes the correct tables to be dropped and re-created. -
If you are using a database to store leasing information, set up and configure a data source according to the procedures outlined in High-availability Database Leasing.
You should set
DataSourceForAutomaticMigrationto this data source in each cluster configuration.Note:
XA data sources are not supported for server migration.For more information on creating a JDBC data source, see "Configuring JDBC Data Sources" in Administering JDBC Data Sources for Oracle WebLogic Server.
-
Grant superuser privileges to the
wlsifconfig.shscript (on UNIX) or thewlsifconfig.cmdscript (on Windows).This script is used to transfer IP addresses from one machine to another during migration. It must be able to run
ifconfig, which is generally only available to superusers. You can edit the script so that it is invoked usingsudo.The Java Node Manager uses the
wlsifconfig.cmdscript, which uses thenetshutility.The
wlsifconfigscripts are available in theWL_HOME/common/binorDOMAIN_HOME/bin/server_migrationdirectory. -
Ensure that the following commands are included in your machine PATH:
-
wlsifconfig.sh(UNIX) orwlsifconfig.cmd(Windows) -
wlscontrol.sh(UNIX) -
nodemanager.domains
The
wlsifconfig.sh,wlsifconfig.cmd, andwlscontrol.shfiles are located inWL_HOME/common/binorDOMAIN_HOME/bin/server_migration. Thenodemanager.domainsfile is located in the directory specified inNodeManagerHome. For the Java-based Node Manager,NodeManagerHomeis typically located inORACLE_HOME\user_projects\domains\domain_name\nodemanagerorORACLE_HOME\oracle_common\common\nodemanager. For the script-based Node Manager, this file's defaultNodeManagerHomelocation isWL_HOME/common/nodemanager, whereWL_HOMEis the location in which you installed WebLogic Server, for example,ORACLE_HOME/wlserver.Depending on your default shell on UNIX, you may need to edit the first line of the
.shscripts. -
-
This step applies only to the SSH version of Node Manager and UNIX. If you are using Windows, skip to step 9.
The machines that host migratable servers must trust each other. For server migration to occur, it must be possible to get to a shell prompt using '
ssh/rsh machine_A' from machine_B and vice versa without having to explicitly enter a username and password. Also, each machine must be able to connect to itself using SSH in the same way.Note:
You should ensure that your login scripts (.cshrc,.profile,.login, and such) only echo messages from your shell profile if the shell is interactive. WebLogic Server uses ansshcommand to login and echo the contents of theserver.statefile. Only the first line of this output is used to determine the server state. -
Set the candidate machines for server migration. Each server can have a different set of candidate machines, or they can all have the same set.
-
Restart the Administration Server.
Using High Availability Storage for State Data
The server migration process migrates services, but not the state information associated with work in process at the time of failure.
To ensure high availability, it is critical that such state information remains available to the server instance and the services it hosts after migration. Otherwise, data about the work in process at the time of failure may be lost. State information maintained by a migratable server, such as the data contained in transaction logs, should be stored in a shared storage system that is accessible to any potential machine to which a failed migratable server might be migrated. For highest reliability, use a shared storage solution that is itself highly available—for example, a storage area network (SAN).
In addition, if you are using a database to store leasing information, the lease table, described in the following sections, which is used to track the health and liveness of migratable servers, should also be stored in a high availability database. For more information, see Leasing.
Server Migration Processes and Communications
The sections that follow describe key processes in a cluster that contains migratable servers:
Startup Process in a Cluster with Migratable Servers
Figure 7-1 illustrates the processing and communications that occur during startup of a cluster that contains migratable servers.
The example cluster contains two Managed Servers, both of which are migratable. The Administration Server and the two Managed Servers each run on different machines. A fourth machine is available as a backup—in the event that one of the migratable servers fails. Node Manager is running on the backup machine and on each machine with a running migratable server.
Figure 7-1 Startup of Cluster with Migratable Servers
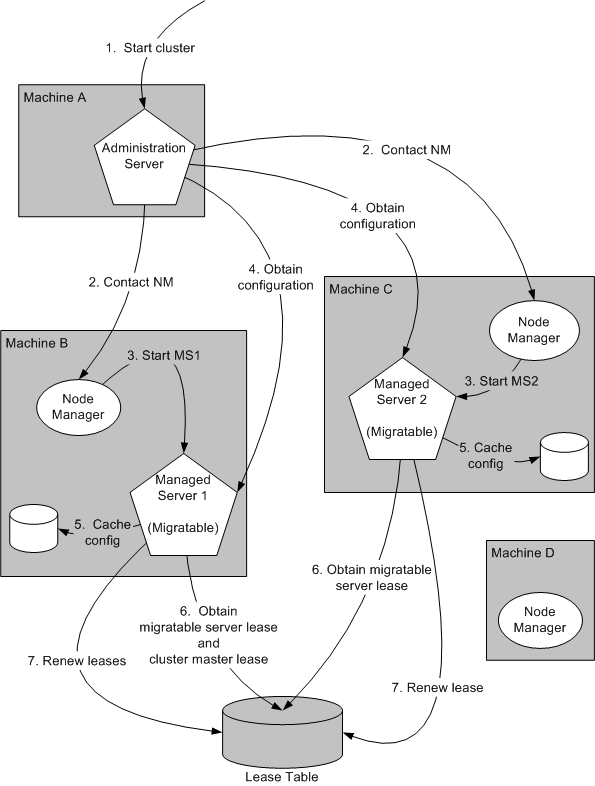
Description of "Figure 7-1 Startup of Cluster with Migratable Servers"
These are the key steps that occur during startup of the cluster illustrated in Figure 7-1:
-
The administrator starts up the cluster.
-
The Administration Server invokes Node Manager on Machines B and C to start Managed Servers 1 and 2, respectively. See Administration Server Role in Whole Server Migration.
-
The Node Manager on each machine starts up the Managed Server that runs there. See Node Manager Role in Whole Server Migration.
-
Managed Servers 1 and 2 contact the Administration Server for their configuration. See Migratable Server Behavior in a Cluster.
-
Managed Servers 1 and 2 cache the configuration with which they started up.
-
Managed Servers 1 and 2 each obtain a migratable server lease in the lease table. Because Managed Server 1 starts up first, it also obtains a cluster master lease. See Cluster Master Role in Whole Server Migration.
-
Managed Server 1 and 2 periodically renew their leases in the lease table, proving their health and liveness.
Automatic Whole Server Migration Process
Figure 7-2 illustrates the automatic migration process after the failure of the machine hosting Managed Server 2.
Figure 7-2 Automatic Migration of a Failed Server
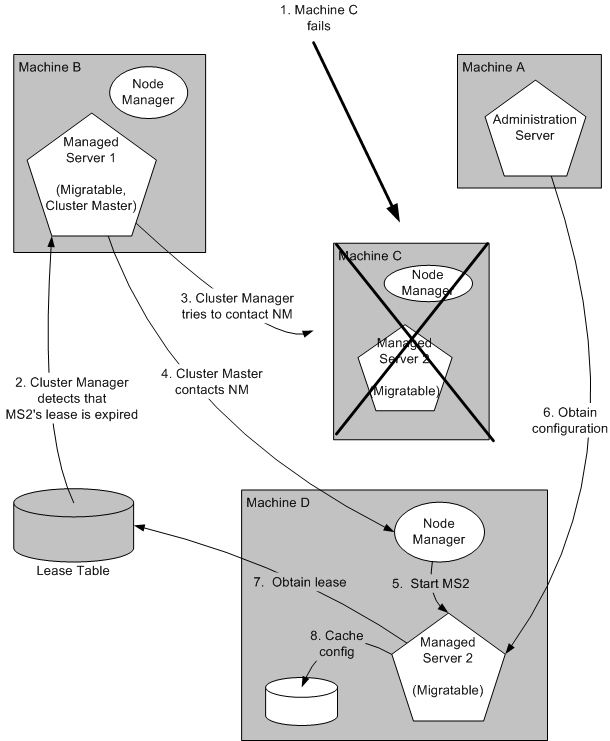
Description of "Figure 7-2 Automatic Migration of a Failed Server"
-
Machine C, which hosts Managed Server 2, fails.
-
Upon its next periodic review of the lease table, the cluster master detects that Managed Server 2's lease has expired. See Cluster Master Role in Whole Server Migration.
-
The cluster master tries to contact Node Manager on Machine C to restart Managed Server 2, but fails, because Machine C is unreachable.
Note:
If the Managed Server 2 lease had expired because it was hung, and Machine C was reachable, the cluster master would use Node Manager to restart Managed Server 2 on Machine C. -
The cluster master contacts Node Manager on Machine D, which is configured as an available host for migratable servers in the cluster.
-
Node Manager on Machine D starts Managed Server 2. See Node Manager Role in Whole Server Migration.
-
Managed Server 2 starts up and contacts the Administration Server to obtain its configuration.
-
Managed Server 2 caches the configuration with which it started up.
-
Managed Server 2 obtains a migratable server lease.
During migration, the clients of the Managed Server that is migrating may experience a brief interruption in service; it may be necessary to reconnect. On Solaris and Linux operating systems, this can be done using the ifconfig command. The clients of a migrated server do not need to know the particular machine to which it has migrated.
When a machine that previously hosted a server instance that was migrated becomes available again, the reversal of the migration process—migrating the server instance back to its original host machine—is known as failback. WebLogic Server does not automate the process of failback. An administrator can accomplish failback by manually restoring the server instance to its original host.
The general procedures for restoring a server to its original host are as follows:
-
Gracefully shutdown the new instance of the server
-
After you have restarted the failed machine, restart Node Manager and the Managed Server.
The exact procedures you will follow depend on your server and network environment.
Manual Whole Server Migration Process
Figure 7-3 illustrates what happens when an administrator manually migrates a migratable server.
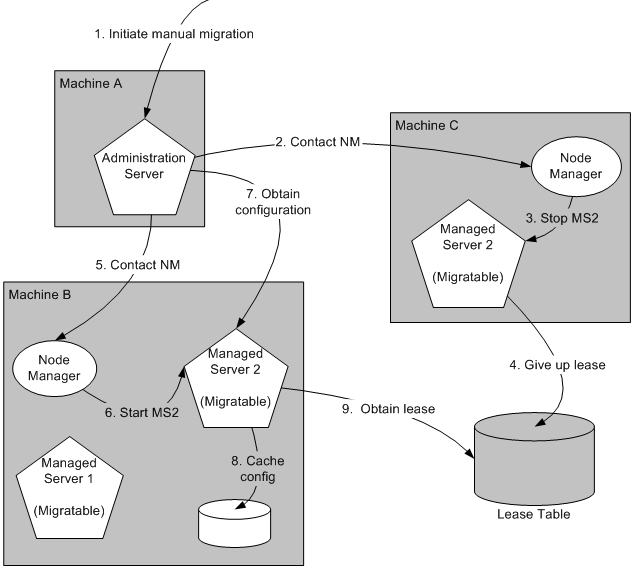
-
An administrator uses the Administration Console to initiate the migration of Managed Server 2 from Machine C to Machine B.
-
The Administration Server contacts Node Manager on Machine C. See Administration Server Role in Whole Server Migration.
-
Node Manager on Machine C stops Managed Server 2.
-
Managed Server 2 removes its row from the lease table.
-
The Administration Server invokes Node Manager on Machine B.
-
Node Manager on Machine B starts Managed Server 2.
-
Managed Server 2 obtains its configuration from the Administration Server.
-
Managed Server 2 caches the configuration with which it started up.
-
Managed Server 2 adds a row to the lease table.
Administration Server Role in Whole Server Migration
In a cluster that contains migratable servers, the Administration Server:
-
Invokes Node Manager, on each machine that hosts cluster members, to start up the migratable servers. This is a prerequisite for server migratability—if a server instance was not initially started by Node Manager, it cannot be migrated.
-
Invokes Node Manager on each machine involved in a manual migration process to stop and start the migratable server.
-
Invokes Node Manager on each machine that hosts cluster members to stop server instances during a normal shutdown. This is a prerequisite for server migratability—if a server instance is shut down directly, without using Node Manager, when the cluster master detects that the server instance is not running, it will call Node Manager to restart it.
In addition, the Administration Server provides its regular domain management functionality, persisting configuration updates issued by an administrator, and providing a run-time view of the domain, including the migratable servers it contains.
Migratable Server Behavior in a Cluster
A migratable server is a clustered Managed Server that has been configured as migratable. These are the key behaviors of a migratable server:
-
If you are using a database to manage leasing information, during startup and restart by Node Manager, a migratable server adds a row to the lease table. The row for a migratable server contains a timestamp, and the machine where it is running.
For more information, see on leasing, see Leasing.
-
When using a database to manage leasing information, a migratable server adds a row to the database as a result of startup, it tries to take on the role of cluster master, and succeeds if it is the first server instance to join the cluster.
-
Periodically, the server renews its lease by updating the timestamp in the lease table.
By default a migratable server renews its lease every 30,000 milliseconds—the product of two configurable
ServerMBeanproperties:-
HealthCheckIntervalMillis, which by default is 10,000. -
HealthCheckPeriodsUntilFencing, which by default is 3.
-
-
If a migratable server fails to reach the lease table and renew its lease before the lease expires, it terminates as quickly as possible using a Java
System.exit—in this case, the lease table still contains a row for that server instance. For information about how this relates to automatic migration, see Cluster Master Role in Whole Server Migration. -
During operation, a migratable server listens for heartbeats from the cluster master. When it detects that the cluster master is not sending heartbeats, it attempts to take over the role of cluster master, and succeeds if no other server instance has claimed that role.
Note:
During server migration, keep in mind that server startup taxes CPU utilization. You cannot assume that because a machine can support x number of servers running concurrently that they also can support that same number of servers starting up on the same machine at the same time.
Node Manager Role in Whole Server Migration
The use of Node Manager is required for server migration—it must run on each machine that hosts, or is intended to host.
Node Manager supports server migration in these ways:
-
Node Manager must be used for initial startup of migratable servers.
When you initiate the startup of a Managed Server from the Administration Console, the Administration Server uses Node Manager to start up the server instance. You can also invoke Node Manager to start the server instance using the standalone Node Manager client; however, the Administration Server must be available so that the Managed Server can obtain its configuration.
Note:
Migration of a server instance that is not initially started with Node Manager will fail. -
Node Manager must be used to suspend, shutdown, or force shutdown migratable servers.
-
Node Manager tries to restart a migratable server whose lease has expired on the machine where it was running at the time of failure.
Node Manager performs the steps in the server migration process by running customizable shell scripts, provided with WebLogic Server, that start, restart and stop servers; migrate IP addresses; and mount and unmount disks. The scripts are available for Solaris and Linux.
-
In an automatic migration, the cluster master invokes Node Manager to perform the migration.
-
In a manual migration, the Administration Server invokes Node Manager to perform the migration.
-
Cluster Master Role in Whole Server Migration
In a cluster that contains migratable servers, one server instance acts as the cluster master. Its role is to orchestrate the server migration process. Any server instance in the cluster can serve as the cluster master. When you start a cluster that contains migratable servers, the first server to join the cluster becomes the cluster master and starts up the cluster manager service. If a cluster does not include at least one migratable server, it does not require a cluster master, and the cluster manager service does not start up. In the absence of a cluster master, migratable servers can continue to operate, but server migration is not possible. These are the key functions of the cluster master:
-
Issues periodic heartbeats to the other servers in the cluster.
-
Periodically reads the lease table to verify that each migratable server has a current lease. An expired lease indicates to the cluster master that the migratable server should be restarted.
-
Upon determining that a migratable server's lease is expired, waits for period specified by the
FencingGracePeriodMillison theClusterMBean, and then tries to invoke the Node Manager process on the machine that hosts the migratable server whose lease is expired, to restart the migratable server. -
If unable to restart a migratable server whose lease has expired on its current machine, the cluster master selects a target machine in this fashion:
-
If you have configured a list of preferred destination machines for the migratable server, the cluster master chooses a machine on that list, in the order the machines are listed.
-
Otherwise, the cluster master chooses a machine on the list of those configured as available for hosting migratable servers in the cluster.
A list of machines that can host migratable servers can be configured at two levels: for the cluster as a whole, and for an individual migratable server. You can define a machine list at both levels. You must define a machine list on at least one level.
-
-
To accomplish the migration of a server instance to a new machine, the cluster master invokes the Node Manager process on the target machine to create a process for the server instance.
The time required to perform the migration depends on the server configuration and startup time.
-
The maximum time taken for the cluster master to restart the migratable server is (
HealthCheckPeriodsUntilFencing*HealthCheckIntervalMillis) +FencingGracePeriodMillis. -
The total time before the server becomes available for client requests depends on the server startup time and the application deployment time.
-