8 Understanding Caching
This chapter introduces and describes caching. The EclipseLink cache is an in-memory repository that stores recently read or written objects based on class and primary key values. The cache improves performance by holding recently read or written objects and accessing them in-memory to minimize database access, manage locking and isolation level, and manage object identity.
The entity caching annotations defined by EclipseLink are listed in "Caching Annotations" in Java Persistence API (JPA) Extensions Reference for Oracle TopLink.
EclipseLink also provides a number of persistence unit properties that you can specify to configure the EclipseLink cache. These properties may compliment or provide an alternative to annotations. For a list of these properties, see "Caching" in Java Persistence API (JPA) Extensions Reference for Oracle TopLink.
This chapter includes the following sections:
8.1 About Cache Architecture
EclipseLink uses two types of cache: the shared persistence unit cache (L2) maintains objects retrieved from and written to the data source; and the isolated persistence context cache (L1) holds objects while they participate in transactions. When a persistence context (entity manager) successfully commits to the data source, EclipseLink updates the persistence unit cache accordingly. Conceptually the persistence context cache is represented by the EntityManager and the persistence unit cache is represented by the EntityManagerFactory.
Internally, EclipseLink stores the persistence unit cache on a EclipseLink session, and the persistence context cache on a EclipseLink persistence unit. As Figure 8-1 shows, the persistence unit (session) cache and the persistence context (unit of work) cache work together with the data source connection to manage objects in a EclipseLink application.
Read requests from the database are sent to the persistence unit (session) cache in EclipseLink session. Write requests from the database are sent to the EclipseLink persistence context (unit of work) cache. The persistence unit (session) cache registers objects with the persistence context. During a commit or merge transaction, the persistence context cache refreshes the persistence unit cache. The object life cycle relies on these mechanisms.
Figure 8-1 Object Life Cycle and the EclipseLink Caches
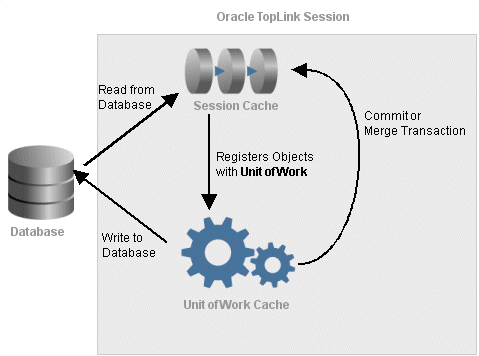
Description of ''Figure 8-1 Object Life Cycle and the EclipseLink Caches''
8.1.1 Persistence Unit Cache
The persistence unit cache is a shared cache (L2) that services clients attached to a given persistence unit. When you read objects from or write objects to the data source using an EntityManager object, EclipseLink saves a copy of the objects in the persistence unit's cache and makes them accessible to all other processes accessing the same persistence unit.
EclipseLink adds objects to the persistence unit cache from the following:
-
The data store, when EclipseLink executes a read operation
-
The persistence context cache, when a persistence context successfully commits a transaction
EclipseLink defines three cache isolation levels: Isolated, Shared, and Protected. For more information on these levels, see Section 8.1.3, "Shared, Isolated, Protected, Weak, and Read-only Caches."
There is a separate persistence unit cache for each unique persistence unit name. Although the cache is conceptually stored with the EntityManagerFactory, two factories with the same persistence unit name will share the same cache (and effectively be the same persistence unit instance). If the same persistence unit is deployed in two separate applications in Java EE, their full persistence unit name will normally still be unique, and they will use separate caches. Certain persistence unit properties, such as data-source, database URL, user, and tenant id can affect the unique name of the persistence unit, and result in separate persistence unit instances and separate caches. The eclipselink.session.name persistence unit property can be used to force two persistence units to resolve to the same instance and share a cache.
8.1.2 Persistence Context Cache
The persistence context cache is an isolated cache (L1) that services operations within an EntityManager. It maintains and isolates objects from the persistence unit cache, and writes changed or new objects to the persistence unit cache after the persistence context commits changes to the data source.
Note:
Only committed changes are merged into the shared persistence unit cache, flush or other operations do not affect the persistence unit cache until the transaction is committed.The life-cycle for the persistence context cache differs between application managed, and container managed persistence contexts. The persistence context (unit of work) cache services operations within the persistence unit. It maintains and isolates objects from the persistence context (session) cache, and writes changed or new objects to the persistence context cache after the persistence unit commits changes to the data source.
8.1.2.1 Application Managed Persistence Contexts
An application managed persistence context is created by the application from an EntityManagerFactory. The application managed persistence context's cache will remain until the EntityManager is closed or clear() is called. It is important to keep application managed persistence units short lived, or to make use of clear() to avoid the persistence context cache from growing too big, or from becoming out of sync with the persistence unit cache and the database. Typically a separate EntityManager should be created for each transaction or request.
An extended persistence context has the same caching behavior as an application managed persistence context, even if it is managed by the container.
EclipseLink also supports a WEAK reference mode option for long lived persistence contexts, such as two-tier applications. See Section 8.1.3.4, "Weak Reference Mode."
8.1.2.2 Container Managed Persistence Contexts
A container managed persistence context is typically injected into a SessionBean or other managed object by a Java EE container, or frameworks such as Spring. The container managed persistence context's cache will only remain for the duration of the transaction. Entities read in a transaction will become detached after the completion of the transaction and will require merging or editing in subsequent transactions.
Note:
EclipseLink supports accessing an entity's LAZY relationships after the persistence context has been closed.8.1.3 Shared, Isolated, Protected, Weak, and Read-only Caches
EclipseLink defines three cache isolation levels. The cache isolation level defines how caching for an entity is performed by the persistence unit and the persistence context. The cache isolation levels can be set with the isolation attribute on the @Cache annotation. the possible values of the isolation attribute are:
-
isolated—entities are only cached in the persistence context, not in the persistence unit. See Section 8.1.3.1, "Isolated Cache." -
shared—entities are cached both in the persistence context and persistence unit, read-only entities are shared and only cached in the persistence unit. See Section 8.1.3.2, "Shared Cache." -
protected—entities are cached both in the persistence context and persistence unit, read-only entities are isolated and cached in the persistence unit and persistence context. See Section 8.1.3.3, "Protected Cache."
8.1.3.1 Isolated Cache
The isolated cache (L1) is the cache stored in the persistence context. It is a transactional or user session based cache. Setting the cache isolation to isolated for an entity disables its shared cache. With an isolated cache all queries and find operations will access the database unless the object has already been read into the persistence context and refreshing is not used.
Use a isolated cache to do the following:
-
avoid caching highly volatile data in the shared cache
-
achieve serializable transaction isolation
Each persistence context owns an initially empty isolated cache. The persistence context's isolated cache is discarded when the persistence context is closed, or the EntityManager.clear() operation is used.
When you use an EntityManager to read an isolated entity, the EntityManager reads the entity directly from the database and stores it in the persistence context's isolated cache. When you read a read-only entity it is still stored in the isolated cache, but is not change tracked.
The persistence context can access the database using a connection pool or an exclusive connection. The persistence unit property eclipselink.jdbc.exclusive-connection.mode can be used to use an exclusive connection. Using an exclusive connection provides improved user-based security for reads and writes. Specific queries can also be configured to use the persistence context's exclusive connection.
Note:
If anEntityManager contains an exclusive connection, you must close the EntityManager when you are finished using it. We do not recommend relying on the finalizer to release the connection when the EntityManager is garbage-collected. If you are using a managed persistence context, then you do not need to close it.8.1.3.2 Shared Cache
The shared cache (L2) is the cache stored in the persistence unit. It is a shared object cache for the entire persistence unit. Setting the cache isolation to shared for an entity enables its shared cache. With a shared cache queries and find operations will resolve against the shared cache unless refreshing is used.
Use a shared cache to do the following:
-
improve performance by avoiding database access when finding or querying an entity by Id or index;
-
improve performance by avoiding database access when accessing an entity's relationships;
-
preserve object identity across persistence contexts for read-only entities.
When you use an EntityManager to find a shared entity, the EntityManager first checks the persistence unit's shared cache. If the entity is not in the persistence unit's shared cache, it will be read from the database and stored in the persistence unit's shared cache, a copy will also be stored in the persistence context's isolated cache. Any query not by Id, and not by an indexed attribute will first access the database. For each query result row, if the object is already in the shared cache, the shared object (with its relationships) will be used, otherwise a new object will be built from the row and put into the shared cache, and a copy will be put into the isolated cache. The isolated copy is always returned, unless read-only is used. For read-only the shared object is returned as the isolated copy is not required.
The size and memory usage of the shared cache depends on the entities cache type. attributes on the @Cache annotation can also be used to invalidate or clear the cache.
8.1.3.3 Protected Cache
The protected cache option allows for shared objects to reference isolated objects. Setting the cache isolation to protected for an entity enables its shared cache. The protected option is mostly the same as the shared option, except that protected entities can have relationships to isolated entities, whereas shared cannot.
Use a protected cache to do the following:
-
improve performance by avoiding database access when finding or querying an entity by Id or index
-
improve performance by avoiding database access when accessing an entity's relationships to shared entities
-
ensure read-only entities are isolated to the persistence context
-
allow relationships to isolated entities
Protected entities have the same life-cycle as shared entities, except for relationships, and read-only. Protected entities relationships to shared entities are cached in the shared cache, but their relationships to isolated entities are isolated and not cached in the shared cache. The @Noncacheable annotation can also be used to disable caching of a relationship to shared entities. Protected entities that are read-only are always copied into the isolated cache, but are not change tracked.
8.1.3.4 Weak Reference Mode
EclipseLink offers a specialized persistence context cache for long-lived persistence contexts. Normally it is best to keep persistence contexts short-lived, such as creating a new EntityManager per request, or per transaction. This is referred to as a stateless model. This ensures the persistence context does not become too big, causing memory and performance issues. It also ensures the objects cached in the persistence context do not become stale or out of sync with their committed state.
Some two-tier applications, or stateful models require long-lived persistence contexts. EclipseLink offers a special weak reference mode option for these types of applications. A weak reference mode maintains weak references to the objects in the persistence context. This allows the objects to garbage-collected if not referenced by the application. This helps prevent the persistence context from becoming too big, reducing memory usage and improving performance. Any new, removed or changed objects will be held with strong references until a commit occurs.
A weak reference mode can be configured through the eclipselink.persistence-context.reference-mode persistence unit property. The following options can be used:
-
HARD—This is the default, weak references are not used. The persistence context will grow until cleared or closed. -
WEAK—Weak references are used. Unreferenced unchanged objects will be eligible for garbage collection. Objects that use deferred change tracking will not be eligible for garbage collection. -
FORCE_WEAK—Weak references are used. Unreferenced, unchanged objects will be eligible for garbage collection. Changed (but unreferenced) objects that use deferred change tracking will also be eligible for garbage collection, causing any changes to be lost.
8.1.3.5 Read-Only Entities
An entity can be configured as read-only using the @ReadOnly annotation or the read-only XML attribute. A read-only entity will not be tracked for changes and any updates will be ignored. Read-only entities cannot be persisted or removed. A read-only entity must not be modified, but EclipseLink does not currently enforce this. Modification to read-only objects can corrupt the persistence unit cache.
Queries can also be configured to return read-only objects using the eclipselink.read-only query hint.
A shared entity that is read-only will return the shared instance from queries. The same entity will be returned from all queries from all persistence contexts. Shared read-only entities will never be copied or isolated in the persistence context. This improves performance by avoiding the cost of copying the object, and tracking the object for changes. This both reduces memory, reduces heap usage, and improves performance. Object identity is also maintained across the entire persistence unit for read-only entities, allowing the application to hold references to these shared objects.
An isolated or protected entity that is read-only will still have an isolated copy returned from the persistence context. This gives some improvement in performance and memory usage because it does not track the object for changes, but it is not as significant as shared entities.
8.2 About Cache Type and Size
EclipseLink provides several different cache types which have different memory requirements. The size of the cache (in number of cached objects) can also be configured. The cache type and size to use depends on the application, the possibility of stale data, the amount of memory available in the JVM and on the machine, the garbage collection cost, and the amount of data in the database.
The cache type of the shared object cache and its size can be configured with the type and size attributes of the @Cache annotation. In addition, the cache type for the query results cache can be configured with the eclipselink.query-results-cache.type persistence unit property. For more information, see the @Cache annotation and eclipselink.query-results-cache.type persistence unit property descriptions in the Java Persistence API (JPA) Extensions Reference for Oracle TopLink.
By default, EclipseLink uses a SOFT_WEAK with an initial size of 100 objects. The cache size is not fixed, but just the initial size, EclipseLink will never eject an object from the cache until it has been garbage collected from memory. It will eject the object if the CACHE type is used, but this is not recommended. The cache size of the SOFT_WEAK and HARD_WEAK is also the size of the soft or hard sub-cache that can determine a minimum number of objects to hold in memory.
You can configure how object identity is managed on a class-by-class basis. The ClassDescriptor object provides the cache and identity map options described in Table 8-1.
Table 8-1 Cache and Identity Map Options
| Option | Caching | Guaranteed Identity | Memory Use |
|---|---|---|---|
|
Yes |
Yes |
Very High |
|
|
Yes |
Yes |
Low |
|
|
Yes |
Yes |
High |
|
|
Yes |
Yes |
Medium-high |
There are two other options, NONE, and CACHE. These options are not recommend.
The value of the type attribute can be overridden with these persistence unit properties: eclipselink.cache.type.<ENTITY> and eclipselink.cache.type.default.
8.2.1 FULL Cache Type
This option provides full caching and guaranteed identity: objects are never flushed from memory unless they are deleted.
It caches all objects and does not remove them. Cache size doubles whenever the maximum size is reached. This method may be memory-intensive when many objects are read. Do not use this option on batch operations.
Oracle recommends using this identity map when the data set size is small and memory is in large supply.
8.2.2 WEAK Cache Type
This option only caches objects that have not been garbage collected. Any object still referenced by the application will still be cached.
The weak cache type uses less memory than full identity map but also does not provide a durable caching strategy across client/server transactions. Objects are available for garbage collection when the application no longer references them on the server side (that is, from within the server JVM).
8.2.3 SOFT Cache Type
This option is similar to the weak cache type, except that the cache uses soft references instead of weak references. Any object still referenced by the application will still be cached, and objects will only be removed from the cache when memory is low.
The soft identity map allows for optimal caching of the objects, while still allowing the JVM to garbage collect the objects if memory is low.
8.2.4 SOFT_WEAK and HARD_WEAK Cache Type
These options are similar to the weak cache except that they maintain a most frequently used sub-cache. The sub-cache uses soft or hard references to ensure that these objects are not garbage collected, or only garbage collected only if the JVM is low on memory.
The soft cache and hard cache provide more efficient memory use. They release objects as they are garbage-collected, except for a fixed number of most recently used objects. Note that weakly cached objects might be flushed if the transaction spans multiple client/server invocations. The size of the sub-cache is proportional to the size of the cache as specified by the @Cache size attribute. You should set the cache size to the number of objects you wish to hold in your transaction.
Oracle recommends using this cache in most circumstances as a means to control memory used by the cache.
8.2.5 NONE and CACHE
NONE and CACHE options do not preserve object identity and should only be used in very specific circumstances. NONE does not cache any objects. CACHE only caches a fixed number of objects in an LRU fashion. These cache types should only be used if there are no relationships to the objects.Oracle does not recommend using these options. To disable caching, set the cache isolation to ISOLATED instead.
8.2.6 Guidelines for Configuring the Cache and Identity Maps
Use the following guidelines when configuring your cache type:
-
For objects with a long life span, use a
SOFT,SOFT_WEAKorHARD_WEAKcache type. For more information on when to choose one or the other, see Section 8.2.6.1, "About the Internals of Weak, Soft, and Hard Cache Types.". -
For objects with a short life span, use a
WEAKcache type. -
For objects with a long life span, that have few instances, such as reference data, use a
FULLcache type.Note:
Use theFULLcache type only if the class has a small number of finite instances. Otherwise, a memory leak will occur. -
If caching is not required or desired, disable the shared cache by setting the cache isolation to
ISOLATED.Note:
Oracle does not recommend the use ofCACHEandNONEcache types.
See Section 8.2.6.1, "About the Internals of Weak, Soft, and Hard Cache Types."
8.2.6.1 About the Internals of Weak, Soft, and Hard Cache Types
The WEAK and SOFT cache types use JVM weak and soft references to ensure that any object referenced by the application is held in the cache. Once the application releases its reference to the object, the JVM is free to garbage collection the objects. When a weak or a soft reference is garbage collected is determined by the JVM. In general, expect a weak reference to be garbage collected with each JVM garbage-collection operation.
The SOFT_WEAK and HARD_WEAK cache types contain the following two caches:
-
Reference cache: implemented as a
LinkedListthat contains soft or hard references, respectively. -
Weak cache: implemented as a
Mapthat contains weak references.
When you create a SOFT_WEAK or HARD_WEAK cache with a specified size, the reference cache LinkedList is exactly this size. The weak cache Map has the size as its initial size: the weak cache will grow when more objects than the specified size are read in. Because EclipseLink does not control garbage collection, the JVM can reap the weakly held objects whenever it sees fit.
Because the reference cache is implemented as a LinkedList, new objects are added to the end of the list. Because of this, it is by nature a least recently used (LRU) cache: fixed size, object at the top of the list is deleted, provided the maximum size has been reached.
The SOFT_WEAK and HARD_WEAK are essentially the same type of cache. The HARD_WEAK was constructed to work around an issue with some JVMs.
If your application reaches a low system memory condition frequently enough, or if your platform's JVM treats weak and soft references the same, the objects in the reference cache may be garbage-collected so often that you will not benefit from the performance improvement provided by it. If this is the case, Oracle recommends that you use the HARD_WEAK. It is identical to the SOFT_WEAK except that it uses hard references in the reference cache. This guarantees that your application will benefit from the performance improvement provided by it.
When an object in a HARD_WEAK or SOFT_WEAK is pushed out of the reference cache, it gets put in the weak cache. Although it is still cached, EclipseLink cannot guarantee that it will be there for any length of time because the JVM can decide to garbage-collect weak references at anytime.
8.3 About Queries and the Cache
A query that is run against the shared persistence unit (session) cache is known as an in-memory query. Careful configuration of in-memory querying can improve performance.
By default, a query that looks for a single object based on primary key attempts to retrieve the required object from the cache first, and searches the data source only if the object is not in the cache. All other query types search the database first, by default. You can specify whether a given query runs against the in-memory cache, the database, or both.
8.3.1 About Query Cache Options and In-memory Querying
JPA defines standard query hints for configuring how a query interacts with the shared persistence unit cache (L2). EclipseLink also provides some additional query hints for configuring the cache usage. For information on JPA and EclipseLink query hints, see Section 9.6, "About Query Hints."
Entities can be accessed through JPA using either find() method or queries. The find() method will first check the persistence context cache (L1) for the Id, if the object is not found it will check the shared persistence unit cache (L2), if the object is still not found it will access the database. By default all queries will access the database, unless querying by Id or by cache indexed fields. Once the query retrieves the rows from the database, it will resolve each row with the cache. If the object is already in the cache, then the row will be discarded, and the object will be used. If the object is not in the shared cache, then it will be built from the row and put into the shared cache. A copy will also be put in the persistence context cache and returned as the query result.
This is the general process, but it differs if the transaction is dirty. If the transaction is dirty then the shared persistence unit cache will be ignored and objects will be built directly into the persistence context cache.
A transaction is considered dirty in the following circumstances:
-
A
flush()has written changes to the database. -
A pessimistic lock query has been executed.
-
An update or delete query has been executed.
-
A native SQL query has been executed.
-
This persistence unit property
eclipselink.transaction.join-existingis used. -
The JDBC connection has been unwrapped from the EntityManager.
-
The
UnitOfWorkAPIbeginEarlyTransactionhas been called.
Entities can also be configured to be isolated, or noncacheable, in which case they will never be placed in the shared cache (see "Shared, Isolated, Protected, Weak, and Read-only Caches").
8.4 About Handling Stale Data
Stale data is an artifact of caching, in which an object in the cache is not the most recent version committed to the data source. To avoid stale data, implement an appropriate cache locking strategy.
By default, EclipseLink optimizes concurrency to minimize cache locking during read or write operations. Use the default EclipseLink isolation level, unless you have a very specific reason to change it. For more information on isolation levels in EclipseLink, see Section 8.1.3, "Shared, Isolated, Protected, Weak, and Read-only Caches".
Cache locking regulates when processes read or write an object. Depending on how you configure it, cache locking determines whether a process can read or write an object that is in use within another process.
A well-managed cache makes your application more efficient. There are very few cases in which you turn the cache off entirely, because the cache reduces database access, and is an important part of managing object identity.
To make the most of your cache strategy and to minimize your application's exposure to stale data, Oracle recommends the following:
8.4.1 Configuring a Locking Policy
Make sure you configure a locking policy so that you can prevent or at least identify when values have already changed on an object you are modifying. Typically, this is done using optimistic locking. EclipseLink offers several locking policies such as numeric version field, time-stamp version field, and some or all fields. Optimistic and pessimistic locking are described in the following sections.
8.4.1.1 Optimistic Locking
Oracle recommends using EclipseLink optimistic locking. With optimistic locking, all users have read access to the data. When a user attempts to write a change, the application checks to ensure the data has not changed since the user read the data. Use @OptimisticLocking to specify the type of optimistic locking EclipseLink should use when updating or deleting entities.
You can use version or field locking policies. Oracle recommends using version locking policies. The standard JPA @Version annotation is used for single valued value and timestamp based locking. However, for advanced locking features use the @OptimisticLocking annotation. The @OptimisticLocking annotation specifies the type of optimistic locking to use when updating or deleting entities. Optimistic locking is supported on an @Entity or @MappedSuperclass annotation.
For more information on the OptimisticLocking annotation and the types of locking you can use, see "@OptimisticLocking" in Java Persistence API (JPA) Extensions Reference for Oracle TopLink.
For more information, see Section 5.2.4.1, "Optimistic Version Locking Policies" and Section 5.2.4.1.3, "Optimistic Field Locking Policies".
8.4.1.2 Pessimistic Locking
With pessimistic locking, the first user who accesses the data with the purpose of updating it locks the data until completing the update. The disadvantage of this approach is that it may lead to reduced concurrency and deadlocks. Use the eclipselink.pessimistic-lock property to specify if TopLink uses pessimistic locking. For more information, see "eclipselink.pessimistic-lock" in Java Persistence API (JPA) Extensions Reference for Oracle TopLink.
Consider using pessimistic locking support at the query level. See Section 5.2.4.2, "Pessimistic Locking Policies."
8.4.2 Configuring the Cache on a Per-Class Basis
If other applications can modify the data used by a particular class, use a weaker style of cache for the class. For example, the @Cache type attribute values WEAK and SOFT_WEAK minimizes the length of time the cache maintains an object whose reference has been removed. For more information about cache types, see Section 8.2, "About Cache Type and Size."
8.4.3 Forcing a Cache Refresh when Required on a Per-Query Basis
Any query can include a flag that forces EclipseLink to go to the data source for the most recent version of selected objects and update the cache with this information. For more information, see Section 8.5, "About Explicit Query Refreshes." See also "Refreshing the Cache" in Solutions Guide for Oracle TopLink.
8.4.4 Configuring Cache Invalidation
You can configure any entity with an expiry that lets you specify either the number of milliseconds after which an entity instance should expire from the cache, or a time of day that all instances of the entity class should expire from the cache. Expiry is set on the @Cache annotation or <cache> XML element, and can be configured either with the expiry or with the expiryTimOfDay attribute. For more information, see "Setting Entity Caching Expiration" in Solutions Guide for Oracle TopLink.
8.4.5 Configuring Cache Coordination
If your application is primarily read-based and the changes are all being performed by the same Java application operating with multiple, distributed sessions, you may consider using the EclipseLink cache coordination feature. Although this will not prevent stale data, it should greatly minimize it. For more information, see Section 8.9, "About Cache Coordination" and Section 8.10, "Clustering and Cache Coordination".
8.5 About Explicit Query Refreshes
Some distributed systems require only a small number of objects to be consistent across the servers in the system. Conversely, other systems require that several specific objects must always be guaranteed to be up-to-date, regardless of the cost. If you build such a system, you can explicitly refresh selected objects from the database at appropriate intervals, without incurring the full cost of distributed cache coordination.
To implement this type of strategy, do the following:
-
Configure a set of queries that refresh the required objects.
-
Establish an appropriate refresh policy.
-
Invoke the queries as required to refresh the objects.
The @Cache annotation provides the alwaysRefresh and refreshOnlyIfNewer attributes which force all queries that go to the database to refresh the cache. The cache is only actually refreshed if the optimistic lock value in the database is newer than in the cache. For more information, see "Refreshing the Cache" in Solutions Guide for Oracle TopLink.
When you execute a query, if the required objects are in the cache, EclipseLink returns the cached objects without checking the database for a more recent version. This reduces the number of objects that EclipseLink must build from database results, and is optimal for noncoordinated cache environments. However, this may not always be the best strategy for a coordinated cache environment.
To override this behavior, set the alwaysRefresh attribute to specify that the objects from the database always take precedence over objects in the cache. This updates the cached objects with the data from the database.
You can implement this type of refresh policy on each EclipseLink entity, or just on certain queries, depending upon the nature of the application.
8.6 About Cache Indexes
The EclipseLink cache is indexed by the entity's Id. This allows the find() operation, relationships, and queries by Id to obtain cache hits and avoid database access. The cache is not used by default for any non-Id query. All non-Id queries will access the database then resolve with the cache for each row returned in the result-set.
Applications tend to have other unique keys in their model in addition to their Id. This is quite common when a generated Id is used. The application frequently queries on these unique keys, and it is desirable to be able to obtain cache hits to avoid database access on these queries.
Cache indexes allow an in-memory index to be created in the EclipseLink cache to allow cache hits on non-Id fields. The cache index can be on a single field, or on a set of fields. The indexed fields can be updateable, and although they should be unique, this is not a requirement. Queries that contain the indexed fields will be able to obtain cache hits. Only single results can be obtained from indexed queries.
Cache indexes can be configured using the @CacheIndex and @CacheIndexes annotations and <cache-index> XML element. A @CacheIndex can be defined on the entity, or on an attribute to index the attribute. Indexes defined on the entity must define the columnNames used for the index. An index can be configured to be re-indexed when the object is updated using the updateable attribute.
It is still possible to cache query results for non-indexed queries using the query result cache. For more information, see Section 8.8, "About Query Results Cache."
8.7 Database Event Notification and Oracle CQN
Some databases and database products allow events to be raised from the database when rows are updated or deleted.
EclipseLink supports an API to allow the database to notify EclipseLink of database changes, so the changed objects can be invalidated in the EclipseLink shared cache. This allows a shared cache to be used, and stale data to be avoided, even if other applications access the same data in the database. EclipseLink supports integration with the Oracle Database feature for Database Change Notification CQN. A custom DatabaseEventListener may be provided for other databases and products that support database events.
There are also other solutions to caching in a shared environment, including:
-
Disable the shared cache (through setting
@Cacheable(false), or@Cache(isolation=ISOLATED)). -
Only cache read-only objects.
-
Set a cache invalidation timeout to reduce stale data.
-
Use refreshing on objects/queries when fresh data is required.
-
Use optimistic locking to ensure write consistency (writes on stale data will fail, and will automatically invalidate the cache).
The JPA Cache API and the EclipseLink JpaCache API can also be used directly to invalidate objects in the shared cache by the application. EclipseLink cache coordination could also be used to send invalidation messages to a cluster of EclipseLink persistence units.
Database events can reduce the chance of an application getting stale data, but do not eliminate the possibility. Optimistic locking should still be used to ensure data integrity. Even in a single server application stale data is still possible within a persistence context unless pessimistic locking is used. Optimistic (or pessimistic) locking is always required to ensure data integrity in any multi-user system.
8.7.1 Oracle Continuous Query Notification
The Oracle database released a Continuous Query Notification (CQN) feature in the 10.2 release. CQN allows for database events to be raised when the rows in a table are modified. The JDBC API for CQN was not complete until 11.2, so 11.2 is required for EclipseLink's integration.
EclipseLink CQN support is enabled by the OracleChangeNotificationListener listener which integrates with Oracle JDBC to received database change events. Use the eclipselink.cache.database-event-listener property to configure the full class name of the listener.
By default all tables in the persistence unit are registered for change notification, but this can be configured using the databaseChangeNotificationType attribute of the @Cache annotation to selectively disable change notification for certain classes.
Oracle CQN uses the ROWID to inform of row level changes. This requires EclipseLink to include the ROWID in all queries for a CQN enabled class. EclipseLink must also select the object's ROWID after an insert operation. EclipseLink must maintain a cache index on the ROWID, in addition to the object's Id. EclipseLink also selects the database transaction Id once each transaction to avoid invalidating the cache on the server that is processing the transaction.
EclipseLink's CQN integration has the following limitations:
-
Changes to an object's secondary tables will not trigger it to be invalidate unless a version is used and updated in the primary table.
-
Changes to an object's OneToMany, ManyToMany, and ElementCollection relationships will not trigger it to be invalidate unless a version is used and updated in the primary table.
8.8 About Query Results Cache
The EclipseLink query results cache allows the results of named queries to be cached, similar to how objects are cached.
By default in EclipseLink all queries access the database, unless they are by Id, or by cache-indexed fields. The resulting rows will still be resolved with the cache, and further queries for relationships will be avoided if the object is cached, but the original query will always access the database. EclipseLink does have options for querying the cache, but these options are not used by default, as EclipseLink cannot assume that all of the objects in the database are in the cache. The query results cache allows for non-indexed and result list queries to still benefit from caching.
The query results cache is indexed by the name of the query, and the parameters of the query. Only named queries can have their results cached, dynamic queries cannot use the query results cache. As well, if you modify a named query before execution, such as setting hints or properties, then it cannot use the cached results.
The query results cache does not pick up committed changes from the application as the object cache does. It should only be used to cache read-only objects, or should use an invalidation policy to avoid caching stale results. Committed changes to the objects in the result set will still be picked up, but changes that affect the results set (such as new or changed objects that should be added/removed from the result set) will not be picked up.
The query results cache supports a fixed size, cache type, and invalidation options.
8.9 About Cache Coordination
The need to maintain up-to-date data for all applications is a key design challenge for building a distributed application. The difficulty of this increases as the number of servers within an environment increases. EclipseLink provides a distributed cache coordination feature that ensures data in distributed applications remains current.
Cache coordination reduces the number of optimistic lock exceptions encountered in a distributed architecture, and decreases the number of failed or repeated transactions in an application. However, cache coordination in no way eliminates the need for an effective locking policy. To effectively ensure working with up-to-date data, cache coordination must be used with optimistic or pessimistic locking. Oracle recommends that you use cache coordination with an optimistic locking policy.
Tune the EclipseLink cache for each class to help eliminate the need for distributed cache coordination. Always tune these settings before implementing cache coordination. For more information, see "Monitoring and Optimizing TopLink-Enabled Applications" in Solutions Guide for Oracle TopLink.
You can use cache invalidation to improve cache coordination efficiency. For more information, see "Setting Entity Caching Expiration" in Solutions Guide for Oracle TopLink.
As Figure 8-2 shows, cache coordination is a session feature that allows multiple, possibly distributed, instances of a session to broadcast object changes among each other so that each session's cache is either kept up-to-date or notified that the cache must update an object from the data source the next time it is read.
Note:
You cannot use isolated client sessions with cache coordination. For more information, see Section 8.1.3, "Shared, Isolated, Protected, Weak, and Read-only Caches."Figure 8-2 Coordinated Persistence Unit (Session) Caches
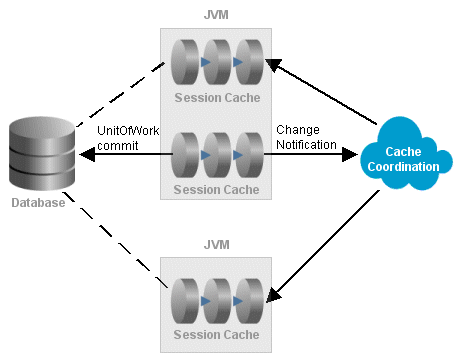
Description of ''Figure 8-2 Coordinated Persistence Unit (Session) Caches''
When sessions are distributed, that is, when an application contains multiple sessions (in the same JVM, in multiple JVMs, possibly on different servers), as long as the servers hosting the sessions are interconnected on the network, sessions can participate in cache coordination. Coordinated cache types that require discovery services also require the servers to support User Datagram Protocol (UDP) communication and multicast configuration. For more information, see Section 8.10.1, "Coordinating JMS and RMI Caches."
8.9.1 When to Use Cache Coordination
Cache coordination can enhance performance and reduce the likelihood of stale data for applications that have the following characteristics:
-
Changes are all being performed by the same Java application operating with multiple, distributed sessions
-
Primarily read-based
-
Regularly requests and updates the same objects
To maximize performance, avoid cache coordination for applications that do not have these characteristics.
For other options to reduce the likelihood of stale data, see Section 8.4, "About Handling Stale Data."
8.10 Clustering and Cache Coordination
An application cluster is a set of middle tier server machines or VMs servicing requests for a single application, or set of applications. Multiple servers are used to increase the scalability of the application and/or to provide fault tolerance and high availability. Typically the same application will be deployed to all of the servers in the cluster and application requests will be load balanced across the set of servers. The application cluster will access a single database, or a database cluster. An application cluster may allow new servers to be added to increase scalability, and for servers to be removed such as for updates and servicing.
Application clusters can consist of Java EE servers, Web containers, or Java server applications.
EclipseLink can function in any clustered environment. The main issue in a clustered environment is utilizing a shared persistence unit (L2) cache. If you are using a shared cache (enabled by default in EclipseLink projects), then each server will maintain its own cache, and each caches data can get out of synchronization with the other servers and the database.
EclipseLink provides cache coordination in a clustered environment to ensure the servers caches are synchronized.
There are also many other solutions to caching in a clustered environment, including:
-
Disable the shared cache (through setting
@Cacheable(false), or@Cache(isolation=ISOLATED)). -
Use only cache read-only objects.
-
Set a cache invalidation timeout to reduce stale data.
-
Use refreshing on objects/queries when fresh data is required.
-
Use optimistic locking to ensure write consistency (writes on stale data will fail, and will automatically invalidate the cache).
-
Use a distributed cache (such as TopLink Grid's integration of TopLink with Oracle Coherence).
-
Use database events to invalidate changed data in the cache (such as EclipseLink's support for Oracle Query Change Notification).
Cache coordination enables a set of persistence units deployed to different servers in the cluster (or on the same server) to synchronize their changes. Cache coordination works by each persistence unit on each server in the cluster being able to broadcast notification of transactional object changes to the other persistence units in the cluster. EclipseLink supports cache coordination over RMI and JMS. The cache coordination framework is also extensible so other options could be developed.
By default, EclipseLink optimizes concurrency to minimize cache locking during read or write operations. Use the default EclipseLink transaction isolation configuration unless you have a very specific reason to change it.
Cache coordination works by broadcasting changes for each transaction to the other servers in the cluster. Each other server will receive the change notification, and either invalidate the changed objects in their cache, or update the cached objects state with the changes. Cache coordination occurs after the database commit, so only committed changes are broadcast.
Cache coordination greatly reduces to chance of an application getting stale data, but does not eliminate the possibility. Optimistic locking should still be used to ensure data integrity. Even in a single server application stale data is still possible within a persistence context unless pessimistic locking is used. Optimistic (or pessimistic) locking is always required to ensure data integrity in any multi-user system.
For more information about cache coordination, including cache synchronization, see "Using Cache Coordination" in Solutions Guide for Oracle TopLink.
8.10.1 Coordinating JMS and RMI Caches
For a JMS coordinated caches, when a particular session's coordinated cache starts, it uses its JNDI naming service information to locate and create a connection to the JMS server. The coordinated cache is ready when all participating sessions are connected to the same topic on the same JMS server. At this point, sessions can start sending and receiving object change messages. You can then configure all sessions that are participating in the same coordinated cache with the same JMS and JNDI naming service information.
For an RMI coordinated cache, when a particular session's coordinated cache starts, the session binds its connection in its naming service (either an RMI registry or JNDI), creates an announcement message (that includes its own naming service information), and broadcasts the announcement to its multicast group. When a session that belongs to the same multicast group receives this announcement, it uses the naming service information in the announcement message to establish bidirectional connections with the newly announced session's coordinated cache. The coordinated cache is ready when all participating sessions are interconnected in this way, at which point sessions can start sending and receiving object change messages. You can then configure each session with naming information that identifies the host on which the session is deployed.
For more information on configuring JMS and RMI cache coordination, see "Configuring JMS Cache Coordination Using Persistence Properties" and "Configuring RMI Cache Coordination Using Persistence Properties" in Solutions Guide for Oracle TopLink.
8.10.2 Coordinating Custom Caches
You can define your own custom solutions for coordinated caches by using the classes in the EclipseLink org.eclipse.persistence.sessions.coordination package.
8.11 Clustering and Cache Consistency
EclipseLink applications that are deployed to an application server cluster benefit from cluster scalability, load balancing, and failover. These capabilities ensure that EclipseLink applications are highly available and scale as application demand increases. EclipseLink applications are deployed the same way in application server clusters as they are in standalone server environments. However, additional planning and configuration is required to ensure cache consistency in an application server cluster.
To ensure cache consistency you perform tasks such as disabling entity caching, refreshing the cache, setting entity expiration, and setting optimistic locking on the cache. For more information on these topics, see "Task 1: Configure Cache Consistency" in Solutions Guide for Oracle TopLink.
8.12 Cache Interceptors
EclipseLink provides a very functional, performant and integrated cache. However, you can integrate third-party external caches by using the EclipseLink CacheInterceptor annotation and API.
8.13 Using Coherence Caches
Oracle TopLink Grid is a feature of Oracle TopLink that provides integration between the EclipseLink JPA and Coherence caches. Standard JPA applications interact directly with their primary data store, typically a relational database. However, with TopLink Grid you can store some or all of your domain model in the Coherence data grid. This configuration is also known as JPA on the Grid.
For information on how to use Coherence caches and TopLink Grid to achieve high availability and to scale out applications, see "Scaling JPA Applications Using TopLink Grid with Oracle Coherence" in Solutions Guide for Oracle TopLink.
For complete details on configuring Toplink Grid and developing applications with TopLink Grid, see "Integrating TopLink Grid with Oracle Coherence" in Integrating Oracle Coherence. See also the oracle.eclipselink.coherence.* APIs in Oracle® Fusion Middleware Java API Reference for Oracle TopLink