Release 2 (8.1.6)
A76937-01
Library |
Product |
Contents |
Index |
| Oracle 8i Data Cartridge Developer's Guide Release 2 (8.1.6) A76937-01 |
|
![]()
![]()
![]()
Building Domain Indexes, 2 of 3
What is extensible indexing? Why is it important to you as a cartridge developer? How should you go about implementing it?
To answer these questions we first need to understand the modes of indexing provided by the Oracle, which in turn requires that we first consider the role of indexing in information management systems.
The impetus to index data arises because of the need to locate specific information and then to retrieve it as efficiently as possible. If you could keep the entire dataset in main memory (equivalent to a person memorizing a book), there would be no need for indexing. Since this is not possible, and since disk access times are much slower than main memory access times, you are forced to wrestle with the art of indexing.
If you think of the form of indexing with which we are most familiar -- the index at the back of a technical book -- you will note that every index token has three characteristics which refer to the item being indexed:
There has many implications. For one, it means that the same data can be subject to different indexing schemes. For another, it means that the indexing scheme provides a pathway of access to the information. The index in the back of the book gives you access to the entire range of topics covered in the book. Provided that its structure meets your needs, its presorting of the data means that you do not have to sift through every iota of information.
10296 HELEN: If you really loved me you wouldn't go to war. 10297 PARIS: If you really loved me you wouln't stand in the way of my duty.
The upshot is that you can retrieve the information much quicker than if you had to page through the entire book (equivalent to sequential scanning of a file)! However, note that while indexing speeds up retrieval, it slows down inserts because you have to update the index.
An index can be any structure which can be used to represent information that can be used to efficiently evaluate a query.
There is no single structure that is optimal for all applications.
Regions contain a city named Metropolis, you will deploy an equality operator that will return an exact match (or not).
In each case, you will want to organize the data in a different index structure since different queries require that information be indexed in different ways. As we will discuss below, a Hash structure is best suited for determining exact match, whereas a B-tree is much better suited for range queries.
Moreover, these are not the only kind of queries. What if you want to discover whether Power Station A or B can best service Quadrant 3, or to determine the overlapping coverage zones derived from different distributions of power stations? In these cases, you will want to create operators (inRangeOf, servesArea, etc.) that meet your specific requirements. Unfortunately, you cannot do this by means of either the Hash or B-tree indextypes.
The limitation of Hash and B-tree indextypes is important because one criterion that distinguishes cartridges from other database applications is that data often incorporates many different kinds of information. While database systems are accomplished in processing scalar values, they cannot encompass the domain-specific data of interest to cartridge developers. Information in these contexts may be made up of text, images, audio, video -- and combinations of these that comprise domain-specific datatypes.
One way to resolve this problem is to create an index that serves as an intermediate structure. This is a logical extension of the basic idea underlying software-based indexing, namely that pointers refer to data (records, pages, files). In this scheme, keywords used to index video may be stored as an index. Going one step further, an intermediate structure may itself be indexed, as you might index abstracts (capsule text descriptions) of films.The advantage of this approach is that it may be easier to construct an index based on textual description of film than it is to index video footage. Employing this strategy you can scan the index without ever referring to the primary data (the film).
Unfortunately, intermediate structures in which text or scalars are used to represent unstructured data cannot satisfy all requirements. For one thing, they are always slower than direct indexing of the data because they introduce a level of indirection. More importantly, if the task is to analyze the density of bone in x-rays, or to categorize primate gestures, or to record the radio emissions of stars, there is no efficient substitute for direct indexing of unstructured data.
While there is no single indextype that can satisfy all needs, the B-tree indextype comes closest to meeting the requirement. Here we describe the Knuth variation in which the index consists of two parts: a sequence set that provides fast sequential access to the data, and an index set that provides direct access to the sequence set.
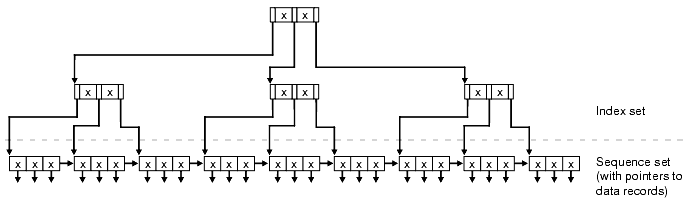
While the nodes of a B-tree will generally not contain the same number of data values, and will usually contain a certain amount of unused space, the B-tree algorithm ensures that it remains balanced (the leaf nodes will all be at the same level).
Hashing gives fast direct access to a specific stored record based on a given field value. Each record is placed at a location whose address is computed as some function of some field of that record. The same function is used both at the time of insertion and retrieval.
The problem with hashing is that the physical ordering of records has little if any relation to their logical ordering. Also, there may be large unused areas on the disk.
Our sample scenario integrates geographic data with other kinds of data. Insofar as we are interested in points that can be defined with two dimensions (latitude and longitude), such as geographic location of power stations, we can use a variation on the k-d tree known as the 2-d tree.
In this structure, each node is a datatype with fields for information, the two co-ordinates, a left-link and a right-link which can point to two children.
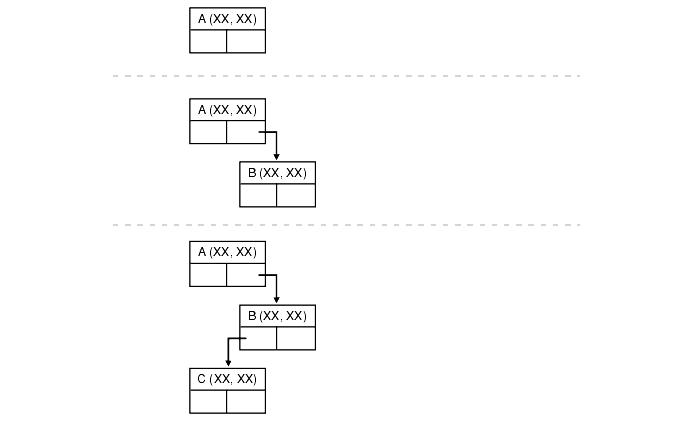
The structure allows for range queries. That is, if the user specifies a point (xx, xx) and a distance, the query will return the set of all points within the specified distance of the point.
2-d trees are very easy to implement. However,the fact that a 2-d tree containing k nodes may have a height of k means that insertion and querying may be complex.
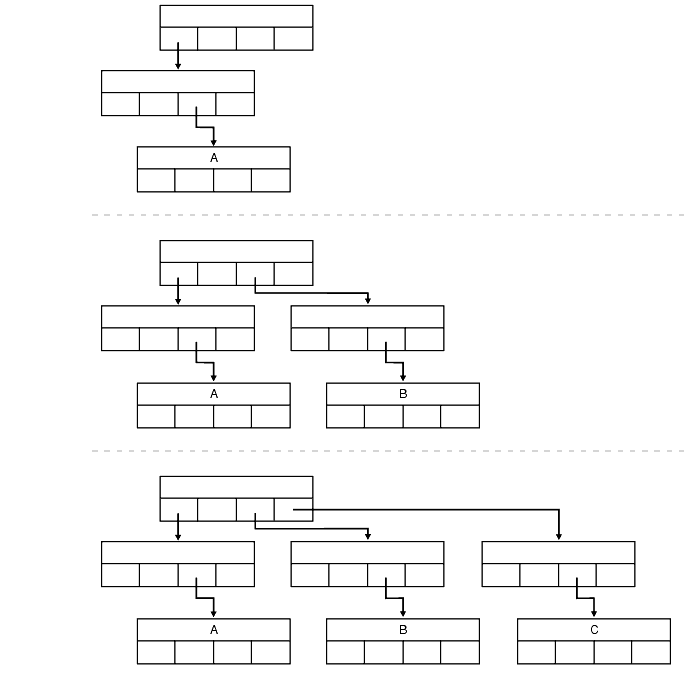
The point quadtree is also used to represent point data in a two dimensional spaces. But these structures divide regions into four parts while 2-d trees divide regions into two. The fields of the record type for this node are comprised of an attribute for information, two co-ordinates, and four compass points (NW, SW, NE, SE) that can therefore point to four children.
Like 2-d trees, point quadtrees are very easy to implement. Also like 2-d trees, the fact that a point quadtree containing k nodes may have a height of k means that insertion and querying may be complex. Each comparison requires comparisons on at least two co-ordinates. However, in practice the lengths from root to leaf tend to be shorter in point quadtrees.
The fact is that Oracle provides a limited number of indextypes, so that if (for instance) you wish to utilize either the k-d tree or the point quadtree, you will have to implement this yourself. As you consider your need to access your data, you need to keep in mind the following restrictions that pertain to the standard indextypes:
Oracle's standard modes of indexing do not permit indexing a column that contains LONG or LOB values.
You may not be able to index a column object using Oracle's standard indexing schemes or the elements of a collection type.
Oracle object types may be compared using either a map function or an order function. If the object utilizes a map function, then you can define a functional index that can be used implicitly to evaluate relational predicates. However, if an order function is used, you will not be able to use this to construct an index.
Further, you cannot utilize functions in predicates in which the range of the parameters is infinite. With Oracle8i functional indexes allow you to include a function in a predicate, provided you can precompute the function values for all the rows. Typically the index would store the rowid and the functional value. Queries that apply relational operators to values based on derived values utilize the index.
However, you can use functional indexes only if the function is so designed that there are a finite number of input combinations. Put another way: you cannot use functional indexes in cases in which the input parameters do not have a limited cardinality.
|
|
 Copyright © 1999 Oracle Corporation. All Rights Reserved. |
|