| Oracle® XML Developer's Kit Programmer's Guide 10g Release 1 (10.1) Part Number B10794-01 |
|






|
View PDF |
| Oracle® XML Developer's Kit Programmer's Guide 10g Release 1 (10.1) Part Number B10794-01 |
|
|
View PDF |
This chapter contains these topics:
Oracle provides eXtensible Stylesheet Language Transformation (XSLT) processing for Java, C, C++, and PL/SQL. This chapter focuses on the XSLT Processor for Java. XSLT is a W3C Internet standard that has a version 1.0, and also a 2.0 version currently in process. XSLT also uses XPath, which is the navigational language used by XSLT and has corresponding versions. The XSLT Processor for Java implements both the XSLT and XPath 1.0 standards as well as a draft of the XSLT and XPath 2.0 standard. Please see the README for the specific versions.
While XSLT is a function-based language that generally requires a DOM of the input document and stylesheet to perform the transformation, the Java implementation uses SAX, a stream-based parser to create a stylesheet object to perform transformations with higher efficiency and less resources. This stylesheet object can be reused to transform multiple documents without re-parsing the stylesheet.
The XSLT Processor for Java includes additional high performance features. It is thread-safe to allow processing multiple files with a single XSLT Processor for Java and stylesheet object. It is also safe to use clones of the document instance in multiple threads.
The XSLT Processor for Java operates on two inputs: the XML document to transform, and the XSLT stylesheet that is used to apply transformations on the XML. Each of these two can actually be multiple inputs. One stylesheet can be used to transform multiple XML inputs. Multiple stylesheets can be mapped to a single XML input.
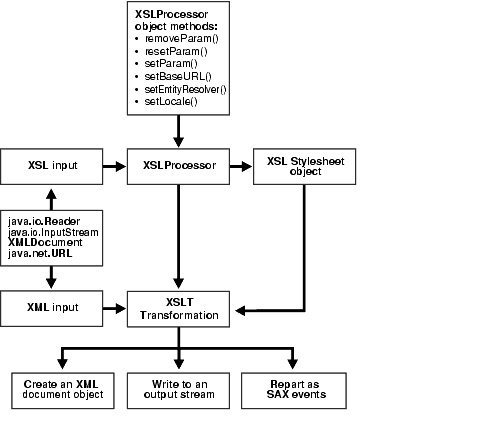
To implement the XSLT Processor in the XML Parser for Java use the XSLProcessor class.
Figure 4-1 shows the overall process used by the XSLProcessor class. Here are the steps:
Create an XSLProcessor object and then use methods from the following list in your Java code. Some of the available methods are:
removeParam() - remove parameter
RESETPARAM() - remove all parameters
setParam() - set parameters for the transformation
setBaseURL() - set a base URL for any relative references in the stylesheet
setEntityResolver() - set an entity resolver for any relative references in the stylesheet
setLocale() - set locale for error reporting
Use one of the following input parameters to the method XSLProcessor.newXSLStylesheet() to create a stylesheet object:
java.io.Reader
java.io.InputStream
XMLDocument
java.net.URL
This creates a stylesheet object that is thread-safe and can be used in multiple XSL Processors.
Create a DOM object by passing one of the XML inputs in step 2, to the DOM parser and creating an XML input object with parser.getDocument.
Your XML inputs and the stylesheet object are input (each using one of the input parameters listed in 2 ) to the XSL Processor:
XSLProcessor.processXSL(xslstylesheet, xml instance)
The results of the XSL Transformation can be one of the following:
Create an XML document object
Write to an output stream
Report as SAX events
Unlike in HTML, in XML every start tag must have an ending tag and that the tags are case sensitive.
This example has many comments. It uses one XML document and one XSL stylesheet as inputs.
public class XSLSample
{
public static void main(String args[]) throws Exception
{
if (args.length < 2)
{
System.err.println("Usage: java XSLSample xslFile xmlFile.");
System.exit(1);
}
// Create a new XSLProcessor.
XSLProcessor processor = new XSLProcessor();
// Register a base URL to resolve relative references
// processor.setBaseURL(baseURL);
// Or register an org.xml.sax.EntityResolver to resolve
// relative references
// processor.setEntityResolver(myEntityResolver);
// Register an error log
// processor.setErrorStream(new FileOutputStream("error.log"));
// Set any global paramters to the processor
// processor.setParam(namespace, param1, value1);
// processor.setParam(namespace, param2, value2);
// resetParam is for multiple XML documents with different parameters
String xslFile = args[0];
String xmlFile = args[1];
// Create a XSLStylesheet
// The stylesheet can be created using one of following inputs:
//
// XMLDocument xslInput = /* using DOMParser; see later in this code */
// URL xslInput = new URL(xslFile);
// Reader xslInput = new FileReader(xslFile);
InputStream xslInput = new FileInputStream(xslFile);
XSLStylesheet stylesheet = processor.newXSLStylesheet(xslInput);
// Prepare the XML instance document
// The XML instance can be given to the processor in one of
// following ways:
//
// URL xmlInput = new URL(xmlFile);
// Reader xmlInput = new FileReader(xmlFile);
// InputStream xmlInput = new FileInputStream(xmlFile);
// Or using DOMParser
DOMParser parser = new DOMParser();
parser.retainCDATASection(false);
parser.setPreserveWhitespace(true);
parser.parse(xmlFile);
XMLDocument xmlInput = parser.getDocument();
// Transform the XML instance
// The result of the transformation can be one of the following:
//
// 1. Return a XMLDocumentFragment
// 2. Print the results to a OutputStream
// 3. Report SAX Events to a ContentHandler
// 1. Return a XMLDocumentFragment
XMLDocumentFragment result;
result = processor.processXSL(stylesheet, xmlInput);
// Print the result to System.out
result.print(System.out);
// 2. Print the results to a OutputStream
// processor.processXSL(stylesheet, xmlInput, System.out);
// 3. Report SAX Events to a ContentHandler
// ContentHandler cntHandler = new MyContentHandler();
// processor.processXSL(stylesheet, xmlInput, cntHandler);
}
}
|
See Also:
|
oraxsl is a command-line interface used to apply a stylesheet on multiple XML documents. It accepts a number of command-line options that determine its behavior. oraxsl is included in the $ORACLE_HOME/bin directory. To use oraxsl ensure the following:
Your CLASSPATH environment variable is set to point to the xmlparserv2.jar file that comes with XML Parser for Java, version 2.
Your PATH environment variable can find the Java interpreter that comes with JDK 1.2 or higher.
Use the following syntax to invoke oraxsl:
oraxsl options source stylesheet result
oraxsl expects to be given a stylesheet, an XML file to transform, and optionally, a result file. If no result file is specified, it outputs the transformed document to the standard output. If multiple XML documents need to be transformed by a stylesheet, use the -l or -d options in conjunction with the -s and -r options. These and other options are described in Table 4-1.
Table 4-1 oraxsl: Command Line Options
| Option | Purpose |
|---|---|
-d directory |
Directory with files to transform (the default behavior is to process all files in the directory). If only a certain subset of the files in that directory, for example, one file, need to be processed, this behavior must be changed by using -l and specifying just the files that need to be processed. You can also change the behavior by using the -x or -i option to select files based on their extension). |
-debug |
Debug mode (by default, debug mode is turned off). |
-e error_log |
The file to write errors and warnings into. |
-h |
Help mode (prints oraxsl invocation syntax). |
-i source_extension |
Extensions to include (used in conjunction with -d. Only files with the specified extension are selected). |
-l xml_file_list |
List of files to transform (enables you to explicitly list the files to be processed). |
-o result_directory |
Directory to place results (this must be used in conjunction with the -r option). |
-p param_list |
List of Parameters. |
-r result_extension |
Extension to use for results (if -d or -l is specified, this option must be specified to specify the extension to be used for the results of the transformation. So, if you specify the extension "out", an input document "foo" is transformed to "foo.out". By default, the results are placed in the current directory. This can be changed by using the -o option which enables you to specify a directory to hold the results). |
-s stylesheet |
Stylesheet to use (if -d or -l is specified, this option needs to be specified to specify the stylesheet to be used. The complete path must be specified). |
-t num_of_threads |
Number of threads to use for processing (using multiple threads can provide performance improvements when processing multiple documents). |
-v |
Verbose mode (some debugging information is printed and can help in tracing any problems that are encountered during processing). |
-w |
Show warnings (by default, warnings are turned off). |
-x source_extension |
Extensions to exclude, used in conjunction with -d. All files with the specified extension not selected. |
XML extension functions for XSLT processing allow users of XSLT processor for Java to call any Java method from XSL expressions.
While these are Oracle extensions, the XSLT 1.0 standard provides for implementation-defined extension functions. Stylesheets using these functions may not be interoperable when run on different processors.The functions are language and implementation specific.
This section contains these topics:
Java extension functions belong to the namespace that starts with the following:
http://www.oracle.com/XSL/Transform/java.101/
An extension function that belongs to the following namespace refers to methods in class classname:
http://www.oracle.com/XSL/Transform/java.101/classname
For example, the following namespace can be used to call java.lang.String methods from XSL expressions:
http://www.oracle.com/XSL/Transform/java.101/java.lang.String
If the method is a non-static method of the class, then the first parameter is used as the instance on which the method is invoked, and the rest of the parameters are passed on to the method.
If the extension function is a static method, then all the parameters of the extension function are passed on as parameters to the static function.
The following XSL, static function example prints out '13':
<xsl:stylesheet
xmlns:math="http://www.oracle.com/XSL/Transform/java.101/java.lang.Math">
<xsl:template match="/">
<xsl:value-of select="math:ceil('12.34')"/>
</xsl:template>
</xsl:stylesheet>
|
Note: The XSL class loader only knows about statically added JARs and paths in theCLASSPATH - and those specified by wrapper.classpath. Files added dynamically using the repositories' keyword in Jserv are not visible to XSLT processor. |
The extension function new creates a new instance of the class and acts as the constructor.
The following constructor function example prints out 'HELLO WORLD':
<xsl:stylesheet
xmlns:jstring="http://www.oracle.com/XSL/Transform/java.101/java.lang.String">
<xsl:template match="/">
<!-- creates a new java.lang.String and stores it in the variable str1 -->
<xsl:variable name="str1" select="jstring:new('Hello World')"/>
<xsl:value-of select="jstring:toUpperCase($str1)"/>
</xsl:template>
</xsl:stylesheet>
The result of an extension function can be of any type, including the five types defined in XSL and the additional simple XML Schema data types defined in XSLT 2.0:
NodeSet
Boolean
String
Number
ResultTree
They can be stored in variables or passed onto other extension functions.
If the result is of one of the five types defined in XSL, then the result can be returned as the result of an XSL expression.
Here is an XSL example illustrating the Return Value Extension function:
<!-- Declare extension function namespace -->
<xsl:stylesheet xmlns:parser =
"http://www.oracle.com/XSL/Transform/java.101/oracle.xml.parser.v2.DOMParser"
xmlns:document =
"http://www.oracle.com/XSL/Transform/java.101/oracle.xml.parser.v2.XMLDocument" >
<xsl:template match ="/"> <!-- Create a new instance of the parser, store it in
myparser variable -->
<xsl:variable name="myparser" select="parser:new()"/>
<!-- Call a non-static method of DOMParser. Since the method is a non-static
method, the first parameter is the instance on which the method is called. This
is equivalent to $myparser.parse('test.xml') -->
<xsl:value-of select="parser:parse($myparser, 'test.xml')"/>
<!-- Get the document node of the XML Dom tree -->
<xsl:variable name="mydocument" select="parser:getDocument($myparser)"/>
<!-- Invoke getelementsbytagname on mydocument -->
<xsl:for-each
select="document:getElementsByTagName($mydocument,'elementname')">
...
</xsl:for-each> </xsl:template>
</xsl:stylesheet>
Overloading based on number of parameters and type is supported. Implicit type conversion is done between the five XSL types as defined in XSL. Type conversion is done implicitly between (String, Number, Boolean, ResultTree) and from NodeSet to (String, Number, Boolean, ResultTree). Overloading based on two types which can be implicitly converted to each other is not permitted.
The following overloading results in an error in XSL, since String and Number can be implicitly converted to each other:
abc(int i){}
abc(String s){}
Mapping between XSL type and Java type is done as follows:
String -> java.lang.String Number -> int, float, double Boolean -> boolean NodeSet -> XMLNodeList ResultTree -> XMLDocumentFragment
Here are the definitions of these Oracle XSL extensions; both are preceded by xmlns:ora="http://www.oracle.com/XSL/Transform/java".
This element can be used as a top-level element similar to xsl:output. It can have all of the attributes of xsl:output, with similar functionality. It has an additional attribute name, used as an identifier. When ora:output is used in a template, it can only have the attributes use and href. use specifies the top-level ora:output to be used, and href gives the output URL
The following example illustrates use of both ora:node-set and ora:output.
If you enter:
$ oraxsl foo.xml slides.xsl toc.html
where foo.xml is any input XML file. You get as output:
A toc.html slide file with a table of contents
A slide01.html file with slide 1
A slide02.html file with slide 2
<!--
| Illustrate using ora:node-set and ora:output
|
| Both extensions depend on defining a namespace
| with the uri of "http://www.oracle.com/XSL/Transform/java"
+-->
<xsl:stylesheet version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform" xmlns:ora="http://www.oracle.com/XSL/Transform/java">
<!-- <xsl:output> affects the primary result document -->
<xsl:output mode="html" indent="no"/>
<!--
| <ora:output> at the top-level enables all attributes
| that <xsl:output> enables, but you must provide the
| additional "name" attribute to assign a name to
| these output settings to be used later.
+-->
<ora:output name="myOutput" mode="html" indent="no"/>
<!--
| This top-level variable is a result-tree fragment
+-->
<xsl:variable name="fragment">
<slides>
<slide>
<title>First Slide</title>
<bullet>Point One</bullet>
<bullet>Point Two</bullet>
<bullet>Point Three</bullet>
</slide>
<slide>
<title>Second Slide</title>
<bullet>Point One</bullet>
<bullet>Point Two</bullet>
<bullet>Point Three</bullet>
</slide>
</slides>
</xsl:variable>
<xsl:template match="/">
<!-- | We cannot "de-reference" a result-tree-fragment to
| navigate into it with an XPath expression. However, using
| the ora:node-set() built-in extension function, you can
| "cast" a result-tree fragment to a node-set which *can*
| then be navigated using XPath. Since we'll use the node-set
| of <slides> twice later, we save the node-set in a variable.
+-->
<xsl:variable name="slides" select="ora:node-set($fragment)"/>
<!--
| This <html> page will go to the primary result document.
| It is a "table of contents" for the slide show, with
| links to each slide. The "slides" will each be generated
| into *secondary* result documents, each slide having
| a file name of "slideNN.html" where NN is the two-digit
| slide number
+-->
<html>
<body>
<h1>List of All Slides</h1>
<xsl:apply-templates select="$slides" mode="toc"/>
</body>
</html>
<!--
| Now go apply-templates to format each slide
+-->
<xsl:apply-templates select="$slides"/>
</xsl:template>
<!-- In 'toc' mode, generate a link to each slide we match -->
<xsl:template match="slide" mode="toc">
<a href="slide{format-number(position(),'00')}.html">
<xsl:value-of select="title"/>
</a><br/>
</xsl:template>
<!--
| For each slide matched, send the output for the current
| <slide> to a file named "slideNN.html". Use the named
| output style defined earlier called "myOutput".
<xsl:template match="slide">
<ora:output use="myOutput href="slide{format-number(position(),'00')}.html">
<html>
<body>
<xsl:apply-templates select="title"/>
<ul>
<xsl:apply-templates select="*[not(self::title)]"/>
</ul>
</body>
</html>
</ora:output>
</xsl:template>
<xsl:template match="bullet">
<li><xsl:value-of select="."/></li>
</xsl:template>
<xsl:template match="title">
<h1><xsl:value-of select="."/></h1>
</xsl:template>
</xsl:stylesheet>
This section lists XSL and XSLT Processor for Java hints, and contains these topics:
To merge two XML documents, you can either use the DOM APIs or use XSLT-based approaches.
If you use the DOM APIs, then you have to copy the DOM node from the source DOM document before you can append it to the destination DOM document. This operation is required to avoid DOM document ownership errors, like WRONG_DOCUMENT_ERR. Both the importNode() method, introduced in DOM 2, and adoptNode() method, introduced in DOM 3, can be used to copy and paste a DOM document fragment or a DOM node across different XML documents.
Document doc1 = new XMLDocument();
Element element1 = doc1.createElement("foo");
Document doc2 = new XMLDocument();
Element element2 = doc2.createElement("bar");
element2 = doc1.importNode(element2);
element1.appendChild(element2);
Document doc1 = new XMLDocument();
Element element1 = doc1.createElement("foo");
Document doc2 = new XMLDocument();
Element element2 = doc2.createElement("bar");
element2 = doc1.adoptNode(element2);
element1.appendChild(element2);
The difference between using adoptNode() and importNode() is that using adoptNode(), the source DOM node is removed from the original DOM document, while using importNode(), the source node is not altered or removed.
If the merging operation is simple, you can also use the XSLT-based approaches. For example, you have two XML documents such as:
<messages>
<msg>
<key>AAA</key>
<num>01001</num>
</msg>
<msg>
<key>BBB</key>
<num>01011</num>
</msg>
</messages>
<messages>
<msg>
<key>AAA</key>
<text>This is a Message</text>
</msg>
<msg>
<key>BBB</key>
<text>This is another Message</text>
</msg>
</messages>
Here is an example stylesheet, that merges the two XML documents, demo1.xml and demo2.xml, based on matching the <key/> element values.
<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output indent="yes"/>
<xsl:variable name="doc2" select="document('demo2.xml')"/>
<xsl:template match="@*|node()">
<xsl:copy>
<xsl:apply-templates select="@*|node()"/>
</xsl:copy>
</xsl:template>
<xsl:template match="msg">
<xsl:copy>
<xsl:apply-templates select="@*|node()"/>
<text><xsl:value-of select="$doc2/messages/msg[key=current()/key]/text"/>
</text>
</xsl:copy>
</xsl:template>
</xsl:stylesheet>
Enter the following at the command line:
$ oraxsl demo1.xml demomerge.xsl
Then, you get the following merged result:
<messages>
<msg>
<key>AAA</key>
<num>01001</num>
<text>This is a Message</text>
</msg>
<msg>
<key>BBB</key>
<num>01011</num>
<text>This is another Message</text>
</msg>
</messages>
This method is obviously not as efficient for larger files as an equivalent database join of two tables, but this illustrates the technique if you have only XML files to work with.
The content of your CDATA, it is just text. If you want the text content to be output without escaping the angle-brackets:
<xsl:value-of select="/OES_MESSAGE/PAYLOAD" disable-output-escaping="yes"/>
XSLT fully supports all options of <xsl:output>. Your XSL stylesheet must be a well-formed XML document. Instead of using the <BR> element, you must use <BR/>. The <xsl:output method="html"/> requests that when the XSLT engine writes out the result of your transformation, it is a proper HTML document. What the XSLT engine reads in must be well-formed XML.
Assume that you have an XSL stylesheet that performs XML to HTML conversion. Everything works correctly with the exception of those HTML tags that end up as empty elements, that is, <input type="text"/>. For example, the following stylesheet creates an HTML document with an <input> element:
<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output method="html"/>
...
<input type="text" name="{NAME}" size="{DISPLAY_LENGTH}" maxlength="{LENGTH}">
</input>
...
</xsl:stylesheet>
It renders HTML in the format of
<HTML>...<input type="text" name="in1" size="10" maxlength="20"/> ... </HTML>
While Internet Explorer can handle this, Netscape cannot. Is there any way to generate completely cross-browser-compliant HTML with XSL?
The solution to this problem is that if you are seeing:
<input ... />
instead of:
<input ...></input>
then you are likely using the incorrect way of calling XSLProcessor.processXSL(), since it appears that it is not doing the HTML output for you. Use:
void processXSL(style,sourceDoc,PrintWriter)
instead of:
DocumentFragment processXSL(style,sourceDoc)
To generate an HTML form for inputting data using column names from the user_tab_columns table here is the XSL code:
<xsl:template match="ROW">
<xsl:value-of select="COLUMN_NAME"/>
<INPUT NAME="{COLUMN_NAME}"/>
</xsl:template>
The following URI is correct:
xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
If you use:
xmlns:xsl="-- any other string here --"
it does not give correct output.
The XML Parser for Java, release 2.0.2.8 and above, supports <ora:output> to produce more than one result from one XML and XSL.
Use this in your code, where (white spaces) means that you enter a space, newline, or tab there:
<xsl:text>...(white spaces)</xsl:text>
XSLT translates from XML to XML, or to HTML, or to another text-based format. What about the other way around?
For HTML, you can use utilities like Tidy or JTidy to turn HTML into well-formed HTML that can be transformed using XSLT. For unstructured text formats, you can try utilities like XFlat at the following Web site:
Multiple threads can use a single XSLProcessor and XSLStylesheet instance to perform concurrent transformations. As long as you are processing multiple files with no more than one XSLProcessor and XSLStylesheet instance for each XML file you can do this simultaneously using threads.
It is safe to use clones of a document in multiple threads. The public void setParam(String,String) throws XSLException method of class oracle.xml.parser.v2.XSLStylesheet is supported. If you copy the global area set up by the constructor to another thread then it works. That method is supported since XML Parser for Java, release 2.0.2.5.
|
 Copyright © 2001, 2003 Oracle Corporation All Rights Reserved. |
|