| Oracle® Retail Bulk Data Integration Cloud Service Implementation Guide Release 19.1.000 F31810-01 |
|

 Previous |
 Next |
| Oracle® Retail Bulk Data Integration Cloud Service Implementation Guide Release 19.1.000 F31810-01 |
|
Previous |
Next |
This chapter discusses the Job Admin Services.
Job Admin provides below RESTful services. These services are secured with SSL and basic authentication.
Batch Service - Ability to start/stop/restart, check status, and so on of jobs. This service is typically used by the BDI Process Flow engine.
Receiver Service - Ability to stream data from one system to another system. This service is used by the Downloader-Transporter job.
System Setting Service - Ability to view, change system settings, and credentials. Refer to Appendix D for details on System Setting REST resources.
Data Service - Ability to get data set information using job information such as job name, execution id or instance id.
Telemetry Service - Ability to get job metrics for jobs that ran between fromTime and toTime.
The Receiver Service is a RESTful service that provides various endpoints to send data transactionally. Receiver Service is part of Job Admin. Receiver Service uploads the data to either database or files. By default, the Receiver Service stores the data in the database. It stores data as files and keeps track of metadata in the database. The Receiver Service also supports various merge strategies for merging files at the end. The Receiver Service is used by the Downloader-Transporter job to transmit data from source to destination.Seed data for Receiver Service is generated during design time and loaded during deployment of the Job Admin application.
BDI_RECEIVER_OPTIONS
The Receiver Service options can be configured at interface level.
Table 3-1 Receiver Options
| Column | Type | Comments |
|---|---|---|
|
ID |
NUMBER |
Primary key |
|
INTERFACE_MODULE |
VARCHAR2(255) |
Name of the interface module |
|
INTERFACE_SHORT_NAME |
VARCHAR2(255) |
Name of the interface |
|
BASE_FOLDER |
VARCHAR2(255) |
This is the base folder for storing files created by Receiver Service. Receiver Service creates a subfolder ”bdi-data” under base folder. Base folder can be changed from ”Manage Configurations” tab of Job Admin GUI. |
|
FOLDER_TEMPLATE |
VARCHAR2(255) |
Folder template provides the folder structure for storing files created by Receiver Service.Default value is ”${basefolder}/${TxId}/${TId}/${BId}/”. TxId - Transaction IdTId - Transmission IdBId - Block IdThis value can't be changed. |
|
MERGE_STRATEGY |
VARCHAR2(255) |
The strategy for merging files. The default value is ”NO_MERGE”. The valid values are NO_MERGE, MERGE_TO_PARTITION_LEVEL, and MERGE_TO_INTERFACE_LEVEL.MERGE_TO_PARTITION_LEVELMerges all files for that partition and creates the merged file in ”${TId}” folder.MERGE_TO_INTERFACE_LEVELMerges all files for interface and creates the merged file in ”${TxId}” folder.MERGE strategies are only supported in cases where the Uploader is not used. |
Endpoints
Ping
This endpoint can be used to check whether the Receiver Service is up or not.
HTTP Method: GET
Path: receiver/ping
Response: alive
Begin Receiver Transaction
This is the first endpoint to be called by the client (for example Downloader-Transporter job) before sending any data. It stores the following metadata in the BDI_RECEIVER_TRANSACTION table and returns the response in JSON format.
| Parameter | Description |
|---|---|
| Transaction Id | Transaction Id (Tx#<Job Instance Id>_<Current Time in millis>_<Source System Name> of the Downloader-Transporter job |
| Interface Module | Name of the interface module (for example Diff_Fnd) |
| Source System Name | Name of the source system (for example RMS) |
| sourceSystemId | ID of the source system (for example URL) |
| sourceDataSetId | ID of the data set |
| Data Set Type | Type of data set (FULL or PARTIAL) |
| Source System Data Set Ready Time | Time when source data set was ready in the outbound tables |
HTTP Method: POST
Path: receiver/beginTransaction/{transactionId}/{interfaceModule}/{sourceSystemName}/{sourceSystemId}/{sourceDataSetId}/{dataSetType}/{sourceSystemDataSetReadyTime}
Sample Response
{
”receiverTransactionId”: ”1”,
”transactionId”: ”Tx#1”,
”sourceSystemName”: ”RMS”,
”interfaceModule”: ”Diff_Fnd”,
”sourceSystemId”: ””,
”sourceDataSetId”: ””,
”dataSetType”: ”FULL”,
”sourceSystemDataSetReadyTime”: ””,
”dir”: ””,
”fileName”: ””,
”receiverTransactionStatus”: ””,
”receiverTransactionBeginTime”: ””,
”receiverTransactionEndTime”: ””
}
Begin Receiver Transmission
This end point needs to be called by client (for example Downloader-Transporter job) before sending any data for a partition. It stores the following metadata in BDI_RECEIVER_TRANSMISSION table and returns response in JSON format.
| Parameter | Description |
|---|---|
| TransmissionId | Generated for each partition |
| InterfaceModule) | Name of the interface module (for example Diff_Fnd |
| InterfaceShortName) | Name of the interface (for example Diff |
| partitionName | Partition number |
| partitionBeginSeqNum | Begin sequence number in the partition |
| partitionEndSeqNum | End sequence number in the partition |
| beginBlockNumber | Begin block number |
HTTP Method: POST
Path: receiver/beginTransmission/{transactionId}/{transmissionId}/{sourceSystemName}/{interfaceMod-ule}/{interfaceShortName}/{partitionName}/{partitionBeginSeqNum}/{partitionEndSeqNum}/{beginBlockNumber}
Parameters:
Query Parameter: sourceSystemInterfaceDataCount
Sample Response:
{
”transmissionId”: ”1”,
”interfaceModule”: ”Diff_Fnd”,
”interfaceShortName”: ”Diff”,
”sourceSystemPartitionName”: ”1”,
”sourceSystemPartitionBeginSequenceNumber”: ”1”,
”sourceSystemPartitionEndSequenceNumber”: ”100”,
”beginBlockNumber”: ”1”,
”endBlockNumber”: ””,
”dir”: ””,
”fileName”: ””,
”receiverTransmissionStatus”: ””
}
Upload Data Block
Clients use this endpoint to send data. This endpoint is typically called by the client multiple times until there is no more data. It creates a csv file with the data it received at the below location.
${BASE_FOLDER}/bdi-data/${TxId}/${TId}/${BId}
BASE_FOLDER - Obtained from the BDI_RECEIVER_OPTIONS table
TxId - Transaction Id of the remote Downloader-Transporter job
TId - Transmission Id associated with the transaction id
BId - Block Id associated with transmission id
It also stores the following metadata in the RECEIVER_TRANSMISSION_BLOCK table.
| Parameter | Description |
|---|---|
| BlockNumber | Number of the block |
| ItemCountInBlock | Number of items in the block |
| Dir | Directory where file is created |
| FileName | Name of the file |
| ReceiverBlockStatus | Status of the block |
| CreateTime | Time when the block is created |
HTTP Method: POST
Path: receiver/uploadDataBlock/{transactionId}/{transmissionId}/{sourceSystemName}/{interfaceModule}/{interfaceShortName}/{blockNumber}/{itemCountInBlock}
Sample Response
{
”blockId”: ”1”,
”transmissionId”: ”1”,
”blockNumber”: ”1”,
”blockItemCount”: ”100”,
”dir”: ””,
”fileName”: ””,
”receiverBlockStatus”: ””,
”createTime”: ””
}
End Transmission
This end point ends transmission for a partition. It updates ”endBlockNumber” and ”receiverTransmisionStatus” in the RECEIVER_TRANSMISSION table.
HTTP Method: POST
Path: receiver/endTransmission/{transmissionId}/{sourceSystemName}/{interfaceModule}/{interfaceShortName}/{numBlocks}
Sample Response
{
”transmissionId”: ”1”,
”interfaceModule”: ”Diff_Fnd”,
”interfaceShortName”: ”Diff”,
”sourceSystemPartitionName”: ”1”,
”sourceSystemPartitionBeginSequenceNumber”: ”1”,
”sourceSystemPartitionEndSequenceNumber”: ”100”,
”beginBlockNumber”: ”1”,
”endBlockNumber”: ””,
”dir”: ””,
”fileName”: ””,
”receiverTransmissionStatus”: ””
}
End Transaction
This end point ends the transaction and called once by the client. It updates ”receiverTransactionStatus” and ”receiverTranasctionEndTime” in the RECEIVER_TRANSACTION table. If ”mergeStrategy” is set to ”MERGE_TO_PARTITION_LEVEL” or ”MERGE_TO_INTERFACE_LEVEL”, then it merges the files and creates the merged file(s) at the appropriate directory. It creates an entry in the BDI_UPLDER_IFACE_MOD_DATA_CTL table so that Uploader job can pick up the data.
HTTP Method: POST
Path: receiver/endTransaction/{transactionId}/{sourceSystemName}/{interfaceModule}
Sample Response
{
”receiverTransactionId”: ”1”,
”transactionId”: ”Tx#1”,
”sourceSystemName”: ”RMS”,
”interfaceModule”: ”Diff_Fnd”,
”sourceSystemId”: ””,
”dataSetType”: ”FULL”,
”sourceSystemDataSetReadyTime”: ””,
”dir”: ””,
”fileName”: ””,
”receiverTransactionStatus”: ””,
”receiverTransactionBeginTime”: ””,
”receiverTransactionEndTime”: ””
}
Uploader Interface Module Data Control Table
The BDI_UPLDER_IFACE_MOD_DATA_CTL table acts as a handshake between the downloader and uploader jobs. When the downloader-transporter job calls endTransaction on Receiver Service, the Receiver Service creates an entry in this table if it successfully received data and created files.
An entry in this table indicates to the uploader job that a data set is ready to be uploaded.
BDI_UPLDER_IFACE_MOD_DATA_CTL
Table 3-2 Module Data Control
| Column | Type | Comments |
|---|---|---|
|
UPLOADER_IFACE_MOD_DATA_CTLID |
NUMBER |
Primary key |
|
INTERFACE_MODULE |
VARCHAR2(255) |
Name of the interface module |
|
REMOTE_TRANSACTION_ID |
VARCHAR2(255) |
Transaction Id of Downloader-Transporter job |
|
SOURCE_DATA_SET_ID |
NUMBER |
NUMBER ID of the source data set |
|
SRC_SYS_DATA_SET_READY_TIME |
TIMESTAMP |
Source Data Set Ready Time |
|
DATA_SET_TYPE |
VARCHAR2(255) |
Type of data set (FULL or PARTIAL) |
|
DATA_SET_READY_TIME |
TIMESTAMP |
Time when data set was available in the outbound tables |
|
DATA_FILE_MERGE_LEVEL |
VARCHAR2(255) |
Merge level for the files (NO_MERGE, MERGE_TO_PARTITION_LEVEL, MERGE_TO_INTERFACE_LEVEL) |
|
SOURCE_SYSTEM_NAME |
VARCHAR2(255) |
Name of the source system (for example RMS) |
Receiver Side Split for Multiple Destinations
If there are multiple destinations that receive data from a source, one of the options is to use the Receiver Service at one destination to receive data from the sender and then multiple destinations use the data from one Receiver Service to upload to inbound tables. The requirements for the Receiver Side Split are such that:
The Receiver Service database schema is shared by all the destinations
The File system is shared by all destinations
The performance of BDI can be improved by using the receiver side split if there are multiple destinations.
Batch service is a RESTful service that provides various endpoints to manage batch jobs in the bulk data integration system. Batch Service is part of Job Admin.
Table 3-3 Batch Service
| REST Resource | HTTP Method | Description |
|---|---|---|
|
/batch/jobs |
GET |
Gets all available batch jobs |
|
/batch/jobs/enable-disable |
POST |
Enable or disable the jobs |
|
/batch/jobs/{jobName} |
GET |
Gets all instances for a job |
|
/batch/jobs/{jobName}/executions |
GET |
Gets all executions for a job |
|
/batch/jobs/executions |
GET |
Gets all executions |
|
/batch/jobs/currently-running-jobs |
GET |
Gets currently running jobs |
|
/batch/jobs/{jobName}/{jobInstanceId}/executions |
GET |
Gets job executions for a job instance |
|
/batch/jobs/{jobName}/{jobExecutionId} |
GET |
Gets job instance and execution for a job execution id |
|
/batch/jobs/{jobName} |
POST |
Starts a job asynchronously |
|
/batch/jobs/executions/{jobExecutionId} |
POST |
Restarts a stopped or failed job |
|
/batch/jobs/executions |
DELETE |
Stops all running job executions |
|
/batch/jobs/executions/{jobExecutionId} |
DELETE |
Stops a job execution |
|
/batch/jobs/executions/{jobExecutionId} |
GET |
Gets execution steps with details |
|
/batch/jobs/executions/{jobExecutionId}/steps |
GET |
Gets execution steps |
|
/batch/jobs/executions/{jobExecutionId}/steps/{stepExecutionId} |
GET |
Gets step details |
|
/batch/jobs/is-job-ready-to-start/{jobName} |
GET |
Gets job if ready to start |
|
/batch/jobs/group-definitions |
GET |
Gets all group definitions |
|
/batch/jobs/job-def-xml-files |
GET |
Gets all job xml files |
Key End Points
Start Job
This end point starts a job asynchronously based on a job name and returns the execution id of the job in the response. If the given job is disabled it throws the exception "Cannot start the disabled Job {jobName}. Enable the Job and start it."
Path: /batch/jobs/{jobName}
HTTP Method: POST
Inputs
Job Name as path parameter
Job Parameters as a query parameter. Job Parameters is a comma separated list of name value pairs. This parameter is optional.
Sample Request
http://localhost:7001/bdi-batch-job-admin/resources/batch/jobs/DiffGrp_Fnd_ImporterJob?jobParameters=dataSetId=1
Successful Response
XML
<executionIdVo targetNamespace=””>
<executionId>1</executionId>
<jobName>DiffGrp_Fnd_ImporterJob</jobName>
</executionIdVo>
JSON
{
”executionId”: 1,
”jobName”: ”DiffGrp_Fnd_ImporterJob”
}
Error Response
XML
<exceptionVo targetNamespace=””>
<statusCode>404</statusCode>
<status>NOT_FOUND</status>
<message>HTTP 404 Not Found</message>
<stackTrace></stackTrace> <!-- optional -->
</exceptionVo>
JSON
{
”statusCode”: ”404”,
”status”: ”NOT_FOUND”,
”message”: ”HTTP 404 Not Found”,
”stackTrace”: ””
}
Error Response in case of disable jobs
JSON
{
"statusCode": 500,
"status": "Internal Server Error",
"message": "Cannot start the disabled Job {jobName}. Enable the Job
and start it.",
"stackTrace": "java.lang.RuntimeException:....."
}
Restart Job
This end point restarts a job asynchronously using the job execution id and returns the new job execution id. If the given job is disabled it throws the exception "Cannot restart the disabled Job {jobName}. Enable the Job and restart."
Path: /batch/jobs/executions/{executionId}
HTTP Method: POST
Inputs
executionId as path parameter
Sample Request
http://localhost:7001/bdi-batch-job-admin/resources/batch/jobs/executions/2
Successful Response
XML
<executionIdVo targetNamespace=””>
<executionId>2</executionId>
<jobName>DiffGrp_Fnd_ImporterJob</jobName>
</executionIdVo>
JSON
{
”executionId”: 2,
”jobName”: ”DiffGrp_Fnd_ImporterJob”
}
Error Response
XML
XML
<exceptionVo targetNamespace=””>
<statusCode>500</statusCode>
<status>INTERNAL_SERVER_ERROR</status>
<message>Internal Server Error</message>
<stackTrace></stackTrace> <!-- optional -->
</exceptionVo>
JSON
{
”statusCode”: ”500”,
”Status”: ”INTERNAL_SERVER_ERROR”,
”Message”: ”Internal Server Error”,
”stackTrace”: ””
}
Error Response in case of disable jobs
JSON
{
"statusCode": 500,
"status": "Internal Server Error",
"message": "Cannot restart the disabled Job {jobName}. Enable the
Job and restart.",
"stackTrace": "java.lang.RuntimeException:....."
}
Enable or Disable the jobs
This endpoint enables or disables the jobs using jobId, jobEnableStatus and returns the jobId, status and message.
Path: /batch/jobs/enable-disable
HTTP Method: POST
Inputs
JSON
[
{
"jobId": "Diff_Fnd_DownloaderAndTransporterToRxmJob",
"jobEnableStatus": "false"
},
{
"jobId": "CodeHead_Fnd_DownloaderAndTransporterToSimJob",
"jobEnableStatus": "true"
}
]
Sample Request
http://localhost:7001/bdi-batch-job-admin/resources/batch/jobs/enable-disable
Successful Response
JSON
[
{
"jobId": "DiffGrp_Fnd_DownloaderAndTransporterToSimJob",
"jobEnableStatus": "DISABLED",
"message": "Job Disabled Successfully"
},
{
"jobId": "CodeHead_Fnd_DownloaderAndTransporterToSimJob",
"jobEnableStatus": "ENABLED",
"message": "Job Enabled Successfully"
}
]
Check Status of a Job
This endpoint returns the status of a job using the job name and execution id.
Path: /batch/jobs/jobName/{jobExecutionId}
HTTP Method: GET
Inputs
jobName as path parameter
jobExecutionId as path parameter
Sample Request
http://localhost:7001/bdi-batch-job-admin/resources/batch/jobs/DiffGrp_Fnd_ImporterJob/1
Successful Response
XML
<jobInstanceExecutionsVo targetNamespace=””>
<jobName>DiffGrp_Fnd_ImporterJob</jobName>
<jobInstanceId>1</jobInstanceId>
<resource>http://localhost:7001/bdi-batch-job-admin/resources/batch/jobs/DiffGrp_Fnd_ImporterJob/1</resource>
<jobInstanceExecutionVo>
<executionId>1<>executionId>
<executionStatus>COMPLETED</executionStatus>
<executionStartTime>2016-07-11 15:45:27.356</executionStartTime>
<executionDuration>10</executionDuration>
</jobInstanceExecutionVo>
</jobInstanceExecutionsVo>
JSON
{
”jobName”: ”DiffGrp_Fnd_ImporterJob”,
”jobInstanceId”: 1,
”resource”: ”http://localhost:7001/bdi-batch-job-admin/resources/batch/jobs/DiffGrp_Fnd_ImporterJob/1”,
[”jobInstanceExecutionVo”: {
”executionId”: 1,
”executionStatus”: ”COMPLETED”,
”executionStartTime”:”2016-07-11 15:45:27.356”,
”executionDuration”: ”10”
}]
}
}
Error Response
XML
<exceptionVo targetNamespace=””>
<statusCode>500</statusCode>
<status>INTERNAL_SERVER_ERROR</status>
<message>Internal Server Error</message>
<stackTrace></stackTrace> <!-- optional -->
</exceptionVo>
JSON
{
”statusCode”: ”500”,
”Status”: ”INTERNAL_SERVER_ERROR”,
”Message”: ”Internal Server Error”,
”stackTrace”: ””
}
Data Service is a RESTful service that provides end points to get data set information based on job level information.
Table 3-4 Data Service
| REST Resource | HTTP Method | Description |
|---|---|---|
|
/data/dataset/{jobName}/executions/{jobExecutionId} |
GET |
Gets a data set based on job name and job execution id |
|
/data/dataset/{jobName}/instances/{jobInstanceId} |
GET |
Gets a data set based on job name and job instance id |
|
/data/dataset/{jobName}nextPending |
GET |
Gets next pending data set based on job name |
Get Data Set for job name and execution id
Job name - Extractor or downloader-transmitter or uploader job name
Execution id - Job execution id
This endpoint is used by a process flow to get the data set id after the extractor job is run successfully.
Sample Request
http://localhost:7001/bdi-batch-job-admin/resources/data/dataset/Diff_Fnd_ExtractorJob/executions/1
Sample Response
Returns response in either XML or JSON format.
<jobDataSetVo>
<interfaceModule>Diff_Fnd</interfaceModule>
<interfaceModuleDataControlId>2</interfaceModuleDataControlId>
<jobName>Diff_Fnd_ExtractorJob</jobName>
<jobDataSetInstance>
<jobInstanceId>1</jobInstanceId>
<jobDataSetExecutions>
<jobExecutionId>1</jobExecutionId>
</jobDataSetExecutions>
</jobDataSetInstance>
</jobDataSetVo>
Get Data Set for job name and instance id
Job name - Extractor or downloader-transmitter or uploader job
Instance id - Job instance id
Sample Request
http://localhost:7001/bdi-batch-job-admin/resources/data/dataset/Diff_Fnd_ExtractorJob/instances/1
Sample Response
<jobDataSetVo>
<interfaceModule>Diff_Fnd</interfaceModule>
<interfaceModuleDataControlId>2</interfaceModuleDataControlId>
<jobName>Diff_Fnd_ExtractorJob</jobName>
<jobDataSetInstance>
<jobInstanceId>1</jobInstanceId>
<jobDataSetExecutions>
<jobExecutionId>1</jobExecutionId>
</jobDataSetExecutions>
</jobDataSetInstance>
</jobDataSetVo>
Get next pending data set for job name
This endpoint is applicable only to the downloader-transporter or uploader jobs.
Sample Request
http://localhost:7001/bdi-batch-job-admin/resources/data/dataset/Diff_Fnd_DownloaderAndTransporterToRpasJob/nextPending
Sample Response
<jobDataSetVo>
<interfaceModule>Diff_Fnd</interfaceModule>
<interfaceModuleDataControlId>9</interfaceModuleDataControlId>
</jobDataSetVo>
Telemetry Service is a RESTful service that provides end points to get job metrics information.
Table 3-5 Data Service
| REST Resource | HTTP Method | Description |
|---|---|---|
|
/telemetry/jobs/ |
GET |
Gets job metrics based on fromTime and toTime |
|
/telemetry/jobs/summary |
GET |
Gets job metrics summary based on fromTime and toTime |
Job telemetry provides an end point to produce metrics for jobs that ran between "fromTime" and "toTime".
Path: /telemetry/jobs HTTP Method: GET Parameters:
fromTime - Query parameter
toTime - Query parameter
Sample Request
http://localhost:7001/<app>-batch-job-admin/resources/telemetry/jobs?fromTime= &toTime=
Sample Response
Returns response in either XML or JSON format. <job-runtime-monitoring-info data-requested-at="2018-11-08T00:44:57.113-05:00" data-requested-from-time="2018-11-07T00:44:57.1-05:00" data-requested-to-time="2018-11-08T00:44:57.1-05:00"> <jobs-server-runtime-info id="external-batch-job-admin.war" app-status="RUNNING" up-since="69461" total-jobs-count="2" total-executions-count="2" successful-executions-count="0" failed-executions-count="2"> <job name="Calendar_Fnd_ImporterJob" slowest-run-duration="0" fastest-run-duration="0" avg-run-duration="0.0"> <executions execution_count="1" success_count="0" failure_count="1"> <execution execution-id="42" instance_id="42" status="FAILED" startTime="2018-11-08T00:44:22-05:00" endTime="2018-11-08T00:44:22-05:00"> <step step-execution-id="42" name="batchlet-step" duration="0" status="FAILED"/> </execution> </executions> </job> </jobs-server-runtime-info> </job-runtime-monitoring-info>
Job telemetry summary provides an end point to produce metrics for jobs summary information that ran between "fromTime" and "toTime".
Path: /telemetry/jobs/summaryHTTP Method: GET Parameters:
fromTime - Query parameter
toTime - Query parameter
Sample Request
http:// localhost:7001/ <app>-batch-job-admin/resources/telemetry/jobs/summary?fromTime= &toTime=
Sample Response
Returns response in either XML or JSON format. <jobExecutionsSummaryVo data-requested-at="2018-11-08T00:45:50.888-05:00" data-requested-from-time="2018-11-07T00:45:50.887-05:00" data-requested-to-time="2018-11-08T00:45:50.887-05:00"> <executions jobName="Calendar_Fnd_ImporterJob" executionId="42" instanceId="42" status="FAILED" startTime="2018-11-08T00:44:22-05:00" endTime="2018-11-08T00:44:22-05:00"averageDuration="0.0"/> <executions jobName="Brand_Fnd_ImporterJob" executionId="41" instanceId="41" status="FAILED" startTime="2018-11-08T00:43:59-05:00" endTime="2018-11-08T00:44:02-05:00" averageDuration="0.0"/> </jobExecutionsSummaryVo>
End points have been added to Batch Service to allow CRUD operations on Job XML.
CREATE Job XML
This end point creates an entry in BDI_JOB_DEFINITION table. It will throw an exception if job already exists.
HTTP Method: PUT
Path: /resources/batch/jobs/job-def-xml/{jobName}
Inputs:
Job Name (e.g. Diff_Fnd_ExtractorJob)
Job XML - It has to be valid XML that conforms to Job XML schema. The value of "id" in the XML should match "jobName" path parameter.
Update Job XML
This end point updates an entry in BDI_JOB_DEFINITION table. It will update if job is not in running state. This end point throws an exception if job doesn't exist in the table.
HTTP Method: POST
Path: /resources/batch/jobs/job-def-xml/{jobName}
Inputs:
Job Name (e.g. Diff_Fnd_ExtractorJob)
Job XML - It has to be valid XML that conforms to Job XML schema. The value of "id" in the XML should match "jobName" path parameter.
Delete Job XML
This end point deletes an entry in BDI_JOB_DEFINITION table. It will delete if job is not in running state and if there is no history in batch database.
HTTP Method: DELETE
Path: /resources/batch/jobs/job-def-xml/{jobName}
Inputs:
Job Name (e.g. Diff_Fnd_ExtractorJob)
Delete Job History
This end point deletes history for a job from batch database. It will delete history if job is not in running state.
HTTP Method: DELETE
Path: /resources/batch/jobs/{jobName}
Inputs:
Job Name (e.g. Diff_Fnd_ExtractorJob)
ReST Endpoints have been introduced for Bulk create/update and Delete of Jobs in BDI/JOS Job admin application. There were existing end points to create/update/delete the individual jobs but it would be a great effort to use them sequentially for high number of jobs. A single end point service which can be used to take care of bulk create OR update operation for new job set has been added. Another end point for deleting multiple jobs has been added. Both the end points provide Job Level success and failure response for Create/Update/Delete.
End point for create/update job definitions
Http method:
Post
Path:
/batch/jobs/bulk/job-definitions
Consumes:
MediaType.APPLICATION_JSON/MediaType.APPLICATION_XML
Sample request:
http://localhost:7001/bdi-batch-job-admin/resources/batch/jobs/bulk/job-definitions
Input:
JSON
{"jobDefinitionsVo":[
{ "jobId": "Job11",
"jobDefXml": "PGpvYi-BpZD0iSm9iMTEiIHZlcnNpb249IjEuMCIgeG1sbnM9Imh0dHA6Ly94bWxucy5qY3Aub3JnL3htbC9ucy9qYXZhZWUiPgogIAgHyb3BlcnRpZXM==" },
{"jobId": "Job12",
"jobDefXml": "PGpvYi-BpZD0iSm9iMTIiIHZlcnNpb249IjEuMCIgeG1sbnM9Imh0dHA6Ly94bWxucy5qY3Aub3JnL3htbC9ucy9qYXZhZWUiPgoJPHByb3BlcnRpZXM+ " } ]
}
Successful Response:
If the result is complete success from endpoint then provide the list of jobDefinitionVo(List<JobDefinitionVo>) for customer reference.
JSON
{
"jobDefinitionsVo": [
{"jobId": "Job1",
"createTime": "create_timestamp",
"updateTime": "update_timestamp",
"status": "Success"
},
{"jobId": "Job2",
"createTime": "create_timestamp",
"updateTime": "update_timestamp",
"status": "Success"
}
]
}
Error Response:
There would be individual calls for each job xml, if any job fails we can still process the next job and can show the list at the end for failed and success jobs.
Possible issues could be:
Cannot update job XML if that job is running.
Cannot create/update the Job if job id was not found in input job xml.
Cannot create/update the Job if input job xml is not readable/parsable.
JSON
{
"jobDefinitionsVo" [
{"jobId": "Job1",
"createTime": "create_timestamp",
"updateTime": "update_timestamp"
"status": "Success"
},
{"jobId": "Job2",
"status": "Failure"
"message": "Currently job is running"
},
{"jobId": "Job3",
"status": "Failure"
"message": "Job id not found in job xml"
}
]
}
Exception Response
End point returns exception response if it is unable to process the request.
{
"statusCode": 500
"status": "Internal Server Error"
"message": "Unable to process"
"stackTrace": ""
}
End point for delete job definitions
Http method:
Delete
Path:
/batch/jobs/bulk/job-definitions
Consumes:
MediaType.APPLICATION_JSON/MediaType.APPLICATION_XML
Sample request:
http://localhost:7001/bdi-batch-job-admin/resources/batch/jobs/bulk/job-definitions
Input:
JSON
{
"jobDefinitionsVo": [
{"jobId":"Job1"},
{"jobId":"Job2"}
]
}
Successful Response:
If the result is complete success from endpoint then provide the list of jobDefinition-Vo(List<JobDefinitionVo>) for customer reference.
JSON
{
"jobDefinitionsVo": [
{"jobId": "Job1",
"deleteTime": "delete_timestamp",
"status": "Success"
},
{"jobID": "Job2",
"deleteTime": "delete_timestamp",
"status": "Success"
},
]
}
Error Response:
There would be individual calls for each job xml, if any job fails to delete we can still process the next job and can show the list at the end for failed and success jobs.
Possible issues could be:
Can't delete job if that job is running.
Can't delete the Job if job id was not found in existing job list.
Can't delete the Job if job is in enabled status.
Can't delete the Job if input job list is not readable/parsable.
JSON
{
"jobDefinitionsVo": [
{"jobID": "Job1",
"deleteTime": "delete_timestamp",
"status": "Success"
},
{"JobId": "Job2",
"status": "Failure",
"message": "Currently job is running"
},
{"jobID": "Job3",
"status": "Failure",
"message": "Cant delete job XML as job job3 is not valid. "
}
]
}
Exception Response
End point returns exception response if it's unable to process the main request.
JSON
{
"statusCode": 500
"status": "Internal Server Error"
"message": "Unable to process"
"stackTrace": ""
}
Bulk Data Export Service is a new Restful Web service packaged under Job Admin, which allows authenticated user to get latest available data sets (either FULL or PARTIAL), fetch data for available data set ids and update status of transaction.
Below are the endpoints provided by Bulk Data Export Service. Ensure to invoke endpoints in below order to export data successfully.
Table 3-6 Bulk Data Export Service
| REST Resource | HTTP Method | Description |
|---|---|---|
|
j9/bulk-data/export/data-set/{interfcace_module}?consumingAppName={consumingAppName}&sourceAppName=rms |
GET |
Gets latest available FULL or PARTIAL dataset for given interface module |
|
/bulk-data/export/begin?dataSetId={dataset_id}&consumingAppName={ consumingAppName } |
POST |
Generates transaction id for given unprocessed transaction id. |
|
/bulk-data/export/data?transactionId={transaction_id} &page={pageNum}&maxRowsPerPage={maxRowsPerPage} |
GET |
Gets data from inbound tables for provided transaction id. |
|
/bulk-data/export/begin?dataSetId=15&consumingAppName=external |
POST |
Updates transaction status as SUCCESS/FAILURE based on input provided. |
Endpoints
Ping
This endpoint can be used to ensure that initial handshake with service is successful.
HTTP Method: GET
Path
resources/bulk-data/export/ping
Produces:
MediaType.APPLICATION_JSON/MediaType.APPLICATION_XML
Sample request:
<hostname>:<port>/<app_name>-batch-job-admin/resources/bulk-data/export/ping
Sample json response:
{
"returnCode": "PING_SUCCESSFUL",
"messageDetail": "Pinged Bulk Data Export Service successfully"
}
getAllAvailableFullOrPartialDataSet
This endpoint can be used to get latest available data set. Data sets of type FULL are given priority over datasets of type PARTIAL. If there are no available datasets of type FULL, then this endpoint checks for data sets of type PARTIAL. If there are multiple PARTIAL data sets for given input, then data sets are sorted based on data set ready time before returning to consumer.
Path parameter consumingAppName and query parameter sourceAppName are not case sensitive.
Path parameter interfaceModule is case sensitive. Ensure to maintain appropriate case for interface module in request.
HTTP Method: GET
Path
resources/bulk-data/export/data-set/{interfaceModule is mandatory}?consumingAppName={consuming app name is mandatory}&sourceAppName={sourceAppName is optional}
interfaceModule : This field indicates name of interface module for which latest available data set is to be returned.
consumingAppName : This field indicates requesting system name.
sourceAppName : This field indicates source system name of data set.
|
Note: interfaceModule and consumingAppName are mandatory inputs. |
Produces
MediaType.APPLICATION_JSON/MediaType.APPLICATION_XML
Sample request
<hostname>:<port>/<app_name>-batch-job-admin/resources/bulk-data/export/data-set/Diff_Fnd?consumingAppName=external&sourceAppName=RMS
Sample json response
{
"Message": {
"returnCode": "DATA_SET_AVAILABLE",
"messageDetail": "data set is available for external"
},
"interfaceModule": "Diff_Fnd",
"dataSetType": "FULL",
"sourceSystemName": "RMS",
"consumingAppName": "external",
"AvailableDataSets": {"AvailableDataSet": [ {
"dataSetId": 10,
"dataSetReadyTime": "2020-03-06T02:21:25-08:00",
"InterfaceDetail": [
{
"interfaceShortName": "DIFF_GRP_DTL",
"interfaceDataCount": 100
},
{
"interfaceShortName": "DIFF_GRP",
"interfaceDataCount": 200
}
]
}]}
}
Error Response
Response when latest data is not available
{"Message": {
"returnCode": "NO_AVAILABLE_DATA_SET",
"messageDetail": "No data set is available for external"
}}
beginExport
This endpoint is used to indicate start of data export. If provided query parameters are valid, then this endpoint generates a transaction id indicating start of transaction, which is required to get data.
If there are multiple datasets (of type PARTIAL) returned by getAllAvailableFullOrPartialDataSet endpoint, ensure to process them in the same order.
HTTP Method: POST
Path
resources/bulk-data/export/begin?dataSetId={dataSetId is mandatory}&consumingAppName={consuming app name is mandatory}
dataSetId: This field indicates the dataset id that is to be exported.
consumingAppName: This field indicates the consuming application name.
|
Note: dataSetId and consumingAppName is mandatory input for this endpoint |
Produces
MediaType.APPLICATION_JSON/MediaType.APPLICATION_XML
Sample request
<hostname>:<port>/<app_name>-batch-job-admin/resources/bulk-data/export/begin?dataSetId=10&consumingAppName=external
Sample json response
{
"Message": {
"returnCode": "TRANSACTION_STARTED",
"messageDetail": "Transaction started for dataset Id 10"
},
"transactionid": "external:Diff_Fnd:10:1585633498380"
}
getData
This endpoint can be used to get data from inbound tables. It uses transaction id provided in input to identify start and end sequence of available dataset for interface module. This end point uses pagination to fetch records. Query parameters "page" and "maxRowsPerPage" can be used to specify page number and number of records per page respectively.
"hasMorePages" field from response can be used to identify if there are more records to be fetched for dataset. True value indicates that there are more records to be fetched and false value indicates that current page is the last page.
"action" node in response signifies the action to be performed on "data" that is returned.
For example, "action:REPLACE" signifies that replace if existing records with the current one that is returned by getData endpoint.
"next" field from response can be used to get available data from next page.
page and maxRowsPerPage are optional query parameters.
If query parameter page is missing in request, then value of it will be defaulted to 1 by Bulk Data Export Service. If query parameter maxRowsPerPage is missing in request, then value of it will be defaulted to 500 records by Bulk Data Export Service
HTTP Method: GET
Path
resources/bulk-data/export/data?transactionId={transactionId is mandatory}&page={page}&maxRowsPerPage=500
transactionId: Provide transaction id generated by beginExport endpoint as value of this field.
page: This is an optional field. Ensure that value of this field is a numeric value.
Value will be defaulted to 1, if not specified in request.
maxRowsPerPage: This is an optional field. Ensure that value of this field is a numeric value.
Value will be defaulted to 500, if not specified in request
|
Note: transactionId is mandatory input for this endpoint |
Maximum number of records that can be returned by getData end point is controlled through an entry in SYSTEM_OPTIONS table called "ROWS_PER_PAGE_MAX_VALUE".
If value of query parameter maxRowsPerPage is greater than ROWS_PER_PAGE_MAX_VALUE, then maxRowsPerPage is defaulted to value of entry "ROWS_PER_PAGE_MAX_VALUE" in SYSTEM_OPTIONS table.
If SYSTEM_OPTIONS table misses entry for ROWS_PER_PAGE_MAX_VALUE, then ROWS_PER_PAGE_MAX_VALUE is defaulted to 10000 by Bulk Data Export Service.
Refer section "Steps to update values in System Options" to add/update ROWS_PER_PAGE_MAX_VALUE in SYSTEM_OPTIONS table.
Produces
MediaType.APPLICATION_JSON/MediaType.APPLICATION_XML
Sample request
<host>:<port>/<app_name>-batch-job-admin/resources/bulk-data/export/data?transactionId=external:Diff_Fnd:10:1585743226654&page=1&maxRowsPerPage=100
Sample Json Response:
{
"Message": {
"returnCode": "GET_DATA_SUCCESSFUL",
"messageDetail": "Records are available for interface module Diff_Fnd"
},
"hasMorePages": true,
"next": "http://blr00ccp:55663/rms-batch-job-admin/resources/bulk-data/export/data?transactionId=external:Diff_Fnd:10:1585743226654&page=2&maxRowsPerPage=5",
"interfaceModule": "Diff_Fnd",
"InterfaceData": [
{
"interfaceShortName": "DIFF_GRP_DTL",
"columnNames": "DIFF_GROUP_ID,DIFF_ID,DISPLAY_SEQ",
"recordCount": 5,
"Records": {"Record": [
{
"action": "REPLACE",
"data": "AAA1,AAAAAAAA,11"
},
{
"action": "REPLACE",
"data": "AAA1,AAAAAAAA,12"
},
{
"action": "REPLACE",
"data": "AAA1,AAAAAAAA,13"
},
{
"action": "REPLACE",
"data": "AAA1,AAAAAAAA,14"
},
{
"action": "REPLACE",
"data": "AAA1,AAAAAAAA,15"
}
]},
"dataSetInterfacesDataVo": {"Record": [
{
"action": "REPLACE",
"data": "AAA1,AAAAAAAA,11"
},
{
"action": "REPLACE",
"data": "AAA1,AAAAAAAA,12"
},
{
"action": "REPLACE",
"data": "AAA1,AAAAAAAA,13"
},
{
"action": "REPLACE",
"data": "AAA1,AAAAAAAA,14"
},
{
"action": "REPLACE",
"data": "AAA1,AAAAAAAA,15"
}
]}
},
{
"interfaceShortName": "DIFF_GRP",
"columnNames": "DIFF_GROUP_DESC,DIFF_GROUP_ID,DIFF_TYPE_DESC,DIFF_TYPE_ID",
"recordCount": 5,
"Records": {"Record": [
{
"action": "REPLACE",
"data": "Test Value,AAA1,Test Value,seq"
},
{
"action": "REPLACE",
"data": "Test Value,AAA1,Test Value,seq"
},
{
"action": "REPLACE",
"data": "Test Value,AAA1,Test Value,seq"
},
{
"action": "REPLACE",
"data": "Test Value,AAA1,Test Value,seq"
},
{
"action": "REPLACE",
"data": "Test Value,AAA1,Test Value,seq"
}
]},
"dataSetInterfacesDataVo": {"Record": [
{
"action": "REPLACE",
"data": "Test Value,AAA1,Test Value,seq"
},
{
"action": "REPLACE",
"data": "Test Value,AAA1,Test Value,seq"
},
{
"action": "REPLACE",
"data": "Test Value,AAA1,Test Value,seq"
},
{
"action": "REPLACE",
"data": "Test Value,AAA1,Test Value,seq"
},
{
"action": "REPLACE",
"data": "Test Value,AAA1,Test Value,seq"
}
]}
}
],
"currentPageNumber": 1
}
Error Response:
{
"Message": {
"returnCode": "GET_DATA_FAILED",
"messageDetail": "Data set is already processed for dataset id .10"
},
"hasMorePages": "false",
"currentPageNumber": "0"
}
endExport
This endpoint can be used to mark status of data export for a given transaction. It accepts status of transaction as query parameter.Transaction status will be defaulted to SUCCESS, if not specified in input.
List of acceptable values for transaction status are "SUCCESS" and "FAILURE"
HTTP Method: POST
Path
resources/bulkdata/export/end?transactionId={transaction id mandatory}&transactionStatus={optional, default to success}
transactionId : Provide transaction id generated by beginExport endpoint as input to this field.
transactionStatus: This is an optional input. Value will be defaulted to SUCCESS, if not specified in input.
List of acceptable values for transaction status are "SUCCESS" and "FAILURE"
Any value apart from above two will result in exception.
|
Note: transactionId is mandatory input to this end point |
Produces
MediaType.APPLICATION_JSON/MediaType.APPLICATION_XML
Sample request
<host>:<port>/<app_name>-batch-job-admin/resources/bulk-data/export/end?transactionId=external:Diff_Fnd:10:1585633498380&transactionStatus=SUCCESS
Sample json response
When transactionStatus=SUCCESS
{
"returnCode": "TRANSACTION_COMPLETE",
"messageDetail": "Transaction completed successfully."
}
When transactionStatus= FAILURE
{
"returnCode": "TRANSACTION_FAILED",
"messageDetail": "Transaction could not be completed.."
}
Error Response
Invalid input for transaction Id:
{
"returnCode": "TRANSACTION_ERROR",
"messageDetail": "Transaction status could not be parsed. Provide one of the following value {SUCCESS,FAILURE}"
}
Steps to test Bulk data export service:
Attached script can be used to test Bulk data export service.
Steps to execute the script:
Open the script using any editor or command line.
Replace the hostname and port number to point deployed app.
Can modify the consumingAppName, by default the script has it as "external"
Save the script.
Run the script with interface name. Below is the command to run the script.
|
Note: Need to run using bash only. The script only works for a full data set. |
bash bdi_poc.sh <Interface_Name> ---- Pass interface name for Full data set.
Example - bash bdi_poc.sh Clearance_Tx
Script will prompt for deployed app username and password.
A thread runs every hour to identify data sets to be purged based on flags in system options table and purges the data from inbound tables.
Eligible data sets are purged every hour from inbound table. Data set is said to be eligible for purge, if either transaction completion date has crossed predefined time interval or data set ready time has crossed predefined time interval.
Below are steps followed to identify data sets to be purged and purge records from inbound data tables automatically.
Auto purge delay can be allowed/restricted for any specific interface by adding autoPurgeInboundData.{interface_ModuleName} flag in SYSTEM_OPTIONS table with value TRUE/FALSE respetively.
Example: autoPurgeInboundData.Diff_Fnd
If interface level entry is missing in SYSTEM_OPTIONS table, then value of global flag autoPurgeInboundData.global is used to decide whether to purge data for interface module or not.
For each ACTIVE interface modules, check if auto purge flag is set at global level (autoPurgeInboundData.global) or interface module level (autoPurgeInboundData.{interface_ModuleName}) from SYSTEM_OPTIONS table. If flag is TRUE either at global level or at any interface module level, continue with the next steps.
If an entry for auto purge flag is missing in SYSTEM_OPTIONS table, then value of flag at global level (autoPurgeInboundData.global) is defaulted to TRUE.
Prepare a list with interface module names that are eligible to be purged based on value of above flags and get list of datasets that already processed for the interface module list.
Get delay duration for each eligible transaction from SYSTEM_OPTIONS table. Check for entry "autoPurgeInboundDataDelay.{interface_name}" in SYSTEM_OPTIONS table to get delay duration for each eligible transaction.
If no entry is available for interface module, then get global delay duration using entry "autoPurgeInboundDataDelay.global" of SYSTEM_OPTIONS table.
Use default delay duration(30 days) if SYSTEM_OPTIONS table does not contain any entries for auto purge delay. Delay duration can specified either in hours or days. Refer table below for possible values for delay. Check if data is ready to be purged based on delay obtained. Data is ready to be purged if duration between transaction begin time and current time is greater than or equal to delay
If list from above step is not empty, then use the below query to get list of data sets that are already processed and ready to be purged. If there are data sets eligible to be purged, proceed with next step, exit otherwise.
Query Template: select tr from ImporterExecutionDataSet dataset, ImporterTransaction tr, ImporterInterfaceModuleDataControl dmc
where dataset.importerTransactionId = tr.id AND tr.interfaceModule IN :interfaceNameList
AND (tr.importerTransactionStatus = IMPORTER_COMPLETED)
AND dataset.importerInterfaceModuleDataControlId = dmc.importerInterfaceModuleDataControlId AND dmc.dataSetDeleteTime IS NULL
Check if there are any data sets that was ready to be consumed before predifined number of days. Data set is considered for purging, if data is set is older than AUTO_PURGE_DELAY_UPPER_LIMIT entry of SYSTEM_OPTIONS table.
Query Template:
select modctl
FROM ImporterInterfaceModuleDataControl modctl, ImporterInterfaceDataControl ctl
WHERE modctl.dataSetDeleteTime IS NULL
AND ctl.importerInterfaceModuleDataControl.importerInterfaceModuleDataControlId = modctl.importerInterfaceModuleDataControlId
AND modctl.dataSetDeleteTime IS NULL
AND modctl.dataSetReadyTime < :autoDelayLimit
Note : autoDelayLimit is the date obtained by subtracting number of days specified in AUTO_PURGE_DELAY_UPPER_LIMIT option of System Options table with current date.
For all the data sets that are ready to be purged, get importer data control details(like begin sequence number, end sequence number, dataset id etc) using transaction ids
Query Template:
SELECT modctl FROM ImporterExecutionDataSet dataset, ImporterInterfaceModuleDataControl modctl
WHERE modctl.importerInterfaceModuleDataControlId = dataset.importerInterfaceModuleDataControlId
AND dataset.importerTransactionId IN :transactionIdList
If there are data sets eligible to be purged from previous steps, then prepare a consolidated list of data sets to purge them and proceed with next steps, exit otherwise.
Purge records from Inbound tables using details fetched from last step.
Query Template:
delete from {InterfaceShortName} where (bdi_seq_id between ? and ?)
Update DATA_SET_DELETE_TIME column of BDI_IMPRTR_IFACE_MOD_DATA_CTL table with current time stamp for the datasets whose inbound data are purged.
Table 3-7 BDI Auto Purge Inbound data
| Name | Allowed Values | Comments |
|---|---|---|
|
autoPurgeInboundDataDelayUpperLimit |
45 |
This flag is used to specify maximum number of days a data set that is unconsumed, can be persisted. After exceeding maximum number of days, data is purged even if it is unconsumed. Ensure that value of this field is a numeric value |
|
autoPurgeInboundData.global |
TRUE FALSE |
This flag is used to enable/disable purging of records if flag is missing at interface level |
|
autoPurgeInboundData.{interface_ModuleName} |
TRUE FALSE |
Replace {interface_ModuleName} with name of interface module to restrict/enable purging of records for given interface Example: autoPurgeInboundData.Diff_Fnd |
|
autoPurgeInboundDataDelay.global |
30d 20h 20 |
This flag is used to fetch delay duration if flag is missing at interface level h: Numeric value followed by h indicates duration in hours. d: Numeric value followed by d indicates duration in days. If neither d nor h follows numeric value or numeric value followed by non numeric value other than d or h, delay is considered to be in days. Example: 20 20a Ensure that value of this field is a numeric value followed by d or h |
|
autoPurgeInboundDataDelay.{interface_name} |
30d 20h 20 |
Replace {interface_ModuleName} with name of interface module to specify delay duration specific to interface. h: Numeric value followed by h indicates duration in hours. Example: 20h d: Numeric value followed by d indicates duration in days. Example:30d If neither d nor h follows numeric value or numeric value followed by non numeric value other than d or h, delay is considered to be in days. Example: 20 20a Ensure that value of this field is a numeric value followed by d or h Example: autoPurgeInboundDataDelay.Diff_Fnd |
Steps to update values in System Options
Approach 1: Update via UI
Login to the job admin web page with valid credentials.
Click the Manage Configurations tab.
Click the System options tab.
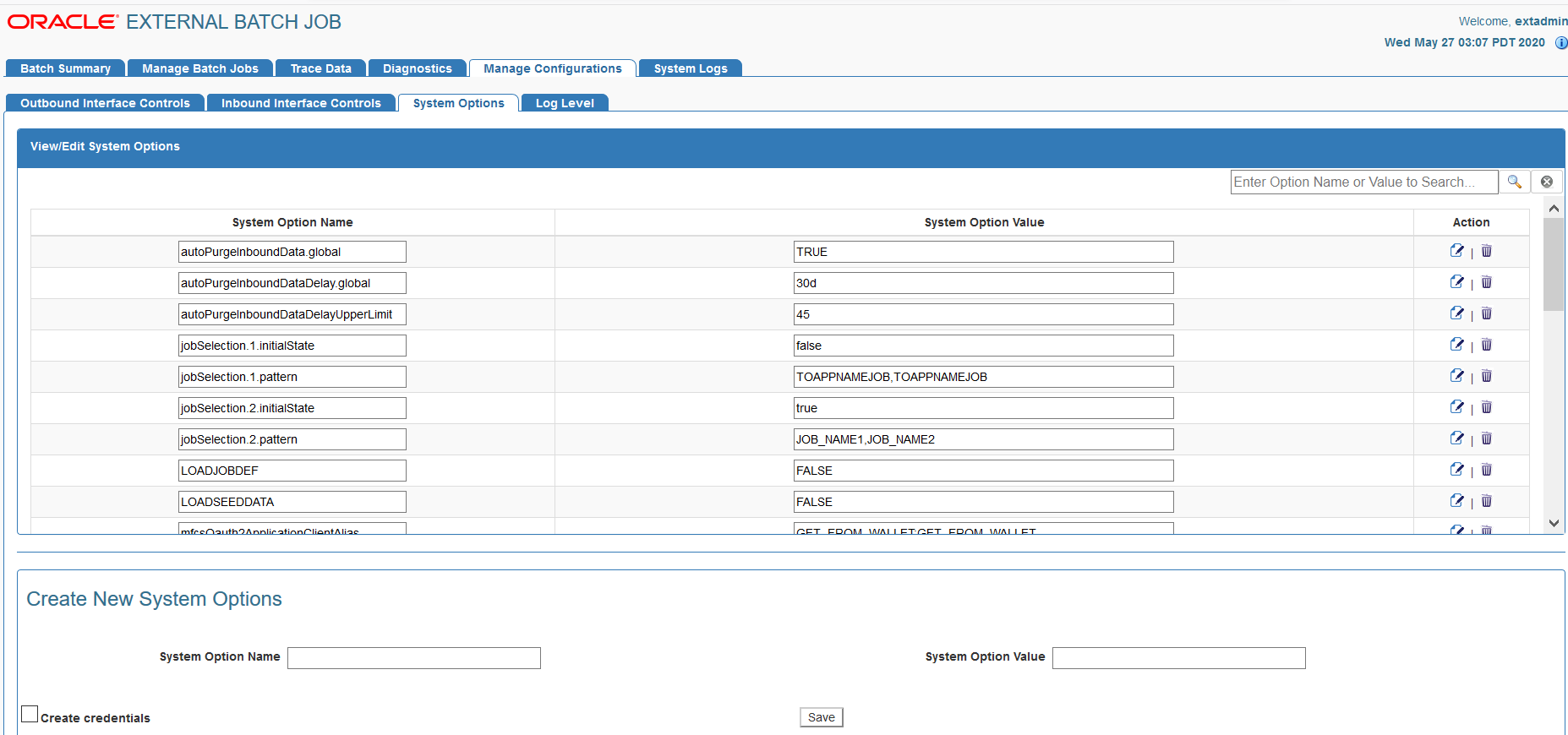
Search for the system option to update. Example: autoPurgeInboundData.global, autoPurgeInboundDataDelay.global, autoPurgeInboundDataDelayUpperLimit etc.
Click the Edit icon to update the value and click the Save icon to save changes.
Approach 2: Update values via REST service endpoints
Below end point can also be used to update System Options via REST service.
URL:
http://<host:port>/<appName>-batch-job-admin/resources/system-setting/system-options
Request Type :
POST
Input Json Example:
{
"key": "autoPurgeInboundData.global",
"value": "false"
}
|
Note: Update key and value in above request with appropriate System Option name and value to be updated. |
During the deployment of Job Admin, seed data gets loaded to various tables. Seed data files are located in the bdi-<app>-home/setup-data/dml folder. If seed data is changed, Job Admin need to be reinstalled and redeployed. For loading seed data again during the redeployment, LOADSEEDDATA flag in the BDI_SYSTEM_OPTIONS table need to be set to TRUE.
Jobs
The following job properties can be changed to improve the performance of the jobs.
Item-count - Number of items read by a job before it writes. Default size is 1000.
fetchSize - Number of items cached by JBDC driver. Default size is 1000.
Receiver Service
The Receiver Service allows maximum number of blocks for transaction based on the following system option in BDI_SYSTEM_OPTIONS table.
receiverMaxNumBlocks - Default value is set to 10000
Seed data need to be changed to update the maximum number of blocks for the Receiver Service. To update the seed data, set the LOADSEEDDATA flag to TRUE, reinstall and redeploy Job Admin. The Value of the LOADSEEDDATA flag can be changed from the Job Admin Manage Configurations Tab.
During the deployment of Job Admin, seed data is loaded to various tables. Seed data files are located in the bdi-edge-<app>-job-home/setup-data/dml folder. If seed data is changed, Job Admin must be reinstalled and redeployed. In order to load seed data again during the redeployment, the LOADSEEDDATA flag in the BDI_SYSTEM_ OPTIONS table must be set to TRUE.
During the deployment, Job XMLs get loaded to BDI_JOB_DEFINITION table. Job XML files are located in the "jos-job-home/setup-data/META-INF/batch-jobs" folder. If job xmls are changed, Job Admin must be reinstalled and redeployed. In order to load job xmls during redeployment, the LOADJOBDEF flag in the BDI_SYSTEM_OPTIONS table must be set to TRUE.
|
Note: Restart of job does not load job definition from the BDI_JOB_DEFINITION table. Java Batch loads job xml from JOBSTATUS table during the restart of a job.If there is an issue with Job XML, job needs to be started after fixing the job XML. |
Throttling is the capability of regulating the rate of input for a system where output rate is slower than input.
Java Batch runtime will not allow to run multiple instances of a job at same time, it will say job is currently running and fail the job. There can be only one instance of a job at any time (unless the job parameters are different).
Throttling is introduced to address the issue caused when there are many job start requests at the same time. In order to honor the throttle limits "throttleSystemLimit" is introduced to make sure the system never runs more than the throttle limit for the group and the system.
Three new tables are added to job schema to handle throttling, these are BDI_GROUP, BDI_GROUP_LOCK, BDI_GROUP_MEMBER.
Table 3-8 BDI Group
| Column | Type | Comments |
|---|---|---|
|
GROUP_ID |
NUMBER |
Primary Key |
|
APP_TAG |
VARCHAR2(255) |
Name of the application |
|
COMMENTS |
VARCHAR2(255) |
Comments |
|
GROUP_ATTRIB_NAME_1 |
VARCHAR2(255) |
Name of the group attribute ex - THROTTLE_JOBS_IN_SAME_GROUP |
|
GROUP_ATTRIB_NAME_2 |
VARCHAR2(255) |
Name of the group attribute |
|
GROUP_ATTRIB_NAME_3 |
VARCHAR2(255) |
Name of the group attribute |
|
GROUP_ATTRIB_NAME_4 |
VARCHAR2(255) |
Name of the group attribute |
|
GROUP_ATTRIB_NAME_5 |
VARCHAR2(255) |
Name of the group attribute |
|
GROUP_ATTRIB_VAL_1 |
VARCHAR2(255) |
Value of the group attribute |
|
GROUP_ATTRIB_VAL_2 |
VARCHAR2(255) |
Value of the group attribute |
|
GROUP_ATTRIB_VAL_3 |
VARCHAR2(255) |
Value of the group attribute |
|
GROUP_ATTRIB_VAL_4 |
VARCHAR2(255) |
Value of the group attribute |
|
GROUP_ATTRIB_VAL_5 |
VARCHAR2(255) |
Value of the group attribute |
|
GROUP_NAME |
VARCHAR2(255) |
Name of the group |
Table 3-9 BDI Group Member
| Column | Type | Comments |
|---|---|---|
|
GROUP_MEMBER_ID |
NUMBER |
Primary Key |
|
APP_TAG |
VARCHAR2(255) |
Name of the application |
|
GROUP_ID |
NUMBER |
Group id |
|
MEMBER_NAME |
VARCHAR2(255) |
Name of the job |
|
MEMBER_TYPE |
VARCHAR2(255) |
Type of the member ex - job |
Table 3-10 BDI Group Lock
| Column | Type | Comments |
|---|---|---|
|
LOCK_ID |
NUMBER |
Primary Key |
|
APP_TAG |
VARCHAR2(255) |
Name of the application |
|
GROUP_NAME |
VARCHAR2(255) |
Name of the group |
Prerequisite: In weblogic console, make sure the job admin data source has "Supports Global Transactions" and "Logging Last Resource" checked in the Transaction tab.
Example on how throttling is handled at runtime:Group1 <--(job1, job2, job3)-Throttle value 3 Group2 <-- (job1, job2) - Throttle value2
Step1:
Start job1, job2, job3 from process1, process2, process3 respectively. All 3 start running.
Step2:
Then start again process1 and process2. Both job1 and job2 get throttled.
There can be only one instance of a job at any time (unless the job parameters are different).
To make a re-runnable sql script which globally works for all sqls that makes a sql script re-runnable, there should be a script which creates package with functions/procedures that returns a necessary result value to the calling function to check whether anything exists in the schema before proceeding to execute the query on the schema. Below are the list of functions/procedures used in the package.
Table 3-11 BDI Global Migration Script Function/Procedure Names and Descriptions
| Function/Procedure Name | Description |
|---|---|
|
checkTableExists |
It checks whether table exists or not in the schema. |
|
checkColumnExists |
It checks whether column of a table exists or not in the schema. |
|
checkConstraintExists |
It checks whether constraint of table exists or not in the schema. |
|
checkIndexExists |
It checks whether index exists for a table or not in the schema. |
|
createTable |
It creates table only after checking whether table exists or not in the schema. |
|
AddColumnToTable |
It adds column only after checking whether table and column exists or not in the schema. |
|
modifyColumnType |
It modifies column datatype/any other related to column changes like making column not null or primary key. |
|
updateColumnName |
It updates column name of the table. |
|
AddTableConstraint |
It adds constraint to table only after checking whether table and constraint exists or not in the schema. |
|
createIndex |
It checks whether index exists or not on table in the schema before index is created. |
|
createSequence |
It checks whether sequence exists or not on table in the schema before sequence is created. |
|
Note: Before running the global migration script you need to provide three permissions to package.Permissions are:
|
DB Schema Auto Migration
Schema migration is to make changes to database like alter column, adding new table on running the migration script. Previously, migration scripts are run manually one by one on sqlplus or sqldeveloper to migrate from one to another version. Now, with the db schema auto migration feature with no user intervention in running the migration scripts, it automatically migrates from currently deployed app version to app version which will be deployed to web logic. For example, the current deployed app version in web logic is 16.0.028 and app which will be deployed to web logic is going to be 19.0.000, So db schema auto migration finds scripts between the versions (inclusive of 16.0.028 and 19.0.000), sorts and runs the migration scripts one by one from 16.0.028 to 19.0.000. This feature can be used on passing the -run-db-schema-migration parameter to bdi-app-admin-deployer.sh script with {-setup-credentials| -use-existing-credentials}.
|
Note: DB Schema auto migration feature should be used from >=16.0.028 version of BDI apps. |
Example to run DB Schema auto migration:
sh bdi-app-admin-deployer.sh { -setup-credentials | -use-existing-credentials } -run-db-schema-migration (Optional parameter)